
Chapter 2: The Data Lakehouse Architecture Overview
A well-thought-out architecture is the cornerstone of any robust information technology (IT) system, and a data lakehouse is no exception. The last chapter elucidated the need for a modern data analytics platform. The chapter also discussed the evolution of the data lakehouse. This chapter will focus on the critical elements of a data lakehouse.
The chapter will begin by describing the system context of a data lakehouse. Then, it will investigate the actors and systems that interact with a data lakehouse.
We will then discuss the logical architecture of a data lakehouse that consists of seven layers. The chapter will then deep-dive into various components of a data lakehouse architecture and elaborate on each element. The last section of this chapter will focus on five sacrosanct architecture principles that provide a framework for implementing a data lakehouse.
To summarize, the chapter covers the following topics:
- Developing a system context for a data lakehouse
- Developing a logical data lakehouse architecture
- Developing architecture principles
Developing a system context for a data lakehouse
A system context diagram shows different entities that interact with a system. In the following case, the system is a data lakehouse:
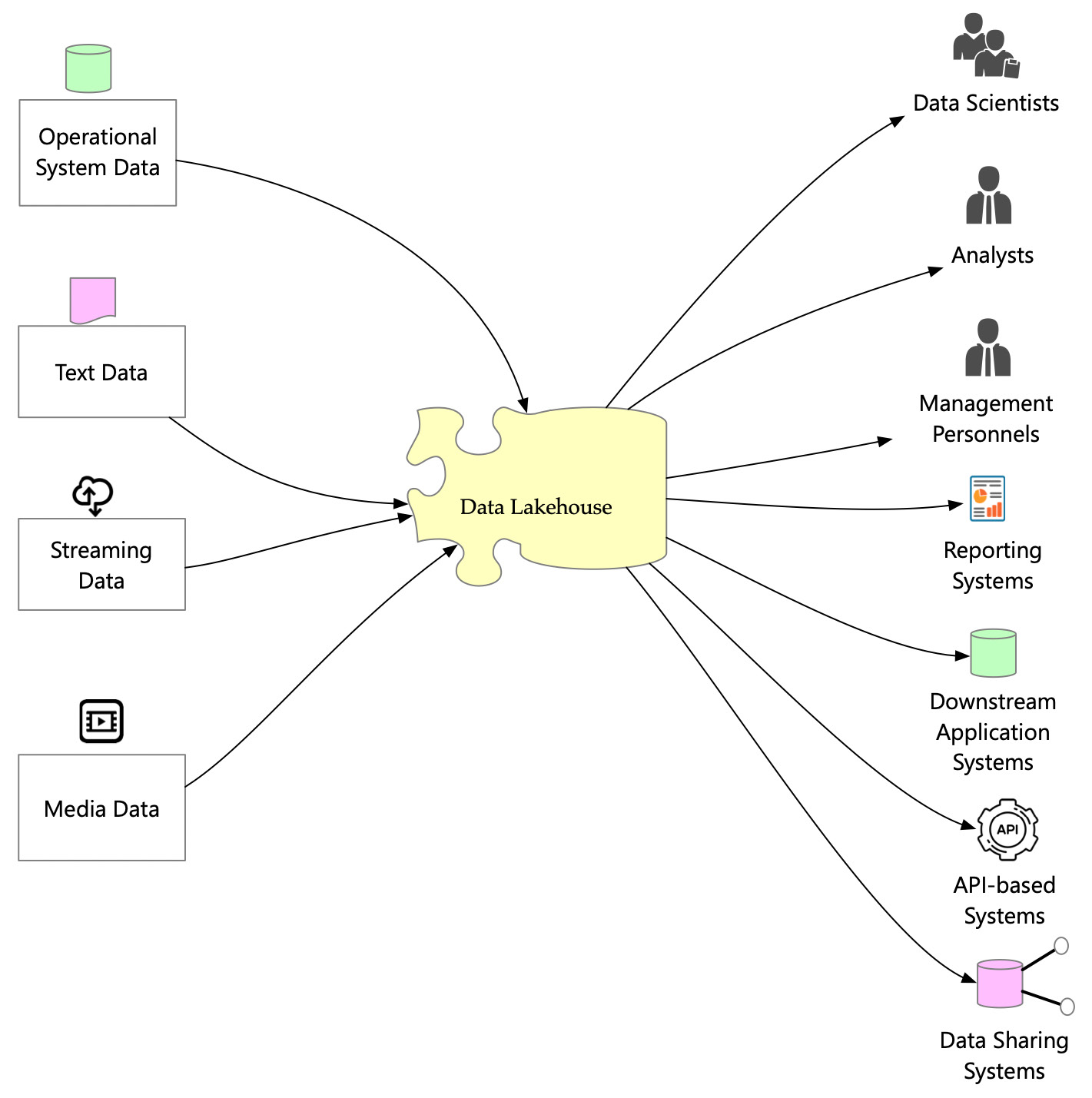
Figure 2.1 – Data lakehouse system context diagram
The preceding diagram shows key entities (systems or actors) that interact with the data lakehouse. The interaction with the data lakehouse has two parts, as outlined here:
- Data providers: Systems or actors that provide data to the data lakehouse
- Data consumers: Systems or actors that consume data from the data lakehouse
Let's examine these entities in detail.
Data providers
Data providers are any system or actor that ingests data into the data lakehouse. Any system that generates data is a potential data provider. A few typical data providers are listed here:
- Operational systems: Any system that generates data is a potential data provider. Typically, online transaction processing (OLTP) systems generate and store transactional data. The data in such systems is stored in relational databases in a highly normalized manner. As the data is highly normalized, the design is optimized for capturing and updating transactions effectively. Such systems are not suitable for analysis. OLTP systems are widespread in all organizations and form the majority of structured data stores. However, not all operational data is relational. The other form of operational data stores includes Not-Only SQL (NoSQL) databases. Data in a NoSQL database is not tabular. It is designed to store data in a flexible schema, and its structure can quickly adapt based on the input data type. Such databases store data in various formats, including key-value pairs, graphs, and JavaScript Object Notation (JSON).
- Text data: When it comes to unstructured data/documents, text data is the most predominant type of unstructured data. This kind of data includes documents and plain texts such as handwritten notes. With natural language processing (NLP), an established branch of artificial intelligence (AI), we can extract a treasure trove of insights out of text data. AI algorithms are becoming more and more sophisticated in their ability to analyze texts.
- Streaming data: Data is found not just at rest. There is a category of data that is in motion. Streaming data implies data that is constantly transmitted from a system in a fixed time. Streaming data includes telemetry data emanated from any internet of things (IoT) device, constant feeds from social media platforms (Twitter, Facebook (Meta), YouTube, clickstream, gaming, and so on), continuous data flowing from financial trading platforms, and geospatial services that transmit location information. If analyzed in real time, this kind of data fulfills a gamut of use cases such as complex event processing (CEP), sentiment analysis, keyword detection, and so on.
- Media data: Media data includes various data structures associated with speech, video, and images. We can use audio data to fulfill use cases such as voice recognition, speech-to-text translation, and real-time voice translation. Media data also includes videos and pictures that we can use to perform an extensive range of use cases. AI algorithms such as convolutional neural networks (CNN) have advanced to the point that they are better suited for identifying objects in an image than humans. With a large corpus of video and image data, AI technologies are being used to fulfill advanced use cases ranging from object detection to self-driving cars.
We have seen typical data providers and a slice of use cases that these types of data can fulfill. Now, let's focus on who are the stakeholders that will use the data from a data lakehouse.
The following table summarizes the key data providers, the type of data, and the typical use cases that are fulfilled:
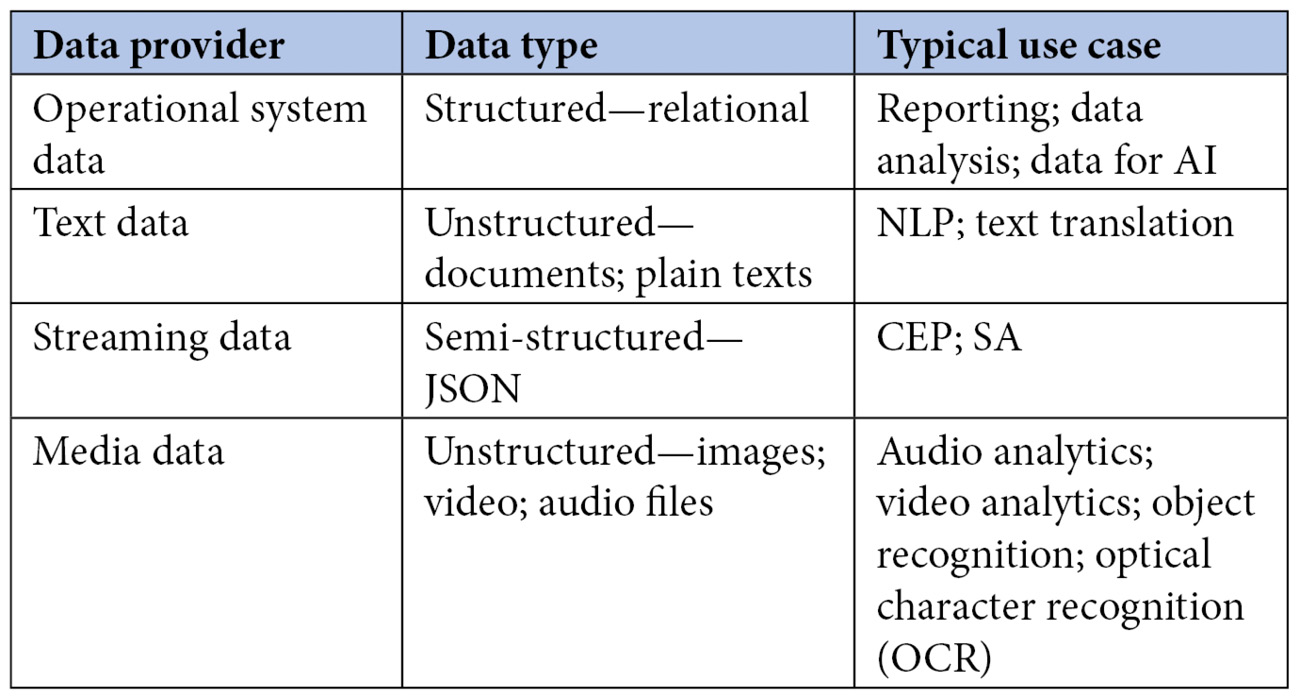
Figure 2.2 – Typical data providers and use cases
Next, let's look at who is going to use the data.
Data consumers
Once the data is ingested into the data lakehouse, various stakeholders will use it in its raw or transformed form. These stakeholders will extract data from the data lakehouse for a specific purpose. Each of these consumers has a personal motivation to use the data lakehouse. A well-architected data lakehouse should be able to cater to the requirements of each of these stakeholders. Let's look at some typical people and systems that consume data from a data lakehouse, as follows:
- Data scientists: The first type of people we see using a data lakehouse are data scientists, who extract data from the data lakehouse to test the various hypotheses they might want to prove or disprove. Data scientists work on all kinds of data: structured, unstructured, raw, and processed. The data lakehouse needs to be able to ensure that the data is easily identifiable for a specific purpose of use, the user must be proficient in many programming languages and technologies, including Python, R, and Structured Query Language (SQL), and the architecture needs to provide the right platform for this user to create and test their models.
- Analysts: The second type of people who use a data lakehouse are analysts. They are primarily business-driven and seek answers to business questions, and are proficient in reporting tools or SQL-based languages. They mainly work on processed data, and their day-to-day jobs include performing business analysis. They accomplish this task by querying, aggregating, and slicing/dicing data, mostly cleaned and processed. The data lakehouse should cater to such users and provide them with a platform to perform effective and seamless data analysis.
- Management personnel: The third type of people who are heavy users of data lakehouses are management personnel who need periodic reports for business decision-making. They delve into processed data that is aggregated and specifically focused on a business requirement. They may be semi tech-savvy and may need a playground to create their reports or analysis using business intelligence (BI) tools. These people generally extract their reports through a reporting system.
- Reporting systems: The other critical consumers of a data lakehouse are the reporting systems. Reporting systems indirectly cater to people who want to subscribe to scheduled, ad hoc, or self-service reports. In addition, there may be other types of reporting systems that are meant for regulatory reporting. These systems extract data from the data lakehouse periodically and then store the reports for delivery.
- Downstream application systems: As data is ingested into the data lakehouse from upstream applications, downstream applications also consume processed information. These applications may be an OLTP system or another data warehouse or data lake with a different mandate from an enterprise data lakehouse (EDL). Typically, data for downstream consumption will be either pulled from the data lakehouse periodically or pushed to a destination using a feasible mechanism.
- Application programming interface (API)-based systems: A data lakehouse also needs to have the ability to expose the data in the form of an API. A data lakehouse processes all kinds of data, and it needs to be served to multiple internal and external systems. While a tightly coupled delivery mechanism may work for select consumers, API-based data consumption is a scalable and practical option. In addition, an API-based system can also expose data consumed by external stakeholders who are not part of the organization.
- Data sharing systems: Data sharing systems represent a new type of data-consuming mechanism. This kind of mechanism is used when the data is consumed or shared as part of a data marketplace. The data-sharing mechanism is also employed when specific terms for data usage need to be agreed upon before subscribing to its consumption.
The following table summarizes the key motivation and typical requirements of data consumers:
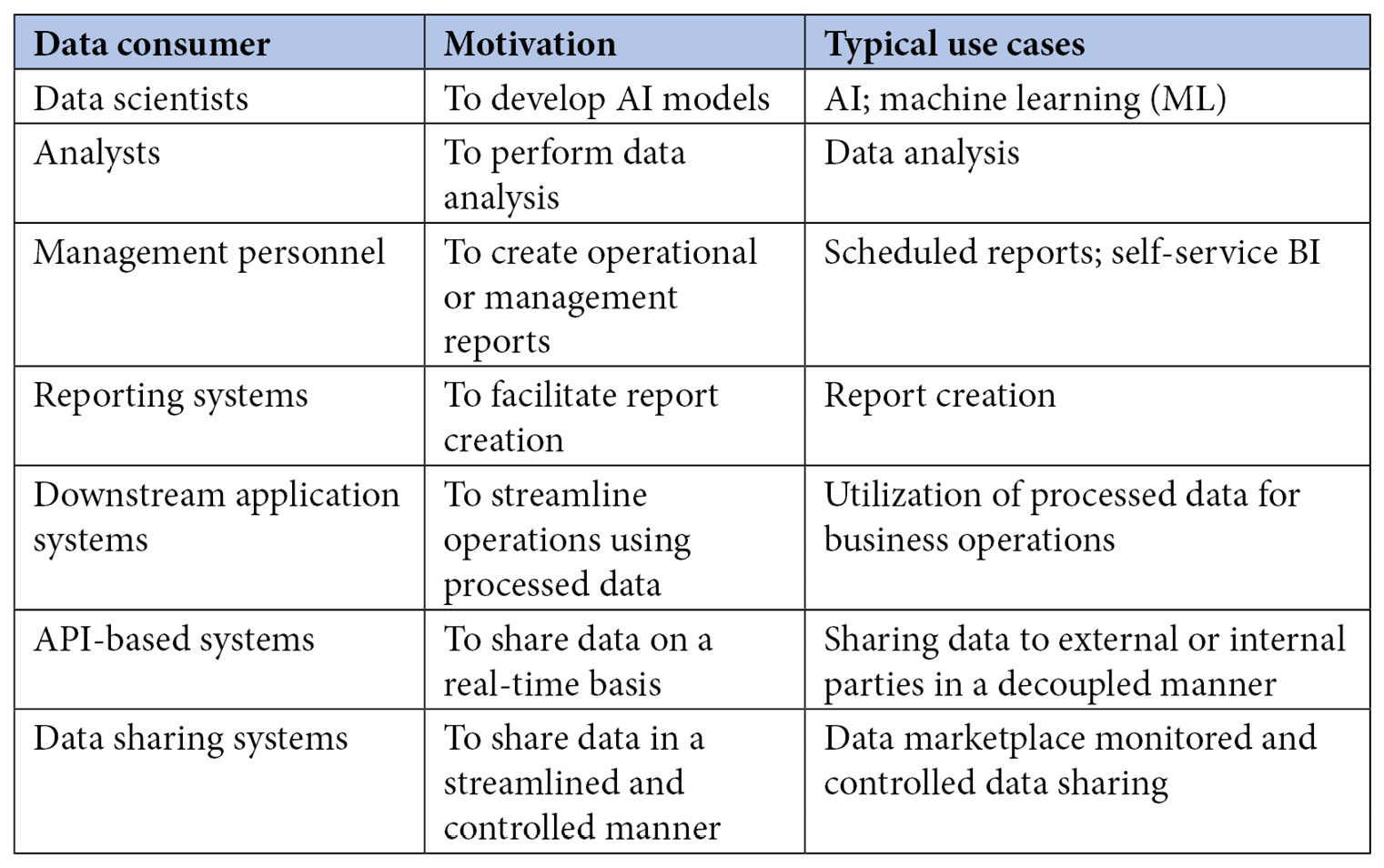
Figure 2.3 – Typical data consumers and use cases
So, now we know who might be using our lakehouse, let's start thinking about how to build it.
Developing a logical data lakehouse architecture
We have discussed a data lakehouse system context. Let's now get into developing a logical data lakehouse architecture. A logical architecture focuses on components that integrate to satisfy specific functional requirements (FRs) and non-functional requirements (NFRs). It is abstracted to a level that is technology-agnostic and focuses on component functionality. A logical architecture focuses on two kinds of requirements, as follows:
- An FR is a requirement that fulfills a specific business or domain-driven behavior. These kinds of requirements are driven by the tasks and the needs of a particular business function.
- An NFR is a requirement that specifies criteria that need to be fulfilled for the system to be helpful in that specific context. For example, a typical NFR includes the time a particular query is expected to complete, a requirement for data encryption, and so on.
A well-architected system ensures that it is architected to fulfill the NFR without too much trade-off. The following diagram depicts a logical architecture of a data lakehouse:
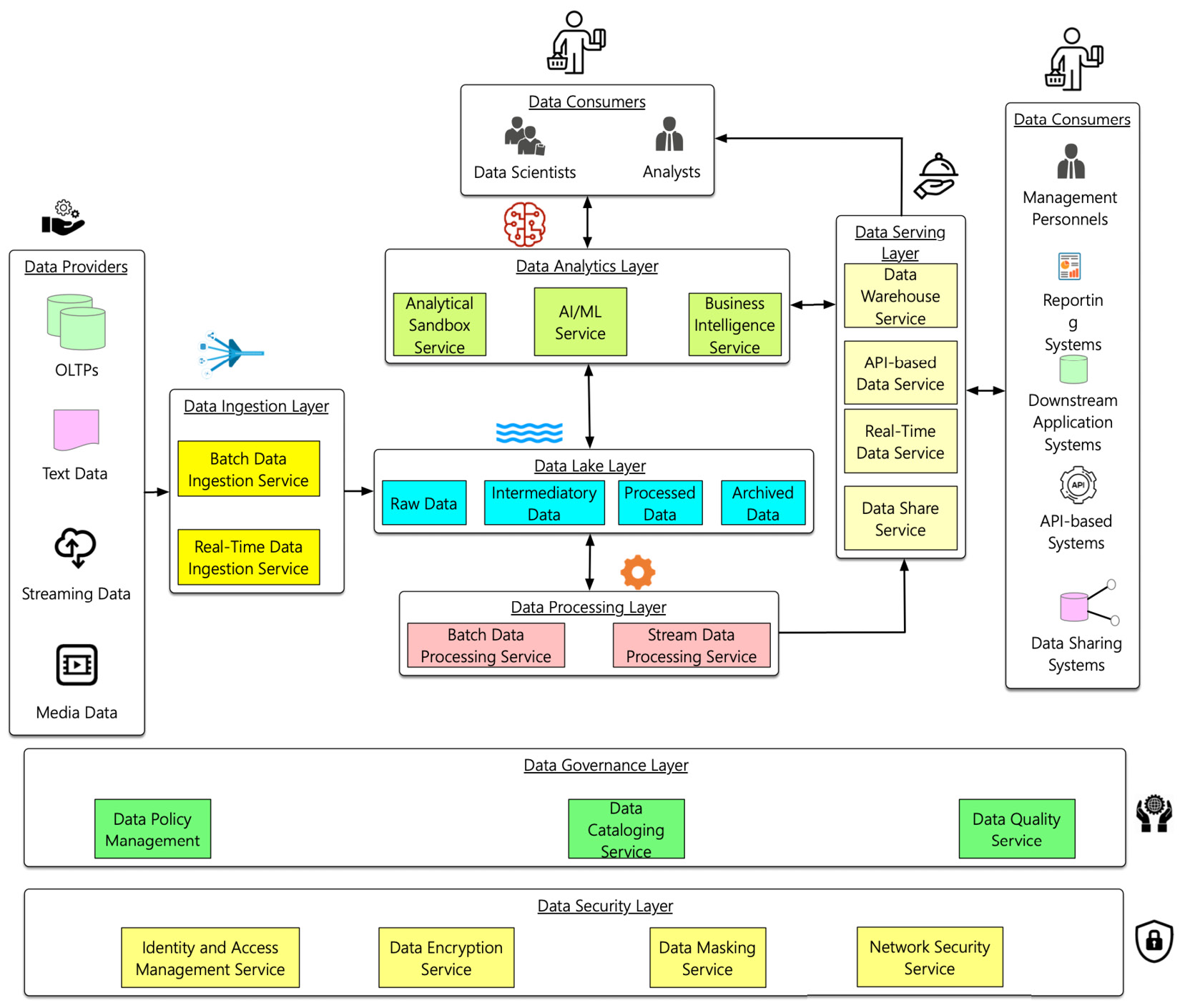
Figure 2.4 – A logical data lakehouse architecture
As depicted in the preceding diagram, a data lakehouse architecture has seven layers that weave together to form a well-architected data lakehouse. Let's now investigate each of these layers in detail.
Data ingestion layer
The first layer to detail is the data ingestion layer. This layer is the integration point between the external data providers to the data lakehouse. There are two types of data ingestion services, as illustrated in the following diagram:
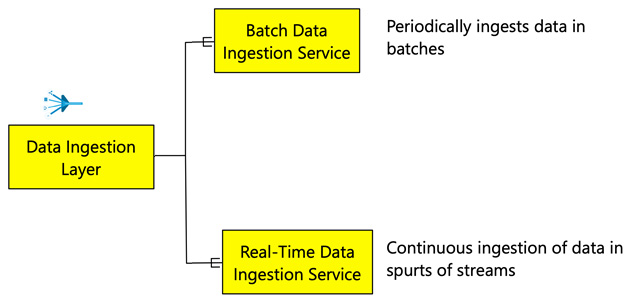
Figure 2.5 – Types of data ingestion services
These are explained in more detail here:
- Batch Data Ingestion Service: The batch ingestion implies that data is periodically ingested into the data lakehouse. The frequency of ingestion may range from a few minutes to days. The periodic frequency would depend on many factors, including the NFRs, the ability of data sources to generate data, and the ability of data sources to push data or allow the service to pull data. Typical operational systems require data to be pushed or pulled into the data lakehouse. A critical consideration to have while ingesting data in batches is the availability of the source system for data ingestion and the size of the batch data ingested. Both these factors will have an impact on how the data is ingested into the data lakehouse.
- Real-Time Data Ingestion Service: The real-time data ingestion service enables data to be pulled into the data lakehouse as it is generated. Real-time data is a constant stream of data, therefore the data of interest must be identified and pulled into the data lakehouse for storage or real-time processing. Real-time ingestion typically consists of a queuing service such as Kafka that would enable the real-time streams to be grouped and stored temporarily as queues for ingestion. Streaming services are also used to continuously capture data changes in databases through change data capture (CDC). Considerations related to the throughput of the streaming data and the requirements related to latencies become important while ingesting streaming data.
Data lake layer
Once the data ingestion layer ingests the data, it needs to be landed into storage, and various transformations need to be performed on it to transform the data for consumption. Finally, the data is anchored in the data lake. You can see a visual representation of this layer here:
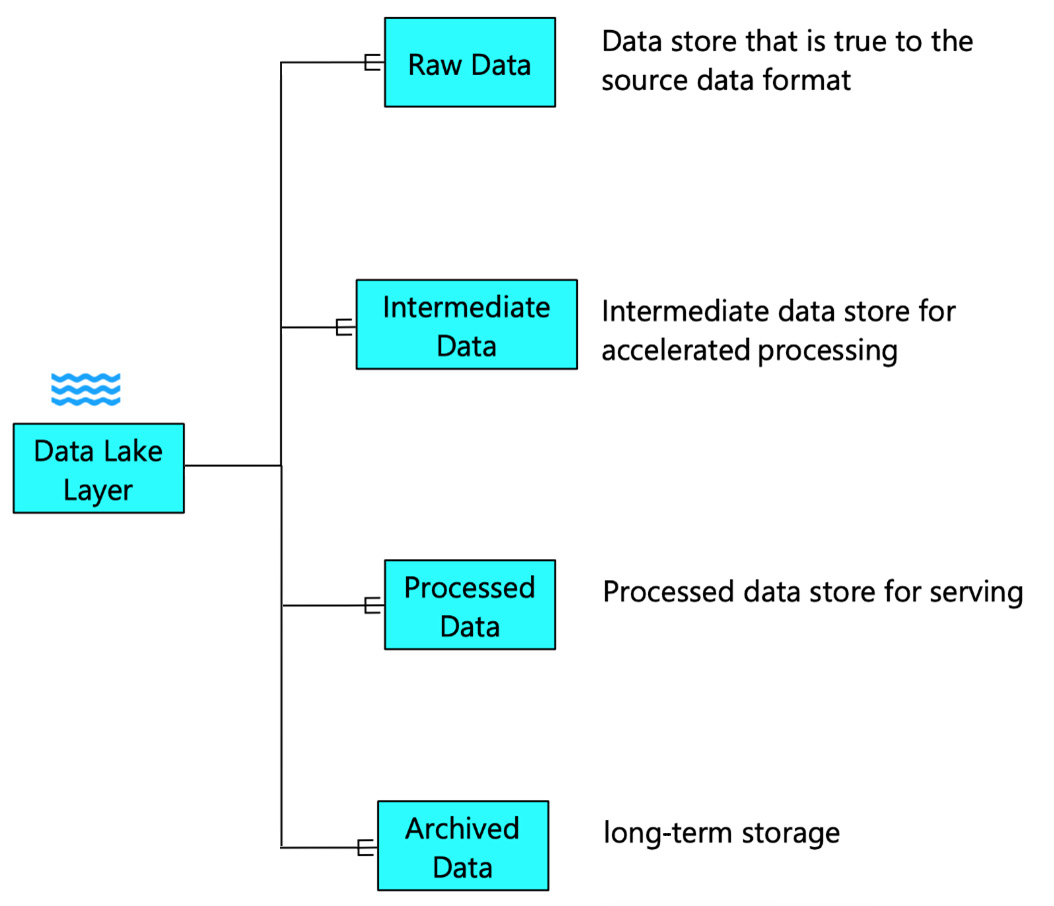
Figure 2.6 – Types of data stores in the data lake layer
The data lake layer has four significant categories of storage, as outlined here:
- Raw Data: Raw data storage is the area where the data lands from the data provider. As the name suggests, the data is stored in the raw data store in its natural form. Thus, the data is true to its source format, structure, and content. The raw data store also enables you to decouple the data generators with the data lakehouse.
- Intermediate Data: As the data traverses through the data lakehouse and is transformed, intermediary datasets are created. These intermediate datasets can be transient or persistent. These datasets can be stored in the data lake layer and can accelerate data processing. Intermediate data also makes the data processing pipeline immune to full restarts.
- Processed Data: Once the data is transformed, we can store the resultant dataset in the data lake. This dataset can then be used for serving or for analytics purposes. The processed data is suited for downstream consumption. However, the processed data in the data lake layer offers a relatively cheaper cost for storage. It also enables data scientists and analysts to use the processed data for experimentation or analysis without the overhead to the serving layer.
- Archived Data: The data that is consumed for insights is generally hot. Hot data implies that the storage technology used to store data ensures a better throughput and accessibility. However, not all data needs to be hot. Data that is not used for analytics but is required to be stored can be moved into cheaper storage technology. This kind of data is called archived data.
Data processing layer
The data needs to be transformed or processed for it to be consumed for insights. Data processing services perform the job of converting data that is ingested into a form that we can serve to the stakeholders. You can see a visual representation of this layer here:
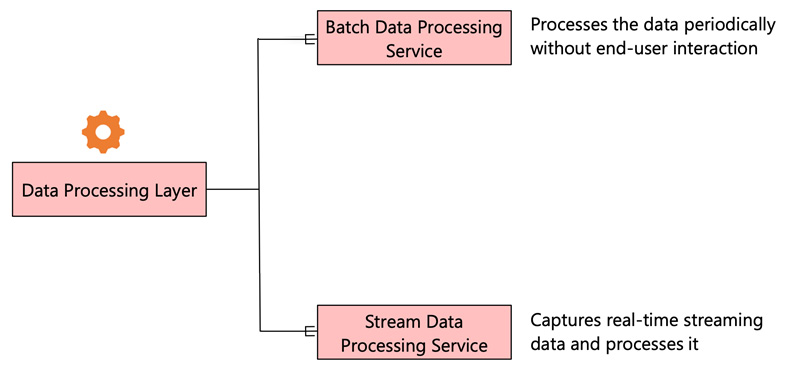
Figure 2.7 – Types of data processing services
There are two types of data processing services, as outlined here:
- Batch Data Processing Service: Batch data processing processes the data periodically without end-user interaction. The data is first landed in the raw data zone. Once the data lands in the raw data zone, the batch processing service picks up the raw data and performs the required transformation. Batch data processing services need to be on-demand and can be scaled as per your needs.
- Stream Data Processing Service: The other kind of processing is stream data processing. This captures real-time streaming data and processes it without needing the data to be landed or stored on a disk. All the stream processing happens in the memory, and data is transformed near real-time. A typical stream data processing service also has a message queuing layer that intermittently captures the data streams and queues them for further processing. When the data stream is ingested and processed, the raw data is sent to the data lake store for storage as one path. Another path does the real-time processing and sends the output for downstream consumption. Finally, the transformed data is also pushed into the data lake layer for persistent storage.
Next, let's cover the data serving layer.
Data serving layer
Once the data is processed, it needs to be served for downstream consumption. The information is made available to various stakeholders, and each of them has requirements tailored to their needs. You can see the services that make up this layer in the following diagram:
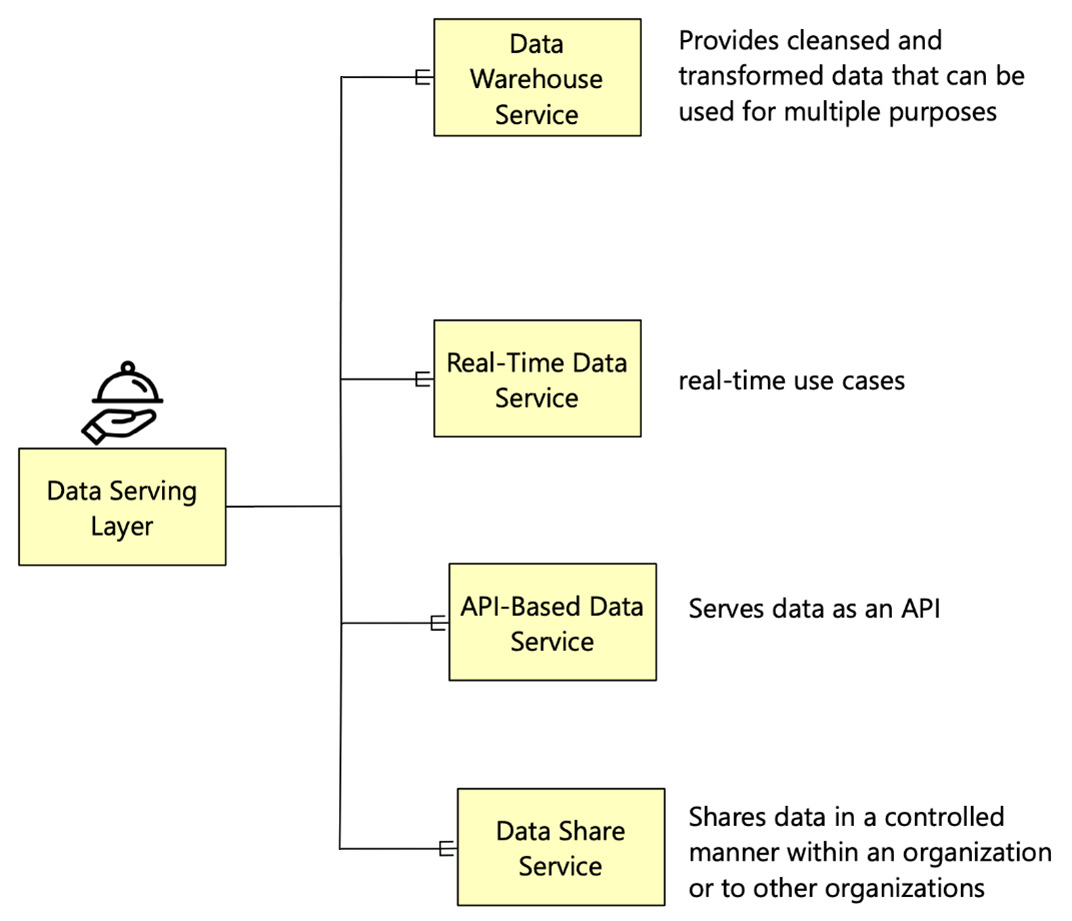
Figure 2.8 – Types of data-serving services
In general, there are four types of data-serving services, outlined as follows:
- Data Warehouse Service: The first type of data-serving service is the data warehouse service. A data warehouse service provides cleansed and transformed data that can be used for multiple purposes. First, it serves as a layer for reporting and BI. Second, it is a platform to query data for business or data analysis. Third, it serves as a repository to store historical data that needs to be online and available. Finally, it also acts as a source of transformed data for other downstream data marts that may cater to specific departmental requirements.
- Real-Time Data Service: The second type of service is to provide real-time data. The real-time data service is used to serve a variety of downstream applications. A few examples of such applications are mobile systems, real-time data provision to downstream applications such as customer relationship management (CRM) systems, recommendation engines on websites or mobile applications, and real-time outlier detection systems such fraud detection. A real-time data service manifests in multiple technology formats and adds tremendous business value if served correctly.
- API-Based Data Service: The third type of service used to share data are API-based data services. An API is an interface that allows applications to interact with an external service using a simple set of commands. Data can also be served as part of API interaction. As the data is exposed to multiple external services, API-based methods can scale to share data securely with external services. Data through an API is served in JSON format, therefore the technology used to serve the data using APIs should be able to support JSON formats. For example, a NoSQL database can store such data.
- Data Sharing Service: The fourth type of service is the data-sharing service. A data sharing data service shares data, in any format and any size, from multiple sources within an organization or other organizations. This type of service provides the required control to share data and allows data-sharing policies to be created. It also enables data sharing in a structured manner and offers complete visibility into how the data is shared and how it is used. A data-sharing system uses APIs for data sharing.
Data analytics layer
The data analytics layer involves the services that extract insights from data. They act as a playground for analysts, data scientists, and BI users to create reports, perform analysis, and experiment with AI/ML models. You can see the services that make us this layer in the following diagram:
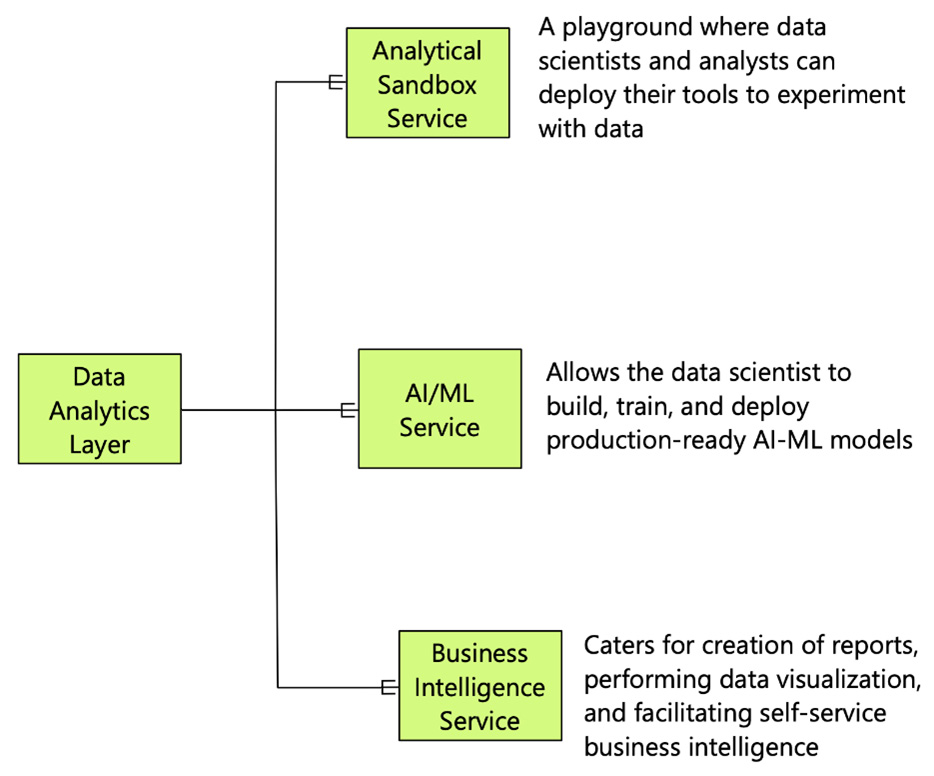
Figure 2.9 – Types of data analytics services
There are three types of services in the data analytics layer, outlined as follows:
- Analytical Sandbox Service: The analytical sandbox is a playground where data scientists and analysts can deploy their tools to experiment with data. The sandbox should provide different kinds of tools for SQL-based analysis and for developing ML models. This layer should also have seamless integration with the data lake layer and the data serving layer. This layer should spin up and shut down sets of tools on an on-demand basis to facilitate rapid experimentation.
- Artificial Intelligence and Machine Learning (AI-ML) Service: AI and ML services are vital components in a modern data analytics platform. The AI-ML service allows data scientists to build, train and deploy production-ready AI-ML models. This layer also provides the framework to maintain and monitor such models. In addition, it gives the ability for teams to collaborate as they go about building these models. This service should be able to scale up and down as required and should be able to facilitate automatic model deployment and operations.
- Business Intelligence (BI) Service: BI services have been around since the days of enterprise data warehouses (EDWs). In the data lakehouse architecture, they fulfill the same function. This service entails tools and technologies for creating reports, performing data visualization, and facilitating self-service BI. It is mainly focused on creating different tabular or visual views of the current and historical views of operations.
Data governance layer
The principle of garbage in, garbage out is also applicable for a data lakehouse. The data in a data lakehouse needs to be governed appropriately, and this layer looks after that. You can see a visual representation of it here:
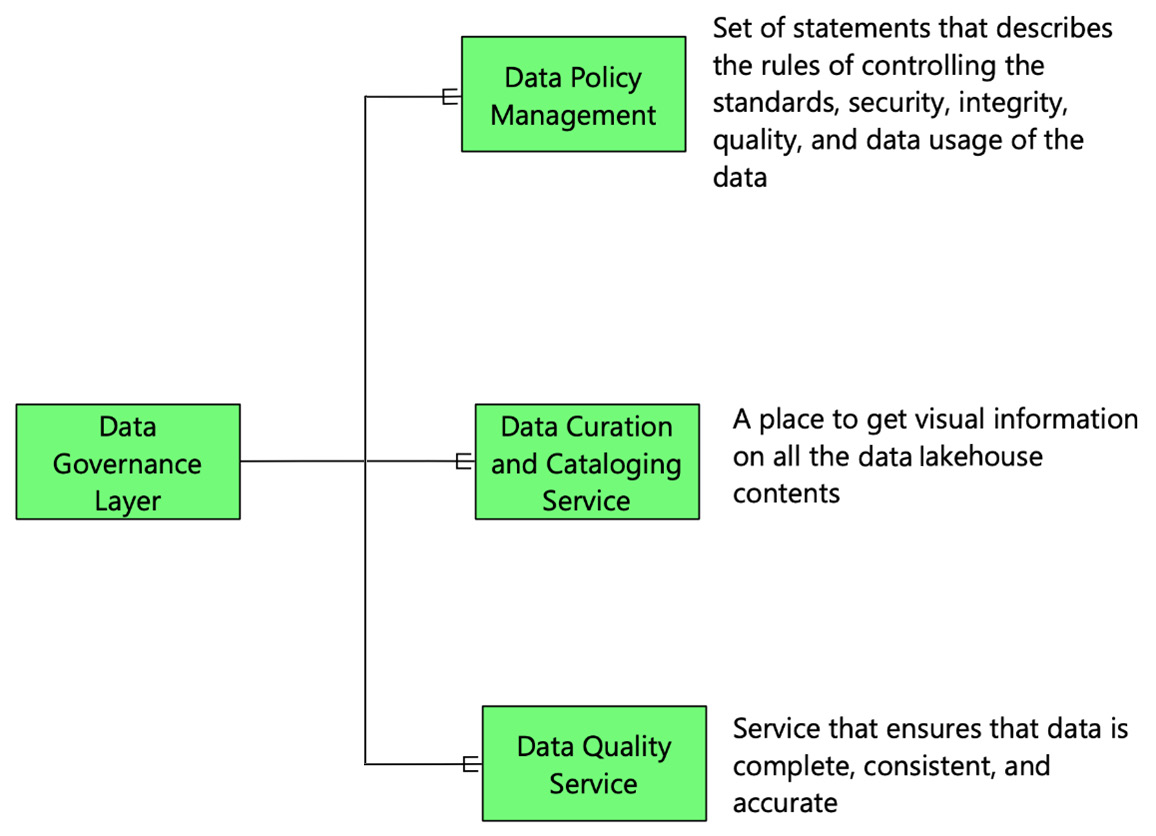
Figure 2.10 – Types of data governance services
Four components help to ensure that the data lakehouse does not become a data swamp. These are outlined as follows:
- Data Policy Management: The first component is not a technology component—it is a set of data policies and standards. A data policy is a set of statements that describe the rules of controlling the standards, security, integrity, quality, and usage of the data in the data lakehouse.
- Data Cataloging and Curation Service: Data cataloging and curation is the process of organizing an inventory of data so that it can be easily identified. This service ensures that all the source system data, data in the data lake and the data warehouse, the data processing pipelines, and the outputs extracted from the data lakehouse are appropriately cataloged. Think of data cataloging services as the Facebook of data—a place to get visual information on all of the data lakehouse's contents, including information about the relationships between the data and the lineage of transformations that the data has gone through.
- Data Quality Service: Any data stored or ingested in the data lakehouse must have a data quality score that determines the reliability and usability of the data. There are many parameters on which the quality of data is determined. A few of these parameters include the completeness of data, the consistency of data, and the accuracy of data. The data quality service ensures that data is complete, consistent, and accurate.
Data security layer
The final layer of the data lakehouse architecture is the data security layer. Data security is intense in itself, and its importance cannot be emphasized enough. You can see the services that make up this layer in the following diagram:
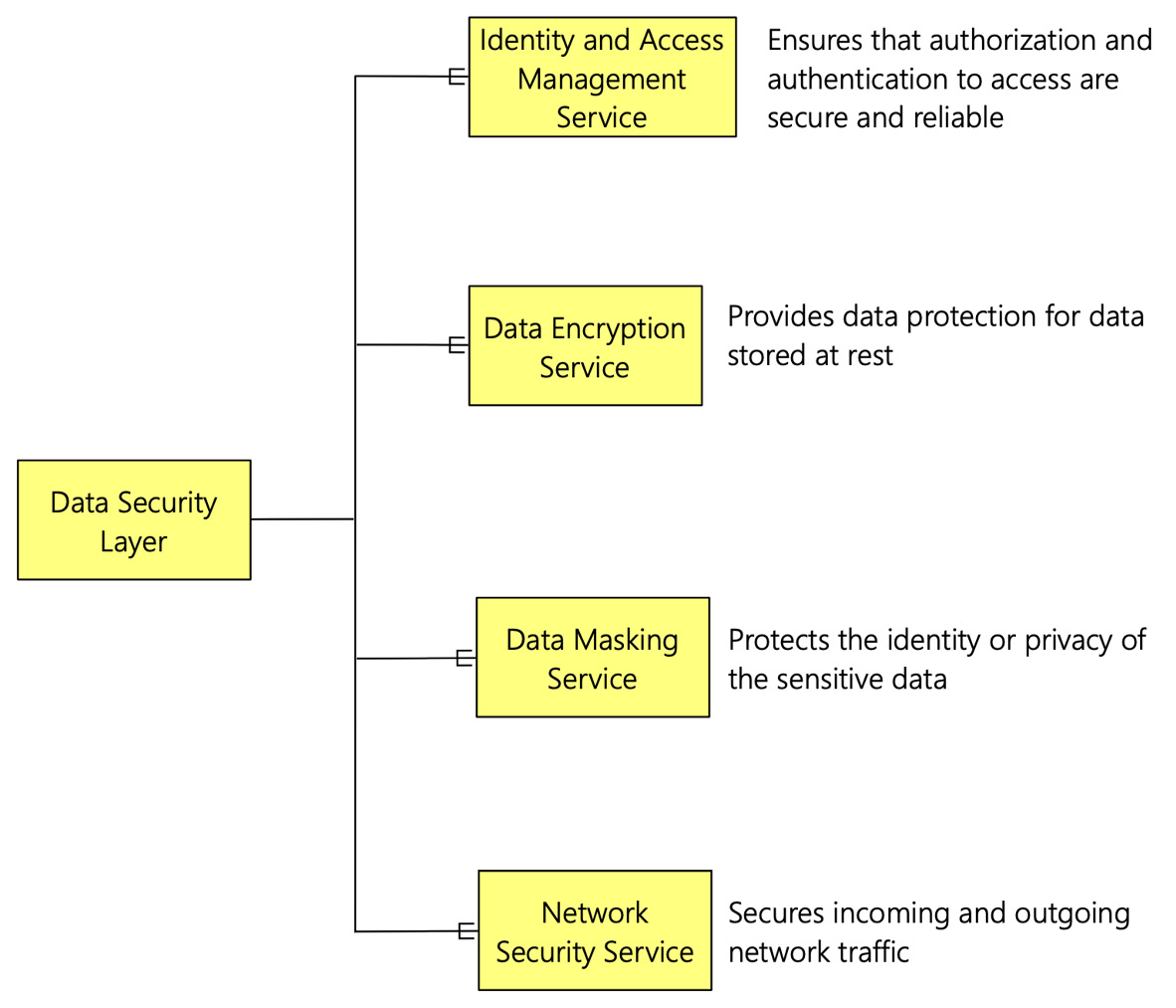
Figure 2.11 – Types of data security services
There are four critical components of the data security layer, as follows:
- Identity and Access Management (IAM) Service: The access to the data lakehouse must be secure and on a need basis. The IAM service acts as a gate for access to the data lakehouse. The IAM service ensures that authorization and authentication to access the data lakehouse are secure and reliable. It provides defense against malicious login attempts and safeguards credentials with risk-based access controls, identity protection tools, and robust authentication options—without disrupting productivity.
- Data Encryption Service: Data encryption is a security method where information is encoded and can only be accessed or decrypted by a user with the correct encryption key. Data encryption is essential when the data is stored in the cloud. Different kinds of algorithms are used to encrypt the data. Encryption provides data protection for data stored at rest. It prevents various types of cyber-attacks and protects sensitive data. Encryption of data may also be required by an organization's need for data governance and compliance efforts. Therefore, the data security layer needs to have the tools to encrypt and decrypt data as required.
- Data Masking Service: Many subsets of data need to be masked to protect the identity or privacy of the individual. This type of data includes emails, social identification numbers, credit card numbers, and so on. Data masking is a way to create a cryptic but readable version of data. The goal is to protect sensitive data while providing a functional alternative when actual data is not needed. The data security layer needs to have the tools to mask this sensitive data and unmask it as required.
- Network Security Services: The data in the Data Lakehouse needs to be secured all the time. The access to the data should be controlled such that any unauthorized access is denied. It also needs to be ensured that the data flowing between the external networks and the Data Lakehouse is secured. The network security service provides these functions.
This section provided an overview of the seven layers of a data lakehouse architecture. Chapters 3 to 7 will cover these layers in detail. The chapters will elaborate on each of these layers and lay out common patterns that are used in practice.
Let's now move on to the architecture principles we will need to apply.
Developing architecture principles
As seen in the preceding section, many components make up a data lakehouse architecture. A data lakehouse architecture needs to be governed by a set of architecture principles that ensure that the data lakehouse can meet its goal of being a flexible platform for AI and BI and being agile to cater to ever-changing requirements.
Architecture principles govern any architectural construct and define the underlying general rules and guidelines for use. We can tailor these principles as per the organization's requirements. However, five principles are sacrosanct. These are represented in the following diagram:
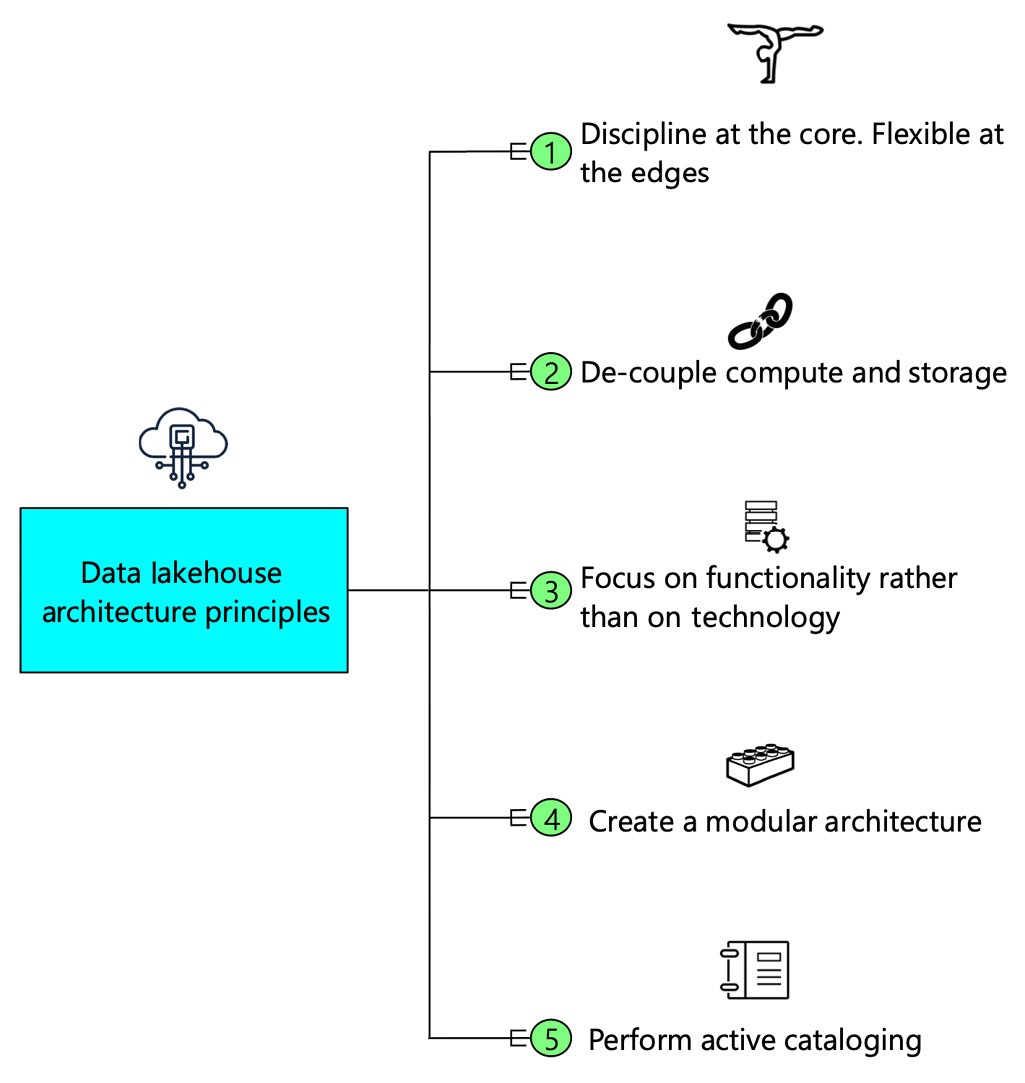
Figure 2.12 – Data lakehouse architecture principles
Disciplined at the core, flexible at the edges
The purpose of creating a new architecture paradigm is to be agile and innovative, yet it needs to be governed pragmatically. This balance is a fine line to tread. The first sacrosanct principle embodies that balance. Being disciplined at the core implies that the layers where data is stored need to be structured in their approach toward data management. These layers need to have detailed governance policies that leave no room for being ambiguous. However, the edges of the data lakehouse, the layers where data is transformed, forged, and made conducive to insights, need to be flexible. Flexibility doesn't mean being haywire in your approach. These layers are still governed within the policies of the data lakehouse. However, they exhibit certain flexibility for creating new features based on the demands of the requirements. An example of being flexible at the edge is mashing raw data from the data lake layer and data warehouse from the data serving layer to create an ML model. These datasets have different levels of quality scores and properties. However, such flexibility is acceptable as it facilitates rapid insight creation.
Decouple compute and storage
A data lakehouse stores a lot of data. It stores data in the data lake layer and the serving layer in structured and unstructured formats. The data needs to be processed with different types of compute engines. It can be a batch-based compute or a stream-based compute. A tightly coupled compute and storage layer strips off the flexibility required in a data lakehouse. Decoupling compute and storage also has a cost implication—storage is cheap and persistent but compute is expensive and ephemeral. It gives you the flexibility to spin up compute services on-demand and scale them as required, and also gives better cost control and cost predictability.
One of the critical challenges in the EDW and data lake pattern was the tight coupling of the compute and storage. The compute needs to be provisioned, whether it is being used or not. As the storage increases, the compute also needs to scale accordingly. Cloud computing platforms provide the flexibility of decoupling compute and storage.
Focus on functionality rather than technology
The next sacrosanct principle is to focus on the functionality of a component rather than its technological avatar. This principle embodies flexibility. As depicted in the system context diagram, a data lakehouse caters to many people. The technology manifestation of a data lakehouse has a plethora of technological choices. It can be deployed on any cloud platform or even on-premises using different types of choices. Also, technology is rapidly changing. Many new products are evolving commercially or in the open source world, focusing on fulfilling a specific functionality. Let's take real-time processing as an example. Apache Storm was a product released in 2011 that was optimized for real-time processing. Apache Spark, open sourced in 2010, gained traction as the de facto stream processing engine by 2013. Apache Spark evolved consistently, and Apache Flink is now challenging Apache Spark's supremacy as a stream processing engine. The technology evolution is rapid. However, the functionality remains the same—stream processing.
Focusing on one task that a component fulfills is essential. Furthermore, as technology evolves, we can easily replace the technology to meet the same functionality.
Create a modular architecture
A modular architecture refers to the design of any system composed of separate components that can connect. The beauty of modular architecture is that you can replace or add any part (module) without affecting the rest of the system.
A modular architecture ensures that a data lakehouse architecture is created flexibly, and we can add new functionality seamlessly without breaking existing functionality. For example, suppose there is a future requirement to add new functionality to the data lakehouse architecture. In that case, a component can be added such that it follows the same pattern as all other components. It gets data from the data lake layer, performs its functionality, and deposits the data into the processed data store for it to be served.
The modular architecture principle ensures that data stays at the core. Different services, based on their functionality, can be instantiated to use data as per the need.
Perform active cataloging
The single most important principle that prevents a data lakehouse from becoming a swamp is the degree of cataloging done within its layers. Thus, performing active cataloging is one of the sacrosanct principles. Cataloging is the key to preventing a data lake from becoming a data swamp. Diligent cataloging ensures that the users of the data lakehouse are data-aware. They should understand the properties of data stored in its various life stages. They need to understand the lineage of data's transformation journey, from its generation to its consumption. All the components that are part of the data lakehouse architecture need to be cataloged to provide a holistic view of the entire data life cycle with a data lakehouse.
Summary
This chapter was a 30,000-feet overview introduction to a data lakehouse architecture. This chapter started with the system context that established the critical systems and people that generate data for a data lakehouse and consume data from it. Next, we discussed the motivations and use cases for different types of data. Once the section clarified the system context, the chapter introduced the logical architecture of a data lakehouse. Next, the chapter provided a brief overview of the seven layers of a data lakehouse and its components. Finally, the chapter concluded with an elaboration of five sacrosanct architecture principles core to a robust data lakehouse architecture. The chapter lays the architectural foundation for a modern data analytics platform. Now that the stage is set, the subsequent chapters will go deeper into each of the layers and discuss design patterns for each layer.
In the next chapter, we will cover storing data in a data lakehouse.
Further reading
- Developing a Data View (opengroup.org): http://www.opengroup.org/public/arch/p4/views/vus_data.htm
- Architectural Artifacts: https://pubs.opengroup.org/architecture/togaf9-doc/arch/chap31.html
- Architecture Principles: https://pubs.opengroup.org/architecture/togaf8-doc/arch/chap29.html
- System context diagram (Wikipedia): https: //en.wikipedia.org/wiki/System_context_diagram
- Lambda architecture (Wikipedia): https: //en.wikipedia.org/wiki/Lambda_architecture