
Chapter 5
DATA INVENTORY CONCEPT
Inventorying data is the first step to resolving data disparity.
The first step toward integrating a disparate data resource is to inventory the existing data. The existing data may be in operational data files, in evaluational data files, in data models, on screens, reports, and forms, in a variety of documentation, or in people’s minds. All of these sources need to be identified and documented to fully understand the existing disparate data resource.
Chapter 5 describes the concepts and principles for inventorying disparate data, the structure for documenting that inventory, and the various components of a disparate data resource that could be inventoried. Chapter 6 describes the actual process and techniques for inventorying and documenting disparate data using the material described in the current chapter.
CONCEPTS
The first major problem that public and private organizations face today, as mentioned in Chapter 1, is that they do not know all of the data that they have at their disposal. Various organization units and individuals know the data that they have available. However, the organization at large does not know all of the data it has at its disposal.
Most organizations do not have a complete inventory of their entire data resource, in one place that is readily available to anyone in the organization. I’ve found, after being involved with the disparate data in many public and private sector organizations, that only about 15% of the organization’s data are inventoried or documented in any manner. When people can’t find the data they need, they will likely create their own data, which increases the data disparity.
The first step to resolve data disparity and begin the data resource integration process is to inventory the existing disparate data. Inventorying disparate data solves the first basic problem of disparate data—a lack of awareness of data, within or without the organization, that are at the organization’s disposal. Inventorying disparate data sets the stage for understanding those data and transforming them to a comparate data resource.
The data inventory concept and data product concept describe what is captured during the data inventory process and how the data inventory is documented.
Data Inventory Concept
Inventory is an itemized list of assets; a catalog of the property of an individual or estate; a list of goods on hand; a survey of natural resources; a list of traits, preferences, attitudes, interest, or abilities; the quality of goods or materials on hand. It is also the act or process of taking an inventory.
A data inventory is the process of identifying and documenting all of the data at an organization’s disposal so those data can be readily understood and used to develop and maintain a comparate data resource that supports the business information demand. It begins the process of understanding disparate data and developing a comparate data resource within a common data architecture.
The data inventory concept is that all data at the organization’s disposal will be completely and comprehensively inventoried, and documented in one location that is readily available to anyone in the organization, so that the organization at large understands the content, meaning, and quality of those data.
The data inventory objective is to identify, inventory, and document all data that currently exist in the organization’s data resource or are readily available to the organization so that those data can be readily understood and used to support the current and future business information demand. It raises the awareness of the data that exist and solves the first problem with disparate data.
The data inventory process identifies the existing data, collects the existing documentation, and enhances that documentation with additional insights. The data inventory process is sometimes referred to as retro-documenting. However, that term in not used because it implies documentation only and not a formal inventory.
The data inventory process identifies the existing data, collects the existing documentation, and enhances that documentation with additional insights.
Inventory Analogy
A traditional data inventory only lists the data available to the organization, but does not help the organization integrate those data because no common base exists for understanding that inventory.
For example, several different organizations keep inventories of plumbing items. Organization A installs plumbing systems and deals with only one-inch pipe, valves, and unions. It’s implied within the organization that all plumbing items are one-inch steel and that all valves are gate valves. Organization B carries all types of valves and its interest is only in the types of valves, such as gate, ball, and so on, and the sizes of valves. It’s implied within the organization that all items are steel valves. Organization C carries all types of pipe and its interest is in the size and composition of pipe, such as steel, copper, plastic.
A traditional inventory of plumbing items from these three organizations would produce three lists that could not be easily integrated. Organization A’s inventory would list the number of pipes, valves, and unions, but would show nothing about size or material. Organization B’s inventory would list quantities by size and type of valve, but indicate nothing about the material. Organization C’s inventory would list quantities of pipe by size and material, but knows nothing about the item. Finding the proper plumbing item from these lists would be difficult and would require additional information.
A common nomenclature provides a base for identifying plumbing parts and for inventorying the items in each organization. Each organization’s inventory shows the type of item, the size, the material, and the quantity. The individual inventory lists are easily combined to identify the existence of plumbing items available in each organization. Development of a common nomenclature requires the participation of all three organizations. It also requires that each organization cross-reference its item descriptions to the common nomenclature.
The same situation exists for data. Each organization, and often each organization unit, has its own data naming, data definition, and data structuring conventions. Any data inventory these organizations produce cannot be readily integrated into a common data inventory, any more than the plumbing inventories could be integrated. Therefore, a formal construct is needed for inventorying disparate data.
Data Product Concept
The formal construct for inventorying is the concept of data products. The data product concept is that the existing data resource, any documentation about the existing data resource, and any insights people have about the existing data resource are a product of some development effort. It’s those products that need to be identified and documented to fully understand the existing disparate data.
The documentation of those products is done within a data product model. The data product model is a subset of data resource data architecture pertaining to documentation of an organization’s disparate data resource. The input for the documentation comes from the data inventory process.
Semantics and Structure
Data resource integration is based on both semantic integration and structural integration, as described in Chapter 2. The data inventory starts that integration process by breaking down the existing data products to their basic components based on both meaning and structure. Any difference in meaning and any combination of business facts in data product items or data properties in data product codes are broken down into their basic components.
PRINCIPLES
The data inventory principles include recognizing that data disparity exists, increased understanding of the disparate data, a simple approach, a detailed approach, changes over time, and data provenance. Each of these principles is described below.
Data Disparity Exists
Data disparity exists in nearly every public and private sector organization. It’s a fact that must be faced and resolved during data resource integration. Data disparity exists with all components of the data, including data names, data definitions, data structure, data integrity, and data documentation. The disparity is described in detail in Chapter 3 on Integrating the Data Resource.
Disparate data have very informal data names. Many disparate data names are short, inconsistent, and often meaningless. Disparate data names often create synonyms and homonyms. They provide little insight into the content or meaning of the data. A disparate data name is any informal data name in the disparate data resource. An explicit disparate data name is a disparate data name that exists in the data resource, such as a data file name. An implicit disparate data name is a disparate data name that is implied through a definition, contents, or use of the data.
The task of forming data names for disparate data is relatively easy. The Data Naming Taxonomy can be used to provide unique names for disparate data, as described below. I was able to uniquely identify any piece of data in public sector agencies in the State of Washington using the Data Naming Taxonomy.
Disparate data have very vague data definitions that are short, truncated sentences or phrases, if they exist at all. Disparate data definitions range from an elongated data name to data entry instructions and use of the data, but seldom provide any real understanding of the data with respect to the business.
A disparate data definition is any vague definition about the data in the existing data resource. An existing disparate data definition is a disparate data definition that currently exists in a data dictionary, database management software, or some other form of documentation. An enhanced disparate data definition is a disparate data definition that is enhanced in some way based on insight gained from another source, such as a person’s memory.
The task of finding comprehensive definitions for disparate data can be frustrating and confusing for most people. However, developing good comprehensive data definitions for disparate data is necessary for a thorough understanding of the data and for accurate cross-referencing to a common data architecture.
Disparate data usually have improper data structures. A disparate data structure is any improper data structure that exists in the data resource. An explicit disparate data structure is a disparate data structure that is explicitly defined in the documentation or in a data model. An implicit disparate data structure is a disparate data structure that is not explicitly defined and is implied through the use of foreign keys.
The task of finding disparate data structures is also frustrating and confusing. Quite often, the foreign keys need to be identified and used to identify the disparate data structure. However, documenting the existing structure of disparate data is necessary for understanding those data and developing a comparate data resource.
Disparate data almost always have imprecise data integrity rules, if they even exist. The data integrity rules that do exist may be conflicting or incompletely defined. A disparate data integrity rule is any data integrity rule that exists in the data resource. An explicit disparate data integrity rule is a disparate data integrity rule that is explicitly stated in the data documentation or in a data model. An implicit disparate data integrity rule is a disparate data integrity rule that is not explicitly stated in the documentation or in a data model, but exists in database management systems or applications.
The task of finding the existing data integrity rules can be quite daunting. The data integrity rules may be buried in database edits or application edits, and may not be formally documented. The data integrity rules may even be buried as edits in the processes that people perform before the data are entered into the database. All of these existing data integrity rules need to be identified and documented.
Increased Understanding
Inventorying disparate data begins the process of understanding those data so they can be transformed into a comparate data resource. The disparate data understanding principle was described in the last chapter. That principle applies to understanding what data exist in the disparate data resource through the data inventory process.
Understanding what data exist raises awareness and begins lowering uncertainty. Data awareness is the knowledge about all of the data that are available to the organization and where those data are located. When people know what data are available, within or without the organization, they can readily use those data to support business activities. Data awareness often uncovers the hidden data resource that most organizations did not know existed.
The all-inclusive data inventory principle states that all existing data, or references to data, will be inventoried and cross-referenced to a common data architecture so they can be thoroughly understood in a common context. No existing data or references to data, such as data files, reports, screens, documents, dictionaries, data flows, and so on, will be exempt from the data inventory and data cross-reference processes, although priorities may be designated.
Simple Approach
Albert Einstein’s simplexity principle was described in Chapter 2. That principle applies to the data inventory process. The data inventory process and documentation of that inventory in a data product model is the simplest approach possible to documenting the existing disparate data.
Albert Einstein also made the statement We are seeking for the simplest possible scheme of thought that will bind together the observed facts.1 That statement readily applies to the inventorying and documentation of disparate data. The observed facts are details obtained during the data inventory process, and the data product model is the simplest possible scheme to bind those details together for understanding the disparate data.
Detailed Approach
The data inventory process, although very simple in principle, is very detailed. All of the detail possible must be identified and documented to fully understand the disparate data. The opt for detail principle states that when in doubt about the level of detail to document during the data inventory, always opt for greater detail. Experience has shown that more detail is needed to fully understand and integrate the data resource.
The best approach is to break down the detail during the data inventory process, not during the data cross-reference process. All of the data variability described in the last chapter is identified and broken down to an elemental level during the data inventory process, when the detail is readily available. Waiting until the data cross-reference process to break down the detail is difficult and time consuming because you have to return to the data inventory process to make the breakdown. Therefore, the most efficient approach is to break down all of the detail during the data inventory process.
Continuous Enhancement
Thoroughly understanding disparate data is a continuous process. The continuous enhancement principle states that documentation of disparate data should be continuously enhanced as additional insight is gained. Documenting and understanding disparate data is not a one-time process—it’s an ongoing process through all phases of data resource integration. Any time additional insight about disparate data is gained, that insight must be documented.
The challenge with data resource integration is determining what the disparate data represent with respect to the business. Each piece of data and each insight into what those data represent must be captured and stored in the data product model. Identifying and documenting all of the detail is a continuous process that begins with the data inventory and continues through data transformation.
I hear some data modelers use the term artifact when referring to disparate data. They state that each artifact must be readily understood and documented. I prefer not to use the term artifact because the business professionals may not consider the disparate data as artifacts, because those data are key to the business, in spite of the disparity. Philosophically, the disparate data may be artifacts, but professionally they should not be referred to as artifacts.
Changes Over Time
The data resource in most public and private sector organizations changes over time. The data values change to represent the current state of the business. New data are added and data that are no longer needed are removed. The disparity of the data may increase or decrease depending on data resource management activities.
Data names and definitions change, data structure changes, data integrity rules change, and data documentation changes. The changes may be slight or they may be major. The changes may be very obvious or they may be very transparent. The changes may improve the data resource or may make the data resource more disparate. The general trend is that these components tend to make the data resource more disparate.
Organizations must face data resource changes that occur over time, and make sure that those changes improve the data resource. One way to make sure that future changes are for the better is to document the past changes. The change documentation principle states that all changes to the data resource that occur over time must be identified and documented, no matter how slight or major those changes may be.
Data Provenance
Provenance comes from the French provenir, meaning to come from. It represents the origin or source of something, the history of ownership, or the current location of an object. The term is used mostly for precious artwork, but is now used in a wide range of fields, including science and computing.
Data provenance is provenance applied to the organization’s data resource. The data provenance principle states that the source of data, how the data were captured, the meaning of the data when they were first captured, where the data were stored, the path of those data to the current location, how the data were moved along that path, and how those data were altered along that path must be documented to ensure the authenticity of those data and their appropriateness for supporting the business. Any gap along the pathway leads to questionable data integrity.
Heritage is property that descends from an heir, something transmitted by or acquired from a predecessor, or something possessed as a result of one’s natural selection or birth. Heritage usually applies to biological or cultural descendants, but can be applied to data.
Data heritage is documentation of the source of the data and their original meaning at the time of data capture. It’s the content and meaning of the data at the time of their origination and as they move from their origin to their current data location. It describes the original content and meaning of the data when initially captured.
Lineage is the direct descent from an ancestor or common progenitor to the descendants of a common ancestor that is regarded as the founder of the line. Lineage is commonly used for biological or cultural descendants, but can be applied to data.
Data lineage is a description of the pathway from the data source to their current location and the alterations made to the data along that pathway. It is a process to track the descent of data values from their origins to their current data sites. It includes determining where the data values originated, where they were stored, and how they were altered or modified. It’s a history of how the content and meaning of the data were altered from their origin to their present location.
A data origin is the location where a data value originated, whether those data were collected, created, measured, generated, derived, or aggregated.
Data tracking is the process of tracking data from the data origin to their current location. It documents any alterations or modifications to the data, the addition of new data, and the creation of derived or aggregated data. It’s a process to help understand and manage the movement of data within and between organizations.
Internal data tracking is data tracking in an environment where the organization has control of the data. It usually deals with data tracking within an organization, where changes to the data may be known. External data tracking is data tracking in an environment where the organization does not have control of the data. It usually deals with data tracking between organizations, where changes to the data may not be known.
Data provenance is very important for understanding data in a disparate data resource and must be documented. Data that have traveled a long pathway and have passed through many different data sites along that pathway tend to show semantic and syntactic drift. Different data origins and different pathways usually mean different data. How much difference is important to the organization depends on the particular data and the organization.
DATA INVENTORY DOCUMENTATION
Disparate data are quite variable, as described in Chapter 4. Documenting that variability is not an easy task; however, it is far from impossible. The structure for documenting an organization’s disparate data is described below. How that structure is used during the data inventory process is described in the next chapter.
Note that some of the terms used for data inventory have been changed from previous books, articles, and presentations. The changes in terms represent a better understanding about how to inventory and document disparate data. That better understanding resulted from years working with the disparate data in a wide variety of public and private sector organizations.
Data Product Model
The structure of the data product model is shown in Figure 5.1. Only the structure portion of the data product model is shown because that’s the most important for understanding how the data inventory is documented. The other details of the data product model are beyond the scope of the current book. Each of the data entities in the data product model is described below.
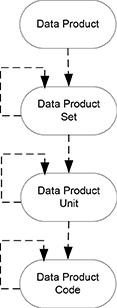
Figure 5.1. Data product model diagram.
Data Product
A data product is a major independent set of documentation of any type that contains the names, definitions, structure, integrity, and so on, of disparate data. It’s anything about the data resource, electronic or manual, that is a product of some development effort. A data product can be an information system, a database, a data dictionary, a major project, a major data model, or anything else that provides insight into the existing disparate data. It is the highest level in the data product model.
Data Product Names
Data products must be uniquely named within the organization. Generally, a unique name does not exist for data products and needs to be created. A unique data product name is created when the data product is first identified to be inventoried. Organizations must plan ahead for developing consistent and unique data product names from the beginning of the data inventory process, with consideration for the ultimate scope of the data inventory.
If the data product names are not unique, the identification of disparate data will not be unique and the data inventory effort will not be successful. For example, using data product names like Health, County, Financial, and Traffic may initially seem unique, but will probably lose their uniqueness as additional data products are identified.
A unique data product name could include the organization, a location, a topic, and so on. For example, data product names like Health Department Data Dictionary, Johnson County Water Sampling Project, State Financial Information System, State Police Traffic Investigation System, and so on, are acceptable. Water Sample Logical Model, Vehicle Accident Logical Model, and Financial Account Physical Model might be typical data model names.
Data Product Definitions
Generally, data products do not have good definitions, if they have any definition at all. However, developing a good data definition is necessary for a thorough understanding of the disparate data and for accurate cross-referencing. Therefore, a comprehensive definition of the data product defining the data product and the scope of the data included in that data product must be developed.
If a data product definition does exist, it’s a poor practice to assume that the definition is complete and accurate—it probably isn’t. Most existing data product definitions were either developed early in a project and forgotten, or developed after the project was completed. Definitions developed early in the project probably changed during the project, but were never enhanced. Definitions developed after the project was completed were likely done quickly and were based on memory, which is poor, at best.
Data product definitions usually need to be developed, or at least enhanced, during data inventory. The data product definitions must comprehensively define a data product and the scope of data included in that data product. Other pertinent information, such as when the data product originated, who or was is responsible for the data product, and so on, is also quite useful.
Data Product Set
A data product contains one or more data product sets. A data product set is a major grouping of data within a data product. It may represent a data file, a data record, a data record type, a screen, a report, a form, a data entity, an application program, and so on.
Data Product Set Variations
A data product set variation is a recursion of a data product set to document multiple variations contained in a data product set. However, only one level of recursion is allowed. The data product set variation is not intended to document a hierarchy of data product sets. A data product set variation could be a data record type, a data entity type, changes over time, or any other breakdown of a data product set.
For example, a data file contains data items about computer hardware. Each hardware component does not contain the same data items. Different data items are placed in the same physical data fields, but their meaning depends on the record type. The three record types might be 1 for Computer Record, 2 for Controller Record, and 3 for Modem Record. The first data item in each record type might represent Hardware Computer Channel Count, Hardware Controller Port Count, and Hardware Modem Baud Rate, respectively. Each of these data record types would be documented as a data product set variation.
Data Product Set Names
Data product set names may exist, or are usually easy to identify. They may be physical data file names, report or screen names, or a data entity name. The data product set name must be unique within a data product. Similarly, the data product set variation name must be unique within a data product set. These names do not need to be unique within the scope of a disparate data resource. The task of creating unique data product set and data product set variation names within a disparate data resource would be quite difficult.
For example, PERS_DATA_NEW, BUDGET_DATA, and WESTERN_REGION are typical data file names. Daily Financial Transaction Report, Monthly Vehicle Summary, and Water Sample Analysis Results are typical report, screen, or form names. Student, Stream Segment, and Timber Stand are typical data entity names.
When these data product set names are combined with the data product name according to the data naming taxonomy they become unique, as shown below.
State Auditor: PERS_DATA_NEW
Financial Information System: Daily Financial Transaction Report
Woodland County: Water Sample
Data Product Set Definitions
Data product set and variation definitions usually do not exist for data records, data record types, screens, reports, forms, and so on. Similarly, data product set variation definitions seldom exist. Comprehensive definitions need to be prepared for data product sets and data product set variations to help people thoroughly understand what they represent.
A data product set definition must describe the data product set with respect to the data product. A data product set variation definition must describe the variation with respect to the data product set. These definitions can be enhanced any time additional insight is gained about their meaning.
If a data product set being inventoried is exactly the same as another data product set that has already been inventoried and documented, it does not have to be inventoried and documented any further. A statement is made in the data product set definition specifying the name of the other data product set to which it is equivalent. The inventory and documentation of that other data product set applies.
Data Product Set Scope
A data product set scope statement describes the scope or extent of the data product set or variation. The scope could be a subset of data, a selection of data, or the role of the data. The scope statement may contain a textual description of the scope of the data product set or variation, and it may contain data selection rules describing how the subset of data were obtained. The scope statement is separate from the data definition and the data integrity rules.
Data Product Set Integrity Rules
Any data integrity rules between data occurrences within a data product set or variation representing a data entity or data file need to be documented. Also, any data derivation of and data retention for a data occurrence need to be documented. Generally, these data integrity rules don’t exist and need to be located and documented. They can usually be found in database management systems, applications, or ancillary documentation. If they do exist, they need to be verified to determine if they are actually enforced.
Data Product Unit
A data product set contains one or more data product units. A data product unit is any unit of data within a data product set, such as data attribute in a data model, a data item in a data record, a data field on a screen or report, a data item in a program, and so on.
Data Product Unit Variations
A data product unit variation is a recursion of a data product unit to document multiple variations contained in a data product unit. However, only one level of recursion is allowed. The data product unit variation is not intended to document a hierarchy of data product units.
A data product unit variation could be used to break down multiple, variable, and complex data items into their individual components. It could be used for changes over time. Each of these situations should be broken down to their lowest level and documented as a data product unit variation. The definition would describe the actual breakdown.
Data Product Unit Names
Data product units are uniquely named within a data product set. Usually, data product unit names are easy to identify and are shown as they appear in the source material. The name is not changed in any way, including, format, spelling, capitalization, underscoring, abbreviation, and so on. The reason the data product unit names are retained as they appear is for ready identification and to draw people into the data inventory process. If the name is changed in any way, it tends to alienate people and they won’t become involved.
If the source is a database, the data product unit names are documented in the exact sequence shown in the database. They are not rearranged in any way. If the source is a screen, report, or form, try to follow a set sequence of right to left and then down. Keeping a regular sequence draws people into the data inventory process. Changing the sequence tends to alienate people.
Data product unit variation names usually need to be created because they don’t appear in the source. The name needs to be unique within a data product unit, just like the data product unit name. A consistent routine should be followed for creating the data product unit variation names similar to the data product unit name.
For example, EMP_BD, SHIP_DT, TYPE, CODE, STATUS, and DATE are typical data product unit names. When these data product unit names are combined with the data product and data product set names according to the data naming taxonomy they become unique, as shown below:
State Auditor: PERS_DATA_NEW. EMP_BD
Financial Information System: Daily Financial Transaction Report. Total Expenditures
Woodland County: Water Sample. Date Collected
Data Product Unit Definitions
Data product unit definitions are usually short phrases or single sentences, and are usually oriented to the capture, entry, storage, or use of the data. Seldom do data product unit definitions define the content and meaning of data with respect to the business because that wasn’t the intent at the time the data were documented.
These definitions should be retained as they are stated in the original documentation. However, as insight is gained, the definitions should be enhanced to provide the meaning of the data with respect to the business. Enhancements could also include statements about the accuracy of data. The enhanced definitions should be comprehensive to aid in understanding and cross-referencing to the common data architecture, and should contain the date, the person making the enhanced definition, any source the person used, and so on,
Data Product Unit Integrity Rules
Any data integrity rules for a data product unit or between data product units need to be documented. Any data derivation and data retention rules should also be documented. Generally, some data integrity rules exist, usually as data edits, but are contained in database management systems or applications. In some situations, the data integrity rules are implemented by people reviewing the data before entry into the database. All data integrity rules must be identified and documented, and a determination made about the extent to which they are enforced.
Data Product Code
A data product unit or data product unit variation could contain many data product codes. A data product code is any coded data value that exists in a data product unit or data product unit variation. It represents a specific property of the subject of interest. For example, data product codes within a management level data product unit might be E for Executive, M for Manager, S for Supervisor, L for Lead worker, and W for Worker.
A data product code may have any combination of coded data values, names, and definitions. The data product code might not have a coded data value with only a name or a definition. It might have only a name or a code and a name. It might have a code, a name, and a definition. In some situations, it has a text field, which might be a name, a long name, or a short definition. All of these situations are considered data product codes.
Data Product Code Variations
A data product code variation is a recursion of a data product code to document multiple variations contained in a data product code. However, only one level of recursion is allowed. The data product code variation is not intended to document a hierarchy of data product codes.
A data product code variation could be used to break down multiple and complex property data product codes, multiple subject data codes, and mixed subject and complex subject data code sets to their individual components. It could be used for changes over time. Each of these situations should be broken down to their lowest level and documented as data product code variations. The definition would describe the actual breakdown.
Data Product Code Values
If the data product code has a coded data value, that data value is documented as a data product code. If the data product code has no coded data value, that field is left blank.
Data Product Code Names
If a data product code has a name, that name is documented with the data product code. The name is documented as it appears in the data resource, the same as with data product units. If the data product code has no name, that field is left blank.
Data Product Code Definitions
Many times it’s difficult to determine whether a textual phrase for a data product code is a name or a short definition. In many situations, the name is considered to be the definition. If both a name and a definition exist, the definition is usually a short phrase that provides little meaning about what the data product code represents. Any definition that does exist must be retained and enhanced as additional insight is gained.
If a short textual phrase appears, a determination will need to be made whether that phrase is the name or a short definition. Usually by looking at the entire domain of data product codes, a determination can be made if the text represents a name or a definition.
Data Relation Diagrams
Diagrams may exist, or could be developed, to show data files and the data relations between those data files, or data entities and data relations between those data entities. Each of these situations is described below.
Data File-Relation Diagrams
A data file-relation diagram shows the arrangement and relationships between data files. It contains only the data files and the data relations between those data files. It does not contain any of the data items in those data files. Ideally, it is developed from the formal denormalization of a data entity-relation diagram that was developed during logical data modeling. Data entities are converted to data files according to formal data denormalization criteria. However, disparate data files are often developed without any formal data normalization or data denormalization.
Data file-relation diagrams seldom exist for disparate data. If they do exist, a variety of different symbols and notations may have been used, depending on what the developer decided to use at the time. The symbols and notations are seldom consistent across different diagrams, and may not be consistent on a single diagram. However, the diagrams do provide some insight into the data files and the data relations between those data files.
Existing data file-relation diagrams should be reviewed to determine if they accurately represent the disparate data. If they do adequately represent the disparate data, they can be documented. If they do not adequately represent the disparate data, they should be enhanced to adequately represent the disparate data.
If data file-relation diagrams do not exist, they should be developed. The best approach is to prepare an initial data file-relation diagram and continually enhance that diagram as additional insight is gained about the disparate data. Some organizations choose to redraw all the data file-relation diagrams so they use consistent symbols and notations.
A formal data file-relation diagram is developed using two symbols that are consistent with semiotic theory. An oval represents a data file, with the name of the data file inside the oval. A dashed line represents a data relation between data files. A dashed line with an arrow on one end designates a one-to-many data relation, which is the most prominent data relation for physical data. A dashed line with no arrows represents a one-to-one data relation, and seldom exists in disparate data. A many-to-many data relation does not exist between data files.
For example, a data file-relation diagram containing four data files for Employee, Department where the employee works, Position that the employee occupies, and Pay Checks that the employee receives is shown in Figure 5.2.
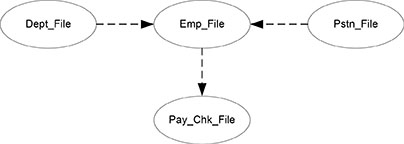
Figure 5.2. Data file-relation diagram example.
Data file-relation diagrams are documented in the data product. The documentation can either be storage of the actual data file-relation diagram, or reference to an external location where the diagram is stored.
Data Entity-Relation Diagrams
A data entity-relation diagram shows the arrangement and relationships between data entities. It contains only data entities and the data relations between those data entities. It does not contain any of the data attributes in those data entities, nor does it contain any roles played by the data attributes. Ideally, it is developed from the formal normalization of data that the business needs. However, disparate data are often developed without any formal data normalization.
Data entity-relation diagrams seldom exist for disparate data. If they do exist, a variety of different symbols and notations may be used, and are seldom consistent across diagrams. However, the diagrams do provide some insight into the data entities and the data relations between those data entities.
Existing data entity-relation diagrams should be reviewed to determine if they accurately represent the disparate data. If they do adequately represent the disparate data, they can be documented. If they do not adequately represent the disparate data, they should be enhanced.
If data entity-relation diagrams do not exist, they should be developed. The best approach is to prepare an initial data entity-relation diagram and continually enhance that diagram as additional insight is gained about the disparate data. Some organizations choose to redraw all the data entity-relation diagrams so that they have consistent symbols and notations.
A formal data entity-relation diagram is developed using two symbols that are consistent with semiotic theory. A box with bulging sides represents a data entity, with the name of the data entity inside the oval. A dashed line represents a data relation between data entities. A dashed line with an arrow on one end designates a one-to-many data relation, which is the most prominent data relation for logical data. A dashed line with no arrows represents a one-to-one data relation, and seldom exists in disparate data. A dashed line with an arrow on each end represents a many-to-many data relation. A typical data entity-relation diagram is shown in Figure 5.1 above.
Data entity-relation diagrams are documented in the data product. The documentation can either be storage of the actual diagram, or a reference to an external location where the diagram can be found.
Data Product Keys
Data relations are identified by data keys, specifically primary and foreign keys. A primary key is a set of one or more data attributes whose values uniquely identify each data occurrence in a data entity in a logical data model. In a database, a primary key is a set of one or more data items whose values uniquely identify each data record in a data file. In logical data models, a foreign key is the primary key of a data occurrence in a parent data entity that is placed in each data occurrence of a subordinate data entity to identify the parent data occurrence in that parent data entity. In data files, a foreign key is the primary key of a data record in a parent data file that is placed in each data record of a subordinate data file to identify the parent data record in that parent data file.
Ideally, the primary keys and foreign keys are defined in logical data models according to formal data normalization, and may be adjusted during formal data denormalization. In addition, more than one primary key may be defined during logical data modeling. During formal data denormalization, one of those primary keys is designated as the preferred primary key for the physical database, and the corresponding foreign key is defined.
However, that process seldom happened with disparate data. Formal data normalization and denormalization may or may not have occurred. Primary and foreign keys may or may not have been formally defined, or if defined, are not readily apparent. The result is often great difficulty identifying the primary and foreign keys and the corresponding data relations.
Data relations are not documented during in the data inventory. Only the primary and foreign keys are documented, and are used to identify the existence of a data relation. However, identifying primary keys and foreign keys in disparate data is not always an easy task because they are often not readily apparent. In some situations, they don’t even exist because databases were built without the concept of a primary key.
Primary keys may exist, but be buried in another data item, such as a large control number. The corresponding foreign key may contain the entire data item, or only the portion of the data item that is necessary for unique identification. Primary keys may be designated, but may contain more data items than are necessary for unique identification. The corresponding foreign key may contain all of the data items, or only the data items necessary for unique identification. The primary key may be correctly defined, but the foreign key may have that primary key imbedded as part of a larger data item. The expect anything principle definitely applies to primary and foreign keys.
Both primary and foreign keys need to be identified and documented to understand the data relations and navigation in the database. The best approach is to identify data items forming a primary key that are required for uniqueness, and then look for those data items in subordinate data files. Remember, however, that the actual data names may be different.
Physical primary and foreign keys are documented in the data product set that represents a data file. The data product set name is Employee. The primary key is EMPL_SSN. The two foreign keys are to Department, using DEPT_ID, and to Job Class, using JBCLS_ID. The data primary and foreign keys are documented as shown below.
EMPL
Primary Key: EMPL_SSN
Foreign Key: DEPT DEPT_ID
Foreign Key: JBCLS JBCLS_ID
Logical primary and foreign keys are also documented in the data product set that represents a data entity, as shown below. The primary key has multiple data items. Foreign keys for Department and Academic Term are shown.
Education Course
Primary Key: Department. Code
Course. Identifier
Academic Term. Code
Foreign Key: Department Department. Code
Foreign Key: Academic Term Academic Term. Code
When multiple primary keys are identified, all are listed. Ideally, any data item or set of data items that uniquely identify a data record, or any data attribute or set of data attributes that uniquely identify a data occurrence, are listed as primary keys. Listing all possible physical primary keys helps identify foreign keys in other data files. Similarly, listing all possible physical foreign keys helps identify possible relations to other data files.
Any description of the data relation is listed with the foreign key, such as a name for the data relation, general data cardinality, or comment. Specific data cardinality is documented as a data integrity rule.
Primary keys and foreign keys may change over time, like other disparate data. These changes over time need to be documented so that people can thoroughly understand the disparate data.
Other Forms of Data
The material above deals largely with operational data in databases, data on traditional screens, reports, and forms, and with logical and physical operational data models. In other words, it deals largely with operational data in the data space.
However, operational summary data exist in the data space and need to be inventoried and documented. In addition, analytical data exist in the aggregation space, and predictive data exist in the influence and variation space. Complex structured data can be operational, analytical, or predictive. All of these types of data need to be inventoried and documented to provide a complete understanding of the entire data resource.
Dimensional Data – Fixed Data Hierarchy
Operational data often contain data in a hierarchy, such as company – department – division – section – unit, or United States – Region – State – County – City. These data hierarchies are fixed in the sense that the parent-child relationship cannot be changed and have any meaning. For example, units cannot be put between department and division, and cities cannot be put between state and county, and have any meaning.
The data totals in these fixed data hierarchies are commonly referred to as summary data. For example, if expenses were accumulated for a company, expense totals would exist for units, sections, divisions, departments, and the company as a whole. These summary data would be named according to their place in the hierarchy, such as unit expense, section expense, division expense, department expense, and company expense. Appendix B provides an example of a fixed data hierarchy with summary data.
The summary data in a fixed data hierarchy are documented in the Data Product Unit Model the same as operational data. The data sets are documented as data product sets, and the summary data are documented as data product units.
The data sets in a fixed data hierarchy are technically data dimensions, although that term was seldom used with fixed data hierarchies. The term data dimensions did not become prominent until data warehouses, OLAP (online analytical processing), and aggregated data became prominent.
Dimensional Data – Variable Data Hierarchy
A data hierarchy can also be variable in the sense that the data sets in the hierarchy can be rearranged so the parent – child relationships change. In other words, the hierarchy has no fixed sequence. These variable data hierarchies led to prominent use of the term data dimensions. The data in a variable data hierarchy could be aggregated in many different ways. The terms data dimensions and aggregated data became prominent.
Unlike a fixed data hierarchy, the aggregated data in a variable data hierarchy are not named by the data set in which they appear. The name of the aggregated data must represent the parent data sets, since those parent data sets can change. Appendix C provides an example of variable data hierarchies and how the aggregated data are named.
Aggregated data are often ignored because they are more difficult to identify, name, and define. However, they must be identified, named, and defined during the data inventory process. In many situations, a misunderstanding of aggregated data can be far more disastrous to the business than a misunderstanding of the elemental data.
The definition of aggregated data should include a description of what those data represent. The data integrity rules should show the data aggregation algorithm. A diagram showing the structure of the aggregated data is helpful for understanding the meaning of those data.
One of my consulting engagements was to identify the problems with widely different results for a variety of analytical analyses and the resulting aggregated data. Data were placed into different data warehouses and different analyses were performed on those data. Further, layer upon layer of slicing-and-dicing was done without any documentation of the aggregated data produced, and much of that was done on different selections of the data. The result was widely different aggregated data and confusion about their meaning. No business decisions could be made based on those data.
Therefore, the names, definitions, and integrity rules for aggregated data must be identified and documented to provide a complete understanding of the organization’s data resource.
Predictive Data
The data used in predictive analysis are no different than operational data or analytical data. Additional data may be brought into the predictive analysis process that doesn’t normally exist in the operational data resource. Data can be produced by the predictive analysis process, but those data are not magical or mythical in any way. They can be documented just like operational and analytical data.
The real power in predictive analysis comes in the processing used. The processing can be simple statistical analyses, like linear regression, chi square, multiple discriminate analysis, and so on; it can be very intensive, analysis using fractals and cellular automaton; or it could be anything in between. It’s the predictive analysis process and the results of that process that are unique to the organization and are kept secret.
Predictive data are designed through rotational data modeling. The process is to move (rotate) through the dimensions of a dimensional data model. For each of those dimensions, the focus and non-focus measures, and the internal and external attributes are identified and documented. The focus and non-focus measures are with respect to the dimension being modeled. The internal and external attributes are with respect to attributes that are within the control of the organization or are outside the control of the organization. These measures and attributes are data attributes that belong to data entities, which have data relations, and can be modeled accordingly.
Therefore, documenting the data used in predictive analysis and the data produced by predictive analysis can be included in the data inventory relatively easily.
Complex Structured Data
A detailed inventory and documentation of complex structured data requires a different approach, using an expanded and enhanced Dublin Core model, and is beyond the scope of the current book. However, complex structured data can be documented in two different ways using the Data Product Model.
First, the complex structured data set, such as an image, a video, text, voice, and so on, are documented as a data product. The complex structured data set is named and the definition provides a comprehensive description of the contents of the data set. No additional documentation below the data product is captured.
Second, the complex structured data set can be broken down into its individual simple structured components. For example, a polygraph examination to determine if someone is telling the truth or showing deception. A polygraph examination consists of a series of questions asked by the examiner. The respondent can answer either Yes or No to each question. The blood pressure, pulse, perspiration, and respiration are measured during each question and answer to provide an indication of truth or deception. At the end of the session, the results are analyzed and a determination is made if the respondent was truthful or deceptive.
You can see how the data might be structured by polygraph examination, polygraph question, and the results of blood pressure, pulse, perspiration, and respiration during each question and answer. The polygraph examination would contain the examiner’s data, the respondent’s data, dates, times, location, machine, and so on. It would also contain the analog graph or a reference to it, and the conclusion for the examination. The polygraph question would contain the text of each question, the pulse, perspiration, and respiration details, and a conclusion about how the respondent answered the question.
Another example is a textual statement. Text can be analyzed by a variety of methods, either human or automated, to determine precedents and conclusion, who wrote the text, based on analysis and comparison with an author’s known writing, and so on. Each of these parameters can be documented to provide additional insight into the text.
Video interviews can also be analyzed by a variety of methods. The video has voice, which can be converted to text and analyzed as mentioned above. In addition, the inflection and intonations in the voice can be analyzed, like the psychological stress evaluator often used in law enforcement. The body language can also be analyzed, such as eye movement, eyelid blinking, mouth, arms, posture, and so on, to determine the speaker’s true feelings.
These brief examples show how complex structured data can be broken down into individual components that can be more easily interpreted and documented
The breakdown of complex structured data can be done by people or can be automated. The process applies to any complex structured data and can be performed to any level of detail desired by the organization. The resulting data entities and data attributes are documented as data product sets and data product units. The breakdown of complex structured data can be totaled to produce summary data, or analyzed to produce aggregated data. The breakdown can also be used in predictive analysis.
Time Relational Data
Time relational data involves relations between data entities based on time, usually referred to as time relations. A time relation is different from a data relation because it does not have fixed values in a primary key and foreign keys. The relation often depends on a point within a range of times.
For example, a person has many addresses over time. Each address has an effective date that is valid until another address that has a more recent effective data is entered. The set of current address and historical addresses provides an address history for a person.
A question might arise whether the person voted in the proper precinct based on their address. Since no direct match exists between the date of the election and the effective dates of the addresses, a data relation doesn’t work. A search needs to be made of the effective data ranges for the addresses to determine which address was active at the time of the election.
Another situation is data reference sets, where each data reference item has a begin date and an end date. The appropriate data reference item must be used based on the effective dates of that data reference item and some corresponding date in the subordinate data entity. The data relation shows the data reference item, but not the effective date.
For example, student type codes frequently vary. Each student has a student type code that must be valid for the date that student registered with the school. The data relation is between Student and Student Type, based on the Student Type. Code. However, that data relation does not enforce the requirement for a valid student type code for the student’s registration date. The date range of the Student Type. Code must be evaluated to determine if the data reference item is valid for the Student. Registration Date.
Time relations are documented as data integrity rules between data attributes in different data entities. The documentation is separate for the documentation of data relations.
Sources of Insight
Many people have asked me where to obtain insights into the disparate data resource. Any source of insight is useful for providing an understanding of disparate data. Sources of insight can be primary or supplemental.
The primary sources of insight about disparate data are databases, data models, application programs, and screens, reports, and forms. XML is treated as a screen or report. These primary sources of insight are documented as separate data products.
Databases provide insight into the meaning and structure of data in the database management system and data edits enforced by the database management systems. Logical and physical data models, whether electronic or manual, provide insight into either the logical design of the data or its physical implementation. Even hand-drawn diagrams can be useful. Generic data architectures and universal data models might provide some insight, but are often too generic and universal to be of much use.
Application programs, whether developed in-house or purchased, provide insight into the data they create or use, definitions about those data, and any data edits that are enforced.
Screens, reports, and forms provide insight about the data they contain and how those data are used by the business. Titles and headings provide clues to what the data represent. Screens, reports, and forms often contain summary data and aggregated data that are not in databases, but are still part of the organization’s disparate data resource.
Supplemental sources of insight about disparate data are formal and informal documentation, and the tacit knowledge of individuals. Formal and informal documentation includes data dictionaries, project descriptions, data entry instructions, instruction manuals, standards, legislation, external reporting requirements, informal notes, e-mails, meeting minutes, memos, and so on. The tacit knowledge of individuals includes employees, business professionals, data management professionals, retirees, contractors and consultants, vendors, other people outside the organization, and anyone else with an insight into the disparate data.
People can be interviewed to determine what tacit knowledge they may have about the disparate data resource. Typically, people who have been with the organization a long time, both business professionals and data management professionals, have considerable knowledge about the data resource. Retired employees could be contacted for knowledge they may have about the data resource. Any providers of data from outside the organization can be contacted for their knowledge about the data. Vendors of purchased products can be contacted for additional knowledge about the data used in their applications or contained in their databases.
Seek out all possible sources of insight about the disparate data resource and document the insights obtained. When these sources have been exhausted, one can reasonably presume that the vast majority of insight about the organization’s disparate data resource has been collected and documented. The point of diminishing returns has been reached and additional effort is not likely to produce substantial new insight.
SUMMARY
Inventorying disparate data is the first step toward achieving the formal data resource state. The existing data must be inventoried to determine the extent of the disparate data before any progress can be made toward resolving those disparate data. The data inventory concept emphasizes that a complete and comprehensive inventory of the disparate data resource must be done so those data are known and can be thoroughly understood. The data product concept provides the structure for documenting the inventory of disparate data.
The data inventory principles include:
Recognizing that disparate data exist and must be inventoried to know the extent of the disparate data.
The data inventory starts the understanding process that continues through the data transformation to a comparate data resource.
The data inventory process is relatively simple, yet very detailed.
The data inventory process requires continuous enhancement as new insight is gained about the data resource.
Changes to the data resource over time must be identified and documented.
The origin of data and changes made along the pathway to the current location must be documented.
The data product model provides the framework for documenting the results of the disparate data inventory. That structure consists of data products, data product sets, data product units, data product code sets, and data product codes. Existing data relation diagrams and new data relation diagrams can be stored or referenced in the data product model. The data key model provides the framework for documenting data relations through primary keys and foreign keys.
Documentation of summary data, analytical data, and predictive data is described. Documentation of complex structured data is briefly described, but is beyond the scope of the current book. Documentation of time relations is described. Sources of material for the disparate data inventory include:
Databases and database management systems.
Application programs, either developed in-house or purchased.
Formal and informal documentation about the data resource.
Logical and physical data models, generic data architectures, and universal data models.
Screens, reports, and forms.
Knowledge retained by people.
Data scanners and data profiling applications.
When all of the sources of material have been exhausted, the point of diminishing returns has been reached. The next step is to cross-reference the inventoried data to a common data architecture to enhance the understanding of those data within a common context.
QUESTIONS
The following questions are provided as a review of the disparate data inventory concept, and to stimulate thought about what is needed to inventory disparate data properly.
- What is the data inventory concept?
- How does the data product concept support the data inventory concept?
- Why is continuous enhancement necessary when inventorying disparate data?
- Why are changes over time important when inventorying disparate data?
- Why is data provenance important to understanding disparate data?
- How do primary and foreign keys define a data relation?
- What’s the difference between summary data and aggregated data?
- Why can’t complex structured data be inventoried and documented the same as tabular data?
- What are the possible sources of insight for understanding disparate data?
- Why is inventorying and documenting disparate data simple, yet very detailed?