
Chapter 8. Accessing External Data
Chapter 4 introduced the notion of an external table, a metadata object that describes the location and access method of data not stored natively in Greenplum. The original use was to facilitate the speedy parallel loading of data into Greenplum.
Another use case for external tables is the ability to integrate external data with native Greenplum data in federated queries. As Greenplum 5 incorporated PostgreSQL 8.4 and Greenplum 6 incorporated PostgreSQL 9.4, it acquired native PostgreSQL external data capabilites, namely dblinks and foreign data wrappers. In addition, Greenplum expanded the now-deprecated gphdfs protocol to a more general and capable method of accessing external files on HDFS in a protocol known as the Platform Extension Framework (PXF). The combination of these facilities allows users to work with a wide variety of external data.
dblink
Although PostgreSQL allows users to access data in different schemas of a single database in a SQL statement, it does not permit cross database references without the notion of a database link, or dblink.
New in Greenplum Version 5
dblinks are new in Greenplum 5.
Introduced into PostgreSQL in 8.4, dblink makes it easier to do this. dblink is intended for database users to perform short ad hoc queries in other databases. It is not
intended for use as a replacement for external tables or for administrative tools such as gpcopy.
As with all powerful tools, DBAs must be careful with granting this privilege to users, lest they should gain access to information that they’re not permitted to see.
dblink is a user-contributed extension. Before you can use it, you must create the extension in the Greenplum instance by using gpadmin, the database superuser. Much of its functionality has been replaced by foreign data wrappers in Greenplum 6.
For this example, suppose that there is a table called ducks in database gpuser22 in the same Greenplum instance as database gpuser. One goal is to be able to query the ducks table while operating in database gpuser.
First, the database superuser must create the dblink functions by using a Greenplum-provided script:
[gpadmin@myhost ~]$ psql -d gpuserpsql -d gpuser
i /usr/local/greenplum-db/share/postgresql/
contrib/dblink.sql
gpuser=# i /usr/local/greenplum-db/share/postgresql/
contrib/dblink.sql
SET
CREATE FUNCTION
CREATE FUNCTION
CREATE FUNCTION
CREATE FUNCTION
REVOKE
REVOKE
CREATE FUNCTION
...
CREATE FUNCTION
CREATE TYPE
CREATE FUNCTION
gpuser=# SELECT dblink_connect('mylocalconn',
'dbname=gpuser22 user=gpadmin');
dblink_connect
OK
(1 row)
gpuser=# select * from dblink('mylocalconn',
'SELECT * FROM public.ducks')
AS duck_table(id int, name text);
id | name
----+--------
1 | Donald
2 | Huey
3 | Dewey
4 | Louie
5 | Daisy
(5 rows)
Setting up the dblink for a non-gpadmin user or for a database on a different host is a bit more complex, but uses the same basic procedure of defining the connection and then executing the dblink function.
Foreign Data Wrappers
Foreign data wrappers are much like dblink. They both allow cross-database queries, but foreign data wrappers are more performant, closer to standard SQL, and persistent, whereas dblinks are active only on a session basis.
New in Greenplum Version 6
Foreign data wrappers are new in Greenplum 6.
Foreign data wrappers require a bit more work than dblinks. You need to create the following:
-
A server definition describing the location of the foreign data
-
A user mapping
-
A foreign table definition
In addition, the Greenplum use of foreign data wrappers differs from the single process PostgreSQL use in the use of an option mpp_execute that identifies which host in the cluster requests data.
This is covered in some detail in the Greenplum 6 documentation.
Platform Extension Framework
The external table mechanism introduced in early versions of Greenplum did an adequate job of allowing users to pull or examine data from external sources into Greenplum. But as the variety of sources grew over time, the mechanism required Greenplum development to build and test a protocol for each new data source, such as HDFS and Amazon S3 files. As the number of different file formats in HDFS increased, it became clear that there was a need for an extensible framework to allow Pivotal to more easily support new formats and allow users to write code for formats that Pivotal Greenplum did not support. This led to the adoption of PXF.
New in Greenplum Version 5
PXF is new in Greenplum 5.
What Greenplum PFX provides is the ability to access data with a Java API. This includes virtually any existing Hadoop file format. It also allows users to build their own adapter by writing a few Java data access tools, described here:
- fragmenter
-
Splits data into chunks that can be accessed in parallel.
- accessor
-
Splits a fragment into separate rows.
- resolver
-
Splits a record into separate values of Greenplum data types.
For a specific data source, the fragmenter, accessor, and resolver are packaged together into a profile.
Pivotal has written these profiles for a large number of the most common HDFS data types:
-
HDFS text file
-
Parquet
-
Avro
-
ORC
-
RCFile
-
JSON
-
Hive RC
-
HBase
-
Apache Ignite community-contributed profiles
-
Alluxio community-contributed profiles
Functionally, PXF uses the external table syntax. For a Parquet file created by Hive in HDFS, an external file definition might be as follows:
CREATE EXTERNAL TABLE public.pxf_read_providers_parquet
(
provider_id text,
provider_name text,
specialty text,
address_street text,
address_city text,
address_state text,
address_zip text
)
LOCATION ('pxf://user/hive/warehouse/
providers.parquet?PROFILE=hdfs:parquet')
FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
In addition, PXF needs to know how to get to the HDFS cluster. This information is held in the configuration files in /usr/local/greenplum-pxf/servers/default.
To access the contents of the Parquet file, a simple select will do:
select * from public.pxf_read_providers_parquet order
by provider_id;
Had the data been stored in a plain CSV text file in HDFS, the external table definition might have been as shown in the preceding example, but the profile, format, and filename would be different:
...
LOCATION ('pxf://tmp/data/providers/
providers_part1.csv?PROFILE=hdfs:text')
FORMAT 'CSV' (HEADER QUOTE '"' delimiter ',' )
The Pivotal PXF documentation describes how to write the three functions for other data types. It’s a nontrivial exercise.
Greenplum Stream Server
Increasingly, Greenplum users need to do more than batch loading. Modern data analytics requires analysis data that streams in from various transactional and other systems. The Greenplum Stream Server (GPSS) provides this capability as well as adding parallel (ETL) capabilities to the Greenplum database. GPSS is based on Google’s open source gRPC architecture. Greenplum users can access it directly through a command-line interface (CLI). In addition it serves as the foundation for both the Greenplum-Informatica Connector as well as the Greenplum-Kafka Integration module, which we’ll look at in a moment.
New in Greenplum Version 5
Greenplum Stream Server requires Greenplum 5.
Users begin the process of a GPSS job via a client application such as the Greenplum-Informatica Connector, the Greenplum-Kafka Connector, or a custom job orchestrated by the gpsscli utility. The client utilizes gRPC to initiate the process of loading data. Load requests come to the GPSS process in the Greenplum cluster and GPSS uses gpfdist to parallelize the load.
Figure 8-1 shows an architectural overview. A full example is beyond the scope of this book but is well described in Pivotal’s GPSS documentation.
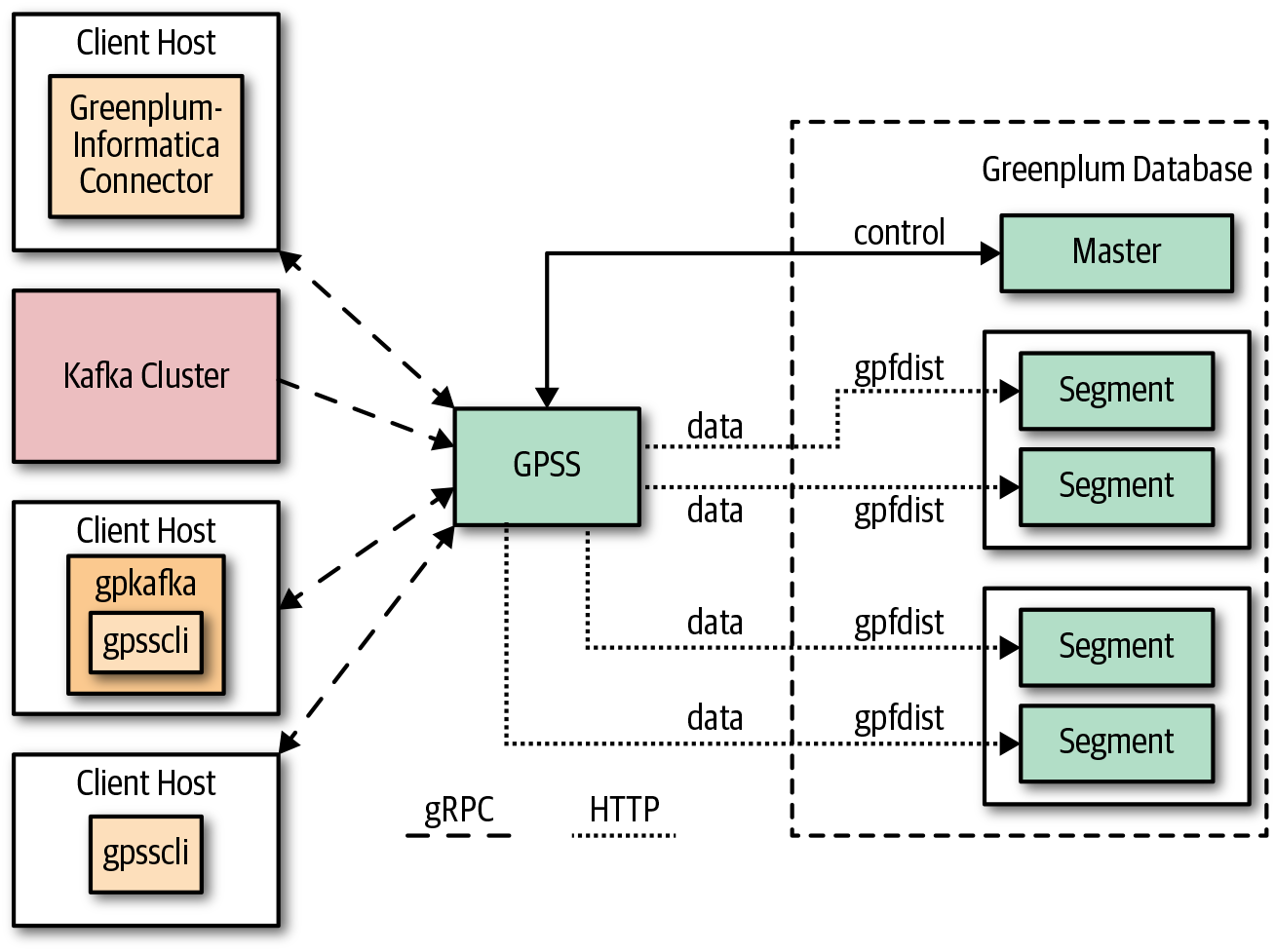
Figure 8-1. The Greenplum Stream Server architecture
Greenplum-Kafka Integration
Apache Kafka and the Confluent Kafka distribution have emerged as a popular distributed streaming platform that does the following:
-
Furnishes a publish-subscribe stream of records
-
Stores and optimally processes records
-
Acts as a reliable pipeline between data sources and sinks
-
Allows for systems to react in near real time to data
Many of the source systems that provide data to Greenplum are able to publish to Kafka streams, called “topics” in Kafka nomenclature. The Greenplum-Kafka Integration module facilitates Greenplum’s ability to act as a consumer of records in a topic.
New in Greenplum Version 5
Greenplum-Kafka integration requires Greenplum 5.
The gpkafka utility incorporates the gpsscli and gpss commands of the GPSS and makes use of a YAML configuration file.
A full example is beyond the scope of this book but is well described in the Greenplum-Kafka Integration documentation.
Greenplum-Informatica Connector
Informatica is a widely used commercial product utilized in ETL. The Greenplum-Informatica Connector uses Informatica’s Power Connector to facilitate high-speed, parallel transfer of data into Greenplum in both batch and streaming mode after Informatica has collected data from multiple sources and transformed it into a structure useful for analytic processing.
New in Greenplum Version 5
Implementing the Greenplum-Informatica Connector requires Greenplum 5 and Informatica’s Power Center.
The Greenplum-Informatica Connector, like the Greenplum-Kafka Integration, uses GPSS utilities. The architecture is much the same for Informatica as a producer as for a Kafka producer, as shown in Figure 8-2.
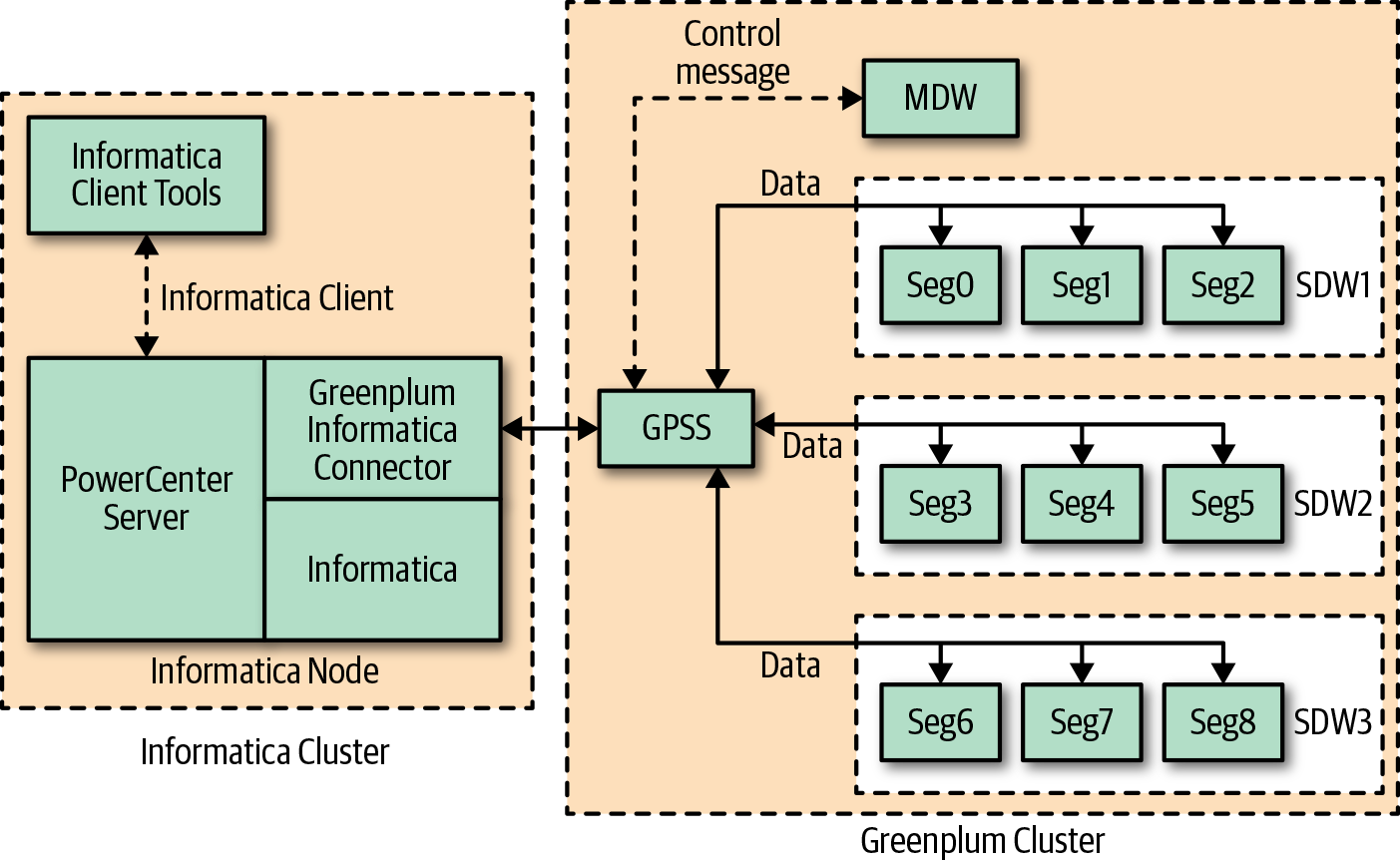
Figure 8-2. The Greenplum-Informatica Connector
GemFire-Greenplum Connector
Greenplum is designed to provide analytic insights into large amounts of data, not real-time response. Yet, many real-world problems require a system that does both. Pivotal GemFire is the Pivotal-supported version of Apache Geode, an in-memory data grid (IMDG). Greenplum is not really a real-time response tool. GemFire provides real-time response, and the GemFire-Greenplum Connector integrates the two.
Detecting and stopping fraudulent transactions related to identity theft is a top priority for many banks, credit card companies, insurers, and tax authorities, as well as digital businesses across a variety of industries. Building these systems typically relies on a multistep process, including the difficult steps of moving data in multiple formats between the analytical systems used to build and run predictive models and transactional systems, in which the incoming transactions are scored for the likelihood of fraud. Analytical systems and transactional systems serve different purposes and, not surprisingly, often store data in different formats fit for purpose. This makes sharing data between systems a challenge for data architects and engineers—an unavoidable trade-off, given that trying to use a single system to perform two very different tasks at scale is often a poor design choice.
GGC is an extension package built on top of GemFire that maps rows in Greenplum tables to plain-old Java objects (POJOs) in GemFire regions. With the GGC, the contents of Greenplum tables now can be easily loaded into GemFire, and entire GemFire regions likewise can be easily consumed by Greenplum. The upshot is that data architects no longer need to spend time hacking together and maintaining custom code to connect the two systems.
GGC functions as a bridge for bidirectionally loading data between Greenplum and GemFire, allowing architects to take advantage of the power of two independently scalable MPP data platforms while greatly simplifying their integration. GGC uses Greenplum’s external table mechanisms (described in Chapter 4) to transfer data between all segments in the Greenplum cluster to all of the GemFire servers in parallel, preventing any single-point bottleneck in the process.
Greenplum-Spark Connector
Apache Spark is an in-memory cluster computing platform. It is primarily used for its fast computation. Although originally built on top of Hadoop MapReduce, it has enlarged the paradigm to include other types of computations including interactive queries and stream processing. A full description is available on the Apache Spark website.
Spark was not designed with its own native data platform and originally used HDFS as its data store. However, Greenplum provides a connector that allows Spark to load a Spark DataFrame from a Greenplum table. Users run computations in Spark and then write a Spark DataFrame into a Greenplum table. Even though Spark does provide a SQL interface, it’s not as powerful as that in Greenplum. However, Spark does interation on DataFrames quite nicely, something that is not a SQL strong point.
Figure 8-3 shows the flow of the Greenplum-Spark Connector. The Spark driver initiates a Java Database Connectivity (JDBC) connection to the master in a Greenplum cluster to get metadata about the table to be loaded. Table columns are assigned to Spark partitions, and executors on the Spark nodes speak to the Greenplum segments to obtain data.
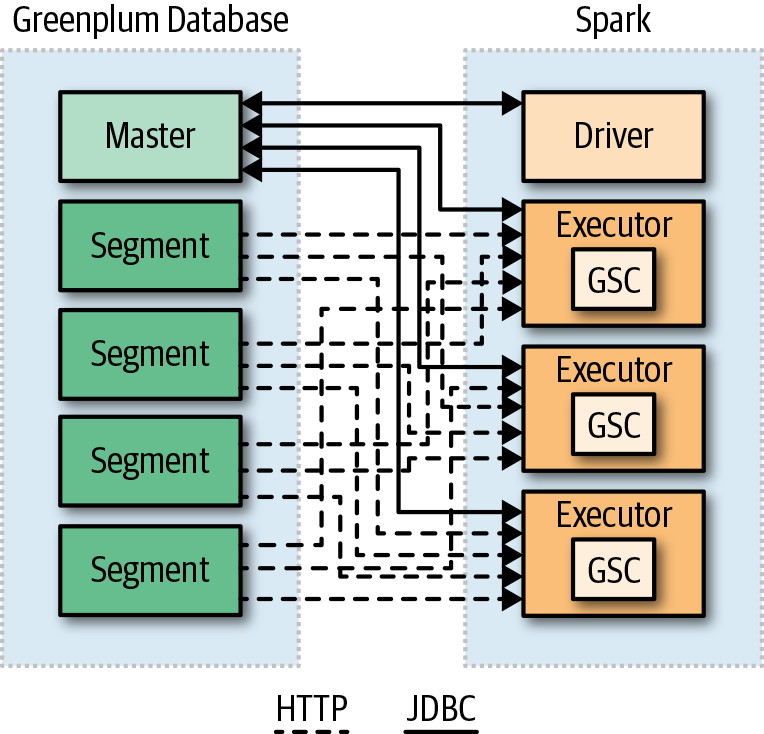
Figure 8-3. The Greenplum-Spark Connector
The details of installation and configuration are located in the Greenplum-Spark Connector documentation.
The documentation provides usage examples in both Scala and PySpark, two of the most common languages Spark programmers use.
Amazon S3
Greenplum has the ability to use readable and writable external tables as files in the Amazon S3 storage tier. One useful feature of this is hybrid queries in which some of the data is natively stored in Greenplum, with other data living in S3. For example, S3 could be an archival location for older, less frequently used data. Should the need arise to access the older data, you can access it transparently in place without moving it into Greenplum. You also can use this process to have some table partitions archived to Amazon S3 storage. For tables partitioned by date, this is a very useful feature.
In the following example, raw data to be loaded into Greenplum is located into an existing Greenplum table.
The data is in a file, the top lines of which are as follows:
dog_id, dog_name, dog_dob 123,Fido,09/09/2010 456,Rover,01/21/2014 789,Bonzo,04/15/2016
The corresponding table would be as follows:
CREATE TABLE dogs (dog_id int, dog_name text, dog_dob date) distributed randomly;
The external table definition uses the Amazon S3 protocol:
CREATE READABLE EXTERNAL TABLE dogs_ext like(dogs)
LOCATION
('s3://s3-us-west-2.amazonaws.com/s3test.foo.com/ normal/)
FORMAT 'csv' (header)
LOG ERRORS SEGMENT REJECT LIMIT 50 rows;
Assuming that the Amazon S3 URI is valid and the file is accessible, the following statement will show three rows from the CSV file on Amazon S3 as though it were an internal Greenplum table. Of course, performance will not be as good as if the data were stored internally.
The gphdfs protocol allows for reading and writing data to HDFS. For Greenplum used in conjunction with Hadoop as a landing area for data, this provides easy access to data ingested into Hadoop and possibly cleaned there with native Hadoop tools.
External Web Tables
Greenplum also encompasses the concept of an external web table, both readable and writable. There are two kinds of web tables: those accessed by a pure HTTP call, and those accessed via an OS command. In general, these web tables will access data that is changing on a regular basis and can be used to ingest data from an external source.
The United States Geological Survey produces a set of CSV files that describe global earthquake activity. You can access this data on a regular basis, as shown in the following example:
CREATE TABLE public.wwearthquakes_lastwk (
time TEXT,
latitude numeric,
longitude numeric,
depth numeric,
mag numeric,
mag_type varchar (10),
...
...
magSource text
)
DISTRIBUTED BY (time);
DROP EXTERNAL TABLE IF EXISTS public.ext_wwearthquakes_lastwk;
create external web table public.ext_wwearthquakes_lastwk
(like wwearthquakes_lastwk)
Execute 'wget -qO - http://earthquake.usgs.gov/earthquakes/feed/
v1.0/summary/all_week.csv' -- defining an OS command to execute
ON MASTER
Format 'CSV' (HEADER)
Segment Reject limit 300;
grant select on public.ext_wwearthquakes_lastwk to gpuser;
The following example illustrates using an OS command that would run on each segment’s output, assuming the script reads from a pipe into stdin (more details are available in the Pivotal documentation):
CREATE EXTERNAL WEB TABLE error_check ( edate date, euser text, etype text, emsg text) EXECUTE 'ssh /usr/local/scripts/error_script.sh' FORMAT 'CSV' ;
To create an external table, users must explicitly be granted this privilege in the following way by gpdamin, the Greenplum superuser. The following command grants gpuser the ability to create external tables using the HTTP protocol:
ALTER ROLE gpuser CREATEEXTTABLE;
Additional Resources
The gRPC website provides a wealth of documentation as well as tutorials. That said, knowledge of gRPC is not required to run GPSS.
There is more detailed information about using the GemFire-Greenplum Connector in the Pivotal GemFire-Greenplum Connector documentation.
GemFire is very different from Greenplum. This brief tutorial from Pivotal is a good place to begin learning about it.
For more on GPSS, visit this Pivotal documentation page.
Greenplum PXF is described in detail on this Pivotal documentation page.
For more details on dblinks, see the Pivotal dblink Functions page.