

3
Terminology
“When I use a word,” Humpty Dumpty said in rather a scornful tone, “it means just what I choose it to mean—neither more nor less.”
—LEWIS CARROLL
THROUGH THE LOOKING GLASS
Topics Covered in This Chapter
Why This Terminology Is Important
The terms in this chapter are important for you to understand before you embark upon learning the design process. Indeed, there are other terms that you’ll need to learn, and I’ll cover them as you work through the process. There’s also a glossary in the back of the book that you can use to refresh your memory on any term you learn here or in the following chapters.
Why This Terminology Is Important
Relational database design has its own unique set of terms, just as any other profession, trade, or discipline. Here are three good reasons why it’s important for you to learn these terms.
They are used to express and define the special ideas and concepts of the relational database model. Much of the terminology is derived from the mathematical branches of set theory and first-order predicate logic, which form the basis of the relational database model.
They are used to express and define the database-design process itself. The design process becomes clearer and much easier to understand after you know these terms.
They are used anywhere a relational database or RDBMS is discussed. You’ll see these terms in materials such as online software manuals, educational course materials, commercial database software books, and database-related websites.
This chapter covers a majority of the terms that define the ideas and concepts of the design process, including definitions and somewhat detailed discussions for each term. (I provide pertinent details or necessary further discussion for a given term at the point where the term is expressly used within a specific technique in the design process.) There are several other terms that I introduce and discuss later in the book because I think you’ll more easily understand them within the context of the specific idea or concept to which they relate.
![]() Note
Note
The glossary contains concise definitions for all the terms in this chapter and throughout the book.
Four categories of terms are defined in this chapter: value-related, structure-related, relationship-related, and integrity-related.
Value-Related Terms
Data
The values you store in the database are data. Data is static in the sense that it remains in the same state until you modify it by some manual or automated process. Figure 3.1 shows some sample data.

Figure 3.1 An example of basic data.
This data is meaningless at this point. For example, there is no easy way for you to determine what “92883” represents. Is it a ZIP code? Is it a part number? Even if you know it represents a customer identification number, is it one that is associated with George Edleman? There’s just no way of knowing until you process the data.
Information
Information is data that you process in a manner that makes it meaningful and useful to you when you work with it or view it. It is dynamic in the sense that it constantly changes relative to the data stored in the database, and also in the sense that you can process it and present it in an unlimited number of ways. You can show information as the result of a SQL SELECT statement, display it in a form on your computer screen, or print it as a report. The point to remember is that you must process your data in some manner so that you can turn it into meaningful information.
Figure 3.2 demonstrates how you might process and transform the data from the previous example into meaningful information. It has been manipulated in such a way—in this case as part of a patient invoice report—that it is now meaningful to anyone who views it.

Figure 3.2 An example of data transformed into information.
It is very important that you understand the difference between data and information. You design a database to provide meaningful information to someone within a business or organization. This information is available only if the appropriate data exists in the database and the database is structured in such a way as to support that information. If you ever forget the difference between data and information, just remember this little axiom:
Data is what you store; information is what you retrieve.
When you fully understand this single, simple concept, the logic behind the database-design process will become crystal clear.
![]() Note
Note
Unfortunately, data and information are two terms that are still frequently used interchangeably (and, therefore, erroneously) throughout the database industry. You’ll encounter this error in numerous trade magazines, commercial database books and websites, and you’ll even see the terms misused by authors who should know better.
Null
Null is a condition that represents a missing or unknown value. You must understand from the outset that a Null does not represent a zero or a text string of one or more blank spaces. The reasons are quite simple.
A zero can have a very wide variety of meanings. It can represent the state of an account balance, the current number of available first-class ticket upgrades, or the current stock level of a particular product.
Although a text string of one or more blank spaces is guaranteed to be meaningless to most of us, it is definitely meaningful to a query language like SQL. A blank space is a valid character as far as SQL is concerned, and a character string composed of three blank spaces (‘ ’) is just as legitimate as a character string composed of three letters (‘abc’). In Figure 3.3, a blank represents the fact that Washington, D.C., is not located in any county whatsoever.
A zero-length string—two consecutive single quotes with no space in between (‘’)—is also an acceptable value to languages such as SQL and can be meaningful under certain circumstances. In an EMPLOYEES table, for example, a zero-length string value in a field called MIDDLEINITIAL may represent the fact that a particular employee does not have a middle initial in his name.
![]() Note
Note
Due to space restrictions, I cannot always show all the fields for a given sample table. I will, however, show the fields that are most relevant to the discussion at hand and use <<other fields>> to represent fields that are unessential to the example. You’ll see this convention in many examples throughout the remainder of the book.
The Value of Null
Null is quite useful when you use it for its stated purpose, and the CLIENTS table in Figure 3.3 clearly illustrates this. Each Null in the CLIENT COUNTY field represents a missing or unknown county name for the record in which it appears. To use Nulls correctly, you must first understand why they occur at all.
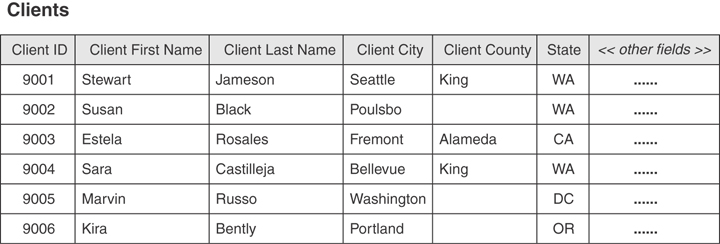
Figure 3.3 An example of a table containing instances of Nulls.
Missing values are commonly the result of human error. For example, consider the record for Susan Black. If you’re entering the data for Ms. Black and you fail to ask her for the name of the county she lives in, that data is considered missing and is represented in the record as a Null. After you recognize the error, however, you can correct it by calling Ms. Black and asking her for the county name.
Unknown values appear in a table for a variety of reasons. One reason may be that a specific value you need for a field is as yet undefined. For instance, you could have a CATEGORIES table in a School Scheduling database that doesn’t currently contain a category for a new set of classes that you want to offer beginning in the fall session. Another reason a table might contain unknown values is that they are truly unknown. Refer to the CLIENTS table in Figure 3.3 once again and consider the record for Marvin Russo. Say that you’re entering the data for Mr. Russo and you ask him for the name of the county he lives in. If he doesn’t know the county name, and you don’t happen to know the county that includes the city in which he lives, then the value for the county field in his record is truly unknown and is represented within the record as Null. Obviously, you can correct the problem after either of you determines the correct county name.
A field value may also be Null if none of its values applies to a particular record. Assume for a moment that you’re working with an EMPLOYEES table that contains a SALARY field and an HOURLYRATE field. The value for one of these two columns is always going to be Null because an employee cannot be paid both a fixed salary and an hourly rate.
It’s important to note that a very slim difference exists between “does not apply” and “is not applicable.” In the previous example, the value of one of the two fields literally does not apply. Now assume you’re working with a PATIENTS table that contains a field called HAIRCOLOR and you’re currently updating a record for an existing male patient. If that patient recently became bald, then the value for that field is definitely “not applicable.” Although you could just use Null to represent a value that is not applicable, I always recommend that you use a true value such as “N/A” or “Not Applicable.” This will make the information clearer in the long run.
As you can see, whether you allow Nulls in a table depends on the manner in which you’re using the data. Now that you’ve seen the positive side of using Null, let’s take a look at the negative implication of using it.
The Problem with Null
The major disadvantage of Null is that it has an adverse effect on mathematical operations. An operation involving a Null evaluates to Null. This is logically reasonable—if a number is unknown, then the result of the operation is necessarily unknown. Note how a Null alters the outcome of the operation in the following example:
(25 × 3) + 4 = 79
(Null × 3) + 4 = Null
(25 × Null) + 4 = Null
(25 × 3) + Null = Null
The PRODUCTS table in Figure 3.4 helps to illustrate the effects Null has on mathematical expressions that incorporate fields from a table. In this case, the value for the TOTAL VALUE field is derived from the mathematical expression “[SRP] * [QTY ON HAND].” As you inspect the records in this table, note that the value for the TOTAL VALUE field is missing where the QTY ON HAND value is Null, resulting in Null for the TOTAL VALUE field as well. This leads to a serious undetected error that occurs when all the values in the TOTAL VALUE field are added together: an inaccurate total. This error is “undetected” because an RDBMS program will not inherently alert you of the error. The only way to avoid this problem is to ensure that the values for the QTY ON HAND field cannot be Null.

Figure 3.4 Nulls in this table will have an effect on mathematical operations involving the table’s fields.
Figure 3.5 helps to illustrate the effect Null has on aggregate functions that incorporate the values of a given field in a table. The result of an aggregate function, such as COUNT(<fieldname>), will be Null if it is based on a field that contains Null. The table in Figure 3.5 shows the results of a summary query that counts the total number of occurrences of each category in the PRODUCTS table in Figure 3.4. The value of the TOTAL OCCURRENCES field is the result of the function expression COUNT([CATEGORY]). Notice that the summary query shows “0” occurrences of an unspecified category, implying that each product has been assigned a category. This information is clearly inaccurate because two products in the PRODUCTS table have not been assigned a category.

Figure 3.5 Null affects the results of an aggregate function in a summary query.
The issues of missing values, unknown values, and whether a value will be used in a mathematical expression or aggregate function are all taken into consideration in the database-design process, and we will revisit and discuss these issues further in Chapter 8, “Keys,” Chapter 9, “Field Specifications,” and Chapter 12, “Views.”
Structure-Related Terms
Table
According to the relational model, data in a relational database is stored in relations, which are perceived by the user as tables. Each relation is composed of tuples (records) and attributes (fields). Figure 3.6 shows a typical table structure.
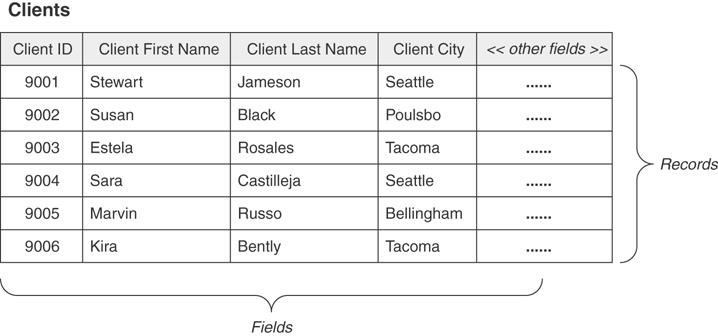
Figure 3.6 A typical table structure.
Tables are the chief structures in the database and each table always represents a single, specific subject. The logical order of records and fields within a table is of absolutely no importance, and every table contains at least one field—known as a primary key—that uniquely identifies each of its records. (In Figure 3.6, for example, CLIENT ID is the primary key of the CLIENTS table.) In fact, data in a relational database can exist independently of the way it is physically stored in the computer because of these last two table characteristics. This is great news for the user because he or she isn’t required to know the physical location of a record in order to retrieve its data.
The subject that a given table represents can either be an object or event. When the subject is an object, it means that the table represents something that is tangible, such as a person, place, or thing. Regardless of its type, every object has characteristics that you can store as data and then process as information in an almost infinite number of ways. Pilots, products, machines, students, buildings, and equipment are all examples of objects that a table can represent, and Figure 3.6 illustrates one of the most common examples of this type of table.
When the subject of a table is an event, it means that the table represents something that occurs at a given point in time having characteristics you want to record. You can store these characteristics as data and then process it as information in exactly the same manner as a table that represents some specific object. Examples of events you may need to record include judicial hearings, movie shoots, elections, and geological surveys. Figure 3.7 shows an example of a table representing an event that we all have experienced at one time or another—a doctor’s appointment.
A table that stores data used to supply information is called a data table, and it is the most common type of table in a relational database. Data in this type of table is dynamic because you can manipulate it (modify, delete, and so forth) and process it into information in some form or fashion. You’ll constantly interact with these types of tables as you work with your database.

Figure 3.7 A table representing an event.
A validation table (also known as a lookup table), on the other hand, stores data that you specifically use to implement data integrity. A validation table usually represents subjects, such as city names, skill categories, product codes, and project identification numbers. Data in this type of table is static because it will very rarely change at all. Although you have very little direct interaction with these tables, you’ll frequently use them indirectly to validate values that you enter into a data table. Figure 3.8 shows an example of a validation table.
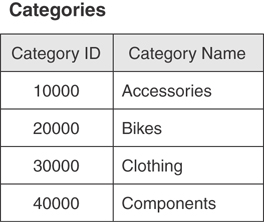
Figure 3.8 An example of a validation table.
I discuss validation tables in more detail in Chapter 11, “Business Rules.”
Field
A field (known as an attribute in relational database theory) is the smallest structure in the database, and it represents a characteristic of the subject of the table to which it belongs. Fields are the structures that actually store data. The data in these fields can then be retrieved and presented as information in almost any configuration that you can imagine. The quality of the information you get from your data is in direct proportion to the amount of time you’ve dedicated to ensuring the structural integrity and data integrity of the fields themselves. There is just no way to underestimate the importance of fields.
Every field in a properly designed database contains one and only one value, and its name will identify the type of value it holds. This makes entering data into a field very intuitive. If you see fields with names such as FIRSTNAME, LASTNAME, CITY, STATE, and ZIPCODE, you know exactly what type of values go into each field. You’ll also find it very easy to sort the data by state or look for everyone whose last name is “Hernandez.”
You’ll typically encounter three other types of fields in an improperly or poorly designed database.
A multipart field (also known as a composite field), which contains two or more distinct items within its value.
A multivalued field, which contains multiple instances of the same type of value.
A calculated field, which contains a concatenated text value or the result of a mathematical expression.
Figure 3.9 shows a table with an example of each of these types of fields.
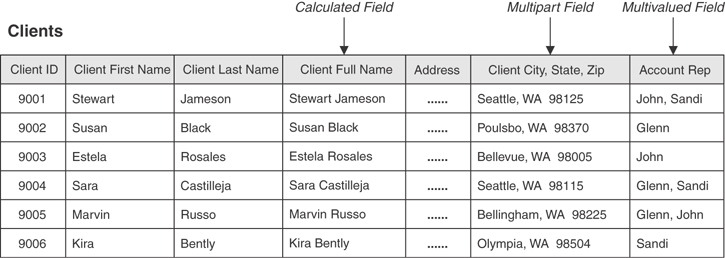
Figure 3.9 A table containing regular, calculated, multipart, and multivalued fields.
I cover calculated, multipart, and multivalued fields in greater detail in Chapter 7, “Establishing Table Structures.”
Record
A record (known as a tuple in relational database theory) represents a unique instance of the subject of a table. It is composed of the entire set of fields in a table, regardless of whether the fields contain values. Because of the manner in which a table is defined, each record is identified throughout the database by a unique value in the primary key field of that record.
In Figure 3.9, each record represents a unique client within the table, and the CLIENT ID field will identify a given client throughout the database. In turn, each record includes all the fields within the table, and each field describes some aspect of the client represented by the record. Consider the record for Sara Castilleja, for example. Her record represents a unique instance of the table’s subject (“Clients”) and includes the total collection of fields in the table, treated as a unit. The values of those fields represent relevant facts about Ms. Castilleja that are important to someone in the organization.
Records are a key factor in understanding table relationships because you’ll need to know how a record in one table relates to other records in another table.
View
A view is a “virtual” table composed of fields from one or more tables in the database; the tables that comprise the view are known as base tables. The relational model refers to a view as being “virtual” because it draws data from base tables rather than storing data on its own. In fact, the only information about a view that is stored in the database is its structure. Many major RDBMS programs support views and typically refer to them as saved queries. Your specific RDBMS program will determine whether views are supported and whether you refer to this object as a query or a view.
Views enable you to see the information in your database from many different aspects, providing you with a great amount of flexibility when you work with your data. You can create views in a variety of ways, and they are especially useful when you base them on multiple related tables. In a school scheduling database, for example, you could create a view that consolidates data from the STUDENTS, CLASSES, and CLASS SCHEDULES tables.
Figure 3.10 shows a view called INSTRUMENT ASSIGNMENTS that is composed of fields taken from the STUDENTS, INSTRUMENTS, and STUDENT INSTRUMENTS tables. The view displays data that it draws from all of these tables simultaneously, based on matching values between the STUDENT ID fields in the STUDENTS and STUDENT INSTRUMENTS tables, and the INSTRUMENT ID fields in the INSTRUMENTS and STUDENT INSTRUMENTS tables.

Figure 3.10 An example of a typical view.
There are three major reasons that views are important.
They enable you to work with data from multiple tables simultaneously. (For a view to do this, the tables must have connections, or relationships, to each other.)
They enable you to prevent certain users from viewing or manipulating specific fields within a table or group of tables. This capability can be very advantageous in terms of security.
You can use them to implement data integrity. A view you use for this purpose is known as a validation view.
You’ll learn more about designing and using views in Chapter 12, “Views.”
![]() Note
Note
Although every major database vendor supports the type of view I’ve described in this section, several vendors support what is known as an indexed (or materialized) view. An indexed view is different from a “regular” view in that it does store data, and you can index its fields to improve the speed at which the RDBMS processes the view’s data. A full discussion of indexed views is beyond the scope of this book because it is a vendor-specific implementation issue. However, you should research this topic further if you are working with RDBMS software such as Oracle, Microsoft SQL Server, IBM DB2, or Sybase SQL, or if you are working with a data warehouse or an online analytical processing (OLAP) database.
Keys
Keys are special fields that play very specific roles within a table, and the type of key determines its purpose within the table. There are several types of keys a table may contain, but the two most significant ones are the primary key and the foreign key.
A primary key is a field or group of fields that uniquely identifies each record within a table; a primary key composed of two or more fields is known as a composite primary key. The primary key is absolutely the most important key in the entire table.
A primary key value identifies a specific record throughout the entire database,
The primary key field identifies a given table throughout the entire database.
The primary key enforces table-level integrity and helps establish relationships with other tables in the database. (You’ll learn more about relationships in the next section.)
Every table in your database should have a primary key!
The AGENT ID field in Figure 3.11 is a good example of a primary key. It uniquely identifies each agent within the AGENTS table and helps to guarantee table-level integrity by ensuring nonduplicate records. It also establishes relationships between the AGENTS table and other tables in the database, as in the case with the ENTERTAINERS table shown in the example.

Figure 3.11 An example of primary and foreign key fields.
When you determine that two tables bear a relationship to each other, you typically establish the relationship by taking a copy of the primary key from the first table and incorporating it into the structure of the second table, where it becomes a foreign key. The name “foreign key” is derived from the fact that the second table already has a primary key of its own, and the primary key you are introducing from the first table is “foreign” to the second table.
Figure 3.11 also shows a good example of a foreign key. Note that AGENT ID is the primary key of the AGENTS table and a foreign key in the ENTERTAINERS table. AGENT ID assumes this role because the ENTERTAINERS table already has a primary key—ENTERTAINER ID. As such, AGENT ID establishes the relationship between both of the tables.
Besides helping to establish relationships between pairs of tables, foreign keys also help implement and ensure relationship-level integrity. This means that the records in both tables will always be properly related because the values of a foreign key must match existing values of the primary key to which it refers. Relationship-level integrity also helps you avoid the dreaded “orphaned” record, a classic example of which is an order record without an associated customer. If you don’t know who made the order, you can’t process it, and you obviously can’t invoice it. That’ll throw your quarterly sales off!
Key fields play an important part in a relational database, and you must learn how to create and use them. You’ll learn more about primary keys in Chapters 8, “Keys,” and 10, “Table Relationships.”
Index
An index is a structure an RDBMS provides to improve data processing. Your particular RDBMS program will determine how the index works and how you use it. However, an index has absolutely nothing to do with the logical database structure! The only reason I include the term index in this chapter is that people often confuse it with the term key.
Index and key are just two more terms that are widely and frequently misused throughout the database industry and in numerous database-related publications and websites. (Remember my comments on data and information?) You’ll always know the difference between the two if you remember that keys are logical structures you use to identify records within a table, and indexes are physical structures you use to optimize data processing.
Relationship-Related Terms
Relationships
A relationship exists between two tables when you can in some way associate the records of the first table with those of the second. You can establish the relationship via a set of primary and foreign keys (as you learned in the previous section) or through a third table known as a linking table (also known as an associative table). The manner in which you establish the relationship really depends on the type of relationship that exists between the tables. (You’ll learn more about that in a moment.) Figure 3.11 illustrates a relationship established via primary/foreign keys, and Figure 3.12 illustrates a relationship established with a linking table.
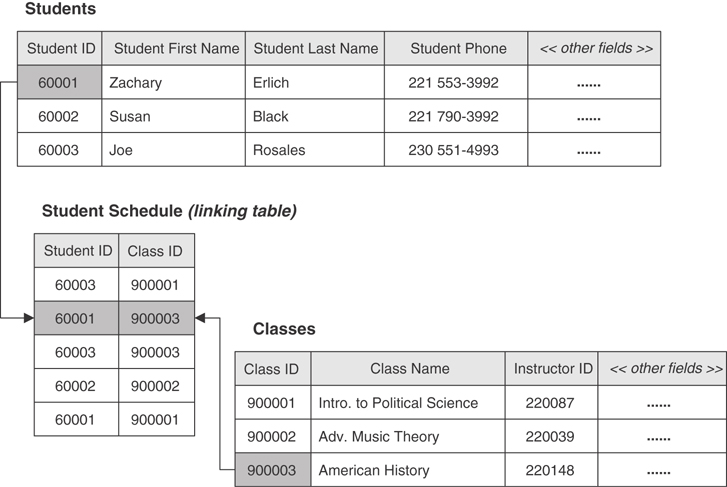
Figure 3.12 A relationship established between two tables with the help of a linking table.
A relationship is an important component of a relational database.
It enables you to create multitable views.
It is crucial to data integrity because it helps reduce redundant data and eliminate duplicate data.
You can characterize every relationship in three ways: by the type of relationship that exists between the tables, the manner in which each table participates, and the degree to which each table participates.
Types of Relationships
Three specific types of relationship (traditionally known as a cardinality) can exist between a pair of tables: one-to-one, one-to-many, and many-to-many.
One-to-One Relationships
A pair of tables bears a one-to-one relationship when a single record in the first table is related to zero or one and only one record in the second table, and a single record in the second table is related to one and only one record in the first table. In this type of relationship, one table serves as a “parent” table and the other serves as a “child” table. You establish the relationship by taking a copy of the parent table’s primary key and incorporating it within the structure of the child table, where it becomes a foreign key. This is a special type of relationship because it is the only one in which both tables may actually share the same primary key.
Figure 3.13 shows an example of a typical one-to-one relationship. In this case, EMPLOYEES is the parent table and COMPENSATION is the child table. The relationship between these tables is such that a single record in the EMPLOYEES table can be related to zero or only one record in the COMPENSATION table, and a single record in the COMPENSATION table can be related to only one record in the EMPLOYEES table. Note that EMPLOYEE ID is indeed the primary key in both tables. However, it will also serve the role of a foreign key in the child table.

Figure 3.13 An example of a one-to-one relationship.
One-to-Many Relationships
A one-to-many relationship exists between a pair of tables when a single record in the first table can be related to zero, one, or many records in the second table, but a single record in the second table can be related to only one record in the first table. The parent/child model I used to describe a one-to-one relationship works here as well. In this case, the table on the “one” side of the relationship is the parent table, and the table on the “many” side is the child table. You establish a one-to-many relationship by taking a copy of the parent table’s primary key and incorporating it within the structure of the child table, where it becomes a foreign key.
The example in Figure 3.14 illustrates a typical one-to-many relationship. A single record in the AGENTS table can be related to one or more records in the ENTERTAINERS table, but a single record in the ENTERTAINERS table is related to only one record in the AGENTS table. As you probably have already guessed, AGENT ID is a foreign key in the ENTERTAINERS table.

Figure 3.14 An example of a one-to-many relationship.
This is by far the most common relationship that exists between a pair of tables in a database. It is crucial from a data-integrity standpoint because it helps to eliminate duplicate data and to keep redundant data to an absolute minimum. You’ll learn more about this as we delve deeper into the design process.
Many-to-Many Relationships
A pair of tables bears a many-to-many relationship when a single record in the first table can be related to zero, one, or many records in the second table and likewise a single record in the second table can be related to zero, one, or many records in the first table. You establish this relationship with a linking table. (You learned a little bit about this type of table at the beginning of this section.) A linking table makes it easy for you to associate records from one table with those of the other and will help to ensure you have no problems adding, deleting, or modifying related data. You define a linking table by taking copies of the primary key of each table in the relationship and using them to form the structure of the new table. These fields actually serve two distinct roles: Together, they form the composite primary key of the linking table; separately, they each serve as a foreign key.
A many-to-many relationship that is not properly established is “unresolved.” Figure 3.15 shows a classic and clear example of an unresolved many-to-many relationship. In this instance, a single record in the STUDENTS table can be related to many records in the CLASSES table, and a single record in the CLASSES table can be related to many records in the STUDENTS table.
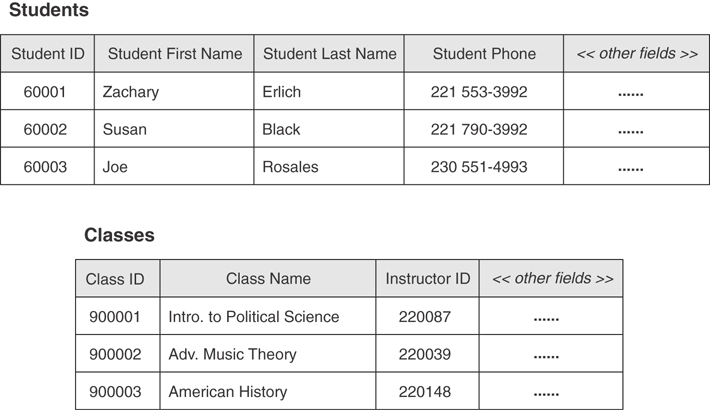
Figure 3.15 An example of an unresolved many-to-many relationship.
This relationship is unresolved due to the inherent peculiarity of the many-to-many relationship. The main issue is this: How do you easily associate records from the first table with records in the second table? To reframe the question in terms of the tables shown in Figure 3.15, how do you associate a single student with several classes or a specific class with several students? Do you insert a few STUDENT fields into the CLASSES table? Or do you add several CLASS fields to the STUDENTS table? Either of these approaches will make it difficult for you to work with the data in those tables and will affect data integrity adversely. The best approach for you to take is to create and use a linking table, which will resolve the many-to-many relationship in the most appropriate and effective manner. Figure 3.16 shows this solution in practice.

Figure 3.16 Resolving the many-to-many relationship with a linking table.
It’s important for you to know the type of relationship that exists between a pair of tables because it determines how the tables are related, whether or not records between the tables are interdependent, and the minimum and maximum number of related records that can exist within the relationship. You’ll learn much more about relationships in Chapter 10.
Types of Participation
A table’s participation within a relationship can be either mandatory or optional. Say a relationship exists between two tables called TABLE_A and TABLE_B.
TABLE_A’s participation is mandatory if you must enter at least one record into TABLE_A before you can enter records into TABLE_B.
TABLE_A’s participation is optional if you are not required to enter any records into TABLE_A before you can enter records into TABLE_B.
Let’s take a look at an example using the AGENTS and CLIENTS tables in Figure 3.17. The AGENTS table has a mandatory participation within the relationship if an agent must exist before you can enter a new client into the CLIENTS table. However, the AGENTS table’s participation is optional if there is no requirement for an agent to exist in the table before you enter a new client into the CLIENTS table. You can identify the appropriate type of participation for the AGENTS table by determining how you’re going to use its data in relation to the data in the CLIENTS table. For example, when you want to ensure that each client is assigned to an available agent, you make the AGENTS table’s participation within the relationship mandatory.
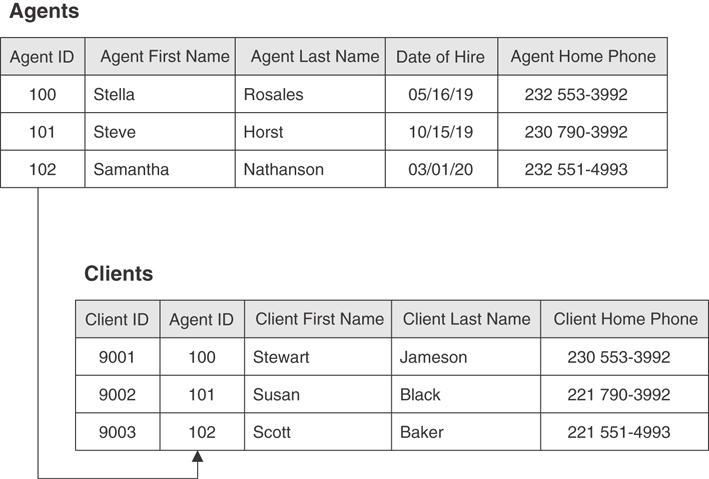
Figure 3.17 The AGENTS and CLIENTS tables.
Degree of Participation
The degree of participation determines the minimum number of records that a given table must have associated with a single record in the related table, and the maximum number of records that a given table is allowed to have associated with a single record in the related table.
Consider, once again, a relationship between two tables called TABLE_A and TABLE_B. You establish the degree of participation for TABLE_B by indicating a minimum and maximum number of records in TABLE_B that can be related to a single record in TABLE_A. If a single record in TABLE_A can be related to no fewer than 1 but no more than 10 records in TABLE_B, then the degree of participation for TABLE_B is 1,10. (The notation for the degree of participation shows the minimum number on the left and the maximum number on the right, separated by a comma.) You can establish the degree of participation for TABLE_A in the same manner. You can identify the degree of participation for each table in a relationship by determining the way the data in each table is related and how you’re using the data.
Consider the AGENTS and CLIENTS tables in Figure 3.17 once more. If you require an agent to handle at least one client, but certainly no more than eight, then the degree of participation for the CLIENTS table is 1,8. When you want to ensure that a client can only be assigned to one agent, then you indicate the degree of participation for the AGENTS table as 1,1. You’ll learn how to indicate the degree of participation for a given relationship in Chapter 10.
Integrity-Related Terms
Field Specification
A field specification (traditionally known as a domain) represents all the elements of a field. Each field specification incorporates three types of elements: general, physical, and logical.
General elements constitute the most fundamental information about the field and include items such as Field Name, Description, and Parent Table.
Physical elements determine how a field is built and how it is represented to the person using it. This category includes items such as Data Type, Length, and Character Support.
Logical elements describe the values stored in a field and include items such as Required Value, Range of Values, and Null Support.
You’ll learn all the elements associated with a field specification, including those mentioned here, in Chapter 9, “Field Specifications.”
Data Integrity
Data integrity refers to the validity, consistency, and accuracy of the data in a database. I cannot overstate the fact that the level of accuracy of the information you retrieve from the database is in direct proportion to the level of data integrity you impose upon the database. Data integrity is one of the most important aspects of the database-design process, and you cannot underestimate, overlook, or even partially neglect it. To do so would put you at risk of being plagued by errors that are very hard to detect or identify. As a result, you would be making important decisions on information that is inaccurate at best, or totally invalid at worst.
There are four types of data integrity that you’ll implement during the database-design process. Three types of data integrity are based on various aspects of the database structure and are labeled according to the area (level) in which they operate. The fourth type of data integrity is based on the way an organization perceives and uses its data. The following is a brief description of each:
Table-level integrity (traditionally known as entity integrity) ensures that no duplicate records exist within the table and that the field that identifies each record within the table is unique and never Null.
Field-level integrity (traditionally known as domain integrity) ensures that the structure of every field is sound; that the values in each field are valid, consistent, and accurate; and that fields of the same type (such as CITY fields) are consistently defined throughout the database.
Relationship-level integrity (traditionally known as referential integrity) ensures that the relationship between a pair of tables is sound and that the records in the tables are synchronized whenever data is entered into, updated in, or deleted from either table.
Business rules impose restrictions or limitations on certain aspects of a database based on the ways an organization perceives and uses its data. These restrictions can affect aspects of database design, such as the range and types of values stored in a field, the type of participation and the degree of participation of each table within a relationship, and the type of synchronization used for relationship-level integrity in certain relationships. All of these restrictions are discussed in more detail in Chapter 11. Because business rules affect integrity, they must be considered along with the other three types of data integrity during the design process.
Summary
This chapter began with an explanation of why terminology is important for defining, discussing, or reading about the relational database model and the database-design process.
The section on value-related terms showed you that a distinct difference exists between data and information and that understanding this difference is crucial to understanding the database-design process. You now know quite a bit about Null and how it affects information you retrieve from the database.
Structure-related terms were covered next, and you learned that the core structures of every relational database are fields, records, and tables. You now know that views are virtual tables that are used, in part, to work with data from two or more tables simultaneously. We then looked at key fields, which are used to identify records uniquely within a table and to establish a relationship between a pair of tables. Finally, you learned the difference between a key field and an index. Now you know that an index is strictly a software device (manifested as a file stored on disc) used to optimize data processing.
In the section on relationship-related terms, you learned that a connection between a pair of tables is known as a relationship. A relationship is used to help ensure various aspects of data integrity, and it is the mechanism used by a view to draw data from multiple tables. You then learned about the three characteristics of table relationships: the type of relationship (one-to-one, one-to-many, many-to-many), the type of participation (optional or mandatory), and the degree of participation (minimum/maximum number of related records).
The chapter ended with a discussion of integrity-related terms. Here you learned that a field specification establishes the general, physical, and logical characteristics of a field—characteristics that are an integral part of every field in the database. You then learned that data integrity is one of the most important aspects of the database-design process because of its positive effect on the data in the database. Also, you now know that there are four types of data integrity—three based on database structure and one based on the way the organization interprets and uses its data. These levels of integrity ensure the quality of your database’s design and the accuracy of the information you retrieve from it.
Review Questions
1. Why is terminology important?
2. Name the four categories of terms.
3. What is the difference between data and information?
4. What does Null represent?
5. What is the major disadvantage of Null?
6. What are the chief structures in the database?
7. Name the three types of tables.
8. What is a view?
9. State the difference between a key and an index.
10. What are the three types of relationships that can exist between a pair of tables?
11. What are the three ways in which you can characterize a relationship?
12. What is a field specification?
13. What three types of elements does a field specification incorporate?
14. What is data integrity?
15. Name the four types of data integrity.