
Automatic scaling of virtual machines in VMSS refers to the addition or removal of virtual machine instances based on configured environments to meet the performance and scalability demands of an application. Generally, in the absence of VMSS, this is achieved using automation scripts and runbooks.
VMSS helps in this automation process with the help of configuration. Instead of writing scripts, VMSS can be configured for automated scaling up and down.
Auto scaling consists of multiple integrated components to achieve its end goal. Auto scaling continuously monitors the virtual machines and collects telemetry data from it. It stores this data and combines it together and evaluates it against a set of rules to determine whether it should trigger auto scale. The trigger could be to a scale out or scale in. It could also be for scale up or down.
Autoscale uses diagnostics logs for collecting telemetry data from virtual machines. These logs are stored in storage accounts as diagnostics metrics. Autoscale also uses the insight monitoring service that reads these metrics, combines them together, and stores them into its own storage account.
Auto scale background jobs continually run to read the insights storage data, evaluate them based on all the rules configured for auto scaling, and executes the process of auto scaling, if any of the rules or combination of rules returns positive. The rules can take into consideration metrics from guest virtual machine as well as host server.
The rules are defined using the following properties. These properties descriptions are available at https://docs.microsoft.com/en-us/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-autoscale-overview.
|
Rule |
Description |
|
metricName |
This value is the same as the performance counter that you defined in the wadperfcounter variable for the diagnostics extension. In the preceding example, the thread count counter is used. |
|
metricResourceUri |
This value is the resource identifier of the VMSS. This identifier contains the name of the resource group, the name of the resource provider, and the name of the scale set to scale. |
|
timeGrain |
This value is the granularity of the metrics that are collected. In the preceding example, data is collected on an interval of one minute. This value is used with timeWindow. |
|
statistic |
This value determines how the metrics are combined to accommodate the automatic scaling action. The possible values are--average, min, and max. |
|
timeWindow |
This value is the range of time in which instance data is collected. It must be between 5 minutes and 12 hours. |
|
timeAggregation |
This value determines how the data that is collected should be combined over time. The default value is average. The possible values are--average, minimum, maximum, last, total, and count. |
|
operator |
This value is the operator that is used to compare the metric data and the threshold. The possible values are--Equals, NotEquals, GreaterThan, GreaterThanOrEqual, LessThan, and LessThanOrEqual. |
|
threshold |
This value is the value that triggers the scale action. Be sure to provide a sufficient difference between the threshold values for the scale-out and scale-in actions. If you set the same values for both actions, the system anticipates constant change, which prevents it from implementing a scaling action. For example, setting both to 600 threads in the preceding example doesn't work. |
|
direction |
This value determines the action that is taken when the threshold value is achieved. The possible values are increase or decrease. |
|
type |
This value is the type of action that should occur and must be set to ChangeCount. |
|
value |
This value is the number of virtual machines that are added to or removed from the scale set. This value must be 1 or greater. |
|
cooldown |
This value is the amount of time to wait for the last scaling action before the next action occurs. This value must be between one minute and one week. |
The auto scale architecture is shown in the following diagram:
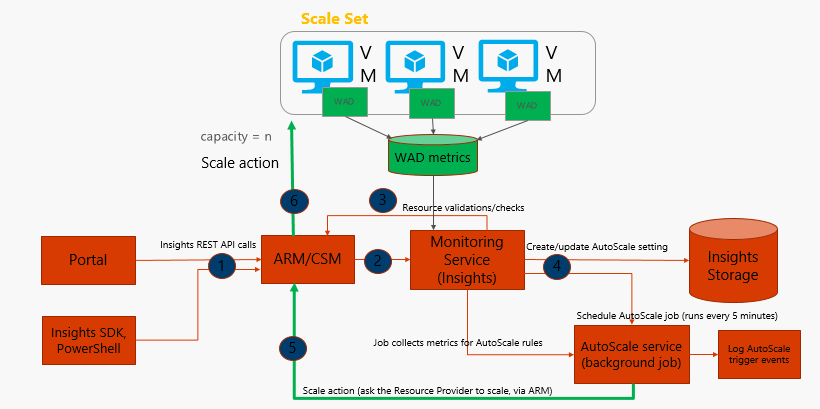
Autoscale can be configured for scenarios that are more complex than general metrics available from environments. For example, scaling could be based on any of the following event:
- Scale on a specific day
- Scale on a recurring schedule such as weekends
- Scale differently on weekdays and weekends
- Scale during holidays that is, one of the events
- Scale on multiple resource metrics
These can be configured using the schedule property of insights resources that help in registering rules.
Architects should ensure that at least two actions--scale out and scale in, should be configured together. Scaling in or scaling out configuration will not help achieve scaling benefits provided by VMSS.