
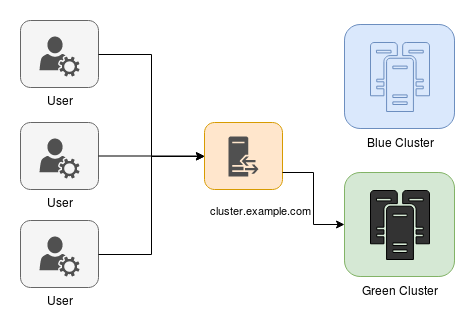
Rolling restarts are nice, but sometimes the changes that you need to apply are on the hosts themselves and will need to be done to every Docker Engine node in the cluster, for example, if you need to upgrade to a newer orchestration version or to upgrade the OS release version. In these cases, the generally accepted way of doing this without a large team for support is usually by something called blue-green deployments. It starts by deploying a secondary cluster in parallel to the currently running one, possibly tied to the same data store backend, and then at the most opportune time switching the entry routing to point to the new cluster. Once all the processing on the original cluster has died down it is deleted, and the new cluster becomes the main processing group. If done properly, the impact on the users should be imperceptible and the whole underlying infrastructure has been changed in the process.
The process starts with the creation of the secondary cluster. At that point there is no effective change other than testing that the new cluster behaves as expected:

After the secondary cluster is operational, the router swaps the endpoints and the processing continues on the new cluster:

With the swap made, after all the processing is done, the original cluster is decommissioned (or left as an emergency backup):
But the application of this deployment pattern on full clusters is not the only use for it--in some cases, it is possible to do this at the service level within the same cluster, using the same pattern to swap in a newer component, but there is a better system for that, which we will cover next.