
Chapter 7. Your Voice User Interface Is Finished! Now What?
YOU’VE DONE IT! You’ve designed and developed your voice user interface (VUI)!
Now what?
It would be wonderful to be able to stop there, put your app out into the wild, and reap the benefits and rewards. But it’s more complicated than that. For one thing, you need to ensure that everything has been thoroughly tested. Then, after you’ve launched, you need to actually verify whether your system is working. Fortunately, there are standardized methods for tracking and analyzing your system’s performance, and you can use that information to tune and improve your VUI.
This chapter describes some VUI-specific testing activities, gets into detail about what needs to be logged, and provides instructions on what to do with all that data.
Prerelease Testing
First, let’s get into testing. Presumably your app has by this point gone through some regular testing methods, making sure it works on different devices; you have run usability tests, and completed basic QA. Now let’s talk about VUI-specific testing.
Dialog Traversal Testing
One type of testing that’s crucial for VUIs is something that the interactive voice response (IVR) system world calls Dialog Traversal Testing (DTT). In this case, a “dialog” refers to a state in your conversational flow, usually one question followed by a user’s response. It includes all transitions, error prompts, help prompts, or anything else that could happen at that state.
Here’s a description from Voice User Interface Design of how it works for IVR systems:
The purpose of Dialog Traversal Testing is to make sure that the system accurately implements the dialog specification in complete detail. You perform the test with the live system, over the telephone, exercising a test script that thoroughly traverses the dialog. The correct actions must be taken at each step, and the correct prompts must be played.
Every dialog state must be visited during the test. Within each dialog state, every universal and every error condition must be tested. For example, you should try an out-of-grammar utterance to test the behavior in response to a recognition reject. You should try silence to test no-speech timeouts. You should impose multiple successive errors within dialog states to ensure proper behavior.[44]
Today’s VUIs have much in common with the earlier IVR systems, but there are some differences. For example, you won’t be calling your VUI over the phone—most likely, you’re using the app on your phone. In addition, for something like a virtual assistant, the tree might be very wide, but very shallow. For example, the main prompt might be something to the effect of “How may I help you?” In this case, you need to test that all the basic functions can be correctly accessed from this point. The DTT does not test every possible way you might say each function, just that the functions can be reached. For more complex systems, complete DTT might be too expensive and difficult; if so, make sure to test as many best paths (and common error paths) as possible.
It’s important to test errors here, as well: no-speech timeouts (when the user did not say anything), and no matches (something was recognized, but the system did not know what to do with it).
For VUIs that have a deeper, fixed, more conversational tree, visiting every state/dialog is essential. I often print out the flow diagram and jot down notes as I test (see Figure 7-1) Traversal testing is time consuming, and it will be tempting to skip states, but your users will thank you for your thoroughness. Or, at least they won’t curse you for your mistakes.
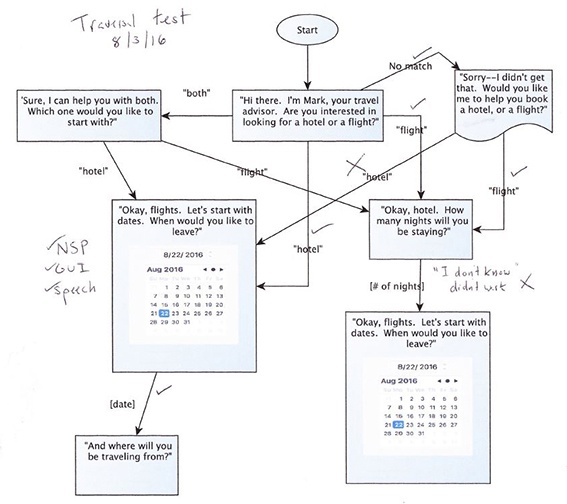
Recognition Testing
In the IVR world, recognition testing is performed to ensure that the base recognition parameters are set correctly. It is generally done by a small set of people (10 to 20) who follow a predetermined script. (Figure 7-2 shows a sample script.)
In today’s world of cloud-based speech recognition, there are fewer parameters to tune, but it can be a helpful exercise, nonetheless. As pointed out in Voice User Interface Design, one of the parameters to look out for here is the end-of-speech setting: saying phone numbers, for example, can require a longer-than-average end-of-speech timeout because people typically pause between sets. This parameter might be something you can set, depending on your speech recognition engine, and it’s important to catch early on in your testing so your pilot users do not have to suffer.
It can also tease out common misrecognitions that you might need to add to your set of expected phrases. For example, a medical app I was designing commonly misrecognized “vial” as “vile” or even “file.” Adding those up front meant more users would have success right out of the gate. As Anne Thyme-Gobbel points out, even using “medically tuned” dictionaries won’t always solve this issue, because users are generally people who don’t have a medical background, and they’re using a few specific terms for their situation; this is a very different use case than, say, dictating medical notes.

Load Testing
Load testing, or verifying that the system will perform under the stress of many concurrent user sessions, might be applicable, depending on what type of recognizer infrastructure you’re using. Third-party services exist to help you simulate load tests for your mobile apps, which is a lot more sophisticated than the method we sometimes used in the early startup days at Nuance: namely, my coworker Madhavan running down the hall yelling “LOAD TEST!” so we’d all pick up our phones at the same time to call the system.
Load testing will inform you as to whether your backend will crash or slow down to a crawl when you hit a certain number of users, and it’s much better to find that out during testing than when your app goes live!
Now that you’ve completed the testing phase, it’s time to think about the launch of the first pilot.
Measuring Performance
Before starting your pilot, you need to define your goals. This will help determine what exactly you need to measure and, therefore, what the system needs to log. You should define your goals as early as possible so as to not be caught short right before launch when you discover your app doesn’t track a crucial detail that your VP wants to see.
In How to Build a Speech Recognition Application, Bruce Balentine and David Morgan describe this process:
Well before application launch, both the developer and the client for whom the application is being developed (marketing, sales, support, and other stakeholders) must state the goals and objectives of the application. For each objective, they must also characterize success or failure. Too often success is measured solely in terms of recognition accuracy. This is perhaps the worst metric. Is an application that obtains 90 precent accuracy and automates 85 percent of calls for a business better or worse than one that achieves 97 percent recognition and automates 40 percent of calls?[45]
As Balentine and Morgan state, it is crucial to involve stakeholders when defining these goals. Designers, marketing, sales, and other departments do not always share the same view on what needs to be measured. As a designer, you might be most interested in whether or not your users are able to utilize your system successfully and complete tasks. As the person in charge of business development, you might be most interested in how many transactions were automated. Business stakeholders do well involving their speech team in this process because they can help explain why something is difficult or easy to measure and why it might or might not actually measure what’s desired.
If you work together to define these goals up front, you can determine what can and cannot be measured as well as lay out your criteria for success. Deciding on success criteria after the launch can lead to frustrations on both sides.
Here are some examples of success criteria:
Sixty percent of users who start to make a hotel reservation complete it.
Eighty-five percent of users complete a daily wellness check-in at least 20 days out of a month.
The error rate for playing songs is less than 15 percent.
Five hundred users download the app in the first month.
The user satisfaction survey gives the app an average rating of at least four stars.
Task Completion Rates
One key measure of success for your VUI is task completion rate. Task completion is when the user has successfully started and completed one specific task. Balentine and Morgan refer to this as a “graceful conclusion.”[46]
Your mobile app might have one task, or it might have many. Each of these tasks should be predefined in order to be measured. Determining when a task is complete sounds easy, but there are subtleties to keep in mind. Ann Thyme-Gobbel has an example from a credit card application. The “pay bill” task was considered successful if the user was able to pay his current balance. However, Thyme-Gobbel and her colleagues found a high percentage of users who dropped out before completing the task.
At first, they were left scratching their heads as to why this was. Recognition performance was fine. Eventually they realized that many people quit after the initial part of the task: hearing their current balance and due date. After this discovery, the designers created two separate tasks—getting a balance and paying a bill—and the “pay bill” task did not start until the user went past the balance prompt and began the bill pay workflow.
As with the previous example, tasks can be considered complete before the end of the conversation. Another example of this is a healthcare app in which users can answer questions about their symptoms to determine if they should see a doctor. After an outcome is given, the user is offered the option to have information emailed to them. Is the task complete only if the user answers the question about email? It makes more sense to have a task labeled “Received health outcome,” which is successful if the user reaches the outcome state, and then separately track how many people agree to receiving email.
Here are some examples of a successful task:
User books a hotel room.
User sets an alarm.
User plays a song.
User turns on the lights.
User answers three questions in a trivia game.
User takes her glucose measurement.
User makes a payment to someone.
User receives her estimated commute time.
User searches for and finds a movie.
Dropout Rate
In addition to measuring whether users completed tasks, it is important to analyze where users drop out. If dropouts occur all along the workflow of a particular task, it can be difficult to ascertain why, but oftentimes there will be clusters of dropouts around particular states of the app. The following list outlines some common reasons for an earlier-than-expected dropout:
User finished the task earlier than anticipated (such as the previous example of getting a bank balance)
Prompt was confusing
High rate of no-matches/out-of-grammars (e.g., user said something that was not expected in that state)
User does not feel they’re getting anywhere toward reaching their goal
When you locate a point in the process with a high dropout rate, it’s important to examine the prompt(s) leading up to that state. It’s always crucial to collect and transcribe what the user is saying. A common example is of a prompt that asks a question that could be answered with a “yes” or “no” but does not have the ability to handle that response, such as “Do you want to send the email, or cancel it?” One response to this sort of phrasing is “yes,” but designers do not always build in a match for it, expecting instead to hear only variations of “send the email” or “cancel it.”
It’s also useful to see what the user did next. Did they leave the app entirely? Did they go back to the top? Did they try rephrasing the request or choosing a different category? If you have menus or categories, it might be that things are not grouped in a way that is clear to the user.
Other Items to Track
In addition to things such as task completion and dropout rates, there are other details that can be useful to record and analyze, such as where users are silent when they should speak, and where they most frequently interrupt the system.
Amount of time in the VUI
In the IVR days, a common measure was call duration. Generally, it was thought that a short time in the IVR system was preferable, because it indicated that the user was getting their task done quickly and efficiently.
Although you don’t want your user wandering around your app in confusion or frustration, a longer duration is not always an indicator that things are not going well. Users can be highly tolerant of long interactions if they feel they are getting somewhere. Duration is not always tied to measuring user satisfaction or success. Thyme-Gobbel refers to this as “perceptual duration, rather than absolute duration,” and says that “many things factor in to that, including quick response time, flatness of prompt delivery (monotone will seem longer), superfluous wording, lack of variation in responses, too many options (causes the user to think more), misrecognitions by the system... anything perceived of as annoying.” In addition, users might be deliberately spending a long time in the app, such as listening to stock quotes over and over again. If the user feels in control, duration is not necessarily a bad thing.
Duration can be useful for other reasons, however. For example, if you are selling a daily conversation of some sort, such as an activity tracking VUI, business development stakeholders might be interested in the average length of the interaction. Users considering downloading the app might also be interested. It might be worth tracking for these types of reasons.
Barge-in
If you have barge-in enabled in your VUI, it is useful to track where users barge-in and whether it’s too sensitive or not sensitive enough. Not all recognizers will allow you to tune barge-in parameters, but even if they do not, you can get insights into your app’s performance by noting where users barge-in the most.
If your users barge-in frequently at particular or unexpected points, examine the prompt at which they barge-in as well as the prompt(s) leading up to it. Perhaps the prompt is too long. A crucial piece of this, however, is comparing barge-in rates with novice versus long-term usage. You might find a high barge-in rate in a particular place, but that only expert users barge-in. Rather than having the same set of prompts for both types of users, your VUI could have shortened prompts for users who have interacted more than a minimum number of times.
Speech versus GUI
Another interesting metric is looking at modality. Your mobile app might have many places in which users can touch the screen or speak. In certain cases, users might be more likely to use touch, whereas in others they prefer to use speech. This can help pinpoint where to invest resources; if there is a place in your app where users predominantly use touch, ensure that the GUI options are clear and accessible. If there is a point at which users almost always speak, you might want to minimize or remove GUI options (or only bring them in for backoff cases if speech is failing).
High no-speech timeouts, no matches
As mentioned previously, pay attention to states in which there is a high rate of no speech detected (NSP) timeouts or no matches (the user’s words were correctly recognized, but the VUI does not have a programmed response to that utterance).
A high number of NSP timeouts can be an indication of a confusing prompt, or perhaps an indication that the user is being asked something they do not have handy, such as an account number. Examine the prompt, and if it is asking for a piece of information, provide a way for the user to pause or ask for help in order to find what’s needed.
There are two types of no matches:
Correct reject
False reject
A correct reject means the user said something that was correctly not matched, because it was not an expected response for that state. For example, if the prompt asks, “What is your favorite color?” and the user responds, “I like to eat spaghetti,” it’s probably not something your VUI system will have a response for—nor should it, at least until we reach a level of AI and natural-language understanding seen in movies such as Her. These types of responses are called out-of-domain.
The other type of no match is a false reject, meaning that the user said something the VUI really should have been able to handle, but it did not. This often occurs in early stages of development, before a lot of user testing, because the designer has not anticipated the various ways users can phrase their requests. For example, a virtual assistant might have functionality to cancel appointments on a calendar, but not have anticipated a user saying, “I can’t make it to my meeting on Thursday, so take it off my calendar,” even though that is a perfectly legitimate request. These types of responses are called in-domain.
It is important to note that the distinction between in-domain and out-of-domain is purely academic. The recognizer rejects the utterance in both cases, and it is only after the utterances are transcribed and analyzed in the process of tuning that we can make the distinction between the two types of errors.
Another level of complexity includes responses that do answer the question, but require more intelligence on the part of the VUI. For example, in response to the question, “What is your favorite color?” a user could say, “The color of my house.” One could imagine in the not-too-distant future handling responses such as these.
Finally, as mentioned in Chapter 5, there are the cases in which a failure occurred because the recognizer did not get it quite right—for example, the recognizer might misunderstand the user asking “What is the pool depth?” as “What is the pool death?” If this is a common occurrence, adding “pool death” to the accepted key phrases is straightforward, but won’t always be anticipated during early design. In addition, using an N-best list would help with this issue; “pool depth” is a likely occurrence later in the list, and walking through it until a more relevant match occurs, rather than just choosing the first, will automatically improve your VUI’s accuracy.
This example is another reminder that there are multiple failure points that can occur in a VUI: the automated speech recognition (ASR), the natural-language understanding (NLU), and accessing appropriate content from the backend. When one of these fails, it doesn’t matter to the user which one it was, only that it failed. It’s important to think about all of these pieces when designing your VUI.
Tracking points at which the user spoke but the wrong thing happened is crucial to the success of your VUI. Users will quickly lose trust in your system if there are too many failures with speech. If you track failure points and have a continuous plan to improve (by rewording prompts so users know what to say, fixing flow issues, and enhancing recognition performance by adding additional key phrases, and retraining your NLU models) your system can quickly improve and keep users coming back.
Navigation
If your app has a Previous or Back button, tracking usage can lead to important insights. Points at which there is frequent use of the Back button often indicate that the user was misled into thinking that was the correct place to go. One strategy to address this is to allow users to get to the same place from multiple starting locations.
Consider a tech support application that asks the user to choose between different help topics, such as “Internet” versus “email.” Although your website FAQ might group questions underneath these as very different, in a user’s mental model there can be a lot of crossover. For example, if the user states, “My email isn’t working,” this could very well be an issue with the user’s WiFi, which is also under the “Internet” topic.
If you have a “repeat” function, examine where there is heavy usage of this. It might indicate that your prompt is too long, or too wordy, making it difficult for users to comprehend the first time. Keep in mind that many users find it more difficult to remember auditory information than visual. Consider breaking it down into multiple steps or adding more visual cues. In addition to the deliberate “repeat,” it’s a good idea to document repeated queries, as well. For example, if your user keeps asking the same thing, such as, “What is the weather this week?” it’s good to dig into why.
Latency
Many recognition engines provide information about latency, meaning how long it takes the recognizer to trigger on end-of-speech detection and return a recognition result. If your latency is too high, users will not think that they’ve been heard and will repeat themselves, which can cause problems. The Google Cloud Speech API provides a Dashboard to show this information (Figure 7-3).
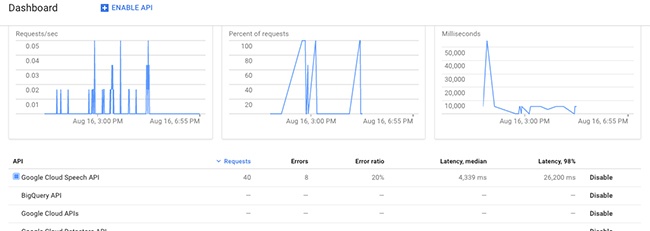
Whole call recording
Although much of what will be analyzed is done on a per-utterance level (meaning one response, or turn, from the user, such as “red” or “I want to go to Golden Gate Park” or “Can you please find me a restaurant that’s open tonight and is within a 10-minute drive?”), sometimes it can be useful to view interactions as part of a whole.
In the IVR world, this was referred to as whole call recording. Instead of just recording the utterances that are the user’s responses, everything, including what the system says, is recorded as one long chunk. This requires a lot more room to store, of course, and is generally done only on a subset of calls.
A less memory-intensive method is to re-create the conversation by stitching together the system prompts that would have been played, with the utterances. If barge-in is enabled, you’ll need the barge-in information, as well, to re-create when and where it occurred.
Listening to the whole call can reveal issues that you might not see when looking at one point in time. If your user is 10 turns into the conversation when things go wrong, listening to what happened up until that point can sometimes shed light.
However, you can also identify many dialog issues from re-created calls. In the early days of Nuance, one of the designers spent all his commute to and from work listening to recordings of calls to deployed systems: “As the traffic problems in Silicon Valley increased, our performance improved.”[47]
Select calls randomly to get a good cross-section; you don’t want only smooth calls or only calls with errors. Because the types of users can also vary based on the time of day and the day of week, don’t be tempted to take a very short sampling for your calls; instead, try to sample over the course of a week at a minimum.
When re-creating conversations on a multimodal app, it will be necessary to show the screen interactions, as well.
This type of analysis might require some homegrown tools because there is not a lot on the market to do this. At Volio, we had a Conversation Dashboard (originally created by Volio’s CTO, Bernt Habermeier). For each turn in the conversation, the dashboard showed what the system said, what the user said, and what happened next (Figure 7-4). It also had a video playback, so you could listen and watch the user’s response.

Logging
We’ve discussed many things that are important to measure, but to measure them, the information must first be logged. Without logging, when you launch your app into the wild, you will be blind. You will not know how well, or how poorly, your system is performing. Your users might be failing, but if you don’t use proper logging, you will not know.
Talk to the development team at the beginning of any VUI project so that they understand the need to build logging in from the early stages. It is much more difficult to add logging information after launch. Information to log includes the following:
Recognition result (what the recognizer heard when the user spoke, including confidence scores)
N-best list, if available (list of possible hypotheses)
Audio of user’s utterance for each state, including pre- and post-endpointed utterances (for transcriptions, since the recognition result is not 100 percent accurate)
If recognition did match to something, what it matched to
Errors: no-speech timeouts (including timing information), no match, recognition errors
State names (or other way to track where in the app the user traversed)
Latency
Barge-in information, if barge-in is enabled
It is important to log utterances and audio even when speech failed, including if the user says more than one thing in a given state. Imagine a virtual travel assistant that is asking the user for her departure airport. The screen shows a list of airports in Washington that the user can either tap or say. Here is a sequence:
User says, “Pasco, Washington.”
Although Pasco is a valid airport, user was misrecognized as “Pass co airport.”
Nothing happens (because this is a multimodal state, there is no “I’m sorry” error prompt).
User repeats, “I said Pasco, Washington!” but is again misrecognized as “Pats go airport.”
Nothing happens.
User is frustrated, taps Pasco, instead.
Some developers might log only the final result that created the next action, but in doing so, important information is lost. Knowing where and how the user failed is key to improving the system.
It’s best to log information after each turn in the conversation because the user might quit the app abruptly, or the app might crash. If you’re only logging best-case scenario, when the user comes to a graceful conclusion, you will be missing important pieces of data.
It should go without saying that the audio information recorded should be anonymized and not used for things outside of analysis.
Transcription
Before you can accurately analyze system performance, one more key task is necessary: having humans listen to and transcribe (by hand) the utterances of users speaking to the VUI.
“But wait,” you’re saying. “I heard speech recognition is 92 percent accurate these days! I’ll just use it to autotranscribe everything. Much cheaper.”
It’s true that, in many cases, speech recognition results are highly accurate. However, in many cases, they are not. And in this case, you’re using what the users actually said to build and improve your dataset. Building a dataset with faulty data is not a recipe for success. As Balentine and Morgan say, “The only accurate way to determine speech recognition performance is by logging each individual utterance and then transcribing it offline.[48]
Transcription does cost money, but you cannot build a good VUI without transcribing at least some of your data. There are companies out there that are dedicated to transcribing, such as Appen, which is a veteran in the field, but there are many other smaller companies that offer the service, as well. QA companies can sometimes do this, too, if provided with the right tools. Planning ahead again comes in handy here because your audio must be in certain formats for the company you choose.
At Volio, part of the Conversation Dashboard tool included a place to write down the transcription. Our QA team would play back the user’s response in the video window, and write down exactly what the user said (see Figure 7-5).

Armed with the speech recognition results, matches, and audio transcriptions, you have what you need to analyze performance and see how your VUI is really doing.
Release Phases
As with any new technology released to the wild, it’s best to roll it out in phases, rather than release it to the entire world at once.
Pilot
If possible, begin with a pilot. Pilots can range from just a few users to a few hundred. This type of rollout is important so that you can identify any show-stopper bugs at the outset. Pilots are also valuable for VUIs because as much QA testing and user testing as you can do up front still won’t prepare you for all the ways in which users talk to your system:
There is no way to evaluate the great variety of ways people will talk to the system until you collect data from users engaged in real, task-oriented behavior, performing tasks that matter to them. [Emphasis mine][49]
If you are able to, plan on several (short) pilots; this way, you can quickly roll out and test improvements to recognition. It might be helpful to set a performance goal before you launch, such as successfully handling 75 percent of user utterances correctly. This starting rate will vary considerably depending on how much data you are able to collect beforehand. In some cases, the performance rate at the start of the pilot will be much lower.
As your pilot users exercise the system, have transcriptions performed on a daily basis, and analyze each utterance. When you identify false rejects, or false accepts, update your key phrases/models and push them out.
Surveys
Another useful way to get feedback is of course to run a survey. Although it’s common to run surveys via a third-party website such as SurveyMonkey, you can also let your VUI give the survey. Users are more likely to do a survey when it’s within the app, rather than having to click a link at a later time. Figure 7-6 shows a sample survey with the Sensely avatar asking the questions. Users can speak or use touch.
Keep the survey a reasonable length (generally no more than five questions), and allow for an “Anything else?” open-ended response.

Thyme-Gobbel suggests using a different persona or avatar to ask the survey questions, not the one who performed the task. For example, if a male avatar helped the user schedule an appointment, a female avatar could ask if the user enjoyed using the app.
In addition, if you ask a quick yes/no question after the task was completed, such as, “Was I able to answer your question?” it can give you a head start in looking into potential problems without combing through the logs.
Finally, it’s important to remember that surveys are inherently biased: generally speaking, those who choose to take a survey are the ones who are the most or the least satisfied. Keeping your survey short can increase engagement; a simple yes/no or rating might be sufficient.
Analysis
You’ve logged everything you need, run your pilot, and transcribed your utterances. What to do with all this data?
First, examine your in-grammar and out-of-grammar rates. These terms are more germane to the IVR world, but the concepts still apply for VUIs. Here are definitions from Voice User Interface Design (examples mine, in response to the question, “What’s your favorite color?”)
In-grammar data
Correct accept: The recognizer returned the correct answer. [“My favorite color is red.” → “red”]
False accept: The recognizer returned an incorrect answer. [“I blew past that question but my favorite’s teal”] → “blue”]
False reject: The recognizer could not find a good match to any path in the grammar and therefore rejected rather returned an answer. [“I think magenta is nice.” → no match]
Out-of-grammar data
Correct reject: The recognizer correctly rejected the input. [“I think I would like to book a hotel” → no match]
False accept: The recognizer returned an answer that is, by definition, wrong because the input was not in the grammar. [“I read the paper” → “red”]
Although these categories are important for analysis, it’s not something the user needs to know about:
From the point of view of the callers, the distinction between in-grammar and out-of-grammar is irrelevant. All they know is that they said something, and the dialog with the system is not proceeding as they expect.[50]
Most modern mobile apps are not dealing with grammars per se, but the general concepts are still a useful way to think about your system performance. In-grammar refers to things the user said that should be recognized; they are in-domain for that particular place in the workflow. Out-of-grammar means that the user said something that you have (deliberately) left out.
It’s important to maintain a balance between accepts and rejects. If you overgeneralize and try to accept as many things as possible, you end up with cases in which your user clearly did not say the right thing, but you recognized something anyway. If you don’t make it robust enough, however, you won’t have to worry about recognizing things you shouldn’t, but you won’t recognize enough things that you should.
Other parameters and design elements can be adjusted, as well. Let’s take a look at them.
Confidence Thresholds
Most ASR systems return a confidence score along with their result. As discussed in Chapter 2, you can use confidence scores to determine confirmation strategies. For example, results above a certain threshold can be implicitly confirmed (“OK, San Francisco.”) and in the middle threshold can be explicitly confirmed (“Sounds like you said San Francisco. Is that right?”)
If you’re using confidence scores to determine your confirmation strategy, it’s important to verify that it’s set correctly at each state. You might find that different states need different confidence thresholds. Ideally, you’ll want to play with the thresholds and rerun your data to optimize the values.
End-of-Speech Timeouts
Different states in your app might require different values of the end of speech. If you can customize these, examine your data to see if people are frequently cut off. A common example, as mentioned previously, is reading groupings of numbers, such as phone numbers or credit cards. For some recognizer engines, you can configure a different value of end of speech timeout for finals versus nonfinals in the grammar, allowing users to pause between groups of digits in a credit card number, yet being snappy at detecting the end-of-speech when the complete card number has been spoken. Another case is when an open question such as “How are you doing?” or “Tell me more about that” is presented to the user; oftentimes, people will pause while telling the VUI the information. You need to strike a balance between not cutting people off and not waiting too long to detect end of speech—waiting too long can cause people to think they were not heard.
Interim Results versus Final Results
Some ASR tools, including Google’s, allow you to receive real-time interim results. This means that as several words are recognized, your app can see the results. Your VUI can match on the user input before the user has even finished speaking. This can make the app very snappy, but it has drawbacks, as well. For example, if you’re working on a pizza-ordering app and you say “What toppings would you like?” your user might reply, “Pepperoni, olives, mushrooms.”
If you’re matching on interim results, you might see that “pepperoni” has matched to one of the ingredients, and finish the turn. This will serve to cut the user off before he has finished speaking, and you will miss some of the ingredients, too.
Look at the data to determine if matching on interim results will be appropriate. For simple yes/no states, it can be a great idea.
Custom Dictionaries
Your VUI might have certain brand names or unusual terms that are rarely (or not at all) recognized. Many ASR tools offer the opportunity to customize the vocabulary, putting specified items as higher probabilities.
Nuance, for example, has a “My Vocabulary” section, in which you can add your own words (Figure 7-7). One example from its Vocabulary Guide is “Eminem”: if you’re creating a music app, you’ll want “Eminem” to have a higher probability of being recognized than “M&M.”
Another example, mentioned previously in this chapter, is a medical app in which patients ask about “vials” of medication. Adding “vial” to your vocabulary will give that a higher probability than “vile,” which is what the speech recognition engine might be more likely to return.

Google’s Speech API provides “word and phrase hints” for this task. This allows you to boost the probability of certain words, or add new words such as proper names or domain-specific vocabulary.
Prompts
In addition to looking at parameters, it’s important to examine your prompts, as well. Subtle changes in wording can often affect how users speak:
For example, if the prompt says “Where are you going?” callers are more likely to give an answer such as “I am going to San Francisco,” whereas if the prompt says “What’s the destination city?” an answer such as, “My destination city is San Francisco” is more likely.[51]
If you notice a lot of no matches, be sure to look at your prompt wording. Are you asking the question in such a way to get the type of answers you’re expecting? In addition, don’t just lump similar types of responses. For example, even basic yes/no key phrases might not always be the same. Look at the difference between these two yes/no questions:
“Are you finished?” might generate “Yes I am”
“Is that correct?” might generate “Yes it is”
Even something as simple as word ordering can modify user’s responses. Thyme-Gobbel has an example of changing a prompt from the format “Do you want A or B?” to “Which do you want—A or B?” and greatly increasing correct responses.
Tools
At this time, not many tools exist to easily allow designers to improve their VUIs based on user data. It might be necessary to build your own.
One thing that is essential is an easy and robust way to enhance your key phrases. As you analyze the transcriptions and no matches, it will quickly become clear where you need to add or enhance your expected recognition phrases. For example, perhaps you are a US designer designing for a UK dialing app, and you discover that a lot of users in the UK say “ring” for making a call. You want a tool that will easily allow you to add this phrase and push out the change without having to access a database, or roll out a new version of the app.
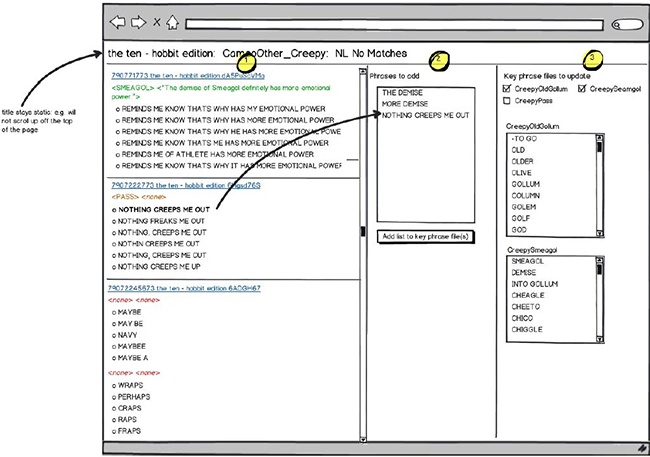
At Volio, we had a tool with which we could easily see, for a particular state, where “no matches” had occurred. It provided a drag-and-drop method for adding key phrases, and a simple way to push these changes into the testing environment (Figure 7-8).
You might have multiple users of your dashboard. External users might want to see details at a higher level. The Sensely Conversation Dashboard shows what the avatar says, what the user said (the recognition result), and any information collected from devices (Figure 7-9).

Voxcom, which develops speech recognition apps for call centers, has an automated script that generates system reports automatically from its call logs (Figure 7-10). It’s very useful for immediately determining key factors such as dropout rates (how far do users get), and how frequently users had to correct responses.
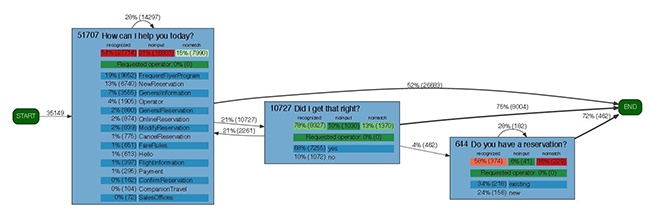
Regression Testing
When you’ve analyzed your data, reworked problem prompts, and tweaked your parameters, it’s important to determine if it actually improved performance.
Don’t just assume. Instead, take your data (audio recordings), and rerun them through the newly tuned system. Do your no match rates drop? Does your false accept rate improve?
Regression testing provides a robust way to ensure that your improvements work well and do not break anything. It’s possible to fix one problem while unintentionally causing another; regression testing will show these issues before you go live with updates.
Conclusion
Launching your app is an exciting milestone. Because VUIs include a complex input method—speech—it’s particularly difficult to be sure that it will perform exactly as expected.
Luckily, there are ways to monitor how your app is doing and allow the designer to quickly improve performance. It’s crucial to log all the information that might be needed, so that analysis can proceed as soon as you begin collecting data. Transcription, in which humans transcribe what users actually said, is essential to understand how your system is truly performing.
Define success measures and task completion definitions at the outset, during the design phase, so that there is agreement among stakeholders, and developers have time to build infrastructure for all the logging tasks.
Tracking your speech failure points and having a way to quickly make improvements is essential for successful VUIs.
[44] Cohen, M., Giangola, J., and Balogh, J. Voice User Interface Design. (Boston, MA: Addison-Wesley, 2004), 6, 8, 75, 218, 247-248, 250-251, 259.
[45] Balentine, B. and Morgan, D. How to Build a Speech Recognition Application: A Style Guide for Telephony Dialogues. (San Ramon, CA: EIG Press, 2001),213, 309–311.
[46] Balentine, B. and Morgan, D. How to Build a Speech Recognition Application, 213, 309–311.
[47] Cohen, M., Giangola, J., and Balogh, J. Voice User Interface Design. (Boston, MA: Addison-Wesley, 2004), 6, 8, 75, 218, 247-248, 250-251, 259.
[48] Balentine, B. and Morgan, D. How to Build a Speech Recognition Application, 213, 309–311.
[49] Cohen, M., Giangola, J., and Balogh, J. Voice User Interface Design. (Boston, MA: Addison-Wesley, 2004), 6, 8, 75, 218, 247-248, 250-251, 259.
[50] Cohen, M., Giangola, J., and Balogh, J. Voice User Interface Design. (Boston, MA: Addison-Wesley, 2004), 6, 8, 75, 218, 247-248, 250-251, 259.
[51] Cohen, M., Giangola, J., and Balogh, J. Voice User Interface Design. (Boston, MA: Addison-Wesley, 2004), 6, 8, 75, 218, 247-248, 250-251, 259.