
Chapter 3. Personas, Avatars, Actors, and Video Games
AN IMPORTANT DECISION THAT you should consider when designing voice user interfaces (VUIs) on mobile devices is whether your VUI should have a visual representation. This could take the form of a still image, a cartoon avatar, or even recorded video of an actor. In addition, there are nonhuman avatars in the form of other familiar shapes such as monsters, animals, robots, aliens, and so on. Finally, there are abstract visual responses a VUI can show, without using an avatar.
This chapter helps you to decide whether your VUI needs a visual component, and if it does, what the best design practices are. This chapter does not go deeply into details of how to create and animate an avatar; it focuses on how an avatar is used specifically within a VUI system.
In addition, this chapter covers persona design. All VUIs, regardless of whether they have a visual component such as an avatar, will still have a persona.
Personas
There is no such thing as a voice user interface with no personality.
—COHEN, GIANGOLA, AND BALOGH, 2004
In Voice User Interface Design, Cohen, Giangola, and Balogh define persona as follows:
“Persona” is defined as the role that we assume to display our conscious intentions to ourselves or other people. In the world of voice user interfaces, the term “persona” is used as a rough equivalent of “character,” as in a character in a book or film. A more satisfying technical definition of persona is the standardized mental image of a personality or character that users infer from the application’s voice and language choices. For the purposes of the VUI industry, persona is a vehicle by which companies can brand a service or project a particular corporate image via speech.
Humans are wired to anthropomorphize. A photo of a bathtub with holes where the faucet used to be becomes a surprised face (Figure 3-1). We talk to our pets as if they were humans.

Trust that your users will be doing the same thing with your VUI. Whether you intended them to do so, users will ascribe personality traits to it. The best strategy is to decide on the personality yourself, while designing, rather than leave it up to chance.
When you’re using an avatar, it becomes even more crucial to think about the personality behind it. When you create a visual representation, people are even more likely to see personality traits. Begin with personality traits and then design the visuals to match. When thinking about personality, here are some questions to ask:
Some virtual assistants, such as Cortana, let you access a log of everything they know about you to edit it. According to the Business Insider article “Why Microsoft Doesn’t Want Its Digital Assistant, Cortana, to Sound Too Human,”[16] this “breaks the illusion that Cortana is a human, which is just fine by Microsoft, while also making it a more useful tool.”
The personality of your VUI will affect its behavior across the board: how it asks questions, how it copes with errors, and how it provides assistance.
Cortana’s writers spent a lot of time thinking about her personality:
Our approach on personality includes defining a voice with an actual personality. This included writing a detailed personality and laying out how we wanted Cortana to be perceived. We used words like witty, confident, and loyal to describe how Cortana responds through voice, text, and animated character. We wrote an actual script based on this definition that is spoken by a trained voice actress with thousands of responses to questions that will have variability to make Cortana feel like it has an actual personality and isn’t just programmed with robotic responses.[17]
Cortana’s writers even have a strategy for dealing with the inevitable harassment that some users will give a female virtual assistant. As Cortana writer Deborah Harrison shared in an interview with this book’s author:
Our stance here is that we want to avoid turning anything resembling genuine harassment—sexual or otherwise—into a game. In lots of other scenarios, we write a variety of responses for any given query so that it’s fun to ask more than once and so that we can explore different nuances of certain scenarios. And for some queries that are merely impertinent or rude or cheeky, we’ll be more apt to respond with some cheekiness of our own. For example, if you say, “I hate you,” Cortana might say, “Oh good, because I’m in opposite world right now!” Or she might say, “The feeling is not mutual.” If you say, “You are boring,” we’ll give you any of several one-word answers like “Hooey!” or “Balderdash!” along with a picture of an animal that looks in some way affronted or surprised. So, she doesn’t take offense just because you say something negative. But if you start saying things that have connotations of abuse, she stops playing and instead just states clearly that that’s not a place where she’ll engage. You could make the argument that she should just not respond at all, but that might feel unintelligent. She understands, but she’s setting a boundary for herself—this isn’t how she wants to be treated, and she’ll say so, without rancor or anger, but firmly.
For other designers facing this conundrum, my advice would be to think carefully about the principles that are consistent with the personality you’re developing. There are a variety of lenses you can apply: product goals, company goals, ethical goals, social goals, and so on. Each of these contributes to the cocktail of principles you develop. Those principles can evolve—should evolve, really—and grow to meet new scenarios, but having a core set of guidelines that define both what you intend to accomplish with your personality and how that looks helps guide the conversations when they arise. For example, this year we needed to figure out how to approach politics. How should Cortana respond when asked about a candidate? A policy? An election? We spent weeks discussing the nuances by looking through each of the lenses I listed above, and we ended up defining how Cortana feels about democracy, voting, candidacy, and political involvement. Now, as new queries arise that warrant attention, we have a set of principles to call on that help inform our approach. The writing still takes whatever time it takes, but we know how Cortana should sound.
Deciding how to approach abusive language is essential for any team undertaking this journey. Every digital assistant will face it.
On the flip side of persona design, make sure you don’t go too overboard with personality traits when they’re not needed. If you’re designing an entertainment app, you may want to go full bore with witty dialog and one-liners (á la, You Don’t Know Jack), but imagine if Google suddenly began imbuing that kind of behavior into its virtual assistant. Consistency in your persona design is important: as Katherine Isbister and Clifford Nass note, “Consistency in others allows people to predict what will happen when they engage with them.”[18]
If you’re designing an app for a particular set of users, you can be more free with the personality. Some people won’t like it, but some people will love it. If you’re designing something more universal, be more cautious. In this case, you might have a subtler personality that is neither loved nor hated.
You might want to give your users choices for the avatar or voice used in your app. It is nice to give people options, but you can’t always swap out an avatar or voice and leave everything else the same. Different looks and different voices imply different personalities, and the interactions different personalities have will not be identical. Ideally, rather than offering a different voice or different avatar, you offer different personas, which then contain different components, including visual and audio. Having a mismatched persona and avatar can cause inconsistencies and lead to distrust.
The book Voice User Interface Design by Cohen, Giangola, and Balogh is a great reference for learning more about persona and VUIs.
Should My VUI Be Seen?
One of the most common use cases for which designers do create avatars is virtual assistants. Websites often use a photo or an avatar (Figure 3-2) for their customer service chatbot (even those who do not speak and cannot be spoken to). Many mobile virtual assistants also have an avatar component.
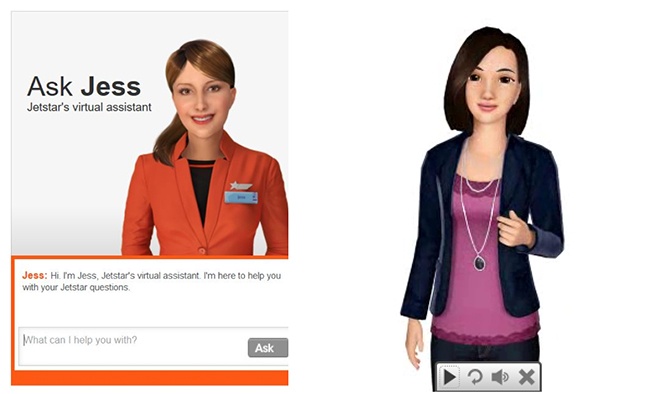
However, many of the most prominent VUI assistants, including Google, Siri, Hound, and Cortana, have no avatar. Some do have simple visual cues, such as a glowing circle. (HAL 9000, a fictitious but very interactive virtual assistant from the 1968 movie 2001: A Space Odyssey, had a glowing red light.) Avatars are not essential to have a successful voice interaction. VUIs can still provide empathy and important visual feedback without using a picture.
The designers of Cortana made a conscious decision to stay away from an anthropomorphic representation. Deborah Harrison, Cortana editorial writer at Microsoft, says:
One reason we stayed away from a human-looking avatar is that we’re clear that Cortana isn’t human. It was more true to her nature to show her as a more purely digital representation.
A good avatar takes more work, both on the design and development. There are third parties out there that will provide an avatar for you to integrate with, or you can invest in building your own.
Using an Avatar: What Not to Do
In “Sweet Talking Your Computer,” Clifford Nass notes:
Clippy’s problem was that he was utterly oblivious to the appropriate ways to treat people. Every time a user typed “Dear...” Clippy would dutifully propose, “I see you are writing a letter. Would you like some help?”—no matter how many times the user had rejected this offer in the past. Clippy never learned anyone’s names or preferences. If you think of Clippy as a person, of course he would evoke hatred and scorn.[19]
Microsoft’s assistant, Clippy, was a failure, but it came with some important lessons. Clippy (Figure 3-3) was oblivious to context. In one cartoon making fun of Clippy, someone has started a letter with “Dear World, I just can’t take it any more” and Clippy has popped up to say “It looks like you’re writing a suicide letter. Let me help with that.”

If your VUI is tone-deaf, the user will notice. Another Nass experiment had subjects “drive” a car simulator and used two different voices: one that was upbeat, and one that was morose. Sad drivers hearing the happy voice had approximately twice as many accidents as those who heard the sad voice. Happy drivers had fewer accidents and paid more attention to the road when they heard the happy voice. When voices matched mood, drivers also reported enjoying driving more and that they liked the voice more.
If your app is just looking up search results and setting timers, emotional tone is not as important. But if the app deals with more sensitive topics such as mood or health, be sure to recognize these instances and handle them appropriately. It’s better to have a neutral response than to have one that is inappropriately happy or sad. Making your VUI appear aware of what the user has said (or done) is crucial.
In a study done by Ann Thyme-Gobbel during her time as head of UX/UI experience and design at healthcare company 22otters (and presented at the Mobile Voice 2016 conference), 72 participants were shown a video with the same instruction done in one of five ways (Figure 3-4 shows some of these):
Static photo
Animated avatar
Static picture of same avatar
Text only
Animated illustration (not an avatar)

Participants heard the same prompts (recorded by a person, not text-to-speech) delivered in one of those formats, and then were asked which one they preferred. Generally speaking, most people preferred the animated illustration. When asked specifically what they thought of the moving avatar, those over the age of 40 rated it the highest.
Subjects appreciated variation—text, for example, is great for listing medications; illustrations are useful for instructions on using a device; and avatars are good for building rapport.
The study began with a static avatar introducing each topic, which as Thyme-Gobbel said, “grounded the voice and made a nice connector throughout the app.”
Though it was a small study, it’s a reminder that avatars are not appropriate all the time. Whenever possible, prototype your VUI early on to discover in advance whether people find your avatar engaging—or creepy.
Using an Avatar (or Recorded Video): What to Do
When should you use an avatar? This section outlines where an avatar or animated character can enhance your VUI and keep users more engaged.
Storytelling
A great time to use an avatar/character is for storytelling and engagement. If you want to draw your user into your world, whether it’s for a game, or for educational purposes, having a character is a great way to do so.
An example of this is from the ToyTalk children’s entertainment app SpeakaZoo. In each scene, an animated animal talks to the child, and when it’s the child’s turn to talk, a microphone button lights up (Figure 3-5).

Based on the child’s responses, the animated character responds in different ways. In this instance, the app does not even use that much speech recognition—it often reacts the same regardless of what the child says. It still creates an immersive experience, although with repeated exposure, kids do catch on that the character is always doing or saying the same thing.
Another example of an interactive game with an avatar is Merly, from Botanic.io (Figure 3-6). Mark Stephen Meadows describes Merly as follows:
Merly, a character that provides backstory on a kid’s mystery fable, answered questions that the story brought up, provided solutions on how to play the game, and stitched together several elements of the story that were not clear on first read. It was a new way to read, and someone that, like the Greek chorus in plays, added meta-commentary by breaking the fourth wall. Narrative bots have to break that fourth wall and what that means, from an interactive narrative point of view, is that they will be an increasingly important part of storytelling as VR eclipses passive narrative media like movies and television.

Teamwork
Another way an avatar can add to your user’s experience is that it allows the user to have a teammate/collaborator when completing tasks. When you speak to Amazon Echo’s Alexa, for example, she’s the one completing the task; you’re making a request.
With an avatar, the VUI can be a separate entity from the system or the company with which the user is interacting. For example, if your doctor has requested that you take your blood pressure every day, a nurse avatar can assist you with that, so together you accomplish the required task someone else has requested.
SILVIA’s Gracie prototype of an avatar (Figure 3-7) allows the user to sing along with her (she’s an animated character). When you want to talk to Gracie, you tap the screen.

Gracie will continue to say things to you even when you haven’t tapped the screen, which adds to the feeling you’re having a real conversation.
Video Games
Video games are another format in which VUIs can enhance the user’s immersion in the virtual experience; however, it must be done well.
Some video games use voice to allow the player to issue commands. For example, in Yakuza Studio’s third-person shooter game Binary Domain you can issue commands to your team such as “Cover me!”, “Regroup!”, and “Fire!”—and they might or might not do it, depending on whether they like you (Figure 3-8). Although you’re allowed to speak and issue these commands at any time during game play, at certain points characters ask you questions, and show options on the screen.
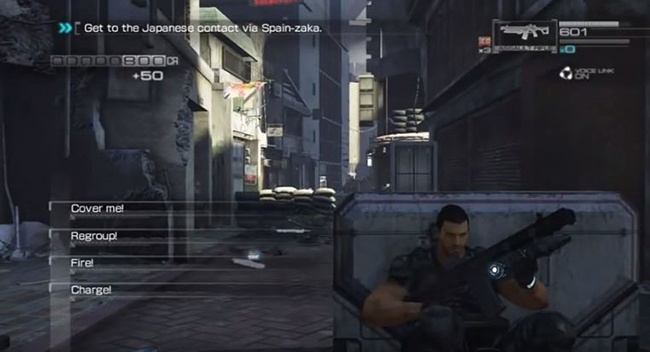
If the system did not understand you, you’ll hear, “Don’t get ya. Tell me later.”
Another game, In Verbis Virtus by Indomitus Games, uses speech recognition to empower the user to cast spells. For example, the user can say, “Let there be light!” and the screen will light up (Figure 3-9).

An interesting twist is that the spells are in a made-up language called Maha’ki, making it even more immersive, since it feels like you’re speaking a magical language. Many users report really enjoying this feature of the game.
There Came an Echo, by Iridium Studios, is a strategy game that allows you to control your team of four via voice commands (Figure 3-10). One nice feature is that you can set up your own aliases; for example, you could substitute “burn it down” for “fire when ready.” You can even call characters by other names of your choice. It allows you to choose your mode: push to talk, or “always listening”. The commands you issued show up on the screen, as well, so you can keep track of how you’ve been directing your team. Characters respond to your commands with “Yes, sir” and “You got it,” adding an element of realism (as well as letting you know it worked).

There Came an Echo has mixed reviews, but users seem to feel the voice command is what makes it a better game. Here’s a YouTube review by a user named TotalBiscuit (emphasis added by this book’s author):
The voice command really is the key factor for this particular title...It’s the voice command that gives it the pacing, and it’s the voice command that makes it challenging, because everything’s being done in real time and it requires you to think on your feet quite rapidly. Not to mention there is a serious amount of cool factor involved in the voice command...This one does it really well because I think it sticks within its means. It doesn’t go overboard with the voice commands. It doesn’t use too many of them, and it limits what you can do to the point where the voice commands are accurate and they’re going to be quick & responsive...The game does not play anywhere near as well without it...This game is more than the sum of its parts thanks to the voice command system.
Most of these games have a calibration setting to help improve accuracy (Figure 3-11). Binary Domain, for example, asks the user to run through various phrases and gives it a score to let the user know how well they can expect performance of speech recognition during game play.

Another unique example of adding VUI to a video game was 2008’s Eagle Eye Freefall, a short interactive experience that went along with the release of the movie Eagle Eye. The game was developed by Telefon Projekt, and the experience began when the user entered their phone number on the game’s website. Shortly thereafter, the user would receive a phone call on their actual phone, and a mysterious voice would direct the user to follow instructions on their computer and speak to different characters over the phone.
When Should I Use Video in My VUI?
There are very few examples of VUI apps out there right now that use real human actors for having interactive conversations. Using real faces can be an extremely engaging way to involve users, but it is also a much more expensive endeavor.
At Volio, we created interactive conversations in which the majority of the screen on a mobile device was filled by the actor’s face, along with a small picture-in-picture element that displayed the user (Figure 3-12).

Having the screen mostly taken up by the actor’s face made the experience very personal and one-on-one for users. Users naturally responded via voice to the actor, with no instructions. Despite knowing the content was not live, many users reported feeling as though they were engaged in a real conversation with the person on the screen.
Technically, however, creating these types of interactions takes a lot of planning. It requires a studio with professional lighting, and for each take, the actor must look the same and have the same head position. This makes it very difficult to add or fix content later; even if you can rebook the actor, replicating the exact lighting, appearance, and head position is challenging.
Adding VUI to prerecorded video only makes sense if the VUI part is also a rich experience. Another example of a video app had a sports celebrity who answered questions. After he spoke, he would end with a question such as “What do you want me to tell you more about?” A screen would then pop up to the let user know what they could say; for example, “Say SPORTS or OFF THE FIELD.” At this point, the user would press the microphone button and say one of those items.
Allowing the user to speak one of these choices did not add to the intimacy of the experience; it was clunky, not conversational. The same could have easily been accomplished by pressing buttons.
Visual VUI—Best Practices
Now that we’ve run through some examples of when it’s a good idea—or not a good idea—to use an avatar/character/actor in your VUI, let’s get into some of the best practices for when you do use one.
Should My Users See Themselves?
In some cases, allowing the user to see herself talking back can provide more engagement. You are probably familiar with the FaceTime model, in which the person you’re speaking with takes up the majority of the screen, and there is a small rectangle showing your face, as well.
A clever example of this in a storytelling context is in the ToyTalk app The Winston Show. In one scene, Winston appears on the bridge of a spaceship and announces he’s just discovered an alien lifeform. He asks his shipmate to put the alien “on screen”—and there is the face of the child using the app (Figure 3-13).
We used the picture-in-picture model in our Volio apps, as well, which was generally a familiar-feeling element because of user’s experience with FaceTime, Skype, and so on. Occasionally users said they preferred not to see themselves on the screen, however, so it is worth considering making this a user-controlled feature.

What About the GUI?
Another key question is whether your avatar or recorded video will have any graphical controls. With mobile devices, allowing the choice of speaking or using a graphical user interface (GUI) lets users decide how they want to respond. (Note: this is dependent on the type of experience you’re designing. In the Volio case, UI elements were not shown unless the user was struggling, because we wanted to remain as much as possible in the speaking world, to keep the user engaged.)
Figure 3-14 shows an example of an avatar interaction in which the user can speak or press a button to respond.
When designing a multimodal app (one that has VUI and GUI), normal VUI timeouts are not applicable: if your user decides to press a button and not speak, it doesn’t make sense for the avatar to suddenly say, “I’m sorry, I didn’t get that,” while the user is mulling over their choice of which button to push. In this case, treat it the same way you would if it were GUI-only: let the user have as much time as they want to either speak or press a button.
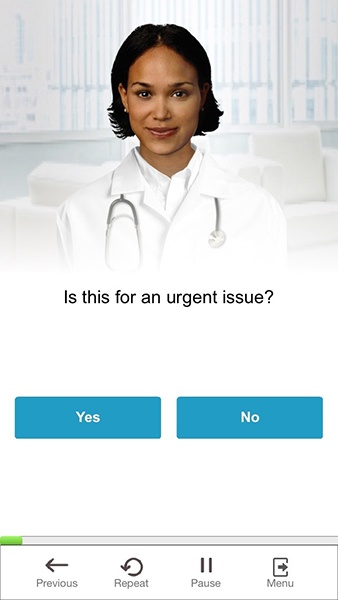
That being said, take note of places in your app where the user does not answer for a long time; there could be an underlying issue that’s causing confusion, or perhaps reluctance for the user to respond.
Additionally, GUI controls do not make sense for all interactions. For example, if you have an open-ended question (such as “How are you feeling?”) and you want to encourage your users to speak naturally, don’t put in a list of possible responses. An additional case is when there is a very long list, such as “Which song would you like to hear?” Let the user first attempt to respond via voice/natural language; after a couple of failures, provide them with a way to select an answer or type one in.
Handling Errors
Speaking of errors, as always, don’t forget to handle these cases in your VUI!
Having an avatar or video can allow for more interesting and clever responses when things go wrong. For example, in the Volio app with a stand-up comic named Robbie, a sample no-match response would show Robbie looking down and saying, “My bad...just looking at my phone and didn’t hear you. When did you say you got married?” It takes the design principle of blaming the system to a whole new level.
An avatar or video also injects another important element for human conversational cues: eye gaze. If you are having a conversation with someone and they turn away, you know they’re no longer paying attention. Your avatar can do the same. This worked well in the Volio case to indicate when the user has not been heard or understood; the first couple of times this occurred, rather than stopping and saying, “I didn’t understand,” the actor continued to simply look and listen. With no instruction, users naturally repeated themselves and quite often continued on successfully.
During filming, when the actors finished speaking, they would continue for 30 to 60 seconds of “active listening,” which could then be played on a loop. The listening should not be exaggerated; all that’s needed is to continue to look straight ahead, with the occasional nod or head movement. This nonverbal reminder gave the user the understanding that the system was continuing to listen, with no verbal or other reminders.
ToyTalk’s The Winston Show allows the avatar to help the child learn how to interact. To speak, it requires the user to press and hold down the button while speaking (unlike most phone apps, which require the user to press once and then speak). If the user presses and releases right away, the animated character, Winston, says, “Oopsy, hold down the microphone!”
I assume that ToyTalk chose this model because very young children are not as likely to succeed with just push-to-talk; having them physically hold down the microphone button (or at least, hold their finger on the screen) reminds them that they are in a mode in which the app is expecting them to speak. It also means less reliance on endpoint detection.
Turn Taking and Barge-In
In a traditional interactive voice response (IVR) system, callers can typically “barge in” (interrupt) during prompt playback. This is very useful in an IVR system because users cannot easily skip ahead and don’t want to hear all the available options before getting on with their tasks. In an IVR system, when a caller barges in, the prompt can be stopped, and after the user speaks again (or after a no-speech timeout) a new prompt can be played.
Allowing a user to barge in during a video is a tricky business. It will be jarring to switch to a new video, presumably one of the actor just listening. For these systems, it is advisable to turn off barge-in because it will be too challenging to handle the interruption from a technical standpoint.
However, because this system is human-like, people do not tend to interrupt, because they’re waiting for their turn to speak—they’re not waiting to issue a command. Your video VUI is unlikely to be droning on about a list of menu options (and if it does, you should revisit your decision to use a recording of an actor in the first place).
Fine-tuning the point at which a user can begin speaking, however, is crucial. It’s essential to turn listening on at the exact second (or millisecond) the actor (or avatar) finishes speaking because this is when the user is most likely to speak. If the first second or two of their utterance is not captured, they are more likely to be misunderstood. It is also essential to let the user know when they can speak, such as highlighting the border around their face (if you’re implementing picture-in-picture) in green, or another type of visual indicator. In this model, in which the user can simply speak without pressing a button, a microphone icon is not necessarily the right indicator, because users might try to press it. Animating the microphone can help. It’s best to test your visual indicator thoroughly with real users to see what works.
In summary, this type of conversational style, in which the video and the user take turns speaking, needs to have multiple components:
No barge-in.
After the actor is finished speaking, they continue in “active listening” mode.
A visual indicator that it’s the user’s turn to speak.
A prompt makes it obvious that it’s the user’s turn (e.g., asks a question, or command, such as “Please tell me more about that.”).
The system begins listening immediately after the actor finishes speaking.
These apply for avatars, as well.
In the avatar world, there might be cases in which these conventions are not followed. For ToyTalk’s animated apps, the microphone icon displays an “X” to indicate when speaking is not allowed. When it’s the child’s turn to talk, the microphone lights up and flashes.
Because these are (a) used by young children and (b) more of a storytelling mode than a back-and-forth conversation, it’s necessary to let the child know when they should speak. Barge-in would not work well here at all, because young kids will often be talking along with the app and it would interrupt the story to stop whenever the system thought it heard something.
There are other cases for which requiring the user to “push to talk” are useful, as well. With a virtual assistant, you might not expect users to have a set conversation every time (such as with some entertainment or health apps). It could be more of a short series of back-and-forths, during which the user is trying to complete a task or get information, and it’s important to allow the user to interrupt. For example, if the user asks for a list of nearby coffee houses with WiFi, the app will produce a list; it’s not yet clear if the user will continue to speak (perhaps by saying, “Which ones are open until 10 PM?”) or whether the user’s request has been satisfied.
In this example, it is very important to allow the user to continue the conversation, but don’t automatically turn the microphone back on—let the user control the conversational pace. This is the methodology used for most of the current virtual assistants out there (Siri, Google, Hound, and Cortana).
Maintaining Engagement and the Illusion of Awareness
Regardless of whether your VUI uses an avatar/video, keeping your users engaged is paramount.
What are the best ways to create and maintain the illusion of awareness? Some great tips come from the creators of the trivia game You Don’t Know Jack (Figure 3-15). Originally released in the late 1990s as a PC game, You Don’t Know Jack later won both the Most Innovative Interface and Best Overall Interface at Apple Computer’s distinguished Human Interface Design Excellence Awards.

It does not use speech recognition, but the game does an amazing job of sucking users in as if they were playing a live game show with a live host. It does this with all prerecorded content.
Harry Gottlieb, the game’s creator, wrote “The Jack Principles of the Interactive Conversation Interface” in 2002. In his paper, Gottlieb outlines tips for creating the illusion of awareness in a conversational system; specifically, he suggests responding with human intelligence and emotion to the following:
The user’s actions
The user’s inactions
The user’s past actions
A series of the user’s actions
The actual time and space that the user is in
The comparison of different users’ situations and actions
How can you accomplish this? As mentioned in Chapter 2, keeping track of the past is very important. If the user has just requested information about primatologist Jane Goodall, and then she follows-up with the question, “Where did she go to college?” don’t act like you don’t know who the user is talking about.
Avatars can even react to a user’s inactions or to errors. If a user hasn’t spoken at a point in the game when they’re expected to, the avatar could cross its arms, tap its foot, or say, “I’m waiiiting!”
By using an avatar or actor, you can help maintain the illusion of awareness even more. An example of this was used in a Volio app that allowed the user to have a conversation with a stand-up comedian. If it was morning, the actor would say, “What are you doing up so early?” to start the conversation. If the time of day is relevant, use that information. Don’t offer to transfer the user to an agent if it’s outside of business hours. Use information about the time to make it more real.
In “Jack Principles” Gottlieb also outlined tips for maintaining the illusion of awareness:
Use dialog that conveys a sense of intimacy
Ensure that characters act appropriately while the user is interacting
Ensure that dialog never seems to repeat
Be aware of the number of simultaneous users
Be aware of the gender of the users
Ensure that the performance of the dialog is seamless
Avoid the presence of characters when user input cannot be evaluated
Another way to build trust with an avatar is to follow human conversational conventions when appropriate. For example, when users call to speak with a call center agent, they don’t usually launch into a full description of the problem. Here’s an example of a nonstandard interaction:
AGENT
Hi, thanks for calling Acme Cable Company.
CALLER
It says on my bill I owe $5.99 for something called federal tax, and I’ve never seen that before and I want you to take it off.
Instead, the agent tries to establish some initial rapport and ease the caller into the conversation, building up trust:
AGENT
Hi, thanks for calling Acme Cable Company. How are you doing today?
I’m good, how are you?
AGENT
I’m fine, thanks. What can I help you with today?
CALLER
I have a question about my bill.
AGENT
OK, I can help you with that. What seems to be the issue?
CALLER
Yeah, well, there is a charge for $5.99 I don’t understand...
Notice how the agent begins with a question unrelated to the cable company: the “How are you doing?” question. Then, when the agent asks how she can help, the caller breaks it into pieces—first, the general topic (“my bill”) and then the specifics. You can do the same thing with your VUI system, if you plan to have a conversation.
People often like to tell their stories via a narrative. When people go to the doctor, they don’t usually give all the details right up front about what’s wrong; instead, they give one piece at a time. I’ve witnessed this at nurse advisor call centers. I have seen good results with this approach using an avatar, as well. Expecting the user to always throw out all the details of their question or issue right off the bat will often result in not understanding; instead, break it into normal conversational snippets.
Think carefully about the beginning of your conversations. As an example, at Sensely, we sometimes begin with a general “How are you doing?” This gets the conversational ball rolling—people often respond with a simple, “I’m fine, thanks,” but sometimes go into more detail. If you choose to utilize this technique, you’ll need to be able to handle both types of responses.
Visual (Non-Avatar) Feedback
Avatars and actors are not the only kind of visual feedback your VUI can have. You can use visual feedback to let the user know when your VUI is listening, when it’s thinking, or when it didn’t understand. Some virtual assistants, like Cortana, go further (Figure 3-16).

Here’s how one designer at Microsoft describes designing Cortana’s visual “moods”:
One of the things we debated quite a bit during the planning process was our decision to include an actual shape to embody Cortana. We explored a variety of concepts ranging from using colors on notifications to simple geometric shapes to a full-blown, human-like avatar. In the end, we worked with the creative team at 343 (the studio that develops Halo!) and landed on something we think makes Cortana feel more alive than if we just used a voice. Cortana is programmed to respond to different questions and present different answers based on the grid of emotions and states below. If Cortana correctly answers your question and is happy, Cortana will let you know. If Cortana can’t understand you, there will be slight embarrassment.[20]
Do the variants on the blue circles work? I doubt users, if shown each circle out of context, could name what emotion or task Cortana was engaged in at that time. However, over time, it’s quite likely users would come to associate them subconsciously. People are very good at patterns and will be quick to pick up on common ones such as the “listening” icon.
As shown in Figure 3-17, the Amazon Echo—a device rather than a mobile app—uses blue lights on the top of its cylinder to let you know when it’s listening (after you say the wake word, “Alexa”). This is a subtle but useful way to let users know that they can speak. After about five seconds, if Alexa does not hear anything, the light disappears.

On the other hand, if you say something that Alexa was completely unable to process, the light pattern changes, and an “end” sound plays, letting you know Alexa did hear you, but was not able to understand. This is particularly useful if you’re talking to it from another room or not facing it. There is one more response for not understanding, which is when Alexa is pretty sure you made a request or asked a question but could not understand it or fulfill it, in which case another light pattern is shown, and she says something along the lines of, “Hmm, I can’t find the answer to the question I heard.”
Jibo, billed as a “family robot,” has a lot of personality without appearing human (Figure 3-18). It’s a small cylinder with a rounded top on a swivel base. Its “face” is a screen that can have animations such as a heart.

Jibo can respond to voice commands and uses text-to-speech (TTS) to generate spoken responses. Jibo is designed to evoke an emotional response from the user. A review in online magazine Mashable states, “Jibo isn’t an appliance, it’s a companion, one that can interact and react with its human owners in ways that delight.”[21]
But a word of caution also applies: Jibo definitely evokes emotion, but is it appropriate in all situations? For example, can it be serious enough to serve as a health advisor?
Choosing a Voice
Choosing a voice for your VUI is another important consideration. Will you use TTS or recorded prompts? The voice is a crucial aspect of your design:
First, designers should cast voices base on more than clarity and tonal quality. They should also attend to the consistency of voices with the behaviors, attitudes, and language of the character or agent to which it will be attached. This will likely require more than instinct. Voices need to be evaluated by users so that consistency can be coordinated and verified... Also, a badly cast voice is likely much worse than no voice at all. Voices will have social meaning, whether it is wanted or not.[22]
Chapter 5 goes more into detail about this topic.
Pros of an Avatar
To summarize, let’s look at the pros and cons of using an avatar. This should help guide your decision about whether to use one for your VUI.
Let’s begin with the advantages of having an avatar as part of your VUI. First, avatars can offer more engagement with the user.
In a study conducted at the University of Southern California’s Institute for Creative Technologies, subjects were asked to respond to a series of questions such as “How old are you?” and “What makes you happy?” There were three groups: an animated virtual human, a still picture of a virtual human, and an audio-only version.
There were 24 questions in all, and the subjects were told they had to answer at least 12 questions and had the option of answering all 24. The number of subjects who answered all 24 questions was much higher in the case for which the questions were asked by the animated virtual human. In addition, on average, people’s responses were longer when answering the animated virtual human.
Another USC ICT study had subjects speak with a virtual assistant who helped people suffering from post-traumatic stress disorder (PTSD) after military service. Subjects reported feeling more comfortable disclosing information to the virtual assistant than to a human, possibly because the virtual assistant was less critical.
I have seen a similar effect at Sensely, which uses a virtual nurse to help people with chronic health conditions. Patients often open up to the avatar and tell her when they’re feeling stressed or about other health conditions.
Even simple faces can evoke emotional responses; “a few lines depicting a ‘smiley face’ can lead people to feel sadness, surprise, or anger with a change in one or two strokes of a pen.[23] In addition, “although people can certainly listen without seeing a speaker’s face, they have a clear and strong bias toward the integration of faces and voices.”[24] Everyone reads lips to a degree; it’s more difficult to understand someone when you can’t see his or her mouth.
Mark Stephen Meadows, president of avatar company Botanic, has this to say about when we should use an avatar:
When should we meet in person, and when can we just talk on the phone? We talk on the phone all the time and we can get along just fine with only voice. But most of us, at least when we have the time, prefer face-to-face meetings. We get more information. It’s more fun, we get more done, there’s less misunderstanding, and it builds cool human things like trust and empathy. So, it’s really dependent on the use case, the user, and specifics.
He calls avatars the GUI of the VUI. Meadows reminds us of another thing avatars provide—additional clues to personality that will tell us how to interface with them:
Go visit a hospital, hotel, or restaurant and you’ll see that the employees have specific personalities, or roles, that they play out. This is important because we need to know how to interact with whom, and so these employees dress in particular ways and act in a particular fashion to frame the interaction. If you visit a hotel, hospital, airport, or some other service-oriented place of business, you can observe these ontologies. They even have hierarchies of power that are reflected in how they act and dress. In hotels, we meet the receptionist, manager, and housekeeper. In airports, we meet attendants, pilots, and mechanics. In restaurants, it’s the hostess, chef, and dishwasher. And in hospitals, we meet the receptionist, doctor, and janitor. These personalities frame the experience and interaction. So, I don’t care if there’s a GUI or not, but virtual assistants need personality so we know how to interface with them. These personalities are reflected in their appearance. The manager, pilot, chef, and doctor all dress in a particular way so we know who they are. These are archetypes, and avatars should be designed with that stuff in mind.
Users anthropomorphize computers, even without an avatar face. We take what we know about our interactions with humans and apply them. As Clifford Nass says:
People respond to computers and other technologies using the same social rules and expectations that they use when interacting with other people. These responses are not spur-of-the-moment reactions. They run broadly and deeply.[25]
People often extend politeness to computers, as well, as evidenced by an experiment Nass ran at Stanford:
After being tutored by a computer, half of the participants were asked about the computer’s performance by the computer itself, and the other half were asked by an identical computer across the room. Remarkably, the participants gave significantly more positive responses to the computer that asked about itself than they did to the computer across the room. These weren’t overly sensitive people: They were graduate students in computer science and electrical engineering, all of whom insisted that they would never be polite to a computer.
If you are designing a system in which you need a high level of engagement, such as for healthcare or entertainment, consider an avatar, or at least a face.
For tasks with less of an emotional component, such as scheduling meetings, choosing a movie, making a shopping list, or doing a search query, an avatar might not be necessary and could even be a distraction.
The Downsides of an Avatar
Now that we’ve seen some of the advantages of using an avatar, let’s look at the other side.
Avatars do take a lot of extra work, and if they’re not done well, they can annoy or put off your users. Avatars that merely blink but show no emotional reaction or awareness can be more of a hindrance than an asset.
As of this writing, the majority of avatars in the virtual assistant space are female, usually young and sexy. Unless you’re writing a virtual assistant for an adult entertainment app, there’s no reason for this. I recently downloaded a virtual assistant that had a young attractive cartoon woman as the default avatar. She doesn’t do anything besides occasionally blink (or wink). The app allows you to choose different avatars, and the list that came up was a series of scantily-clad women. Plus, a dog.
If you have an avatar, spend time deciding on who it will be. Don’t just let your user pick one at random. Begin with the avatar’s top personality traits. Should the avatar be more authoritative or more caring? Professional? Knowledgeable? Create the persona first, and design the avatar that speaks to those qualities. Persona is not just about looks; it influences how your VUI speaks and responds. If the image of the VUI changes, the persona and prompts should change, as well. If your VUI has an avatar, another set of questions will need to be answered: how much of the avatar will be shown: just the face? The face and upper body? The entire body? Will it be two-dimensional or three-dimensional? How many emotional expressions can be shown? How will the lip synching be done? Will your avatar occupy the entire screen or just a part of it? All of these things influence how your users will respond and interact with your VUI.
One thing to keep in mind when designing your avatar is that a very strong personality can have a negative effect. As Thyme-Gobbel says, “the stronger its persona, the more polarized the user reaction.”
You might have people who love it and some who hate it. You might have users who love having an avatar, and others who do not. Depending on your app, that might be OK—sometimes it’s best to not design for everyone; instead, you might find it advantageous to design for a particular user group that might appreciate that “strong” personality. For example, fans of a particular video game might love an avatar that is “in character” and demonstrates that character’s personality traits. On the other hand, an avatar that’s supposed to be a personal assistant for a whole host of user groups should tone down some of the more extreme traits.
In addition, don’t make assumptions about what your user will want. For example, don’t assume that everyone wants a female avatar over a male avatar. As always, do as much user testing as possible with your avatar choice and prompts. If your avatar is too gimmicky—for example, using a lot of slang—it might make it more difficult to predict what the user will say back.
The Uncanny Valley
Another thing to be aware of when designing an avatar is not to fall into the uncanny valley. The uncanny valley refers to the shudder of horror you feel when you see something that is very close to being human—but not quite. Figure 3-19 shows the dip into the uncanny valley—for example, a zombie is at the bottom of the valley and very disturbing to us.

One way to avoid the uncanny valley is to make the avatar not photorealistic, or make it nonhuman (such as an animal).
As Meadows points out, having a recorded human voice with a cartoon doesn’t trip our “uncanny valley” sensors: just think about Pixar movies.
It’s important to match the avatar’s expressions with the words and emotions it is expressing, or it can be very jarring and unpleasant. An example of this can be seen in a conversation with a robot named Sophia. She has just said, “I feel like I could be a good partner to humans. An ambassador,” but at the end of that sentence, her lip curls into a sneer (Figure 3-20). It makes one doubt the sincerity of her words—a worse outcome than having no expression at all. As Nass says, “Facial expression needs to match what is said, or people perceive an attempt at deception.”[27]

Conclusion
Spend time deciding whether your VUI will have a visual component. Don’t just add an avatar because it’s cool. Is your system conversational? Entertaining? Empathetic? These are better candidates for an avatar or actor.
Investing in an avatar is not a small task. To build your own avatar, you’ll need a design team just for that piece, or you can use avatars made by third parties. Having your avatar show emotion, without looking creepy or repeating the same gestures over and over, is challenging. Think carefully about why you want to use an avatar, and do user testing on prototypes to make sure you’re on the right path.
Using a real actor can be an incredibly engaging experience, but this comes with a cost, as well: because everything must be filmed in a studio, you really need to get it right the first time.
A virtual assistant can still be very successful, even without a face. Do take advantage of other types of visual feedback, however, to let the user know when the system is listening or doesn’t understand.
[16] Weinberger, M. (2016). “Why Microsoft Doesn’t Want Its Digital Assistant, Cortana, to Sound Too Human.” Retrieved from http://www.businessinsider.com/why-microsoft-doesnt-want-cortana-to-sound-too-human-2016-2/.
[17] Ash, M. (2015). “How Cortana Comes to Life in Windows 10.” Retrieved from http://blogs.windows.com/.
[18] Isbister, K., and Nass, C. “Consistency of Personality in Interactive Characters: Verbal Cues, Non-Verbal Cues, and User Characteristics.” International Journal of Human–Computer Studies 53 (2000): 251–267.
[19] Nass, C. (2010). “Sweet Talking Your Computer: Why People Treat Devices Like Humans; Saying Nice Things to a Machine to Protect its ‘Feelings.’” Retrieved from http://wsj.com/.
[20] Ash, M. (2015). “How Cortana Comes to Life in Windows 10.” Retrieved from http://blogs.windows.com/.
[22] Nass, C., and Reeves, B. The Media Equation. (Stanford, CA: CSLI Publications, 1996), 177.
[23] Nass, C., and Reeves, B. The Media Equation. (Stanford, CA: CSLI Publications, 1996), 177.
[24] Nass, C., and Brave, S. Wired for Speech. (Cambridge, MA: The MIT Press, 2005), 176–177.
[25] Nass, C. (2010). “Sweet Talking Your Computer: Why People Treat Devices Like Humans; Saying Nice Things to a Machine to Protect its ‘Feelings.’” Retrieved from http://wsj.com/.
[26] By Smurrayinchester: self-made, based on image by Masahiro Mori and Karl MacDorman at http://www.androidscience.com/theuncannyvalley/proceedings2005/uncannyvalley.html, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=2041097.
[27] Nass, C., and Brave, S. Wired for Speech. (Cambridge, MA: The MIT Press, 2005), 181.