
System-Level Performance Simulation of Distributed Embedded Systems via ABSOLUT
CONTENTS
4.2.1 Structure of Application Workload Models
4.2.2 Application Workload Modelling Techniques
4.2.4 Mapping and Co-Simulation
4.3 Requirements for SLPE of Distributed Applications
4.3.1 Requirements for Performance Evaluation of Distributed Systems
4.3.2 Enhancements Needed for ABSOLUT
4.4 Modelling Multithreaded Support
4.4.2 Inter-Process Communication and System Synchronisation Model
4.5 Modelling ABSOLUT OS Services
4.5.1 Deriving New OS Services
4.5.2 Registering OS Services to OS Models
4.5.4 Data Link and Transport Layer Services
4.5.5 Modelling Guidelines and Lessons Learnt
4.6.1 Analysing Accuracy of Bit Error Rate Calculation
4.6.2 Analysing Accuracy of Frame Error Rate Calculation
4.6.3 Analysing Accuracy of Packet Error Rate
4.7 Workload Modelling via Run-Time Performance Statistics
4.7.1 Workload Extraction via CORINNA
4.7.2 Comparing ABSINTH, ABSINTH-2 and CORINNA
4.9 Conclusion and Future Work
An embedded system can be defined as a special-purpose computing system (meant for information processing), which is closely integrated into the environment. An embedded system is generally dedicated to a particular application domain. Therefore, the embedding into a technical environment and the constraints that are a consequence of their application domain mostly result in implementations that are both heterogeneous and distributed. In such cases, the systems comprise hardware components that communicate by means of an interconnection network [1].
Owing to the dedication to a particular application domain, heterogeneous distributed implementations are common. In such implementations, each node specialises by incorporating communication protocols and other functionalities that facilitate optimum and reliable performance in its local environment [1]. For example, in automotive applications, each network node (usually called embedded control units) contains a communication controller, a central processing unit (CPU), memory and I/O interfaces [1]. But as per functionality, a particular node in the network might contain additional hardware resources such as digital signal processors, CPUs and a different memory capacity [1].
Distributed embedded systems can be classified as real-time and non-real-time distributed systems. Real-time systems are required to complete their tasks or deliver their services within a certain time frame. In other words, the real-time systems have strict timing requirements that must be met. Digital control, signal processing and telecommunication systems [2] are usually distributed real-time systems. On the other hand, personal computers (PCs) and workstations that run non-real-time applications, such as our email clients, text editors and network browsers, are common examples of distributed non-real-time systems.
Also, the networking revolution is driving an efflorescence of new distributed systems for new application domains, for example, telesurgery, smart cars, unmanned air vehicles and autonomous underwater vehicles. The components of these systems are distributed over the Internet or wireless local area networks (LANs) [2]. Owing to these technological advancements, the spatial limitations seem to be progressively fading away, which has given rise to new paradigms such as mobile computing. These technologies have enabled us to connect to the Internet while we are on the move via pocket-sized, battery-powered embedded devices, for example, personal digital assistants (PDAs) and cellular phones, which communicate over a wireless channel. The applications of computing devices have also been changing in response to ever-improving hardware and software technologies [2]. Nowadays, we routinely use a variety of multimedia-based services instead of text-based ones by using nomadic hand-held devices such as high-end mobile phones.
The burgeoning market for information, entertainment and other content-rich services can be seen as a consequence of the rising popularity of mobile devices with high-quality multimedia capabilities [3]. These services should not just adapt to a continuously changing computing environment but also meet the different requirements of individual users. In such cases, we need to consider additional real-time and embedded non-functional properties of multimedia applications, for example, the maximum allowable time for each delivered packet and battery life. Therefore, the challenge from the system design perspective is to reduce the form factor and energy consumption of the mobile nomadic devices, thus increasing the portability and durability of these devices. This will enable these devices to be used by many customers for everyday use by maintaining low power consumption, which is important due to the limited power available from the battery. Since Moore’s law predicts that the computing power will continue to increase, the energy constraints demand that we shall sacrifice the performance in portable devices in return for a longer operation time. Generally speaking, the focus of recent research has been topics such as efficient usage of storage space, various I/O devices [4, 5, 6] and processing elements available from the device platforms. In distributed embedded systems, the end–end communications between applications is provided by transport protocols or layer 4 of the open systems interconnection (OSI) model. It provides different services to the applications such as stream support, reliability, flowcontrol and multiplexing. The most widely used transport protocols are the transmission control protocol (TCP) and user datagram protocol (UDP). TCP is used for connection-oriented transmissions, whereas UDP is connectionless and is used for simpler messaging transmissions. TCP is a more complex protocol due to its state-based design. It incorporates reliable transmission and data stream services.
Wireless sensor networks (WSNs) are also an example of distributed real-time embedded systems that are composed of a cooperative network of nodes [7]. Owing to the small form factor of the network nodes, each consists of limited processing capability (for example, microcontrollers, CPUs or digital signal processor (DSP) chips) and memory (program, data and flash memories) resources. Each node has a radio frequency (RF) transceiver, a power source (e.g., batteries and solar cells) and contains sensors and/or actuators. The nodes communicate wirelessly and have the ability to self-organise after ad hoc deployment. WSNs of 1000s or even 10,000 nodes are anticipated and are perceived to revolutionise the way we live and work. Since WSNs are distributed real-time systems that are rapidly evolving technologically, an important question is to know how many existing solutions (transport protocols and data link protocols, etc.) for existing distributed and real-time systems can be used in these systems. It has become obvious that many protocols that were developed beforehand will not perform well in the domain of WSNs. The reason is that WSNs do not employ many of the assumptions underlying the previous networks, for example, medium access control (MAC) protocols.
An MAC protocol is employed by the network nodes for the coordination of actions over a shared channel. The most commonly used MAC protocols are contention-based. One generally used distributed contention-based strategy is that a node that has a message to transmit tests the channel to see if it is busy; if the channel is not busy, it transmits, and if it is busy, it waits and tries again later. In most cases, MAC protocols are optimised for the general cases and arbitrary communication patterns and workloads. Contrarily, WSNs have more specific requirements that include a local unicast or broadcast. The traffic flow is usually from many nodes towards one or a few sinks (most traffic is thus directed in one direction). The individual nodes have periodic or rare communication and must consider energy consumption as a major factor. An effective MAC protocol for WSNs must have reduced power consumption, shall avoid collisions, should be implemented with a small code size and memory requirements, be efficient for a single application and be tolerant to changing radio frequency and networking conditions [2]. That is why many WSNs employ highly efficient MAC protocols for the transfer of frames over the wireless channels, for example, NANO MAC [8] and BMAC [9].
Many modern distributed systems contain networked embedded devices that contain multicore processors. For some of these devices, it might be necessary to remain responsive to inputs. Multithreading is a programming model that allows multiple threads to exist within the context of a single process. This allows a multithreaded program to operate faster on a device that has multiple or multicore CPUs. In some systems, the system functionality dictates that the application has to remain responsive to inputs. One convenient way to resolve this issue is to allow one or more threads to monitor the inputs and execute in parallel with the main execution thread of the application. This enables the application to retain responsiveness to input(s) while executing tasks in the background.
Owing to the various communication technologies (operating at the transport and data link layers of the OSI model) and multitude of distributed multithreaded applications supported by distributed systems, the overall complexity of the distributed embedded systems in many application domains is huge. To simplify the design of these complex systems, the methodology used for architectural exploration must provide the models that will enable efficient design space exploration by validating the non-functional properties of the system. The methodology should also report the contribution of protocols at different layers of the OSI model in non-functional properties of the system such as end–end communication delays. Therefore, the early-phase performance simulation of the distributed computer systems must use functionally accurate models of MAC and transport protocols to provide estimates of non-functional properties that are accurate enough for taking design decisions at early phases of the system development and architectural exploration.
The rest of the section is organised as follows. Section 4.2 provides an overview of the ABSOLUT SLPE approach. Section 4.3 describes the requirements that must be fulfilled by a performance evaluation approach to be applied for the performance evaluation of distributed systems. The section also describes the models and tools that must be integrated to ABSOLUT to extend it to the SLPE of distributed systems. The tools and models already provided by ABSOLUT are listed while the tools and models that the ABSOLUT approach lacks are identified. These missing tools and models (which were not provided by ABSOLUT), identified in Section 4.3, are described in Sections 4.4 through 4.7. Section 4.8 provides an overview of the case studies conducted for validating the approach. Conclusions and references are provided in the end. The research articles that provide a detailed description of the extensions made to ABSOLUT are mentioned in Section 4.9.
ABSOLUT uses the Y-chart approach [10] for SLPE and consists of the application workload model and execution platform as shown in Figure 4.1.
The complete performance model is formed by mapping the application workload models to the execution platform model, which is simulated to obtain the performance numbers. The performance numbers are analysed by the system designer. If the results do not meet the design constraints, the platform models or application models or both are changed in the next iteration.
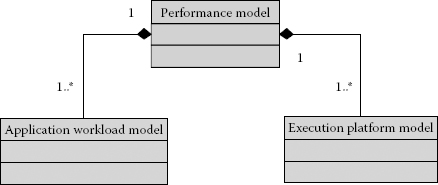
FIGURE 4.1
Main parts of an ABSOLUT performance model.
4.2.1 Structure of Application Workload Models
The workload models consist of three layers, that is, main workload, application workload and function workload, as shown in Figure 4.2.
The topmost layer consists of the main workload that is composed of one or more application workloads, each of which corresponds to an application supported by the system:
(4.1) |
where A1, A2…An represent different application workload models and Ca is the control. In the second layer, each application workload is refined to one or more (platform-level) services or process workload models. Each of these (service or process) workloads is denoted by Pi:
(4.2) |
where Cp is the control and P1, P2…Pn show service or process workload models. In the third layer, each process or service workload is represented as a composition of one or more function workloads:
(4.3) |
where Cf is the control between function workload models, that is, F1, F2…Fn. The ABSOLUT operating system (OS) model of the platform handles the scheduling of workloads at the process level. The function workloads are control flow graphs:
(4.4) |
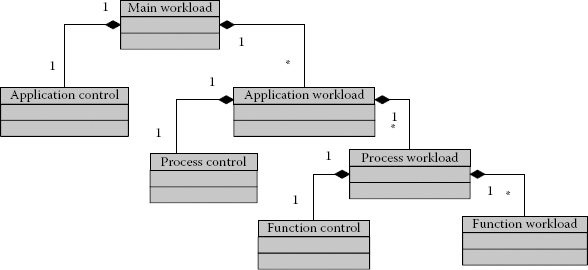
FIGURE 4.2
The ABSOLUT application workload model layers.
where the nodes represent the basic blocks and gi ∈ G represent the branches. Each basic block is an ordered set of load primitives used for load characterisation.
4.2.2 Application Workload Modelling Techniques
ABSOLUT application workload models can be generated via three methods, that is, analytical, measurement-based, trace-based and compiler-based workload generation methods. The analytical workload generation requires moderate modelling effort and is based on the analysis or functional description of the algorithms. After analysis, the number of operations required to perform the application tasks is estimated. These operations are used to estimate the number of abstract instructions in the corresponding ABSOLUT workload models [4]. The measurement-based workload modelling technique is based on the extraction of data from the partial traces of the modelled use cases. The trace-based application workload generation method generates workloads by tracking the instructions executed by the processors while running the modelled application [4].
The compiler-based workload generation method uses a tool called abstract instruction extraction helper (ABSINTH) [4]. It is based on GNU compiler collection (GCC) version 4.5.1 with additional passes in the compiler middle end, which enable workload model generation. The workload generation takes place in three distinct phases. In the first phase, application source code is compiled via ABSINTH with profiling information extraction enabled. These data are used by ABSINTH in the second phase for statistical modelling of branch probabilities and extraction of a number of loop iterations. In the second phase, the selected use case is executed by running the application to produce the profiling data. In the last phase, the source code is recompiled to produce workload models that are based on actual true execution of the application [4]. ABSINTH generates one workload model for each function in the application source code. These models can contain calls to other function workloads without the knowledge of implementations of these workloads. Before compiling the models for simulation, they are post-processed with the ABSINTH manager. It is a Python script that detects function dependencies from a set of workload functions and modifies the files by linking them in the order in which the functions were called in the application.
The platform model is also layered and consists of three layers, that is, component layer, subsystem layer and the platform architecture layer, as shown in Figure 4.3.
The component layer is composed of processing, storage and interconnection elements. The subsystem layer is built on top of the component layer. This layer shows the components of the system and the way they are connected. The platform architecture layer, which is built on top of the subsystem layer, incorporates the platform software and also serves as a portal that links the workload models to the platform during the mapping process [4].
4.2.4 Mapping and Co-Simulation
The workload models are mapped to the execution platform model, which involves the selection of a part of the platform that will execute a particular workload model. This is performed during the initialisation of a workload model by passing a pointer to correct the host in each workload constructor. Mapping is done at each layer, that is, by mapping application workloads to subsystems, process workloads to OSs inside subsystems and functional workloads to processing units. The system model is built on the Linux platform via CMake [4] and the Open SystemC Initiative (OSCI) SystemC library [4]. The simulator is executed from the command line. During simulation, the progress information is printed to the standard output and after the completion of simulation, the gathered performance results are displayed.
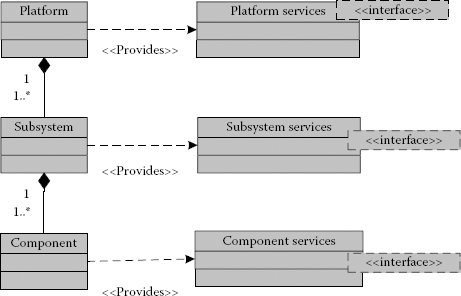
FIGURE 4.3
The ABSOLUT platform architecture model layers.
4.3 Requirements for SLPE of Distributed Applications
After investigating the protocols and technologies employed by the distributed embedded systems in Section 4.1, we conclude that, to validate the non-functional properties (NFPs) of distributed embedded systems at an early stage, an SLPE methodology must provide the models of the communication protocols and other technologies employed by the distributed embedded systems. These models must be accurate enough so that the system designer can take design decisions during architectural exploration. We first provide a list of requirements that must be fulfilled by a performance evaluation methodology to evaluate the performance of distributed embedded systems. Afterwards, we describe the extensions needed for ABSOLUT to fulfil these requirements.
4.3.1 Requirements for Performance Evaluation of Distributed Systems
An SLPE methodology must fulfil the following requirements to perform SLPE of distributed embedded systems in different domains.
I. |
Model of computation (MOC) agnostic (no domain restriction): The methodology should not employ a specific MOC for modelling applications and platforms. Using an MOC restricts the methodology to a particular domain of systems, for example, the methodologies that use the Kahn process network (KPN) MOC for application modelling are usually targeted only at streaming applications [11,12]. |
II. |
Multithreaded application modelling: For performance evaluation of multithreaded applications, the methodology must model the multithreading support [13]. |
III. |
Physical layer models: Physical layer models such as channel models, coding and modulation models to evaluate the contribution of these layers in non-functional properties of distributed applications [14]. |
IV. |
Transport layer models: Functional models of OSI data link and transport layer protocols for evaluating their contribution in non-functional properties such as end–end packet and frame delays [14]. |
V. |
Performance evaluation of protocols: The methodology must be capable of evaluating the performance of protocols operating on a particular layer of the OSI model in isolation just like widely used network simulators, for example, OMNeT++ and ns-2 by abstracting application workload models via traffic generators [14]. |
VI. |
Workload model generation of user space code, external libraries and system calls: Since, from an implementation perspective, all the application processes use user space code, external libraries, background processes and system calls, the methodology must therefore provide tools and methods for generating the workload models of not only the user space code but also the external libraries, background processes and system calls [11,14,15]. |
VII. |
Workload generation of middleware technologies: It must be capable of workload extraction of API functions of the various middleware technologies such as the device interconnect protocol (DIP) stack employed by network on a terminal architecture (NoTA). This will enable the methodology to span the domain of distributed streaming and context-aware applications [14]. |
VIII. |
Detailed as well as highly abstract workload modelling: The methodology must provide/define application workload modelling tools/techniques for generating the application workload models with varying degrees of refinement and detail. The more refined and detailed workload models result in slower simulation speed due to increased structure and control, while the less detailed workload models usually result in faster simulation speed [4,15,16] at the expense of accuracy. Once this is achieved, the system designer can freely choose the workload models that will result in more accurate or faster simulation. |
IX. |
Integration of application design and performance evaluation: For early-phase evaluation of the distributed applications, the methodology must automate the workload extraction process by seamless integration of the application design and performance simulation phase. This can be achieved if the application and workload modelling phases are linked in such a way that application models act as a blueprint or starting point for the application workload models. The proposed technique must be experimented with modern service-oriented architectures (SOAs) such as the generic embedded system platform (GENESYS) and NoTA [11,17]. |
X. |
Non-functional properties validation: The non-functional properties of the system must be carried through the application design phase and be validated by the SLPE approach. The non-functional properties are usually modelled and elaborated in the application model views [11,17,18]. |
4.3.2 Enhancements Needed for ABSOLUT
ABSOLUT uses transaction-level modelling (TLM) 2.0 and SystemC for modelling platform components only; it is not restricted to a particular domain or TLM 2.0 for modelling applications. Also, ABSOLUT provides an OS model that is hosted on one or more processor models in the platform. The OS model consists of a scheduler for scheduling application processes and provides the possibility to model different OS services. A variety of services provided by the platform can be implemented by the system designer. The scheduling of the implemented services closely mimics the way services are scheduled by the widely used platforms (mostly via scheduling queues). The design and implementation of these services in SystemC (as ABSOLUT OS services) requires a thorough knowledge of the transport and data link layer technologies and event-driven simulation paradigms.
Also, ABSOLUT workload generation tools provide a high level of automation for the extraction of application workload models to test their feasibility on a variety of platforms. This is especially useful when the source code of the application is available. In the absence of a source code, the ABSOLUT workload models can be created via an analysis of the algorithmic details and the control of the application. For fast performance evaluation and architectural exploration, the ABSOLUT workload modelling phase and performance simulation phase can be integrated [18]. This reduces the time and effort involved in the performance simulation. Also, the non-functional properties must be carried through the application design phase and be validated by the performance evaluation phase [18]. This seamless integration of application design and the performance simulation phase has been demonstrated for different SOA-based application design methodologies such as GENESYS and NoTA [11,17].
In ABSOLUT, the cycle accurate platform component models are avoided, and instead, cycle approximate models are used for faster simulation speed to enable brisk iterations in the architectural exploration phase [4]. We now list the features mentioned in Section 4.3.1 that were provided by ABSOLUT beforehand, that is, before the extensions made to ABSOLUT for enabling it to be used for the performance simulation of distributed systems. We also provide the references to research articles that describe these contributions. This information is shown in Tables 4.1 and 4.2.
Features Provided by ABSOLUT Beforehand for the Performance Evaluation of Distributed Embedded Systems
ABSOLUT |
|||||
Feature |
Description |
References |
|||
I |
MOC agnostic |
X1 |
[4] |
||
II |
Multithreaded applications modelling |
N |
|||
III |
Physical layer models |
N |
|||
IV |
Transport layer models |
N |
|||
V |
Performance evaluation of protocols |
N |
|||
VI |
Workload model generation of user space code, external libraries and system calls |
X2 |
|||
VII |
Workload generation of middleware technologies |
X3 |
|||
VIII |
Detailed and highly abstract workload modelling |
X4 |
|||
IX |
Integration of application design and performance evaluation |
N |
|||
X |
Non-functional properties validation |
X5 |
[4] |
||
Description of the Terms Shown in Table 4.1
X |
Feature completely provided |
N |
Feature, related model or tool not provided |
X1 |
Restricted to the domain of non-distributed systems (single device-based systems). but not restricted to any application domain |
X2 |
Cannot generate the workload models of system calls, for example, Berkeley Software Distributions (BSD), API functions, etc. |
X3 |
Only if the middleware is implemented as an external library. It cannot generate the workload of middleware technologies if it is implemented as OS services or system calls or runs as a background process, for example, NoTA operates in Daemon mode |
X4 |
Only for user space code and external libraries. It cannot generate the workload for system calls |
X5 |
Only for non-distributed applications running on a single device. In other words, it cannot validate the non-functional properties due to MAC and transport protocols in use cases that involve two or more devices |
From Table 4.1, it is clear that many features mentioned in Section 4.3.1 are either completely or partially absent in ABSOLUT. The modelling and integration of Feature II, that is, multithreading support, is described in Section 4.4. The modelling and integration of Features III–V are covered in Sections 4.5 and 4.6. Features VI, VII and VIII are provided by a novel methodology of workload modelling that uses run-time performance statistics. This methodology provides the ability to automatically extract the workload models of system calls. The methodology is described in Section 4.7. Features IX and X are described via a set of case studies described in Section 4.8.
4.4 Modelling Multithreaded Support
In recent years, multithreaded programming has gained popularity since general-purpose processors have evolved to multicore platforms. This has resulted in new challenges for software designers in the early stages of development of multithreaded applications (both distributed and non-distributed). In other words, designers need to make important design decisions related to load-balancing, thread management and synchronisation. This implies that even for moderately complex applications that have a few concurrent threads, the design space will be huge. The exploration of the design space will require the ability to quickly evaluate the performance of different software architectures on one or more platforms. The ABSOLUT performance simulation approach has been extended to achieve a faster simulation of multithreaded applications in the early phases of the design process. Abstract workload models are generated from the source code of the POSIX threaded applications, which are then mapped to the execution platform models for the transactionlevel simulation in SystemC.
In case of ABSOLUT, the workload models do not contain timing information. To enhance the simulation speed, the ABSOLUT execution platform models contain cycle-approximate timing information. Thus, the platform model dictates the duration of the execution of a particular workload model. The system must ensure the correct behaviour while the concurrent processes are being executed in parallel. This demands a system synchronisation mechanism that respects the causal relations between the processes. In other words, this means that any particular execution order of processes or threads is allowed as long as their causal dependencies are respected. From the perspective of POSIX threads modelling, this can be illustrated via the example shown in Figure 4.4.
We assume that the target the application is following is the master–worker programming model. T1 acts as the master thread (main function) and is also a workload process. It creates two worker threads T2 and T3 by calling the ‘pthread_create ()’ primitive function. Apart from that, the T3 thread is detached (‘pthread_detach ()’), that is, the creator thread (T1) will never block and will wait for T3 to terminate.
On the other hand, when T1 calls T2 to terminate (‘pthread_join ()’), it will block (which is shown via the dotted line between T12 and T13) and waits for T2 to complete before it will continue. Both T2 and T3 are independent of each other. The order of execution within each process T1, T2, T3 is as follows:
(4.5) |
(4.6) |
(4.7) |
From the correct system synchronisation perspective, the following are the additional constraints between the processes T1, T2, T3:
(4.8) |
(4.9) |
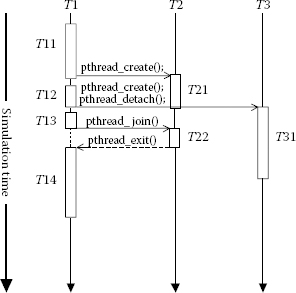
FIGURE 4.4
System synchronisation between POSIX threads.
It should be noted that the POSIX standard does not place any particular order constraint between T13 and T22, for example, the thread T22 can terminate (reach pthread_exit ()) before T13 calls it to terminate (‘pthread_join ()’). In this case, T1 will not block after T13 but will proceed to T14. The following are some examples of the possible overall execution orders in this example:
(4.10) |
(4.11) |
Since untimed TLM does not guarantee the deterministic execution of concurrent processes, a mechanism for inter-process communication and system synchronisation must be integrated to the ABSOLUT platform model. It must also guarantee that the correct intra-process execution order is respected.
4.4.2 Inter-Process Communication and System Synchronisation Model
During the execution of the ABSOLUT performance model, the function workloads running on the execution platform model can request different software services by using the service interface called Generic_Serv_IF as shown in Figure 4.5. This interface is realised in the OS model called the Generic_Serv_OP_Sys model in Figure 4.5.
To support the POSIX service calls from the function workload models, a mechanism is needed. We modelled this mechanism in the form of a run-time library service process, that is, ‘Pthread_lib’ as shown in Figure 4.5. Pthread_lib acts not only as an inter-process communication mechanism but also as a thread synchronisation layer between the OS model and application workloads as illustrated in Figure 4.5. A new thread can be created by the function workload by calling the ‘Use Service ()’ call. The service name is used as an attribute to the call, for example, Use Service (‘Serv_1’) along with optional attributes. The unique service name is assigned to a particular service when it is registered to the OS model during the elaboration phase. This is explained in detail in Ref. [14]. This is a non-blocking request and the calling thread can therefore continue while the service is being processed. The Use_Service () call also returns a unique service identifier that can be given to the blocking ‘Wait_Service ()’ call to wait for the completion of a requested service.
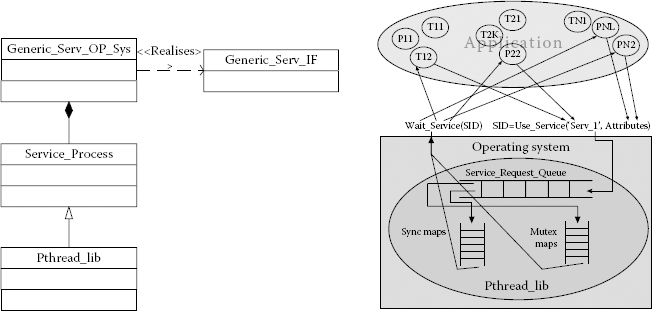
FIGURE 4.5
Application workload structure (left) and usage of Pthread_lib OS_Service by application workload models (right).
The OS model relays every new service request to the Pthread_lib service process, which puts these requests in the Service_Request_Queue. As the simulation proceeds, a new service request is taken from the queue for processing. Depending on the service name, the ‘Pthread_lib’ object relays the service request to OS. The OS model schedules the call for execution on the platform. The relaying mechanism can be different and depends on the service type. Further details of the ABSOLUT multithreading support modelling and POSIX threads, along with a complete case study, are described in Ref. [13]. The case study describes the modelling of POSIX-based multithreaded applications on a high-level general-purpose multicore architecture-based processor [13]. A run-time thread service process that ensures correct intra-process execution of application workloads in association with a high-level OS model has been described in Ref. [13]. So far, the correctness of the inter- and intra-process execution order and compatibility with the POSIX API has been emphasised in the development. Therefore, generalisation of the methodology to support other parallel programming models like message passing will be one of the focus areas in future development of ABSOLUT methodology.
4.5 Modelling ABSOLUT OS_Services
Extension of ABSOLUT for the performance evaluation of distributed applications requires the modelling of protocols operating at different layers of the OSI model. This, in turn, requires a mechanism for instantiating new hardware (HW) and software (SW) services. These services are registered to the ABSOLUT OS model and are used by the application workload models. Furthermore, the services operating at a higher layer of the OSI model can use lower-layer services, for example, transport-level services such as TCP can use data-link-level services such as IEEE 802.11 MAC protocols for the transmissions of frames of a packet as shown in [14]. These services are instantiated by deriving them from the OS_Service base class as shown in Ref. [14]. The modelled services implement the Generic_Serv_IF as explained in Ref. [14]. ABSOLUT functional workload models request the services from the ABSOLUT OS model by using this interface. The modelling and integration of highly accurate data link- and transport-level services are explained in Ref. [14]. The relationship between OS services operating at the transport layer, data link layer, OS model, OS_Service base class and function workload models is shown in Figure 4.6.
4.5.1 Deriving New OS_Services
Only the service-specific functionality is implemented by the derived services, which make the modelling of services straightforward. These services are registered to the OS model during the elaboration phase and executed during the simulation phase when process- or application-level workload models request them from the OS. Other HW and SW services, apart from the data link and transport protocols, can also be derived from the OS_Service base class. This is shown in Figure 4.7.
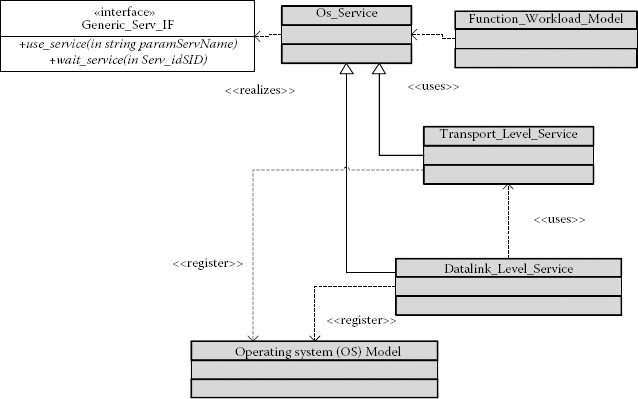
FIGURE 4.6
OS services implemented to model use cases spanning multiple devices and for modelling BSD API as OS services.
The OS_Service base class implements the functionality related to the scheduling of requests made by processes via priority queues. After requesting the service from the OS, the requesting process goes to the sleep state. The OS informs the requesting process on service completion after which it goes back to the running state. This is shown in Figure 4.7.
4.5.2 Registering OS_Services to OS Models
The services residing at the higher layers of the OSI model use the services at the next lower layer of the OSI model in the same way as real world systems, for example, transport layer services use data link layer services for transmitting the individual frames of the packets. The services are accessed from the platform using the service name assigned during registration to the OS model. For example, the BSD socket application programming interface (API) function ‘send()’ can be modelled as an OS_Service and registered by a unique service name, for example, ‘PktTx’ to the OS as shown in Figure 4.8. It can then be accessed by the process workload models by using its unique service name via Generic_Serv_IF as shown in Figure 4.9.
As mentioned before, the implementation of the Generic_Serv_IF by the OS_Service base class enables the function- or process-level ABSOLUT workload models to request services by their name as shown in Figure 4.9. This invokes the functionality of that service, which is implemented by the service derived from the OS_Service base class. The implementation of the OS_Service base class is described next.
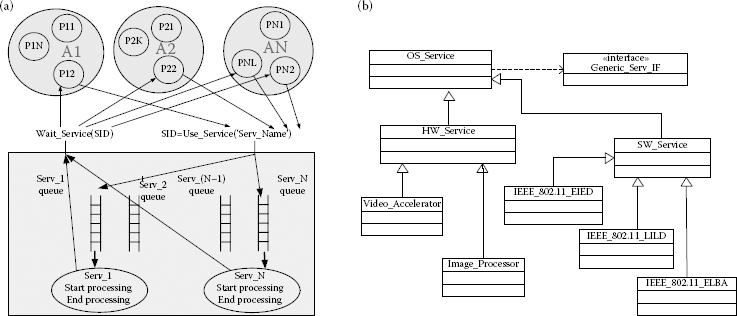
FIGURE 4.7
Processing of service requests by OS_Services base class (a) and the way new OS_Services are derived from the base class ‘OS_Service’ (b).

FIGURE 4.8
Registration of services to the OS model.

FIGURE 4.9
Accessing an OS_Service via Generic_Serv_IF.
4.5.4 Data Link and Transport Layer Services
The transport layer services, that is, TCP, UDP, etc., and data link services, for example, IEEE 802.11 distributed coordination function (DCF), are derived from the OS_Service base class. The transport services use the data-link-level services for the transmission of one or more frames of their packets. The IEEE 802.11 DCF operating at the data link layer can be shown in the form of a flow chart as shown in Figure 4.10.
Every frame received by the MAC layer is transmitted via the IEEE 802.11 DCF, which uses linear increase and linear decrease (LILD) or exponential increase and linear decrease (EIED) algorithms for contention resolution as shown in Figure 4.10. The transport layer simply divides a packet into frames and forwards them to the data link layer for transmission. The data link layer stores the frames in a queue and services them one by one for transmission over the channel. The recorded simulation results achieve an accuracy of over 92% when averaged after 20 simulation runs when compared with the analytical results for packet lengths of 228 and 2228 as shown in Ref. [14]. The packet loss probability achieved an accuracy of over 85% when compared with the analytical results as shown in Ref. [14]. The accuracy of these models is therefore enough for the SLPE of distributed systems.
4.5.5 Modelling Guidelines and Lessons Learnt
The following conclusions related to workload extraction and accuracy can be drawn from the case studies and literature review:
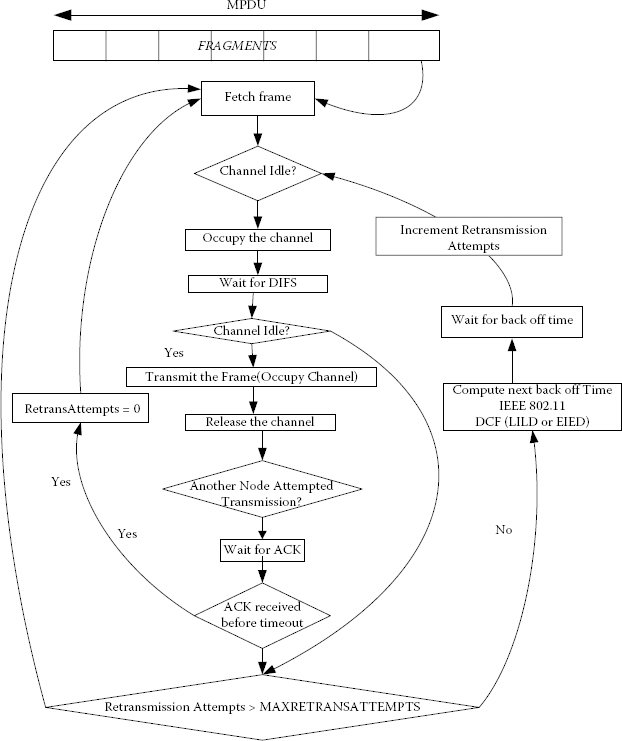
FIGURE 4.10
Flow chart of IEEE 802.11 DCF.
1. The MAC and transport layer models are functionally accurate and follow the same trend as the corresponding ns-2 and OMNeT++ models.
2. The workload models of the highly efficient and specialised MAC protocols can be obtained via ABSINTH-2 and CORINNA [15].
3. The main contribution of the MAC and transport protocols as far as non-functional properties are concerned is in end–end delays, etc., but not platform utilisation.
The following points can be taken into consideration while comparing the ABSOLUT MAC and transport models to ns-2, OMNeT++ or other network simulators:
1. The functionality related to the network layer has been abstracted out in ABSOLUT currently.
2. The alignment of traffic generators in time at the start of simulation.
3. The way system calls are modelled, that is, blocking or non-blocking.
4. Random number generators used for back-time calculation and the seeds used for randomisation can vary the simulation results significantly from other simulators, though the trend will be the same [14], and hence the models provided by these simulators are always functionally correct.
5. The queue sizes used for implementing the OS_Services must match those used in the simulators.
6. The way a collision is determined and defined in a network simulator is also very important to consider. In many network simulators, two or more nodes will collide if they transmit at exactly the same time. In the real world though, the propagation time due to distance between the nodes might also be a potential cause of collision. For example, if two nodes can sense the channel is idle, one starts to transmit and the other node(s) can still sense the channel is idle and transmit, causing collision.
The functionally correct models of MAC protocols and related OS_Services will be provided as a part of the ABSOLUT component library. Specialised probes and use cases will be provided to facilitate the system designer to modify and enhance the MAC and transport protocol models and make necessary adjustments as per use case.
To study the MAC protocols in isolation under a particular scenario, the application workloads can be abstracted by using traffic generators. Three types of traffic generators, that is, pareto on off, exponential and constant-bit rate available in ns-2, have been integrated to ABSOLUT [14]. Two modulation techniques, that is, QPSK and BPSK have been modelled along with the multicarrier code division multiple access (MC-CDMA) technique. Two channel coding techniques, that is, convolutional and Reed Solomon codes, and two channel models, that is, a binary symmetric channel and additive white Gaussian noise (AWGN) channels, have been integrated by using models available in the itpp library [14]. The performance model is configured with a certain type of modulation scheme, coding scheme and channel model. Bit errors are computed using the functions available in the itpp library. Frame lengths can be chosen randomly or fixed to a value before simulation to analyse the MAC and transport protocols in a particular scenario.
4.6.1 Analysing Accuracy of Bit Error Rate Calculation
Different modulation schemes available in the itpp library have been used without modification. We present the results for multicode CDMA with QPSK modulation. For 1e6 bits, the results are over 99.8% accurate (when compared with theoretical results) as shown in Figure 4.11.
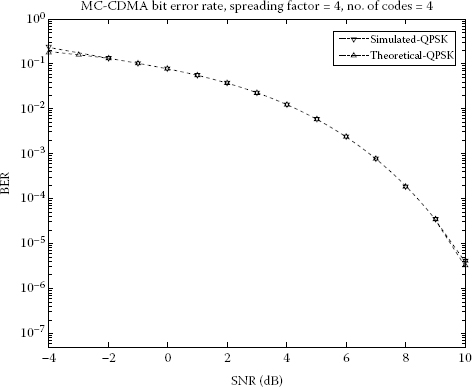
FIGURE 4.11
Theoretical versus simulation bit error rate for MC-CDMA with QPSK. Number of codes (M) = 4. Spreading factor (k) = 4. Number of bits = 100,000.
4.6.2 Analysing Accuracy of Frame Error Rate Calculation
In the absence of any encoding in IEEE 802.11, the fragment and the bit error rate are related by Equation 4.12.
(4.12) |
where S is the fragment size, BER is the bit error rate and Pe is the probability of frame error. The bit error rates are plotted against the frame error rates for different values of frame lengths as shown in Figure 4.12. The frame and bit error rates can be recorded directly from simulation and plotted for different values of bit error rates as shown in Figure 4.12. The recorded simulation results are over 92% accurate when averaged after 20 simulation runs. The simulation results are compared with the analytical results for packet lengths of 228 and 2228 as shown in Figure 4.12.
4.6.3 Analysing Accuracy of Packet Error Rate
In case of IEEE 802.11, one MAC service data unit (MSDU) can be partitioned into a sequence of smaller MAC protocol data units (MPDUs) to increase reliability. Fragmentation is performed at each immediate transmitter. The process of recombining MPDUs into a single MSDU is called defragmentation. Defragmentation is also done at each immediate recipient. When a directed MSDU is received from the LLC with a length greater than a fragmentation threshold, the former is divided into MPDUs. Each fragment’s length is smaller or equal to a fragmentation threshold [14]. MPDUs are sent as independent transmissions, each of which is separately acknowledged. The loss probability of transmitting a transport packet fragmented at the MAC layer into N fragments is given by the Equation 4.13 [14]
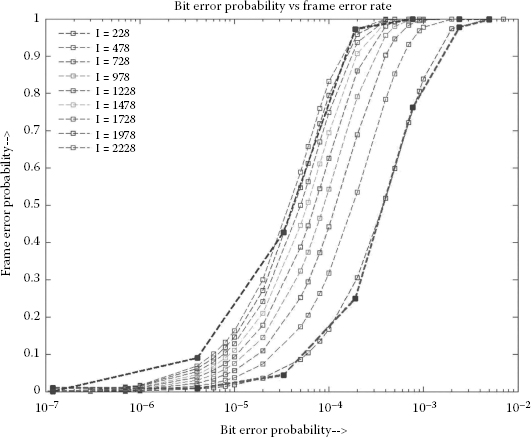
FIGURE 4.12
Frame error probability versus bit error rate. Theoretical results compared with simulation results for frame lengths 228 and 2228.
(4.13) |
where Pl denotes the successful transmission probability of one attempt, i denotes the retransmission attempts and M is the maximum number of retransmission attempts. Figure 4.13 shows the transport packet loss rate as a function of the MAC frame loss probability during each transmission retry for a fixed number of fragments (N = 10) and for different values of maximum retransmission attempts [14] (M = 1 → 10). The simulation results are compared with the analytical results as shown in Figure 4.13. The values of M and N were fixed, the value of the signal-to-noise ratio (SNR) was varied and the simulation was repeated several times. The results for each value of SNR were averaged to obtain each point on the two curves. The simulation was run 20 times and the averaged results achieved an accuracy of over 85% when compared with analytical results as shown in Figure 4.13.
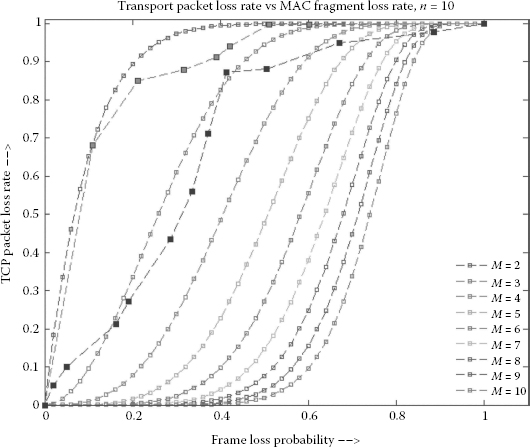
FIGURE 4.13
Theoretical versus simulation results. MAC frame loss probability versus transport packet loss rate, for maximum retransmission attempts (M = 2 and 3) and number of fragments (N = 10).
4.7 Workload Modelling via Run-Time Performance Statistics
The novel methodology for automatic workload extraction presented in this section is called configuration and workload generation via code instrumentation and performance counters (CORINNA) [15]. This methodology is completely dependent on the information read from CPU performance counters and is not compiler dependent. Furthermore, the instantiation of this methodology on a certain platform only requires re-implementation of the interface functions so as to access the CPU performance counters of that machine. The methodology can generate the application workload models of system calls, user space code and external libraries automatically. Furthermore, it does not employ additional programs like Valgrind and SAKE (abstract external library workload extractor) for the extraction of workload of external libraries as in ABSINTH-2 [16]. CORINNA is implemented as C++ classes and can be compiled in the form of a static and dynamic library.
4.7.1 Workload Extraction via CORINNA
The application workload model generation via CORINNA consists of three phases, that is, the pre-compilation, application execution and post-execution phases. In the pre-compilation phase, tags are inserted at different points in the source code automatically via a Python script called tag source-code parser written in python for CORINNA tags insertion (CORINNA-SCENT) [15]. In the execution phase, the run-time performance statistics of the application are recorded by reading performance counters for generating the function workload model primitive instructions.
After the execution phase, two CORINNA output files are obtained as shown in Figure 4.14, apart from the normal output (when the application is not compiled with the CORINNA library and no tags are inserted) of the program. In the post-execution phase, the two CORINNA output files are parsed to generate the classes for function workload models. Also, the configuration of CPU models is carried out by adjusting cache-hit and cache-miss probability, etc., according to the run-time statistics. Also, a top-level process model is generated that calls the generated function workload models in the order in which they appear in the trace information. The post-execution phase is also done via a Python script called CORINNA output parser for function workload generation and process model configuration (CORINNA-PERFUME). The workload modelling and platform configuration via CORINNA is summarised in Figure 4.14.

FIGURE 4.14
Pre-compilation and post-compilation steps of workload model extraction via CORINNA.
As explained earlier, the workload modelling via CORINNA consists of three phases: the pre-compilation phase, the application execution phase and the post-execution phase. The pre-compilation phase inserts CORINNA tag pairs around selected source code lines in the source code. One tag in each tag pair marks the entry to that code line while the other marks the exit. The second phase is called the application execution phase. This phase ends when the application execution ends. During application execution, a separate data structure for function workload model creation is generated for each instruction between tags and a separated data structure for function workload model creation for the set of instructions encountered along the execution path to the entry of another tag pair, thus giving full coverage of the application source code. Also, the execution order is recorded by storing the names of workload models as they are generated. This trace information is used to call the function workload models in correct order, mimicking the true order of execution of the instructions during application execution. In the final step, the text files created after the application execution that contains the workload model creation data and CPU models configuration data are parsed and the function workload model classes generated and the CPU models are configured according to run-time statistics. The aforementioned three phases are described in detail in Ref. [15].
4.7.2 Comparing ABSINTH, ABSINTH-2 and CORINNA
The ABSINTH application workload generation methodology is compiler based [4], whereas CORINNA generates application workload models based on the run-time statistics gathered during the execution of an application. The salient features of ABSINTH and CORINNA are compared as follows:
1. gcc compiler compatibility: ABSINTH works with certain versions of gcc compiler, for example, gcc-4.3.1, whereas CORINNA is totally independent of the gcc compiler version used to compile the application source code.
2. Workload of external libraries: To extract workload models, for example, the current version of ABSINTH uses a tool called SAKE (abstract external library workload extractor) [16]. CORINNA does not use any other tool to extract workload models for external libraries.
3. Workload of system calls: ABSINTH is limited to the user space code and external libraries. Therefore, it cannot generate function workload models for the system calls. CORINNA has no such limitations and the insertion of tags around system calls will provide the required workload models.
4. Coverage of C++ applications/g++ compiler: ABSINTH cannot generate the workload of C++ applications. ABSINTH works as a patch of GNU gcc compiler and has certain limitations with error and exception handling what comes to C++ applications compilation. CORINNA has no such limitations and is not compiler based.
5. Distributed applications: Most of the distributed applications communicate via transport technologies such as TCP/IP and UDP. These transport technologies are available to the application programmer as system calls and are used for both message-based communications and also audio/video streaming in the case of real-time multimedia client server applications. ABSINTH cannot generate function workload models for these system calls since it is limited to user space code and external libraries. CORINNA only requires the insertion of tags in the precompilation step via CORINNA-SCENT for the generation of function workload models for these transport API functions.
6. Processor models configuration: CORINNA records the cache-hits/miss statistics during the entire execution of the application, and when the execution of the use case ends, it writes the overall cache-hit and cache-miss rates of the application to the CacheStatistics {sec.hours.min.dd.mm.yy}.txt file for different cache levels. These data are used to configure the CPU models in the ABSOLUT platform model for more accurate SLPE. ABSINTH does not provide this functionality.
7. Portability: CORINNA is highly portable, but it might require the re-implementation of only the class member functions used to access the hardware counters in some cases. The complicated tasks of gathering the performance statistics, generation of function workload models during execution, reporting results, pre-compilation and post-execution Python scripts, that is, CORINNA-SCENT and CORINNA-PEFUME, do not need to be re-implemented and are totally machine independent.
Therefore, the application workload extraction methods previously employed by ABSOLUT, called ABSINTH and ABSINTH-2, had some shortcomings, for example, these are compiler-based workload extraction methods and cannot be used to extract the application workload models of kernel space code, for example, system calls. They lack the support for the g++ C++ compiler and cannot configure the platform processor models according to run-time statistics of the application, for example, cache-hits/misses [4]. To solve these issues, a novel method for workload generation based on run-time performance statistics called CORINNA has been developed, which is non-compiler-based. Also, CORINNA has some shortcomings; since it uses the hardware counters to generate the workload models, the latter might result in less accurate results when the ABSOLUT platform model has very different hardware architecture.
In Ref. [4], the performance evaluation of the transport and MAC protocols via ABSOLUT is described. The article describes the way the different MAC and transport protocols can be modelled as OS services and integrated into the ABSOLUT framework. In Refs. [17] and [18], the performance evaluation of distributed and non-distributed GENESYS applications via ABSOLUT is described. These articles describe the way the application design and performance simulation phases can be linked to reduce time and effort in the performance evaluation phase. In Ref. [11], the system-level performance of distributed NoTA systems via ABSOLUT is described. The modelling of NoTA DIP in all the three modes is explained and the approach is demonstrated via a case study. Also, in Ref. [15], we give two different case studies of how to extract ABSOLUT workload models and to show how to map the application workload models to the platform model for performance evaluation. For case studies, we used two different applications, Qt-based submarine attack game and office security application with video streaming.
4.9 Conclusion and Future Work
The complexity of the distributed embedded systems is growing rapidly in different application domains. To achieve faster deployment and a more optimal design of these systems, their feasibility must be evaluated at an early design phase. For a performance evaluation methodology to be applicable across multiple domains of distributed systems, the methodology must provide the easy instantiation and modelling of transport and data link protocol models as well as multithreaded applications.
This chapter presents the modelling and integration of the related protocols and models in ABSOLUT. New models and protocols can be added to the framework as they are developed and used in the performance models for SLPE. The functionalities that are common among these protocols are implemented in the base classes so that new models can be developed with minimal effort. The modelled protocols developed during the research presented in this section were applied in a number of case studies. The models integrated to ABSOLUT are accurate enough for SLPE and architectural exploration [14]. Table 4.3 provides an overview of the authors’ contributions. It lists the research articles that describe the missing/partially provided features/models elaborated in Table 4.1. These references related to novel contributions are listed in bold font.
The network layer protocols of the OSI model were not modelled and the research efforts were mainly directed towards the SLPE of single hop distributed embedded systems. The network protocols can be instantiated by using the OS_Service base class models used for modelling the transport and data link layer protocols. The protocols at the data link and transport layer are functionally correct, and therefore the functional network layer protocols can be integrated into the framework just like the transport and data link layer protocols. Furthermore, the models/probes for estimating the energy consumption of the application, transport, middleware and data link OSI model layers are planned to be integrated to the ABSOLUT framework.
Features Provided by ABSOLUT Beforehand for the Performance Evaluation of Distributed Embedded Systems
ABSOLUT |
|||||
Feature |
Description |
References |
|||
I |
MOC agnostic |
X |
[4] |
||
II |
Multithreaded applications modelling |
X |
[13] |
||
III |
Physical layer models |
X |
[14] |
||
IV |
Transport layer models |
X |
[14] |
||
V |
Performance evaluation of protocols |
X |
[14] |
||
VI |
Workload model generation of user space code, external libraries and system calls |
X2 |
|||
VII |
Workload generation of middleware technologies |
X3 |
|||
VIII |
Detailed and highly abstract workload modelling |
X4 |
|||
IX |
Integration of application design and performance evaluation |
X |
|||
X |
Non-functional properties validation |
X5 |
|||
1. S. Perathoner, E. Wandeler, L. Thiele, A. Hamann, S. Schliecker, R. Henia, R. Racu, R. Ernst and M. González Harbour, Influence of different abstractions on the performance of distributed hard real-time systems, in Proceedings of the 7th ACM & IEEE International Conference on Embedded Software, pp. 193–202, 2007.
2. I. Lee, J.Y-T. Leung, S.H. Son, Handbook of Real-Time and Embedded Systems, Chapman & Hall/CRC Computer & Information Science Series, Taylor & Francis Group, Boca Raton, pp. 207, 2008, ISBN-10: 1-58488-678-1.
3. K. Tachikawa, A perspective on the evolution of mobile communications, IEEE Communications Magazine, 41(10), 66–73, October 2003.
4. J. Kreku, M. Hoppari, T. Kestilä, Y. Qu, J.-P. Soininen, P. Andersson and K. Tiensyrjä, Combining UML2 application and SystemC platform modelling for performance evaluation of real-time embedded systems, EURASIP Journal on Embedded Systems, 2008, 712329, January 2008.
5. A. Vahdat, A. Lebeck and C.S. Ellis, Every Joule is precious: The case for revisiting OS design for energy efficiency, in Proceedings of the 9th ACM SIGOPS European Workshop, pp. 31–36, September 2000.
6. M. Weiser, Some computer science issues in ubiquitous computing, Communications of the ACM, 36(7), 75–84, July 1993.
7. J. Hill, R. Szewczyk, A. Woo, S. Hollar, D. Culler and K. Pister, System architecture directions for networked sensors, ASPLOS, 35(11), 93–104, November 2000.
8. J. Haapola, Nano MAC: A distributed MAC protocol for wireless ad hoc sensor networks, in Proceedings of the XXVIII Convention on Radio Science & IV Finnish Wireless Communication Workshop, pp. 17–20, 2003.
9. J. Polastre, J. Hill and D. Culler, Versatile low power media access for wireless sensor networks, in SenSys ‘04 Proceedings of the 2nd International Conference on Embedded Networked Sensor Systems, pp. 95–107, November 2004.
10. B. Kienhuis, E. Deprettere, K. Vissers and P. van der Wolf, Approach for quantitative analysis of application-specific dataflow architectures, in Proceedings of the IEEE International Conference on Application-Specific Systems, Architectures and Processors (ASAP ‘97), pp. 338–349, Zurich, Switzerland, July 1997.
11. P. Lieverse, P. van der Wolf and E. Deprettere, A trace transformation technique for communication refinement, in Proceedings of the 9th International Symposium on Hardware/Software Codesign (CODES 2001), pp. 134–139, 2001.
12. P. Lieverse, P. van der Wolf, K. Vissers and E. Deprettere, A methodology for architecture exploration of heterogeneous signal processing systems, Kluwer Journal of VLSI Signal Processing 29(3): 197–207, 2001.
13. J. Saastamoinen, S. Khan, K. Tiensyrjä and T. Taipale, Multi-threading support for system-level performance simulation of multi-core architectures, in Proceedings of the 24th International Conference on Architecture of Computing Systems 2011 (ARCS 2011), VDE Verlag Gmbh, 169–177, pp. 2011.
14. S. Khan, J. Saastamoinen, M. Majanen, J. Huusko and J. Nurmi, Analyzing transport and MAC layer in system-level performance simulation, in Proceedings of the International Symposium on System on Chip, SoC 2011. Tampere, Finland, 31 October–2 November 2011. IEEE Computer Society, 8 p.
15. S. Khan, J. Saastamoinen, J. Huusko, J.-P. Soininen and J. Nurmi, Application workload modelling via run-time performance statistics, International Journal of Embedded and Real-Time Communication Systems (IJERTCS), IGI Global, Copyright © 2013 (In press.).
16. J. Saastamoinen and J. Kreku, Application work load model generation methodologies for system-level design exploration, in Proceedings of the 2011 Conference on Design and Architectures for Signal and Image Processing, DASIP 2011. Tampere, Finland, 2–4 November 2011. IEEE Computer Society 2011, pp. 254–260.
17. S. Khan, J. Saastamoinen, K. Tiensyrjä and J. Nurmi, SLPE of distributed GENESYS applications on multi-core platforms, in Proceedings of the 9th IEEE International Symposium on Embedded Computing (EmbeddedCom 2011). Sydney, pp. 12–14 December 2011.
18. S. Khan, S. Pantsar-Syväniemi, J. Kreku, K. Tiensyrjä and J.-P. Soininen, Linking GENESYS application architecture modelling with platform performance simulation, in Forum on Specification and Design Languages 2009 (FDL2009), Sophia Antipolis, France, pp. 22–24, September 2009, ECSI.