
ORB DESIGN
The Object Request Broker (ORB) is the key component of the CORBA architecture. Its key responsibility is to forward method invocations from a client to an object implementation, including the tasks associated with this process in heterogeneous environments. In particular, invoked objects may be located in the same process as the caller, in a different process on the same computer, or on a remote computer. Also, objects can be implemented using different programming languages, running on different operating systems and hardware, and connected by diverse types of networks. The ORB has to provide a consistent interface to invoke these different types of objects.
Because the ORB is closely linked with the other components of a CORBA system (partially through proprietary interfaces), the developers of specialized ORBs were forced to develop new versions of these components of the CORBA system or not to provide them at all. This happens with some research projects in the integration of Quality of Service (QoS) aspects into CORBA ([25] and [32]).
So this is the starting point for MICO as a platform for research and training projects: the development of an extendible and modifiable ORB. The microkernel approach from the area of operating systems has been applied to CORBA for this purpose. For this, the minimal necessary ORB functionality has to be identified, such that modifications and extensions can be implemented outside the ORB as services.
Consequently, the following sections start by compiling the tasks of an ORB. An analysis will be undertaken to determine which components are required for fulfilling these tasks, which of these components can be implemented as ORB core components, and which as services. Lastly, an overview of the design of a microkernel ORB will be presented.
5.1 ORB FUNCTIONALITY
From a conceptual standpoint, an ORB offers all the functionality that is independent of certain types of objects. The object adapter carries out object-specific tasks. The ORB is in a sense the smallest common denominator in functionality among all conceivable types of objects. Its responsibilities include
Object references contain addressing information along with the type and the identity of the object. The generation of type and identity is the task of object adapters, and the ORB provides the addressing information. Object adapters and the ORB must therefore cooperate closely in the creation of object references.
Once the objects are created, there is the question of how a client is informed of the object reference. A commonly used approach is the use of a naming service. Because the naming service itself is realized as a set of CORBA objects, the question is how the client finds out the object reference of the naming service. To solve this bootstrapping problem, the ORB offers clients an integrated bootstrapping service.
From the view of an ORB, a method invocation consists of three tasks: First, after an invocation adapter (see Section 3.2.5) initiates a method invocation, the location of the target object has to be looked up based on the target object reference. Second, in the event that the target object is not located in the address space of the caller, the method invocation must be forwarded to the address space of the target object through the use of suitable transport mechanisms. Third, the object adapter responsible for the target object is identified on the basis of the object reference of the target object. The object adapter then invokes the method on the target object. Any results are returned to the caller on the reverse path.
5.2 ORB ARCHITECTURES
Conceptually, the ORB is a cross-address system, like the one shown in Figure 5.1. It permits transparent communication between objects in different address spaces.
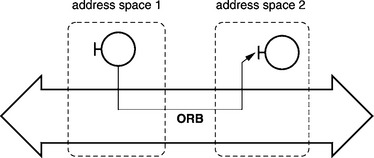
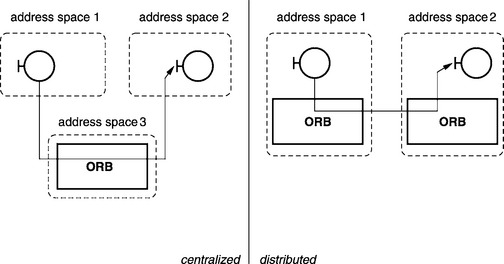
So there are many opportunities for converting this conceptual idea into an implementation. A distinction is essentially made between a centralized approach and a distributed approach (see Figure 5.2). With a distributed approach the ORB is implemented as a library that is linked to each CORBA application. The ORBs in different address spaces then communicate with one another on a direct path. For security, reliability, and performance reasons, this library could also be located directly in the underlying operating system. The distributed approach is characterized by the following:
![]() Good performance because clients and server communicate directly with one another
Good performance because clients and server communicate directly with one another
![]() Complex management because information is distributed over local ORBs
Complex management because information is distributed over local ORBs
In a centralized solution the ORB is implemented as a separate process. All communication between two CORBA applications takes place over this server. Of course hybrid solutions are also possible. In this case, part of the communication avoids the indirect route over the central ORB. The centralized approach is characterized by the following:
![]() Simple management because all information is available in a central location
Simple management because all information is available in a central location
![]() Reduced performance because communication between clients and servers is not on a direct route
Reduced performance because communication between clients and servers is not on a direct route
Totally new developments of CORBA implementations (such as MICO) almost exclusively follow the distributed approach because of the disadvantages inherent in the centralized approach. The centralized approach may be used when new programming languages or systems are being linked to an existing ORB.
5.3 DESIGN OF MICO’S ORB
MICO’s ORB is implemented as a library that is linked to each program as depicted in the right-hand side of Figure 5.2. That is, each program has its own local ORB, which consists of a set of objects implemented in C++. However, in order to achieve a maximum of flexibility in terms of extending and modifying the ORB, Mico follows a microkernel approach, where the functionality of the local ORB is restricted to the bare minimum. Additional functionality can be plugged into the ORB by extending the ORB with additional components or services such as invocation adapters, object adapters, and transport protocols. Simultaneous use of many of these components is essential.
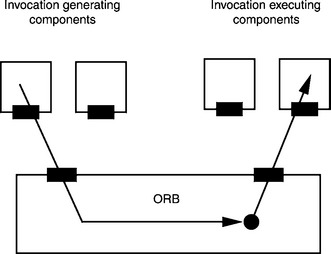
From the point of view of the ORB, the components mentioned are divided into two categories: components that request method invocations to the ORB and components that execute method invocations on behalf of the ORB:
So it suffices for an ORB to be equipped with a generalized invocation adapter interface as well as a generalized object adapter interface. In addition to these interfaces, the ORB has an invocation table in which it keeps a record of the method invocations currently being executed.
Because a CORBA system has many subtasks that have to be processed simultaneously (see Section 5.3.4), an ORB also has a scheduler. The scheduler itself is implemented as a service outside the ORB due to the variety of demands placed on it (multithreaded versus single-threaded, real-time-enabled). Again the ORB only supplies a suitable scheduler interface.
Section 5.1 pointed out that the creation of object references requires a close cooperation between object adapter (provides type and identity) and ORB (provides address). Due to the arrangement of transport modules outside the ORB, it is the transport module and not the ORB that has the addresses where an object can be found. Therefore, the ORB must supply a mechanism for communication between the transport modules and the object adapters.
All interfaces are designed so components can be registered and deregistered with the ORB anytime during runtime. Because a microkernel ORB offers an interface for loading modules, it can even be extended through the addition of new object adapters, transport modules, and so forth during runtime.
Figure 5.3 presents an overview of the major components in a microkernel ORB. The individual components and interfaces of the ORB will be covered in detail in the following sections.
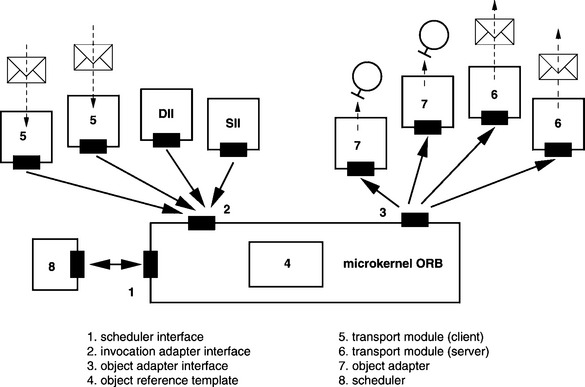
5.3.1 Invocation Adapter Interface
The invocation adapter interface is used to initiate a remote method invocation on an ORB. To execute method invocations, stub objects indirectly use this interface via the Static Invocation Interface (SII). Method invocations generated via the Dynamic Invocation Interface (DII) by CORBA applications also indirectly use this interface. Transport modules on the client side (box 5 in Figure 5.3) receive messages from ORBs in other address spaces and transform these messages into invocations to the invocation adapter interface of the local ORB.
The difficulty in designing an invocation adapter interface is that the components directly using this interface do not have equal detail of information about the method invocation being executed. The signature of the invoked method, including the parameter types, is usually known to invocation adapters such as DII and SII, but this is usually not the case with transport modules on the server side. The reason for this is that inter-ORB protocols such as IIOP try to minimize the amount of information being transmitted. Therefore, they only supply the object reference, the method name, and the values of the parameters, but not their types, because the invoked object is able to reconstruct this information from the method name. The transport module on the server side could theoretically use the interface repository to obtain the type information. The problem is that, first, it is entirely possible that no type information for a particular method is available in the repository and, second, the level of performance would be impacted considerably because a repository other than the local one might have to be consulted for each method invocation.
As a consequence, due to the lack of type information, server-side transport modules normally cannot reconstruct the values of parameters of method invocations from the byte streams of coded parameters. This reconstruction is not possible until much later when the method invocation reaches the target object that knows the signature of the invoked method, as described above. At the same time it should be transparent to the target object whether the method invocation was initiated locally from DII, SII, or a transport module.
The principle of lazy evaluation is used to resolve this problem. Here evaluation of the expressions of a programming language is deferred until the value of the expression is actually needed and all input values for the evaluation are available. A thunk object, which contains the expression itself and all the information needed to evaluate it, is created for each expression requiring lazy evaluation. The thunk is not evaluated until the value of the expression is required.
Lazy evaluation was included in Algol 60 as a method for passing parameters by name. Another important application of this technology is the lazy evaluation of data streams in Lisp, first described in [21]. The name thunk originates from the implementation of the name invocation in Algol 60. The origin of the word is unknown, but it is said that it resembles the sound produced by data in a running Algol 60 system when it is being written to the stack [1].
What this means to the invocation adapter interface of an ORB is that a special thunk object containing the coded parameters and other information important to the decoding (such as a reference to the decoding procedure to be used) is generated for the method invocation. The thunk object is not supplied with the known type information or evaluated (i.e., the parameters decoded) until the values of the parameters for invoking the method are actually needed.
The invocation adapter interface must be asynchronous if several method invocations are to be executed simultaneously. This means that the control flow returns directly to the caller once a method invocation has been initiated in the ORB. The semantics for what under CORBA is usually a synchronous method invocation can therefore be simulated. The interface supports the operations:
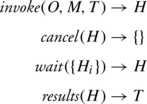
The operation invoke supplies the ORB with a method invocation in the form of a tuple (O, M, T), consisting of a target object O, the method name M, and parameters in the form of a thunk T, and returns a handle H for the initiated method invocation. The method invocation associated with the handle can be canceled by the operation cancel. Note, however, that this cancellation is only a local operation that marks the associated record in the ORB for removal. The remote process that actually executed the method invocation is not affected. The operation wait waits for the completion of one of the method invocations indicated in the form of a set of handles and supplies the handle of the first completed method invocation as a result. Lastly, the operation results can be used to obtain the results of the method invocation in the form of a thunk T from the ORB. Lazy evaluation also has to be used for the results because the types of output parameters, return value, or exception are first known in the stub object that triggered the method invocation.
5.3.2 Object Adapter Interface
An object adapter interface is in a sense the opposite of an invocation adapter interface. An ORB uses this interface to forward a method invocation to the component responsible for its execution. This can either be an object adapter that executes the method invocation directly or a transport module that forwards the method invocation to another address space.
The difficulty in designing this interface is that it is supposed to hide the dissimilarities of object adapters and transport modules from the ORB. However, the ORB still must be able to determine from the object reference which transport module is responsible for the execution of a method invocation on the target object.
The way to solve this problem is to allow the object adapter or the transport module—and not the ORB—to make this choice. The interface offered to the ORB by the object adapters and transport modules comprises the following operations:
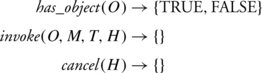
The ORB can use has_object to query an object adapter or a transport module whether it is responsible for the object reference O. An important requirement of has_object is that has_object(O) returns TRUE for at most one object adapter or transport module for each possible object reference O. This is the only way that a unique association among object references and object adapters is possible for the ORB. The operation invoke transfers a method invocation in the form of a tuple (O, M, T, H), consisting of an object reference O, method name M, parameters in the form of a thunk T, and a handle H to the object adapter or transport module. If necessary, the ORB can cancel a method invocation through cancel.
Object adapter interfaces also have to be asynchronous if several method invocations are to be executed simultaneously. Consequently, in addition to operations for registering and deregistering object adapters, the interface offered by the ORB to object adapters and transport modules also includes the operation answer_invoke:
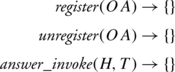
Object adapters and transport modules use answer_invoke to inform the ORB through a thunk T of the results of a method invocation specified by the handle H.
5.3.3 Invocation Table
Due to the asynchrony of the object adapter interface, the ORB has to keep a record of currently active method invocations. For this purpose it has a table of these method invocations. The table contains entries of the form (H, O, M, Tin, Tout), consisting of handle H, object reference O of the target object, method name M, thunk Tin for the input parameters, and (sometimes empty) thunk Tout for results.
Therefore, from the point of view of an ORB, a method invocation is executed in three steps. First the ORB accepts a method invocation from an invocation-generating component and forwards it to the invocation-executing component:
1. Acceptance of method invocation (O, M, Tin) via invoke.
2. Generation of a new handle H and entry of (H, O, M, Tin, NIL) in the invocation table.
3. Selection of component responsible for executing the invocation and transfer of the method invocation to this component.
The component executing the invocation then processes the method invocation and notifies the ORB of the results of the method invocation:
5. Acceptance of Tout for the method invocation with handle H at the object adapter interface via answer_invoke.
6. Replacement of the associated entry (H, O, M, Tin, NIL) in the table of active method invocations with entry (H, O, M, Tin, Tout).
For the third and last step the component generating the invocation may use wait({Hi}) to wait for the completion of one of the invocations indicated by the handles {Hi}. Internally the ORB then blocks until answer_invoke is invoked for one of the handles and then returns this handle to the caller. The component generating the invocation then uses results(H) to fetch the results of the method invocation with handle H at the invocation adapter interface:
5.3.4 Scheduler
There are various situations in a complex system like an ORB in which many tasks have to be executed simultaneously. The following examples list some of these situations:
EXAMPLE 5.2.
Situations exist in which two or more CORBA objects mutually invoke methods to one another. One example of this is a callback, where a client invokes a method in the server, which in turn invokes a method (the callback method) in the client while the original invocation is still pending. See Figure 5.4 for an illustration of this scenario. To ensure that this operation functions and does not result in a deadlock, the ORB must be able to wait for both the completion of the method invocation and the arrival of new method invocations (e.g., the callback).
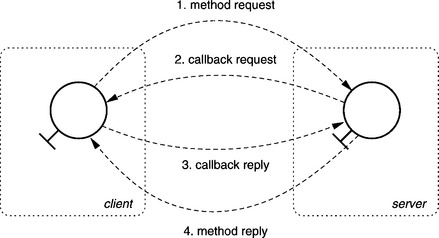
What complicates matters is that the ORB is not always able to foresee these situations because any number of transport modules can be integrated into a system during runtime and then removed again. As an extendable platform, the microkernel ORB should function in both single- and in multithreaded environments. Thus the problem cannot simply be solved by using a thread package. Consequently, the ORB itself must offer some form of scheduler that allocates processing time to the program parts that are to be executed simultaneously. Because scheduling algorithms largely depend on the area of application of an ORB, the scheduler should be interchangeable and therefore must be embedded as a service outside the microkernel ORB.
SCHEDULER ABSTRACTION
What is needed is a scheduling mechanism with the following characteristics:
• Functions in single- and multithreaded environments
• Allows the implementation of different scheduling algorithms
The following assumptions about the subtasks are made in the design of such a mechanism:
1. The code of the tasks to be executed in parallel can be divided into two categories:
— Wait operations that wait for the occurrence of certain events
— Calculation operations are all operations that are not wait operations
2. The time required to carry out each sequence of calculation operations for a task is negligible.
3. There are only a limited number of different events (e.g., message arrived, timeout).
Note the following concerning assumption 1: At first glance some operations cannot easily be classified into one of the two categories and are a combination of both. For example, in some cases input/output operations can block until input/output is completed. However, these hybrid operations can be transformed into a sequence of pure wait and calculation operations.
EXAMPLE 5.3.
![]()
reads the number of bytes indicated in buffer_size in buffer from the network connection that is represented by socket. The operation blocks until the number of bytes indicated in buffer_size are received. Thus, read_blocking() is neither a wait operation nor a calculation operation but is both. The code piece

also reads the number of bytes indicated in buffer_size in buffer from the network connection socket. In this case, use is made of the wait operation wait_for_data(socket) that is waiting for the event Data has arrived on the connection socket and the computing operation read_not_blocking that reads what is currently available without blocking.
Referring to assumption 2, “negligible” in this case means that for any prescribed time span Δt > 0, the time required for the execution of each sequence of computing operations for all subtasks is less than or equal to Δt. This is by no means an obvious assumption. One should note, however, that each sequence of computing operations that does not comply with this condition can be transformed into a set of equivalent computing operations that comply with this condition. All that is needed is the simple insertion of a dummy wait operation in the middle (timewise) of the sequence. This then produces two new sequences of computing operations that either comply with the conditions or not. If the new sequence does not comply, the procedure is repeated until all sequences comply.
Referring to assumption 3, in principle a single primitive suffices for interprocess communication, such as a semaphore with the associated event Down on Semaphore X possible. All conceivable events can be mapped to this primitive [35]. However, some events occur so frequently that it makes sense to make them directly available:
As shown above, a CORBA runtime system contains different subtasks that basically have to be executed simultaneously. According to assumption 1, sub-tasks can be divided into blocks consisting of a wait operation followed by calculations. Since each subtask is executed sequentially and execution time of calculations is negligible according to assumption 2, most of the time each subtask waits for the occurrence of a certain event. Scheduling then means waiting for the occurrence of one of those events and executing the respective block.
For many applications, such a nonpreemptive scheduling is sufficient. However, as the scheduling does not only apply to the CORBA runtime system itself, but also to application code (e.g., the method implementations of a CORBA object), splitting long methods into smaller blocks may be inconvenient for the application developer. If the application is additionally subject to real-time constraints (i.e., certain tasks have to be completed with given deadlines), non-preemptive scheduling may not be sufficient. However, the scheduler abstraction presented here does allow the use of scheduling algorithms that support preemption—for example, using thread packages.
MICO’s scheduler abstraction basically implements waiting for a given set of events to occur. When a block is “executed,” the associated event is registered with the scheduler, which notes which block is associated with the event. Using appropriate mechanisms, the scheduler waits for the occurrence of the next registered event. It then removes the corresponding entry from its list of pending events and executes the block associated with the event. The scheduling algorithm controls what happens when many events occur simultaneously.
EXAMPLE 5.4.
Figure 5.5 shows two subtasks, A (consisting of two blocks) and B (consisting of one block). A wait operation occurs at the beginning of each block; the rest of the block (shaded area) consists of calculation operations. The dotted arrows show the control flow between the blocks. The execution of subtasks starts at block A1 for subtask A and B1 for subtask B. So initially the associated events E1 and E3 are registered with the scheduler. The scheduler uses the method schedule() to implement the scheduling. This method is invoked at the start and continues through to the end of the program. The scheduler now waits for event E1 or E3 to occur. Assuming that E1 occurs first, E1 is removed from the list of the scheduler and block A1 is executed. In ac-
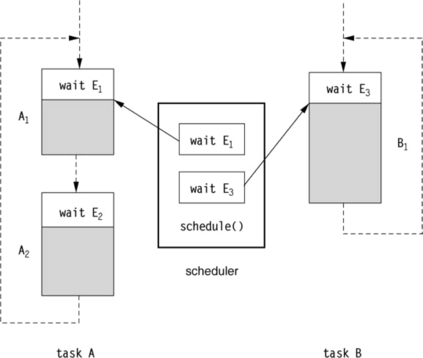
cordance with the control flow, block A2 has to be executed next. This means that event E2 is registered with the scheduler, and the scheduling starts from the beginning.
SCHEDULER INTERFACE
What makes it difficult to design a general interface to the scheduler abstraction above is that each scheduling algorithm requires special configuration data. For example, round robin requires the duration of a time slice, with scheduling by priority, a priority has to be assigned for each subtask. The user must therefore be aware of which scheduling algorithm is being applied, which means that a general interface cannot be used to encapsulate all scheduling algorithms.
On the other hand, it turns out that using a special scheduler in CORBA systems is often linked to other special components that use the services of the scheduler in the system. For example, for applications in real-time environments, TAO [32] contains special real-time inter-ORB protocols and realtime object adapters that use a real-time scheduler. Therefore, for MICO to be equipped with real-time features, the scheduler and the components that use the scheduler would have to be interchanged simultaneously. This would enable the components using the scheduler to know the algorithm used in the interchanged scheduler.
MICO schedulers therefore offer two interfaces: a general interface independent of algorithms and specific to the configuration data (such as priorities and deadlines) and a specialized interface customized to the algorithm used. When invocations are executed via the general interface, the missing configuration data is replaced by appropriate default values. System components that do require a special scheduling algorithm use the specialized interface. Other components that do not depend on specific scheduler instances use the general interface.
5.3.5 Object Generation
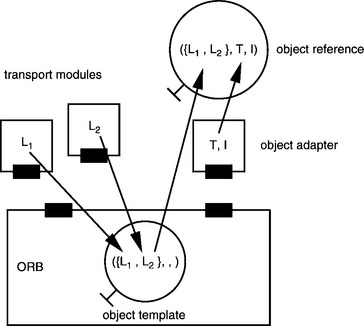
An object reference is a tuple ({Li}, T, I) consisting of the locators Li, the type T, and the identity I of an object. A locator describes the mechanism that allows an object to be accessed. Because different mechanisms could be available for accessing an object, each object reference may have not only one but a number of locators.
Locators are closely related to addresses, since a locator identifies the location of an object as does an address. The difference between the two is the more abstract nature of an address. Although an address can provide unique identification of an object, it does not necessarily describe a way to locate the object. Therefore, a tuple [country, city, street, house number] is an address but not a locator. A locator could be a route description.
EXAMPLE 5.5.
The locators described above are similar in their function to the Uniform Resource Locators (URL) [5], familiar from the WWW world. In the same vein, the syntax of locators in MICO visible to the user is similar to that of URLs. Locators for objects that can be accessed via IIOP follow this format:
![]()
In comparison, communication between processes on the same computer is supported by named pipes that are visible as special files in a file system. The format of the associated locators is
![]()
The special locator local: is used to access objects in the same address space.
Object adapters work closely with the ORB to create new object references. The object adapter contributes the type and the identity; the locators originate from the server-side transport modules that enable access to the address space from outside. As shown in Figure 5.6, the ORB supplies a template in which the transport modules enter locators; this template is used for the communication between object adapters and transport modules. Through the addition of type and identity to the template, the object adapter generates a new object reference.
5.3.6 Bootstrapping
One of the fundamental tasks of distributed systems is service mediation—a bringing together of service providers and service users. A fundamental distinction is made between two approaches: name-oriented mediation and content-oriented mediation. In the first case, the mediation is carried out through names the user allocates to services. In the second case, the mediation is based on characteristics of the service. The first type of mediators is called name services; the second type, traders.
In CORBA these mediators are carried out as an object service, which is a set of CORBA objects located outside the ORB core. However, this raises the question of how a service user obtains knowledge about the object reference of the mediator (name service or trader), also referred to as a bootstrapping problem.
The CORBA specification offers a solution to this problem with the ORB supplying an interface for querying initial object references based on a name (such as NameService for the object reference of the name service):

MICO provides a set of different options to configure the object references that can be retrieved via this interface. All of these are based on representations of object references as strings, which contain locator(s), object type, and identity in an encoded form. As discussed in Section 3.4.3, CORBA defines stringified IORs that contain this information in an opaque, unreadable form. However, as part of the Interoperable Naming Service (INS), more readable stringified representations of object references have been introduced that are similar to URLs as known from the Web. Additionally, it is possible to specify Web URLs that point to a place (e.g., file or Web server) where the stringified object reference is stored or can be retrieved from (see Section 3.7). Essentially, traditional stringified IORs and all the variants of URLs can be used interchangeably. The ORB contains functions to parse and interpret all these different representations in order to obtain the internal representation of an object reference.
For bootstrapping with the above interface, a mapping of a service name (e.g., NameService) to such a string representation of an object reference can be specified on the command line or in a configuration file.
5.3.7 Dynamic Extensibility
For some applications it may be desirable to extend an executing CORBA application with new modules (e.g., other transport modules). With many compiled languages such as C++, loading such modules into a running program requires appropriate support by the operating system. In particular, cross-references between the running program and the loaded module must be resolved using a dynamic linker. Through its use of the dynamic linker, MICO offers the possibility of extending running CORBA systems through the addition of new modules, such as object adapters.
5.4 SUMMARY, EVALUATION, AND ALTERNATIVES
The microkernel approach has been applied to CORBA to enable the design of extensible and modifiable CORBA platforms. This has involved dividing the components of a CORBA system into microkernel components and services (components outside the microkernel ORB) and designing the necessary interfaces for the microkernel ORB. What comes to light is that the services can essentially be broken down into invocation-generating and invocation-executing services, with each group requiring a special interface to the microkernel ORB. As shown in Figure 5.7, in simplified terms the function of the microkernel ORB during method invocation is to select an invocation-executing component.
A microkernel ORB incorporates the following characteristics:
![]() Easy extensibility through the addition or exchange of services
Easy extensibility through the addition or exchange of services
![]() Extensibility restricted to service types that are considered during the design of the microkernel ORB
Extensibility restricted to service types that are considered during the design of the microkernel ORB
The additional overhead required is a disadvantage often associated with generic approaches. Conventional CORBA systems in which a specific communication mechanism, a specific object adapter, and the ORB core are merged to create a monolithic component allow for a great deal of optimization. This type of optimization is not possible when components are separated because a microkernel ORB is used. For example, some conventional CORBA systems incorporate a centralized table that allocates CORBA object servants (see Chapter 7) and communication end points (see Chapter 6). In contrast, with a microkernel ORB each communication module and each object adapter has to have a separate table.
In general, extensibility of the microkernel ORB is limited to remote method invocations. The introduction of new communication abstractions such as data streams is not supported. Because data streams cannot be mapped to the method invocation semantics of the current CORBA specification, extensions would be required in some cases to enable the integration of data streams. The problem is that these extensions cannot be implemented as services and would therefore necessitate changes to the microkernel ORB.
Another approach for implementing an extensible ORB could be the provision of a framework [12], such as ACE [31] or the framework that originated in the ReTINA environment [36], which could be used to implement ORBs. The idea behind this approach is that specialized ORBs could be produced through the configuration and assembly of preproduced components. Unfortunately, the implementation of a CORBA system even with a powerful framework is complex, as demonstrated in the TAO example [32].