
Chapter 5. Containers and Orchestration
As mentioned in the previous chapter, with the cattle approach to managing infrastructure, you don’t manually allocate certain machines for certain applications—instead, you leave it up to a scheduler to manage the life cycle of the containers. While scheduling is an important activity, it is actually just one part of a broader concept: orchestration.
In Figure 5-1, you can see that orchestration includes things such as health checks, organizational primitives (e.g., labels in Kubernetes or groups in Marathon), autoscaling, upgrade/rollback strategies, as well as service discovery. Sometimes considered part of orchestration but outside of the scope of this book is the topic of base provisioning, such as setting up a Mesos Agent or Kubernetes Kubelet.
Service discovery and scheduling are really two sides of the same coin. The entity that
decides where in a cluster a certain container is placed is called a scheduler. It
supplies other systems with an up-to-date mapping containers -> locations,
which then can be used to expose this information in various ways, be it in
distributed key-value stores such as etcd or through DNS as the case with,
for example, Mesos-DNS.

Figure 5-1. Orchestration and its constituents
In this chapter, we will discuss service discovery and networking from the point of view of the container orchestration solution. The motivation behind this is simple: assume that you’ve decided to go with a certain platform, say, Kubernetes. Then, your primary concern is how service discovery and networking is handled in the context of this platform.
Note
In the following, I’ve made the choice to discuss container orchestration systems that fulfill two requirements: they are open source and they have a considerable community up-take (or in Nomad’s case, this is expected to happen, relatively soon).
There are several other solutions out there you could have a look at, including Facebook’s Bistro or hosted solutions such as Amazon EC2 Container Service ECS.
And, should you want to more fully explore the topic of distributed system scheduling, I suggest reading Google’s research papers on Borg and Omega.
Before we dive into container orchestration systems, let’s step back and review what the scheduler—which is the core component of orchestration—actually does in the context of Docker.
What Does a Scheduler Actually Do?
A distributed systems scheduler takes an application by request of a user and places it on one or more of the available machines. For example, a user might request to have 100 instances (or replicas, in the case of Kubernetes) of the app running.
In the case of Docker, this means that (a) the respective Docker image must exist on a host, and (b) the scheduler tells the local Docker daemon to launch a container based on it.
In Figure 5-2, you can see that the user requested three instances of the app running in the cluster. The scheduler decides the actual placement based on its knowledge of the state of the cluster, primarily the utilization of the machines, resources necessary to successfully launch the app, and constraints such as launch this app only on a machine that is SSD-backed. Further, quality of service might be taken into account for the placement decision.

Figure 5-2. Distributed systems scheduler in action
Learn more about this topic via Cluster Management at Google by John Wilkes.
Warning
Beware of the semantics of constraints that you can place on scheduling containers. For example, I once gave a Marathon demo that wouldn’t work as planned because I screwed up concerning the placement constraints: I used a combination of unique hostname and a certain role and it wouldn’t scale, because there was only one node with the specified role in the cluster. The same thing can happen with Kubernetes labels.
Vanilla Docker and Docker Swarm
Out of the box, Docker provides a basic service discovery mechanism:
Docker links. By default, all containers can communicate directly with
each other if they know each other’s IP addresses. Linking allows a user
to let any container discover both the IP address and exposed ports of
other Docker containers on the same host. In order to accomplish this,
Docker provides the --link flag, a convenient command-line option that
does this automatically.
But hard-wiring of links between containers is neither fun nor scalable. In fact, it’s so bad that, going forward, this feature will be deprecated.1
Let’s have a look at a better solution (if you nevertheless want to or need to use links): the ambassador pattern.
Ambassadors
The idea behind this pattern, shown in Figure 5-3, is to use a proxy container that stands in for the real container and forwards traffic to the real thing.2 What it buys you is the following: the ambassador pattern allows you to have a different network architecture in the development phase and in production. The network ops can rewire the application at runtime, without changing the application’s code.
In a nutshell, the downside of ambassadors is that they don’t scale well. The ambassador pattern can be used in small-scale, manual deployments but should be avoided when employing an actual container orchestration tool such as Kubernetes or Apache Mesos.
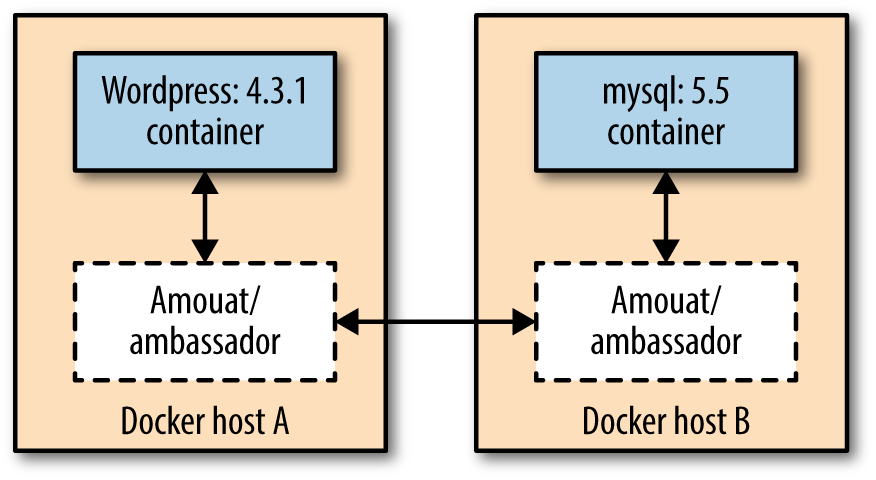
Figure 5-3. Fully configured Docker linking using the Ambassador pattern
Note
If you want to know how to actually implement the ambassador pattern in Docker, I’ll again refer you to Adrian Mouat’s awesome book Using Docker. In fact, in Figure 5-3, I’m using his amouat/ambassador Docker image.
Docker Swarm
Beyond the static linking of containers, Docker has a native clustering tool called Docker Swarm. Docker Swarm builds upon the Docker API3 and works as follows: there’s one Swarm manager, responsible for the scheduling and one each host an agent runs, which takes care of the local resource management (Figure 5-4).
The interesting thing about Swarm is that the scheduler is plug-able, so you can, for example, use Apache Mesos rather than one of the included schedulers. At the time of writing this book, Swarm turned 1.0 and subsequently it was awarded General Availability status; new features such as high availability are being worked on an ongoing basis.
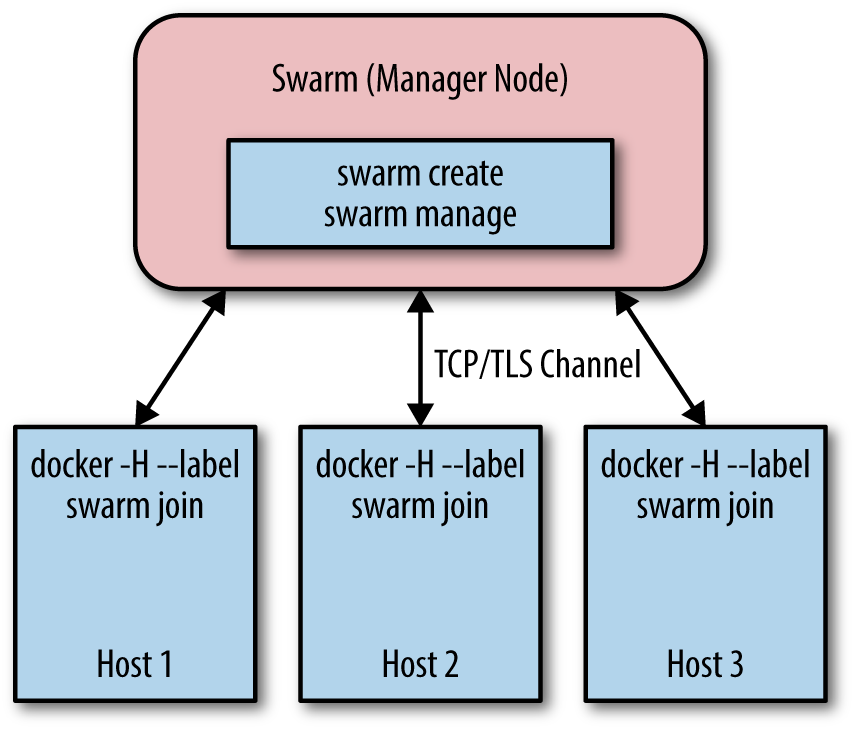
Figure 5-4. Docker Swarm architecture, based on Swarm - A Docker Clustering System presentation
Service Discovery
Docker Swarm supports different backends: etcd, Consul, and Zookeeper. You can also use a static file to capture your cluster state with Swarm and only recently a DNS-based service discovery tool for Swarm, called wagl, has been introduced.
If you want to dive deeper into Docker Swarm, check out Rajdeep Dua’s “Docker Swarm” slide deck.
Kubernetes
Kubernetes (see Figure 5-5) is an opinionated open source framework for elastically managing containerized applications. In a nutshell, it captures Google’s lessons learned from running containerized workloads for more than 10 years, which we will briefly discuss here. Further, you almost always have the option to swap out the default implementations with some open source or closed source alternative, be it DNS or monitoring.
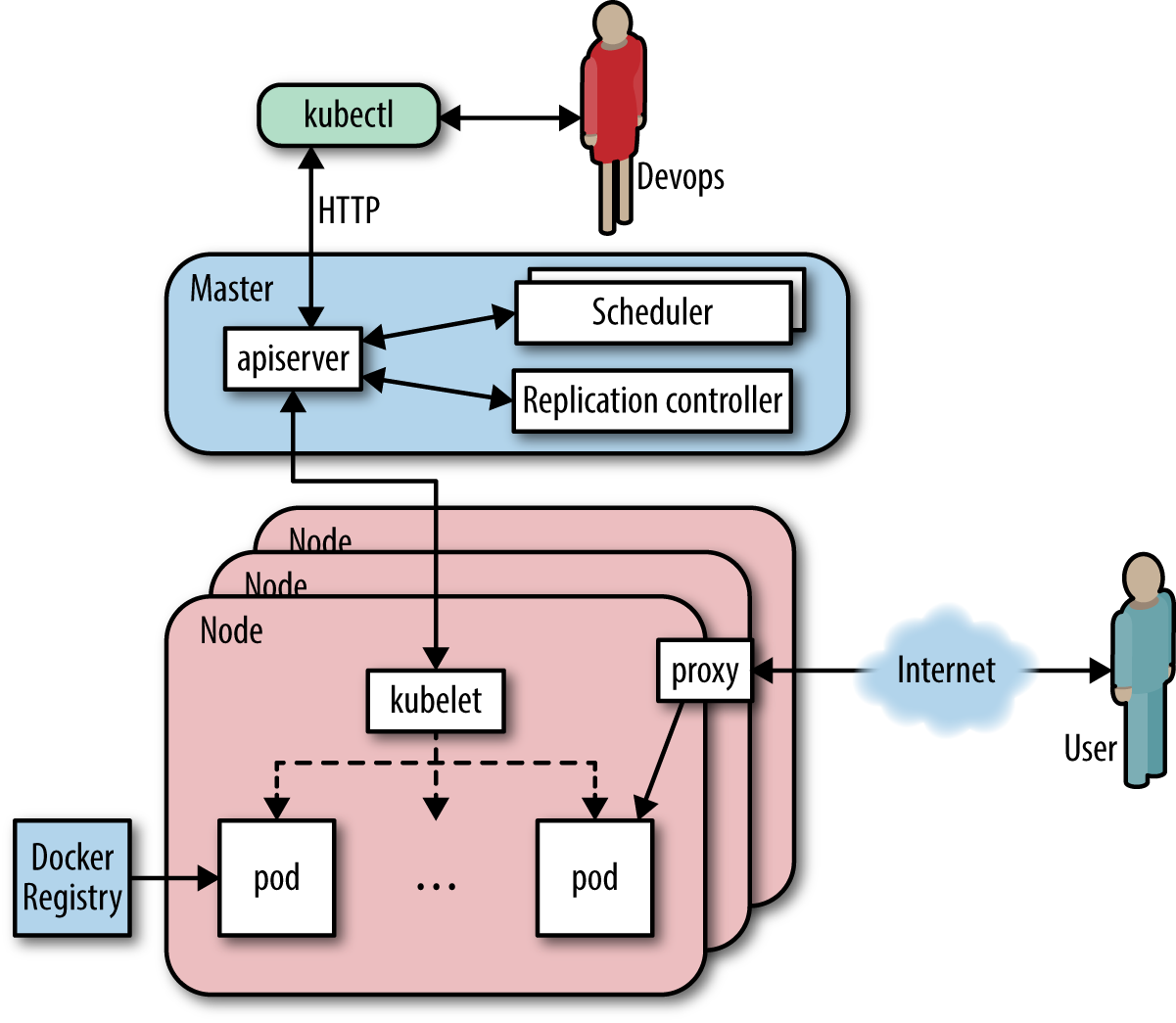
Figure 5-5. An overview of the Kubernetes architecture
This discussion assumes you’re somewhat familiar with Kubernetes and its terminology. Should you not be familiar with Kubernetes, I suggest checking out Kelsey Hightower’s wonderful book Kubernetes Up and Running.
The unit of scheduling in Kubernetes is a pod. Essentially, this is a tightly coupled set of containers that is always collocated. The number of running instances of a pod (called replicas) can be declaratively stated and enforced through Replication Controllers. The logical organization of pods and services happens through labels.
Per Kubernetes node, an agent called Kubelet runs, which is responsible for controlling the Docker daemon, informing the Master about the node status and setting up node resources. The Master exposes an API (for an example web UI, see Figure 5-6), collects and stores the current state of the cluster in etcd, and schedules pods onto nodes.
Figure 5-6. The Kubernetes Web UI
Networking
In Kubernetes, each pod has a routable IP, allowing pods to communicate across cluster nodes without NAT. Containers in a pod share a port namespace and have the same notion of localhost, so there’s no need for port brokering. These are fundamental requirements of Kubernetes, which are satisfied by using a network overlay.
Within a pod there exists a so-called infrastructure container, which is the first container that the Kubelet instantiates and it acquires the pod’s IP and sets up the network namespace. All the other containers in the pod then join the infra container’s network and IPC namespace. The infra container has network bridge mode enabled (see “Bridge Mode Networking”) and all the other containers in the pod share its namespace via container mode (covered in “Container Mode Networking”). The initial process that runs in the infra container does effectively nothing,4 as its sole purpose is to act as the home for the namespaces. Recent work around port forwarding can result in additional processes being launched in the infra container. If the infrastructure container dies, the Kubelet kills all the containers in the pod and then starts the process over.
Further, Kubernetes Namespaces enable all sorts of control points; one example in the networking space is Project Calico’s usage of namespaces to enforce a coarse-grained network policy.
Service Discovery
In the Kubernetes world, there’s a canonical abstraction for service discovery and this is (unsurprisingly) the service primitive. While pods may come and go as they fail (or the host they’re running on fails), services are long-lived things: they deliver cluster-wide service discovery as well as some level of load balancing. They provide a stable IP address and a persistent name, compensating for the short-livedness of all equally labelled pods. Effectively, Kubernetes supports two discovery mechanisms: through environment variables (limited to a certain node) and DNS (cluster-wide).
Apache Mesos
Apache Mesos (Figure 5-7) is a general-purpose cluster resource manager that abstracts the resources of a cluster (CPU, RAM, etc.) in a way that the cluster appears like one giant computer to you, as a developer.
In a sense, Mesos acts like the kernel of a distributed operating system. It is hence never used standalone, but always together with so-called frameworks, such as Marathon (for long-running stuff like a web server), Chronos (for batch jobs) or Big Data frameworks like Apache Spark or Apache Cassandra.
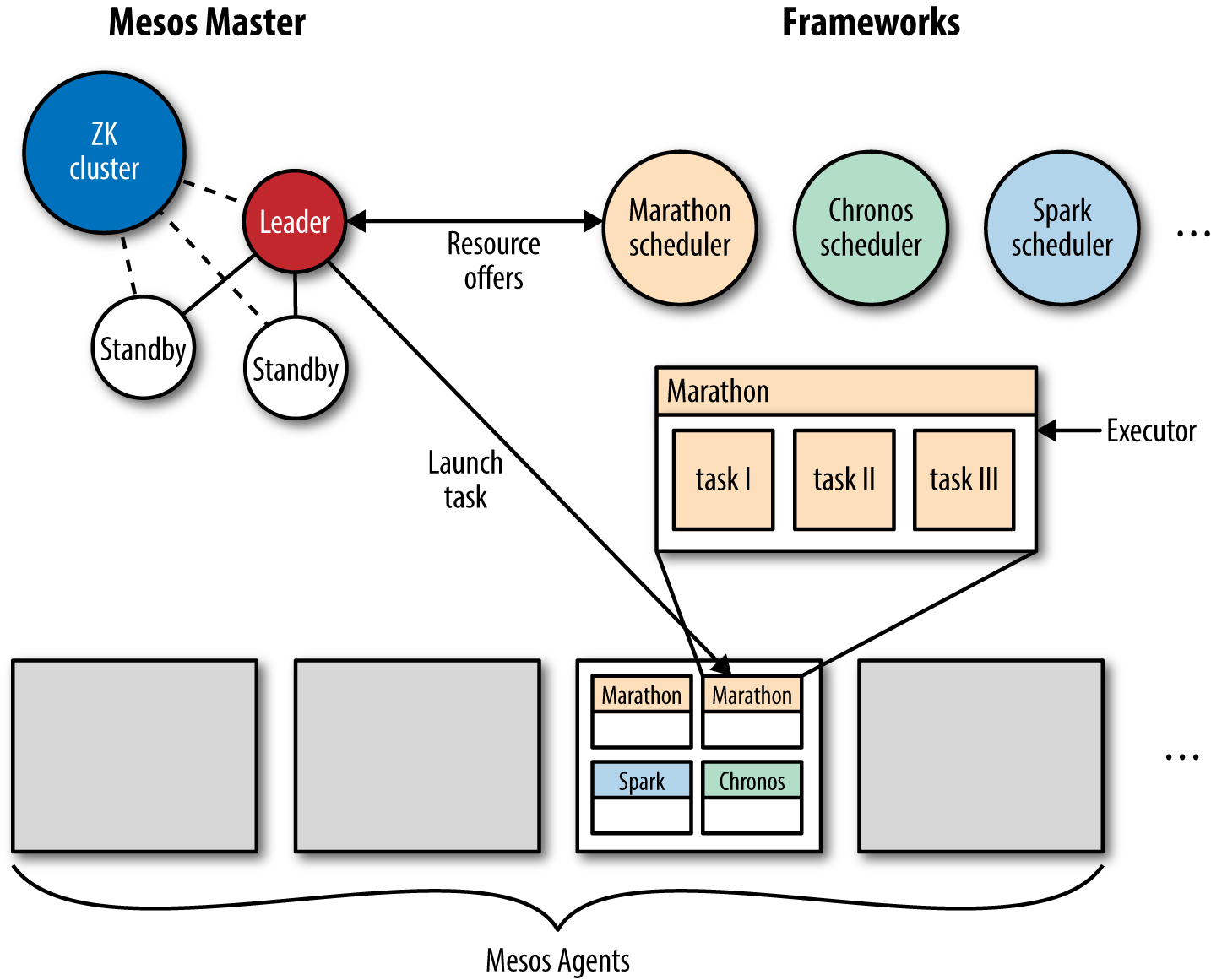
Figure 5-7. Apache Mesos architecture at a glance
Mesos supports both containerized workloads, that is, running Docker containers as well as plain executables (including bash scripts, Python scripts, JVM-based apps, or simply a good old Linux binary format) for both stateless and stateful services.5
In the following, I’m assuming you’re familiar with Mesos and its terminology. If you’re new to Mesos, I suggest checking out David Greenberg’s wonderful book Building Applications on Mesos, a gentle introduction into this topic, particularly useful for distributed application developers.
In Figure 5-8, you can see the Marathon UI in action, allowing you to launch and manage long-running services and applications on top of Apache Mesos.
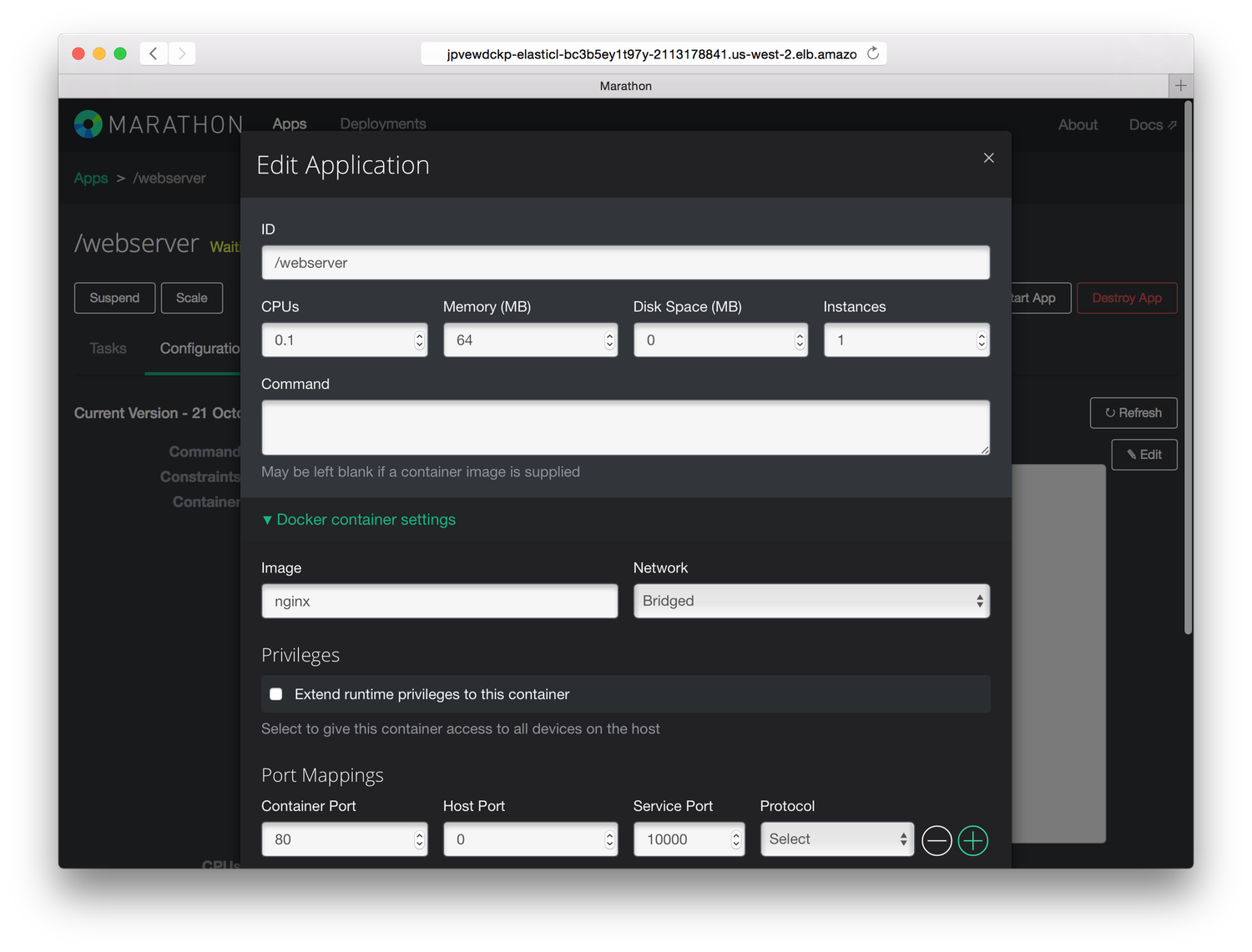
Figure 5-8. The Apache Mesos framework Marathon, launching an NGINX Docker image
Networking
The networking characteristics and capabilities mainly depend on the Mesos containerizer used:
-
For the Mesos containerizer, there are a few prerequisites such as a Linux Kernel version > 3.16, and
libnlinstalled. You can then build a Mesos Agent with the network isolator support enabled. At launch, you would use something like the following:mesos-slave --containerizer=mesos --isolation=network/port_mapping --resources=ports:[31000-32000];ephemeral_ports:[33000-35000]
This would configure the Mesos Agent to use non-ephemeral ports in the range from 31,000 to 32,000 and ephemeral ports in the range from 33,000 to 35,000. All containers share the host’s IP and the port ranges are then spread over the containers (with a 1:1 mapping between destination port and container ID). With the network isolator, you also can define performance limitations such as bandwidth and it enables you to perform per-container monitoring of the network traffic. See the MesosCon 2015 Seattle talk “Per Container Network Monitoring and Isolation in Mesos” for more details on this topic.
-
For the Docker containerizer, see Chapter 2.
Note that Mesos supports IP-per-container since version 0.23 and if you want to learn more about the current state of networking as well as upcoming developments, check out this MesosCon 2015 Seattle talk on Mesos Networking.
Service Discovery
While Mesos is not opinionated about service discovery, there is a Mesos-specific solution, which in praxis is often used: Mesos-DNS (see “Pure-Play DNS-Based Solutions”). There are, however, a multitude of emerging solutions such as traefik (see “Wrapping It Up”) that are integrated with Mesos and gaining traction. If you’re interested in more details about service discovery with Mesos, our open docs site has a dedicated section on this topic.
Note
Because Mesos-DNS is currently the recommended default service discovery mechanism with Mesos, it’s important to pay attention to how Mesos-DNS represents the tasks. For example, the running task you see in Figure 5-8 would have the (logical) service name webserver.marathon.mesos.
Hashicorp Nomad
Nomad is a cluster scheduler by HashiCorp, the makers of Vagrant. It was introduced in September 2015 and primarily aims at simplicity. The main idea is that Nomad is easy to install and use. Its scheduler design is reportedly inspired by Google’s Omega, borrowing concepts such as having a global state of the cluster as well as employing an optimistic, concurrent scheduler.
Nomad has an agent-based architecture with a single binary that can take on different roles, supporting rolling upgrade as well as draining nodes (for re-balancing). Nomad makes use of both a consensus protocol (strongly consistent) for all state replication and scheduling and a gossip protocol used to manage the addresses of servers for automatic clustering and multiregion federation. In Figure 5-9, you can see a Nomad agent starting up.
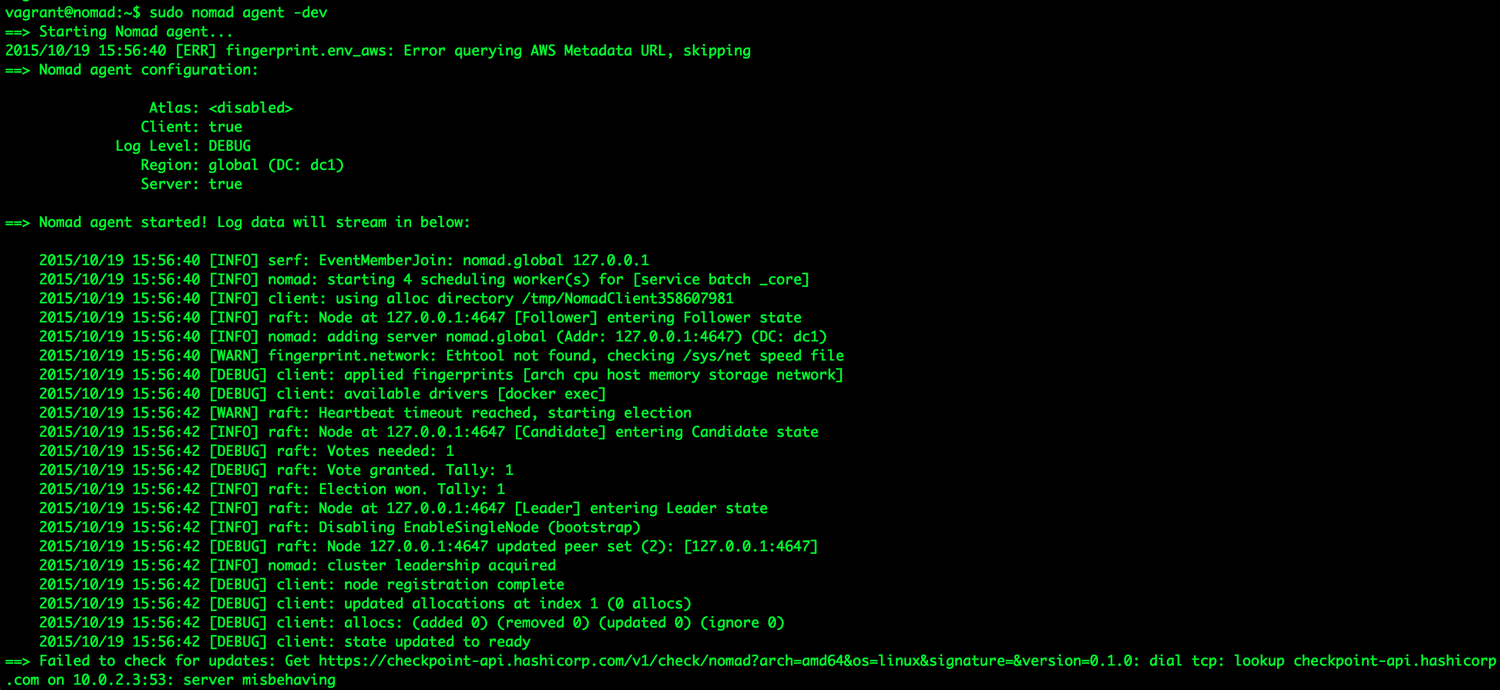
Figure 5-9. A Nomad agent, starting up in dev mode
Jobs in Nomad are defined in a HashiCorp-proprietary format called HCL or in JSON, and Nomad offers both a command-line interface as well as an HTTP API to interact with the server process.
In the following, I’m assuming you’re familiar with Nomad and its terminology (otherwise I suppose you wouldn’t be reading this section). Should you not be familiar with Nomad, I suggest you watch “Nomad: A Distributed, Optimistically Concurrent Schedule: Armon Dadgar, HashiCorp” (a very nice introduction to Nomad by HashiCorp’s CTO, Armon Dadgar) and also read the docs.
Networking
Nomad comes with a couple of so-called task drivers, from general-purpose exec to Java to qemu and Docker. We will focus on the latter one in the following discussion.
Nomad requires, at the time of this writing, Docker in the version 1.8.2. and uses port binding to expose services running in containers using the port space on the host’s interface. It provides automatic and manual mapping schemes for Docker, binding both TCP and UDP protocols to ports used for Docker containers.
For more details on networking options, such as mapping ports and using labels, I’ll point out the excellent docs page.
Service Discovery
With v0.2, Nomad introduced a Consul-based (see “Consul”) service discovery mechanism; see the respective docs section. It includes health checks and assumes that tasks running inside Nomad also need to be able to connect to the Consul agent, which can, in the context of containers using bridge mode networking, pose a challenge.
Which One Should I Use?
The following is of course only a suggestion from where I stand. It is based on my experience and naturally I’m biased toward stuff I’ve been using. Your mileage may vary, and there may be other (sometimes political?) reasons why you opt for a certain technology.
From a pure scale perspective, your options look like this:
| Tool | Up to 10 nodes | 10 to 100 nodes | Up to 1,000 nodes | 1,000s of nodes |
|---|---|---|---|---|
Docker Swarm |
++ |
+ |
? |
? |
Kubernetes |
++ |
++ |
+ |
? |
Apache Mesos |
+ |
++ |
++ |
++ |
Nomad |
++ |
? |
? |
? |
For a handful of nodes, it essentially doesn’t matter: choose any of the four solutions, depending on your preferences or previous experience. Do remember, however, that managing containers at scale is hard:
-
Docker Swarm reportedly scales to 1,000 nodes, see this HackerNews thread and this Docker blog post.
-
Kubernetes 1.0 is known to be scale-tested to 100s of nodes and work is ongoing to achieve the same scalability as Apache Mesos.
-
Apache Mesos has been simulated to be able to manage up to 50,000 nodes.
-
No scale-out information concerning Nomad exists at the time of this writing.
From a workload perspective, your options look like this:
| Tool | Non-containerized | Containerized | Batch | Long-running | Stateless | Stateful |
|---|---|---|---|---|---|---|
Docker Swarm |
– |
++ |
+ |
++ |
++ |
+ |
Kubernetes |
– |
++ |
+ |
++ |
++ |
+ |
Apache Mesos |
++ |
++ |
++ |
++ |
++ |
+ |
Nomad |
++ |
++ |
? |
++ |
++ |
? |
Non-containerized means you can run anything that you can also launch from a Linux shell (e.g., bash or Python scripts, Java apps, etc.), whereas containerized implies you need to generate Docker images. Concerning stateful services, pretty much all of the solutions require some handholding, nowadays. If you want to learn more about choosing an orchestration tool:
-
See the blog post “Docker Clustering Tools Compared: Kubernetes vs Docker Swarm”.
-
Read an excellent article on O’Reilly Radar: “Swarm v. Fleet v. Kubernetes v. Mesos”.
For the sake of completeness and because it’s an awesome project, I will point out the spanking new kid on the block, Firmament. Developed by folks who also contributed to Google’s Omega and Borg, this new scheduler construct a flow network of tasks and machines and runs a minimum-cost optimization over it. What is particularly intriguing about Firmament is the fact that you can use it not only standalone but also integrated with Kubernetes and (upcoming) with Mesos.
A Day in the Life of a Container
When choosing a container orchestration solution, you should consider the entire life cycle of a container (Figure 5-10).
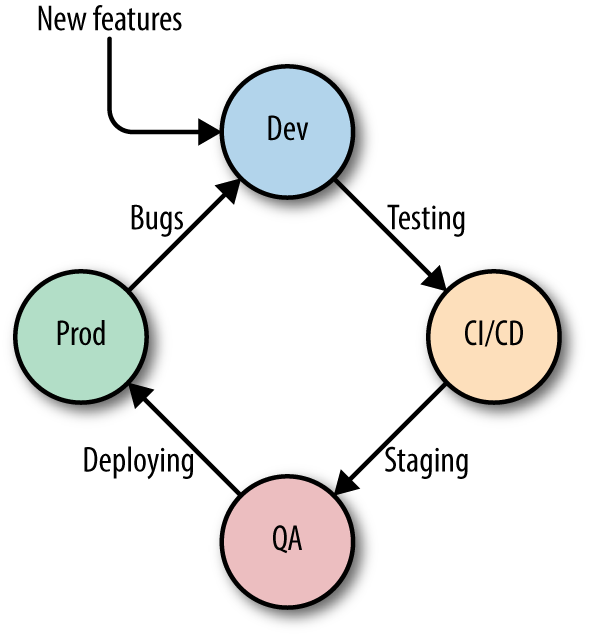
Figure 5-10. Docker container life cycle
The Docker container life cycle typically spans the following phases:
- Phase I: dev
-
The container image (capturing the essence of your service or app) starts its life in a development environment, usually on a developer’s laptop. You use feature requests and insights from running the service or application in production as inputs.
- Phase II: CI/CD
-
Then, the container goes through a pipeline of continuous integration and continuous delivery, including unit testing, integration testing, and smoke tests.
- Phase III: QA/staging
-
Next, you might use a QA environment (a cluster either on premises or in the cloud) and/or a staging phase.
- Phase IV: prod
-
Finally, the container image is deployed into the production environment. When dealing with Docker, you also need to have a strategy in place for how to distribute the images. Don’t forget to build in canaries as well as plan for rolling upgrades of the core system (such as Apache Mesos), potential higher-level components (like Marathon, in Mesos’ case) and your services and apps.
In production, you discover bugs and may collect metrics that can be used to improve the next iteration (back to Phase I).
Most of the systems discussed here (Swarm, Kubernetes, Mesos, Nomad) offer instructions, protocols, and integration points to cover all phases. This, however, shouldn’t be an excuse for not trying out the system end to end yourself before you commit to any one of these systems.
Community Matters
Another important aspect you will want to consider when selecting an orchestration system is that of the community behind and around it.6 Here a few indicators and metrics you can use:
-
Is the governance backed by a formal entity or process, such as the Apache Software Foundation or the Linux Foundation?
-
How active is the mailing list, the IRC channel, the bug/issue tracker, Git repo (number of patches or pull requests), and other community initiatives? Take a holistic view, but make sure that you actually pay attention to the activities there. Healthy (and hopefully growing) communities have high participation in at least one if not more of these areas.
-
Is the orchestration tool (implicitly or not) de facto controlled by a single entity? For example, in the case of Nomad, it is clear and accepted that HashiCorp alone is in full control. How about Kubernetes? Mesos?
-
Have you got several (independent) providers and support channels? For example, you can run Kubernetes or Mesos in many different environments, getting help from many (commercial or not) organizations and individuals.
With this, we’ve reached the end of the book. You’ve learned about the networking aspects of containers, as well as about service discovery options. With the content of this chapter, you’re now in a position to select and implement your containerized application.
If you want to dive deeper into the topics discussed in this book, check out Appendix A, which provides an organized list of resources.
1 See the last section of the “Understand Docker Container Networks” page.
2 Why it’s called ambassador when it clearly is a proxy at work here is beyond me.
3 Essentially, this means that you can simply keep using docker run commands and the deployment of your containers in a cluster happens automagically.
4 See pause.go for details; basically blocks until it receives a SIGTERM.
5 It should be noted that concerning stateful services such as databases (MySQL, Cassandra, etc.) or distributed filesystems (HDFS, Quobyte, etc.), we’re still in the early days in terms of support, as most of the persistence primitives landed only very recently in Mesos; see Felix Hupfeld and Jörg Schad’s presentation “Apache Mesos Storage Now and Future” for the current (end 2015) status.
6 Now, you may argue that this is not specific to the container orchestration domain but a general OSS issue and you’d be right. Still, I believe it is important enough to mention it, as many people are new to this area and can benefit from these insights.