
Chapter 4. Containers and Service Discovery
The primary challenge arising from adopting the cattle approach to managing infrastructure (introduced in Chapter 1) is service discovery. Service discovery and container scheduling are really two sides of the same coin. If you subscribe to the cattle approach to managing infrastructure, you treat all of your machines equally and you do not manually allocate certain machines for certain applications; instead, you leave it up to a piece of software (the scheduler) to manage the life cycle of the containers.
Then the question is: How do you determine on which host your container ended up being scheduled? Exactly! This is called service discovery, and we will discuss the other side of the coin, container orchestration, in Chapter 5 in greater detail.
The Challenge
Service discovery has been around for a while, considered to be part of zeroconf (see the sidebar that follows).
In the context of Docker containers, the challenge boils down to reliably maintaining a mapping between a running container and its location. By location, I mean its IP address (or the address of the host from which it has been launched) and potentially on which port it is reachable. This mapping has to be done in a timely manner and accurately across relaunches of the container throughout the cluster. Two distinct operations must be supported by a container service discovery solution:
- Register
-
Establishes the
container -> locationmapping. Because only the container scheduler knows where containers “live,” we can consider it to be the absolute source of truth concerning a container’s location. - Lookup
-
Enables other services or applications to look up the mapping we stored during registration. Interesting properties include the freshness of the information and the latency of a query (average, p50, p90, etc.).
Let’s take a look at a few slightly orthogonal considerations for the selection process:
-
Rather than simply sending a requestor in a certain direction, how about excluding unhealthy hosts or hanging containers from the lookup path? You’ve guessed it, it’s the strongly related topic of load balancing, and because it is of such importance we’ll discuss options in the last section of this chapter.
-
Some argue it’s an implementation detail, others say the position in the CAP triangle (see “The CAP Theorem and Beyond”) matters: the choice of strong consistency versus high availability in the context of the service discovery tool might influence your decision. Be at least aware of it.
-
Your choice might also be impacted by scalability considerations. Sure, if you only have a handful of nodes under management then all of the thereafter discussed solutions are a fit. If your cluster, however, is in the high 100s or even 1,000s of nodes, then you will want to make sure you did some proper load testing before you commit to one particular technology.
If you want to learn more about requirements and fundamental challenges in this space, read Jeff Lindsay’s “Understanding Modern Service Discovery with Docker” and check out what Simon Eskildsen of Shopify shared on this topic at a recent DockerCon.
Technologies
This section briefly introduces each technology, listing pros and cons and pointing to further discussions on the Web (if you want to gain hands-on knowledge with these technologies, you should check out Adrian Mouat’s excellent book Using Docker).
ZooKeeper
Apache ZooKeeper is an ASF top-level project and a JVM-based, centralized tool for configuration management,1
providing comparable functionality to what Google’s
Chubby brings to the
table. ZooKeeper (ZK) organizes its payload data somewhat like a
filesystem, in a hierarchy of so-called znodes. In a cluster, a leader is elected and clients can connect to any of the servers to retrieve data. You want 2n+1 nodes in a ZK cluster. The most often found configurations in the wild are three, five, or seven nodes. Beyond that, you’ll experience diminishing returns concerning the fault tolerance–throughput tradeoff.
ZooKeeper is a battle-proven, mature, and scalable solution, but has
some operational downsides. Some people consider the installation and
the management of a ZK cluster as a not-so-enjoyable experience. Most ZK
issues I’ve seen come from the fact that certain services (Apache Storm
comes to mind) misuse it. They either put too much data into the znodes, or even worse, they have an unhealthy
read-write ratio, essentially writing too fast. If you plan to use ZK,
at least consider using higher-level interfaces, such as
Apache Curator, which is a wrapper library around ZK, implementing a number of recipes, as well as
Netflix’s Exhibitor for managing
and monitoring a ZK cluster.
Looking at Figure 4-1, you see two components: the R/W (which stands for registration watcher, a piece of software you need to provide yourself), and NGINX, controlled by R/W. Whenever a container is scheduled on a node, it registers with ZK, using a znode with a path like /$nodeID/$containerID and the IP address as it’s payload. The R/W watches changes on those znodes and configures NGINX accordingly. This setup also works for HAProxy and other load balancers.
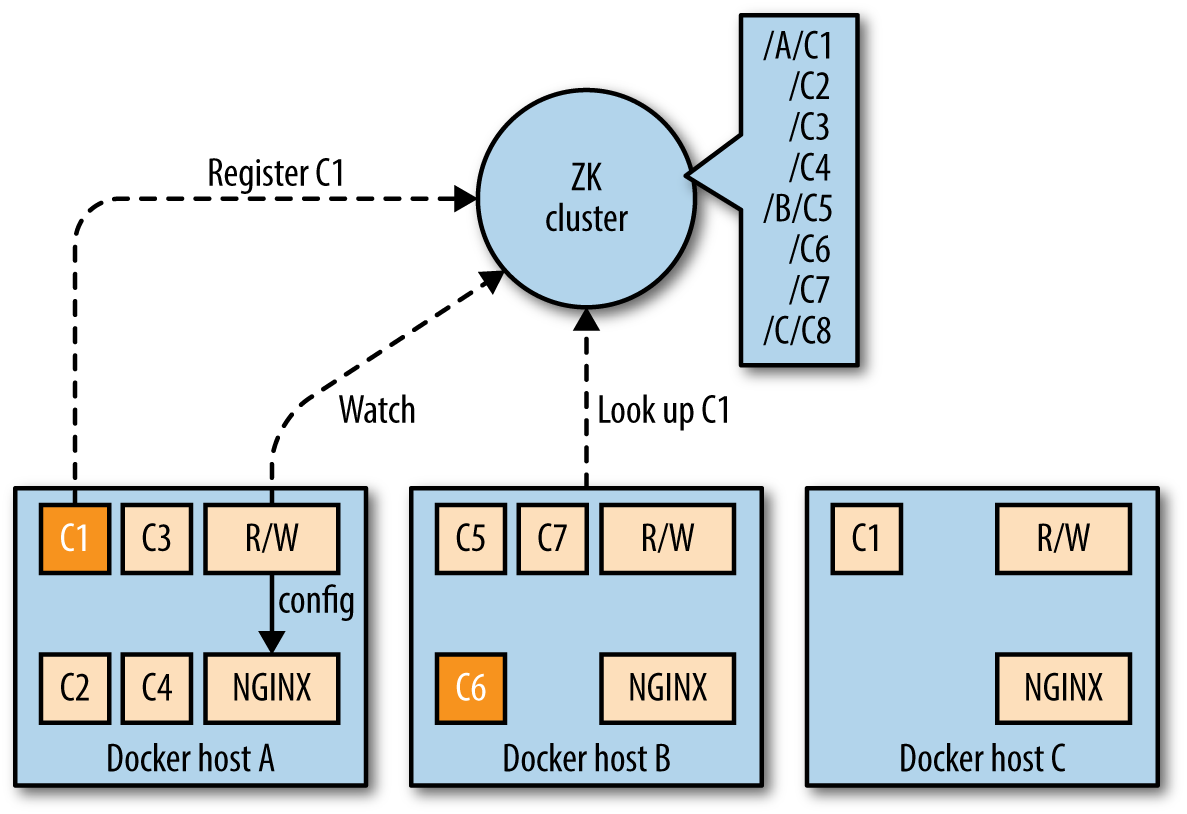
Figure 4-1. Example service discovery with ZooKeeper
etcd
Written in the Go language, etcd is a product of the CoreOS team.2 It is a lightweight, distributed key-value store that uses the Raft algorithm for consensus (leader–follower model, with leader election) and employing a replicated log across the cluster to distribute the writes a leader receives to its followers. In a sense, etcd is conceptually quite similar to ZK. While the payload can be arbitrary, etcd’s HTTP API is JSON-based3 and as with ZK, you can watch for changes in the values etcd makes available to the cluster. A very useful feature of etcd is that of TTLs on keys, which is a great building block for service discovery. In the same manner as ZK, you want 2n+1 nodes in an etcd cluster, for the same reasons.
The security model etcd provides allows on-the-wire encryption through TLS/SSL as well as client cert authentication, both for between clients and the cluster as well as between the etcd nodes.
In Figure 4-2, you can see that the etcd service discovery setup is quite similar to the ZK setup. The main difference is the usage of confd, which configures NGINX, rather than having you write your own script. As with ZK, this setup also works for HAProxy and other load balancers.
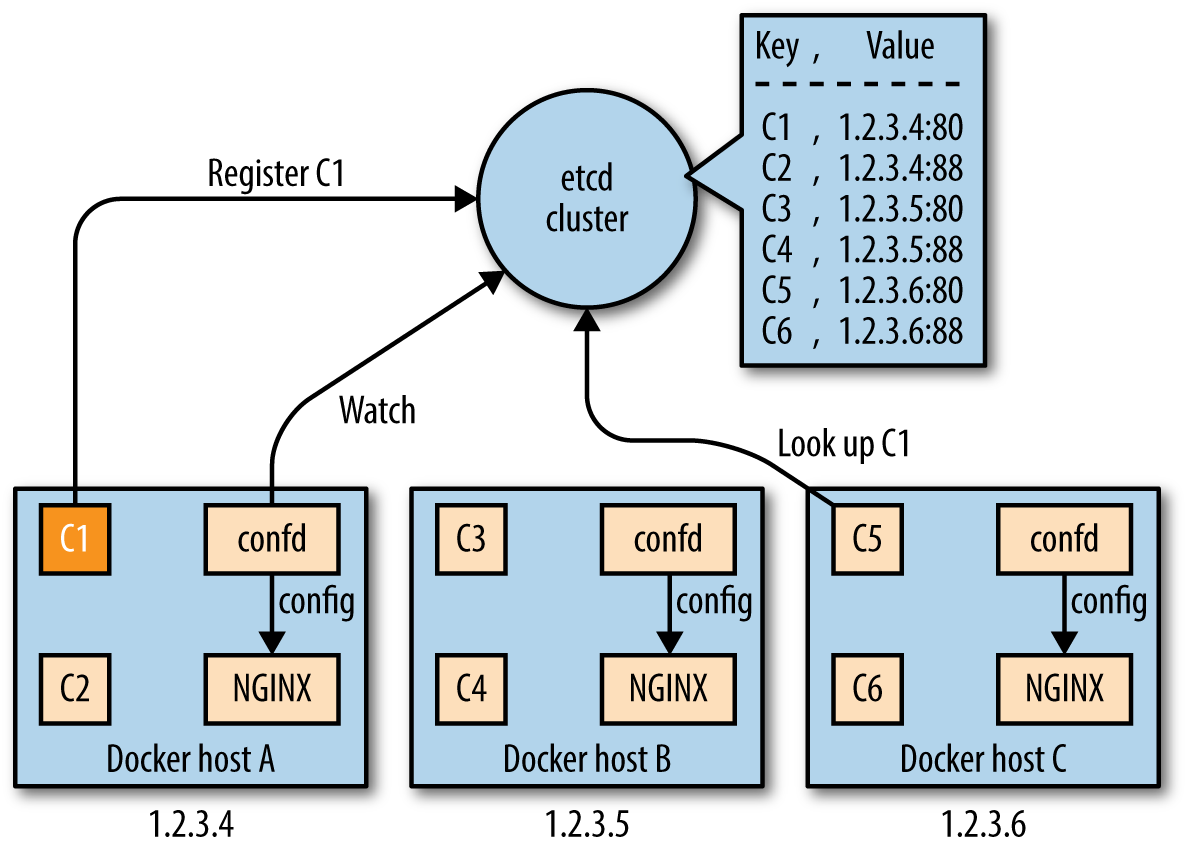
Figure 4-2. Example service discovery with etcd
Consul
Consul, a HashiCorp product also written in the Go language, exposes functionality for service registration, discovery, and health checking in an opinionated way. Services can be queried using either the HTTP API or through DNS. Consul supports multi-datacenter deployments.
One of Consul’s features is a distributed key-value store, akin to etcd. It also uses the Raft consensus algorithm (and again the same observations concerning 2n+1 nodes as with ZK and etcd apply), but the deployment is different. Consul has the concept of agents, which can be run in either of the two available modes: as a server (provides key-value store and DNS), or as a client (registers services and runs health checks) and with the membership and node discovery implemented by serf.
With Consul, you have essentially four options to implement service discovery (from most desirable to least desirable):
-
Use a service definition config file, interpreted by the Consul agent.
-
Use tools like traefik, which have a Consul backend.
-
Write your own side-kick process that registers the service through the HTTP API.
-
Bake the registration into the service itself through leveraging the HTTP API.
Want to learn more about Consul for service discovery? Check out these two great blog posts: “Consul Service Discovery with Docker” and “Docker DNS & Service Discovery with Consul and Registrator”.
Pure-Play DNS-Based Solutions
DNS has been a robust and battle-proven workhorse on the Internet for many decades. The eventual consistency of the DNS system, the fact that certain clients aggressively cache DNS lookups,4 and also the reliance on SRV records make this option something you will want to use when you know exactly that it is the right one.
I’ve titled this section “Pure-Play DNS-Based Solutions” because Consul technically also has a DNS server, but this is only one option for how you can use it to do service discovery. Here are some popular and widely used pure-play DNS-based service discovery solutions:
- Mesos-DNS
-
This solution is specific for service discovery in Apache Mesos. Written in Go, Mesos-DNS polls the active Mesos Master process for any running tasks and exposes the IP:PORT info via DNS as well as through an HTTP API. For DNS requests for other hostnames or services, Mesos-DNS can either use an external nameserver or leverage your existing DNS server to forward only the requests for Mesos tasks to Mesos-DNS.
- SkyDNS
-
Using etcd, you can announce your services to SkyDNS, which stores service definitions into etcd and updates its DNS records. Your client application issues DNS queries to discover the services. Thus, functionality-wise it is quite similar to Consul, without the health checks.
- WeaveDNS
-
WeaveDNS was introduced in Weave 0.9 as a simple solution to service discovery on the Weave network, allowing containers to find other containers’ IP addresses by their hostnames. In Weave 1.1, a so-called Gossip DNS was introduced, making lookups faster through a cache as well as timeout functionality. In the new implementation, registrations are broadcast to all participating instances, which subsequently hold all entries in memory and handle lookups locally.
Airbnb’s SmartStack and Netflix’s Eureka
In this section, we’ll take a look at two bespoke systems that were developed to address specific requirements. This doesn’t mean you can’t or shouldn’t use them, just that you should be aware of this heritage.
Airbnb’s SmartStack is an automated service discovery and registration framework, transparently handling creation, deletion, failure, and maintenance work. SmartStack uses two separate service that run on the same host as your container: Nerve (writing into ZK) for service registration, and Synapse (dynamically configuring HAProxy) for lookup. It is a well-established solution for non-containerized environments and time will tell if it will also be as useful with Docker.
Netflix’s Eureka is different. This comes mainly from the fact that it was born in the AWS environment (where all of Netflix runs). Eureka is a REST-based service used for locating services for the purpose of load balancing and failover of middle-tier servers and also comes with a Java-based client component, which makes interactions with the service straightforward. This client also has a built-in load balancer that does basic round-robin load balancing. At Netflix, Eureka is used for red/black deployments, for Cassandra and memcached deployments, and for carrying application-specific metadata about services.
Participating nodes in a Eureka cluster replicate their service registries between each other asynchronously; in contrast to ZK, etcd, or Consul, Eureka favors service availability over strong consistency, leaving it up to the client to deal with the stale reads, but with the upside of being more resilient in case of networking partitions. And you know: The network is reliable. Not.
Load Balancing
One aspect of service discovery—sometimes considered orthogonal, but really an integral part of it—is load balancing: it allows you to spread the load (service inbound requests) across a number of containers. In the context of containers and microservices, load balancing achieves a couple of things at the same time:
-
Allows throughput to be maximized and response time to be minimized
-
Can avoid hotspotting (i.e., overloading a single container)
-
Can help with overly aggressive DNS caching such as found with Java
The following list outlines some popular load balancing options with Docker:
- NGINX
-
A popular open source load balancer and web server. NGINX is known for its high performance, stability, simple configuration, and low resource consumption. NGINX integrates well with the service discovery platforms presented in this chapter, as well as with many other open source projects.
- HAProxy
-
While not very feature-rich, it is a very stable, mature, and battle-proven workhorse. Often used in conjunction with NGINX, HAProxy is reliable and integrations with pretty much everything under the sun exist. Use, for example, the tutumcloud/haproxy Docker images; because Docker, Inc., acquired Tutum recently, you can expect this image will soon be part of the native Docker tooling.
- Bamboo
-
A daemon that automatically configures HAProxy instances, deployed on Apache Mesos and Marathon; see also this p24e.io guide for a concrete recipe.
- Kube-Proxy
-
Runs on each node of a Kubernetes cluster and reflects services as defined in the Kubernetes API. It supports simple TCP/UDP forwarding and round-robin and Docker-links-based service
IP:PORTmapping. - vulcand
-
A HTTP reverse proxy for HTTP API management and microservices, inspired by Hystrix.
- Magnetic.io’s vamp-router
-
Inspired by Bamboo and Consul-HAProxy, it supports updates of the config through REST or Zookeeper, routes and filters for canary releasing and A/B-testing, as well as provides for stats and ACLs.
- moxy
-
A HTTP reverse proxy and load balancer that automatically configures itself for microservices deployed on Apache Mesos and Marathon.
- HAProxy-SRV
-
A templating solution that can flexibly reconfigure HAProxy based on the regular polling of the service data from DNS (e.g., SkyDNS or Mesos-DNS) using SRV records.
- Marathon’s servicerouter.py
-
The servicerouter is a simple script that gets app configurations from Marathon and updates HAProxy; see also this p24e.io recipe.
- traefik
-
The new kid on the block. Only very recently released but already sporting 1,000+ stars on GitHub, Emile Vauge (traefik’s lead developer) must be doing something right. I like it because it’s like HAProxy, but comes with a bunch of backends such as Marathon and Consul out of the box.
If you want to learn more about load balancing, check out this Mesos meetup video as well as this talk from nginx.conf 2014 on load balancing with NGINX+Consul.
Wrapping It Up
To close out this chapter, I’ve put together a table that provides you with an overview of the service discovery solutions we’ve discussed. I explicitly do not aim at declaring a winner, because I believe it very much depends on your use case and requirements. So, take the following table as a quick orientation and summary but not as a shootout:
| Name | Consistency | Language | Registration | Lookup |
|---|---|---|---|---|
ZooKeeper |
Strong |
Java |
Client |
Bespoke clients |
etcd |
Strong |
Go |
Sidekick+client |
HTTP API |
Consul |
Strong |
Go |
Automatic and through traefik (Consul backend) |
DNS + HTTP/JSON API |
Mesos-DNS |
Strong |
Go |
Automatic and through traefik (Marathon backend) |
DNS + HTTP/JSON API |
SkyDNS |
Strong |
Go |
Client registration |
DNS |
WeaveDNS |
Strong |
Go |
Auto |
DNS |
SmartStack |
Strong |
Java |
Client registration |
Automatic through HAProxy config |
Eureka |
Eventual |
Java |
Client registration |
Bespoke clients |
As a final note: the area of service discovery is constantly in flux and new tooling is available almost on a weekly basis. For example, Uber only recently open sourced its internal solution, Hyperbahn, an overlay network of routers designed to support the TChannel RPC protocol. Because container service discovery is overall a moving target, you are well advised to reevaluate the initial choices on an ongoing basis, at least until some consolidation has taken place.