
Chapter 1. Motivation
In February 2012, Randy Bias gave an impactful talk on architectures for open and scalable clouds. In his presentation, he established the pets versus cattle meme:1
-
With the pets approach to infrastructure, you treat the machines as individuals. You give each (virtual) machine a name and applications are statically allocated to machines. For example,
db-prod-2is one of the production servers for a database. The apps are manually deployed and when a machine gets ill you nurse it back to health and again manually redeploy the app it ran onto another machine. This approach is generally considered to be the dominant paradigm of a previous (non-cloud-native) era. -
With the cattle approach to infrastructure, your machines are anonymous, they are all identical (modulo hardware upgrades), have numbers rather than names, and apps are automatically deployed onto any and each of the machines. When one of the machines gets ill, you don’t worry about it immediately, and replace it (or parts of it, such as a faulty HDD) when you want and not when things break.
While the original meme was focused on virtual machines, we apply the cattle approach to infrastructure to containers.
Go Cattle!
The beautiful thing about applying the cattle approach to infrastructure is that it allows you to scale out on commodity hardware.2
It gives you elasticity with the implication of hybrid cloud capabilities. This is a fancy way of saying that you can have a part of your deployments on premises and burst into the public cloud (as well as between IaaS offerings of different providers) if and when you need it.
Most importantly, from an operator’s point of view, the cattle approach allows you to get a decent night’s sleep, as you’re no longer paged at 3 a.m. just to replace a broken HDD or to relaunch a hanging app on a different server, as you would have done with your pets.
However, the cattle approach poses some challenges that generally fall into one of the following two categories:
- Social challenges
-
I dare say most of the challenges are of a social nature: How do I convince my manager? How do I get buy-in from my CTO? Will my colleagues oppose this new way of doing things? Does this mean we will need less people to manage our infrastructure? Now, I will not pretend to offer ready-made solutions for this part; instead, go buy a copy of The Phoenix Project, which should help you find answers.
- Technical challenges
-
In this category, you will find things like selection of base provisioning mechanism of the machines (e.g., using Ansible to deploy Mesos Agents), how to set up the communication links between the containers and to the outside world, and most importantly, how to ensure the containers are automatically deployed and are consequently findable.
Docker Networking and Service Discovery Stack
The overall stack we’re dealing with here is depicted in Figure 1-1 and is comprised of the following:
- The low-level networking layer
-
This includes networking gear,
iptables, routing, IPVLAN, and Linux namespaces. You usually don’t need to know the details here, unless you’re on the networking team, but you should be aware of it. See Chapter 2 for more information on this topic. - A Docker networking layer
-
This encapsulates the low-level networking layer and provides some abstractions such as the single-host bridge networking mode or a multihost, IP-per-container solution. I cover this layer in Chapters 2 and 3.
- A service discovery/container orchestration layer
-
Here, we’re marrying the container scheduler decisions on where to place a container with the primitives provided by lower layers. Chapter 4 provides you with all the necessary background on service discovery, and in Chapter 5, we look at networking and service discovery from the point of view of the container orchestration systems.
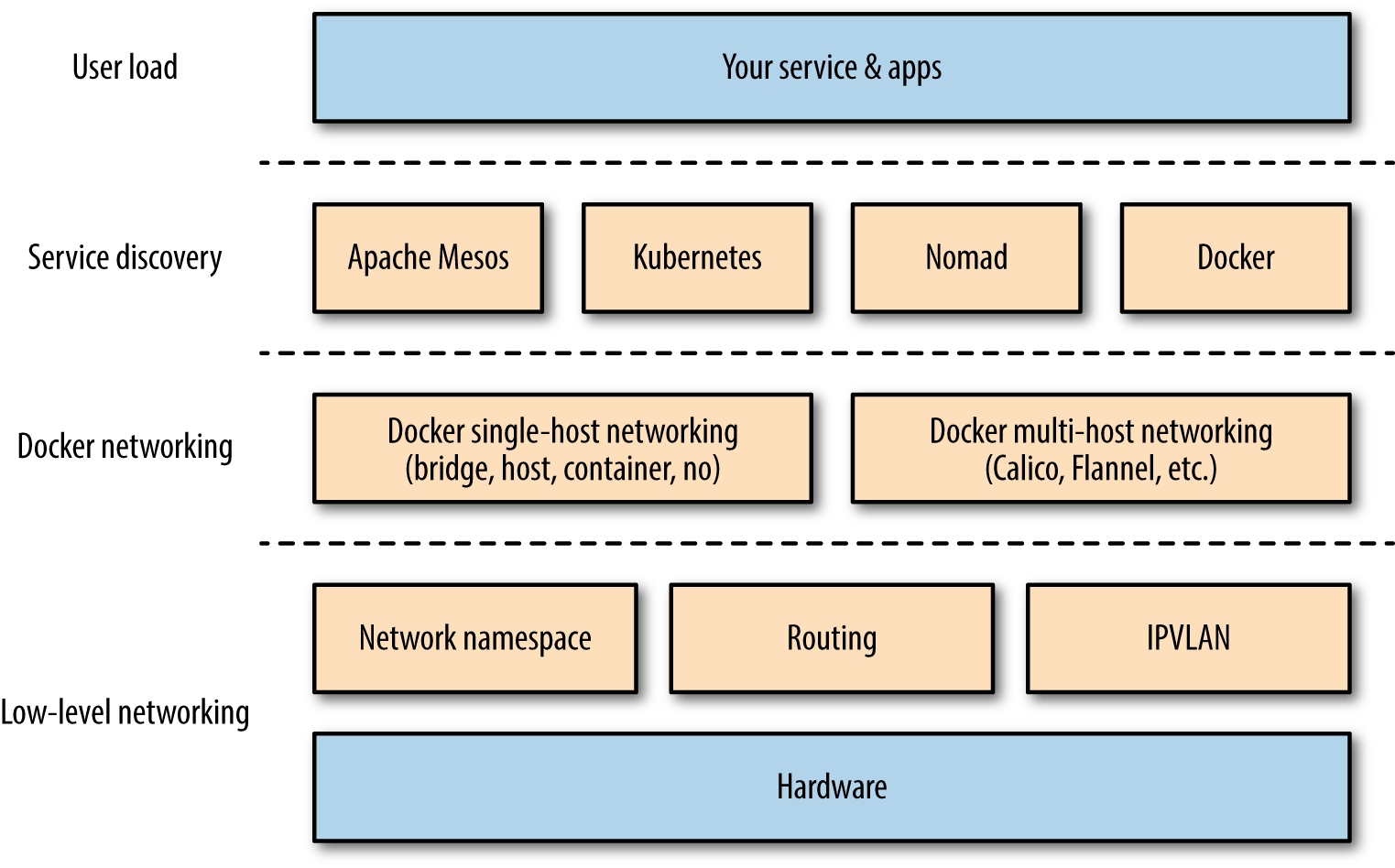
Figure 1-1. Docker networking and service discovery (DNSD) stack
If you are on the network operations team, you’re probably good to go for the next chapter. However, if you’re an architect or developer and your networking knowledge might be a bit rusty, I suggest brushing up your knowledge by studying the Linux Network Administrators Guide before advancing.
Do I Need to Go “All In”?
Oftentimes when I’m at conferences or user groups, I meet people who are very excited about the opportunities in the container space but at the same time they (rightfully) worry about how deep they need to commit in order to benefit from it. The following table provides an informal overview of deployments I have seen in the wild, grouped by level of commitment (stages):
| Stage | Typical Setup | Examples |
|---|---|---|
Traditional |
Bare-metal or VM, no containers |
Majority of today’s prod deployments |
Simple |
Manually launched containers used for app-level dependency management |
Development and test environments |
Ad hoc |
A custom, homegrown scheduler to launch and potentially restart containers |
RelateIQ, Uber |
Full-blown |
An established scheduler from Chapter 5 to manage containers; fault tolerant, self-healing |
Google, Zulily, Gutefrage.de |
Note that not all of these examples use Docker containers (notably, Google does not) and that some start out, for instance, in the ad-hoc stage and are transitioning to a full-blown stage as we speak (Uber is such a case; see this presentation from ContainerSched 2015 in London). Last but not least, the stage doesn’t necessarily correspond with the size of the deployment. For example, Gutefrage.de only has six bare-metal servers under management, yet uses Apache Mesos to manage them.
One last remark before we move on: by now, you might have already realized that we are dealing with distributed systems in general here. Given that we will usually want to deploy containers into a network of computers (i.e., a cluster), I strongly suggest reading up on the fallacies of distributed computing, in case you are not already familiar with this topic.
And now, without further ado, let’s jump into the deep end with Docker networking.
1 In all fairness, Randy did attribute the origins to Bill Baker of Microsoft.
2 Typically even very homogenous hardware—see, for example, slide 7 of the PDF slide deck for Thorvald Natvig’s Velocity NYC 2015 talk “Challenging Fundamental Assumptions of Datacenters: Decoupling Infrastructure from Hardware”.