
Key resources to any computer system are the central processing units (CPUs). Many modern systems from Sun boast numerous CPUs or virtual CPUs (which may be cores or hardware threads). The CPUs are shared by applications on the system, according to a policy prescribed by the operating system and scheduler (see Chapter 3 in Solaris™ Internals).
If the system becomes CPU resource limited, then application or kernel threads have to wait on a queue to be scheduled on a processor, potentially degrading system performance. The time spent on these queues, the length of these queues and the utilization of the system processor are important metrics for quantifying CPU-related performance bottlenecks. In addition, we can directly measure CPU utilization and wait states in various forms by using DTrace.
A number of different tools analyze CPU activity. The following summarizes both these tools and the topics covered in this section.
Utilization. Overall CPU utilization can be determined from the idle (
id) field fromvmstat, and the user (us) and system (sy) fields indicate the type of activity. Heavy CPU saturation is more likely to degrade performance than is CPU utilization.Saturation. The run queue length from
vmstat(kthr:r) can be used as a measure of CPU saturation, as can CPU latency time fromprstat -m.Load averages. These numbers, available from both the
uptimeandprstatcommands, provide 1-, 5-, and 15-minute averages that combine both utilization and saturation measurements. This value can be compared to other servers if divided by the CPU count.History.
sarcan be activated to record historical CPU activity. This data can identify long-term patterns; it also provides a reference for what CPU activity is “normal.”Per-CPU utilization.
mpstatlists statistics by CPU, to help identify application scaling issues should CPU utilization be unbalanced.CPU by process. Commands such as
psandprstatcan be used to identify CPU consumption by process.Microstate accounting. High-resolution time counters track several states for user threads;
prstat -mreports the results.DTrace analysis. DTrace can analyze CPU consumption in depth and can measure events in minute detail.
Table 2.1 summarizes the tools covered in this chapter, cross-references them, and lists the origin of the data that each tool uses.
Table 2.1. Tools for CPU Analysis
Tool | Uses | Description | Reference |
|---|---|---|---|
| Kstat | For an initial view of overall CPU behavior | 2.2 and 2.12.1 |
| Kstat | For physical CPU properties | 2.5 |
|
| For the load averages, to gauge recent CPU activity | 2.6 and 2.12.2 |
| Kstat, sadc | For overall CPU behavior, and dispatcher queue statistics; sar also allows historical data collection | 2.7 and 2.12.1 |
| Kstat | For per-CPU statistics | 2.9 |
|
| To identify process CPU consumption | 2.10 and 2.11 |
| DTrace | For detailed analysis of CPU activity, including scheduling events and dispatcher analysis | 2.13, 2.14, and 2.15 |
The vmstat tool provides a glimpse of the system’s behavior on one line and is often the first command you run to familiarize yourself with a system. It is useful here because it indicates both CPU utilization and saturation on one line.
$ vmstat 5 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr dd f0 s1 -- in sy cs us sy id 0 0 0 1324808 319448 1 2 2 0 0 0 0 0 0 0 0 403 21 54 0 1 99 2 0 0 1318528 302696 480 6 371 0 0 0 0 73 0 0 0 550 5971 190 84 16 0 3 0 0 1318504 299824 597 0 371 0 0 0 0 48 0 0 0 498 8529 163 81 19 0 2 0 0 1316624 297904 3 0 597 0 0 0 0 91 0 0 0 584 2009 242 84 16 0 2 0 0 1311008 292288 2 0 485 0 0 0 0 83 0 0 0 569 2357 252 77 23 0 2 0 0 1308240 289520 2 0 749 0 0 0 0 107 0 0 0 615 2246 290 82 18 0 2 0 0 1307496 288768 5 0 201 0 0 0 0 58 0 0 0 518 2231 210 79 21 0 ...
The first line is the summary since boot, followed by samples every five seconds. vmstat reads its statistics from kstat, which maintains CPU utilization statistics for each CPU. The mechanics behind this are discussed in Section 2.12.
Two columns are of greatest interest in this example. On the far right is cpu:id for percent idle, which lets us determine how utilized the CPUs are; and on the far left is kthr:r for the total number of threads on the ready to run queues, which is a measure of CPU saturation.
In this vmstat example, the idle time for the five-second samples was always 0, indicating 100% utilization. Meanwhile, kthr:r was mostly 2 and sustained, indicating a modest saturation for this single CPU server.
vmstat provides other statistics to describe CPU behavior in more detail, as listed in Table 2.2
Table 2.2. CPU Statistics from the vmstat Command
Counter | Description |
|---|---|
| |
| Total number of runnable threads on the dispatcher queues; used as a measure of CPU saturation |
| |
| Number of interrupts per second |
| Number of system calls per second |
| Number of context switches per second, both voluntary and involuntary |
| |
| Percent user time; time the CPUs spent processing user-mode threads |
| Percent system time; time the CPUs spent processing system calls on behalf of user-mode threads, plus the time spent processing kernel threads |
| Percent idle; time the CPUs are waiting for runnable threads. This value can be used to determine CPU utilization |
The following sections discuss CPU utilization and saturation in greater detail.
You can calculate CPU utilization from vmstat by subtracting id from 100 or by adding us and sy. Keep in mind the following points when considering CPU utilization.
100% utilized may be fine—it can be the price of doing business.
When a Solaris system hits 100% CPU utilization, there is no sudden dip in performance; the performance degradation is gradual. Because of this, CPU saturation is often a better indicator of performance issues than is CPU utilization.
The measurement interval is important: 5% utilization sounds close to idle; however, for a 60-minute sample it may mean 100% utilization for 3 minutes and 0% utilization for 57 minutes. It is useful to have both short- and long-duration measurements.
An server running at 10% CPU utilization sounds like 90% of the CPU is available for “free,” that is, it could be used without affecting the existing application. This isn’t quite true. When an application on a server with 10% CPU utilization wants the CPUs, they will almost always be available immediately. On a server with 100% CPU utilization, the same application will find that the CPUs are already busy—and will need to preempt the currently running thread or wait to be scheduled. This can increase latency (which is discussed in more detail in Section 2.11).
The kthr:r metric from vmstat is useful as a measure for CPU saturation. However, since this is the total across all the CPU run queues, divide kthr:r by the CPU count for a value that can be compared with other servers.
Any sustained non-zero value is likely to degrade performance. The performance degradation is gradual (unlike the case with memory saturation, where it is rapid).
Interval time is still quite important. It is possible to see CPU saturation (kthr:r) while a CPU is idle (cpu:idl). To understand how this is possible, either examine the %runocc from sar -q or measure the run queues more accurately by using DTrace. You may find that the run queue is quite long for a short period of time, followed by idle time. Averaging over the interval gives both a non-zero run queue length and idle time.
To determine the number of processors in the system and their speed, use the psrinfo -v command. In Solaris 10, -vp prints additional information.
$ psrinfo -vp
The physical processor has 1 virtual processor (0)
UltraSPARC-III+ (portid 0 impl 0x15 ver 0x23 clock 900 MHz)
The physical processor has 1 virtual processor (1)
UltraSPARC-III+ (portid 1 impl 0x15 ver 0x23 clock 900 MHz)
The uptime command is a quick way to print the CPU load averages.[1]
$ uptime 12:29am up 274 day(s), 6 hr(s), 7 users, load average: 2.00, 1.07, 0.46
The numbers are the 1-, 5-, and 15-minute load averages. They represent both utilization and saturation of the CPUs. Put simply, a value equal to your CPU count usually means 100% utilization; less than your CPU count is proportionally less than 100% utilization; and greater than your CPU count is a measure of saturation. To compare a load average between servers, divide the load average by the CPU count for a consistent metric.
By providing the 1-, 5-, and 15-minute averages, recently increasing or decreasing CPU load can be identified. The previous uptime example demonstrates an increasing profile (2.00, 1.07, 0.46).
The calculation used for the load averages is often described as the average number of runnable and running threads, which is a reasonable description.[2] As an example, if a single CPU server averaged one running thread on the CPU and two on the dispatcher queue, then the load average would be 3.0. A similar load for a 32-CPU server would involve an average of 32 running threads plus 64 on the dispatcher queues, resulting in a load average of 96.0.
A consistent load average higher than your CPU count may cause degraded application performance. CPU saturation is something that Solaris handles very well, so it is possible that a server can run at some level of saturation without a noticeable effect on performance.
The system actually calculates the load averages by summing high-resolution user time, system time, and thread wait time, then processing this total to generate averages with exponential decay. Thread wait time measures CPU latency. The calculation no longer samples the length of the dispatcher queues, as it did with older Solaris. However, the effect of summing thread wait time provides an average that is usually (but not always) similar to averaging queue length anyway. For more details, see Section 2.12.2.
It is important not to become too obsessed with load averages: they condense a complex system into three numbers and should not be used for anything more than an initial approximation of CPU load.
The system activity reporter (sar) can provide live statistics or can be activated to record historical CPU statistics. This can be of tremendous value because you may identify long-term patterns that you might have missed when taking a quick look at the system. Also, historical data provides a reference for what is “normal” for your system.
The following example shows the default output of sar, which is also the -u option to sar. An interval of 1 second and a count of 5 were specified.
$ sar 1 5
SunOS titan 5.11 snv_16 sun4u 02/27/2006
03:20:42 %usr %sys %wio %idle
03:20:43 82 17 0 1
03:20:44 92 8 0 0
03:20:45 91 9 0 0
03:20:46 94 6 0 0
03:20:47 93 7 0 0
Average 91 9 0 0
sar has printed the user (%usr), system (%sys), wait I/O (%wio), and idle times (%idle). User, system, and idle are also printed by the vmstat command and are defined in 2.2. The following are some additional points.
%usr,%sys(user, system). A commonly expected ratio is 70%usrand 30%sys, but this depends on the application. Applications that use I/O heavily, for example a busy Web server, can cause a much higher%sysdue to a large number of system calls. Applications that spend time processing userland code, for example, compression tools, can cause a higher%usr. Kernel mode services, such as the NFS server, are%sysbased.%wio(wait I/O). This was supposed to be a measurement of the time spent waiting for I/O events to complete.[3] The way it was measured was not very accurate, resulting in inconsistent values and much confusion. This statistic has now been deliberately set to zero in Solaris 10.%idle(idle). There are different mentalities for percent idle. One is that percent idle equals wasted CPU cycles and should be put to use, especially when server consolidation solutions such as Solaris Zones are used. Another is that some level of%idleis healthy (anywhere from 20% to 80%) because it leaves “head room” for short increases in activity to be dispatched quickly.
The -q option for sar provides statistics on the run queues (dispatcher queues).
$ sar -q 5 5 SunOS titan 5.11 snv_16 sun4u 02/27/2006 03:38:43 runq-sz %runocc swpq-sz %swpocc 03:38:48 0.0 0 0.0 0 03:38:53 1.0 80 0.0 0 03:38:58 1.6 99 0.0 0 03:39:03 2.4 100 0.0 0 03:39:08 3.4 100 0.0 0 Average 2.2 76 0.0 0
There are four fields.
runq-sz(run queue size). Equivalent to thekthr:rfield fromvmstat; can be used as a measure of CPU saturation.[4]%runocc(run queue occupancy). Helps prevent a danger when intervals are used, that is, short bursts of activity can be averaged down to unnoticeable values. The run queue occupancy can identify whether short bursts of run queue activity occurred.[5]swpq-sz(swapped-out queue size). Number of swapped-out threads. Swapping out threads is a last resort for relieving memory pressure, so this field will be zero unless there was a dire memory shortage.%swpocc(swapped out occupancy). Percentage of time there were swapped out threads.
To activate sar to record statistics in Solaris 10, use svcadm enable sar.[6] The defaults are to take a one-second sample every hour plus every twenty minutes during business hours. This should be customized because a one-second sample every hour isn’t terribly useful (the man page for sadc suggests it should be greater than five seconds). You can change it by placing an interval and a count after the sa1 lines in the crontab for the sys user (crontab -e sys).
At some point in a discussion on CPU statistics it is obligatory to lament the inaccuracy of a 100 hertz sample: What if each sample coincided with idle time, mis-representing the state of the server?
Once upon a time, CPU statistics were gathered every clock tick or every hundredth of a second.[7] As CPUs became faster, it became increasingly possible for fleeting activity to occur between clock ticks, and such activity would not be measured correctly. Now we use microstate accounting. It uses high-resolution timestamps to measure CPU statistics for every event, producing extremely accurate statistics. See Section 2.10.3 in Solaris™ Internals
If you look through the Solaris source, you will see high-resolution counters just about everywhere. Even code that expects clock tick measurements will often source the high-resolution counters instead. For example:
cpu_sys_stats_ks_update(kstat_t *ksp, int rw)
{
...
csskd->cpu_ticks_idle.value.ui64 =
NSEC_TO_TICK(csskd->cpu_nsec_idle.value.ui64);
csskd->cpu_ticks_user.value.ui64 =
NSEC_TO_TICK(csskd->cpu_nsec_user.value.ui64);
csskd->cpu_ticks_kernel.value.ui64 =
NSEC_TO_TICK(csskd->cpu_nsec_kernel.value.ui64);
...
See uts/common/os/cpu.c
In this code example, NSEC_TO_TICK converts from the microstate accounting value (which is in nanoseconds) to a ticks count. For more details on CPU microstate accounting, see Section 2.12.1.
While most counters you see in Solaris are highly accurate, sampling issues remain in a few minor places. In particular, the run queue length as seen from vmstat (kthr:r) is based on a sample that is taken every second. Running vmstat with an interval of 5 prints the average of five samples taken at one-second intervals. The following (somewhat contrived) example demonstrates the problem.
$ vmstat 2 5 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr cd s0 -- -- in sy cs us sy id 0 0 23 1132672 198460 34 47 96 2 2 0 15 6 0 0 0 261 392 170 2 1 97 0 0 45 983768 120944 1075 4141 0 0 0 0 0 0 0 0 0 355 2931 378 7 25 67 0 0 45 983768 120944 955 3851 0 0 0 0 0 0 0 0 0 342 1871 279 4 22 73 0 0 45 983768 120944 940 3819 0 0 0 0 0 0 0 0 0 336 1867 280 4 22 73 0 0 45 983768 120944 816 3561 0 0 0 0 0 0 0 0 0 338 2055 273 5 20 75 $ uptime 4:50am up 14 day(s), 23:32, 4 users, load average: 4.43, 4.31, 4.33
For this single CPU server, vmstat reports a run queue length of zero. However, the load averages (which are now based on microstate accounting) suggest considerable load. This was caused by a program that deliberately created numerous short-lived threads every second, such that the one-second run queue sample usually missed the activity.
The runq-sz from sar -q suffers from the same problem, as does %runocc(which for short-interval measurements defeats the purpose of %runocc).
These are all minor issues, and a valid workaround is to use DTrace, with which statistics can be created at any accuracy desired. Demonstrations of this are in Section 2.14.
The mpstat command summarizes the utilization statistics for each CPU. The following output is an example from a system with 32 CPUs.
$ mpstat 1
CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl
0 0 0 279 267 112 106 7 7 85 0 219 85 2 0 13
1 1 0 102 99 0 177 9 15 119 2 381 72 3 0 26
2 2 0 75 130 0 238 19 11 98 5 226 70 3 0 28
3 1 0 94 32 0 39 8 6 95 2 380 81 2 0 17
4 1 0 70 75 0 128 11 9 96 1 303 66 2 0 32
5 1 0 88 62 0 99 7 11 89 1 370 74 2 0 24
6 4 0 78 47 0 85 24 6 67 8 260 86 2 0 12
7 2 0 73 29 0 45 21 5 57 7 241 85 1 0 14
8 2 0 94 21 0 17 10 3 73 0 392 86 2 0 12
9 3 0 64 106 0 198 23 12 85 7 209 66 2 0 32
10 2 0 23 164 0 331 20 13 85 7 89 17 2 0 81
11 3 0 31 105 0 200 14 11 63 4 144 33 2 0 66
12 0 0 47 129 0 260 3 8 86 0 248 33 2 0 65
13 4 0 76 48 0 90 25 5 77 8 255 75 2 0 24
14 5 0 39 130 0 275 17 9 83 10 158 36 2 0 62
15 2 0 67 99 0 183 18 5 101 4 207 72 2 0 25
16 3 0 79 61 0 103 20 2 89 3 252 83 2 0 15
17 2 0 17 64 0 123 8 7 38 2 65 18 1 0 81
18 4 0 86 22 0 21 21 0 98 4 283 98 2 0 0
19 1 0 10 75 0 148 9 5 38 1 47 9 3 0 88
20 1 0 49 108 1 208 4 6 85 0 252 29 2 0 69
21 5 0 90 46 0 77 29 1 75 8 277 92 2 0 6
22 2 0 56 98 0 186 15 5 71 3 176 59 2 0 39
23 5 0 37 156 0 309 19 6 75 4 136 39 2 0 59
24 0 0 32 51 0 97 2 3 32 1 198 15 1 0 83
25 8 0 82 56 0 142 13 8 87 13 294 82 2 0 16
26 2 0 66 40 0 75 12 3 66 2 237 73 2 0 25
27 6 0 80 33 0 57 21 5 89 3 272 86 2 0 13
28 1 0 97 35 0 56 7 3 94 2 369 76 2 0 22
29 4 0 83 44 0 79 27 3 69 7 286 89 2 0 9
30 1 0 95 41 1 69 8 4 105 1 382 80 2 0 18
31 5 0 16 31 2 99 5 9 20 15 97 9 1 0 90
...
For each CPU, a set of event counts and utilization statistics are reported. The first output printed is the summary since boot. After vmstat is checked, the mpstat processor utilization metrics are often the next point of call to ascertain how busy the system CPUs are.
Processor utilization is reported by percent user (usr), system (sys), wait I/O (wt) and idle (idl) times, which have the same meanings as the equivalent columns from vmstat (Section 2.2) and sar (Section 2.7). The syscl field provides additional information for understanding why system time was consumed.
syscl(system calls). System calls per second. See Section 2.13 for an example of how to use DTrace to investigate the impact and cause of system call activity.
The scheduling-related statistics reported by mpstat are as follows.
csw(context switches). This field is the total of voluntary and involuntary context switches. Voluntary context switches occur when a thread performs a blocking system call, usually one performing I/O when the thread voluntarily sleeps until the I/O event has completed.icsw(number of involuntary context switches). This field displays the number of threads involuntarily taken off the CPU either through expiration of their quantum or preemption by a higher-priority thread. This number often indicates if there were generally more threads ready to run than physical processors. To analyze further, a DTrace probe,dequeue, fires when context switches are made, as described in Section 2.15.migr(migrations of threads between processors). This field displays the number of times the OS scheduler moves ready-to-run threads to an idle processor. If possible, the OS tries to keep the threads on the last processor on which it ran. If that processor is busy, the thread migrates. Migrations on traditional CPUs are bad for performance because they cause a thread to pull its working set into cold caches, often at the expense of other threads.intr(interrupts). This field indicates the number of interrupts taken on the CPU. These may be hardware- or software-initiated interrupts. See Section 3.11 in Solaris™ Internals for further information.ithr(interrupts as threads). The number of interrupts that are converted to real threads, typically as a result of inbound network packets, blocking for a mutex, or a synchronization event. (High-priority interrupts won’t do this, and interrupts without mutex contention typically interrupt the running thread and complete without converting to a full thread). See Section 3.11 in Solaris™ Internals for further information.
The locking-related statistics reported by mpstat are as follows.
smtx(kernel mutexes). This field indicates the number of mutex contention events in the kernel. Mutex contention typically manifests itself first as system time (due to busy spins), which results in high system (%sys) time, which don’t show insmtx. More useful lock statistics are available throughlockstat(1M)and the DTracelockstatprovider (see Section 9.3.5 and Chapter 17 in Solaris™ Internals).srw(kernel reader/writer mutexes). This field indicates the number of reader-writer lock contention events in the kernel. Excessive reader/writer lock contention typically results in nonscaling performance and systems that are unable to use all the available CPU resources (symptom is idle time). More useful lock statistics are available withlockstat(1M)and the DTrace lockstat provider—See Section 9.3.5 and Chapter 17 in Solaris™ Internals.
See Chapter 3 in Solaris™ Internals, particularly Section 3.8.1, for further information.
The prstat command was introduced in Solaris 8 to provide real-time process status in a meaningful way (it resembles top, the original freeware tool written by William LeFebvre). prstat uses procfs, the /proc file system, to fetch process details (see proc(4)), and the getloadavg() syscall to get load averages.
$ prstat PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP 25639 rmc 1613M 42M cpu22 0 10 0:33:10 3.1% filebench/2 25655 rmc 1613M 42M cpu23 0 10 0:33:10 3.1% filebench/2 25659 rmc 1613M 42M cpu30 0 10 0:33:11 3.1% filebench/2 25644 rmc 1613M 42M cpu14 0 10 0:33:10 3.1% filebench/2 25658 rmc 1613M 42M cpu16 0 10 0:33:10 3.1% filebench/2 25636 rmc 1613M 42M cpu21 0 10 0:33:10 3.1% filebench/2 25646 rmc 1613M 42M cpu15 0 10 0:33:10 3.1% filebench/2 25661 rmc 1613M 42M cpu8 0 10 0:33:11 3.1% filebench/2 25652 rmc 1613M 42M cpu20 0 10 0:33:09 3.1% filebench/2 25647 rmc 1613M 42M cpu0 0 10 0:33:10 3.1% filebench/2 25641 rmc 1613M 42M cpu27 0 10 0:33:10 3.1% filebench/2 25656 rmc 1613M 42M cpu7 0 10 0:33:10 3.1% filebench/2 25634 rmc 1613M 42M cpu11 0 10 0:33:11 3.1% filebench/2 25637 rmc 1613M 42M cpu17 0 10 0:33:10 3.1% filebench/2 25643 rmc 1613M 42M cpu12 0 10 0:33:10 3.1% filebench/2 25648 rmc 1613M 42M cpu1 0 10 0:33:10 3.1% filebench/2 25640 rmc 1613M 42M cpu26 0 10 0:33:10 3.1% filebench/2 25651 rmc 1613M 42M cpu31 0 10 0:33:10 3.1% filebench/2 25654 rmc 1613M 42M cpu29 0 10 0:33:10 3.1% filebench/2 25650 rmc 1613M 42M cpu5 0 10 0:33:10 3.1% filebench/2 25653 rmc 1613M 42M cpu10 0 10 0:33:10 3.1% filebench/2 25638 rmc 1613M 42M cpu18 0 10 0:33:10 3.1% filebench/2 Total: 91 processes, 521 lwps, load averages: 29.06, 28.84, 26.68
The default output from the prstat command shows one line of output per process, including a value that represents recent CPU utilization. This value is from pr_pctcpu in procfs and can express CPU utilization before the prstat command was executed (see Section 2.12.3).
The system load average indicates the demand and queuing for CPU resources averaged over a 1-, 5-, and 15-minute period. They are the same numbers as printed by the uptime command (see Section 2.6). The output in our example shows a load average of 29 on a 32-CPU system. An average load average that exceeds the number of CPUs in the system is a typical sign of an overloaded system.
The microstate accounting system maintains accurate time counters for threads as well as CPUs. Thread-based microstate accounting tracks several meaningful states per thread in addition to user and system time, which include trap time, lock time, sleep time, and latency time. The process statistics tool, prstat, reports the per-thread microstates for user processes.
$ prstat -mL PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 25644 rmc 98 1.5 0.0 0.0 0.0 0.0 0.0 0.1 0 36 693 0 filebench/2 25660 rmc 98 1.7 0.1 0.0 0.0 0.0 0.0 0.1 2 44 693 0 filebench/2 25650 rmc 98 1.4 0.1 0.0 0.0 0.0 0.0 0.1 0 45 699 0 filebench/2 25655 rmc 98 1.4 0.1 0.0 0.0 0.0 0.0 0.2 0 46 693 0 filebench/2 25636 rmc 98 1.6 0.1 0.0 0.0 0.0 0.0 0.2 1 50 693 0 filebench/2 25651 rmc 98 1.6 0.1 0.0 0.0 0.0 0.0 0.2 0 54 693 0 filebench/2 25656 rmc 98 1.5 0.1 0.0 0.0 0.0 0.0 0.2 0 60 693 0 filebench/2 25639 rmc 98 1.5 0.1 0.0 0.0 0.0 0.0 0.2 1 61 693 0 filebench/2 25634 rmc 98 1.3 0.1 0.0 0.0 0.0 0.0 0.4 0 63 693 0 filebench/2 25654 rmc 98 1.3 0.1 0.0 0.0 0.0 0.0 0.4 0 67 693 0 filebench/2 25659 rmc 98 1.7 0.1 0.0 0.0 0.0 0.0 0.4 1 68 693 0 filebench/2 25647 rmc 98 1.5 0.1 0.0 0.0 0.0 0.0 0.4 0 73 693 0 filebench/2 25648 rmc 98 1.6 0.1 0.0 0.0 0.0 0.3 0.2 2 48 693 0 filebench/2 25643 rmc 98 1.6 0.1 0.0 0.0 0.0 0.0 0.5 0 75 693 0 filebench/2 25642 rmc 98 1.4 0.1 0.0 0.0 0.0 0.0 0.5 0 80 693 0 filebench/2 25638 rmc 98 1.4 0.1 0.0 0.0 0.0 0.0 0.6 0 76 693 0 filebench/2 25657 rmc 97 1.8 0.1 0.0 0.0 0.0 0.4 0.3 6 64 693 0 filebench/2 25646 rmc 97 1.7 0.1 0.0 0.0 0.0 0.0 0.6 6 83 660 0 filebench/2 25645 rmc 97 1.6 0.1 0.0 0.0 0.0 0.0 0.9 0 55 693 0 filebench/2 25652 rmc 97 1.7 0.2 0.0 0.0 0.0 0.0 0.9 2 106 693 0 filebench/2 25658 rmc 97 1.5 0.1 0.0 0.0 0.0 0.0 1.0 0 72 693 0 filebench/2 25637 rmc 97 1.7 0.1 0.0 0.0 0.0 0.3 0.6 4 95 693 0 filebench/2 Total: 91 processes, 510 lwps, load averages: 28.94, 28.66, 24.39
By specifying the -m (show microstates) and -L (show per-thread) options, we can observe the per-thread microstates. These microstates represent a time-based summary broken into percentages for each thread. The columns USR through LAT sum to 100% of the time spent for each thread during the prstat sample. The important microstates for CPU utilization are USR, SYS, and LAT. The USR and SYS columns are the user and system time that this thread spent running on the CPU. The LAT (latency) column is the amount of time spent waiting for CPU. A non-zero number means there was some queuing for CPU resources. This is an extremely useful metric—we can use it to estimate the potential speedup for a thread if more CPU resources are added, assuming no other bottlenecks obstruct the way. In our example, we can see that on average the filebench threads are waiting for CPU about 0.2% of the time, so we can conclude that CPU resources for this system are not constrained.
Another example shows what we would observe when the system is CPU-resource constrained. In this example, we can see that on average each thread is waiting for CPU resource about 80% of the time.
$ prstat -mL PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 25765 rmc 22 0.3 0.1 0.0 0.0 0.0 0.0 77 0 42 165 0 filebench/2 25833 rmc 22 0.3 0.3 0.0 0.0 0.0 0.0 77 0 208 165 0 filebench/2 25712 rmc 20 0.2 0.1 0.0 0.0 0.0 0.0 80 0 53 132 0 filebench/2 25758 rmc 20 0.3 0.1 0.0 0.0 0.0 0.0 80 0 84 148 0 filebench/2 25715 rmc 20 0.3 0.1 0.0 0.0 0.0 0.0 80 0 56 132 0 filebench/2 25812 rmc 19 0.2 0.1 0.0 0.0 0.0 0.0 81 0 50 132 0 filebench/2 25874 rmc 19 0.2 0.0 0.0 0.0 0.0 0.0 81 0 22 132 0 filebench/2 25842 rmc 19 0.2 0.2 0.0 0.0 0.0 0.0 81 1 92 132 0 filebench/2 25732 rmc 19 0.2 0.1 0.0 0.0 0.0 0.0 81 0 54 99 0 filebench/2 25714 rmc 18 0.3 0.1 0.0 0.0 0.0 0.0 81 0 84 165 0 filebench/2 25793 rmc 18 0.3 0.1 0.0 0.0 0.0 0.0 81 0 30 132 0 filebench/2 25739 rmc 18 0.3 0.3 0.0 0.0 0.0 0.0 81 0 150 115 0 filebench/2 25849 rmc 18 0.3 0.0 0.0 0.0 0.0 0.0 81 1 19 132 0 filebench/2 25788 rmc 18 0.2 0.1 0.0 0.0 0.0 0.0 81 0 77 99 0 filebench/2 25760 rmc 18 0.2 0.0 0.0 0.0 0.0 0.0 82 0 26 132 0 filebench/2 25748 rmc 18 0.3 0.1 0.0 0.0 0.0 0.0 82 0 58 132 0 filebench/2 25835 rmc 18 0.3 0.1 0.0 0.0 0.0 0.0 82 0 65 132 0 filebench/2 25851 rmc 18 0.2 0.1 0.0 0.0 0.0 0.0 82 0 87 99 0 filebench/2 25811 rmc 18 0.3 0.2 0.0 0.0 0.0 0.0 82 0 129 132 0 filebench/2 25767 rmc 18 0.2 0.1 0.0 0.0 0.0 0.0 82 1 25 132 0 filebench/2 25740 rmc 18 0.3 0.2 0.0 0.0 0.0 0.0 82 0 118 132 0 filebench/2 25770 rmc 18 0.2 0.1 0.0 0.0 0.0 0.0 82 0 68 132 0 filebench/2 Total: 263 processes, 842 lwps, load averages: 201.45, 192.26, 136.16
We can further investigate which threads are consuming CPU within each process by directing prstat to examine a specific process.
$ prstat -Lm -p 25691
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID
25691 rmc 17 0.2 0.2 0.0 0.0 0.0 0.0 83 0 74 99 0 filebench/2
25691 rmc 0.0 0.0 0.0 0.0 0.0 0.0 100 0.0 0 0 0 0 filebench/1
The example shows us that thread number two in the target process is using the most CPU, and spending 83% of its time waiting for CPU. We can further look at information about thread number two with the pstack command.
$ pstack 25691/2 25691: shadow -a shadow -i 2 -s ffffffff10000000 -m /var/tmp/fbenchJDailY ----------------- lwp# 2 / thread# 2 -------------------- 000000010001ae90 flowoplib_hog (30d40, ffffffff6518dc60, 30d40, ffffffff37352c88, 1, 2570d) + 68 00000001000194a4 flowop_start (ffffffff37352c88, 0, 1, 0, 1, 1000888b0) + 408 ffffffff7e7ccea0 _lwp_start (0, 0, 0, 0, 0, 0)
In this example, we’ve taken a snapshot of the stack of thread number two of our target process. At the time the snapshot was taken, we can see that the function flowop_start was calling flowoplib_hog. It’s sometimes worth taking several snapshots to see if a pattern is exhibited. DTrace can analyze this further.
The following is a brief reference for how some of the CPU statistics are maintained by the kernel.
The percent user, system and idle times printed by vmstat, sar, and mpstat are retrieved from kstat statistics. These statistics are updated by CPU microstate counters, which are kept in each CPU struct as cpu->cpu_acct[NCMSTATES]; these measure cumulative time in each CPU microstate as high-resolution time counters (hrtime_t). There are three CPU microstates, CMS_USER, CMS_SYSTEM, and CMS_IDLE (there is also a fourth, CMS_DISABLED, which isn’t used for microstate accounting).
These per CPU microstate counters are incremented by functions such as new_cpu_mstate() and syscall_mstate() from uts/common/os/msacct.c. When the CPU state changes, a timestamp is saved in cpu->cpu_mstate_start and the new state is saved in cpu->cpu_mstate. When the CPU state changes next, the current time is fetched (curtime) so that the elapsed time in that state can be calculated with curtime - cpu_mstate_start and then added to the appropriate microstate counter in cpu_acct[].
These microstates are then saved in kstat for each CPU as part of the cpu_sys_stats_ks_data struct defined in uts/common/os/cpu.c and are given the names cpu_nsec_user, cpu_nsec_kernel, and cpu_nsec_idle. Since user-land code expects these counters to be in terms of clock ticks, they are rounded down using NSEC_TO_TICK (see Section 2.8), and resaved in kstat with the names cpu_ticks_user, cpu_ticks_kernel, and cpu_ticks_idle.
Figure 2.1 summarizes the flow of data from the CPU structures to userland tools through kstat
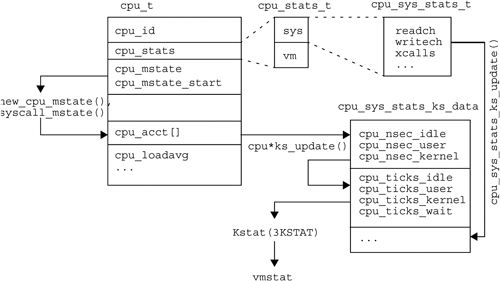
This is the code from cpu.c which copies the cpu_acct[] values to kstat.
static int
cpu_sys_stats_ks_update(kstat_t *ksp, int rw)
{
..
css = &cp->cpu_stats.sys;
bcopy(&cpu_sys_stats_ks_data_template, ksp->ks_data,
sizeof (cpu_sys_stats_ks_data_template));
csskd->cpu_ticks_wait.value.ui64 = 0;
csskd->wait_ticks_io.value.ui64 = 0;
csskd->cpu_nsec_idle.value.ui64 = cp->cpu_acct[CMS_IDLE];
csskd->cpu_nsec_user.value.ui64 = cp->cpu_acct[CMS_USER];
csskd->cpu_nsec_kernel.value.ui64 = cp->cpu_acct[CMS_SYSTEM];
...
Note that cpu_ticks_wait is set to zero; this is the point in the code where wait I/O has been deprecated.
An older location for tick-based statistics is cpu->cpu_stats.sys, which is of cpu_sys_stats_t. These are defined in /usr/include/sys/sysinfo.h, where original tick counters of the style cpu_ticks_user are listed. The remaining statistics from cpu->cpu_stats.sys (for example, readch, writech) are copied directly into kstat’s cpu_sys_stats_ks_data.
Tools such as vmstat fetch the tick counters from kstat, which provides them under cpu:#:sys: for each CPU. Although these counters use the term “ticks,” they are extremely accurate because they are rounded versions of the nsec counters; which are copied from the CPU microstate counters. The mpstat command prints individual CPU statistics (Section 2.9) and the vmstat command aggregates statistics across all CPUs (Section 2.2).
The load averages that tools such as uptime print are retrieved using system call getloadavg(), which returns them from the kernel array of signed ints called avenrun[]. They are actually maintained in a high precision uint64_t array called hp_avenrun[], and then converted to avenrun[] to meet the original API. The code that maintains these arrays is in the clock() function from uts/common/os/clock.c, and is run once per second. It involves the following.
The loadavg_update() function is called to add user + system + thread wait (latency) microstate accounting times together. This value is stored in an array within a struct loadavg_s, one of which exists for each CPU, each CPU partition, and for the entire system. These arrays contain the last ten seconds of raw data. Then genloadavg() is called to process both CPU partition and the system wide arrays, and return the average for the last ten seconds. This value is fed to calcloadavg(), which applies exponential decays for the 1-, 5-, 15-minute values, saving the results in hp_avenrun[] or cp_hp_avenrun[] for the CPU partitions. hp_avenrun[] is then converted into avenrun[].
This means that these load averages are damped more than once. First through a rolling ten second average, and then through exponential decays. Apart from the getloadavg() syscall, they are also available from kstat where they are called avenrun_1min, avenrun_5min, avenrun_15min. Running kstat -s avenrun* prints the raw unprocessed values, which must be divided by FSCALE to produce the final load averages.
The CPU field that prstat prints is pr_pctcpu, which is fetched by user-level tools from procfs. It is maintained for each thread as thread->t_pctcpu by the cpu_update_pct() function in common/os/msacct.c. This takes a high-resolution timestamp and calculates the elapsed time since the last measurement, which was stored in each thread’s t_hrtime. cpu_update_pct() is called by scheduling events, producing an extremely accurate measurement as this is based on events and not ticks. cpu_update_pct() is also called by procfs when a pr_pctcpu value is read, at which point every thread’s t_pctcpu is aggregated into pr_pctcpu.
The cpu_update_pct() function processes t_pctcpu as a decayed average by using two other functions: cpu_grow() and cpu_decay(). The way this behaves may be quite familiar: If a CPU-bound process begins, the reported CPU value is not immediately 100%; instead it increases quickly at first and then slows down, gradually reaching 100. The algorithm has the following comment above the cpu_decay() function.
/* * Given the old percent cpu and a time delta in nanoseconds, * return the new decayed percent cpu: pct * exp(-tau), * where 'tau' is the time delta multiplied by a decay factor. * We have chosen the decay factor (cpu_decay_factor in param.c) * to make the decay over five seconds be approximately 20%. * ...
This comment explains that the rate of t_pctcpu change should be 20% for every five seconds (and the same for pr_pctcpu).
User-level commands read pr_pctcpu by reading /proc/<pid>/psinfo for each process, which contains pr_pctcpu in a psinfo struct as defined in /usr/ include/sys/procfs.h.
DTrace can be exploited to attribute the source of events noted in higher-level tools such as mpstat(1M). For example, if we see a significant amount of system time (%sys) and a high system call rate (syscl), then we might want to know who or what is causing those system calls.
# mpstat 2 CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl 0 117 0 1583 883 111 1487 593 150 6104 64 11108 7 92 0 1 1 106 0 557 842 0 1804 694 150 6553 84 10684 6 93 0 1 2 112 0 664 901 0 1998 795 143 6622 64 11227 6 93 0 1 3 95 0 770 1035 0 2232 978 131 6549 59 11769 7 92 0 1 ^C # dtrace -n 'syscall:::entry { @[execname] = count(); }' dtrace: description 'syscall:::entry ' matched 229 probes ^C inetd 1 svc.configd 1 fmd 2 snmpdx 2 utmpd 2 inetd 1 svc.configd 1 fmd 2 snmpdx 2 utmpd 2 svc.startd 13 sendmail 30 snmpd 36 nscd 105 dtrace 1311 filebench 3739725
Using the DTrace syscall provider, we can quickly identify which process is causing the most system calls. This dtrace one-liner measures system calls by process name. In this example, processes with the name filebench caused 3, 739, 725 system calls during the time the dtrace command was running.
We can then drill deeper by matching the syscall probe only when the exec name matches our investigation target, filebench, and counting the syscall name.
# dtrace -n 'syscall:::entry /execname == "filebench"/ { @[probefunc] = count(); }'
dtrace: description 'syscall:::entry ' matched 229 probes
^C
lwp_continue 4
lwp_create 4
mmap 4
schedctl 4
setcontext 4
lwp_sigmask 8
nanosleep 24
yield 554
brk 1590
pwrite 80795
lwp_park 161019
read 324159
pread 898401
semsys 1791717
Ah, so we can see that the semsys syscall is hot in this case. Let’s look at what is calling semsys by using the ustack() DTrace action.
# dtrace -n 'syscall::semsys:entry /execname == "filebench"/ { @[ustack()] = count();}'
dtrace: description 'syscall::semsys:entry ' matched 1 probe
^C
libc.so.1`_syscall6+0x1c
filebench`flowop_start+0x408
libc.so.1`_lwp_start
10793
libc.so.1`_syscall6+0x1c
filebench`flowop_start+0x408
libc.so.1`_lwp_start
10942
libc.so.1`_syscall6+0x1c
filebench`flowop_start+0x408
libc.so.1`_lwp_start
11084
We can now identify which system call, and then even obtain the hottest stack trace for accesses to that system call. We conclude by observing that the filebench flowop_start function is performing the majority of semsys system calls on the system.
Existing tools often provide useful statistics, but not quite in the way that we want. For example, the sar command provides measurements for the length of the run queues (runq-sz), and a percent run queue occupancy (%runocc). These are useful metrics, but since they are sampled only once per second, their accuracy may not be satisfactory. DTrace allows us to revisit these measurements, customizing them to our liking.
runq-sz: DTrace can measure run queue length for each CPU and produce a distribution plot.
# dtrace -n 'profile-1000hz { @[cpu] = lquantize( curthread->t_cpu->cpu_disp->disp_ nrunnable, 0, 64, 1); }' dtrace: description 'profile-1000hz ' matched 1 probe ^C 0 value ------------- Distribution ------------- count < 0 | 0 0 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 4665 1 |@@@@ 489 2 | 41 3 | 25 4 | 4 5 | 0
Rather than sampling once per second, this dtrace one-liner[8] samples at 1000 hertz. The example shows a single CPU system with some work queuing on its run queue, but not a great deal. A value of zero means no threads queued (no saturation); however, the CPU may still be processing a user or kernel thread (utilization).
What is actually measured by DTrace is the value of disp_nrunnable from the disp_t for the current CPU.
typedef struct _disp {
...
pri_t disp_maxrunpri; /* maximum run priority */
pri_t disp_max_unbound_pri; /* max pri of unbound threads */
volatile int disp_nrunnable; /* runnable threads in cpu dispq */
struct cpu *disp_cpu; /* cpu owning this queue or NULL */
} disp_t;
See /usr/include/sys/disp.h
%runocc: Measuring run queue occupancy is achieved in a similar fashion.disp_nrunnable is also used, but this time just to indicate the presence of queued threads.
#!/usr/sbin/dtrace -s
#pragma D option quiet
profile-1000hz
/curthread->t_cpu->cpu_disp->disp_nrunnable/
{
@qocc[cpu] = count();
}
profile:::tick-1sec
{
normalize(@qocc, 10);
printf("
%8s %8s
", "CPU", "%runocc");
printa("%8d %@8d
", @qocc);
clear(@qocc);
}
This script samples at 1000 hertz and uses a DTrace normalization of 10 to turn the 1000-count into a percentage. We ran this script on a busy 4-CPU server.
# ./runocc.d
CPU %runocc
3 39
1 49
2 65
0 97
CPU %runocc
1 2
3 8
2 99
0 100
...
Each CPU has an occupied run queue, especially CPU 0.
These examples of sampling activity at 1000 hertz are simple and possibly sufficiently accurate (certainly better than the original 1 hertz statistics). While DTrace can sample activity, it may be is better suited to trace activity, measuring nanosecond timestamps for each event. The sched provider exists to facilitate the tracing of scheduling events. With sched, runq-sz and %runocc can be measured with a much higher accuracy.
The sched provider makes available probes related to CPU scheduling. Because CPUs are the one resource that all threads must consume, the sched provider is very useful for understanding systemic behavior. For example, using the sched provider, you can understand when and why threads sleep, run, change priority, or wake other threads.
As an example, one common question you might want answered is which CPUs are running threads and for how long. You can use the on-cpu and off-cpu probes to easily answer this question systemwide as shown in the following example.
#!/usr/sbin/dtrace -s
sched:::on-cpu
{
self->ts = timestamp;
}
sched:::off-cpu
/self->ts/
{
@[cpu] = quantize(timestamp - self->ts);
self->ts = 0;
}
The CPU overhead for the tracing of the probe events is proportional to their frequency. The on-cpu and off-cpu probes occur for each context switch, so the CPU overhead increases as the rate of context switches per second increases. Compare this to the previous DTrace scripts that sampled at 1000 hertz—their probe frequency is fixed. Either way, the CPU cost for running these scripts should be negligible.
The following is an example of running this script.
# ./where.d
dtrace: script './where.d' matched 5 probes
^C
0
value ------------- Distribution ------------- count
2048 | 0
4096 |@@ 37
8192 |@@@@@@@@@@@@@ 212
16384 |@ 30
32768 | 10
65536 |@ 17
131072 | 12
262144 | 9
524288 | 6
1048576 | 5
2097152 | 1
4194304 | 3
8388608 |@@@@ 75
16777216 |@@@@@@@@@@@@ 201
33554432 | 6
67108864 | 0
1
value ------------- Distribution ------------- count
2048 | 0
4096 |@ 6
8192 |@@@@ 23
16384 |@@@ 18
32768 |@@@@ 22
65536 |@@@@ 22
131072 |@ 7
262144 | 5
524288 | 2
1048576 | 3
2097152 |@ 9
4194304 | 4
8388608 |@@@ 18
16777216 |@@@ 19
33554432 |@@@ 16
67108864 |@@@@ 21
134217728 |@@ 14
268435456 | 0
The value is nanoseconds, and the count is the number of occurrences a thread ran for this duration without leaving the CPU. The floating integer above the Distribution plot is the CPU ID.
For CPU 0, a thread ran for between 8 and 16 microseconds on 212 occasions, shown by a small spike in the distribution plot. The other spike was for the 16 to 32 millisecond duration (sounds like TS class quanta—see Chapter 3 in Solaris™ Internals), for which threads ran 201 times.
The sched provider is discussed in Section 10.6.3.
[1] w -u prints the same line of output, perhaps not surprising since w is a hard link to uptime.
[2] This was the calculation, but now it has changed (see 2.12.2); the new way often produces values that resemble those of the old way, so the description still has some merit.
[3] Historically, this metric was useful on uniprocessor systems as a way of indicating how much time was spent waiting for I/O. In a multiprocessor system it’s not possible to make this simple approximation, which led to a significant amount of confusion (basically, if %wio was non-zero, then the only useful information that could be gleaned is that at least one thread somewhere was waiting for I/O. The magnitude of the %wio value is related more to how much time the system is idle than to waiting for I/O. You can get a more accurate waiting-for-I/O measure by measuring individual thread, and you can obtain it by using DTrace.
[4] sar seems to have a blind spot for a run queue size between 0.0 and 1.0.
[5] A value of 99% for short intervals is usually a rounding error. Another error can be due to drifting intervals and measuring the statistic after an extra update; this causes %runocc to be reported as over 100% (e.g., 119% for a 5-second interval).
[6] Pending bug 6302763; the description contains a workaround.
[7] In fact, once upon a time statistics were gathered every 60th of a second.
[8] This exists in the DTraceToolkit as dispqlen.d.