
Chapter 1. Introduction to the Games of Nature
“ To me art is a desire to communicate.”
—Endre Szasz
Computer virus research is a fascinating subject to many who are interested in nature, biology, or mathematics. Everyone who uses a computer will likely encounter some form of the increasingly common problem of computer viruses. In fact, some well-known computer virus researchers became interested in the field when, decades ago, their own systems were infected.
The title of Donald Knuth's book series1, The Art of Computer Programming, suggests that anything we can explain to a computer is science, but that which we cannot currently explain to a computer is an art. Computer virus research is a rich, complex, multifaceted subject. It is about reverse engineering, developing detection, disinfection, and defense systems with optimized algorithms, so it naturally has scientific aspects; however, many of the analytical methods are an art of their own. This is why outsiders often find this relatively young field so hard to understand. Even after years of research and publications, many new analytical techniques are in the category of art and can only be learned at antivirus and security vendor companies or through the personal associations one must forge to succeed in this field.
This book attempts to provide an insider's view of this fascinating research. In the process, I hope to teach many facts that should interest both students of the art and information technology professionals. My goal is to provide an extended understanding of both the attackers and the systems built to defend against virulent, malicious programs.
Although there are many books about computer viruses, only a few have been written by people experienced enough in computer virus research to discuss the subject for a technically oriented audience.
The following sections discuss historical points in computation that are relevant to computer viruses and arrive at a practical definition of the term computer virus.
1.1 Early Models of Self-Replicating Structures
Humans create new models to represent our world from different perspectives. The idea of self-replicating systems that model self-replicating structures has been around since the Hungarian-American, Neumann JE1nos (John von Neumann), suggested it in 19482, 3, 4.
Von Neumann was a mathematician, an amazing thinker, and one of the greatest computer architects of all time. Today's computers are designed according to his original vision. Neumann's machines introduced memory for storing information and binary (versus analog) operations. According to von Neumann's brother Nicholas, “Johnny” was very impressed with Bach's “Art of the Fugue” because it was written for several voices, with the instrumentation unspecified. Nicholas von Neumann credits the Bach piece as a source for the idea of the stored-program computer5.
In the traditional von Neumann machine, there was no basic difference between code and data. Code was differentiated from data only when the operating system transferred control and executed the information stored there.
To create a more secure computing system, we will find that system operations that better control the differentiation of data from code are essential. However, we also will see the weaknesses of such approaches.
Modern computers can simulate nature using a variety of modeling techniques. Many computer simulations of nature manifest themselves as games. Modern computer viruses are somewhat different from these traditional nature-simulation game systems, but students of computer virus research can appreciate the utility of such games for gaining an understanding of self-replicating structures.
1.1.1 John von Neumann: Theory of Self-Reproducing Automata
Replication is an essential part of life. John von Neumann was the first to provide a model to describe nature's self-reproduction with the idea of self-building automata.
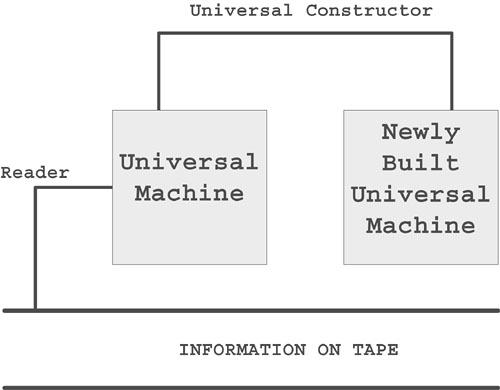
In von Neumann's vision, there were three main components in a system:
- A Universal Machine
- A Universal Constructor
- Information on a Tape
A universal machine (Turing Machine) would read the memory tape and, using the information on the tape, it would be able to rebuild itself piece by piece using a universal constructor. The machine would not understand the process—it would simply follow the information (blueprint instructions) on the memory tape. The machine would only be able to select the next proper piece from the set of all the pieces by picking them one by one until the proper piece was found. When it was found, two proper pieces would be put together according to the instructions until the machine reproduced itself completely.
If the information that was necessary to rebuild another system could be found on the tape, then the automata was able to reproduce itself. The original automata would be rebuilt (Figure 1.1), and then the newly built automata was booted, which would start the same process.
Figure 1.1. The model of a self-building machine.
A few years later, Stanislaw Ulam suggested to von Neumann to use the processes of cellular automation to describe this model. Instead of using “machine parts,” states of cells were introduced. Because cells are operated in a robotic fashion according to rules (“code”), the cell is known as an automaton. The array of cells comprises the cellular automata (CA) computer architecture.
Von Neumann changed the original model using cells that had 29 different states in a two-dimensional, 5-cell environment. To create a self-reproducing structure, he used 200,000 cells. Neumann's model mathematically proved the possibility of self-reproducing structures: Regular non-living parts (molecules) could be combined to create self-reproducing structures (potentially living organisms).
In September 1948, von Neumann presented his vision of self-replicating automata systems. Only five years later, in 1953, Watson and Crick recognized that living organisms use the DNA molecule as a “tape” that provides the information for the reproduction system of living organisms.
Unfortunately, von Neumann could not see a proof of his work in his life, but his work was completed by Arthur Burks. Further work was accomplished by E.F. Codd in 1968. Codd simplified Neumann's model using cells that had eight states, 5-cell environments. Such simplification is the base for “self-replicating loops”6 developed by artificial life researchers, such as Christopher G. Langton, in 1979. Such replication loops eliminate the complexity of universal machine from the system and focus on the needs of replication.
In 1980 at NASA/ASEE, Robert A. Freitas, Jr. and William B. Zachary7 conducted research on a self-replicating, growing lunar factory. A lunar manufacturing facility (LMF) was researched, which used the theory of self-reproducing automata and existing automation technology to make a self-replicating, self-growing factory on the moon. Robert A. Freitas, Jr. and Ralph C. Merkle recently authored a book titled Kinematic Self-Replicating Machines. This book indicates a renewed scientific interest in the subject. A few years ago, Freitas introduced the term ecophagy, the theoretical consumption of the entire ecosystem by out of control, self-replicating nano-robots, and he proposed mitigation recommendations8.
It is also interesting to note that the theme of self-replicating machines occurs repeatedly in works of science fiction, from movies such as Terminator to novels written by such authors as Neal Stephenson and William Gibson. And of course, there are many more examples from beyond the world of science fiction, as nanotech and microelectrical mechanical systems (MEMS) engineering have become real sciences.
1.1.2 Fredkin: Reproducing Structures
Several people attempted to simplify von Neumann's model. For instance, in 1961 Edward Fredkin used a specialized cellular automaton in which all the structures could reproduce themselves and replicate using simple patterns on a grid (see Figure 1.2 for a possible illustration). Fredkin's automata had the following rules9:
• On the table, we use the same kind of tokens.
• We either have a token or no token in each possible position.
• Token generations will follow each other in a finite time frame.
• The environment of each token will determine whether we will have a new token in the next generation.
• The environment is represented by the squares above, below, to the left, and to the right of the token (using the 5-cell-based von Neumann environment).
• The state of a square in the next generation will be empty when the token has an even number of tokens in its environment.
• The state of a square in the next generation will be filled with a token if it has an odd number of tokens in its environment.
• It is possible to change the number of states.
Figure 1.2. Generation 1, Generation 2, and…Generation 4.
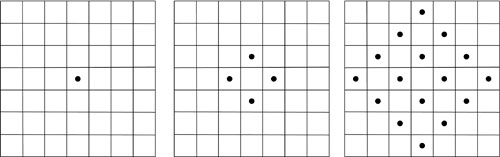
Using the rules described previously with this initial layout allows all structures to replicate. Although there are far more interesting layouts to explore, this example is the simplest possible model of self-reproducing cellular automata.
1.1.3 Conway: Game of Life
In 1970, John Horton Conway10 created one of the most interesting cellular automata systems. Just as the pioneer von Neumann did, Conway researched the interaction of simple elements under a common rule and found that this could lead to surprisingly interesting structures. Conway named his game Life. Life is based on the following rules:
• There should be no initial pattern for which there is a single proof that the population can grow without limit.
• There should be an initial pattern that apparently does grow without limit.
• There should be simple initial patterns that work according to simple genetic law: birth, survival, and death.
Figure 1.3 demonstrates a modern representation of the original Conway table game written by Edwin Martin11.
Figure 1.3. Edwin Martin's Game of Life implementation on the Mac using “Shooter” starting structure.
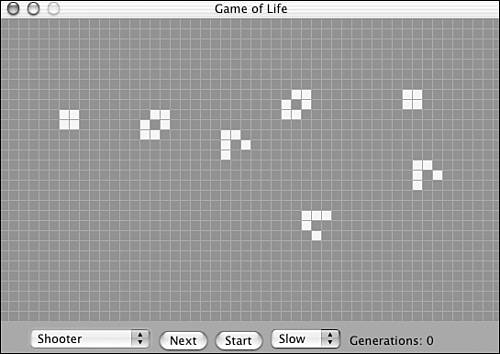
It is especially interesting to see the computer animation as the game develops with the so-called “Shooter” starting structure. In a few generations, two shooter positions that appear to shoot to each other will develop on the sides of the table, as shown in Figure 1.4, and in doing so they appear to produce so-called gliders that “fly” away (see Figure 1.5) toward the lower-right corner of the table. This sequence continues endlessly, and new gliders are produced.
Figure 1.4. “Shooter” in Generation 355.
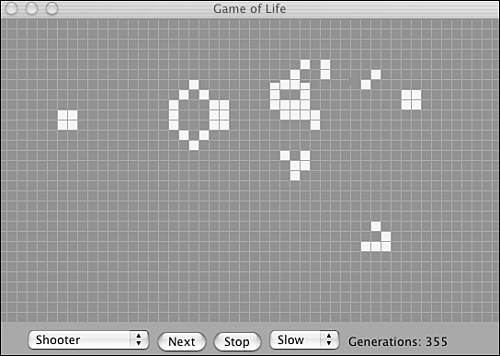
Figure 1.5. The glider moves around without changing shape.
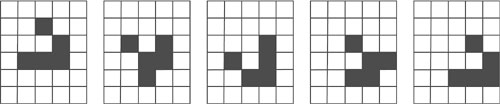
On a two-dimensional table, each cell has two potential states: S=1 if there is one token in the cell, or S=0 if there is no token. Each cell will live according to the rules governed by the cell's environment (see Figure 1.6).
Figure 1.6. The 9-cell-based Moore environment.

The following characteristics/rules define Conway's game, Life:
Birth: If an empty cell has three (K=3) other filled cells in its environment, that particular cell will be filled in a new generation.
Survival: If a filled cell has two or three (K=2 or K=3) other filled cells in its environment, that particular cell will survive in the new generation.
Death: If a filled cell has only one or no other filled cells (K=1 or K=0) in its environment, that particular cell will die because of isolation. Further, if a cell has too many filled cells in its environment—four, five, six, seven, or eight (K=4, 5, 6, 7, or 8), that particular cell will also die in the next generation due to overpopulation.
Conway originally believed that there were no self-replicating structures in Life. He even offered $50 to anyone who could create a starting structure that would lead to self-replication. One such structure was quickly found using computers at the artificial intelligence group of the Massachusetts Institute of Technology (MIT).
MIT students found a structure that was later nicknamed a glider. When 13 gliders meet, they create a pulsing structure. Later, in the 100th generation, the pulsing structure suddenly “gives birth” to new gliders, which quickly “fly” away. After this point, in each 30th subsequent generation, there will be a new glider on the table that flies away. This sequence continues endlessly. This setup is very similar to the “Shooter” structure shown in Figures 1.3 and 1.4.
Games with Computers, written by Antal Csakany and Ferenc Vajda in 1980, contains examples of competitive games. The authors described a table game with rules similar to those of Life. The table game uses cabbage, rabbits, and foxes to demonstrate struggles in nature. An initial cell is filled with cabbage as food for the rabbits, which becomes food for the foxes according to predefined rules. Then the rules control and balance the population of rabbits and foxes.
It is interesting to think about computers, computer viruses, and antiviral programs in terms of this model. Without computers (in particular, an operating system or BIOS of some sort), computer viruses are unable to replicate. Computer viruses infect new computer systems, and as they replicate, the viruses can be thought of as prey for antivirus programs.
In some situations, computer viruses fight back. These are called retro viruses. In such a situation, the antiviral application can be thought to “die.” When an antiviral program stops an instance of a virus, the virus can be thought to “die.” In some cases, the PC will “die” immediately as the virus infects it.
For example, if the virus indiscriminately deletes key operating system files, the system will crash, and the virus can be said to have “killed” its host. If this process happens too quickly, the virus might kill the host before having the opportunity to replicate to other systems. When we imagine millions of computers as a table game of this form, it is fascinating to see how computer virus and antiviral population models parallel those of the cabbage, rabbits, and foxes simulation game.
Rules, side effects, mutations, replication techniques, and degrees of virulence dictate the balance of such programs in a never-ending fight. At the same time, a “co-evolution”12 exists between computer viruses and antivirus programs. As antivirus systems have become more sophisticated, so have computer viruses. This tendency has continued over the more than 30-year history of computer viruses.
Using models along these lines, we can see how the virus population varies according to the number of computers compatible with them. When it comes to computer viruses and antiviral programs, multiple parallel games occur side by side. Viruses within an environment that consists of a large number of compatible computers will be more virulent; that is, they will spread more rapidly to many more computers. A large number of similar PCs with compatible operating systems create a homogeneous environment—fertile ground for virulence (sound familiar?).
With smaller game boards representing a smaller number of compatible computers, we will obviously see smaller outbreaks, along with relatively small virus populations.
This sort of modeling clearly explains why we find major computer virus infections on operating systems such as Windows, which represents about 95% of the current PC population around us on a huge “grid.” Of course this is not to say that 5% of computer systems are not enough to cause a global epidemic of some sort.
Note
If you are fascinated by self-replicating, self-repairing, and evolving structures, visit the BioWall project, http://lslwww.epfl.ch/biowall/index.html.
1.1.4 Core War: The Fighting Programs
Around 1966, Robert Morris, Sr., the future National Security Agency (NSA) chief scientist, decided to create a new game environment with two of his friends, Victor Vyssotsky and Dennis Ritchie, who coded the game and called it Darwin. (Morris, Jr. was the first infamous worm writer in the history of computer viruses. His mark on computer virus history will be discussed later in the book.)
The original version of Darwin was created for the PDP-1 (programmed data processing) at Bell Labs. Later, Darwin became Core War, a computer game that many programmers and mathematicians (as well as hackers) play to this day.
Note
I use the term hacker in its original, positive sense. I also believe that all good virus researchers are hackers in the traditional sense. I consider myself a hacker, too, but fundamentally different from malicious hackers who break into other people's computers.
The game is called Core War because the objective of the game is to kill your opponent's programs by overwriting them. The original game is played between two assembly programs written in the Redcode language. The Redcode programs run in the core of a simulated (for example, “virtual”) machine named Memory Array Redcode Simulator (MARS). The actual fight between the warrior programs was referred to as Core Wars.
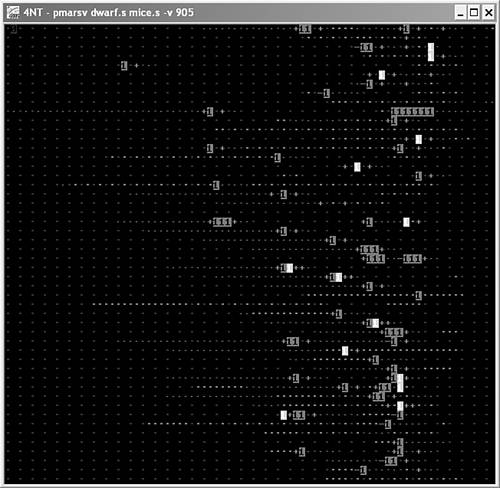
The original instruction set of Redcode consists of 10 simple instructions that allow movement of information from one memory location to another, which provides great flexibility in creating tricky warrior programs. Dewdney wrote several “Computer Recreations” articles in Scientific American13,14 that discussed Core War, beginning with the May 1984 article. Figure 1.7 is a screen shot of a Core War implementation called PMARSV, written by Albert Ma, Na'ndor Sieben, Stefan Strack, and Mintardjo Wangsaw. It is interesting to watch as the little warriors fight each other within the MARS environment.
Figure 1.7. Core Wars warrior programs (Dwarf and MICE) in battle.
As programs fight in the annual tournaments, certain warriors might become the King of the Hill (KotH). These are the Redcode programs that outperform their competitors.
The warrior program named MICE won the first tournament. Its author, Chip Wendell, received a trophy that incorporated a core-memory board from an early CDC 6600 computer14.
The simplest Redcode program consists of only one MOV instruction: MOV 0,1 (in the traditional syntax). This program is named IMP, which causes the contents at relative address 0 (namely the MOV, or move, instruction itself), to be transferred to relative address 1, just one address ahead of itself. After the instruction is copied to the new location, control is given to that address, executing the instruction, which, in turn, makes a new copy of itself at a higher address, and so on. This happens naturally, as instructions are executed following a higher address. The instruction counter will be incremented after each executed instruction.
The basic core consisted of two warrior programs and 8,000 cells for instructions. Newer revisions of the game can run multiple warriors at the same time. Warrior programs are limited to a specific starting size, normally 100 instructions. Each program has a finite number of iterations; by default, this number is 80,000.
The original version of Redcode supported 10 instructions. Later revisions contain more. For example, the following 14 instructions are used in the 1994 revision, shown in Listing 1.1.
Listing 1.1. Core War Instructions in the 1994 Revision

Let's take a look at Dewdney's Dwarf tutorial (see Listing 1.2).
Listing 1.2. Dwarf Bombing Warrior Program

Dwarf follows a so-called bombing strategy. The first few lines are comments indicating the name of the warrior program and its Redcode 1994 standard. Dwarf attempts to destroy its opponents by “dropping” DAT bombs into their operation paths. Because any warrior process that attempts to execute a DAT statement dies in the MARS, Dwarf will be a likely winner when it hits its opponents.
The MOV instruction is used to move information into MARS cells. (The IMP warrior explains this very clearly.) The general format of a Redcode command is of the Opcode A, B form. Thus, the command MOV.AB #0, @-2 will point to the DAT statement in Dwarf's code as a source.
The A field points to the DAT statement, as each instruction has an equivalent size of 1, and at 0, we find DAT #0, #0. Thus, MOV will copy the DAT instruction to where B points. So where does B point to now?
The B field points to DAT.F #0, #0 statement in it. Ordinarily, this would mean that the bomb would be put on top of this statement, but the @ symbol makes this an indirect pointer. In effect, the @ symbol says to use the contents of the location to where the B field points as a new pointer (destination). In this case, the B field appears to point to a value of 0 (location 0, where the DAT.F instruction is placed).
The first instruction to execute before the MOV, however, is an ADD instruction. When this ADD #4, $-1 is executed, the DAT's offset field will be incremented by four each time it is executed—the first time, it will be changed from 0 to 4, the next time from 4 to 8, and so on.
This is why, when the MOV command copies a DAT bomb, it will land four lines (locations) above the DAT statement (see Listing 1.3).
Listing 1.3. Dwarf's Code When the First Bomb Is Dropped

The JMP.A $-2 instruction transfers control back relative to the current offset, that is, back to the ADD instruction to run the Dwarf program “endlessly.” Dwarf will continue to bomb into the core at every four locations until the pointers wrap around the core and return. (After the highest number possible for the DAT location has been reached, it will “wrap” back around past 0. For example, if the highest possible value were 10, 10+1 would be 0, and 10+4 would be 3.)
At that point, Dwarf begins to bomb over its own bombs, until the end of 80,000 cycles/iterations or until another warrior acts upon it. At any time, another warrior program might easily kill Dwarf because Dwarf stays at a constant location—so that it can avoid hitting itself with friendly fire. But in doing so, it exposes itself to attackers.
There are several common strategies in Core War, including scanning, replicating, bombing, IMP-spiral (those using the SPL instruction), and the interesting bomber variation named the vampire.
Dewdney also pointed out that programs can even steal their enemy warrior's very soul by hijacking a warrior execution flow. These are the so-called vampire warriors, which bomb JMP (JUMP) instructions into the core. By bombing with jumps, the enemy program's control can be hijacked to point to a new, predefined location where the hijacked warrior will typically execute useless code. Useless code will “burn” the cycles of the enemy warrior's execution threads, thus giving the vampire warrior an advantage.
Instead of writing computer viruses, I strongly recommend playing this harmless and interesting game. In fact, if worms fascinate you, a new version of Core War can be created to link battles in different networks and allow warrior programs to jump from one battle to another to fight new enemies on those machines. Evolving the game to be more networked allows for simulating worm-like warrior programs.
1.2 Genesis of Computer Viruses
Virus-like programs appeared on microcomputers in the 1980s. However, two fairly recounted precursors deserve mention here: Creeper from 1971-72 and John Walker's “infective” version of the popular ANIMAL game for UNIVAC15 in 1975.
Creeper and its nemesis, Reaper, the first “antivirus” for networked TENEX running on PDP-10s at BBN, was born while they were doing the early development of what became “the Internet.”
Even more interestingly, ANIMAL was created on a UNIVAC 1100/42 mainframe computer running under the Univac 1100 series operating system, Exec-8. In January of 1975, John Walker (later founder of Autodesk, Inc. and co-author of AutoCAD) created a general subroutine called PERVADE16, which could be called by any program. When PERVADE was called by ANIMAL, it looked around for all accessible directories and made a copy of its caller program, ANIMAL in this case, to each directory to which the user had access. Programs used to be exchanged relatively slowly, on tapes at the time, but still, within a month, ANIMAL appeared at a number of places.
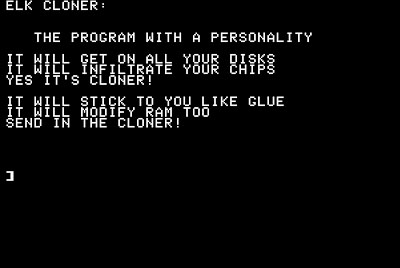
The first viruses on microcomputers were written on the Apple-II, circa 1982. Rich Skrenta17, who was a ninth-grade student at the time in Pittsburgh, Pennsylvania, wrote “Elk Cloner.” He did not think the program would work well, but he coded it nonetheless. His friends found the program quite entertaining—unlike his math teacher, whose computer became infected with it. Elk Cloner had a payload that displayed Skrenta's poem after every 50th use of the infected disk when reset was pressed (see Figure 1.8). On every 50th boot, Elk Cloner hooked the reset handler; thus, only pressing reset triggered the payload of the virus.
Figure 1.8. Elk Cloner activates.
Not surprisingly, the friendship of the two ended shortly after the incident. Skrenta also wrote computer games and many useful programs at the time, and he still finds it amazing that he is best known for the “stupidest hack” he ever coded.
In 1982, two researchers at Xerox PARC18 performed other early studies with computer worms. At that time, the term computer virus was not used to describe these programs. In 1984, mathematician Dr. Frederick Cohen19 introduced this term, thereby becoming the “father” of computer viruses with his early studies of them. Cohen introduced computer virus based on the recommendation of his advisor, Professor Leonard Adleman20, who picked the name from science fiction novels.
1.3 Automated Replicating Code: The Theory and Definition of Computer Viruses
Cohen provided a formal mathematical model for computer viruses in 1984. This model used a Turing machine. In fact, Cohen's formal mathematical model for a computer virus is similar to Neumann's self-replicating cellular automata model. We could say, that in the Neumann sense, a computer virus is a self-reproducing cellular automata. The mathematical model does not have much practical use for today's researcher. It is a rather general description of what a computer virus is. However, the mathematical model provides significant theoretical foundation to the computer virus problem.
Here is Cohen's informal definition of a computer virus: “A virus is a program that is able to infect other programs by modifying them to include a possibly evolved copy of itself.”
This definition provides the important properties of a computer virus, such as the possibility of evolution (the capability to make a modified copy of the same code with mutations). However, it might also be a bit misleading if applied in its strictest sense.
This is, by no means, to criticize Cohen's groundbreaking model. It is difficult to provide a precise definition because there are so many different kinds of computer viruses nowadays. For instance, some forms of computer viruses, called companion viruses, do not necessarily modify the code of other programs. They do not strictly follow Cohen's definition because they do not need to include a copy of themselves within other programs. Instead, they make devious use of the program's environment—properties of the operating system—by placing themselves with the same name ahead of their victim programs on the execution path. This can create a problem for behavior-blocking programs that attempt to block malicious actions of other programs—if the authors of such blockers strictly apply Cohen's informal definition. In other words, if such blocking programs are looking only for viruses that make unwanted changes to the code of another program, they will miss companion viruses.
Note
Cohen's mathematical formulation properly encompasses companion viruses; it is only the literal interpretation of the single-sentence human language definition that is problematic. A single-sentence linguistic definition of viruses is difficult to come up with.
Integrity checker programs also rely on the fact that one program's code remains unchanged over time. Such programs rely on a database (created at some initial point in time) assumed to represent a “clean” state of the programs on a machine. Integrity checker programs were Cohen's favorite defense method and my own in the early '90s. However, it is easy to see that the integrity checker would be challenged by companion viruses unless the integrity checker also alerted the user about any new application on the system. Cohen's own system properly performed this. Unfortunately, the general public does not like to be bothered each time a new program is introduced on their systems, but Cohen's approach is definitely the safest technique to use.
Dr. Cohen's definition does not differentiate between programs explicitly designed to copy themselves (the “real viruses” as we call them) from the programs that can copy themselves as a side effect of the fact that they are general-purpose copying programs (compilers and so on).
Indeed, in the real world, behavior-blocking defense systems often alarm in such a situation. For instance, Norton Commander, the popular command shell, might be used to copy the commander's own code to another hard drive or network resource. This action might be confused with self-replicating code, especially if the folder in which the copy is made has a previous version of the program that we overwrite to upgrade it. Though such “false alarms” are easily dealt with, they will undoubtedly annoy end users.
Taking these points into consideration, a more accurate definition of a computer virus would be the following: “A computer virus is a program that recursively and explicitly copies a possibly evolved version of itself.”
There is no need to specify how the copy is made, and there is no strict need to “infect” or otherwise modify another application or host program. However, most computer viruses do indeed modify another program's code to take control. Blocking such an action, then, considerably reduces the possibility for viruses to spread on the system.
As a result, there is always a host, an operating system, or another kind of execution environment, such as an interpreter, in which a particular sequence of symbols behaves as a computer virus and replicates itself recursively.
Computer viruses are self-automated programs that, against the user's wishes, make copies of themselves to spread themselves to new targets. Although particular computer viruses ask the user with prompts before they infect a machine, such as, “Do you want to infect another program? (Y/N?),” this does not make them non-viruses. Often, novice researchers in computer virus labs believe otherwise, and they actually argue that such programs are not viruses. Obviously, they are wrong!
When attempting to classify a particular program as a virus, we need to ask the important question of whether a program is able to replicate itself recursively and explicitly. A program cannot be considered a computer virus if it needs any help to make a copy of itself. This help might include modifying the environment of such a program (for example, manually changing bytes in memory or on a disk) or—heaven forbid—applying a hot fix to the intended virus code itself using a debugger! Instead, nonworking viruses should be classified as intended viruses.
The copy in question does not have to be an exact clone of the initial instance. Modern computer viruses, especially so-called metamorphic viruses (further discussed in Chapter 7, “Advanced Code Evolution Techniques and Computer Virus Generator Kits”), can rewrite their own code in such a way that the starting sequence of bytes responsible for the copy of such code will look completely different in subsequent generations but will perform the equivalent or similar functionality.
References
1. Donald E. Knuth, The Art of Computer Programming, 2nd Edition, Addison-Wesley, Reading, MA, 1973, 1968, ISBN: 0-201-03809-9 (Hardcover).
2. John von Neumann, “The General and Logical Theory of Automata,” Hixon Symposium, 1948.
3. John von Neumann, “Theory and Organization of Complicated Automata,” Lectures at the University of Illinois, 1949.
4. John von Neumann, “The Theory of Automata: Contruction, Reproduction, Homogenity,” Unfinished manuscript, 1953.
5. William Poundstone, Prisoner's Dilemma, Doubleday, New York, ISBN: 0-385-41580-X (Paperback), 1992.
6. Eli Bachmutsky, “Self-Replication Loops in Cellular Space,” http://necsi.org:16080/postdocs/sayama/sdrs/java.
7. Robert A. Freitas, Jr. and William B. Zachary, “A Self-Replicating, Growing Lunar Factory,” Fifth Princeton/AIAA Conference, May 1981.
8. Robert A. Freitas, Jr., “Some Limits to Global Ecophagy by Biovorous Nanoreplicators, with Public Policy Recommendations,” http://www.foresight.org/nanorev/ecophagy.html.
9. György Marx, A Természet Játékai, Ifjúsági Lap és Könyvterjesztô Vállalat, Hungary, 1982, ISBN: 963-422-674-4 (Hardcover).
10. Martin Gardner, “Mathematical Games: The Fantastic Combinations of John Conway's New Solitaire Game 'Life,'” Scientific American, October 1970, pp. 120–123.
11. Edwin Martin, “John Conway's Game of Life,” http://www.bitstorm.org/gameoflife (Java version is available).
12. Carey Nachenberg, “Computer Virus-Antivirus Coevolution,” Communications of the ACM, January 1997, Vol. 40, No. 1., pp. 46-51.
13. Dewdney, A. K., The Armchair Universe: An Exploration of Computer Worlds, New York: W. H. Freeman (c), 1988, ISBN: 0-7167-1939-8 (Paperback).
14. Dewdney, A. K., The Magic Machine: A Handbook of Computer Sorcery, New York: W. H. Freeman (c), 1990, ISBN: 0-7167-2125-2 (Hardcover), 0-7167-2144-9 (Paperback).
15. John Walker, “ANIMAL,” http://fourmilab.ch/documents/univac/animal.html.
16. John Walker, “PERVADE,” http://fourmillab.ch/documents/univac/pervade.html.
17. Rich Skrenta, http://www.skrenta.com.
18. John Shock and Jon Hepps, “The Worm Programs, Early Experience with a Distributed Computation,” ACM, Volume 25, 1982, pp. 172–180.
19. Dr. Frederick B. Cohen, A Short Course on Computer Viruses, Wiley Professonal Computing, New York, 2nd edition, 1994, ISBN: 0471007684 (Paperback).
20. Vesselin Vladimirov Bontchev, “Methodology of Computer Anti-Virus Research,” University of Hamburg Dissertation, 1998.