
Now that the first two chapters have addressed at a high level the basic questions of why you need high availability and how to achieve it, it is time to delve into the world of technology. It is not enough to consider technology and high availability from a Microsoft SQL Server standpoint only—you must also consider the operating system, which is Microsoft Windows. Without Windows there is no SQL Server. This chapter helps you to make an informed decision by providing a basic understanding of the high availability technologies used throughout this book. The following technologies are discussed:
Windows Clustering, which includes:
Server clusters
Network Load Balancing clusters
Geographically dispersed clusters
Microsoft SQL Server 2000, which includes:
Failover clustering
Log shipping
Replication
Backup and restore
The word cluster describes clustered servers, clustered indexes for databases, and more. As you can see from the preceding list, clustering is involved in many of the options discussed in this chapter. This chapter standardizes the terminology and helps you distinguish between the different types of clusters for the rest of the book.
One thing this chapter and this book will not do is to give you a decision tree and point to one right answer. Two words govern high availability solution decisions—it depends. High availability is not a clear-cut concept, but one that involves a lot of ambiguity.
Before addressing SQL Server high availability technologies, it is important to understand what the operating system provides, as some of the SQL Server functionality depends on its foundation—Windows.
Windows Clustering is the name that represents the umbrella of clustering technologies in the Microsoft Windows 2000 Server and Microsoft Windows Server 2003 families. Windows Clustering is a feature in the following versions of the operating system:
Windows 2000 Advanced Server (32-bit)
Windows 2000 Datacenter Server (32-bit)
Windows Server 2003 Enterprise Edition (32-bit and 64-bit)
Windows Server 2003 Datacenter Edition (32-bit and 64-bit)
Windows Clustering is comprised of two technologies: server clusters and Network Load Balancing clusters.
More Info
Chapter 5, reviews in depth the planning, configuration, and administration of a highly available Windows server and how these factors relate to SQL Server high availability.
A server cluster is Microsoft’s form of clustering for the operating system that is designed for availability. It has also been referred to as Microsoft Cluster Service (MSCS) when the component itself was available as part of Microsoft Windows NT 4, Enterprise Edition. It is a collection of servers that, when configured, provide an environment for hosting highly available applications. A server cluster protects against hardware failures that could take down an individual server, operating system errors that cause system outages (for example, driver problems or conflicts), and application failures. Simply put, it protects the business functionality within certain limitations, but not necessarily the server itself.
Once a problem is detected, a cluster-aware application tries to restart the process on the current server first. (The cluster-aware application must be installed into the cluster.) If that is not possible, it automatically switches to another server in the cluster. The process of switching from one server to another in a cluster is known as a failover. Failovers can also happen manually, as in the case of planned maintenance on a server.
Server clustering requires a minimum of two servers; otherwise you essentially have a stand-alone system. A server cluster by itself does not really do much—applications or specific uses, such as SQL Server or file and print servers, must be configured to use the cluster to provide availability. An instance of Microsoft SQL Server 2000 installed on a node that is part of a server cluster will not failover to another node if it is not configured to use the cluster mechanics; it will act as a stand-alone SQL Server.
Important
All server cluster configurations must appear as a complete hardware solution under the cluster list on the Microsoft Hardware Compatibility List (HCL) for the operating system choice you are making. The configuration is a viewed as complete solution, not individual parts that can be put together like a jigsaw puzzle. Microsoft can support only a completely HCL-compliant cluster solution. Please consult http://www.microsoft.com/hcl/ for more information.
The main constraint of a server cluster is the distance between redundant parts within the cluster itself. Conceptually, the limit is just a latency for synchronous operations, which is really a data consistency issue dependent on the underlying technology and its limitations (for example, in an older cluster, the limitations of Small Computer System Interface [SCSI]). During implementation, this means that any intracluster communications would be affected, because a server cluster relies on a single image view of the storage subsystem used, whether it is direct attached storage or a storage area network (SAN).
Another important aspect of any solution that has a server cluster as the basis for a back end is the compatibility of the applications that will be running on the cluster. One of the biggest misconceptions about server clusters is that because of automatic failover, they solve most availability problems. As noted in Chapter 1, a solution is only as good as its weakest link. For most applications to work properly in a cluster, they should be coded to the Microsoft Clustering application programming interface (API) and become cluster-aware, allowing them to react to cluster-specific events. This means that if a problem is detected in the cluster and the process fails over to another server, the application handles the failover gracefully and has minimal or no impact on end users. More information about the Clustering API and coding cluster-aware applications appears in Chapter 5.
Important
When using any prepackaged application from a vendor, such as backup software, consult the vendor to ensure that the application will run properly on your cluster.
A server cluster is comprised of the following essential elements:
Virtual Server. A virtual server is one of the key concepts behind a server cluster: to a client or an application, a virtual server is the combination of the network name and Internet Protocol (IP) address used for access. This network name and IP address are the same for a clustered service, no matter what node it is running on. The actual name and IP are abstracted so that end users or applications do not have to worry about what node to access. In the event of a failover, the name and IP address are moved to the new hosting node. This is one of the primary benefits of a server cluster. Two examples: When SQL Server 2000 failover clustering is installed on a cluster it acts as a virtual server, as does the base cluster.
Cluster Node. A node is one of the physical servers in the cluster. With Windows Server 2003, the operating system might support more nodes than the version of SQL Server that you are using. Please review Table 3-1 and consult Chapter 6, for more details.
Private Network. The private network is also commonly referred to as "the heartbeat." It is a dedicated intracluster network that is used for the sole purpose of running processes that check to see if the cluster nodes are up and running. It detects node failure, not process failure. The checks occur at intervals known as heartbeats.
Public Network. The public network is used for client or application access. The heartbeat process also occurs over the public network to detect the loss of client connectivity, and can serve as a backup for the private network.
Shared Cluster Disk Array. The shared cluster disk array is a disk subsystem (either direct attached storage or a SAN) that contains a collection of disks that are directly accessible by all the nodes of the cluster. A server cluster is based on the concept of a "shared nothing" disk architecture, which means that only one node can own a given disk at any given moment. All other nodes cannot access the same disk directly. In the event that the node currently owning the disk fails, ownership of the disk transfers to another node. This configuration protects the same data stored on the disk from being written to at the same time, causing contention problems.
Shared versus shared nothing is a topic of debate for some. A completely shared environment would require whatever clustered software is accessing the shared disk from n number of nodes to have some sort of a cluster-wide synchronization method, such as a distributed lock manager, to ensure that everything is working properly. Taking that to the SQL Server 2000 level, any given clustered instance of SQL Server has its own dedicated drive resources that cannot also be used by another SQL Server clustered instance.
Quorum Disk. The quorum disk is one of the disks that resides on the shared cluster disk array of the server cluster, and it serves two purposes. First, the quorum contains the master copy of the server cluster’s configuration, which ensures that all nodes have the most up-to-date data. Second, it is used as a "tie-breaker" if all network communication fails between nodes. If the quorum disk fails or becomes corrupt, the server cluster shuts down and is unable to start until the quorum is recovered.
LooksAlive Process. LooksAlive is an application-specific health check that is different for each application. For SQL Server, this is a very lightweight check that basically says, "Are you there?"
IsAlive Process. The IsAlive check is another, more thorough, application-specific health check. For example, SQL Server 2000 in a cluster runs the Transact-SQL statement SELECT @@SERVERNAME to determine if the SQL Server can respond to requests. It should be noted that in the case of SQL Server, this check does not guarantee that there is not a problem in one of the databases; it just ensures that if someone wants to connect and run a query in SQL Server, they can.
As shown in Figure 3-1, for SQL Server, the external users or applications would connect to the SQL Server virtual IP address or name. In the example, Node 1 currently owns the SQL resources, so transparent to the client request, all SQL traffic goes to Node 1. The solid line connected to the shared disk array denotes that Node 1 also owns the disk resources needed for SQL Server, and the dashed line from Node 2 to the shared disk array means that Node 2 is physically connected to the array, but has no ownership of disk resources.
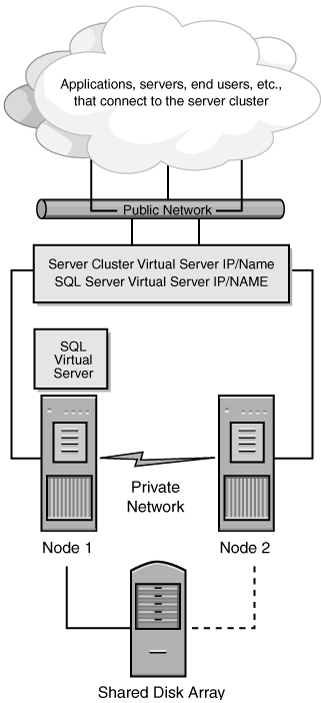
Now that the basics of the cluster components have been covered from a high level, it is important to mention two important cluster concepts that are exposed when a cluster is installed and used by an administrator:
Cluster Resource. The most basic, lowest level unit of management in a server cluster. Some of the standard resource types include Dynamic Host Configuration Protocol (DHCP), File Share, Generic Application, Generic Service, IP, Network Name, Physical Disk, Print Spooler, and Windows Internet Naming Service (WINS).
Cluster Group. A collection of server cluster resources that is the unit of failover. A group can only be owned by one node at any given time. A cluster group is made up of closely related resources and resembles putting a few documents about the same subject in a folder on your hard disk. For example, each SQL Server 2000 instance installed on a server cluster gets its own group.
A Network Load Balancing cluster is a collection of individual servers configured to distribute Transmission Control Protocol/Internet Protocol (TCP/IP) and User Datagram Protocol (UDP) traffic among them according to a set of rules. Network Load Balancing creates an available, scalable solution for applications such as Internet Information Services (IIS) and Internet Security and Acceleration Server (ISA Server), but not necessarily SQL Server.
Important
Unlike a server cluster, a Network Load Balancing cluster can be made up of nonspecialized complete solutions. However, the hardware must still be on the HCL.
From a SQL Server perspective, Network Load Balancing is not always the best choice to provide either scalability or availability, as it presents some challenges in the way that it operates, which differs from the transactional way in which SQL Server operates. For Network Load Balancing and SQL Server to work in, say, a load balanced and write situation, they would have to be coded to use the shared disk semantics described earlier with some sort of lock manager. Network Load Balancing, however, can be used to load balance read-only SQL Servers (such as catalog servers for a Web site), which also provides greater availability of the catalog servers in the event one of them fails. Network Load Balancing can also be used in some cases to abstract the log shipping role change and switch to another replicated SQL Server if those are used as availability technologies in your environment.
Important
Administrators commonly want to combine the functionality of server clusters with Network Load Balancing to provide both availability and scalability, but that is not how the product is currently designed, as each technology has specific uses.
The following concepts are important to understanding how Network Load Balancing works:
Virtual Server. Like a server cluster, a virtual server for Network Load Balancing represents the "virtualized" network name and IP address used for access. The important difference is that Network Load Balancing does not persist state in which each node knows if all the member nodes are up or not, but it does know which nodes are running. In a server cluster, every node knows about all cluster members, whether they are online or not, as state is persisted.
Cluster Node. A node is one of the physical servers in the cluster, just like in a server cluster. However, each node is configured to be identical to all the other nodes in the cluster (with all of the same software and hardware) so that it does not matter which node a client is directed to. There is no concept of shared disks as there is with a server cluster. That said, for example, a Web service could be making requests to one file share, but it is not the same as the shared disk array for a server cluster. There can be up to 32 nodes in a Network Load Balancing cluster.
Heartbeat. Like a server cluster, a Network Load Balancing cluster has a process for ensuring that all participating servers are up and running.
Convergence. This process is used to reach consensus on what the cluster looks like. If one node joins or leaves the Network Load Balancing cluster, because all nodes in the cluster must know which servers are currently running, the convergence process occurs again. Because of this, convergence results in the high availability of services that can take advantage of Network Load Balancing because connections that were going to a now-dead node are automatically redistributed to others without manual intervention.
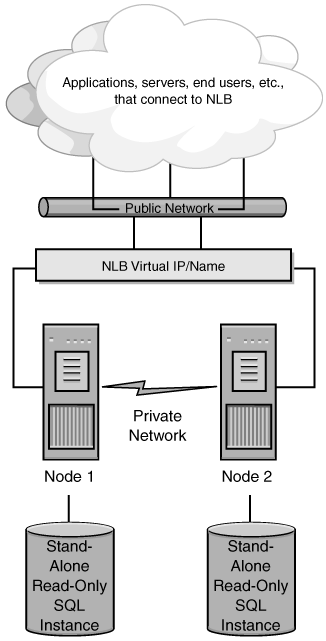
Figure 3-2 shows how a read-only SQL Server could be used with Network Load Balancing. The external users or applications would connect to the Network Load Balancing virtual IP address or name; however, behind the virtual IP address, things are different. Each node has its own database configuration and disk. When a client request comes in, an algorithm at each node applies the port rules and convergence results to drop or accept the request. Finally, one of the nodes services the request and sends the results back.
A geographically dispersed cluster is no different from a standard server cluster, except that one or more nodes of the server cluster reside in another location. This type of cluster is achieved through specialized hardware, software, or a combination of both. There are still distance restrictions due to how long, say, a dark fibre network can be, but a geographically dispersed cluster removes the data center as a single point of failure. (See Chapter 4, for more information about a dark fibre network.) One barrier to adoption is the cost of implementation, because the network needs great bandwidth across a long distance, as well as a duplicate set of hardware, including the disk subsystem, in both locations. Technically, the secondary location does not have to completely mirror the primary location (that is, it could have fewer nodes and disks as long as it has enough processing power to handle the highest priority applications if something occurs on the primary), but the environment should mirror the production environment as closely as possible.
Important
All geographically dispersed server cluster configurations must appear as a complete hardware solution under the specific geographic cluster list on the Microsoft HCL for the operating system choice you are making. The configuration is a viewed as complete solution, not individual parts that can be put together like a jigsaw puzzle. Microsoft supports only a completely HCL-compliant cluster solution. Please consult http://www.microsoft.com/hcl/ for more information.
Now that the technologies for the operating system have been laid out, it is time to focus on what SQL Server 2000 offers for providing availability. Each of the topics introduced in this section has its own chapter later in this book.
When you install SQL Server 2000 for use on a server cluster, this configuration is known as SQL Server 2000 failover clustering. This installation is also considered a virtual server, and is an instance of SQL Server 2000. The virtual server can either be a named instance or a default instance, but just like a stand-alone configuration, there can only be one default SQL Server 2000 instance per server cluster. A SQL Server 2000 failover cluster supports the core SQL Server functionality; Analysis Services is not cluster-aware. Chapter 10, "Designing High Availability Solutions with Microsoft SQL Server," addresses how to make Analysis Services available. To administrators and end users alike (with any exceptions noted here or in Chapter 6), a failover cluster should act, look, and feel like a stand-alone SQL Server. Each SQL Server 2000 failover cluster installation gets its own group and set of resources in the server cluster.
More Info
Chapter 6 details the planning, configuration, and administration of a SQL Server 2000 failover cluster.
If you are familiar with the Microsoft SQL Server 6.5 or Microsoft SQL Server 7.0 implementation of clustering, you will realize that SQL Server 2000 greatly enhances clustering functionality. In fact, with SQL Server 2000, clustering support was redesigned from the ground up. This is one of the reasons that the feature in SQL Server 2000 is called failover clustering, whereas in SQL Server 7.0, it was just called clustering.
One of the first differences with SQL Server 2000 failover clustering is the support for more than a two-node server cluster. Microsoft Windows NT 4.0 Enterprise Edition, the platform for which SQL Server 8.0 clustering was originally designed, only supported two-node clustering. SQL Server 2000 takes advantage of more nodes when they are available. With the introduction of Windows Server 2003, up to eight nodes can be supported by the operating system. As noted in Table 3-2, the 32-bit version of SQL Server is still limited to a maximum of four nodes per virtual server.
Table 3-2. SQL Server Node Support per Version
SQL Server Version | Maximum Number of Nodes |
|---|---|
SQL Server 6.5 and 7.0 | 2 |
SQL Server 2000 (32-bit) | 4 |
SQL Server 2000 (64-bit) | 8 |
Instance support is the primary difference between SQL Server 2000 and earlier versions. An instance, simply put, is a separate installation of SQL Server that can run side-by-side with another SQL Server installation on the same machine. The instance can either be a default instance or a named instance. Think of a default instance as the way SQL Server has historically been architected. A named instance is just that—one that is given a name to make it distinct. SQL Server 2000 supports up to 16 instances (clustered or not), which can include 1 default and 15 named instances, or 16 named instances. Instances allow multiple SQL Server virtual servers to be installed on a cluster with ease. With SQL Server 6.5 and SQL Server 7.0 clustering, you were limited to at most two installations of SQL Server on any given server cluster.
SQL Server 6.5 and SQL Server 7.0 clustering relied on the concept of active/passive and active/active clustering. When you only have two installations of SQL Server, these concepts are easy to grasp. Active/passive clustering occurs when you have only two nodes, and one controls the active resources. Active/active clustering occurs when both nodes in the cluster have active resources (such as two SQL Servers). When instances were introduced with SQL Server 2000, these definitions proved problematic. Because the operating system and SQL Server itself can now support more than two nodes, the terms really do not fit. The new equivalent terms are single-instance cluster for active/passive and multiple-instance cluster for active/active. If you only have up to two nodes and two SQL virtual servers, active/passive and active/active might still apply, but it is better to use the new terminology. Single-instance clusters are also sometimes referred to as single active instance clusters, and multiple-instance clusters are sometimes referred to as multi-instance clusters or multiple active instance clusters.
Other enhancements with SQL Server 2000 failover clustering include the following:
Installing and uninstalling a SQL Server 2000 failover cluster are both now done using the SQL Server 2000 Setup program, and not through the combination of setting up your database server as a stand-alone server, then running a wizard. Clustering is part of the installation process. This also means that SQL Server 2000 failover clustering is a permanent option, and the only way to remove it is to uninstall the clustered instance of SQL Server.
SQL Server 2000 includes extensive support for recovering from a server node failure in the cluster, including a one-node cluster. If a node fails it can be removed, reinstalled, and rejoined to the cluster while all other nodes continue to function properly. It is then a simple operation with SQL Server 2000 Setup to add the new server back into the virtual server definition. SQL Server 6.5 and SQL Server 7.0 clustering did not have this capability, and in some cases, a severe problem could result in a complete cluster rebuild. Although, this can still happen with SQL Server 2000 in extreme cases, it can be avoided for most problems.
All nodes now have local copies of the SQL Server tools (including performance counters) as well as the executables, so in the event of a failover, you can administer the server from a remote system or the clustered node itself. SQL Server 6.5 and SQL Server 7.0 required that the binaries be installed on the shared cluster disk subsystem. This was a problem, because only the cluster node that performed the installation had the tools registered.
Each SQL Server 2000 virtual server has its own full-text resource. In previous versions of SQL Server clustering, full-text functionality was not supported. The underlying Microsoft Search service is shared among all things accessing it on the node, but if your database requires Full-Text Search it is now an option if you decide to use failover clustering.
SQL Server 2000 failover cluster configurations can be updated by rerunning the setup program, which simplifies the configuration process.
Database administrators can now use all of the SQL Server tools, including SQL Server Service Manager or SQL Server Enterprise Manager, to fully administer the database, including starting and stopping SQL Server. Previously some functionality, such as stopping and starting SQL Server, required using Cluster Administrator. That meant database administrators (DBAs) had to be SQL Server experts, as well as Server Cluster experts, which could cause problems if something was done in the wrong place.
Service packs are applied directly to the SQL Server 2000 virtual server. With SQL Server 7.0, you had to uncluster the server prior to applying a service pack.
SQL Server 2000 is now a fully cluster-aware application. This allows SQL Server 2000 to interact properly with the Cluster service, and it provides some benefits such as preventing the creation of databases on invalid logical drives.
Each node of the cluster is capable of "owning" a resource, whether it is SQL Server, a disk, and so on. The node currently owning the disk resource (whether it is a SQL Server disk, or the quorum disk), which hopefully is the designated primary owner, reserves the resource every three seconds. The point of the reservation process is to protect against physical access by another node; if a node loses the reservation, another node can now take ownership.
For example, if the node owning the instance fails due to a problem (network, disk, or something else) at second 19, the competing node detects it at the next reservation cycle. If the reservation cycle fails for the node that owned the disk resource three more times, the new node takes ownership, in this case at around second 34.
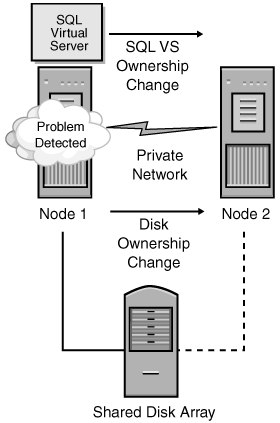
From a SQL Server perspective, the node hosting the SQL Server resource does the LooksAlive check. Remember that this does not mean that SQL Server is up and running. The IsAlive is then run, and that issues the aforementioned SELECT @@SERVERNAME. Again, this does not guarantee that the database you need can service a request, but SQL Server itself can. Should the IsAlive check fail (which means the query fails), it is retried five times. In the event all five retries fail, the SQL Server resource fails. Depending on the failover threshold configuration (discussed in Chapter 6) of the SQL Server resource, the server cluster either attempts to restart the resource on its current node or fails it over to the next preferred node that is still running (see Figure 3-3). The execution of the IsAlive tolerates a few errors, such as licensing issues or having a paused instance of SQL Server, but ultimately fails if its threshold is exceeded.
During the failover process from one node to another, the server cluster starts the SQL Server service for that instance on the new node and goes through the recovery process to start the databases. The entire switch of the SQL Server virtual server from one node to another takes a fairly short time. After the service is started and the master database is online, the SQL Server resource is considered to be running (see Figure 3-4). This process, on average, takes less than a minute or two. However, keep in mind the user databases will go through the normal recovery process, which means that any completed transactions in the transaction log are rolled forward, and any incomplete transactions are rolled back. The complete length of the recovery process depends on how much activity must be rolled forward or rolled back at startup, so the entire failover process takes longer than it takes to start the processes and bring up the master on the other node. This behavior is the same as a stand-alone instance of SQL Server that would be stopped and started.
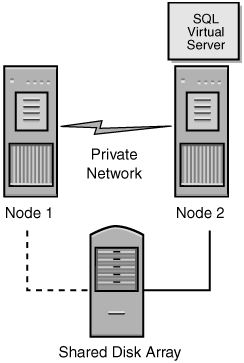
As noted earlier, end users and applications access the SQL virtual server with either its name or IP address, not the name or IP address of the node hosting the resources. Users and applications do not need to worry about which node owns the resources. That is one of the best benefits of failover clustering—things are largely transparent to the end user. One noticeable result, depending on how the application is designed, is that during the failover process, any active connections are broken because the SQL Server is stopped and started. Therefore, whatever the user was working on when the server fails over might not be completed unless the transaction completes before the server goes down or the transaction and subsequent reconnect is handled within the application. This possibility must be taken into account in any decision to involve a cluster on the back end.
SQL Server 2000 failover clustering is always transactionally current: when the database is started on another node, it starts at the exact state it was in prior to failover. This is one of the benefits—no transactions are lost from a database, so the database is always current. Only transactions that were incomplete or issued after the failure and before SQL Server is restarted are lost, and that can be handled in the application. In fact, because the whole SQL Server instance fails over to another node, all databases and their objects (including logons, stored procedures, and so on) survive the switch intact.
This topic is dealt with in more depth in Chapter 6, but sometimes there is the notion—especially in a single-instance cluster or a multiple-node Windows Datacenter cluster with only one SQL virtual server—that unused nodes are being wasted. However, these nodes serve as an insurance policy in the event of a failure. If you start utilizing the "wasted" node for something else, what will happen in a failover? Will SQL Server have enough resources to allocate to it?
Because only one SQL Server can own a given disk resource (for more information, see Chapter 4, Chapter 5, and Chapter 6), you cannot share certain resources among clustered SQL instances. For example, if you have a drive D with 100 GB of space and need only 30 GB of it for one SQL virtual server, you cannot use any of the remaining disk space on drive D for another SQL virtual server.
Finally, because there is no load balancing with failover clustering, two SQL Servers cannot share the same underlying database because of the shared nothing mechanics of the server cluster. So you cannot, for example, use one SQL Server instance to do the reporting and another to do the inserting on the same database.
Log shipping is not a new technology for SQL Server 2000; DBAs have used it for some time. Log shipping is the process of taking a full database backup from a specific point in time and restoring it in a special way on another server such that transaction log backups can be applied to it. Transaction logs are then made on the active server, also known as the primary, and then copied and applied to the waiting server. This server can be known as the secondary or warm standby. The secondary server stays in this mode until it needs to be brought online. If the switch needs to be made to the warm standby, this process is called a role change, not a failover. (Role change is described in detail in Chapter 7.)
The first released Microsoft implementation of log shipping was released in the Microsoft BackOffice Resource Kit 4.5 (published by Microsoft Press, ISBN 0-7356-0583-1), and it was script-based. SQL Server 2000 took the log shipping functionality a step further and integrated it into the platform, but and it is available only in SQL Server 2000 Enterprise Edition and SQL Server 2000 Developer Edition (which can only be used for development purposes). Microsoft does recommend the use of the built-in functionality, as it also provides a Log Shipping Monitor to display the status of the process. Log shipping can be custom scripted for other editions of SQL Server or to accommodate other requirements, such as compression or encryption of the files being sent across the wire. Functionality like the Log Shipping Monitor would also need custom coding. Log shipping does not require any specialized hardware or solutions other than the proper version of SQL Server.
Log shipping is always transactionally consistent, although there is usually some sort of latency involved. It is not considered "real time," in which each transaction is sent as soon as it occurs. With log shipping, you are only as current as:
The last transaction completed on the primary
The last transaction log backed up on the primary
The last transaction log copied from the primary
The last transaction log applied to the secondary
The log sent to the secondary is only as current as the last transaction log that is applied, so if the delta is five minutes off of the primary, your secondary should always remain five minutes behind if all is functioning properly. Analyzing these points is fairly straightforward given the previous sentence. If a transaction is completed, it is written to the transaction log. If the SQL Server experiences a failure before that transaction log is backed up, there is a chance that if the server cannot recover and read the transaction log, it will be lost, and you will only be as current as the secondary. If a transaction log is backed up but not copied over to the secondary, and either the copy process fails or the hard disk that contains that transaction log is lost, again, you are only as current on the secondary as what is available to it. If a transaction log is copied from the primary, and is still accessible to the secondary, it can be applied, so your secondary will be as current as the last transaction in the transaction log.
One benefit of log shipping is that anything that is recorded as a transaction for the database being log shipped is applied to the secondary. On the flip side, when the log shipped database is configured, only the objects found in that database exist at the secondary. Anything outside of the immediate database—logons, stored procedures used in another database, and so on—would have to be transferred using another process external to the core log shipping process.
Another use of log shipping, but not its main or intended use, is that the secondary database can potentially be used for read-only reporting-type access. The problem, however, is that to apply the transaction log, SQL Server needs exclusive access to the database, so no users can be accessing the database. If even one connection is left open, you could be putting your availability solution at risk. If the transaction logs are applied frequently, there might not be enough time between transactions to allow read-only access.
If full-text searching is required by the database that is being log shipped, you need to consider what to do in the event of a role change. Here is the crux of the issue: you cannot generate a full-text index on the secondary while the database is loading transaction logs. Even if you are backing up the full-text index and performing maintenance on it on the primary, even on the primary it will be out of sync if applied to a database that is at a later moment in time. Unless you can get to the full-text index and ensure that it is exactly at the same point as the log shipped secondary, you cannot "bolt it on" to the secondary. In that case, you will likely have to regenerate the full-text index after the database is brought online.
Another consideration regarding log shipping is its affect on clients and applications. Applications do need to take various things into account, including connecting to another server, as it will have another name. Application issues relating to log shipping are detailed in Chapter 7. Because the role change is not an automatic process, you need to have a tested plan in place to perform the switch in servers. There will definitely be some sort of availability outage during the switch. Network Load Balancing might be able to help abstract the name change of the server, but it certainly does not prevent downtime. The switch time could take anywhere from seconds if all available transaction logs are applied, to much longer if they are not.
More Info
Chapter 7 details the planning, configuration, and administration of log shipping.
Replication is another technology that is not new to SQL Server. Replication has been part of SQL Server since SQL Server 4.21a. There are three forms of replication, as follows:
Merge Replication. Designed to allow sites to work autonomously and allow updates of data to occur in multiple places, and then have those changes rolled up to a central repository at specified intervals. Merge replication is a good choice for disconnected environments that need to update data, but is not appropriate for most availability scenarios.
Snapshot Replication. Just that, a "snapshot" of where the data is at a particular moment. Because a snapshot is a complete copy of the data and there is usually quite a bit of latency between publications, it is not appropriate for availability.
Transactional Replication. Allows data to be replicated to a subscriber as soon as it is modified at the publisher. Transactional replication can be bidirectional, meaning subscribers can update publishers. Because of the low latency involved with transactional replication, it is appropriate in certain cases to use for SQL Server high availability. Any further discussions in this chapter and book refer to transactional replication in the availability context.
Each form of replication shares a similar architecture. Each has a publisher, a distributor, and a subscriber. The publisher is the originator of the data or publication, which then sends it to the distributor. The distributor sends the data to be published to the appropriate subscribers. The subscriber is the "end user" of the data from a SQL Server perspective. For more information about each form of replication, consult SQL Server 2000 help files—SQL Server Books Online.
Transactional replication was not designed with availability in mind, much like using Network Load Balancing with SQL Server was not the original intention of Network Load Balancing. Replication allows the customization of articles and publications sent. So, if you need to have only a certain portion of data available, transactional replication allows you to send a smaller portion of your data elsewhere. No other SQL Server-based technology allows this customization.
There are some issues to consider when using replication as your method of high availability. One of the main issues is that certain objects associated with each database or that are created do not necessarily get re-created as part of the article or publication. It is important to understand what objects replication brings over and what it does not. Another issue is that because it was not designed for transactional replication, there is really no out-of-the box solution for switching from one server to the replicated warm standby. Tasks that ensure synchronization of the proper logons, stored procedures, and so on must also now have a process devised to move them to the standby.
Transactional replication is always transactionally consistent. With replication (any form), you are only as good as the following:
The last transaction completed on the publisher
The last transaction or publication sent to the distributor
The last transaction or publication applied to the subscriber
The scenarios are similar to the one detailed earlier for log shipping in terms of what the delta is between the publisher and the subscriber.
Obviously, one of the main uses of replication is that you are making data available elsewhere, whether it is reporting or another use. Therefore, you do not have to worry about accessing the secondary while it is being updated.
Full-text indexing will have to be configured against the replicated database. If you intend on possibly using the replicated database as a primary at some point, do not wait to start generating the full-text index. In addition, if only a subset of the data is replicated, and that database now needs to assume full functionality, you might not be able to use that database with the application. Different types of replication have limits on how much data is transferred in an article or publication.
Replication suffers from the same dilemmas as log shipping when it comes to clients: if a client or application expects to be connected to one server, how does it handle being changed to another server? The switch process also needs to be planned; it is not automatic. Replication does not detect the failure, other than, perhaps, showing up in the Replication Monitor as everything being out of sync. There will be downtime in the switch and the length of the downtime varies depending on the circumstances.
More Info
Chapter 8, details the planning, configuration, and administration of replication for high availability.
Backup and restore really needs no introduction. You do not have to be a DBA to understand that databases and all files related to the solution (including the operating system) need to be properly backed up, no matter what other availability methods are employed, such as failover clustering. You still need a proper backup and restore plan. The other technologies do not supplant the need to do the basics!
No matter your current situation, there is a chance that backup and restore might be the only option available. A well-planned backup and restore process can greatly increase availability. For most DBAs, this simply means that being able to restore the system quickly is a good idea in addition to whatever else you are doing to increase uptime. However, in the case of a very large database, you might need to consider a hardware-assisted solution to assist with quick restoration of the data.
It is imperative to ensure that backups are made frequently and tested to verify that the backups made are good and that you know the timings. If you have an overall availability goal as well as service level agreements (SLAs) that require certain availability requirements, you need to know if the restore will not meet the time specified in the SLA, and then possibly adjust your backup and restore strategy accordingly.
More Info
Chapter 9, and Chapter 10, go into depth about the planning, configuration, and administration of the backup and restore process for high availability.
When selecting the right availability technology or technologies for your environment, trust becomes a huge issue: can your company, whether it is a small business or a global powerhouse, bet your server or solution availability, and possibly even the survival of the company, on the investment? That is a lot of pressure, but it is also one of the main reasons that this book emphasizes proper planning: the wrong decision could be costly on many levels.
The decision process itself is, like achieving availability itself, deceptively simple: analyze your requirements, compare those against the technologies being evaluated, and select the technology that will provide you the best availability based on all factors. This, of course, is easier said than done.
Look back at the guiding principles that came out of the questions posed in Chapter 1. Those guide the rest of the decision process, as they detail the overall availability goals for the solution. The technology should meet those goals, but there will obviously be some compromise involved. No one solution can be 100 percent perfect. The choice or choices made should meet your most important criteria. If perfection is the goal, the end implementation will never happen, and it will be costly on many fronts.
One crucial decision that comes up at this stage is the budget for the project. The amount of money you have to spend greatly affects what type of availability solution you can implement. Do not plan a solution—even down to rollout plans and support documents—only to find out you cannot afford it. As casinos tell gamblers, "Bet with your head, not over it." For example, a regional financial company provides online services 24 hours a day, including all aspects of banking (automated teller machines, bill payments, account balances, investments, and so on). Any moment of downtime could cost millions of dollars in lost transactions—an unacceptable situation on the surface. Geographically dispersed clusters seem like an ideal solution, right? They provide an automatic switch that log shipping does not, and should be transparent to end users. It also protects you from having one data center as a single point of failure.
Unfortunately, most geographically dispersed clusters, whether pure hardware or a combination of hardware and software, cost—at a bare minimum—hundreds of thousands of dollars. Realistically, the cost is probably in the millions. Add to that the cost of the network to ensure the cluster response time and overall network performance. A wide area network (WAN) of this type is very expensive to implement and requires specialized hardware as well. This combined price tag rules out even many enterprise customers. The sooner that you realize that the "ultimate" in availability might be out of your reach, the better off you will in planning a solution that will provide you with the best availability you can afford and manage. This is not to say that geographically dispersed clustering is not the solution for you—it might very well be, and it might work well. However, if you cannot afford it, it is not worth putting the company out of business and yourself out of a job just to say you achieved the ultimate in high availability.
With the cost factor out of the way, it is easier to focus on how to make the right decision for your environment—as long as you stick to the guiding principles. Other sample questions to ponder during this phase are:
What is the skill level of the staff that will deploy, administer, and maintain the solution? Do they have any experience with the technologies being considered? Do you have the proper staff in place or do you need to hire? Is there the budget to hire more staff?
What is the deployment time frame? Will the technology choice meet that goal?
Do the applications using the technologies being considered work well with the technology of choice? If the technology is not compatible or does not produce the desired results, it will be a painful experience for everyone involved, making it a bad choice. Consult application vendors or developers to see what their disaster recovery scenarios include for their applications on your platform of choice.
If you are building an application and complete solution from the ground up, do the application developers and testers have experience with the technologies, or do they need training? How long will that training take, and how will it impact the schedule?
Can you afford to have duplicate equipment for development, testing, staging, and production environments?
What hardware will be used? Is it new? Repurposed? Will it actually work and be a supported platform for the technology?
Now that you have analyzed your internal situation, it is time to evaluate the technologies. First, pick the version of Windows that meets your current and future growth needs from a memory, processor, and feature standpoint. That said, your decision might change depending on the SQL Server technologies being considered. The operating system choice is usually a fairly straightforward one, but the SQL Server choice is not. For a direct comparison of the SQL Server-based technologies, see the section "A Comparison of the SQL Server Technologies" later in this chapter. Consult other chapters in the book for more information and attend conferences, ask consultants or salespeople, ask for trial versions, and perform actual proofs of concept. Go into the actual selection process with as much knowledge as you can to make the right decision. Hopefully this book will assist in that process, but it would be naïve to think that it is the only source of information on high availability on the Microsoft platform. It is better to take your time than to make the wrong decision.
This section compares and contrasts failover clustering, log shipping, and replication. Backup and restore is woven in.
On the surface, log shipping and transactional replication are deceptively similar. They both offer the ability to send transactions from one server to another in an automated fashion to create a warm standby. They both involve a manual switch to a secondary server, both can be used for reporting, and so on. The subtle differences ultimately become the key points.
The biggest considerations are the ones loosely described in the earlier sections about log shipping and replication:
How many transactions are generated per hour? Will the solution be able to keep the secondary in sync quickly enough to allow low latency between the two?
How much downtime is acceptable to the end users? Will the switch process invalidate any availability SLA you have in place?
How much data can you realistically afford to lose in an extreme emergency? Will the solution meet your transactional requirements?
Will the solution be too expensive from a hardware, software, or administrative standpoint?
Do you have enough network bandwidth between the primary and secondary?
How large are the entities (transaction log files or transactions) being sent across the wire?
How long will it take to apply the transaction or transaction log to the secondary? Seconds? Minutes? Hours?
What is the capacity of the secondary server? Can it handle the current production load?
Is it a goal to eventually switch back to the original primary after a failure? If so, how will you perform this task?
The answers must be in line with your business requirements.
Transactional replication stores the transactions both at the publisher and the distributor. At the publisher, they are kept in the publication database, and if for some reason they are not published, they still exist there. If they have been replicated, they also exist in the distribution database. Should the publication or distribution databases fail, the log reader process cannot read the transactions.
Log shipping stores the transactions only in the database (and subsequently in the transaction log). Depending on what transaction log backups are available, and assuming you can still get to the transaction log on the primary server if it has been updated after the last transaction log backup, you might still be able to get the remaining transactions. This means that with log shipping, not with transactional replication, there is a higher probability of transactional recoverability.
Replication might require more server overhead than log shipping. Both log shipping and replication will have input/output (I/O) overhead, but remember that replication has replication agents doing work that consumes system resources. If you are sending over every transaction in a highly utilized online transaction processing (OLTP) database, this cannot be discounted. Log shipping has overhead, but because it is run less frequently, the overhead might be less. Log shipping and replication both use SQL Server msdb database, but neither really uses it more than the other.
Latency between the primary server and the secondary server is also a concern. Although transactional replication might have a lower latency, it also requires a synchronized backup strategy, which log shipping does not. See the topic "Strategies for Backing Up and Restoring Transactional Replication" in SQL Server Books Online for more information. When the replication option Sync With Backup is set on both the publisher and distributor to ensure that both can be restored to the same point, you will get roughly the same latency as log shipping.
For transactional replication, it is paramount that the distribution database is available, so making that SQL Server available impacts the end solution. If you are using the built-in version of log shipping found in SQL Server 2000 Enterprise Edition, the monitor needs to be made available to report status. Not having all pieces available could affect the solution. The backup and restore situation with replication comes into sharper focus if for some reason you need to restore replication for disaster recovery, because if Sync With Backup is not set, replication has to be started from scratch, which could be troublesome.
With transactional replication, there might be an issue if the publisher, distributor, and subscriber are out of sync in terms of the SQL Server version. Generally, a distributor must be of a version equal to or greater than its publishers and a publisher must be of a version equal to or greater than the subscribers. There are sometimes exceptions to the rule in terms of subscribers. Log shipping should function no matter what version of SQL Server 2000 is installed, but all SQL Servers should be at the same level to ensure compatibility and similar behavior after the role change.
Because the distribution database contains the transactions that will be sent to the warm standby, a failure of the distribution database will impact transactional recoverability if the transactions are lost, as well as ability to recover the standby after a failure. You should weigh which one is more important to your business, as log shipping will give you better transactional recoverability. In a catastrophic failure, both log shipping and replication would need to be set up again.
If using the standby as a reporting server is crucial to your business and if you are choosing only one technology, replication might be the better option. Log shipping and its requirement to have exclusive database access, combined with frequent transaction log loads, makes it less than ideal for read-only access to that particular database. However, you also have the ability to stack transaction logs and apply them later. Obviously, this puts your log shipped secondary more out of sync with higher latency, but it can be used for reporting. If disaster recovery is more important than read-only databases, log shipping definitely has the edge in this category.
The process of bringing either the replicated database or log shipped database-online must be considered. Technically, the replicated database is online, but does it have all the elements to assume the production role? Does the log shipped database have all the transaction logs applied? How long does the entire process take? Is it tested? How will you notify the end users? The complexity will vary a little, but historically, it is much more defined from an availability standpoint for log shipping. Transactional replication and its lower latency might mean that a replicated standby is closer to the source for disaster recovery purposes, but the lack of processing would make log shipping a much more attractive option. You still need to weigh what is more important to your business.
Does introducing log shipping or transactional replication add more complexity because there are "moving parts" and dependencies? Be certain your availability solution cannot end up becoming a barrier to availability! Remember the maintenance of these added points of failure, too. All servers need to be well maintained. Managing and monitoring log shipping is generally easier than it is for replication.
If you base your decision purely on the choice between automatic or manual switching to a standby server, SQL Server 2000 failover clustering wins hands down. The problems for most people considering it are the aforementioned "wasting of resources" and the interruption in service that results from the automatic switch. These two factors, coupled with the fact that the hardware is a more specialized solution (even down to driver levels), might scare some away, but they should not. In reality, although SQL Server 2000 failover clustering is a little more complex in some ways than a log shipping or replication solution, in other ways it is not. Failover clustering has "moving parts," but you do not need to worry about things like Log Shipping Monitors or making sure that the distributor is up and running to keep the process going. As long as the underlying server cluster is properly configured, there should be no issues with the failover cluster built on top of it.
Now, log shipping or replication might be considered by some "poor man’s clustering" if Network Load Balancing is thrown in the mix to abstract the role change so that the back-end SQL Servers appear to act as one. In reality, however, it is not a server cluster or a failover cluster, so if you really do need the functionality provided by failover clustering, please consider it.
Here is a guide to the terminology used in Table 3-3:
Standby type. How Microsoft classifies the solution. The ratings are hot, warm, and cold. Hot represents a solution that provides excellent uptime given all of its features and considerations. Warm provides good availability. Cold is not the best, but it can be achieved. For example, backup and restore would be considered cold.
Failure detection. Processes invoked by the technology can detect a failure and react to it.
Automatic switch to standby. No manual intervention is required to switch to the standby.
Masks disk failure. Does not mean that it completely masks a failure to a local or shared disk subsystem. It means that in the switching process, you will not encounter the same disk failure and can still recover on the standby.
Masks SQL process failure. If something goes wrong in the process, the technology can handle the problem.
Metadata support. The level of data definition language (DDL) support offered by the technology.
Transactionally consistent. The standby server is transactionally consistent.
Transactionally current. The standby server is at exactly the same point as the primary server.
Perceived downtime. The time that an interruption in service might occur.
Client transparency. The client will notice a problem.
Hardware requirements. The technology requires specialized hardware.
Distance limitations. The technology is constrained by distance.
Complexity. The technology is significantly more complex than implementing a normal SQL Server-based solution.
Standby accessible for read-only access. The standby server is available for reporting or other read-only functionality.
Performance impact. The technology impacts overall server performance.
Impact to backup strategy. A backup and restore plan needs to take into account additional complexities due to the technology.
Full-text support. The technology supports Full-Text Search in a disaster recovery scenario.
Table 3-3. SQL Server Availability Technology Comparison Table
Availability Feature | Failover Clustering | Log Shipping | Transactional Replication |
|---|---|---|---|
Standby type | Hot | Warm | Warm |
Failure detection | Yes | No | No |
Automatic switch to standby | Yes | No, but Network Load Balancing might help | No, but Network Load Balancing might help |
Masks disk failure | No, shared disk can possibly be a single point of failure | Yes | Yes |
Masks SQL process failures | Yes | Yes | Yes |
Masks other Process failures | Yes | No | No |
Metadata support | Yes, the entire server is failed over | Yes, but only all metadata in the logshipped database; anything outside the database, no | Only selected objects |
Transactionally consistent | Yes | Yes | Yes(transactional only) |
Transactionally current | Yes, database in a failover is always at the point it is at the time of failure | No, only as current as the last transaction applied | No, only as good as the last transaction log applied |
Usually under two minutes, plus database recovery | Time to switch servers plus any transaction logs that need to be applied | Time to switch servers | |
Client transparency | Yes, if referring to the server name or IP address; application must still reconnect or be made cluster aware, so there might be minimal impact | No | No |
Hardware requirements | Specialized solutions | No | No |
Distance limitations | Normal networking limitations | None | None (limited to network bandwidth,though) |
Complexity | Potentially more | Some | More |
Standby accessible for read-only access | No, only one copy of the data | Possibly, depending ontransaction log load times | Yes |
Performance impact | Minimal to none | Minimal: I/O and overhead of log shipping jobs | Minimal: I/O and overhead of replication agents |
Impact to backup strategy | Minimal | Minimal to none, depending on if transaction logs are already backed up | Yes, because in a disaster recovery scenario, the publisher and distributor would need to be in sync |
Full-text support | Yes, full-text functions normally after failover | No, full-text indexes would need to be rebuilt after database is brought online or if the database from the primary was left at the same point the secondary was brought online, you might be able to attach the indexes | Yes, but need to configure an index to be built on the standby as the transactions are inserted |
The general rule of thumb is that failover clustering provides the highest availability. That statement has merit from a technology standpoint—whether or not a geographically dispersed cluster is involved—because you get an automatic process that switches resources from one computer to another without human intervention.
If you cannot afford SQL Server 2000 Enterprise Edition and the versions of Windows that support clustering, failover clustering is obviously not an option. It might be right for your situation, but if you cannot afford the solution, you need to think about alternatives.
Log shipping is a great primary or secondary solution, and it compliments failover clustering well. It is a trusted, time-tested method that is geared toward making a standby server. The issue winds up becoming the delta of time between the primary server and the secondary server. Because log shipping is not an ideal reporting solution, but a good availability solution, if reporting is needed, you could combine replication with log shipping to provide that functionality. Transactional replication might work for some, but in terms of availability, it should be considered after failover clustering or log shipping.
Again, no matter what, remember your backup and restore strategy. In a complete disaster recovery scenario, your backups might be the only remaining option.
This section outlines some basic guidelines. They will help, although ultimately additional considerations based on the technical details of each technology will help you decide which choice is the best fit for your particular environment.
Making technology decisions for high availability is not easy. Remember these two words and apply them to your environment: it depends. What works for one company or one solution might not be appropriate for another; there are no absolutes. Consider what each technology brings to the table in terms of strengths and weaknesses, and then match those against your needs—cost, application, administration, and so on. If possible, as an insurance policy, choose more than one method of high availability. For a complete example of designing a solution that includes cost, hardware, and technology choices, see Chapter 10.