
Replication is a popular feature of SQL Server because it allows you to make copies of your data and keep them synchronized with a standardized process that can be automatic or manual. How does replication fit into the high availability picture? This chapter discusses the two ways to think about replication: using replication to make your databases available and making your replication architecture available.
As noted in Chapter 3, although transactional replication or merge replication can be used to make a database available, they would be third on the list of Microsoft SQL Server technology choices. For the purposes of high availability, if you had to choose one form of replication, it would be transactional because it has the lowest latency from Publisher to Subscriber. Remember that you can only use replication for high availability in certain scenarios and with certain considerations.
The best (and most likely) scenario is one in which you need to make a copy of all your data for read-only reporting purposes, which is something log shipping cannot do well. In the event of a disaster, with the proper objects and users added, you might also be able to use the replicated data for your application. If you generate this copy of the database by transactional replication, also unlike log shipping, your latency can perhaps be seconds instead of minutes. This section details what you need to know to plan for implementing replication for availability purposes.
The other likely scenario is the need to make a synchronized copy of a subset of your data, which is also not possible using log shipping. Log shipping, like clustering, provides a solution for your entire database—you cannot log ship a single table or a subset of a table.
As noted already, you more than likely will employ transactional replication for high availability uses. Depending on the situation, more than one form of replication might provide some sort of benefit for you.
Merge replication is useful when the following criteria are met:
Multiple Subscribers have to update data at various times. Those changes are sent back to the Publisher and finally to other Subscribers. An example of this is near-real-time inventory updates for a chain of stores. This would allow each individual store to query other stores for an out-of-stock item. As long as the employee knew there was a bit of latency (for example, updated every half hour), he or she could call the other store to check. All of this would ensure customer satisfaction and maybe a sale.
Site autonomy is critical. As with the previous inventory example, each individual store needs to have data specific to that location, but also needs some shared corporate data (such as product numbers and prices).
Merge replication provides a rich framework for conflict resolution for updating Subscribers. You can either use the conflict resolution provided by SQL Server or code your own custom solution. As a general rule, conflicts should be infrequent. The data should not be very complex if you are allowing Subscribers to update data, because it means a more complex conflict resolution. Remember, data ownership is at the heart of all conflicts.
Snapshot replication is unlikely to be useful as a means of providing high availability, but a short description is provided here for completeness. Snapshot replication can be used when the following criteria are met:
The amount of data you are replicating is not large, and is read-only.
The data being replicated does not change often. Snapshot replication is useful if changes to the data are substantial, but infrequent. For example, if you batch update catalog data and you affect most of the database, it is more efficient to generate and deliver a complete snapshot than replicate individual rows. If you want to compare this to any other SQL Server–based technology, you can think about backup and restore. A snapshot is a point-in-time picture of your data, just like a backup is a point-in-time picture of your data. How current the Subscriber will be is dependent on the frequency of the snapshots you generate and apply.
New data does not have to be distributed immediately because out-of-date data is still usable. This also infers that latency would be acceptable in this case because Subscribers do not need up-to-the-minute updates. A good example of this type of data is census information, which is updated every 10 years in the United States.
Subscriber sites are often disconnected, as when they are located all around the world. Again, this implies that a high latency tolerance exists, especially if your network connection is slow and possibly unreliable.
Transactional replication is useful when the following criteria are met:
Low latency for change delivery to the Subscriber is required. In this case, you are looking for things like real-time reporting that will give you accurate information that is much more current than merge or snapshot replication can provide.
In terms of transactional consistency, with transactional replication, all the changes associated with a transaction executed at the Publisher are guaranteed to be delivered to the Subscriber together and in the same order. Merge replication, on the other hand, achieves data convergence using row-by-row reconciliation and does not guarantee that all the changes associated with a transaction will be delivered in the same synchronization session.
You need high throughput and low data latency. Merge replication can run frequently, as can log shipping, but it is measured in minutes and not seconds. With transactional replication, depending on the volume of transactions, you need good network connectivity and guarantees that the links between your sites will be available. The larger the distance between sites, the more you need to plan your architecture properly.
Your application cannot tolerate changes to the database schema.
If you are going to use replication to create a warm standby, it is like log shipping: You can use Network Load Balancing to abstract the name change, or you can change the name of the instance if it is possible to match the name of the original Publisher.
More problematic, however, is ensuring that the logins needed for use at the Subscriber exist so that the warm standby can function as the Publisher. Part of the problem here, too, is that all data might not be at the Subscriber, so can you really use the Subscriber as a new database?
In using replication, your schema design is very important because it dictates if you can use replication or not. If you are considering replication, you need to think about it long before you even implement your solution. It starts with the design phase.
With transactional and merge replication, all published tables must contain a declared primary key. Merge replication requires that for any tables that have foreign keys, the referenced table should also be in the publication. You are ensuring data integrity at the Subscriber. You therefore need to design your schema properly to include proper primary and foreign keys.
Only transactional replication requires an explicitly declared primary key on a published table. Furthermore, merge replication does not require all referenced tables to be in the publication.
Some packaged applications do not support the modification of your database schema, in particular primary keys and foreign keys. Do not implement replication without asking your third-party software vendor if this invalidates their application support.
If your replicated table does not contain a column with a uniqueidentifier data type, SQL Server adds one when the publication is generated. This is used to identify a row so that it can be reconciled if it is updated elsewhere.
Different forms of replication support different row sizes and numbers of columns that can be replicated. With snapshot or transactional replication, a table being replicated can support up to 255 columns and a maximum row size of 8000 bytes in the publication. A table used by merge replication can have up to 246 columns and a maximum row size of 6000 bytes to allow 2000 bytes for the overhead of conflict resolution. If the row size is greater than 6000 bytes, conflict-tracking metadata may be truncated. Think back to Chapter 4, where you learned how to calculate a table’s row size. Using this, you will know enough about your schema to help you configure replication. Do not assume that you will be able to send every column in your table to a Subscriber if you want to send the entire table and you exceed the 6000- or 8000-byte limit for each row.
One major difference from log shipping is that not all changes tracked in the transaction log are sent over as part of replication in any model.
Important
If you update replicated objects beyond their initial publication, it is not straightforward to send these as part of replication.
More important, your schema cannot be very flexible. If you make constant changes to your database structure, it might be hard to maintain a replication solution. The only things you can do schema-wise are add a column to a publication or delete a column from a publication using Enterprise Manager or using sp_repladdcolumn and sp_dropreplcolumn directly. Considering that adding and dropping a column are the most common schema changes people make on their tables, this satisfies most requirements.
If you are replicating these columns as parts of your publications, consult the SQL Server Books Online topics "Planning for Transactional Replication" and "Planning for Merge Replication." One of the biggest differences between transactional replication and merge replication is that with merge, WRITETEXT and UPDATETEXT are not supported. You must perform an explicit UPDATE on the column as described in the steps later in this section.
With transactional replication or snapshot replication, you can send text or image data types, but if you are using the immediate updating or queued updating options, changes made at the Subscriber to data replicated with text or image data types is not supported. If these are read-only subscriptions, replicating text and image data types as part of transaction or snapshot replication is supported.
If you are using UPDATETEXT or WRITETEXT to update text and image columns when publishing those columns using transactional replication, the text pointer should be retrieved within the same transaction as the UPDATETEXT or WRITETEXT operation with read repeatability. For example, do not retrieve the text pointer in one transaction and then use it in another. It might have moved and become invalid.
In addition, when you obtain the text pointer, you should not perform any operations that can alter the location of the text pointed to by the text pointer (such as updating the primary key) before executing the UPDATETEXT or WRITETEXT statements.
This is the recommended way of using UPDATETEXT and WRITETEXT operations with data to be replicated:
Begin the transaction.
Obtain the text pointer with read repeatable isolation.
Use the text pointer in the UPDATETEXT or WRITETEXT operation.
Commit the transaction.
DECLARE @textpointer binary(16) WRITETEXT MyTable.MyColumn @textpointer 'Sample Text' -- Dummy update to fire the trigger that will update metadata and ensure the -- update gets propagated to other Subscribers. If you set the value to -- itself, there is no change. UPDATE MyTable SET MyColumn = MyColumn WHERE ID = '1'
In your current schema, if you are using automatically generated integer columns as identity columns or as columns to help partition data, you might have to use the NOT FOR REPLICATION constraint in your schema.
Note
NOT FOR REPLICATION can only be implemented using Transact-SQL and not through Enterprise Manager. NOT FOR REPLICATION is an option of ALTER TABLE, ALTER TRIGGER, CREATE TABLE, and CREATE TRIGGER.
Note that with transactional replication, the identity property is not propagated by default to a read-only Subscriber. If you are using data types with the identity property, consider these carefully when setting up replication for warm standby to ensure that your application works correctly after failover to the warm standby database. In this case, there are two options: Choose another technology to create the warm standby server, or manually manage the identity property at the Subscriber as described in the "Replication Data Considerations" section in SQL Server Books Online.
You can replicate timestamp columns with merge replication or transactional replication with queued updating, but note that the column is replicated and the value is regenerated at the Subscriber. Therefore, you do not get the value that is at the Publisher. Generally, this does not create a problem for an application. Timestamps are not specifically representative of clock time, but are instead increasing numbers based in part on the ID of the database in which the timestamp column exists. As a result, these columns have unique context only within the database in which they are generated.
Timestamps are most commonly used to perform optimistic concurrency control where a preread timestamp value on a row is compared to the current value just before issuing an update on the row. If the timestamps differ, you know another user updated the row. The application can then choose to prevent the update or take other appropriate action. Replicating the actual originating value of a timestamp column from one location to another is, in many cases, not highly useful, so the replication subsystem masks this column out of the propagated update and allows each site to calculate a unique timestamp value for each row that is appropriate to its database context. This helps ensure consistency in most common timestamp uses (for example, optimistic locking), regardless of whether an update arrived at a given replica as part of a replicated transaction or directly from a user application. If you do want to replicate timestamp columns and keep values the same, you might have to store it in another way and perform a conversion. If you want to include time-based data, consider the use of a datetime data type instead of a timestamp.
If you are using timestamp data type columns in your database and employing snapshot or transactional replication with read-only Subscribers or those that allow immediate updating, the literal values are replicated but the data type of the column at the Subscriber is changed to a binary(8). This might cause problems if you want to use the Subscriber later in a failure scenario. For example, a data type difference at the Subscriber means that any application behavior that is expecting a timestamp will not function if the secondary is used for updating. If the secondary is for read-only reporting or for read-only access in a disaster recovery scenario while the primary is being repaired, the data type change might not matter.
If you are replicating between SQL Servers with different character sets, no translation of data and data types occurs between Publisher and Subscriber. You therefore need to ensure that all servers in your replication topology have the same code page and sort order. If you do not ensure that all of the Subscribers match the Publisher in this regard, you might experience different results from your queries. If such a scenario exists, you might not want to use that Subscriber as a potential secondary.
There are three words that should apply to any replication architecture: keep it simple. The more complex it is, the more difficult it is to maintain over the long term. In the event of a disaster (see the later section, "Disaster Recovery with a Replicated Environment"), the simpler the topology, the easier it should be to recover. You should also test the normal operation of replication and simulate an actual switch to the replicated secondary, and, if applicable, a switch back to the original Publisher, prior to rolling out your replication architecture in a production environment.
The three obvious components that you are looking to protect are the Publisher, Distributor, and Subscriber. Of these three, the first two—the Publisher and Distributor—are the most important to protect. Without the Publisher, you have no source. Without the Distributor, you do not have anything to push the data. It is as simple as that.
Note
Remember that if you are deploying merge or bidirectional transactional replication, you will need some sort of conflict resolution to ensure that there will always be a "winner" if more than one update of the same bit of data is generated. Merge replication has conflict resolution built in, and transactional replication needs custom resolvers. For more information, see the topic "Implementing Non-partitioned, Bidirectional Transactional Replication" and the whole topic "Merge Replication Conflict Detection and Resolution" in the updated SQL Server Books Online. They describe more factors you need to take into account in any disaster recovery scenario.
Before you can plan for your architecture you must understand which replication agents, the underlying components that initiate different actions of replication, are used by the different methods of replication (see Table 8-1).
Table 8-1. Agents Per Model of Replication
Snapshot | Merge | Transactional | |
|---|---|---|---|
Snapshot Agent | Yes | Yes | Yes |
Distribution Agent | Yes | No | Yes |
Log Reader Agent | No | No | Yes |
Merge Agent | No | Yes | No |
Queue Reader Agent | No | No | Yes |
Warning
Do not modify any replication objects—tables, triggers, stored procedures, and so on—that are created on your Publisher, Distributor, or Subscriber. Doing so makes your solution unsupported.
The Snapshot Agent is used with all models of replication. It prepares schema and initial data files of published tables and stored procedures, stores the snapshot files, and inserts information about initial synchronization in the distribution database. The Snapshot Agent typically runs at the Distributor.
There is one Snapshot Agent per publication. When you create a snapshot of data, there are physical files, or objects, associated with it, and it differs with the model of replication, as shown in Table 8-2. These objects vary in number depending on your replication configuration’s publication and articles; there is no exact formula to calculate it. You can only get the exact count by testing. All forms of replication imply that a snapshot initiates them.
Table 8-2. File Types Associated with Replication
Merge | Snapshot or Transactional | |
|---|---|---|
Conflict tables (.cft) | Yes | No |
Constraints (.idx) | No | Yes |
Constraints and indexes (.dri) | Yes | Yes |
Data (.bcp) | Yes | Yes |
Schema (.sch) | Yes | Yes |
System table data (.sys) | Yes | No |
Triggers (.trg) | Yes | No |
Once you create the initial snapshot, you should consider backing up the snapshot files if you want to use them to initiate replication again. You can either back up the snapshot folder itself or allow another execution of the snapshot agent to generate another snapshot. As part of a disaster recovery plan, you can use the old or the new snapshot files (depending on your strategy) for the publication prior to creating a new subscription or reinitializing an existing one.
The Distribution Agent is used with snapshot replication and transactional replication. It moves snapshot files and incremental changes held in the distribution database to Subscribers. The Distribution Agent typically runs at the Distributor for push subscriptions and at the Subscriber for pull subscriptions.
The Log Reader Agent is used with transactional replication. It moves transactions marked for replication from the transaction log on the Publisher to the distribution database. Each database marked for transactional replication has one Log Reader Agent that runs on the Distributor and connects to the Publisher.
The Merge Agent is used only with merge replication. It applies the initial snapshot at the Subscriber. It then moves and reconciles incremental data changes that occurred after the initial snapshot was created. Each merge subscription has its own Merge Agent that connects to and updates both Publisher and Subscriber. The Merge Agent typically runs at the Distributor for push subscriptions and at the Subscriber for pull subscriptions.
The Queue Reader Agent is used with snapshot or transactional replication when you select the Queued Updating Subscribers option. It moves transactions and reconciles those incremental changes from a Subscriber with those at the Publisher as needed. There is one Queue Reader Agent per published database and the Queue Reader Agent typically runs at the Distributor regardless of whether push or pull subscriptions are employed.
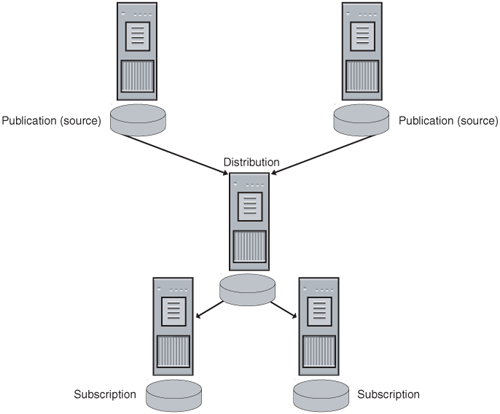
When you use transactional replication, you should not put the Publisher and Distributor on the same server, which is otherwise known as a Local Distributor (see Figure 8-1).

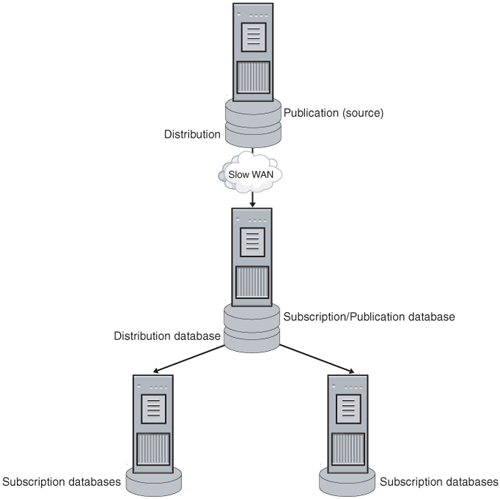
It is better to separate the Publisher and Distributor and create what is known as a Remote Distributor (see Figure 8-2). In fact, you can have more than one Distributor, but a Publisher can only talk to one Distributor. Multiple Publishers can share the same Distributor.
Using a Remote Distributor has the following benefits:
It can improve performance because it offloads work performed by the Replication Agents from the primary computer.
It allows for the smoothest possible upgrade paths. SQL Server replication is designed to support replication among servers of differing versions. This can be an advantage because you can upgrade one computer at a time, redirecting client connections to a replica during the upgrade process. Users achieve an aggregate data-access availability that might not be possible in a nonreplicated scenario. You can also do this with merge and transactional replication with queued updating even if the Publisher and Distributor are on the same machine, but the best scenario is if they are separated.
One SQL Server with both Publisher and Distributor roles is removed as a single point of failure. Although the Publisher and Distributors can still potentially be single points of failure, you are not creating a bigger problem with them on the same server.
In a disaster recovery scenario, you might only be dealing with one server and one piece of functionality, not multiple problems. This approach helps to minimize single points of failure, and is a compelling reason to use a Remote Distributor.
This scenario is not dissimilar to using a Remote Distributor. You still have a Publisher and a Distributor, but you then take a Subscriber and have it publish the data out to other servers. That Subscriber is then known as a Republisher, or a Publishing Subscriber (see Figure 8-3). In this case, the Republisher would act as its own Distributor, or you could even set up another one. This scenario would benefit you if your company has sites around the world. Because of network issues, it is easier and more cost-effective to have more local resources generating data to Subscribers. This also increases the availability of your solution so that even if the original Publisher or Distributor goes down, if there are changes to be propagated out to other Subscribers that are still in the Republisher, they will still get to the other Subscribers.
SQL Server service packs will definitely make an impact on your replication implementation. If you apply them wrongly, you might need to reinitialize your replicated environment or use the disaster recovery procedures detailed here. See the section "Applying a SQL Server 2000 Service Pack" in Chapter 13, for more information on replication and SQL Server service packs. The order in which you apply the service pack to your servers participating in replication matters. First, you must update the Distributor; then comes the Publisher; and finally the Subscriber.
You can also use replication to help keep your database available during a service pack install, much like you can use log shipping. Switch to the standby, and allow updates to happen on the standby assuming that it can function as the primary in every way it needs to. Once the service pack is done on the Publisher, switch back and upgrade the Subscriber. This is only applicable after the Distributor upgrade, which might even be the same server as the Publisher.
Replication makes an impact on your planning for your disk capacity (in addition to anything outlined in Chapter 4 and the rest of the book), which is an obvious concern for any highly available environment. You do not want to run out of disk space before you even implement your solution. Table 8-3 walks through the requirements for each model of replication.
Table 8-3. Disk Requirements for Replication
Model of Replication | Impact on Transaction Log | Disk Space Needed |
|---|---|---|
Merge | Database and its log file will have a small amount of growth when updates to a published table are made because the change tracking meta data results in additional inserts, updates, or deletes to system tables during the execution of user transactions. Changes are tracked in the database itself, not in the log, so there is no impact on backup strategy of replication frequency as it relates to truncating the transaction log. | Review SQL Server Books Online for a description of the change tracking tables created by merge replication in a user database. The maximum size of data columns is rarely used, but row-tracked tables can incur up to 249 bytes of change tracking overhead and column-tracked tables can incur up to 2048 bytes per changed row. Remember, only changed rows get a meta data entry; rows that are never updated do not result in change meta data accumulation. Also, the merge agent takes care of trimming aged meta data out of these system tables based on the publication retention period. The distribution database does not store tracked changes and instead only stores history and error information, which is also trimmed periodically based on the publication retention period. |
Snapshot | Not a concern from a replication standpoint because the Subscriber gets everything in the primary. | A snapshot generates files in the filing system representing the schema and data for all published objects. The Snapshot Agent typically BCPs (bulk copies) data out from the Publisher to a file in a SQL Server binary format. Further reduction in disk impact can be achieved by setting a publication property such that the files generated by the snapshot are compressed in a .cab file. The ultimate disk impact then varies depending on the number of objects published, the amount of data published, and the use of compression in generating the snapshot files. In general, if you have a large database, the file system storage requirements will be large. The distribution database itself will store relatively little and will include a few bytes of control data directing the subsequent forwarding of the snapshot files to the Subscribers and a small amount of history and error information reflecting the execution of the Snapshot Agent. |
Transactional | Transactional changes are tracked in the transaction log of the publishing database. The Log Reader Agent moves transactions from the publishing database’s transaction log to the distribution database where they are queued for subsequent distribution to Subscribers. The transaction log cannot be truncated beyond the last transaction processed by the Log Reader Agent so additional log growth can incur when replication is employed. To minimize the potential growth of the publishing database log, run the Log Reader Agent continuously. | Disk space is an obvious concern because the Distributor is now storing copies of the transactions generated at the publishing database until they can be distributed to all Subscribers. The transaction log is a concern because on the database being replicated, transactions might not be flushed until they are put into the distribution database. So you need to set your data and log portions appropriately for your database and the distribution database. |
Important
No matter what model of replication you use, you should not use the Simple Recovery model for your databases. For more information on recovery models, consult Chapter 9, and Chapter 10.
In the event of a problem with a SQL Server solution using replication, you need to know how to recover. If this is a temporary outage, as when you are applying an update (like a hotfix) to each one, then there really is no problem. You need to assess why the servers are unavailable before you reinitialize snapshots or restore servers from backups.
Tip
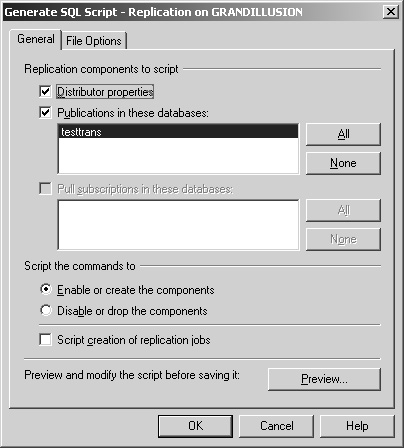
No matter what model of replication you employ or what architecture you decide on, always script out your replication installations once they are configured and working properly.
To script your replication on an instance of SQL Server, select the Replicationfolder in Enterprise Manager, and right-click it. Select the Generate SQL Script option. You then see the dialog box shown in Figure 8-4. This should be done on each participating server. Place these scripts in a safe place that is documented in your run book for use in any disaster recovery scenario or ease of recreating in a test environment.
Your backup and restore strategy is crucial when you deploy replication. To recover from a disaster, you must back up the databases used in replication. The strategy changes depending on your replication model. If you are using transactional replication with log shipping, it impacts everything. See the later section "Log Shipping and Replication" for more information.
A comprehensive backup and restore plan for replication must include the Publisher, Distributor, and Subscriber, as well as SQL Server system databases. Good backups are crucial for disaster recovery. You have to test and stress every aspect of the replication environment; otherwise you have no test, meaning you really do not have a replicated environment you can feel confident about. Whatever your eventual plan, its complexity will match that of your replication topology.
Note
This topic is not covered in Chapter 9 or Chapter 10, as it is specific to replication and its dependencies. Remember to take this into account when reading Chapter 9 and Chapter 10, as this obviously affects an overall backup and restore plan.
The Publisher is arguably the most important part of your replication, as it is the source of your data for Subscribers. You should be doing full backups on the publication database, as well as backing up msdb and master databases, because they are integral to the success of replication. Besides full backups, you should also perform differential or transaction log backups and periodically generate SQL scripts from the Publisher database. Here are some common things that influence your Publisher backups; each bullet point represents a change to the Publisher:
Creating new publications
Altering any publication property including filtering
Adding articles to an existing publication
Performing a publication-wide reinitialization of subscriptions
Altering any published table using a replication schema change
Performing on-demand script replication
Cleaning up merge meta data (running
sp_mergecleanupmetadata)Changing any article property, including changing the selected article resolver
Dropping any publications
Dropping any articles
Disabling replication
For snapshot replication, you only need to back up the publication database when changes are made to publications (adding, deleting, or modifying them). With merge replication, because the data can potentially reside anywhere, your backup scheme might or might not be more flexible. You have other ways of synchronizing your data, because Global Subscribers can be used to catch a restored Publisher and include previously merged changes that were not part of the backup.
The Distributor is equally as important as the Publisher, as it pushes the data out to the Subscribers. With merge replication, the Distributor does not push data, but it does store history and information. A backup plan for a distribution database must include backing up the distribution database along with master and msdb. Realistically, a recovery strategy would include full as well as transaction log or differential backups because the distribution database can grow large, depending on your model of replication. Here are some common things that influence your Distributor backups; each changes the distributor database:
Creating or modifying replication agent profiles
Modifying replication agent profile parameters
Changing the replication agent properties (including schedules) for any push subscriptions
For snapshot replication, you need to synchronize the backup of this database with the Publisher. That means you need at least two SQL Server Agent jobs executed in parallel. You might also want to run the Distribution Cleanup Task to shorten your backup time and remove unused data from the distribution database prior to backing it up. While you are backing up these databases, do not add new publications or subscriptions.
The sync with backup option affects how often transactional replication sends transactions to the Distributor. This option should always be used when configuring transactional replication, because it is the only way to ensure that the distribution and publication databases can be recovered to the same point in time. The only way you can get to a point in time without using sync with backup is to stop all updates, perform a backup of both the Publisher and Distributor while no activity is occurring, and then allow activity again. Sync with backup is not an option for any other model of replication, nor is it available if your Publisher is another version of SQL Server (such as Microsoft SQL Server 7.0). To set this option, use the following syntax:
sp_replicationdboption 'publication_db', 'sync with backup', 'true'
This restricts the Log Reader Agent from sending any transactions at the Publisher to the Distributor’s distribution database until they have been backed up. Although this creates a bit of latency that will be as frequent as your transaction log backups are made, it ensures that the Distributor will never get ahead of any Subscriber and both will be perfectly in sync. The last backup for the Publisher and Distributor can then be restored with identical transactions. On the distribution database, sync with backup prevents transactions that have not been backed up at the Distributor from being removed from the transaction log of the Publisher until the Distributor has been backed up. Your latency for transactional replication is dependent on the volume of transactions, the time it takes to complete the transaction log backup, and the frequency of the backup.
If you use this option, you need to back up the publication database and distribution databases (usually you would back up the transaction log or make differential backups) frequently because the frequency of backups determines the latency with which replication delivers changes to Subscribers.
If you try to restore the Publisher without setting sync with backup, your Publisher and Subscriber might be out of sync.
For a Subscriber, you should back up the subscription database. If you are using pull subscriptions, you should also back up msdb and master (if you are not doing so already) for replication purposes.
When using merge replication or transactional replication, restoration of a qualified Subscriber backup allows replication to continue normally. A nonqualified backup requires a reinitialization of the subscription after the backup is restored. For a merge backup to be qualified, it must be a backup from within the meta data cleanup interval. For a transactional replication backup to be a qualified backup, the publication must have the immediate_sync property set to true and the backup must be taken within the transaction retention period of the Distributor.
Note
When setting the transaction retention period or meta data retention periods, you must consider the space and performance trade-offs.
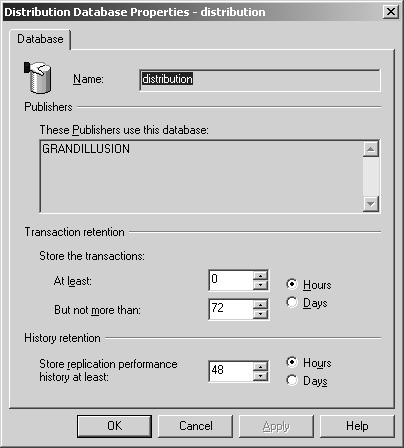
To set the transaction retention period, follow these steps:
Select the Replication folder in SQL Server Enterprise Manager or a database participating in replication, and right-click it. Select the Configure Publishing, Subscribers, And Distribution ... option.
When the Publisher And Distributor Properties dialog box appears (shown in Figure 8-5), make sure the Distributor tab is selected.
Select the correct distribution database, and click Properties.
Modify the transaction retention setting to the period for which you want to have a transaction stored in the distribution database. Remember that this has an impact on the size of your database, but it also ensures recoverability.
Click OK when you are done. Click Apply, and finally click OK to close the Publisher And Distributor Properties dialog box.
Modify any scheduled SQL Agent backup jobs configured on the database that are used to back it up so that you can recover from this scenario.
If you configure this, it guarantees that when you restore a Subscriber’s database, all the transactions necessary for the Subscriber to catch up will still be available in the distribution database. After you restore the Subscriber, the Distribution Agent delivers any transactions the Subscriber is missing.
To set the merge meta data retention period, execute this stored procedure on the publication database:
sp_changepublication @publication= 'publication_name', @property=
'retention', @value=nwhere n is number of hours, value for the retention property.
Msdb contains all of the job definitions for the replication agents. With transactional replication, if you are using pull subscriptions, you have to back up this database on the Distributor and Subscriber if you add or drop a subscription or make any changes to the replication agent. If you are using Data Transformation Services (DTS) packages as part of transactional replication, you also need to back up msdb. Otherwise, you have to ensure that the DTS packages are saved to the file system and easily restorable. Here are some common actions that influence your msdb backups in relation to replication:
Enabling or disabling replication
Adding or dropping a distribution database (at the Distributor)
Enabling or disabling a database for publishing (at the Publisher)
Creating or modifying replication agent profiles (at the Distributor)
Modifying any replication agent profile parameters (at the Distributor)
Changing the replication agent properties (including schedules) for any push subscriptions (at the Distributor)
Changing the replication agent properties (including schedules) for any pull subscriptions (at the Subscriber)
Each time you add a new Subscriber, the sysservers table is updated in master, so you have to back up master on your servers after you add a new Publisher or Subscriber. Here are some common actions that influence your master backups in relation to replication:
Enabling or disabling replication
Adding or dropping a distribution database (at the Distributor)
Enabling or disabling a database for publishing (at the Publisher)
Adding the first or dropping the last publication in any database (at the Publisher)
Adding the first or dropping the last subscription in any database (at the Subscriber)
Enabling or disabling a Publisher at a Distribution Publisher (at the Publisher and Distributor)
Enabling or disabling a Subscriber at a Distribution Publisher (at the Subscriber and Distributor)
Table 8-4 lists scenarios that you must consider if you ever need to restore your replication solution.
Table 8-4. Replication Disaster Recovery Scenarios
Scenario | Publisher | Distributor | Subscriber |
|---|---|---|---|
1 | Up | Up | Down |
2 | Up | Down | Up |
3 | Up | Down | Down |
4 | Down | Up | Up |
5 | Down | Up | Down |
6 | Down | Down | Up |
7 | Down | Down | Down |
Scenario 1 is the least problematic in terms of overall replication availability. Although users accessing the data from the Subscriber are affected, the processes driving replication are still intact. This does become a problem, however, is if this database also publishes data elsewhere. This underscores the point that the more complex your replication configuration, the more it affects any disaster recovery planning that involves replication.
When you restore the Subscriber database to the last good backup, assuming the database backup is made after replication was configured and contains the replication tables, you might not have to reinitialize the subscription. If possible, the subscription resynchronizes the data without requiring a reinitialization; however, you need to reinitialize the subscription if the data required to bring the Subscriber up to date has been cleaned up.
Note
This scenario obviously works with merge and transactional replication. Snapshot replication is a complete snapshot of your data (there is no way to do a "differential" snapshot like a differential backup), so modifying your replication settings if you are sending out all of your data each time makes no sense.
If you are using transactional replication and specify sync with backup on both the Publisher and Distributor, you can restore the Publisher or Distributor to the same point. If you are using merge replication and want to restore a Publisher, you have a few options. You could reinitialize all subscriptions with the restored publication database, but you might lose data at a Subscriber that was updated. You could also synchronize the Publisher with another database so it is fully in sync. If you choose the latter option, you must synchronize with a Subscriber that has a global subscription. If you use a Subscriber with anonymous subscriptions, it will not have enough meta data to apply the changes to the production database.
If you lose both the Distributor and the Subscriber databases at the same time, the procedures outlined for Scenario 1 and Scenario 2 apply in most cases. Merge replication and queued are exceptions.
If you lose both the publication and the subscription database at the same time, the procedures outlined for Scenarios 1 and 3 apply.
This can happen if the Distributor is local (that is, the Publisher and Distributor are running on the same server). In this case, the Publisher and Distributor databases can be restored as outlined in Scenarios 2 and 4.
This is the absolute worst-case scenario, in which every participating server is down for something other than a temporary reason. However, if the servers are genuinely damaged (for example, the datacenter burned down), you will be relying on the restore steps outlined for Scenarios 1, 2, and 4 to get your replication environment up and running again.
Log shipping and replication can coexist, and in some cases, log shipping can be used to protect replication. However, you need to understand how these two features work together and the caveats of implementing them on the same databases.
Important
You cannot use a log shipped secondary’s database as part of an active replication environment (such as a Republisher or a Distributor) because it is in STANDBY or NORECOVERY. You can only use the database once it is fully recovered.
Both transactional and merge replication interoperate with log shipping. The main reason to use log shipping with replication in a highly available environment is to provide protection in the event of a Publisher failure. The secondary server can assume the Publisher’s role if you meet all conditions, including the renaming of the server. If you cannot rename the server, you have to reinitialize all subscriptions.
Important
If you use SQL Server 7.0 (with Service Pack 2) as your source, you cannot enable log shipping to work with a database that has replication.
If the Publisher fails, you can use log shipping to protect it. This can only be configured between Microsoft SQL Server 2000 instances only; you cannot combine log shipping and replication if SQL Server 7.0 is the source. There are two modes that enable transactional replication to work with log shipping: synchronous and semisynchronous.
Synchronous mode means that you are going to synchronize the various replication agents with your Publisher and Distributor backups using the Publisher and Distributor sync with backup options. The primary benefit of using synchronous mode is that in the event of a role change, your new Publisher (the old secondary) is completely synchronized with the backups. You do not have to worry about the Publisher, Distributor, and Subscriber being out of sync as long as the backups are completely applied after the restore. Note, however, that the restored Publisher will be missing any of the transactions that were not present in the backup.
If your business needs dictate that the latency of synchronous mode is unacceptable, you can use semisynchronous mode instead. After a restore when using semisynchronous mode, the Publisher and the Subscribers are possibly out of sync because transactions that were on the old primary or Publisher might not have been backed up, sent, and applied to the warm standby. Despite this problem, you can get replication up and running after a role change. Once you perform the role change and the additional steps provided in the later section "Performing a Role Change Involving Replication," you must also run the sp_replrestart stored procedure. Once you run sp_replrestart, change the profile of the Distribution Agent to SkipError or set -SkipError on the command line at run time to ensure that transactions that exist at the Subscriber but not the Publisher can be reapplied to the Publisher.
-SkipError is required because the Publisher and Subscriber might be out of sync after issuing the sp_replrestart because the Publisher backup does not match the Subscriber state. If you do not specify -SkipError, additional failures could occur during replication. For example, if the Publisher has a row that the Subscriber does not yet have, then an update or delete to that row could cause a "not found" failure when replicated to a Subscriber. If the Publisher is missing a row that the Subscriber has, then an insert of a row with the same key could cause a "duplicate" failure when replicated to the Subscriber. Once the Publisher has been completely synchronized with the Subscribers again, you can disable the -SkipError option.
Like transactional replication, merge replication can use log shipping to protect the Publisher. You have two options for using merge replication with log shipping: semisynchronous mode and alternate synchronization partners.
This is similar to the semisynchronous mode of transactional replication: your Publishers and Subscribers might be out of sync. If this is the case, you have only two real options. You can reinitialize the Subscribers to the new Publisher immediately after it is recovered, but this could cause data loss. The other option is to synchronize the Publisher with a Subscriber that has newer data.
Subscribers of merge replication are able to use other servers besides the Publisher to synchronize their data. If the Publisher is down for some reason (planned or unplanned, including a log shipping role change), replication can continue uninterrupted. There are different methods of setting up alternate synchronization partners for named and unnamed subscriptions, and you can use Windows Synchronization Manager, Enterprise Manager, or the SQL Server merge replication ActiveX control to select your alternate synchronization partner. For a named subscription, you have to enable the Subscriber at the designated alternate synchronization partner and also create a subscription that is the same as the one on the current Publisher. If it is an unnamed subscription, set the alternate synchronization partner on the publication itself.
If you plan to use the secondary database after it is restored as a new primary (regardless of the model), you need to ensure that the @keep_replication option of the sp_change_secondary_role is set to 1 if you are using the functionality of Microsoft SQL Server 2000 Enterprise Edition. You also have to set the @do_load option to 1 as well; otherwise setting @keep_replication has no impact. If you do not set these parameters, all replication settings are erased when the database is recovered. If this is a custom implementation of log shipping, you need to set the WITH KEEP_REPLICATION option of the RESTORE LOG (or RESTORE DATABASE) functionality. Using WITH KEEP_REPLICATION is not possible with databases restored with NORECOVERY, so if you are using replication, make sure you restore your database with STANDBY.
More Info
To see the exact steps for performing a log shipping role change, see the section "Performing a Role Change" in Chapter 7.
In addition to the normal role change process, there are a few additional steps that you need to add after the database is recovered:
If you recover a database from secondary status to be the active database servicing requests, you do not need to reapply a SQL Server 2000 service pack unless there are meta data changes that would affect the database in question (as noted earlier). This would be clearly documented in the documentation that ships as part of the update. An exception to this rule occurs if you are using replication and use the KEEP_REPLICATION option when bringing the database online. Once the database is fully recovered, before opening it up to users and applications, run the
sp_vupgrade_replicationstored procedure to upgrade the replication meta data. If you do not do this, the replication meta data for that database will be out of sync. If runningsp_vupgrade_replicationis not necessary, it should be noted in the accompanying documentation.You have to rename the secondary server to be the same as the original primary. This affects you in a few ways. First and foremost, you cannot use a clustered instance of SQL Server 2000 as your primary or secondary, as you cannot rename them. Second, if you want to eventually perform a role change back to the original primary, you cannot have two servers of the same name in the same domain.
Tip
You can mitigate this using Network Load Balancing like you would to abstract the role change. That way anything connecting to the underlying SQL Server would only have to know about the name to connect to, which is the Network Load Balancing cluster. Again, this is a very specific use of Network Load Balancing with SQL Server and is not meant for load balancing. See the section "Implementing Network Load Balancing for SQL Server–Based Architectures" in Chapter 5, for information on setting up this solution.
Replication can be used to enable high availability through data redundancy by storing your application data in more than one database. When deploying replication to solve problems other than high availability, you should still consider the impact of a failure on the replicated system and plan accordingly by combining a sound backup strategy and replication retention periods. There is no easy solution when it comes to replication and high availability, but combining replication with the other technologies covered in this book can make your environment more highly available.