
7
Events and Complex Events
Events and event objects are the fundamental building blocks in event-processing application systems. Identifying and specifying the right events to use to address a particular business problem is an important and nontrivial activity. This chapter explores the issues involved in event object design. We’ll start by taking a closer look at the nature of events and event data. Then we’ll explain the characteristics of complex events, how they are computed, and their relationship to simple events.
Defining “Event” in Earnest
The experts in this field don’t entirely agree on the best way to define events and event objects. We are aware of three major schools of thought (other good definitions may also exist):
![]() State-change view —An event is a change in the state of anything. An event object is a report of a state change.
State-change view —An event is a change in the state of anything. An event object is a report of a state change.
These statements have clear technical meanings and are the most widely used definitions in the IT world. An event is the change reported by an event object, no more and no less.
![]() Happening view —An event is “anything that happens, or is contemplated as happening.” An event (object) is “an object that represents, encodes, or records an event, generally for the purpose of computer processing.”
Happening view —An event is “anything that happens, or is contemplated as happening.” An event (object) is “an object that represents, encodes, or records an event, generally for the purpose of computer processing.”
These definitions are quoted from the Event Processing Technical Society’s Event Processing Glossary (available in PDF format at www.ep-ts.com). The EPTS definitions draw largely from work done by Dr. David Luckham and presented in his book, The Power of Events, a seminal document in this field (see Appendix A for the full citation). His definition of event was based, in turn, on the Oxford English Dictionary. It’s the definition assumed by people in everyday life. The notion of event object is the translation of that concept into the IT realm. An event (object) signifies, or is a record of, an activity that happened.
![]() Detectable-condition view —An event is “a detectable condition that can trigger a notification.” A notification is “an event-triggered signal sent to a runtime-defined recipient.”
Detectable-condition view —An event is “a detectable condition that can trigger a notification.” A notification is “an event-triggered signal sent to a runtime-defined recipient.”
Ted Faison uses these definitions in his thorough and well-regarded book, Event-Based Programming (see Appendix A for the full citation). These definitions apply primarily in a software development context. The precise description of a notification helps software engineers distinguish between a conventional procedure call to a server and a more dynamic procedure call that conveys an event signal to a run-time defined event consumer. Faison’s notion of an event as a detectable condition can be applied within or outside the realm of computers.
The three sets of definitions largely overlap. Things that are considered events in one definition generally are also considered events in the other two. However, each represents a slightly different concept of events:
![]() The state-change view assumes a thing and a change in that thing from a before state to an after state. The event object represents the change, although it doesn’t have to contain all of the details about the change.
The state-change view assumes a thing and a change in that thing from a before state to an after state. The event object represents the change, although it doesn’t have to contain all of the details about the change.
![]() The happening view sees events as activities that occur. When activities occur, state changes, but the definition doesn’t require anyone to specify how many things are involved or be able to document the before and after states.
The happening view sees events as activities that occur. When activities occur, state changes, but the definition doesn’t require anyone to specify how many things are involved or be able to document the before and after states.
![]() The detectable-condition view considers something to be an event only if it can be observed and give rise to a report about it (the notification). If a tree falls in the forest and no one is there to hear it, then it made no sound. Similarly, if something changed and nothing could detect it, it wasn’t an event. Moreover, if a condition can be reported, it is an event even if nothing changed.
The detectable-condition view considers something to be an event only if it can be observed and give rise to a report about it (the notification). If a tree falls in the forest and no one is there to hear it, then it made no sound. Similarly, if something changed and nothing could detect it, it wasn’t an event. Moreover, if a condition can be reported, it is an event even if nothing changed.
The happening view and the detectable-condition view are at opposite poles in some respects, representing the physical world and software world, respectively. The state-change view is roughly in the middle. Summarized in simplistic terms:

Each view applies to some kinds of events more naturally than it applies to other kinds of events. The views also differ on the fundamental issue of whether an event happens at a point in time or has a finite duration. We’ll illustrate the differences among the views by examining three examples of events and then look at the implications on the subject of event duration.
State-Change Example
Changes to a single thing or a few things are described well by the state-change definition. Our recurring example of an RFID tag reading is a quintessential state change. The item was previously outside of the range of the RFID reader, and now it is within the range of the RFID reader. A computer-science state diagram can easily show this, and the state transition from “it’s not here” to “it’s here” can be reported by a notification message going from an RFID reader to a software agent elsewhere in the network. Because some activity occurred, the “happening” definition also applies nicely to this situation—the item showed up and the event (object) reports that happening. This is also a good detectable condition—the presence of the item is detected and a notification message can be created and sent.
Happening Example
Happening events are centered on an activity or work done as opposed to the object upon which the work was done. Complex software events and real-world events, such as buying a house, landing a plane, and World War II, are addressed well by the happening definition. People intuitively recognize these things as events. Various event objects that summarize such events can be easily designed, although they may not give a full accounting of what transpired. For example, here are three event objects that signify the activity of buying a house:
![]() A person sends an e-mail conveying the news to a friend.
A person sends an e-mail conveying the news to a friend.
![]() A notice is inserted into a newspaper to report the address, date, and sale price of the transaction.
A notice is inserted into a newspaper to report the address, date, and sale price of the transaction.
![]() An application program in a local realtor’s information system sends an XML document that summarizes the transaction to a real-estate clearinghouse.
An application program in a local realtor’s information system sends an XML document that summarizes the transaction to a real-estate clearinghouse.
None of these event objects tells the whole story. However, that’s not a problem in the happening view of events because the observation and notification are not essential to the fact of the activity.
Buying a house is a complex event. It could entail a three-month process encompassing multiple house tours, dozens of phone calls and e-mails, many meetings, preparing and signing various legal documents, multiple bank transactions, a pest inspection, and other minor events. The state-change and detectable-condition definitions can be applied to complex, multifaceted events such as this, but the fit is more challenging. The state of the world, and hundreds of things in it, have changed, including legal title to the house; the bank accounts of the buyer, seller, two realtors, two lawyers, various tradespeople, and the government; and dozens of other things. Many state changes that occurred during the three-month process are not visible at the end of the process because they’ve been reversed or forgotten. No snapshot can capture the entire before and after state. World War II was more complex than a house purchase by many orders of magnitude—it changed the state of the world in countless ways. An expert can find plenty of detectable conditions and state changes in very complex events, but none of them captures the essence of the whole activity.
Detectable-Condition Example
Simple observations are well described by the detectable-condition definition. The term “detectable condition” reflects the fact that events and event objects can address things that aren’t changing. For example, consider a truck with a GPS tracking device that emits a reading of its location every minute. When the truck is parked for 10 minutes, it emits ten readings with the same geospatial coordinates. The notifications differ only because they are generated at different times. The position of the truck is a detectable condition, so each reading is clearly an event notification according to our third definition.
Nothing has changed in the thing ostensibly being reported, the truck’s location. Nevertheless, the state-change definition can be applied by thinking of the passing of time as the change. The state of the world, including the truck and the central monitoring system 200 miles away, has changed with respect to time for each notification. Similarly, the happening definition of “event” can be applied because the GPS device made an observation and emitted a notification—nothing happened to the truck but something happened in the GPS device.
Event Duration
Your chosen perspective on events affects whether events are instantaneous or have a measurable duration. Most “happening” events have a measurable duration (they are “interval events”). Buying the house took three months. A notification that describes that event may have three time stamps: one to record the start time, another to record the end time, and a third to record the time that the notification was created or emitted by the producer. A happening event can be of long duration (Hundred Years’ War). However, some happening events are apparently instantaneous. Instantaneous means that the start time and end time are the same. If your clock can only measure time in one-second increments and the end time occurs less than one second after the start time, the measured duration can be literally zero seconds. When an event is instantaneous, the notification may only need one time stamp.
If an event is a state change, the duration of the event is the state transition time. This could be measured in years or it could be virtually instantaneous. However, those who believe that an event is always instantaneous would say that the end of the state transition is the point in time when the event occurs. In this interpretation, the house purchase event took place in the instant that the last signature was put on a certain document, or perhaps when the deed with the new owner’s name was placed into the county hall of records.
The notion of event duration is less applicable in the “detectable condition” view because an event is a snapshot of the condition of something. A time stamp will generally reflect the point in time when the observation was taken.
Designing Events
Theoreticians have a lot more to say about the definition of events, but analysts and architects designing business applications probably don’t need to drill any deeper into this subject. However, they do need to be aware of certain implications of these definitions.
General Guidelines
Regardless of which definition of event you use, the following guidelines apply:
![]() There is no limit on the number of event objects (or notifications) that can be designed to report a particular business event. It is up to the person who designs the system to determine what kind of notifications will be generated and what data items will be included in each.
There is no limit on the number of event objects (or notifications) that can be designed to report a particular business event. It is up to the person who designs the system to determine what kind of notifications will be generated and what data items will be included in each.
![]() The term “event object” doesn’t mean object in the object-oriented programming (OOP) sense. OOP objects include code as well as data whereas event objects are just data, or have methods restricted to getting data from the event object.
The term “event object” doesn’t mean object in the object-oriented programming (OOP) sense. OOP objects include code as well as data whereas event objects are just data, or have methods restricted to getting data from the event object.
![]() An observation of something that isn’t changing is a valid event under any of these definitions. Time is always changing, and an observer taking a reading is inherently something that happens.
An observation of something that isn’t changing is a valid event under any of these definitions. Time is always changing, and an observer taking a reading is inherently something that happens.
![]() An event object is not just data about something; it is the record of a particular observation, according to all three definitions. The existence of data describing a state change or condition doesn’t constitute an event object unless it is associated with an act of observation. A notification is an event object conveyed from an event producer to an event consumer (however, a notification can be stored in an event log in a database at an event consumer or a potential event producer—it’s a notification if it was conveyed in the past or could be in the future).
An event object is not just data about something; it is the record of a particular observation, according to all three definitions. The existence of data describing a state change or condition doesn’t constitute an event object unless it is associated with an act of observation. A notification is an event object conveyed from an event producer to an event consumer (however, a notification can be stored in an event log in a database at an event consumer or a potential event producer—it’s a notification if it was conveyed in the past or could be in the future).
![]() There is nothing special about the data in a notification—all application systems have always dealt with data about events. State changes are nothing new either—all applications involve state changes. The unique nature of notifications, and event processing in general, derives from the way in which agents exchange and process the event data. The five principles of EDA are special. Three of the principles (“Reports current events,” “Pushes notifications,” and “Responds immediately”) facilitate timeliness, and the other two (“Communicates one-way” and “Is free of commands”) facilitate flexibility through minimal coupling. Other kinds of interactions among software agents have some of these characteristics, but only EDA has all five of them.
There is nothing special about the data in a notification—all application systems have always dealt with data about events. State changes are nothing new either—all applications involve state changes. The unique nature of notifications, and event processing in general, derives from the way in which agents exchange and process the event data. The five principles of EDA are special. Three of the principles (“Reports current events,” “Pushes notifications,” and “Responds immediately”) facilitate timeliness, and the other two (“Communicates one-way” and “Is free of commands”) facilitate flexibility through minimal coupling. Other kinds of interactions among software agents have some of these characteristics, but only EDA has all five of them.
![]() Some people think of an event as a thing that causes a change to occur. They’re partly right—many events do cause a change. Others think of an event as a report of a change, happening, or condition. They’re always right— all events report a change, happening, or condition. The confusion arises because there are two different kinds of notifications. We’ll elaborate on this in the next chapter.
Some people think of an event as a thing that causes a change to occur. They’re partly right—many events do cause a change. Others think of an event as a report of a change, happening, or condition. They’re always right— all events report a change, happening, or condition. The confusion arises because there are two different kinds of notifications. We’ll elaborate on this in the next chapter.
Event Types
In Chapter 6, we described the various ways that event producers notify event consumers. A notification can consist of any of the following:
![]() A message containing an event object sent from the producer to the consumer
A message containing an event object sent from the producer to the consumer
![]() An event object in a shared file, database, cache, or some other place in memory where the producer and consumer can both access it
An event object in a shared file, database, cache, or some other place in memory where the producer and consumer can both access it
![]() A procedure call or method invocation from producer to consumer, usually containing event data as parameters or in an attached document
A procedure call or method invocation from producer to consumer, usually containing event data as parameters or in an attached document
In most event processing, including all complex event processing (CEP), the event object is a set of data. The degenerate case, in which the event object is implicit (the event is signaled by a procedure call or method invocation without any data in parameters or attached documents), applies to certain event-based programming scenarios but is outside the scope of this discussion. Here, we are dealing with event objects that are composed of explicit data items (fields or attributes) that describe things about the event that occurred.
Note: All event objects are instances of an event type.
An XML document that represents Fred’s order for a computer is an instance of the order event (object) type. Different kinds of event objects are of different types. An event type is sometimes called an event class, so Fred’s order would be said to be an instance of the order event class. All of the event objects of the same type have the same structure—that is, they have the same kind of data items, and the data items are organized in the same way.
One of the fundamental tasks in developing an event-processing application is identifying the data items to include in the event object. Some of the kinds of data that may be included are
![]() A tag that indicates the type of event (for example, an order event, an RFID reading, a change-of-address event)
A tag that indicates the type of event (for example, an order event, an RFID reading, a change-of-address event)
![]() A unique event identifier used to reference the event instance (Fred’s order has a different identifier than Susan’s order)
A unique event identifier used to reference the event instance (Fred’s order has a different identifier than Susan’s order)
![]() A time stamp that indicates when the event object was created (it may include the date as well as the time of day)
A time stamp that indicates when the event object was created (it may include the date as well as the time of day)
![]() Time stamps for the start and end times (and dates) of an interval event
Time stamps for the start and end times (and dates) of an interval event
![]() The name, address, or a unique identifier of the producer software agent that generated the event
The name, address, or a unique identifier of the producer software agent that generated the event
![]() Indicators of the urgency or priority of the event
Indicators of the urgency or priority of the event
![]() A small or large number of other data items that describe the event (any data of the sort that is typically handled in application programs and databases)
A small or large number of other data items that describe the event (any data of the sort that is typically handled in application programs and databases)
![]() The unique event identifiers for the base events that were used to generate this event, if this event is a complex event (these identifiers can be used by an event consumer to trace back the origins of a complex event—this is sometimes called the event’s pedigree or genetics)
The unique event identifiers for the base events that were used to generate this event, if this event is a complex event (these identifiers can be used by an event consumer to trace back the origins of a complex event—this is sometimes called the event’s pedigree or genetics)
![]() A copy of the base events (and their data items) that were used to generate the event, if this event is a complex event (if a complex event contains all of its base events, then it is called a composite event)
A copy of the base events (and their data items) that were used to generate the event, if this event is a complex event (if a complex event contains all of its base events, then it is called a composite event)
Developers are free to include any or all of these data items, or anything else that they think would be useful for the purposes of the application that they are designing. This is like any kind of data modeling—there is no one right answer, although some choices will be better than others.
Note: In many cases, an event is reported by more than one type of event object because there are multiple event consumers (people or application programs) with different information needs.
The “Happening Example” section, earlier in the chapter, described three complex-event objects that described buying a house. Each would be used for different purposes:
![]() If the buyer wants to tell a friend what they did with their old house and how close the nearest park is to their new house, he or she would probably put that in an e-mail (the event notification listed first).
If the buyer wants to tell a friend what they did with their old house and how close the nearest park is to their new house, he or she would probably put that in an e-mail (the event notification listed first).
![]() If neighbors want to know when the property sold and the purchase price, they would probably look in the newspaper (the notification listed second).
If neighbors want to know when the property sold and the purchase price, they would probably look in the newspaper (the notification listed second).
![]() If someone is compiling statistics on average house prices, or investigating the quality of housing stock in a particular neighborhood, he or she would probably download a copy of XML documents from the real-estate clearinghouse (the third type of notification).
If someone is compiling statistics on average house prices, or investigating the quality of housing stock in a particular neighborhood, he or she would probably download a copy of XML documents from the real-estate clearinghouse (the third type of notification).
In many event-processing applications, developers work with event streams provided by another organization so the base event types are already defined before development of the new application begins.
Complex Events
As you know, the fundamental idea behind CEP is “connecting the dots.” Event-driven CEP systems generate complex events by distilling the facts from multiple incoming base events into a few complex events. Complex events represent summary-level insights that are more meaningful and helpful for making decisions than are the base events. A complex event is abstract in the sense that it is one or more steps removed from the raw input data.
Note: The EPTS Event Processing Glossary (version 1) defines complex event as “an event that is an abstraction of other events called its members.”
In the physical world, house tours, e-mails, and bank transactions are “members” in the complex event called buying a house. In a computer system, member events are the base event objects that CEP software uses to compute a complex-event object.
Events that your application generates by performing some computation on base events are always complex events (they also can be called derived or synthesized events). When events come in from somewhere outside of your system, they may be simple or complex. We’ll come back to this point after we discuss the nature of complex events.
Event Hierarchies
The relationship between a synthesized, complex event and its base events can be depicted as a hierarchy. A complex event is at a higher level in the hierarchy than the base events that were used to generate it. Consider the example introduced in Chapter 3 of a continuous monitoring system in a customer contact center. Each customer call is an event recorded in an event object. The event object contains information such as the time and date of the call, whether the call was inbound or outbound, length of time that the customer waited on hold, the number of times the customer was transferred, the duration of the call, whether the issue was resolved during the first call, the name or identifier of the agent who took the call, and perhaps some measure of customer satisfaction or other data items. The event objects record things that happen at the transaction, or operations, level in the call center (see the bottom level in Figure 7-1). Other events also happen at the operations level. For example, customer service agents log in to indicate that they are available to take calls and log out to indicate that they are taking a break or leaving for the day. Operations-level events are base events in an event hierarchy.
Team supervisors are interested in the volume of customer calls and the performance of the agents who work for them. They have a dashboard that reports metrics such as the call volume, the number of agents logged in as available, and the average time that customers spent waiting on hold. “Team A Average Wait Time1” is a complex-event object that reports the average waiting time for the calls into team A between 10 A.M. and 10:15 A.M. (see the middle level in Figure 7-1). It is calculated from 70 event objects, the base events that signify the 70 calls to the team during that time window. The average wait time is an abstraction; it happened in the physical world but it’s intangible—you can’t see it or hear it, and it can’t be directly measured and reported by the phone system. It’s visible to the Team A supervisor because it’s displayed on a dashboard that is refreshed every minute or every 5 minutes. “Team A Average Wait Time2” could be calculated and displayed at 10:16 to reflect the average wait time between 10:01 and 10:16. It will encompass many of the same base events (for example, Call4) that were reflected in the previous calculation of average wait time, but some older call events will be dropped and new ones added. The dashboard for the team B supervisor reflects “Team B Average Wait Time1,” which was synthesized from the event objects of a different set of calls.
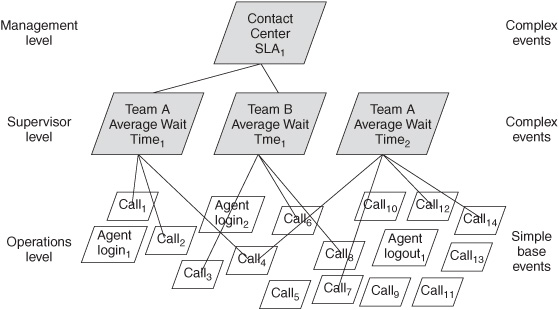
Figure 7-1: Event hierarchy in customer contact center.
A higher level of complex events is relevant on the management level. For example, the contact center manager may have a dashboard that continuously monitors the overall performance of the contact center. “Contact Center SLA1” is a complex event that is computed from the average wait times from all of the teams—its base events are complex events. The dashboard might represent this complex event in a “traffic signal” that turns yellow if the contact center wait times are beginning to deteriorate. It turns red if the average wait time has exceeded the threshold specified in the service-level agreement (SLA) that the contact center has with the marketing department. Missing an SLA is another abstract event—it’s intangible but real. An alert could be generated just when an SLA is missed or an SLA event notification could be routinely sent to update a graphic on a dashboard every few seconds depending on the needs of the end user.
A manager who sees a yellow light warning that the customer wait times are becoming too long may want to drill down into the details to find which team is experiencing the problems. A dashboard generally has the capability to show the individual events that contributed to a higher-level event. If the manager sees a problem in Team A, he or she might consult the Team A supervisor and take remedial action, such as reassigning Team B from making outgoing calls to helping Team A with incoming calls. Remedial actions at the supervisory level are typically at a finer level of granularity than those at the management level. A supervisor who sees that the average customer wait time is too long may drill down into the average call duration for each of their agents. If a particular agent has had several unusually long calls, the supervisor may need to give the agent additional coaching on a new product or service procedure or respond in some other manner.
Note: The volume of events forwarded up an event hierarchy generally is sharply reduced at each level. In many cases, thousands of simple events are condensed into one or two complex events, depending on the nature of the data and the business situation.
In this example, the records for each individual call don’t need to be sent to the manager’s dashboard because a handful of complex events provides the level of information needed at the upper level.
We should also point out that the association between levels in an event hierarchy and levels in a company’s organization chart in our example is largely coincidental. Although it is common to find that higher level complex events are of interest to higher levels in a company’s organization chart, as in the contact center example, in other CEP applications, several levels of an event hierarchy may be relevant to the work done by one person or multiple people at one level in the organization chart. Event hierarchies reflect the degree of refinement and abstraction of the event data irrespective of the level of the person who uses the data.
Event-Processing Rules and Patterns
The logic to transform simple events into complex events is carried out in CEP software at run time. Chapter 3 summarized the role of CEP software at a high level. This section explores event computation in more detail.
Programming CEP Software
CEP software is any computer program that can generate, read, discard, or perform calculations on complex-event objects. In some cases, CEP computation is implemented by the code of a packaged or custom application. CEP logic can be written in any programming language, such as C++, C#, or Java. However, when the event processing is more complex or needs frequent modification to adjust to changing business requirements, using a software tool that is specially designed for CEP may be more practical (Chapter 11 discusses the build versus buy issue in more detail).
The core technology for CEP is also available in purpose-built commercial products such as event-processing suites, business activity monitoring (BAM) products, CEP-enabled DBMSs, or CEP-enabled industry- or application-specific frameworks. The core technology is capable of reading notifications from event channels and performing calculations on them, but it needs to be tailored to each business situation.
Note: The background understanding needed to design event-processing business systems comes from users and business analysts. Analysts, software developers, or, in some cases, technology-savvy users then turn the business understanding into instructions for the CEP software.
The language used to give instructions to a CEP system is called Event Processing Language (EPL). Every product uses a different EPL because there is no industry standard. The CEP product’s development tool can use pull-down menus, a graphical interface with drag-and-drop icons, a scripting language, or a combination of these. The details of the language, development process, and nature of the development interface are different for every product. Developers typically specify the following things:
![]() The source of the incoming base events
The source of the incoming base events
![]() The data format and types of content in the base events
The data format and types of content in the base events
![]() The algorithms and functions to be applied to the base events and the patterns to be detected
The algorithms and functions to be applied to the base events and the patterns to be detected
![]() What to do with the complex events that are computed or detected (such as emitting alerts and other outgoing notifications, invoking a software agent, or controlling an actuator)
What to do with the complex events that are computed or detected (such as emitting alerts and other outgoing notifications, invoking a software agent, or controlling an actuator)
CEP Computation
The kinds of operations that can be applied to the base events typically include
![]() Filtering the incoming base events and discarding those that are irrelevant to the task at hand. To calculate “Team A Average Wait Time1,” only the event objects that pertain to customer calls to particular agents within a certain time window are used.
Filtering the incoming base events and discarding those that are irrelevant to the task at hand. To calculate “Team A Average Wait Time1,” only the event objects that pertain to customer calls to particular agents within a certain time window are used.
![]() Calculating aggregate figures such as totals and averages, counting the number of events, or sorting the events in order of ascending or descending value of some data item. The algorithm to compute average wait time in our example is trivial—the system adds the wait times and divides by the number of calls.
Calculating aggregate figures such as totals and averages, counting the number of events, or sorting the events in order of ascending or descending value of some data item. The algorithm to compute average wait time in our example is trivial—the system adds the wait times and divides by the number of calls.
![]() Transforming the data in a base event to another format to be used in the outgoing complex event.
Transforming the data in a base event to another format to be used in the outgoing complex event.
![]() Enriching the data by using the value of a data item to look up an entry in a table or database, and then inserting the data that is found in the table or database into the complex-event object that is being generated.
Enriching the data by using the value of a data item to look up an entry in a table or database, and then inserting the data that is found in the table or database into the complex-event object that is being generated.
![]() Splitting an event stream, forwarding some event notifications to one destination and others to another destination.
Splitting an event stream, forwarding some event notifications to one destination and others to another destination.
![]() Looking for patterns in the base events by correlating events from different streams or within one stream.
Looking for patterns in the base events by correlating events from different streams or within one stream.
Pattern Detection
Pattern detection warrants a more complete explanation because it is at the heart of “connecting the dots.” Developers tell the CEP software what combination of things to look for in the base events—the event pattern. A simple event pattern could look like this:
NewsArticle(About Stock X) followed by StockPriceRise(Stock X, > 5%) within 3 minutes.
This tells the CEP software to listen to the NewsArticle event stream for published articles that mention companies and also listen to the StockPriceRise event stream for reports of companies whose stock has increased more than 5 percent. When any company appears in a NewsArticle event object within 3 minutes of the time that the same company appears in a StockPriceRise event object with a price rise of greater than 5 percent, the CEP software has detected a complex event that is a pattern match (the pattern match is called a pattern instance).
This example demonstrates correlation between two event streams based on a match of company names (called a join). It also shows the importance of time in many CEP applications. The pattern requires that two events happen within 3 minutes of each other (a temporal constraint). It also requires a particular time order—the stock price change had to happen after the article was published, not before it.
Although it is not obvious, some additional continuous event processing had to take place to make this application possible because the StockPriceRise data is not directly available from any external event stream provider. The raw event data that is used to generate the StockPriceRise event stream comes from a stock exchange that publishes a basic trade data event stream. A continuous analytic function—coded in a separate section of event-processing language—is applied to the incoming trade data to calculate price change data that are published in a newly generated StockPriceRise event stream used in the example described above. Such value-added, CEP-based continuous analytic pre-processing is common in event-processing applications. Analytics may be used to calculate moving averages, discard outliers that are presumed to be bad data, or perform other tasks to improve the information quality of a raw event stream. In our example, the NewsArticle event stream may not require such preliminary analytics if high quality, tagged event data can be directly obtained from a third party information service.
Some event patterns refer to causal relationships between the events.
Note: An event A is said to have a causal relationship with event B if A had to happen first for B to happen.
Dr. Luckham identifies two kinds of causality, vertical and horizontal, in his book The Power of Events. Vertical causality is a causal relationship between events at two different levels in an event hierarchy. For example, a complex event called AvailableAgent2 can be generated at the supervisory level to report that customer Agent2 is available for calls. This event would be based on a pattern of simple base events from the operations level that indicates that the Agent Login2 event has occurred and it has not been followed by a corresponding Agent Logout2 event. Agent Login2 at the operations level has a causal relationship with the AvailableAgent2 event at the supervisory level.
Horizontal causality refers to relationships among events that are on the same level of an event hierarchy. Agent Login1 is horizontally causal to Agent Logout1 because they are on the same level and an agent can’t log out unless he or she first logged in.
Note: Causality in event processing is not a cause-and-effect relationship in an ordinary sense. Rather, the term causality in this field implies that the causal event is necessary although it may not be sufficient to determine that the subsequent event will occur.
In our example, Agent Login1 must have happened if Agent Logout1 happened so it is said to be causal. However, Agent Login1 can happen without Agent Logout1 ever occurring because an agent might forget to log out.
How does the developer know what patterns to look for? This is the subject of event pattern discovery, an essential part of the CEP application development process. Analysts must study the business situation to identify patterns that reflect situations of interest. In some cases, analysts will replay copies of event logs from the past and try various combinations of rules to see which ones reveal the most meaningful connections. This is similar to the analysis performed in analytical business intelligence applications.
The vast majority of CEP applications today use patterns that are prepared by people using software tools to perform the event analytics. It is also possible to discover patterns with the assistance of machine learning, a kind of artificial intelligence. Academic research is actively underway in this area.
Note: Pattern discovery is done mostly by people. It happens before the application is deployed or when the application is being modified, as part of the application development process. Pattern matching to find instances of the pattern is done by CEP software at run time as incoming base events are processed.
Time Windows
CEP applications often are set up to work with time windows. In our earlier example, the average call wait time for a 15-minute window could be continuously sliding or jumping forward into the future, depending on how the developer has written the EPL. The window could jump once a minute by discarding everything that is more than 15 minutes old, adding everything that has occurred within the last minute, and recomputing the 15-minute total. Or the window could slide forward in time by discarding old notifications the second they are more than 15 minutes old, adding new notifications as soon as they arrive, and recalculating the total every time a new notification is added or an old notification expires. The choice of jumping or sliding window depends on whether very current (for example, up-to-the-second) information is significantly more valuable than almost current (for example, up-to-the-minute) information. A sliding window consumes more computer resources than a jumping window so it isn’t warranted in many cases.
Commercial CEP software handles time windows more efficiently than conventional applications. A direct, conventional approach to computing an average call wait time would treat all of the relevant input data records at one time, summing the wait time and dividing by the number of calls. When the next time window was computed, the same operation would be repeated on a slightly different set of input records. Most CEP software can handle this with less overhead by only calculating the difference between the two time windows. It takes the results of the previous calculation, subtracts out the calls whose time had expired (those more than 15 minutes old), and adds in the new calls that had occurred since the previous calculation. If the volume of data is high, this algorithm can produce the updated result faster and with less computer overhead than the brute force calculation. Other aspects of CEP software are also optimized for its purpose—continuous intelligence.
Variations on Complex Events
An event-processing system is said to detect a situation if it finds a simple or complex event that a user of the system deems to be meaningful for any reason. A situation indicates that some event data item, combination of data items, or pattern instance has met some criterion that indicates a threat or an opportunity. For example, the system might calculate a complex event that reports an average on-hold waiting time for customers of 2 minutes and 10 seconds. If the developer had specified 2 minutes as the threshold for defining a threat situation, the event-processing system would act upon the rule it has been given for such situations. The rule might tell the system to turn a stop light on a dashboard yellow or send an e-mail alert to a manager.
Uncertain Events
In some cases, the meaning of a synthesized event can’t be conclusively determined. So, a situation that is indicated by a CEP system may have a probability associated with it. For example, consider a CEP system that is designed to detect money laundering. It tracks streams of funds-transfer events and spots a person who has received $8,000, $9,000, and $8,000 on successive days. This set of events matches an event pattern that has been designed to identify suspicious activity. However, an analyst may have studied the historical event data and determined that this pattern indicates money laundering 40 percent of the time. The CEP system can be told to report the pattern match and the details of the transactions, along with an explicit indication of the probability that it is money laundering. Probabilities can apply to past events, as in this case. They are even more common for predictive events in which the pattern indicates something that will probably happen in the future. For example, a tsunami detection system might predict a 70 percent chance of a tsunami of certain magnitude hitting a particular location within a certain time interval.
Absent Events
Chapter 2 pointed out that the absence of a notification conveys information. A parent on a business trip expects to receive a message if an emergency occurs at home. If the parent hasn’t received such a message, he or she assumes that no emergency has occurred. Sometimes the opposite protocol is used: the absence of a notification conveys information that there is a problem. A teenager is asked to call home by 11 P.M. to report that they are leaving a party to come home. If no call event occurs, the parent may call the teenager or go looking for them.
In our call center example, an inbound customer call (Call3) could raise a question that can’t be resolved during the initial call. An agent must call back with an answer at a later time. The lack of a return call event, such as Call9, within 4 hours requires a supervisor’s attention. An analyst defines an event pattern to detect when an initial call happens without a return call. This pattern will result in creating a complex event called UnansweredQuestion1. The pattern is matched by the occurrence of Call3 and a subsequent timer event Tn that occurs 4 hours after the time of Call3 with the absence of a return call event. The pattern would not be matched by the combination of Call3, Call9, and Tn because the return call was made. You may note that Call3 had to happen for Call9 to happen, so it is horizontally causal. Call3 also had to happen for the UnansweredQuestion1 event to occur at the supervisory level, so it is also vertically causal to UnansweredQuestion1.
Complex Events Sometimes Are Relative
How can you reliably distinguish a complex event from a simple event? Any event that is generated (synthesized) by applying some processing logic to a set of base events is a complex event. If something is synthesized locally, you know that it is complex. However, you don’t always know the nature of events coming from sensors, application systems, or other producers in the outside world.
You know that an incoming event is complex if the person who designed the event tells you that it is complex. He or she gives you a description (metadata) that describes the event type. If it includes data items that identify the base events that were used to compute the event, then you know that it is a complex event. If it is a composite event, the event object will even contain the actual base events that contributed to it.
You may also know that an incoming event is complex because you understand its inherent nature. It’s obvious that buying a house and World War II are complex events, irrespective of what data items are in the event object or how a producer generates the event object.
However, incoming events with no information about their genetics may appear to you as simple events. For example, stock trade reports in financial data feeds from stock exchanges are difficult to categorize. The notifications are short and simple, often less than 100 bytes in length and containing only a few data items on the trade price and number of shares. They would seem to be the quintessential simple, base event. However, a trade report summarizes a transaction that is a complex event to the buyer, seller, and the traders who executed it. Before the trade occurred, the participants looked at the data from previous trades in that stock earlier in the day, and probably considered other market data, financial news, information from quarterly and annual reports, and various other sources. A trade is a complex event to those involved in its creation, but the trade report is a simple event object to those who receive it.
Almost any event is the result of prior events, arguably going back to the Big Bang that started the universe (perhaps that event had prior events too). This would seem to indicate that almost any event is complex if you know enough about it. The only possible exception would be purely random activity or noise that has no predecessors. These could be truly simple to all observers—but we’ll leave that discussion for another venue.
Note: For those designing event-processing systems, the important implication is that complex and simple events are often in the eye of the beholder. If you have reason to be aware of the member or base events that contributed to event X, then event X is complex. If you don’t care about the details, then X is a simple event.
When you develop a CEP application, most base events that come from outside of your system will be treated as simple events because you don’t know or care what events led up to them. If a domino falls, you may only need to know about the domino that struck it, not the domino that struck the domino that struck it. An application that uses a stock trade report as input rarely needs to delve further into the origins of the trade. Only if the incoming event contains genetic information about its origins do you have the opportunity to treat it as other than a simple event.
Summary
Identifying business events and designing event objects are essential steps in the development of event-processing applications. In many cases, an event is reported by more than one type of event object because there are multiple event consumers (people or application programs) with different information needs. The fundamental principle of CEP is to generate one or a few high-level, meaningful complex events from multiple simpler base events. Analysts, software developers, or, in some cases, technology-savvy users turn their understanding of the business process and business requirements into instructions for the CEP software. The value of a complex event is only limited by the availability of event data and the creativity of people defining the patterns and algorithms to process it.