
6
Event-Processing Architecture
This chapter takes a deeper look at how event-processing application systems work. We’ll summarize how the flow of event-driven interactions differs from the flow of time- and request-driven interactions. Next, we’ll present a reference architecture for event-processing networks (EPNs) and show some common variations of EPNs used to implement different kinds of applications. Then we’ll look at how an EPN helps support the five principles of EDA. Finally, we’ll explain some of the architectural issues associated with publish-and-subscribe systems because of their growing popularity in EDA systems.
Application Flow
As you know, the flow of control in an event-driven interaction differs from the flow of control in time- and request-driven interactions in fundamental ways. This has a big impact on the way applications are constructed.
An event-driven software component (an event consumer) is triggered by the arrival of an event object (E1 in the top diagram in Figure 6-1). A time-driven component (call it a time-driven agent for lack of any specific label) is triggered by a signal from a clock (see Et in the middle diagram). A request-driven component (a software “server”) is triggered by the arrival of a request message (bottom of diagram).
Event consumer, time-driven agent, and server are merely roles; they don’t imply anything else about the nature of a software component. A component is an event consumer only because it receives and acts in response to an event object. A component is a server only because it receives and acts in response to a request message. A software component could be event-driven in one interaction and request- or time-driven in another interaction. Moreover, a component that is event-driven in one interaction could be an event producer or a client in a request-driven interaction a minute later, and so forth. This is reflected on the right side of Figure 6-1 by the gray arrows connecting to and from other agents elsewhere in the environment.
The flow of work can be compared to a bucket brigade: each instance of a process is analogous to a pail of water that is handed from one firefighter to the next. In the course of a day, thousands or more process instances may be passed from one step to the next. The component that first controls the process instance—the event producer, the clock, or the client—is the firefighter who has the bucket first (left column in Figure 6-1).
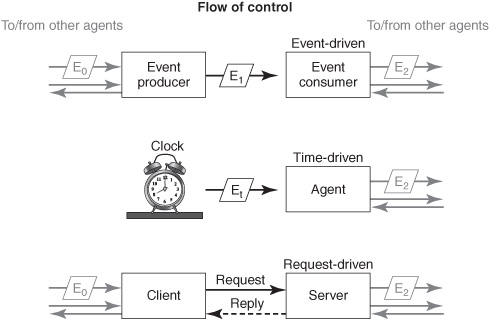
Figure 6-1: Flow of control in interactions.
Note: The terms event-driven, time-driven, and request-driven always refer to the second component in the interaction being studied—the firefighter who receives the bucket (right column in Figure 6-1).
Chapter 3 introduced a simple order-fulfillment process. Figure 6-2 shows the flow of the first part of that process in more detail. A new process instance comes into being when the order-entry component captures a particular customer order—for example, Fred Smith’s order. The person designing the process must decide whether the second step, credit check, will be event-driven or request-driven. If the orderentry component passes an event object, it will be event-driven (top diagram in Figure 6-2); if it passes a request, the second step will obviously be request-driven (bottom diagram). The interaction that occurs between the first and second steps doesn’t indicate how the first component, order entry, interacted with other agents further upstream. Order entry could capture the order through a conversation with a person entering the order through a web browser, in which case the order-entry component would itself be request-driven. Or it could accept incoming orders through an e-mail notification (E0 on the left in Figure 6-2), in which case it would be event-driven. However, the nature of the order-entry component is not specified when the second component (credit service) is made event- or request-driven.
Chapter 2 explained that contracts are essential to the design of software systems. Contracts describe the expectations of component behavior with respect to other components in the system. The contracts for event-, time-, and request-driven roles differ in how the components behave regarding the flow of control:
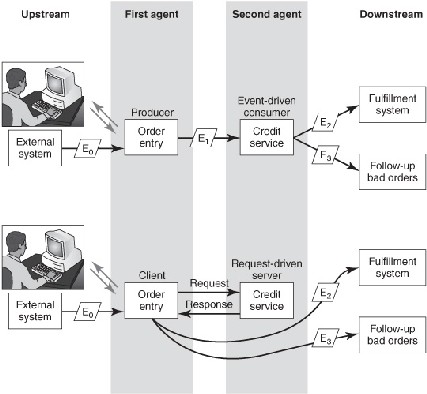
Figure 6-2: Order-fulfillment process.
![]() An event producer is expected to emit an event object whenever it detects that something happened. Order entry has a duty to emit a notification containing an order object every time it detects that someone has entered an order. The event consumer won’t run correctly, and might not run at all, unless the event producer sends the notifications.
An event producer is expected to emit an event object whenever it detects that something happened. Order entry has a duty to emit a notification containing an order object every time it detects that someone has entered an order. The event consumer won’t run correctly, and might not run at all, unless the event producer sends the notifications.
![]() An event consumer has no obligation to the event producer. It doesn’t return control of the process instance back to the producer and it can even decide not to receive a notification (the order, E1) in the first place. The event producer will run correctly in software terms even if the events it emits are not consumed. Of course, the process may not fulfill its business role if the consumer component doesn’t do its job, so the event consumer has an obligation at a higher level, but not to the producer.
An event consumer has no obligation to the event producer. It doesn’t return control of the process instance back to the producer and it can even decide not to receive a notification (the order, E1) in the first place. The event producer will run correctly in software terms even if the events it emits are not consumed. Of course, the process may not fulfill its business role if the consumer component doesn’t do its job, so the event consumer has an obligation at a higher level, but not to the producer.
![]() A clock is expected to emit a signal (Et) at a designated time. All computers have internal clocks. A clock is a highly constrained type of event producer because it emits only one kind of event and doesn’t depend on anything from an external source. It simply increments a counter at regular intervals and emits the event when the appropriate time comes (clocks also can respond to requests if a component wants to know what the time or date is).
A clock is expected to emit a signal (Et) at a designated time. All computers have internal clocks. A clock is a highly constrained type of event producer because it emits only one kind of event and doesn’t depend on anything from an external source. It simply increments a counter at regular intervals and emits the event when the appropriate time comes (clocks also can respond to requests if a component wants to know what the time or date is).
![]() A time-driven agent is an application component that runs when it receives the time event (Et). Like any other event consumer, it has no obligation to do anything. It can choose to ignore the clock’s signal, and the clock will still work properly, although the overall process wouldn’t work right from a business point of view.
A time-driven agent is an application component that runs when it receives the time event (Et). Like any other event consumer, it has no obligation to do anything. It can choose to ignore the clock’s signal, and the clock will still work properly, although the overall process wouldn’t work right from a business point of view.
![]() A client in a request-driven relationship has no contractual obligation to the server. It can choose to send a request message or it can choose to never call the server. In this sense, it is like an event consumer—it is free to behave as it sees fit, although it may have other obligations to fulfill at a business level.
A client in a request-driven relationship has no contractual obligation to the server. It can choose to send a request message or it can choose to never call the server. In this sense, it is like an event consumer—it is free to behave as it sees fit, although it may have other obligations to fulfill at a business level.
![]() A server in a request-driven relationship is expected to perform the action specified in the request message. In most cases, it will send to the client a reply containing some application data, a notification that it successfully performed the task, or at least an acknowledgment that it received the request. A client in a request-driven relationship lends control of the process to the server but usually doesn’t give it control permanently. The client remembers the process instance (it retains some state data on Fred’s order) that it uses in combination with the reply to do further work on that instance. If the server doesn’t do its job, and in most cases that includes sending a reply, the client cannot finish its work.
A server in a request-driven relationship is expected to perform the action specified in the request message. In most cases, it will send to the client a reply containing some application data, a notification that it successfully performed the task, or at least an acknowledgment that it received the request. A client in a request-driven relationship lends control of the process to the server but usually doesn’t give it control permanently. The client remembers the process instance (it retains some state data on Fred’s order) that it uses in combination with the reply to do further work on that instance. If the server doesn’t do its job, and in most cases that includes sending a reply, the client cannot finish its work.
We can now explain why event- and request-driven mindsets are sometimes compared to left- and right-brain thinking: the two interaction patterns reflect fundamentally dissimilar ways of operating.
Note: In event-driven relationships, the first agent helps the second agent by notifying it of the event. In request-driven relationships, the second agent helps the first agent by doing some work that the first agent wants to have done.
In an SOA system, a requesting client is called a “service consumer,” demonstrating the similarity between it and an event consumer (see Chapter 9 for more discussion of the overlap of SOA and EDA concepts). However, the consumer in an event-driven relationship “consumes” event objects, whereas the consumer (client) in a request-driven relationship “consumes” a function or a service. The consumer in an event-driven relationship acts second in the interaction, but the consumer in a request-driven interaction acts first.
Reference Architecture for Event-Processing Networks
A reference architecture provides a formal template for system design in a particular domain. It describes the vocabulary, components, component interfaces, and the relationship among the components inside and outside of the system. In this section, we focus on the reference architecture for the EDA domain.
Note: Application systems or sections of application systems that process event objects using the EDA model are structured as EPNs.
The reference architecture for EPNs incorporates four kinds of components: event producers, channels, consumers, and intermediaries. Figure 6-3 shows the general structure of an EPN. Producers, consumers, and some intermediaries are event-processing agents (EPAs).
Note: An EPA is an agent that creates, reads, discards, or performs calculations on event objects. A physical EPA is a software component. A conceptual EPA is an abstraction that performs logical functions on event obects.
A physical EPA doesn’t have to be a separate module; it can be a section of code in an application, a database management system (DBMS), or any other program. Channels are not EPAs but they contribute to the EPN by providing communication capabilities.
Producers
EDA processing begins when a software component, the event producer, detects an event in its environment (see Figure 6-3, left column). A producer (sometimes called an “event source”) is any EPA that emits event objects. For example, a radio frequency identification (RFID) reader may receive a message from an RFID tag indicating the presence of a package that was not within range a second earlier. The RFID reader recognizes this change in its environment as a business event, creates an event object, puts it into a notification message, and emits it through an event channel. The event producer in this example is software embedded in the RFID reader. Event producers can be embedded in a device or run on a general-purpose computer as an autonomous software program or part of a larger software package.
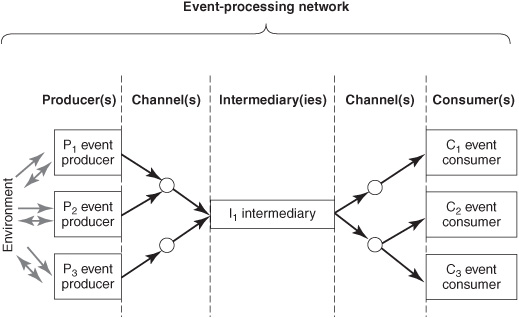
Figure 6-3: Reference architecture for EPNs.
Channels
An event channel is any means of conveying a notification from one EPA to another. The arrival of the notification signals the event occurrence. Channels work in any of three ways:
![]() By sending messages (the most obvious and common technique)
By sending messages (the most obvious and common technique)
![]() By putting an event object in a shared location where the producer and consumer can both access it
By putting an event object in a shared location where the producer and consumer can both access it
![]() By the producer calling the event consumer
By the producer calling the event consumer
Later in this chapter, we’ll explain how these options work in more detail.
Any technique for conveying a notification is a valid channel in the EPN reference architecture as long as the five principles of EDA outlined in Chapter 3 are observed. However, the EPN reference architecture doesn’t apply to other types of event processing, such as time- or request-driven event processing. The event objects in those styles of computing are at rest in a file or database for an undetermined amount of time and the processing occurs at a time that is unrelated to the delivery of the event object. We don’t present a reference architecture for time- and request-driven eventprocessing applications in this book.
A channel can carry events of multiple types. For example, “approved order” events can be sent over the same channel as “rejected order” events even though the types of data in the event objects are different, they may be received by different consumers, and they will be treated differently. Events conveyed by one channel may be delivered to multiple consumers (the channel is said to “fan out”). Events conveyed by one channel may originate in multiple producers and be delivered to one consumer (the channel is said to “fan in”). Figure 6-3 shows examples of fan out (on the right) and fan in (on the left).
Consumers
An event consumer is an EPA that receives event objects. The consumer evaluates the event and decides which of the following to do with it:
![]() Perform a response locally
Perform a response locally
![]() Invoke a service
Invoke a service
![]() Trigger a business process
Trigger a business process
![]() Emit a message
Emit a message
![]() Save the event object to use in the future when additional events arrive
Save the event object to use in the future when additional events arrive
![]() Discard the event without doing anything
Discard the event without doing anything
Consumers are sometimes called event handlers, sinks, listeners, or responders.
Intermediaries
All EPNs are intermediated because something is always interposed between the producer and consumer. EPNs may be intermediated by channels or by channels with EPAs.
Channels as Intermediaries
A channel is a low-level intermediary because its function is limited to communication-related tasks. A channel may itself be intermediated—a physical intermediary within an intermediary. For example, the circles in the channels in Figure 6-3 could be message servers in a message oriented middleware (MOM) channel. A message server is a software component that acts as a hub to relay messages from one computer or software component to another.
A message server or other channel intermediary is part of the channel; it’s messageaware but not event-aware. For example, many MOM channels can selectively decide where to deliver messages based on the message topics or message properties. Topics are data that describe the subject of the message. Properties are data that describe other characteristics of the messages. Software developers design message topics and properties at development time. The producer agent typically puts this data into a message header—the “envelope” of a message—at run time. Channel intermediaries can use topic and property data to implement publish-and-subscribe messaging (we’ll describe how this works in more detail later in this chapter). However, a channel intermediary is not an EPA, because it doesn’t read or modify the event attributes, which are typically held in the message body—the contents of the “envelope.”
Channels don’t always have physical internal intermediaries. The software that implements a channel can be distributed to the endpoints of the network with no central hub.
EPAs as Intermediaries
Some EPNs also have higher-level intermediaries. A high-level intermediary that manipulates the event object within the message is an EPA (see I1 in the center of Figure 6-3). It is an event consumer and an event producer because it receives notifications, interprets and processes them, and emits notifications. There are two kinds of intermediary EPAs: event routing and event generating.
Event-Routing Intermediaries
Routing EPAs don’t alter the makeup of the event objects—every object that is emitted is identical to an object that was received. They read event objects, filter out (discard) those that are not needed by any consumer, and direct the remaining events to particular destinations depending on the contents of the event (“content-based routing”). This may be done using a high-level form of publish-and-subscribe that is more sophisticated than a channel’s publish-and-subscribe because it is event-aware—able to deal with the event attributes in the message body. For example, a consumer agent could subscribe to all customer order events where the value of the order is more than $500 and the ship-to address is out of state.
Event-Generating Intermediaries
Event-generating EPAs do more than relay events; they actually terminate (receive and discard) the incoming “base” event objects and originate (create and send) new event objects that are created by performing calculations on the incoming events. An outgoing event may refer to the same real-world event as the base event, but the event object is different in one or more of its attributes. Event-generating intermediaries may
![]() Selectively copy data items from base events, change their format, reorder them, and put them into the outgoing event objects
Selectively copy data items from base events, change their format, reorder them, and put them into the outgoing event objects
![]() Enrich events by adding relevant data from databases or other sources
Enrich events by adding relevant data from databases or other sources
![]() Compute aggregate values such as totals, averages, minimums, and maximums from multiple events
Compute aggregate values such as totals, averages, minimums, and maximums from multiple events
![]() Perform other kinds of complex event processing (CEP) by applying rules to detect patterns in a set of base events (see Chapter 7 for more details)
Perform other kinds of complex event processing (CEP) by applying rules to detect patterns in a set of base events (see Chapter 7 for more details)
Applying the Reference Architecture
As you know, EDA is based on the precept that producers are only minimally coupled to consumers. EPNs are used to implement EDA applications specifically because EPNs have channels and intermediary EPAs that insulate the EPAs from each other. A producer or consumer can be changed without requiring a change in other producers and consumers as long as the same types of event objects are transmitted through the channels.
Note: The combination of one or more channels and zero or more event-routing intermediary EPAs is a dissemination network. An entire EPN consists of one or more event producers, one or more consumers, zero or more event-generating intermediaries, and the dissemination network between them.
An EPN is not actually separate from the rest of a company’s network, but rather is a conceptual description of how some parts of a company’s network are being used. An EPN is physically implemented by some of the application programs, middleware subsystems, and messages that participate in the company’s tangible network. The remaining programs, middleware subsystems, and messages are those that support request-driven applications (for example, web service calls), time-driven applications (for example, batch file transfers over FTP), e-mail, web interactions, IP phone traffic, and all the other aspects of a modern communication backbone. Chapter 8 includes more discussion of EPN implementation issues.
Architects who use reference architectures usually specialize or extend them, or combine them with other architectures to meet specific business requirements. The EPN reference architecture has several common variations that are employed depending on the circumstances.
EPN for Information Dissemination
An EPN that is used for simple information dissemination or data consistency often doesn’t need an intermediary EPA. Its dissemination network may just consist of a channel (see Figure 6-4). A channel doesn’t perform any logical operations on the contents of event objects, so the event received is the same as the event published (E1). The software that implements the channel may be in multiple pieces that are physically collocated with the producer and consumer application endpoints. Or, especially if the channel is implemented using MOM, some of the functions may run in a channel intermediary such as a MOM message server (described previously). Examples of this simple EPN pattern include RSS feeds and real-time financial data feeds in capital markets trading activities implemented using publish-and-subscribe middleware. The producer publishes an event once and a copy may be delivered to thousands of consumers.
EPN for Situation Awareness
EPNs used for situation awareness typically need to gather events from multiple sources, process them internally to logically “connect the dots” and derive some complex events, and then distribute alerts and other notifications to multiple people and systems. These EPNs have event-generating intermediary EPAs and multiple channels. The channels could be a diverse collection of basic network protocols, MOM products, and other middleware. Each channel may have a channel intermediary and be connected to multiple producer or consumer agents (see the channels in Figure 6-5). The higher-level intermediary EPA I1 may be implemented by means of an enterprise service bus (ESB), integration broker, business process orchestration engine, CEP software agent, custom application code, or some combination of those. The intermediary terminates incoming events (E1, E2, and E3), transforming them and performing some type of computation to produce events E4 and E5, which are distributed to the consumer agents.
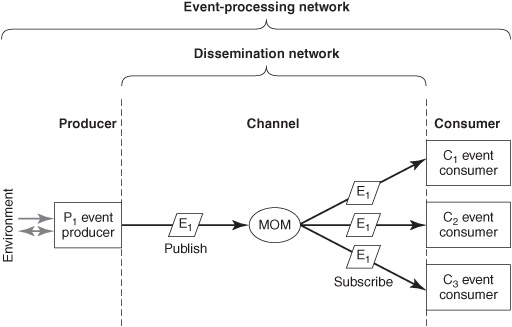
Figure 6-4: Simple EPN for information dissemination.
EPN for Application Integration
In a large configuration, it sometimes helps to think about a set of channels and EPAs as a single entity for design purposes. In this case, architects treat an entire EPN as one conceptual EPA (see P21 in Figure 6-6).
Note: The reference architecture is recursive—it allows a conceptual EPA to be an EPN and vice versa.
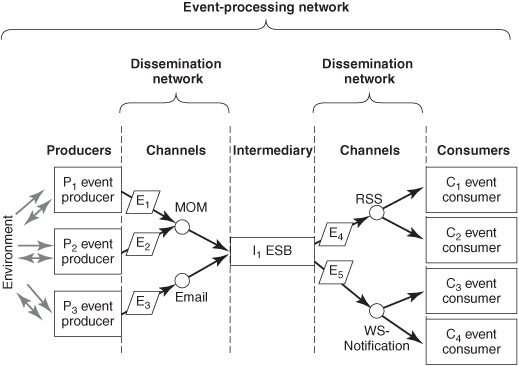
Figure 6-5: Complex EPN for situation awareness.
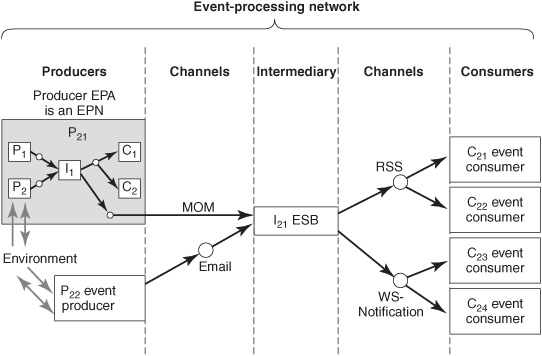
Figure 6-6: EPN as EPA in a larger EPN.
Implementing the Principles of EDA in an EPN
Chapter 3 outlined the principles of EDA at a conceptual level. Now we’re ready to explore how developers apply those conceptual principles on a logical and physical level as they implement an event-processing application using software and an EPN. The five principles are listed again here and described in depth in the following sections:
![]() Reports current events
Reports current events
![]() Pushes notifications
Pushes notifications
![]() Responds immediately
Responds immediately
![]() Communicates one-way
Communicates one-way
![]() Is free of commands
Is free of commands
The most effective way of implementing these five principles is usually by means of a publish-and-subscribe communication model. We’ll describe why after we examine the principles in more detail.
Reports Current Events
Principle: A notification reports a discrete occurrence as it happens.
Implementation details: An application component acting as a producer agent emits a notification as soon as an event is recognized. For example, when an RFID reader detects the presence of an RFID tag, it sends a notification message to report that event. However, developers may take some liberties with the way communication is actually handled by the software.
To reduce the number of messages going over a network, multiple notifications are sometimes bundled into one message. The system might send the message when it has accumulated five or ten readings, when a second or two has elapsed, or whichever comes first. On the receiving side, the message is unpacked and the notifications are separated and passed individually to the event consumers. A small increase in latency, typically less than a second or two, is incurred to get the benefit of reduced network overhead. This tradeoff is a quality-of-service (QoS) policy decision. An analyst identifies the business requirements and documents the willingness of the application owner to accept the slightly higher latency associated with bundling notifications or pay a bit more for the faster delivery of individual messages.
As long as the producer addresses each occurrence as it happens, the application style is EDA. The system would be time-driven if the producer postponed sending the notification to a prescheduled time, but that is not the case here. The clock plays only a minor role in constraining the time for sending the message.
Pushes Notifications
Principle: Notifications are “pushed” by the producer, not “pulled” by the consumer. The producer decides when to send the notification because it knows about the event before the consumer does.
Implementation details: The principle of push refers to the overall conceptual relationship between the producer and consumer agents, not the relationship between the agents and EPN channels. The producer-consumer relationship is always a push, but agent-channel relationships are more complex. The producer always pushes the notification to a channel. The channel may push the notification to the consumer or the consumer may pull the notification from the channel (the timing of a pull is determined by the consumer).
Channels work in any of three ways: by sending messages, by putting an event object in a shared location where the producer and consumer can both access it, or by the producer calling the event consumer.
Sending Messages
The most common kind of channel moves event objects between agents by sending them in messages. The producer may send the event object through MOM; put it in an e-mail; use a web-oriented communication protocol such as HTTP or RSS on HTTP; use a SOAP-based web services message; or use another kind of messaging.
If a channel is implemented by MOM, the consumer gets the notification from the MOM in one of three ways (see Figure 6-7):
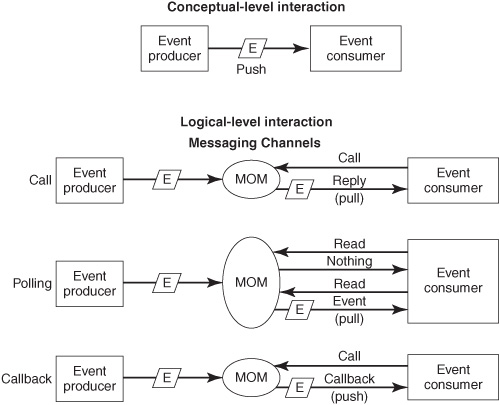
Figure 6-7: Implementing notification through messaging.
![]() Direct pull (call) —A consumer agent can call the MOM to ask for the next notification. It stops doing other work (it is “blocked”) until the notification arrives in a reply (see the “Call” row in Figure 6-7). The MOM is an intermediary between the producer and consumer. When it gets the notification from the producer, it relays the notification to the consumer as a reply to the call. This is a request and a reply at a logical level. However, the timing of the reply is largely determined by the event producer, because it decides when to send the notification to the channel. If the producer sends two notifications very quickly, the MOM will temporarily hold the second one until the consumer issues another call to get it. However, if notifications are infrequent and far apart, the consumer may have to wait a long time. The consumer could potentially wait forever if a notification never comes. Sometimes the consumer is allowed to specify a timeout value, after which the MOM will return control back to the consumer even if a notification hasn’t arrived.
Direct pull (call) —A consumer agent can call the MOM to ask for the next notification. It stops doing other work (it is “blocked”) until the notification arrives in a reply (see the “Call” row in Figure 6-7). The MOM is an intermediary between the producer and consumer. When it gets the notification from the producer, it relays the notification to the consumer as a reply to the call. This is a request and a reply at a logical level. However, the timing of the reply is largely determined by the event producer, because it decides when to send the notification to the channel. If the producer sends two notifications very quickly, the MOM will temporarily hold the second one until the consumer issues another call to get it. However, if notifications are infrequent and far apart, the consumer may have to wait a long time. The consumer could potentially wait forever if a notification never comes. Sometimes the consumer is allowed to specify a timeout value, after which the MOM will return control back to the consumer even if a notification hasn’t arrived.
![]() Periodic pull (polling) —The consumer can poll the MOM periodically (see the “Polling” row in Figure 6-7). In this case, the consumer calls the MOM at regular intervals, occasionally getting a notification in return. This is more complicated to program than a simple call to the MOM, but it means that the consumer doesn’t sit idle for indeterminate periods of time, as it would with a simple call. This gives the developer more control over the consumer’s behavior, which can be important if a notification doesn’t arrive in a timely fashion.
Periodic pull (polling) —The consumer can poll the MOM periodically (see the “Polling” row in Figure 6-7). In this case, the consumer calls the MOM at regular intervals, occasionally getting a notification in return. This is more complicated to program than a simple call to the MOM, but it means that the consumer doesn’t sit idle for indeterminate periods of time, as it would with a simple call. This gives the developer more control over the consumer’s behavior, which can be important if a notification doesn’t arrive in a timely fashion.
![]() Push via callback —When the consumer agent starts up and becomes ready to listen to events, it can call the MOM to convey its identity (see the “Callback” row in Figure 6-7). When the MOM receives an event from the event producer, it calls back to the consumer to pass the notification message. The callback is not a reply to a consumer’s request—it is a separate call. A callback is logically a push because its timing is determined by the producer.
Push via callback —When the consumer agent starts up and becomes ready to listen to events, it can call the MOM to convey its identity (see the “Callback” row in Figure 6-7). When the MOM receives an event from the event producer, it calls back to the consumer to pass the notification message. The callback is not a reply to a consumer’s request—it is a separate call. A callback is logically a push because its timing is determined by the producer.
In some cases, the consumer agent isn’t running when the producer sends a notification. Some MOM software can be configured to start up the appropriate consumer agent according to the type of notification that is sent. When the consumer is started, it gets the notification from the channel using a call or polling, as described in the previous bullets. This avoids the overhead of having an event consumer sitting idle for long periods of time. However, it increases the latency of the response because of the time it takes for the computer to start up the consumer agent.
Messaging channels other than MOM generally support some variation of these three communication patterns. In all of the options, the conceptual relationship between the event producer and consumer remains a push. However, the logical relationship between the channel and the consumer may be either a pull or a push.
Data-Sharing Channel
In a data-sharing channel, the producer writes the event object to a file, database, shareable cache, or some other place in memory (see “temporary store” in the middle diagram in Figure 6-8). A write is essentially a push. The event consumer periodically polls the file, database, cache, or other place in memory to see if the data has changed. When new data (the event object) is found, the consumer knows that the event has occurred. A read is logically a pull because the timing is determined by the consumer and the command is a request (read) and reply (the data).
The event object can be a simple one-bit semaphore (“0” could mean no event yet, and “1” would then mean that the event has occurred). Often a semaphore is a number (“0” could mean no event yet, and “2” could mean that two events have occurred). Or, the event object can be a large data structure containing hundreds of data items that describe various aspects of the event in great detail.
The polling interval is a tradeoff between latency and overhead. If the polling interval is short, say, every 100 milliseconds, then the event object will be found almost as soon as it arrives and the latency of notification delivery will be low. However, this can place a heavy burden on the computer because the read may be done thousands or millions of times before the consumer finally gets an event. If the polling interval is long, say, every 10 minutes, the overhead is lower but the latency is higher (up to 10 minutes). The tradeoff is a QoS policy decision. An analyst and middleware specialist may need to confer with the application owner to determine the appropriate polling interval for each application.
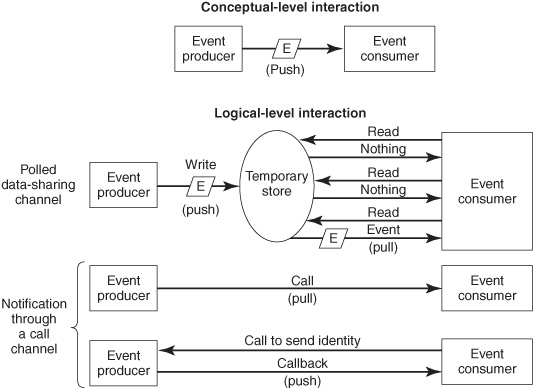
Figure 6-8: Notification through data sharing channels and call channels.
Notification Through a Call
A producer can notify a consumer by calling it through a procedure call, method invocation, remote procedure call (RPC), or remote method invocation (bottom section “Notification through a call channel” in Figure 6-8). Procedure calls and method invocations work within one computer, whereas RPCs and remote method invocations work across a network.
When a call is used in EDA, there is no reply message and the function to be performed by the consumer is not identified in the call (a nonspecific function name such as “event handler” is used). Request-driven systems use calls in a different way, always specifying the consumer’s function and usually sending a reply.
In event-driven systems, the identity of the consumer agent is not built into a producer agent when it is compiled and deployed. The producer has to acquire this information when it runs so that it knows where to send the notification. One way of accomplishing this is to programmatically insert the consumer’s identity into the producer at run time before the call occurs (For details, see Event-Based Programming by Ted Faison, listed in Appendix A). The other way for the producer to find out about the consumer is through the callback pattern described earlier (see the lower part of Figure 6-8). When it’s ready to receive events, the consumer agent calls the producer to convey its identity. When an event occurs, the producer calls back to the identified event handler method to signal the event. A callback is logically a push because its timing is determined by the producer.
A call is a kind of messaging in the sense that it usually carries some event data as parameters or in an attached document. However, it is dissimilar to other kinds of messaging because the event producer also passes control of the application flow directly to a specific point (such as an event handler method) in the consumer agent. And a call doesn’t have to pass event data. A call with no parameters or attachments still signals an event by the mere act of passing control of flow. In this case, it’s a bit of a stretch to say that there is an event object—it is an imaginary or empty event object. We could compare this to a wakeup call at a hotel where the phone rings but no one says anything—a signal has been conveyed but no content beyond the act of ringing the phone is needed.
Responds Immediately
Principle: The consumer does something in response immediately after it recognizes an event.
Implementation details: In a simple EDA system, the consumer agent performs its function as soon as a notification arrives. In some cases, it may evaluate and discard the incoming event with no further action, so the evaluation is the extent of its function. In a CEP system, however, the consumer’s reaction is more nuanced. Its only immediate response may be to make some calculations and discard the message or save the event object for later use when additional notifications have arrived.
For example, a customer contact center monitoring system could be designed to emit an alert if the average customer during a 15-minute window has to wait on hold for more than 2 minutes. The data to enable this alert comes from notifications that are created every time a customer call is received. The notifications report the customer’s wait time along with other information such as the customer’s phone number and the identity of the service agent who takes the call. The notifications don’t trigger an alert directly. The continuously running monitoring system uses the notifications to recalculate the 15-minute average waiting time every time a new notification arrives. If the average waiting time is under the 2-minute threshold, the system just saves the data for future use. The system takes action—sends an alert—only when it reaches a “tipping point,” that is, when it calculates an average waiting time greater than 2 minutes for any 15-minute window. The system is not reacting directly to the arrival of any input base event, but rather is responding to its own calculation of a complex event that reflects information from potentially hundreds of notifications.
Communicates One-Way
Principle: EDA notification is a “fire-and-forget” type of communication. The producer emits the notification and goes on to do other work, or it may end processing and shut down. It does not get a reply from the consumer.
Implementation details: Chapter 3 explained that the benefit of this principle is to free the producer from any dependency on the consumer at run time. If a producer needs a response from the consumer to complete its work on a particular process instance— for example, Fred’s order—then the system isn’t implementing the EDA design.
“Forget” means that the producer doesn’t have to retain any data about that particular process instance. A producer could temporarily keep some data on Fred’s order after sending a notication about the order to a consumer but this approach is rarely used. It would only be used if the producer has some additional work to do on the order before shutting down or moving on to work on the next process instance. Regardless, a producer never holds data about the process instance in anticipation of getting a reply back from the consumer or any other agent that later works on this process instance. In some business processes, the control of the process instance might actually come back to an agent that had been an event producer at an earlier time (the process would be “cyclical”). If the original event producer has forgotten that it worked on the process instance before, then it still complies with the principles of EDA. If it depends on a reply and has kept instance data in the expectation of getting a reply, then it is not implementing EDA.
However, “fire and forget” raises integrity concerns in some situations. How can a producer be sure that Fred’s order isn’t lost after it’s sent? This concern doesn’t arise in a request/reply architecture because the reply implicitly confirms that the consumer has received the message, but no reply occurs in fire-and-forget. Architects and developers can resolve this issue in fire-and-forget by using a channel that offers reliable delivery. For example, a producer sends the notification to a MOM facility that saves a copy on disk and sends back to the producer agent a confirmation that it has the message. The producer is then free to forget everything about Fred’s order and move on to another task. It’s conceptually a push, because the producer determined the timing and doesn’t get a reply from the consumer, but the producer actually did get a technical reply from the MOM to verify that the message was accepted for transmission.
The MOM transports the notification to the consumer and doesn’t delete the copy that it saved until the consumer has acknowledged (to the MOM) that it has received the notification. If the notification can’t be delivered, the channel will generally try several more times. If it still can’t deliver it to the consumer, it will send it to a “dead letter” agent for follow-up action. Analysts and developers determine what the dead-letter agent will do, just as they would design a recovery procedure for the original producer if a reply was not returned in a request/reply system.
If an event-driven system doesn’t fire and forget, then it is not implementing an EDA pattern. It may be event-driven to the extent that it complies with the other four principles (Reports current events, Pushes notifications, Responds immediately, and Is free of commands) but the agents are coupled and mutually dependent in an important respect, making changes more complex to implement. The idea that an eventdriven system is not always EDA can be disquieting to some architects, but event-driven systems with responses are not uncommon in real-world systems. They have more flexibility than request-driven systems, but they have less flexibility than full-blown, fire-and-forget EDA systems.
Is Free of Commands
Principle: A notification is a report, not a specific request or command. It does not prescribe the action the event consumer will perform.
Implementation details: This is the other aspect of minimal coupling. Chapter 3 explained that this is fundamentally different from a request-driven system, where both parties must agree on the function that the consumer will perform. In a requestdriven system, the client might tell the server to “give me the data about Fred’s order,” “update Fred’s order,” or “delete Fred’s order,” for example. In an event-driven system by contrast, the message from producer to consumer is just “Fred has submitted an order (do what you will with this information).”
In rare cases, request-driven interactions are designed to have no reply—they fireand-forget a “request” message. This makes the sender (the client) independent of the receiver (the server) at run time. However, they still are interdependent at development time, because the consumer’s function is explicitly built into the sender and receiver. Both agents must be modified if a change in the business requirement dictates a change in function.
Although an EDA system is free of requests and commands at a conceptual level, the agents use commands at a logical and physical level to communicate with the channel. The event producer issues commands such as “write” to a shared location; or “open the channel,” “send a message,” and “close the channel.” A consumer uses similar commands to “read” (poll) a shared location; or to “open,” “get” a message, and “close” a message channel. These are different from commands in a request-driven system because they refer to the mechanics of communication instead of describing a function that is part of the business process. Even when a channel is implemented as a call directly from producer to consumer, no application-related request or command is built into the communication. A call to an “event handler” function in a consumer agent is unspecific—it doesn’t tell the consumer what to do except “handle” the event as the consumer sees fit.
Publish-and-Subscribe
Publish-and-subscribe is a communication pattern that is well suited for implementing the five principles of EDA, although its use is not definitional to EDA. You can implement a successful event-processing application that conforms to all five EDA principles without using it. However, an increasing number of EPNs use channels that support publish-and-subscribe because it further enhances the flexibility of the application.
Many architects and analysts are initially drawn to publish-and-subscribe because one message can be delivered to zero, one, or millions of consumers without the producer having to send it multiple times. Publish-and-subscribe also allows multiple producers to send to one consumer, or multiple producers to send to multiple consumers (and it supports one-to-one communication too, of course). However, flexibility is arguably an even more important benefit of publish-and-subscribe.
Note: Publish-and-subscribe is a communication pattern in which the message delivery instructions are explicitly defined in an independent entity, the subscription, rather than being built into the producer or the channel.
A subscription describes the kind of messages that should be sent to each consumer. A subscriber agent sends subscriptions to a subscription manager that controls event delivery. In traditional publish-and-subscribe systems, each consumer is its own subscriber because it creates the subscription rules that describe the messages that it will receive. However, in some publish-and-subscribe systems, the subscription can originate in a third-party subscriber or in the producer rather than in the consumer.
A subscription manager applies the subscription rules to each message to determine which consumers, if any, should receive it. A subscription manager is typically implemented as part of a MOM subsystem or other channel, but in some systems, the event producer itself manages the subscriptions without the involvement of a third party.
Subscription rules can apply to data fields in the message header or message body. We pointed out earlier that channels implement publish-and-subscribe by looking at topic or property data in the message headers. EPA intermediaries can implement publish-and-subscribe by looking at any data fields in the body of the message. Publish-and-subscribe systems usually allow “wild-carding” using “*” qualifiers. For example, a message pertaining to currency trades might have three segments in its topic: From_Currency, To_Currency, and Date. A subscription rule could then specify “Give me all messages of the type ‘From_Dollars.To_Yen.*,’” indicating that the consumer wants all trades related to those currencies regardless of the date. Or the rule could specify “Give me all messages of the type ‘From_Dollars.*.June2010,’” indicating an interest in all dollar trades in June 2010 regardless of the destination currency. Subscriptions reduce the number of superfluous messages that are delivered; consumers receive only filtered information that is relevant to them.
Publish-and-subscribe is more flexible than other kinds of messaging or calling mechanisms because the delivery instructions are not statically defined. The subscription can be transmitted and applied when the agents start up, or even altered dynamically as the system runs. A new producer or consumer can be added at any time, or a producer or consumer can drop out at any time.
The task of moving the messages is logically separate from the task of managing subscriptions. Publish-and-subscribe systems use a wide range of communication protocols, some standard and some proprietary.
Summary
EDA applications can evolve gracefully because their components can be modified individually at different times. The flow of control in EDA is unidirectional and communication is generalized, unlike request-driven systems, in which agents depend more heavily on the behavior of other agents in the system. The reference architecture for EPNs describes the relationships among four kinds of software components found in EDA systems: event producers, channels, consumers, and intermediaries. The five fundamental principles of EDA refer to the relationship between producer and consumer agents at a conceptual level. However, analysts and architects designing EDA systems must understand the tradeoffs and other implementation considerations that arise at the logical and physical levels. Publish-and-subscribe communication enhances the agility of an EDA system because it routes notifications in a dynamically customizable manner.