
3
Using Event Processing
in Business Applications
This chapter explores the business implications of the two seminal aspects of event processing: event-driven architecture (EDA) and complex event processing (CEP). Each is valuable by itself, but they’re even more interesting when used together as event-driven CEP. Event-driven CEP is the underlying technology for continuous intelligence systems in which computers analyze events as they occur instead of afterthe fact. The main reason for the recent upsurge of interest in event processing is that continuous intelligence has become practical to use in a wide variety of business situations. This chapter explains the nature of EDA and CEP and describes how they are applied separately and together to improve the timeliness, agility, and information availability in business.
Event-Driven Architecture
“EDA” refers to a particular style of event processing; it is not an umbrella term for every activity related to events. Progressing from the general to the specific (see Figure 3-1), EDA fits this way into the overall scheme of event processing:
1. Events —Things that happen or, viewed another way, changes in the state of anything. Broadly speaking, everything in the world participates in events, so the concept is too general to help in designing business processes or IT systems.
2. Business events —Events that are meaningful in a business context. Other events occur in our personal lives, politics, science, sports, the weather, and other realms but they’re not directly relevant to business computing. Every application system used in business during the past 50 years has processed business events in a sense, so it’s still a very broad area.
3. Event objects —Discrete reports of events. An address change on a paper form is an event object that a person can use. Computers, of course, use electronic, machine-readable event objects, such as XML documents. When people say “event processing” in an IT context, they usually imply event object processing. Intent is essential to the definition of event object—it is intended to convey information, not just store information. As one wag put it, “An event (object) is a message with an attitude.” An amorphous set of data scattered about in various databases, files, electronic documents, and sections of memory doesn’t constitute an event object even if it is all related to a real-world business event. That’s data about an event, but it isn’t a discrete report that can be used to notify another software component. Event objects don’t need to convey everything known about the event; they may be only a simple electronic signal. Chapter 7 drills down deeper into the design of event objects for business applications.
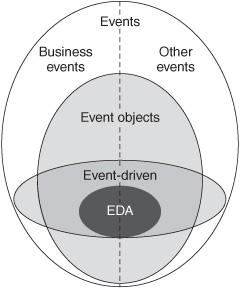
Figure 3-1: Positioning EDA in an event-filled world.
4. Event-driven —The behavior of an entity that acts when it recognizes an event. A person is event-driven when he or she reacts immediately upon finding out that something has happened, perhaps by seeing it or hearing about it. A person can be event-driven without receiving a tangible event object. When software is event-driven, however, it is event object –driven, meaning it has received news about an event in a discrete, intentional, electronic form. The notion of being “event-driven” is implemented in many different ways in computer systems (see Chapter 7). Something can be event driven without using EDA, just as something can be service oriented (see Chapter 9) without using serviceoriented architecture (SOA).
5. EDA —An architectural style in which one or more of the components in a software system are event-driven and minimally coupled. “Minimally coupled” means that the only relationship between the event producer component and the event consumer component is the one-way transfer of event objects.
A business application implements EDA if it complies with five principles:
![]() Reports current events —A notification reports a discrete occurrence as it happens.
Reports current events —A notification reports a discrete occurrence as it happens.
![]() Pushes notifications —Notifications are “pushed” by the event producer, not “pulled” by the event consumer. The producer decides when to send the notification because it knows about the event before the consumer does.
Pushes notifications —Notifications are “pushed” by the event producer, not “pulled” by the event consumer. The producer decides when to send the notification because it knows about the event before the consumer does.
![]() Responds immediately —The consumer does something in response immediately after it recognizes an event.
Responds immediately —The consumer does something in response immediately after it recognizes an event.
![]() Communicates one-way —Notification is a “fire-and-forget” type of communication. The producer emits the notification and goes on to do other work, or it may end processing and shut down. It does not get a reply from the consumer.
Communicates one-way —Notification is a “fire-and-forget” type of communication. The producer emits the notification and goes on to do other work, or it may end processing and shut down. It does not get a reply from the consumer.
![]() Is free of commands —A notification is a report, not a specific request or command. It does not prescribe the action the event consumer will perform.
Is free of commands —A notification is a report, not a specific request or command. It does not prescribe the action the event consumer will perform.
The first three of these principles describe what it means to be “event-driven.” The last two specify the meaning of “minimally coupled.” If an event producer tells the event consumer what action to perform, the consumer is event-driven but the application is not using EDA because the two parties had to explicitly agree on the function of the consumer. If an event consumer sends a reply back to the producer, it is eventdriven but not EDA because the producer is dependent on the consumer. Software engineers have used EDA for years, although they were more likely to call it “continuous processing,” “message-driven processing,” “data-driven,” or “document-driven.” An EDA system always adheres to these principles at a conceptual level but the implementation details are more complex, as we’ll explore in Chapter 6.
The next four sections of this chapter explore how the EDA principles are used to improve timeliness, agility, data consistency, and information dissemination in business scenarios. Following that, the latter half of the chapter describes CEP and explains how event-driven CEP enables situation awareness.
Timeliness
Business processes that need to be completed in a short amount of time are automated by continuous-processing, event-driven systems rather than batch-oriented, time-driven systems.
Consider the limitations of classical batch-based processes, such as the order-tocash process summarized in the upper diagram in Figure 3-2. The first step, order capture, is request-driven because a person can submit an order at any time and the interactions between the person and the application involve a sequence of requests and replies. The person engages in a conversation with the application to look up product information, enter and validate the order, correct any input errors, and receive confirmation that the order was submitted. The order-entry application could be either an internal application operated by a salesperson or an externally facing, webbased ordering system used directly by a customer. The application puts the orders in a database or file, where they accumulate throughout the day.
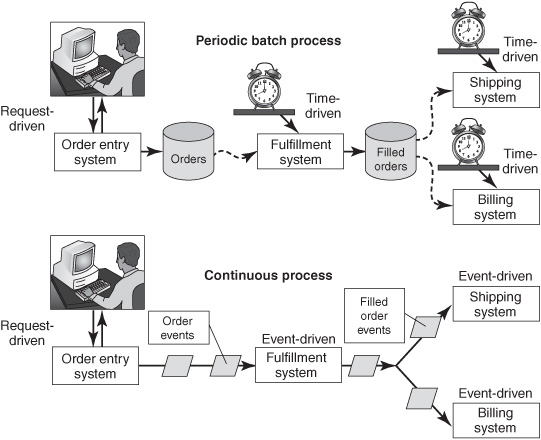
Figure 3-2: EDA reduces elapsed time of multistep processes.
Note: A time-driven system is inherently a batch system if more than one transaction has accumulated while waiting for the work to commence.
After the initial step, the remainder of the process is time-driven. At a designated time, typically once a day (at night), a batch of orders is sent to an order-fulfillment system in an operations department. The next day, the operations department picks items from shelves, packs them for shipment, and relays the goods and related data to the next functional areas, such as the billing and shipping departments, generally through other time-based batch file transfers. The IT applications that support this multistep process literally do event processing, because they’re processing event objects—each order is an event in a general sense—but the work is instigated on a time-driven schedule, not by the arrival of the event objects (orders).
The process can be accelerated by redesigning it as a continuous-processing system. The customer’s order is still captured through a request-driven, conversational interaction, but the order-capture application immediately sends a notification message to the next step in the process, the operations department (see lower diagram in Figure 3-2). The order-fulfillment, shipping, and billing systems run all day (and in many cases, around the clock), ready to respond as soon as each new item of work is received. In event processing terminology, the orderentry application is an event (object) producer and the order-fulfillment system in the operations department is a consumer of order events and a producer of filledorder events. A growing number of web-based and other sales systems operate continuously, so it is becoming common for orders to be dispatched within hours of receiving them.
Continuous-processing systems also have the benefit of distributing the work more evenly to eliminate bottlenecks, peaks, and troughs. Companies are having an increasingly difficult time squeezing growing batch workloads into the traditional overnight slow periods. “Batch windows” are shrinking because business hours are expanding and global operations often force some applications to remain online for more hours—sometimes 24 hours, 7 days a week.
Before the 1970s, even the first step, order capture, would typically have been done manually. Transactions were written on paper and typed into a data entry system as a separate step. Transaction data was made available to the first IT system in the process in an offline, time-driven, batch mode. Companies migrated most of the initial transaction-capture steps in business processes to request-driven online systems by the end of the 1980s, but most of the subsequent steps in processes remained batch-based, as shown in the top diagram in Figure 3-2. Since the 1990s, companies have been gradually reimplementing those subsequent steps in some multistep processes as continuous, event-driven systems, although a surprising amount of work is still done in batch. This is not necessarily a problem. Some batch systems are still perfectly sensible because the business would derive no benefit by accomplishing the work more quickly, and in a few circumstances, the business may actually gain by deferring the work.
Some companies have gone partway to continuous processing by running batch jobs more frequently. For example, they may process a small batch every hour rather than waiting for a whole day’s worth of work to accumulate. Depending on the business requirements, this may be fast enough to harvest most of the benefits of continuous-processing systems. Moreover, this sometimes allows the company to maintain its investment in legacy batch-based applications rather than redesigning them as continuous-processing systems. However, unforeseen side effects on other applications often crop up, so it’s not as easy as it sounds to run batch jobs more often. Ultimately, the notion of frequent batch jobs is appropriate and valuable in some circumstances where the absence of truly immediate processing doesn’t matter.
Note: As a rule of thumb, new systems should use continuous processing as the default choice. However, if you’re trying to retain batch programs that are otherwise sound, running frequent small batches may be a good alternative until the system needs to be replaced for other reasons.
The choice between continuous or batch processes has important implications outside of the IT department. This is a business architecture issue, not just an application architecture issue. The flow of raw materials and finished goods, job descriptions, customer interactions, policies and procedures, the organizational chart, and even product makeup and prices may be affected by the style of processing. However, further analysis of organizational and business architecture issues are outside of the scope of this book.
Note: Analysts should work with operations managers and other businesspeople to reengineer the business process before designing the IT systems to avoid “paving cow paths” (automating obsolete process models).
If fast process execution is a goal, analysts re-engineering the business should eliminate unnecessary steps, combine steps, perform steps in parallel, and accelerate activities within each step as the first phase of designing the new application systems. This is sometimes described as “taking the air out of business processes.” In most situations, it leverages EDA to achieve continuous processing. Chapter 10 has more discussion of the overlap between business process management and event processing.
Continuous processes can be a mix of human- and machine-based automated activities, or they can be fully automated from end-to-end as straight-through processes. The term straight-through processing (STP) originally came from the financial industry, where it is a key objective for payment systems and other applications. STP is also increasingly popular in most other industries, sometimes under the label of “flow-through provisioning” (in telecommunications), “paperless acquisition” (in the military), “lights-out processing” (in manufacturing), or “no touch” or “hands-free processing” (in insurance and other industries). STP reduces the duration of a process and eliminates the need to enter data manually. The most obvious benefit of STP is eliminating the delays that occur when people rather than computers perform the work. However, eliminating clerical error is usually more important. Wherever people re-enter data, some mistakes will be made. If errors are undetected, the wrong goods may be shipped, the wrong amount of goods may be shipped, or the customer may be overcharged or undercharged. Recovering from clerical errors can add substantial time and cost and reduce customer satisfaction.
However, many processes can’t be made entirely straight through because machines can’t handle exceptional situations or make certain kinds of complex decisions. Processes that require human participation can’t run as fast as STP processes, but they can still use EDA and be relatively continuous, therefore demonstrating shorter elapsed times than time-driven processes. The human steps in a continuous process can be event-driven by using workflow software to manage task lists and “push” new work items to people as soon as they appear.
Agility
It’s fairly obvious why EDA-based, continuous-processing systems demonstrate better timeliness than batch systems, but it is less obvious why EDA systems have advantages over request-driven systems. Request-driven applications operate in an immediate, message-at-a-time fashion, just like event-driven systems, so they often match the timeliness of EDA systems. However, EDA is minimally coupled, so it has an inherent advantage over request-driven interactions with respect to agility, as explained next.
In Chapter 2, you saw that an agent in a request-driven interaction is dependent on the response that is returned by a server. The agent can’t finish its task if the server is not running or if the network is down. The team that designs and builds the requesting software agent must know a lot about what the server is going to do and the team that builds the server must know a lot about the requesting agent. If the requester or server is modified in a way that affects the request or response messages, the other agent must also be changed. This logic coupling makes the overall system more brittle and difficult to modify.
By contrast, the contract in an EDA relationship is minimally coupled. Agents have fewer expectations regarding each other’s behavior and communicate in only one direction. An event producer emits the notification message in a “fire and forget” manner, and goes on to do other work or ends its work and shuts down. It does not get a reply or any other returning message from the event consumer. Fewer things can go wrong and it is easier to change or add one component without changing another.
Note: EDA systems are more agile than request-driven systems because they are minimally coupled. Developers can change one EDA component without having to change another component as long as the event notifications don’t change.
For example, a company might want to add a step to its order-fulfillment process to check the credit rating of the buyer before an order is filled. This activity could be added to the order-capture step using a request-driven design pattern (see top diagram in Figure 3-3), but this approach introduces unnecessary dependencies among the components. The order-entry application would be modified to invoke a credit-checking service, wait for a reply, and send an approved-order notification or a rejectedorder notification for further processing. Developers would have to modify the order-entry application, including recompiling, retesting, and redeploying the software to implement this new step.
Alternatively, the new function could be added to the business process using EDA without changing the initial order-entry application (see lower diagram in Figure 3-3). The order-entry system would capture the order in a request-driven conversational mode and emit the new order object as it did before credit checking was added. A new, event-driven credit-checking software service would be inserted into the business process after the order-entry step. It would consume the order event in place of the order-fulfillment system, verify the credit of the customer, and send an approved-order notification to the order-fulfillment system or a rejected-order notification to a component that handles problem cases. Adding the credit-checking step is non-disruptive because the order-entry and order-fulfillment applications don’t have to change. EDA makes this kind of “pluggability” possible because a notification message comes with “no strings attached.” The order-entry application doesn’t specify the action that a subsequent step would execute, so analysts and developers are free to change the business process with minimal effort.
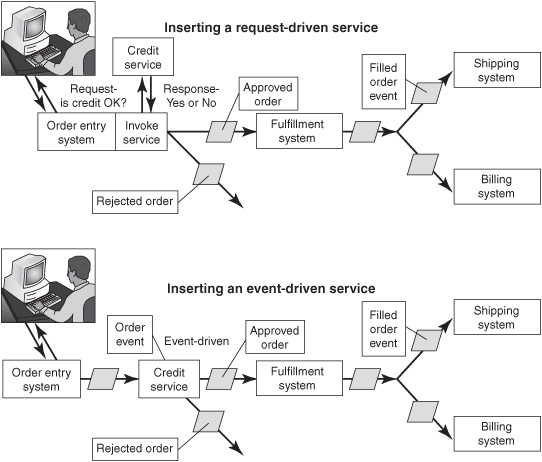
Figure 3-3: EDA facilitates process modifications and agility.
EDA systems are agile and can accommodate piecemeal, incremental changes more quickly and at lower cost than request-driven systems. So why aren’t all functions designed this way? Chapter 2 introduced the answer—EDA comes with inherent limitations that affect the behavior of the application in ways that are sometimes undesirable. Our example of an event-driven credit-checking step assumed that the business would implement an asynchronous “rejected order” step to handle orders that failed the credit verification test. A rejected-order notification triggers a person or software agent to inform the customer that their order has been rejected; or the customer might be asked for payment or payment guarantees to put the order back into the system. However, if the company wanted to handle credit problems synchronously as part of the initial order-entry conversation, the EDA approach would not have worked. The credit-checking step would have had to be implemented as a request-driven interaction with a software service (top diagram in Figure 3-3).
Note: One size does not fit all. When business requirements can be supported by either EDA or request-driven approaches, analysts and architects should use EDA to leverage its minimal coupling and superior agility. However, when a reply to the transaction originator is required, a request-driven approach should be used.
Request-driven interactions will remain more common than EDA relationships in business systems, although the trend is to use EDA more often than in the past.
Data Consistency
The case for EDA in data-consistency scenarios is compelling. For the same reasons that EDA improves the timeliness of multistep processes, it also improves the timeliness of data-consistency work compared to time-driven, batch approaches.
The most common method of synchronizing the contents of two or more databases is still to create a file containing updates in the application that has the most recent information and then transfer the file to other interested applications in a time-driven batch job. This is typically done using a combination of custom programs, an extracttransform-load (ETL) utility, File Transfer Protocol (FTP), or managed file-transfer utilities. Batch synchronization is simple, easy to develop, and slow. The downstream applications and their databases operate with obsolete data until the synchronization job runs. This is increasingly unacceptable in a connected world where customers and customer-facing service agents need to have current information to ensure customer satisfaction and avoid making errors.
If a customer places an order, requests a service call, changes her address, or makes a financial transaction, she expects the new information to be visible almost immediately through any system owned by the same company. An EDA approach to data consistency meets that requirement. For example, a company may have 11 or more application systems (A through K) that maintain copies of customer address data (see the left side of Figure 3-4). When application A captures an address-change event from a web page, it updates its local database and immediately publishes the event to a messaging infrastructure that delivers it to all applications that have registered an interest in receiving that type of data. The fire-and-forget nature of EDA is inherently suited for one-to-many communication mechanisms that deliver an event to multiple recipients. Every authorized customer and user in every business unit using systems A through K will have the most-current information within a few seconds.
In theory, it would also be possible to implement a near-real-time data-consistency solution using a request-driven approach, but it would be intolerably clumsy and impractical. Request-driven systems are almost always one-to-one—that is, a requester interacts with one server at a time. In this case, the original application A would have to invoke an address-change function in each of the other systems in succession (see the right side of Figure 3-4). Application A would send a request containing the new address to system B, which would update its customer database and return an acknowledgment. A then would call C with a similar request, and so forth. After ten request-driven interactions, systems B through K would have posted the change to their respective databases. However, if a communication problem occurs, or if any system isn’t running, A won’t get an expected response. Developers would have to implement complex logic in system A so that it can keep working if it doesn’t get a response back from one of the other systems that are supposed to do an update. Moreover, application A would have to be changed, recompiled, and redeployed to add another application, L, that needs the new data.
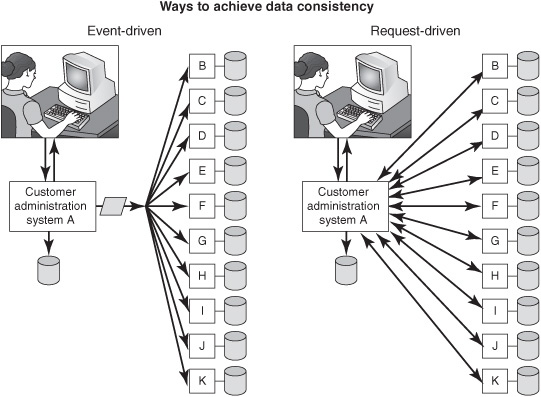
Figure 3-4: EDA supports immediate data synchronization.
This business problem cries out for EDA-style continuous processing and a fireand-forget communication pattern. Nothing in the business logic in application A really needs to get information back from any of the other systems. The only role of a reply is to confirm that the update was delivered, but application A should not be in the business of verifying delivery. That function should be delegated to an intermediary, such as a publish-and-subscribe middleware agent, that distributes the updates, retries the message if a consuming application is temporarily unavailable, or puts a report in a “dead letter” file for subsequent, asynchronous follow-up if the update can’t be conveyed successfully. The use of an intermediary insulates application A from changes in the other systems (we’ll explore how this is accomplished in more detail in Chapter 6).
Information Dissemination
EDA is the obvious choice of interaction pattern for mass-notification situations where the information must be conveyed quickly and the timing of the event cannot be predicted. The one-to-many, fire-and-forget nature of EDA makes it fast and efficient for this purpose. The point of mass e-mail distribution lists, “reverse 911” systems, Really Simple Syndication (RSS) feeds, and other kinds of alerting systems is to convey the data to many recipients as quickly as the communication channel will allow. Time-driven systems have too much latency and request-driven systems are too inflexible and inefficient for the majority of dissemination problems.
However, time- and request-driven patterns are appropriate in some dissemination scenarios. If the timing of the notification is not urgent, or if the timing of the event can be accurately predicted, then a time-driven notification would work fine. Timedriven notifications can be fire-and-forget and one-to-many because they are variations on event-driven interactions. A request-driven notification is appropriate when the number of recipients is low and the recipients change infrequently because it is then practical to build their identity and address into the sending agent. A requestdriven pattern is also appropriate when the sender needs some information in response to perform some subsequent task.
Complex Event Processing
Much of the growing interest in events is focused on the second aspect of event processing, CEP. CEP is a way of distilling the information value from a number of simple business events into a few more-useful, summary-level “complex” events. CEP helps companies make better and faster decisions in scenarios that range from simple decision support to robust situation awareness.
CEP isn’t new, but the way computer systems are used to implement CEP is new. For most of history, people did CEP in their heads, and even today computers are used in a minority of CEP calculations. However, some critical, high-value business processes depend on automated CEP, and it is spreading steadily out to other parts of the business world. In this section, we’ll present three ways to perform CEP: manual CEP (without computers), partially automated CEP (a blend of machine and human intelligence), and fully automated sense-and-respond enabled by CEP. All three approaches to event processing involve three phases: event capture, analysis, and response, but they are handled differently in each approach.
Manual CEP
Figure 3-5 shows how CEP works when people are at the center of the process.
1. Event capture —People find out about events by observing or interacting with the world. They talk to other people, receive phone calls, use IT systems, read thermometers and other sensor devices, get text messages, navigate the Web, subscribe to RSS feeds, watch television, listen to the radio, and read business reports, mail, newspapers, e-mail messages, and other documents.
2. Analysis —Each person analyzes the available event data and puts it into context. Part of what they do is “connect the dots”—that is, they make connections between simple events to develop big-picture insights (“complex events”) that represent emerging threats or opportunities. This is the heart of CEP.
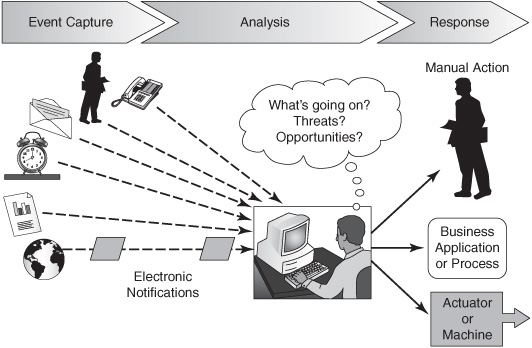
3. Response —The person initiates a response to threats and opportunities that have been identified in the analysis phase. They may undertake some action personally, send a message to another person or other people, kick off a transaction in an IT system, or start up a machine or other device.
Note: Although the label “complex” may initially seem off-putting, complex events actually simplify data by summarizing and abstracting what is happening.
For example, suppose the district sales manager at a power equipment distributor receives weekly sales reports from the 20 stores in his region. Think of each sales report as an event object that records the store identifier, date, and the quantity of snow blowers, chain saws, and other equipment sold. Every Thursday, the sales manager looks through the reports, calculates the total sales for the district for certain key items, and compares the results with historical data. In event-processing terms, the fact that “the district sold 193 snow blowers this week” is a complex event that reflects the collective significance of the base events, the 20 individual sales reports. No sales report was important by itself, but when analyzed together, they revealed a meaningful insight about what is happening on the district level. The sales manager enriches this complex event by comparing it to historical data to produce another, yet-more-complex event, “snow blower sales volume was 30 percent above average this week.” He combines this with another type of event data—the weather forecast for next week predicting more snow—to synthesize a further complex event that “this is an opportunity situation to sell more snow blowers.” This complex event is said to be an abstraction because it is several steps removed from the original input data, but it is now in a form that is directly usable for decision making or for communicating with his boss. The sales manager might respond by ordering a rush shipment of additional snow blowers.
Note: A complex event is an abstraction because it is one or more steps removed from a physical world event. However, it is more usable for decision-making purposes because it summarizes the collective significance of multiple events.
This example should sound familiar to anyone who makes operational decisions or who builds operational intelligence applications for use by others. We’ve described a routine decision-making scenario using event-processing terms as a way of demonstrating the commonsense nature of CEP. Strictly speaking, this actually involves CEP although no one would call it that. The application that generated the sales reports is an event (object) producer. The sales manager who synthesized the series of complex events (“the district sold 193 snow blowers,” “snow blower sales volume was 30 percent above average,” and “this is an opportunity situation to sell more snow blowers”) was performing a kind of manual CEP.
This style of “CEP” is unremarkable partly because it is time-driven (the reports and the sales manager’s analysis happen every Thursday) and partly because most of it is performed manually. Companies have been operating this way for decades. It’s reasonably effective as long as the volume of data is low, people are available to do the analysis, and decisions don’t have to be made very quickly. When the business requirements are more demanding, however, automated CEP becomes appropriate.
Partially Automated CEP
Most partially or fully automated CEP systems involve many more than 20 base event objects, and they come in much faster—every few seconds, or even a few milliseconds apart. Nevertheless, automated CEP follows the same three general phases as manual CEP (see Figure 3-6):
1. Event capture —An increasing amount of business event data is available in digital form through a company’s network or the Internet:
![]() Web-based RSS news feeds convey reports that used to come from newspapers, television, and radios.
Web-based RSS news feeds convey reports that used to come from newspapers, television, and radios.
![]() New types of market data are distributed from exchanges and clearinghouses.
New types of market data are distributed from exchanges and clearinghouses.
![]() More of a company’s internal functions are automated in application systems that can be tapped to provide near-real-time data about what is happening in sales, manufacturing, transportation, accounting, and other departments.
More of a company’s internal functions are automated in application systems that can be tapped to provide near-real-time data about what is happening in sales, manufacturing, transportation, accounting, and other departments.
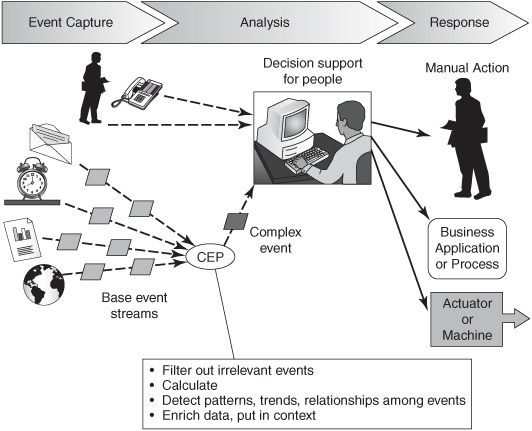
Figure 3-6: Partially automated CEP.
![]() Bar code and radio frequency identification (RFID) readers and Global Positioning System (GPS) devices pump out reports on the location of specific items.
Bar code and radio frequency identification (RFID) readers and Global Positioning System (GPS) devices pump out reports on the location of specific items.
![]() Web page scrapers can poll a competitor’s website every 10 minutes to see if the company’s prices have changed.
Web page scrapers can poll a competitor’s website every 10 minutes to see if the company’s prices have changed.
Some of this data wasn’t generated in the past. Other data was available to people but computers couldn’t read it. Now, however, more data is produced and most of it is electronic so it can be handled by automated CEP systems.
2. Analysis —CEP software can be used to handle some or all of the analysis phase. CEP software is any computer program that can generate, read, discard, or perform calculations on complex event objects. It can be packaged as a stand-alone CEP agent running on its own; it can be implemented as a section of code intertwined in a larger application program; or it can be built into a software framework or business event processing (BEP) platform that can be extended by a software developer to construct a complete application. CEP software is technically a type of rule engine. (See Chapter 10 for an explanation of how CEP relates to other kinds of rule engines.)
CEP software may do the following:
![]() Read through all the incoming base events and discard those that are irrelevant to the task at hand (called filtering, or screening, the data)
Read through all the incoming base events and discard those that are irrelevant to the task at hand (called filtering, or screening, the data)
![]() Calculate totals, averages, maximums, minimums, and other figures
Calculate totals, averages, maximums, minimums, and other figures
![]() Use predefined rules to look for patterns in the base events, such as trends, relative timing (the order in which events took place), or causal relationships (an event that led to another event)
Use predefined rules to look for patterns in the base events, such as trends, relative timing (the order in which events took place), or causal relationships (an event that led to another event)
![]() Enrich the event data by comparing it to historical data or adding data from other kinds of databases
Enrich the event data by comparing it to historical data or adding data from other kinds of databases
CEP computation produces one or more new complex events that summarize the significance of the available data. This is connecting the dots in a highperformance, sophisticated fashion (Chapter 7 explains this process in more detail). Most key performance indicators (KPIs) are actually complex events (but not all complex events are KPIs). Complex events may be reactive, summarizing past events, or predictive, identifying things that are likely to happen based on what has occurred recently compared to historical patterns.
3. Response —In the majority of cases, CEP software is used for decision support. It can’t do the whole job of analyzing the situation by itself, so it does some of the preliminary calculations and turns the complex events over to people who determine what to do next. The single most common way of delivering complex events is through a business dashboard in a web browser, although many other channels are also utilized depending on the circumstances. In a growing number of situations, CEP can trigger a response without human involvement (it is an STP model of operation). We’ll describe this further in the section “Fully Automated Sense-and-Respond.”
Event-Driven CEP
A traditional partly automated IT solution for the power equipment distributor (in the example presented in the “Manual CEP” section) would be time-driven and its computation limited in scope. It would be CEP but only in the broadest and weakest sense of the term. An application would generate sales reports from the 20 stores, calculate totals, and produce a summary report that says “the district sold 193 snow blowers this week.” A well-designed system would go further by comparing the results to historical data and highlighting the fact that “snow blower sales volume was 30 percent above average this week.” The sales manager would need to take the initiative to check the report, notice that the sales volume was out of the ordinary, and check the weather forecast.
This scenario becomes more novel and the solution more helpful if automated as event-driven CEP. The sales manager can specify that he wants to be proactively alerted whenever the sales of an item are outside of an expected range, such as more than 20 percent above or below the average. The software could be context aware in the sense that it could adjust its behavior according to the season—comparing results to a different weekly average depending on the time of the year or whether the season for that equipment was beginning or ending. A sophisticated system could base its decision to send an alert partly by parsing an RSS feed of weather information to see if the word “snow” appears in the forecast for the next five days. The resulting complex event, “this may be an opportunity situation to sell more snow blowers,” would be transmitted to the sales manager through a web-based business dashboard, e-mail message, SMS message, automated phone call, or some other notification channel.
In this event-driven CEP solution, the sales manager doesn’t have to remember to look at the weekly sales reports. The system notifies him only when there is something that needs attention, which frees him up to focus on other things (it’s using “management by exception”). The CEP software helps him get to a faster or better understanding of whether a threat or opportunity exists by offloading the mechanical aspects of event computation. This scenario would probably not be designed using STP. The manager probably wants to remain in the loop and, in many cases, will want to drill down into the underlying data to understand why the alert was sent before he places the order for more snow blowers.
Event-driven CEP would be marginally useful in the power equipment distributor scenario, but timeliness is of limited value because orders for additional goods are only placed weekly and at a predictable time (Thursdays). It’s more useful in scenarios that need continuous intelligence.
Note: Event-driven CEP is most important in business situations with a lot of event data and short decision cycles.
For example, customer contact centers generate records throughout the day for all customer interactions, including the wait time for phone calls, number of times the call is transferred, dropped calls, call duration, whether the issue was resolved in the first contact, and the service agent’s name or identifier. These operational metrics are generally reported on a time-driven basis through hourly or daily reports. This supports service-level reporting, issue identification, root-cause analysis, and problem resolution of systemic weaknesses.
Increasingly, however, contact centers are moving to an event-driven, continuousintelligence view of operations. This enables immediate detection and correction of problems as they appear rather than after the fact. For example, an agent dealing with a customer who has been transferred several times or has been on hold for more than 5 minutes can be prompted (and allowed) to give additional compensation for the negative experience. The contact center software may also generate “screen pops” to prompt agents to ask customer-specific questions to drive up-selling or cross-selling. If feedback indicates that an agent was irate, a supervisor may be alerted to give the agent an early break to recover. These immediate interventions require the use of event-driven design patterns for low latency and CEP intelligence to connect the dots. Commercial software that supports these capabilities for a contact center is available today and in use in a growing number of companies. The products are categorized as customer relationship management (CRM) analytic suites.
Note: Event-driven CEP provides continuous intelligence. Problems can be detected and opportunities can be pursued as they appear.
Fully Automated Sense-and-Respond
Some event processing scenarios can be fully automated because both the event analysis and the response to the situation can be done without direct human involvement. This involves the same three general phases found in manual and partially automated CEP.
1. Event capture —All of the input event data must be available in electronic form if the process is to be fully automated (see Figure 3-7). If any of the data requires human interpretation, the process must be done manually or with a partially automated approach.
2. Analysis —If the analysis phase is to be fully automated, the event processing logic and business rules must be expressed in explicit algorithms that CEP software is capable of executing. This works only if the factors that go into the decision are well understood and business decision makers, business analysts, and software engineers have worked together to articulate the processing rules. Chapter 7 explains how people specify event processing logic to CEP software in more detail.
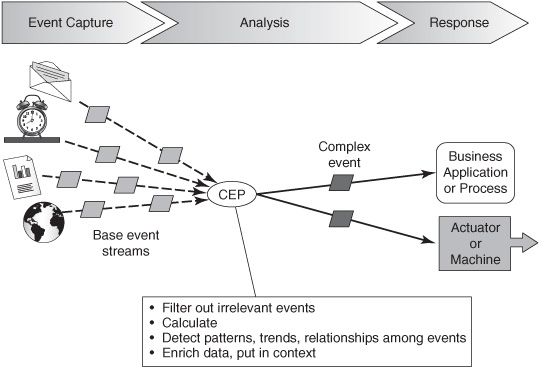
Figure 3-7: Fully automated CEP system.
3. Response —After the CEP software determines the appropriate response to a situation, it kicks off a transaction or SOA service in an IT system, initiates a business process through a software orchestration engine, or sends a signal to an actuator to start a machine, lock a door, increase the heat, or perform some other action.
Full automation of both the analysis and response phases is especially important in scenarios that call for an ultra-low-latency response. For example, sophisticated, event-driven CEP systems are widely used in capital markets trading operations. Algorithmic trading systems can calculate and issue buy and sell orders for stocks or foreign currency in less than 5 milliseconds without human involvement. A person cannot think that fast or even type one character on a keyboard in 5 milliseconds, so people must be left out of the process. Systems for smart order routing, market surveillance, fraud detection, anti–money laundering, and various kinds of risk management also use event-driven CEP-based technology. Some aspects of businesses have become similar to an “arms race,” in which small differences in response time can lead to major financial gains or losses. Much of what is known about ultra-low-latency CEP came from research done for real arms races where CEP is used to control weapons and defense systems.
Benefits of Automated CEP over Manual CEP
Partially or fully automated event-driven CEP improves a company’s situation awareness and its ability to behave in an intelligent sense-and-respond manner. As the examples in this chapter have demonstrated, automated CEP offers four key benefits:
![]() Improved quality of decisions —Computers extract the information value from dozens, thousands, or millions of base events (as long as the events are simple). By contrast, a person can assimilate only a few events per second and thus cannot consider nearly as many factors when making a decision. Moreover, computers don’t succumb to boredom, so they make fewer mistakes in simple computations. Computer calculations are consistent and repeatable because they always implement the same algorithms the same way, as defined by knowledge workers, analysts, and software developers.
Improved quality of decisions —Computers extract the information value from dozens, thousands, or millions of base events (as long as the events are simple). By contrast, a person can assimilate only a few events per second and thus cannot consider nearly as many factors when making a decision. Moreover, computers don’t succumb to boredom, so they make fewer mistakes in simple computations. Computer calculations are consistent and repeatable because they always implement the same algorithms the same way, as defined by knowledge workers, analysts, and software developers.
![]() Faster response —Partially automated decision-support CEP systems save time because people don’t have to perform manual calculations. Fully automated CEP systems are even faster because they don’t have to wait for people to digest and respond to the information.
Faster response —Partially automated decision-support CEP systems save time because people don’t have to perform manual calculations. Fully automated CEP systems are even faster because they don’t have to wait for people to digest and respond to the information.
![]() Preventing data overload —CEP systems reduce the volume of unwanted, unnecessary data (“information glut”) presented to people. In some cases, a CEP system may run for hours or days, turning millions of base events into thousands of complex events before detecting a complex event that must be brought to the attention of a person. CEP systems are often used to implement management-by-exception strategies. People are disturbed less often, so they can reserve their attention for the few situations in which their involvement is important.
Preventing data overload —CEP systems reduce the volume of unwanted, unnecessary data (“information glut”) presented to people. In some cases, a CEP system may run for hours or days, turning millions of base events into thousands of complex events before detecting a complex event that must be brought to the attention of a person. CEP systems are often used to implement management-by-exception strategies. People are disturbed less often, so they can reserve their attention for the few situations in which their involvement is important.
![]() Reduced cost —CEP systems offload the drudgery of repetitive calculations and pattern detection comparisons from people to computers. This reduces the amount of human labor needed to analyze the data. For example, the spread of algorithmic-based program trading in capital markets has reduced the number of human traders operating on certain categories of investments.
Reduced cost —CEP systems offload the drudgery of repetitive calculations and pattern detection comparisons from people to computers. This reduces the amount of human labor needed to analyze the data. For example, the spread of algorithmic-based program trading in capital markets has reduced the number of human traders operating on certain categories of investments.
The amount of decision making that should be offloaded to CEP systems varies depending on the business problem. Managers and knowledge workers can delegate as little or as much as they want to the software.
CEP in Perspective
Most of the discussion of event processing in the remainder of this book—and in the industry in general—refers to event-driven CEP because it’s new and different. Traditional management reports and business intelligence (BI) have always done timeand request-driven CEP (although it wasn’t called CEP), both of which are discussed a bit later in this section. They are retrospective, presenting information after the fact, or passive, requiring the recipient to initiate the activity. Technology has recently made event-driven CEP, and thus continuous intelligence, attainable in many areas where it was previously impractical. However, it’s only appropriate in business situations that have particular characteristics.
Event-Driven CEP
Automated and partially automated event-driven CEP systems are applied in diverse ways. They help monitor, manage, and enrich continuous operations, such as supply chains, transportation operations, factory floors, casinos, hospital emergency rooms, web-based gaming systems, and the customer contact center in this chapter’s example. Many of the most sophisticated, high-volume CEP applications are found in capital markets trading operations. Other companies may have their first experience with event-driven CEP when they implement a business activity monitoring (BAM) dashboard that they acquire with a business process management suite (BPMS) (see Chapter 10 for more details).
Most of the examples in this book can be categorized as business event processing (BEP) applications because they deal with business events rather than personal, political, scientific, sports-related, weather, or other events. Event-driven CEP was used in military, scientific, and system and network management applications before its use became common in business applications. However, the term CEP was not widely recognized until the publication of David Luckham’s book The Power of Events in 2002. BEP is now the fastest-growing type of event processing because more companies are starting to recognize its commercial advantages. Some people use the term BEP to mean applications that don’t require low latency—computation in a second or two may be fast enough. Others use the term to refer to applications in which a business person has input the event processing rules directly into the system without involving an IT expert. However, we use the term to mean any CEP in a business context.
Event-driven CEP is sometimes called event-stream processing (ESP). An event stream is technically a sequence of event objects arranged in some order, usually the order of arrival. Some people use the term ESP to connote applications that involve only one or a few event streams, each of which has a high volume of events (thousands or hundreds of thousands of notifications per second) and the events must be processed very quickly (for example, in a few milliseconds each). Other experts use the term to mean CEP systems that can’t readily deal with events that arrive out of order. In view of the ambiguity of the term, it is best to get a detailed description of the usage scenario or software product before drawing any conclusions about anything that is described as ESP. All software that can perform event-driven CEP can handle event streams as input.
One way to describe event-driven CEP is that the query (the search for a particular subset or pattern in the data) is more or less permanent, and the data is ephemeral, continuously arriving and then disappearing as it becomes out of date. This contrasts with traditional database applications, in which the data is more or less permanently stored, and the query is ephemeral (it is instigated in a request-driven manner).
Time-Driven CEP
Time-driven CEP applications do the same kinds of computation as event-driven CEP applications: they filter events, calculate totals and other figures, enrich the data using other data sources, and detect patterns. However, they deal with event objects “at rest” in a file or database table, rather than event objects “in motion” in the form of arriving messages. Time-driven CEP is used when the business situation does not require an immediate response or when processing has to wait for event data to accumulate. For example, an update to a dashboard could be generated every 15 minutes, or a batch report could be prepared every night at 8:00 P.M. Offline, batch-oriented CEP is ubiquitous in many traditional applications where the term CEP is unknown and unnecessary.
The sophisticated, modern tools used for event-driven CEP (or “ESP”) are sometimes used in an offline mode by replaying a log of an event stream from the previous day or some other time frame. These applications are time-driven although they are pseudo-event-driven in their structure. Examples of this are found in market-surveillance, fraud-detection, and regulatory applications, such as payment card industry (PCI) compliance.
Request-Driven CEP
As with time-driven CEP, request-driven CEP deals with the event data at rest in memory, a file, or a database. A person can issue an ad hoc query using a BI tool or some other interactive application, or an application can make a programmatic request for data. The time of the processing is determined by the person or application making the request, unrelated to when the event notifications arrived. This is a useful type of CEP, although it is not EDA. Most traditional analytical BI applications deal with event data and thus conform to a literal definition of “request-driven CEP,” but there’s no clear benefit to applying event-processing terminology to traditional BI. (See Chapter 10 for more discussion on the overlap of CEP and BI.)
Summary
When people say “event processing” in an IT context, they mean event-object processing. The contemporary discipline of event processing is based on two big ideas. The first is EDA—sensing and responding to individual events as soon as possible. The second is CEP—developing insight into what is happening by combining multiple individual data points (event objects) into higher-level complex events that summarize and abstract the collective significance of the input data. EDA and CEP are important, useful, and well worth pursuing in their own right, but they’re nothing new when considered apart. Used together as event-driven CEP, however, they enable new kinds of responsive and intelligent business processes that were impractical until recently. In the next chapter, we’ll take a closer look at the costs and benefits of applying event processing to business problems.