
Soft Biometric Attributes in the Wild: Case Study on Gender Classification
Modesto Castrillón-Santana; Javier Lorenzo-Navarro SIANI, Universidad de Las Palmas de Gran Canaria, Las Palmas de Gran Canaria, Spain
Abstract
Soft biometrics has become an active field of research, as it provides useful attributes to assist in recognition systems. Its fusion with strong traits may serve to achieve reasonable recognition rates in less cooperative scenarios. These attributes can also be used to speed up database searches, or to describe an anonymous subject within a demographic group. Agreeing with recent research trends on the need to evaluate biometric systems using “in the wild” datasets, the current state-of-the-art in the emerging field of soft biometrics is presented, together with proposals and results on the particular problem of gender classification “in the wild”.
Keywords
Soft biometrics; In the wild; Gender classification
7.1 Introduction
A biometric trait may be defined as any living physical or behavioral characteristic that can be measured rather than being something possessed, memorized, attached, or injected. Biometrics is the science devoted to automatically recognizing humans based on common traits. Typical human biometric traits are fingerprints, face, iris, gait, DNA, etc.
This field is not necessarily restricted to humans, as similar traits may be present in other creatures. This fact is shown by emerging interest in animal biometrics [71,78], in particular, with applications for identification to aid conservation. For animals, the most frequently used traits are nose prints, DNA, and Retinal Vascular Pattern (RVP), or tail fluke in whales.
This chapter focuses on soft biometric attributes in the wild for humans. We, as humans, are required to prove our identity in our daily lives. Biometric traits used to identify people are assumed to be strong, as they are characteristics that present distinctiveness and permanence to differentiate clearly any two individuals. There is, however, additional or ancillary information that may be extracted from the same biometric traits, as for example, gender, race, mood, kinship, and apparent age from a face [68]. This extra information is not unique, comprising discrete attributes that serve to describe people in pre-defined and meaningful, non-overlapping categories or groups, i.e., to anonymously determine the broad characteristics of an individual [38,39,92,135]. Some attributes or descriptors may lack sufficient distinctiveness to distinguish between two individuals, but are valid for other purposes by providing several qualitative and personal descriptions of an individual [38,68]. These attributes are known as soft biometrics after Jain et al. [67], but have also been known as light biometrics [3] or semantics [107].
Among these semantic attributes, we can mention: gender, age, height, weight, ethnicity, body geometry, skin color, eye color, or hair color and length [135], and others that not every person necessarily has, such as the presence of scars, marks, or tattoos [59].
Different taxonomies have been proposed for soft biometric attributes in the recent literature. Klare and Jain focused exclusively on attributes extracted from the facial pattern [75]. Initially, Dantcheva et al. [39] distinguished facial, body, and accessory descriptors. In a more recent and deeper analysis, those authors have extended the attribute collection emphasizing ease of extraction, and low requirement of subject cooperation [38]. Their updated taxonomy considers four groups of attributes: demographic, anthropometric, medical, material, and behavioral.
Contrary to classical traits, soft biometric attributes present low variance across subjects, offering robustness when faced with low quality and resolution images [38,108]. This is illustrated in Fig. 7.1 presenting different captures in which the facial region to obtain individuals' strong identity information is often not available for various reasons, such as occlusion or distance. However, some soft biometric descriptors such as gender, hair length and color, and clothes color are easily extracted by humans in a natural way. They are useful to distinguish one individual from others [96], and may be obtained from low quality imagery [108]. Most attributes based on appearance are estimated using vision, but alternatives may be designed to obtain at least some of them differently, as an example, we mention a sensing seat to obtain body characteristics [65].

As mentioned above, soft biometric descriptors are not distinctive by themselves, but in the literature their utility has been demonstrated in applications for different purposes such as for [38,39,68,108]: (i) soft biometric multimodal fusion for recognition, (ii) improving the performance obtained from (strong) biometric traits, (iii) searching for space reduction or indexation, and (iv) for demographic and user profiling. Below, each application is briefly described.
Multimodal fusion for recognition. The first mention of soft biometrics was by Jain et al. [67] who suggested that these attributes provide valid information to recognize individuals. Their lack of distinctiveness is certainly not homogeneous; some labels such as gender, ethnicity, and skin color are described as global by some authors [108]. Others have a higher discriminative power like leg thickness. However, this lack of distinctiveness may be overcome by considering multiple soft biometric descriptors that together can define a signature that is robust and more distinctive (and more computational demanding) [108]. Certainly, multimodal strong biometrics is well known as a standard boosting approach [105]. However, focusing strictly on soft biometrics, multimodality was adopted by Alphonse Bertillon in the 19th century to register criminals based on biometric, morphological, and anthropometric measurements. Bertillon created a procedure, Bertillonage, to categorize individuals, with the advantage of generally speeding up the search process [39,96,104]. Most of the characteristics used by Bertillonage are nowadays considered soft biometric labels. Currently, the fusion of multiple soft biometric facial attributes, with the possibility of missing ones, is being used for identification, exploiting visual attributes and a bag of soft biometrics [39,73,96], as well as extending the fusion to body soft biometrics [1]. The multimodal soft biometric approach provides a solution in less constrained scenarios where strong biometrics is not available in a non-intrusive way.
Improved classical biometric performance. Considering that soft biometric fusion allows identification, it may be expected that its fusion with one or more available strong biometric traits will be relevant under highly variable conditions. As mentioned above, the first application of soft biometrics, following Bertillonage, for recognition was by Jain et al. [67]. These authors studied, for the first time, the fusion of classical biometric traits with soft biometric descriptors. In fact, they combined gender, ethnicity and height, with fingerprint recognition, improving recognition accuracy by around 6%. Soft biometric descriptors aid recognition rather than being used for identification, serving to discriminate between groups rather than individuals [67]. Along these lines, it is indeed known that FBI makes use of some offline demographic information to check fingerprint recognition [96]. Similarly, social context information has shown to add useful information to improve face identification [11].
Results achieved with face verification and recognition have recently confirmed [74,117,135] that soft biometrics provides useful additional discriminatory information [4]. In particular, soft biometrics can improve or compensate for the performance of low quality captures of classical strong traits, as they can be applied to more realistic scenarios such as “at a distance” or “on the move” situations. In these scenarios, likely face images are usually captured with low resolution and poor quality [125,127].
Search space indexation. The Bertillonage system categorizes individuals, thus speeding up the search process. This feature may be adopted not only to reduce search time in large biometric databases [133], but also in image retrieval from surveillance video footage or multimedia content databases; all these tasks are time consuming. Therefore, the aim of using soft biometric descriptors is to leverage the human operator by constraining the search to people within a specific group [38,86,96], speeding up the overall process, and thus reducing the processing costs. It should be noted that soft biometric attributes have a semantic meaning for humans to describe anonymous people [6], such as in a typical re-identification scenario, where unregistered people have been captured by non-overlapping camera networks. The re-identification problem refers to determining whether a target person has been observed by any other camera of the system at any moment [19]. It is also worth mentioning the existence of uncommon or unusual features, which are useful for a limited set of users [94,130], as shown in [69,101] with features such as scars, moles, freckles, acne, and wrinkles.
Demographic user profiling. Demographic profiling is used in marketing and broadcasting to describe a market segment in terms of age range, social class, and gender (or even urban tribe [77]). Customer profiling, for example, requires knowing as exactly as possible the number and demographic attributes of people entering/leaving a shopping area. Currently, an important aspect is automatic audience analytics using existing solutions, such as Quividi1 and TruMedia,2 for applications related to market analysis or public security.
In fact, there is the potential for a wide range of applications for marketing purposes. Individual demographic profiles may be used for offline customer analytics but also online ones, where demographic patterns serve to adapt or even restrict (drink vending machines that detect age) the offer to the user. In this sense, available digital signages may update their content in real time to the audience, catching their attention more effectively [33]. The concept of a consumer profile involves the creation of a mavatar (marketing avatar) [62]. Thus, advertising can be designed to target consumers belonging to a group, or even to make personalized offers, like, for example, FaceDeals.3
There is an emerging field of proposals to identify with sufficient accuracy who makes the purchasing decision in a group based on demographic characteristics and the size of the buying group [111]. This involves recognizing kinship [80,81,131] or family members in a group [37], and there are even commercial solutions to provide marketers with the emotional reaction of customers (Kairos,4 emotient,5 or affectiva6), or even the emotional state in a social relation between two or more people [136].
The rest of the chapter is divided into three sections. In the second section, we argue for the need for in the wild scenarios to evaluate biometric proposals in situations closer to real world applications. The third section focuses specifically on the gender classification problem, presenting some selected datasets and an overview of recent proposals and results. The chapter ends summarizing the main conclusions.
7.2 Biometrics in the Wild
So far, computer vision solutions have reported relevant results in several challenging problems. Focusing on biometric systems, recent proposals have been able to solve different tasks with high precision. However, their adaptation to real scenarios is still far from achieving similar performances, which is probably partially due to the limitations and bias present in the datasets used for experimental evaluations [124]. Considering vision based biometrics, in most cases these datasets have been collected under laboratory conditions making use of a single sensor, using similar image resolutions and illumination conditions.
However, real world applications must cope with capture variations that are far different from controlled laboratory conditions. Different internal and external factors hamper progress to solutions to a chosen biometric task. Internal complications can be illustrated by considering, for example, the facial trait, which is of great relevance for soft biometrics. Face muscles allow great plasticity; the use of facial make-up may also significantly affect the facial appearance, all of which lead to modifications to the viewed area. All of these are parameters that will present challenging changes to be dealt with by any automatic system. In addition, external factors comprise variability in terms of illumination conditions, background, distance, and capturing device [92].
Biometric recognition in unconstrained settings (outdoors, at a distance, without cooperation), commonly referred as “in the wild”, imposes restrictions on the acquisition procedure. Thus, this fact increases the domain where biometrics can be used, representing a far more demanding task, as there is a decrease in discriminability of the information obtained. In this sense, people analysis in real scenarios presents a wider collection of challenging situations to cope with due to highly variable lighting conditions, occlusions, weather, pose, expression, illumination, background, and resolution, which severely affect the intra-class variations. As an example, lower quality captures among other alterations degrades computer vision solutions' performance during biometric processing [5,54,57].
These observations added to the current large deployment of cameras is increasing the amount of available data captured by millions of sensors of a wide range of characteristics. This can provide information that may be analyzed to extract useful and valuable data, justifying the interest in tackling real world scenarios with biometric systems. For this purpose, it is necessary to build benchmarks that allow the unbiased evaluation of research proposals. These datasets must therefore contain wider and more challenging imagery closer to real situations as a test-bed for the development of new robust biometric solutions.
To sum up, there is an increasing interest in building datasets that reduce experimental bias [124], including ones with larger variability to better evaluate current solutions in situations closer to real world scenarios. This can be illustrated by the facial recognition problem. This is a field that has progressed far beyond still image recognition in controlled imaging environments. Face recognition “in the wild” must tackle face appearance that is evidently affected by internal and external factors such as age, pose, illumination, and expression (A-PIE) [44], and by artificial modifications due to plastic surgery [91], or hormonal treatments [90]. All these modifications may affect biometric recognition. Some efforts have already been made as, for example, the gathering of the Labeled Faces in the Wild (LFW) dataset [64]. This dataset contains face photographs designed for studying the problem of unconstrained face recognition. It is currently used as the reference benchmark for face recognition systems.
State-of-the-art face recognition with LFW is currently reporting accuracy of 99.5% [84]. Does this mean that face recognition “in the wild” has now been solved? The answer is no [76], suggesting the limitations of this particular dataset, that though showing a step forward, still seems to be far from truly wild conditions. The dataset lacks these full wild conditions, e.g., it includes high-quality images, avoids severe occlusions [44], all of which benefit recognition. In the best cases, wild or non-ideal conditions have been taken into account when building a dataset by diving into Internet photo albums, with the advantage of avoiding illumination, pose, sensor, and partially good resolution limitations. However, these images have been artificially selected to be contained in an album. Therefore, their processing results will certainly be affected by imagery that results in some quality and conditions being introduced by human filtering. This circumstance produces an undesirable effect when some solutions are over-fitted to restricted conditions, and therefore cannot be generalized to other unrestricted scenarios. However, data availability in wilder conditions is increasing, in line with community interest, although substantial effort in expensive annotation is needed. Below, is a list of some, though not all, of the initiatives that have been recently proposed for in the wild challenges and for different biometric related problems:
• Labeled Faces in the Wild (LFW) [64],
• Emotion Recognition in the Wild Challenge (EmotiW) [42],
• Acted Facial Expression in the Wild (AFEW)/Static Facial Expression in the Wild (SFEW) [113],
• Kinship Face in the Wild (KinFaceW) [80],
• International Workshop on Biometrics in the Wild 2015 [8],
• 300 Faces in the Wild [123],
• Quis–Campi [98,119], biometrics in a surveillance scenario.
In the next section, we will specifically focus on one of the global soft biometric attributes that have received the widest attention by the community – gender.
7.3 Gender Classification in the Wild
This section aims to provide an overview of the most relevant solutions related to gender classification (GC) in the wild. It provides a comprehensive starting point for those who are considering approaching this research field.
According to Bruce and Young [15], gender is one of the first attributes extracted from the face by human facial analysis. Indeed, it is obtained before face recognition. In computer vision, gender is probably the soft biometric attribute that has received the most attention. It is of great interest for different applications as well as for the recognition purposes mentioned above, since it is an important variable for social interactions, and commonly studied by marketers.
The GC problem is a bi-class task, which is performed effortlessly with high precision by humans. First attempts on GC using biometrics were based on geometrical features [13,45], but the current standard appearance-based approach was adopted by SexNet in the early 1990s [55].
Nowadays, GC is an active field of research. It should be noted that in 2015, the National Institute of Standards and Technology (NIST) edited for the first time a Face Recognition Vendor Tests (FRVT) report devoted to the problem [97]. This is the result of the recent attention received by the field and is reflected in different surveys [18,93,112], and recent proposals.
According to Dantcheva et al. [38], automated GC has been accomplished by making use of different biometric traits: face, iris, fingerprint, body, hand and speech. Among them, the most useful traits from a distance are face and body. As mentioned, most state-of-the-art GC solutions are based on the facial pattern in the visible spectrum, as suggested by recent surveys and leading proposals [6,7,9,23,35,66,93,97,99,129], but there is increasing interest beyond static 2D visible spectrum face-images to consider 3D data, as well as thermal and near-infrared face images [24,92].
In the standard GC approach, after detecting the biometric trait, the face in most cases, gender information is obtained in two stages: feature extraction and then classification [38,112]. The former extracts features from the biometric trait, the latter assigns the extracted features to one of two classes: male or female. However, many proposals also include, after trait detection, a normalization step. To illustrate this approach, let us consider the face as the input trait. Following face detection, some techniques extract features directly from the detection container, whereas others perform a light 2D normalization that fixes some main facial elements, such as the eye location, comprising 2D translation, scale, and rotation. Another more sophisticated and expensive 3D normalization, also referred to as frontalization, may involve 3D rotations, and is generally based on multi-fiducial points creating an Active Appearance Model (AAM) or similar.
Some authors have pointed out that observing only face patterns may lead to both restrictions of application, as an almost frontal face is needed, and perception errors or illusions [110]. Non-facial cues seem to be particularly important in real scenarios where degraded, low resolution, occluded or noisy images are present [120] rather than in a typical experimental setup with large, high quality facial images [70,120].
Indeed, the integration of non-facial features is consistent with the human perception that is able to perform GC, making use of just non-facial cues or hybrid approaches [16,17,20,70,126]. Among non-facial areas, we may mention external facial features [12,23,73,85,114], the individual clothing [21,47,82], the body [12,20,32,58,121], or a combination of these with other cues [63].
Of great interest in surveillance scenarios are methods based on the full body. However, even including wild conditions, the reduced size datasets used so far makes them very limited compared to facial-based ones. There is also the additional problem of frequently requiring the whole body view, a circumstance that is not always present. Despite these setbacks, body-based approaches are summarized in the next paragraphs.
Full body frontal and back views are used by Cao et al. [20]. The authors designed a part-based approach evaluated sing a subset of the MIT pedestrian dataset (888 images), achieving slightly better results for frontal images, around 76% accuracy. The reduced dataset dimensions indicate the difficulties in building a large series of benchmarks. The results are therefore not easily generalized. Back facing video sequences have been studied by Tan et al. [128] who designed a pyramid segmentation approach to process the sequence, achieving an accuracy of over 92% in a dataset containing 720 videos of 60 individuals.
The recent availability of low cost RGBD sensors provides the possibility of performing the task with 3D data. Linder et al. [87], instead of considering frontal body views, made use of RGBD data including side and back views as well. They built a dataset with 118 individuals using 3D point cloud data to achieve better accuracy, close to 90%, higher than appearance-based alternatives.
In the following subsections, we will give more details on face-based GC, first introducing the most used in the wild facial datasets for GC, and then summarizing other interesting proposals and results.
7.3.1 Datasets
GC in restricted datasets, i.e., those that have been collected under well-constrained environments, has reported very high classification rates that unfortunately have not been generalized to other independent datasets. This conclusion is evidenced by the GC results achieved by the Face Recognition Technology (FERET) dataset [102], a database containing 2413 high-resolution images of 856 individuals, see Fig. 7.2. Even though FERET was created to evaluate facial recognition, it has also been used to evaluate facial GC, as suggested by the Mäkinen et al. survey [93].

Although several tests have achieved almost perfect performance for FERET, the resulting classifiers are not able to maintain a similar performance in unrestricted image collections, evidencing that the dataset bias advantage produces an optimistic GC performance [9]. In fact, different authors have suggested that correct classification rates of such classifiers trained with FERET drop substantially when tested with wild datasets, see, for example, Erdogmus et al. [43] who showed that after almost perfect GC on FERET, only 65.2% was achieved on LFW.
In this sense, recent GC work has shifted towards more challenging and unconstrained viewing conditions, following a similar development in facial recognition research, suggesting the community interest in evaluating GC in the wild, i.e., uncontrolled conditions related to capture (illuminations, sensor, etc.), and subject. This situation has also been remarked in the FRVT report, where large in-the-wild datasets mean greater variability in terms of (i) identity, age, and ethnicity, (ii) pose and illumination conditions, and (iii) image resolution.
In addition to the LFW and GROUPS in the wild datasets considered in the FRVT report, we will also briefly describe PubFig and Adience, and later mention other datasets referred to in the literature:
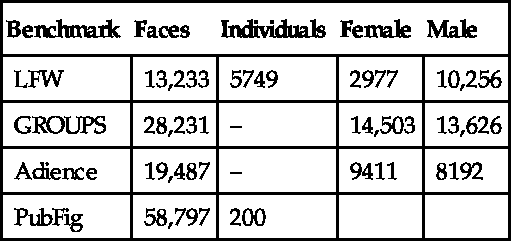
• Labeled Faces in the Wild (LFW) [64]. As mentioned above, this dataset was created collecting photographs to study the problem of unconstrained face recognition, which nowadays is the standard benchmark for this purpose [84]. The dataset contains more than 13,000 images of 5749 individuals collected from the web. Among them, 1680 have two or more photos in the dataset. Related to GC, we can mention some characteristics: (i) it contains several samples per individual, (ii) both classes are not balanced, and (iii) the inclusion of public figures introduces a selection bias [124]. As argued by Baluja and Rowley [14], GC results are biased when the same individual is present in both the training and test sets.
• Public Figures Face Database (PubFig) [72]. The dataset contains 58,797 images of 200 individuals taken in completely uncontrolled situations with non-cooperative subjects, presenting large variation in pose, lighting, expression, scene, camera, imaging conditions and parameters, etc. However, we are unaware of any previous work which used this set for GC, probably due to the low number of different identities.
• The Images of Groups (GROUPS) [51]. This dataset was created to study social interaction with images present in Flickr with more than one individual. The complete dataset contains 5080 images with 28,231 annotated faces in terms of gender and age group. According to the FRVT report [97], this database is currently the hardest for GC.
• Adience [41]. The authors claim to have included a far wider range of challenging real-world imaging conditions, compared to other datasets such as LFW or PubFig. The dataset comprises changes in appearance, noise, pose, lighting and more, without careful preparation or posing. Once again the sources are Flickr albums. The dataset includes 26,580 samples belonging to 2284 individuals.
The various dataset statistics are summarized in Table 7.1, and some dataset images are shown in Fig. 7.3, excluding PubFig, that, as far as we know, has no GC results reported.
Table 7.1
In the wild datasets statistics
| Benchmark | Faces | Individuals | Female | Male |
| LFW | 13,233 | 5749 | 2977 | 10,256 |
| GROUPS | 28,231 | – | 14,503 | 13,626 |
| Adience | 19,487 | – | 9411 | 8192 |
| PubFig | 58,797 | 200 |

As well as to the 2015 NIST report, the recent survey by Santarcangelo et al. [112] included the following alternatives in their list of unconstrained datasets for GC: ClothesDB [50], Genki-4K [53], and KinFace [122]. The limited number of samples contained in them, 931, 3000 and 600, respectively, compared to GROUPS, LFW, and Adience, led us to exclude them in the proposals summarized below.
We would also like to mention the dataset created by Satta et al. [114] to evaluate GC in children. Their aim was to tackle the difficulties, even for humans, to classify gender among children due to their lack of many gender-specific adult face traits. They have collected a dataset making use of standard face detection techniques, integrating contextual features to boost classification accuracy.
A final remark may be made on the influence of ethnicity and age in GC [10,52,56]. The former may be analogous to the human “other-race” effect, which is explained by psychologists with the “contact hypothesis”, that highlights the difficulties in extracting demographics from faces of other races [31].
Similarly, automatic systems might be positively affected by an ethnicity-balanced training set, or the alternative would be to create ethnicity-specific gender classifiers [48]. In any case, balanced datasets in terms of ethnicity have rarely been considered in the literature for GC. We should mention the EGA (Ethnicity, Gender, and Age) dataset [109], originally created for face recognition purposes, which has recently been evaluated for GC [25,26]. EGA has been created with images from other known face datasets. These samples have been chosen to reduce the distortions due to pose, illumination, and expression (PIE), to concentrate more on demographics. Unfortunately, these PIE restrictions and number of samples do not qualify the dataset as being in-the-wild.
7.3.2 Proposals Summary
As mentioned above, current state-of-the-art GC approaches achieve high precision based simply on visual facial features in controlled scenarios. This fact has also been proven with commercial solutions, as stated in the 2015 FRVT report on Performance of Automated Gender Classification Algorithms, which focused for the first time on GC [97]. This evaluation reported an accuracy of around 96.5% with an independent dataset containing roughly one million facial samples acquired under constrained conditions.
However, these results were not reproduced in datasets with unconstrained capture conditions or in the wild. Two of the above mentioned datasets were evaluated by Ngan et al. [97]: (i) LFW and (ii) GROUPS. In these datasets, available commercial solutions were not able to maintain similar classification rates in both cases. On the one hand, LFW seems to be a simpler dataset as the best accuracy reported by standard commercial solutions was 95.2%, certainly quite close to the numbers reported for constrained datasets. On the other hand, the accuracy achieved for GROUPS was significantly worse, hardly reaching 90.4%. This evidence confirms the difficult scenario represented by this particular dataset. This conclusion has already been highlighted by recent surveys and experimental evaluations [23,96].
Below we summarize GC results for three of the above mentioned in-the-wild datasets: LFW, GROUPS, and Adience. Observe that PubFig is not included due to the absence of experimental evaluations. Two scenarios are considered, depending on if the experimental evaluation includes a single or double datasets. When a single dataset is used, training and test sets are built based on the same dataset, a fact that may be affected by the dataset gathering protocol, or even include the same identity in both training and test sets. These results are commonly referred to in the literature as single/in/intra/within-database GC. A summary of recent results is reported in Table 7.2.
Table 7.2
GC accuracies in recent literature for LFW and GROUPS. Full datasets are used (28,000 samples for GROUPS or 13,233 for LFW) with the following exceptions: 1 Dago's protocol [36] containing around 14,000 samples with inter ocular distance larger than 20 pixels, ![]() over 20-year-old individuals present in Dago's protocol, 2 22,778 automatically detected faces, 3 over 12-year-olds, 4 1978 facial images, 5 7443 of the total images, 6 BEFIT protocol
over 20-year-old individuals present in Dago's protocol, 2 22,778 automatically detected faces, 3 over 12-year-olds, 4 1978 facial images, 5 7443 of the total images, 6 BEFIT protocol
| Reference | Dataset | Accuracy (%) |
| [36] | GROUPS1 | 86.6 |
| [27] | GROUPS1 | 89.8 |
| [23] | GROUPS1 | 91.6 |
| [88] | GROUPS1 | 91.59 |
| [30] | GROUPS1 | 92.46 |
| [28] | GROUPS1 | 93.26 |
| [29] | GROUPS1 | 94.04 |
| [23] | GROUPS1b | 94.28 |
| [73] | GROUPS2 | 86.4 |
| [22] | GROUPS2 | 90.4 |
| [10] | GROUPS3 | 80.5 |
| [89] | GROUPS4 | 93.3 |
| [61] | GROUPS | 87.14 |
| [41] | GROUPS | 88.6 |
| [23] | GROUPS | 97.2 |
| [115] | LFW5 | 94.8 |
| [129] | LFW5 | 98.0 |
| [106] | LFW5 | 98.0 |
| [36] | LFW6 | 94.01 |
| [43] | LFW6 | 93.98 |
| [88] | LFW6 | 96.25 |
| [10] | LFW | 79.5 |
| [40] | LFW | 91.5 |
| [118] | LFW | 94.6 |
| [61] | LFW | 95.4 |
| [83] | LFW | 94.0 |
| [23] | LFW | 98.1 |
| [41] | Adience | 76.1 |
| [60] | Adience | 79.3 |
| [79] | Adience | 86.8 |
| [132] | Adience | 87.2 |
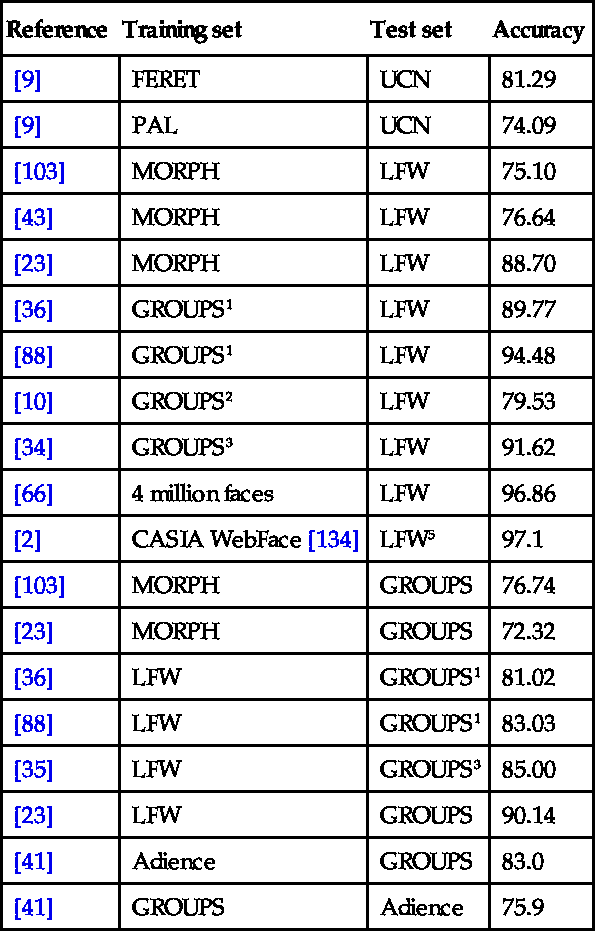
However, single dataset results may be overly optimistic. Indeed, the community knows that achieving high GC rates for a dataset does not generalize to all scenarios due to the influence of dataset bias [124]. Close to perfect accuracies in FERET [102] have been achieved. The work by Moghaddam and Yang [95] reported an accuracy of 96.62%, making use of pixel intensities and support vector machines (SVM). However, even more recent developments, trained with FERET, have not been able to reach significant accuracies on in-the-wild datasets, as, for example, those reported by Erdogmus et al. [43], who achieved an accuracy of just 65.2% on LFW. Therefore, a more challenging evaluation is referred to as cross-database GC where independent datasets are used for training and testing. As observed in Table 7.3, summarizing cross-database results, the achieved accuracies for the test dataset are commonly lower.
Table 7.3
Cross-database accuracies in the literature: 1 Dago's protocol [36] containing around 14,000 samples with inter ocular distance larger than 20 pixels, 2 over 20-year-olds, 3 automatically detected faces of over 20-year-olds, 4 single face per identity, 5 subset containing 10147 samples
| Reference | Training set | Test set | Accuracy |
| [9] | FERET | UCN | 81.29 |
| [9] | PAL | UCN | 74.09 |
| [103] | MORPH | LFW | 75.10 |
| [43] | MORPH | LFW | 76.64 |
| [23] | MORPH | LFW | 88.70 |
| [36] | GROUPS1 | LFW | 89.77 |
| [88] | GROUPS1 | LFW | 94.48 |
| [10] | GROUPS2 | LFW | 79.53 |
| [34] | GROUPS3 | LFW | 91.62 |
| [66] | 4 million faces | LFW | 96.86 |
| [2] | CASIA WebFace [134] | LFW5 | 97.1 |
| [103] | MORPH | GROUPS | 76.74 |
| [23] | MORPH | GROUPS | 72.32 |
| [36] | LFW | GROUPS1 | 81.02 |
| [88] | LFW | GROUPS1 | 83.03 |
| [35] | LFW | GROUPS3 | 85.00 |
| [23] | LFW | GROUPS | 90.14 |
| [41] | Adience | GROUPS | 83.0 |
| [41] | GROUPS | Adience | 75.9 |
Added to the training and test data used to evaluate the different approaches, the main differences among them are related to the features used and classification design adopted [96]. Assuming the state-of-the-art appearance-based methods, approaches are based on features such as intensity raw values, or local descriptors, which may later be filtered or not, while the classification may cover SVMs, linear discriminant, nearest neighbor, or neural networks among others.
Among the three datasets, it can be observed that GROUPS and LFW have received far more attention, with the former apparently being the most challenging of them. The recently arrived Adience has attracted interest in Convolutional Neural Networks (CNN) based solutions. Below, we present a rough chronological summarized description of the different approaches evaluated in the wild, considering single and cross-database results.
Prior to Dago et al. [36], GC evaluations mainly focused on single datasets such as FERET, covering a relative large population containing a significant number of individuals. However, the dataset high quality images and controlled capture conditions are rather different from the image variety of uncontrolled or real-world scenarios. Dago et al. presented results for LFW making use of the BEFIT protocol,7 and configured an experimental protocol for GROUPS using a subset with larger faces.8 In the study, they evaluated the use of LBP and Gabor features using LDA or SVM for classification. For single dataset GC, both features reached similar results, slightly better using Gabor jets, achieving an accuracy of 86.61% for GROUPS and 94.01% for LFW. They also included additional cross-database results, i.e., results after training with one dataset and testing with a different one to avoid dataset bias [124]. They were probably the first researchers interested in performing cross-database evaluations considering in the wild databases. When training with GROUPS and testing with LFW, they reported an accuracy of 89.77% using LBP and SVM, while the opposite combination reached only 81.02%.
Bekios et al. [9] also reported cross-database GC results, but their experiments were restricted to PAL, UCN, and FERET. Their approach combined LDA/PCA features with a Bayesian classifier, focusing on reaching similar to state-of-the-art GC rates with linear classification. On those datasets, they succeeded in achieving quite similar performances while reducing computational requirements needed by SVM based systems. A major conclusion was the proof that cross-database experiments are closer to real-world scenarios and demonstrated that single database experiments are optimistically biased.
In a subsequent study, Bekios et al. [10] tackled the in-the-wild scenario. Their study evaluated dependencies among gender, age, and pose. The authors integrated pose information in the classification, avoiding the initial need for face alignment. Their evaluation using a five-fold strategy reported an accuracy of 80.5% for single database GC in GROUPS.
More recently, other single dataset GC experiments have been carried out on LFW. Shan [115] extracted LBP features that were later classified using SVM to obtain an accuracy of 94.8% in LFW. Subsequently, Shafey et al. [118] reported results for FERET and LFW, making use of Total Variability (i-vectors) and Inter-Session Variability (ISV) modeling techniques, reaching an accuracy of 94.6% for LFW. Tapia et al. [129] compared the fusion of different LBP-based features, scales, and mutual information measures, reporting for LFW an accuracy of 98%. Ren and Li [106] evaluated two types of local descriptors (gradient features and Gabor wavelets), introducing a later selection step based on RealAdaBoost. A linear SVM was applied as a classifier, and results for FERET, KinFace, and LFW were presented. For LFW, they reported 98%, claiming it to be faster than other previous approaches with similar accuracy. Erdogmus et al. [43] explored the best grid setup for the LBP-based features extraction with BANCA and MOBIO databases. Later, they evaluated on FERET, MORPH, and LFW, the latter with the BEFIT protocol and achieved an accuracy of 98%.
Reducing the working image resolution, El Din et al. [40] designed a two-stage system that combined appearance and shape features in the first stage, activating the second stage only for images with low confidence. Their reported accuracy for small, normalized thumbnails, ![]() pixels, of LFW reached an accuracy of 91.5%.
pixels, of LFW reached an accuracy of 91.5%.
Specifically using cross-database results for LFW, Jia and Cristianini [66] focused on assembling and labeling large datasets automatically, avoiding the workload of human annotation. They evaluated their approach with LFW after gathering four million images and achieved an accuracy of 96.86%. Antipov et al. [2] applied CNN to GC on LFW, the authors claimed to use 10 times less training samples than Jia and Cristianini [66], i.e., 400,000, for identical experimental setup. They reported an accuracy of ![]() using three CNNs.
using three CNNs.
Chen and Gallagher [22] built a facial appearance representation based on the 100 most common names in the USA. Each pairwise name classifier provided a score, the whole collection was used to create the feature vector. The voting of the top five names is used to assign a gender to a test image. The achieved accuracy for GROUPS reached 90.4%. They claimed to beat any previous evaluation on GROUPS, including the application of the gender classifier designed by Kumar et al. [73] integrated into a face verification approach based on describable visual attributes, which using GROUPS gave rise to an accuracy of 86.4%.
Han and Jain [61] applied pose and photometric normalizations before extracting biologically inspired features (BIF), which are later classified with SVM to get age, gender, and race. Their experimental results on GROUPS and LFW reported 87.14% and 95.4% accuracy, respectively. Also for GROUPS, Fazl-Ersi et al. [46] reached an accuracy of 91.4% using a combination of different visual information sources. They combined LBP, SIFT, and color histograms after a feature selection stage. More recently, Mery and Bowyer [89] evaluated a technique based on the sparse representation of random patches achieving in a GROUPS subset containing roughly 2000 samples, an accuracy of 93.3%.
Danisman et al. [34] presented different cross-database results, making use of pixel intensities and SVM classification. Training with their dataset, WebDB, they reported an accuracy for LFW and GROUPS of 91.87% and 88.16%, respectively. In a more recent work [35], they have integrated a Fuzzy Inference System (FIS), combining inner and outer facial features training with GROUPS. The system achieved a performance of 93.35% when testing with LFW.
Eidinger et al. [41] reported results on GROUPS and Adience. Their approach based on LBP-like features and SVM reported accuracies of 87.5% and 76.1%, respectively. From these results, they claimed that Adience represents better real world conditions. More recently, Hassner et al. [60] focused on the frontalization problem to better synthesize the frontal face from a given view. The GC evaluations in Adience boosted accuracy up to 79.3%.
In relation to our work on GC in the wild, we initially proposed, similar to other authors, the integration of facial and non-facial features. More specifically, we focused on the face, and head and shoulder patterns (F and HS, see Fig. 7.4) [23,27,103], extracting features based on LBP and HOG. The best reported in-dataset accuracies for LFW and the GROUPS Dago's protocol were 95% and 91.65%, respectively, though the latter increased to 94.28% when considering only adults for training and testing. The exploration of a larger collection of local descriptors, grid resolutions and the combination with more densely extracted features from the periocular area (P) [30], and the mouth area (M) [28,29] (see Fig. 7.4) have more recently led to an improvement in performance. For the GROUPS Dago's protocol, the accuracy integrating P increased up to 93.54%, including both P and M areas achieved 94.04%.

Deep learning has recently achieved significant results in different computer vision tasks. Facial analysis is a problem, where the pattern variation complexity is well suited for applications in the wild. Liu et al. [83] adopted this focus to extract up to 40 facial attributes from CelebFaces and LFW, they achieved an accuracy of 94% for GC in LFW. Levi and Hassner [79] apparently reported the first GC results based on Deep CNN for a hard in the wild dataset, particularly for Adience. Using the in-plane aligned version of faces, they increased performance to 86.8%, suggesting the need to work on better alignment and frontalization to boost performance further. Another conclusion was the evidence of a larger number of classification errors in babies and children, an aspect also observed in our studies related to GROUPS [23].
More recently, different studies have suggested combining CNN outputs and local descriptors, also called handcrafted features, for GC. Wolfshaar et al. [132] proposed the fusion of Deep-CNN and SVM for GC, reporting results from FERET and Adience datasets. The latter achieved an accuracy of 87.25%. Mansanet et al. [88] weighted local features and CNN outputs achieving single dataset GC for LFW and GROUPS of 96.25% and 90.58%, respectively. Their cross-database experiments reported 94.48% training with GROUPS and testing with LFW, and 83.03% for the reverse.
Considering this trend, we have also performed a study to compare GC performance based on the fusion of local descriptors versus CNN [23]. The rather similar accuracies achieved for LFW, GROUPS, and MORPH motivated us to evaluate the integration of the CNN outputs in the fusion approach. The outcome is an evident increase in GC performance, reporting state-of-the-art accuracies in both in-database and cross-database GC performance. For full in-database cross-validation, accuracies reached over ![]() (
(![]() in adults) and
in adults) and ![]() for GROUPS and LFW, respectively. Related to cross-database results [23], training with LFW and testing with GROUPS reported 90.14% and, while for the reverse combination, accuracy was 98%, considering full datasets in both cases. These cross-database accuracies beat most literature in-dataset evaluations for both datasets.
for GROUPS and LFW, respectively. Related to cross-database results [23], training with LFW and testing with GROUPS reported 90.14% and, while for the reverse combination, accuracy was 98%, considering full datasets in both cases. These cross-database accuracies beat most literature in-dataset evaluations for both datasets.
7.3.3 Discussion
Observing the summarized results for single database experiments in Table 7.2, the first impression suggests that LFW accuracies are typically over 90%, achieving up to 98%, thus suggesting little room for improvement. LFW is the lightest in the wild datasets studied as its performance is similar to constrained datasets, and quite different from the typical results achieved for Adience and GROUPS, which clearly exhibit lower accuracies. Thus, both datasets seem to be closer to real world situations, including larger variations in terms of pose, background and resolution. The former is a recent dataset with relatively few experimental evaluations so far, with accuracies under 88%. The latter is, according to the 2015 NIST report, currently the most challenging dataset with difficulties to achieve results over 92%, similar to commercial systems. It is worth highlighting our own recent approach that combines handcrafted features and CNN reaching over 97.2% for the GROUPS dataset.
This conclusion is also confirmed by observing the cross-database results in Table 7.3, where, with the exception of testing with the biased FERET or LFW, accuracy hardly reaches 85%, showing a lack of accuracy of state-of-the-art solutions in cross-database GC in most cases. This is probably due to the special test dataset characteristics, which reduce the complexity. We therefore agree that high accuracy can be achieved for homogeneous, biased and/or reduced datasets of good quality, etc.
Another conclusion is the current challenge scenario is to provide high precision with cross-database classification, i.e., testing with a completely independent in the wild dataset. Cross-database GC is closer to real world applications and avoids any dataset bias. In realistic applications, a gender classifier is first trained with a set of images, and then deployed under different scenarios that may certainly differ from those of the training dataset.
This fact has been demonstrated several times in recent GC literature, single dataset experiments with FERET have reported very high GC rates [7,9,93,132], but the generalization of the classifier is poor if tested in the wild [132], with a significant drop in accuracy [6]. This observation is also confirmed in Table 7.3, when LFW is used for training, in which accuracy testing with GROUPS is remarkably lower than for the reverse situation. GROUPS dataset again highlights the difficulties. Unfortunately, we are aware of just one reported cross-database results testing with Adience, reducing the relevance of further conclusions.
The latest results that integrate CNNs suggest their utility. The characteristic of CNNs as end-to-end classifier reduces the need for human design to select the features to use. This was suggested by Perlin et al. [100] for GC using full or almost full body images. Specifically, ViPer [49] and HATdb [116] extract information from the upper and lower body added to GC performance. Under this approach, the feature extraction task is mainly performed by the CNN. However, several recently reported results combining handcrafted features and CNN [23,88,132] suggest an improvement in the overall performance, when CNN and features are combined, indicating a promising research avenue.
To explore future improvements in GC, we would like to mention the results presented by Klare et al. [74] and the proven connection between age and gender by Bekios et al. [10]. Two aspects are highlighted: (i) the need for training on datasets that are evenly distributed across demographics, to manage different demographic groups; and (ii) the interest in designing solutions for different demographic groups to increase performance on such groups.
The former is evidenced by cross-database results, where training with the hardest datasets, reported higher accuracies than in lighter ones. It is also likely to be affected by the demographic variations included. The latter agrees with the results reported in [23], removing under 20-year-old individuals from the Dago's protocol, and reaching significantly higher GC accuracy, up to 94.2%. Table 7.4 presents the GROUPS average faces per age range and gender, with some evident appearance differences.
Table 7.4
Mean facial patterns per gender and age group in GROUPS
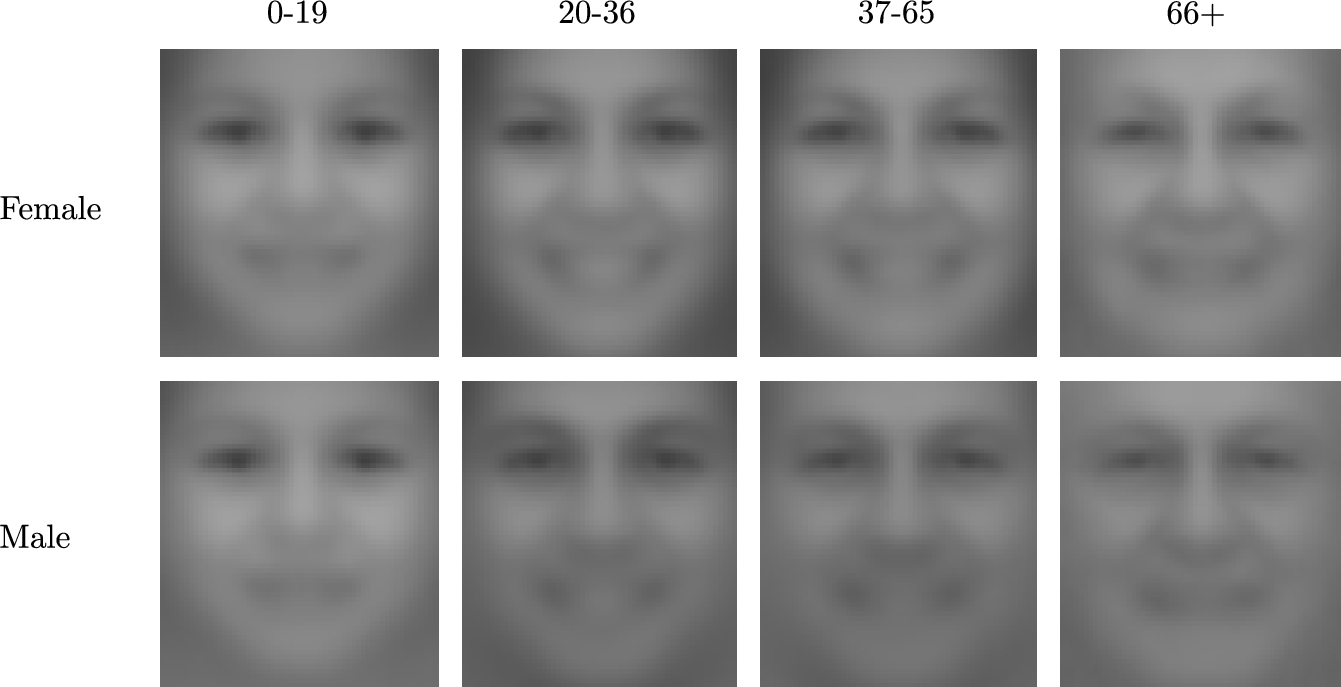
Given existing in the wild datasets, whose compilations have not taken into consideration the balance in terms of variables such as ethnicity, age, etc., it is not straightforward to obtain a general conclusion about the current leading solutions. Fig. 7.5 illustrates a subset of the classification errors obtained when evaluating GROUPS with the state-of-the-art classifier proposed in [23]. The upper and bottom rows present, respectively, females and males wrongly classified in the samples. For both classes only the five most distant to the classification border samples are shown, presenting them according to their output score. For females, two samples produced a score significantly farther from the class border. Both belong to elderly ladies, and is likely to be due to a poor representation of that demographic group within the training set. For male samples, age seems to be again a misclassification factor, but also annotation errors might be present. In any case, it is clear that there is still room for improvement.

A final comment can be made related to difficult or ambiguous samples [25], El Din et al. [40] made use of a second classifier specialized in difficult or borderline samples, which may be an approach to be considered.
7.4 Conclusions
In this chapter, we have reviewed different approaches in human recognition focusing on soft biometrics. Soft biometrics refers to attributes or descriptors that are extracted from different traits like the face or body. Unlike strong biometrics such as fingerprints, soft biometrics does not have the ability to discriminate between any two different individuals, but does allow people to be grouped into semantic categories like gender, age, ethnicity, and so on. We have explained the different applications, where these traits can be used: identity recognition by means of multimodal fusion; improved classical biometric performance; reduced search space for people in large databases or surveillance systems, and to obtain demographic user profiling in marketing.
After the general introduction to soft biometrics, the need for in the wild experimental evaluation is argued for as the logical evolution of methods that were conceived for solving problems under restricted conditions, and have been successful. In the near future, soft biometrics must be able to tackle deployment in real world scenarios. A key element of this evolution is the need for benchmarks that reproduce conditions similar to those that the systems will face in real situations. Some initiatives in this direction have been presented such as the LFW or EmotiW datasets.
One of the most useful and applied soft biometric traits, gender, is analyzed in depth, focusing exclusively on real world applications and therefore reporting on GC proposals evaluated on in the wild datasets. Indeed, the pros and cons of each of most referenced in the wild public datasets have been analyzed. Additionally, related to the datasets, the two main experimental setups, namely in-database and cross-database are explained. Finally, a review of the different GC proposals, from the first ones to the most recent, was carried out, showing the performance of the different methods.