
5 Optimizing change management (phase 3)
“They always say time changes things, but you actually have to change them yourself. Andy Warhol”
Change management must be adapted to fit the needs of the adopting organization. In this chapter I’ll cover a number of approaches to optimizing aspects of change management that help with its adoption.
5.1 Reducing changes going to the CAB
Depending on the size of your organization, the volume of changes to be reviewed can easily exceed the capacity of a weekly change advisory board (CAB) meeting. In large organizations, it’s not uncommon to have dozens or even hundreds of changes every day. Obviously in these cases, a weekly CAB meeting is insufficient.
As change management matures, and more changes are brought into the process for review, the CAB meetings grow longer, making for marathon sessions that are unpopular, which hurts the cultural adoption process.
One approach is to classify changes into groups, so members and requesters can attend shorter, focused CAB sessions. These can be held on the same day, back to back, or additional weekly meetings can be introduced – infrastructure changes one day, application changes another, for example.
Another challenge a high volume of changes presents is that all changes tend to get lumped together, where large and potentially high-impact changes receive less review than is perhaps warranted, and smaller, more common changes get more than their risk deserves.
It’s a pretty straightforward supply versus demand equation, where you can either increase the capacity of the CAB to process requests, or reduce the volume of changes requiring CAB review.
By far, the best approach is to reduce the amount of changes coming to the CAB, while still achieving the fundamental goals.
5.1.1 Standard changes
A frequent criticism made by change management and the CAB is that many changes are minor and rarely cause issues. It’s both wasteful of time and disrespectful of staff to require these types of change to come to the CAB. Establishing standard changes allows for appropriate handling of these types of change, while maintaining appropriate oversight.
Let’s start with a quick description of standard changes. Standard changes are:
• Carried out frequently in daily operation
• Considered low risk and non-complex
• Reviewed by the CAB and approved by the appropriate change authority
• Approved for a specified period (e.g. length of a volume purchase agreement) and regularly reviewed to ensure the change type ‘standard’ still applies.
Standard changes are a form of delegated change authority (see section 5.1.2) where identified (standard) changes can be executed at will at the local level. It’s not that standard changes cease to be proper changes; it’s that the authority to approve their use in daily operations has been delegated to a more local authority based on analysis, review and acceptance of the risks.
How to deal with daily operational changes
Changes that are performed so frequently that it’s impractical for them to be reviewed by the CAB are a challenge in many organizations. On the one hand, by their very nature, these types of change cannot wait for the weekly CAB meeting to be reviewed, as that would hamstring any organization, and would rightfully be viewed as ‘bureaucracy’.
On the other hand, ignoring them and hoping for the best isn’t a good option either.
IT environments are very complex. Incidents are often the result of an intricate combination of changes or events. The most minor of changes, when combined with unknown other environmental factors, can cause problems. If operational changes are made without change management knowing, incident management will not have a complete view for effective troubleshooting, which will contribute to longer resolution times.
Even the most minor changes pose some risk, but the fact that many operational changes happen daily makes them good candidates for being classified as ‘standard’ and being placed under the authority of the operations manager.
Standard change is therefore an effective means of managing the risks of frequent operational changes without the increased overhead of bringing each instance to the CAB for review.
To facilitate their timely implementation, maintenance changes can be proposed as a standard change. For this to work effectively there must be clear criteria for what constitutes a maintenance change and responsibility for approving the list of such changes must be assigned. Maintenance changes are tracked through the reviewed/approved maintenance process, and can be accessed by support staff.
5.1.1.1 Identifying standard changes
Standard changes are often identified and managed by domain owners and/or the subject matter experts in areas such as:
• Network operations
• Applications development
• Infrastructure and server teams
• Security.
The change manager can ask the domain owners to create a listing of frequently implemented changes to be considered as standard changes. Domain owners often welcome the opportunity to increase the standard changes that can be approved locally without approaching the CAB.
The CAB should be actively looking for changes that could be made into standard changes; they should review every RFC bearing that in mind.
5.1.1.2 Candidates for standard changes
The following questions will help you identify good candidates to be standard changes:
• Is the change performed frequently in daily operation?
• Would errors relating to the change cause little impact and be easy to recover from?
• Are the means in place to record details of the changes (e.g. system logs)?
• Has the CAB found issues with similar change requests in the recent past?
• Change requests that have significant issues discovered by the CAB in the review process may not be mature or stable enough to be good candidates.
• Have there been incidents or disruptions to service caused by similar changes in the recent past?
• Changes that have caused post-implementation issues in the past are probably not good candidates, though it’s possible that the process of documenting and reviewing these types of change – especially if the cause of previous issues has been identified and addressed – can make them suitable for consideration.
• Is there a documented process for the requested change, and is it consistently followed? (If not, could one be created?)
• Changes that are consistently carried out following a well-understood process (even if not documented) are very promising candidates. If the process is consistently followed, documentation can be created, validated and submitted as a standard change candidate.
• Is the change associated with delivery of services listed in the service catalogue?
• Is the request associated with any critical business functions or a highly sensitive infrastructure?
• Changes to key infrastructure or associated with the delivery of critical business services require a higher level of review and don’t generally make good standard changes. This is not a hard and fast rule, however. Some organizations classify configuration items (CIs) according to their business criticality; such labelling can be used to determine whether standard changes are appropriate.
• Is the change associated with a highly automated infrastructure?
• Infrastructure components with a high degree of virtualization and automation, such as automated provision of standardized infrastructure components or automated testing and deployment of code (following DevOps or similar continuous flow methodologies), are good candidates for standard changes.
Examples include:
• PC hardware replacement/repair
• Backup and recovery
• User account management
• Daily job scheduling, processing and operational work
• Scheduled periodic system patching of non-critical systems such as PCs
• Infrastructure capacity upgrades
• Adding switch port capacity in office areas
• Most movements/additions/changes to telecoms equipment.
5.1.1.3 Making a standard change
If a change looks like a good candidate for a standard change, it should be assigned an owner who will:
•Ensure there’s good documentation for how the standard change is/will be carried out.
Documentation for standard changes varies widely from company to company. The format is largely unimportant but should specifically identify:
• The steps required to complete the change
• Who will be responsible for performing the process steps
• Where and how the change status is logged and communicated to other stakeholders
• How the change will be tested to ensure it works as planned and doesn’t cause unintended consequences
• The steps to undo the change (roll-back) if issues are discovered
• Submit the standard change documentation to the CAB as an RFC for review.
The CAB will review the proposed standard change process for risk and operational concerns, much as they would any other change request. The only difference is that they are reviewing a process for performing certain defined changes. The CAB must review it for risk, value realization and unintended consequences, as well as ensuring that such changes are captured for governance and compliance (often in system logs).
The appropriate change authority then approves (or rejects) the proposal for a standard change.
Once a standard change has been approved, it is carried out as needed in daily operation, following the approved process.
5.1.1.4 Operational considerations
Despite change management delegating authority to allow standard changes to be executed without hesitation as needed in daily operations, such changes remain under their authority. Nevertheless, once the risks and operational controls of a standard change have been reviewed and approved, they do not need to be revisited unless issues arise.
If any incidents do arise from approved standard changes, change management should act to determine the underlying reason(s) and appropriate corrective action.
In daily operation, standard changes should not be:
• Submitted as RFCs
• Reviewed individually by the CAB
but should be:
• Completed following the approved, documented process
• Recorded in a way that can be reviewed by operational staff (for incident and problem management, continual improvement and compliance)
• Periodically reviewed for improvements.
5.1.1.5 Standard change workgroups
Some organizations combine the elements of standard changes with delegated authority (section 5.1.2) by establishing (change management) workgroups who are tasked with managing standard changes within a given domain (e.g. network, database etc.). This is an excellent practice, especially for organizations with a large volume of changes.
Standard change workgroups are empowered to operate with coordinated independence to recommend, review, establish, oversee, revise and deny standard changes under their authority. Representatives of the various workgroups should be standing members of the CAB to facilitate two-way communication and coordination of standard changes.
The process and practice is as above, except that the tasks are carried out by the workgroup, not at the normal CAB meetings. The CAB is made aware of standard changes that are under consideration and that have been approved, but beyond that, the work is completely delegated to the workgroup.
5.1.1.6 In practice
Standard changes are an excellent way to allow the CAB to focus on much larger and more critical changes while maintaining appropriate control. Once the level of risk has been identified and accepted in the form of a standard change, change management should be keen to give operations staff the authority to use it as needed, rather than begrudgingly, as if doing them a favour.
The mature view of standard changes is that it’s achieving one of the key goals of change management – appropriately managing risk (Chapter 1). Therefore, unless or until issues arise, the CAB should pay very little attention to standard changes.
If you are just getting started with formal change management, or if you have an unpopular and bureaucratic CAB, standard changes will be a welcome relief. I strongly encourage setting a goal for number or percentage of standard changes, and track that as a change management operational metric.
5.1.2 Delegated change authority
It is common for change management to directly review all changes through the CAB. In many cases, however, those involved with the development of changes are better able to effectively manage change-related risks. Delegated change authority formally recognizes and embraces this reality while maintaining effective change oversight.
As change management matures, it becomes increasingly concerned with the overall process. To focus on the bigger picture and higher-risk changes, the CAB should delegate parts of its responsibility. Establishing a clear and well-understood structure for delegating change authority is an effective way to achieve the need to manage risk without a CAB review.
Care must be taken to eliminate ambiguity and confusion with delegated authority. Whatever structure is chosen, it must be kept as simple as possible and easy to communicate. Roles and responsibilities must be clear and well understood by all staff.
As much as possible, delegated domains should be logical groupings, with few if any exceptions – for example, all network changes at a remote office could easily be delegated to the local operations manager. (Exceptions to the delegated authority structure may include response to a defined risk or incident occurrence.) Delegation must also consider the organizational culture around ownership and accountability. A typical approach is that higher levels of organizational authority are required to approve changes that have a higher risk and potential business impact.
Whatever form of change delegation is employed, it should be documented in a written change policy and communicated to all staff (see Appendix A). The policy should clearly define domains and the criteria for determining ownership of them. It should also state when other domains must be engaged or the change escalated to a higher authority. Lack of clarity in this regard is a common source of tension and ineffectiveness.
5.1.2.1 Hierarchical change delegation
The structure shown in Table 5.1 illustrates how changes with higher risk and impact must be approved at higher authority levels. It is important to note that those with higher authority don’t necessarily do the detailed change and risk analysis, but because of their level in the organization (and also higher degree of accountability), they are in a position to make the important business decisions and accept responsibility for the potential of negative impact in the form of financial or other losses.
Use operational metrics (discussed in sections 3.3 and 4.4) to determine whether adjustments to delegation levels are required to maintain appropriate risk management. In concept, changes should be pushed down to as low a level in the appropriate hierarchy as possible. If, over time, certain change types have a good track record for successful implementation, change management should consider moving authority for these changes to a lower level with ongoing monitoring for continued success.
Where there’s a hierarchical structure, there must be clarity regarding why and how changes are escalated from one authority to another.
Table 5.1 Hierarchical change authority
| Authority level | Extent of risk/impact on the organization |
| Business management | High risk to entire enterprise |
| Significant cost | |
| Senior IT | Multiple IT services impacted |
| Multiple lines of business impacted | |
| Change manager | Single IT service impacted |
| Single business unit impacted | |
| Local delegated authority | Low-risk changes |
| Standard changes |
Another approach is delegation by domain. In Figure 5.1 you can see how small changes in each domain can be approved by an identified local authority such as the operations manager for that domain.
For changes that cross organizational boundaries – infrastructure or applications that support multiple business units – responsibility is assigned to a level that has the organizational authority to accept risk on behalf of all involved.
This model acknowledges that many changes have localized risk and can be effectively reviewed and authorized by an authority at the site.
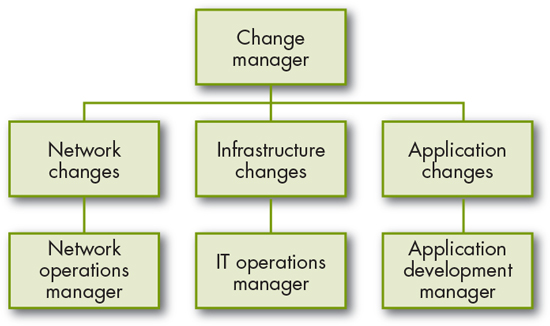
Figure 5.1 Domain delegation
For instance, a company with offices in multiple locations may have network managers at each site who have delegated change authority for network changes at that location, provided the changes do not impact on other sites. An example of this regional model can be seen in Figure 5.2.
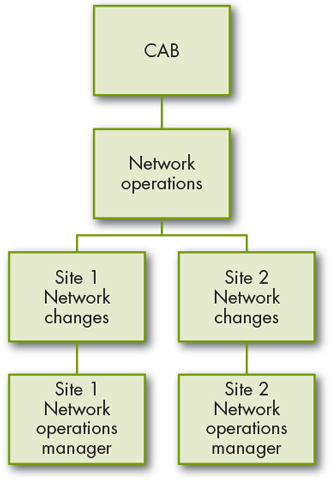
Figure 5.2 Sample regional delegation within domain
Authority for changes made to routers that connect to the wide area network (WAN) between sites must be referred upwards to an individual with the authority for all impacted locations (in some organizations this will mean the person responsible for the entire WAN).
In the same way, if systems and resources from other sites regularly access systems at the local site, authority for changes that could potentially compromise access to the local networks or systems should also reside with a higher authority.
The organization’s change policy should include a provision that clearly states all delegated change authority is provisional. Each delegate must understand that if they approve changes that cause issues or negatively impact on the business, they are accountable to the delegating authority and can have their authority revoked. The tension between desire for the autonomy to move quickly to meet business need and the potential to lose that autonomy after significant failure creates an effective method of managing delegated change authority. In practice, if the delegate is not completely comfortable with a proposed change, or is not 100% convinced that there will be no impact on other parts of the business, they should escalate the decision to a higher level.
The entire change delegation must be kept as simple as possible. Well-understood domains (such as network and infrastructure) and clear criteria are key. The main requirement is that the policy be clear, understood and acknowledged by the staff.
5.1.3 Change models
Change models provide a defined approach to specific types of change. Once approved, requesters simply plug in the particulars of their situation, components and parameters.
They are a useful way of streamlining changes that are common but don’t meet the criteria for standard change (usually because they’re either not performed frequently or they involve higher risk). Change models can be considered for changes such as:
• Application deployments, especially where automated
• Deploying monthly PC patches
• Service requests that are not routine, such as:
• Access requests to critical infrastructure components
• Firewall policy changes
• Regular system maintenance such as:
• Balancing server loads
• Storage capacity upgrades
• Installing new wireless access points.
In practice, change models are a generic, defined procedure that’s been approved by change management for certain types of change. Once approved, change models become straightforward templates that ensure the RFC is completed with the requisite information.
The model should include:
• Process steps for completing the change
• Sequence for completing the steps, especially noting dependencies
• Generic roles and responsibilities, including:
• Who will perform which parts of the change
• What change authority approves the change
• Timeframe for change implementation, including roll-back checkpoints
• Escalation process in the event that things do not go as planned.
Change model: server decommission
An organization had several high-impact incidents that resulted from decommissioning servers that were thought to no longer be in use. Because staff were convinced that the servers were not being used, the servers were not only shut down, but physically removed. When it was discovered that the servers were still in use by production systems, it took significant time and effort to reinstall them and bring them back online.
Change management requested the server subject matter expert to propose a standard decommissioning process that would avoid a recurrence of this problem.
The process included steps to verify remote connections and activity. Only after verification that there was no remote network activity and all remote connections were severed, without impact, could the servers to be decommissioned be logically removed.
The server would be left in the standby mode for a week. After a week with no production problems, the server would be shut down.
The server would be left in this shutdown state for another week. After a second week with no problems, the server would be physically decommissioned and removed.
The steps were documented in a change model that was strictly followed. RFCs for server decommissions were filled out with the specific configuration items using the model.
Decommissioning servers went from a lengthy CAB discussion to a delegated change using a predefined model, while greatly reducing the number of related issues.
5.2 Change windows
All services require periodic maintenance and upgrading. Change windows should be established early in the design phase of a service or of critical infrastructure components. It is important for these to be negotiated early, because once a service is live, users develop expectations and find downtime for any reason to be problematic. If users know from the outset that the service will be unavailable every Sunday from 10:00 pm to 12:00 midnight (for instance), they will consider it an integral part of the service and build expectations around the window.
Change windows should be reflected in the service availability parameters included in applicable service level agreements.
Be careful to ensure there is no unexpected impact from maintenance windows. For instance, components of one service that’s undergoing maintenance may be used by other services, with unintended consequences for the second service.
Establish various types of change window to meet the needs of the organization and the growing change management programme.
Weekly windows could be established for:
• Network
• Infrastructure
• Maintenance.
Specific change windows should be established for major and minor release implementations. Figure 5.3 shows what a change window calendar may look like. It shows weekly windows that are focused on a specific infrastructure component, with scheduled releases on the first weekend of the month and minor releases on the third weekend. This is by no means a recommendation but represents a typical calendar. Obviously, the needs of your organization should determine the optimal solution.
In conjunction with release management, the establishment of a release cycle is important to handle normal changes to services. A typical release schedule has a monthly release for normal service updates. Normal changes are proposed with a target release window in mind, and can be scheduled well in advance, as a normal part of release planning.
Typically, approved changes are implemented in the next scheduled change window – generally the next available after-hours slot.
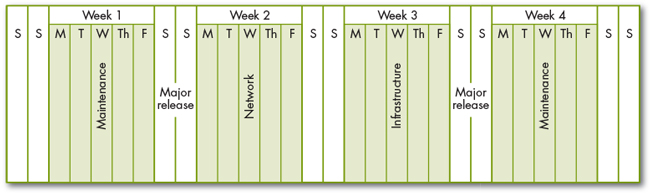
Figure 5.3 Sample change windows calendar
Emergency changes are unique in that they have high impact and urgency necessitating immediate implementation. Emergency changes can target an existing change window, or, based on business impact, can be implemented as needed with appropriate communication and coordination. Because the need for an emergency change is typically unplanned, the organization may elect to use a workaround as a temporary approach to address scheduling or other immediate issues.
5.2.1 Maintenance
Established change windows help change management understand customer requirements and expectations without having to inform customers each time a change is planned. Because customers already know the service will be down, no further customer coordination is required (as long as changes are successful within the pre-established window).
5.2.2 Change implementation staff
The staff responsible for performing the implementation of changes must be included in the process of establishing change windows. Change windows frequently require after-hours work and must be coordinated with the teams performing the work.
Not including staff in the negotiation process nearly guarantees they will feel undue pressure and resentment when asked to implement changes in timeframes they had no part in deciding. Again, establishing windows as early as possible during service design goes a long way towards gaining full support for your change programme.
5.2.3 Minimizing customer impact
Change windows are always negotiated with customers and users, and based on minimizing business impact, while maximizing the ability to effectively implement required changes. Understanding patterns of business activity is crucial to identifying change windows. All customers must be considered, as not all users have the same usage patterns.
Before establishing change windows, be sure to have them thoroughly reviewed by your technical experts who are familiar with the inner workings of the infrastructure. Also be on the lookout for maintenance windows that are mutually exclusive; for instance, a network maintenance window overlapping a server maintenance window, making the server inaccessible to its administrators.
5.2.4 Window length
The length of each change window must match the timeframe required for both the implementation and roll-back of anticipated changes. In other words, the window must be long enough for changes to be successfully completed within the given timeframe, but also for changes that are not successful to be fully rolled back before the window ends. It is also wise to build in enough buffer to allow for unexpected circumstances.
Patterns of business activity and change windows
When negotiating a weekly change window on the company’s order processing system, the order processing staff were consulted, and agreed that any night after 5:30 pm would be fine. Their key concern was making sure the tool was available early in the morning so they could generate the sales reports required for daily management reporting.
It was agreed that Thursday nights at 6:00 pm would be the change window.
After several months, word got around that the field sales staff were very frustrated with the order processing system. Looking into it, it was discovered that, unlike main office staff, field sales representatives meet with customers all day, generally taking a client to dinner. After dinner, they would return to their hotel room and update their sales.
Unbeknownst to the office and IT staff, Thursday night was the cut-off for weekly sales submissions used to calculate commissions.
After talking with the sales staff and management, it was determined that it would be very rare for any sales staff to be on the road Friday night. This made Friday at 6:00 pm a much better choice for the maintenance window.
Key lesson: it is important to engage all stakeholders when negotiating change windows.
Each organization must set its own policies around change windows usage, but they must be documented and well understood by the operations staff.
5.2.5 Change windows and change planning
Having established, customer-agreed maintenance windows greatly simplifies the scheduling aspect of change evaluation. Medium- and lower-priority changes should always be performed in the agreed maintenance window.
This simplifies the RFC somewhat, as the requester simply selects which change window the proposed change is targeting for implementation. The CAB can then take a holistic view of all the proposed changes for a given window. Are there too many changes for the window? Are any mutually exclusive? If change windows are becoming overloaded, or there are conflicts, the CAB must reconcile them, based on priority and business need.
Only emergency changes should be considered for implementation outside the change window.
5.3 Chapter 5: key concepts
The key concepts in Chapter 5 can be summarized as follows:
• Reduce the number of changes coming to the CAB by:
• Delegating change authority
• Introducing standard changes
• Using change models
• Establish change windows to reduce logistical coordination.