
OpenCL device-side memory model
The device-side memory model defines the abstract memory spaces that work-items within an OpenCL application may target when executing a kernel. The memory model also defines the memory consistency that work-items can expect in each memory space. This chapter discusses each memory space in detail, describes the mapping of memory objects to memory spaces, and introduces synchronization and memory ordering.
On OpenCL devices, the memory space is classified into four categories:
2. local memory
3. constant memory
4. private memory
These memory spaces are visualized in Figure 7.1. As discussed in Chapter 2, OpenCL is designed to run on a range of architectures. The purpose of arranging a memory hierarchy of this form is to allow OpenCL programs to perform efficiently on such architectures. The actual meaning of each memory space in terms of a hardware mapping is very much implementation dependent. Regardless of how they are mapped to hardware, as a programming construct, these memory spaces are disjoint. Furthermore, as shown in Figure 7.1, local memory and private memory are divided into disjoint blocks across work-groups and work-items. When separate layers of address space are defined in this way, the mapping to hardware can efficiently use anything from relaxed memory consistency models with programmatically controlled scratchpad buffers, as seen on most graphics processing unit (GPU) devices, to fully coherent memory systems such as x86-based architectures.
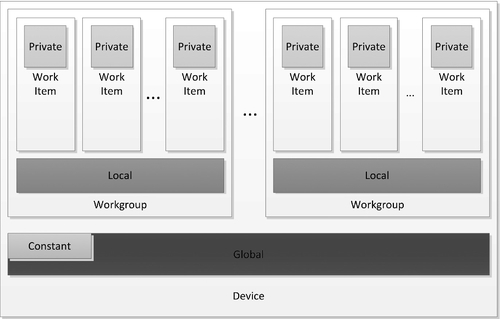
The default address space for function arguments and local variables within a function or block is private. Pointer arguments can be placed in one of the other address spaces depending on where the data comes from or where it is to be used. The pointer itself is always in the private address space wherever the data lies. The address spaces are strictly disjoint when used through pointers. Casting from one address space to another is not legal because this would imply either that the data lives at a globally accessible address or that the compiler would have to generate a copy to go with the cast, which is not feasible in practice. However, as we will see later in this chapter, OpenCL 2.0 has introduced a generic address space, which does allow address spaces to be inferred automatically in some cases. Image arguments always live in the global address space, so we discuss images in those terms.
Before the memory spaces are discussed in detail, the following section outlines the capabilities of work-items to synchronize and communicate. This information will be useful when discussing the qualities of each memory space.
7.1 Synchronization and Communication
When describing the host memory model, we said that by default OpenCL does not guarantee that writes will be visible to the host until the kernel completes. Similarly, regular accesses by work-items are not required to be visible to other work-items during a kernel’s execution. However, the OpenCL C language (combined with the memory model) does provide certain synchronization operations to allow visibility within various memory spaces using barriers, memory fences, and atomics. The hierarchy of consistency is as follows:
• Within a work-item, memory operations are ordered predictably: any two reads from and writes to the same address will not be reordered by hardware or the compiler. Specifically for image accesses, synchronization is required for any read-after-write operation, even when it is performed by the same work-item.
• Between work-items and within a work-group, memory is guaranteed to be consistent only after synchronization using an atomic operation, memory fence, or barrier.
• Between work-groups, memory is guaranteed to be consistent only after a synchronization operation using an atomic operation or memory fence. Work-items from different work-groups cannot synchronize using a barrier.
7.1.1 Barriers
Within a work-group, the programmer may require all work-items in the work-group to synchronize at a barrier using a call to work_group_barrier(). The two versions of the barrier function are as follows:
The barrier requires that all work-items in the work-group reach it and that visibility requirements are met before any is allowed to continue execution. As barrier operations are often used to ensure data visibility within the work-group (e.g., after manually caching a subset of global memory into local memory), the flags parameter to work_group_barrier() is used to specify which types of accesses must be visible after the barrier completes. The three options are CLK_LOCAL_MEM_FENCE, CLK_GLOBAL_MEM_FENCE, and CLK_IMAGE_MEM_FENCE, which ensure that all local memory, global memory, or image accesses are visible to the entire work-group, respectively.
The second version of work_group_barrier() also allows a memory scope to be specified. The memory scope can be used in combination with the flags argument for fine-grained control of data visibility. Two possible options for memory scope are memory_scope_work_group and memory_scope_device. If CLK_GLOBAL_MEM_FENCE and memory_scope_work_group are used together, the barrier will ensure that all global memory accesses from every work-item in the work-group are visible to all other work-items in the work-group before any proceed past the barrier. If CLK_GLOBAL_MEM_FENCE and memory_scope_device are used, then the barrier will ensure that its accesses are visible to the entire device. The flag CLK_LOCAL_MEM_FENCE can be used only with memory_scope_work_group, as work-items outside the group do not have access to the memory space.
7.1.2 Atomics
The atomics defined in OpenCL 2.0 are based on C/C++11 atomics and are used to provide atomicity and synchronization. Atomicity safely allows a series of operations (such as read-modify-write) to execute without another work-item or host thread being able to view or modify the memory location in between. When used for synchronization, atomics are used to access special variables (called synchronization variables) that enforce parts of the memory consistency model. There are different flavors of atomic operations, including variations of atomic read-modify-writes, atomic loads, and atomic stores.
As we have mentioned, atomics are used to ensure that threads do not see partial results in a series of events—this is a problem in shared-memory, concurrent programming. Consider the example where we have two threads and both are trying to increment a shared value. Thread 0 must read the value from memory, increment the value, and write the new value to memory. Thread 1 must do the same. Figure 7.2 shows that the ordering of operations will produce different results. This is referred to as a data race. The same data race occurs even when the threads are running on a single core, as thread 0 can be preempted in the middle of performing the operation.
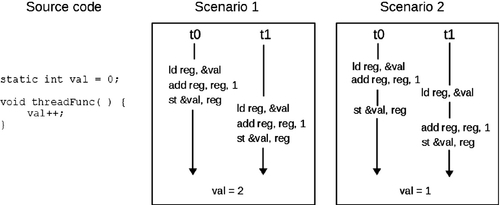
For similar reasons, atomic load and store operations are required. The C/C++11 standards, and likewise OpenCL, do not guarantee any load or store operations to be atomic. Imagine a scenario where a 64-bit store to memory is broken into two machine instructions. It is feasible that at some point in time the first store operation has finished but the second has not. At this time, another thread performs a load, reading 32 bits of the new stored value, and 32 bits of the old stored value. The value read by the second thread would be nonsensical and lead to unexpected results. In practice, most architectures do guarantee that loading or storing data at some granularity will be atomic (usually aligned types that fit within a cache line). However, portable code should never assume that any operation on shared memory is implicitly guaranteed to be atomic.
Atomic operations have changed considerably in the OpenCL 2.0 specification. The OpenCL C language defines atomic types that correspond to basic types, and requires support for integer and single-precision floating-point atomics:
Additional types are provided if optional 64-bit atomic extensions are supported:
The atomic pointer types require only 64-bit extension support if the compute device uses a 64-bit address space.
There are many variations of atomic operations specified in the OpenCL C language. Floating-point operands are supported only for the compare-and-swap class of atomic operations (e.g., atomic_exchange()). The operations that perform arithmetic and bitwise operations are referred to as atomic fetch-and-modify functions. The basic signature for operations of this type is as follows:
C atomic_fetch_ key (volatile A *object, M operand)
Here key can be add, sub, or, xor, and, min, or max. The parameter object is a pointer to a variable of one of the atomic types, and operand is the value to be applied. The return value, C, is the nonatomic version of type A, and holds the value pointed to by object immediately prior to the atomic operation. As an example use of an atomic function, suppose a work-item wants to find the minimum of a shared variable, atomic_int curMin, and a value in one of its variables, int myMin. The atomic function could be called as follows:
The new minimum will be stored in curMin. Specifying a variable to hold the return value is optional, and not specifying a variable for the return value is a potential performance optimization. On some GPU architectures, for example, atomics are performed by hardware units within the memory system. Thus, certain types of atomic operations can be considered complete as soon as they are issued to the memory hierarchy. However, utilizing the return value requires data to be sent back to the compute unit, potentially adding dozens to hundreds of cycles of latency.
The reason why atomics are being discussed as part of the memory model chapter is that they now play a fundamental role in synchronization. Whenever an atomic operation is performed, the programmer has the ability to specify whether the atomic should be treated as a synchronization operation that serves as an acquire operation, a release operation, or both. Using this mechanism allows work-items to control the visibility of their data accesses, enabling communication paradigms that were not possible in prior versions of OpenCL.
7.2 Global Memory
Global memory is identified in OpenCL C code by a pointer with the type qualifier _ _global (or global), by one of the image types, or by the pipe type. Data in the global memory space are accessible by all work-items executing a kernel (i.e., by all compute units in the device). The types of objects differ in their scope and use cases. The following sections discuss each global memory object type in detail.
7.2.1 Buffers
The _ _global address space qualifier refers to a pointer referencing data in a buffer object. A buffer can carry any scalar data type, vector data type, or user-defined structure. Whatever the type of buffer, it is accessed at the end of a pointer and can be read/write accessible as well as read only or write only.
Buffer objects map very easily to the standard array representation that programmers expect in the host C program. Consider the following host code, which is legal C:
The example shows that we can access a and b either through pointers or using array access syntax. This is important because it implies that data is allocated sequentially, such that the ith element of array a, a[i], is stored at location (a + i). We can use sizeof() operations on array elements to calculate offsets into arrays to cast to pointers of different types. In low-level code, it is useful to have these features, and it is a natural expectation for OpenCL, a C-derived language.
Thus, the following trivial operation code is an example of valid use of a buffer:
7.2.2 Images
Image objects, although conceptually in the _ _global memory space, are treated differently from buffers, and are not mappable to _ _global pointers. Image objects can be one-dimensional, two-dimensional, or three-dimensional, and are specified using the image1d_t, image2d_t, or image3d_t type qualifiers. Prior to OpenCL 2.0, images could be either read only or write only, but never both within the same kernel. This was a result of the design of GPU hardware supporting very high performance caching and filtering. Beginning in the 2.0 version of the specification, reading and writing the same image is supported.
Images are opaque memory objects. Although we can read or write the data on the basis of coordinates, we do not really know the relative memory locations of two different values in the image. As a result, and to support parameterization of the style of read, rather than accessing images through pointers, we use a set of built-in functions. The built-in functions to read an image are read_imagef(), read_imagei(), and read_imageui(), for floating-point, integer, and unsigned-integer data, respectively. Each of the image read functions takes three parameters: the image object, the image sampler, and the coordinates to sample.
The coordinates may be specified as integer or floating-point values. The output always returns a four-element vector type based on the type of the built-in read function. For example, the two signatures for reading floating-point data from a two-dimensional image are as follows:
Notice that the coordinates in the listed signatures are of type int2 and float2, respectively. This is because these signatures are specific to the two-dimensional image type, image2d_t. The functions for one-dimensional images (image1d_t) take int and float coordinates, and three-dimensional images (image3d_t) take int4 and float4 coordinates with the last component of the vector ignored.
If the image contains data that has less than four channels, most image types will return 0 for the values of the unused color channels and 1 in the alpha channel. For example, if a single channel image (CL_R) is read, then the float4 vector will contain (r, 0.0, 0.0, 1.0).
The second parameter to the read function is a sampler object. It is the sampler object that defines how the image is interpreted by the hardware or runtime system. The sampler can be defined either by declaring a constant variable of sampler_t type within the OpenCL C source or by passing as a kernel parameter a sampler created in host code using the clCreateSampler() function. The following is an example of using a constant-variable-declared sampler:
The sampler object determines the addressing and filtering modes used when accessing an image, and whether or not the coordinates being passed to the function are normalized.
Specifying normalized coordinates (CLK_NORMALIZED_COORDS_TRUE) tells the sampler that the dimensions of the image will be addressed in the range of [0, 1]. Use of nonnormalized (CLK_NORMALIZED_COORDS_FALSE) coordinates specifies that the coordinates will be used to index into a location within the image as if it were a multidimensional array.
The addressing mode options specify what to do on out-of-bounds accesses. These can sometimes be very useful for programmers who may otherwise have to write specific bounds checks within a program (e.g., a convolution where apron pixels reside out-of-bounds). The options include clamping to the value at the image’s border (CLK_ADDRESS_CLAMP) and wrapping around the image (CLK_ADDRESS_REPEAT).
The filtering mode has two options: return the image element nearest to the supplied coordinates (CLK_FILTER_NEAREST), or linearly interpolate the surrounding elements on the basis of the coordinates’ relative location (CLK_FILTER_LINEAR). For linear filtering of a two-dimensional image, a 2 × 2 square of image elements will be interpolated. For a three-dimensional image, a 2 × 2 × 2 cube of elements will be interpolated.
To facilitate more succinct use of image objects, the OpenCL C language also supplies samplerless read functions:
These simplified functions use a predefined sampler with fixed attributes: coordinates are unnormalized, there is no filtering with surrounding pixels, and results of out-of-bounds accesses are undefined. Accessing an image using this type of sampler is comparable to how we would access one- or multi-dimensional arrays in C; however, the opaque access function still allows for hardware optimizations.
Unlike reads, write functions do not take a sampler object. Instead the sampler is replaced with the value to be written:
When an image is being written to, the coordinates provided must be unnormalized and in the range between 0 and the size of the image dimension − 1.
As we have mentioned, implementing images as opaque types enables optimizations in the runtime system and hardware that buffers cannot support. Take one common optimization as an example. Any given multidimensional data structure, of which an image is an example, must be mapped to a one-dimensional memory address at some point. The obvious method, and indeed the method applied to multidimensional arrays in most programming languages, is a dictionary order in either a row-major or a column-major pattern. If data is stored in row-major order, (x, y) comes before (x + 1, y), which comes long before (x, y + 1), and so on. The long distance in memory between (x, y) and (x, y + 1) means that an access of consecutive addresses in the y-dimension strides inefficiently through memory, hitting a large number of cache lines. In contrast, the fact that (x, y) is adjacent to (x + 1, y) means consecutive accesses in the x-dimension stride efficiently (and cause memory accesses to coalesce).
Z-order, or Morton-order, memory layouts apply a mapping that preserves spatial locality of data points. Figure 7.3 shows that the data is stored in order (0, 0), (1, 0), (0, 1), (1, 1), (2, 0), and so on. By storing data according to its position in a Z-ordered mapping, we may hit the same cache line repeatedly when performing a vertical read. If we go further by laying out our computational work in a two-dimensional layout (as we see in the graphics pipeline), we further improve this data locality. This sort of optimization is possible transparently (and hence different optimizations can be performed on different architectures) only if we offer the kernel programmer no guarantees about the relative locations of memory elements.
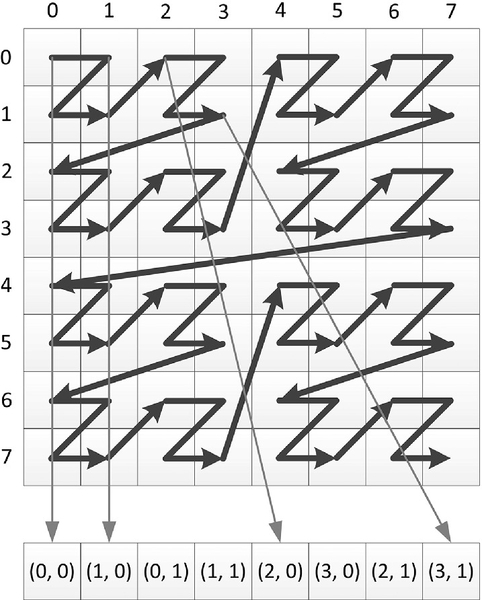
We can go a step further with this approach. If for execution we are using an architecture that does not have vector registers and does not perform vector reads from memory, we might wish float4 a = read_imagef( sourceImage, imageSampler, location) to compile down to four scalar reads instead of a single vector read. In these circumstances, it might be a more efficient use of the memory system to read from the same offset into four separate arrays instead of four times from the single array because the data in each separate array would exhibit better locality on each individual read operation.
7.2.3 Pipes
Recall that a pipe is an ordered sequence of data items that are stored in a first in, first out (FIFO) structure. Declaration of a pipe is slightly different than declaration of both buffers and images. An address space qualifier is not required for a pipe: since pipes are meant to communicate between kernel-instances, they implicitly store their data in global memory. Similarly to images, the keyword pipe is used to specify that a kernel argument is a pipe. Unlike images, a type must be provided that specifies the data type of the packets that are stored in the pipe. The data type can be any OpenCL C supported type (scalar or vector, floating point or integer), or a user-defined type built from the supported types. Along with the type, the programmer should supply an access qualifier that tells the kernel whether the pipe is readable (_ _read_only or read_only) or writable (_ _write_only or write_only) during its execution. The default is readable. A pipe cannot be both read by and written from the same kernel, so specifying the read/write access qualifier (_ _read_write or read_write) is invalid and will cause a compilation error.
An example of a kernel declaration containing one input pipe and one output pipe is as follows:
Similarly to images, pipe objects are opaque. This makes sense because the purpose of the pipe is to provide FIFO functionality, and therefore pipes should not be randomly accessed. OpenCL C provides functions in order to read packets from or write packets to a pipe. The most basic way to interact with a pipe is with the following read and write commands:
The function calls both take a pipe object, and a pointer to the location where the data should be written to (when reading from the pipe) or read from (when writing to the pipe). For both reading from and writing to a pipe, the function calls return 0 upon success. In some cases, these function calls may not complete successfully: read_pipe() returns a negative value if the pipe is empty, and write_pipe() returns a negative value if the pipe is full.
The programmer can ensure that reads from and writes to a pipe will always be successful by reserving space in the pipe ahead of time. The commands reserve_read_pipe() and reserve_write_pipe() both have a pipe object and number of packets as parameters, and return a reservation identifier of type reserve_id_t.
The reservation identifier returned by reserve_read_pipe() and reserve_write_ pipe() can then be used to access overloaded versions of read_pipe() and write_pipe(). The signature for the version of read_pipe() that takes a reservation identifier is as follows:
When reservation identifiers are used, OpenCL C provides blocking functions to ensure that reads or writes have finished: commit_read_pipe() and commit_write_pipe(), respectively. These functions take a pipe object and a reservation identifier as parameters, and have no return value. Once the function call has returned, it is safe to assume that all reads and writes have committed.
In addition to individual work-items reading from or writing to a pipe, some kernels may produce or consume data from the pipe on a work-group granularity. In order to remove some of the need to mask off individual work-items, OpenCL C provides intrinsic functions to reserve and commit accesses to the pipe per work-group. These functions are work_group_reserve_read_pipe() and work_group_reserve_write_pipe(). Similarly, the functions to guarantee that accesses have completed are work_group_commit_read_pipe() and work_group_commit_write_pipe(). In both cases, the work-group functions have signatures that mirror those for individual work-items. Note that all work-items must encounter these work-group-based functions, otherwise the behavior produced is undefined. Actual accesses to the pipe still occur using read_pipe() and write_pipe(). In Chapter 4, we demonstrated using pipes and their associated application programming interface (API).
7.3 Constant Memory
The constant address space, described by the _ _constant qualifier, intends to cleanly separate small sets of constant values from the global address space such that the runtime can allocate caching resources or utilize efficient constant memory banks if possible. Data can be created for the constant address space in two ways:
1. A buffer may be allocated and passed as a kernel argument. The kernel signature should specify the pointer using the _ _constant qualifier.
2. Variables within the kernel may be specified using the _ _constant qualifier as long as they are initialized and compile-time constant.
Architectures differ in how they treat this data. For example, in AMD GPUs, constant data is stored in a cache separate from the cache where general-purpose data is stored. This cache has lower latency than the level 1 (L1) cache, and can greatly reduce memory traffic within the GPU. Depending on the pattern of the access, the address may even be stored within the instruction, freeing up other functional units, and leading to even lower latency.
OpenCL defines a limited number of constant arguments for each device that, along with the constant buffer size, can be queried with CL_DEVIce:MAX_CONSTANT_ ARGS and CL_DEVIce:MAX_CONSTANT_BUFFER_SIZE arguments to clDeviceInfo(). Chapter 8 describes the implementation of constant memory on a modern GPU.
7.4 Local Memory
A subset of the architectures supported by OpenCL, including many of the GPUs and the Cell Broadband Engine, possess small scratchpad memory buffers distinct from the primary DRAM and caching infrastructure. Local memory in these cases is disjoint from global memory, and is often accessed using separate memory operations. As a result, data must be copied into and out of it programmatically. Depending on the architecture, this occurs either through direct memory access transfers (most efficiently accessed using the async_work_group_copy() function) or by memory-to-memory copies. Local memory is also supported in central processing unit (CPU) implementations, but it sits in standard cacheable memory; in such cases, use of local memory can still be beneficial because it encourages cache-aware programming.
Local memory is most useful because it provides the most efficient method of communication between work-items in a work-group. Any allocated local memory buffer can be accessed at any location by an entire work-group, and hence writes to the local array will be visible to other work-items. Remember that OpenCL work-items are conceptually, if not literally, executed independently. Local memory is defined by the _ _ local address space qualifier, and can either be defined within the kernel or passed as a parameter. Both examples are shown in the following code:
Figure 7.4 shows a diagrammatic representation of the data flow in the previous code sample. Note that data will be read from global memory and written to the two local arrays C and aLocalArray at unpredictable times as the work-items execute independently in an undefined order. The reality will be slightly more predictable on a given device because implementations will map to hardware in predictable ways. For example, on AMD GPUs, execution occurs in lockstep over a wide single instruction multiple data (SIMD) vector, meaning that the read and write operations will have an ordering guarantee over the entire vector in the same way that they would over a single work-item. However, this feature does not apply generally. In the general case, we must insert the barrier operation: only at this barrier can we guarantee that all writes to local arrays, and the global memory reads that fed them, will have been completed across the work-group such that the data is visible to all work-items. Beyond this barrier, the data can be used by the entire work-group as shown in the lower part of the diagram.
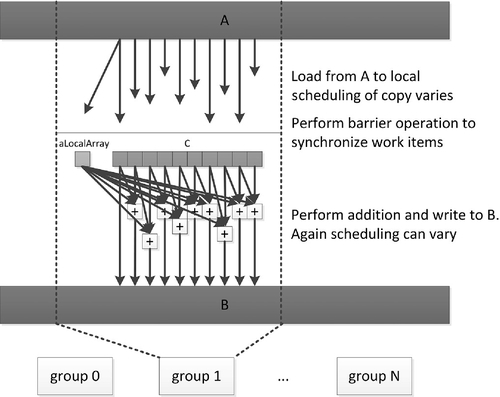
In the kernel code, aLocalArray is at function scope lexically but is visible to the entire work-group. That is, there is only one 32-bit variable in local memory per work-group, and any work-item in the group using the name aLocalArray has access to the same 32-bit value. In this case, after the barrier we know that work-item 0 has written to aLocalArray, and hence all work-items in the group can now read from it.
The alternative method for creating local arrays is through a kernel parameter, as we see for array C. This version is created by a runtime API call. To allocate the memory, we call clSetKernelArg() as we would for passing a global array to the kernel, but we leave the final pointer field as NULL. We therefore allocate a per-work-group amount of memory on the basis of the third parameter but with no global object to back it up, so it sits in local memory:
7.5 Private Memory
Private memory refers to all variables with automatic storage duration and kernel parameters. In principle, private data may be placed in registers, but owing to either a lack of capacity spilling or an inability for the hardware to dynamically index register arrays, data may be pushed back into global memory. The amount of private memory allocated may impact the number of registers used by the kernel. Like local memory, a given architecture will have a limited number of registers. The performance impact of using too large a number will vary from one architecture to another.
CPUs of the x86 type have a relatively small number of registers. However, because of large caches, the operations of pushing these registers to memory on the stack and returning them to registers later often incur little overhead. Variables can be efficiently moved in and out of scope, keeping only the most frequently used data in registers.
GPUs do not generally have the luxury of using a cache in this way. Some devices do not have read/write caches, and those that do may be limited in size, and hence spilling registers from a large number of work-items would rapidly lead to filling this cache, leading to stalling on a miss when the data is required again. Spilling to DRAM on such a device causes a significant performance degradation, and is best avoided.
When registers are not spilled, the capacity of the register bank of a GPU trades against the number of active threads in a manner similar to that of local data shares (LDS) as described in Chapter 8. The AMD Radeon HD R9 290X architecture has 256 kB of registers on each compute unit. This is four banks (one per SIMD) of 256 registers, with each register a 64-wide vector with 4 bytes per lane. If we use 100 registers per work-item, only two waves will fit per SIMD, which is not enough to cover anything more than instruction latency. If we use 49 registers per work-item, we can fit five waves, which helps with latency hiding.
Moving data into registers may appear to improve performance, but if the cost is that one fewer wavefront can execute on the core, less latency hiding occurs, and we may see more stalls and more wasted GPU cycles.
7.6 Generic Address Space
In all prior versions of OpenCL, the use of named address spaces required programmers to write multiple versions of callable OpenCL C functions based on the address space of where the arguments resided. Consider the following example that doubles the data in a buffer, either directly within global memory, or after first caching the data in local memory. While doubling a value is trivial, it is easy to imagine functions that may prefer to use a global memory pointer directly (e.g., when executing on a CPU with an automatic caching system), or sometimes prefer to work from local memory (e.g., when executing on a GPU with fast scratchpad storage). Prior to OpenCL 2.0, the function to perform the doubling operation would have to be written twice, once per address space as shown in Listing 7.1.

Starting in OpenCL 2.0, pointers to a named address spaces can be implicitly converted to the generic address space as shown in Listing 7.2.


The generic address space subsumes the global, local, and private address spaces. The specification states that the constant address cannot be either cast or implicitly converted to the generic address space. Even though the constant address space is logically considered a subset of the global address space, in many processors (especially graphics processors), constant data is mapped to special hardware units that cannot be targeted dynamically by the instruction set architecture.
7.7 Memory Ordering
A very important part of the memory model provided by any programming language is the ordering guarantees that threads can expect. When we are working with multiple threads and shared data, the memory consistency model defines how threads can interact to generate “correct” results. With OpenCL, a language that provides portability of highly parallel applications to multiple classes of devices, the formal specification of these requirements is very significant.
As we have discussed, work-items executing a kernel have shared access to data in global memory. Additionally work-items within a work-group have shared access to data in local memory. Until now, we have dealt largely with the case of what is referred to as OpenCL’s “relaxed” consistency model. For global memory, we have simplified the more complicated memory model away, and said that by default work-items from different work-groups cannot expect to see updates to global memory. In regard to updates to a memory object, we have said that updates cannot be assumed to be complete until the correspond command utilizing the object is set to CL_COMPLETE. Indeed, this simplification is largely correct and will likely cover the majority of OpenCL kernels. As we saw in Chapter 4, this view of the memory consistency model was enough to support applications such as a histogram and a convolution.
In recent years, languages such as C, C++, and Java have all converged to support acquire-release operations to enable lock-free synchronization between threads. These operations help support additional classes of parallel applications, such as those that require critical sections of code. OpenCL 2.0 has also added support for acquire-release operations based on the C11 specification. In addition to allowing OpenCL developers to expand the classes of problems that they can solve, support for these synchronization operations also makes it easier for higher-level languages to target OpenCL.
The most intuitive way for programmers to reason about memory is using the sequential consistency model. If a system were to implement sequential consistency, memory operations from each processor would appear to execute in program order, and operations from all processors would appear in a sequential order. However, sequential consistency would greatly restrict optimizations that have no effect on program correctness (e.g., reordering of instructions by the compiler or using a store buffer in the processor). Therefore, memory models often “relax” the requirements of sequential consistency while producing the equivalent output. Relaxing sequential consistency requires hardware and software to adhere to certain rules. For the programmer, this comes at the cost of sometimes telling the hardware when data needs to be made visible to other threads.
Although sometimes required for program correctness, synchronization opera- tions have more overhead than does working with the relaxed memory model. OpenCL therefore provides options to be specified with each synchronization operation that allow the programmer to specify only the required strength and scope of synchronization. These options are referred to as memory order and memory scope, respectively.
OpenCL provides options to specify three different degrees of consistency (from weakest to strongest): relaxed, acquire-release, and sequential. These options are specified as memory order options with the following semantics:
• Relaxed (memory_order_relaxed): This memory order does not impose any ordering constraints—the compiler is free to reorder this operation with preceding or subsequent load and store operations, and no visibility guarantees are enforced regarding preceding or subsequent side effects. Atomic operations in previous versions of the OpenCL standard were implied to have a relaxed memory order. Because of their limited guarantees, programmers may find using relaxed ordering provides the best performance for operations such as incrementing counters.
• Acquire (memory_order_acquire): Acquire operations are paired with loads. When this memory order is specified for a synchronization operation, any shared memory stores that have been “released” by other units of execution (e.g., other work-items, or the host thread) are guaranteed to be visible. The compiler has the liberty to move preceding load and store operations to be executed after the synchronization; however, it may not move subsequent load and store operations to execute prior to the synchronization.
• Release (memory_order_release): Complementary to acquire operations, release operations are paired with stores. When a release memory order is specified for a synchronization operation, the effects of any preceding stores must be made visible, and all preceding loads must have completed before the synchronization operation can complete. Complementary to acquire operations, the compiler has the liberty to move subsequent load and store operations prior to the synchronization; however, it may not move any prior load or store operations after the synchronization.
• Acquire-release (memory_order_acq_rel): This memory order has the properties of both the acquire and release memory orders: it will acquire any released side effects from other units of execution, and will then immediately release its own side effects. It is typically used to order read-modify-write operations.
• Sequential (memory_order_seq_cst): This memory order implements sequential consistency for data-race-free programs.1 With sequential consistency, the loads and stores of each unit of execution appear to execute in program order, and the loads and stores from different units of execution appear to be simply interleaved. This is stronger than memory_order_acq_rel because it imposes a single total ordering of accesses.
When synchronization operations to global memory are performed, specifying only a memory order may introduce more overhead than is strictly required by the program. For instance, imagine a system that includes multiple devices, sharing a context that contains a fine-grained shared virtual memory (SVM) buffer. If a work-item performed a synchronization operation with a release, the device executing the work-item would need to ensure that all stores performed by the work-item were first visible to all devices in the system—incurring significant overhead if not required for algorithmic correctness. Therefore, for many operations, memory order arguments are optionally accompanied by a memory scope, which limits the visibility of operations to the specified units of execution.
The options that can be specified as a memory scope are as follows:
• Work-item (memory_scope_work_item): Specifies that memory ordering applies only to the work-item. This is required for RAW operations on image objects.
• Work-group (memory_scope_work_group): Specifies that memory ordering applies to work-items executing within a single work-group. This could potentially be used as a lighter-weight synchronization than the barrier with memory fence that we have needed in the past for work-group synchronization.
• Device (memory_scope_device): Specifies that memory ordering applies to work-items executing on a single device.
• All devices (memory_scope_all_svm_devices): Specifies that memory ordering applies to work-items executing across multiple devices and the host (when using fine-grained SVM with atomics).
Unlike accesses to global memory, specifying a memory scope for accesses to local memory is not required (and in fact will be ignored)—local atomics will always have a scope of memory_scope_work_group. Since local memory is accessible only by work-items from a work-group, trying to provide ordering guarantees to execution units outside the work-group with memory_scope_device or memory_scope_all_svm_devices does not make sense.
7.7.1 Atomics Revisited
Earlier in this chapter we briefly described support for atomics in OpenCL 2.0. Now that we have been introduced to memory ordering and scope, we will briefly revisit atomics.
Recall that we introduced groups of atomic operations, such as atomic loads, atomic stores, and atomic fetch-and-modify operations. We showed the following signature for fetch-and-modify operations:
C atomic_fetch_ key (volatile A *object, M operand)
Here, key could be replaced by operations such as add, min, and max. Recall that for these type of operations, the parameter object is a pointer to a variable of one of the atomic types, and operand is the value to be applied. The return value, C, is the nonatomic version of type A, and holds the value pointed to by object immediately before the atomic operation.
In addition to the aforementioned properties regarding atomics, C/C++11 and OpenCL 2.0 utilize them for enforcing memory ordering. Thus, all atomic functions provide multiple signatures that support order and scope arguments. For example, fetch-and-modify functions also include the following signatures:
C atomic_fetch_ key _explicit(volatile A *object, M operand, memory_order order)
C atomic_fetch_ key _explicit(volatile A *object, M operand, memory_order order, memory_scope scope)
This, by design, makes atomic operations the primary mechanism for synchronization between threads. The reason that synchronization was implemented as a property of atomics is that atomic operations on a flag are a common way for one thread to let another know that data is ready or to permit access to a region of code. It therefore becomes natural that when one thread wants another to be able to see some data, it should (atomically) set a flag and then release its shared data. The other thread should be able to read the flag, and upon finding a success condition, should have acquired the latest copy of any shared data.
Notice that atomic operations that include the parameter for memory order have explicit appended to their name. Functions that do not end in explicit are implemented to have the same semantics as if the memory order were specified as memory_order_seq_cst, and the memory scope were specified as memory_scope_ device.
In addition to the load, store, and fetch-and-modify classes of atomic instructions, OpenCL C also supports functions for atomic exchange, compare-and-exchange (i.e., compare-and-swap), and test-and-set functionality. One version of the compare-and-swap function has the following signature:
Unlike any previous signature we have seen, atomic_compare_exchange_strong_ explicit() has memory order arguments success and failure. These arguments specify what ordering should be performed when the compare operation succeeds (i.e., the exchange happens) and when it fails. This can enable the programmer to limit potentially expensive synchronizations to occur only when necessary. For example, the programmer may want to pass memory_order_relaxed as an argument to the failure parameter in the case that a work-item is waiting for a successful exchange operation before proceeding.
So far we have discussed the use of atomic operations, but have not described how they are initialized. OpenCL C has two options for initializing atomics depending on the scope of their declaration. Variables declared with a program scope can be initialized with the macro ATOMIC_VAR_INIT(), with the following signature:
This macro initializes atomic objects that are declared in program scope and allocated in the global address space. For example,
Atomic variables declared with automatic storage should be initialized using the (nonatomic) function atomic_init(). Notice that because atomic_init() is nonatomic itself, it cannot be called concurrently by multiple work-items. Instead, initialization requires serialization and synchronization, such as in the following code:
7.7.2 Fences
A synchronization operation without an associated memory location is a fence. Although we have seen some practical use of fences for work-group synchronization, we have not yet detailed their use for memory ordering. In OpenCL C, a fence operation is performed by calling atomic_work_item_fence(), with the following signature:
The flags parameter can be set to CLK_GLOBAL_MEM_FENCE, CLK_LOCAL_MEM_FENCE, or CLK_IMAGE_MEM_FENCE, or a combination of these using a bitwise OR. A combination of these values has the same effect as if the fence were called with each parameter individually. The memory order and memory scope parameters have the effect of defining ordering constraints and setting the scope of the fence, as we have seen previously.
Recall that on many systems image objects are still subject to the constraints of non-general-purpose graphics hardware. The OpenCL specification recognizes this, and requires atomic_work_item_fence() to be called with CLK_IMAGE_MEM_FENCE to ensure that image writes are visible to later reads—even by the same work-item. If multiple work-items will be synchronizing and reading data that were previously written by a different work-item from the group, then work_group_barrier() called with CLK_IMAGE_MEM_FENCE should be used instead. Another subtle case where work-item fences are required is for ordering accesses to local and global memory together.
We previously introduced the combination of a work-group barrier and memory fence to be used as a synchronization function. More formally, this can be thought of as two fence operations—referred to as entry and exit fences. The entry fence is a release fence with the specified flags and scope. Likewise, the exit fence is an acquire fence with the specified flags and scope.
7.8 Summary
This chapter provided details on the abstract memory model used by work-items when executing OpenCL kernels. The memory model includes memory spaces, memory object types, and the consistency models for these spaces and types supported by the specification. Combined with the host-side memory model presented in Chapter 6, the reader should now have a solid understanding of the management and manipulation of data within an OpenCL application.