
Introduction to model management and analytics
Bedir Tekinerdogana; Önder Baburb; Loek Cleophasb,c; Mark van den Brandb; Mehmet Akşitd aInformation Technology Group, Wageningen University, Wageningen, The Netherlands
bEindhoven University of Technology, Eindhoven, The Netherlands
cStellenbosch University, Matieland, Republic of South Africa
dUniversity of Twente, Computer Science, Formal Methods & Tools Group, Enschede, The Netherlands
Abstract
Model management and analytics (MMA) aims to use models and related artifacts to derive relevant information to support decision making processes of organizations. Various different models as well as analytics approaches could be identified. In addition, MMA systems will have different requirements and as such apply different architecture design configurations. In this chapter we will discuss the key concepts related to MMA by referring also to existing data analytics approaches. We present and discuss the current key data analytics reference architectures in the literature and the key requirements for MMA. Subsequently, we provide the reference architecture of MMA using multiple architecture viewpoints. We illustrate the framework using a real-world example.
Keywords
model-driven engineering; scalability; model analytics; data mining; Machine Learning
1.1 Introduction
The idea of creating business value from data has always been an important concern. Many businesses have extracted information from data to gain new insights and make smarter decisions. Together with the advancements of disruptive technologies such as Cloud Computing and Internet of Things, the ability to capture and store vast amounts of data has grown at an unprecedented rate and soon did not scale with traditional data management techniques. Yet, to cope with the rapidly increasing volume, variety, and velocity of the generated data we can now adopt the available novel technical capacity and the infrastructure to aggregate and analyze huge and variant sets of data. This situation has led to new and unforeseen opportunities for many organizations. Data science, and Big Data in particular, has now become a very important driver for innovation and growth for various industries, such as health, administration, agriculture, and education.
Big Data is usually characterized using four V's, that is, volume, variety, velocity, and veracity. Volume is one the key characteristics of Big Data, indicating the large amount of data that usually does not fit on one computer. Variety relates to the different data types, including structured data, semistructured data, and unstructured data. Velocity refers to the speed at which the data are generated as well as being processed. Finally, veracity refers to the trustworthiness of the data.
With Big Data, different types of data have been addressed, including text, audio, and video. A different type of data that did not get much attention yet is the whole set of models that is used in various engineering and science disciplines. A model is an abstract representation of selected parts of the considered domain. In science, models can relate to, for example, physical and chemical models. In engineering, models can relate to the intermediate artifacts for realizing the eventual system. In software engineering, models are, for example, the UML design artifacts.
In this context, model management and analytics (MMA) aims to use models and related artifacts to derive relevant information to support, in the most general sense, decision making processes of organizations. This can have several benefits, including the understanding, development, maintenance, and management of those artifacts. Various different models as well as analytics approaches could be identified. In this chapter we will borrow from existing domains, potentially to be adapted and exploited for MMA.
1.2 Data analytics concepts
Data analytics is the discovery, interpretation, and communication of meaningful patterns in data. Using data analytics, data are examined in order to gain insight, from which one can make decisions and take actions that lead to effective outcomes. Hence, the goal of analytics is usually to improve the business by gaining knowledge which can be used to make improvements or changes. Traditionally, data analytics predominantly refers to various set of applications, such as basic business intelligence (BI), online analytical processing (OLAP), and various forms of advanced analytics. Data analytics is related to the term business analytics, with the difference that the latter is focused on business uses, while data analytics has a broader focus.
Data analytics is important to support decision making and likewise help organizations better achieve their business goals. Different types of analytics can be distinguished, including:
- • Descriptive analytics uses historical data to provide insight into what has happened.
- • Diagnostics analytics again uses the historical data to answer why something has happened.
- • Predictive analytics elaborates on the insight of the analyzed data and answers what can happen.
- • Prescriptive analytics, which usually builds on and uses the other types of analytics, answers the question what to do.
Each of these types of analytics can be understood quite simply as using data to answer different types of questions. In the case of data analytics the source is the traditional data (e.g., text, audio, video, etc.). With model analytics we assume that the analytics takes as input a set of models to support the decision making process.
Model analytics can thus be considered as a subcategory of data analytics orienting particularly on model artifacts.
Based on the observations above, we thus advocate a perspective where model-* (as an umbrella term for model-driven, model-based, and other related approaches) artifacts are treated holistically as data, processed, and analyzed with various scalable and efficient techniques, possibly inspired by related domains. Tackling large volumes of artifacts has been commonplace in other domains, such as text mining for natural language text [1] and repository mining for source code [2]. While we might not be able to apply those techniques as-is on model-* artifacts, the general data analytics workflow appears to be applicable with the steps of data collection, cleaning, integration and transformation, feature engineering and selection, modeling (e.g., as statistical models or neural networks), and finally deployment, exploration, and visualization.
1.3 The inflation of modeling artifacts
The problem of the large number of models is not new in the model-* world. Several efforts have indeed been initiated to store and manage large numbers of models and related artifacts [3,4]. Further efforts include mining public repositories for MDE-related items from GitHub, e.g., Eclipse-based MDE technologies [5] and UML models [6] (the Lindholmen dataset). In the latter, the number of UML models can reach more than 90k. We have previously demonstrated the increasing number of newly created Ecore metamodels, as well as a number of commits on them, on GitHub [7]. A part of the results is given in Fig. 1.1, depicting a strong upward trend for the number of commits and newly created files over the years. It is evident that there are increasingly more Ecore metamodels in GitHub. We have further evidence that other types of modeling artifacts and repositories follow similar trends [8].
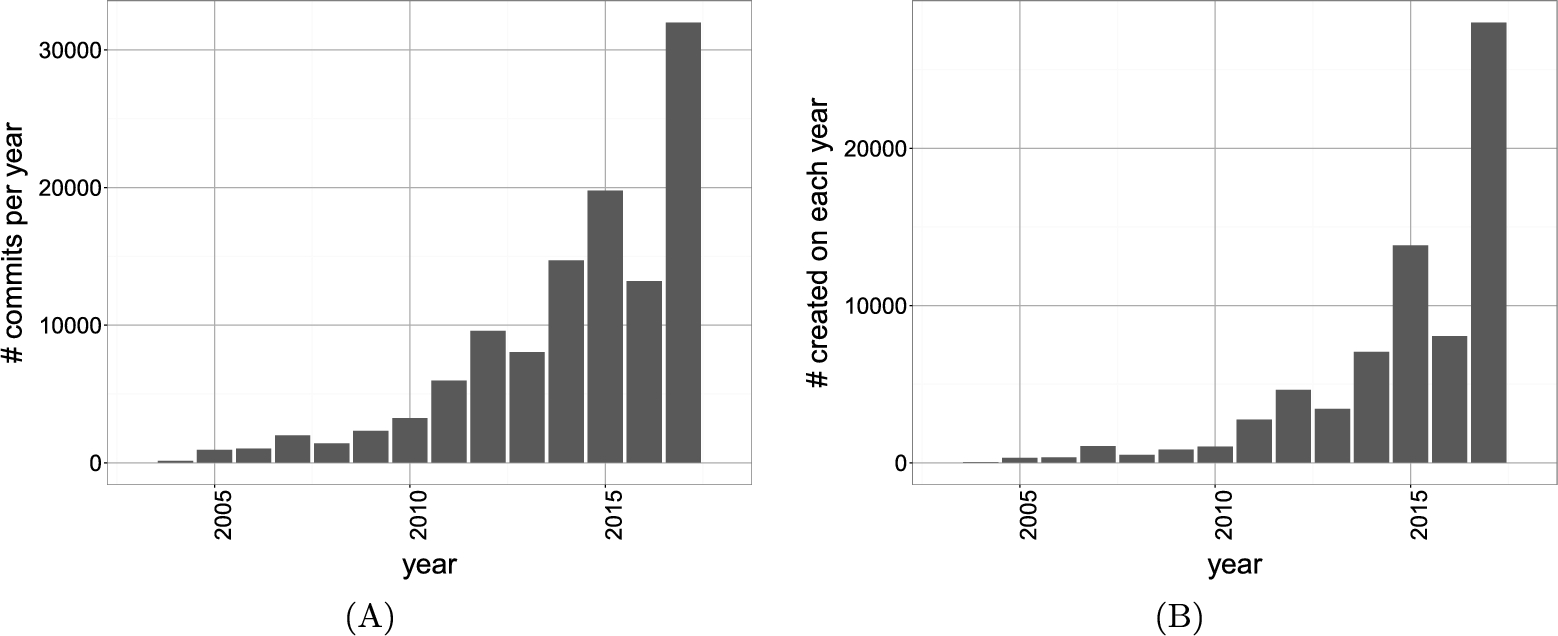
Moreover, it appears that even within a single industry or organization, a similar situation emerges with the increasing adoption of model-* approaches. Just a single company might need to manage an ecosystem consisting of dozens of metamodels, thousands of models, and tens of thousands LOCs of transformations. With the complete revision history, the total number of artifacts can reach tens of thousands. Along with conventional forward engineering approaches, we can observe an increasing trend with legacy software: automated migration into model-driven/-based engineering using process mining and model learning.
All the presented facts, from open source as well as industry, let us confirm the statement by Brambilla et al. [9] and Whittle et al. [10] that the adoption of model-* approaches in (at least some parts of) the industry grows quite rapidly, and we conclude that tackling these artifacts, namely MMA, will be increasingly important in the future.
1.4 Relevant domains for MMA
Despite the different nature of models, as exemplified above, we can be inspired by techniques from other disciplines and try to adapt them for the problems in MMA. As a preliminary overview, in this section we list and discuss several such domains. While there is related model-* research on some of the items on the list, we believe a conscious and integrated mindset would mitigate the challenges for scalable application of model-* approaches.
Descriptive statistics Several model-* researchers have already performed empirical studies on model-* artifacts with a statistical mindset. For instance, Kolovos et al. assess the use of Eclipse technologies in GitHub, giving related trend analyses [5]. Mengerink et al. present an automated analysis framework on version control systems with similar capabilities [11]. Di Rocco et al. perform a correlation analysis on metrics for various model-* artifacts [12]. Descriptive statistics could in the most general sense be exploited to gain insight in large numbers of model-* artifacts in terms of general characteristics, patterns, outliers, statistical distributions, dependence, etc.
Information retrieval Techniques from information retrieval (IR) can facilitate indexing, searching, and retrieving of models, and thus their management and reuse. The adoption of IR techniques on source code dates back to the early 2000s, and within the model-* community there has been some recent effort in this direction (e.g., by Bislimovska et al. [13]). Further IR-based techniques can be found in [14,15] involving repository management and model searching scenarios.
Natural language processing Accurate natural language processing (NLP) is needed to handle realistic models with noisy text content, compound words, and synonymy/polysemy. In our experience, it is very problematic to blindly use NLP tools on models, e.g., just WordNet synonym checking without proper part-of-speech tagging and word sense disambiguation. More research is needed to find the right chain of NLP tools applicable for models (in contrast to source code and documentation), and reporting accuracies and disagreements between tools (along the lines of the recent report in [16] for repository mining). Note that NLP offers further advanced tools, such as language modeling, which are still to be investigated for model-* approaches.
Data mining Following the perspective of approaching model-* artifacts as data, we need scalable techniques to extract relevant units of information from models (features in data mining jargon) and to discover patterns, including clusters, outliers/noise, and clones. Several example applications can be found in [14,15,17] for domain clustering EMF metamodels, and in [18] for classifying forward vs. reverse engineered UML models. To analyze, explore, and eventually make sense of the large model-* datasets (e.g., the Lindholmen dataset [6]), we can investigate what can be borrowed from comparable approaches in data mining for structured data.
Graph databases and graph-based methods Given that quite some commonly used models, such as UML, are based on an underlying graph, graph databases can be used to store, query, and reason about models. There has already been some effort using graph databases, such as Neo4EMF [19] as a persistence layer for (potentially very big) models, and Mogwaï [20] as a fast and complex querying mechanism for models. Another related idea is presented by Clarisó and Cabot [21], who advocate using graph kernel-based methods for several model-* tasks such as model searching and clustering.
Machine learning The increasing availability of large amounts of model-* data can be exploited, via Machine Learning, to automatically infer certain qualities and predictor functions (e.g., performance). There has been a thrust of research in this direction for source code (e.g., for fault prediction [23]), and it would be noteworthy to investigate the emerging needs of the model-* communities and feasibility of such learning techniques for model-* approaches. The approaches in [24] for learning model transformations by examples and [25] for automatic model repair using reinforcement learning are some of the few pieces of such work in model-* approaches.
Visualization We propose visualization and visual analytics techniques to inspect a whole dataset of artifacts (e.g., cluster visualizations in [15], in contrast with visualizing a single big model in [26]) using various features such as metrics and cross-artifact relationships. The goals could range from exploring a repository to analyzing a model-* ecosystem holistically and even studying the (co-)evolution of model-* artifacts.
Distributed/parallel computing With the growing amount of data to be processed, employing distributed and parallel algorithms in model-* approaches is very relevant. There are conceptually related approaches worthwhile investigating, e.g., distributed model transformations for very large models [27,28] or model-driven data analytics [29]. Yet we wish to draw attention here to performing computationally heavy data mining or Machine Learning tasks for large model-* datasets in an efficient way.
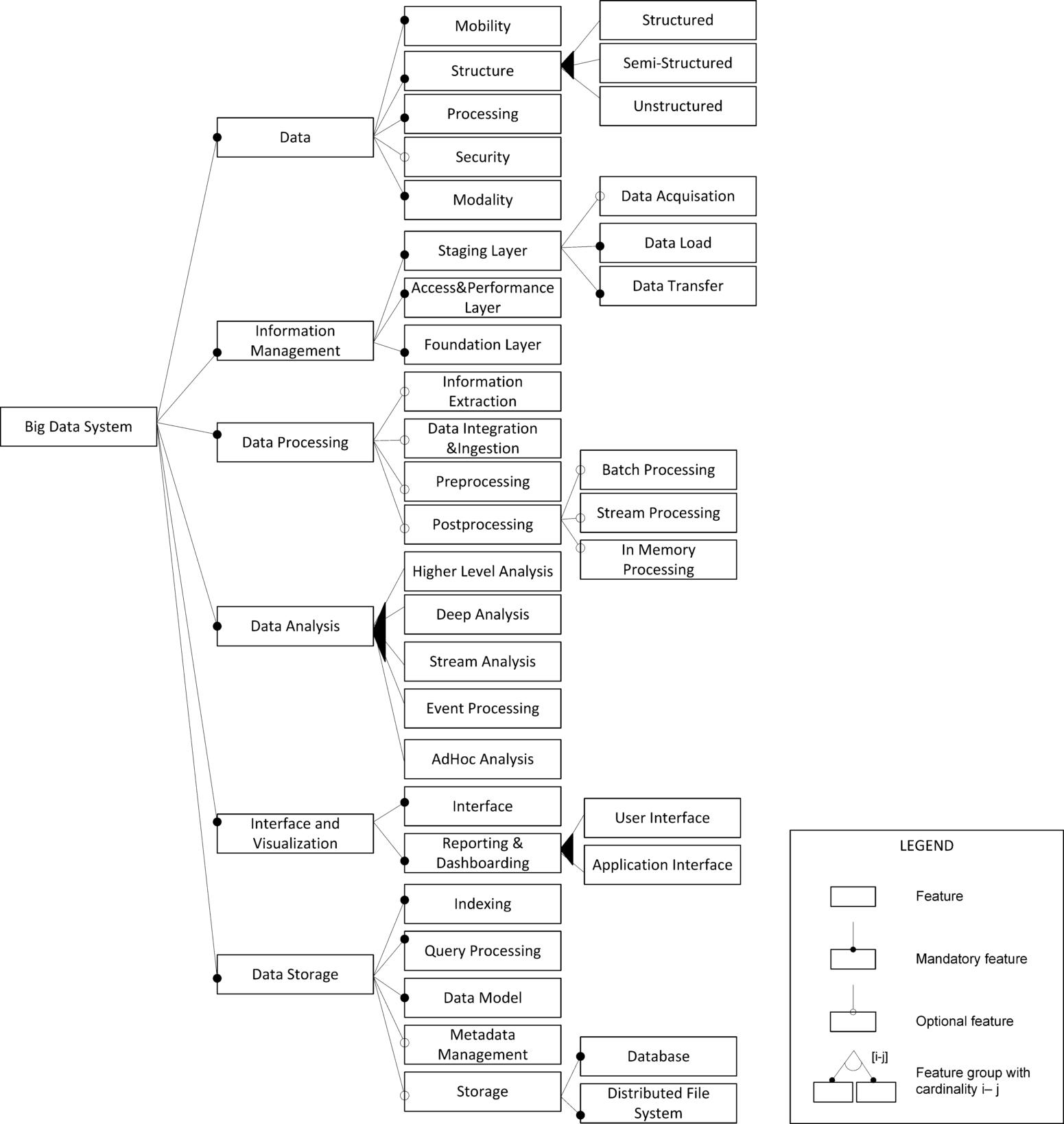
(Big) data analytics One of the key domains that is related to and required for managing large collections of models is obviously Big Data. Based on the literature, we have derived the family feature model for Big Data systems, as shown in Fig. 1.2. This has been largely adopted from our earlier work on a feature-based analysis of Big Data systems [22]. The feature diagram contains features representing the essential characteristics or externally visible properties of the system. Features may be mandatory or alternative/optional and may have subfeatures which as such can lead to a hierarchical tree. Besides the conceptual model, MMA can get inspiration from the different Big Data reference architectures in the literature. Notable ones would include the lambda architecture, which is a three-layer architecture aimed at a robust and fault-tolerant system [30], and a functional architecture with six key modules representing phases from data extraction and loading to interfacing and visualization [31]. MMA could be seen from the Big Data perspective. In that case, the MMA approaches can be represented using the features of the family feature diagram of Fig. 1.2.
The above represents a nonexhaustive list of domains as a preliminary exploitation guideline for MMA. Although the aforementioned domains themselves are quite mature on their own, it should be investigated to what extent results and approaches can be transferred into the model-* technical space, particularly for MMA. The chapters in this book approach the topic from these and other different perspectives, and likewise provide valuable insight in the MMA domain.