
Model analytics for industrial MDE ecosystems
Önder Babura; Aishwarya Suresha; Wilbert Albertsb; Loek Cleophasa,c; Ramon Schiffelersa,b; Mark van den Branda aEindhoven University of Technology, Eindhoven, The Netherlands
bASML N.V., Veldhoven, The Netherlands
cStellenbosch University, Matieland, Republic of South Africa
Abstract
Widespread adoption of Model-Driven Engineering (MDE) in industrial contexts, especially in large companies, leads to an abundance of MDE artifacts such as Domain-Specific Languages and models. ASML is an example of such a company where multidisciplinary teams work on various ecosystems with many languages and models. Automated analyses of those artifacts, e.g., for detecting duplication and cloning, can potentially aid the maintenance and evolution of those ecosystems. In this chapter, we explore a variety of model analytics approaches using our framework SAMOS in the industrial context of ASML ecosystems. We have performed case studies involving clone detection on ASML's data and control models within the ASOME ecosystem, cross-language conceptual analysis and language-level clone detection on three ecosystems, and finally architectural analysis and reconstruction on the CARM2G ecosystem. We discuss how model analytics can be used to discover insights in MDE ecosystems (e.g., via model clone detection and architectural analysis) and opportunities such as refactoring to improve them.
Keywords
Model-Driven Engineering; Domain-Specific Languages; model analytics; model clone detection; clustering; topic modeling; architectural analysis; software ecosystems; software maintenance
11.1 Introduction
The increased use of Model-Driven Engineering (MDE) techniques leads to the need to address issues pertaining to the growing number and variety of MDE artifacts, such as Domain-Specific Languages (DSLs) and the corresponding models. This is indeed the case when large industries adopt MDE for multiple domains in their operation. ASML, the leading producer of lithography systems, is an example of such a company where multidisciplinary teams work on various MDE ecosystems involving tens of languages and thousands of models [1]. Automated analyses of those artifacts can potentially aid in the maintenance and evolution of those ecosystems. One example issue with these ecosystems is that of duplication and cloning in those artifacts. The presence of clones might negatively affect the maintainability and evolution of software artifacts in general, as widely reported in the literature [2]. In the general sense, when multiple instances of software artifacts (e.g., language or model fragments in our case) exist, a change required in such a fragment (to fix a bug, for instance) would also have to be performed on all other instances of this fragment. Inconsistent changes to such fragments might also lead to incorrect behavior. Therefore, eliminating such redundancy in software artifacts might result in improved maintainability. While not all cases of encountered clones can be considered negative [3], as some might be inevitable or even intended, it is worthwhile to explore what types of clones exist and what their existence might imply for the system.
The growing number of DSLs in the variety of ecosystems, on the other hand, also demands ways to automatically analyze those languages, e.g., to give an overview of the domains and subdomains of the enterprise-level ecosystem (i.e., system of ecosystems). Other interesting analyses would include the similarities, conceptual relatedness, and clone fragments among the various languages both within and across the ecosystems.
In this work, we explore a variety of model analytics approaches using our framework SAMOS (Statistic Analysis of MOdelS) [4,5] in the industrial context of ASML ecosystems. We perform case studies involving clone detection on ASML's data models and control models of the ASOME ecosystem, cross-DSL conceptual analysis and language-level clone detection on three ecosystems (ASOME, CARM2G, wafer handler), and finally architectural analysis and reconstruction, using a technique called topic modeling [6], on the CARM2G ecosystem DSLs. We provide insights into how model analytics can be used to discover factual information on MDE ecosystems (e.g., what types of clones exist and why) and opportunities such as refactoring to improve the ecosystems.
The rest of the chapter is structured as follows. In Section 11.2 we introduce our main objectives for analyzing MDE ecosystems. In Sections 11.3 to 11.5, we give some background information on our SAMOS analysis framework as the basis of our studies, ASML ecosystems, and the concept of model clones, respectively. We detail how we used and extended SAMOS for the clone detection tasks on ASML's ASOME ecosystem models in Section 11.6. We provide extensive case studies in Section 11.7: clone detection in ASOME data models and control models, cross-DSL conceptual analysis and language-level clone detection, and finally architectural analysis of the CARM2G ecosystem. We continue in Section 11.8 with a general discussion and threats to validity, with related work on important topics such as model clone detection and topic modeling in Section 11.9, and finally with conclusions and pointers for future work in Section 11.10.
11.2 Objectives
This section presents the objectives that we pursued to analyze the MDE ecosystems at ASML. First, we would like to point out that we used and extended our model analytics framework, SAMOS, to perform various analyses on the MDE artifacts. Since SAMOS already provides a means to detect clones for Ecore metamodels (representing the DSLs in the ecosystems), we explore how this framework can be extended (1) to analyze models adhering to the domain-specific metamodels used at ASML and (2) to incorporate additional techniques, e.g., for architectural analysis.
ASML uses the ASOME modeling language [7] to model the behavior of its machines. To analyze ASOME models in SAMOS, we first need to understand the elements involved in these models, based on the metamodels they adhere to. This is necessary to extend the feature extraction part, determining, e.g., which model parts to extract (and in which specific way) or to ignore. Moreover, while SAMOS defines comparison schemes for the comparison of features extracted from, e.g., Ecore metamodels, it has yet to be examined if these comparison schemes are suitable for ASOME models.
Our analysis of ASOME models in this work, namely, clone detection, also needs to be evaluated with respect to accuracy and relevance. The goal of clone detection in this context is to find a way to use this information to investigate, and if possible reduce, the level of cloning in the models. The largest part of the analysis done in this chapter is clone detection on ASOME models at ASML. We consider three aspects: (1) applying and extending SAMOS to detect clones in ASOME models, (2) assessing the accuracy and relevance of the clones found, and (3) improving the maintainability of the MDE ecosystems at ASML based on the discovered cloning information.
Given the variety of MDE ecosystems at ASML, each of which consists of several languages represented by metamodels, we have a few additional objectives related to language-level analyses. First of all, we would like to investigate what overview and high-level insights we can gain by clustering the metamodels of multiple ecosystems. Similarly, we are also interested in the cloning at the language-level within and among the ecosystems, along with their relevance, nature, and actionability for improving the quality of the ecosystems. Finally we also consider a focused study on the CARM2G ecosystem only and reconstruct it in terms of the conceptual and architectural layers for architectural understanding and conformance.
The related analyses, addressing the objectives presented above, are discussed in various sections of the chapter. The extension of SAMOS for clone detection on ASOME models is addressed in Sections 11.6.1 and 11.6.2. The actual clone detection and the interpretation of the results are discussed in the first case studies in Sections 11.7.1 and 11.7.2. The case studies in Sections 11.7.3–11.7.5 on the MDE ecosystems address the rest of the objectives on the language level.
11.3 Background: SAMOS model analytics framework
The SAMOS framework is a tool developed for the large-scale analysis of models using a combination of information retrieval, natural language processing, and statistical analysis techniques [8]. The model analytics workflow of SAMOS is shown in Fig. 11.1. The process starts with an input of a collection of models that adhere to a particular metamodel. SAMOS has so far been used for the analysis of, e.g., Ecore metamodels [9] and feature models [10].
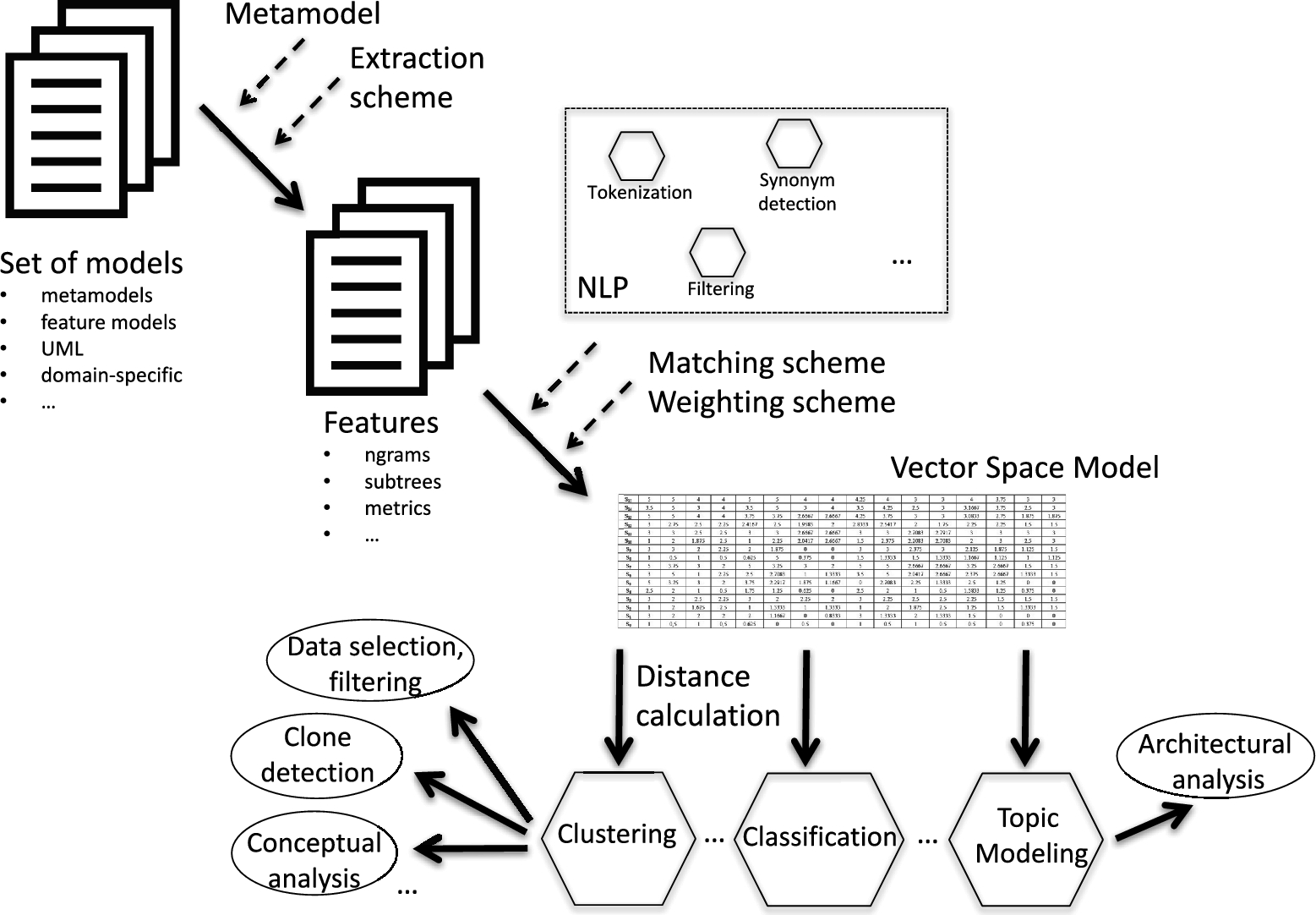
Given a collection of models,1 SAMOS first applies a metamodel-specific extraction scheme to retrieve the features of these models and store them in feature files. Features can be, for instance, singleton names of model elements or larger fragments of the underlying graph structure such as n-grams [8]. Once the features have been extracted, the following steps are independent of the type of the input models. SAMOS computes a term frequency-based Vector-Space Model (VSM), using comparison schemes (for instance determining whether to match metaclasses or ignore them), weighting schemes (for instance classes weighted higher than attributes), and natural language processing (NLP) techniques such as stemming and synonym checking. After choosing the suitable schemes, a VSM is constructed where each model is represented as a vector comprised of the features that occur in these models. Applying various distance measures suitable to the problem at hand, SAMOS applies different clustering algorithms (using R statistical software [11]) and can output automatically derived cluster labels, for instance for clone detection, or diagrams for visualization and manual inspection and exploration.
The workflow as detailed above can be modified to include scopes. By identifying meaningful scopes for models (such as treating classes and packages separately in a class diagram, in contrast to the whole model as a single entity), the settings in SAMOS allow for an extraction of features at the level of the defined scope. This allows to extract model fragments, effectively mapping a model into multiple data points for comparison among as well as within the models.
11.4 MDE ecosystems at ASML
The development of complex systems involves a combination of skills and techniques from various disciplines. The use of models allows one to abstract from the concrete implementation provided by different disciplines to enable the specification, verification, and operation of complex systems. However, shortcomings or misunderstandings between the disciplines involved at the model level can become visible at the implementation level. To avoid such shortcomings, it is essential to resolve such conflicts at the model level. To this end, MultiDisciplinary Systems Engineering (MDSE, used synonymously with MDE in our work for simplicity, although strictly speaking it is a broader domain) ecosystems are employed to maintain the consistency among interdisciplinary models.
ASML is developing such MDE ecosystems by formalizing the knowledge of several disciplines into one or more DSLs [12]. The separation of concerns among the different disciplines helps with handling the complexity of these concerns. Clear and unambiguous communication between the different disciplines is facilitated to enable not only the functioning of the complex system, but also its ability to keep up with the evolving performance requirements. Furthermore, the design flow is optimized, resulting in a faster delivery of software products to the market [7,12].
In such an ecosystem, concepts and knowledge of the several involved disciplines are formalized into of one or more DSLs. Each MDE ecosystem has its own well-defined application domain. Examples of developed MDE ecosystems at ASML are:
- • ASOME, from ASML's Software application domain. It enables functional engineers from different disciplines to define data structures and algorithms, and it allows software engineers to define supervisory controllers and data repositories [7].
- • CARM2G, from ASML's Process Control application domain. It enables mechatronic design engineers to define the application in terms of process (motion) controllers (coupled with defacto standard Matlab/Simulink), providing a means for electronic engineers to define the platform containing sensors, actuators, the multiprocessor, multicore computation platform and the communication network, and means for software engineers to develop an optimal mapping of the application onto the platform; see [13,14].
- • Wafer handler (WLSAT), from ASML's Manufacturing Logistics application domain. It provides a formal modeling approach for compositional specification of both functionality and timing of manufacturing systems. The performance of the controller can be analyzed and optimized by taking into account the timing characteristics. Since formal semantics are given in terms of a (max, +) state space, various existing performance analysis techniques can be reused [15–17].
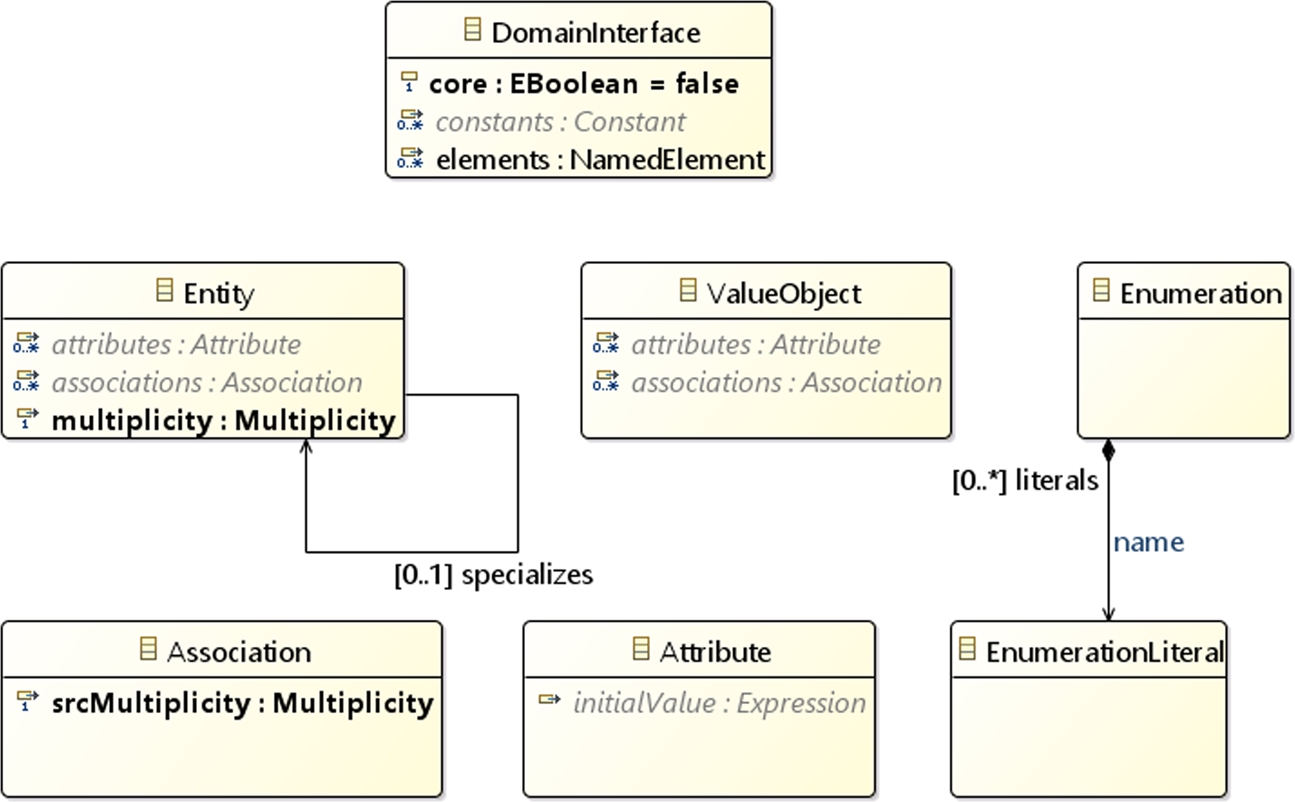
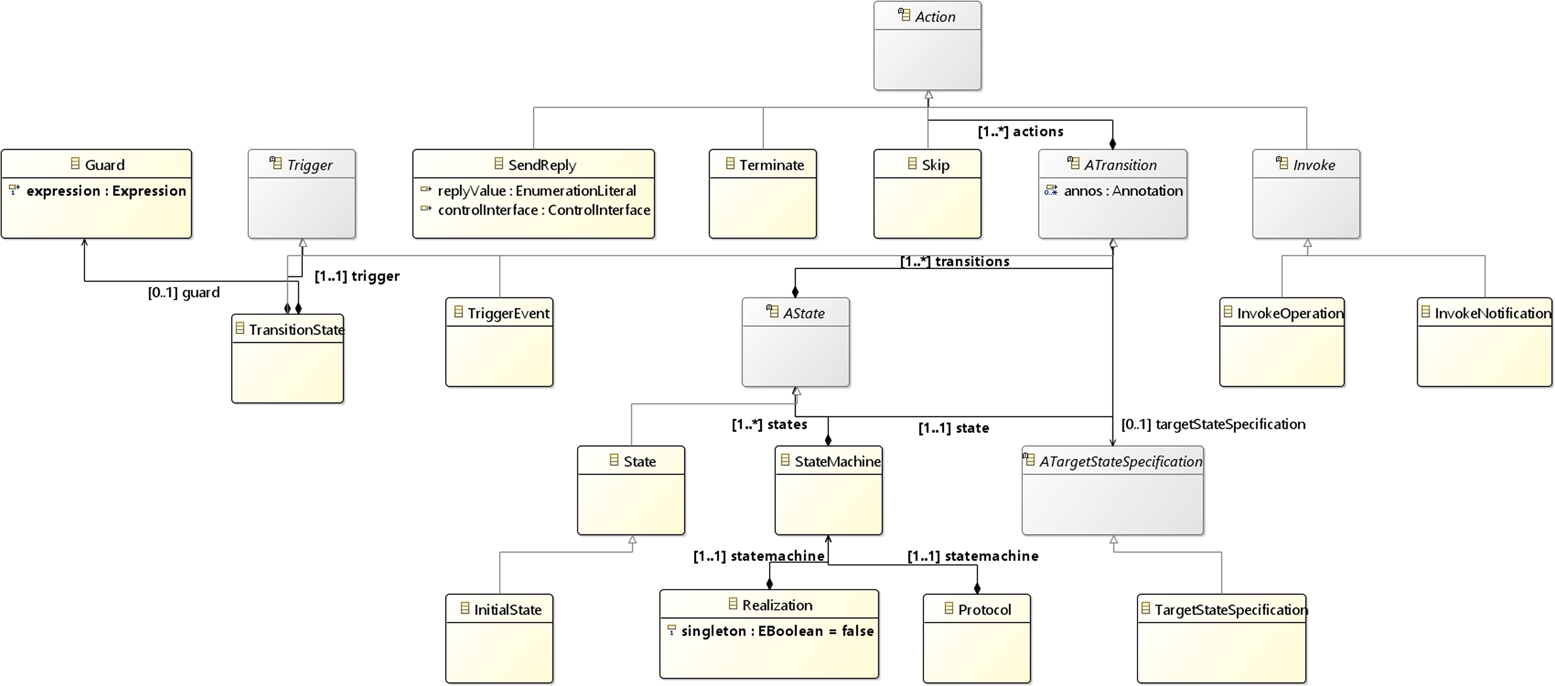
The ASOME MDE ecosystem is a software development environment that supports the DCA architecture, which separates Data, Control, and Algorithms. A motivation to employ this architecture pattern is to avoid changes in the control flow of a system based on a change in data. Using techniques of MDE, ASOME provides metamodels to create data and control models independently of each other. In the context of DCA and ASOME, data are one of the aspects. Similarly, we also talk about the “control,” “algorithm,” and (overall) “system” aspects. Within this data aspect, several kinds of systems, interfaces, and realizations can be recognized. Domain interfaces and system realizations are just a few examples; other operational examples would include data shifters and services. We further limit our studies on domain interfaces in the data models.2 Data elements of an ASML component are represented using one or more data models adhering to several metamodels. Data models contain the following (Fig. 11.2): Control models, on the other hand, allow a user to model the flow of control of different components of the system at hand. This is done using state machines. Control models can be of three different types – composite, interface, and design.3 The construction of complex systems in ASOME control models is done using instances of some smaller systems. Composite models contain a decomposition defining what system instances are made up of, along with how they are connected through ports and interfaces. An interface model provides a protocol for a state machine along with a definition of how the system and its interfaces can be defined. A design model uses this protocol to define a concrete realization of this system. Fig. 11.3 represents the elements of interest in a control model. These elements are the following: We will refer to the above basic concepts within ASOME models, when discussing our approach for clone detection in Section 11.6. While ASOME also facilitates the specification of Algorithm models, these are not considered for the purpose of finding clones in this work. This is due to the fact that there is ongoing effort at ASML to model algorithms and as a consequence there are no models that contain sufficient algorithmic aspects to analyze.11.4.1 ASOME models
11.5 Model clones: concept and classification
Before detailing the process of clone detection, it is essential to consider what defines a clone. Model clone detection is a relatively new area of exploration as compared to code clone detection [18]. While there are clear definitions of what constitutes a clone for code, such a definition is not as clear for models. The first step to approach the problem of clone detection for ASML models using SAMOS was to define what model clones are. A model fragment (a part of a model) is considered to be a clone of another fragment if the fragments are considered to be highly similar to each other. Therefore, the idea of model clones boils down to groups of model fragments that are highly similar to each other in the general sense.
Another aspect of model clone detection is the categorization of the types of clones that can be detected. For the purposes of this work, the classification used in [8] has been used, i.e., the following:
- • Type A. Duplicate model fragments except secondary notation (layout, formatting) and internal identifiers, including cosmetic changes in names such as case.
- • Type B. Duplicate model fragments with a small percentage of changes to names, types, and attributes with little addition or removal of parts.
- • Type C. Duplicate model fragments with a substantial percentage of changes, addition, or removal of names, types, attributes, and parts.
For the ASOME data models, the names of elements are considered relevant (argument being that they are similar to conceptual domain models) and the classification of clone types takes changes in the name of model fragments into account. However, for the ASOME control models, since the behavior of these models is analyzed and the structure of the models represents behavior, the classification of clones takes into account the addition or removal of components that modify the structure of the model (in the sense of finding structural clones). This is partly in line with the clone category of renamed clones, as investigated in the model clone detection literature (e.g., in [19] for Simulink model clones).
11.6 Using and extending SAMOS for ASOME models
SAMOS is natively capable of analyzing certain types of models, such as Ecore metamodels. However, it needs to be extended and tailored to the domain-specific ASOME models; this can be considered an extended implementation rather than a conceptual extension. The current section discusses the applicability and extension of SAMOS for clone detection on the ASOME models at ASML. The workflow of SAMOS, as represented in Fig. 11.1, involves the extraction of relevant features from the models. This extraction scheme is metamodel-specific and, therefore, an extension to SAMOS is first required, to incorporate a feature extraction scheme based on the ASOME metamodels. As addressed in Section 11.3, SAMOS already uses a customizable workflow for extracting and comparing model elements, e.g., for clone detection. The first step to do this is the metamodel-based extraction of features, i.e., via a separate extractor for each model type, which is addressed in the following sections.
11.6.1 Feature extraction
The first step for detecting model clones is to determine the information that is relevant for comparing model elements. In feature extraction, first, the collection of metamodels which jointly define what the Data and Control models adhere to were inspected. Along with input from a domain expert, we gained insight into the features for each model element that could be considered relevant for clone detection. These include, among others, names and types of the model elements, depending on the particular model element involved. Separate extraction schemes were developed for the Data and Control models.
The above settings describe how a model element (i.e., the vertex in the underlying graph) should be represented as a feature. Next, SAMOS allows a structure setting for feature extraction: unigrams, effectively ignoring the graph structure; n-grams, capturing structure in linear chunks; and subtrees, capturing structure in fixed-depth trees [5]. These have implications on the comparison method needed (as will be explained in the following sections; see [5] for details) and on the accuracy of clone detection overall.
The extraction in SAMOS can be specified to treat models as a whole (i.e., map each model to the set of its model elements). In addition, the extraction scope can be narrowed to smaller model fragments, such as extracting features per class in a class diagram. In such cases the analysis done in SAMOS is performed on a model fragment level rather than at the model level, effectively allowing SAMOS to compare and relate model fragments at the chosen scope. For the ASOME models, a number of scopes were investigated. The relevant ones used in the scope of this work are the following.
Scopes for data models Fig. 11.2 is a basic representation of the elements contained in the data models. The extraction scopes are listed below:
- • Structured Type and Enumerations: Similar to the EClass scope we used for metamodel clone detection [5], we treat each entity, value object, and enumeration within a model separately.
- • LevelAA: This lowest-level scope treats each attribute or association separately; hence the name AA denoting attributes and associations. These could be considered as one-liner microclones considered in the code clone detection literature [20].
Scopes for control models Fig. 11.3 represents the basic elements of ASOME control models. For those models, we considered the following scope:
- • Protocol: A Control Interface, defined in an interface model, uses a state machine to specify the allowed behavior, i.e., Protocol, along with its interface. A Control Realization, defined in a design model, needs to provide a specification that adheres to the Control Interfaces it provides and requires. Similarly, this specification takes the form of a state machine.
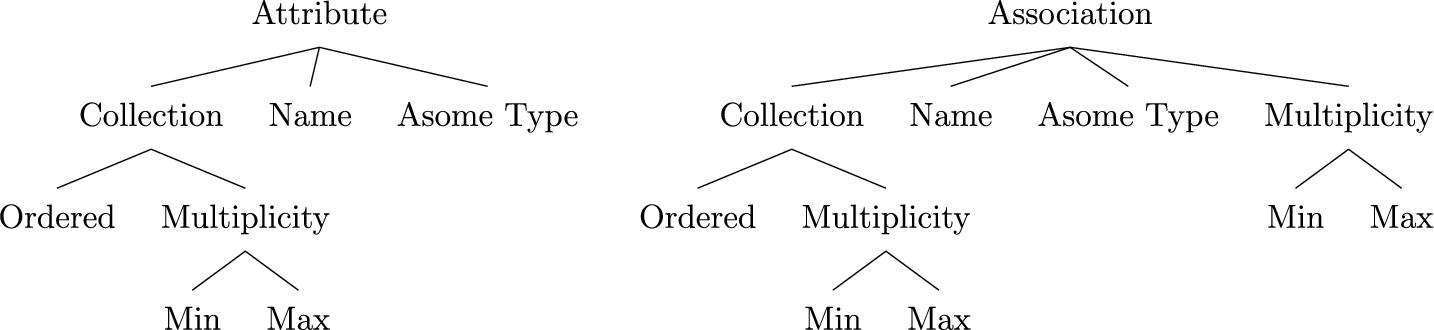
A direct (and nonfiltered) treatment of the models as their underlying graphs might lead to inaccurate (and noisy) representations, and in turn inaccurate comparison results. We had several domain-specific adaptations for feature extraction of the new model types. Fig. 11.4 represents the structure of attributes and associations, respectively, as modeled in the ASOME language. A blind extraction of features along the tree structure for these model fragments would lead to redundant representation of features. For instance, consider a tree-based comparison of any two attributes based on this representation. Since the tree nodes of Collection and Multiplicity would by definition exist in any attribute, the tree comparison would always detect some minimum similarity (2/7 tree nodes matching). In the extreme case, all attributes with matching multiplicities would have a too high similarity (at least 5/7 tree nodes matching). This would lead to unfair similarities between those model fragments, and this is against the fine-tuned distances policy of SAMOS [5]. To solve this problem, we appended the multiplicity bounds and ordering flag into the attribute or association. Fig. 11.5 depicts the new flattened representation for Association. This allows us to have a more meaningful comparison, and in turn more accurate clone detection. With MDE systems, maintaining traceability between models and eventually derived or generated artifacts, such as code, is important. ASOME uses annotations in Control models to provide this traceability between systems. In Control models, for transition states within a state, such annotations are introduced. During the extraction of features from models, annotations are also extracted. However, the behavior of the model does not depend on these annotations and therefore, including these annotations hampers the accuracy of detecting relevant clones for our interest. To avoid this, the extraction of model features excluded the extraction of these annotations.11.6.1.1 Domain specific concerns for extraction
Redundant information in the model graphs

Filtering out some model elements
11.6.2 Feature comparison, VSM calculation, and clustering
While SAMOS has the basic building blocks for the next steps in clone detection, namely, feature comparison and VSM construction (see Section 11.3 for a summary, and [5] for details), we need to specify and extend the comparison needed for our case studies. The feature comparison setting on the vertex or unit level in SAMOS involves, e.g., whether to consider domain type (i.e., metaclass) information of model elements for comparison, and whether and how to compare names using NLP techniques such as tokenization and typo and synonym checking. For this work, we introduced a new option to effectively ignore names (i.e., the No Name setting). This extension was introduced specifically to find structural clones within ASOME control models, where names do not possess much significance. As for aggregate features containing structural information, such as subtrees (of one-depth in this work), SAMOS has a built-in unordered comparison technique using the Hungarian algorithm [5]. We employed a specific combination of such settings for various case studies, as will be explained in Section 11.7 per case study.
Building on top of this comparison on the feature level, SAMOS performs an all-pairs comparison to compute a VSM, representing all the models (or model fragments, depending on the extraction scope) in a high-dimensional space. In the case of clone detection, by selecting distance measures (specifically masked Bray–Curtis) and clustering methods (density-based clustering), SAMOS performs the necessary calculations to identify clone pairs and clusters [5].
11.7 Case studies with ASML MDE ecosystems
We have performed a wide range of case studies on the models and languages/metamodels used at ASML. In the first two case studies we have detected and investigated the clones in ASOME data and control models, while the others contain language-level analyses on various ecosystems.
11.7.1 Clone detection in ASOME data models
This section discusses the results of the case studies performed using the different settings of SAMOS on the ASOME data models.
11.7.1.1 Dataset and SAMOS settings
The dataset consists of 28 data models, containing one domain interface each. These domain interfaces in total contain 291 structured type and enumeration model fragments and 574 attributes and associations. Our preliminary runs with the scopes Model and Domain Interface did not yield significant results, and therefore we report here only the lower-level scopes. The settings of SAMOS for this case study are as follows:
- • Scopes: Structured Type and Enumerations, LevelAA.
- • Structure: Unigrams. For the model fragments at the chosen (low-level) scopes, there is no deep containment structure. So, a unigram representation suffices for this case study.
- • Name Setting: Name-sensitive comparison, as model element names are important parts of the data models.
- • Type Setting: A relaxed type comparison (standard setting of SAMOS) for the scope Structured Types and Enumerations and strict type comparison for LevelAA. For the latter, we are interested in strictly similar microclones, facilitating easy refactoring.
On the given set of data models, using the settings above, we discuss the results we found in the next section.
11.7.1.2 Results and discussion
This section discusses, per scope, the results obtained through the chosen settings. The discussion is structured as follows. First, the model fragments considered to be clones are discussed; second, the proposition for reducing the level of cloning is presented, and finally, the opinion of a domain expert on this proposition is presented.
We found the following clone clusters in the scope of Structured Type and Enumerations:
- • Type A Clones. Only one clone cluster was found for this category consisting of two Value Objects, named XYVector, representing coordinates. This is a small example of duplication in two models and can be easily eliminated by reuse. The domain expert has commented that in fact one of the models is actually called core, with the intention that it contains the commonalities, while other models import and reuse it.
- • Type B Clones. We found four clone clusters, each having a single clone pair. We show an example of such Type B clone pairs in Fig. 11.6A, consisting of model fragments with partly similar names (e.g., End Position vs. Start Position) and otherwise the same content. The domain expert's remark was that such cases of redundancy can be considered candidates for elimination via inheritance abstraction. However, due to specific design constraints and the additional effort to integrate this abstraction in the existing practice, the expert told it is difficult and unlikely that such improvements will be realized.
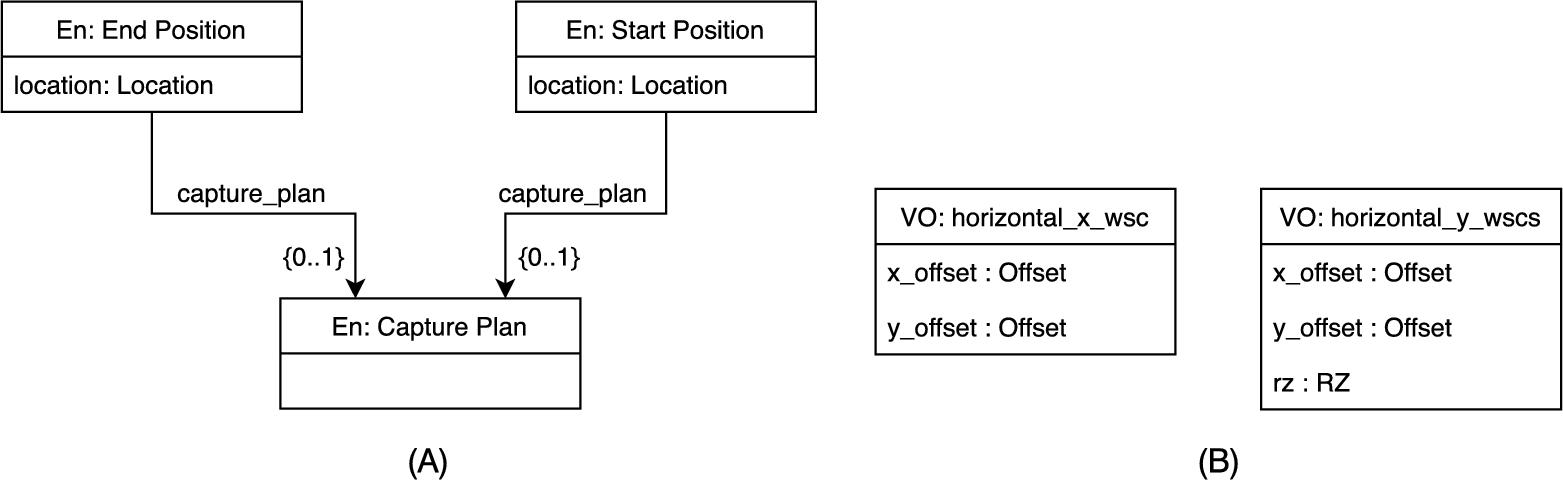
- • Type C Clones. We found 23 Type C clone clusters. Fig. 11.6B shows an example clone pair, with a slight name difference and an additional attribute. Other pairs included changes in names and attributes. For such clones, redundancy can be eliminated by creating an abstract class with commonalities and extending it. The domain expert commented it is in any case useful to discover such variants in the modeling ecosystem, and it can be investigated which ones can be refactored (as in the discussion above for Type B clones).
As for the microclones at scope LevelAA, we have the following results.
- • Type A Clones. We found 53 Type A clone clusters. The most interesting result proved to be the Association task, found in a cluster of nine items. The target of this association is an entity Task which belongs to a core data model (a specific instance of a data model which other models depend on). This pattern, along with the fact that these associations were all named the same, is an indication of consistency and good design, as confirmed by the domain expert. This is an example of the fact that not all clones are harmful and in this case, the clones are an indication of good design; outliers (if any) can be investigated as an indication of violation of the common practice. As for the duplication in Attributes, the idea of refactoring by lifting these attributes up to a common superclass was considered by the domain expert with suspicion, due to the additional complexity of introducing inheritance. Duplicate associations in some cases cannot even be eliminated at all, especially in entities from different models.
- • Type B and C Clones. We found 65 Type B clones clusters, consisting with very similar elements with small differences in, e.g., multiplicities. Clones of these types are not candidates for elimination or refactoring however, as remarked by the domain expert. Similarly, among the 81 Type C clone clusters with a higher percentage of differences, the domain expert could not find any good candidate for refactoring. This might indicate that only exact duplicate microclones should be considered as useful and actionable, and therefore studied.
We have provided separate discussions above for our results on different scopes and clone types. A general remark is to be made about the NLP component of SAMOS. In the current setting, due to the tokenization and stopword removal, SAMOS considers model elements with names element_m_1 and element_m_2 as identical; numbers and short tokens are omitted. Moreover, the lemmatization and stemming steps lead SAMOS to consider the following as identical or highly similar names: changed, unchanged, changing. In the future we might consider further fine-tuning (and partly disabling) several NLP components considering the problem at hand, when looking for exact clones under the scope of LevelAA.Overall discussion
11.7.2 Clone detection in ASOME control models
This section discusses the case studies performed on control models as well as the results of these case studies.
11.7.2.1 Dataset and SAMOS settings
The approach taken to detect clones within control models is different compared to the one for data models. This is due to the importance of structure in these models. However, the tree-based setting in SAMOS is still considerably expensive for large datasets. On the other hand, a structure-agnostic unigram-based detection with SAMOS [4] would not be accurate enough. Therefore, we follow an iterative approach (similar to [5]). We first narrow down the number of elements for comparison using a cheaper unigram-based analysis. On each cluster found in this first step, we perform a more accurate clone detection separately, thereby reducing the total complexity of the problem. In our previous work [5], we showed that this iterative process leads to only minor drops in recall, but we leave the assessment of its accuracy in this work for future work.
The dataset of control models for this case study contained 691 models, 531 protocols, and realizations. A preprocessing step excluded 10 protocols and realizations because these protocols and realizations were very large compared to the other models. Excluding these for the comparison was justified considering it was less likely to find models similar to these based on their size. Moreover, these models would slow down the comparison significantly while constructing the VSM. The following settings were chosen for the comparison of control models.
- • Scope: Protocol level. On this level of comparison, one can compare models based on their behavior, as defined using the state machines residing in these protocols or realizations.
- • Structure: For the first round of comparisons, the unigram setting was used to find clusters of similar model elements. Fifty such clusters of models were found. The second round of comparison involved inspecting some of the clusters found in the first round. For this round, one-depth subtrees were extracted and compared.
- • Name Setting: A no-name setting was used for the two rounds of comparison of control models. This was done so we could find models that were structurally equivalent ignoring names.
- • Type Setting: A strict type setting was used for both rounds of comparisons for control models. In a no-name comparison, to find structurally similar models, this setting allows one to detect model elements with similar types and other attributes.
11.7.2.2 Results and discussion
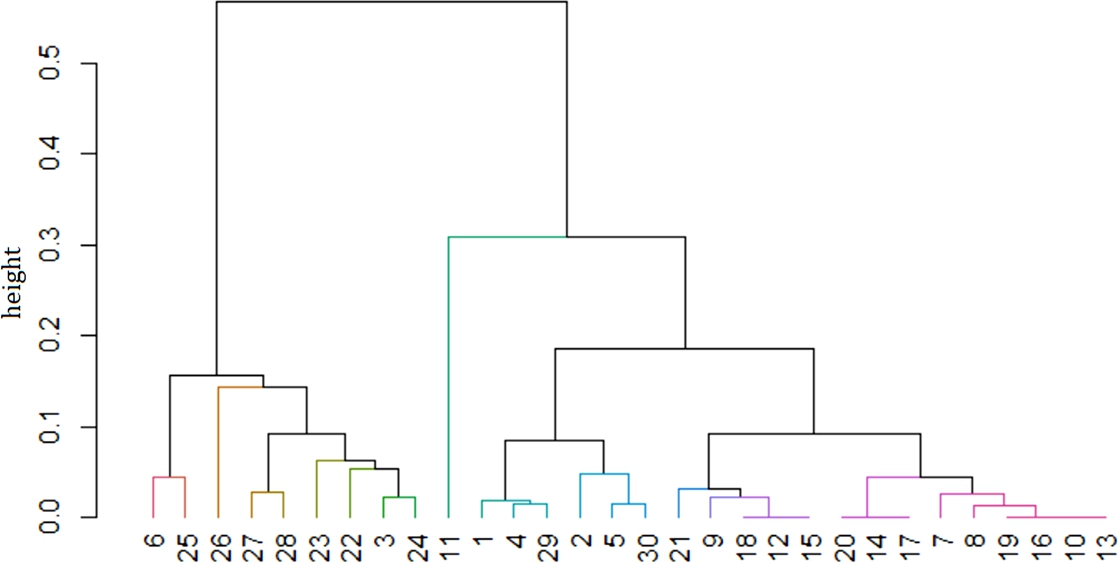
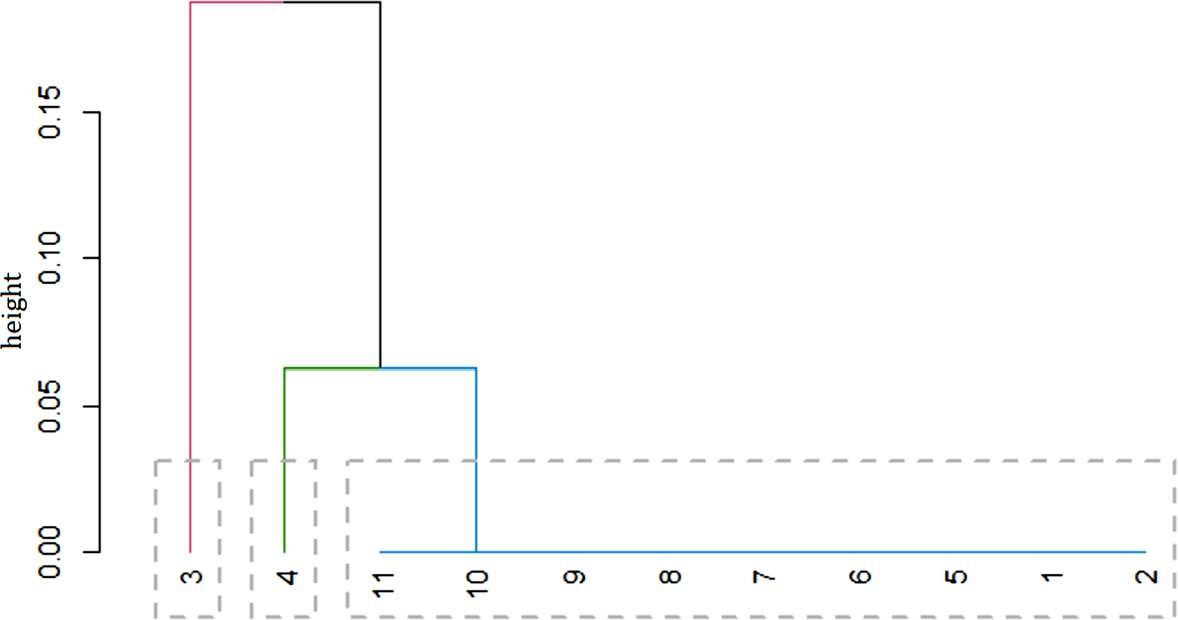
In this section we provide a detailed discussion and qualitative evaluation on some exemplary control model clone clusters found by SAMOS. Based on the first round, which results in a number of buckets with potential candidates for clones, we ran SAMOS with the more accurate subtree setting for a second round of clustering. Fig. 11.7 represents the hierarchical clustering of elements contained in one bucket. Note that this hierarchical clustering of elements is used for clarification and discussion purposes only; SAMOS employs a threshold-based automatic cluster extraction technique. The dendrogram represents the Protocol-scope model fragments at each leaf represented by a number, and the vertical axis and the joints in the tree denote the distance, i.e., dissimilarity, of the fragments.
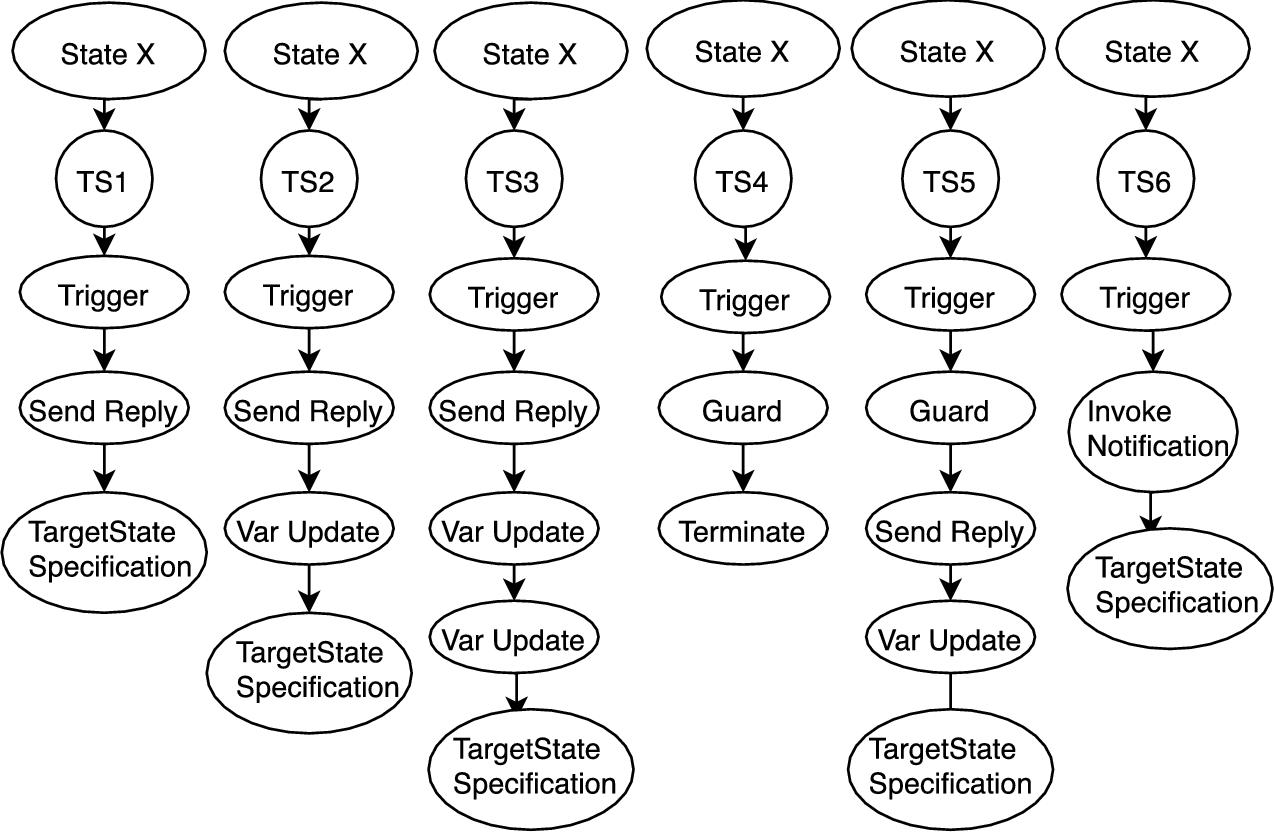
The models inspected in this cluster were quite large. These contained a single state with a variation in the number and type of transition states, representing an all accepting state. A combination of patterns found in the models is shown in Fig. 11.9. The state X contains a number of transition states. The patterns of the different types of transition states found in the models are represented by TS1 through TS6.
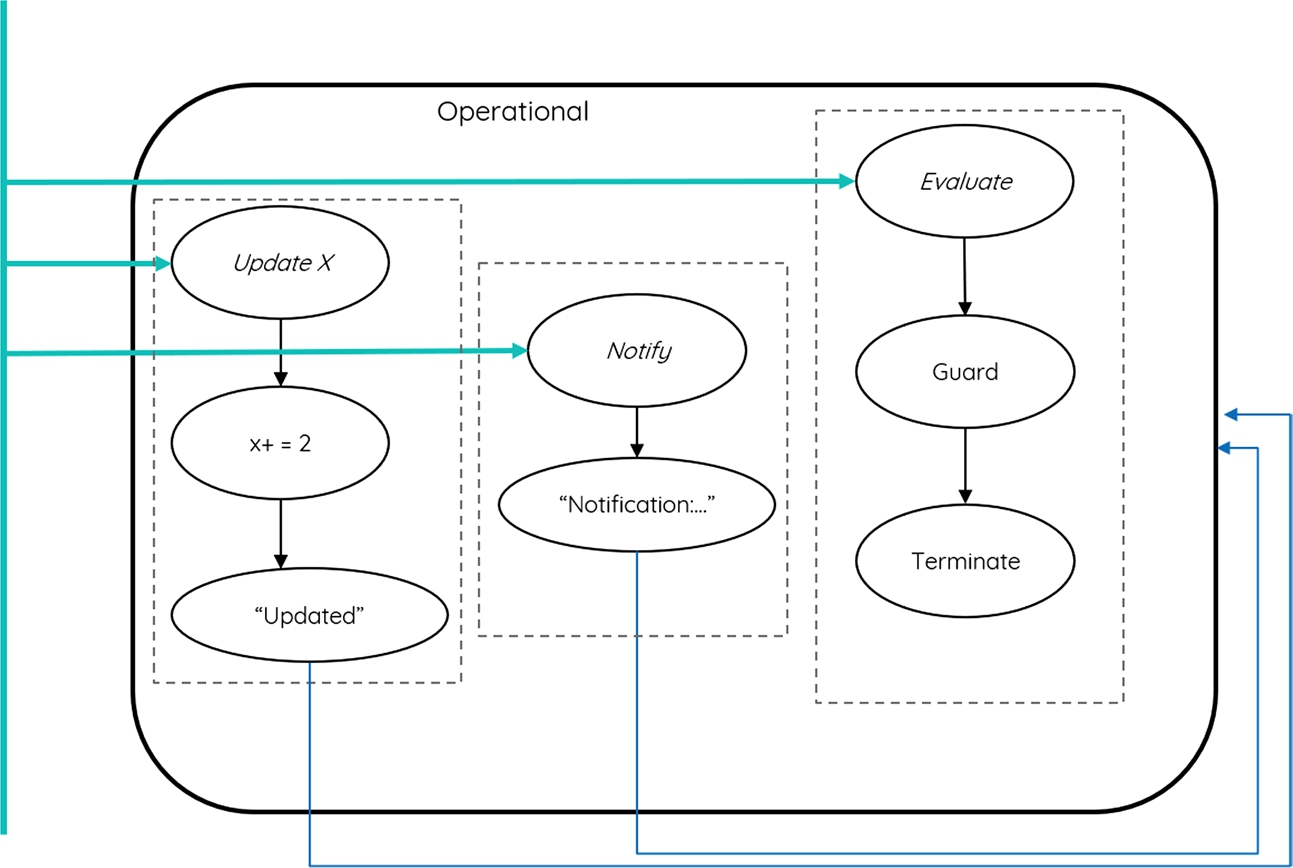
Fig. 11.8 is an example of a visualization of a few of the transition states in the single state models found in this cluster. The figure shows a single state Operational which defines behavior using three transition states. A trigger exists for each transition state. The triggers here are Update X, Notify, and Evaluate. Depending on the trigger that has been received, the corresponding transition state is executed. For example, the Update X trigger is followed by the action of a State Variable Update where the variable x is updated. As a result, the value “Updated” is sent as a reply. Once the reply is sent, the transition state specifies the same state Operational as a target state.
A discussion of the different types of clones, based on the number of occurrences of each type of transition state in the models, is given as follows:
- • Type A Clones. The elements shown in Fig. 11.7 that are represented at the same height and are part of the same hierarchical cluster can be considered type A clones. Examples of such clones are models 20, 14, and 17 and models 18, 12, and 15. An inspection of a collection of models of this type showed that these models had a single state X with multiple transition states. The behavior of the transition states is as shown in Fig. 11.9. An inspection of models 19, 16, 10, and 13 showed that they each had 18 occurrences of the pattern TS1; one occurrence each of patterns TS2, TS3, and TS4; and eight occurrences of pattern TS5. TS6 however, did not occur in these models.
- • Type B Clones. We can use the dendrogram as guidance to identify elements that are not exactly the same as but could be considered similar to each other (up to 10% distance, as an intuitive estimate). Model 8, for instance, is similar to the cluster of models 19, 16, 10, and 13; that group is already mentioned above as Type A clones. Model 8 in this case is highly similar to those in the Type A cluster, but contains additionally two occurrences of TS5. This makes it a Type B clone compared to the rest of the models mentioned.
- • Type C Clones. Again by inspecting the dendrogram, we can consider, for instance, models 27 and 24 as candidate Type C clones to validate. Table 11.1 shows the number of times each transition state pattern was found in the models; the number of occurrences is slightly different for four out of six transition state patterns. Therefore, we manually label these as Type C clones as well.
Table 11.1
| Transition states | Model 24 | Model 27 |
|---|---|---|
| TS1 | 5 | 6 |
| TS2 | 1 | 1 |
| TS3 | 1 | 1 |
| TS4 | 1 | 2 |
| TS5 | 7 | 4 |
| TS6 | 2 | 0 |
We further examined another example cluster to validate the results of SAMOS. Fig. 11.10 shows the resulting dendrogram for Cluster 2. The three types of clones in this cluster are discussed as follows. Note that all the models in this cluster share a common pattern (with minor differences as will be discussed below), as shown in Fig. 11.11.
- • Type A Clones. All the elements in this cluster excluding models 3 and 4 can be considered type A clones. The models were all protocols, defining state machines with this structure. The action of sending a reply is associated with a control interface defined in the model. In each of these models, it was observed that the value of the reply sent to the control interfaces was void.
- • Type B Clones. The models excluding model 3 and model 4 could be considered similar to model 4, though not exactly the same. Upon investigating these models, it was noted that the difference between the other models and model 4 is in the action Send Reply. While the other models sent an empty reply to the control interface, model 4 replied to the control interface with a value. Since this is a small percentage of change between these models, model 4 and the models excluding model 3 can be considered type B clones.
- • Type C Clones. Model 3 can be considered significantly different from the models in this cluster, excluding model 4. The differences between these models is that model 3 was a realization while the other models were protocols. In addition to this, model 3 also sent a value back to the control interface in the Send Reply action, like model 4.

Overall discussion
The example clusters discussed above represent the types of clusters detected after performing a comparison on the extracted one-depth trees representing control models on the 50 unigram-based clusters. Some clusters that were investigated, however, only contained type A clones because all the models found were similar to the other models in that cluster.
While eliminating clones was straightforward for cases in data models, this is not as easy for control models. The presence of duplicates in terms of a sequence of actions might be inevitable if that is the intended behavior of the models. This presents the case for the idea that not all clones can be considered harmful, and some are in fact intended. However, many occurrences of some transition state patterns have been found in the models. The transition state pattern TS1 as seen in the example cluster 1 (Fig. 11.9) was found 18 times each in two inspected models. For such transition states, maybe the language could allow for an easier representation of such a pattern to make it easier for a user to implement this sequence of actions.
According to the domain expert, “detecting such patterns of control behavior definitely can be used to investigate whether the user could benefit from a more comfortable syntax. Then an evaluation is needed that needs to take into account:
- 1. whether the new syntax requires more time to learn by the user, and
- 2. whether the simplification really simplifies a lot (see below).
For instance, in the example above, even for TS1, the user will need to specify the trigger somehow. In case of a nonvoid reply, also the reply value will need to be specified. So, TS1 cannot be replaced by one simple keyword. It will always need two or three additional inputs from the user. In this case, we will not likely simplify this pattern. However, the way of thinking to inspect whether we can support the user with simplifying the language is interesting. It will always be a tradeoff between introducing more language concepts vs. writing (slightly) bigger models.”
Another suggestion for control models is to investigate the unigram clusters to find the different types of patterns found within the control models. Following this, checking what models do not adhere to these patterns might reveal outliers to investigate, to find unexpected behavior.
A domain expert commented, “I see the line of reasoning and it brings me to the idea of applying Machine Learning to the collection of models and let the learning algorithm classify the models. Then, investigating the outliers indeed might give some information about models that are erroneous. However, these outliers could also be models describing one single aspect of the system, which would justify the single instance of a pattern. However, I would expect that the erroneous models would also have been identified by other, less costly, means such as verification, validation, review, etc.”
11.7.3 Overview on multiple ASML MDE ecosystems
As introduced in Section 11.4, ASML has a very diverse conglomerate of MDE ecosystems, developed and maintained by different groups and involving different domains in the company's overall operation. While the architects and managers might have a good idea of (parts of) the enterprise-level big picture, we would like to (semiautomatically) investigate the relation among the different ecosystems with respect to the domains.
Objectives Given the multitude of languages which belong to the various ecosystems, we would like to perform a concept analysis via hierarchical clustering based on the terms used in the metamodels which represent the abstract syntaxes of those languages. Note that we will use the terms metamodel and language interchangeably through our case studies. We have two main subobjectives in this case study. First we would like to get a good overall picture of the enterprise ecosystem and its compartmentalization into meaningful domains and subdomains. It is worthwhile to investigate, e.g., whether different ecosystems occupy distinct or intersecting conceptual spaces. Furthermore, it can be interesting to see what close-proximity metamodel pairs or clusters across different ecosystems imply. Furthermore, we can study whether this information leads to quality improvement opportunities in the ecosystems, such as metamodel refactoring and reuse of language fragments.
Approach To address the objectives above, we process the 86 metamodels belonging to three ecosystems. Using SAMOS, we extract the element names from the metamodels, using the normalization steps including tokenization and lemmatization. We then compute the VSM over the words, using a tf-idf (with normalized log idf as in [4]) setting also using advanced NLP features such as WordNet checks for semantic relatedness. We then apply hierarchical clustering with average linkage over the cosine distances in the vector space.
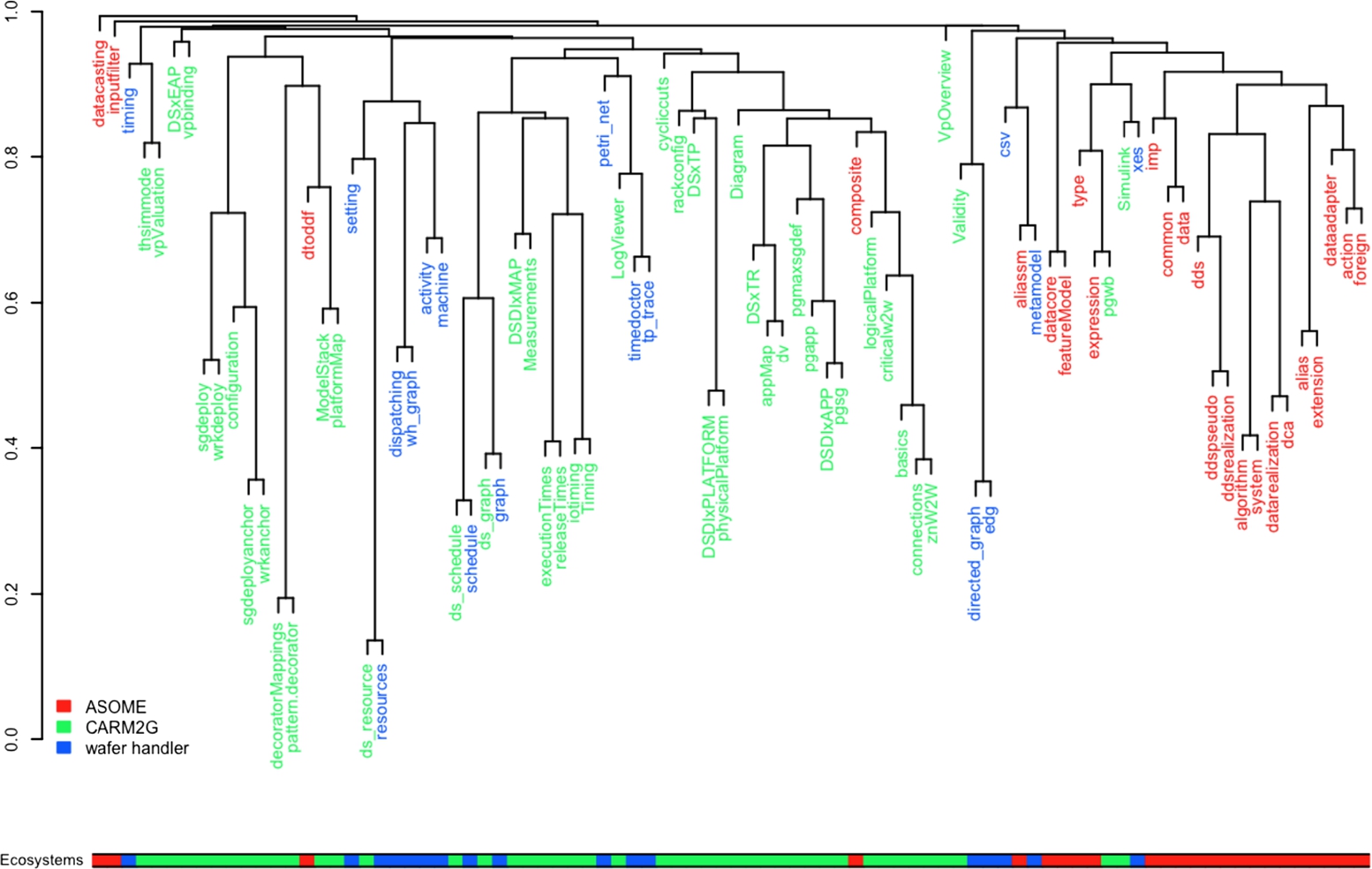
Results and discussion We present our result in the dendrogram depicted in Fig. 11.12. Each leaf in the dendrogram corresponds to a metamodel, and all the metamodels are color-coded with respect to their ecosystems. The colored leaves are also projected into the horizontal bar as a complementary visualization. The joints of the leaves and branches can be traced in the y-axis, which denotes the distance (dissimilarity) of the (groups of) metamodels. For instance, metamodel pairs in the lower parts of the dendrogram (such as ds_resource and resource) are very similar. By discussing with the language engineers and domain experts for each ecosystem, we gathered a list of remarks that address the objectives above. Next we present a representative summary of those findings, along with key subobjectives of this case study.
Some remarks involving the general overview, domains, subdomains, and proximities across ecosystems would include the following:
- • The ecosystems roughly occupy distinct conceptual spaces. As can be seen from the horizontal bar at the bottom, ASOME models are mostly on the right-hand side, while wafer handler (less consistently) is in the middle regions.
- • There are however small intersections (i.e., impurities in the colored bar or different colors in the subtrees) among the ecosystems. These are not always surprising or bad because different ecosystems might reuse languages and potentially share subdomains. However, our automated analysis allows having a full overview, in contrast to partial insights of the individual experts.
- • Within ecosystems, the domain experts can already detect subdomains, such as platform, deployment, timing, and scheduling for CARM2G and data for ASOME.
We wish to conclude with the following points regarding highly similar metamodels within and across ecosystems:
- • Except two metamodels within CARM2G which are highly similar (height < 0.2, i.e., decoratorMappings and pattern.decorator) – one of which happens to be very small and insignificant, so discarded by the domain experts – no metamodels within a single ecosystem are too similar. This indicates a healthy design, where each language deals with a distinct conceptual subspace. There are still somewhat similar (height <0.4) pairs, which might lead to a consideration of a within-ecosystem refactoring. Examples for such pairs would include sgdeployanchor and wrkanchor from CARM2G.
- • Across the ecosystems, there is a pattern of similar (height < 0.4) pairs for CARM2G and wafer handler, specifically for resources, schedule, and graph metamodels. This is apparently due to the fact that wafer handler borrowed these metamodels from CARM2G in early development, while making custom changes as required in time. Our visualization correctly reveals this in a straightforward manner.
- • Similarly, somewhat similar couples of metamodels across ASOME vs. the other ecosystems exist, though not as similar as the ones above. Examples are aliassm vs. metamodel, which partly contain state machine languages, and expression vs. pswb, which partly contain expression languages.
In summary, according to the feedback we received from the domain experts, such an automated and visual overview of the MDE ecosystems used within a company indeed reveals useful information. This can be used to aid the governance, usage, and maintenance of the ecosystems. However, some additional information, such as dependencies across languages, the corresponding model instantiations and their relations, usage, etc., could be utilized to further augment our study. Furthermore, we currently cannot detect subtle relations among similar languages which use different terminology. The experts exemplified it by various graph description languages, some of which use the terms node, edge; others use task, dependency. This can potentially be mitigated by using a domain-specific thesaurus, in contrast to just relying on general-purpose WordNet for synonyms.
11.7.4 Cross-DSL clone detection across ecosystems
The concept analysis performed above only deals with the element names, and not the other information in the metamodels such as types, attributes, and the structure. It also treats metamodels as a whole. In this case study, we would like to perform a more precise and fine-grained analysis on the metamodel fragments (i.e., subparts), in order to reveal similar fragments across, as well as within, the different ecosystems and languages.
Objectives As metamodels across the different ecosystems can have duplicate or highly similar fragments (due to various reasons, e.g., clone-and-own approaches in development or language limitations [5]), we would like to perform clone detection in a more accurate manner, including all the information in the metamodels (not only names). We would like to inspect the clones, their nature (why they occur), and their distribution across the ecosystems. As in the model clone detection case studies, we are also interested to identify potential candidates among these clones which can be used for improving the MDE ecosystems, e.g., in terms of elimination or refactoring.
Approach We considered the 86 metamodels representing three ecosystems in this study. Using SAMOS, we extracted the one-depth subtrees with full set of model element information from the metamodels, with the EClass scope. Note that we ignored EClasses with no content and supertypes (i.e., zero number of contained elements), assuming they would make less significant cases for refactoring. We then computed the VSM over the subtrees, using the tree-hung setting [5]. Finally, we applied the clone detection procedure with reachability clustering over the masked Bray–Curtis distances in the vector space.
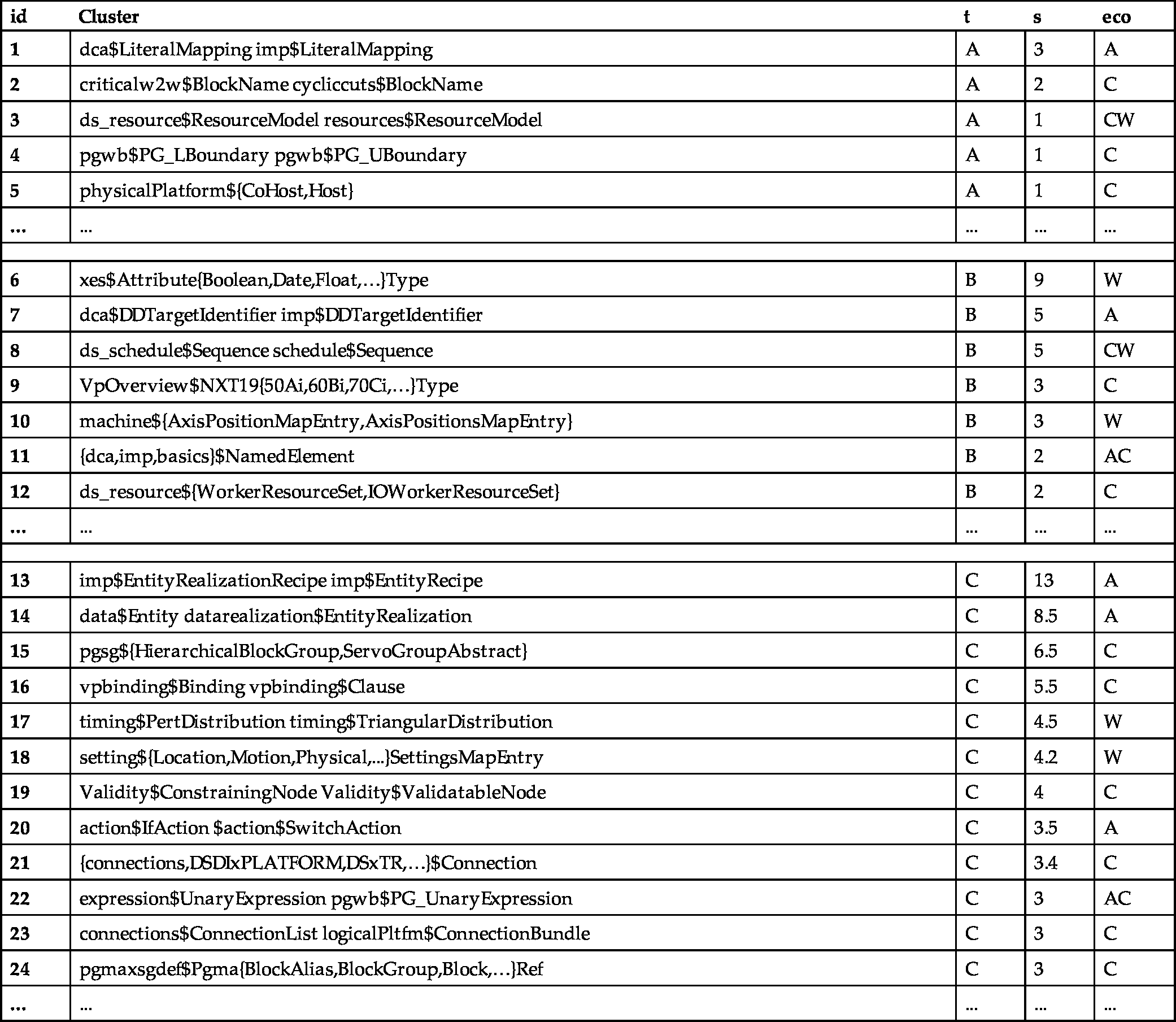
Results and discussion Using SAMOS, we found 9 Type A, 13 exclusively Type B (i.e., discarding Type A clusters), and 55 exclusively Type C clone clusters. Table 11.2 gives some of the interesting clusters, which we will discuss next.
Table 11.2
Some of the EClass-scope clones in the metamodels (reported using the convention metamodelName$EClassName); t denotes the clone type (A, B, or C), s the average size of the clones in a cluster (with respect to the total number of attributes, operations, etc., for each clone, counting the EClass itself as well), and eco the ecosystem of the cluster, where A = ASOME, C = CARM2G, W = wafer handler [42].
| id | Cluster | t | s | eco |
|---|---|---|---|---|
| 1 | dca$LiteralMapping imp$LiteralMapping | A | 3 | A |
| 2 | criticalw2w$BlockName cycliccuts$BlockName | A | 2 | C |
| 3 | ds_resource$ResourceModel resources$ResourceModel | A | 1 | CW |
| 4 | pgwb$PG_LBoundary pgwb$PG_UBoundary | A | 1 | C |
| 5 | physicalPlatform${CoHost,Host} | A | 1 | C |
| ... | ... | ... | ... | ... |
| 6 | xes$Attribute{Boolean,Date,Float,…}Type | B | 9 | W |
| 7 | dca$DDTargetIdentifier imp$DDTargetIdentifier | B | 5 | A |
| 8 | ds_schedule$Sequence schedule$Sequence | B | 5 | CW |
| 9 | VpOverview$NXT19{50Ai,60Bi,70Ci,…}Type | B | 3 | C |
| 10 | machine${AxisPositionMapEntry,AxisPositionsMapEntry} | B | 3 | W |
| 11 | {dca,imp,basics}$NamedElement | B | 2 | AC |
| 12 | ds_resource${WorkerResourceSet,IOWorkerResourceSet} | B | 2 | C |
| ... | ... | ... | ... | ... |
| 13 | imp$EntityRealizationRecipe imp$EntityRecipe | C | 13 | A |
| 14 | data$Entity datarealization$EntityRealization | C | 8.5 | A |
| 15 | pgsg${HierarchicalBlockGroup,ServoGroupAbstract} | C | 6.5 | C |
| 16 | vpbinding$Binding vpbinding$Clause | C | 5.5 | C |
| 17 | timing$PertDistribution timing$TriangularDistribution | C | 4.5 | W |
| 18 | setting${Location,Motion,Physical,...}SettingsMapEntry | C | 4.2 | W |
| 19 | Validity$ConstrainingNode Validity$ValidatableNode | C | 4 | C |
| 20 | action$IfAction $action$SwitchAction | C | 3.5 | A |
| 21 | {connections,DSDIxPLATFORM,DSxTR,…}$Connection | C | 3.4 | C |
| 22 | expression$UnaryExpression pgwb$PG_UnaryExpression | C | 3 | AC |
| 23 | connections$ConnectionList logicalPltfm$ConnectionBundle | C | 3 | C |
| 24 | pgmaxsgdef$Pgma{BlockAlias,BlockGroup,Block,…}Ref | C | 3 | C |
| ... | ... | ... | ... | ... |
Here we provide a discussion of Type A clones and opportunities for eliminating duplication:
- • There are not too many Type A clones overall and they are quite small (size < 3). This indicates little redundancy in general in terms of exact duplication.
- • Clusters 1 and 2 show two examples of small clones across different languages, which can be easily refactored and reused.
- • Cluster 3 shows an exact clone across ecosystems for the resource language, which we discovered in the previous study to be an evolution/modification from CARM2G to wafer handler.
- • Due to our NLP settings (notably ignoring stopwords and typo detection compensating for minor changes), SAMOS finds clone clusters such as 4 and 5 as identical. While they are significantly similar and some of these might indicate room for refactoring, the domain experts generally found them to be uninteresting from a maintenance perspective.
As for Type B and C clones and potential refactoring opportunities, we make the following points:
- • There is a significant number of Type B and C clones. This indicates that there might be good opportunities to improve the ecosystems.
- • Cluster 6 with sizeable (of average size 9) clones shows a clone pattern that we encountered a few more times in this study. According to the domain experts, xes is a generated metamodel from xml schemas. There is hence an opportunity to refactor either the xml schema or the generation process in such a way that the commonality, for instance, is abstracted to a superclass.
- • Cluster 7, as well as clusters 13 and 14, shows a cloning pattern which happens a few times in the ASOME ecosystem: design vs. realization/implementation. This is a case where clones are intended: this pattern is devised to allow the extension of existing language elements for the sake of (a) backwards compatibility and (b) clear (conceptual) separation of concerns, i.e., abstract design vs. client-specific implementations.
- • Cluster 8 (and some more clusters omitted in the table for conciseness) shows modified fragments of the metamodels adopted from CARM2G into wafer handler.
- • Cluster 9 indicates near-duplicate entities for different machine types at ASML. These could be easily refactored, for example, into enumerations, which solves the cloning problem.
- • Cluster 10 is an interesting case: the only difference between these metamodels is the multiplicity of an EReference. Domain experts remarked that this is an intended clone for improving the performance while processing the models in real-time in ASML machines.
- • Cluster 11 shows small-sized clones with a single attribute name, differing only in cardinality – considered as a very minor issue, which does not urge for a refactoring. Cluster 12 similarly indicates small clones, which the experts commented they could refactor, for instance, using generics.
- • Clusters 15 and 16 show medium-sized clones with common EAttributes and EOperations defined, so the common parts can be abstracted into superclasses. However, for the latter, the domain experts remarked that actually there is a superclass which is overridden in subclasses. Due to the limitations of EMF (needing to duplicate the EOperation and pointing to the overridden implementation in EAnnotations), cloning here is supposedly inevitable.
- • For the rest of the clusters, the experts indicated a varying degree of usefulness (in terms of refactoring), i.e., low-medium (e.g., in cluster 23 – cardinality difference in small EClasses and in cluster 20 – similar control structures which could be refactored into an abstract superclass) and high (e.g., cluster 17 – one statistical distribution being the ontological superclass of the other smoothed distribution).
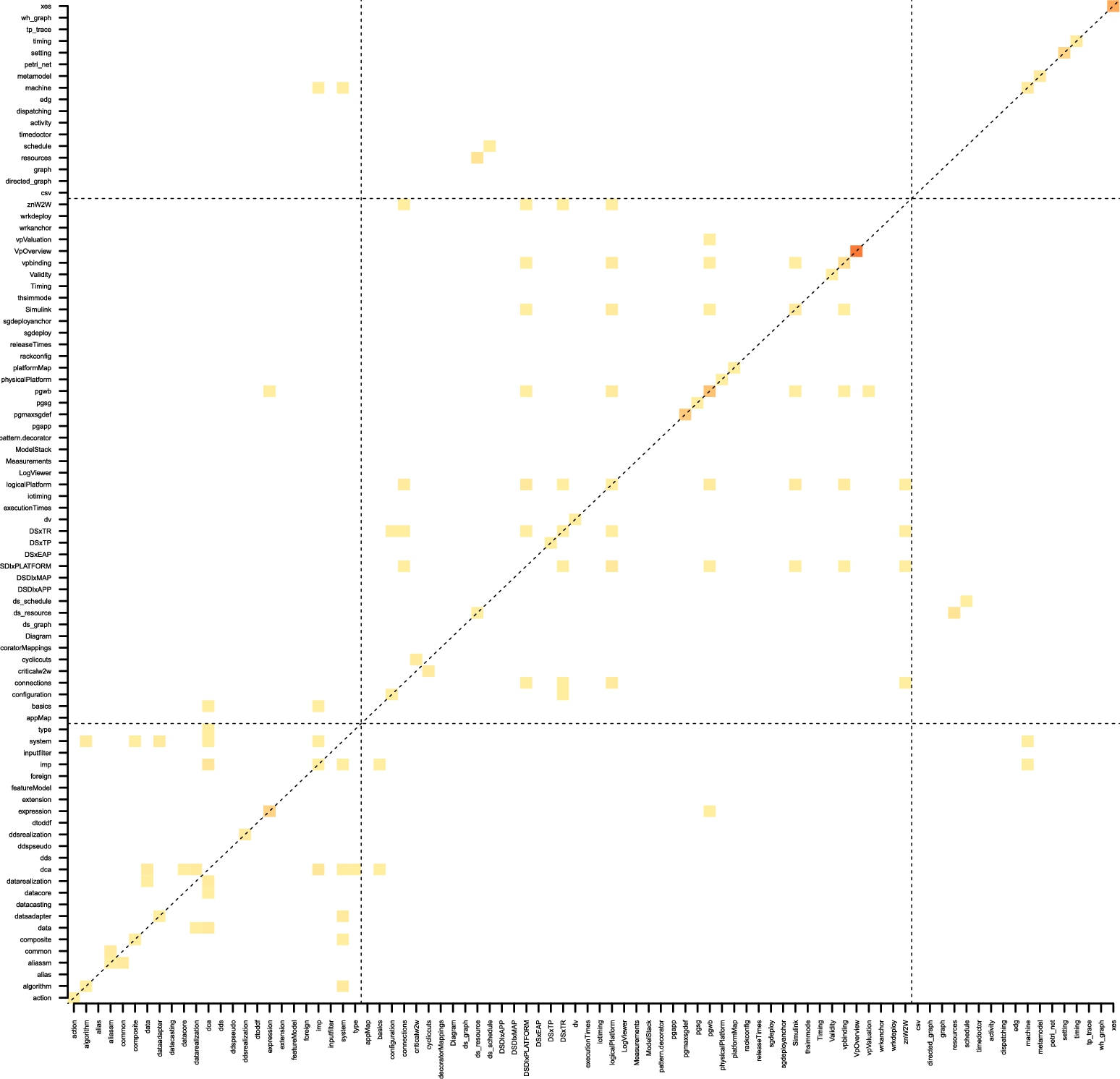
Table 11.2 presents the clone occurrences in a flat list. However, we would like to explicitly investigate and visualize the distribution of the clones across languages and ecosystems. To address that, we have constructed the heatmap shown in Fig. 11.13. It is evident from the figure that there are only a few clones across ecosystems. Notable ones include the resource and schedule languages in CARM2G and wafer handler, parts of expression languages across ASOME and CARM2G and some small basic constructs across all three ecosystems (as discussed above in individual clone clusters). Darker yellow and red parts (i.e., high number of clones) are generally on the diagonal, meaning clones within languages themselves. We can see the reason for these in Table 11.2, e.g., in clusters 9 and 18 with multiple clone pairs. The fact that most clones are within ecosystems is positive, as refactoring across ecosystems might involve multiple developers or teams, projects, and even companies (in the case of outsourcing) and hence make it much more difficult and costly to realize.
With the case study in this section, we are able to give both an overview of clones across the ecosystems and insights into the individual clone clusters and pairs. Overall, the results indicate many opportunities to improve the quality of the enterprise-level MDE ecosystem and its maintenance. Our discussions with the domain experts shed light on specific cases where clones might not only be due to suboptimal design, but can also be intended (e.g., for performance concerns) or inevitable (e.g., due to language limitations). Our analysis and insights can be used to aid the language design and engineering life cycle, given the growing number of ecosystems and evolving languages at ASML and other similar companies with large-scale MDE practice.
11.7.5 CARM2G architectural analysis
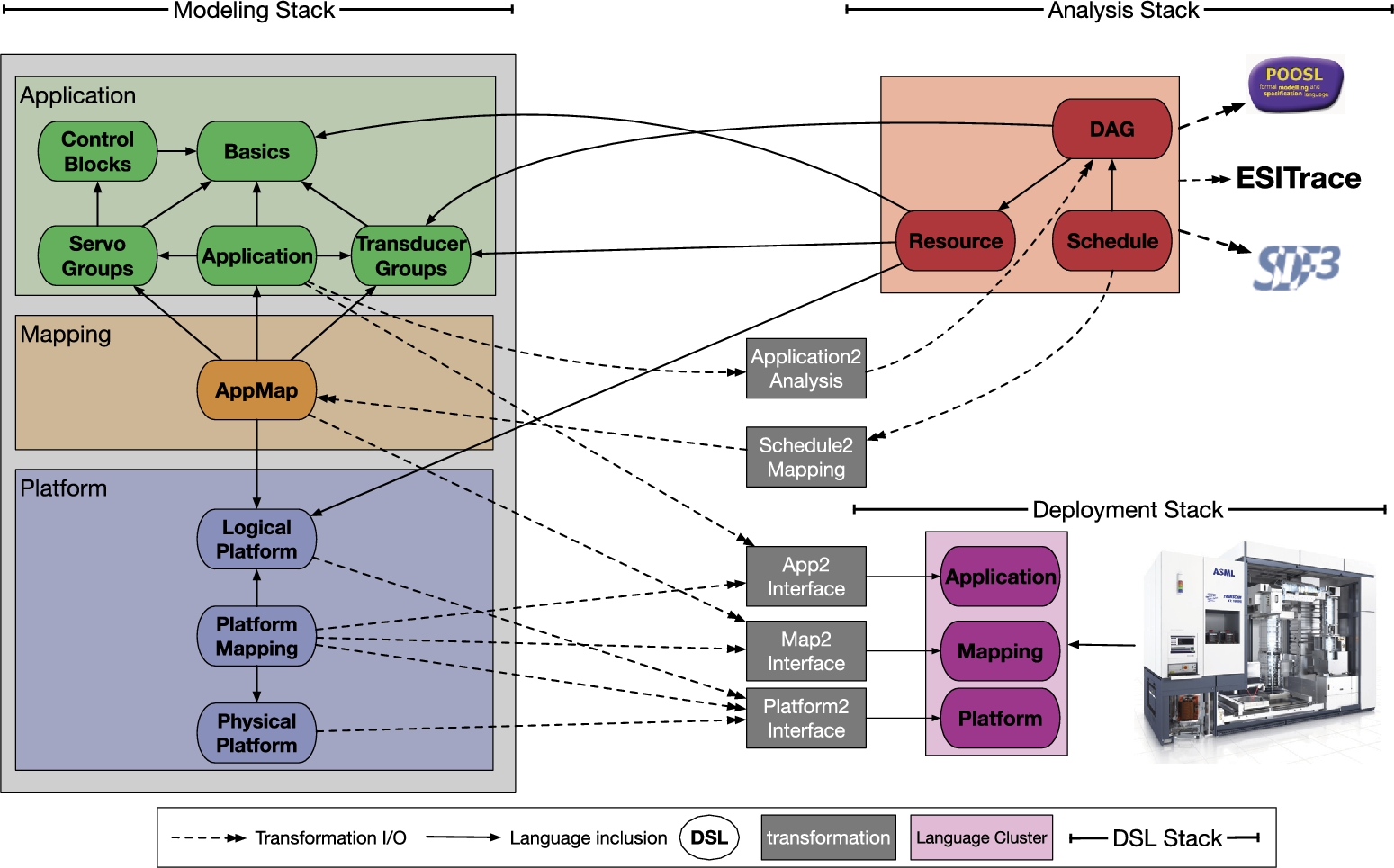
The CARM2G ecosystem consists of several architectural layers, as depicted in Fig. 11.14. We can regard it as having five layers: application, platform, mapping, analysis, and deployment, with distinct color coding (given by the domain experts) in the figure. As in the previous case study, the relation between the different layers and sublanguages of CARM2G captured in the 41 metamodels is implicit in the domain expertise of the CARM2G developers. We would like to analyze those metamodels and try to automatically infer useful information with respect to the architecture of the ecosystem.
Objectives By topic modeling the terms (i.e., element names) in the metamodels, we aim to reconstruct architectural partitions (arguably layers) and their relation with the individual metamodels. We formulate the following subobjectives, n being the number of latent topics in the dataset:
- 1. (unknown n) identifying how many “topics” there are in the dataset, guessing an optimal n;
- 2. (
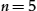 ) assessing the correspondence of the automatically mined topics (i.e., partitions) to the architectural layers given by the domain experts;
) assessing the correspondence of the automatically mined topics (i.e., partitions) to the architectural layers given by the domain experts; - 3. (
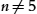 ) identifying additional or redundant partitions or layers by picking different n's.
) identifying additional or redundant partitions or layers by picking different n's.
Approach As in the first case study, using SAMOS we extracted the element names from the CARM2G metamodels, using the normalization steps including tokenization and lemmatization. After removing regular stopwords in English (such as “of” and “and”) and domain-specific stopwords as determined by the domain experts (such as “name” and “type”), we computed a simplistic VSM over the words in the form of a basic frequency matrix (i.e., no idf). We then performed several experiments with Latent Dirichlet Allocation (LDA, see Section 11.9.3 for details) based on Gibbs sampling [21], to infer the topic-term distributions in the dataset. We did not change the default parameters of LDA (due the exploratory nature of this case study and the complexity of the parameter setting [22]); we only kept the number of iterations at a relatively high value of 10,000 to increase the likelihood of convergence to a global maximum.
Results and discussion Before going into the results involving topic modeling and the individual subobjectives, we would like to present a word cloud for the whole ecosystem, as depicted in Fig. 11.15. According to the domain experts, this is a very nice summary of CARM2G concepts, and it can be used, for instance, to describe and document the ecosystem and to teach it to new language engineers and modelers.

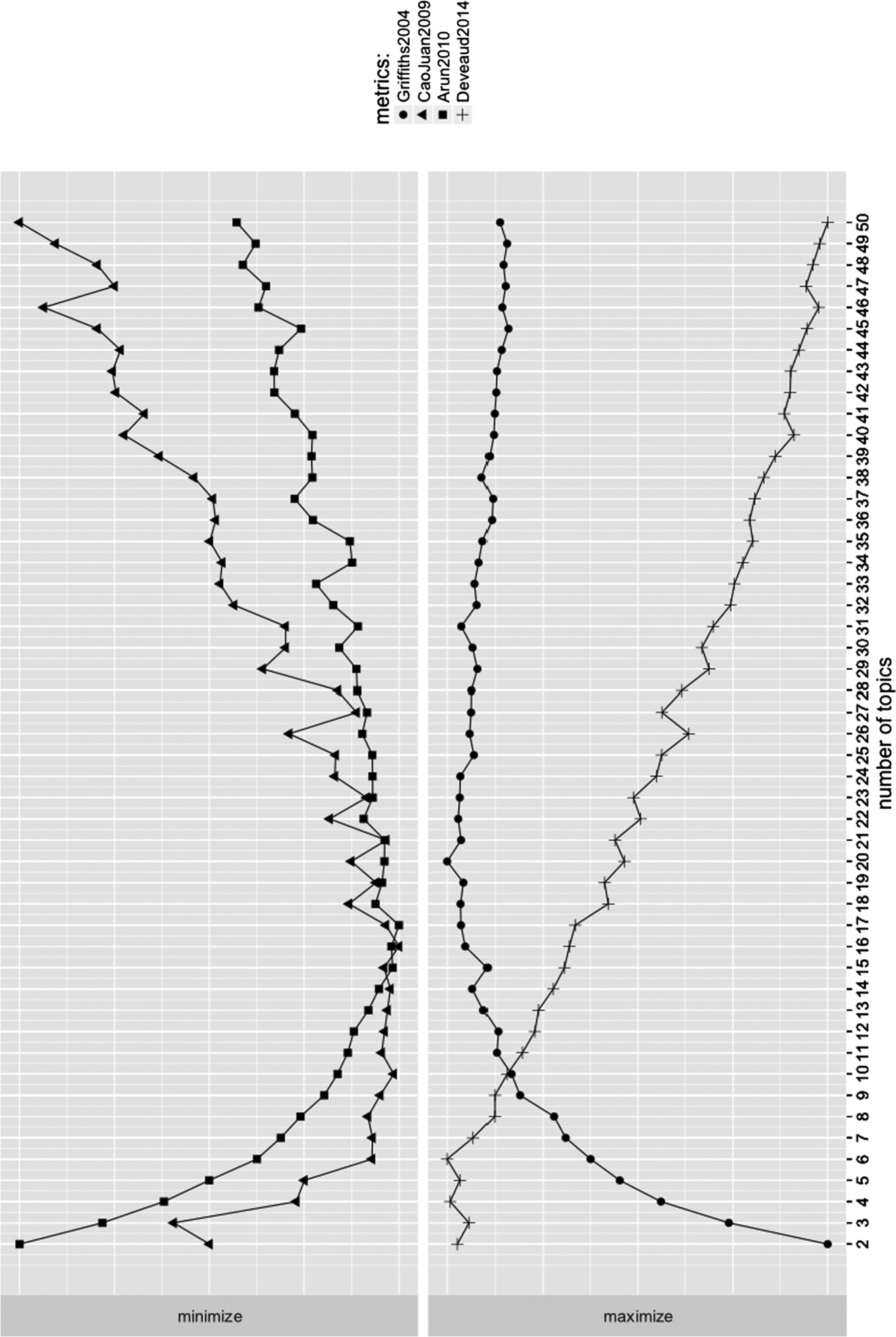
To address the first subobjective, we ran LDA with n from 2 to 50 and analyzed the graphs of several metrics in the ldatuning package5 to investigate near-optimal (minimized or maximized depending on the metric) values for n, as shown in Fig. 11.16. We can deduce various near-optimal – while aiming for a small n as much as possible – picks for n: ![]() (Deveaux2014), 20 (Griffith2004),
(Deveaux2014), 20 (Griffith2004), ![]() (CaoJuan2009), and
(CaoJuan2009), and ![]() (Arun2010). Two of these metrics have optimum values close to
(Arun2010). Two of these metrics have optimum values close to ![]() , as given to us by the domain experts, while others predict a larger number of topics. We proceed with
, as given to us by the domain experts, while others predict a larger number of topics. We proceed with ![]() , and we will discuss the implications of picking a lower or higher n later in this section.
, and we will discuss the implications of picking a lower or higher n later in this section.
After establishing that the number of topics given by the domain experts is (nearly) agreed on by some of the metrics above, we proceeded with topic modeling with ![]() . For the second subobjective, we are interested in prominent terms per topic, terms by metamodel, and the distribution of the topics by metamodel. To evaluate the results, we used a subset of 15 metamodels chosen by the domain experts as key representatives of the CARM2G architectural layers (see Fig. 11.14). In Fig. 11.17, we present the results of topic modeling specifically for those key metamodels. The interpretation of the figure is as follows. Each row (i.e., y-axis) represents a topic (labeled with the top five most prominent terms). Each column (i.e., x-axis) represents a key metamodel, as also shown in the legend. The bars at each cell of the matrix represent how likely the metamodels are represented by that topic. Each document is associated with a number of topics, hence the probability values in each column for a specific metamodel add up to 1.
. For the second subobjective, we are interested in prominent terms per topic, terms by metamodel, and the distribution of the topics by metamodel. To evaluate the results, we used a subset of 15 metamodels chosen by the domain experts as key representatives of the CARM2G architectural layers (see Fig. 11.14). In Fig. 11.17, we present the results of topic modeling specifically for those key metamodels. The interpretation of the figure is as follows. Each row (i.e., y-axis) represents a topic (labeled with the top five most prominent terms). Each column (i.e., x-axis) represents a key metamodel, as also shown in the legend. The bars at each cell of the matrix represent how likely the metamodels are represented by that topic. Each document is associated with a number of topics, hence the probability values in each column for a specific metamodel add up to 1.
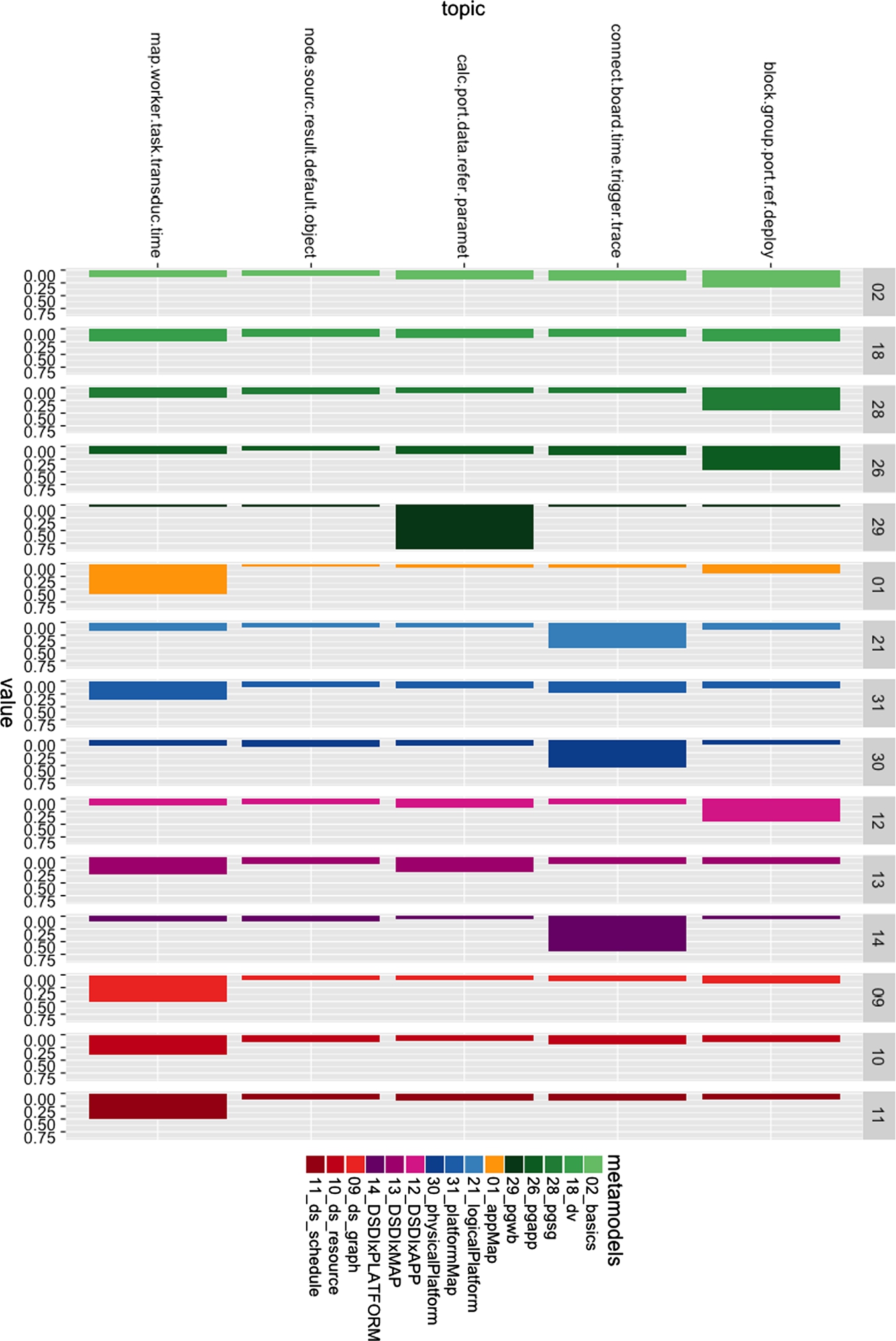
Note that we color-coded the metamodels with respect to the architectural layers, green being the application layer, orange mapping, blue platform, purple interface, and red analysis. By inspecting the figure along these color codes, for ![]() we can deduce the following:
we can deduce the following:
- Topic-1: The first (top-most) topic roughly represents the application layer, mostly represented in four of the application layer metamodels. Nevertheless, basics and dv metamodels, being rather generic and common metamodels, have a mixture of the topics; pg_wb, which is originally considered in the CARM2G application layer, does not reside in this layer however, and will be discussed below (referred to as
 ). Note that DSDIxAPP from the interface layer mostly covers this topic as well.
). Note that DSDIxAPP from the interface layer mostly covers this topic as well. - Topic-2: The second topic can mostly be associated with the platform layer (most related term: board). It is found in the platform layer metamodels (except platformMap, to be discussed below) and the DSDIxPlatform from the interface layer.
- Topic-3: In the third topic, pg_wb stands out, with almost no association with any other topic. This is due to it being a very large and fundamental language describing general-purpose language building blocks such as statements and expressions.
- Topic-4: The fourth topic does not associate with any of the key metamodels, but potentially (a mixture of) some other niche set of languages in the dataset (e.g., variation point languages). We will discuss this further in our experiments with increasing n, referring to it as outlier layer, i.e.,
 .
. - Topic-5: The final topic has a mixture of mapping and analysis layers; appMap naturally is mostly associated with this topic and platformMap, DSDIxMAP across the other layers as well, all being related. Furthermore, the three metamodels from the analysis layer also consistently reside here.
According to our detailed inspection and the feedback from the domain experts, we argue the following. The most prominent terms per topic give only a limited idea about the topics and layers. However, the partitioning into topics across languages makes a lot of sense. This indeed gives an orthogonal view on the architecture, in terms of the conceptual space. There is still room to change the parameter n for the number of topics, to see whether we can find redundant partitions, and additional (niche) groups of languages besides the standard architectural layers – addressing the final subobjective. Following the different near-optimal estimates as discussed above, we remark on the cases with ![]() in text without giving the figures (due to space limitations).
in text without giving the figures (due to space limitations).
 We obtain a very similar partitioning as for : roughly the application, platform, and mapping+analysis layers. The topic which did not correspond to any key metamodel disappears. This might indicate a more optimal partitioning than with if aiming for a high-level layering.
We obtain a very similar partitioning as for : roughly the application, platform, and mapping+analysis layers. The topic which did not correspond to any key metamodel disappears. This might indicate a more optimal partitioning than with if aiming for a high-level layering. With larger n, we still get the clear-cut partitions corresponding to platform and mapping+analysis layers; and also remain as is. We see, however, that instead of a single application layer, we have two (with divided probabilities for the related metamodels): one with terms block, group and another with connect, port. These might partly relate to different aspects of an application description.
With larger n, we still get the clear-cut partitions corresponding to platform and mapping+analysis layers; and also remain as is. We see, however, that instead of a single application layer, we have two (with divided probabilities for the related metamodels): one with terms block, group and another with connect, port. These might partly relate to different aspects of an application description. We start getting further decompositions: a mapping+analysis layer into resource with platformMap, ds_resource (terms: worker, map, resource), and scheduling with appMap, ds_graph, ds_schedule (terms: task, sequence, schedule). Some of the other partitions, however, start getting a lot fuzzier; platform metamodels for instance are distributed across different topics, logicalPlatform is now strongly associated with the application (sub)topic. However, inspecting all the metamodels involved, we discover further topics, sometimes even represented by a single metamodel: system variants (vpOverview), variant binding with a visitor pattern (vpbinding), deployment and anchor (configuration, sgdeploy, wrkdeploy, wrkanchor) intermixed with simulation (thsimmode).
We start getting further decompositions: a mapping+analysis layer into resource with platformMap, ds_resource (terms: worker, map, resource), and scheduling with appMap, ds_graph, ds_schedule (terms: task, sequence, schedule). Some of the other partitions, however, start getting a lot fuzzier; platform metamodels for instance are distributed across different topics, logicalPlatform is now strongly associated with the application (sub)topic. However, inspecting all the metamodels involved, we discover further topics, sometimes even represented by a single metamodel: system variants (vpOverview), variant binding with a visitor pattern (vpbinding), deployment and anchor (configuration, sgdeploy, wrkdeploy, wrkanchor) intermixed with simulation (thsimmode). The topics are further diluted, which makes it very difficult to argue about meaningful partitioning compared to the previous run with .
The topics are further diluted, which makes it very difficult to argue about meaningful partitioning compared to the previous run with .
This exploratory study reveals that we can indeed automatically infer valuable architectural information to a certain extent, as a complementary conceptual viewpoint to architectural layering. It can reveal conceptual partitions in an MDE ecosystem for checking architectural conformance, reveal similar groups and subgroups of languages, see the cross-cutting concerns across the languages, etc. The accuracy and reliability of topic modeling on the MDE ecosystems, however, is yet to be quantitatively evaluated and further improved. See Sections 11.8 and 11.10 for threats to validity and potential room for improvements in the future.
11.8 Discussion
We have performed a variety of analyses for the MDE ecosystems at ASML. While we presented discussions for each case study separately, in this section we would like to present an overall discussion for our approach.
For the clone detection studies on models, we have extended SAMOS with partly custom-tailored, domain-specific extraction and comparison methods, particular for the ASOME data and control models. The development of these, with the domain experts in the loop, has indicated that the different nature of the (domain-specific) modeling languages and what the domain experts consider as relevant and irrelevant pieces of information in the models are crucial for an accurate, intuitive, and actionable clone detection exercise on those models. These additionally lead to implications on the setting and type of clone detection desired. For example, for the control models, the domain experts were interested in structural clones, while not so much for the data models.
As for the accuracy for the model and metamodel clone detection, we have achieved considerable success in general. However, especially for the structural clone detection for control models, which has been a new extension to SAMOS as introduced in this work, our approach possesses certain shortcomings. We will discuss these as threats to validity later in this section.
For both models and metamodel clones, we have participated in discussions with the domain experts on the nature of the clones and actionability for improving the MDE ecosystems. Our discussions reveal that some of those clones are indeed harmful and desirable to eliminate or refactor, while others might be inevitable due to language restrictions or even intended, e.g., for certain design goals, performance criteria, or backwards compatibility. Some of those harmful clones are indeed confirmed by the domain experts to be potential candidates for improvement, e.g., in the form of refactoring or abstraction. On the other hand, other such harmful clones have been identified as difficult or undesirable to refactor. Reasons for these would include deliberate design decisions (e.g., keeping singleton repositories, as reported in Section 11.7.1) or organizational limitations (e.g., language clones across ecosystems maintained by different teams, as reported in Section 11.7.4).
Interestingly, the results of the clone detection in control models might be used not to refactor the models themselves, but to introduce new language concepts, e.g., in the form of syntactic sugar or abstractions. This could increase the modelers' consistency and efficiency. Nevertheless, there can be certain limitations, such as the additional learning time for the new syntax and additional modeling effort in the case of abstractions.
Furthermore, we have discovered another use of model clone detection thanks to our discussions with the domain experts. When the cloning pattern is expected and desirable in a certain set of models, we can investigate the occurrence of those clone fragments in all the expected models. Outlier models, i.e., expected to have this pattern but not detected in the corresponding clone clusters, might actually indicate inconsistent design. We believe this to be an interesting additional use of SAMOS, and we hope to investigate this angle of clone detection in our future work.
Our studies on the system of ecosystems, i.e., the languages and their corresponding metamodels, have been shown to be potentially useful for maintaining the growing and evolving system of ecosystems at ASML. A high-level conceptual overview of the enterprise-level ecosystem and finer-grained clone detection on the languages can provide valuable sources of information in an automatic manner, to understand and monitor the ecosystems, while identifying certain shortcomings of those ecosystems, for instance, in the form of duplication and cloning. The architectural analysis we have performed on the CARM2G ecosystem, on the other hand, can provide a complementary conceptual perspective, in terms of automatic architectural reconstruction and conformance checking with respect to the intended layering. The limitations of the architectural study, a newly explored type of analysis in SAMOS, will be elaborated in the next section as threats to validity.
Threats to validity Thanks to our extension in this work, SAMOS has been adapted for detecting clones in ASOME data and control models. However, there are several threats to validity for our current implementation. Data models have been compared in a structure-agnostic manner (i.e., using unigrams) at a relatively small scope (i.e., structured types and LevelAA; not, e.g., the whole model with a deeper containment hierarchy). For larger scopes we would need to use more powerful settings of SAMOS, capturing structure as well (e.g., subtrees, as done for control models).
On the other hand, clone detection for control models has been done on the Protocol scope using a similar structure-agnostic setting of unigrams, followed by another comparison using subtrees. The use of one-depth subtrees allowed us to reduce the computational time for comparison while still including structural information from the models (when compared, for example, to comparing full trees per model fragment). Note that this is still an approximation, and it could lead to certain inaccuracies, in which case maybe fully fledged (and very costly) graph comparison techniques should be employed instead. Obviously there is a tradeoff between the accuracy and the running time (hence the scalability) of the selected techniques.
Another issue arises with the requirement for selectively employing ordered comparison and unordered comparison for certain parts of the models. In the current implementation of SAMOS, we have it one way or another for the whole process. ASOME Control models prove to be a mixture of both, where order matters for the list of sequential actions and does not matter for the list of states in a state machine. A selective combination of both would be needed for a more accurate representation and comparison in the case of control models.
The comparison of elements for control models using the No Name setting is similar to the blind renaming approach taken in [19]. In such an approach, the identifiers of all the model elements are blindly renamed to the same name, effectively ignoring the relevance of names for the comparison. This approach allows us to find model elements that have similar structure but different values for elements such as guards or triggers or target state specification. While this improves the recall of the results found, the behavior of the two states as shown in Fig. 11.18 cannot be distinguished. The two cases on the left-hand side of the figure are treated the same, as depicted on the right-hand side. While the structure is mainly captured by the extracted trees, some structural value is also attached to the names of elements, especially target state specifications. While consistent renaming of model elements might solve this problem, this approach was not taken because the order in which these states are renamed could result in inaccurate comparison results; see Fig. 11.19 for an example.
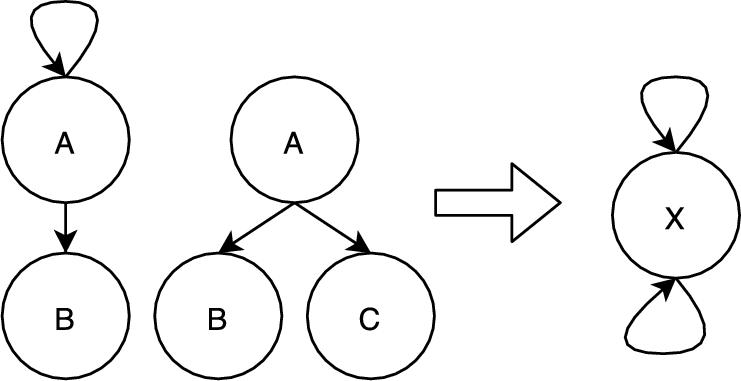
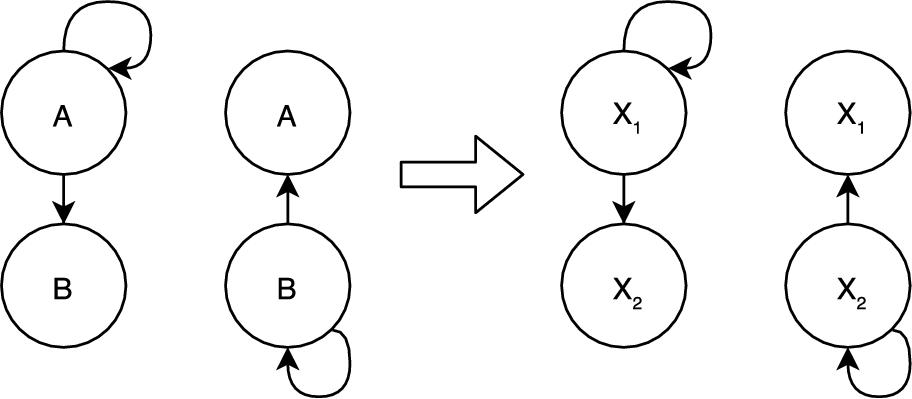
As for the language analyses presented in this work, several threats to validity exist as well. These would include, for instance, inaccurate NLP for language elements due to the lack of domain-specific dictionaries, cryptic element identifiers, and abbreviations. The topic modeling analysis part, however, is treated in a more exploratory manner in this work, in contrast to the domain analysis and clone detection parts, which have been validated considerably in previous work. The accuracy and reliability of topic modeling used for the architectural analysis is yet to be studied in detail, quantitatively evaluated, and further improved as well. As emphasized in Section 11.9.3, the technique used for topic modeling, namely, LDA, is very sensitive to the parameter settings, especially the number of topics. Hierarchical variants of LDA could be investigated to partly overcome this limitation. More specialized topic modeling approaches for shorter bodies of text (e.g., in social media data) could also be experimented with, as the languages in our case also have significantly less content (in the form of metamodel identifiers) than regular text documents.
11.9 Related work
There are various studies related to the model analytics case studies in this work. In this section we present those along with brief discussions relevant for this work.
11.9.1 Model pattern detection
Model pattern detection is a prominent research area, related to the tasks we are interested in for our research. However, the word pattern has been mostly considered synonymous to design patterns or antipatterns in the literature [23]. One approach uses pattern detection as a means to comprehend the existing design of a system to further improve this design [24]. This approach involves a representation of the system at hand, as well as of the design pattern to be detected, in terms of graphs. Ultimately, the similarity between the two graphs is computed using a graph similarity algorithm. The chapter claims to find (design) patterns within the system even when the pattern has been slightly modified. This approach, however, involves building a collection or catalogue of expected patterns as graphs. Since there were no expectations (by ASML) of the kind of patterns that needed to be detected in our case, we focused on finding, e.g., model clones in an unsupervised manner, as discussed in Section 11.9.2.
11.9.2 Model clone detection
While code clones have been previously explored in abundance and hence can be associated with some standard definition and classifications [25,26], relatively little work has been done in the field of model clone detection, resulting in the lack of such clear definitions. Model clones have been defined as “unexpected overlaps and duplicates in models” [27]. Störrle discusses the notion of model clones in depth, defining them as “a pair of model fragments with a high degree of similarity between each other” [28]. Model fragments are further defined as model elements closed under the containment relationship (the presence of this relationship between elements implies that the child in the relationship cannot exist independently of its parent).
Quite a few approaches advocate representing and analyzing models with respect to their underlying graphs, for clone detection purposes. One such approach involves representing Simulink models in the form of a labeled model graph [29]. In such graph-based methods, the task of finding clones in the models boils down to finding similar subgraphs within the constructed model graph. To do this, all maximal clone pairs are found within the graph (with a specification as to what constitutes a clone pair in their case). The approach of finding these maximal clone pairs is NP-complete and to reduce the running time, [29] the approach is modified to construct a similarity function for two nodes as a measure of their structural similarity. Finally, the detected clone pairs are aggregated using a clustering algorithm to find the resulting clone classes in the model. The disadvantage of this approach, however, is that approximate clones are not captured.
The work presented by Holthusen et al. [30] compares block-based models by assigning weights to relevant attributes for comparison, such as names, functions of the block, and interfaces. A similarity measure is defined to assign a value for the comparison and this value is stored for every pair of blocks being compared. This approach is taken to find variability in models in the automotive domain. Variations were introduced to a base model to add or remove functionality. By inspecting the similarity values, one could find models similar to a selected base model. SAMOS also uses the idea of computing similarity using a VSM to represent the occurrence of features in each model.
Störrle provides a contradictory notion however, i.e., that for some UML models, the graph structure may not necessarily be the most important aspect of the models to consider for clone detection [28]. He discusses that for some UML models, most of the information worth considering resides in the nodes as opposed to the links between these nodes. Therefore, the approach taken in this chapter defines the similarity of model fragments as the similarity of the nodes in such model fragments instead of the similarity of the graph structure of these model fragments. To construct this measure of similarity, the approach involves using heuristics based on the names of the elements being compared. Such an approach is justified when considering that “most elements that matter to modelers are named” [28]. This approach works for models where structure does not represent much in terms of model behavior. However, when the behavior of the models is represented in terms of structure, this approach cannot be used.
11.9.3 Topic modeling
Topic modeling, an approach in Information Retrieval and Machine Learning domains, involves a set of statistical techniques in text mining to automatically discover prominent concepts or topics in natural language text document collections [21,6]. Topics are typically conceived as collections or distributions of frequently co-occurring words in the corpus, which are assumed to be often semantically related. Topic models are often employed as an effective means to work on unstructured and unlabeled data such as natural language text, to infer some latent structure in the form of topic distributions (over the documents) and term distributions (over the topics).
Topic modeling applications for software engineering Besides in text mining tasks, topic models are used in other disciplines, such as bioinformatics and computer vision, and recently in software engineering (SE) as well. Various surveys in the SE literature investigate the application of topic modeling to subdomains such as SE [22], mining software repositories (MSRs) [31], and Software Architecture (SA) [32]. The overall goal is to exploit automated techniques to better understand the underlying systems and processes, aid in reconstructing and improving certain parts of them, and eventually increase their quality in a cost-effective manner. A large volume of literature can be found on topic modeling for SE and MSR tasks, such as concept, aspect and feature mining or location from source code, clustering similar SE artifacts, recovering traceability links among heterogeneous sets of SE artifacts/entities (e.g., source code, documentation, requirements), bug localization and prediction, test case prioritization, evolution analysis, and finally clone detection [22,31]. The common denominator of all those approaches is the fact that there exists textual content in all those artifacts. Based on a similar observation of textual content in SE artifacts and the fact that they might also contain architectural information, another set of approaches investigate the use of topic modeling in architecture-related tasks. The exhaustive list of activities to be supported by topic modeling in the mapping study by Bi et al. [32] includes architectural understanding, (automatic) recovery, and documentation on the one hand, and architectural analysis, evaluation, and maintenance on the other hand. The authors in general emphasize the value of those activities, such as architectural understanding for distribution of responsibilities in a software system, architectural analysis for evaluating the conformance in the case of a layered architecture, and so on.
All the topic modeling approaches reported in the three surveys above typically operate on a set of traditional software artifacts, notably source code and documentation. In a recent work, Perez et al. [33] observe this as well, and propose applying feature location directly on the models in model-based product families. They however use it in a very particular setting: for assessing the fitness of model fragments in a query reformulation problem using genetic algorithms. To the best of our knowledge, there are no approaches in the literature which apply topic modeling for SA-related tasks in MDE and DSL ecosystems, in which we are interested in this work.
Latent Dirichlet Allocation One of the most popular topic modeling techniques, also in SE tasks [22,32,31], is LDA [34]. LDA is a particular probabilistic (Bayesian) variant of topic modeling, which assumes Dirichlet prior distributions on the topics (per document, θ) and words (per topic, ϕ) and fits a generative model on the word occurrences in the corpus. Similar to the VSM setting (see Section 11.3), a collection of documents is transformed into a frequency matrix. Instead of the distance and measurement (as done for clustering in Section 11.3), the matrix is fed to LDA, which identifies the latent variables (topics) hidden in the data. The probability distributions θ and ϕ effectively describe the entire corpus. LDA relies on a set of hyperparameters to be set in advance, notably n being the number of topics, α and β being the parameters of the prior Dirichlet distributions, and additional ones depending on the particular inference technique used.
While the details of the statistical inference process (e.g., computing the posterior distributions using collapsed Gibbs sampling [21] as typically used in SE-related topic modeling tasks) is beyond the scope of this work, from an end-user perspective the output of LDA consists of two matrices: (given the fixed number of topics) one for the probability of each document belonging to various topics (i.e., multiple topics allowed, resulting in a kind of soft clustering) and one for the probability of each term belonging to various topics. The term probabilities can be manually inspected, for instance, to deduce what “concept” the topic actually corresponds to, while topic probabilities can be used to get the most prominent topics for the documents and identify document similarities.
The regular application of LDA as described above requires that the number of topics is given in advance, unlike, e.g., some other nonparametric variants such as Hierarchical Dirichlet Process [35]. One can either rely on domain expertise with respect to the corpus such that n is already known, or try to estimate the number using various heuristics. The latter involves running LDA with a range of candidate values and trying to optimize certain metrics: maximize the log likelihood of the inferred model [36] or minimize the topic density [37]. There are advanced techniques aiding or automatizing this estimation process; some notable examples within the SE literature include Panichella et al. [22], based on genetic algorithms, and Grant et al. [38], based on heuristics using vector similarity and source code location.
LDA has a proven track record of successful application in mining problems for natural language text documents. Yet one should be cautious while applying it, especially for other types of artifacts. First of all, there is the nontrivial task of determining the parameters of LDA in advance (such as number of topics, as discussed above); an incorrect choice of parameters [31] and even incorrect order of input [39] can lead to nonoptimal results. The authors in [22] further emphasize the difference between natural language text vs. source code, the latter of which has been recently studied and found to have a higher level of regularity than text in English [40], and claim that topic modeling for source code should be treated differently in order to get better results. For other artifacts, such as models, metamodels, and DSLs, no thorough empirical studies have been conducted regarding their nature yet.
11.10 Conclusion and future work
In this chapter, we have presented our approach for model analytics in an industrial context, with various analyses on ASML's MDE ecosystems. We have used and extended our model analytics framework, SAMOS, to operate on ASML's languages and models. We have elaborated the domain-specific extension of SAMOS, specifically for ASML's ASOME data and control models, to enable clone detection on those models. We have provided extensive case studies, where we performed clone detection on ASML's models, and additionally language-level analyses ranging from cross-DSL conceptual analysis and clone detection to architectural analysis for the CARM2G ecosystem. We have presented our findings along with valuable feedback from domain experts on the nature of cloning in the ecosystems and opportunities such as refactoring to support the maintenance and quality of the ever-growing and evolving ecosystems.
Besides the wide range of analyses presented in this work, there is still a lot of room for improvements and future work. While SAMOS has many combinations of settings and scopes available for model clone detection, not all these combinations were chosen for the case studies (considering the time constraints of our collaborative project with ASML). As future work we could explore different aspects of comparison using the different available settings, such as type-based and idf weighting. Furthermore, as indicated in our discussion on threats to validity, advanced comparison schemes (e.g., selective ordered vs. unordered comparison for different model parts) could be integrated to improve the accuracy of our clone detection. Other directions would include the detection of patterns, e.g., design patterns (as in [24]), or antipatterns. As a useful example application of this, one could create a pattern catalogue and find what models do not adhere to these patterns (i.e., as a potential indication of unexpected behavior in models). Finding structural clones, especially in the control models, is another promising direction for future work. Lastly, the language analyses could be improved to overcome the limitations as addressed in our discussion on the threats to validity, e.g., with more sophisticated NLP and more advanced, fine-tuned topic modeling techniques. Considering the time dimension of the languages, it would also be very interesting to investigate their evolution, in terms of concept drift [41] and cloning.