
5 Phase 1: Reconnaissance
When launching an attack, the most effective attackers do their homework to discover as much about their target as possible. Whereas an inexperienced script kiddie might jump in unprepared, indiscriminately trolling the Internet for weak systems without regard to who owns them, more experienced attackers take their time and conduct detailed reconnaissance missions before launching a single attack packet against a target network.
To understand why reconnaissance (also known as “recon” for short) is so important to the attacker’s trade, think about attacks in the plain old real world for a minute. Before bandits rob a bank, they typically visit the particular branch they are targeting, record the times that security guards enter and leave, and observe the location of security cameras. They might also try to determine the alarm system vendor, and perhaps investigate the vault manufacturer. Even a novice bandit might use the phone book to find the address of the bank and a map of the city to plan a getaway route.
Just like bank robbers, many computer attackers first investigate their target using publicly available information. By conducting determined, methodical reconnaissance, attackers can determine how best to mount their assaults successfully. Unlike some of the other attacks described in the rest of this book, a lot of this recon activity is not terribly deep technically. However, don’t dismiss it! If you think, “That recon stuff isn’t very useful because it’s not technically elegant,” you are a fool. A solid attacker recognizes the immense value of all kinds of recon before attacking a target. Whenever our penetration testing team embarks on a new project, we always schedule at least a day, and sometimes several days, of comprehensive recon work before firing up our scanning tools.
In this chapter, we explore a variety of reconnaissance techniques, including low-technology reconnaissance, Web searches, whois database analysis, Domain Name System (DNS) interrogation, and a variety of other techniques.
Low-Technology Reconnaissance: Social Engineering, Caller ID Spoofing, Physical Break-In, and Dumpster Diving
Without even touching a computer, an attacker might be able to gain very sensitive information about an organization. With low-tech recon, a determined attacker can potentially learn passwords, gain access to detailed network architecture maps and system documentation, and even snag highly confidential information from under the nose of system administrators and security personnel. Neither high-tech nor sexy, these techniques can be very effective when used by an experienced attacker.
Social Engineering
What if I told you about a brand-new computer attack methodology that slices through all of our greatest defensive policies, procedures, and technologies? It bypasses perfectly configured firewalls, defeats superstrong crypto, and evades even the most finely tuned Intrusion Prevention System (IPS) tools. It allows a bad guy to compromise a target completely, owning the machine in every way possible. It costs an attacker almost nothing, yet, in the proper hands, this ultrapowerful attack tool is almost always successful. It’s not a zero-day buffer overflow, a superfunctional bot, or a tricked-out kernel-mode rootkit. It’s not really brand new either. No, it’s just old-fashioned social engineering. By exploiting the weaknesses of the human element of our information systems, skilled attackers can achieve their goals without even touching a keyboard.
In its most widely practiced form, social engineering involves an attacker calling employees at the target organization on the phone and duping them into revealing sensitive information. The most frustrating aspect of social engineering attacks for security professionals is that they are nearly always successful. By pretending to be another employee, a customer, or a supplier, the attacker attempts to manipulate the target person to divulge some of the organization’s secrets. Social engineering is deception, pure and simple. The techniques used by social engineers are often associated with computer attacks, most likely because of the fancy term “social engineering” applied to the techniques when used in computer intrusions. However, scam artists, private investigators, law enforcement, and—heaven help us—even determined sales people employ virtually the same techniques every single day.
When conducting a social engineering assault, the attacker first develops a pretext for the phone call, a detailed scenario to dupe the victim. This pretext usually includes the role the attacker will assume (such as a new employee, administrative assistant, manager, or system administrator), and the purported reason for the call (such as getting an appropriate contact name and number, a sensitive document, or possibly an existing password or new account). Using this basic pretext, the best social engineers improvise, acting their way through the telephone call using techniques that might earn them an Academy Award if they were in the movie business.
Although there are an infinite number of pretexts, several of social engineering’s “greatest hits” are
- A new employee calls the help desk trying to figure out how to perform a particular task on the computer.
- An angry manager calls a lower level employee because a password has suddenly stopped working.
- A system administrator calls an employee to fix an account on the system, which requires using a password.
- An employee in the field has lost some important information and calls another employee to get the remote access phone number.
Using a pretext, the attacker contacts an organization’s employees and attempts to build their trust with friendly banter. The most effective social engineering attackers establish an emotional link with the target individual by being very friendly, yet realistic. Generally speaking, most people want to be helpful to others (and some people get paid to provide helpful service), so if a friendly voice calls asking for information, most employees will be more than happy to help out.
Although some social engineers look for the quick hit and try to retrieve the sensitive information briskly, others spend weeks or even months building the trust of one or more people in the target organization. In investigations that I’ve been involved with, I’ve observed that a female voice on the phone is more likely than a male voice to gain trust in a social engineering attack, although attackers of either gender can be remarkably effective. Attackers try to learn and mimic the informal lingo used by an organization to help establish trust. After gaining the trust of the target individual, the attacker casually asks for the sensitive information, just by working the request into the normal conversational pattern used while building trust.
Although some attackers are both technical experts and exceptional social engineers, most do not have both skill sets. Therefore, the more elite attackers often pool their expertise to maximize their effectiveness. The expert social engineer gathers information, which is then used by the expert technical attacker to gain access.
For several dozen additional social engineering pretexts, as well as some very entertaining reading, I recommend that you check out Kevin Mitnick’s book The Art of Deception (Wiley, 2002).
In-House Voice Mailboxes and Spoofing Caller ID to Foster Social Engineering
A good way to establish almost instant credibility in some organizations is to have a phone number within the organization. When we conduct social engineering attacks professionally as part of a penetration test, we often try to trick someone into giving us control of a voice mailbox at the target organization. After thoroughly researching the target organization, we pose as a new employee and call individuals there to ask them for the phone number of the computer help desk. We then call the help desk and ask them for the number of the voice mail administrator. Finally, we call the voice mail administrator, often posing as a new employee or an administrator, and request voice mail service. Sometimes, we are successful, establishing a number and voice mailbox on the target network. We can then contact other employees, leaving them voice mail asking for sensitive information or password resets. In the message we leave for these employees, we tell them to respond to our in-house voice mailbox, leaving a message with the requested data. Users often blindly trust anyone who has an account on the internal voice mail system.
Alternatively, an attacker could place a phone call with a faked caller ID number. Again, most people blindly trust the calling phone number that flashes on their telephone set. They must think, “If the phone company sent it to me, it must be true.” Hardly. Caller ID numbers can be spoofed (that is, altered to a value of the attacker’s choosing) in several ways.
The simplest way to spoof caller ID involves using a caller ID spoofing service. Several Internet-based companies allow their customers to place phone calls to a given number, sending a caller ID number of the attacker’s choosing. As of this writing, Star38 (www.star38.com) and Telespoof (www.telespoof.com) are two such organizations that sell their services to law enforcement agencies and investigators, and Camophone (www.camophone.com) is targeted to the general public. For each service, the user who wants to spoof caller ID accesses the Web page for the service. The user types three phone numbers into a Web form: a number to call (the intended recipient’s phone number), a phone number where the user can receive a call, and a number of the user’s choosing that will be sent as caller ID information to the recipient’s phone. The caller ID number can be anything the attacker wants, such as a real phone number associated with the target organization, a phone number of a government agency, or a bogus number like 2345678901 or 0031337000. The user could even send a caller ID number that is the same as the destination number!1 To recipients, such calls would look like they are calling themselves.
The service then performs the following actions. First, it calls the destination number and sends it the caller ID specified by the user. Next, it calls the service user’s phone number. Finally, it bridges together those two calls, so that the user can hear the ringing of the destination number, wait for someone to answer, and begin a dialogue.
All of this can be yours for 25 cents per minute (with a $175 set-up fee) for the Star38 service, 10 cents per minute (with a $25 application fee) for Telespoof, or a measly 5 cents per minute (with no set-up fee) for Camophone. Camophone, the user interface of which is shown in Figure 5.1, even lets you pay with credit card, a Paypal account, or money order.
Figure 5.1 The Camophone user interface: It’s not pretty, but it sure is simple and very functional.

What’s to deter an attacker from using such services? For Star38 and Telespoof, somewhat detailed subscription information is required to create an account. For Camophone, however, no such detailed registration is needed, other than a simple Paypal account. Thus, the only things limiting such attacks are the following:
- Your own users’ mistrust of caller ID instilled through solid security awareness programs, which we discuss in more detail at the end of this section
- The potential attacker’s conscience, if it exists
- Laws dealing with prosecuting fraudsters, who dupe users by making illegitimate claims about their identity or services
Beyond these particular services, there are even more ways to spoof caller ID. Many users have discovered that they can use Voice over IP (VoIP) services to make calls and alter their caller ID information. By reconfiguring their VoIP equipment—especially using highly configurable, free VoIP Private Branch eXchanges (PBXs) like Marc Spencer’s Asterisk for Linux, OpenBSD, and Mac OS X—users can send any caller ID numbers they choose. The specific procedure for altering the caller ID number depends on both the VoIP equipment and the VoIP service provider, as you’d no doubt suspect.
Finally, the phone companies themselves sell special telecommunications services for businesses that feature interfaces allowing a business to send arbitrary caller ID information. Although expensive (ranging upwards of several hundred dollars or more per month), a Primary Rate Interface (PRI) ISDN line supports setting caller ID numbers for outbound calls. Phone companies designed PRI interfaces so that a company’s internal voice switches, that is, their PBXs, could interface with the phone network. Because the phone network accepts caller ID information from PBXs, attackers sometime use their own PRI lines or those hijacked from a legitimate company to spoof caller ID. To accomplish this attack, the bad guys must configure the PBX to send a specific phone number, a process that depends heavily on the type of PBX used.
Defenses Against Social Engineering and Caller ID Spoofing Attacks
The most effective method of defending against social engineering and caller ID spoofing attacks is user awareness. Computer users of all kinds, ranging from technical superstars to upper management to the lowliest serf, must be trained not to give sensitive information away to friendly callers. Your security awareness program should inform employees about social engineering attacks and give several explicit directions about information that should never be divulged over the phone. For example, in most organizations, there is no reason for a system administrator, secretary, or manager to ask a rank-and-file employee for a password over the phone, so one should not be given. Instead, if an employee forgets a password and requires emergency access, establish a support line (such as a help desk) where the employee can be directed for password resets, 24 hours per day. The help desk should have specific processes defined for verifying the identity of the user requesting the password reset, such as checking the telephone number, zip code, date of hire, mother’s birth name, and so on. The particular process and items to check depend on the depth of security required by the organization and its culture.
Furthermore, if someone unknown to the user calls on the phone looking to verify computer configurations, passwords, or other sensitive items, the user should not give out the sensitive data, no matter how friendly or urgent the request, without verifying the requestor’s identity. These situations can get very tricky, but you must educate your user community to prevent your secrets from leaking out to smooth-talking attackers.
Finally, in your awareness program, make sure you tell your users that caller ID information cannot be trusted as a sole method for verifying someone’s identity. Let them know that fraudsters sometimes fake caller ID messages, and they should use alternative forms of verifying the identity of an employee.
Physical Break-In
Although reaching out to an organization over the phone using social engineering techniques can give attackers very useful information, nothing beats a good, old-fashioned break-in for accessing an organization’s most critical assets. Bad guys with physical access to your computer systems might find that a user walked away from a machine while logged in, giving them instant access to accounts and data. Alternatively, attackers might plant backdoors on your internal systems, giving them remote control capabilities of your systems from the outside (for more information on these backdoor techniques, please refer to Chapter 10, Phase 4: Maintaining Access). Alternatively, instead of blatantly using your own machines on your premises, with physical access to an ethernet plug in the wall, an attacker can start scanning your network from the inside, effectively bypassing your Internet firewalls simply by walking through a (physical) door. At a bare minimum, an attacker might simply try grabbing a USB Thumb drive, CD, DVD, backup tape, hard drive, or even a whole computer containing sensitive data and walking out with it tucked under a coat.
There are countless methods of gaining physical access to an organization. An external attacker might try to walk through a building entrance, sneaking in with a group of employees on their way into work. If badge access is required for a building, an attacker could try to piggyback into the premises, walking in right after a legitimate user enters. As with social engineering, most people want to be helpful to their fellow humans. During physical security reviews in the course of my job, I have frequently been given access to buildings or secure rooms within a building just by asking politely and looking confident in my reasons for being there.
Because they could be arrested or even shot (depending on the target), only a small proportion of external attackers actually attempt physical break-ins. However, attackers already inside an organization, such as employees, temps, contractors, customers, and suppliers, might deliberately wander into sensitive physical areas to grab information. Indeed, some attackers hire on as an employee or a temp with the sole purpose of gaining sensitive information about a target organization or planting malicious software. After committing their dastardly deeds in a single day or over the course of a week, the malicious employee quits, having gained access to systems and information.
Defenses Against Physical Break-Ins
Security badges issued to each and every employee are an obvious and widely used defense against physical break-in. A guard at the front door or a card reader should check all employees coming into a given facility. Yet, although many organizations spend big money issuing badges and using card readers, they do not educate employees about the dangers of letting people in the building without checking their credentials. Again, those darn humans just trying to be friendly will often let a person who claims to have forgotten a badge that day in through a back door. Several times, my customers have issued me badges to access their buildings using card readers at their doors. Almost always, I’ve been encountered by people who ask me to do them just one small favor and let them in even though they forgot their badge. When I politely decline, they often get rather snippy. To avoid this problem, your awareness campaigns should focus on making proper badge checks a deeply ingrained part of your organizational culture. Someone who asks to see an employee’s badge before giving access to a building or instructs the person without a badge to contact security is doing a great job and should be commended.
For particularly high-risk buildings and rooms, such as sensitive computer facilities, you might want to invest in a special revolving door and card readers that allow only one authorized employee to enter at a time. That way, the decision of whether to allow a smooth-talking person who claims to have lost his or her badge into the building will require a call to the physical security organization, and is out of the hands of rank-and-file employees. Security cameras can augment such a system, helping your physical security team keep an eye on the situation.
Of course, to prevent attackers from walking out of your buildings with computer equipment, you should have a tracking system for all computers (including laptops) brought into and out of your facilities. Make sure you have sign-in procedures for technology that tell all employees that any computer-related equipment and media entering the building is subject to search and seizure while inside your organization. Just in case someone fails to sign in some equipment, hang a poster stating this policy at all of your building entranceways. That gives your security team the policy tool they might need in a sensitive situation.
It is also critical to make sure that you have locks on computer room doors and wiring closets. A temporary employee or consultant with physical access to your systems must not be able to explore your electronic infrastructure that easily. Furthermore, it is absolutely essential that you have locks on cabinets with sensitive machines to prevent attackers from stealing a whole computer or hard drive. These cabinet locks must actually be used, as well. On far too many occasions, I have seen locking cabinets with the key permanently left in the lock so that the cabinet could be easily opened. This is bad news, foiling any security offered by the lock. Additionally, you should lock down servers and even desktops to make sure they don’t disappear at night.
Also, you must have a policy regarding the use of automatic password-protected screen savers. After five minutes or so of nonuse, each of your machines should bring up a screen saver requiring the user to type in a password before being given access to the system. There is an ironic fact of life that senior management personnel, those whose systems could pose the highest risk if compromised, often demand that their screen savers be turned off because they consider them an annoyance. Thus, some careful political maneuvering and persuasion might be required to establish and enforce this policy.
Finally, for traveling workers with laptop machines and those with sensitive desktop systems, consider installing a file system encryption tool, and training users about its function and importance. If an attacker swipes a laptop from one of your executives at an airport, your life will be slightly less complicated if the executive has an encrypted file system on the machine. Otherwise, major secrets extracted from the laptop could be for sale on the open market. Modern Microsoft Windows machines include the built-in Encrypting File System (EFS), or you could purchase more flexible file and e-mail encrypting tools such as PGP (www.pgp.com). Free solutions include the stellar Gnu Privacy Guard (www.gnupg.org). But keep in mind this critical point: If you are using file or drive encryption, make sure you deploy it with some sort of corporate recovery key, just in case a user’s encryption key gets corrupted or lost. Without a corporate recovery key, all of the data would be lost, including information stored on encrypted backups.
Dumpster Diving
Dumpster diving is a variation on physical break-in that involves rifling through an organization’s trash, looking for sensitive information. Attackers use dumpster diving to find discarded paper, CDs, DVDs, floppy disks, tapes, and hard drives containing sensitive data. In the computer underground, dumpster diving is sometimes referred to as trashing, and it can be a smelly affair. The attacker acts like a rubbish-oriented Jacques Cousteau, diving into the hidden darkness of a giant trash bin to recover the mysteries of the deep. In the massive trash receptacle behind your building, an attacker might discover a complete diagram of your network architecture right next to the remains of your salami sandwich from yesterday’s lunch. Or, a user might have carelessly tossed out a sticky note with a user ID and password, which got covered with last week’s coffee grinds, yet remains readable. Although possibly disgusting, a good dumpster diver can often retrieve informational gems from an organization’s waste.
Dumpster diving is especially effective when used for corporate espionage. In mid-2000, many major news sources broke a story about Oracle Corporation hiring private investigators to go through the trash to retrieve sensitive information about Oracle’s archrival, Microsoft. The controversial case came to be known by some as Trashgate. Oracle spending its hard-earned money digging up secrets from the trash about Microsoft illustrates the usefulness of dumpster-diving techniques. However, before you embark on a dumpster-diving trek yourself, keep in mind that in many localities, it is illegal to trespass on others’ property, even if you plan on merely taking their refuse.
Defenses Against Dumpster Diving
Paper and media shredders are the best defense against dumpster diving. Employees should have widespread access to shredders, and should be encouraged to use them for discarding all sensitive information on paper, CDs, and DVDs. Alternatively, your organization could supply each user with an additional trash can for sensitive information. Normal, nonsensitive garbage goes into the regular trash can, and the more important data gets deposited in the extra receptacle, which is promptly shredded in a central facility. Your awareness program must clearly spell out how to discard sensitive information. Some organizations with extreme security needs go even further, burning or mulching documents after shredding.
When an employee transfers from one office to another, a significant, information-rich trash event occurs. When moving between offices, employees often throw away sensitive data indiscriminately, including architecture diagrams, manuals, old CDs and DVDs, and all kinds of goodies useful to an attacker. To minimize the damage a dumpster diver poses, you should provide a large trash receptacle outside the office of the mover. All trash associated with the move should be deposited in this special bin, which is then completely shredded.
Finally, whenever you discard or recycle old, worn-out, or broken computers, make sure you yank out the hard drives. These drives are likely loaded with sensitive information, and should be physically destroyed. Yes, you could scrub them using a data wiping tool that overwrites all sectors with zeros and ones several times, or even employ a degausser that zaps them with a magnetic pulse. However, there is still a chance that some data will survive the wiping or degaussing process. The best way to be sure all data is unrecoverable by your adversaries is to crunch up the drives, physically destroying the media. Although some would claim that this approach is not as environmentally friendly as recycling the hard drives, with the relentless march of technology, in a few years these drives would be hopelessly small anyway, and would find their way to a landfill somewhere.
Search the Fine Web (STFW)
Now that we understand the low-technology means for conducting reconnaissance, let’s analyze how attackers can use computers and various Internet resources to learn more about their targets. A huge number of very useful public information sources are available today, just waiting for an attacker to look in the proper areas and ask the right questions. Because an attacker is merely searching public resources for information about a target, all of the following recon activities are legal and can be conducted by anyone with an interest in the target organization. Using these sources, attackers attempt to determine the domain names, network addresses, contact information, and numerous other useful tidbits of information about their target.
In the computer industry, if you ask someone a question with an obvious answer, you might be told to “RTFM.” Although this acronym includes a word not appropriate for this family-oriented book, “Read The Fine Manual” is a close-enough interpretation of RTFM for our purposes. When someone tells you to RTFM, it means the answer to your question is obvious if you just refer to the software’s documentation. Harried system administrators and power users often growl “RTFM” with derision to uninformed users getting on their nerves.
This basic computer phrase has been updated to reflect the most commonly used research tool today, the World Wide Web. If someone tells you to “STFW,” they are more or less suggesting that you “Search the Fine Web.” For an attacker looking for information about a target, STFW is a great strategy.
The Fine Art of Using Search Engines and Recon’s Big Gun: Google
Attackers frequently turn to Internet search engines to grab all kinds of fascinating data associated with a target. A good rule in life is that if you want answers, you need to ask someone who knows a lot. Today’s search engines, including Google, Yahoo!, and Microsoft’s MSN Search, are information-rich gold mines with lots of answers. To extract the really good nuggets, though, you’ve got to ask questions properly.
To focus our discussion on how to ask the right questions when performing computer attack recon, let’s take a look at the capabilities of the most popular search engine of all: Google. In a magazine interview, Adrian Lamo, noted attacker of major newspapers, petroleum companies, Internet Service Providers (ISPs), and financial services firms, was asked what his favorite hacking tool is. Without so much as blinking, he instantly responded that Google is his favorite hacking tool, hands down, emphasizing the importance of good, detailed search-engine recon.
Most everyone thinks they know how to use Google. You just surf to www.google.com, type in a search term, and get your answer. Admittedly, that simple-minded technique will perform a rudimentary search, but it might not give you the most valuable information you seek. To maximize the usefulness of search engines in computer attacks, attackers must carefully formulate their queries. To see how this is done, let’s analyze what Google really is. Putting aside all of Google’s fancy add-on services, these are four of the most important elements of Google’s technology:
- The Google bots. These programs, which run on Google’s own servers, constantly surf the Internet, acting as Google’s sentinels. They crawl Web site after Web site, following hyperlinks to retrieve information about what’s out there. My own Web site gets visited by a Google bot approximately every 24 hours, and sometimes even more frequently. As I watch my logs, on occasion I shout with excitement, “The Google bot is here! The Google bot is here!”
- The Google index. Based on what the Google bots retrieve, Google creates a massive index of Web sites. As of this writing, Google claims its index holds references to over 8 billion Web pages, with the number rocketing skyward every day. When you submit a query to Google, this index is what you search. In creating the index, Google associates similar Web pages together and relates them to each other and various search terms using an algorithm called PageRank. The original Google algorithm, which was created by Google’s near-mythic founders Sergey Brin and Lawrence Page while at Stanford University, is described in a history-making white paper at www-db.stanford.edu/~backrub/google.html. Since its inception, however, Google has continuously refined this algorithm without disclosing the current magical details of how the index is created. They keep that information hush-hush for two reasons: to prevent their competitors from knowing exactly how their technology works, and to lower the chance of unscrupulous people gaming the Google index to force Web pages to appear first in searches, an activity known as Google-bombing.
- The Google cache. As the Google bots scour the Internet, they bring back a copy of the text of each document in the index, pulling in up to 101k of text for each page, including HTML, DOC, PDF, PPT, and a variety of other file types. These document elements are stored in the Google cache, an immense amount of information that represents Google’s very own copy of a large portion of the Internet. Larger documents are indexed, but only their first 101k of text, not images or code, are cached.
- The Google API. In addition to the normal Web-page interface for Google that was designed for us humans, Google has also created a method for computer programs to perform searches and retrieve results, known as the Google API. A program can create an Extensible Markup Language (XML) request and send it to Google using a protocol called Simple Object Access Protocol (SOAP). Google responds with more XML containing the search results. Hundreds of developers have written applications that use the Google API to perform all kinds of nifty queries and data massaging. Check out www.soapware.org/directory/4/services/googleApi/applications for a list of some of these applications. To use the Google API for your own programs or with programs written by others, you need a Google API key, available for free from Google at www.google.com/apis. This key must be loaded into each query your programs submit. The Google API is wonderful, but, as of this writing, it limits you to 1,000 searches per day per key, and Google’s terms of use limit each user to one key. If you get more than one key, you are violating Google’s rules and could face severe penalties, ranging from Google banishment (“No more Google for you!”) to possibly a lawsuit.
Another important aspect of Google is a major constraint they place on the number of results you can retrieve from the index for a single search: 1,000. Some people think, “That’s not true ... I did a search for ‘dog’ and got 55.4 million hits!” Yes, that’s the approximate number of pages in Google’s index, but you are only allowed to view the first 1,000 results. Other people might think, “1,000 pages is a lot! How is that a major constraint?” When performing recon, attackers sometimes suck down all 1,000 results and perform data mining on them, likely using some custom code and Google’s own API to pull down all of the responses programmatically. If hit number 1,001 has the vital data the attackers are looking for, they are out of luck.
For this reason, attackers (and other Google users) try to maximize the precision of their search, using a variety of search directives and other search operators to retrieve items of maximum value. Table 5.1 contains a brief summary of some of the more interesting and useful search directives. Experienced Google users type these directives along with their search terms right into Google’s search bar or via the Google API to yield far more refined searches, thereby maximizing the value of the 1,000 results.
Table 5.1 Useful Google Search Directives and Other Search Operators
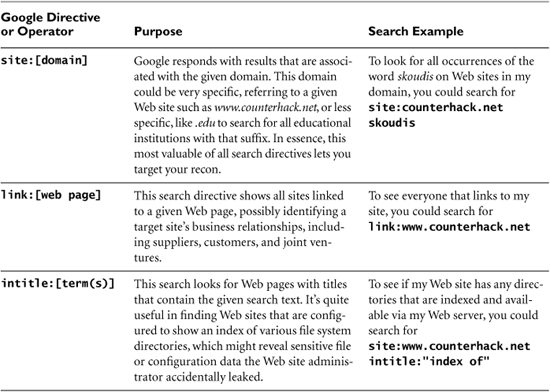

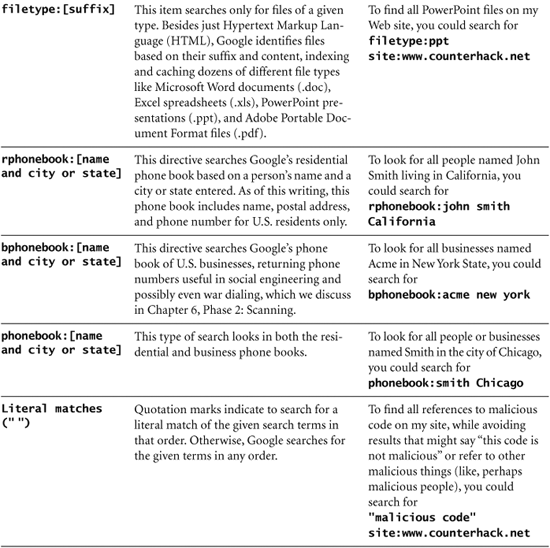

When searching Google with or without these directives, keep in mind these additional important tips:
- Remember to avoid putting a space between the directive and at least one of your search terms. The items should be smashed together (i.e.,
site:www.counterhack.netis good, butsite: wwwcounterhack.netwith a space in it is usually bad). - Google searches are always case insensitive. Searching for
site:www.counterhack.net skoudisandsite:www.counterhack.net SkouDisproduces the same results. - Google allows up to a maximum of ten search terms, including each directive you provide. In other words,
site:counterhack.net skoudiscontains two search terms, not one or three.
Things get really interesting when attackers combine various search directives and operators to find useful information about given targets. For example, suppose an attacker wants to go after a large financial institution called The Freakishly Big Bank with a Web site located at www.thefreakishlybigbank.com.
The attacker could perform a search like this:
site:thefreakishlybigbank.com filetype:xls ssn
This search causes Google to look for all Microsoft Excel spreadsheets on the bank’s site that contain “ssn,” a common abbreviation for Social Security Number, a crucial piece of personally identifiable information. Alternatively, the attacker could replace that acronym with “credit card,” “account,” “password,” or any one of a myriad of interesting terms. Quite often, such searches return very interesting information. Sometimes, an organization generates a spreadsheet with very detailed sensitive customer data in it. Then, this data is massaged to create a graph or pie chart of aggregate data that is pasted within the spreadsheet right on top of the sensitive data. The aggregates in the pie chart, however, are not personally identifiable information, and are therefore not sensitive by themselves. This spreadsheet, when opened, merely displays the pie chart, obscuring the more sensitive data underneath. Then, some marketing genius decides to put the spreadsheet on the Web site, because, after all, it doesn’t appear to show any sensitive data. Next, a Google bot indexes and caches the page. Then, this search can generate paydirt, letting an attacker pull up the whole spreadsheet, sensitive data and all.
Now, suppose the marketing genius realizes the mistake and removes the spreadsheet from the Web site. The attacker is still in great shape, because the Google index still refers to the file and the Google cache contains its data! Merely removing something from your Web site doesn’t eradicate it. That information lives on in Google’s cache until you make Google remove it, a process we discuss later. Also, even if the data has been removed from Google, it still might live in another Internet cache.
One of my favorite long-term caches is the Wayback Machine located at www.archive.org. Having nothing whatsoever to do with Google, this site features cached pages from billions of Web pages for the last several years. What’s more, if you click on a link on a Wayback Machine page, it loads the old, archived page associated with that link from the archive itself, not the original Web page. That way, it feels like you have really traveled back in time to look at crusty old Web pages that might harbor interesting information.
In addition to searching for Excel files, it’s always a good idea for the attackers to look for Microsoft PowerPoint files, because they, too, might have sensitive data lying under pictures that have been pasted over certain parts of a slide. That’s why searches like site:thefreakishlybigbank.com filetype:ppt are so useful.
Now, instead of looking inside of spreadsheets or presentations, suppose the attacker wants to scour an entire site for references to Social Security Number information. In my experience, this type of search is best done as follows:
site:thefreakishlybigbank.com ssn -filetype:pdf
The -filetype:pdf on the end filters out all PDF documents. Without this addition, the search usually pulls up a bunch of forms for customers to fill out, which seldom have useful information. Slicing all PDF files out of the search focuses us on more juicy terrain.
Another useful alternative involves looking for active scripts and programs on the target site, including Active Server Pages (ASPs), Common Gateway Interface (CGI) scripts, PHP Hypertext Preprocessor (PHP) scripts, JavaServer Pages (JSPs), and so on. Given that there could be 1,000 or more of these types of pages in a given domain, I typically search for each one individually, looking for:

With these results, I’ve harvested the target domain for various forms of user-activated scripts and programs that run on the Web site itself, each of which might have a security flaw. However, instead of scanning for these programs, I’ve allowed Google to do all the scanning work, and have merely plucked from the results the useful data I need. The attacker can even look for specific scripts that are known to have security flaws that allow for direct compromise of the system. In late 2004 and early 2005, the Santy worm spread by finding vulnerable systems using a Google search for flawed PHP software called phpBB that implements discussion forums for Web sites.
We can expand on this idea even further, by simply submitting queries to Google that look for systems that are very likely vulnerable, based on information retrieved by the Google bots. For example, an attacker can perform searches for default content included with certain Web servers and Web development environments. If I search Google for a specific site with the text “Test Page for the Apache Web Server” or “Welcome to Windows 2000 Internet Services,” I’ll find servers that still have those default Web pages loaded on them. Now, you might think that such servers aren’t all that useful, because if they still have the default page, they likely don’t have much sensitive information on them. But consider this: If those default pages are still on the boxes, there is also likely other default and possibly vulnerable content on the machines. Making matters worse for the target, the administrator might not have patched these systems either, making them ripe targets for attack. Even though these servers might not have sensitive data on them, an attacker can compromise this low-hanging fruit, and then use these weaker servers as staging points for further attacks from inside the DeMilitarized Zone (DMZ) of the target environment. Yikes!
Attackers can also look for command shell history, and even hidden hyperlinks and indexes that aren’t easily accessible by humans. The attackers just let the Google bots and the index work their magic. If an attacker can find ipconfig, cmd.exe, ifconfig, or bash, the Web sites might have allowed for indexing of critical system and binary directories, a grievous mistake.
Johnny Long, a gentleman known as the “I hack stuff” guy, maintains a list of more than 1,000 useful searches to find vulnerable servers in his astonishingly cool Google Hacking DataBase (GHDB) located at http://johnny.ihackstuff.com. This list is updated almost daily, and includes both the most recent and most popular items, ranked by Johnny’s users.
You could perform all of the searches for vulnerable systems we just discussed by hand, of course, methodically typing each into the Google search form and harvesting all responses. But you’ll quickly become bored with even a small sample of the GHDB. A more efficient way of performing these large numbers of searches involves using a tool specifically designed to automate Google recon for vulnerabilities. These tools essentially are nifty graphical front ends that query Google using its API and your Google API key to look for evidence of vulnerabilities in a site of your choosing.
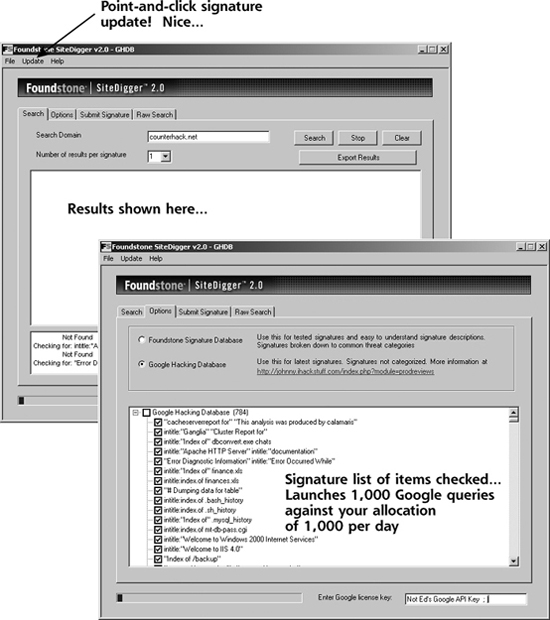
Two of the most popular tools in this category are Foundstone’s SiteDigger (www.foundstone.com/resources/proddesc/sitedigger.htm) and Wikto by Roelof Timmingh (www.sensepost.com/research/wikto). Both of these tools require you to provide your own Google API key.
The user interface for SiteDigger is shown in Figure 5.2. Note that the user simply types in a target domain name and a Google API key. Then SiteDigger automatically formulates queries for Google, looking for known vulnerabilities that can be found via Google. As of this writing, SiteDigger performs approximately 1,000 queries based on automatically updateable search signatures created by Foundstone or Johnny Long’s GHDB, thereby burning up your Google API key’s daily usage of 1,000 searches. So, with a single SiteDigger or Wikto search, you’ve burned your Google API key for that day and have to come back the next day for more automated Google adventures.
Figure 5.2 SiteDigger by Foundstone.
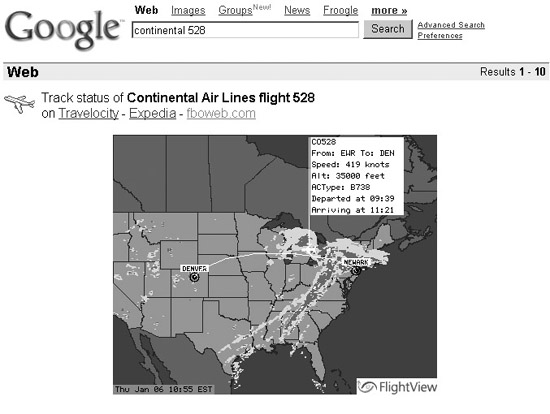
Finally, although not directly related to finding vulnerable systems, some cute and useful searches in Google can prove incredibly useful. Google supports looking up an airline and flight number. As displayed in Figure 5.3, Google responds with the current status of the flight and its location in the air on a map! Also, you can search for a Vehicle Identification Number (VIN) or Universal Product Code (UPC) number to get detailed motor vehicle or product data. In essence, Google is acting as a front end for Travelocity, Expedia, and fboweb.com for flight tracking; CarFax for VINs; and UPCDatabase.com for product information.
Figure 5.3 Flight tracking via Google.
Using Google for detailed recon is both an art and a science. If you’d like to get more information about using Google for recon activities, there are two great books on the topic: Johnny Long’s Google Hacking for Penetration Testers (Syngress, 2004) and Tara Calishain and Rael Dornfest’s Google Hacks (O’Reilly, 2004). I’ve read both books cover to cover, and keep them within arm’s reach whenever I’m doing penetration testing.
Although Google is king of the search engines, it’s important to note that Google itself is increasingly filtering some searches for sensitive data, including some Social Security Numbers and certain vulnerabilities, a process known as search scraping. Google is doing this for wholesome reasons—to help limit identity theft and thwart Google-based worm propagation. Because of scraping, whenever I’m performing detailed recon, I always check out Google along with other search engines including Yahoo! (http://search.yahoo.com) and Microsoft’s MSN Search (http://search.msn.com). In my experience, Yahoo! and Microsoft perform far less scraping than Google, as of this writing, although their search directives tend to be a small subset of the bounty that is Google.
Listening in at the Virtual Water Cooler: Newsgroups
Another realm with great promise for an attacker involves Internet newsgroups so frequently used by employees to share information and ask questions. Newsgroups often represent sensitive information leakage on a grand scale. Employees submit detailed questions to technical newsgroups about how to configure a particular type of system, get around certain software coding difficulties, or troubleshoot a problem. Attackers love this type of request, because it often reveals sensitive information about the particular vendor products a target organization uses and even the configuration of these systems.
Additionally, attackers sometimes even send a response to the requestor, purposely giving wrong advice about how to configure a system. Hoping that the victim will follow the evil advice, the attacker attempts to trick the user into lowering the security stance of the organization. Recently, we were performing a penetration test and discovered that a software developer working at our target company posted a question on a newsgroup asking for help developing his code. He was having trouble with an antivirus tool’s heuristic searches triggering every time his code ran, shutting down his program. Someone responded to his query with a little snippet of new code that would solve his problem. This new code, of course, simply shut off the antivirus program before it could get in the way. The original “problem” was solved, but the “solution” created even bigger concerns by bypassing all antivirus protection.
To search newsgroups, the Google newsgroup Web search engine at http://groups.google.com provides a massive archive of newsgroups, and has an easy-to-use query mechanism for searching the archive. In early 2001, Google acquired the very popular DejaNews Web site, and repackaged it in this very useful interface. All major newsgroups are archived. When conducting a penetration test, I frequently peruse the newsgroups at Google, doing searches for target names, domains, and employee names.
Using the advanced search capabilities of Google’s groups, you can focus searches on particular newsgroups, certain message authors, or even given date ranges. Since the acquisition of DejaNews, Google has done a great job of keeping this immense archive up to date.
Searching an Organization’s Own Web Site
In addition to search engine recon and newsgroup analysis, smart attackers also look extra carefully at a target’s own Web site. Web sites often include very detailed information about the organization, including the following:
- Employees’ contact information with phone numbers. These numbers can be useful for social engineering, and can even be used to search for modems in a war dialing exercise.
- Clues about the corporate culture and language. Most organizations’ Web sites include significant information about product offerings, work locations, corporate officers, and star employees. An attacker can digest this information to be able to speak the proper lingo when conducting a social engineering attack.
- Business partners. Companies often put information about business relationships on their Web sites. Knowledge of these business relationships can be useful in social engineering. Additionally, by attacking a weaker business partner of the target organization, an attacker might find another way into the target. Although it’s trite, a chain really is only as strong as its weakest link. Therefore, by targeting a weaker link (the business partner), the attacker might find a way to break the chain.
- Recent mergers and acquisitions. In the flurry of activity during a merger, many organizations forget about security issues, or put them on the back burner. A skillful attacker might target an organization during a merger. Additionally, a company being acquired could have a significantly lower security stance than the acquiring company. When there is a difference in the security stance, the attacker can benefit by going after the weaker organization.
- Technologies in use. Some sites even include a description of the computing platforms and architectures they use. For example, many companies specifically spell out that they have built their infrastructure using Microsoft IIS Web servers and Oracle databases. Or, a site might advertise its use of an Apache Web server running on a Linux box. Such morsels of information are incredibly useful for attackers, who can refine their attack based on such information.
- Open job requisitions. This type of data is really useful for attackers. For example, if your Web site claims that you are looking for NetScreen firewall administrators, that tells the attacker two things: First, you are likely running NetScreen firewalls. Second, and perhaps even more important, you don’t have enough experienced staff to run your existing firewalls. If you did, you wouldn’t be looking to hire that experience.
Defenses Against Search Engine and Web-Based Reconnaissance
With so many useful sources of information for attackers on the Web, where do you start in making sure you are not a victim of good search engine and Web-based reconnaissance? Start at home, by establishing policies regarding what type of information is allowed on your own Web servers. Don’t allow people to put sensitive customer or other data on your Web site, even if it is a directory with an unguessable name. The all-seeing eyes of the Google bots might still find it. Also, avoid including information about the products used in your environment, and particularly their configuration. Some would argue that this is merely security through obscurity. I agree that just obscuring data is not really securing it, because a determined attacker will spend a lot of time and effort battling through the obscurity. However, although obscurity by itself is not a good security tactic, it certainly can help. There’s no sense putting an expensive lock on your door and leaving milk and cookies outside so the lock picker can have a snack. Therefore, although attackers can use other means to find out what vendor products you are using and their configuration (as we discuss in Chapter 6), you do want to make sure that you are not making things easier for them by publishing sensitive information on your public Web site.
In addition to making sure your own Web site does not contain sensitive data available to the public, your organization must have a policy regarding the use of newsgroups and mailing lists by employees. Your workforce must be explicitly instructed to avoid posting information about system configurations, business plans, and other sensitive topics in public venues like mailing lists and newsgroups. Furthermore, you should enforce this policy by periodically and regularly conducting searches of open, public sources such as the Web and newsgroups to review what the world (including your own employees) are saying about your organization. In addition to helping prevent information leakage, this open source monitoring can help keep you informed about employees searching for jobs, disgruntled customers, potential legal action, and a host of other information. Many times, within a single organization, the public relations, legal, and human resources organizations work in coordination with the security team to conduct these open source searches. A handful of security companies also offer services based on gathering open source intelligence.
Finally, if you find that Google has indexed a URL or cached a page that you didn’t want it to, you can have Google remove it. First, you have to update your Web site, removing the sensitive data from it or indicating to Google not to index or cache it. Google respects the following markers for data:
- The robots.txt file is a world-readable file in a Web server’s root directory that tells well-behaved Web crawlers not to search certain directories, files, or the entire Web site. This file is immensely useful, but is a double-edged sword. Although it will keep well-behaved crawlers from going through certain sensitive portions of your Web site, it also tells the real bad guys and evil crawlers where to focus to find the really good stuff.
- The noindex meta tag tells well-behaved crawlers not to include the given Web page in an index.
- The nofollow meta tag tells well-behaved crawlers not to follow links on a page in an effort to find new pages.
- The noarchive meta tag says that a given page should be indexed (so it can be searched for), but should not be cached.
- The nosnippet meta tag specifies that Google shouldn’t grab summary snippets of your Web page for display with search results on Google’s site.
An example of some of these tags that you could place at the top of a Web page to keep it out of Google’s index and archive would be as follows:
<meta name=“robots” content=“noindex,noarchive”>
After updating your Web site by removing specific pages, updating robots.txt, or adding the appropriate meta tags, you could simply wait for the Google bots to recrawl you. That could take some time, possibly a few weeks (although, as I said earlier, my own Web site gets crawled about every 24 hours). If you have an urgent need to remove something from Google, use the URL removal request submission form from Google, available at http://services.google.com/urlconsole/controller. According to Google, this request recrawls the page within 24 hours, removing the requested content, although I’ve observed much faster turnaround time, usually less than 1 hour!
For instructions on how to remove items from non-Google search engines, a topic that goes beyond the scope of this book, please check out the wonderful Web site www.robotstxt.org. For instructions about how to remove items from the Wayback Machine at www.archive.org, refer to www.archive.org/about/faqs.php. The folks behind the Wayback Machine claim that they don’t want to archive old pages created by people who don’t want those pages available anymore. Of course, you have to show that you are the administrator of a given Web site or the person whose personal data has been exposed to get these folks to remove the offending content. After all, the Wayback Machine folks don’t want some unscrupulous person deleting huge parts of history. So, by using a simple robots.txt file or sending the Wayback folks a kindly e-mail, you can delete your own past for those Web sites you control.
Whois Databases: Treasure Chests of Information
In addition to Web search engines, other extremely useful sources of information are the various whois databases on the Internet, which act like Internet white pages listings. These databases contain a variety of data elements regarding the assignment of domain names, individual contacts, and even Internet Protocol (IP) addresses. A domain name refers to one machine or a group of machines on the Internet, such as www.counterhack.net, my particular Web server, or counterhack.net, a group of machines associated with my organization. When your organization establishes an Internet presence for a World Wide Web server, e-mail servers, or any other services, you set up one or more domain names for your organization with a registration company, known as a registrar. Your domain name and other crucial details are automatically loaded into several whois databases run by various registrars and certain Internet infrastructure organizations.
In exchange for your registration fee, the registrar makes sure that your domain name is unique, and assigns it to your organization by entering it into various databases (including whois databases and DNS) so that your machines will be accessible on the Internet using your domain name. When an attacker conducts research using whois databases, the approach used depends on the suffix of the organization’s domain name, known as a top-level domain. The most popular top-level domains in use are .com, .net, .org, and .edu.
Researching .com, .net, .org, and .edu Domain Names
Registrars for domain names ending with .com, .net, .org, and .edu are commercial entities, competing for customers to register their domain names. Prior to 1999, a single registrar, Network Solutions, had a monopoly on domain name registration for most of the Internet. Since then, the Internet Corporation for Assigned Names and Numbers (ICANN) has established an accreditation process for new and competing registrars. Because of ICANN’s efforts, the number of domain name registrars has bloomed, with several hundred registrars offering services today. Registrars range from small mom-and-pop establishments to giant Internet companies. Some registrars charge a handsome price and offer a variety of value-added services, whereas others are bare bones, offering free registration in exchange for ad space on your Web site. A complete list of all accredited registrars is available at www.internic.net/alpha.html, as shown in Figure 5.4.
Figure 5.4 A list of accredited registrars on the InterNIC site.
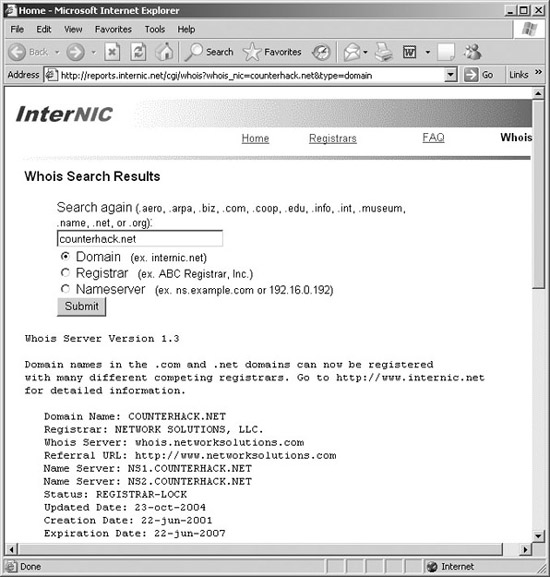
A first step in using whois databases for recon of .com, .net, .org, and .edu domains is to consult with the Internet Network Information Center (InterNIC) whois database. InterNIC also holds information associated with the .aero, .arpa, .biz, .coop, .info, .int, and .museum top-level domains. The InterNIC is a comprehensive center developed by several companies, along with the U.S. government, to allow people to look up information about domain name registration services. The InterNIC’s whois database, located at www.internic.net/whois.html, lets users enter an organization’s domain name, registrar, or DNS server. Attackers typically enter the domain names discovered during their Web searches (with input like “counterhack.net”). Based on this input, as shown in Figure 5.5, the InterNIC whois database displays a record that contains the name of the registrar that the organization used to register its domain name.
Figure 5.5 Using the InterNIC whois database to find the target’s registrar.
Researching Domain Names Other Than .com, .net, .org, .edu, .aero, .arpa, .biz, .coop, .info, .int, and .museum
Organizations around the world can use the familiar .com, .net, .org, and .edu top-level domains, which are known as global top-level domains. Additionally, a whole world of organizations utilizes domain names that do not end in these four suffixes. Many organizations rely on country code top-level domains, such as .uk (for the United Kingdom), .ru (for Russia), .cn (for China), and .jp (for Japan). Furthermore, military and government organizations in the United States use a variety of different registrars and cannot be researched using InterNIC. How do you research such organizations?
For organizations outside of the United States, one of the most useful research tools is the Uwhois Web site (www.uwhois.com). This site includes a front end for registrars in 246 countries, ranging from Ascension Island (.ac) to Zimbabwe (.zw). Uwhois points you to the appropriate registrar for any particular country you need to research.
Additionally, for U.S. military (.mil) organizations, a quick trip to the whois database at www.nic.mil/dodnic reveals registration information. Finally, U.S. government registration data can be retrieved from www.dotgov.gov/whois.aspx.
We’ve Got the Registrar, Now What?
At this stage of reconnaissance, the attacker knows the target’s registrar, based on data retrieved from InterNIC, Uwhois, or one of the other whois databases. Next, the attacker contacts the target’s particular registrar to obtain the detailed whois entries for the target. Figure 5.6 shows an attacker using the Network Solutions whois lookup capability to get information about a potential victim. Note that Network Solutions, still one of the biggest registrars in the world, supports several types of searches. Using their whois database, you can conduct searches based on a variety of different information, including the following:
- Domain name, such as counterhack.net
- NIC handle (or contact), by typing a convenient alphanumeric value assigned to each record in the whois database, such as ES1234.
- IP address, by typing the dotted-quad IP address notation, such as 10.1.1.48
Figure 5.6 Looking up a domain name at a particular registrar.
So, if the attackers know only the domain name of the target, they can use this whois database to search for more information about the given organization, including registered domain names, name servers, contacts, and so on.
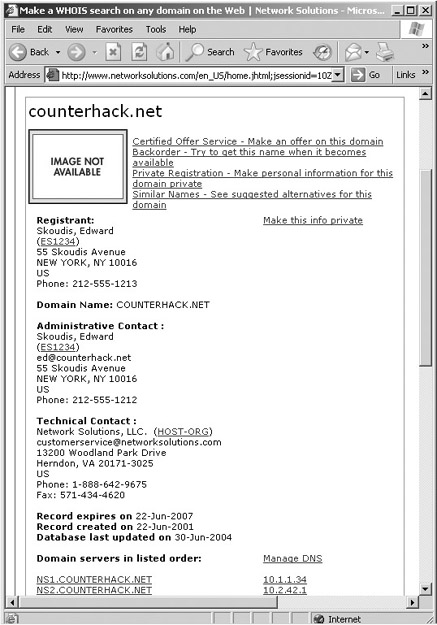
A search of the target’s registrar, as illustrated in Figure 5.7, returns several very useful data elements, including these:
- Names. Complete registration information includes the administrative, technical, and billing contact names. Although some entries don’t have all three, most have at least one contact. An attacker can use this information to deceive people in the target organization during a social engineering attack.
- Telephone numbers. The telephone numbers associated with the contacts can be used by an attacker in a war-dialing attack, as described in Chapter 6.
- E-mail addresses. This information includes contact information for a handful of people at the target, but, more important, it also indicates to an attacker the format of e-mail addresses used in the target organization. For example, if e-mail addresses are of the form [email protected], the attacker knows how to address e-mail for any user given a name.
- Postal addresses. An attacker can use this geographic information to conduct dumpster-diving exercises or social engineering. Alternatively, if the attacker determines that the postal address is nearby, he or she might mount a war-driving attack to find unsecured wireless access points, as we discuss in Chapter 6.
- Registration dates. Older registration records tend to be inaccurate. Also, a record that hasn’t been recently updated might indicate an organization that is lax in maintaining the security of its Internet connection. After all, if the company doesn’t keep its vital registration records up to date, it might not keep its servers or firewalls up to date either.
- Name servers. This incredibly useful field includes the addresses for the DNS servers for the target. We discuss how to use this DNS information later in this chapter.
Figure 5.7 The results of a registrar whois search.
An attacker can use each one of these items to further hone the attack, grabbing even more information about the target environment.
IP Address Assignments Through ARIN and Related Sites
In addition to the information offered by the target’s registrar, another source of target information is the various geographically based IP address block assignment whois databases. For example, an organization called the American Registry for Internet Numbers (ARIN) maintains a Web-accessible whois-style database that allows users to gather information about who owns particular IP address ranges, based on company or domain names, for organizations in North America, a portion of the Caribbean, and subequatorial Africa. So, whereas the registrar whois database tells users about particular contact information, the ARIN database contains all IP addresses assigned to a particular organization in those geographies. You can access the ARIN whois database at www.arin.net/whois/arinwhois.html. If the target organization is located in a different geography, the following IP address whois databases can be consulted:
- Europe, the Middle East, central Asia, and Africa north of the Equator are served by the Réseaux IP Européens Network Coordination Centre (RIPE NCC), at www.ripe.net.
- Asia Pacific is handled by the Asia Pacific Network Information Center (APNIC), at www.apnic.net.
- Latin America and the Caribbean are found in the Latin American and Caribbean Internet Address Registry (LACNIC), at http://lacnic.net.
Note that many organizations don’t have their own IP address allocation, opting instead to borrow IP addresses from their ISPs. In such cases, ARIN, RIPE NCC, APNIC, and LACNIC reveal very little information about the target.
Defenses Against Whois Searches
You might be thinking that all of this whois database information that is so useful for attackers should not be available to the public. Further, you might think that having erroneous or misleading registration information will make you safer, because an attacker won’t be able to rely on it. Although your desires might be commendable from a security perspective, you’d be very wrong on both counts. Accurate and up-to-date whois databases are an absolute necessity in maintaining overall security on the Internet.
Keep in mind that the Internet is really a community, and the various whois databases truly are the white-pages listings for our community. If you need to contact the administrator of another network for whatever reason, you can quickly and easily get the contact information using whois searches. Several times in my career, I have been confronted with a determined attacker during an incident investigation. We analyzed the attack packets to determine their apparent source IP address. By researching this source address using various whois databases, we were able to quickly contact the administrators of the network where the attack appeared to originate. By working closely with these administrators, we could determine whether their systems were compromised, or whether the attacker was using their addresses in a spoofing attack. On several occasions, the whois database information let us inform administrators that their systems were being used in an attack.
For this reason, there really is no comprehensive defense to prevent attackers from gaining registration data while still making this information available to other legitimate administrators in our Internet community. You must make sure that your registration data is accurate so that the proper person can be contacted without interruption if an incident occurs. As contacts change jobs, you have to be diligent to ensure that phone numbers and e-mail addresses are updated with your registrar. Furthermore, make sure there is no extraneous information in your registration records that could be used by an attacker, such as account names for an administrator.
Some registrars offer anonymous registration services. These companies allow you to register through them, and enter their contact information into whois databases, instead of your own contact data. Examples of such services include Aplus.net (http://domains.aplus.net/anonindex.php) and Domains By Proxy (www.domainsbyproxy.com). Network Solutions even offers such a service for an additional $9 per year plus the registration fee itself. I’m not fond of these anonymous registration services because I strongly believe they could really harm their customers and the rest of the Internet more generally. Incident handlers depend on being able to use whois information to contact each other quickly when computer attacks occur. If you go through a registrar that doesn’t reveal your information, you slow down how quickly I can reach you. Even if the registrar passes critical information about an attack from me to you, that gives bad guys more time to attack us all, sadly. I recommend you avoid anonymous registration, instead focusing on keeping your information up to date and training your staff to avoid social engineering scams.
The Domain Name System
DNS is an incredibly important component of the Internet and another immensely useful source of recon information. DNS is a hierarchical database distributed around the world that stores a variety of information, including IP addresses, domain names, and mail server information. DNS servers, also referred to as name servers, store this information and make up the hierarchy. In a sense, DNS is to the Internet what telephone directory assistance is for the phone system. DNS makes the Internet usable by allowing people to access machines by typing a human-readable name (such as www.counterhack.net) without having to know IP addresses (like 10.1.1.48). In their wonderful book, DNS and BIND, Paul Albitz and Cricket Liu (O’Reilly, 2001) say of DNS, “Almost all business that gets done over the Internet wouldn’t get done without DNS.”
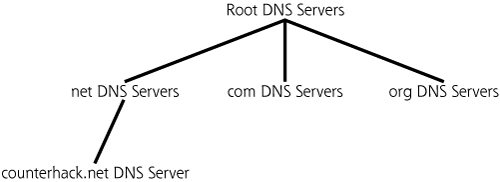
As shown in Figure 5.8, at the top of the DNS hierarchy are the root DNS servers, which contain information about the DNS servers in the next level down the hierarchy. Various authorities around the world maintain and run the 13 root DNS servers on the Internet, which act as a starting point for DNS searches. The next level down the hierarchy includes DNS servers for the .com, .net, and .org domains, as well as many others. Note that in the DNS hierarchy, the preceding dot (“.”) is not included in front of the com, net, and org DNS server names. Going down the hierarchy another level, we find DNS servers for individual organizations and networks. These DNS servers contain information about other lower level DNS servers, as well as the IP addresses of individual machines. The hierarchy of DNS servers can get very deep, depending on how individual organizations structure their own part of the hierarchy.
Figure 5.8 The Domain Name System (DNS) hierarchy.
Using a process called resolving, users and programs search the DNS hierarchy for information about given domain names. In particular, DNS is most frequently used to resolve given domain names into IP addresses so that an application can contact a particular machine across the network.
To begin a DNS search for a name like www.counterhack.net, client software first checks a local configuration file (called the hosts file) as well as a local cache on the client machine to see if it already knows the IP address associated with the domain name. If not, the client sends a DNS request to its local DNS server asking for the IP address associated with the domain name, as shown in Figure 5.9. If the local DNS server has the information cached from a previous DNS search, or has the required record in its own DNS master files, it sends a response. If the local DNS server doesn’t have the information, it resolves the name by doing a search of DNS servers on the Internet. The type of search most commonly done by local DNS servers is a recursive search, where various servers in the DNS hierarchy are systematically queried to find the desired information.
Figure 5.9 A recursive search to resolve a domain name.
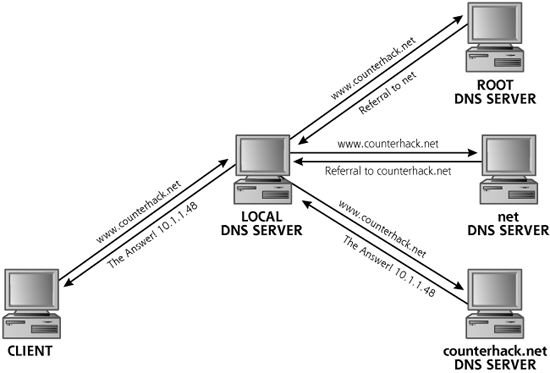
In a recursive search, the local DNS server consults a root DNS server to see if it knows the IP address for the desired domain name. If the root DNS server does not have the information, it sends back a referral with the IP address of the next DNS server down the hierarchy, the net DNS server in our example. Using the IP address in this referral response as a destination, the local DNS server then queries the net DNS server. If the net DNS server has the requested IP address, it sends a reply to the local DNS server. If not, the net DNS server sends a referral with the IP address of the counterhack.net DNS server. We step closer and closer to the final system, gathering information at each step. Finally, when a sufficiently low-level DNS server is found with the requested information, the response is sent back to the local DNS server, which in turn sends its response back to the requesting client. At every step of the search, the local DNS server stores the entries it receives to simplify future requests. In the next search for something in the .net domain, for example, the local DNS server will not have to query the root DNS server, because it already knows where to find the net DNS server. Similarly, if someone wants to look up mail.counterhack.net, the local DNS server already knows where to find the counterhack.net DNS server to ask it for information about mail.counterhack.net, bypassing both the root and net DNS servers.
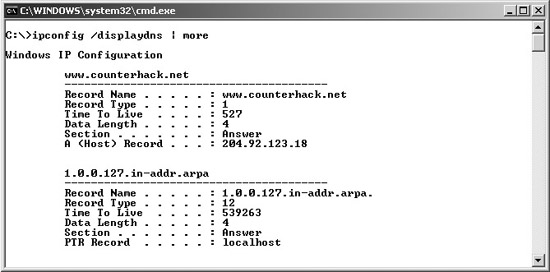
Likewise, the client itself that made the original request caches the answer for a given time, called the Time To Live, a field included in the DNS response. On a modern Windows machine, you can dump your client’s DNS cache by typing the command ipconfig /displaydns at a command prompt, as shown in Figure 5.10. Run the command multiple times, and notice how those Time To Live values, listed in seconds, are decremented each time you run it. Unfortunately, unlike Windows, this client resolver information on UNIX and Linux is stored inside each running process that uses DNS and cannot be easily dumped.
Figure 5.10 Dumping a client’s DNS cache on a Windows machine.
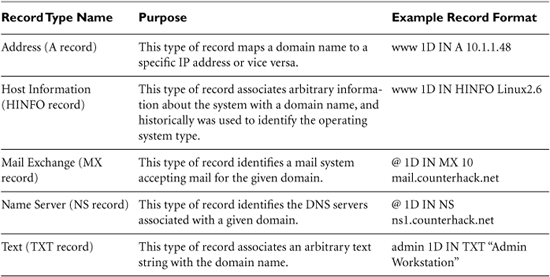
So we can use DNS servers to retrieve the IP addresses associated with domain names. However, a good deal of other information is stored in DNS. The most popular and interesting DNS record types are shown in Table 5.2. In the example record formats, we see the domain name, followed by the Time To Live, indicating how long the record should be retained (ranging from mere seconds to several days, although we display one day in these examples). The third field (IN) means that the record is for the Internet class, which is the only record class in widespread use today. The fourth field is the record type (A for Address, HINFO for Host Information, MX for Mail eXchange, and so on). Finally, we have the information that maps to the domain name, such as an IP address, some host information, mail server information, and so on.
Table 5.2 Some DNS Record Types
Every organization with systems accessible via domain names on the Internet must have publicly accessible DNS records for those systems. A DNS server just houses a bunch of DNS records like those shown in Table 5.2. For example, the DNS server might have 20 address records for the addresses of mail servers, File Transfer Protocol (FTP) servers, and Web servers, one or two MX records specifying which server will accept mail, and two DNS server records spelling out the DNS servers themselves. Most DNS implementations are built around at least two DNS servers: a primary server and a secondary server for fault tolerance. An organization can choose to implement its own DNS servers to hold these records. Alternatively, some organizations select an ISP or specialized DNS service provider to run their DNS services. Other organizations have a mixed approach, running their primary DNS servers themselves, but outsourcing the operation of their secondary DNS servers to an ISP or other provider.
Regardless of whether DNS service is provided in house or outsourced, a large amount of very interesting information can be retrieved from DNS. By consulting an organization’s DNS server, an attacker can harvest a list of systems to attack. If HINFO records are included, the attacker even knows the target operating system type and can search the Internet for vulnerabilities affecting this type of system.
Interrogating DNS Servers
So how does an attacker get DNS information? First, the attacker needs to determine one or more DNS servers for the target organization. This information is readily available in the registration records obtained from the registrar’s whois database searches, as discussed in the previous section. In the registrar records, these DNS servers for the target organization are listed as name servers and domain servers, depending on the specific registrar. In our example from Figure 5.7, the DNS servers have IP addresses 10.1.1.34 and 10.2.42.1. The first is the primary DNS server and the other is the secondary DNS server.
Using this DNS server information, an attacker has a variety of tools to choose from for getting DNS information. One of the most common tools used to query DNS servers is the nslookup command, which is included in modern versions of Windows and most variations of UNIX and Linux. By simply typing “nslookup,” an attacker can invoke the program and begin interrogating name servers. Attackers typically attempt to perform a zone transfer, an operation that asks the name server to send all information it has about a given domain, a group of information referred to collectively as a zone file. Zone transfers were created so that secondary DNS servers can get updates from primary DNS servers. However, attackers also attempt to use this feature in recon. If the target’s DNS infrastructure supports zone transfers, the attacker’s recon actions are put into full throttle, giving the bad guy an immense amount of useful attack information very quickly.
To conduct a zone transfer, the nslookup command must be instructed to use the target’s primary or secondary DNS server, using the server [target_DNS_server] command. Then, nslookup must be instructed to look for any type of record (A records, MX records, and so on) by using the set type=any directive at the command line. Then, the zone transfer is initiated by entering ls -d [target_domain], which requests the information and displays it in the nslookup output. The following commands show a zone transfer for the counterhack.net domain:
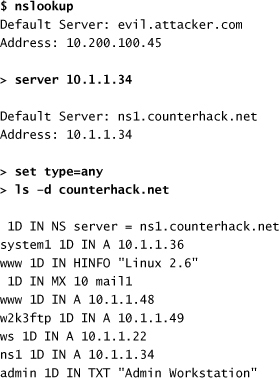
This zone transfer output is abbreviated for readability. Note that using a zone transfer, we have found some extremely interesting information. The first column of our output tells us a bunch of system names. One of these names (w2k3ftp) appears to indicate the operating system type and the purpose of the machine (a Microsoft Windows 2003 machine running an FTP server). In the last column, we have the payoff: IP addresses, mail server names, and even operating system types. The text record points out an administrator workstation, surely a worthwhile target. We now have a list of machine names and IP addresses that we can scan, looking for vulnerabilities.
Unfortunately, on most modern Linux machines, the nslookup command has been partially incapacitated so it can no longer perform zone transfers. Therefore, to run zone transfers from a modern Linux system, you need to use another command, such as the dig command built into most Linux distributions. To make dig do a zone transfer, run the dig command like this:
$ dig @10.1.1.34 counterhack.net -t AXFR
This command invokes dig, tells it to query the DNS server located at 10.1.1.34, sends a request for information about the counterhack.net domain, and asks for the entire zone file (which is indicated by the -t AXFR syntax).
Defenses From DNS-Based Reconnaissance
So how do we defend against attackers grabbing a bunch of information from DNS servers? There are several techniques that should be employed together. First, make sure you aren’t leaking additional information through DNS. For your Internet presence to function properly, DNS is needed to map names to and from IP addresses, as well as indicate name servers and mail servers. Additional information is not required and can only tip off an attacker. In particular, your domain names should not indicate any machine’s operating system type. Although it might be tempting to name the Windows 2003 server on your DMZ w2k3dmzserver, don’t do it. Similarly, don’t include HINFO or TXT records at all, because there is no need to advertise the machine types you are using or other textual information about your machines.
Next, you should restrict zone transfers. Zone transfers are usually required to keep a secondary DNS server in sync with a primary server. No one else has any business copying the zone files of your DNS server. The primary DNS server should allow zone transfers only from the secondary DNS server (and tertiary if you have one). The secondary (and tertiary) DNS servers should allow zone transfers from no one. To limit zone transfers, you need to configure your DNS server appropriately. For the most commonly used DNS server, BIND, you can use the allow-transfer directive or the xfernets directive to specify exactly the IP addresses and networks you will allow to initiate zone transfers. You should also configure your firewall or external router with filtering rules to allow access to Transmission Control Protocol (TCP) port 53 on your primary DNS server only from those machines that act as secondary DNS servers. Remember, User Datagram Protocol (UDP) port 53 is used for DNS queries and responses, and must be allowed for DNS to resolve names. TCP port 53, on the other hand, is used for zone transfers (and other large DNS queries and responses, which are a tip-off of something strange), which should only be allowed from a short list of known secondary DNS servers.
Now, you might be thinking, “Doesn’t everyone limit zone transfers by now?” I wish that were so. When we perform penetration tests, we usually find that the primary DNS server has been configured to deny zone transfers from arbitrary places on the Internet. However, we almost always also discover that the secondary DNS server allows anyone anywhere to perform a zone transfer. This common occurrence is often a result of the organization hardening its own DNS server (the primary), but relying on an ISP to run its secondary. Many ISPs aren’t very careful about zone transfers, and thus we are almost always able to lift a zone from their DNS servers. If you outsource DNS services—either primary, secondary, or both—try doing a zone transfer to each server. If you can do it successfully, contact the DNS administrators and ask them to limit zone transfers to only secondary DNS servers. If an ISP is running your DNS server, you might need to send them a nice letter emphasizing the importance of limiting zone transfers to make you, the customer, a happy camper.
Finally, you should employ a technique called split DNS to limit the amount of DNS information about your infrastructure that is publicly available. The general public on the Internet only needs to resolve names for a small fraction of the systems in your enterprise, such as external Web, mail, and FTP servers. There is no reason to publish on the Internet DNS records for all of your sensitive internal systems. A split DNS infrastructure, also called a split-brain or split-horizon DNS, allows you to separate the DNS records that you want the public to access from your internal names.
Figure 5.11 shows a split DNS infrastructure. Two sets of DNS servers are used, an external DNS server and an internal DNS server. (Note that the internal and external servers here are primary DNS servers. Each might also have an associated secondary DNS server, which I’ve omitted from the figure for clarity reasons.) The external DNS server contains only DNS information about those hosts that are publicly accessible. The internal DNS server contains DNS information for all of your internal systems (so your internal users can access machines on your internal network). When a user on the Internet wants to connect to one of your public machines, the external DNS server resolves the names. Similarly, the internal DNS server resolves names for internal users. Pretty straightforward. But how does an internal user resolve names on the Internet? After all, your internal users might need to surf the Internet, and will need to map names to IP addresses for external systems. A split DNS accomplishes this by having the internal DNS configured to forward requests from internal users for external machines to the external DNS server. The internal DNS acts rather like a proxy server, getting a request from the inside and forwarding it out. The external DNS server resolves the name by querying other servers on the Internet, and returns the response to the internal DNS server, which forwards the response back to the requesting user. Therefore, with a split DNS infrastructure, your internal users can resolve both internal and external names, but external users (and attackers) can access only external names.
Figure 5.11 A split DNS (also known as a split-brain or split-horizon DNS).
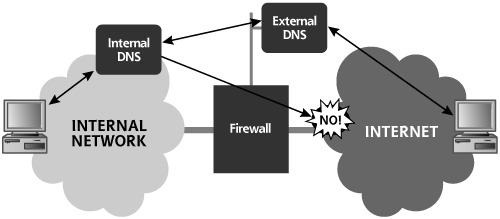
One common mistake in deploying split DNS infrastructures is to allow the internal DNS server to perform recursive lookups directly on the Internet, instead of having it forward requests through the external DNS server. This is a bad idea, illustrated by the “No!” element in Figure 5.11. If there is a vulnerability in your internal DNS server, and it is talking directly with external machines on the Internet through recursive lookups, an attacker might be able to take over the internal DNS server directly, causing you immense heartache. Therefore, make sure that your internal DNS servers cannot directly interact with the outside world, but instead forward requests to external DNS servers for recursive resolution.
General-Purpose Reconnaissance Tools
We have discussed a variety of methods for conducting reconnaissance activities against a target. A significant amount of work has been done to roll many of these techniques together in unified reconnaissance suites. These suites of tools fall into two general categories. The first set consists of completely integrated client executables, such as Sam Spade, which are run on an end user’s machine and perform recon queries on behalf of that user. The second category includes a motley group of Web-based tools, accessed across the Internet using a Web browser. Let’s explore these two categories in more detail.
Sam Spade: A General-Purpose Reconnaissance Client Tool
One of the easiest to use and most functional integrated reconnaissance suites available today is the freeware Sam Spade, written by Steve Atkins and available at www.samspade.org/ssw. Sam Spade, which is shown in Figure 5.12, contains many reconnaissance tools and a lot of bells and whistles, all rolled together in a single executable with a pretty Graphical User Interface (GUI), which runs on all modern Windows systems.
Figure 5.12 The incredibly useful Sam Spade user interface.
Among its numerous reconnaissance features, Sam Spade includes the following capabilities:
- Ping. This tool sends an Internet Control Message Protocol (ICMP) Echo Request message to a target to see if it is alive and how long it takes to respond.
- Whois. Sam Spade performs whois lookups using default whois servers, or by allowing the user to specify which whois database to use.
- IP Block Whois. This feature determines who owns a particular set of IP addresses by querying ARIN, RIPE NCC, APNIC, and LACNIC.
- Nslookup. This feature queries DNS servers to convert domain names to IP addresses.
- DNS Zone Transfer. This feature transfers all information about a given domain from the proper name server.
- Traceroute. This feature returns a list of router hops between the source machine and the chosen target. We discuss tracerouting in more detail in Chapter 6.
- Finger. This feature supports querying a UNIX system to determine its user list, provided that the target runs the ancient, rarely used finger daemon.
- SMTP VRFY. This function can be used to determine whether given e-mail addresses are valid on a target e-mail server. It is based on the Simple Mail Transfer Protocol (SMTP) Verify command, the option within the most widely used e-mail protocol to check the validity of e-mail addresses.
- Web browser. Sam Spade’s built-in mini Web browser lets its user view raw Hypertext Transfer Protocol (HTTP) interactions, including all HTTP headers. This information is useful in attacking Web applications, as we shall see in Chapter 7, Phase 3: Gaining Access Using Application and Operating System Attacks.
- Web crawler. With this feature, a user can grab the entire contents of a Web site, creating a local copy for easy perusal on the attacker’s own system. Web crawler functionality is sometimes called a Web spider.
As you can see, Sam Spade is a very powerful tool providing an attacker with a significant amount of useful recon information for mounting an attack. Other client-based reconnaissance tools similar to Sam Spade include the following:
- The Active Whois Browser, a shareware program that supports whois and DNS recon, for a $19.95 registration fee, at www.tucows.com/preview/335945.html.
- NetScanTools Pro, a $199.00 tool for Windows available at www.netscantools.com/nstmain.html.
- iNetTools, a feature-limited demonstration tool for Windows and Macintosh (yes, the Mac!), available at www.wildpackets.com/products/inettools.
Web-Based Reconnaissance Tools: Research and Attack Portals
Beyond integrated client tools like Sam Spade, an enormous number of Web-based reconnaissance tools are freely available on the Internet. An attacker accesses these tools using a browser, typing in the target name or IP address into a Web form. The Web site then performs a variety of recon activities against the target. Results, of course, are displayed in the attacker’s browser. Some of these sites even support the user in moving beyond reconnaissance to performing denial-of-service attacks or even vulnerability scans.
Keep in mind that some of these Web sites are run by rather shady operators, others are run by consulting companies, and still others are run by shady consulting companies. As with all of the computer underground tools and Web sites listed in this book, don’t surf to these sites from your organization’s network or using a machine storing sensitive information. Because the sites could monitor your actions, or even attack you, you should only access them from an ISP separate from your own organization’s Internet connection, using a sacrificial system without any sensitive information as a client. Some of the most interesting Web-based reconnaissance and attack tools include the following:
- www.samspade.org (In addition to offering the Sam Spade client, these folks offer a Web-based tool as well.)
- www.dnsstuff.com
- www.traceroute.org
- www.network-tools.com
- www.cotse.com/refs.htm
- www.securityspace.com
- www.dslreports.com/scan
The illustrious David Rhoades has created a comprehensive Web site called AttackPortal.net featuring a searchable database with more than 100 different Web-based reconnaissance and attack tools like those listed previously. You can search his site, shown in Figure 5.13, at www.attackportal.net for tools that let you research, probe, and attack systems simply by filling out forms on Web sites.
Figure 5.13 Attackportal.net: A Web-based reconnaissance and attack portal.
With these tools, from the target’s perspective, all recon and attack traffic comes from the Web server running the recon tool, and not the attacker’s own machine. This is very different from the Sam Spade client, with which all traffic originates at the attacker’s machine. Therefore, these Web-based tools can help an attacker remain more anonymous. It is important to note, though, that the Web server the attack is launched through can still record the IP address of the client running the browser and initiating the query and attack.
Also, as a final note, please do check with your legal counsel to ensure that you have proper permission before launching any tests through these Web sites. Otherwise, you could get into significant trouble.
Conclusion
From social engineering scams to automated reconnaissance on the Web, the attacker has gained very useful insight into the target organization and infrastructure. A very lucky and skilled attacker can gain numerous phone numbers and system addresses from Internet queries, as well as detailed system information through social engineering and dumpster diving. At the end of the reconnaissance phase, the attacker has, at a minimum, a telephone number or two and a list of IP addresses and domain names. Possibly, the attacker has found critical hints about the technologies in use at the target, and even a list of vulnerabilities to try to exploit. Not bad for a day’s work. These reconnaissance trophies are the building blocks for the next phase of the attack, scanning.
Summary
Many attacks start with a reconnaissance phase, whereby an attacker tries to gain as much information about a target as possible before actually attacking it. Many low-technology reconnaissance techniques are in widespread use by attackers. Social engineering involves tricking a victim into revealing sensitive information through smooth talking. A social engineer is an attacker who usually works over the telephone, conning users into giving up phone numbers, names, passwords, or other sensitive items. Attackers can even spoof caller ID using a variety of mechanisms to trick victims into giving up information. Through physical break-in, intruders can walk through a computing facility, gaining access to an internal network or just stealing equipment containing sensitive data. Implementing strong computer security is impossible without good physical security. Dumpster diving is the process of looking through an organization’s trash for discarded sensitive information. Dumpster divers often obtain system documentation, user lists, phone numbers, passwords written on sticky notes, discarded CDs, old hard drives, and so on. To avoid these attacks, user awareness is key. You must instruct users to handle sensitive information carefully when requested by an unknown person on the telephone, to implement physical security mechanisms, and to shred sensitive information before discarding it.
The World Wide Web is a cornucopia of useful information for an attacker. Many organizations put information on their Web sites that can be quite valuable to an attacker, such as employees’ contact information, business partners, and technologies in use. Attackers use Web search engines, especially Google, to research targets, gaining knowledge about aspects of and events in the target organization. Some of the most useful Google search directives and operators include site:, link:, and -. Automated Google recon tools, such as SiteDigger and Wikto, help to find vulnerabilities on target sites by querying Google using issues from the GHDB. Newsgroups also provide incredibly useful information. To defend against attackers gathering information from the Internet, you must have policies regarding the use of sensitive information on the Internet, and periodically monitor the Internet for sensitive information about your organization. You can also use a robots.txt file and specific HTML meta tags to prevent indexing and caching by well-behaved search engine bots.
Whois databases provide information about a target’s Internet addresses, domain names, and contacts. The InterNIC provides a whois database for .com, .net, .org, and several other top-level domain names, identifying the registrar an organization used to establish a domain name. The Uwhois Web site is quite useful in researching domain names registered in 246 different countries. After determining the target’s registrar from InterNIC, an attacker usually consults the whois database of the target’s registrar. The target’s registrar provides the administrative, technical, and billing contact information, as well as DNS server information. Finally, the ARIN, RIPE NCC, APNIC, and LACNIC whois databases can be used to find the IP addresses for specific geographical locations. You should make sure that your domain name registration entries are up to date.
DNS servers hold a great deal of information valuable for an attacker, including the mapping of domain names to IP addresses, a list of mail servers for an organization, and other name servers for the organization. DNS is a distributed hierarchical database, used by people and programs to resolve domain names. DNS stores a variety of record types, including Address records that map domain names to IP addresses and vice versa, Host Information records that identify the system type associated with a given domain name, and MX records that identify the mail server for a given domain name.
The nslookup tool included with modern Windows systems and UNIX can be used to interrogate DNS servers. Nslookup can be used to send single queries and get responses for given domain names. Alternatively, nslookup can be used for a zone transfer, which grabs all records from a DNS server. On most modern Linux machines, nslookup cannot perform a zone transfer, so the dig command can be used instead. To defend against DNS attacks, you should configure your DNS servers to allow zone transfers only from appropriate servers, and avoid including sensitive information in domain names and records.
A variety of general-purpose reconnaissance tools can be downloaded from the Internet. One of the most useful is Sam Spade, which supports many techniques for getting recon information. Also, a large number of Web-based tools are available for conducting reconnaissance or simply attacking a target.