
Hour 4. The Normalization Process
What You’ll Learn in This Hour:
• What normalization is
• Benefits of normalization
• Advantages of denormalization
• Normalization techniques
• Guidelines of normalization
• The three normal forms
• Database design
In this hour, you learn the process of taking a raw database and breaking it into logical units called tables. This process is referred to as normalization. The normalization process is used by database developers to design databases in which it is easy to organize and manage data while ensuring the accuracy of data throughout the database. The great thing is that the process is the same regardless of which relational database management system (RDBMS) you are using.
The advantages and disadvantages of both normalization and denormalization of a database are discussed in this hour, as well as data integrity versus performance issues that pertain to normalization.
Normalizing a Database
Normalization is a process of reducing redundancies of data in a database. A technique that is used when designing and redesigning a database, normalization optimally designs a database to reduce redundant data. The actual guidelines of normalization, called normal forms, are discussed later in this hour. It was a difficult decision to cover normalization in this book because of the complexity involved. Understanding the rules of the normal forms can be difficult this early in your SQL journey. However, normalization is an important process that, if understood, increases your understanding of SQL. We have attempted to simplify the process of normalization as much as possible in this hour. At this point, don’t be overly concerned with all the specifics of normalization; it is most important to understand the basic concepts.
The Raw Database
A database that is not normalized might include data that is contained in one or more tables for no apparent reason. This could be bad for security reasons, disk space usage, speed of queries, efficiency of database updates, and, maybe most importantly, data integrity. A database before normalization is one that has not been broken down logically into smaller, more manageable tables. Figure 4.1 illustrates the database used for this book before it was normalized.

Determining the set of information that the raw database consists of is one of the first and most important steps in logical database design. You must know all the data elements that comprise your database to effectively apply the techniques discussed in this chapter. Taking the time to perform the due diligence of gathering the set of required data keeps you from having to backtrack your database design scheme because of missing data elements.
Logical Database Design
Any database should be designed with the end user in mind. Logical database design, also referred to as the logical model, is the process of arranging data into logical, organized groups of objects that can easily be maintained. The logical design of a database should reduce data repetition or go so far as to completely eliminate it. After all, why store the same data twice? Additionally, the logical database design should strive to make the database easy to maintain and update. Naming conventions used in a database should also be standard and logical to aid in this endeavor.
What Are the End User’s Needs?
The needs of the end user should be one of the top considerations when designing a database. Remember that the end user is the person who ultimately uses the database. There should be ease of use through the user’s front-end tool (a client program that enables a user access to a database), but this, along with optimal performance, cannot be achieved if the user’s needs are not considered.
Some user-related design considerations include the following:
• What data should be stored in the database?
• How does the user access the database?
• What privileges does the user require?
• How should the data be grouped in the database?
• What data is the most commonly accessed?
• How is all data related in the database?
• What measures should be taken to ensure accurate data?
• What measures can be taken to reduce redundancy of data?
• What measures can be taken to ensure ease of use for the end user who is maintaining the data?
Data Redundancy
Data should not be redundant; the duplication of data should be kept to a minimum for several reasons. For example, it is unnecessary to store an employee’s home address in more than one table. With duplicate data, unnecessary space is used. Confusion is always a threat when, for instance, an address for an employee in one table does not match the address of the same employee in another table. Which table is correct? Do you have documentation to verify the employee’s current address? As if data management were not difficult enough, redundancy of data could prove to be a disaster.
Reducing redundancy also ensures that updating the data within the database is relatively simple. If you have a single table for the employees’ addresses and you update that table with new addresses, you can rest assured that it is updated for everyone who is viewing the data.
The Normal Forms
The next sections discuss the normal forms, an integral concept involved in the process of database normalization.
Normal form is a way of measuring the levels, or depth, to which a database has been normalized. A database’s level of normalization is determined by the normal form.
The following are the three most common normal forms in the normalization process:
• The first normal form
• The second normal form
• The third normal form
There are normal forms beyond these, but they are used far less often than the three major ones noted here. Of the three major normal forms, each subsequent normal form depends on normalization steps taken in the previous normal form. For example, to normalize a database using the second normal form, the database must be in the first normal form.
The First Normal Form
The objective of the first normal form is to divide the base data into tables. When each table has been designed, a primary key is assigned to most or all tables. Remember from Hour 3, “Managing Database Objects,” that your primary key must be a unique value, so try to select a data element for the primary key that naturally uniquely identifies a specific piece of data. Examine Figure 4.2, which illustrates how the raw database shown in Figure 4.1 has been redeveloped using the first normal form.
Figure 4.2. The first normal form.
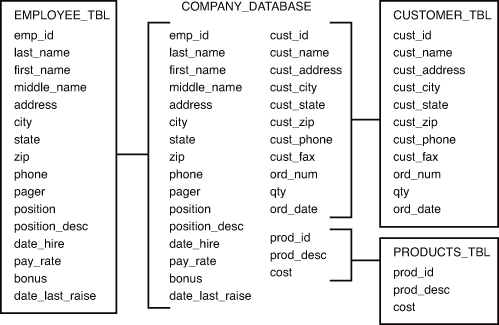
You can see that to achieve the first normal form, data had to be broken into logical units of related information, each having a primary key and ensuring that there are no repeated groups in any of the tables. Instead of one large table, there are now smaller, more manageable tables: EMPLOYEE_TBL, CUSTOMER_TBL, and PRODUCTS_TBL. The primary keys are normally the first columns listed in a table, in this case, EMP_ID, CUST_ID, and PROD_ID. This is a normal convention that you should use when diagramming your database to ensure that it is easily readable.
However, your primary key could also be made up of more than one of the columns in the data set. Often times, these values are not simple database-generated numbers but logical points of data such as a product’s name or a book’s ISBN number. These are commonly referred to as natural keys because they would uniquely define a specific object regardless of whether it was in a database. The main thing that you need to remember in picking out your primary key for a table is that it must uniquely identify a single row. Without this, you introduce the possibility of adding duplication into your results of queries and prevent yourself from doing even simple things such as removing a particular row of data based solely on the key.
The Second Normal Form
The objective of the second normal form is to take data that is only partly dependent on the primary key and enter that data into another table. Figure 4.3 illustrates the second normal form.
Figure 4.3. The second normal form.
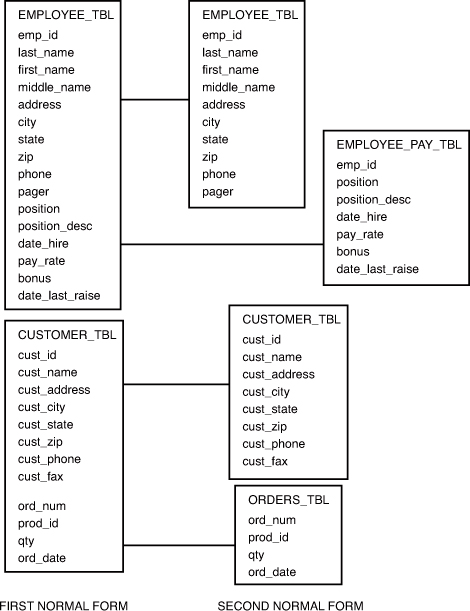
According to the figure, the second normal form is derived from the first normal form by further breaking two tables into more specific units.
EMPLOYEE_TBL is split into two tables called EMPLOYEE_TBL and EMPLOYEE_PAY_TBL. Personal employee information is dependent on the primary key (EMP_ID), so that information remained in the EMPLOYEE_TBL (EMP_ID, LAST_NAME, FIRST_NAME, MIDDLE_NAME, ADDRESS, CITY, STATE, ZIP, PHONE, and PAGER). On the other hand, the information that is only partly dependent on the EMP_ID (each individual employee) populates EMPLOYEE_PAY_TBL (EMP_ID, POSITION, POSITION_DESC, DATE_HIRE, PAY_RATE, and DATE_LAST_RAISE). Notice that both tables contain the column EMP_ID. This is the primary key of each table and is used to match corresponding data between the two tables.
CUSTOMER_TBL is split into two tables called CUSTOMER_TBL and ORDERS_TBL. What took place is similar to what occurred in the EMPLOYEE_TBL. Columns that were partly dependent on the primary key were directed to another table. The order information for a customer depends on each CUST_ID but does not directly depend on the general customer information in the original table.
The Third Normal Form
The third normal form’s objective is to remove data in a table that is not dependent on the primary key. Figure 4.4 illustrates the third normal form.
Figure 4.4. The third normal form.
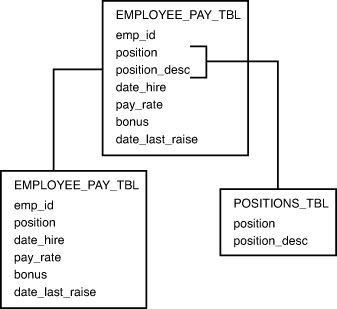
Another table was created to display the use of the third normal form. EMPLOYEE_PAY_TBL is split into two tables: one table containing the actual employee pay information and the other containing the position descriptions, which really do not need to reside in EMPLOYEE_PAY_TBL. The POSITION_DESC column is totally independent of the primary key, EMP_ID. As you can see, the normalization process is a series of steps that breaks down the data from your raw database into discrete tables of related data.
Naming Conventions
Naming conventions are one of the foremost considerations when you’re normalizing a database. Names are how you refer to objects in the database. You want to give your tables names that are descriptive of the type of information they contain so that the data you are looking for is easy to find. Descriptive table names are especially important for users who had no part in the database design but who need to query the database.
Companies should have a company-wide naming convention to provide guidance in the naming of not only tables within the database, but users, filenames, and other related objects. Naming conventions also help in database administration by making it easier to discern the purpose of tables and locations of files within a database system. Designing and enforcing naming conventions is one of a company’s first steps toward a successful database implementation.
Benefits of Normalization
Normalization provides numerous benefits to a database. Some of the major benefits include the following:
• Greater overall database organization
• Reduction of redundant data
• Data consistency within the database
• A much more flexible database design
• A better handle on database security
• Reinforcement of the concept of referential integrity
Organization is brought about by the normalization process, making everyone’s job easier, from the user who accesses tables to the database administrator (DBA) who is responsible for the overall management of every object in the database. Data redundancy is reduced, which simplifies data structures and conserves disk space. Because duplicate data is minimized, the possibility of inconsistent data is greatly reduced. For example, in one table an individual’s name could read STEVE SMITH, whereas the name of the same individual might read STEPHEN R. SMITH in another table. Reducing duplicate data increases data integrity, or the assurance of consistent and accurate data within a database. Because the database has been normalized and broken into smaller tables, you have more flexibility in modifying existing structures. It is much easier to modify a small table with little data than to modify one big table that holds all the vital data in the database. Lastly, security is provided in the sense that the DBA can grant access to limited tables to certain users. Security is easier to control when normalization has occurred.
Referential integrity simply means that the values of one column in a table depend on the values of a column in another table. For instance, for a customer to have a record in the ORDERS_TBL table, there must first be a record for that customer in the CUSTOMER_TBL table. Integrity constraints can also control values by restricting a range of values for a column. The integrity constraint should be created at the table’s creation. Referential integrity is typically controlled through the use of primary and foreign keys.
In a table, a foreign key, normally a single field, directly references a primary key in another table to enforce referential integrity. In the preceding paragraph, the CUST_ID in ORDERS_TBL is a foreign key that references CUST_ID in CUSTOMER_TBL. Normalization helps to enhance and enforce these constraints by logically breaking down data into subsets that are referenced by a primary key.
Drawbacks of Normalization
Although most successful databases are normalized to some degree, there is one substantial drawback of a normalized database: reduced database performance. The acceptance of reduced performance requires the knowledge that when a query or transaction request is sent to the database, there are factors involved, such as CPU usage, memory usage, and input/output (I/O). To make a long story short, a normalized database requires much more CPU, memory, and I/O to process transactions and database queries than does a denormalized database. A normalized database must locate the requested tables and then join the data from the tables to either get the requested information or to process the desired data. A more in-depth discussion concerning database performance occurs in Hour 18, “Managing Database Users.”
Denormalizing a Database
Denormalization is the process of taking a normalized database and modifying table structures to allow controlled redundancy for increased database performance. Attempting to improve performance is the only reason to denormalize a database. A denormalized database is not the same as a database that has not been normalized. Denormalizing a database is the process of taking the level of normalization within the database down a notch or two. Remember, normalization can actually slow performance with its frequently occurring table join operations. (Table joins are discussed during Hour 13, “Joining Tables in Queries.”)
Denormalization might involve recombining separate tables or creating duplicate data within tables to reduce the number of tables that need to be joined to retrieve the requested data, which results in less I/O and CPU time. This is normally advantageous in larger data warehousing applications in which aggregate calculations are being made across millions of rows of data within tables.
There are costs to denormalization, however. Data redundancy is increased in a denormalized database, which can improve performance but requires more extraneous efforts to keep track of related data. Application coding renders more complications because the data has been spread across various tables and might be more difficult to locate. In addition, referential integrity is more of a chore; related data has been divided among a number of tables.
There is a happy medium in both normalization and denormalization, but both require a thorough knowledge of the actual data and the specific business requirements of the pertinent company. If you do look at denormalizing parts of your database structure, carefully document the process so you can see exactly how you are handling issues such as redundancy to maintain data integrity within your systems.
Summary
A difficult decision has to be made concerning database design—to normalize or not to normalize, that is the question. You always want to normalize a database to some degree. How much do you normalize a database without destroying performance? The real decision relies on the application. How large is the database? What is its purpose? What types of users are going to access the data? This hour covered the three most common normal forms, the concepts behind the normalization process, and the integrity of data. The normalization process involves many steps, most of which are optional but vital to the functionality and performance of your database. Regardless of how deep you decide to normalize, there is almost always a trade-off, either between simple maintenance and questionable performance or complicated maintenance and better performance. In the end, the individual (or team of individuals) designing the database must decide, and that person or team is responsible.
Q&A
Q. Why should I be so concerned with the end user’s needs when designing the database?
A. The end users are the real data experts who use the database, and, in that respect, they should be the focus of any database design effort. The database designer only helps organize the data.
Q. Is normalization more advantageous than denormalization?
A. It can be more advantageous. However, denormalization, to a point, could be more advantageous. Remember, many factors help determine which way to go. You will probably normalize your database to reduce repetition in the database, but you might turn around and denormalize to a certain extent to improve performance.
Workshop
The following workshop is composed of a series of quiz questions and practical exercises. The quiz questions are designed to test your overall understanding of the current material. The practical exercises are intended to afford you the opportunity to apply the concepts discussed during the current hour, as well as build upon the knowledge acquired in previous hours of study. Please take time to complete the quiz questions and exercises before continuing. Refer to Appendix C, “Answers to Quizzes and Exercises,” for answers.
Quiz
1. True or false: Normalization is the process of grouping data into logical related groups.
A. True.
2. True or false: Having no duplicate or redundant data in a database, and having everything in the database normalized, is always the best way to go.
3. True or false: If data is in the third normal form, it is automatically in the first and second normal forms.
4. What is a major advantage of a denormalized database versus a normalized database?
5. What are some major disadvantages of denormalization?
6. How do you determine if data needs to be moved to a separate table when normalizing your database?
7. What are the disadvantages of overnormalizing your database design?
Exercises
1. You are developing a new database for a small company. Take the following data and normalize it. Keep in mind that there would be many more items for a small company than you are given here.
Employees:
Angela Smith, secretary, 317-545-6789, RR 1 Box 73, Greensburg, Indiana, 47890, $9.50 per hour, date started January 22, 2006, SSN is 323149669.
Jack Lee Nelson, salesman, 3334 N. Main St., Brownsburg, IN, 45687, 317-852-9901, salary of $35,000.00 per year, SSN is 312567342, date started 10/28/2005.
Customers:
Robert’s Games and Things, 5612 Lafayette Rd., Indianapolis, IN, 46224, 317-291-7888, customer ID is 432A.
Reed’s Dairy Bar, 4556 W 10th St., Indianapolis, IN, 46245, 317-271-9823, customer ID is 117A.
Customer Orders:
Customer ID is 117A, date of last order is December 20, 2009, the product ordered was napkins, and the product ID is 661.
2. Log in to your new database instance just as you did in Hour 3. Ensure that you are in the learnsql database by using the following statement:
Use learnsql;
In Oracle this is known as a schema; by default you create items in your user schema.
Now that you are in the database, open a command window and enter some CREATE TABLE statements based on the tables you defined in Exercise 1.