
1
Understanding Video and Audio
Compression is one of the linchpins of the video production world. It is the quiet savior (and killer) of projects every day and is a process that, if done correctly, goes unnoticed. When was the last time you watched a TV show and marveled at how great the compression was? Bad compression, by contrast, is unmistakable and can render (pun fully intended) almost any video unwatchable.
The primary function of video compression is fairly straightforward: to conform the video to the desired delivery method, whether it’s a TV, a phone, a computer, or a theater screen. The difficulty is trying to work within the technical specifications required and the limitations of the delivery medium to provide an audiovisual experience that’s satisfying to the end user. If you’re delivering content over the Internet, for example, you need to consider file-size issues as well as the ability to deliver content in real time. You might have the greatest film of all time, but if it’s so big nobody can actually download it, then who exactly will be watching this masterpiece? Likewise, if your content will be broadcast on TV, you need to guarantee all the fields and frames of your edited, compressed program are still intact after the lengthy creation process.
But we’re just getting ahead of ourselves. You see, there are some fundamentals at play within any discussion of video that are important to be aware of before delving into the intricacies of video compression. If you have worked with video for a long time, these are all familiar concepts. In fact, you most likely don’t even think of them consciously in your everyday work. If you are new to video, getting a foundation in the basics of video will make solving your next compression problem considerably easier.
Elements of Video
Unlike film, which creates images by projecting light through transparent celluloid, video is an electronic signal. Though the term video originally was used to describe any signal broadcast (or televised) to a TV set, it has been more broadly redefined over time to encompass any images displayed electronically (such as those on video billboards, cell phones, ATMs, and so on).
Video has become a pervasive part of our lives, particularly since computers (and their video displays) came along. We use video daily for our interactions, for our entertainment, for our communication, and for tasks as simple as taking money out of the bank. The technology has shifted so much that we now regularly see video on the nightly news that was shot by citizens on their cell phones. As our uses of video have evolved, the technology that supports it has changed as well.
Frames and Fields
When a group of sequential images is displayed in rapid succession, an amazing phenomenon occurs. Instead of perceiving each individual picture, humans see smoothly moving animation. This phenomenon is known as persistence of vision, and it is the basis for how film and video work. The number of pictures shown per second is called the frame rate (seconds is the most common measurement of the frame rate but not the only one). It can take as few as about 8 frames per second (fps) for the viewer to perceive smooth motion; however, the viewer will also detect a distinct flicker or jerkiness. To avoid that flicker between frames, you generally need a frame rate greater than 16 frames per second (though this is a subjective opinion, and many believe you need 24–30 fps or more to completely remove the flicker). The faster the motion you are attempting to re-create, the more frames you need to keep that motion smooth. Modern film has a frame rate of 24 fps, and TV has a frame rate of approximately 30 fps (29.97 fps) in the United States, Japan, and other countries that use the National Television Standards Committee (NTSC) standard. Phase-Alternating Line (PAL) and Sequentiel Couleur Avec Memoire (SECAM) are the other standards, and they use 25 fps.
A frame can be presented to a viewer in two ways: progressive or interlaced scanning. You were probably more aware of this before we moved to high-definition TV (HDTV). If you have ever seen an HDTV’s specs referred to as 1080i or 720p, the i and p stand for interlaced and progressive, respectively. (The 1080 and 720 represent horizontal lines of resolution; more on that later.)
![]() TIP
TIP
For a deeper dive into interlaced video, check out www.100fps.com.
Interlaced scanning was developed in the early 1930s as a way of improving the image quality on cathode-ray tube (CRT) monitors (basically every TV you owned until plasma and LCD TVs emerged). Inside the tube, an electron beam scans across the inside of the screen, which contains a light-emitting phosphor coating. These phosphors had a very short persistence, meaning the amount of time they could sustain their illumination was short (computer CRT monitors tended to have a longer persistence). In the time it took the electron beam to scan to the bottom of the screen, the phosphors at the top were already going dark. To solve this problem, the early TV engineers designed an interlaced system for scanning the electron beam. With an interlaced system, the beam scans only the odd-numbered lines the first time and then returns to the top and scans the even-numbered lines. These two alternating sets of lines (as shown in Figure 1.1) are known as the upper (or odd) and lower (or even) fields in the TV signal. So, a TV that displays 30 fps is actually displaying 60 fps—two interlaced images per frame.

Figure 1.1 With interlaced video, the system scans the odd-numbered lines and then the even-numbered lines, combining fields to produce a complete frame. It takes both fields of the interlaced image to make a whole picture.
Progressive Scan Video
In progressive scan video, the entire video frame is captured and displayed in a single frame, rather than in two interlaced fields. Progressive scanning has many advantages over interlacing to deliver the same smooth motion (although when played back, the progressive image would also be a slightly higher resolution than the interlaced one). Figure 1.2 shows the difference between interlaced and progressive frames.

Figure 1.2 Motion in the progressive image (on the top) would appear much smoother than in the interlaced image (bottom).
As the ball moves across the screen in Figure 1.2, the interlaced image (bottom) must display fields that are slightly out of sync (because the ball is moving constantly). This can lead to slight distortions or other poor image qualities. The progressive image (top), by contrast, shows a complete frame each time, so the image quality will be improved, and the motion will be smoother, though you are using more bandwidth to transmit the image.
Progressive video has superseded interlaced in much of the video world for a number of reasons. For one, most modern TV technologies are inherently progressive. As many manufacturers stop making traditional CRT-based monitors, newer display technologies have taken over. Most TV and monitor manufacturers have moved away from CRT technology, although some still exist as specialty items. Starting in about 2010, LCD or DLP-based screens became the dominant consumer-grade screens on the market. This technology has continued to improve, giving way to light-emitting diode (LED) or organic light-emitting diode (OLED) screens.
Resolutions
The quality of the images you see in film and video is not based just on the number of frames you see per second or the way those frames are composed (full progressive frames or interlaced fields). The amount of information in each frame, or spatial resolution, is also a factor. In Table 1.1, you can see that image resolution varies greatly for different screen types. Older standard-definition TVs max out at 720 by 486, while current high-definition TVs are 1080p (1920 by 1080). Content delivery in 4K resolution (3840 by 2160) has started to emerge, but the content library is still relatively small, and consumers have been slower to upgrade to 4K from 1080p than they were in moving from SD to 1080p.
Table 1.1 Today’s modern video resolutions and the devices commonly associated with them
Resolution name |
Horizontal × vertical pixels |
Other names |
Devices |
SDTV |
720 × 486 (or 576) |
Standard definition |
Older TVs |
720p |
1,280 × 720 |
HD, high definition |
TVs |
1080p |
1,920 × 1,080 |
Full HD, FHD, HD, high definition |
TVs, monitors |
WUXGA |
1,920 × 1,200 |
Widescreen Ultra Extended Graphics Array |
Computer monitors, projectors |
2K Scope |
2,048 × 858 |
Cinema 2K |
Projectors |
2K Flat |
1,998 × 1,080 |
Cinema 2K |
Projectors |
2K Full |
2,048 × 1,080 |
Cinema 2K |
Projectors |
UHD |
3,840 × 2,160 |
4K, Ultra HD, Ultra-High Definition |
TVs |
4K Scope |
4,096 × 1,716 |
Cinema 4K |
Projectors |
4K Flat |
3,996 × 2,160 |
Cinema 4K |
Projectors |
4K Full |
4,096 × 2,160 |
Cinema 4K |
Projectors |
8K |
7,680 × 4,320 |
None |
Concept TVs |
![]() NOTE
NOTE
Since video was invented, resolutions have continually evolved, and they continue to scale up. The past ten years has been no different and in fact have increased dramatically. Our phones now shoot and display video resolutions higher than those of the TVs we watched a decade ago. With that in mind, be aware that over time the resolutions suggested here may seem outdated.
The resolution of analog video is represented by the number of scan lines per image, which is actually the number of lines the electron beam draws across the screen or vertical resolution.
![]() NOTE
NOTE
Why are there two different aspect ratios for SD? This has to do with the pixel aspect ratio, which you’ll learn about in Chapter 2 (see “Square and Nonsquare Pixels”) and Chapter 4.
The resolution for digital images, on computer displays and digital TV sets, for example, is represented by a fixed number of individual picture elements (pixels) on the screen and is often expressed as a dimension: the number of horizontal pixels by the number of vertical pixels. For example, 640 × 480 and 720 × 486 are full-frame SD resolutions, and 1920 × 1080 is a full-frame HD resolution.
Aspect Ratio
The width-to-height ratio of an image is called its aspect ratio. Keeping video in the correct aspect ratio is one of the more important parts of video compression. As we scale the video to different sizes to accommodate different screens and resolutions, it is easy to lose the relationship between the original height and width of the image. When this happens, the distorted image can become distracting, even impossible to watch.
The 35mm still photography film frame on which motion-picture film was originally based has a 4:3 (width:height) ratio, which is often expressed as a 1.33:1 or 1.33 aspect ratio (multiplying the height by 1.33 yields the width).
From the beginnings of the motion-picture industry until the early 1950s, the 4:3 aspect ratio was used almost exclusively to make movies and to determine the shape of theater screens. When TV was developed, existing camera lenses all used the 4:3 format, so the same aspect ratio was chosen as the standard for the new broadcast medium.
In the 1950s, the motion-picture industry began to grow concerned over the impact of TV on their audience numbers. In response, the movie studios introduced a variety of enhancements to provide a bigger, better, and more exciting experience than viewers could have in their own living rooms. The most visible of these was a wider image. Studios produced wide-screen films in a number of “scope” formats, such as Cinemascope (the original), Warnerscope, Technicscope, and Panascope.
One major problem with these wide-screen formats is they didn’t translate well to TV. When wide-screen films were shown on standard TVs, the sides of the image were typically cut off to accommodate the 4:3 ratio of TV, as shown on the left in Figure 1.3. This process is known as pan and scan because the focus of the image is moved around based on the action on-screen. To solve this, studios often use letterboxing—black bars positioned above and below the wide-screen image—to present the entire image as originally intended, as shown on the right in Figure 1.3.

Figure 1.3 Here’s a wide-screen image cropped to 4:3 on the left, with the entire frame restored in letterbox on the right.
The adoption of HDTV drove us to migrate from 4:3 TVs to a newer wide-screen TV format. The aspect ratio of wide-screen TV is 16:9 (1.78), which is close to the most-popular film aspect ratio of 1.85. Much of the production and postproduction equipment we use today attempts to acquire and output video to these standards. By and large, modern mobile phones and tablet devices have defaulted to screen resolutions that are close to 16:9 when held horizontally, so this has become the standard across these devices as well.
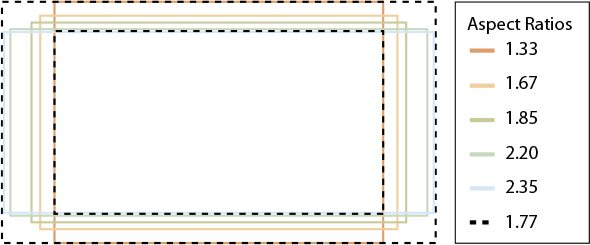
Why 16:9?
Dr. Kerns Powers of the David Sanroff Research Center in Princeton, New Jersey, a leading research lab on the advancement of TV, studied all the major aspect ratios in popular use and mapped them together. He then discovered something interesting. If he took a rectangle of a certain proportion and scaled it two different ways, he could encompass both the width and the height of all the other aspect ratios. That magic rectangle had the proportions of 16 units wide by 9 units high, or 16:9 (Figure 1.4). Because of this discovery, 16:9 was adopted as the new aspect ratio standard for HDTV, and most HDTV-capable TV sets have been designed with 16:9 screens.
How Compression Works
At its most basic level, video compression works by analyzing the content of every frame and figuring out how to re-create it using less information (the technological equivalent of paraphrasing). This feat is accomplished by codecs—shorthand for compression/decompression algorithm—which reduces information in various ways. Let’s say you have an entire black frame of video (say, before your content has started); all the codec has to remember is the phrase “every pixel in this frame is the same shade of black.” That’s a lot less data than writing “0, 0, 0” 2,073,600 times (that’s 1920 × 1080 for those of you following along).
But most video isn’t just one solid color, is it? So, a codec has to look at where the values begin to differ within the frame—borders between light and dark shades, for instance—and describe those values more efficiently. It does this by dividing the scene into groups of pixels, called macroblocks, and representing them with numbers that can re-create the patterns within them. Figure 1.5 shows an example of a macroblock grid.

Figure 1.5 Macroblocks represent the ability of codecs to break the image into a grid or into groups of pixels that are located near each other in order to process them more efficiently. Certain codecs have the ability to divide macroblocks into smaller groups called partitions.
With information about preceding frames registered in these blocks, the codec needs to record only the differences within those blocks, rather than the entire frame, to construct the complete frame. This works extremely efficiently in video with little or no motion—such as in an interview scene or in static titles.
Despite the complexity of this process, it’s an established approach and works very well. But it doesn’t give a good-enough compression ratio to reduce high-definition video to manageable file sizes. This is where the notion of changes over time comes into play. You’ve just learned that video compression works by looking for easily describable features within a video frame. Very little information may need to be carried forward from frame to frame to render the entire image. However, in video with lots of motion, such as footage shot with handheld cameras or clips showing explosions, more pixels change from frame to frame (as shown in Figure 1.6), so more data must be passed along as well.

Figure 1.6 The sequence on top, with lots of motion and little redundancy, is more challenging to compress than the sequence on the bottom, which changes relatively little from frame to frame.
In the top set of frames, the football player is moving across the screen, and the camera is tracking his movements. This means virtually every pixel is changing from frame to frame as the sequence progresses, making it difficult to make a high-quality compression of it without using a lot of data. The bottom sequence, on the other hand, would compress more efficiently. The camera is locked down, and very little in the frame is changing except the motion path of the biker as he jumps the ramp.
That’s how compression works in the most general terms, but there is of course a great deal more specific terminology used to describe how and what is occurring in the compression process. It’s important to understand some of these terms described in the next sections and how they may affect your production, the actual compression and delivery, or the archival process you might use with your video content. You don’t necessarily need to be able to recite chapter and verse on the topic, but you should be able to identify the words when they come up. The more compression you do, the more they will come up in the context of your work, and being able to use them correctly can only help you.
Lossless and Lossy Compression
All the codecs covered in this book (as well as all the ones not covered) are either lossless or lossy. Just like they sound, lossless video codecs are ones that, when decompressed, are a bit-for-bit perfect match with the original. Although lossless compression of video is possible, it is rarely used. This is because lossless compression systems will sometimes result in a file (or portions thereof) that is as large as or has the same data rate as the uncompressed original. As a result, all hardware used in a lossless system would have to be able to run fast enough to handle uncompressed video, which eliminates all the benefits of compressing the video in the first place.
With lossy compression, on the other hand, compressing data and then decompressing the data you retrieve postcompression may well be different from the original, but it is close enough to be useful in some way. Lossy compression is the most common method used to compress video, especially in preparing for final delivery such as on DVD, the Web, or mobile devices.
Spatial (DCT) and Wavelet Compression
Now that we’ve established the lossless/lossy distinction, we’ll move on to explaining two other types of codecs, spatial and wavelet-based codecs. Spatial compression is the basis for what was described earlier as a general description of how video compression works—the frame-by-frame removal of redundant material over time. DCT is a form of spatial compression that is always lossy.
![]() NOTE
NOTE
We discuss DCT-based codecs further in Chapter 3.
Wavelet-based video compression is a more advanced form of compression that’s well suited for images and video but is less commonly used. Unlike DCT Compression, wavelet compression can be either a perfect, lossless data compression or a lossy compression. Wavelet-based codecs are fewer and further between than their DCT-based counterparts; the files created with them are often much larger, and they typically take more processor power to play back. Thus, they’re less suitable for common video playback, though they are more common in acquisition systems, such as the Red camera.
One example of a wavelet video codec is JPEG 2000, considered an excellent intermediate (or mezzanine) format.
What makes JPEG 2000 better than DCT-based codecs? Three things:
Superior compression performance: At high bit rates, where artifacts become nearly imperceptible, JPEG 2000 has little fidelity over other codecs; however, at lower bit rates, JPEG 2000 has a much greater advantage.
Lossless and lossy compression: Unlike DCT-based codecs, wavelet codecs can be both lossless and lossy, allowing for a broader range of options when working with video.
Side channel spatial information: Wavelet codecs fully support transparency and alpha channels.
You’ll see more examples of wavelet-based codecs in Chapter 3.
Quantization
The use of both DCT- and wavelet-based video compression involves quantization. Quantization is the process of approximating a continuous range of values by a relatively small set of discrete symbols or integer values; in other words, it’s a way of mathematically finding an efficient way to describe all the pixels in an image.
Quantization plays a major part in lossy data compression and can be viewed as the fundamental element that distinguishes lossy data compression from lossless data compression.
Interframe and Intraframe Compression
Earlier in this chapter, we described compression as being dependent on the ability to keep track of how the pixels evolve frame by frame over time. Interframe and intraframe are ways of describing how that compression relates the various frames of the video to one another.
With interframe, the most common method compares each frame in the video with the previous one. Since interframe compression copies data from one frame to another, if the original frame is simply cut or lost (either through editing or dropped during broadcast), the following frames cannot be reconstructed properly. Only video ready to distribute (and no longer edited or otherwise cut) should be compressed in an interframe format.
Some video formats such as Apple’s ProRes, however, compress each frame independently using intraframe compression. Editing intraframe-compressed video is similar to editing uncompressed video, in that to process the video, the editing system doesn’t need to look at any other frames to decode the information necessary to construct the frame at hand.
Another difference between intraframe and interframe compression is that with intraframe systems, each frame uses a similar amount of data. In most interframe systems, however, certain frames (called I-frames) don’t copy data from other frames and so require much more data to create than other nearby frames. See Chapter 2 for more information on the types of frames that exist, including I-frames.
It is now possible for nonlinear editors such as Apple Final Cut Pro and Adobe Premiere Pro to identify problems caused when I-frames are edited out while other frames need them. This has allowed formats such as high bitrate MPEG-4 to be used for editing without requiring conversion to all I-frame intermediate codecs. However, this process demands a lot more computing power than editing intraframe-compressed video with the same picture quality because the processor is constantly looking to other frames to find the information needed to re-create the frame the user wants to edit.
High Dynamic Range
High dynamic range (HDR) video is one of the newest buzzwords to enter the video lexicon. It can push video images past the previous limitations of the display contrast. Some say it offers more visual enhancement than what the move from 1080p to 4K offered in terms of picture quality. It’s impressive to see on TVs that can handle it (and yes, it takes an HDR-capable display to take advantage of HDR), but it is still an emerging technology and the catalog of content available today is fairly small when compared to standard dynamic range (SDR). The amount of HDR content will continue to grow, however, and being aware of it and knowing how to handle it will be useful knowledge.
In a nutshell, SDR dates back to the days of CRT monitors, which did not support as great a range of color and brightness when compared to modern flat screens. HDR increases both the luminosity and the color depth of the image, resulting in a display image that is much closer to film quality (Figure 1.7).
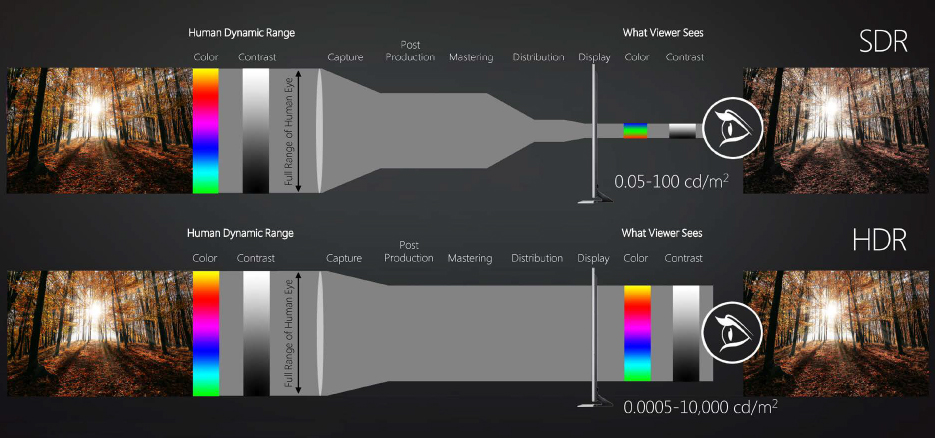
Figure 1.7 Much more color information is sacrificed in the SDR image, and the resulting image is less rich in color.
Audio Compression
With all this talk of video compression, it’s easy to forget that video has audio with it almost all the time. In fact, many filmmakers will tell you that audio is more important than the visuals in the film-watching experience. Certainly it’s no less important, though the process for capturing and compressing it is less complex, only because there is less data present to work with.
The term compression has several meanings in audio, so it’s good to be aware of that, especially when speaking with an audio professional. There is lossy data compression (just like video), level compression, and limiting. We’ll touch on compression and limiting a bit in Chapter 4 as part of the preprocessing techniques for audio.
As with video compression, both lossy and lossless compression algorithms are used in audio compression, lossy being the most common for everyday use (such as with MP3). In both lossy and lossless compression, information redundancy is reduced, using methods such as coding, pattern recognition, and linear prediction to reduce the amount of information used to describe the data.
The compression of audio can quickly go too far, however, and the results are quite noticeable, especially in music, which has a more dynamic sound than spoken words. Music is similar to high-motion video; with more action in the content, the compressors have to keep track of more information continuously. In a monologue, by contrast, where much less is happening, less data is needed to capture what is happening. When very dynamic audio is restricted to too few bits to re-create it, the results sound distorted—either tinny or degraded by pre-echo or an absence of high or low end.
As mentioned earlier, good audio compression is just as important as video compression, and with the rise in popularity of podcasting, many people have come to pay attention to it much more than they have in the past. The key to good audio, perhaps even more than video, is to acquire good source material.
There is a lot—way more—that goes into actually encoding content for delivery, but let’s pause for a moment and talk about delivery. Specifically, the most prevalent distribution channel today: the Internet.
Online Video Delivery
Let’s face it, in this day and age, you are likely to deliver content online in some way. Whether it’s on YouTube, your own site, or somewhere else, there are some basics you’ll need to understand. Or perhaps you have bigger plans and are looking to get into adaptive bitrate streaming. Not sure what that is? Let’s explore all of these a bit.
Traditional Streaming vs. Download
Video and audio content can be delivered in two ways on the Internet: as a streaming file or as a progressive download file.
The same technology used to share web pages can be used for distributing media. The content can be embedded in a web page. The content is accessed through the browser, downloaded to a temporary file on your computer’s hard drive, and then played by the player. This process is called progressive download and doesn’t require a special server, other than the standard web server.
With progressive download, the browser handles the buffering and playing during the download process. If the playback rate exceeds the download rate (you run out of content that’s been downloaded), playback is delayed until more data is downloaded. Generally speaking, files that are downloaded over the Web are able to be viewed only after the entire file is downloaded. With progressive download video, however, most formats allow the user to start watching before the entire video has downloaded.
Traditional streaming media works differently. In this scenario, the server, like the standard web server, is connected to a high-speed Internet connection. However, in this case, the computer is running specialized streaming media server software such as Windows Media Services (Microsoft) or the Flash Media Server (Flash Video).
Streaming addresses use a different protocol than the standard Hypertext Transfer Protocol (HTTP) and appear like this:
mms://x.x.x.x/streaming_media_file_directory/media_file_name.wmv
or like this:
rtsp://x.x.x.x/directory/filename.flv
A streaming server works with the client to send audio and video over the Internet or an intranet and plays it almost immediately. Streaming servers allow real-time “broadcasting” of live events and the ability to control the playback of on-demand content. Playback begins as soon as sufficient data has been transmitted. The viewer can skip to a point partway through a clip without needing to download from the beginning.
Adaptive Bitrate Streaming
![]() NOTE
NOTE
ABR will be covered in more detail in Chapter 6.
Adaptive bitrate streaming as a concept existed in 2008, but there were no practical consumer examples of it available. Today, the majority of the content viewed online is delivered this way. While not a standard to begin with, it has still become a ubiquitous method for delivery, with few competing methods. In fact, it has consolidated around one or two implementations and will likely stay that way as a few others slowly fade away. The ABR formats we focus on in this book are Apple’s HTTP Live Streaming (HLS) and MPEG-DASH. Check out Chapter 6 for more details about online video delivery and MPEG-DASH in particular.
Conclusion
Understanding these basics is a good start to mastering video compression. These fundamentals are important to refer to as you progress deeper into the world of video compression. From here, we’ll dive deeper into the specifics of compression and expand on delivery information for a multitude of devices.