
Chapter 11. Incident Response and Recovery
This chapter covers the following topics:
E-Discovery: This section covers electronic inventory and asset control, data retention policies, data recovery and storage, data ownership, data handling, and legal holds.
Data Breaches: This section describes detection and collection methods, mitigation approaches, recovery techniques, response processes, and disclosure handling.
Facilitate Incident Detection and Response: This section covers hunt teaming; heuristics; behavioral analytics; and establishing and reviewing system, audit, and security logs.
Incident and Emergency Response: Topics include chain of custody, forensic analysis of compromised systems, continuity of operations, disaster recovery, incident response team, and order of volatility.
Incident Response Support Tools: This section describes the use of dd, tcpdump, nbtstat, netstat, nc (Netcat), memcopy, tshark, and foremost.
Severity of Incident or Breach: This section discusses the impact of scope, impact, cost, downtime, and legal ramifications.
Post-incident Response: This section covers root-cause analysis, lessons learned, and after-action reports.
This chapter covers CAS-003 objective 3.3.
To determine whether an incident has occurred, an organization needs to first document the normal actions and performance of a system. This is the baseline to which all other activity is compared. Security professionals should ensure that the baseline is captured during periods of high activity and low activity in order to better recognize when an incident has occurred. In addition, they should capture baselines over a period of time to ensure that the best overall baseline is obtained.
Next, the organization must establish procedures that document how the security professionals should respond to events. Performing a risk assessment allows the organization to identify areas of risk so that the procedures for handling the risks can be documented. In addition, security professionals should research current trends to identify unanticipated incidents that could occur. Documenting incident response procedures ensures that the security professionals have a plan they can follow.
After an incident has been stopped, security professionals should then work to document and analyze the evidence. Once evidence has been documented, systems should be recovered to their operational state. In some cases, it may be necessary for an asset to be seized as part of a criminal investigation. If that occurs, the organization needs to find a replacement asset as quickly as possible.
This chapter discusses e-discovery, data breaches, incident detection and response, incident and emergency response, incident response support tools, issues impacting the severity of an incident or breach, and post-incident response.
E-Discovery
E-discovery is a term used when evidence is recovered from electronic devices. Because of the volatile nature of the data on electronic devices, it is important that security professionals obtain the appropriate training to ensure that evidence is collected and preserved in the proper manner. E-discovery involves the collection of all data, including written and digital, regarding an incident.
When e-discovery occurs in a large enterprise, security professionals must focus on obtaining all the evidence quickly, usually within 90 days. In addition to the time factor, large enterprises have large quantities of data residing in multiple locations. While it may be fairly simple to provide an investigator with all the data, it can be difficult to search through that data to find the specific information that is needed for the investigation. Large organizations should invest in indexing technology to help with any searches that must occur.
Consider a situation in which an employee is suspected of transmitting confidential company data to a competitor. While it is definitely necessary to seize the employee’s computer and mobile devices, security professionals also need to decide what other data needs to be examined. If a security professional wants to examine all emails associated with the employee, the security professional needs access to all emails sent by the employee, all emails received by the employee, and possibly any emails that mention the employee. This is quite a task with even the best indexing technology!
Electronic Inventory and Asset Control
An asset is any item of value to an organization, including physical devices and digital information. Recognizing when assets are stolen is impossible without an item count or an inventory system or with inventory that is not kept updated. All equipment should be inventoried, and all relevant information about each device should be maintained and kept up-to-date. Each asset should be fully documented, including serial numbers, model numbers, firmware version, operating system version, responsible personnel, and so on. The organization should maintain this information both electronically and in hard copy.
Security devices, such as firewalls, NAT devices, and intrusion detection and prevention systems, should receive the most attention because they relate to physical and logical security. Beyond this, devices that can easily be stolen, such as laptops, tablets, and smartphones, should be locked away. If that is not practical, then consider locking these types of devices to stationary objects (for example, using cable locks with laptops).
When the technology is available, tracking of small devices can help mitigate the loss of both devices and their data. Many smartphones now include tracking software that allows you to locate a device after it has been stolen or lost by using either cell tower tracking or GPS. Deploy this technology when available.
Another useful feature available on many smartphones and other portable devices is a remote wipe feature. This allows the user to send a signal to a stolen device, instructing it to wipe out the data contained on the device. Similarly, these devices typically also come with the ability to be remotely locked when misplaced.
Strict control of the use of portable media devices (including CDs, DVDs, flash drives, and external hard drives) can help prevent sensitive information from leaving the network. Although written rules should be in effect about the use of these devices, using security policies to prevent the copying of data to these media types is also possible. Allowing the copying of data to these drive types as long as the data is encrypted is also possible. If these functions are provided by the network operating system, you should deploy them.
It should not be possible for unauthorized persons to access and tamper with any devices. Tampering includes defacing, damaging, or changing the configuration of a device. Integrity verification programs should be used by applications to look for evidence of data tampering, errors, and omissions.
Encrypting sensitive data stored on devices can help prevent the exposure of data in the event of theft or inappropriate access to the device.
Data Retention Policies
All organizations need procedures in place for the retention and destruction of data. Data retention and destruction must follow all local, state, and government regulations and laws. Documenting proper procedures ensures that information is maintained for the required time to prevent financial fines and possible incarceration of high-level organizational officers. These procedures must include both the retention period and the destruction process. Data retention policies must be taken into consideration for e-discovery purposes when a legal case is first presented to an organization and has the greatest impact on the ability to fulfill the e-discovery request. In most cases, organizations implement a 90-day data retention policy for normal data that is not governed by any laws or regulations.
For data retention policies to be effective, data must be categorized properly. Each category of data may have a different retention and destruction policy. However, security professionals should keep in mind that contracts, billing documents, financial records, and tax records should be kept for at least seven years after creation or last use. Some organizations may have to put into place policies for other types of data, as dictated by laws or regulations. For example, when a system administrator needs to develop a policy for when an application server is no longer needed, the data retention policy needs to be documented.
Data Recovery and Storage
In most organizations, data is one of the most critical assets when recovering from a disaster. However, an operations team must determine which data is backed up, how often the data is backed up, and the method of backup used.
An organization must also determine how data is stored, including data in use and data that is backed up. While data owners are responsible for determining data access rules, data life cycle, and data usage, they must also ensure that data is backed up and stored in alternate locations to ensure that it can be restored.
Let’s look at an example. Suppose that an organization’s security administrator has received a subpoena for the release of all the email received and sent by the company’s chief executive officer (CEO) for the past three years. If the security administrator is only able to find one year’s worth of email records on the server, he should check the organization’s backup logs and archives before responding to the request. Failure to produce all the requested data could possibly have legal implications. The security administrator should restore the CEO’s email from an email server backup and provide whatever is available up to the last three years from the subpoena date. Keep in mind, however, that the organization should provide all the data that it has regarding the CEO’s emails. If the security administrator is able to recover the past five years’ worth of the CEO’s email, the security administrator should notify the appropriate authorities and give them access to all five years’ data.
As a rule of thumb, in a subpoena situation, you should always provide all the available data, regardless of whether it exceeds the requested amount or any internal data retention policies. For example, if users are not to exceed 500 MB of storage but you find that a user has more than 3 GB of data, you should provide all that data in response to any legal requests. Otherwise, you and the organization could be held responsible for withholding evidence.
Data Ownership
The main responsibility of a data, or information, owner is to determine the classification level of the information she owns and to protect the data for which she is responsible. This role approves or denies access rights to the data. However, the data owner usually does not handle the implementation of the data access controls.
The data owner role is usually filled by an individual who understands the data best through membership in a particular business unit. Each business unit should have a data owner. For example, a human resources department employee better understands the human resources data than does an accounting department employee.
The data custodian implements the information classification and controls after they are determined by the data owner. Whereas the data owner is usually an individual who understands the data, the data custodian does not need any knowledge of the data beyond its classification levels. Although a human resources manager should be the data owner for the human resources data, an IT department member could act as the data custodian for the data. This would ensure separation of duties.
The data owner makes the decisions on access, while the data custodian configures the access permissions established by the data owner.
During a specific incident response and recovery process action, the response team should first speak to the data owner, the person ultimately responsible for the data.
Data Handling
The appropriate policies must be in place for data handling. When data is stored on servers and is actively being used, data access is usually controlled by using access control lists (ACLs) and implementing group policies and other data security measures, such as data loss prevention (DLP). However, once data is archived to backup media, data handling policies are just as critical.
Enterprise data archiving is usually managed using a media library. All media should be properly labeled to ensure that those responsible for recovery can determine the contents of the media. Enterprises should accurately maintain media library logs to keep track of the history of the media. This is important because all media types have a maximum number of times they can safely be used. A media librarian should keep a log that tracks all media (backup and other types, such as operating system installation discs). With respect to the backup media, use the following guidelines:

Track all instances of access to the media.
Track the number and locations of backups.
Track the age of media to prevent loss of data through media degeneration.
Inventory the media regularly.
An organization should clearly label all forms of storage media (tapes, optical, and so on) and store them safely. Some guidelines in the area of media control are to:
Accurately and promptly mark all data storage media.
Ensure proper environmental storage of the media.
Ensure the safe and clean handling of the media.
Log data media to provide a physical inventory control.
The environment where the media will be stored is also important. For example, damage starts occurring to magnetic media above 100 degrees Fahrenheit.
During media disposal, you must ensure that no data remains on the media. The most reliable, secure means of removing data from magnetic storage media, such as a magnetic tape cassette, is through degaussing, which involves exposing the media to a powerful, alternating magnetic field. It removes any previously written data, leaving the media in a magnetically randomized (blank) state. Some other disposal terms and concepts with which you should be familiar are:
Data purging: This involves using a method such as degaussing to make the old data unavailable even with forensics. Purging renders information unrecoverable against laboratory attacks (forensics).
Data clearing: This involves rendering information unrecoverable by a keyboard.
Remanence: This term refers to any data left after the media has been erased. This is also referred to as data remnants or remnant magnetization.
Legal Holds
An organization should have policies regarding any legal holds that may be in place. Legal holds often require that organizations maintain archived data for longer periods. Data on a legal hold must be properly identified, and the appropriate security controls should be put into place to ensure that the data cannot be tampered with or deleted.
Let’s look at an example of the use of legal holds. Suppose an administrator receives a notification from the legal department that an investigation is being performed on members of the research department, and the legal department has advised a legal hold on all documents for an unspecified period of time. Most likely this legal hold will violate the organization’s data storage policy and data retention policy. If a situation like this arises, the IT staff should take time to document the decision and ensure that the appropriate steps are taken to ensure that the data is retained and stored for a longer period, if needed.
Data Breach
A data breach is any incident that occurs where information that is considered private or confidential is released to unauthorized parties. An organization must have a plan in place to detect and respond to these incidents in the correct manner. Simply having an incident response plan is not enough, though. An organization must also have trained personnel who are familiar with the incident response plan and have the skills to respond to any incidents that occur.
It is important that an incident response team follow incident response procedures. Depending on where you look, you might find different steps or phases included as part of the incident response process. For the CASP exam, you need to remember the following steps:
Step 1. Detect the incident.
Step 2. Respond to the incident.
Step 3. Report the incident to the appropriate personnel.
Step 4. Recover from the incident.
Step 5. Remediate all components affected by the incident to ensure that all traces of the incident have been removed.
Step 6. Review the incident and document all findings.
If an incident goes undetected or unreported, the organization cannot take steps to stop the incident while it is occurring or prevent the incident in the future. For example, if a user reports that his workstation’s mouse pointer is moving and files are opening automatically, he should be instructed to contact the incident response team for direction.
The actual investigation of an incident occurs during the respond, report, and recover steps. Following appropriate forensic and digital investigation processes during the investigation can ensure that evidence is preserved.
Detection and Collection
The first step in incident response involves identifying the incident, securing the attacked system(s), and identifying the evidence. Identifying the evidence is done through reviewing audit logs, monitoring systems, analyzing user complaints, and analyzing detection mechanisms. As part of this step, the status of the system should be analyzed.
Initially, the investigators might be unsure about which evidence is important. Preserving evidence that you might not need is always better than wishing you had evidence that you did not retain.
Identifying the attacked system(s) (crime scene) is also part of this step. In digital investigations, the attacked system is considered the crime scene. In some cases, the system from which the attack originated can also be considered part of the crime scene. However, fully capturing the attacker’s systems is not always possible. For this reason, you should ensure that you capture any data that can point to a specific system, such as capturing IP addresses, usernames, and other identifiers.
Security professionals should preserve and collect evidence. This involves making system images, implementing chain of custody (which is discussed in detail later in this chapter), documenting the evidence, and recording timestamps. Before collecting any evidence, consider the order of volatility (which is also discussed in detail later in this chapter).
Data Analytics
Any data that is collected as part of incident response needs to be analyzed properly by a forensic investigator or a similarly trained security professional. In addition, someone trained in big data analytics may need to be engaged to help with the analysis, depending on the amount of data that needs to be analyzed.
After evidence has been preserved and collected, the investigator then needs to examine and analyze the evidence. While examining evidence, any characteristics, such as timestamps and identification properties, should be determined and documented. After the evidence has been fully analyzed using scientific methods, the full incident should be reconstructed and documented.
Mitigation
Mitigation is the immediate countermeasures that are performed to stop a data breach in its tracks. Once an incident has been detected and evidence collection has begun, security professionals must take the appropriate actions to mitigate the effect of the incident and isolate the affected systems.
Minimize
As part of mitigation of a data breach, security professionals should take the appropriate steps to minimize the effect of the incident. In most cases, this includes being open and responsive to the data breach immediately after it occurs. Minimizing damage to your organization’s reputation is just as important as minimizing the damage to the physical assets. Therefore, organizations should ensure that the plan includes procedures for notifying the public of the data breach and for minimizing the effects of the breach.
Isolate
Isolating the affected systems is a crucial part of the incident response to any data breach. Depending on the level of breach that has occurred and how many assets are affected, it may be necessary to temporarily suspend some services to stop the data breach that is occurring or to prevent any future data breaches. In some cases, the organization may only need to isolate a single system. In other cases, multiple systems that are involved in transactions may need to be isolated.
Recovery/Reconstitution
Once a data breach has been stopped, it is time for the organization to recover the data and return operations to a state that is as normal as possible. While the goal is to fully recover a system, it may not be possible to recover all data due to the nature of data backup and recovery and the availability of the data. Organizations may only be able to restore data to a certain point in time, resulting in the loss of some data. Organizations should ensure that their backup/recovery mechanisms are implemented to provide data recovery within the defined time parameters. For example, some organizations may perform transaction backups within an ecommerce database every hour, while others may perform these same backups every four hours. Security professionals must ensure that senior management understands that some data may be unrecoverable. Remember that organizations must weigh the risks against the costs of countermeasures.
Recovery procedures for each system should be documented by the data owners. Data recovery and backup types are covered in more detail earlier in this chapter.
Response
Once a data breach has been analyzed, an organization should fully investigate the actions that can be taken to prevent such a breach from occurring again. While it may not be possible for the organization to implement all the identified preventive measures, the organization should at minimum implement those that the risk analysis identifies as necessary.
Disclosure
Once a data breach is fully understood, security professionals should record all the findings in a lessons learned database to help future personnel understand all aspects of the data breach. In addition, the incident response team and forensic investigators should provide full disclosure reports to senior management. Senior management can then decide how much information will be supplied to internal personnel as well as the public.
Let’s look at an example of a data breach not being properly reported due to insufficient training in incident response. Suppose a marketing department supervisor purchased the latest mobile device and connected it to the organization’s network. The supervisor proceeded to download sensitive marketing documents through his email. The device was then lost in transit to a conference. The supervisor notified the organization’s help desk about the lost device, and another one was shipped out to him. At that point, the help desk ticket was closed, stating that the issue was resolved. In actuality, this incident should have been investigated and analyzed to determine the best way to prevent such an incident from occurring again. The loss of the original mobile device was never addressed. Changes that you should consider include implementing remote wipe features so that company data will be removed from the original mobile device.
Facilitate Incident Detection and Response
As part of its security policies, an enterprise should ensure that systems are designed to facilitate incident response. Responding immediately to a security breach is very important. The six-step incident response process discussed earlier should be used to guide actions. Not all incidents will actually lead to security breaches because the organization could have the appropriate controls in place to prevent an incident from escalating to the point where a security breach occurs.
To properly design systems to aid in incident response, security professionals should understand both internal and external violations—specifically privacy policy violations, criminal actions, insider threat, and non-malicious threats/misconfigurations. Finally, to ensure that incident response occurs as quickly as possible, security professionals should work with management to establish system, audit, and security log collection and review.
Internal and External Violations
When security incidents and breaches occur, the attacker can involve either internal or external individuals or groups. In addition, a security breach can result in the release of external customer information or internal personnel information. System access should be carefully controlled via accounts associated with internal entities. These accounts should be assigned different levels of access, depending on the needs of the account holder. Users who need administrative-level access should be issued accounts with administrative-level access as well as regular user accounts. Administrative-level accounts should be used only for performing administrative duties. In general, users should use the account with the least privileges required to carry out the duties in question. Monitoring all accounts should be standard procedure for any organization. However, administrative-level accounts should be monitored more closely than regular accounts.
Internal violations are much easier to carry out than external violations because insiders already have access to systems. These insiders have a level of knowledge regarding the internal workings of the organization that also gives them an advantage. Finally, users with higher-level or administrative-level accounts have the capability to carry out extensive security breaches. Outsiders need to obtain credentials before they can even begin to attempt an attack.
When evaluating internal and external violations, security professionals understand the difference between privacy policy violations, criminal actions, insider threats, and non-malicious threats or misconfigurations and know how to address these situations.
Privacy Policy Violations
Privacy of data relies heavily on the security controls that are in place. While organizations can provide security without ensuring data privacy, data privacy cannot exist without the appropriate security controls. Personally identifiable information (PII) is discussed in detail in Chapter 8, “Software Vulnerability Security Controls.” A privacy impact assessment (PIA) is a risk assessment that determines risks associated with PII collection, use, storage, and transmission. A PIA should determine whether appropriate PII controls and safeguards are implemented to prevent PII disclosure or compromise. The PIA should evaluate personnel, processes, technologies, and devices. Any significant change should result in another PIA review.
As part of prevention of privacy policy violations, any contracted third parties that have access to PII should be assessed to ensure that the appropriate controls are in place. In addition, third-party personnel should be familiarized with organizational policies and should sign non-disclosure agreements (NDAs).
Criminal Actions
When dealing with incident response as a result of criminal actions, an organization must ensure that the proper steps are taken to move toward prosecution. If appropriate guidelines are not followed, criminal prosecution may not occur because the defense may challenge the evidence.
When a suspected criminal action has occurred, involving law enforcement early in the process is vital. The order of volatility and chain of custody are two areas that must be considered as part of evidence collection. Both of these topics are covered in more detail later in this chapter.
Insider Threats
Insider threats should be one of the biggest concerns for security personnel. As discussed earlier, insiders have knowledge of and access to systems that outsiders do not have, giving insiders a much easier avenue for carrying out or participating in an attack. An organization should implement the appropriate event collection and log review policies to provide the means to detect insider threats as they occur. System, audit, and security logs are discussed later in this chapter.
Non-malicious Threats/Misconfigurations
Sometimes internal users unknowingly increase the likelihood that security breaches will occur. Such threats are not considered malicious in nature but result from users not understanding how system changes can affect security.
Security awareness and training should include coverage of examples of misconfigurations that can result in security breaches occurring and/or not being detected. For example, a user may temporarily disable antivirus software to perform an administrative task. If the user fails to reenable the antivirus software, she unknowingly leaves the system open to viruses. In such a case, an organization should consider implementing group policies or some other mechanism to periodically ensure that antivirus software is enabled and running. Another solution could be to configure antivirus software to automatically restart after a certain amount of time.
Recording and reviewing user actions via system, audit, and security logs can help security professionals identify misconfigurations so that the appropriate policies and controls can be implemented.
Hunt Teaming
Hunt teaming is a new approach to security that is offensive in nature rather than defensive, which has been common for security teams in the past. These teams work together to detect, identify, and understand advanced and determined threat agents. They are a costly investment on the part of an organization. They target the attackers. To use a bank analogy, when a bank robber compromises a door to rob a bank, defensive measures would say get a better door, while offensive measures (hunt teaming) would say eliminate the bank robber. These cyber guns-for-hire are another tool in the kit.
Hunt teaming also refers to a collection of techniques used by security personnel to bypass traditional security technologies to hunt down other attackers who may have used similar techniques to mount attacks that have already been identified, often by other companies. These techniques help in identifying any systems compromised using advanced malware that bypasses traditional security technologies, such as an intrusion detection system/intrusion prevention system (IDS/IPS) or antivirus (AV) application. As part of hunt teaming, security professional could also obtain blacklists from sources like DShield. These blacklists would then be compared to existing DNS entries to see if communication was occurring with systems on these blacklists that are known attackers.
Hunt teaming can also emulate prior attacks so that security professionals can better understand the enterprise’s existing vulnerabilities and get insight into how to remediate and prevent future incidents.
Heuristics/Behavioral Analytics
Heuristics is a method used in malware detection, behavioral analysis, incident detection, and other scenarios in which patterns must be detected in the midst of what might appear to be chaos. It is a process that ranks alternatives using search algorithms, and although it is not an exact science and is rather a form of guessing, it has been shown in many cases to approximate an exact solution. It also includes a process of self-learning through trial and error as it arrives at the final approximated solution. Many IPS, IDS, and anti-malware systems that include heuristics capabilities can often detect zero-day issues by using this technique.
Establish and Review System, Audit and Security Logs
System logs record regular system events, including operating system and services events. Audit and security logs record successful and failed attempts to perform certain actions and require that security professionals specifically configure the actions that are audited. Organizations should establish policies regarding the collection, storage, and security of these logs. In most cases, the logs can be configured to trigger alerts when certain events occur. In addition, these logs must be periodically and systematically reviewed. Security professionals should also be trained on how to use these logs to detect when incidents have occurred. Having all the information in the world is no help if personnel do not have the appropriate skills to analyze it.
For large enterprises, the amount of log data that needs to be analyzed can be quite large. For this reason, an organization may implement a security information event management (SIEM) device, which provides an automated solution for analyzing events and deciding where the attention needs to be given.
Say that an IDS logged an attack attempt from a remote IP address. One week later, the attacker successfully compromised the network. In this case, it is most likely that no one was reviewing the IDS event logs.
Consider another example of insufficient logging and mechanisms for review. Say that an organization did not know its internal financial databases were compromised until the attacker published sensitive portions of the database on several popular attacker websites. The organization was initially unable to determine when, how, or who conducted the attacks but rebuilt, restored, and updated the compromised database server to continue operations. If the organization remains unable to determine these specifics, it needs to look at the configuration of its system, audit, and security logs.
Incident and Emergency Response
Organizations must ensure that they have designed the appropriate response mechanisms for incidents or emergencies. As part of these mechanisms, security professionals should ensure that organizations consider the chain of custody, forensic analysis of compromised system, continuity of operations plan (COOP), and order of volatility.
Chain of Custody
At the beginning of any investigation, you should ask who, what, when, where, and how questions. These questions can help get all the data needed for the chain of custody. The chain of custody shows who controlled the evidence, who secured the evidence, and who obtained the evidence. A proper chain of custody must be preserved to successfully prosecute a suspect. To preserve a proper chain of custody, the evidence must be collected following predefined procedures, in accordance with all laws and regulations.
The primary purpose of the chain of custody is to ensure that evidence is admissible in court. Law enforcement officers emphasize chain of custody in any investigations they conduct. Involving law enforcement early in the process during an investigation can help ensure that the proper chain of custody is followed.
If your organization does not have trained personnel who understand chain of custody and other digital forensic procedures, the organization should have a plan in place to bring in a trained forensic professional to ensure that evidence is properly collected.
As part of understanding chain of custody, security professionals should also understand evidence and surveillance, search, and seizure.
Evidence
For evidence to be admissible, it must be relevant, legally permissible, reliable, properly identified, and properly preserved. Relevant means that it must prove a material fact related to the crime in that it shows a crime has been committed, can provide information describing the crime, can provide information regarding the perpetuator’s motives, or can verify what occurred. Reliability means that it has not been tampered with or modified. Preservation means that the evidence is not subject to damage or destruction.
All evidence must be tagged. When creating evidence tags, be sure to document the mode and means of transportation and provide a complete description of evidence, including quality, who received the evidence, and who had access to the evidence.
An investigator must ensure that evidence adheres to five rules of evidence:
Be authentic
Be accurate
Be complete
Be convincing
Be admissible
In addition, the investigator must understand each type of evidence that can be obtained and how each type can be used in court. Investigators must follow surveillance, search, and seizure guidelines. Finally, investigators must understand the differences among media, software, network, and hardware/embedded device analysis. Digital evidence is more volatile than other evidence, and it still must meet these five rules.
Surveillance, Search, and Seizure
Surveillance, search, and seizure are important facets of an investigation. Surveillance is the act of monitoring behavior, activities, or other changing information—usually related to people. Search is the act of pursuing items or information. Seizure is the act of taking custody of physical or digital components.
Investigators use two types of surveillance: physical surveillance and computer surveillance. Physical surveillance occurs when a person’s actions are reported or captured using cameras, direct observation, or closed-circuit TV (CCTV). Computer surveillance occurs when a person’s actions are reported or captured using digital information, such as audit logs.
A search warrant is required in most cases to actively search a private site for evidence. For a search warrant to be issued, probable cause that a crime has been committed must be proven to a judge. The judge must also be given corroboration regarding the existence of evidence. The only time a search warrant does not need to be issued is during exigent circumstances, which are emergency circumstances that are necessary to prevent physical harm, evidence destruction, a suspect’s escape, or some other consequence improperly frustrating legitimate law enforcement efforts. Exigent circumstances have to be proven when evidence is presented in court.
Seizure of evidence can occur only if the evidence is specifically listed as part of the search warrant—unless the evidence is in plain view. Evidence specifically listed in the search warrant can be seized, and the search can only occur in areas specifically listed in the warrant.
Search and seizure rules do not apply to private organizations and individuals. Most organizations warn their employees that any files stored on organizational resources are considered property of the organization. This is usually part of any no-expectation-of-privacy policy.
Forensic Analysis of Compromised System
Forensic analysis of a compromised system varies greatly depending on the type of system that needs analysis. Analysis can include media analysis, software analysis, network analysis, and hardware/embedded device analysis.
Media Analysis
Investigators can perform many types of media analysis, depending on the media type. The following are some of the types of media analysis:
Disk imaging: This involves creating an exact image of the contents of a hard drive.
Slack space analysis: This involves analyzing the slack (marked as empty or reusable) space on a drive to see whether any old (marked for deletion) data can be retrieved.
Content analysis: This involves analyzing the contents of a drive and gives a report detailing the types of data, by percentage.
Steganography analysis: This involves analyzing the graphic files on a drive to see whether the files have been altered or to discover the encryption used on the file. Data can be hidden within graphic files.
Software Analysis
Software analysis is a little harder to perform than media analysis because it often requires the input of an expert on software code. Software analysis techniques include the following:
Content analysis: This involves analyzing the content of software, particularly malware, to determine the purpose for which the software was created.
Reverse engineering: This involves retrieving the source code of a program to study how the program performs certain operations.
Author identification: This involves attempting to determine the software’s author.
Context analysis: This involves analyzing the environment the software was found in to discover clues related to determining risk.
Network Analysis
Network analysis involves the use of networking tools to provide logs and activity for evidence. Network analysis techniques include the following:
Communications analysis: This involves analyzing communication over a network by capturing all or part of the communication and searching for particular types of activity.
Log analysis: This involves analyzing network traffic logs.
Path tracing: This involves tracing the path of a particular traffic packet or traffic type to discover the route used by the attacker.
Hardware/Embedded Device Analysis
Hardware/embedded device analysis involves using the tools and firmware provided with devices to determine the actions that were performed on and by a device. The techniques used to analyze the hardware/embedded device vary based on the device. In most cases, the device vendor can provide advice on the best technique to use depending on the information needed. Log analysis, operating system analysis, and memory inspections are some of the general techniques used.
Continuity of Operations
Continuity planning deals with identifying the impact of any disaster and ensuring that a viable recovery plan is implemented for each function and system. Its primary focus is how to carry out the organizational functions when a disruption occurs.
A COOP considers all aspects that are affected by a disaster, including functions, systems, personnel, and facilities. It lists and prioritizes the services that are needed, particularly the telecommunications and IT functions. In most organizations, the COOP is part of the business continuity plan (BCP). The COOP should include plans for how to continue performance of essential functions under a broad range of circumstances. It should also include a management succession plan that provides guidance if a member of senior management is unable to perform his or her duties.
Disaster Recovery
Disaster recovery tasks include recovery procedures, personnel safety procedures, and restoration procedures. In this chapter on incident response, the focus is on the restoration of information assets when lost due to an incident or continued access to information assets when an incident occurs. Security professionals must understand all data backup types and schemes as well as methods of maintaining access to data during drive failures.
Data Backup Types and Schemes
To design an appropriate data recovery solution, security professionals must understand the different types of data backups that can occur and how these backups are used together to restore the live environments.
Security professionals must understand the following data backup types and schemes:
Copy backup
Daily backup
Transaction log backup
First-in, first-out rotation scheme
Grandfather/father/son rotation scheme
The three main data backup types are full backups, differential backups, and incremental backups. To understand these three data backup types, you must understand the concept of archive bits. When a file is created or updated, the archive bit for the file is enabled. If the archive bit is cleared, the file will not be archived during the next backup. If the archive bit is enabled, the file will be archived during the next backup.
With a full backup, all data is backed up. During the full backup process, the archive bit for each file is cleared. A full backup takes the longest time and the most space to complete. However, if an organization uses only full backups, then only the latest full backup needs to be restored. Any backup that uses a differential or an incremental backup will first start with a full backup as its baseline. A full backup is the most appropriate for offsite archiving.
In a differential backup, all files that have been changed since the last full backup will be backed up. During the differential backup process, the archive bit for each file is not cleared. A differential backup might vary from taking a short time and a small amount of space to growing in both the backup time and amount of space it needs over time. Each differential backup will back up all the files in the previous differential backup if a full backup has not occurred since that time. In an organization that uses a full/differential scheme, the full backup and only the most recent differential backup must be restored, meaning only two backups are needed.
An incremental backup backs up all files that have been changed since the last full or incremental backup. During the incremental backup process, the archive bit for each file is cleared. An incremental backup usually takes the least amount of time and space to complete. In an organization that uses a full/incremental scheme, the full backup and each subsequent incremental backup must be restored. The incremental backups must be restored in order. If your organization completes a full backup on Sunday and an incremental backup daily Monday through Saturday, up to seven backups could be needed to restore the data.
Table 11-1 provides a comparison of the three main backup types.
Table 11-1 Backup Types Comparison
Type |
Data Backed Up |
Backup Time |
Restore Time |
Storage Space |
Full backup |
All data |
Slowest |
Fast |
High |
Incremental backup |
Only new/modified files/folders since the last full or incremental backup |
Fast |
Moderate |
Lowest |
Differential backup |
All data since the last full backup |
Moderate |
Fast |
Moderate |
Copy and daily backups are two special backup types that are not considered part of any regularly scheduled backup scheme because they do not require any other backup type for restoration. Copy backups are similar to normal backups but do not reset the file’s archive bit. Daily backups use a file’s timestamp to determine whether it needs to be archived. Daily backups are popular in mission-critical environments where multiple daily backups are required because files are updated constantly.
Transaction log backups are used only in environments where it is important to capture all transactions that have occurred since the last backup. Transaction log backups help organizations recover to a particular point in time and are most commonly used in database environments.
Although magnetic tape drives are still in use today and are used to back up data, many organizations today back up their data to optical discs, including CD-ROMs, DVDs, and Blu-ray discs; high-capacity, high-speed magnetic drives; solid state drives; or other media. No matter the media used, retaining backups both onsite and offsite is important. Store onsite backup copies in a waterproof, heat-resistant, fire-resistant safe or vault.
As part of any backup plan, an organization should also consider the backup rotation scheme that it will use. Cost considerations and storage considerations often dictate that backup media be reused after a period of time. If this reuse is not planned in advance, media can become unreliable due to overuse. Two of the most popular backup rotation schemes are first-in, first-out and grandfather/father/son:
First-in, first-out (FIFO): In this scheme, the newest backup is saved to the oldest media. Although this is the simplest rotation scheme, it does not protect against data errors. If an error in data exists, the organization might not have a version of the data that does not contain the error.
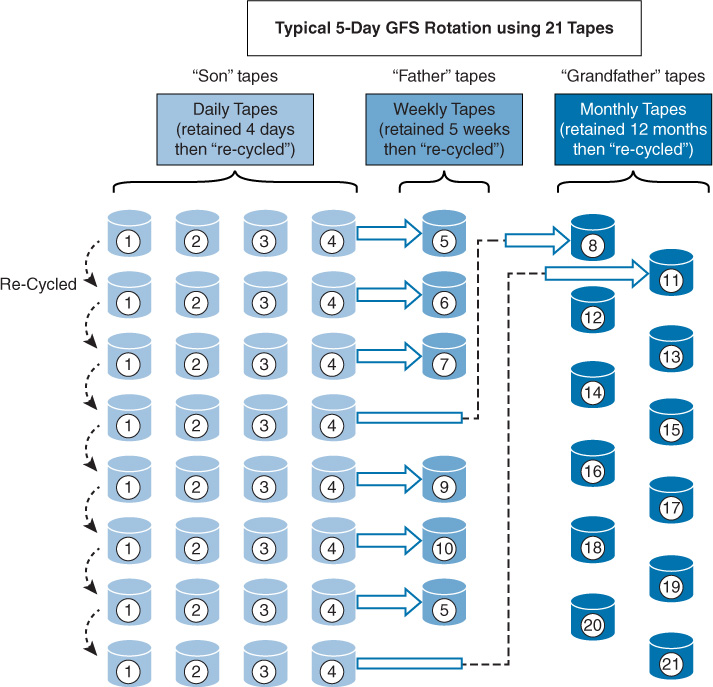
Grandfather/father/son (GFS): In this scheme, three sets of backups are defined. Most often these three definitions are daily, weekly, and monthly. The daily backups are the sons, the weekly backups are the fathers, and the monthly backups are the grandfathers. Each week, one son advances to the father set. Each month, one father advances to the grandfather set.
Figure 11-1 displays a typical five-day GFS rotation using 21 tapes. The daily tapes are usually differential or incremental backups. The weekly and monthly tapes must be full backups.
Electronic Backup
Electronic backup solutions back up data more quickly and accurately than the normal data backups and are best implemented when information changes often. You should be familiar with the following electronic backup terms and solutions:
Electronic vaulting: This method involves copying files as modifications occur in real time.
Remote journaling: This method involves copying the journal or transaction log offsite on a regular schedule, in batches.
Tape vaulting: This method involves creating backups over a direct communication line on a backup system at an offsite facility.
Hierarchical storage management (HSM): This method involves storing frequently accessed data on faster media and less frequently accessed data on slower media.
Optical jukebox: This method involves storing data on optical discs and uses robotics to load and unload the optical discs as needed. This method is ideal when 24/7 availability is required.
Replication: This method involves copying data from one storage location to another. Synchronous replication uses constant data updates to ensure that the locations are close to the same, whereas asynchronous replication delays updates to a predefined schedule.
Cloud backup: Another method growing in popularity is to back up data to a cloud location.
Incident Response Team
When establishing an incident response team, an organization must consider the technical knowledge of each individual. The members of the team must understand the organization’s security policy and have strong communication skills. Members should also receive training in incident response and investigations.
When an incident has occurred, the primary goal of the team is to contain the attack and repair any damage caused by the incident. Security isolation of an incident scene should start immediately when the incident is discovered. Evidence must be preserved, and the appropriate authorities should be notified.
The incident response team should have access to the incident response plan. This plan should include the list of authorities to contact, team roles and responsibilities, an internal contact list, procedures for securing and preserving evidence, and a list of investigations experts who can be contacted for help. A step-by-step manual should be created for the incident response team to follow to ensure that no steps are skipped. After the incident response process has been engaged, all incident response actions should be documented.
If the incident response team determines that a crime has been committed, senior management and the proper authorities should be contacted immediately.
Order of Volatility
Before collecting any evidence, an organization should consider the order of volatility, which ensures that investigators collect evidence from the components that are most volatile first. The order of volatility, according to RFC 3227, “Guidelines for Evidence Collection and Archiving,” is as follows:
CPU, cache, and register content
Routing table, ARP cache, process table, and kernel statistics
Memory
Temporary file system/swap space
Data on hard disk
Remotely logged data
Data contained on archival media
To make system images, you need to use a tool that creates a bit-level copy of the system. In most cases, you must isolate the system and remove it from production to create this bit-level copy. You should ensure that two copies of the image are retained. One copy of the image will be stored to ensure that an undamaged, accurate copy is available as evidence. The other copy will be used during the examination and analysis steps. Message digests should be used to ensure data integrity.
Although the system image is usually the most important piece of evidence, it is not the only piece of evidence you need. You might also need to capture data that is stored in the cache, process tables, memory, and the Registry. When documenting a computer attack, you should use a bound notebook to keep notes. In addition, it is important that you never remove a page from the notebook.
Remember to use experts in digital investigations to ensure that evidence is properly preserved and collected. Investigators usually assemble a field kit for use in the investigation process. This kit might include tags and labels, disassembly tools, and tamper-evident packaging. Commercial field kits are available, or you can assemble your own, based on organizational needs.
Table 11-2 list the order along with tools that can be used to acquire the data.
Table 11-2 Order of Volatility and Tools
Order of Volatility |
Type of Artifact |
Tool |
Free/Pay |
Media |
Highly volatile |
Process/ARP cache/routing table |
PSTools, Sysinternals |
Free |
Run from USB/remotely/CD |
More volatile |
RAM (memory) |
Magnet RAM Capture |
Free |
Local or USB/remote/CD |
More volatile |
RAM (memory) |
FTK Imager |
Free |
Local or USB/remote/CD |
More volatile |
RAM (memory) |
Volatility |
Free |
Analysis machine |
More volatile |
Various artifacts |
Carbon Black |
Pay |
Endpoint protection |
Volatile |
Network traffic |
Packet Sled |
Pay |
Network |
Volatile |
Network traffic |
Wireshark |
Free |
Network |
Less volatile |
Hard disk |
FTK/Access Data |
Pay |
Forensic machine/network share |
Less volatile |
Hard disk |
Autopsy/Sleuth Kit |
Pay |
Forensic machine |
Less volatile |
Hard disk |
EnCase/Digital Intelligence |
Pay |
Forensic machine/network share |
Incident Response Support Tools
In the process of supporting the incident response process, security professionals must become comfortable with using an array of tools. This section takes a look at some of these tools and the proper use of each.
dd
Before any analysis is performed on the target disk in an investigation, a bit-level image of the disk should be made. Then the analysis should be done on that copy. This means that a forensic imaging utility should be part of your toolkit. There are many of these, and many of the forensic suites contain them. Moreover, many commercial forensic workstations have these utilities already loaded.
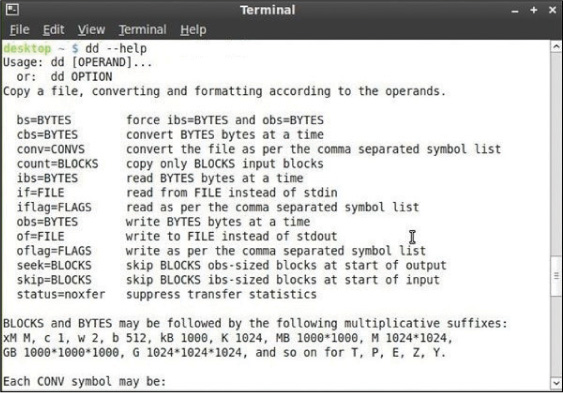
The dd command is a UNIX/Linux command that is used to convert and copy files. The U.S. Department of Defense (DoD) created a fork (a variation) of this command called dcfldd that adds additional forensic functionality. While simply using dd with the proper parameters and using the correct syntax, you can make an image of a disk. Using dcfldd gives you the ability to also generate a hash of the source disk at the same time. For example, the following command reads 5 GB from the source drive and writes that information to a file called mymage.dd.aa. It also calculates the MD5 hash and the sha256 hash of the 5 GB chunk. It then reads the next 5 GB and names that myimage.dd.ab. The MD5 hashes are then stored in a file called hashmd5.txt, and the sha256 hashes are stored in a file called hashsha.txt. The block size for transferring has been set to 512 bytes, and in the event of read errors, dcfldd writes zeros.
dcfldd if=/dev/sourcedrive hash=md5,sha256 hashwindow=10G
md5log=hashmd5.txt sha256log=hashsha.txt hashconv=after bs=512
conv=noerror,sync split=5G splitformat=aa of=myimage.dd
Figure 11-2 shows the parameters of dd.
tcpdump
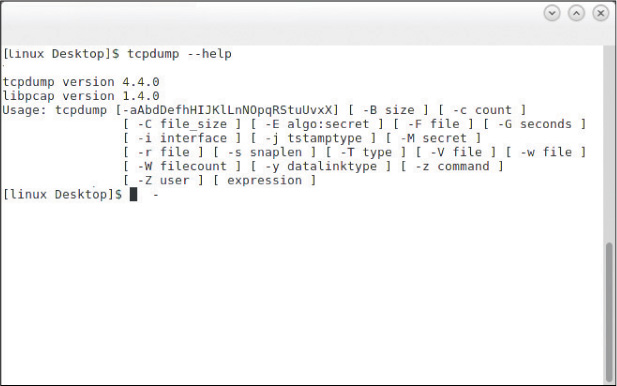
The tcpdump command captures packets on Linux and UNIX platforms. A version for Windows, called WinDump, is also available. Using the tcpdump command is a matter of selecting the correct parameter to go with it. For example, the following command enables a capture (-i) on the Ethernet 0 interface:
tcpdump -i eth0
The parameters of tcpdump are shown in Figure 11-3.
For other switches for the tcpdump command, see http://www.tcpdump.org/tcpdump_man.html.
nbtstat
Microsoft networks use an interface called Network Basic Input/Output System (NetBIOS) to resolve workstation names with IP addresses. The nbtstat command can be used to view NetBIOS information. In Figure 11-4, it has been executed with the -n switch to display the NetBIOS names that are currently known to the local machine. In this case, this local machine is aware only of its own NetBIOS names.

Figure 11-5 shows the list of switches for nbtstat.
netstat
The netstat (network status) command is used to see what ports are listening on a TCP/IP-based system. The -a option is used to show all ports, and /? is used to show what other options are available. (The options differ based on the operating system you are using.) When executed with no switches, the command displays the current connections, as shown in Figure 11-6.
Figure 11-7 shows the list of switches for netstat.
nc (Netcat)
nc (Netcat) is a command-line utility that can be used for many investigative operations, including port scanning, file transfers, and port listening. For example, the following command scans for ports 1 through 1,000 on the target at 192.168.1.2:
nc -v 192.168.1.2 1-1000
Figure 11-8 shows the switches used with nc.

memcopy
The memcpy command is a controversial C+ function used to copy the bytes from the source memory location directly to the destination memory block. It is controversial because if the source and destination overlap, this function does not ensure that the original source bytes in the overlapping region are copied before being overwritten. For more information, see http://man7.org/linux/man-pages/man3/memcpy.3.html.
The command syntax is:
void *memcpy( void *dest, const void *src, size_t count);
where:
dest = The new buffer
src = The buffer to copy from
count = The number of characters to copy
tshark
The tshark command captures packets on Linux and UNIX platforms—much like tcpdump. It writes a file in pcap format, as Wireshark does. Whenever a scenario calls for working from the terminal interface rather than a GUI interface, this tool supports the same filter functions as Wireshark, and because it is a command-line tool, it can be scripted. The following are some examples of the filtering that can be done with tshark:
Parameters:
-i to choose the interface on your machine
-a for duration, which is in seconds
-w to write the capture packets in the file
Filter with a specific IP address:
# tshark -i eth3 host 10.168.1.10
Filter with a specific source:
# tshark -i eth0 src net 19.0.0.0/8
Filter with a port:
# tshark -i eth0 host 192.168.1.1 and port 80
For more information, see https://www.wireshark.org/docs/wsug_html_chunked/AppToolstshark.html
foremost
The foremost command recovers files for Linux systems, using a process called file carving. It can recover image and data files from hard drives using ext3, FAT, and NTFS, and it can also recover files from iPhones. In the example in Figures 11-9 and 11-10, foremost was set to look for .jpeg, .png, and .gif files on a drive that had been wiped just before the command was executed.
As you can see in Figure 11-9 and continuing in Figure 11-10, foremost recovered 17 such files!
Severity of Incident or Breach
To properly prioritize incidents, each must be classified with respect to the scope of the incident and the types of data that have been put at risk. Scope is more than just how widespread the incident is, and the considerations may be more varied than you expect. The following sections discuss the factors that contribute to incident severity and prioritization.
Scope
The scope is a function of how widespread the incident is. Does this incident involve a single device, or is it a malware infection that has already spread across a subnet? The scope must be identified early on because it will indicate the amount of resources to dedicate to the incident and typically the escalation procedures. The scope is also related to the impact in that as the scope goes up, it multiplies the impact.
Impact
The impact of an incident is directly related to the criticality of the resources involved. See Chapter 2, “Security, Privacy Policies, and Procedures,” for more information.
System Process Criticality
Some assets are not actually information but systems that provide access to information. When these systems or groups of systems provide access to data required to continue to do business, they are called critical systems. While it is somewhat simpler to arrive at a value for physical assets such as servers, routers, switches, and other devices, in cases where these systems provide access to critical data or are required to continue a business-critical process, their value is more than the replacement cost of the hardware. The assigned value should be increased to reflect its importance in providing access to data or its role in continuing a critical process.
Cost
The economic impact of an incident is driven mainly by the value of the assets involved. Determining those values can be difficult, especially for intangible assets such as plans, designs, and recipes. Tangible assets include computers, facilities, supplies, and personnel. Intangible assets include intellectual property, data, and organizational reputation. The value of an asset should be considered with respect to the asset owner’s view. The following considerations can be used to determine an asset’s value:
Value to owner
Work required to develop or obtain the asset
Costs to maintain the asset
Damage that would result if the asset were lost
Cost that competitors would pay for asset
Penalties that would result if the asset were lost
After determining the value of assets, you should determine the vulnerabilities and threats to each asset.
Downtime
One of the issues that must be considered is the potential amount of downtime an incident could inflict and the time it will take to recover from the incident. If a proper business continuity plan has been created, you will have collected information about each asset that will help classify incidents that affect each asset. For more information, see Chapter 5, “Network and Security Components, Concepts, and Architectures.”
Legal Ramifications
While the legal ramifications of a security incident can be damaging to an organization, the public relations damage can be even worse if the organization is seen by the public at large to have mishandled the event or to have been less than transparent about the event. Moreover, when an organization operates in a regulated industry such as the medical, financial, or retail sector that is bound by even stricter data controls (that is, HIPAA, GLBA, and PCI-DSS), the impact is multiplied.
Organizations should also ensure that law enforcement officials are involved at the appropriate time in all investigations.
Post-incident Response
When an incident has been wrapped up, there is still work to be done. While it’s tempting to move on, you are not done until the paperwork is done, so let’s talk about that follow-up work.
Root-Cause Analysis
In many cases, in the heat of battle, security professionals don’t completely understand how or why an issue is occurring and just want it to go away; afterward, even though they still don’t know what happened, the security professionals are thankful it’s over. This sometimes goes for attack vectors as well. Security professionals may have been successful in thwarting an attack and perhaps removing the attacker from the environment but may not have been completely sure how the attack evolved and how it worked.
In scenarios such as this, you cannot just drop this issue, or you are asking to fall prey to the same attack or device issue again. You must dedicate the time to performing a root-cause analysis of the issue or attack.
Lessons Learned
During almost every security incident, you will learn things about the scenario that require making changes to your environment. Then you must take corrective actions to either address the new threat or make changes to remove a vulnerability you have discovered. The first document that should be drafted is a lessons learned report. It briefly lists and discusses what is currently known either about the attack or about the environment that was formerly unknown. This report should be compiled during a formal meeting shortly after the incident. This report provides valuable information that can be used to drive improvement in the security posture of the organization. This report might answer questions such as the following:
What went right, and what went wrong?
How can we improve?
What needs to be changed?
What was the cost of the incident?
After-Action Report
The lessons learned report may generate a number of changes that should be made. An after-action report drives the process of handling these changes. It leads to changes in other documents as well.
Change Control Process
A number of changes may need to be made to the network infrastructure. All these changes, regardless of how necessary (or minor) they are, should go through the standard change control process. They should be submitted to the change control board, examined for unforeseen consequences, and studied for proper integration into the current environment. Only after gaining approval should they be implemented. You may find it helpful to create a “fast track” for assessment in your change management system for changes such as these when time is of the essence.
Update Incident Response Plan
The lessons learned exercise may also uncover flaws in your incident response plan. If it does, you should update the plan appropriately to reflect the needed procedure changes. Then, when it is complete, ensure that all software and hard-copy versions of the plan have been updated so everyone is using the same information when the next event occurs.
Exam Preparation Tasks
You have a couple choices for exam preparation: the exercises here and the practice exams in the Pearson IT Certification test engine.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 11-3 lists these key topics and the page number on which each is found.
Table 11-3 Key Topics for Chapter 11
Key Topic Element |
Description |
Page Number |
List |
Backup media guidelines |
453 |
List |
Media storage and labeling guidelines |
453 |
List |
Data disposal terms and concepts |
453 |
List |
Incident response procedures |
454 |
List |
Rules of evidence |
462 |
List |
Types of media analysis |
464 |
List |
Software analysis techniques |
464 |
List |
Network analysis techniques |
464 |
List |
Data backup types and tape rotation schemes |
466 |
Backup types |
467 |
|
List |
Electronic backup terms and solutions |
469 |
List |
Order of volatility |
470 |
List |
Considerations used to determine asset value |
479 |
Paragraph |
Terms related to downtime |
479 |
List |
Topics in a lessons learned report |
480 |
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
continuity of operations plan (COOP)
hierarchical storage management (HSM)
incident detection and response
security information event management (SIEM)
Review Questions
1. Which of the following should not be taken into consideration for e-discovery purposes when a legal case is presented to a company?
data ownership
data retention
data recovery
data size
2. Your organization does not have an e-discovery process in place. Management has asked you to provide an explanation for why e-discovery is so important. What is the primary reason for this process?
to provide access control
to provide intrusion detection
to provide evidence
to provide intrusion prevention
3. The data owner has determined all the data classifications of the data he owns. He determines the level of access that will be granted to users. Who should be responsible for implementing the controls?
the data owner
the data custodian
the data owner’s supervisor
a security specialist
4. You are formulating the data retention policies for your organization. Senior management is concerned that the data storage capabilities of your organization will be exceeded and has asked you to implement a data retention period of 180 days or less. Middle management is concerned that data will need to be accessed beyond this time limit and has requested a data retention period of at least 1 year. In your research, you discover a state regulation that requires a data retention period of 3 years and a federal law that requires a data retention period of 5 years. Which data retention policy should you implement?
5 years
3 years
1 year
180 days
5. Your company performs a full backup on Mondays and a differential backup on all other days. You need to restore the data to the state it was in on Thursday. How many backups do you need to restore?
one
two
three
four
6. A user reports that his mouse is moving around on the screen without his help, and files are opening. An IT technician determines that the user’s computer is being remotely controlled by an unauthorized user. What should the IT technician do next?
Remediate the computer to ensure that the incident does not occur again
Recover the computer from the incident by restoring all the files that were deleted or changed
Respond to the incident by stopping the remote desktop session
Report the incident to the security administrator
7. What command captures packets on Linux and UNIX platforms?
tcpdunp
nbtstat
netstat
ifconfig
8. Your company has recently been the victim of a prolonged password attack in which attackers used a dictionary attack to determine user passwords. After this occurred, attackers were able to access your network and download confidential information. Your organization only found out about the breach when the attackers requested monetary compensation for keeping the information confidential. Later, it was determined that your audit logs recorded many suspicious events over a period of several weeks. What was the most likely reason this attack was successful?
No one was reviewing the audit logs.
The audit logs generated too many false negatives.
The audit logs generated too many false positives.
The attack occurred outside normal operating hours.
9. During a recent data breach at your organization, a forensic expert was brought in to ensure that the evidence was retained in a proper manner. The forensic expert stressed the need to ensure the chain of custody. Which of the following components is not part of the chain of custody?
who detected the evidence
who controlled the evidence
who secured the evidence
who obtained the evidence
10. A forensic investigator is collecting evidence of a recent attack at your organization. You are helping him preserve the evidence for use in the lawsuit that your company plans to bring against the attackers. Which of the following is not one of the five rules of evidence?
Be accurate.
Be volatile.
Be admissible.
Be convincing.