
5. Data Conditioning
Because many service-oriented solutions, especially those earmarked as enterprise solutions, are likely to be fraught with complexities,1 problems will occasionally surface. When a problem occurs, isolating and zeroing in on the perceived problem area appears is a prudent approach. The natural tendency for anyone tasked with identifying or resolving a problem associated with data is to focus their efforts within the boundary of the observed problem and attempt to avoid opening Pandora’s box.
1. Complexities extend from the initial design, to the quantity of services deployed, to the management a unit of work, and to the integration of data along the orchestrated path navigated by each execution.
Justifiably, service-oriented problem resolution may follow techniques of reductionism. In reductionism, problems are believed to be made easier by breaking the problem area under analysis into progressively smaller constituent parts. René Descartes (1596–1650) helped formulate reductionism as a method to “first reduce complicated and obscure propositions step by step to simpler ones.”2
The converse to reductionism is systems thinking. In systems thinking, analysis takes a holistic approach, following the concept that isolated parts can be thought to act differently when viewed outside of the whole. Systems thinking stems from the systems dynamics work originated in the early 1960s by MIT professor Jay Forrester (b. 1918) and further popularized by MIT faculty member Peter Senge (b. 1947). Senge regards systems thinking as the fifth discipline, “The discipline that integrates the disciplines, fusing them into a coherent body of theory and practice.”3
Hypothetically, if someone working on an automobile wants to improve the vehicle’s braking system, and in doing so decides to focus on the brake pad as a means to that end, that person’s thought process reflects a reductionist, Descartes-like approach. However, if the thought process for the braking system is broadened to include the entire car, the driver, the road, and any plausible weather conditions, the individual exhibits a broader thought process, or systems thinking.
From the perspective of a service-oriented approach to building a business solution, systems thinking is more likely to be applied to any work associated with the upfront design. Reductionism, on the other hand, is more readily applied to post-implementation problem resolution. So, when viral data is observed in a message or in a persisted data store, a broader view may be required to limit future occurrences or to help understand any potential ripple effects caused by sharing the data.
The email in Figure 5-1 alerts an internal service desk to an issue regarding a series of internal material numbers.4 The material numbers are missing an associated hierarchy number (related to a timing issue from an adjunct feed). The application experiencing the problem is a demand forecasting system that is fed using real-time messages via JMS5 from a commercial ERP6 application. In turn, the demand forecasting system feeds several other systems that loop back and ultimately send messages to the original ERP application.
4. The email text regarding the viral data situation at BigCo was taken verbatim from an actual email thread. However, the company, employee, and system names have been intentionally masked.
5. JMS: Java Message Service is a Java message-oriented middleware API for sending messages.
6. ERP: Enterprise resource planning is a term referring to a system that can serve the needs of many departments within an organization.
Figure 5-1 An email alerting the corporate service desk to a viral data issue. All identifying information has been obfuscated.

An email sent in response to the email shown in Figure 5-1 stated, “The impact this has created is bad for the business...it’s straining your valuable time...more importantly the Forecaster was not able to publish a new Forecast to the Schedulers plus some previous numbers are wrong. We need to do a Loss Investigation on this. We definitely need to get somebody from XX / other functional areas to look into this depending on their level of involvement.” Smith then escalated the problem to his management (see Figure 5-2).
Figure 5-2 A follow-up email that escalated the viral data issue.

Subsequently, the email in Figure 5-2 was forwarded to another manager by one of the persons carbon-copied. That manager responded to the email group by saying, “We need to slow down on escalating items like this outside of our support teams. This incident has been raised within the support organization and has been given the appropriate criticality... After we resolve the matter and have a solution in place, we will perform an incident investigation and root cause.”
The viral data situation with the demand forecasting system at BigCo shows that problem solving can be both technical and political. Thus, viral data can affect system behavior and human behavior. In part, the phrase “we need to slow down” may be influenced by a lack of understanding about what is occurring within the executed services and potentially demonstrates political cautiousness.
If the services were written to leave informational by-products associated with the messages that interoperate, any cautious behaviors may be lessened, and “incident investigation” may become part of “resolv[ing] the matter.” When attempting to resolve a viral data situation, a balance between reductionism and systems thinking is both practical and necessary. However, “root cause” analysis may not necessarily be as extensive as systems thinking.
In the email, the problem was reported to the BigCo service desk with a severity of High. However, when possible, viral data should be reported using quantitative measures (preferably, in monetary units), not just qualitative measures. At BigCo, each missing hierarchy was equivalent to about $2.5 million in terms of inaccurate forecasting. Quantitative reporting influences human behavior differently than qualitative reporting.
Viruses have caused devastating epidemics in human societies. Even so, English astronomer Sir Fred Hoyle (1915–2001)7 once hypothesized that viruses fell into our atmosphere after being incubated in the heads of extraterrestrial comets. Hoyle believed that people become ill by breathing infected air,8 and he also helped promote the concept of panspermia.9
7. Hoyle is credited with coining the term big bang, which is a theory that explains the creation of the cosmos. However, Hoyle did not believe in the big bang theory and helped model the steady state theory, which was originally published in 1948. See Sullivan (2001).
Hoyle’s theories on viral origins have often been derided,10 but the quip “from outer space” may be a retort to questions associated with viral data such as “how did this get here?” and fixing production data is not necessarily as trivial as overtyping a set of values. Typically, production data stores cannot be pulled offline on a whim, and sometimes, modifying production data can be time-consuming because of regulatory restrictions or the need to find someone with the right authority and security permissions.
Fixing an erroneous value does not address the question of “how did this get here?” The technique to trace data from its origin through all of its manifestations is known as data provenance. The word provenance is used to refer to origination and authenticity.11 Data provenance can represent informational by-products (such as messages and interoperable data) that services can persist.
The concepts associated with provenance are not unique to data provenance. Other disciplines also seek to determine provenance of material relevant in their field, including diplomatics, forensics, manufacturing and distribution, phylogenetics, and art.
Provenance in the art world attests to the pedigree (the recorded ancestry12) of an artifact such as a painting or sculpture. In art, provenance encompasses all documentation (which may also become subject to authentication) that can support the historical elements of the artifact, “from its creation through its purchasings and exhibitions to its current ownership.”13 These elements are deemed crucial, especially when reselling the artwork. A comparable element in a service-oriented application might be to demonstrate where a specific customer order originated.
12. Ibid.
In phylogenetics, phylogeny is a means to show relationships between organic species. Implicitly, phylogeny has a time axis14 and represents an evolutionary history. In information technology, concepts of phylogeny can be found in data chains. Data chains are a data-oriented equivalency to Michael Porter’s (b. 1947) activity-based concept of the value chain.
A value chain is a sequenced chain of activities whereby a product can logically or physically pass through an activity to accrue in worth (an increase in monetary value), whether perceived or real. For example, an assembled product is typically worth more than its disassembled parts, and the assembled product can further increase in value after promotional activities have commenced. “A firm’s value chain and the way it performs individual activities are a reflection of its history, its strategy, its approach to implementing its strategy, and the underlying economics of the activities themselves.”15
Juxtaposed to a value chain, the data chain is associated with knowledge (potentially as the result of an activity). The extent as to what type of knowledge can be gleaned from the data is a direct correlation to a given point in the life cycle of that data. For example, a DTD or DDL can describe a record as containing the following:
• Policyholder’s name
• Policy number
• Claim number
• Paid amount
Here, an individual (a customer) must be known prior to the issuance of a policy. Likewise, a policy must be in place before a claim can be filed. In turn, a claim must be processed before an amount can be paid back to the policyholder. This structure is independent of a life cycle and the passage of time. The structure is regarded as being out of context to any transpiring events that cause data to be populated.
Therefore, elements of the structure (or class) can be known or populated only at certain points in time and within the context of the business event. So, viewing any data from the standpoint of a data chain (identifying what is knowable at any given point in time with a life cycle) can help determine the appropriateness of a data store in terms of a system of record or as a gold source. Each business event forms a lineage, a semantic equivalence to phylogeny.
In a manufacturing and distribution scenario, companies such as the Italian clothier Loro Piana use mechanisms that incorporate provenance into the production of clothes as a means to help prevent counterfeiting and to provide a method whereby material can be “traced all the way back to the piece of fabric from which it was made, as well as to the batch of yarn used in weaving the raw fibre.”16
Radio frequency identification, or RFID, also enable companies to record traceable movements of a product throughout a supply chain and even trans-enterprise.17 RFID uses tags to reflect information via integrated circuits or product fibers (otherwise known as chipless identifiers).
17. Trans-enterprise is the transcending involvement of two or more enterprises in the life cycle or provisioning of a product or service.
For instance, a consumer diagnosed by her doctor with food poisoning may have her ingested food tracked back to tags on a consumer package. This information might identify the grocery store, and then in a backward-looking chain the distributor, the warehouse or cross-docking facility, the transportation company, the manufacturer, the farmer, and then even the seed wholesaler (perhaps continuing further backward to a natural endpoint). From any point, the process can be played forward to establish an area-of-concern.
From a service standpoint, recording the lineage at the service level or at the instance level of each message is comparable to the manufacturing and distribution provenance associated with RFIDs and other tracing techniques.
Tracing and the provenance associated with evidence in criminal law is known as chain of custody. Under normal circumstances, forensic evidence must be presented in a court of law in the same condition that the evidence was in at the time of its collection. “A chain of custody is the more complex foundation needed for the admissibility of certain types of exhibits as evidence.”18 A log is maintained to demonstrate every access to evidence. The log must be exhaustive and without gaps.
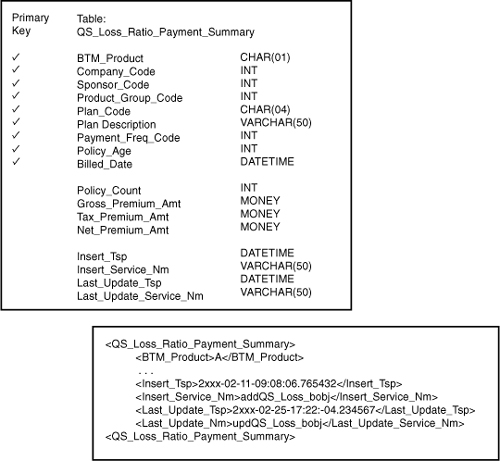
As a form of provenance, chain of custody accentuates notions of accountability. Data stores are often modeled to allow for the inclusion of the name of the service that created or last updated an individual record along with an associated date and time. In this way, information technology has offered primitive forms of accountability and provenance in service-oriented applications (see Figure 5-3).
Figure 5-3 Sample XML schema and DDL illustrating accountability columns/elements.
The science of diplomatics or forensic paleography is a study of origin and authenticity for written documents. When assessing a document, the materials are analyzed for appropriateness to the time period and geographical location. Textual composition is evaluated for penmanship, language, and language style. The goal of the diplomatics “is validation of the record of an act as proof of the validity of the act itself.”19
In today’s business environment, displomatics still has applicability in the assessment of scanned digital images and electronic content such as email and other documents. Electronic discovery (e-discovery) is a legal provision for the disclosure of discovery of electronically stored information. E-discovery involves the tracing the lineage and dissemination of content.
“The problem of e-discovery reached such epidemic proportions that on December 1, 2006, the Supreme Court promulgated new Rules of Civil Procedure for all federal courts to follow to try to address these issues.”20 The rules apply to the preservation and production of data. However, challenges exist in determining relevance of any piece of data, “where it might be located, and who might have custody and control of it.”21
Provenance, within the context of business data, enables us to comprehensively support e-discovery, audits, or the assessment of viral data and trusted information (preemptively and passively).22 In all cases, observations and recommendations would follow the SÉANCE workflow outlined in Chapter 3, “Reference Model.” Any resulting course of action based on data provenance could be used to promote systems thinking and cultivate a learning organization.
22. In relationship to the reference model shown in Chapter 3, preemptive situations would have closer affinity to preflight data, whereas passive situations would have a closer affinity to post flight data.
Within the realm of organizational forensics, viral data may contribute to privacy breaches, and data provenance can assist by allowing a complete case to be replayed and analyzed. Data provenance improves our understanding as to the origin of exact causes of viral data. Furthermore, in the realm of corporate law enforcement, data provenance offers additional data that can be used to assist the inspection of orchestration in terms of compliance.
From a viewpoint of data governance, provenance can help establish appropriate policies for data management and business management. Provenance data can also provide a means to quantitatively monitor and evaluate policy effectiveness. When automated assessments of data and provenance are continuous—in preflight, in-flight, and post flight stages—alarms (service-based triggers and notifications) on viral data can be effectuated.
Systematic determination of provenance and data lineage both heavily depend on the visibility and accessibility of metadata. In fact, “establishing data lineage for each data element is a monumental effort given the fact that organizations have millions of data elements in thousands of files and tables.”23 The metadata associated with a service may be bound early or late, and the time of binding can obviously affect what can be known at what point in time.
Provenance associated with business data in a message or in a persisted data store is always associated with late binding because the data must first be materialized to associate any provenance. On the other hand, aspects of data lineage can be known prior to runtime, when some bindings are early or static in nature (see Figure 5-4).
Figure 5-4 Pseudo code illustrating systemic awareness of the use of queue A and queue B.
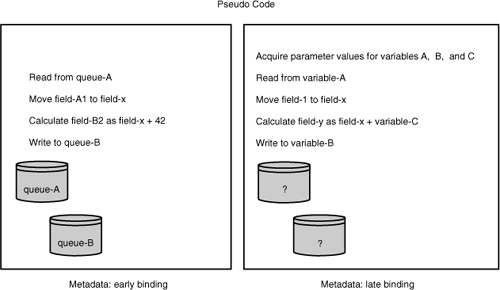
In terms of provenance, early or static bindings refer to the types of metadata potentially available before an invocation. Late or dynamic bindings refer to the types of metadata that can be made available only during or after an invocation. In Figure 5-4, the metadata to know that queue A is used in the service can be accessible before an invocation, whereas the actual queue name substituted for variable A cannot be known with absolute certainty until the service has been invoked.
From the viewpoint of a data lineage, queue A can readily be determined to be an input, and queue B can be confirmed to be an output. Therefore, data from queue A enters the service, and data from queue B exits the service. The loose association between an input and an output can be used to assert a lineage. With only this level of knowledge (the identity of an input and the identity of an output), any explicit relationship between queue A and queue B is ambiguous.
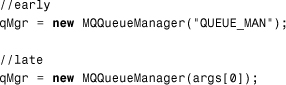
The following Java code illustrates the creation of a WebSphere® message queue connection (first with early binding, and then with late binding):
However, by navigating the program metadata (the code), an association can be drawn between field A1 and field B2. Therefore, the data lineage can be expanded to link the two queues: queue-A.field-A1 → queue-B.field-B2.
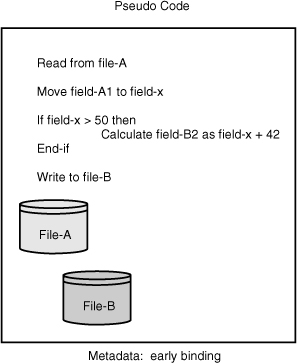
In Figure 5-5, the association between field A1 and field B2 is now conditional, and the frequency of that affinity is unknown. In Figure 5-4, any relationship between an inbound queue and an outbound queue can be discovered only when the service is invoked. If the service could be run in a no-op (NOP or no operation) mode, some additional bindings could be resolved without a formal execution having to take place, but granular details regarding frequencies and execution paths would remain unanswered.
Figure 5-5 Conditional lineage.
In some environments, the metadata associated with early binding may be referred to as technical metadata, whereas metadata associated with late binding may be referred to as operational metadata. In either case, data lineage provides for a higher (coarse)-grained association only and is not used as a technique to relay tracings of discrete messages, records, or fields.
Lower (fine)-grained lineage is affiliated with data provenance Although, in general, data provenance can be associated with various grains (or levels) of information—the granularity of provenance. For example, knowing that 5,000 records from queue A were consumed on a given date, time is perceived as a higher grain of provenance information. Even if the server name, IP address, and invocation mode were added to the information collected, the data provenance would still be regarded as high-grained information.
The finest grain of data provenance is tracing information associated with each individual element or column and account for any changes in value or meaning over time. A higher grain of data provenance is to relate tracing information with a single payload within a message or row. Figure 5-6 illustrates a table design to capture certain demographic information about a person. The data provenance applies to the entire row and denotes the last time a row was updated, identifies the originating user, and specifies a unique transaction identifier.
Figure 5-6 Row-level data provenance.

When using a design such as the one shown in Figure 5-6 as part of a master data solution, problems may surface in how well the provenance can keep track of multiple services or sources of information that contribute data to a shared table. Resolving viral data issues or proving that data is trustworthy can require the provenance to be columnar based rather than record based.
Certainly, a number of data and service design patterns can be established and considered to determine how to best accommodate provenance data. An initial consideration is to decide on what provenance exists or can be surmised. Other decisions include the following:
• In terms of granularity, what types of data provenance should be persisted?
• In terms of completeness within a level of granularity, how much data provenance (or what kinds of provenance information) should be persisted?
• What type of data provenance already exists or is currently available?
• What data provenance can be captured with traditional operational or runtime metadata?
• Should data provenance be kept with the business data as opposed to being separately held?
• Which data provenance design patterns can be used for transient messages and which for persistent data stores?
• Which data provenance can be gathered and stored synchronously versus asynchronously?
• Do different parts of the data architecture require different considerations for data provenance? A data architecture would normally accommodate different types of data stores, including those associated with operational systems and decisional systems.
• How can the quality of data provenance be controlled?
• How will the data provenance be reported?
• Who will have access to provenance data?
• Will the provenance data be allowed to be updated or otherwise modified?
• How will data provenance impact transactional or message latencies?
Within the context of viral data, provenance serves to help identify problems, facilitate resolution, and ascertain overall data trustworthiness. Beyond raw counts of records-in and records-out, data provenance can provide a basis for establishing meaningful metrics to be quantified and reported. In terms of which provenance to capture, the primitive interrogatives of the English language can serve as a means to assist and organize the types of data provenance that may be of interest.
An interrogative is a “word used in questions.”24 The six primitive interrogatives are what, how, where, who, when, and why. Other interrogatives include which, whether, whose, whither, whence, will, can, are, have, and should. The primitive interrogatives serve as aspects in the Zachman Framework for Enterprise Architecture.25 Collectively, the six interrogative-based aspects are used to form a comprehensive view; and when the aspects are interrelated, they form a holistic view of anything that can be rationalized.26
25. The Zachman Framework uses the term aspects to refer to the interrogatives.
The interrogative what is represented by the Zachman aspect inventory; how by process; where by network; who by organization; when by timing; and why by motivation. Overall, Zachman’s framework represents an ontology to express the essential elements used in the creation, maintenance, and operation of a concept.
The aspect inventory associated with the interrogative what can be used to establish a stake in the ground or a “rallying point”27 for which types of provenance are desired. Here, the rallying point is the business data and any associative structures (e.g., an element or column name, a domain, a table or XML schema, a database, or an instance).
27. Ibid.
Data provenance information “can be applied for data quality, auditing, and ownership, among others. By having records of who accessed the data, data misuse can be determined.”28 We can use the following questions to help derive what type of provenance could or should be captured to help affirm the creation, maintenance, and operational use of business data:
The rallying point
• How/process
Application name
Service name
Service hierarchy (all coarse- and fine-grained services that touch the data)
Service version
Programming language
Service compiled date
Invocation mechanism
Push/publish, pull/subscribe, or registry mechanism
Consumer or producer
Counts
• Where/network
Server name
Server IP address
For grid processing, which grid node or blade
For load balancing, which server
Router
SAN, NAS, or other storage device
Hardware platform
Type of message queue
Software compiler
Environment type: development, test, production
Operating system, version, and patch level
• Who/organization
Workflow or orchestration
Corporation name
Department name
Individual name
Report
• When/timing
Business trigger
Business event
Date and time
Business rule or rule set
Transformation rule or rule set
Figure 5-7 illustrates how the interpretation of business data values may be assisted by provenance. The truck on the left is weighed unladened. The same truck is then weighed fully laden. The two scales are accurately calibrated, but differ in their degrees of precision for reporting weight. Which scale is used at which point in time could have repercussions on fuel consumption, road taxes, and or other items.29
29. The use of scales is just one type of example where inconsistent precision can affect a result. While the business data represents a result, the data provenance provides the background for rationalizing the result (in this case, the particular type of scale that was used to capture a measurement).
Figure 5-7 What is the true weight?
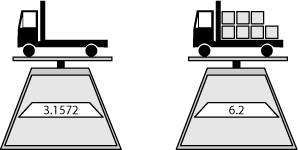
Capturing the actual device that is used to weigh the truck as well as other pertinent information such as the device’s year of manufacture, its last maintained date and time, the measuring precision associated with the device, and even the external temperature and humidity levels present at the time of a reading can all participate as vital facts in a provenance-aware application. A similar situation for data provenance surrounds the discussion from Figure 4-4 where the provenance for the hardware and software environment is required.
Both data lineage and data provenance are types of metadata associated with business data. As financial regulations are revised in the wake of the global economic and financial crisis that occurred towards the end of the first decade of the 21st Century, some data provenance may be mandated; other provenance may remain discretionary. However, all provenance data can help quantify the trustworthiness of data.
Therefore, knowing that a business data value was originally entered by a known person on a known portal at known location and processed by known versions of a series of services and that the final value of the business data was the result of passing through a known set of business rules provides a context for the data and establishes a set of markers that can be used to assert the condition of data.
Keeping data in a conditioned state can certainly be measured over time by the use of correct data values. As business needs continually change (a topic covered in Chapter 1, “Viral Data”), information technology must adopt the appropriate types of structural data designs. These designs can significantly contribute toward the overall conditioning process—whether they are for a schema, a table, or a file.
Generally, the length and data type of a field is explicitly defined in a relational table, as shown in Figure 5-6. As mentioned in Chapter 1, it is not necessarily easy to orchestrate the changes to a data structure. Therefore, when a new business requirement warrants a change to the length or the data type of a field, workarounds are often sought (which may increase the potential for introducing viral data).
Because lengths and data types generally represent hard-coded information, developing a technique to add flexibility can be essential to prevent viral data. Generally speaking, each discrete value of structured business information fits onto a single line—whether that line appears on a screen or a printable report. For example, each of the columns in Figure 5-6 readily fit onto one line.
Using the premise that when new lengths for business information are required, the business information can still fit onto a single line as the basis for an axiom, the following heuristic can be developed. A landscaped U.S. legal-size piece of paper (which is a little longer and marginally wider than a sheet of A4) can generally accommodate up to 260 characters of 8-point font (depending on the actual font and combination of letters and numbers used). Therefore, as a generalized starting point, all character-based columns may be defaulted to 254 characters or VARCHAR(254).
The length of 254 would serve to accommodate most changes in length to a business field. As a default, if the length of 254 seems somewhat too long for all alphanumeric-based fields, a shorter length can be substituted. The value 254 represents a length that can accommodate the vast majority of structured concepts requiring an alphanumeric data type and is suggested as means to artificially create an unbound length.
When a concept requires a longer length, adjustments should be made. Figure 5-8 shows an example where default lengths are set to 2000 bytes, and certain columns, such as Character, represent denormalized concepts (in this case, a comma-separated list of character roles in a movie). In most cases, however, a business concept can safely use a shorter length than 254. Regardless, the chosen length should equal or exceed any length that might ever be required for a field.
Figure 5-8 Example of a data structure that attempts to unbind a length.

The value of 254 represents a reasonable maximum length for a single field printed on a single line of landscaped U.S. legal-size paper. The rationale for adopting a larger length than a business concept appears to warrant is based on the maxim that changing the length of a column is simple in principle, but is usually extremely difficult and costly in practice.
Changing the length of a column can also have reverberations on fine-grained services that are often associated with CRUD30 operations.31 For some organizations, the effort to change a single VARCHAR2(18) column to VARCHAR2(20) can be insurmountable. The expense and effort associated with the year 2000 rewrites and replacements attests to the complexities involved with field length changes.
30. CRUD is an acronym for create, retrieve, update, and destroy. See St. Laurent (2009).
31. Create is synonymous with an SQL insert statement and an HTTP post method; retrieve is synonymous with an SQL select statement and a HTTP get method; update is synonymous with an SQL update or upsert statement and a HTTP put method; and destroy is synonymous with an SQL delete statement and a HTTP delete method.
When deciding to use an artificial field length, two issues should be considered:
• Heuristics that help decide an artificial field length
• How a service should be informed of the real maximum length
OSAPI, pronounced oh-sap-ee, is an acronym that represents a heuristic intended to assist a data administrator, data modeler, or a data designer in the applicability of using an artificial field length. OSAPI is an acronym for:

Ownership, stability, abstraction, performance, and interfaced are the five characteristics that form the artificial field heuristic. Each characteristic is associated with a simple yes or no question. Each yes or no answer is then associated with a numeric value that, when summed up, provides rudimentary guidance to model a data type length.
The characteristic ownership explores an organization’s control over all aspects of an attribute or column. Ownership was a topic examined in Chapter 4, “Assessing the Damage.” Stability inquires into the mutability of the column’s domain over time. Abstraction explores the degree of modeled generalization. Performance analyzes latency issues and interfaced is used to look at whether the column is shared.
The OSAPI questions are phrased as follows. The use of the term concept covers elements, attributes, columns, and fields:
• Ownership
Is the concept owned, controlled, and governed by our organization?
• Stability
Has the domain set for the concept been stable over time (past, present, and the anticipated future)?
• Abstraction
Is the concept represented in an abstract form (not concrete—i.e., last name is a concrete concept, and a party name that accommodates both people and organizations would be an abstract concept)?
• Performance
Does this concept have distinct performance requirements?
• Interfaced
Is this concept shared beyond this system or application?
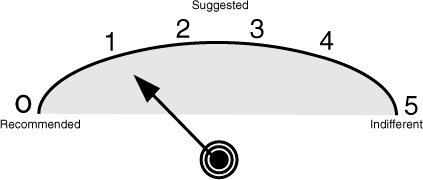
Each question should be answered yes or no for each concept in a table. Each yes or no answer is awarded a point value (see Figure 5-9). By summing the points awarded for each concept, the total can be evaluated against the gauge shown in Figure 5-10.
Figure 5-9 OSAPI scoring grid.

Figure 5-10 OSAPI scoring gauge.
The closer an OSAPI score is to zero, the stronger the recommendation is to make use of an artificial length. For example, all automobiles are identified through a vehicle identification number (VIN). “The modern 17-digit VIN not only uniquely identifies a particular vehicle but also contains information that describes the vehicle itself.”32
VINs are a global concept used by automobile manufacturers, insurance companies, government agencies, law enforcement agencies, vehicle distributors, banks, identification and credentialing verification service providers, and others.
The VIN structure was designated by the Society of Automotive Engineers (SAE) and is currently controlled by the International Standards Organization (ISO). Therefore, a VIN is not owned by any particular community that has business operations to create or maintain the number. In addressing the OSAPI ownership question for a VIN, the answer would be no and would be scored as a zero.
Historically, the VIN structure has never been a stable concept. Prior to 1980, different manufacturers used different formats, and in October 1980, the SAE published a standard to guarantee unique numbers for 30 years. Soon after the year 2000, the SAE was obliged to readdress the standard because duplicate VIN numbers would be unacceptable to many organizations, especially insurance companies and law enforcement agencies.33
33. An option to simply obliterate all vehicles over 30 years of age rings in a sense of Johnson and Nolan’s dystopian novel Logan’s Run.
The 1980, the VIN standard was organized around a 17-byte composite field. While exploring options to revise the standard, the SAE discovered that extending the length was not an option—not even by a single character. The change in length was insurmountable. A substantial number of organizations would be confronted with too many systems to change.
The resolution adopted by the SAE involved adjusting some of the embedded characteristics of the 17-byte composite field, which extended the VIN life span by another 30 years. In the lingua franca of information technology, the SAE simply applied a temporary patch. Ultimately, the VIN problem remains unresolved and cannot be viewed as a stable concept. The OSAPI stability question for VIN, therefore, would be answered in the negative and would therefore be scored as a zero.
Germane to abstraction, if a VIN is modeled and instantiated as a vehicle identification number, the concept is concrete. A VIN is a real-world business concept, and an element called VIN_id would simply reflect a real-world view. In addressing the abstraction question, the answer would be no and would also be scored as a zero.
Performance requirements for using a VIN would in all likelihood depend on whether the VIN was going to be used as a single field or decomposed into its constituent or atomic parts. Even when processing the VIN in its atomic parts, additional latencies or overhead are unlikely should the VIN be cast with an artificial length that exceeds 17 bytes. Additional performance considerations can be taken into account if the column was included as part of an index. Therefore, for the performance question for VIN, the answer would be no and would also score a zero.
The final OSAPI question addresses whether a concept is actively shared between services. As a major identifier, the VIN is likely to be shared by many services and applications. Consequently, addressing the interfaced OSAPI question, the answer would be yes and would score as zero.
In the example of VIN, all five OSAPI questions are scored as zero. Summing each score obviously results in the grand total of zero. Grading the final score against the scoring gauge denotes a recommendation that an artificial length is used for implementation.
The gauge values range from zero to five. The gauge values are associated with a proposition. Zero and one are associated with a rating of recommended. Two and three are associated with a rating of suggested, and four or five are associated with a rating of indifferent.
A gauge reading of recommended means that a default length value should exceed the maximum length used or currently known. A gauge reading of indifferent indicates that fixing the data type length to the current maximum is acceptable, whereas a gauge reading of suggested implies that using a larger length is prudent.
Should a service require knowledge of a concept’s actual length, a meta-driven framework consisting of a persistent data store, data, and an access method can be instantiated. The following examples in Figures 5-11, 5-12, and 5-13 use a relational table and SQL, but a comparable equivalent can be established with an XML document and XQuery.
Figure 5-11 Sample schema to help govern element or column lengths through the use of metadata.

Figure 5-12 Sample metadata that could be used to govern element or column lengths.

Figure 5-13 Sample query to obtain length metadata for elements or columns.

Figure 5-11 shows a sample table design to house metadata associated with managing artificial lengths, and Figure 5-12 provides some sample metadata. In this case, the sample metadata is based on the use of a customer’s name as the concept with an artificial length.
The first record in Figure 5-12 indicates that the customer’s name is restricted to 30 bytes. The length is subsequently increased on two occasions, initially by 5 bytes to 35 bytes and later on to 50 bytes. The aspect of time is managed by the effective and expiration time stamps. Expressing a period of validation allows the table to be populated in advance of a change becoming effective (and provisions a historical record).
In Figure 5-13, an SQL query accessing the current length metadata is shown. Predicating on the runtime date and time (CURRENT TIMESTAMP), only the current length is obtained. The length can then be used to restrict entry of customer names exceeding the retrieved length. Any future changes made to the length can be achieved without changing or reinstalling the code base (vital to reduce costs associated with maintaining a service and to mitigate any workaround solutions).
Length concepts can be extended to handle additional data types, including numeric data and composite data types such as time stamps. Length metadata and the metadata represented by data lineage and data provenance convey how the role (or use) of metadata can help in controling viral data. An additional technique using metadata can help manage composite business elements such as a Social Security Number and a vehicle identification number.
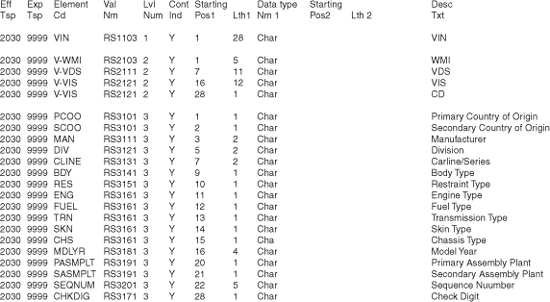
The vehicle identification number is a multilevel composite field (see Figure 5-14). The root level of the “structured combination of characters”34 is the 17-byte identifier. When taken in its entirety, the identifier uniquely identifies a motor vehicle. The second or nonleaf level of the identifier is composed of three elements: a 3-byte world manufacturer identifier, a 6-byte vehicle descriptor, an 8-byte vehicle identifier section.
Figure 5-14 Basic structure of a VIN.
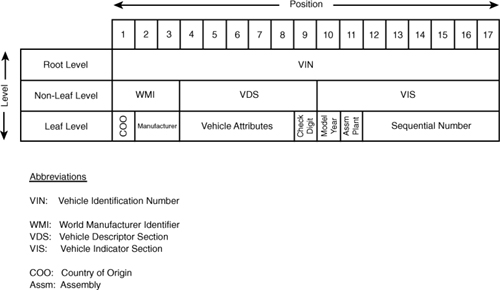
Figure 5-15 shows several VINs associated with Chevrolet Corvettes to illustrate how VIN styles have changed over the years.

The sequential number in positions of 12 through 17 of the leaf level is not always numeric. Rolls Royce has traditionally started their numbering schemes with an L or an R—to differentiate between left-hand and right-hand drive vehicles.35 Light- and medium-weight trucks follow the same general scheme as passenger vehicles except that the vehicle attributes are used differently.
The area for the vehicle descriptor is defined by each manufacturer and can also vary from one model-year to the next. In addition, the same codification values can change over time. In 1982, for example, General Motors used alphabetic characters in position four to indicate a vehicle’s restraint system. In 2008, however, the restraint system was located in position seven and used a numeric-based codification scheme.
In 2008, the code value 1 for a restraint system in a General Motors passenger car meant “Driver & Passenger Inflatable Restraint—Front,”36 and in 1992, General Motors used that code value to mean “Active (Manual) Belts.”37 In the same position, position seven, Toyota uses the code value of 1 to indicate “STD, High, S.”38 Mitsubishi uses the code value 1 to designate “5-door wagon or SUV”39 as a type of vehicle and not as a restraint system as used by General Motors and Toyota.
36. http://www.goodwrench.com/gmgoodwrenchjsp/gmspo/Vin/2008vincard.pdf
37. http://www.goodwrench.com/gmgoodwrenchjsp/gmspo/Vin/1992car.pdf
38. http://www.weber.edu/WSUImages/automotive/T-TEN/2008%20VIN%20Toyota.pdf
39. http://www.mitsubishicars.com/media/owners/pdf/09VINs.pdf
Specialty vehicle manufacturers, specifically those that manufacturer fewer than 500 vehicles per year, follow a slight variation. The WMI codes, which are allocated by the SAE40 on behalf of the ISO and the U.S. National Highway Traffic Safety Administration, are found in the first three positions of the VIN. However, if the third digit of the WMI code is a 9, the first three digits of the sequential number are used to extend the WMI. For example, the SAE provided the specialty sports car manufacturer Panzo the WMI code 1P9.
Analyzing the WMI code backward, the 9 means that the manufacturer makes fewer than 500 vehicles per model-year, and the P indicates that the manufacturer’s name begins with the letter P. For high-volume manufacturing, P is currently used by Porsche, and in the past was used by Plymouth. The code 1 means that the vehicle’s origin is the United States. The code 213 in positions 12 through 14 completes the extended WMI identification for Panzo.
Figure 5-16 illustrates how variable length and variable meanings can be accommodated through the use of metadata. The metadata is intended to handle a concept that is deemed volatile and provide a dynamic way to handle semantics as a means of vaccinating against viral data.
Figure 5-16 Descriptive metadata for a VIN.
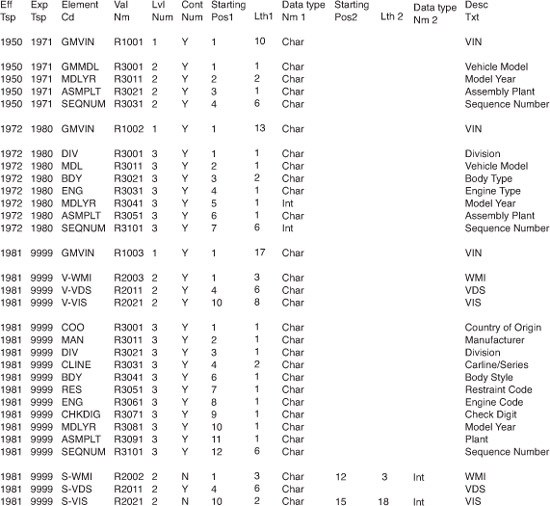
The structure of the metadata is as follows:

For purposes of brevity, only the year is shown for the effective and expiration time stamps in Figure 5-16.
Each record in this structure is uniquely identified by a combination of an effective time stamp, expiration time stamp, and element code. In this way, element codes can be reused as necessary. The effective time stamp represents the date and time an element code takes effect, and the expiration time stamp indicates the date and time that an element code ceases to be effective. The element code itself indicates an aspect of the VIN across any of the levels.
The contiguous indicator is used to explicitly denote whether a field is split (as in the WMI code for specialty manufacturers). Therefore, two sets of starting positions, lengths, and data types are available. For contiguous fields, only the first set of numbers is used. The element validation rule name provides for a service name that can be invoked to perform rule checking or validation on an element. An alternative approach is to use a service registry. Finally, the element description text is used to provide a descriptive explanation of the element code.
To calculate the check digit in position nine of the VIN, all alphabetic characters are converted to a numeric value; numbers retain their original value. Alphabetic characters are converted as follows: A is converted to the number 1, B → 2, C → 3, D → 4, E → 5, F → 6, G → 7, H → 8, J → 1, K → 2, L → 3, M → 4, N → 5, P → 7, R → 9, S → 2, T → 3, U → 4, V→ 5, W → 6, X → 7, Y → 8, and Z → 9. Special characters and the letters I, O, and Q are not used in a VIN.
Next, a weighted value is associated with each positional digit (including the check digit in position nine, which is given a weight value of zero to discount its effect on the check digit calculation). The weighted values are as follows: The first position 1 is weighted with an 8, 2 → 7, 3 → 6, 4 → 5, 5 → 4, 6 → 3, 7 → 2, 8 → 10, 9 → 0,10 → 9, 11 → 8, 12 → 7, 13 → 6, 14 → 5, 15 → 4, 16 → 3, and finally 17 → 2.
Next, each number is multiplied by its weighted value, and then the accumulated total is divided by 11. The remainder is then used to determine the check digit. Figure 5-17 shows the check digit calculation for VIN 1G1YY36W085113575.
Figure 5-17 VIN check digit calculation.
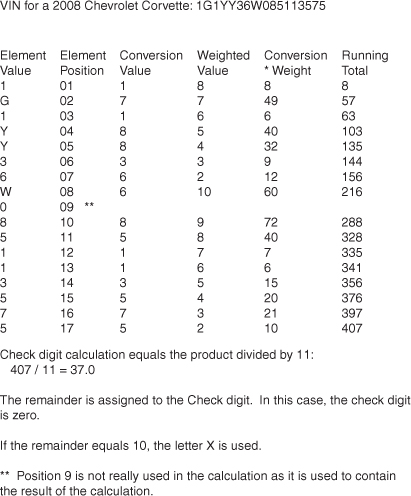
Figure 5-18 shows an example of the rule validation written as a Java routine. To determine the validity41 of the 17-digit string, the program logic calculates the check digit for a VIN and then compares the calculated value with the ninth position of a VIN that was passed to the routine. A Boolean pass or fail value is returned to the calling service. All general validation is assumed to have been performed by the level 1 validation rule.
41. In terms of data quality, validity and accuracy are not the same. In terms of validity, the program can assert that the string represents a plausible VIN. Accuracy would assert that the VIN has been assigned and that the assignment and the vehicle match.
Figure 5-18 VIN check digit calculation written in Java.

The assembly plant portion of the VIN might not always be associated with the country of origin. Some vehicles intended for export are built and subsequently dismantled prior to shipment in what is referred to as a “complete knockdown.”42 A partial disassembly is called a semi-knockdown.
An imported disassembled vehicle may incur less tax duty (to the point that the retail price will be lower even after the vehicle has been reconstructed for a second time). In this case, the final assembly is in a different country than the country of origin.
When a vehicle is knocked down, some of the parts may not be transportable. For example, most “driver and passenger side airbags now use some type of solid propellant pyrotechnic inflator.”43 In other words, airbags represent an explosive device. In the United States, the Bureau of Industry and Security is responsible for implementing and enforcing the export administration regulations and may place restrictions on the permissibility of an explosive device being exported to another country.
In addition, if a consumer pickup truck is fitted with an accessory such as a gun rack, the vehicle will probably be reclassified as a military vehicle. This reclassification would not necessarily be the same for a retrofitted or after-market gun rack. Business rules associated with a military vehicle are distinct from those associated with a consumer vehicle, and in the case of a VIN, the VIN may be replaced by a military data plate.
VINs provide one example of a volatile and complex business concept. As shown, metadata is a viable method to help ensure against viral data being introduced into a system. In Figure 5-19, the metadata has been modified to illustrate a fictitious VIN layout.
Figure 5-19 Possible future VIN design.
Through the use of metadata, the length has been modified (extended) to 28 bytes. In addition, the check digit has been elevated to its own section on the nonleaf level. A number of new attributes have been added for future-oriented vehicles, such as the power supply source (e.g., gasoline, electric, ethanol, and hydrogen) and the vehicle’s skin material (such as metal, plastic, fiberglass, or some other type of polymer); see Figure 5-19.
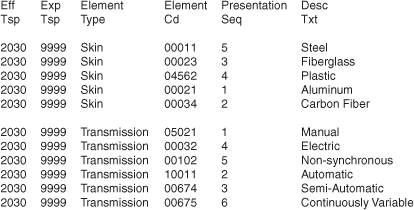
Should some of the business requirements become instantiated as metadata, many of the changes in Figure 5-19 could be accomplished without any coding changes to a program. Figure 5-11 illustrates a lookup table for vehicle skin types and types of transmissions. In addition, a column denoting a presentation sequence has been added to help show the valid types.
Figure 5-20 Metadata-driven validation: The use of lookup tables.
Once a VIN has been recorded, there is a presumption that the vehicle exists. However, at some point in time, the vehicle may be discarded (perhaps because of damage, irrelevance, or as general wear and tear). In this case, the real-world object, the vehicle, no longer exists. The relationship between the data and the object has been severed.
When the relationship between the instantiated data and a business object is such that the data should not be reused or be used to reflect a current business need, that data can be said to have decayed. There is speculation that “approximately 20 percent of the values in that field will change over a 12-month period.”44 Often, in data decay, there is a potential to reverse the decay and revitalize the data. With regard to a discarded vehicle, any revitalization of the data does not make sense other than to associate a vehicle discard date with the VIN.
However, what about a consumer’s address when that consumer has moved from the address? The data about the person can be revitalized by ascertaining the consumer’s current address. Propagating decayed data may result in viral data, especially when that data is used for new business purposes.
If a consumer living at Sinking Spring Farm, in southeast Hardin County, Kentucky, receives shipment of a product and subsequently moves to 1600 Pennsylvania Avenue in a different town, then revising the shipment address would be erroneous even though the old address could be viewed as decayed information. Therefore, any data revitalization should not be performed at the expense of changing history.
Uncovering decaying or decayed data is a matter of establishing a mechanism that can keep the data synchronized with a real-world object. Methods to proactively synchronize data vary based on the type of real-world object being tracked: A consumer’s mailing address and a product’s dimensions would leverage different monitoring facilities. A cost/benefit analysis is often required to ascertain whether a proactive synchronization is advantageous or if a reactive approach will suffice.
Although data can be modified to rectify a data deficiency, the best way to combat viral data is to maintain sufficient rule sets to inhibit anomalies from being introduced followed by synchronization methods to revitalize data that has decayed. To best support the reactive needs of a system, devising a service based on a thin-process model is preferred as business rules are externalized.
As a result, combating viral data requires a holistic approach leveraging multiple disciplines and techniques. Beginning with the understanding of the business, introducing a prudent governance program, adopting a reference model to evaluate the flow of data, then using a means to assess the damage or trustworthiness of data, and the use of appropriate designs whereby each contributes to helping maintain the health of data where everything (the entire services solution) works harmoniously together.