
4. Assessing the Damage
Symbolically and culturally, the American flag, the Stars and Stripes, remains a significant part of many lives. Most Americans, when asked who created their first flag, would probably answer “Betsy Ross” (1752–1836).1 In 1870, her grandson George Canby (1829–1907) documented and popularized that mistaken idea: “Who, when she was the widow of John Ross, made the first American Flag containing stars.”2
1. Based on an informal poll of 47 colleagues and their families.
In all likelihood, however, Francis Hopkinson (1737–1791) designed the first American flag. (Hopkinson was also an artist and signatory of the Declaration of Independence.) The first Stars and Stripes was probably made in 1777 during the American Revolutionary War by the defenders of Fort Schuyler in Rome, New York. In addition, the flag appears to have been significantly influenced by George Washington’s (1732–1799) family’s English coat of arms, which includes five-pointed stars set above red and white stripes.
“The only documented evidence that Betsy Ross ever made a flag of any kind is found in the minutes of the Pennsylvania State Navy Board. It shows a payment to Elizabeth Ross for making ‘ship’s colors.’”3
Historical revisionism and historiography are means to reevaluate and rectify misstated facts about the past. When assessing data used in a service-oriented application, there is often a need to reestablish what is considered historical truth. Services leave behind forensic evidence in terms of business data that can be assessed in an attempt to obtain a sense of what happened here.
However, business data can be misinterpreted, and the facts concerning what happened here could have been incorrectly communicated. For example, an order associated with a customer at one address may get shipped to alternative location because of an undetected heap overflow problem during a service innovation. Business data can also be interpreted to provide a sense of what is happening as well as what might happen, thus covering a spectrum of historical, current, and future events.4
4. The concept of now (current) was also covered in Chapter 2, “Data Governance.”
As another example, a service captures and persists the following Social Security Number: 111-11-1111. Many people may instantly regard this particular Social Security Number as invalid data. However, a user community within an organization may decide to use this particular numeric sequence to convey additional information that cannot readily be captured in the presentation layer or originating message. In this case, 111-11-1111 might be used to identify a child who has not yet been assigned a number.5
5. Based on a real-world service-oriented solution that handles public data for a government-run agency, where numerous invalid Social Security Numbers are used to communicate different facts.
In the United States, a Social Security Number is a method by which individuals can be softly tagged through the issuance of a unique national identification number. The number is assigned by the federal government to applicants who meet certain criteria (for both citizens and noncitizens). Other countries around the world use a similar concept; in Canada, the concept of tagging individuals is called a Social Insurance Number, and in Brazil, tagging is known as cadastro de pessoas físicas.
The government agency responsible for issuing Social Security Numbers in the United States is the Social Security Administration (SSA). “A Social Security Number (SSN) is a nine digit number SSA assigns to individuals to identify their records of earnings in employment or self-employment covered by Social Security and to pay benefits.”6
In the sample situation of a Social Security Number containing the digits 111-11-1111, the definition just given would not substantiate whether the numbers are erroneous in any manner. Without possessing too much knowledge about an underlying application, the historical record could indicate potentially invalid data. In the context that 111-11-1111 contains an embedded business meaning, the potential to discover multiple records with the same value is quite likely. As such, the frequency of how often the value occurs is counter to the ability to singularly “identify their records of earnings in employment....”
Revisionism would be able to go beyond the definition and the data value and uncover the intended context for which the number was supplied. Using root-cause analysis, the definition may be found to be insufficient and potentially contribute to the loss of meaning within an organization.
For many business attributes, much more can be discovered about a business concept beyond the cursory (single-sentence) definitions that are all too often associated with a business attribute. For example, a Social Security Number is a composite identifier. The nine-digit number comprises three parts: The first three digits represent an area number, the second two digits represent a group number, and the last four digits are called the serial number.7
The form of the Social Security Number is traditionally represented using the pattern 999-99-9999, where dashes are used to surround the group number. However, keep in mind that from the viewpoint of a service the dashes, although useful in the presentation layer, are (in this case) completely unnecessary in the process and persistence layers. The dashes constitute a visual to aid reading, and as a general practice, the dashes, or any presentation feature, should not be persisted.
The initial three digits of the Social Security Number are based on the zip (postal) code specified on the applicant’s form. Initially, the United States was divided into 579 areas, with each state assigned a set of area numbers based on expected demand. Currently, area numbers go up to 647—with the exception of the numbers 000 and 588, which have yet to be assigned.8 A practice of assigning railroad workers numbers between 700 through 728 was abandoned in 1963.
8. In a business setting, exceptions are just additional business rules.
Due to the increased mobility of the population, the area number has less meaning in today’s business world. The group number has no special significance except to break the numbers into convenient blocks. Group numbers are not sequentially allocated, but do follow a predefined provisioning scheme. The last four-digit group, the serial number, is assigned sequentially within each group. No group contains only zeroes.
Whereas most businesses use and refer to a Social Security Number as an atomic identifier, due to the three discrete components the number is still a composite identifier. However, unless an organization has a need (real or foreseeable) to decompose and interrogate the constituent parts of a concept, such as an identifier like the U.S. Social Security Number, using the concept as an atomic concept is an acceptable practice (especially if additional metadata is available to support any decomposition needs should they arise). Chapter 5, “Data Conditioning,” discusses the use of metadata to support decomposition.
For numerous applications, a Social Security Number may represent one of many types of identifiers that need to be associated with a particular individual. For example, a driver’s license number, an employee number, birth certificate number, and a passport number are several other types of identifiers that an organization may want to capture and associate with an individual. When this happens, the use of a generalized or abstract construct may be better suited to handling the identifiers in the process and persistence layers.
At least one additional element or field is typically required to further describe the abstract concept when using a generalized or abstract construct. In this way, the abstract manifests into a concrete concept. Ultimately, the basis of an abstraction is likely to be based on a real form. As Pablo Picasso (1881–1973) once observed, “There is no abstract art. You must always start with something. Afterward you can remove all traces of reality.”
Knowing how to design an abstract concept has corollaries with how Picasso approached his work in the artistic style known as cubism. In cubism, Picasso analyzed objects in terms of their shapes, and then broke them up and reassembled them (often in some befuddled manner). Deciding on an approach to model an abstract (or even composite) concept can initially lead others to look on in a befuddled manner. Although leveraging design techniques that involve abstractions can enable ready reaction to a new requirement, ill-defined abstracts can serve as a point of confusion.
In his paper Western Reminiscences, Henry Smith recalled a personal encounter with President Abraham Lincoln (1809–1865). Smith wrote, “In the midst of the discussion he [President Lincoln] turned suddenly to one of the visitors and said, ‘Peter, if you call a sheep’s tail a leg how many legs will a sheep have?’ ‘Five, of course,’ said the other. ‘Well Peter that might be true, but unfortunately calling a sheep’s tail a leg does not make it a leg.”9
9. Smith’s paper is included in the 1879 edition of The Worcester Society of Antiquity. See Jillson (1880).
In a service-oriented setting, a similar question might be phrased, “What do you call a Social Security Number with nine digits?” In a reversal of the Smith story, the Social Security Number might well be used to represent some fact other than a Social Security Number. When you have a Social Security Number such as 111-11-1111 used in conjunction with a predefined meaning, the outcome, as in this case, is not a (valid) Social Security Number. This type of scenario is often referred to as blind overloading.
Overloading, when unqualified, is the general awareness of using an element for multiple purposes, whereas the qualified term blind overloading is the undocumented use of an element for multiple purposes. Assessing a situation for overloaded elements (elements with more than one business intent) is a primary activity that needs to be carried out when assessing data for any damage that may be the result from acting on the information.
In assessing the Social Security Administration’s definition of a Social Security Number or a more tradition business definition such as “The U.S. government Social Security Number assigned to a PERSON,” both are typical in their brevity and tend to serve as a gist rather than a definition. Ideally, discovering that an element is overloaded should start with the definition, not with a visual observation.
An Extensible Markup Language (XML) document and an accompanying Document Type Definition (DTD) may also be insufficient to indicate whether any overloading is in play (see Figure 4-1). The XML document includes an element called Employee. Employee consists of five child elements. Each child element contains text data (a Social Security Number, a first name, and so on). The accompanying DTD is used to help validate the document.
Figure 4-1 Sample XML document and DTD referencing a Social Security Number.

Having a reasonable definition is an important part of combating viral data. Certainly, a definition should serve to clarify the boundaries of a concept in terms of what the concept represents, and in situations where the potential for ambiguity exists, what the concept is not. Potentially, the definition should contain sufficient information to allow a value to be tested for membership.
A weak definition is not necessarily a bad definition. An important factor in deciding on an appropriate amount of detail in a definition is the intended audience of that definition. Targeting a definition toward a defined audience helps establish the degree of background knowledge an individual is expected to hold. In this way, the degree of precision elucidated by a formal definition can vary, and the reason for the variance can be predicated upon the intended audience.
Any potential definition should consider including these qualities:
• A specification of genus and differentia
• A depiction of scope that is neither too broad nor too narrow
• Essential attributes of the concept’s referents
• Is absent of any circular references
• Avoids the use of negative terminology
• Uses language that aids clarity
• Provides explicit examples
In reality, the genus and differentia can normally be used implicitly in a formal definition because they are often deducible from a schema or model. The genus denotes a kind or a type, and the differentia identifies a particular characteristic of the genus. The genus and differentia are often documented in the following style: genus verb-phrase differentia.
For example, the model in Figure 4-2, depicts that an individual isa (is a type of) party where party is the genus, isa represents the verb phrase, and individual is the differentia. Likewise, an individual hasa (has a) name and a party plays a role. The inverse would be stated as a name belongs to an individual, and a role is played by a party.
Figure 4-2 Genus and differentia in a model.
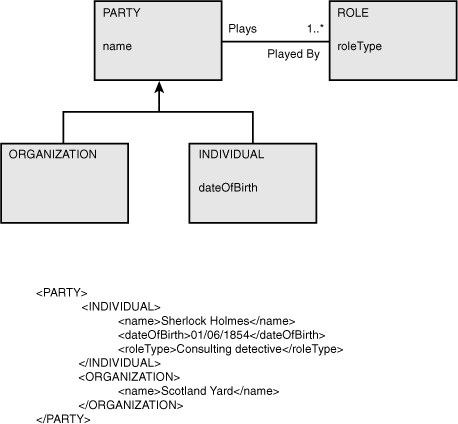
Isa and hasa are commonly used relationship terms that denote either a specialization (isa) or a belonging (hasa). The explicit use of isa and hasa are not recommended for use in a formal business-centric definition because they have limited business value as a verb phrase.
Typically, cardinalities and optionality are not expressed in the genus and differentia because these connote a (business) rule and are therefore associated with the specificity of any applicable rules that act on the field being defined. In the absence of a model, such as in a business glossary, the need to make the genus and differentia explicit may be necessary.
The scope of a definition should be neither too broad nor too narrow. For example, if the definition for a party affirms “represents all participants that may have contact with the company,” the definition may be regarded as too general in the sense that this could include direct and indirect participants. For instance, if the company sold cardigans and one was given as a gift, the recipient would be an indirect consumer.10 If an alternative definition for the party specifies “represents all participants that purchase consumer products,” the definition in this case omits any speculative or potential customers who may be being solicited by a marketing department.
10. This type of indirection is prevalent in the automobile industry when the automobile manufacturer sells the vehicle to a distributor and the distributor in turn resells the vehicle to the recipient. The automobile manufacturer is normally interested in both the direct customer (the distributor) and the indirect customer (the recipient).
Documenting the essential attributes of a concept is seen to add clarity, remove ambiguity, and account for any temporal variations. For example, a general definition of gender may specify “the code or shorthand representation (M, F) used by people to identify this GENDER.” The definition represents a general notion that a person is either male or female and maintains that gender throughout his or her life. However, an organization may need to use gender as a physical characteristic or a personal preference (either of which can change over the course of time). Knowing the context or the essential attributes for what the concept connotes can speak to its clarity.
The reason workarounds can often be found in a service is that rules and behaviors are vague or thought to contain a well-understood intent. The following is an example of individuals following the letter of the law to circumvent the law. In 2008, the Nebraska State Legislature passed a safe-haven bill for babies known as LEGISLATIVE BILL 157. The entire bill reads as follows:
Without the specificity of the essential attribute, in this case, the clarity of what is meant by a child, the state found itself saturated with parents legally abandoning their not-so-young babies. Some parents even crossed state lines just to leave their unwanted children with Nebraska hospitals. Some of these children were as old as seventeen (17).12
Nebraska’s part-time State Legislature was brought back for an emergency session and passed into law Legislative Bill 1 on November 21, 2008. The revised bill reads:
The use of essential attributes should help curtail definitions that just reference the term being defined. A definition that is defined by the term is said to be a circular definition. For example, if an element is labeled AccountNumber, a circular reference would read “the number of the account.” Traditionally, an account number is used as a means to consolidate or associate various types of business activities to a given individual or organization (a party).
Some terms or phrases are inherently negative, but for purposes of clarity, the use of negative terms should be minimized. The word prospect is negative in that a prospect is not yet a customer. Unapproved credit can be a phrase associated with a transaction that failed to be authorized. Null is unknown or unknowable. In some situations, a suffix or prefix can provide a linguistic clue as to a word’s negative connotation (e.g., immutable, paperless, atypical).
When defining terms, positive language should be sought before introducing any negative phrasing. Especially in the English language, positive phrasing is viewed as being easier to follow. “Readers understand passages that are positively worded more quickly and accurately then they do those that are negatively worded.”14
A definition such as “free text describing this FACILITY” may be construed as vague for an element labeled Description. Should the data value associated with the element contain a single word BIG, the vagueness and obscurity of the data value is supported by the definition such that the value BIG passes a test for membership.
In defining a concept, the first step is to establish the genus and the differentia that provide the basis for establishing the essential attributes of the referents and that distinguish them from other essential attributes. In addition, the definition should be checked by seeking counterexamples and by making sure that the definition is not circular, negative, or unclear.
Other definitional elements can include examples, concrete examples of an abstract concept, rules, use status, ownership, accepted abbreviations, synonyms, homonyms, antonyms, short and long descriptions, informal and formal descriptions, descriptions based on the intended audience, temporal variation, and a change history. In all cases, a single-sentence definition is likely to be the easiest and quickest to create and the least valuable.
The need to support definitions in multiple languages, dialects, or with regional variations may be necessary. Language translations are not always perfect, and sometimes words or phrases can be easily mistranslated. As such, a given language may not always have an appropriate counterpart or a means to express a particular nuance in a different language.
In late 2007, the council for the City and County of Swansea, or in Welsh Dinas a Sir Abertawe, erected a street sign near a supermarket at the crossroads of Clase Road and Pant-y-Blawd Road. With an arrow pointing left, the bilingual sign read: “No entry for heavy goods vehicles. Residential site only ------ Nid wyf yn y swyddfa ar hyn o bryd. Anfonwch unrhyw waith i’w gyfieithu.”
The translation following the English reads, “I am not in the office at the moment. Send any work to be translated.”15 Further translating from British-English to American-English, the last sentence reads, “Mail [to me] any work [that needs] to be translated.” The request for translation had been sent via email, and the sender believed the out-of-office reply was the solicited translation. The blunder remained in public view for nearly a year.
Because the audience is a vital consideration in the creation of a definition, the necessity to establish multiple definitions may be present. As such, a single definition may not satisfy all communities and may require specific details or contexts (see Figure 4-3):
• Programmer: Who designs a service
• Database administrator: Who designs a physical schema
• Data administrator: Who designs a logical schema
• Knowledge worker: Who interacts with the data
Figure 4-3 Definitions for a Social Security Number based on different types of audience.
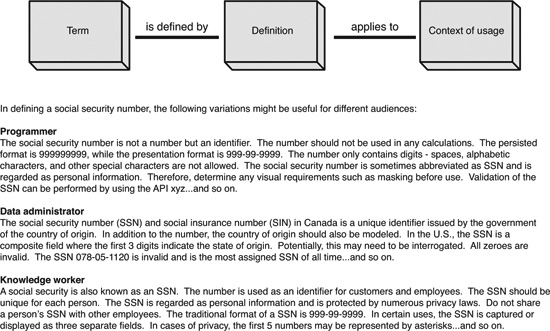
Furthermore, depending on the business unit and type of knowledge worker, multiple definitions may be needed to support the business-oriented person. For instance, the definition to accompany an element appearing on a business intelligence report may need to be fundamentally different from a definition used to assist the person capturing and entering the information.
In rationalizing or interpreting definitional meaning and in the discrete evaluation of the underlying data, multiple modes of reasoning may be employed. The following types are different forms of reasoning, all of which are applicable in assessing definitions as well as schemas and business data values:
• Logical inference
• Consistency-based reasoning
• Probabilistic reasoning
• Case-based reasoning
• Imprecise reasoning
• Nonmonotonic reasoning
• Parametric reasoning
• Semantic reasoning
• Reasoning through classification
• Reasoning through specialization
• Reasoning through generalization
Abduction, induction, and deduction are all forms of logical inference. If assessing data values for gender, the following examples can be used as a summary of all uniquely observed values:

If an analyst looking at this data surmises that regardless of capitalization and abbreviation M, F, m, MALE, and Female represent two gender types, that person is making use of deductive reasoning. In this case, M and m are abbreviations of male, and F is an abbreviation of female. Thus, a deductive statement could read: The masculine gender is represented as M, m, or Male, while F and Female represent the feminine gender.
Reasoning by the method of abduction could lead an analyst to connote that zero and one are alternative representations of the two gender forms: male and female. However, which applies to which cannot be assumed at the moment. A statement of abduction could read: The numbers zero and one are representative of the types of gender attributable to a person.
Using just the list of observed values and barring other possible gender types such as hermaphrodite, protandry, and protogyny, induction permits an inference that only two types of genders are present. The presumption that a person is associated with one of two types of gender is an inductive statement.
If in the list of gender types the zeroes and ones account for less than one percent of all nonunique genders, consistency-based reasoning could be used to derive a conclusion that the presence of the values zero and one account for some form of a data entry anomaly or that the values may not in fact be corollaries of male and female.
Subsequently, probabilistic reasoning could be used to draw conclusions about other data series that are found to use zeroes and ones to establish types of gender. In this regard, if after a series of observations the percentages continue to show that genders with a zero and one account for less than one percent of all nonunique data values, then probabilistically, the next series to be observed could be expected to contain a similar distribution frequency. If the frequency of the next series is found to be outside of the range of precedence, further investigation may be required to better understand the pattern.
In many cases, elements or fields must be assessed with other elements to ascertain a form of business context. If a person’s name is analyzed in combination with the person’s gender, and every time a person’s last name is missing the gender is either a zero or one, case-based reasoning can be used to deduce a potential problem based on previous problems. Case-based reasoning is a prominent kind of reasoning through an analogy or axiom.
Case-based reasoning differs from heuristic reasoning in that heuristic reasoning is typically predicated on a previously formed maxim or rule of thumb. For example, Figures 3-10 through 3-16 from Chapter 3, “Reference Model,” each showed a different way to denote active and inactive data. The discovery that the use of an asterisk in Figure 3-14 denotes inactive data could be drawn from the fact that each of the other worksheets uses techniques to distinguish between active and inactive data.
As a rule of thumb, the heuristic that all worksheets contain active and inactive data can be used to explore which type of method was used to distinguish between active and inactive data in Figure 3-14. Heuristic reasoning is also a form of plausible reasoning. Although heuristic reasoning is potentially subjective in nature, it is distinguishable from imprecise reasoning, which includes all forms of fuzzy and rough reasoning.
Imprecise reasoning may be overly influenced by opinion, feelings, candid judgment, conjecture, cost, and so on. Imprecise reasoning often draws from past experiences to conclude results in terms of c![]() ter
ter![]() s p
s p![]() ribus. The Latin phrase is commonly translated as “all other things being equal.” Rather than objectively derived, conclusions are often subjective in nature. Imprecise reasoning may be used as the rationale to not bother conducting certain observations, preferring to assume their results.
ribus. The Latin phrase is commonly translated as “all other things being equal.” Rather than objectively derived, conclusions are often subjective in nature. Imprecise reasoning may be used as the rationale to not bother conducting certain observations, preferring to assume their results.
As an extension of imprecise reasoning, nonmonotonic reasoning is also a form of reasoning based on incomplete information. In nonmonotonic reasoning, the addition of more information may alter previously drawn inferences. The U.S. legal reasoning of presumed innocence is a form of nonmonotonic reasoning; the burden is to prove guilt, not innocence. Under nonmonotonic reasoning, a data store described as a single version of the truth will probably be presumed a de facto data store from which to acquire data until unreliability or other forms of business risk become evident.
Parametric reasoning limits or narrows data that is to be reasoned. One example of parametric reasoning through exclusion is the division of data into active and inactive data the worksheets—either the exclusion of the active data from the inactive data or vice versa. Narrowing data may actually expand the physical amount of data that needs to be examined. Narrowing may focus on certain data characteristics but require joins or unions to prepare the sample series to be assessed.
Truth tables are often used to assist with semantic reasoning. Truth tables are used to help cast truth, validity, or consistency across data values. For example, if a customer’s address has been verified as a deliverable mailing address by a third-party service, and if the customer has engaged in commerce within the past 30 days, a truth table can be used to assert that any marketing literature sent to this customer is likely to reach the customer and not be returned to the company as undeliverable. An inverse situation can greatly assist in detecting potential data anomalies.
Reasoning through classification typically leverages pattern matching, similarity, or distance analysis to reach a conclusion. In such a scenario, if multiple systems each perform a return on investment calculation,16 the results shown in Figure 4-4 might be obtained.
16. The calculation for return on investment (ROI) is as follows:
ROI = (Gain from investment – Cost of investment) / Cost of investment.
Figure 4-4 Disparate results from a common calculation.
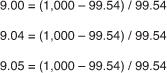
Disparate results from the same calculation can occur because of variances in either the hardware or software services being used. The answer going 15 places to the right of the decimal point is 9.046212577858147, and illustrates that the answers are subject to various degrees of rounding or truncation.
In reasoning through generalization, an analyst can reason by extrapolating a generality from a set of specifics. For example, the address 239 Arch Street Philadelphia, PA 19106-1915 and the geocode 39.952073, −75.144423 are two types of specific facts, but they both indicate the same location: Betsy Ross’ house. Likewise, a single analysis task to verify or validate a location can be carried out regardless of the persistence or message style.
The converse of generalization is specialization. Specialization reasoning interpolates specifics from a generality. For example, the cultural aspects of an individual’s name can seemingly vary. In lieu of a last name, some cultures specify a clan name. Others specify a paternal name followed by a maternal name, or a maternal name followed by a paternal name; other cultures use a tribal name, and so on. Variances can be numerous, but through typing (establishing the genus), the number of variations can be limited. Any cultural name can ultimately be assessed using a first name, a middle name, and a family name (see Figures 4-5 through 4-7).
Figure 4-5 Specializing cultural names when maintained in English, rules to establish the syntax for the last name.

Figure 4-6 Specializing cultural names when maintained in English, sample styles for last names.

Figure 4-7 Specializing cultural names when maintained in English, common name styles.

Decomposing a person’s name into the primary constituent parts of first name, middle name, and family name17 should be modeled in the process and persistence layers so as to remain independent from any ordering needs in the presentation layer. When capturing or deducing a common name style, the presentation sequence can be inferred and subsequently amended, if necessary, without having to change the constituent values in any underlying parts.
17. Any constituent part from the whole name may be absent of any value, contain initials, consist of a single word or multiple words, or be a mixture of words and initials. In the case of a constituent part containing multiple words, words may be separated by a space or connected by a hyphen. From the perspective of the English language, some names do not contain any vowels, such as the Vietnamese names Ng and Png.
The name Sol L Sedarsky has the following constituent parts: The first name is Sol; the middle name is L; the last name is Sedarsky. In this particular situation, Sol is not an abbreviation for Solomon. Sol is Sol. Regarding the middle name L, L is not an initial. Sol’s middle name is just the letter L. Former U.S. President Harry S. Truman (1884–1972) also had a middle name that was not an initial. Therefore, a period should not follow the middle name in its presentation. Therefore, Sol L. Sedarsky would be an incorrect instantiation.
A person’s name is a concept that is both ubiquitous and subject to regional variations. In addition, a name can be used in multiple contexts, which might affect what parts should or could be communicated. An organization reporting an employee’s tax contributions might report the name by using the family name and just the first letter (or initial) of the first name (in that sequence). The same organization mailing a solicitation might choose to use just a title and a family name.18
18. One particular U.S.-based health-care company writes all of their service coverage checks to doctors using the following format: title, initial of the first name, and family name. However, when a check is made payable to a doctor in Malaysia, the check has to be manually pulled from the print line before the check is inserted into an envelope. Then, an employee looks up the doctor’s full name in the physician database, and then manually corrects the payee name using a manual typewriter.
In Malaysia, a bank may refuse to accept a check or other financial instrument on which the payee’s name is not identical with that of the customer. Therefore, the use of just an initial for the first name can be problematic (for the recipient of the check). Viral data may show up in any of the architecture layers: presentation, process, and persistence.
The name Sra. Sara Laurita de los Rios vda de Costa Feliz can be decomposed as follows:

Sara’s name is probably Hispanic in origin. The semantic that her name may be Hispanic is ascertained by comparing her whole name against other cultural name profiles. For example, many of the following regional cultures bear distinguishing features (words, sequences, word frequencies, abbreviations, titles, prefixes, suffixes, spelling variants, gender associations, and indications of life events) that when viewed holistically can be classified with varying degrees of confidence: Afghani, Arabic, Chinese, French, German, Hispanic, Farsi, Anglo, Indian, Indonesian, Japanese, Judaic, Korean, Pakistani, Russian, Thai, Yoruba, and Vietnamese.
The abbreviation used in Sara’s title indicates that she is married. Sra is an abbreviation for señora, whereas the abbreviation Srta is an abbreviation for señorita (an unmarried woman). De los and vda de are both prefixes. Vda is an abbreviation for viuda and means widow. As a Hispanic name, Rios represents her paternal father’s family, and Costa Feliz her husband’s paternal father’s name.
A person’s name can be modeled in many different ways. For example, a single element, PersonName, could be used to capture an entire name verbatim (regardless of sequence, format, abbreviation use, or consistency). A more elaborate technique could take the form shown in Figure 4-8.
Figure 4-8 A flexible model for managing a person’s name.
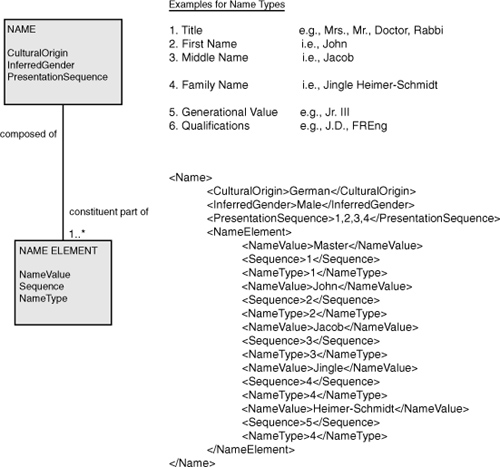
In Figure 4-8, the presentation sequence 1,2,3,4 is used to infer that the title (name type 1) should precede the first name (name type 2), the first name should precede the middle name (name type 3), and the middle name should precede the family name (name type 4). Because the family name contains two names, Jingle and Heimer-Schmidt, the sequence is used to order names within a name type.
A model in between an all-encompassing single element and the one shown in Figure 4-8 is the model shown in Figure 4-9. Here, all the name elements are clustered. If representing the model in a logical data model using this technique, the data modeler may proclaim that the entity named PERSON adheres to third-normal form (3NF). This is not the case and may potentially propagate into a viral data problem.
Figure 4-9 Alternative model for a person’s name.

In 3NF, a relvar R is in third normal form, “if and only if, for every nontrivial FD A → B satisfied by R, A is a superkey or B is a subkey.”19 However, assuming that PersonID represents the superkey (the primary key), some of the functional dependencies (FD) fail the test A → B. Even in Boyce-Codd Normal Form (BCNF) where “every nontrivial FD satisfied by R is implied by some superkey of R; equivalently, if and only if for every nontrivial FD A → B satisfied by R, A is a superkey for R,”20 testing the functional dependency between A and B fails.21
20. Ibid.
21. The same type of normalization misconception applies to the common form of modeling a mailing address. For example, a mailing address is often composed of a street name (including the street number), a city name, a state or province, and a postal code. In accordance with U.S. postal standards, the street name is functionally dependent on the city and the city upon the state. Using both a fully expressed postal code (meaning a nine-digit zip code) in combination with a street number can act as a synonym to the street name (excluding the street number), city name, and state.
Composite elements can also present a normalization anomaly. For example, with regard to a U.S. Social Security Number (which is made up of three parts), the group and serial numbers are functionally dependent upon the area number.
The attributes for origin, gender, and presentation are all functionally dependent on the name (B) and not the key (A). When assessing data and any prevailing data models, determining that each relvar (R) factually contributes toward establishing the intended semantic can be tested.
Assessing data via the use of semantics differs from assessing via the use of a pattern. The previous examples regarding gender used a pattern-sensing approach to determine correctness of the domain. Notwithstanding any encoding or presentation schemes, the domain associated with gender is bounded, especially from a business perspective. Gender can be assessed and validated against the domain to which it belongs. In this way, the assessment is pattern oriented and out of context.
A semantic evaluation would place gender in context of the name and the cultural affinity accompanying the name. For example, the name Ashley is Anglo in origin. In the United Kingdom, when the name is used as a first name, the name is typically associated with males.22 However, in the United States, the same name, with the same spelling, is more likely to be associated with females.23 Knowing the name, the cultural origin of the name, the nationality of the individual, and the gender enables the decision to make a semantic evaluation as to the validity, consistency, and integrity of the whole, in context.
22. Ashley Cole (b. 1980), a male English soccer player.
23. Ashley Olsen (b. 1986), an American actress.
As a pattern, the discussion about assessing a person’s name can be applied to many different business situations. Along with definitions, one of the first starting places to form an approach in performing an assessment is a data model. Figure 4-10 shows a typical-looking data model.
Figure 4-10 Sample data model.
From the onset, the model in Figure 4-10 may serve an organization in one of two ways:
1. As a model that embeds useful information
2. As a model that negates all intrinsic value
A model in this form, regardless of how useful some of the (deeply) embedded information might be, is a visual catastrophe. Figure 4-10 is in all likelihood going to prompt any onlooker to believe there has been some type of a metaphorical maelstrom. A data model, such as this, must be regarded as unusable; rejected and ideally, refactored.24
24. Refactoring is a process by which changes are applied to “make it [the model] easier to understand and cheaper to modify without changing its [the model’s] observable behavior [semantic].” See Fowler (1999).
All too often, data modelers produce their visuals to neatly fit onto one printed page or arrange them (as in the example of Figure 4-10) to minimize the overall amount of white space. Either way, a model’s aesthetic is almost as important as its content because something that is difficult to read will not be harvested and understood (or maintained). If the model represents a design, the layout can be thought of as an architecture. Modelers must capitulate and apply an aesthetic to both the content and the visual. In general, models are easiest to read when laid out in a top/down, left/right manner.
A model, a DTD, a style sheet, or any another form of documentation represents some structural metadata about the underlying data. The structural metadata may be further classified as business or technical metadata. Figure 4-11 shows part of a data model involving antigens and blood.
Figure 4-11 Portion of a data model for antigens and blood.
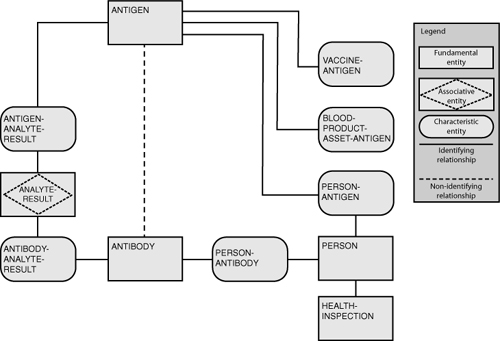
The definition for the entity labeled antibody is given as follows:
The definition for the entity labeled antigen is given as follows:
One of the attributes of the entity labeled antigen is called antigen_code, and its definition is given as follows:
Each definition contains three meta-oriented facts: a reference number,25 a classification code as to the acceptance or candidacy of the entity or attribute,26 and a description in uppercase letters. Each facet of the metadata can be evaluated and assessed for accuracy. In the same way that the typographical errors occurring in the spellings of “A NTIGEN” and “RESPONS E” can be evaluated as to the presence of an embedded space, so each fact can be tested for uniqueness, frequency, value pattern, and overall semantics in relation to any other portion of the data model or to any associated data values.
25. Within the first set of parentheses.
26. Within the second set of parentheses.
Data models should be viewed and presented as stories, scoped by limited views of interest (as though a Yeatsian epiphany). The view should be symbolic and suggestive to aid in the storytelling and associated with a deliberate message that needs to be communicated. Each suggestive message should illuminate some physical aspect or nature of the business. The use of color, legends, descriptive annotations, bespoke stereotypes, and placement can help convey a message in the same way that the consistent use of color and indentation aids the programmer who operates in a language-aware editor.
While models and the definitions contained therein contribute in the specificity for creating and manipulating data as well as in building a glossary of terms (or a controlled vocabulary). The models, the terms, and the definitions can be used for business rule development, the creation of guidance policies, and in the interpretation of regulations. Collectively, rules, policies, etc. can be used to form a specification. A specification is just one dimension associated with data. Other dimensions can also be used to help quantify or qualify the extent of viral data.
Figure 4-12 illustrates an example of viral data experienced by a grocery store chain. The chain had accumulated its customer data from a loyalty program that required the customer to provide certain demographic information. Over time, the data decayed and became erroneous. The chain gave up an attempt to remediate the quality of the data, believing the effort to be futile. Management then made a decision to abandon every customer record associated with the existing loyalty program and to start fresh with a new program.
Figure 4-12 Sample data model.
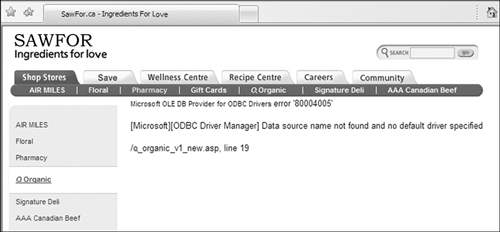
In Figure 4-13, a web-service travel application calculates a flight plan involving a change of airplane in Berlin, Germany. The displayed flight plan is flawed because the connecting flight is invalid. Here, viral data is directly associated with the cast business rules, resulting in a missed connection. Figure 4-14 shows another missed connection, but this time to a database.
Figure 4-13 Nonconnecting flight.
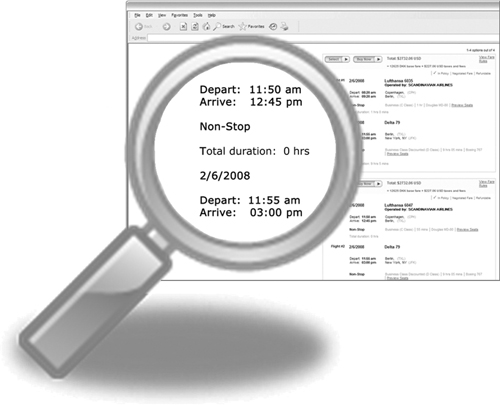
Figure 4-14 Nonconnecting database.
Viral data can navigate through an orchestrated flow of services in multiple ways. Fat fingering27 by a knowledge worker is one of the easiest methods. In December 2005, Japan’s government reprimanded the Tokyo Stock Exchange and one of the biggest brokerage firms in the country after a fat-fingered typing error by an employee of Mizuho Securities caused the company to lose more than 40 billion yen on a stock trade. The ripple effect from the error caused the Nikkei index to drop significantly and forced the president of the Tokyo Stock Exchange to resign.
27. Fat fingering is caused when the fingers of a keyboard user “hit more that one key at a time.” See Peckham (2007).
The trouble started when Mizuho sold 610,000 shares at the price of one yen. Mizuho had actually intended to sell one share at 610,000 yen. The error represented a sales order that was 41 times larger than the number of outstanding shares.28
Although Mizuho attempted to cancel the order, the stock exchange has a policy not to cancel transactions even when they are executed in error. However, a reasonable set of business rules executing during data entry process could have prevented the situation from occurring. Mizhho’s parent company backed the security arm’s losses from the erroneous trade, but the devastation left an awful lot of red faces and red ink.
Other data entries can result in the misalignment of (meta) data (see Figure 4-15).
Figure 4-15 Connecting product metadata.
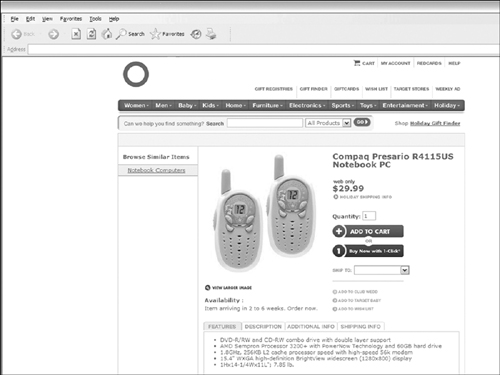
In Figure 4-15, the description associated with a laptop computer is matched to a child’s walkie-talkie toy. In an attempt to uncover which parts of the webpage were in error (the product graphic, the product price, or the product description), the product was classified under: Electronics / Home Office / Computers + Accessories / Notebook Computers. As such, the problem was traceable to the metadata associated with the product graphic and price. When this metadata mistake occurred, the company sold out of their available stock within one hour.
Upon inquiring to the company via an email as to which particular product would be shipped—the laptop or the walkie-talkies—the company retorted, “To avoid the inconvenience I’ve cancelled your order as you requested... Please let us know if this e-mail resolved your question... Best regards, Abhijeet.”29 As if to add a final exclamation point, the email’s footnote read, “Please note: this e-mail was sent from an address that cannot accept incoming e-mail.”
29. Personal correspondence.
In certain situations, misaligned values can be caused by the attachment of a default value. However, circumstances can arise where the defaulted value is not immediately recognized as a default value in a traditional sense of programming; where in the absence of an explicit value, a substitute value is assigned.
For example, a default value may be represented by the first item in a drop-down list. Often, the first item can be the easiest one for a knowledge worker to select when that worker is not too picky about choosing an appropriate selection. Another means by which a default value is repetitively chosen is from a particular entry in a vector, especially if the service does not process the vector as intended. The last record in a block that shares a common key can also be the source of a default value. In all cases, the default value is a side effect attributable to either laziness, confusion, or the misapplication of an intended business rule.
In association with a data governance initiative, accurately determining ownership of each concept can prove useful as part of the assessment process. Commonly, all data is thought to be owned by someone in the organization. Semantically, this is far from true. When referring to ownership of the concept, the intent is to identify an owner who can exercise or enforce control.
For instance, any corporation in the United States that reports taxable income to the government has to record the Social Security Number for each employee. In some organizations, the vice-president of human resources might be viewed as the owner of all employee data and ergo the owner of the Social Security Number. However, should the U.S. government exhaust its supply of Social Security Numbers, the government may choose to extend the length of the number or possibly turn the number into an alphanumeric-based value.
A corporation may use Social Security Numbers, but ownership cannot be attributed to anyone in the organization. Ownership has to do with control, and an organization cannot control what the organization does not own. Other items such as mailing addresses, customer names, and blood types are additional examples of elements that may be used by an organization but ones in which the organization cannot exercise complete control.
Attempting to remediate and prevent viral data may be easier to accomplish on data that is truly owned (and controlled) by the organization. Knowing what type of data an organization owns (and therefore controls) versus what type of data the organization uses as a caretaker may help inform an approach to diligently managing and forming trusted information.
After dealing with issues of ownership, a useful next step is to classify each concept or element according to a taxonomy of data classes. In Figure 4-16, the primary types of data classes shown in the taxonomy are QuIT CITeD:

Figure 4-16 Data class taxonomy with primary data classes and sample secondary data classes.
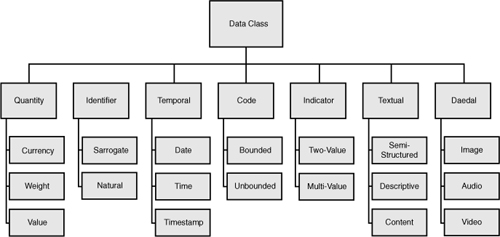
The primary data class types form a basis for establishing or vetting class words associated with an element or column names. In this respect, the class word name (often abbreviated to nm or nme) is a class word typically associated with the data class text. The class word name may be appended to a modify word such as first, last, and course to form examples such as first_nm, lastNme, or CourseName.
An identifier is generally used as a correlation mechanism. Often, the value associated with an identifier is either a surrogate value or a natural value. A surrogate value is a value that is contrived and under normal circumstances is limited to having value only within the boundaries of a single system. Conversely, a natural identifier such as a telephone number has additional utility. Other natural identifiers include account numbers and order numbers.
A quantity is a numeric value that is independent of precision. To qualify as a quantity, the number must have some relevance if used in a mathematical algorithm—whether or not the number is regarded as immutable or represents a constant. An interstate number is an example of a number that would not have any particular relevance in a calculation.
Like quantity data, temporal data can also be involved in calculations. Temporal data can include a point in time or a duration. A person’s age is considered temporal and not a quantity. Points in time are subject to levels of granularity, calendaring systems, and can reflect the past, present, or the future.
By and large, an indicator is Boolean, which denotes that a concept can be on or off, true or false, right or wrong. Additional types of values can be used to illustrate various forms of unknown. In general, an indicator is only used in 2-value or 3-value logic. However, an indicator can be used to record states of being, especially if the states represent a prescribed sequence or a type of life cycle. If the states are independent of a set sequence or a life cycle, the data class code should be used.
A code is a data class for codified data. Codified values can be bounded (immutable) or unbounded (mutable). For example, codes associated with blood groups are bounded because the codification is both finite and known, whereas codification of the periodic table for chemical elements is unbounded because new elements are periodically discovered.
Textual data classes denote elements of freeform values. The freeform text can be somewhat structured, as in a mailing address, a URL, and in some cases, a product description. Content for other forms of freeform text may be unknown until fully investigated. As described in Chapter 3, textual data may be structured, semistructured, and unstructured data.
Images, audio, video, and other complex data types are associated with the daedal data classes. In all cases, daedal data is deemed unstructured data. Especially with these data class types, additional metadata may be necessary to make use of the data in an application. Metadata for an image file may contain, for example, the type of image, when the image was created, where the image was created, and so forth.
Any column or element is likely to exhibit basic traits that can be assessed out of context. Included among these traits are size, precision, format, cardinality, and domain. Collectively, these traits help establish a broad picture for realizing a set of general observations or comparisons. When a structural design involves some type of abstract concept, element coupling may be necessary.
As an example, if a generalized concept called party is used to represent either an organization or a person, of which, one or the other is identified through a codified element, combining (coupling) the codified element with other elements to form a virtualized element or column might assist in the observation process. In this way, a sense of context can be introduced into the process. An alternative approach is to split the assessment effort into two discrete scenarios: one for organization type parties and the other for person type parties.
As mentioned in Chapter 3 (refer back to Figures 3-10 through 3-16), the use of scenarios as part of a scenario-based analysis while establishing a context can be enhanced by placing a story around the contextual preparation of data. Here, a story can be articulated around individuals as living entities, with a separate story for organizations as legal entities.
The trait of size can be evaluated in terms of minimum, maximum, average, and mean lengths. Precision is associated as a type of granularity. A corporation’s annual report might list earnings in terms of millions of dollars and report a number such as 82,000, where eighty-two thousand must be reinterpreted as eighty-two billion. A value such as pi might be given as 3.14 or possibly 3.14159265.
Each of these amounts has a maximum precision by which they can be expressed. Precision is not restricted to numeric-based data. Time-oriented data represents expressions of precision (e.g., Q1 [first quarter], or 2525 [a year, regardless of month, day, or time], or 25 seconds in a time-motion study with no subsecond delineation).
A format can be as simple as alphanumeric or more discrete, such as tinyint, smallint, int, varchar, smalldatetime, blob, XML, or as a specialized user-defined type such as currency. Associated Unicode or page set encoding may also important to note for managing NLS30 or double-byte data. In certain cases, formatting might be expressed via accompanying metadata. For example, the use of dashes in a national identifier or in the placement of spaces, hyphens, or periods in certain national telephone numbers. In these examples, an assessment in context is required.
30. NLS: National Language Support.
When an element is designed to accommodate different business facts, that element, as previously mentioned, represents an abstract concept. An abstract concept designed for an unlimited set of personal identifiers such as a Social Security Number, professional society affiliation identifiers, passport numbers, driver’s license number, and so on may all be associated with different formats.
External metadata can be used to describe a format type for each type of personal identifier. For example, the format for a Social Security Number might be numeric, while the format for a professional society affiliation number might be exclusively alpha based. Metadata can be used to associate each of these format types. Using metadata to dynamically drive values is described in Chapter 5, “Data Conditioning.”
As a basic trait, cardinality is generally limited to account for the uniqueness of values within a single element and not uniqueness in terms of a relationship to other elements. Nulls, empty values, and null collieries31 should be grouped together in a broad assessment and isolated in a contextual assessment.
31. Examples of null collieries include [NULL], n&ull, and ‘’ (conjoined single quotes). [NULL] and n&ull are textual representations to connote a null value, and the conjoined single quotes can be used to imply either a null value or a zero length field. The intended interpretation of conjoined quotes should be discovered during an assessment. Brackets and an embedded ampersand are devices used to distinguish between a null value and the English language word null.
The unique set of data values for a concept combine to form a domain. The unique values represent a superset. When assessing a sample set of data, the domain superset can prove a rapid technique to quantify acceptable values and unacceptable values. Additional use can be to quantify against a range of values or level of tolerance. Qualitatively, values can be assessed in terms of reasonable appearance or consistency.
Figure 4-17 contains sample field names and data that can be viewed in context with one another. The taxonomic data class for the fields SPSPECCD, SSSASPCD, SABBRNME is code; indicator for SHAFFRQI and APCPRLI; and textual for SNARSPTX. Although the class word NME (or name) is used for field SABBRNME and was intended by the designer to be a short name for the longer text description associated in field SNARSPTX, the physical use of the name is as a code.
Figure 4-17 An assessment in context.
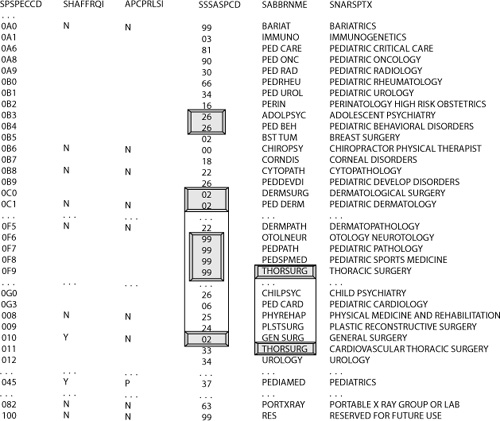
The field SPSPECCD serves as a unique code to identify each individual record. The size of SPSPECCD is consistent—the length is three alphanumeric characters, where the first character is always numeric. Each textual description is unique, and with the exception of “RESERVED FOR FUTURE USE,” each value seems reasonable for active use.
In general, the indicators contain the domain values Y, N, and null—therefore, the indicators participate in 3-value logic. Further investigation would be necessary to determine whether N and null should share the same behavior in a service. If so, each occurrence of null would better be served by an explicit N. The value P associated with APCPRLSI would require further exploration to determine why this value appears. If valid, the use of the P would recast the taxonomic data class for APCPRLSI from indicator to code.
Each occurrence of SABBRNME is unique except for THORSURG (a code for thoracic surgery). Whether THORSURG is erroneous would hopefully be discovered during an assessment process. The codes associated with SSSASPCD provide a general classification.
Code 99 appears to indicate miscellaneous (using abduction logic), and again, the explicit meaning should be gathered as part of an assessment exercise. In all likelihood, further metadata would be necessary to denote each classification type. Code 26 appears to be associated with procedures for minors (adolescent or pediatric). Code 02 appears to be associated with surgeries, but the association with PEDIATRIC DERMATOLOGY would place that assumption in doubt.
The record structure in Figure 4-17 does not explicitly support the means to track historical changes, or explain when a specific type came into existence, or even when a value was last changed and by whom. By culling from the multiple forms of reasoning, a general sense of completeness, conformity, consistency, accuracy, duplicity, integrity, topicality, and timeliness can be formed.
In a transient state, the XML message in Figure 4-18 contains two records. In both cases, the element SABBRNME contains the value PED.
Figure 4-18 An XML message illustrating one style of truncation.

In the XML message shown in Figure 4-19, both occurrences of SABBRNME contain the value PED CAR.
Figure 4-19 An XML message illustrating a second style of truncation.

The actual SBBRNME value associated with element SPSPECCD and value 0A6 is PED CARE, and for value 0G3 is PED CARD. In these examples, each occurrence of SABBRNME is truncated. The first example reveals that the values are truncated based on the presence of space, which was interpreted by the service as a delimiter. In the second example, the values are truncated based on length; in this case, the length appears to have a maximum length of seven characters, whereas the nontruncated values extend up to eight characters.
In addition to an assessment on the actual values, a pattern assessment on the element value can also prove useful. For example, all SPSPECCDs follow one of these patterns:
• Number-alpha-number
• Number-alpha-alpha
• Number-number-number
• Number-number-alpha
SHAFFRQIs follow these patterns:
• Alpha
• Null
SABBRNME follow these patterns:
• String
• String-space-string
SNARSPTX follows these patterns:
• String
• String-space-string
• String-space-string-space-string
• String-space-string-space-string-space-string
• String-space-string-space-string-space-string-space-string
• String-space-alpha-space-string-space-string-space-string
• String-space-special character-space-string-space-string
• String-space-string-space-special character-space-string-space-string
Codifying each of the patterns for SNARSPTX, they can be simplified and restated as follows:
• Number-alpha-number could become
#a# The hash sign signifies a numeric, and the lowercase A implies a single alphabetic character, or
> The greater than sign is used to imply that a leading numeric is followed by one or more numeric or alphabetic characters.
• String-space-string could become
ss The lowercase S signifies a string, or
? The question mark implies a series of space delimited words.
• String-space-string-space-special character-space-string-space-string could become
?~? Again, the question mark implies a series of space-delimited words, and the tilde represents a special character such as a hash sign or a carat symbol.
Following these codified patterns, all SNARSPTX patterns can be summarized as follows:
• ?
• ?~?
• ?a?
The lowercase A in the pattern ?a? represents a single alphabetic character found in an nonhyphenated word: x ray.
Obviously, each data situation poses its own degree of simplicity or difficulty. The street address 123 St. Angus St. contains the abbreviation St. in two places. In the first occurrence, St. needs to be interpreted as saint, whereas in the second occurrence St. must be interpreted as street. Therefore, placement can be contextual, and a common value may require a different interpretation and assessment based on that context. As previously stated, the name James Joyce can serve as a potential point of confusion. Both James and Joyce serve as commonly used first names and commonly used family names.
Scenarios for assessing data can be composed in terms of assessing data in place or assessing the data in terms of movement that might be needed for interoperability or integration. A scenario can be used to represent a sample of the available or anticipated data population. In general, being able to assess the entire population for each scenario would allow for a complete and comprehensive set of observations.
When a population size is deemed too large, devising a method to create a statistical sample of the data may be necessary. The sample can be the first n records, every nth record, or a random selection of n records—a hybrid approach can be used, too. Casting an additional set of scenarios over the sample can afford an intelligent method to refine the sample size.
Those records not included in a scenario form the outliers, which in turn, can be used as a type of scenario that can be assessed and evaluated. The use of scenarios (stories or analogies and so on) can visually or programmatically simplify the identification of viral data. When viral data is identifiable, an organization is better positioned to control (hold in check) the problem, treat (remediate) the problem, or condition (improve) the problem.