
6. Putting in Place
Charles Ponzi (1882–1949) excelled in human greed and created a scheme of white-collar crime commonly referred to as the Ponzi scheme. “The ingredients of a Ponzi scheme are very simple. You have to get enough people interested in putting money into whatever investment you are promoting by promising them whirlwind profits.”1
Bernard Madoff (b. 1938) once held an honored position as chairman of the NASDAQ stock exchange, but was charged in 2008 with perpetrating the largest investor fraud ever committed by a single individual. Madoff’s chosen device was the Ponzi scheme.2 In contrast, businessman Reinhard Siekaczek (b. 1951) preferred to use bribery to satisfy his greed. Siekaczek managed a subsidiary of Siemens AG until 2004, and during that time he oversaw an annual bribery budget approximating $50 million. He viewed his siphoned payments to government officials as “vital to maintaining the competitiveness of Siemens.”3
Abuse of privilege and trust within the shroud of organized business is why some corporate boards attempt to take the high road and promote transparency. Abuse is why regulatory bodies dictate rules of fair play. In these situations, viral data is not just about data that causes an impact on the business, but poorly conducted business practices that leave their wake in corporate databases.
Disciplines such as forensic accounting “where auditing, accounting, and investigative skills are used to assist in disputes involving financial issues and data”4 and integration forensics where data practices (including uses of data) are reviewed to uncover disruptive or negative behaviors as well as outcomes can often become labor-intensive processes. Such activities can be further aided by data governance and data management practices: from trending data through assessment, to gathering data provenance, to having complete awareness of all redundant data stores—assets of the data architecture.
Anchor and journalist for the U.S. television news channel CNBC, Michelle Caruso-Cabrera (b. 1969) reported on the possible misrepresentations by corporate leaders just weeks before their financial companies failed during the early stages of the 2008 financial crisis. Caruso-Cabrera postulated that we may never know whether “these people believed what they were saying at the time was true; whether they were bending the truth; or whether they were succumbing to the inbred inclination of executive leaders to always put a positive spin on things.”5
Caruso-Cabrera’s segment aired interview quotes from former executives, including the following:
• Alan Schwartz (b. 1950), a former chief executive of Bear Stearns: “The markets have certainly gotten worse, but our liquidity position has not changed at all; our balance sheet has not weakened at all.”
• Erin Callan (b. 1966), a former chief financial officer of Lehman Brothers: “I think that we are in a great spot now with this capital behind us; with wind in our sails.”
• Daniel Mudd (b. 1956), a former president and chief executive of Fannie Mae: “This is a good market, it’s a sold company, the business that we are putting on is terrific.”
A data governance charter must complement a corporate culture to avoid duplicity and promote sufficient openness such that complex data scenarios can be investigated in terms of data values and corporate behaviors discoverable through the data. In this way, integrating risk management into the fabric of information technology can be more tightly coupled.
During his working career, Lemuel Boulware (1895–1990) adopted a business approach based on doing the right thing voluntarily: “Try to operate as closely as humanly possible to what was in the balanced-best-interests of all the contributors to and corresponding claimants... and to try equally hard to make them all recognize the fact.”6
For a data governance body, attempting to balance what is in the best interest of all parties may require an additional role of advocate in addition to the traditional role of overseer. An advocate would communicate positive outcomes across the organization regardless of the body’s involvement in the outcome.
Viral data in an organization can be as simple as the misspelling of a name. An urban legend has entertainer Barbra Streisand (b. 1942) closing an investment account because the bank spelled her first name as Barbara on a statement. Viral data could also be a misalignment of facts—resulting in a product with the incorrect price or description (refer back to Figure 4-15).
Viral data can be the result of implicit information that contributes to a misunderstanding. In the case of the Mars Climate Orbiter, the “failure to convert English units to metric units of force”7 caused the spacecraft to burn up in the Martian atmosphere. Carelessness is also a cause of viral data, as in the case of Mizuho Securities discussed in Chapter 4, “Assessing the Damage.”
Simplistically, Basel II8 and Sarbanes-Oxley9 are intended to keep certain accounting or business practices visible. Enron chief financial officer Andrew Fastow (b. 1961) once declared that “we accessed $1.5 billion in capital, but expanded the Enron balance sheet by only $65 million.”10
8. Basel II is the second of the Basel Accords issued by the Basel Committee on Banking Supervision. Basel II contains recommendations on banking laws and regulations.
9. Sarbanes-Oxley is also known as the Public Company Accounting Reform and Investor Protection Act of 2002.
Subsequently, Fastow was sentenced to a prison term for his participation in off-balance-sheet business practices. Data hiding is also a viral form of data. Even the complex weave of financial derivatives that obfuscated layers of debt associated with the downfall of many financial institutions can be attributed to or result in viral data.
When addressing viruses that affect human beings, medical professionals often take different approaches depending on the specific strain of virus: from inoculations to suppression treatments to cocktail therapies to eradication programs.11 Metaphorically, there is more than one type of data virus, such that each type of virus may need a separate type of treatment.
11. For example, “In May of 1959, the 12th World Health Assembly adopted the goal of global eradication of smallpox... WHO certified the world free of smallpox on December 9, 1979.” See Mercer (2007).
A series of typographical errors is understandably easier to identify and remediate than uncovering a series of deceitful business practices. With the appropriate type of data provenance, data governance, and approach to assessing and designing data stores, many viral data problems can be prevented or mitigated in a timely manner.
The purpose of controlling viral data is to avert any negative behaviors that the virus, the poison,12 could otherwise impute. As stated in the Introduction, “Data by itself is inert. Data requires software (or people) for the data to appear alive (or actionable) and cause a positive, neutral, or negative effect.”
12. A Latin translation of the word virus is poison. See Simpson (1977).
A service-oriented solution built upon interoperable, reusable, and discoverable services and paired with consolidated data stores (whether those data stores represent single views, master data, or managed federation) represents an ideal host for viral data:
• Interoperability: Condensed time frames to complete a business transaction13 during which a data-oriented problem is readily propagated from service to service
13. A business transaction may be represented by multiple transactions in an information technology application. For example, a business transaction to satisfy the need of a customer could be further decomposed into finer business transactions such as receiving an order, fulfilling an order, shipping an order. Each business transaction may further require more than one IT-based transactions.
• Shared data: Ease by which any single data anomaly can be simultaneously and ubiquitously distributed
Addressing a problem may involve changing software, where the ability to continually react in a timely and in a cost-effective manner applies to both corrective work as well as to accommodating a new business need. The necessity to react is a positive quality initially postulated in Chapter 1, “Viral Data.”
The ease in which an existing data store or a service can be enhanced to serve a new business purpose benefits the organization. The ability to react can be qualified through independence, flexibility, and adaptability:
• Independence: Free from external influence
• Flexibility: The ease by which a data store or service can be configured
• Adaptability: The ease by which a data store or service can be transformed
Of the three qualities listed, independence is arguably the most desirable. A solution that is independent can accommodate a new or changing situation without the aid of human intervention. Independence is a design trait that is probably the most difficult to realize and the techniques adopted are likely to have access to a knowledge base, a registry of discoverable services, external rule sets, as well as other attributes.
In terms of desirability, flexibility is next. An implemented solution that is flexible is likely to require some level of human interaction, but in the periphery of the service or data store that may need to be modified. The periphery refers to something that can be manipulated without requiring a formal deployment. For example, metadata that serves to configure or reset boundaries or domains, parameter settings, or modifying some type of descriptive business rule.
Last on the desirability list of reactive traits is adaptability. Something that is adaptable is likely to have some part of its form or function manually changed—whether by cloning, revision, or some other technique of transformation. The basis of being reactive is such that a system model (logical or physical) of the service, message, or data store would not have to change. A change to a business model is not viewed as a critical path element to effectuating a change.
How abstract14 or concrete the constituent parts of a service-oriented solution are formed can make a difference as to how reactive the solution is as a whole. Abstraction and concreteness can serve as two ends of a spectrum. Within information technology, abstract concepts generally begin from a concrete concept. Here is a part of the Picasso quotation on abstraction from Chapter 4: “You must always start with something.” In all likelihood, a highly abstract solution may be complicated to understand and may suffer from some performance latencies. On the other hand, something that is unduly concrete may not be readily extensible.
14. Water is often depicted as H2O, a compound containing two parts hydrogen and one part oxygen. Similarly, bits and bytes (streams of information) in a computer are normally shown as strings of 1s and 0s (whether in a transient or persistent state).
In both cases, the Hs, Os, 1s, and 0s are an abstraction representation. Sometimes, abstractions such as these become so common they appear real. Ultimately, implemented abstractions in software do become real. In software, abstraction is a vehicle that can help simplify concepts that are complex, help advance communication, and provide a defensive mechanism to a changing environment. Abstractions can provide a high degree of stabilization.
The life span of a service or data store can often be measured in terms of its cost to maintain. Once a service or overall solution is deemed extremely expensive to sustain in terms of applying changes, the solution is often sunsetted15 or replaced. Abstraction is one method by which a useful life span can be extended. Design choices in a service-oriented solution often play efficiencies in maintenance against efficiencies in performance.
15. In Sangwan (2007), sunsetting refers to a point in time “when [a solution] will no longer be maintained.” Thus, a fixed or loose retirement date is established for the solution, and further enrichment is curtailed.
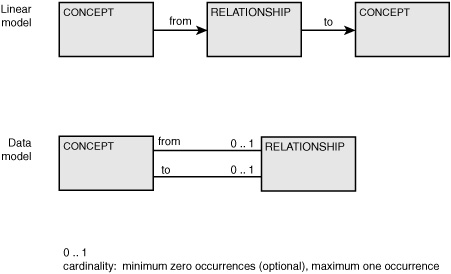
The building blocks of an abstraction are often depicted through the use of metamodel. An abstract metamodel that addresses data can be notated as concept-relationship-concept.16 Here, a concept may have a relationship to some other concept and is a basis for data notations such as entity relationship or XML tree diagramming (see Figure 6-1).
16. In Hay (2006), concept is referred to a THING and relationship as THING RELATIONSHIP. In Chapter 1, this metamodel was also referred to as thing-relationship-thing.
Figure 6-1 Concept-relationship-concept: Shown as a linear model and as a data model.
In addition, message-service-message17 can be used as an abstract metamodel for a service. In this case, the metamodel conveys how a service expects an inbound message to produce an outbound message. Message-service-message has alignment with the flight-path pattern presented in Chapter 3, “Reference Model” as preflight, in-flight, and post flight.
17. In Miller (1967), message-service-message was conveyed as input-process-output.
The underlying form for both of the abstract metamodels is noun-verb-noun. Although more complex structures could have been developed, establishing a fundamental essence that an action is intrinsic as a central and binding agent to enable movement between states is a useful paradigm.
Building on from the data model shown in Figure 6-1, the data model in Figure 6-2 provides an abridged set of attributes. Other attributes that could be figured into the concept table include a sequence number for columns within a table and a default value for columns. As is, the tables can also be used to notate grouping elements, such as a person’s name consisting of a first name, middle name, and last name.
Figure 6-2 Attributed concept-relationship-concept model.
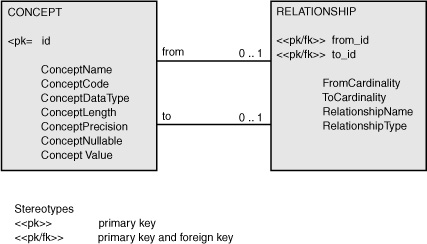
The columns ConceptDataType, ConceptLength, ConceptPrecision, and ConceptNullable are intended to represent some of the properties that could be pertinent about columns or elements (e.g., the data type and length of the element, the maximum degree of precision for decimal data types, and whether the element can contain a null value). Therefore, these properties do not necessarily apply to all types of concepts. For example, a data type is not an applicable property for a database instance.
The column named ConceptCode is used for stating the type of concept being described, such as an instance, a database, a table, and a column. ConceptName represents the name of the concept depicted by ConceptCode. The column ConceptValue contains the persisted value associated with a column or an element.
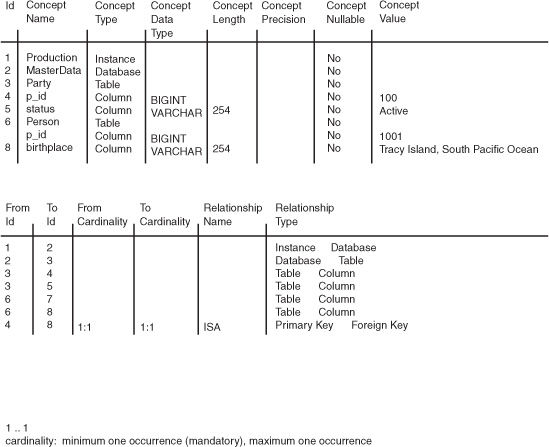
Figure 6-3 shows sample data for the tables concept and relationship. The data exemplifies that more than just the table and column information can be provided. In the sample data, a database instance is the highest level. The instance is named Production and is related to a database called MasterData. The database contains two tables: one named Party and the other named Person. Only two columns are shown from each table, and the tables are related through a column named p_id, an abbreviation for party identifier.
Figure 6-3 Sample concept and relationship data.
Although these two tables could be attributed to accommodate any need, the design may be regarded as too extreme for practical use in most business scenarios. Conversely, exclusive modeling of concrete business concepts should also be regarded as undesirable. Ideally, a blended approach that leans toward abstraction represents an appropriate compromise.
Abstract design patterns are possibly more prevalent for services than they are for data. The party model may potentially be the most widely used abstract design pattern for data. A typical interpretation of the party model in a physical data model is shown in Figure 6-4. The physical model contains three tables: party, person, and organization. A party can be either a person or an organization, but not both. This particular fact is more readily seen in the logical equivalent shown in Figure 6-5, where the semantic but not both is shown as a generalized supertype/subtype relationship.
Figure 6-4 Abstract physical data model.
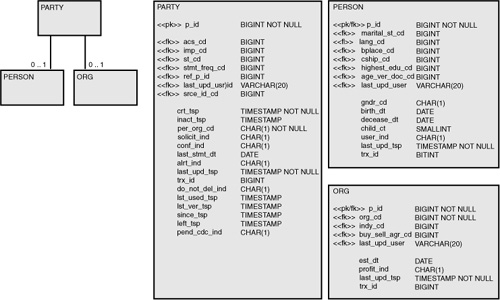
Figure 6-5 Accompanying abstract logical data model.
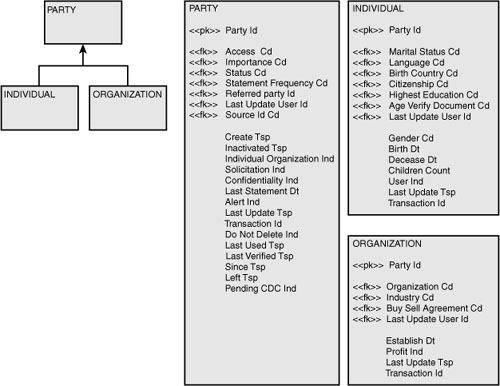
The logical and physical representations illustrate several common design traits that can be improved upon. The first is the high frequency of sameness between the two models. In many respects, the only real difference between the two data models is the adopted naming convention. The logical data model is based on fully spelled words with abbreviated class words.18 The physical data model is based on abbreviating as many words as possible. In addition, the logical entity individual was renamed to the physical table person.
18. A common construct for naming attributes follows this pattern:
• An optional role name
• Prime word, words, or phrase
• Modify word, words, or phrase
• Class word
For example, a column named Mailing_Location_Line_1_Txt might use the word mailing to represent the role name, location to represent the prime word, line 1 to represent two modify words, and txt for the class word.
The column p_o_cd (an abbreviation for person_organization_code) in the table party is paired with the attribute Individual Organization Ind in the entity party. Although the class word was changed, these fields are representative that all too often logical data models are just treated as a first-cut physical data model.
Because the supertype and subtype relationship between the supertype party and the subtypes individual and organization is explicit, the attribute Individual Organization Ind is a derivable fact. In other words, the attribute is redundant. Definitions for the logical attributes in the entity organization are shown in Figure 6-6, and for the entities individual and organization in Figure 6-7.
Figure 6-6 Attribute definitions for the entity party.

Figure 6-7 Attribute definitions for the entities individual and organization.
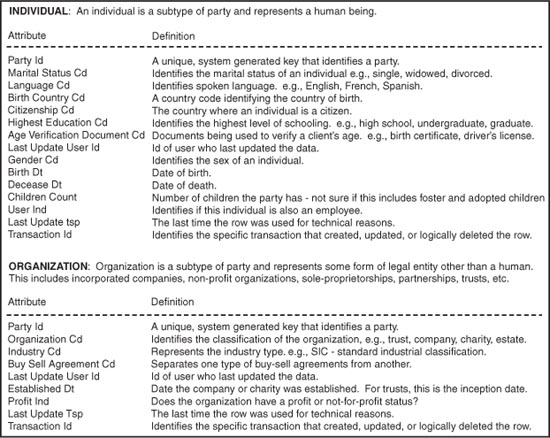
With regard to the definitions in Figures 6-6 and 6-7, several questions can be raised. First, in the entity named party, the definitions for the attributes source id cd and do not delete ind appear to be similar in nature, and any distinguishing nuance appears unclear. The definitions for the attributes solicitation ind and alert ind are written as questions. By and large, definitions should be written as statements and not posed as rhetorical questions.
The entity named individual contains the attribute children count. However, the definition provided contains an actual question addressed to the organization—the definition demonstrates uncertainty. In all three entities, the definition for the attribute party id is articulated in terms of an implementation. Referencing that a value is system generated convolutes the logical and physical paradigm.
Even though the party model is a design abstraction, many of the attributes specified within the model tend to be concrete from the standpoint of the business. Inconsistency in modeling can contribute to potential viral data situations over the course of an implementation.
Following a general method of design, the logical data model and the physical data model are intentionally related, but the sameness undermines why an organization would need to express the data design across two separate model types. After all, any subtle differences concerning denormalization, naming conventions, or indexes could easily be annotated in the physical data model.
In addition to producing a logical data model and a physical data model, some organizations attempt a conceptual data model. However, the conceptual data model can also be misunderstood: “A conceptual data model depicts a high-level, business-oriented view of information.”19 For example, high-level does not connote a model type. All three data models can be produced as a high-level model (or as a mid-level model or low-level model).
Ideally, a conceptual data model should depict the concrete needs of the business. Any abstractions should be business abstractions. In this regard, a health-care company may refer to physicians as a general term that incorporates surgeons, chiropractors, nurses, and ambulance services. Thus, the conceptual data model is, by design, a volatile model. Again, the conceptual data model can be produced at different levels of granularity: high level, mid level, and low level.
The logical data model should represent the ideal implementation model, balancing manageable abstractions with limited concrete business concepts to help address volatility in the business and to support a reactive environment. The ideal implementation model represents a schema that, barring any of the laws of physics, is perceived as perfect for the organization. Thus, the logical data model is organized such that any query or any result set can be returned in zero seconds.
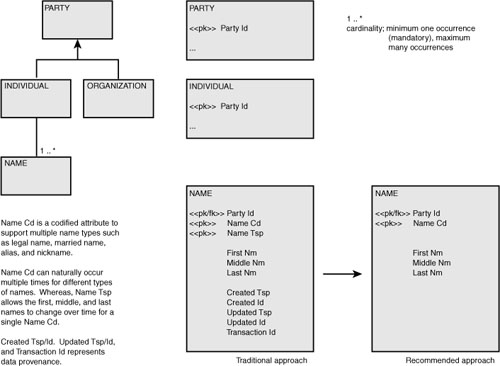
Because the physical laws are present, the perfect logical data model still requires a physical data model to take into account all implementation issues. Because the logical data model is not an implemented model, several steps can then be taken to help simplify the effort of the model’s creation. For example, the logical data model could be created without attributes for data provenance and attributes to accommodate historical data (data that may change over time). However, naturally occurring time series data or naturally repeating data should be taken into account (see Figure 6.8).
Figure 6-8 Guidelines for producing a logical data model.
In general, neither the conceptual or logical data model can adequately represent a canonical model. A canonical data model would be “accepted as being accurate and authoritative”20 to a broad audience of business and information technology personnel. The conceptual data model is potentially too volatile, and the logical data model may be overly abstract for broad, acceptable use.
As mentioned in Chapter 1, organizations are naturally siloed. Therefore, a typical organization may require numerous conceptual data models to represent different business areas, line of businesses, or communities of interest. The conceptual data model is not an appropriate vehicle to move the business-speak21 to a singular business tongue (an internal lingua franca).
21. Fugere (2005) refers to business-speak as “Jargon, wordiness, and evasiveness are the active ingredients of modern business-speak.” But, business-speak can also refer to the internal lingua franca. For example, an account, a salesperson, and a marketing person may all use the term revenue. However, when understanding what revenue represents, each person may have a different viewpoint based on his or her segment of the business.
Achieving a singular business vocabulary typically requires an executive mandate. Business communities normally evolve their own terminology. Information technology is an example of where new terms have been coined or notations devised just because they are different. In the end, all organizational vocabulary results should be recorded in some type of a business glossary.
The logical data model can be perceived as an enterprise data model (or a subset thereof). An enterprise data model “is a model that covers the whole of, or a substantial part of, an organization.”22 A logical data model that is also an enterprise data model can serve as an independent model of the data architecture. Conceivably, all physical data models and XML schemas should be able to share the logical data model as a common root.
Regardless of master data solutions and single views, a data architecture typically requires separate data stores for transactional processing and decisioning—based on different access patterns and performance latencies. Figure 6-9 provides an illustration of a sample data architecture.
Figure 6-9 A sample data architecture.
Each physical implementation, regardless of schema design, can share a common enterprise data model. Therefore, the schema for a transactional data store, a data store for master data, an operational data store, an atomic data warehouse, a data mart, a data cube, and an XML document may represent different physical implementations (transformations) from a common source—a common logical data model whereby each distinct physical data store does not require its own pairing of logical and physical data models.
A physical data model whether manifested as a relational database, a hierarchical database, a flat file, or an XML schema represents a model based on certain constraints. If the logical data model is indifferent to constraints such as latency, concurrency, business continuity, volume, access patterns, and viral data, the physical data model, and subsequently the physical implementation, is normally designed to care about these elements.
Finnish Architect Eliel Saarinen (1873–1950) once remarked, “Always design a thing by considering it in its next larger context—a chair in a room, a room in a house, a house in an environment, an environment in a city plan.”23 For a data model to be reactive to the changing needs of the business, the next larger context is to accommodate the next unknown business need. Inoculating against viral data begins with the underlying data model.
In all likelihood, accommodating the unknown may require a liberally applied use of abstract design techniques—foregoing concrete alignment with corporate silos to support a business maxim for sustaining competitiveness through evolution and change. Using Figure 6-5 as a starting point, we can develop and consider further abstractions.
For instance, the entity named individual contains an attribute for when a person enters into the world (a birth date). The entity organization has a comparable attribute for when an organization emerges (the established date). These concepts are analogous (creation) and share a common semantic. Because these attributes exist within the subtypes, a shared attribute could be located in the supertype to represent the concept of nascency.
In addition, the entity named individual contains an attribute for when a person is regarded as having legally departed (the deceased date). Notably, the entity organization does not contain an equivalent concept. However, any department, company, or government is unlikely to be eternal.
Even when business personnel fail to identify a requirement to monitor the dissolution of an organization, anticipating the need will guide the designer’s thought process toward a reactive model. In the same vein as a shared creation date, a shared attribute in the supertype to accommodate a departure date might represent an appropriate design consideration.
Before promoting the concepts of birth date and expiration (or termination) date to the supertype, additional thoughts should be given to these concepts in terms of their abstracted use. Whereas birth represents a beginning, death represents an end. Together, both represent events that most people and organizations typically encounter. However, they are not necessarily the only events in a life cycle.
If birth and death dates represent events that transpire during a life, a designer of data models can consider whether any of the other attributes already identified connote a type of life event for a person or organization. In addition, as part of an attempt to anticipate or rationalize an unknown future requirement, the designer should contemplate whether the business might ever become interested in life events that have not already been identified.
In all probability, the attribute named marital status cd will be overlooked as a candidate attribute for a life event. The attribute is modeled as a multivalued field where a person is deemed to be single, married, divorced, or widowed. However, the act of getting married is a life event. Subsequently, the date of a divorce or the date one becomes widowed also represents a life event. Each of the codes associated with marital status cd connote changes to one’s life: a life event.
The attribute language cd represents the language a person prefers to use for all written or oral communication. However, a preferred language could be considered to change over time, and that time can be represented through an event. The birth country cd attribute is intended to codify the place of birth, and the place of birth can be associated as a property of the birth event. Although a death country cd attribute is not modeled, its inclusion would conform with the life event pattern.
Citizenship cd is another codified attribute, but attainment of citizenship is part of an event—a life event. The highest education cd attribute is also associated with an event that occurs in one’s life. Gender cd is another codified attribute and is typically represented in a business system as male, female, or unknown, and can also be portrayed as being associated with a life event.
With respect to the entity party, the attributes named since tsp, left tsp, importance cd, and status cd can also be associated with a life event. However, although importance cd and status cd could be considered life events, their underlying semantics have some fundamental differences. Examined more closely, these two attributes represent life events that are under the control of the business. Importance cd and status cd do not fit the life event abstraction. In a case such as this, we should consider the following:
• Incorporating importance cd and status cd into the life event abstraction
• Evolving the life event abstraction to a higher level of abstraction—life and business events
• Creating a separate business event abstraction
• Leaving importance cd and status cd in the party entity
Figure 6-10 contains a revised logical data model that incorporates an abstraction for life events associated with a party. The attributes named importance cd and status cd have been retained in the entity party and have not been integrated into the life event abstraction. The life event concept in Figure 6-10 is therefore intended to capture useful events in the life of a party.
Figure 6-10 Revised logical data model that includes the life event abstraction.
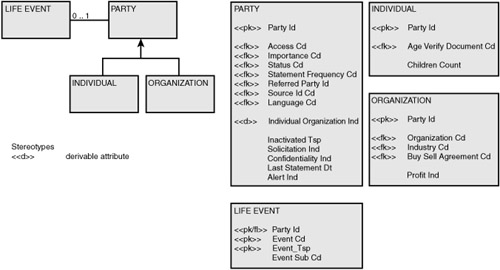
By following this type of thought process, useful abstractions can be built. In building out the abstract concept of a life event, a business can now readily expand the types of life events that are meaningful to the organization without changing the underlying data model and (most likely) the services that interact with a life event.
Tracking an IPO24 date for an organization, a merger date, a dissolution date, or immunization dates for people can now become a trivial task. New codified values can be added to a reference mechanism to assist with ensuring integrity of the life event domain.
24. IPO: An initial public offering is when a company issues stock or shares to the public for the first time.
To promote the use of an abstraction, a story (which could include a scenario, a metaphor, an analogy, an allegory, or a similar device that proves useful to figuratively paint the concept) can be built around the abstraction to make the concept easier to communicate. The following is an example to assist with an understanding of the life event abstraction:
On January 15, 2009, US Airways flight 1549 lost power in both engines within minutes after takeoff. The captain skillfully glided his craft onto the Hudson River between Manhattan and Hoboken. At 15:24:54: The airplane is cleared for takeoff from New York’s LaGuardia Airport. At “15:25:51: Pilot Chesley Sullenberger (b. 1951) tells the departure controller he is at 700 feet... [At] 15:27:01: Radar shows the plane intersect ‘primary targets’... [At] 15:27:32: The pilot reports... We lost thrust in both engines... [At] 15:28:05: [the pilot reports] We may end up in the Hudson... [At] 15:30:30: The plane touches down in the water...”25
The event, which became known as the miracle on the Hudson,26 can be understood and analyzed by unfolding a timeline that culminated in the fortunate landing: Dates and times that airline tickets were purchased, the times that each individual person boarded, the time that the flight departed, the time for each course correction, the time of impact, the time that rescue services arrived, and other situations related to the overall event.
26. The phrase was coined by Governor David Paterson (b. 1954). See Weiss (2009).
Between a beginning and an end, the timeline pieces together a picture. Timelines not only help to put into perspective situations of concern, but also situations of bliss and normalcy. Whereas some events are worth remembering, others are gladly forgotten.
Within the course of conducting business, certain events are worth discovering and recalling. With respect to the constituents with whom a business engages (whether passively or actively), recording a timeline of events can create an otherwise lost perspective.
Pertaining to the business, life events represent transpired events (regarding a constituent) that are perceived to contain intrinsic value to serve and assist the business. Life events may be used to capture a birth, a graduation, or a job promotion, but the types of events that can be captured can always be adapted to the needs of the business.
Sample data for the life event is shown in Figure 6-11. To clarity, the event names have been used in place of a codified value. Ideally, an implementation would use a reference table to ensure that only the appropriate event codes can be used.
Figure 6-11 Sample data for the life event abstraction.
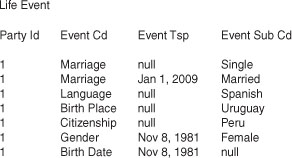
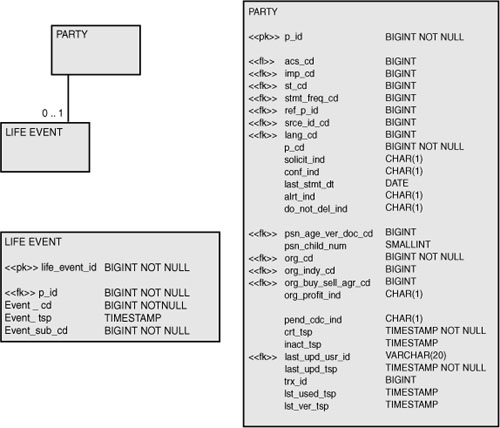
Figure 6-12 shows a modified physical data model. Here, the subtypes from the logical data model have been rolled up into the supertype and used to form a single table for the party regardless of whether the table represents a person or an organization.27 In the transformation, the column per_org_cd has been replaced by a column called p_cd (party code). The logical data model identified two subtypes, but by elevating the level of abstraction in the new physical data model, additional subtypes can be accommodated without mandating a change to any of the table structures or the physical data model in general.
27. Alternative physical design considerations could have included translating the supertype and subtypes directly into tables or to roll down the supertype into each subtype—whereby the attributes of the supertype would be duplicated into each subtype and the subtypes would then be translated into tables.
Figure 6-12 Revised physical data model that includes the life event abstraction and a single party table.
Zoological societies, industrial manufacturers, and police departments are examples of organizations that may seek to expand the number of subtypes associated to party. A health-care company might elect to keep track of robotic devices that assist surgeons during surgery. Thus, all robots can become recognized and managed parties. In addition, media companies may need to track the identities of fictional parties (characters) for purposes of royalties or managing intellectual property rights.
Robots can receive serial numbers (a recognizable identifier akin to a national identity number). In addition, robots can be associated with their own series of life events, including equivalences to birth and death dates as well as enhancement or upgrade dates.
Police departments, veterinarians, and any business that incorporates the use of animals in their day-to-day business activities can expand the use of the rolled-up party table without necessitating any data store or coding changes. In addition to names, animals can be given identifiers (e.g., microchipping, tagging, or branding) and can obviously create their own life events that an organization might be interested in tracking.
The party code (p_cd) can represent a logical subtype such as person, organization, robot, or an animal. The attribute organization code was initially intended to help manage different types of organizations such as trusts, limited liability, and partnership, and may be recast and renamed to support a broader abstraction that can act as a subclassification of a party subtype. For example, dogs and horses can be subclassifications of the party subtype animal, and articulated and parallel can be used as subclassifications of the party subtype robot.
By expanding the data model to incorporate the types of roles that a party can play (a role-based data model was shown in Figure 2-3), we can readily accommodate additional roles for a robotic device or an animal. Overall, forming the right type of data abstraction can heavily influence subsequent software abstractions in a positive manner, but more important, can serve to promote trusted information.
Elements for data provenance can be added to each physical implementation as necessary. If, as recommended, provenance is absent from the logical data model, the appropriate degrees of provenance can be added to each data store or message and managed discretely based on the type of system and the location of the data within the data architecture.
A specific logical data model of provenance could be developed, but that data model should be a separate model from the business-oriented logical data model. The result would be an abstract logical data model of the business data and an abstract logical data model of provenance. Both models could then serve as inputs into the physical data modeling process.
Data abstractions often use meta-oriented techniques that serve as a dynamic way to configure or satisfy a business need. While a data structure represents a form of hard-coding, abstraction techniques coupled with the OSAPI method (see Chapter 5, “Data Conditioning”) add a high degree of flexibility and a sense of late binding in terms of addressing a business need.
For complex or convoluted abstractions, views can be used to reverse the abstraction into a more concrete or visually tangible concept (whereby the view acts as a surrogate concept simplification tool). If a view is used, the view should be classified as an asset of the presentation layer—in the context of a multi-tier architecture (refer back to Figure 1-9)—and not as a persistence layer asset. Although views can be used by the process layer, programmers should be able to work with a data abstraction.
Views can prove particularly useful in terms of assessing data. Figure 6-13 shows a high-level model with three tables from which a simplified view can be derived. A party can have zero or more life events as well as participate in zero or more roles. A person is an example party, a customer an example role, and a birth date an example life event. A more sophisticated model might also include relationships between the role and the life event.
Figure 6-13 High-level data model showing the major tables: party, life event, and role.

Figures 6-14, 6-15, and 6-16 contain sample data in an XML document format for the data model. Figure 6-14 contains data for the party, Figure 6-15 contains sample data for the life events, and Figure 6-16 contains role data. In addition, the Document Type Definitions (DTDs) to support the XML data are shown in Figure 6-17.
Figure 6-14 Sample party data.

Figure 6-15 Sample life event data.


Figure 6-17 DTDs for party, life event, and role XML schemas.

Figure 6-18 contains an XQuery FLWOR expression. FLWOR can be used to create a join across the three XML schemas. FLWOR (pronounced flower) is an acronym named after its five clauses: FOR, LET, WHERE, ORDER BY, RETURN. “[A] FLWOR-expression generates an ordered sequence of tuples of bound variables...,”28 which could be considered analogous to a row in a table. FLWOR-expressions represent one way to establish a view in XML.
Figure 6-18 A FLWOR expression joining party, life event, and role.

The FLWOR expression forms a join across the party, life event, and role XML documents. The intent is to limit the result (the view) to just those parties that play the role of a service provider and who also contain a birth date. Therefore, the view resolves to a specific data scenario.
Figure 6-19 contains the result of the FLWOR-expression when executed on the data shown in Figures 6-14, 6-15, and 6-16.
Figure 6-19 XML output from the FLWOR-expression.

Because the FLWOR-expression could have presented the results in a more human-friendly form, Figure 6-20 is included here to complete the formatting transformations for the view through the use of XSLT. Figure 6-21 shows the resulting HTML from the Extensible Stylesheet Language Transformations (XSLT). The final result identifies two animals that act as service providers.

Figure 6-21 Final results of the view.
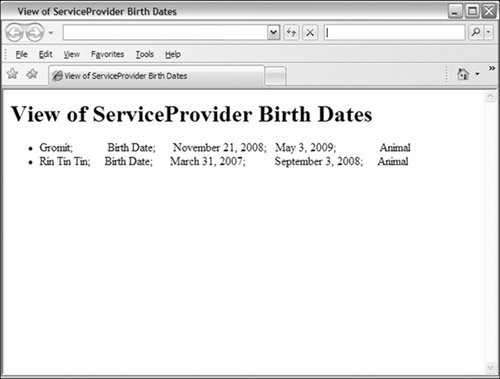
If taken out of context, the role of service provider might appear extremely ambiguous. To avoid any misassumptions, the role could have been designated as a guide dog for a sight-impaired human. Using views to establish some type of contextual precision can aid scoring the conciseness and accuracy of data as a means to avert the creation of viral data through ambiguity.
As set forth in Chapter 3, a view can be established in terms that complement the flight paths: preflight, in-flight, and post flight. Views can be constructed to organize data in the context of the current flight segment or organized in the context of a past or future flight segment. Therefore, a view can be constructed on top of an inbound message and surface the data in the context of outbound message.
Contextual views help to address viral data or trusted information in several key ways:
• By helping to simplify and communicate concepts incorporated into a modeled abstraction
• By joining data across tables or schemas to produce a business scenario for evaluation or assessment
• By preparing and contrasting data across flight segments
Ultimately, evaluating or using data contextually is one way to benchmark or scoreboard, and measurement is a contributing factor to assert control and oversight through management or governance practices. After all, “you can’t control what you can’t measure.”29
Frequency counting is a rudimentary practice in monitoring data values that may not reveal sufficient traits. For instance, when counting the frequencies of null values or empty strings within a data store, additional information may be required to yield an accurate interpretation; the new information could be surfaced as a context. In terms of a business context, comparing the differences in the data content between a newly added column or element and a column or element that is sparsely populated may not be readily discernable in gross counting or scoring.
Similarly, evaluating event dates in a life event table might not prove as beneficial as evaluating the dates in the context of a specific event type, which in turn might not be as useful as evaluating the date and event type in the context of a party and a role. While “business professionals insist on ‘trusted’ sources of data for inclusion in an SOA,”30 in practice trust stems from context and is derived from facts. Trust evokes a sentiment of semantic integrity.
Conversely, “semantic disintegrity”31 is a term that was originally referenced with respect to erroneous result sets stemming from data relations being incorrectly modeled. The essence of semantic disintegrity could also accommodate a situation where data values within a given context do not make sense despite the accuracy of the underlying model. For example, a data store containing prescription medications could contain the name of the drug, how the drug is applied (swallowed, injected, topical, and so on), strength, unit of measure, and dosage frequencies.
The following could represent a sampling of the unique values found in the data store:
• Drug name
Niacin
Hydrocortisone
Pamidronate Disodium
• Drug application
Inhalation
Topical Cream
Injection
0.5
50
100
• Unit of measure
Cubic centimeter
Ounces
Microgram
• Dosage frequency
As needed
Daily
Hourly
An overarching (or out-of-context) view of the data store might show that all the drug names, application types, strengths, and other fundamentals are valid within each of their domains. As for the compound C13H18O2—otherwise known as ibuprofen—is a painkiller with analgesic and anti-inflammatory properties that is taken orally. Pills, capsules, or caplets are often sold in increments of 200 milligrams (mg). However, if a strength of 400 were to be associated with the unit of measure grams (g) or even micrograms (mcg), the relationships between the drug, the strength, and the unit of measure would exhibit a semantic disintegrity.
Only when data is presented in a business context can a semantic and trust begin to be asserted. Whether from a transient message or a persistent data store, services consume and provision data in a context. Assessing data for viral properties within these contexts is an important part of managing the data environment.
When formulating a context for both services and business personnel, assembling numerous views may be necessary. Producing multiple views may seem contrary to the notion of a “single version of truth.”32 But, when taking into account how many organizations are naturally siloed33 and that all internal business activities are generally organized around value chains,34 which represent siloed-activities of an overall “value system,”35 this may mean that “there is no single version of the truth. For all important data, there are too many customers, too many uses, too many viewpoints.”36
32. Within information technology, the term single version of the truth was originally attributed to the data warehouse. See Watson (1998).
“Pharmaceutical product development goes through a sequential process, beginning with screening large numbers of compounds and then investigating promising ones in more detail, moving from laboratory to animal testing, shifting from animal testing to human testing, and then traversing complex governmental review and certification processes.”37 Each process is a silo that links to another process through inputs and outputs. Truth in data is ordained as a function process.
As another example, a meat department in a grocery store may sell a rib-eye steak, but in all likelihood, the meat was a part of a complete side of beef that was delivered to the store’s premises. Earlier in the store’s supply chain, the company may have purchased an entire cow. A cow, a side of beef, and a steak cannot be adequately represented as a single view of the same product to all business consumers of the different products.
This grocery store may also sell bottles of shampoo in their health and beauty department. Every bottle of a particular brand’s shampoo is going to occupy a certain amount of shelf space. However, the company’s distribution center would in all probability receive the shampoo bottles in a palette or a box possessing a different set of dimensions. In addition, a palette or box is going to have limitations on stacking.
Occasionally, manufacturers send their products bundled with promotional items. So, if the bottle of shampoo is shipped wrapped with a small, free bottle of hair conditioner, the products as well as the shipping package now have different dimensions.
A procurement, a store designer, and a warehousing view are likely to need their own characteristics. If all these independent views are squeezed into a single view, the single view may become fractured along the lines of a value chain, which in turn may cause processing ambiguities or complexities within the services and lead to viral data.
Truth can also be established through redundancy, which may also be counterintuitive to establishing a single version of truth. Corporate accounting practices can establish credibility through counterbalancing credits and debits (double-entry bookkeeping). “Double-entry is a formulation of ‘where-got, where-give.’”38 This implies that an outcome has a high degree of truth when the result is confirmed or reconciled by two independent means.
38. See Riahi-Belkaoui (2004).
Whereas determining a single version of organizational truth may be difficult, determining a single version on a smaller scale—focused within a community of interest and within a value chain—may be achievable. Along those lines, master data is likely to stand a better chance of establishing trustworthy data if its reach is:
• Aligned to portions of the data architecture and not the entire data architecture
• Aligned to value chains
• Aligned to communities of interest
Customer master data is one type of master data that is limited to certain value chains and communities of interest within the organization. Design-wise, customer data may be based on a broader party data model, but limiting what types of parties or roles participate can heighten the long-term value proposition of the master data. Single views or mastered data stores based on value chains are likely to avoid becoming an aggregation hub, a phenomenon mentioned in Chapter 2, “Data Governance.”
For viral data, master data solutions that are built around services represent the perfect conduit. Interoperability and service reuse represent ideal hosts to transport and publish the virus (data in its inert state waits to find a new host). Single copies of mastered data mean that the inert data, when hosted by a service, can equally and rapidly contaminate all subscriptions without discrimination.
In the same way the human immunodeficiency virus is treated with a cocktail (assortment) of drugs, viral data is also treated with a different kind of cocktail, which includes the following:
• A reference model for moving data
• Methods by which to assess data
• Capture of data provenance
• Use of meta-driven coding techniques
• Use of abstract model
• Use of contextual views
• Continuous monitoring
• An appropriate data architecture
• Data governance
Measuring trustworthiness in data may require a combination of subjective and objective measures. Achieving an upper hand on viral data requires participation from the business and information technology departments. Managing the knowledge base of the corporation requires a multitude of techniques and disciplines. The memory for many of today’s corporations is directly limited to what is currently persisted. For many, archived data becomes lost and forgotten knowledge.
Structured, semistructured, and unstructured are all susceptible to viral data and can be managed and governed by voluntarily doing the right thing. Primarily, any organization that wants to view data as an asset needs to ensure their strategic approaches to information technology and depart from their shortsighted tactical approaches.
Corporations must become self-reflective and engage in systems thinking—examining past behaviors, markets, and fluctuations in the economy. information technology cannot blindly rely on subject matter experts from the business to be the ultimate soothsayers of all things business. Information technology must take a defensive role toward design to safeguard the integrity of the corporation’s data.
The acronyms FARMADE, ED-SODA, ASPECT, DQA3, CIDER, SÉANCE, QuIT CITeD, and OSAPI represent elementary tools to help acclimate a mitigation program against the potential threat of an enterprise pandemic in viral data and help establish an environment of trustworthy data.
When devised, the Shannon-Weaver communication model mentioned in Chapter 3, focused on the technical, semantic, and effectiveness of communication and elements that remain cornerstones for communication (or the movement of data) across service-oriented solutions.
Overall, viral data in SOA has the capacity to become an enterprise pandemic and disable a company. Service-oriented solutions that incorporate interoperability, reusability, layering of abstractions, and loose coupling can serve as perfect hosts to propagate misinformation: That is the knife’s edge of SOA.
Whether viral data in a services-oriented solution is being created, discovered, remediated, conditioned, or inoculated, chances are that representatives from all facets of the enterprise are involved. Those included may be business personnel and subject matter experts as well as participants in a governance body, architects, analysts, developers, and database administrators. Crafting trustworthy information necessitates a coordinated common cause across each of these specialized communities.
If information technology deploys a service-oriented solution directed at managing single views of data (including mastered data), the business can thwart information technology’s desired outcome by persisting data values based on their silo-oriented use cases. As mentioned in Chapter 2, in this type of scenario, the single-view directive is recast in the role of an aggregation hub. Although this type of effect can be in plain view, the effect is not necessarily self-evident.
Trusted information in SOA requires a concerted and coordinated effort within the enterprise, including from the following:
• Business personnel (Chapter 1)
• Governance and management personnel (Chapter 2)
• Architects (Chapter 3)
• Analysts (Chapter 4)
• Developers (Chapter 5)
• Data management (Chapter 6)
Viral data is unlikely to be fixed by a single specialized community from the enterprise. In a services-oriented solution, addressing viral data usually requires complementary deliverables from all specialized communities. Whereas IT architects can create a loosely coupled multi-tier architecture, other technicians can deploy solutions that undermine loose coupling by inadvertently leveraging tight-coupling techniques. Such an example would include the aforementioned binding of field lengths between the presentation and persistence layers.
Viral data should be approached holistically in the context of the business, management, software, and data storage—leveraging applicable active and passive techniques to monitor, inhibit, and remedy. Natively, data is inert, and only when data is made actionable by an individual or by a software program can that data find a host to beget or propagate a negative outcome. For viral data, SOA represents an ideal host because the software itself is generally complex and ever evolving. Success will be measured by trust.