
Hour 22
Operating at Scale
What You’ll Learn in This Hour:
 Summary and Case Study
Summary and Case Study
In this hour, we go beyond what it means to simply deploy a solution and focus instead on what it means to scale that solution and the team behind it. We explore the operational and sustainment changes necessary behind the scenes to improve operational resiliency as our user base grows. Finally, we explore three additional techniques for sustaining our newly scaled systems. A “What Not to Do” related to addressing the “Should we scale to satisfy more users, or should we build more features to satisfy our current users?” question concludes Hour 23.
Techniques and Exercises for Effective Scaling
In the world of business and citizen-enabling solutions, scaling those solutions for more people to use and benefit from them eventually trumps the need for developing new features for an MVP or Pilot audience. And scaling our solutions means scaling the skillsets and number of our people and support teams. However, if our people-scaling strategies are not sound, we may not be able to responsibly deploy our prized solution to the broader community for which it was intended.
Fortunately, there are several Design Thinking–inspired strategies for scaling people and teams effectively. In the pages that follow, we consider how to expand our teams through Scaling by Fives. We also explore how to refine our team’s effectiveness and velocity through the Subtraction Game. Afterward, we consider how AntiFragile Validation can be used to confirm individual strength or resiliency while positioning our teams for greater longevity. Use these techniques and methods together to create a powerful recipe for scaling.
Design Thinking in Action: Scaling by Fives
When we look around the workplace, we find many different sizes of teams and workgroups. Some are very large, with a span of control between leaders and workers of 1:20 to 1:50. In other cases, smaller teams are often led by individuals who both manage and participate in the day-to-day workplace tasks. Such managing directors, managing architects, managing consultants, and so on might run 1:5 to 1:10. In yet other cases, project managers might run virtual teams composed of 5 to 50 people who still have direct line managers. And in still other cases, some organizations employ self-managed teams where management and leadership are collectively decided and spread across smaller 3- to 10-person feature teams or other self-managed and semi-autonomous teams.
What is the best approach if we’re concerned about growth and scalability? Experts, experience, and research surprisingly agree that the magic number is somewhere between four and six people, which in turn led to the rise of the Scaling by Fives technique.
The point of Scaling by Fives isn’t so much about span of control or the type of management structure as it is about the size of the most productive teams. Research shows the optimal team size is five, with team dysfunction and other performance problems increasing exponentially as team size reaches double digits. The U.S. Navy Seals and Marine Corps fire teams organize in groups of four. So, too, does McKinsey’s engagement teams. Typical surgical teams are composed of six people, and studies have shown that the optimal size for innovation teams is between four and six people.
As we see in Figure 22.1, the larger our teams become, the greater the need for, and therefore overhead of, additional point-to-point communications and collaboration. The weight of these connections ultimately consumes valuable bandwidth, robbing the team of its effectiveness and ability to drive consensus building, decision-making, and velocity.
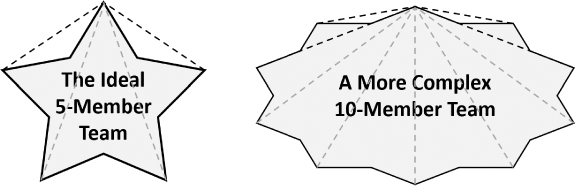
FIGURE 22.1
Scale organizations through the growth of teams composed of four to six team members; additional team members require point-to-point complexity that drives overhead and robs teams of their valuable bandwidth.
Note
The Two Pizza Rule!
Jeff Bezos of Amazon fame used to talk of the “Two Pizza Rule.” His perspective on the ideal team size? Teams should consist of no more than the number of people who can be fed by two pizzas, or about four to six people.
Design Thinking in Action: The Subtraction Game
As we scale our teams to numbers that potentially exceed five or six people, we need to consider what might be removed from those teams. What is hindering the team as it grows, what is no longer effective today, and what should therefore be eliminated? One way to consider these questions is to play the Subtraction Game.
TIME AND PEOPLE: A Subtraction Game exercise requires a full team (likely 4–10 people) for 20 minutes total.
The Subtraction Game is a hyper-focused timed exercise reflecting a combination of Divergent Thinking and Brainstorming. It comprises three timed steps spanning a mere 10 minutes, with another 10 minutes earmarked afterward for sharing and discussing what to eliminate and how to do so:
For the first three minutes, each team member brainstorms solo about how the team or workgroup operates today. What aspects of the team (or factors immediately external to the team) serve as constraints? What was once useful but today is an impediment to progress or to velocity? What is adding needless friction or randomizing our team and our individual attention? True to Divergent Thinking, the goal is quantity; the longer the list of ideas and subtraction targets, the better.
For the next four minutes, in pairs or in groups of three, share our lists with one another. Identify and add new subtraction targets to a group list.
For the next three minutes, in these same two- to three-person groups, converge around a single subtraction target. How might the group envision eliminating this one item off all the combined lists? Given the small two- to three-person group size, three minutes is sufficient. Take care not to overthink this elimination exercise. A group as small and therefore as close to the challenges should quickly arrive at what to eliminate and how to eliminate it.
With the 10 minutes expired, round-robin through the broader team to share and discuss our single subtraction target with other groups of two to three people. Present to others as needed to further discuss, prioritize, and make these changes necessary to preserve the team’s effectiveness and velocity.
Design Thinking in Action: AntiFragile Validation for Longevity
Rooted in psychology and medicine, and popularized recently by Nassim Taleb (2012), the notion behind antifragility is to recognize our individual stresses and struggles through the lens of strength. How are we growing stronger from our challenges, from what opposes us? Not just surviving or coping, but actually growing stronger, the opposite of fragile. Consider how a broken bone heals faster and grows back stronger in the wake of external stress on that bone. Those who are antifragile don’t just recover from adversity; they grow stronger. The antifragile reflect more than resilience; they come out of tough situations better and stronger.
AntiFragile Validation seeks to confirm how well we are converting the stress of life into tools and experiences for newfound strength and adaptability. How might we validate antifragility?
- Look for an attitude of perseverance, an attitude that says we will outlast the hardship. This attitude embodies antifragile. We have all endured tough work situations and near-impossible relationships. If we told ourselves that we would survive those situations and relationships, and we indeed did so, we were showing off our antifragile skills.
- Look for the outward signs of stress and its internal manifestations. Are we getting through and letting go? If we are giving ourselves permission to view stresses and struggles as something that simply needs our attention for a season, then we are reflecting an antifragile perspective. The antifragile embrace the fact that hardship ends one day.
- Understand the position our colleagues and teams occupy on the continuum of antifragile recognition. How well are they coping? How well are they growing and adapting? Consider how the team’s culture or workplace climate reflects an antifragility attitude. Does the team operate and respond in healthy ways to the inevitable stresses surrounding teamwork, projects, and schedules?
Validating antifragility is about checking in with our teams and ourselves, exploring how we and our teams cope and respond to hardship and trauma. Self-medication is not antifragile, nor is ignoring stress. The antifragile recognize, confront, and take steps to manage it. Help is found in connecting with others a la Mesh Networking (Hour 4), leaning on our Shared Identities (Hour 15), Actively Listening to one another (Hour 6), and more. The most visible signs of antifragility are found in individual and team track records of effectively coping, growing, and progressing.
QUOTE: “A wind extinguishes a candle but fuels a fire.”
—Nassim Taleb
Operational Resiliency Techniques
With a nod toward Service Reliability Engineering mentioned in Hour 19, we need to harden and automate not only our solution but our team as well. AntiFragile Validation helps us go beyond resiliency as we covered, but there are also practical techniques to increase team resiliency. Design Thinking in particular gives us an interesting arsenal of helpful techniques, including two borrowed directly from the worlds of disaster recoverability and risk management. In this next section we explore Buddy System Pairing and Slaying the Hero. Together, they form a time-tested duo and recipe for increasing team resiliency.
Design Thinking in Action: Buddy System Pairing for Risk
It is common practice to pair team members together, including pairing a new team member together with a veteran team member. The newer team member benefits from the wisdom and experience of the more senior peer, and interestingly the veteran tends to learn new ways of thinking and operating as well. Called Buddy System Pairing, it is one of the strongest and oldest techniques for shadowing, ensuring redundancy, and performing knowledge transfer as quickly as possible while safeguarding and preserving operations. And again, through this intentional redundancy, Buddy System Pairing not only provides operational resiliency but also serves as a risk management and disaster recovery best practice.
There are other benefits to Buddy System Pairing too. We can learn and put much into practice from the other well-intentioned and positive people to whom we are connected. Step one is simply to show up, to connect.
Step two, who we connect with, is just as important. For example, if we or our leaders are really interested in growing and executing smarter, we need to buddy-up in a way that reflects intentional diversity. Consider the following:
- We should connect with someone who looks different or sounds different than ourselves or our team members.
- We should consider how “buddying” would play out; watching, learning, and considering another person’s “Day in the Life of” (DILO) would be an ideal step prior to confirming a pair.
- We should also consider connecting with a variety of different people for shorter periods of time to get exposed to more ways of thinking and executing.
As pairs are formed, we need to consider our buddy’s track record of past successes and learnings or failures to help us plug into lessons and learnings that we can personally use today. For example:
- Connect with a buddy who has a history of completing difficult projects and initiatives.
- Connect with those who might hold a senior role (if that is indeed possible), again to learn from a broader base of experiences.
- Connect with a buddy who has a reputation for navigating through ambiguity and uncertainty. Such a buddy can help us with the “what” of a role as well as the “how” to navigate complexity.
Again, remember that partnering and buddying with others does not only help our new or junior member. Buddying helps the other half of the partnership too. And buddying will naturally help other colleagues and our entire team as well. Pairing intentionally and leaning on one another has an interesting way of making everyone stronger. It is fundamental to why we buddy in the first place.
Design Thinking in Action: Slaying the Hero for System Resiliency
Our next technique, Slaying the Hero, is a long-time staple of disaster recovery planning and exercises. The idea is both simple and brilliant, and for our purposes akin to “human prototyping and testing.” We use Slay the Hero to test our systems and processes for human resiliency.
At work, we might consider Faizel our superstar production support expert and all-around subject matter expert for our solution. We count on Faizel day to day and even more so when the system is undergoing monthly system updates and the annual disaster recovery exercise. We don’t know what we would do without Faizel. And this is exactly why we need to figuratively slay Faizel on occasion: to see how the team “steps up” and covers his responsibilities in his absence.
Why else is Slaying the Hero important? People casually say that everyone can be replaced, but we’re not so sure when it comes to Faizel’s skills, calm demeanor, and ability to work through seemingly any problem. Just like a good system, though, we cannot allow a single person to become a single point of failure (SPOF). And Faizel is indeed a SPOF; he is our only network hub tech on the team, for example. We need “people redundancy,” just as we have technology and facilities redundancy built into our cloud infrastructures and new generation of cloud apps.
What happens when Faizel takes an unexpected holiday? What if he needs to stay home to take care of sick loved ones? What if he simply disappears one day? What are our workarounds? More to the point, “who” are our workarounds? Before these scenarios ever play out in reality, we need to play them out mentally (and typically through a tangible exercise as well). Do this by imagining that our key person, team, or process—Faizel in this case, our hero—is removed from the picture for a period of time. What would happen if our lone network hub tech, Faizel, disappeared from Figure 22.2? Do we have a backup?
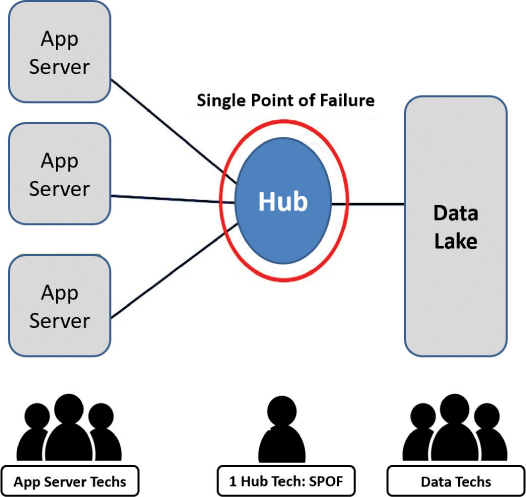
FIGURE 22.2
Use the Slaying the Hero technique to prototype and test our human single points of failure (SPOFs).
Use Slay the Hero to prototype and test our team’s resiliency and our personal ability to recover from everything from slight system hiccups to major disasters. Are we too dependent on a specific person or system or process? Do we have the right skills distributed across enough people? Do we have fallback people and partners we may lean on in an emergency? Knowing these options in advance—and thinking through and testing how we would operate without the benefit of our heroes—will help us survive such conditions when they inevitably occur in the real world.
Techniques for Sustaining Systems and Value
Once a solution begins delivering its expected benefits and other outcomes, we need to focus even more on sustainability. Value and other benefits are only sustained via a prescriptive strategy for operating, monitoring, upgrading, evolving, and extending our solutions in alignment with our people and teams.
Design Thinking in Action: Operating Structures for Scale
As we move through deployments and begin operating at scale, there is the need to plan for, deploy, and over time optimize our Operating Structures for Scale. Though outside the scope of this book, we need to prototype, test, and harden our support organization in the same way that we do our products, services, and solutions, so they can help us maintain an available, scalable, and resilient solution. There are many implications, but some of the most overlooked include
- Timing. Establish the initial support organization as soon as we have deployed an MVP or Pilot or other production-like solution supporting a cast of end users.
- Evolution. Remember that our support organization needs to grow with our solution as it is developed and deployed; consider this need as just another requirement for iterating as we fine-tune our support structure and their connections to the user community.
- Onboarding. Onboard key support personnel as early into a solution’s lifecycle as possible, again to create a record of institutional knowledge and experience.
Consider the breadth of support required too. Readying our Operating Structures for Scale means putting people at the center of the particular problems and situations we may encounter. For systems that run at scale:
- Our solution team will need access and help from an internal or contracted team of developers and testers tasked with maintenance and updates.
- Our global user community will need a Level 1 Help Desk that is available in some form 24 hours a day.
- Our Level 1 Help Desk will need knowledge management capabilities and a second level of support for escalations (sometimes called an L2, or Level 2, Support Organization).
- Our Level 2 Support Organization will require liaisons to work with our hardware and infrastructure providers, cloud providers, application and software providers, security and third-party app vendors, and so on (typically the responsibility of an L3, or Level 3, Application Support Team).
Additional teams and people will need to be employed along the lines of support as well (again, outside the scope of this book). Practice our Design Thinking process to understand and empathize with the myriad of people and teams connected to our products and solutions. Through creating intentional partnerships and building support organizations early, we can intentionally sustain our solution’s usefulness and its value and other benefits to our end users and stakeholders.
Design Thinking in Action: Validating OKRs and Value
Once a solution is deployed to production—regardless of whether this means as an MVP or Pilot or full production systems—we need to sustain its benefits over time. To do so, it is common to create an intentional and ongoing benefits or value workstream. To be clear, we should have been validating and thinking about measures for value earlier as we ideated, problem-solved, prototyped, and tested. But once users and customers begin realizing value from the time spent in the Design Thinking process, we owe it to ourselves and our stakeholders to actively and regularly validate that we
- Are delivering and realizing value as identified in our solution’s objectives
- Can measure that value in the form of a set of objective-specific key results
- Are aligning our people and teams to the value creation and sustainment process
- Are taking the necessary steps to sustain and grow that value
This imperative to realize and measure value needs to be captured in the organizations’ Sustainment Plan. A good Sustainment Plan maps back to the organization’s vision, mission, evolving strategies, products and solutions used to realize value, and the various objectives and key results established to realize and measure the effectiveness of the organization’s strategies, products, and solutions—all of which serves as a wonderful feedback loop for further growth and transformation.
Note
Aligning People to Value
Value realization is predicated on team members who understand, respect, and hold themselves accountable for delivering value and other expected outcomes. This alignment between individual people and the outcomes they are expected and accountable to deliver is required for realizing value and therefore success. Be sure to align our people and teams to the value their products and solutions are expected to provide!
Design Thinking in Action: Silent Design for Sustainment
As previously outlined in Hour 20, we must not forget to bake in learnings gleaned from the Silent Design choices that our users are already making to our products and services in production. Remember that the modifications and additions our user communities make to our production systems represent yet another opportunity to collect and use their feedback for the continuous improvement and sustainment of our products and solutions.
As design leaders and thinkers, we need to learn from our users who are working around our unknown and known product gaps and processes. And we need to be proactive as we learn, baking those learnings into our product and solution backlogs. Anything we might do sooner rather than later to make our products and solutions more useful will return time back to everyone who adopts and adapts them today.
What Not to Do: The Scale versus Features Mandate
As we arrive at the point in time when we absolutely must deliver measurable value, we need to eventually decide when scale trumps new features; that is, when the many needs of a community outweigh the “eyes closed” wishful needs of a handful of super users. For a 100-year-old insurance company, a CRM project’s business liaison finally needed to make that decision unilaterally. Her technology leadership counterpart seemed happy to continue improving on the features and capabilities of a successful MVP (as we discussed in Hour 17). The MVP started life with 40 elated users, and six months later this MVP was much improved in terms of capabilities but was only servicing 50 elated users.
In the meantime, the business was screaming for its long-promised solution. The company had grown weary of the mixed bag of partial solutions strung together with nightly interface updates and a swivel chair to pivot between different systems and screens. It had grown equally weary of the “next quarter” promises made over the course of nine months by the slow-to-deploy-value technology leader.
The company’s business liaison had to eventually step in and demand that the current solution, as is, be turned over to the remainder of the business. She rightly explained that the solution was Good Enough (as we covered in Hour 11). The time had come for scale to trump the desire to deploy new features. In increments of 500 and 1,000 users, different parts of the business were onboarded every two to three weeks over the next three months. As most of the team expected, the new users were also elated with their new solution. The solution’s business liaison helped the entire organization sidestep a major landmine on the journey to deploying and realizing value.
Summary
In Hour 22, we explored how to scale and refine the team underpinning our solution through Scaling by Fives, the Subtraction Game, and AntiFragile Validation for Longevity. We then outlined two operational and sustainment techniques useful for improving operational resiliency as our user base grows, including Buddy System Pairing and Slaying the Hero. Later, we explored three additional techniques for sustaining our newly scaled systems using Operating Structures for Scale, Validating OKRs and Value, and considering Silent Design for Sustainment. A “What Not to Do” related to avoiding the “Scale versus New Features” decision concluded Hour 22.
Workshop
Case Study
Consider the following case study and questions. You can find the answers to the questions related to this case study in Appendix A, “Case Study Quiz Answers.”
Situation
Satish and the Executive Committee (EC) of BigBank have been happy with your support of their initiative leaders, executives, and other stakeholders. They are now enlisting your aid to help BigBank scale several of its OneBank initiatives on their journey to reimagining the Bank’s future and reinventing how the Bank delivers its new business capabilities and outcomes with velocity. Satish has asked you to host a Q&A session to answer several of the committee’s questions surrounding scale methods, solution scalability approaches, operational considerations, and more.
Quiz
1. While several methods exist, which two have we explored that can give organizations such as BigBank a way of thinking about and scaling the teams underpinning the Bank’s various projects and initiatives, especially as they become productive and grow quickly?
2. Which technique forces us to consider value measures and how the notion of value might have changed throughout a project’s lifecycle?
3. What are two techniques for bolstering operational resiliency?
4. What role does Silent Design play in the overall pursuit of solution and system sustainability?
5. Which technique might help BigBank consider the fragility of its teams as well as its people?