
CHAPTER 5
Dynamic Shared Memory Allocation
Dynamic memory allocation has been used extensively in applications for several important reasons. For example, dynamic memory allocation provides flexibility when the data sizes change during the lifetime of a program, and allows memory reuse for better utilization of the memory resources when data sizes are very large. In the private space of a UPC program, dynamic memory allocation can be done using the standard dynamic memory allocation functions available in ISO C. Dynamic memory allocation in the shared space is also possible. However, this is accomplished by special UPC memory allocation and deallocation functions. In this chapter we discuss dynamic shared memory allocation in UPC.
Dynamic shared memory allocation functions can be collective or noncollective. A function is collective if it is required to be called by all threads to produce the required impact. A function is noncollective if it should be called by a single thread. UPC has three basic dynamic shared memory allocation functions and one deallocation function. The allocation functions can create a global shared space collectively or noncollectively, or a local shared space by a thread. All dynamically allocated shared space can be released using the same deallocation function.
5.1 ALLOCATING A GLOBAL SHARED MEMORY SPACE COLLECTIVELY
To allocate one global shared space collectively, upc_all_alloc() is used. The upc_all_alloc() function is a collective function that is called by all threads using the same argument values and returns a single pointer, to the shared space allocated, to all threads. The function upc_all_alloc() has the following syntax:
shared void *upc_all_alloc(size_t nblocks, size_t nbytes);
where nblocks is the number of blocks and nbytes is the block size in bytes.
The shared space allocated is distributed by blocks across the threads in round-robin fashion. The upc_all_alloc() function takes two arguments: one specifying the number of blocks to be allocated, nblocks, the other specifying the size of each block in bytes, nbytes. The arguments are of type size_t, which is simply an ISO standard type definition intended to represent the maximum allocatable storage space in the target machine. The total space allocated in this case is of size nblocks*nbytes bytes.
Thus, the upc_all_alloc() function allocates shared space similar to what can be obtained from the following static declaration:
shared [nbytes] char [nblocks * nbytes]
The upc_all_alloc() function returns the same pointer value on all threads. However, if nblocks*nbytes is zero, no memory is allocated and a null pointer-to-shared is returned. The lifetime of a dynamically allocated object extends from the time of completing the call to upc_all_alloc() until any thread has deallocated the object.
Figure 5.1 shows how upc_all_alloc() allocates dynamic space based on the following:
shared [N] int *ptr;
ptr = (shared [N] int *)
upc_all_alloc(THREADS, N*sizeof(int));
The following is a more comprehensive example that demonstrates the collective allocation and use of dynamic shared space.
Example 5.1: heat_conduction3.upc
1. #include <stdio.h> 2. #include <math.h> 3. #include <upc_relaxed.h> 4. #include “globals.h” 5. #define CHECK_MEM(var) { 6. if(var == NULL) 7. { 8. printf(“TH%02d: ERROR: %s == NULL ”, 9. MYTHREAD, #var ); 10. upc_global_exit(1); 11. } } 12. shared [BLOCKSIZE] double *sh_grids; //pointer to the grids 13. shared double dTmax_local [THREADS]; 14. int initialize(shared [BLOCKSIZE] double (*grids)[N][N][N]) 15. { 16. int y, x; 17. /* sets one edge of the cube to 1.0 (heat) */ 18. for(y=1; y<N−1; y++) 19. upc_forall( x=1; x<N−1; x++; &grids [0][0][y][x]) 20. grids [0][0][y][x]= grids [1][0][y][x] = 1.0; 21. } 22. void heat_conduction(shared [BLOCKSIZE] double (*grids)[N][N][N]) 23. { 24. double dTmax, dT, epsilon; 25. int finished, x, y, z, i; 26. double T; 27. int nr_iter; 28. int sg, dg; // stands for source grid and destination grid indexes 29. /* sets the constants */ 30. epsilon = 0.0001; 31. finished = 0; 32. nr_iter = 0; 33. sg = 0; // using grids(0,,,) as source array 34. dg = 1–sg; // using grids(1,,,) as destination array 35. do 36. { 37. dTmax = 0.0; 38. for(z=1; z<N–1; z++) 39. { 40. for(y=1; y<N–1; y++) 41. { 42. upc_forall(x=1; x<N–1; x++; &grids [sg][z][y][x]) 43. { 44. T=(grids[sg][z+1][y][x] + grids [sg][z–1][y][x]+ 45. grids [sg][z][y–1][x]+ grids [sg][z][y+1][x]+ 46. grids[sg][z][y][x–1]+grids[sg][z][y][x+1]) / 6.0; 47. dT = T–grids [sg][z][y][x]; 48. grids [dg][z][y][x] = T; 49. if(dTmax < fabs(dT)) 50. dTmax = fabs(dT); 51. } 52. } 53. } 54. dTmax_local[MYTHREAD] = dTmax; 55. upc_barrier; 56. dTmax = dTmax_local[0]; 57. for(i=1; i < THREADS; i++) 58. if(dTmax < dTmax_local[i]) 59. dTmax = dTmax_local[i]; 60. upc_barrier; 61. if(dTmax < epsilon) 62. finished = 1; 63. else 64. { 65. // swapping the source and destination “pointers” 66. dg = sg; 67. sg = 1–sg; 68. } 69. nr_iter++; 70. } while(finished == 0); 71. return nr_iter; 72. } 73. int main(void) 74. { 75. int nr_iter; 76. /* allocate the memory required for grids [2][N][N][N] */ 77. sh_grids = (shared [BLOCKSIZE] double *) upc_all_alloc(2*N*N*N/BLOCKSIZE, BLOCKSIZE*sizeof(double)); 78. CHECK_MEM(sh_grids); 79. /* initialize the grids */ 80. initialize((shared [BLOCKSIZE] double (*)[N][N][N]) sh_grids); 81. /* synchronization */ 82. upc_barrier; 83. /* performs the heat conduction computations */ 84. nr_iter = heat_conduction( (shared [BLOCKSIZE] double (*)[N][N][N]) sh_grids); 85. /* synchronization */ 86. upc_barrier; 87. if( MYTHREAD == 0 ) 88. printf(“%d iterations ”, nr_iter ); 89. return 0; 90. }
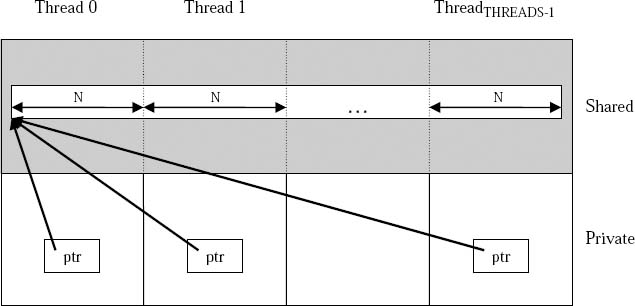
Figure 5.1 Shared Space Allocation Using upc_all_alloc
Example 5.1 gives a variation of the heat transfer problem presented in Example 4.5, which uses upc_all_alloc() to allocate space dynamically for the two three-dimensional grids, grids [2][N][N][N]. The example is also designed in a much more modular way than Example 4.5, with more functions to stress some of the points that have to do with dynamic storage allocation, pointers, and passing of array parameters.
In line 4, BLOCKSIZE as well as N are defined in globals.h. Lines 5 through 11 define a macro, CHECK_MEM(), which is used by the main program to check that memory allocation completed successfully, and if not, exits the program. Although our macro will be executed by all threads, it is sufficient to have only one thread perform this check since the allocation is done by a collective call that returns the same thing to all.
Line 12 declares a private pointer to a shared double with a block size of BLOCKSIZE. These pointers will be used to receive the address of the dynamically allocated space, which is to be used to hold the two three-dimensional grids. Thus, it will be viewed as a four-dimensional array of dimensionality 2 × N × N × N, where the first index is used to identify which of the two three-dimensional grids we are using.
Lines 14 through 21 list an initialization function that sets one face on each of the cubes to 1.0, or hot, so that they become the heat sources. This function will be called from main() with sh_grids pointer. Note that the function, however, uses array index notations for accessing its data. Alternating between pointer and array index notations is allowed in C, and the same is also valid for UPC.
Lines 22 through 72 the heat_conduction() function, which performs the major heat transfer iterations. It is, once again, similar to the code of Example 4.5 and included here for completeness and to demonstrate the alternation between array and pointer notations. The rest of the code is for the main() function. Lines 76 through 78 allocate a shared space enough to hold the two three-dimensional grids as a single four-dimensional array. The size of the space needed is sufficient to hold 2*N*N*N double elements. To distribute this as blocks of BLOCKSIZE double elements across the threads, the number of blocks is given as 2*N*N*N/BLOCKSIZE, and the number of bytes per element are given by BLOCKSIZE* sizeof(double). Allocated space is basically one large space of bytes, and therefore a simple pointer to shared is returned. Given the way the pointer sh_grids was declared, assigning the returned pointer from upc_all_alloc() to it requires a pointer cast to (shared [BLOCKSIZE] double *).
The rest of main() then calls CHECK_MEM() to check whether the previous allocation was successful, and then it calls initialize() to initialize one face on each cube to “hot.” The main() then uses a barrier synchronization to ensure that all initializations are completed before calling heat_transfer() to perform the actual heat transfer simulation. A barrier synchronization is used after this call to make certain that all threads finished working before we print the number of iterations.
5.2 ALLOCATING MULTIPLE GLOBAL SPACES
One alternative allocation scheme is to use upc_global_alloc(), which works similar to upc_all_alloc(), except that it is not a collective operation. The syntax for upc_global_alloc() is
shared void *upc_global_alloc(size_t nblocks,
size_t nbytes);
where nblocks is the number of blocks and nbytes is the block size in bytes. In this case the space allocated is specified by the number of blocks and a block size in bytes. The function returns a pointer-to-shared, which points to the space allocated. If nblocks*nbytes is zero, a null pointer-to-shared is returned.
The upc_global_alloc() function is not a collective function. If called by multiple threads, all threads that make the call get different allocations. Each calling thread will then allocate a shared space that is distributed in a similar manner to the space resulting from the static declaration
shared [nbytes] char [nblocks * nbytes]
Figure 5.2 and 5.3 show the result from upc_global_alloc() when called by all threads. Figure 5.2 represents how the space will be accessible if the pointer returned to shared is assigned to a private pointer to shared. This can be accomplished by
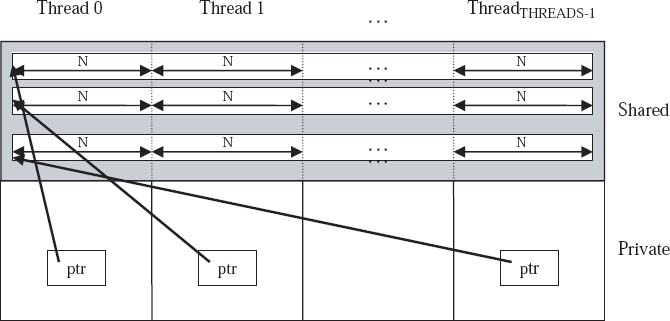
Figure 5.2 Illustration of upc_global_alloc
With N defined in the beginning of the program, this allocates a shared space of blocks of N integers, distributed in a round-robin way, one block per thread. There will be THREADS ptr private pointers to shared pointing at the beginning of the space allocated. These pointers will follow the pointer arithmetic of blocked pointers with a block size of N.
Figure 5.3 shows the case when an array of shared pointers to shared is used for accessing the space. This can be done by the code
shared [N] int *shared myptr [THREADS];
myptr [MYTHREAD] = (shared [N] int *)
upc_global_alloc(THREADS, N*sizeof(int));
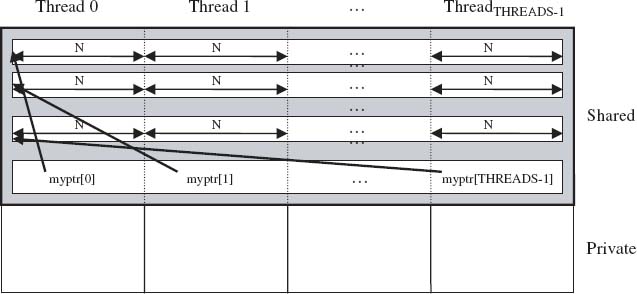
Figure 5.3 Illustration of upc_global_alloc with a Shared-to-Shared Pointer
With N defined in the beginning of the program, a shared space of blocks of N integers is allocated and distributed in a round-robin way, one block per thread. There will be an array of THREADS shared pointer to shared, with each myptr[MYTHREAD] pointing at the beginning of the space allocated by that thread. These pointers will follow the pointer arithmetic of blocked pointers with a block size of N.
Example 5.2 is a more comprehensive example using upc_global_alloc(). It is a simple variant of Example 5.1 in which upc_all_alloc() is replaced by upc_global_alloc().
Example 5.2: heat_conduction4.upc
1. …
2. #include <upc_relaxed.h>
3. #include “globals.h”
4. // dynamically allocated sh_grids[] to be matched to
// [2][N][N][N]
5. shared [BLOCKSIZE] double *shared sh_grids;
6. shared double dTmax_local[THREADS];
7. int main(void)
8. {
9. int nr_iter;
10. if(MYTHREAD == 0)
11. {
12. // allocate the memory required for grids[2][N][N][N]
13. sh_grids = (shared [BLOCKSIZE] double *shared)
upc_global_alloc(2*N*N*N/BLOCKSIZE,BLOCKSIZE*sizeof(double));
14. CHECK_MEM(sh_grids);
15. }
16. /* synchronization */
17. upc_barrier;
18. /* do all the remaining, as usual */
19. . . .
20. return 0;
21. }
Since upc_global_alloc() is noncollective and can result in multiple shared spaces if called by multiple threads, only thread 0 is making the allocation call, lines 11 through 15. Thread 0 is also checking whether the space was allocated successfully by calling the CHECK_MEM macro. The rest of the code is similar to that of Example 5.1.
In modeling and simulation of linear systems, system dynamics can be represented by a matrix, while inputs to the system are vectors that need to be multiplied by the system matrix to produce an output vector. Example 5.3 considers the problem of multiplying a matrix by a sequence of vectors.
Example 5.3: matvect7.upc
1. #include <upc_relaxed.h>
2. #include <stdio.h>
3. shared int *a;
4. shared int *shared b[THREADS], *shared c[THREADS];
5. int main (void)
6. {
7. shared [THREADS] int (*mat_a)[THREADS];
8. int i, j, vect_no;
9. a=(sharedint*)upc_all_alloc(THREADS,THREADS*sizeof(int));
10. CHECK_MEM(a);
11. mat_a = (shared [THREADS] int (*)[THREADS]) a;
12. b[MYTHREAD] =(sharedint *shared)upc_global_alloc(THREADS,
sizeof(int));
13. CHECK_MEM(b[MYTHREAD]);
14. c[MYTHREAD] =(sharedint *shared)upc_global_alloc(THREADS,
izeof( int ));
15. CHECK_MEM(c[MYTHREAD]);
16. /* synchronization */
17. upc_barrier;
18. /* initialize mat_a [][], b [][] and c [][] */
…
19. /* synchronization */
20. upc_barrier;
21. /* compute the matrix by vector multiplications */
22. for(vect_no=0; vect_no<THREADS; vect_no++)
23. {
24. upc_forall(i = 0; i < THREADS; i++; i)
25. {
26. c[vect_no][i] = 0;
27. for (j= 0; j < THREADS; j++)
28. c [vect_no][i] += mat_a [i][j]*b [vect_no][j];
29. }
30. }
31.
32. /* synchronization */
33. upc_barrier;
34.
35. /* print results */
…
36. return 0;
37. }
In Example 5.3, a is a private pointer to shared, which points to the matrix, while b[] and c[] are arrays of shared pointers to shared. Each element of b[] can be used to point to one input vector, and each element of c[] can be used to point to one result vector. Lines 9 through 13 allocate the needed memory for each one of these arrays and check to ensure that the allocation operation was performed successfully using a macro similar to the macro discussed in Example 5.1. It is noted here that upc_all_alloc() is used to allocate the space for the matrix. This is because only one matrix is needed. Meanwhile, since multiple vectors (in this case, THREADS of them are assumed for simplicity) are to be allocated in case of input and output, we use upc_global_alloc() to simplify the syntax.
Lines 21 through 30 perform the actual computations, going through vector by vector, and for each vector number the computations are distributed by rows of a[] across the threads. This segment of code is preceded by barrier synchronization to ensure that space allocation and initializations of data structures are completed before the computation takes place. A barrier synchronization follows this block of nested loops to ensure that computations are completed before printing.
5.3 ALLOCATING LOCAL SHARED SPACES
In many cases it could be desirable to allocate shared but local storage. This can be done in UPC using the upc_alloc() function. This function takes only one argument, the number of bytes, and allocates that much shared storage with affinity to the calling thread. Thus, upc_alloc() is not a collective function, and it operates in a manner similar to malloc() in ISO C, except that the pointer returned points into the shared space. The syntax for upc_alloc() is as follows:
shared void *upc_alloc(size_t nbytes);
where nbytes is the total number of bytes to allocate. If nbytes is zero, the result is a null pointer-to-shared.

Figure 5.4 Illustration of upc_alloc
Figure 5.4 shows how upc_alloc() allocates and accesses space based on the statements
shared [] int *ptr; ptr = (shared [] int *)upc_alloc(N*sizeof(int));
where ptr is a private pointer-to-shared with indefinite block size. The statements ultimately result in allocating N integers on each thread when called by all threads. Each thread will get a different pointer, and its instance of ptr will be pointing at the beginning of the local space allocated to it. In this case, if ptr is only to traverse the locally allocated memory, ptr does not have to be a pointer-to-shared and can be a pointer into the private space.
Figure 5.5 shows how upc_alloc allocates space based on the statements
shared [] int *shared myptr [THREADS];
myptr [MYTHREAD] = (shared [] int *shared)
upc_alloc(N*sizeof(int));
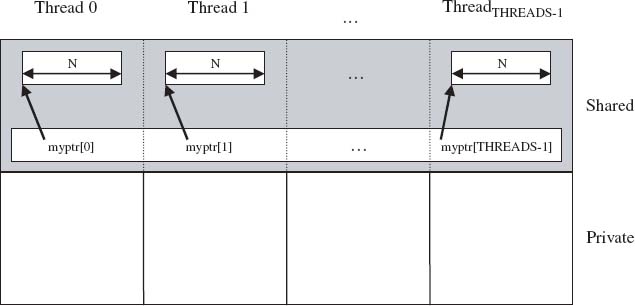
Figure 5.5 Illustration of upc_alloc with a Shared-to-Shared Pointer
where myptr[] is an array of THREADS shared pointers-to-shared, with indefinite block size. The statements ultimately result in allocating N integers on each thread when called by all threads. Each thread will get a different pointer, and its element of myptr will be pointing at the beginning of the local space that is allocated to it.
Example 5.4 is a modified version of the heat conduction code used throughout Chapters 4 and 5. Recalling the basic distributions of three-dimensional data in Figure 4.1, in this case we are considering a distribution in which each thread gets the largest possible chunk of faces. Those data chunks will be allocated dynamically, where each thread allocates its own chunk in its local shared space. The block size will then be N*N*N/THREADS.
Example 5.4: heat_conduction5.upc
1. #include <stdio.h>
2. #include <math.h>
3. #include <upc_relaxed.h>
4. typedef struct chunk_s chunk_t;
5. struct chunk_s {
6. shared [] double *chunk;
7. };
8. // considering the blocksize as the biggest chunk of faces
9. int N;
10. shared chunk_t sh_grids[2][THREADS];
11. shared double dTmax_local[THREADS];
12. #define grids(no,z,y,x)
sh_grids[no][((z)*N*N+(y)*N+(x))/(N*N*N/THREADS)].
chunk[((z)*N*N+(y)* N+(x))%(N*N*N/THREADS)]
13. void initialize(shared chunk_t (*sh_grids)[THREADS])
14. {
15. // grids[][][][] has to be changed to grids(,,,,)
16. }
17. int heat_conduction(shared chunk_t (*sh_grids)[THREADS])
18. {
19. // grids[][][][] has to be changed to grids(,,,,)
20. }
21. int main(int argc, char **argv)
22. {
23. int nr_iter, no;
24. /* Usage */
25. if(argc != 2)
26. {
27. if(MYTHREAD == 0)
28. printf(“Usage: %s [N]
”, argv [0]);
29. return –1;
30. }
31. /* get N */
32. sscanf(argv[1], “%d”, &N);
33. if( (N*N*N)%THREADS != 0)
34. {
35. if(MYTHREAD == 0)
36. printf(“N*N*N should be divisible by THREADS
");
37. return –2;
38. }
39. /* allocate */
40. for(no=0; no<2; no++)
41. {
42. sh_grids[no][MYTHREAD].chunk = (shared [] double *)
upc_alloc( N*N*N/THREADS*sizeof(double));
43. CHECK_MEM(sh_grids[no][MYTHREAD].chunk);
44. }
45. /* initialize the grids */
46. initialize(sh_grids);
47. /* synchronization */
48. upc_barrier;
49. /* performs the heat conduction computation */
50. nr_iter = heat_conduction(sh_grids);
51. /* synchronization */
52. upc_barrier;
53. if(MYTHREAD == 0)
54. printf(“%d iterations
", nr_iter);
55. return 0;
56. }
Instead of giving a line-by-line explanation of Example 5.4, we will discuss only the lines that are interesting or not readily intuited. Lines 4 through 7 define a private-to-shared pointer type with indefinite blocking. In other words, when incremented, it traverses the local shared space. The intent is to have data structures of that type holding the local chunks. Lines 9 and 10 do exactly that; they create a shared array of 2*THREADS pointers of type chunk_t. Each row of these pointers is used to access one of the two three-dimensional grids, needed as the source and destination of a given iteration. In line 12 the macro grids(), used to simplify the indexing of the three-dimensional grids, is slightly different from its pervious instances and reflects the distribution of each of the two three-dimensional grids by the largest chunk of faces, where each chunk is N*N*N/THREADS. Lines 24 through 38 modify the previous implementations of this example to allow the size of the problem, N, to be specified by the user interactively. This can now be afforded for two reasons. The first is clearly the use of dynamic shared memory allocation. The second is the fact that upc_all_alloc() and upc_global_alloc() require specifying both the block size and the number of blocks to allocate. To create a particular distribution, the block size must be a function of the problem size, N, which we would like to allow the user to specify at run time. However, UPC requires that the block size be a constant. In the case of upc_alloc(), the block size of the space allocated is always the indefinite block size. In our example, chunk always has an indefinite block size, and sh_grids has the default block size of 1.
Figure 5.6 shows the scalar ITPACK notation for compressed sparse matrixes. The nonzero elements are stored in the array values, the column indexes of the nonzero elements in the matrix are stored in the colind [] array, and rowptr expresses where and how many nonzero elements there are in each row.
Example 5.5 shows a UPC program to compress a sparse matrix. The example addresses the allocation and use of unequal blocks across the threads.

Figure 5.6 Matrix Compression Using Scalar ITPACK Format
Example 5.5: matcompress.upc
1. #include <stdio.h>
2. #include <upc_relaxed.h>
3. #define N 128
4. /* matrix to be compressed */
5. shared [N*N/THREADS] double data_A [N][N];
6. /* same matrix in its sparse representation */
7. typedef struct sparse_mat_s sparse_mat_t;
8. struct sparse_mat_s {
9. int no_nz;
10. shared [] int *colind;
11. shared [] int *rowptr;
12. shared [] double *values;
13. };
14. shared sparse_mat_t sparse_data_A [THREADS];
15. void initialize_A(void)
16. {
17. int i, j;
18. upc_forall(i=0; i<N; i++; i*THREADS/N)
19. for(j=0; j<i/2; j++)
20. data_A [i][j] = (i–j)/(N*1.0);
21. }
22. void compress_A(void)
23. {
24. int ind, i, j;
25. shared [] int * rowptr_ptr;
26. /* step 1: count the number of NZ */
27. upc_forall( i=0, sparse_data_A[MYTHREAD].no_nz=0; i<N;
i++; i*THREADS/N)
28. for(j=0; j<N; j++)
29. if(data_A[i][j] > 1E–6)
30. sparse_data_A[MYTHREAD].no_nz ++;
31. /* step 2: allocate colind, rowind and values arrays */
32. sparse_data_A [MYTHREAD].colind = (shared [] int *)
upc_alloc(sparse_data_A[MYTHREAD].no_nz * sizeof(int));
33. CHECK_MEM(sparse_data_A[MYTHREAD].colind);
34. sparse_data_A [MYTHREAD].rowptr = (shared [] int *)
upc_alloc(N+1 * sizeof(int));
35. CHECK_MEM(sparse_data_A [MYTHREAD].rowptr);
36. sparse_data_A [MYTHREAD].values = (shared [] double *)
upc_alloc(sparse_data_A [MYTHREAD].no_nz * sizeof(double));
37. CHECK_MEM(sparse_data_A [MYTHREAD].values);
38. /* step 3: create the sparse representation */
39. rowptr_ptr = sparse_data_A [MYTHREAD].rowptr;
40. upc_forall(i=0, ind=0; i<N; i++, rowptr_ptr++; i*THREADS/N)
41. {
42. *rowptr_ptr = i;
43. for(j=0; j<N; j++)
44. if(data_A [i][j] > 1E–6)
45. {
46. sparse_data_A [MYTHREAD] .colind [ind]= j;
47. sparse_data_A[MYTHREAD] .values[ind]=data_A [i][j];
48. ind++;
49. }
50. }
51. *rowptr_ptr = ind;
52. }
53. int main(void)
54. {
55. initialize_A();
56. upc_barrier;
57. compress_A();
58. return 0;
59. }
Lines 4 through 13 create the data structures necessary for the input data as well as the compressed data. The original matrix data is held in data_A[][], an N × N shared matrix distributed by the largest possible chunk of rows across the threads. A structure holding the compressed matrix array values and indexes is declared, with each index and its associated value declared as private pointers to shared, with indefinite block size. A fourth field of the structure is used to hold the number of zero elements available locally. Thus, each thread will have one instance of these three pointers that can easily be used to access this information locally. The space for the nonzero values and the indexes can be allocated dynamically to be just big enough to accommodate the local needs, as the number of zero elements per chunk can vary.
Lines 15 through 21 initialize the array data. The initialization sets the nonzero elements in a lower triangle such that the base is only one-half of the matrix dimensionality. The function compress_A() extends from lines 22 through 52 and performs the bulk of the work. Lines 26 through 30 use a upc_forall() to find out how many nonzero elements each thread has in its chunk. The affinity field is selected such that each thread computes that for its own chunk in order to exploit locality.
Lines 31 through 37 allocate the memory space to hold the values and the indexes for the new representation. The space allocated for each thread is only enough to hold these data for the local chunk, based on the local nonzero element count that was found earlier from lines 26 through 30. Lines 38 through to the end of the function perform the operations needed to compute the elements that go into the nonzero values and the index arrays. The main program follows and calls the previously mentioned functions to initialize and then wait on a barrier to ensure that all initializations took place before the compression took place.
5.4 FREEING ALLOCATED SPACES
The benefit from dynamic memory allocation would not be complete without being able to deallocate the space when it is no longer needed. This is one of the main distinctions between dynamic and static memory allocation. In many cases, when reusing the space is not an issue, one may simply do nothing, and at the program exit, all allocated space is freed. However, for large applications where reusing space is important, upc_free() can be used. This call has the following syntax:
void upc_free(shared void *ptr);
The upc_free() function frees the dynamically allocated shared storage pointed to by ptr. If ptr is a null pointer, no action occurs. Otherwise, if the argument does not match a pointer returned earlier by the upc_alloc(), upc_global_alloc(), upc_all_alloc(), or upc_local_alloc() functions, or if the space has been deallocated by a previous call, by any thread, to upc_free(), the behavior is undefined.
In many of the previous programming examples, we could have used upc_free(). For example, in Example 5.1 we can use
upc_free(sh_grids);
between lines 87 and 88. Similarly, for Example 5.5 we could have used
upc_free(sparse_data_A [MYTHREAD].colind); upc_free(sparse_data_A [MYTHREAD].rowptr); upc_free(sparse_data_A [MYTHREAD].values);
between lines 57 and 58.
There are many intriguing examples that require changing the size of the memory used, such as iterative data compression (e.g., using the Wavelet transform, where data gets smaller after each iteration). Memory allocation and freeing can work nicely in these cases.
5.5 SUMMARY
In this chapter we discussed the three different ways to allocate shared storage space under UPC. The function upc_all_alloc() is a collective function that is called by all threads and allocates one shared space and returns one pointer to the space allocated to the threads. The function upc_global_alloc() is a noncollective version of the upc_all_alloc(). Each calling thread gets a separate shared space and is returned a different shared pointer to that space. Finally, upc_alloc() is a noncollective function. When called, each calling thread gets a pointer to a shared space with affinity to the calling thread, and a different pointer is returned to each calling thread. To free the space allocated previously, one can use upc_free().
EXERCISES
5.1 Improve the matrix-squaring example to accept any N dimension, as specified at the command line [using upc_all_alloc()].
5.2 Enhance the vector addition example to allow the user to enter N and the values for vectors v1 and v2 interactively [using upc_global_alloc()].
5.3 Develop an N × N matrix multiplication with N given at the command line, using N*N/THREADS as the block size [using upc_alloc()].
5.4 Implement the three-dimensional cell variant of the heat conduction problem, accepting N at the command line [using upc_alloc()].
UPC: Distributed Shared Memory Programming, by Tarek El-Ghazawi, William Carlson, Thomas Sterling, and Katherine Yelick
Copyright © 2005 John Wiley & Sons, Inc.