
In Chapter 5 I explained how your app could navigate various storage folders to manipulate files. However, I did not explain how to access the contents of the files. In this chapter, you’ll learn how to transfer data to and from files using stream input and output. However, streams are not just for files; you can use them as a general-access mechanism to transfer data. For example, you also use streams to transfer data over sockets. (See Chapter 7.) Streams are also used to manipulate in-memory data, as I’ll show later in this chapter’s “Compressing and decompressing data” and Encrypting and decrypting data sections.
Before diving into streams, I want to show some WinRT APIs that simplify reading and writing the contents of a file for common scenarios. Internally, these simple APIs wrap the slightly more complex stream APIs. The FileIO class looks like this:
public static class FileIO {
public static IAsyncAction WriteBytesAsync(IStorageFile file, Byte[] buffer);
public static IAsyncAction WriteBufferAsync(IStorageFile file, IBuffer buffer);
public static IAsyncOperation<IBuffer> ReadBufferAsync(IStorageFile file);
public static IAsyncAction WriteLinesAsync(IStorageFile file, IEnumerable<String> lines);
public static IAsyncAction AppendLinesAsync(IStorageFile file, IEnumerable<String> lines);
public static IAsyncOperation<IList<String>> ReadLinesAsync(IStorageFile file);
public static IAsyncAction WriteTextAsync(IStorageFile file, String contents);
public static IAsyncAction AppendTextAsync(IStorageFile file, String contents);
public static IAsyncOperation<String> ReadTextAsync(IStorageFile file);
}Files always contain arrays of bytes, and the first three methods shown transfer byte arrays or buffers (which are also byte arrays). The IBuffer interface is explained in this chapter’s Transferring byte buffers section. The remaining methods simplify working with text files. Text (characters) are always converted to byte arrays via an encoding. The remaining six methods all convert the specified string to a byte array using a UTF-8 encoding. There are overloads of these six methods (not shown) that allow you to pass a UnicodeEncoding parameter. UTF-8 and UTF-16 (big-endian and little-endian) are supported.
The following code creates a file in our package’s temporary folder, writes strings to that file, and then reads the strings back:
// Create a file:
StorageFile file = await ApplicationData.Current.TemporaryFolder.CreateFileAsync("MyFile.txt");
// Write 2 lines of text to the file (encoded with UTF-8):
String[] output = new[] { "This is line 1", "This is line 2" };
await FileIO.WriteLinesAsync(file, output);
// Read the lines of text from the file (decoded with UTF-8):
IList<String> input = await FileIO.ReadLinesAsync(file);WinRT also provides a static PathIO class whose methods are identical to those of the FileIO class except that the methods accept an absolute path string instead of an IStorageFile. In addition, PathIO’s methods require that the file already exist. Here is the previous code modified to use the PathIO class:
// NOTE: You MUST create the file before writing to it:
StorageFile file = await ApplicationData.Current.TemporaryFolder.CreateFileAsync("MyFile.txt");
// Write 2 lines of text to the file (encoded with UTF-8):
String[] output = new[] { "This is line 1", "This is line 2" };
await PathIO.WriteLinesAsync(file.Path, output);
// Read the lines of text from the file (decoded with UTF-8):
IList<String> input = await PathIO.ReadLinesAsync(file.Path);As you can see, FileIO’s and PathIO’s methods are straightforward to use. All their methods open the file, transfer the data, and subsequently close the file. These methods are great for some common scenarios, but they provide little control and are certainly not suitable for working with large files because they read the whole file into memory all at once. When you need more control over the stream, you’ll use the WinRT interfaces and classes defined in the Windows.Storage.Streams namespace. These types make up the streams object model.
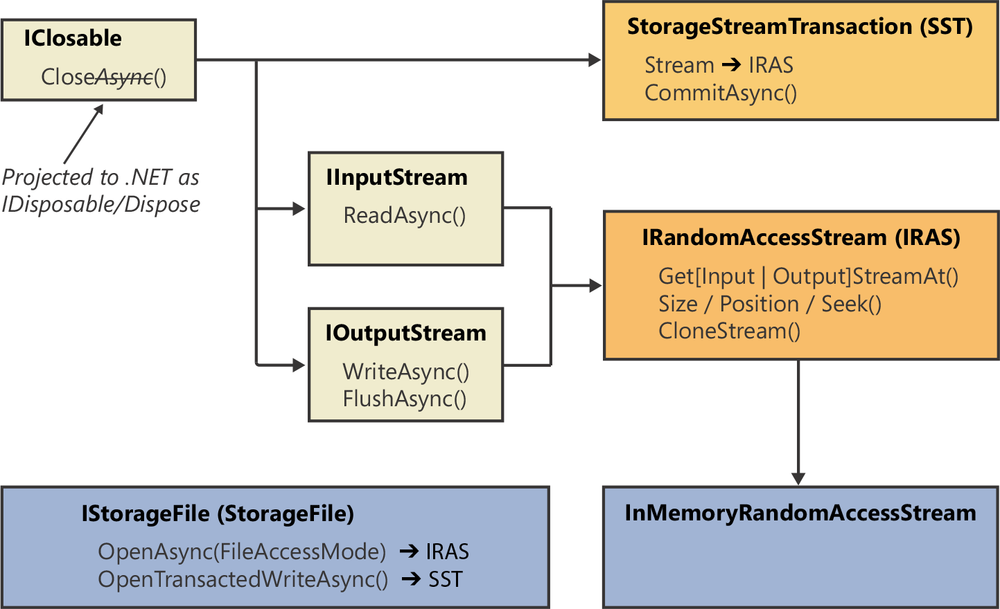
Figure 6-1 shows WinRT’s streams object model. Both IInputStream and IOutputStream inherit from IClosable. This indicates that classes implementing either of these interfaces require special cleanup because they wrap a native resource like a file or socket handle. In Chapter 1 I discussed how the CLR projects WinRT’s Windows.Foundation.IClosable interface (which has only a Close method) as the .NET Framework’s System.IDisposable interface (with its Dispose method). This allows you to use C#’s using statement with WinRT IClosable types so that their Close method is called within a finally block, causing cleanup to occur immediately after the try block executes or if an exception is thrown as opposed to waiting for a future garbage collection.
Important
One thing to take note of here is that all WinRT APIs that perform I/O operations are implemented asynchronously. Because the name for IClosable’s method is Close and not CloseAsync, the Close method cannot perform any I/O operations. This is semantically different from how Dispose works in the Microsoft .NET Framework. For .NET Framework–implemented types, calling Dispose can do I/O and, in fact, it frequently causes buffered data to be flushed before actually closing a device. When C# code calls Dispose on a WinRT type, however, I/O (like flushing) will not be performed and a loss of data is possible. You must be aware of this and, in some cases, you might have to flush data in your code explicitly. I will explicitly point out in this chapter when it is necessary to do this.
IInputStream and IOutputStream are the basic interfaces that read buffers (byte arrays) from and write buffers to a stream. IInputStream’s ReadAsync method reads bytes from a stream into a buffer and IOutputStream’s WriteAsync method writes bytes from a buffer to a stream.
IOutputStream has an additional method: FlushAsync. Most apps will never call this method. Let me explain its purpose. When writing to a stream, Windows internally buffers (caches) the data in memory and writes the data to the stream when the memory buffer fills or if the buffer sits idle for a while. Windows does this to improve performance for apps that frequently issue small write operations because accessing the hardware (which is slower than RAM) incurs a performance hit. Because of this, an app could “write data to a stream” and, if the power fails on the machine before the data is flushed to the stream, the data would be lost.
Apps that are working with critically important data can call FlushAsync to reduce the chance of data being lost. Beware that calling FlushAsync does not guarantee that data will not be lost because a power failure could still occur between calling WriteAsync and FlushAsync. Internally, WinRT’s FlushAsync method does the same thing as Win32’s FlushFileBuffers function. (See http://msdn.microsoft.com/en-us/library/windows/desktop/aa364439.aspx.) Note that calling FlushAsync frequently hurts the performance of your app, and this is why most apps will not call it.[43]
The IInputStream and IOutputStream interface methods let you access a stream sequentially and are useful when you don’t know the number of bytes in the stream (as is the case with network streams). However, the IRandomAccessStream interface allows you to access the underlying stream randomly. Because IRandomAccessStream inherits from both IInputStream and IOutputStream, it can be used for both reading and writing.
To start reading from or writing to a specific byte within a stream, call IRandomAccessStream’s Seek method to position the stream to the desired byte and then call ReadAsync or WriteAsync to start accessing the stream sequentially from the desired position. Alternatively, you can call GetInputStreamAt or GetOutputStreamAt to get a stream starting at a byte offset within the stream. The stream’s Position property advances whenever you call ReadAsync or WriteAsync.
Important
Make sure you issue read and write operations sequentially against a single stream to maintain the integrity of the stream’s current position. Issuing multiple requests concurrently produces non-deterministic results.
The IRandomAccessStream interface offers a Size property you can use to query or set the size of the stream. Under normal circumstances, you would not set the size because the system automatically grows it when appending to a random-access stream. But, if you know what size you want the stream to be before writing to it, you might want to set the size first because this tends to improve performance when writing to the stream.
Therefore, to read from or write to a file, you would simply call IStorageFile’s OpenAsync method to obtain an IRandomAccessStream and then start calling its ReadAsync or WriteAsync methods. When done, you can call Dispose or let the garbage collector take care of it for you. You’ll see code demonstrating this shortly. IStorageFile offers an OpenTransactedWriteAsync method that returns a reference to a StorageStreamTransaction object that implements the IClosable interface. The StorageStreamTransaction class is discussed in this chapter’s Performing transacted write operations section.
Understanding the streams object model is critically important when building Windows Store apps because many WinRT components use streams. For example,
The
IRandomAccessStreaminterface is used by storage files, images, bitmaps, thumbnails, media, and theInMemoryRandomAccessStreamclass.The
IInputStreaminterface is used by the background transfer manager and theDataReader, DataProtectionProvider, Decompressor, andAtomPubClientclasses.The
IOutputStreaminterface is used by networking, as well as theDataWriter, DataProtectionProvider, Compressor, andInkManagerclasses.
The .NET Framework has its System.IO.Stream class (and many types derived from it), and there are many useful classes in the .NET Framework designed to take input and output from these Stream-derived classes. LINQ to XML and the serialization technologies are two that immediately come to mind. So, if you want to use these .NET technologies with WinRT storage files, you’re going to have to use the framework projection methods (as discussed in Chapter 1) defined in the System.IO.WindowsRuntimeStorageExtensions class to help you:
namespace System.IO { // Defined in System.Runtime.WindowsRuntime.dll
public static class WindowsRuntimeStorageExtensions {
public static Task<Stream> OpenStreamForReadAsync(this IStorageFile file);
public static Task<Stream> OpenStreamForWriteAsync(this IStorageFile file);
public static Task<Stream> OpenStreamForReadAsync(this IStorageFolder rootDirectory,
String relativePath);
public static Task<Stream> OpenStreamForWriteAsync(this IStorageFolder rootDirectory,
String relativePath, CreationCollisionOption creationCollisionOption);
}
}Here is an example that opens a WinRT StorageFile and reads its contents into a .NET Framework System.Xml.Linq.XDocument object:
StorageFile winRTfile = await Package.Current.InstalledLocation
.GetFileAsync("AppxManifest.xml");
using (Stream netStream = await winRTfile.OpenStreamForReadAsync()) {
XDocument xml = XDocument.Load(netStream);
// Use the xml here...
}The System.IO.WindowsRuntimeStreamExtensions class also offers extension methods, which “cast” WinRT stream interfaces (such as IRandomAccessStream, IInputStream, or IOutputStream) to the .NET Framework’s Stream type and vice versa:
namespace System.IO { // Defined in System.Runtime.WindowsRuntime.dll
public static class WindowsRuntimeStreamExtensions {
public static Stream AsStream(this IRandomAccessStream winRTStream);
public static Stream AsStream(this IRandomAccessStream winRTStream, Int32 bufferSize);
public static Stream AsStreamForRead(this IInputStream winRTStream);
public static Stream AsStreamForRead(this IInputStream winRTStream, Int32 bufferSize);
public static Stream AsStreamForWrite(this IOutputStream winRTStream);
public static Stream AsStreamForWrite(this IOutputStream winRTStream, Int32 bufferSize);
public static IInputStream AsInputStream (this Stream netStream);
public static IOutputStream AsOutputStream(this Stream netStream);
public static IRandomAccessStream AsRandomAccessStream(this Stream netStream);
}
}Now that you have the basic concepts around working with streams, let’s take a closer look at the specifics. The IInputStream and IOutputStream interfaces are shown here:
public interface IInputStream : IDisposable {
IAsyncOperationWithProgress<IBuffer, UInt32> ReadAsync(
IBuffer buffer, UInt32 count, InputStreamOptions options);
}
public interface IOutputStream : IDisposable {
IAsyncOperationWithProgress<UInt32, UInt32> WriteAsync(IBuffer buffer);
IAsyncOperation<Boolean> FlushAsync();
}As you can see, the ReadAsync and WriteAsync methods both operate on IBuffer objects. So, what is an IBuffer? Well, an IBuffer object represents a byte array and the interface looks like this:
public interface IBuffer {
UInt32 Capacity { get; } // Maximum size of the buffer (in bytes)
UInt32 Length { get; set; } // Number of bytes currently in use by the buffer
}As you can see, the IBuffer interface has length and maximum capacity properties. Oddly enough, this interface offers no way to access the buffer’s bytes. The reason for this is that WinRT types cannot express pointers in their metadata because pointers do not map well to some languages (like JavaScript or safe C# code). The interface could offer a method to access individual bytes in the buffer, but calling a method to get each byte would hurt performance too much. Therefore, an IBuffer object lets you pass buffers around, but you can’t access their contents.
However, all is not lost because all WinRT IBuffer objects implement an internal COM interface known as IBufferByteAccess. Note that this interface is a COM interface (because it returns a pointer) and it is not a WinRT interface. The CLR defines an internal (not public) Runtime Callable Wrapper (RCW) for this COM interface that looks like this:
namespace System.Runtime.InteropServices.WindowsRuntime {
[ComImport]
[InterfaceType(ComInterfaceType.InterfaceIsIUnknown)]
[Guid("905a0fef-bc53-11df-8c49-001e4fc686da")]
internal interface IBufferByteAccess {
unsafe Byte* Buffer { get; }
}
}Internally, the CLR can take an IBuffer object, query for its IBufferByteAccess interface, and then query the Buffer property to get an unsafe pointer to the bytes contained within the buffer. With the pointer, the bytes can be accessed directly.
To avoid having developers write unsafe code that manipulates pointers, the .NET Framework Class Library includes a WindowsRuntimeBufferExtensions class that defines a bunch of extension methods that .NET Framework developers explicitly call to convert between .NET byte arrays and streams to WinRT IBuffer objects. The methods are shown here:
// Defined in System.Runtime.WindowsRuntime.dll
namespace System.Runtime.InteropServices.WindowsRuntime {
public static class WindowsRuntimeBufferExtensions {
public static IBuffer AsBuffer(this Byte[] source);
public static IBuffer GetWindowsRuntimeBuffer(this MemoryStream stream);
public static Byte[] ToArray(this IBuffer source);
public static Stream AsStream(this IBuffer source);
// Not shown: other overloads, CopyTo, GetByte, & IsSameData
}
}Note
In general, methods that start with As (like AsBuffer and AsStream) are like casts; that is, they make one type look like another type. These methods are fast and efficient. On the other hand, methods that start with To (like ToArray) convert one type to another type by copying data and are therefore not as efficient as the As methods.
Here is code demonstrating how to use many of WindowsRuntimeBufferExtension’s framework projection methods:
private async void SimpleWriteAndRead(StorageFile file) {
using (IRandomAccessStream raStream = await file.OpenAsync(FileAccessMode.ReadWrite)) {
Byte[] bytes = new Byte[] { 1, 2, 3, 4, 5 };
UInt32 bytesWritten = await raStream.WriteAsync(bytes.AsBuffer()); // Byte[] -> IBuffer
using (var ms = new MemoryStream())
using (var sw = new StreamWriter(ms)) {
sw.Write("A string in a stream");
sw.Flush(); // Required: Flushes StreamWriter's contents to underlying MemoryStream
bytesWritten =
await raStream.WriteAsync(ms.GetWindowsRuntimeBuffer()); // Stream -> IBuffer
}
} // Close the stream
using (IRandomAccessStream raStream = await file.OpenAsync(FileAccessMode.Read)) {
// NOTE: This is the most efficient way to allocate, populate, & access data:
Byte[] data = new Byte[5]; // Allocate the Byte[]
IBuffer proposedBuffer = data.AsBuffer(); // Wrap it in an object that implements IBuffer
IBuffer returnedBuffer = await raStream.ReadAsync(proposedBuffer,
proposedBuffer.Capacity, InputStreamOptions.None);
if (returnedBuffer != proposedBuffer) {
// The proposed & returned IBuffers are not the same.
// Copy the returned bytes into the original Byte[]
returnedBuffer.CopyTo(data);
} else {
// The proposed & returned IBuffers are the same.
// The returned bytes are already in the original Byte[]
}
// TODO: Put code here to access the read bytes from the data array...
data = new Byte[raStream.Size - 5]; // Allocate Byte[] for remainder
proposedBuffer = data.AsBuffer(); // Wrap it in an object that implements IBuffer
returnedBuffer = await raStream.ReadAsync(proposedBuffer,
proposedBuffer.Capacity, InputStreamOptions.None);
// We just use the returned IBuffer here
using (var sr = new StreamReader(returnedBuffer.AsStream())) {
String str = sr.ReadToEnd();
}
} // Close the stream
}When you call AsBuffer, it internally constructs a System.Runtime.InteropServices.WindowsRuntimeBuffer object around your byte array. The WindowsRuntimeBuffer class also offers a static Create method that can allocate the array and wrap it with a WindowsRuntimeBuffer object.
Similarly, WinRT offers a Windows.Storage.Streams.Buffer class that creates an IBuffer object whose bytes are in the native heap. For most .NET Framework developers, there should be less need to use this class because memory in the managed heap can be pinned and accessed from native code without copying.
When calling ReadAsync, you pass it a proposed IBuffer where the code implementing the IInputStream interface can put the read bytes. However, the code can ignore the proposed IBuffer and instead use another IBuffer that it creates internally (which may have a different Capacity). An implementation might do this if it has prefetched data that is already residing in one of its buffers, for example. So, when calling ReadAsync, you must always access the read bytes using the IBuffer it returns. If ReadAsync returns the same buffer that was proposed, you can optimize the code (as shown in the preceding code). ReadAsync’s InputStreamOptions parameter is discussed in Chapter 7’s StreamSocket: Client-side TCP communication section.
Streams contain bytes. But, in our apps, we frequently have other primitive data types like Int32s, Strings, DateTimeOffsets, and so on. To write any of these to a stream, we’d have to decompose each one into its constituent bytes. And, to read these from a stream, we’d have to read the right number of bytes and then compose them into an object of the right type. In the .NET Framework, you use the System.IO.BinaryWriter and System.IO.BinaryReader classes to store and retrieve primitive data types from a stream. The equivalent WinRT classes are the Windows.Storage.Streams.DataWriter and Windows.Storage.Streams.DataReader classes. In essence, these classes provide an abstraction over a byte buffer and a stream.
Here is what the DataWriter class looks like (personally, I think my comments explain how the class works better than the MSDN documentation):
public sealed class DataWriter : IDataWriter, IDisposable {
// Constructs a DataWriter over a growable buffer (see DetachBuffer below)
public DataWriter();
// Constructs a DataWriter over an output stream and a growable buffer
public DataWriter(IOutputStream outputStream);
// All WriteXxx methods append data to the buffer (growing it if necessary)
public void WriteBoolean(Boolean value);
public void WriteByte(Byte value);
public void WriteBytes(Byte[] value);
public void WriteBuffer(IBuffer buffer);
public void WriteBuffer(IBuffer buffer, UInt32 start, UInt32 count);
public void WriteInt16(Int16 value);
public void WriteUInt16(UInt16 value);
public void WriteInt32(Int32 value);
public void WriteUInt32(UInt32 value);
public void WriteInt64(Int64 value);
public void WriteUInt64(UInt64 value);
public void WriteSingle(Single value);
public void WriteDouble(Double value);
public void WriteGuid(Guid value);
public void WriteDateTime(DateTimeOffset value);
public void WriteTimeSpan(TimeSpan value);
// For WriteXxx methods, indicates how bytes append to buffer (big/little endian)
public ByteOrder ByteOrder { get; set; } // Default=BigEndian
// Strings are encoded via UnicodeEncoding (Utf8, Utf16LE, or Utf16BE) instead of ByteOrder
public UnicodeEncoding UnicodeEncoding { get; set; } // Default=Utf8
// Returns how many bytes a string requires when encoded via UnicodeEncoding
public UInt32 MeasureString(String value);
// Appends the encoded string's bytes to the buffer
public UInt32 WriteString(String value);
// Returns the current size of the buffer
public UInt32 UnstoredBufferLength { get; }
// Writes the buffer to the underlying stream & clears the internal buffer
public DataWriterStoreOperation StoreAsync();
// Returns the buffer the DataWriter was using and associates a new empty buffer with it
public IBuffer DetachBuffer();
// Disassociates stream; stream will NOT be closed when Dispose is called
public IOutputStream DetachStream();
// Closes stream (if not detached); does NOT call StoreAsync
public void Dispose();
// Calls FlushAsync on underlying stream
public IAsyncOperation<Boolean> FlushAsync();
}Important
To work effectively with the DataWriter class, you must really appreciate that only XxxAsync methods perform I/O operations and all the other methods cannot perform I/O operations. Therefore, all the WriteXxx methods cannot do I/O; they all append bytes to an in-memory buffer. You must periodically call StoreAsync to have the in-memory buffer’s contents written to the underlying stream. And, if you do not call StoreAsync and later call Dispose, the contents of the in-memory buffer will not be written to the underlying stream and the contents of it will be thrown away. Because Dispose is not an asynchronous method, it cannot perform I/O operations, and therefore it cannot internally call StoreAsync for you.
The following code shows how to use a DataWriter to store a byte array and a string into a stream:
private async void DataWriterSample(StorageFile file) {
using (var dw = new DataWriter(await file.OpenAsync(FileAccessMode.ReadWrite))) {
dw.WriteBytes(new Byte[] { 1, 2, 3, 4, 5 });
const String text = "Some text";
// Store the string length first followed by the string so we can read it back later
UInt32 encodedStringLength = dw.MeasureString(text);
dw.WriteUInt32(encodedStringLength);
dw.WriteString(text);
UInt32 bytesStored = await dw.StoreAsync(); // Commit buffer to stream
} // Close DataWriter & underlying stream
}Here is what the DataReader class looks like:
public sealed class DataReader : IDataReader, IDisposable {
// Constructs a DataReader over an existing buffer instead of loading a buffer from a stream
public static DataReader FromBuffer(IBuffer buffer);
// Constructs a DataReader over an input stream and a growable buffer
public DataReader(IInputStream inputStream);
// Reads count bytes from stream appending them to buffer
public DataReaderLoadOperation LoadAsync(UInt32 count);
// Indicates whether LoadAsync can prefetch more bytes than requested to by 'count'
public InputStreamOptions InputStreamOptions { get; set; }
// Returns number of bytes in buffer yet to be read
public UInt32 UnconsumedBufferLength { get; }
// All ReadXxx methods read data from buffer (throwing Exception if buffer is empty)
public Boolean ReadBoolean();
public Byte ReadByte();
public void ReadBytes(Byte[] value);
public IBuffer ReadBuffer(UInt32 length);
public Int16 ReadInt16();
public UInt16 ReadUInt16();
public Int32 ReadInt32();
public UInt32 ReadUInt32();
public Int64 ReadInt64();
public UInt64 ReadUInt64();
public Single ReadSingle();
public Double ReadDouble();
public Guid ReadGuid();
public DateTimeOffset ReadDateTime();
public TimeSpan ReadTimeSpan();
// For ReadXxx methods, indicates how bytes get read from the buffer (big/little endian)
public ByteOrder ByteOrder { get; set; } // Default=BigEndian
// Strings are decoded via UnicodeEncoding (Utf8, Utf16LE, or Utf16BE) instead of ByteOrder
public UnicodeEncoding UnicodeEncoding { get; set; } // Default=Utf8
// Decodes codeUnitCount bytes from the buffer to a string via UnicodeEncoding
public String ReadString(UInt32 codeUnitCount);
// Returns the buffer the DataReader was using and associates a new empty buffer with it
public IBuffer DetachBuffer();
// Disassociates stream; stream will NOT be closed when Dispose is called
public IInputStream DetachStream();
// Closes stream (if not detached)
public void Dispose();
}The following code shows how to use a DataReader to read back the data stored in the file by the DataWriterSample method shown earlier:
private async void DataReaderSample(StorageFile file) {
using (var dr = new DataReader(await file.OpenAsync(FileAccessMode.Read))) {
Byte[] bytes = new Byte[5];
UInt32 bytesRead = await dr.LoadAsync((UInt32) bytes.Length);
dr.ReadBytes(bytes);
// Get length of string & read the rest of it in:
bytesRead = await dr.LoadAsync(sizeof(UInt32));
var encodedStringLength = dr.ReadUInt32();
bytesRead = await dr.LoadAsync(encodedStringLength);
String text = dr.ReadString(encodedStringLength);
} // Close DataReader & underlying stream
}If you have objects more complex than the primitive types supported by DataWriter and DataReader, you’re probably best off using a .NET serialization technology (such as the DataContractSerializer or the DataContractJsonSerializer) to convert the objects to a byte array or JSON string first, and then you can write this to a stream. Later, you can read it back from the stream and deserialize the byte array or string back to an object graph.
Imagine you’re writing an app that allows the user to enter some data and then you write the data to a file. If, while saving the user’s data, your app crashes or the power goes out, the file’s contents are incomplete and your app might not be able to read the file back successfully. To make matters worse, what if the user was saving the new data in an existing file. Now the old data is destroyed and the new data is corrupt.
To address this problem, WinRT allows you to perform file write operations in a transacted fashion. That is, either the entire write occurs or none of it occurs. When writing data to a file, you should use the technique shown in this section to guarantee the consistency of file data. The reason not to use this technique is that it temporarily requires some additional disk space and, if you are making changes to a large existing file, there is a performance impact.
To start, you must first open a file with transacted write access by calling IStorageFile’s OpenTransactedWriteAsync method. This method returns a StorageStreamTransaction object:
public sealed class StorageStreamTransaction : IDisposable {
public IRandomAccessStream Stream { get; }
public IAsyncAction CommitAsync();
public void Dispose();
}Once you have this object, all you need to do is query its Stream property, which returns an IRandomAccessStream. You get this same interface back when you call IStorageFile’s OpenAsync method. With the IRandomAccessStream, you can use all the techniques already discussed in this chapter. For example, you can pass the IRandomAccessStream when constructing DataWriter and DataReader objects.
The first time you actually write data to the stream, WinRT creates a hidden file in the same directory as the original file and your writes actually go into this hidden file. For example, if the original file is called “MyFile.txt”, the hidden file is called “MyFile.txt.~tmp”. This temporary file is filled with a copy of the original file’s bytes up to the offset where you start writing new data. Depending on what offset within the stream you start writing, there could be a performance impact on your app while bytes are being copied. After copying the bytes, any new data is written to the temporary file. If your app crashes or if a power failure occurs, the original file is left untouched and the user still has access to the original file.
Once your app has finished writing to the temporary file’s stream, you call StorageStreamTransaction’s CommitAsync method. This method copies any unchanged bytes from the original file to the temporary file, and then it atomically deletes the original file and renames the temporary file with the original file’s name (calls the StorageFile.RenameAsync method, passing NameCollisionOption.ReplaceExisting).
The following code demonstrates how to perform an atomic write operation to a file:
private async void TransactedWriter(StorageFile file) {
// Populate the file with some original data
const String header = "Data: ";
using (var dw = new DataWriter(await file.OpenAsync(FileAccessMode.ReadWrite))) {
dw.WriteString(header + "The original data.");
await dw.StoreAsync();
}
// Now, perform a transacted write to the file. The 1st time we won't commit the new data.
for (Int32 commit = 0; commit <= 1; commit++) {
// Perform transacted write without & with commit
using (StorageStreamTransaction txStream = await file.OpenTransactedWriteAsync())
using (var dw = new DataWriter(txStream.Stream.GetOutputStreamAt((UInt32)header.Length))) {
dw.WriteString("The new & improved data.");
await dw.StoreAsync();
if (commit == 1) await txStream.CommitAsync();
}
String text = await FileIO.ReadTextAsync(file);
}
}When this code executes, the first time through the loop CommitAsync is not called and text will contain “Data: The original data.” But the second time through the loop, CommitAsync is called and therefore text will contain “Data: The new & improved data.”
Long-time users of Windows might be familiar with a problem that has plagued Windows for quite some time. Sometimes, when using an app to save a file, the save operation fails with an error indicating that the file is in use by another app. If you wait a few seconds and try to save the file again, the save operation succeeds. This problem occurs when an app (like the Windows Content Indexing service) opens the file for reading with exclusive access, preventing other apps from opening the same file at the same time.
Many users have complained about this situation and, with the WinRT API, Microsoft took steps to solve it. When an app calls IStorageFile’s OpenAsync method passing FileAccessMode.Read, the app opens the file in such a way that allows other apps to also open the file for reading. In addition, the file is opened with a feature of the file system called an opportunistic lock (or oplock for short). With the oplock applied to the file, if another app attempts to open the file by calling the IStorageFile’s OpenAsync method passing FileAccessMode.ReadWrite, the app gets access to the file, and any app that had the file opened for reading will get an exception thrown the next time it attempts to read from the file.
The behavior I just described is referred to as polite reader behavior because the app reading from the file is being polite to the app that wants to write to the file. The idea is based on the notion that writes to a file are based on explicit end-user actions. On the other hand, reads from a file can be app initiated (like content indexing or backup apps) and app-initiated operations should not interfere with explicit user actions; the user should always be in control, and the system should behave predictably to them.
Although this WinRT API behavior is great for end users, it does make more work for the app developer. There are three approaches for how to handle the polite reader issue in an app:
Wrap your code that reads from a file in a loop containing a
try/catchblock. If a read fails, catch the exception, close the file, and loop around to try again. Writing the code this way is annoying, but this is really the best approach to follow.Do not catch the exception, and let your app terminate. Then the user will relaunch your app, which will try to access the file again. Most likely, your app will be successful. Or, if the code is executed by a recurring background task, the OS will automatically re-execute it in the future. As much as it pains me to suggest this option, many developers take this route because it is very unlikely that another app will try to write to a file while your app is reading from it. The other reason why many developers take this route is simply that they are not aware of WinRT’s polite reader behavior. Because the exception almost never occurs, most developers have never seen it, so they don’t even know that this is something they should be taking into consideration when implementing their code.[44]
Always open the file for writing, even if you just intend to read from the file. WinRT allows only one app to open a file for writing. If other apps use WinRT APIs in an attempt to open the file for reading or writing, the open operation fails. So, if an app has a file open for writing, it never loses its access to the file. I can’t really recommend this approach, though, because it is not in keeping with the philosophy that the user should always be in control. If you go this route, users might get errors when they are actively interacting with an app that tries to write to the same file.
Here is a method that demonstrates how to implement polite reader logic:
private async void PoliteReader(StorageFile file) {
await FileIO.WriteTextAsync(file, "Here is some data I wrote to the file");
Int32 injectWriteForTesting = 0; // Demos polite reader recovery
while (true) {
injectWriteForTesting++;
try {
// Open the file for read access
using (IRandomAccessStream readOnly = await file.OpenAsync(FileAccessMode.Read)) {
if (injectWriteForTesting == 1) {
// NOTE: another app can write to file while this app has file open for reading:
await FileIO.WriteTextAsync(file, "Write NEW data to the file");
}
// This app tries to read from the file it already opened:
Byte[] bytes = new Byte[readOnly.Size]; // NOTE: Size returns 0 if file written to
IBuffer buffer = bytes.AsBuffer();
if (injectWriteForTesting == 2) {
// NOTE: another app can write to file while this app has file open for reading:
await FileIO.WriteTextAsync(file, "Write NEWER data to the file");
}
// NOTE: If Size is 0, this throws IndexOutOfRangeException; otherwise this throws
// Exception (HResult=0x80070323) if file is written to; else no exception
await readOnly.ReadAsync(buffer, buffer.Capacity, InputStreamOptions.ReadAhead);
// TODO: Process the data read here...
}
break; // Success, don't retry
}
catch (IndexOutOfRangeException) {
// NOTE: Thrown from ReadAsync if Size is 0
// If we get here, we'll loop around and retry the read operation
}
catch (Exception ex) {
const Int32 ERROR_OPLOCK_HANDLE_CLOSED = unchecked((Int32)0x80070323);
if (ex.HResult != ERROR_OPLOCK_HANDLE_CLOSED) throw;
// If we get here, we'll loop around and retry the read operation
}
}
}This code is a little depressing to look at because of the unobvious and undocumented behaviors it exhibits. The code tries to open a file for reading, reads the file’s contents, and then closes the file. But, after the file is open for reading, another app could successfully write to the file. The first time through the loop, I inject a write operation after opening the file for reading and before querying the stream’s Size property. The write operation causes the Size property to return zero, which causes my code to create a 0-byte array/buffer, and then I call ReadAsync. When 0 is passed to ReadAsync’s second parameter, it throws an IndexOutOfRangeException. I catch this and retry the read operation.
The second time through the loop, the Size property does not return zero. Therefore, my code allocates an actual array/buffer and attempts to read from the stream. This time, I inject a write operation just before the call to ReadAsync, causing ReadAsync to throw a System.Exception object whose HResult property contains the value 0x80070323 corresponding to the Windows error ERROR_OPLOCK_HANDLE_CLOSED.[45] If you look at the exception object’s Message property, you’ll see the following: “The handle with which this oplock was associated has been closed. The oplock is now broken. (Exception from HRESULT: 0x80070323).” The code shows the best way to detect this failure. On the third retry, no writes are injected and the read operation completes successfully.
Important
For Windows Store apps, it is just a good practice to avoid keeping files open for long periods of time. It is much better to open a file, access its contents, and then close the file. Not keeping files open makes it easier to implement code that deals with this polite reader issue because the longer a file is open, the greater chance there is another app could open it for writing, making recovery much harder. And it also makes it easier to deal with Process Lifetime Management (discussed in Chapter 3) issues where the OS can terminate your app at any time, requiring you to architect your app to launch back to where the user was when last using your app. Figuring out where in your code you’d have to re-open files can be very complicated. This complication goes away if, at every place in your code where you need to access the file’s contents, you open and close the file.
When writing data to a stream, you can compress the data thereby minimizing the amount of data you’re sending over a network or persisting in a file. To do this, you’ll use the Windows.Storage.Compression.Compressor class:
public sealed class Compressor : IOutputStream, IDisposable {
// Bytes are compressed in a buffer of 'blocksize' bytes and written to underlying stream
public Compressor(IOutputStream stream, CompressAlgorithm algorithm, UInt32 blockSize);
// Compresses a buffer's bytes; the first write includes a header indicating the algorithm
public IAsyncOperationWithProgress<UInt32, UInt32> WriteAsync(IBuffer buffer);
// Called after last WriteAsync; stores internal buffer's remaining bytes to stream
public IAsyncOperation<Boolean> FinishAsync();
// Disassociates stream; stream will NOT be closed when Dispose is called
public IOutputStream DetachStream();
// Closes stream (if not detached); does NOT call FinishAsync
public void Dispose();
// Calls FlushAsync on underlying stream
public IAsyncOperation<Boolean> FlushAsync();
}This is the currently supported set of compression algorithms:
public enum CompressAlgorithm {
InvalidAlgorithm = 0, // Invalid; used for error checking
NullAlgorithm = 1, // No compression; typically used for testing
Mszip = 2, // MSZIP algorithm
Xpress = 3, // XPRESS algorithm
XpressHuff = 4, // XPRESS algorithm with Huffman encoding
Lzms = 5, // LZMS algorithm
}So now you could trivially write a method that compresses a file:
async Task CompressFileAsync(IStorageFile originalFile, IStorageFile compressedFile) {
using (var input = await originalFile.OpenAsync(FileAccessMode.Read))
using (var output = await compressedFile.OpenAsync(FileAccessMode.ReadWrite))
using (var compressor = new Compressor(output, CompressAlgorithm.Mszip, 0)) {
// NOTE: Compressor implements the IOutputStream interface
await RandomAccessStream.CopyAsync(input, compressor);
await compressor.FinishAsync();
}
}When reading data from a stream, you can decompress the data using the Windows.Storage.Compression.Decompressor class:
public sealed class Decompressor : IInputStream, IDisposable {
// Bytes are decompressed as they are read from the underlying stream
public Decompressor(IInputStream underlyingStream);
// Decompresses a stream's bytes; the first read includes a header indicating the algorithm
public IAsyncOperationWithProgress<IBuffer, UInt32> ReadAsync(
IBuffer buffer, UInt32 count, InputStreamOptions options);
// Disassociates stream; stream will NOT be closed when Dispose is called
public IInputStream DetachStream();
// Closes stream (if not detached)
public void Dispose();
}The method to decompress a file is even simpler:
async Task DecompressFileAsync(IStorageFile compressedFile, IStorageFile decompressedFile) {
using (var decompressor = new Decompressor(
await compressedFile.OpenAsync(FileAccessMode.Read)))
using (var output = await decompressedFile.OpenAsync(FileAccessMode.ReadWrite)) {
// NOTE: Decompressor implements the IInputStream interface
await RandomAccessStream.CopyAsync(decompressor, output);
}
}So this is all there is to it; pretty easy. Note that Compressor’s WriteAsync method and Decompressor’s ReadAsync method both return an IAsyncOperationWithProgress. With this, your app can give progress updates to the user if the buffer/stream is large. Finally, note that these classes compress/decompress a stream. They do not compress multiple files into a library like common ZIP utilities. Although WinRT does not offer classes to accomplish this, the .NET Framework does; see the System.IO.Compression.ZipArchive class.
When writing data to a stream, you can encrypt the data thereby making it difficult for others to interpret it when sending it over a network or persisting it to a file. To do this, you’ll use the Windows.Security.Cryptography.DataProtection.DataProtectionProvider class:
public sealed class DataProtectionProvider {
// When encrypting a buffer or stream, use these three members
public DataProtectionProvider(String protectionDescriptor);
public IAsyncOperation<IBuffer> ProtectAsync(IBuffer data);
public IAsyncAction ProtectStreamAsync(IInputStream src, IOutputStream dest);
// When decrypting a buffer or stream, use these three members
public DataProtectionProvider();
public IAsyncOperation<IBuffer> UnprotectAsync(IBuffer data);
public IAsyncAction UnprotectStreamAsync(IInputStream src, IOutputStream dest);
}The following code shows how to encrypt the contents of a file:
async Task EncryptFileAsync(IStorageFile originalFile, IStorageFile encryptedFile,
String protectionDescriptor) {
using (var input = await originalFile.OpenAsync(FileAccessMode.Read))
using (var output = await encryptedFile.OpenAsync(FileAccessMode.ReadWrite)) {
var dpp = new DataProtectionProvider(protectionDescriptor);
await dpp.ProtectStreamAsync(input, output);
}
}When encrypting data, you must create a DataProtectionProvider, passing a string to its constructor. This string indicates the encryption method you want to use. The method is written to the encrypted stream and is read back when decrypting. This is why you create a DataProtectionProvider object for decrypting by invoking its parameterless constructor.
Here are some sample protection-descriptor strings:
“LOCAL=logon” encrypts for the current logon session only on the local computer.
“LOCAL=user” encrypts for the logged-in user on the local computer.
“LOCAL=machine” encrypts for any user on the local computer.
“WEBCREDENTIALS=Jeffrey,wintellect.com” encrypts for Jeffrey on Wintellect.com.
“SID=S-1-5-21-4392301 AND SID=S-1-5-21-3101812” encrypts for the domain account.
“SDDL=O:S-1-5-5-0-290724G:SYD:(A;;CCDC;;;S-1-5-5-0-290724)(A;;DC;;;WD)” encrypts for the domain account.
When using SID or SDDL, the machine must be domain joined. In addition, your app must specify the Enterprise Authentication capability in its manifest and will pass Windows Store certification only if submitted by a company (not an individual account). For more information about protection descriptors, look up “CNG DPAPI Protection Providers” and “CNG DPAPI Constants” on MSDN.
Many of these protection descriptors are self-explanatory, but the one related to web credentials could benefit from some additional discussion. If you want your app to retain web credentials for a user, you store them securely in a Windows.Security.Credentials.PasswordCredential object and then add this object to the user’s PasswordVault:
// Create a web credential (resource/username/password tuple) & add it to the password vault String webSite = "Wintellect.com", username="Jeffrey", password="P@ssw0rd"; var pc = new PasswordCredential(new HostName(webSite).CanonicalName, username, password); new PasswordVault().Add(pc);
Once the credential is added to the password vault, the user can view it via the Control Panel’s Credential Manager applet. Then, to encrypt data using these web credentials, you construct the protection-descriptor string like this:
String webSite = "Wintellect.com", username="Jeffrey"; PasswordCredential pc = new PasswordVault() .Retrieve(new HostName(webSite).CanonicalName, username); String protectionDescriptor = "WEBCREDENTIALS=" + pc.UserName + "," + pc.Resource; // Now, pass protectionDescriptor to DataProtectionProvider's constructor
When reading data from a stream, you can decrypt it using the same DataProtectionProvider class. The following code shows how to decrypt the contents of a file:
async Task DecryptFileAsync(IStorageFile encryptedFile, IStorageFile decryptedFile) {
using (var input = await encryptedFile.OpenAsync(FileAccessMode.Read))
using (var output = await decryptedFile.OpenAsync(FileAccessMode.ReadWrite)) {
var dpp = new DataProtectionProvider();
await dpp.UnprotectStreamAsync(input, output);
}
}Frequently, we use StorageFile objects to transfer data from one app to another. For example, Windows allows you to launch an app via a file-type association (discussed in Chapter 5) or to transfer a file via the clipboard or the Share charm (discussed in Chapter 10), and there are also FileOpenPicker and FileSavePicker activations.
Windows provides a mechanism allowing you to create and pass a StorageFile object to other apps before the file’s contents are available. In addition, the app creating the StorageFile object can populate its contents while the consuming app is reading it. You leverage this mechanism by calling StorageFile’s static CreateStreamedFileAsync method:
public static IAsyncOperation<StorageFile> CreateStreamedFileAsync( String displayNameWithExtension, StreamedFileDataRequestedHandler dataRequested, IRandomAccessStreamReference thumbnail);
The first parameter identifies the name of the StorageFile. The second parameter identifies a callback method that is invoked only when the contents of the stream are required; this method populates the file’s stream with contents at this time. The third parameter identifies a thumbnail image that a receiving app can display to the user if it desires; the app calling CreateStreamedFileAsync can pass null for this parameter if it does not wish to provide a thumbnail image.
The following method creates a thumbnail image and then creates a StorageFile object whose stream will be populated on demand:
private async void StreamOnDemand(Object sender, RoutedEventArgs e) {
// Get a generic thumbnail image for PNG files
StorageItemThumbnail thumbnail =
await GetTypeThumbnailAsync(".png", ThumbnailMode.SingleItem);
RandomAccessStreamReference thumbnailSource =
RandomAccessStreamReference.CreateFromStream(thumbnail);
// Create a StorageFile object whose stream will be populated by OnDataRequested
Uri uri = new Uri("http://WintellectNOW.com/assets/img/winnow-logo.png");
StorageFile file = await StorageFile.CreateStreamedFileAsync(
"MyImage.png",
outputStream => OnDataRequested(outputStream, uri),
thumbnailSource);
// Show it works by passing the StorageFile to another app
var noWarning = Launcher.LaunchFileAsync(file);
}The StreamOnDemand method obtains a generic thumbnail image based on a file extension by calling GetTypeThumbnailAsync:
private async static Task<StorageItemThumbnail> GetTypeThumbnailAsync(
String fileType, ThumbnailMode mode) {
// Gets a thumbnail for a specific file type
StorageFile file = await ApplicationData.Current.TemporaryFolder.CreateFileAsync(
"~" + fileType, CreationCollisionOption.GenerateUniqueName);
StorageItemThumbnail sitn = await file.GetThumbnailAsync(mode);
await file.DeleteAsync();
return sitn;
}The method that populates the stream on demand is OnDataRequested, and it looks like this:
private async void OnDataRequested(StreamedFileDataRequest outputStream, Uri uri) {
// Have the background downloader transfer the image
DownloadOperation download = new BackgroundDownloader().CreateDownload(uri, null);
var noWarning = download.StartAsync();
// Copy the downloaded image's bytes to the storage stream
// NOTE: The consuming app can read the stream's contents while it is downloading;
// it does not have to wait until the download is complete
using (IInputStream inputStream = download.GetResultStreamAt(0)) {
// NOTE: StreamedFileDataRequest implements IOutputStream
await RandomAccessStream.CopyAndCloseAsync(inputStream, outputStream);
// We get here when the download and copy is complete.
}
}It is interesting to think about how all of this works. You see, if your app creates a StorageFile and then passes it to another app, the other app comes to the foreground and your app goes to the background. This means that Windows suspends your app’s threads (as discussed in Chapter 3) and might even terminate your app. Therefore, when launching a StorageFile, Windows invokes the OnDataRequested callback method as soon as LaunchFileAsync is called, regardless of whether the app receiving the StorageFile actually wants the file’s contents. Therefore, in this scenario, you might think that rendering the stream’s contents on demand is not that useful. However, it does allow you to launch an app immediately while the callback method renders the stream’s contents as opposed to rendering the contents first and then launching the app; this can improve the end-user experience.
When passing a StorageFile via a share source app, OnDataRequested is called only when the target app requests the stream’s contents. This is allowed because the source app must remain active to complete the share operation. However, for the share operation, there is another way to defer rendering of a StorageFile by using DataPackage’s SetDataProvider method. If an app copies a StorageFile object to the clipboard and then the app is suspended, Windows resumes the app for up to 30 seconds so that it can render the stream’s contents. If the app terminated, an exception is raised in the consuming app because the stream’s contents cannot be rendered. CreateStreamedFileAsync is most useful by an app that declares the FileOpenPicker activation. It allows the user to add a StorageFile to her basket and subsequently remove it or cancel the picker without rendering the stream’s contents at all.
CreateStreamedFileAsync creates a temporary and read-only StorageFile object. Conceptually, this StorageFile object is in memory, and querying its Path property returns an empty string. However, the StorageFile is implicitly backed by a file that Windows creates. The data written to the stream by the OnDataRequested method is persisted in this file. This way, if the receiving app opens the StorageFile object again (or passes it to another app), the callback method is not invoked again; the data is simply returned from the file Windows created. If a StorageFile object is passed to a desktop app, the system creates a read-only copy of the file in the user’s Temporary Internet Files directory (similar to what Outlook does when the user opens an email attachment).
In my code example, I populated the file’s stream by downloading data from the Internet; but, of course, you can populate a stream any way you’d like. However, because populating a stream from the Internet is so common, the StorageFile class offers a static CreateStreamedFileFromUriAsync method. I can use this method to simplify my example by removing the need for a callback method:
StorageFile file = await StorageFile.CreateStreamedFileFromUriAsync( "MyImage.png", uri, thumbnailSource);
Finally, the StorageFile class offers two other static methods that, instead of creating a file, will replace the contents of an existing StorageFile on demand:
public static IAsyncOperation<StorageFile> ReplaceWithStreamedFileAsync( IStorageFile fileToReplace, StreamedFileDataRequestedHandler dataRequested, IRandomAccessStreamReference thumbnail); public static IAsyncOperation<StorageFile> ReplaceWithStreamedFileFromUriAsync( IStorageFile fileToReplace, Uri uri, IRandomAccessStreamReference thumbnail);
The StorageFile object returned from these methods can refer to a file that is both readable and writable. These methods are most useful when implementing the CachedFileUpdater activation. They allow an app to replace the contents of a local file that is caching a remote file. For example, the SkyDrive app uses these methods to replace a local file’s contents with a new version of the file residing in the cloud.
The last stream-related technology I’d like to bring to your attention is the content indexer. The content indexer gives you a way to quickly perform rich search queries over your app’s data. The content indexer is the same one that Windows uses when users search for documents on their PCs. With it, a user can perform a rich search query looking for documents containing desired text, modified after a certain date, and authored by a particular person. However, when used by your app, you are creating a private content index whose content is not accessible to other apps or to Windows itself.
You use the content indexer to index files that the built-in Windows indexer would not normally index or to index streams of data that do not reside in files.[46] Typically, an app allows the user to search its content by showing the user a Windows.UI.Xaml.Controls.SearchBox control. The content indexer returns results very fast; therefore, it’s a good technology choice when you want to return search results as the user types characters into a SearchBox control incrementally refining his search. Of course, you do not have to use the content indexer only with the SearchBox control; you can use it in any way you wish.
Using the content indexer is extremely easy. First, you call ContentIndexer’s static GetIndexer method to create or get a reference to your package’s default index or to a named index. Named indexes allow your package to have multiple indexes separate from one another. Here is what the ContentIndexer class looks like:
public sealed class ContentIndexer {
// Static members to create/get a reference to your package's default or named index:
public static ContentIndexer GetIndexer();
public static ContentIndexer GetIndexer(String indexName);
// Instance members to add/update an item and delete item(s) from an index:
public IAsyncAction AddAsync(IIndexableContent indexableContent);
public IAsyncAction UpdateAsync(IIndexableContent indexableContent);
public IAsyncAction DeleteAsync(String contentId);
public IAsyncAction DeleteMultipleAsync(IEnumerable<String> contentIds);
public IAsyncAction DeleteAllAsync();
// Every method (above) that modifies the index increments the index's Revision
public UInt64 Revision { get; }
// Get the properties for a specific item:
// For valid properties, see http://msdn.microsoft.com/en-us/library/dd561977(VS.100).aspx
public IAsyncOperation<IReadOnlyDictionary<String, Object>> RetrievePropertiesAsync(
String contentId, IEnumerable<String> propertiesToRetrieve);
// Query the index passing an Advanced Query Syntax (AQS) filter,
// properties to retrieve, sort order, and language
// For AQS, http://msdn.microsoft.com/en-us/library/windows/desktop/bb266512(v=vs.85).aspx
public ContentIndexerQuery CreateQuery(
String searchFilter, IEnumerable<String> propertiesToRetrieve);
public ContentIndexerQuery CreateQuery(
String searchFilter, IEnumerable<String> propertiesToRetrieve,
IEnumerable<SortEntry> sortOrder, String searchFilterLanguage);
}To add an item to a content index, you construct an IndexableContent object, which looks like this:
public sealed class IndexableContent : IIndexableContent {
public IndexableContent();
public String Id { get; set; } // Uniquely identifies item in index
public IRandomAccessStream Stream { get; set; } // Stream with content to index
public String StreamContentType { get; set; } // Mime type of stream's content
public IDictionary<String, Object> Properties { get; } // Pre-defined Windows properties
}After constructing an IndexableContent object, set its Id property (which uniquely identifies the item in the index). Then you set its Stream property to refer to the content you wish to have indexed and its StreamContentType property to the mime type that describes the format of the stream’s contents. The indexer does not save the original stream because this would be too memory intensive; if you need to get back to the original stream contents, you must manage this yourself. Then you can also add any of the standard predefined Windows properties documented at http://msdn.microsoft.com/en-us/library/dd561977(VS.100).aspx and also described in Chapter 5’s Storage item properties section. Although you must use the Windows predefined properties, you can interpret them however you’d like. For example, I show later how I use the System.Media.Duration property to indicate how long it takes to create a recipe, and I use the System.Keywords property to reflect a recipe’s ingredients. By the way, you can construct an item without a stream; the item could have only properties. Then you could retrieve the properties for an item. Property values can have a language associated with them too.
After you populate an index with items, you call ContentIndexer’s CreateQuery method, passing in an AQS string, what properties you want returned, the sort order of the results, and optionally a language. The CreateQuery method returns a ContentIndexerQuery object:
public sealed class ContentIndexerQuery {
public IAsyncOperation<UInt32> GetCountAsync(); // Returns the count of resulting items
// Returns resulting items' Id and requested properties (not Stream & StreamContentType)
public IAsyncOperation<IReadOnlyList<IIndexableContent>> GetAsync();
// Returns just the properties for each resulting item:
public IAsyncOperation<IReadOnlyList<IReadOnlyDictionary<String, Object>>>
GetPropertiesAsync();
// Some members not shown here...
}To help put all this together, imagine a recipe app where users can search for recipes by ingredients or by the time it takes to cook. First, let’s define a Recipe data type:
internal sealed class Recipe {
private readonly List<String> m_ingredients = new List<String>();
public String Title { get; set; } // Stream content
public List<String> Ingredients { get { return m_ingredients; } } // System.Keywords property
public UInt64 MinutesToCreate { get; set; } // SystemProperties.Media.Duration property
}Now, let’s define a few recipes:
private static readonly Recipe[] s_recipes = new Recipe[] {
new Recipe { Title = "Chicken Parmesan", MinutesToCreate = 45,
Ingredients = { "chicken", "cheese", "tomatoes" } },
new Recipe { Title = "Chicken Teriyaki", MinutesToCreate = 30,
Ingredients = { "chicken", "teriyaki", "sauce", "rice" } },
new Recipe { Title = "Macaroni and Cheese", MinutesToCreate = 20,
Ingredients = { "Macaroni", "pasta", "cheese" } },
new Recipe { Title = "Chicken Alfredo", MinutesToCreate = 45,
Ingredients = { "chicken", "Pasta", "alfredo", "sauce" } }
};When our app runs, we’ll have to add these recipes to a content index. Here’s a method that does that:
private async Task PopulateRecipeContentIndexAsync() {
// Create or get a reference to a "Recipes" content index:
ContentIndexer indexer = ContentIndexer.GetIndexer("Recipes");
await indexer.DeleteAllAsync(); // Clear contents to start fresh
// Add all the recipes to the index:
for (Int32 r = 0; r < s_recipes.Length; r++) {
IndexableContent content = new IndexableContent {
Id = r.ToString(), // ID = index into s_recipes array
// Index words in the recipe's title by converting the string to a UTF-8 byte stream
StreamContentType = "text/plain",
Stream = CryptographicBuffer.ConvertStringToBinary(
s_recipes[r].Title, BinaryStringEncoding.Utf8).AsStream().AsRandomAccessStream(),
// For each recipe, Duration is how long it takes to cook & Keywords is ingredient list
Properties = { // http://msdn.microsoft.com/en-us/library/dd561977(VS.100).aspx
{ SystemProperties.Media.Duration, s_recipes[r].MinutesToCreate },
{ SystemProperties.Keywords, String.Join(";", s_recipes[r].Ingredients) },
}
};
await indexer.AddAsync(content);
}
}And now, after all this is done, we can perform rich queries against the index. The following code demonstrates many of the content indexer’s features:
// Search for all recipes with "Chicken" in their title, sauce as an ingredient and that take
// 30 minutes or less to make. The results come back sorted in duration order with the Duration property.
ContentIndexer indexer = ContentIndexer.GetIndexer("Recipes");
ContentIndexerQuery query = indexer.CreateQuery(
"chicken System.Keywords:"sauce" System.Media.Duration:<=30",
new[] { SystemProperties.Media.Duration },
new[] {
new SortEntry { PropertyName = SystemProperties.Media.Duration, AscendingOrder = true }
});
UInt32 resultCount = await query.GetCountAsync(); // 1
IReadOnlyList<IIndexableContent> resultItems = await query.GetAsync();
foreach (var r in resultItems) {
Int32 recipeIndex = Int32.Parse(r.Id); // 1
String recipeTitle = s_recipes[recipeIndex].Title; // "Chicken Teriyaki"
}
// Here's how to update an item's properties (make "Chicken Alfredo" take 20 minutes to cook):
IndexableContent contentItem = new IndexableContent {
Id = 3.ToString(),
Properties = { { SystemProperties.Media.Duration, 20 } }
};
await indexer.UpdateAsync(contentItem);
// Now if we perform the same query, we get back 2 results:
query = indexer.CreateQuery(
"chicken System.Keywords:"sauce" System.Media.Duration:<=30",
new[] { SystemProperties.Media.Duration },
new[] {
new SortEntry { PropertyName = SystemProperties.Media.Duration, AscendingOrder = true }
});
resultCount = await query.GetCountAsync(); // 2
resultItems = await query.GetAsync();
foreach (var r in resultItems) {
Int32 recipeIndex = Int32.Parse(r.Id); // 3, 1
String recipeTitle =
s_recipes[recipeIndex].Title; // "Chicken Alfredo", "Chicken teriyaki"
}
// Here's how to get just the properties (no Ids) for a query's items:
IReadOnlyList<IReadOnlyDictionary<String, Object>> itemsProperties =
await query.GetPropertiesAsync();
foreach (IReadOnlyDictionary<String, Object> item in itemsProperties) {
foreach (var property in item) {
String propertyInfo =
String.Format("Property: Name={0}, Value={1}", property.Key, property.Value);
}
}[43] For more information, read http://blogs.msdn.com/b/oldnewthing/archive/2010/09/09/10059575.aspx.
[44] You can detect how your app crashes in the field by using the Windows Store developer dashboard. (See Chapter 11.)
[45] If you’re interested, you can read more about opportunistic lock at http://msdn.microsoft.com/en-us/library/windows/desktop/aa365433(v=vs.85).aspx.
[46] In Chapter 5’s Accessing read-write package files section, I explained how Windows automatically indexes any files in the “Indexed” subdirectory of your package’s local folder.