


Model scoring
In predictive analytics, understanding the difference between model creation and model apply or model scoring is important.
In model creation, typically large parts of prepared data from various data sources are analyzed using data mining or machine learning algorithms in order to find patterns in that data. Training models on fraud is possible if enough data exists and if the attribute combinations that were fraud in the past are known. The algorithm might detect that the probability for fraud is high whenever a credit card is used to purchase jewelry just after a drink was purchased at a gas station. Or, that in order to properly segment customers with similar behavior, having the highest education level as an input parameter makes sense.
After the learning is done, a model is created that can then be deployed to the production system. Now for model apply or scoring, what is typically done is that the model function is applied on a new set of input parameters. If a new transaction is received, the score function for fraud detection will calculate the fraud risk based on the given input parameters. Or, if a new customer registers with a given company, that company might calculate the cluster of that customer based on data available at that time.
This chapter discusses model scoring with regards to in-transactional scoring, real-time scoring, near real-time scoring, and batch scoring. It provides a more in-depth discussion of batch scoring. This chapter contains the following topics:
It also has an overview of Operational Decision Manager (ODM) and SPSS Collaboration and Deployment Services (C&DS), which are higher-level offerings to better manage and automate all analytical assets and to associate business rules to the score results in order to better drive decisions in the operational environment.
6.1 In-transactional scoring (single-record scoring)
In-transactional scoring, which is also known as single-record scoring, means you score one record at a time. Having the invocation effort of the scoring function be minimized is important. Often architecture is implemented to establish a (distributed) server dedicated for scoring and to connect it using network-based interfaces like web services. In pseudocode, transaction code might look like Example 6-1.
Example 6-1 Pseudocode
select customer_name, product_name from tab1 inner join tab2 on ...;
invoke web service;
wait until the request has been transferred through the network and the distributed box has queued and later on processed the request;
wait until the response from the distributed box finds its way back to your z/OS;
This has no advantages but significant disadvantages:
•The web services overhead on the z/OS side is typically higher than the execution of a complete score operation.
•Scalability is typically a problem, especially for high transaction rates.
•Network issues in distributed environments can bring down the mainframe transactional workload. So if the scoring user-defined function (UDF) is essential, overall availability of the business application is no longer the good number of the mainframe but just the number of the distributed computers.
•WLM cannot help, it cannot donate resources to distributed computers.
•Your data leaves z/OS control. A hacker can choose to attack either z/OS or your distributed computers if the hacker wants to attack the service in question.
For some models, creating SQL for the scoring is possible. Depending on the model, this can be a good or a bad alternative. For example, if the model is simple enough, it might be faster than the scoring adapter and still have all of the advantages from scoring in-database. If it contains many switch expressions in SQL, it might be slow in relation. And in some cases, you might not be able to get a score function in pure SQL.
Imagine you created a predictive model that takes a number of input parameters from your database you consolidated on z/OS and that is used for online transaction processing (OLTP). The database is free from redundancy (“single version of the truth”), and with atomicity, consistency, isolation, and durability (ACID) transactions operating on the data, DB2 ensures that new transactions always see the most current data (real real-time data). Now your predictive model can determine the probability that a given transaction is fraudulent.
For those requirements, a better alternative is if the score function is invoked from within the transaction code (which can be written in any language, but it must be able to access the database using an interface like ODBC, JDBC, CICS DB2 attachment facility, or whatever is most appropriate for you).
In pseudocode, the transaction might do something similar to Example 6-2.
Example 6-2 Pseudo-ode of score function invoked from within the transaction code
select customer_name, product_name, score_UDF( fraudMode1, customer_number, merchant_number) as fraud_probability from tab1e inner join tab2 on ... ;
This example means you prefer to invoke your predictive model named fraudModel, with input parameters customer_number and merchant_number and an output value for fraud probability, plus additional parameters from the database. All this is running in the database, with the score_UDF function being a generic implementation which can score predictive models.
Deploying the model to your production OLTP system is triggered by a user that is capable of deploying it from perhaps SPSS Modeler to DB2. In the case of the scoring adapter, the models, which need to be highly available for business-critical transactional workloads, are stored in DB2 tables. Regarding existing backup, disaster recovery, security, and availability related procedures, nothing changes.
Although this example is oversimplified, it outlines the SPSS Modeler Scoring Adapter for z Systems platform. In reality, it uses several steps with the use of PACK and UNPACK commands for efficient parameter movement but in principle it works as outlined.
Another valid alternative is Zementis with in-application scoring, assuming you are running Java workload so you can invoke Zementis scoring functions (which are implemented by Zementis PMML scoring API in Java) from within your own application environment.
6.2 In-database scoring and scoring adapter
Real-time data is usually found in the OLTP system, in z/OS DB2. Most, if not all, transactions obtain input data from z/OS DB2. So for real-time in-transactional scoring, it works well if the database is able to provide the dynamically calculated score value in addition to the retrieved static values.
6.2.1 Real-time scoring and near real-time scoring
With SPSS Modeler Scoring Adapter for DB2 z/OS, you can score a Predictive Model Markup Language (PMML) model, which is deployed to the scoring adapter from SPSS Modeler client, using scoring UDFs.
With the scoring adapter, there is no need to move data in real-time (or near real-time) from z/OS to the system running the scoring engine. Actually, an easy approach is to use the latest available, real-time data available in DB2. In a performance study, we found that the invocation of a web service is typically more expensive (with regard to elapsed time and to consumed z/OS MSUs) than doing the score UDF including the actual scoring function within z/OS altogether. Predictive model creation is resource consuming, but doing an individual model score is not if compared to the overhead of invoking a standard-based web service call. In addition, getting a distributed scoring engine that can scale is challenging. If using the scoring adapter score UDFs, scaling occurs with DB2 so that achieving a WLM-enforced SLAs becomes easier.
To publish the model to z/OS DB2, complete the following steps:
1. double-click the model nugget icon and click the File tab. On the file tab page, select Publish for Server Scoring Adapter as shown in Figure 6-1.

Figure 6-1 Publish for Server Scoring Adapter
2. Enter the required connection information, as shown by the example in Figure 6-2.

Figure 6-2 Publish for Server Scoring Adapter connection information
Create a text file containing SQL code by selecting the Generate Example SQL check box. Provide a file name, and click OK.
An example of the SQL code generated from this stream is provided in Example 6-3.
Example 6-3 Sample generated SQL code
SELECT T0."UNIQUE_ID" AS "UNIQUE_ID", T0."ACAUREQ_HDR_CREDTTM" AS
"ACAUREQ_HDR_CREDTTM", T0."ACAUREQ_HDR_RCPTPTY_TP" AS
"ACAUREQ_HDR_RCPTPTY_TP", T0."ACAUREQ_AUREQ_ENV_CPL_XPRYDT" AS
"ACAUREQ_AUREQ_ENV_CPL_XPRYDT", T0.AGE AS AGE, UNPACK
(HUMSPSS.SCORE_COMPONENT('P','PlayKMeans',PACK(CCSID
208,T0."UNIQUE_ID",T0."ACAUREQ_HDR_CREDTTM",T0."ACAUREQ_HDR_RCPTPTY_TP
",T0."ACAUREQ_AUREQ_ENV_CPL_XPRYDT",T0.AGE))).* AS (C5 VARCHAR(1024)
CCSID UNICODE, C6 DOUBLE) FROM (SELECT T0."UNIQUE_ID" AS
"UNIQUE_ID",T0."ACAUREQ_HDR_CREDTTM" AS
"ACAUREQ_HDR_CREDTTM",T0."ACAUREQ_HDR_RCPTPTY_TP" AS
"ACAUREQ_HDR_RCPTPTY_TP",T0."ACAUREQ_AUREQ_ENV_CPL_XPRYDT" AS
"ACAUREQ_AUREQ_ENV_CPL_XPRYDT",T0.AGE AS AGE FROM ${TABLE0} T0) AS T0
The highlighted text is the SQL code that can be incorporated in OLTP application code used to score transactions in real time.
Figure 6-3 shows the messages displayed while the data modeling stream is executing.

Figure 6-3 Data modeling stream messages
6.2.2 Export PMML from SPSS model apply node
After a new model is created, you can either publish it to the SPSS Modeler Scoring Adapter for DB2 z/OS or export it in standardized PMML format. If you want to get the PMML, double-click the model nugget icon and click the File tab. On the File tab, select Export PMML as shown in Figure 6-4.

Figure 6-4 Export PMML
As explained previously, this PMML can now be used by other vendor tools, such as Zementis, which offers in-application scoring for SPSS generated models and for models generated by SAS Enterprise Miner or other tools. For in-transactional scoring, in-application scoring can show similar advantages like in-database scoring.
Alternatively, consider the generated PMML, which is a well-defined XML format. Example 6-4 is from one of our streams.
Example 6-4 Sample generated PMML
<?xml version="1.0" encoding="UTF-8"?><Parameters debug="false" version="8.0" xmlns="http://xml.spss.com/pasw/extension" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xml.spss.com/pasw/extension http://xml.spss.com/pasw/extension/parameters.xsd">
<Parameter name="scoring.kmLabelPrefix" value=""/>
<Parameter name="scoring.time_interval" value="1.0"/>
<Parameter name="scoring.adSupressNonAnomalousRecords" value="false"/>
<Parameter name="scoring.resultType">
<StructuredValue>
<Attribute name="prediction" value=""/>
<Attribute name="probability" value="P"/>
<Attribute name="probcategory" value="P"/>
<Attribute name="confidence" value="C"/>
<Attribute name="stddev" value="S"/>
<Attribute name="clustering-kohonen-x" value="X"/>
<Attribute name="clustering-kohonen-y" value="Y"/>
<Attribute name="clustering-kohonen-xy" value="XY"/>
<Attribute name="clustering-kmeans-distance" value="D"/>
<Attribute name="association_confidence" value="C"/>
<Attribute name="selflearning_confidence" value="C"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.confidenceBasedOn" value="onProbability"/>
<Parameter name="scoring.labelPattern">
<StructuredValue>
<Attribute name="prediction" value="kSCORING_PredictedValue_0"/>
<Attribute name="probability" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="probcategory" value="kSCORING_Probability_2"/>
<Attribute name="confidence" value="kSCORING_ConfidencePP_0"/>
<Attribute name="stddev" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="tree-nodeid" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="cox-cumhazard" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="knn-caseid" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="knn-distance" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="knn-caselabel" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="adjustedpropensity" value="kSCORING_UndefinedLabel_0"/>
<Attribute name="rawpropensity" value="kSCORING_UndefinedLabel_0"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.resolveNameConflict" value="true"/>
<Parameter name="scoring.isRawPropensity" value="false"/>
<Parameter name="scoring.assocCheckBasket" value="isOutsideBasket"/>
<Parameter name="scoring.time_field" value=""/>
<Parameter name="scoring.isStandardDeviation" value="false"/>
<Parameter name="scoring.encoding" value="UTF-8"/>
<Parameter name="scoring.selflearningTargetFields">
<ListValue/>
</Parameter>
<Parameter name="scoring.selflearningRandomization" value="0.0"/>
<Parameter name="scoring.isEnsemble" value="true"/>
<Parameter name="scoring.isPrediction" value="true"/>
<Parameter name="scoring.assocIsOnlyOutputValue" value="false"/>
<Parameter name="scoring.scoreValue" value=""/>
<Parameter name="scoring.predicateList">
<StructuredValue>
<Attribute name="closeTo" value="kSCORING_Predicate_CloseTo"/>
<Attribute name="crosses" value="kSCORING_Predicate_Crosses"/>
<Attribute name="intersect" value="kSCORING_Predicate_Intersect"/>
<Attribute name="touch" value="kSCORING_Predicate_Touch"/>
<Attribute name="overlap" value="kSCORING_Predicate_Overlap"/>
<Attribute name="within" value="kSCORING_Predicate_Within"/>
<Attribute name="contain" value="kSCORING_Predicate_Contain"/>
<Attribute name="northOf" value="kSCORING_Predicate_NorthOf"/>
<Attribute name="southOf" value="kSCORING_Predicate_SouthOf"/>
<Attribute name="eastOf" value="kSCORING_Predicate_EastOf"/>
<Attribute name="westOf" value="kSCORING_Predicate_WestOf"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.isStandardDeviationRequired" value="false"/>
<Parameter name="scoring.isNodeID" value="false"/>
<Parameter name="scoring.assocTransactionalID" value=""/>
<Parameter name="pasw.annotation_toolTipText" value=""/>
<Parameter name="scoring.isPropensity" value="false"/>
<Parameter name="scoring.assocIsOnlyTrueForFlag" value="true"/>
<Parameter name="scoring.isOutputIntNodeId" value="false"/>
<Parameter name="pasw.annotation_keywords" value=""/>
<Parameter name="scoring.modelDll">
<StructuredValue>
<Attribute name="TreeModel" value="TreeModel"/>
<Attribute name="discriminant-model" value="discriminant-model"/>
<Attribute name="GeneralRegressionModel" value="GeneralRegressionModel"/>
<Attribute name="ClusteringModel" value="ClusteringModel"/>
<Attribute name="NeuralNetwork" value="NeuralNetwork"/>
<Attribute name="AssociationModelLattice" value="AssociationModelLattice"/>
<Attribute name="SeqAssociationLattice" value="SeqAssociationLattice"/>
<Attribute name="NaiveBayesModel" value="NaiveBayesModel"/>
<Attribute name="AssociationModel" value="AssociationModel"/>
<Attribute name="RuleSetModel" value="RuleSetModel"/>
<Attribute name="BayesNetModel" value="BayesNetModel"/>
<Attribute name="SupportVectorMachineModel" value="SupportVectorMachineModel"/>
<Attribute name="NearestNeighborModel" value="NearestNeighborModel"/>
<Attribute name="MiningModel" value="MiningModel"/>
<Attribute name="RegressionModel" value="RegressionModel"/>
<Attribute name="TimeSeriesModel" value="TimeSeriesModel"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.selflearningRandomSeed" value="876547"/>
<Parameter name="scoring.nameList">
<StructuredValue>
<Attribute name="prediction" value=""/>
<Attribute name="probability" value=""/>
<Attribute name="probcategory">
<ListValue/>
</Attribute>
<Attribute name="confidence" value=""/>
<Attribute name="stddev" value=""/>
<Attribute name="tree-nodeid" value=""/>
<Attribute name="cox-cumhazard" value=""/>
<Attribute name="knn-caseid">
<ListValue/>
</Attribute>
<Attribute name="knn-distance">
<ListValue/>
</Attribute>
<Attribute name="knn-caselabel">
<ListValue/>
</Attribute>
<Attribute name="adjustedpropensity" value=""/>
<Attribute name="rawpropensity" value=""/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.assocRepeatPredications" value="false"/>
<Parameter name="scoring.maxCategories" value="25"/>
<Parameter name="scoring.adScoreMethod" value="FLAG_AND_SCORE"/>
<Parameter name="scoring.enableSQL" value="false"/>
<Parameter name="scoring.isRuleID" value="false"/>
<Parameter name="scoring.selflearningReliability" value="true"/>
<Parameter name="scoring.cumulative_hazard" value="false"/>
<Parameter name="scoring.isConfidence" value="true"/>
<Parameter name="scoring.maxPredictions" value="3"/>
<Parameter name="pasw.annotation_description" value=""/>
<Parameter name="scoring.isOutputInputData" value="true"/>
<Parameter name="scoring.past_survival_time" value=""/>
<Parameter name="scoring.scoringDll">
<StructuredValue>
<Attribute name="SmartScore" value="mcscorersmart"/>
<Attribute name="NeuralNetwork" value="mcscorernnet"/>
<Attribute name="MiningModel" value="mcscorermining"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.useNameList" value="false"/>
<Parameter name="scoring.adNumAnomalyFields" value="3"/>
<Parameter name="scoring.isBaseModels" value="false"/>
<Parameter name="scoring.modelID">
<StructuredValue>
<Attribute name="TreeModel" value="R"/>
<Attribute name="discriminant-model" value="discriminant-model"/>
<Attribute name="GeneralRegressionModel" value="L"/>
<Attribute name="ClusteringModel" value="ClusteringModel"/>
<Attribute name="NeuralNetwork" value="N"/>
<Attribute name="AssociationModelLattice" value="AssociationModelLattice"/>
<Attribute name="SeqAssociationLattice" value="SeqAssociationLattice"/>
<Attribute name="NaiveBayesModel" value="NaiveBayesModel"/>
<Attribute name="AssociationModel" value="A"/>
<Attribute name="RuleSetModel" value="RuleSetModel"/>
<Attribute name="BayesNetModel" value="B"/>
<Attribute name="SelflearningModel" value="S"/>
<Attribute name="SupportVectorMachineModel" value="S"/>
<Attribute name="NearestNeighborModel" value="KNN"/>
<Attribute name="MiningModel" value="MiningModel"/>
<Attribute name="CLUSTER_KOHONEN" value="K"/>
<Attribute name="ANOMALYDETECTION" value="O"/>
<Attribute name="CLUSTER_KMEANS" value="KM"/>
<Attribute name="RULESET_DL" value="D"/>
<Attribute name="GZLR" value="G"/>
<Attribute name="LR" value="E"/>
<Attribute name="RegressionModel" value="RegressionModel"/>
<Attribute name="TimeSeriesModel" value="TS"/>
<Attribute name="SELF_LEARNING" value="S"/>
<Attribute name="CLUSTER_TWOSTEP" value="T"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.isDistance" value="false"/>
<Parameter name="scoring.assocRuleCriterion" value="confidence"/>
<Parameter name="scoring.isProbability" value="false"/>
<Parameter name="pasw.annotation_autoLabel" value="true"/>
<Parameter name="scoring.future_time_as" value="None"/>
<Parameter name="scoring.assocIsOutputOrigInterval" value="false"/>
<Parameter name="scoring.namePattern">
<StructuredValue>
<Attribute name="prediction" value="${M}{S}-{T}"/>
<Attribute name="probability" value="${M}{R}{S}-{T}"/>
<Attribute name="probcategory" value="${M}{R}{S}-{C}"/>
<Attribute name="confidence" value="${M}{R}{S}-{T}"/>
<Attribute name="stddev" value="${M}{R}-{T}"/>
<Attribute name="tree-nodeid" value="NodeID"/>
<Attribute name="cox-cumhazard" value="CumHazard"/>
<Attribute name="knn-caseid" value="${M}{S}-neighbor-{G}"/>
<Attribute name="knn-distance" value="${M}{S}-distance-{G}"/>
<Attribute name="knn-caselabel" value="${M}{S}-neighbor-{G}"/>
<Attribute name="adjustedpropensity" value="$AP{S}-{T}"/>
<Attribute name="rawpropensity" value="$RP{S}-{T}"/>
<Attribute name="clustering-clusterid" value="clustering-clusterid"/>
<Attribute name="clustering-kohonen-x" value="${M}{R}{S}-Kohonen"/>
<Attribute name="clustering-kohonen-y" value="${M}{R}{S}-Kohonen"/>
<Attribute name="clustering-kohonen-xy" value="${M}{R}{S}-Kohonen"/>
<Attribute name="anomaly-flag" value="${M}{S}-Anomaly"/>
<Attribute name="anomaly-index" value="${M}{S}-AnomalyIndex"/>
<Attribute name="anomaly-clusterid" value="${M}{S}-PeerGroup"/>
<Attribute name="anomaly-varname" value="${M}{S}-Field-{G}"/>
<Attribute name="anomaly-avrimpact" value="${M}{S}-FieldImpact-{G}"/>
<Attribute name="clustering-kmeans-clusterid" value="${M}{S}-{N}"/>
<Attribute name="clustering-kmeans-distance" value="${M}{R}{S}-{N}"/>
<Attribute name="association_prediction" value="${M}{S}-{T}-{G}"/>
<Attribute name="association_confidence" value="${M}{R}{S}-{T}-{G}"/>
<Attribute name="association_ruleid" value="${M}{S}-Rule_ID-{G}"/>
<Attribute name="selflearning_prediction" value="${M}{S}-{T}-{G}"/>
<Attribute name="selflearning_confidence" value="${M}{R}{S}-{T}-{G}"/>
<Attribute name="ruleset-dl-probability" value="${M}P{S}-{T}"/>
<Attribute name="ruleset-firstid" value="${M}I{S}-{T}"/>
<Attribute name="timeseries-lowerconfidence" value="${M}LCI{S}-{T}"/>
<Attribute name="timeseries-upperconfidence" value="${M}UCI{S}-{T}"/>
<Attribute name="timeseries-noiseresiduals" value="${M}NR{S}-{T}"/>
</StructuredValue>
</Parameter>
<Parameter name="scoring.isKohonenY" value="true"/>
<Parameter name="scoring.selflearningSort" value="descending"/>
<Parameter name="scoring.isKohonenX" value="true"/>
<Parameter name="scoring.isCumHazard" value="false"/>
<Parameter name="scoring.assocNameTable">
<ListValue/>
</Parameter>
<Parameter name="scoring.isOthers" value="false"/>
<Parameter name="scoring.missingValuePolicy" value="asMissingPredictor"/>
<Parameter name="pasw.annotation_lastSavedBy" value="oliver.benke"/>
<Parameter name="pasw.annotation_id" value="id3K7RSNB1Z5N"/>
<Parameter name="scoring.num_future_times" value="1"/>
<Parameter name="scoring.assocEqualsBasket" value="false"/>
<Parameter name="scoring.isOutputAll" value="false"/>
<Parameter name="scoring.isProbabilityCategory" value="false"/>
<Parameter name="scoring.isCaseLabel" value="false"/>
<Parameter name="scoring.adAnomalyIndexCutoff" value="0.0"/>
<Parameter name="scoring.isReferenceModel" value="false"/>
<Parameter name="scoring.versionSupported" value="4.0"/>
<Parameter name="scoring.isNeighbor" value="false"/>
<Parameter name="pasw.annotation_lastSavedDate" value="1.44854280264E9"/>
<Parameter name="pasw.annotation_label" value=""/>
<Parameter name="override_isDistance" value="true"/>
<Parameter name="scoring.all_probabilities" value="true"/>
</Parameters>
6.3 Batch scoring
Batch scoring means scoring complete bulks of data at once. Therefore, be sure that the processing effort per score value is minimized, and that data transfer (if required) is optimized or bulked.
6.3.1 Complete batch scoring example with accelerated in-database
predictive modeling
predictive modeling
Figure 6-5 shows that SPSS Modeler generates a new K-Means predictive model in-database, in the accelerator. After the model is created in the accelerator (see the call inza.kmeans() message in line one of the SPSS SQL messages shown in Figure 6-5), the accelerator retrieves the PMML model through z/OS DB2. After that, all temporary artifacts are dropped by SPSS Modeler on the accelerator, so the data scientist is not required to take care of any house keeping or cleanup activity.

Figure 6-5 K-Means model create, using a source table on the Accelerator and running on the Accelerator
6.3.2 Batch scoring using Scoring Adapter into accelerator-only tables
(less efficient method)
(less efficient method)
For SPSS Modeler to now do batch scoring, it must first add an output table to the SPSS Modeler Scoring Adapter, it must first add an output table to it. The user adds a new accelerator-only table to the stream, with the intention that this table stores the scored results.
First, create a new Export node against Accelerator database connection: DW01ACCL in this installation (see Figure 6-6).

Figure 6-6 Select a database source with or without accelerator (DB2 base table or accelerator-only table)
You can choose a name for your new accelerator-only table in the dialog shown in Figure 6-7.

Figure 6-7 Settings of Database Export node in SPSS Modeler Export Database node
Select the Drop existing table so that with every new run of the batch scoring stream, the table is completely replaced. Because SPSS Modeler with DB2 Analytics Accelerator is case-sensitive with table names, the best approach is to use all uppercase letters for the table name.
While running the stream, SPSS Modeler changes the color of the icons to purple to indicate everything runs in-database, as shown in Figure 6-8.

Figure 6-8 Batch scoring with accelerated tables as source and accelerator-only table as target (not recommended)
Using an accelerator-only table for batch scoring results is not a good idea, as described subsequently. First, consider what happens next.
After this stream is executed (by selecting the Export Database node and then clicking Run selection), SPSS Modeler (shown in Figure 6-9 on page 131) does the following steps:
1. The Export Database node that contains the output table to be dropped and re-created is selected. First it drops and re-creates the BATCH_SCORE_RESULTS table by using the following SQL:
DROP TABLE "BATCH_SCORE_RESULTS"
CREATE TABLE "BATCH_SCORE_RESULTS" ( "UNIQUE_ID" BIGINT, "ACAUREQ_HDR_CREDTTM" VARCHAR(255), ..., "$KM-KMEANS_20151119211654UTC_V" VARCHAR(255), "$KMD-KMEANS_20151119211654UTC_" DOUBLE ) IN ACCELERATOR "SBSDEVV4" CCSID UNICODE
The score result table contains all attributes used as input for the model create and for the model apply node, plus generated attributes for the following score results:
"$KM-KMEANS_20151119211654UTC_V"
"$KMD-KMEANS_20151119211654UTC_"

Figure 6-9 Batch scoring to accelerator-only table: first retrieves all score results using DB2 Scoring Adapter on DB2 z/OS, then single-row insert into accelerator-only table
2. If the SPSS Scoring Adapter is installed and enabled but the model is not yet published to the Scoring Adapter, the SPSS Modeler Client first automatically stores the PMML model to the Scoring Adapter on DB2 for z/OS by inserting the model as a BLOB to the Scoring Adapter tables. In the SPSS Modeler client SQL Messages, if the SPSS Modeler automatically publishes a model required for batch scoring to the scoring adapter, a message similar to the following example is displayed:
INSERT INTO HUMSPSS.COMPONENTS (ID, DATA) VALUES ("B94CE38BFECB70149DD72CD91D673537", ?)
3. The SPSS Modeler usually tries the SQL first to verify how it works. In such cases, you can see Previewing SQL at the beginning of the SQL in question. If the database management system (DBMS) being used indicates that the SQL works, it will issue the same SQL. This then appears in the messages as a line prefixed with Executing SQL.
|
Note: SPSS Modeler sometimes tries several variations of SQL before “giving up.” SPSS knows which database is connected, so it usually starts with SQL suitable for DB2 for z/OS but it might try alternatives if it sees an error from the DBMS. With regard to “giving up,” if SPSS cannot generate SQL, which is accepted by the database for whatever reason (such as reaching an edge-case restriction on a special data type in the table in use), it usually fails back to enumerating the input tables and doing all complex processing within SPSS Modeler server.
|
4. The following SQL invokes the SPSS Scoring Adapter:
SELECT T0."UNIQUE_ID" AS "UNIQUE_ID", T0." ACAUREQ_HDR_CREDTTM " AS ."ACAUREQ_HDR_CREDTTM", …, T0.C5 AS "$KM-KMEANS_20151119211654UTC_V", T0.C6 AS "$KMD-KMEANS_20151119211654UTC_"
FROM (SELECT T0."UNIQUE_ID" AS "UNIQUE_ID", T0."ACAUREQ_HDR_CREDTTM" AS ."ACAUREQ_HDR_CREDTTM", …,, UNPACK(HUMSPSS.SCORE_COMPONENT('H', '9f79359f6887124bbb54ce1009941d8a', PACK(CCSID 1208, T0."UNIQUE_ID", T0. ."ACAUREQ_HDR_CREDTTM", …))).* AS (C5 VARCHAR(1024) CCSID UNICODE, C6 DOUBLE) FROM (SELECT T0."UNIQUE_ID" AS "UNIQUE_ID", T0."ACAUREQ_HDR_CREDTTM" AS ."ACAUREQ_HDR_CREDTTM", …, FROM CARDUSR.PAYHISTORY T0) AS T0) T0
The score UDF function is HUMSPSS.SCORE_COMPONENT. The PACK and UNPACK functions, were introduced in APAR PM56631 for DB2 V10 for z/OS and were added to DB2 to allow for more efficient parameter transfer to the score UDF. The score UDF is a generic C++ implementation; it checks the HUMSPSS tables to determine if the model component is registered.
The generically returned score values are converted using the UNPACK function to C5 and C6 values.
5. In doing it this way, SPSS Modeler must insert all results into the accelerator-only table. To better understand what SPSS Modeler has done out of the stream created, look at the SQL code. It shows that SPSS inserts all score values retrieved into the accelerator-only table as shown in the SPSS Modeler SQL log:
INSERT INTO "BATCH_SCORE_RESULTS" ("UNIQUE_ID", "ACAUREQ_HDR_CREDTTM", … , "$KM-KMEANS_20151119211654UTC_V", "$KMD-KMEANS_20151119211654UTC_") VALUES (?. ?. ?. ?. ?. ?. ?)
Because multi-row insert for accelerator-only tables is not yet implemented in DB2 for z/OS, SPSS Modeler must use single-row insert for that. This works if you only want to score something like 100 scores, but it already took more than 2 minutes to score 1000 scores, with almost all of that time spent in this INSERT statement. So if you are about to do batch scoring with millions of scores, a better approach is to do it with DB2 base tables as described in the next section.
6.3.3 Batch scoring using Scoring Adapter into z/OS DB2 base tables
(more efficient method)
(more efficient method)
A better approach is to score into a base table. This works exactly as explained in 6.3.2, “Batch scoring using Scoring Adapter into accelerator-only tables (less efficient method)” on page 128 from a user perspective, except that the tables used must be DB2 base tables (both the source table and the target node table in which the scores are saved.
If you combine base tables and accelerator-only tables in one stream, SPSS Modeler will execute the stream, which is called database federation. What happens if you transform data from a base table to an accelerator-only table is that SPSS Modeler reads all data from the source database, performs potential transformation and then stores it to the accelerator-only table. From SPSS Modeler perspective, a database connection with accelerator is an independent DBMS, completely unrelated to a database connection without accelerator, even if the underlying z/OS DB2 subsystem is always the same. This is usually not what is intended, and it does not show acceptable performance.
Therefore, start by adding a new base source table. So far, you have the stream that created the model in accelerator, so all tables used so far are accelerator-only tables as shown in Figure 6-10 on page 133.

Figure 6-10 Add z/OS DB2 base table corresponding to the accelerated table used for model create
Now the transformations are done before the model create node is required for the model apply node (gold nugget) also. Therefore, you must copy the Filler and Filter nodes, connect them to the DB2 z/OS K-Means gold nugget (model apply node) and then connect it to an export database node with a DB2 base table target, as shown in Figure 6-11.

Figure 6-11 Stream where data transformation is replicated on DB2 z/OS, so the model gold nugget gets same input as for model create, then scoring to z/OS DB2 base table
As shown in Figure 6-11, while running that stream, only the database export node turns purple. However that does not mean that it is not running in-database, as you can see by verifying the SQL output of the stream shown in Figure 6-12 on page 135.

Figure 6-12 Efficient batch scoring from and to DB2 base table, running completely within z/OS, with no data transfer outside and no single-row insert
All SQL that is issued by SPSS Modeler looks similar to the stream above, with target accelerator-only table, however it does not do a SELECT using score UDF followed by single-row INSERT. Rather it does an INSERT FROM SELECT, using the score UDF in the SELECT part of that statement. Everything else is identical.
This way, we were able to score one million rows with that stream in 48 seconds.
If you want the batch score results on the Accelerator, you must load the result tables. That task is one that the z/OS DB2 DBA does, using Data Studio with DB2 Analytics Accelerator plug-ins. SPSS Modeler is intended for the data scientists and does not implement DBA tasks. Data Studio is intended for the DBA.
6.4 DMG and PMML
Predictive Model Markup Language (PMML) is an XML-based standard that is defined by the Data Mining Group (DMG), a non-profit organization:
The goal is to have an interoperable standard between statistical and data mining model producer and consumer. The PMML model can be produced using tools (such as R, SPSS Modeler, SAS Enterprise Miner, or others) and then deployed for real-time scoring in an OLTP layer using scoring technology (such SPSS Scoring Adapter or Zementis).
6.4.1 Zementis and in-application scoring
Zementis delivers Java libraries that can run in-application if the transaction environment contains a Java Virtual Machine (JVM). Note that on z Systems platform, this workload is eligible to use IBM z Systems Integrated Information Processor (zIIP).
6.5 Scoring and smart decisions
With IBM SPSS Collaboration and Deployment Services, you can manage analytical assets, automate processes, and efficiently share results widely and securely.
Predictive analytics uses historical data to find patterns, and the outcome of such analysis is often mathematical scores that are best applied when combined with an experience human to deliver the smarter decisions.
A smart decision system encapsulates business rules and predictive models. Business rules codify the best practices and human knowledge that a business builds over time. Predictive models use statistics and mathematical algorithms to recommend the best action at any given time.
The combination of those two disciplines enables organizations to optimize their decisions.
A solution that combines technologies such as predictive analytics and business rules can improve customer service, reduce fraud, manage risk, increase agility, and drive growth.
6.5.1 Solution architecture
Figure 6-13 on page 137 shows the relationship between the key components to implement a scoring execution solution for smarter decisions.
The client application running in CICS or IMS on z/OS interacts with a Decision Service Orchestration component. This component is responsible to orchestrate calls to these services:
•Data preparation
•Scoring model execution
•Business rules execution
This Decision Service Orchestration component can be implemented either in the CICS and IMS application or in an integration layer running on z/OS, such as IBM Integration Bus.

Figure 6-13 Implementing a scoring execution solution for smarter decisions
Data preparation
Before the execution of the scoring model, the data might need to be prepared and formatted before being sent to the scoring execution engine.
In some scenarios, the IBM DB2 Analytics Accelerator can significantly accelerate the preparation of that data by calculating some aggregates in real time and remove many of the burdens that are associated with the traditional batches for data aggregation.
Predictive model execution
The predictive model execution allows the analysis of every individual incoming transaction and assigns each transaction a score based on specific factors that are indicators of the quality of the transaction. Those indicators might have been calculated during the data preparation stage.
If using SPSS Collaboration and Deployment Services, two scoring engines for predictive models execution can be used on IBM z Systems platform:
•IBM SPSS Collaboration and Deployment Services Scoring Service
•IBM SPSS Scoring Adaptor for DB2 for z/OS
Business rules execution
The business rules execution step refers to the core logic of how the business decision is made, taking the input of the context and the predictive behavior of the subject of interest. Basically a business rule is a statement that describes a business policy or procedure. Business rules describe, constrain, or control some aspect of the business. IBM Operational Decision Manager can be used to automate the decision-making process.
6.5.2 Operational Decision Manager overview
A business rule management system (BRMS) is an essential technology within operational decision management (ODM). It allows organizational policies, and the repeatable decisions associated with those policies such as claim approvals, cross-sell offer selection, pricing calculations, and eligibility determinations, to be defined, deployed, monitored, and maintained separately from application code. With a BRMS, organizations can be more agile and effective in their decision management processes.
A BRMS manages decisions represented by collections of rules. These rules provide solutions to complex decisions that can be stateless or stateful. When decisions are stateless, the ability of the system to provide a result depends on two items:
•Data provided to the system
•Defined business rules
These business rules are evaluated against provided data and when conditions in the rules are met, actions are taken. Stateless decisions do not keep any history on previous results, so every time that the system is started, all the business rules are evaluated against provided data. These types of decisions are considered request-driven decisions because there is no history of previous invocations. Request-driven decisions are always made in a passive mode, which means you always need a client application to trigger a request for a decision.
IBM Operational Decision Manager is the offering to support complex decisions for both request-driven and situation-driven decisions. It provides a set of components to fully support needs for authoring, storing, and running decisions. The following main components are part of the solution:
•IBM Decision Center
This component focuses on the rule management process and provides all tools that are needed for authoring and governing business rules. This component provides two main web-based consoles:
– One for users to author, validate, and maintain rules
– Oriented toward administrative tasks
•IBM Decision Server
This component focuses on the execution, design, and monitoring of all executable artifacts.
Operational Decision Manager provides options for running the Decision Server on z/OS:
•zRule Execution Server for z/OS (zRES)
This option offers a native integration with existing z/OS applications. A supplied stub program provides an API to directly execute decisions in the zRule Execution Server for z/OS. The zRES can run in two modes:
– Stand-alone mode provides a zRES address space that can be invoked from existing COBOL or PL/I applications by way of the supplied API stub.
– In IBM CICS Transaction Server for z/OS V4.2 and later, a local execution option uses the Java virtual machine (JVM) server environment to host the zRES within the CICS region.
•Rule Execution Server on WebSphere Application Server for z/OS
This option brings the full power of WebSphere Application Server for z/OS to the rule execution on z/OS.
6.5.3 SPSS Collaboration and Deployment Services
IBM SPSS Collaboration and Deployment Services provides a flexible, enterprise level foundation for managing and deploying analytics in an enterprise. The product enables collaboration and provides reliable automation of analytical processes for better orchestration and discipline in an organization. It also streamlines deployment of analytical results throughout the enterprise to enable better decision-making.
The IBM SPSS Collaboration and Deployment Services Deployment Portal allows the generation of scores from models deployed in the Collaboration and Deployment Services repository. The SPSS Modeler streams scenario files, and PMML files can be scored. This component facilitates scoring of individual incoming transactions in real time. The scoring is performed directly within the OLTP application.
This real-time capability and the ability to incorporate the scoring into the decision-making process makes this a powerful solution for real-time analytic applications such as fraud detection.
The SPSS Collaboration and Deployment Services platform supports also predictive model governance in the following ways:
•Suitable roles and permissions can be configured to deploy and manage the model, such as an IT admin to schedule jobs or real-time scoring for the models.
•Model performance is automatically monitored and can be configured to provide an alert when a model’s accuracy degrades to a predetermined level.
•Models and the related performance metrics are version-controlled.
•The predictive model is periodically trained on new data, and this is done using a model refresh. A model refresh is the process of rebuilding an existing model in a stream using newer data.
6.5.4 SPSS Scoring Adaptor for DB2 z/OS
Scoring data is defined as deploying a predictive model on new data with an unknown outcome. This predictive model processes incoming data and produces a predictive score about the likelihood or probability of an event.
The IBM SPSS Modeler Server Scoring Adapters for DB2 z/OS allows data to be scored by the generated models within the database, which improves performance. DB2 z/OS allows SQL pushback of most of the SPSS Modeler model nuggets. In these cases, model scoring can be performed within the database, avoiding the need to extract the data before scoring.
The Scoring Adapter for DB2 z/OS defines a UDF that applications can start by using SQL to run the scoring models synchronously, inline within their transactions, by using live transaction data as the input for scoring to maximize the effectiveness of scoring results.
SPSS Modeler is used to publish the model nugget to the scoring adapter. When a model is published to a server scoring adapter, it generates a sample SQL statement. This SQL statement uses UDFs to start the SPSS model that was built earlier and generates a predictive score that can be used by a decision management system.
6.6 Examples of integration for scoring solutions using ODM on z/OS
This section describes two integration examples using ODM on z/OS.
6.6.1 Example: Calling the SPSS Scoring Adapter for IBM DB2 for z/OS
Figure 6-14 illustrates an example of an optimized infrastructure solution based on the SPSS Scoring Adapter for DB2 for z/OS for the scoring engine and ODM on z/OS for the business rules management system.
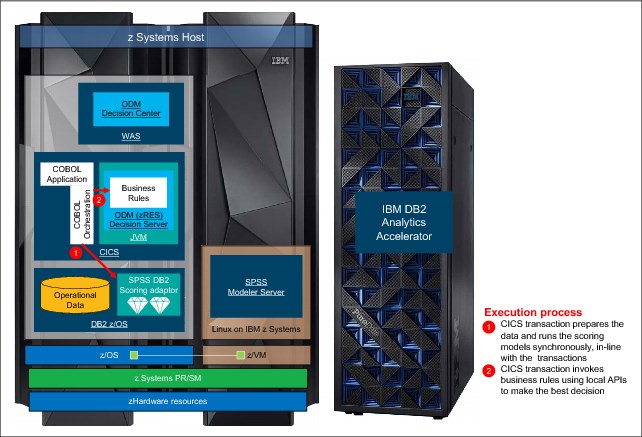
Figure 6-14 Optimized infrastructure
In this example, the decision service orchestration is implemented in COBOL in CICS. The CICS transaction will prepare the data for the scoring and will call the scoring engine running in DB2 z/OS within the same transaction. This data preparation and access to the scoring engine maximizes the effectiveness of scoring results.
For the business rules execution, the CICS transaction calls the zRule Execution Server (zRES) running inside CICS in a JVM using local APIs provided by ODM.
This example is an optimal solution from a performance, high availability, and system management perspective to perform real-time analytics on IBM z Systems platform.
6.6.2 Example: Calling SPSS Collaboration and Deployment Services
In the example discussed in 6.6.1, “Example: Calling the SPSS Scoring Adapter for IBM DB2 for z/OS” on page 140, the model is run and data is processed in the DB2 environment. In the alternative approach, the process occurs in the Collaboration and Deployment Services environment. The data is outside of a Collaboration and Deployment Services environment and must travel from the database to Collaboration and Deployment Services for processing, which causes this approach to be slower than the DB2 scoring adapter approach.
Figure 6-15 shows this alternative scoring method. The predictive model is developed by using IBM SPSS Modeler Client and the model is published to IBM SPSS Collaboration and Deployment Services running on Linux on IBM z Systems platform. First, the CICS transaction calls DB2 z/OS to prepare the data, then the predictive model is called with a web service call from the CICS transaction. The model processes the data and produces a real-time score that will be used to make business decisions in ODM running in CICS.

Figure 6-15 Alternative optimized infrastructure
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.