


Data modeling using SPSS and DB2 Analytics Accelerator
The third phase in the data lifecycle is data modeling. This chapter describes the design of the SPSS data model stream used in this solution. The design supports the solution to the business problem discussed in the beginning of this book. For more information about IBM SPSS Modeler with Scoring Adapter for DB2 z/OS, see the following web page:
This chapter contains the following topics:
5.1 Introduction
IBM SPSS Modeler with Scoring Adapter for z Systems platform is a software package designed for building, validating, and deploying accurate predictive data models and has a powerful predictive analytics engine. The graphical user interface provides an efficient way to connect data sources to models, run advanced analyses, and deliver results. For example, data scientists can develop a model to analyze existing patterns and trends in customer purchases, evaluate current transactions, and calculate resulting scores. Ultimately, the aggregation of data and results can be used to predict a customer’s future purchasing behavior. IBM SPSS Modeler can also deploy a Predictive Model Markup Language (PMML) model to the scoring adapter or some other scoring component. Furthermore, it can store results like transformed data needed in transactional systems or batch score results back to the OLTP system.
If a data scientist interactively works with source data to do model creation accelerated in-database, the advantages are that all the real work must be done by the Accelerator, that no data access or data movement cost exists in z/OS DB2, and that the overall elapsed time, exploiting the massively parallel architecture of the Netezza based accelerator with dedicated FPGAs and analytics-optimized system architecture is significantly shorter, especially if the amount of data to be processed is significant.
Note that for small models, accelerated in-database modeling does not always lead to shortened elapsed time as the IBM Netezza Analytics models used have a startup time of approximately 1 - 2 minutes. In our observations, IBM Netezza Analytics models are usually faster if the input table has at least one million rows. For smaller tables, SPSS Modeler alone is usually able to create a model on one Integrated Facility for Linux (IFL) on z13 in less than the mentioned startup time of IBM Netezza Analytics (if it is connected using HiperSockets and z/OS DB2 delivers the requested data at full speed).
5.2 SPSS data modeling stream design
The end-to-end data lifecycle phases are divided into smaller streams. The following sections describe the design of the SPSS in-database modeling stream used in this solution. The nodes are selected from those available in the tables presented in 4.3, “Nodes supporting SQL generation for DB2 Accelerator” on page 88.
5.2.1 SPSS data modeling stream
Figure 5-1 on page 109 shows the data modeling stream used in this solution. This figure is a representation of the basic components of a modeling stream. Simple scenarios might require only a Source node and a Model node; more complex scenarios might require additional nodes for further filtering beyond what was performed in the data transformation stream.

Figure 5-1 SPSS data modeling stream
Figure 5-1 shows the following nodes (from left to right) in the data modeling stream:
•The first node is a Source node. In this solution, the data source is an IBM DB2 table named CARDUSR.PAYHISTORY. In practice, however, this node can be replaced with the output of the data transformation stream.
•The second node is a Filler node. The Filler node is used to help cleanse the data by replacing null values for any field in the table with a choice of a value or an expression. Double-click the Filler node icon and click the Settings tab to access this feature. An example of the logic added for this solution is shown in Figure 5-2 on page 110.
The green cylindrical database symbol in the upper-right corner of the Filler node icon indicates that caching is enabled. By selecting this feature, cache is created in the database automatically, and data is stored in a temporary table rather than in the file system. This feature can improve performance in streams with tables that are used frequently.
With SPSS Modeler, you can enable caching for individual nodes. For in-database modeling, in-database caching is required, which means that in the stream where the cache is enabled, SPSS Modeler creates a temporary table (in-database if accelerator is associated to the used data source) and fills it using an INSERT FROM SELECT statement, caching everything up to that node. This process can help DB2 with Accelerator process complex queries.
|
Note: While testing our prototype at a client, we found that the existing SPSS streams of that client lead to SQL with about 1200 tables. Because z/OS DB2 has a limitation that a query cannot contain more than 500 tables, those client streams were able to be processed only by introducing in-database caching. Nevertheless, the client was satisfied with the reduction of stream execution time from days (with heavily used DB2) to minutes (running completely within DB2 Accelerator).
|
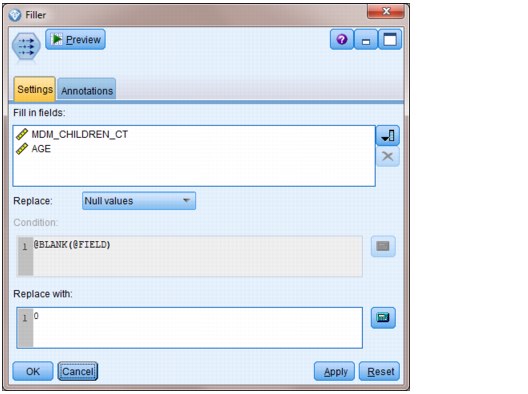
Figure 5-2 Filler node settings
•The third node is a Filter node. The Filter node is used to filter the fields that are required to build the model. Double-click the Filter node icon, then double-click the field names in the right column to select or deselect the desired fields. An example of the fields selected for this solution is shown in Figure 5-3.

Figure 5-3 Filter node settings
•The last node is the Database Model node. The Database Model palette contains five model options: DB2 z/OS K-Means, DB2 z/OS Naive Bayes, DB2 z/OS Decision Tree, DB2 z/OS Regression Tree, and DB2 z/OS TwoStep.
A DB2 z/OS K-Means model is used to perform a cluster analysis on the data in the z/OS DB2 table for this solution. Figure 5-4 shows the fields included in this model.
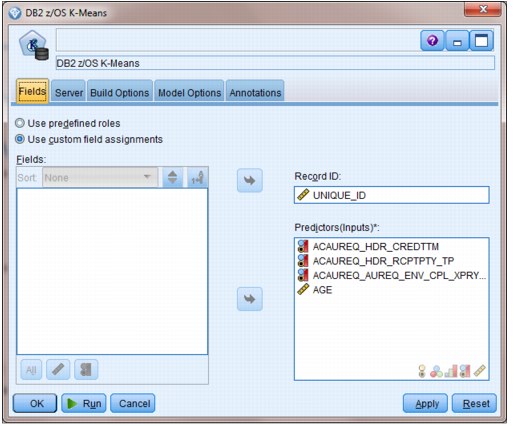
Figure 5-4 DB2 z/OS K-Means model fields
After running the data modeling stream, the model nugget icon is created (shown in Figure 5-1 on page 109 and Figure 5-5). The model is now ready to publish to DB2 and is also temporarily stored in the DB2 Analytics Accelerator. More information about publishing the model to DB2 is in 6.2.1, “Real-time scoring and near real-time scoring” on page 119.

Figure 5-5 The K-Means model nugget
5.2.2 Example of how to optimize pruning a decision tree
Especially for a decision tree model, one of the problems to avoid is overfitting, which means that the predictive model does not describe the real-world relationships but rather random error and noise. In an extreme case, the model can describe the used training data set perfectly well however this does not guarantee that scoring of future items has a high precision. In addition and if possible, a favorable step is to reduce the complexity of a model in general by replacing sub-trees with leaves.
SPSS Modeler decision tree nodes offer an option to use a given percentage of input data for model training and the rest for tree pruning, as shown Figure 5-6.

Figure 5-6 DB2 for z/OS Decision Tree build model options with tree pruning
This means that first, SPSS Modeler calls an IBM Netezza Analytics stored procedure to randomly split the accelerated input table into two accelerator-born tables containing different subsets of the original input:
•One subset is used for original training of the decision tree model.
•Another subset is used for model pruning.
The example stream (shown in Figure 5-7) uses split data and decision tree pruning.

Figure 5-7 Simple SPSS stream using split data and decision tree pruning
If running this stream, the SQL (Figure 5-8) is generated by the SPSS Modeler.

Figure 5-8 SQL generated by SPSS Modeler for the example stream
First, the example input table (intable) is split into two tables: traintable and testable.
Although the traintable is used by the inza.dectree() stored procedure, the table that is created as testable by inza.split_data() stored procedure is later consumed by the inza.prune_dectree() stored procedure as valtable for decision tree pruning, as shown in Figure 5-9.
Figure 5-9 Invocation of inza.prune_dectree() stored procedure
After everything finishes correctly, the model applier node is added to the stream. In it, the original decision tree model is replaced by the pruned decision tree model (Figure 5-10 on page 115). A model applier node defines a container for a generated model for use when the model is added to the IBM SPSS Modeler canvas from the Models tab of the manager pane.

Figure 5-10 Stream with pruned decision tree model apply node
5.3 Adding record IDs to input tables
All IBM Netezza Analytics models require a a record ID, which must be unique. Ideally, you already have attributes in your data that are unique.
If you do not have any unique attributes in your input data, adding a unique attribute using the SPSS Modeler Derive node unfortunately does not perform well. The problem is that SPSS Modeler cannot push this down to the accelerated database but does that processing in the Modeler server. Then, it inserts the values into accelerated tables, using single-row inserts that do not perform well in DB2 Analytics Accelerator 4.x or DB2 Analytics Accelerator 5.1.
If you are able to add an attribute to the table, one possible solution is to add an attribute to the z/OS DB2 base table and then insert unique values based on a sequence, as shown in Example 5-1.
Example 5-1 Inserting unique values
sampleBegin
ALTER TABLE myTab ADD COLUMN UNIQUE_ID BIGINT ;
CREATE SEQUENCE mySeq AS BIGINT START WITH 1 INCREMENT BY 1 CYCLE CACHE 1000 NO ORDER ;
UPDATE TESTOB SET UNIQUE_ID = NEXT VALUE FOR mySeq;
sampleEnd
Remember to reload the extended table to the Accelerator after running these SQL commands.
5.4 Combining in-database transformation on Accelerator with
traditional model creation
traditional model creation
In many cases, the most significant resource consumption is in the data transformation and preparation step, where all of the input data is analyzed, aggregated, restructured and combined. The result of this transformation might go directly to a predictive modeling algorithm used to generate a new scoring model that can predict, for example, whether a transaction is fraud or whether a given person might be interested in some offer.
SPSS Modeler offers many more model creation algorithms than what is currently available based on IBM Netezza Analytics. The best approach might be to do everything within the Accelerator, so no additional data movement is required. However, combining in-database transformation with “traditional” modeling might make sense, especially if the Modeler server is running on Linux on z, connected using fast HiperSockets within the mainframe. At our customer proof of concept (POC) we have seen that many streams the customer used today are data intensive for the preparation, with actual customer pain points to work with all that data. However, at the point in time when the data scientist prepared the data for model creation, aggregated and reduced it to the principal components for modeling, the model itself on the SPSS Modeler was not the customer’s pain point. That only took minutes (however, as it only took minutes (however of course, this depends on SPSS Modeler server connectivity, amount of data to transfer and the used modeling node).
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.