


Analytics implementation on z Systems platform
The architecture described in this book combines technologies optimized for online transaction processing (OLTP) with technologies optimized for online analytics processing (OLAP) workloads in one system, combining the strengths of both and allowing the overall system to have leading capabilities for hybrid workloads that are relevant for typical enterprise environments. This type of architecture combines high volume real-time transaction processing environment doing a large number of update operations, following strict service-level agreements (SLAs) with the needs of data scientists analyzing the same data with machine learning algorithms or OLAP reporting tools and potentially deploying new models to the transactional system. The analytical workload can be processed without impacting the transactional workload in a DB2 data sharing environment on z Systems, all without the need to offload the critical data to less secure environments.
This chapter describes the architecture that was used as the basis in writing this book, starting first with an overview of how to add an analytics environment to a preexisting data-sharing environment and continuing with a guide to installation and customization of the environment. The chapter also discusses the phases of analytics lifecycle with reference to the architecture used.
This chapter contains the following topics:
2.1 Adding analytics to a mainframe data sharing environment
The offloading of data-intense workloads, often involving the need for table scan operations on complete databases, to the accelerator with its asymmetric massively parallel processing (AMPP) architecture, enables the delivery of the complete solution at a competitive process. Although the accelerator box does not have the same reliability or quality as the IBM z13™ mainframe, it is used only for workloads that are not business-critical. If a transactional system goes down, the result can be direct revenue loss, significant damage to the company, or both loss and damage; however, if an analytical model cannot be refreshed or a report generation is delayed, the impact is usually less significant. Nevertheless, the data processed is often critical data, data which is simply to valuable to risk that attackers might steal it.
The architectural overview (Figure 2-1) shows the concepts involved in the data sharing function of DB2 for z/OS. With this function, you can completely isolate analytic workloads from business-critical transactional workloads.

Figure 2-1 Architectural overview
The DB2 Accelerator will not do anything unless it is first routed through DB2 for z/OS with the IBM RACF® component or similar security component. This is also true for the in-accelerator stored procedures (INZA) work on all the accelerator tables (including accelerator-only tables, or AOTs). Before the request is sent from DB2 for z/OS to the accelerator, z/OS validates access privileges on all involved tables, and it creates a sandbox environment on the accelerator, so the accelerator stored procedure (more information is in 2.1.2, “DB2 Analytics Accelerator wrapper stored procedure” on page 16) can see only those tables required for the processing, and only if the invoking user has the correct access rights.
Sample scenario explaining the architecture of the solution
In our sample scenario, the corporation has core operational data on the mainframe, managed with DB2 for z/OS in a data sharing environment. One data sharing member is dedicated to the transactional workload, the second member is used for analytical and for reporting workload. The usual components on the host are in place. The usual components might geoplex and an automation product for high availability (HA) and disaster recovery, Workload Manager (WLM) to enforce service level agreements (SLAs) and to keep resource utilization high without sacrificing performance for users, and Resource Access Control Facility (RACF) to protect resources. Recently, a request was to add social data to the system in order to make use of sentiment data within individual transactions.
By using the DB2 Analytics Accelerator Loader for z/OS, adding the social data to the accelerator can be done easily without the need to materialize it into z/OS DB2 first. In contrast to the data currently stored on z/OS, where the assumption is that it has to be persisted for at least 10 years (due to regulatory requirements), social data is used only to improve business decisions and only valuable while it is current enough, so it should not stay on the system for a longer period of time.
With all the data loaded by the database administrator (DBA) to the accelerator, the data scientist using SPSS Modeler will be able to interactively investigate the data. With the MPP power available in the accelerator, the possibility exists to process many queries or operations for data transformation rapidly, allowing the scientist to work with the tool interactively. After the data scientist basically understands the data, a predictive model is to be created from it. This can be done within the accelerator also, by using stored procedures running there. This all works although no one has direct access to the accelerator appliance, that is, all requests go through z/OS DB2, which keeps z Systems security high although not all processing is done within the CEC.
In the relational OLTP database, data is stored with a normalized schema (such as BCNF or 3NF), avoiding data redundancy and related problems in doing updates in the transactions (“single version of the truth,” which is one of the core benefits of relational databases in general). Modeling algorithms in predictive analytics typically require that all related data is found in a single table, being denormalized. Now with recently added accelerator-only tables, the accelerator is able to transform the input data, using operations, such as join, and to materialize the intermediate results back on the accelerator, in accelerator-only tables. Potentially doing extra data cleansing and general transformation operations on the data, for example in order to remove rows where some values are NULL, those accelerator-only tables do not need to be backed up like “normal” DB2 tables: first, they can be easily re-created based on the base tables; second, they are often needed only once, and can be discarded as soon as the modeling algorithms are done.
SPSS Modeler offers many more modeling algorithms than what’s available for in-database mining. Now although those “normal” mining algorithms are not as performant as the in-database counterparts, they are still available and might prove to be useful. In many cases, the streams can be organized in a way so much of the work can be done in-database, accelerated in the accelerator and then, only the (hopefully already to some degree aggregated) result needs to be queried once by SPSS Modeler, which can then apply advanced modeling algorithms. For this scenario, it is best if the SPSS Modeler server is running on Linux on z on the same CEC, with IBM HiperSockets™ connectivity. In case the data being processed is of significant size, a large enough file system for that Linux partition or guest is required. If caching is at the end of the in-database part of the stream, the data is read by SPSS Modeler only once; after it has the data in memory (or at least on own file system), the data scientist can explore the data and create multiple models from it without additional resource requirements against the z/OS DB2 partition.
After the data scientist is confident with the newly created model, the model might be deployed to the SPSS Modeler Scoring Adapter for DB2 z/OS, for in-database scoring. In the deploy step, a sample SQL is generated, which can be given to the customers COBOL programmer for integration into the existing transaction code. In-database scoring has the advantage that it can be run based on real-time data, scaling with DB2 (so z Systems can easily achieve SLAs), something that was problematic at the point in time the company was forced to do the scoring in a distributed scoring engine, where there was network in between DB2 and the distributed server and where overall response time was out of control for z/OS, leading to unpredictable results.
An alternative exploitation of the predictive models is using batch scoring, where all elements of a complete table may be stored at once, with a single operation. This can be useful if the distribution of the score results is to be analyzed. For batch scoring, the tight integration into scalable transaction processing is not required, and the cost for the service invocation is not as critical (as the overall operation takes much longer). For batch scoring, various efficient alternatives exist, including doing this in SPSS Modeler server and doing it using SPSS Modeler Scoring Adapter for DB2 z/OS, or using third-party scoring software like the one offered by Zementis, as SPSS creates the model in standard-based PMML format.
2.1.1 SPSS Modeler
Figure 2-2 shows an architecture overview of Linux on z Systems and IBM HiperSockets with SQL pushback to the database and actually to the accelerator.

Figure 2-2 SPSS Modeler and on which layer processing can be performed (ModerlDatabase.png)
SQL generation
SPSS Modeler can generate SQL out of the stream, also known as SQL pushback. With this feature, SQL can be generated that can be “pushed back” to (or executed in) the source database. In general, this is efficient because eliminates data movement between the database and the SPSS Modeler server. If DB2 Analytics Accelerator comes into play and the tables used are huge (so DB2 Optimizer decides to do query evaluation in the Netezza based accelerator), the advantage is even more significant because the accelerator can benefit from its AMPP architecture, especially if the operation requires table scans (and this is often the case for streams developed using SPSS for analytics; a DB2 index seldomly helps here).
Using SQL generation in combination with in-database modeling (see 1.3, “In-database analytics” on page 5) results in streams that can be processed in-database from start to finish.
Partial stream execution in-database
To evaluate an SPSS stream, the variation that always works is that SPSS Modeler retrieves all data sources into its own memory (or to temporary files on the server if the memory available is not large enough) and then perform the stream operations on its own. Those operations include joins on various data sources or tables, aggregation operations, simple transformations, and so on.
Although SPSS does its best to generate SQL, generating SQL out of a stream is not always possible. An extreme example might be a join operation between two data sources (different DB management systems), where database federation technologies are necessary to come up with a working SQL solution (which does not exist), or the combination of Microsoft Excel data with a z/OS DB2 table, or even some expressions found in SPSS CLEM expression, a SPSS specific language with higher expressive power than standard SQL. In such cases, SPSS Modeler retrieves the required data from the database and performs the operations on its own. SPSS Modeler tries to re-order the stream, so the nodes that can be pushed down to the database are done first (of course, only within limits and without changing semantics).
2.1.2 DB2 Analytics Accelerator wrapper stored procedure
Accelerated in-database modeling is implemented using predictive modeling stored procedures. For instance, the INZA.DECTREE stored procedure creates a decision tree model from an input table plus output parameter indicating which attribute is being predicted. As you might know, a client application cannot connect directly to the accelerator. It can connect only to DB2 for z/OS; the accelerator itself remains completely isolated and out of reach of any client application. So for this to work, the INZA.DECTREE stored procedure is a DB2 for z/OS stored procedure.
It is called a wrapper stored procedure because the tasks are restricted to security-related processing, table name mapping, and other minor administrative tasks. After the stored procedure on z/OS checks which target accelerator, which DB2 z/OS tables (which need to be accelerated) are involved, whether the calling user ID has READ privileges to those tables and so on, it lets the accelerator create a controlled environment, a kind of a sandbox in which only the tables required for the stored procedure execution are accessible.
The next step is then to invoke the corresponding stored procedure on the accelerator, which has the same procedure name and which is an IBM Netezza Analytics stored procedure (see “IBM Netezza Analytics stored procedures” on page 190). More information about the stored procedures is in the following documents:
•IBM Netezza Analytics Release 3.2.0.0, In-Database Analytics Developer’s Guide (November 20, 2014)
•IBM Netezza Analytics Release 3.0.1, IBM Netezza In-Database Analytics Reference Guide
DB2 wrapper stored procedures parameter structure
The wrapper stored procedures are implemented generically. Every IBM Netezza Analytics wrapper stored procedure has the following parameters:
•ACCELERATOR_NAME: This is the name of the accelerator to be used.
•PARTAMETERS: This parameter string is passed to the IBM Netezza Analytics stored procedures within the accelerator after some processing to map the table names of input and output tables. For accelerator-born tables, which are first created on the accelerator, the DB2 Analytics Accelerator code remembers that in order to be able to create the metadata in z/OS DB2 catalog and to establish mapping information in case the IBM Netezza Analytics SP on the accelerator successfully finished. The output tables are created in the database, which is specified in the AQT_ANALYTICS_DATABASE environment variable in AQTENV. All output tables are accelerator-only tables, so the data is not moved back to DB2 z/OS. If you need the data values available in DB2 z/OS base tables, an INSERT FROM SELECT SQL expression can be used, inserting into a DB2 base table and selecting from the accelerator-born output table.
•RETURN_VALUE: Although this is not SQL standard-compliant, some IBM PureData® for Analytics (Netezza) stored procedures return a value to the caller. Because DB2 z/OS does not allow stored procedures to return a value such as a user-defined function in SQL, this parameter is mapped to an output parameter in DB2. Possible types are SMALLINT, INTEGER, BIGINT, DOUBLE, REAL, VARCHAR and CLOB. This parameter is optional.
•MESSAGE: This parameter is well-known to those familiar with DB2 Analytics Accelerator, and both the input XML and the output XML are identical to what is also used by the existing administration stored procedures in DB2 Analytics Accelerator.
Result sets
Some IBM Netezza Analytics stored procedures return text output in addition to the RESULT return value. This is returned as part of the first result set of the wrapper stored procedure.
If trace is enabled in the MESSAGE parameter, the trace is returned in the next result set of the wrapper stored procedure.
If the length of the text exceeds 32698, it is split into multiple result rows. For DB2 for z/OS, this means that the information becomes part of a declared global temporary table (DGTT) that is created by the SQL statement, shown in Example 2-1.
Example 2-1 DGTT used by IBM Netezza Analytics stored procedure to return multiple rows
CREATE GLOBAL TEMPORARY TABLE
DSNAQT.ACCEL_TABLES_DETAILS
( SEQID INTEGER, TABLES_DETAILS VARCHAR(32698))
CCSID UNICODE
The concatenation of the result set VARCHAR column in ascending order of SEQNO provides the original text output of the IBM Netezza Analytics procedure.
Authorizations
The user ID under which this stored procedure is invoked must have the following privileges:
•EXECUTE on the wrapper procedure
•EXECUTE on the SYSACCEL.* packages
•Privilege to read the accelerated tables referenced in the PARAMETERS parameter as an input table
•Write access to /tmp directory for the user calling the stored procedure (for tracing)
•DISPLAY privilege (for calling SYSPROC.ADMIN_COMMAND_DB2(-DIS GROUP))
•Authorization to create an accelerated table (specified as output table) in DB2 (in the database specified by AQT_ANALYTICS_DATABASE if this environment variable is set in AQTENV)
Prerequisites for calling a wrapper stored procedure are as follows:
•Accelerator is started.
•All input tables are enabled for query acceleration.
•Output tables do not exist in DB2.
•Authorizations are in place.
•ZPARM OPTHINT must be set to YES.
Calling INZA.KMEANS stored procedure from DB2 for z/OS
Typical invocation of the wrapper stored procedure from DB2 for z/OS is like the one shown in Example 2-2.
Example 2-2 Sample call to INZA.KMEANS stored procedure from DB2 for z/OS
CALL INZA.KMEANS(
‘ACCEL01’,
‘model=customer_mdl, intable=TPCH30M_U.CUSTOMER, outtable=customer_out, id=C_CUSTKEY, target=C_NATIONKEY, transform=S,distance=euclidean, k=3, maxiter=5, randseed=12345,idbased=false,
‘<?xml version= "1.0" encoding= "UTF-8" ?><aqttables:messageControl
xmlns:aqttables = "http://www.ibm.com/xmlns/prod/dwa/2011" version = "1.2">
<traceConfig keepTrace="false" forceFlush="true" location="/tmp/INZAKMeansTableSim16.trc">
<component name = "PROCEDURE" level = "DEBUG" />
</traceConfig>
</aqttables:messageControl>
If the execution of the CALL shown in Example 2-2 is successful on the accelerator and a KMEANS clustering model is created, the result is like Example 2-3 (the requested debug trace was intentionally removed from this sample output).
Example 2-3 Sample XML output from a call to INZA.KMEANS stored procedure
RETVAL 1 MESSAGE <?xml version="1.0" encoding="UTF-8" ?><dwa:messageOutput xmlns:dwa="http://www.ibm.com/xmlns/prod/dwa/2011" version="1.0"> <message severity="informational" reason-code="AQT10000I"><text>The operation was completed successfully.</text><description>Success message for the XML MESSAGE output parameter of each stored procedure.</description><action></action></message></dwa:messageOutput>
2.1.3 Using accelerator-only tables
After an accelerator is installed and activated, the DB2 optimizer treats the appliance as a new access path and will offload SQL processing transparently when doing so is more efficient. Not every query will be accelerated. Some might have incompatible SQL statements, or the DB2 optimizer might decide that offloading this processing is not the best choice.1
An accelerator-only table is automatically created in the accelerator when the CREATE TABLE statement is issued on DB2 with the IN ACCELERATOR clause. Any queries that reference an accelerator-only table must be executed in the accelerator and will be accelerated. If the query is not eligible for query acceleration, an error is returned.
Running queries and data change statements on the accelerator can significantly increase the speed of SQL statements, such as INSERT from SELECT statements. Accelerator-only tables are used by statistics and analytics tools, which can quickly gather all the data that is required for reports. Because the data in these tables can be modified so quickly, they are also ideal for data-preparation tasks that must be completed before the data can be used for predictive modeling.
For more information about accelerator-only tables, see 4.1.1, “Accelerator-only table (AOT)” on page 85.
2.2 Installation and customization
For this publication, the authors set up a demo with z/OS DB2 subsystems in a data sharing group being paired with DB2 Analytics Accelerator.
One DB2 subsystem contained tables in EBCDIC, the other tables in UNICODE, purposely not mixing EBCDIC and UNICODE in one subsystem.
SPSS Modeler server was running on a Linux on z LPAR on the same z13 machine, connected to z/OS DB2 through IBM HiperSockets.
The overall architecture of the systems and components installed and used is summarized in Figure 2-3.
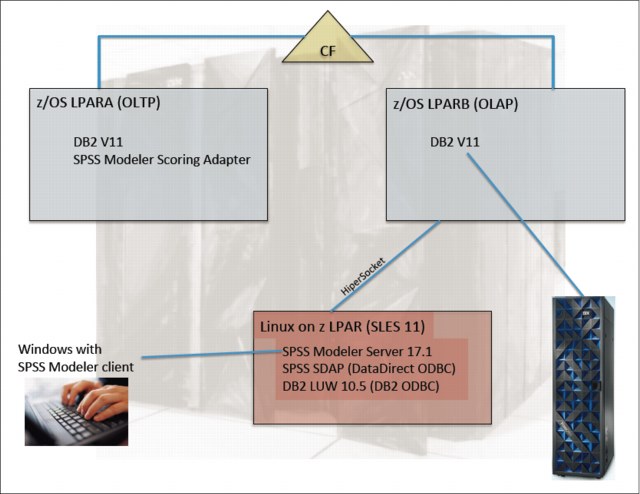
Figure 2-3 Architecture used
2.2.1 DB2 and DB2 Analytics Accelerator setup and installation
On DB2 V11, we ensured that all PTFs that are required for DB2 Analytics Accelerator 4.1 PTF6 are installed. At the time of this writing, no additional DB2 requirements were required for DB2 Analytics Accelerator 5.1.
ZPARM OPTHINT must be set to YES.
Next, we installed the DB2 Analytics Accelerator 5.1 development versions (available at the time of this writing) in the usual way, including IBM DB2 Data Studio 4.1.2 DB2 Analytics Accelerator 5.1 plug-ins, Netezza Performance Server® (NPS®) level 7.2.1.0 (build 46322, 20151102-2301), Access Server and Replication Engine for CDC replication, z/OS DB2 Stored Procedures, and the Accelerator server itself.
|
Note: If you are familiar with the installation of previous versions of DB2 Analytics Accelerator, SAQTOSR is no longer required.
|
Installation of optional server packages
IBM Netezza Analytics is the first DB2 Analytics Accelerator extension package installed in a new way. Basically, the installation process includes these steps:
1. Transfer a software package signed by IBM from z/OS hierarchical file system (HFS) mount point to the Accelerator. For integrity reasons, only packages correctly signed by IBM are applicable for transfer to the Accelerator appliance. This is to avoid uncontrolled software components being enabled for execution on the Accelerator.
2. Apply that new package so the software gets installed.
3. Enable or disable the package for a given database on the accelerator. Note that this only works after the first table is accelerated. At the time IBM Netezza Analytics is enabled, additional internal management data structures to hold information on predictive models are initialized.
Enabling the new IBM Netezza Analytics package on the Accelerator
The HFS used for transfer is, as in previous releases of DB2 Analytics Accelerator, the one specified in AQT_HOST_PACKAGE_DIRECTORY in AQTENV on z/OS. After copying the IBM Netezza Analytics package file (in this example, dwa-inza-3.2.1-20151101-2301.tar) there and clicking on Transfer updates in Data Studio (under About → Server), the Transfer dialog opens (Figure 2-4).

Figure 2-4 Enabling IBM Netezza Analytics package on Accelerator: Transfer Update process
Complete these steps:
1. Select the IBM Netezza Analytics RPM package and click Transfer. After the RPM file is transferred to the Accelerator, a success message is displayed (Figure 2-5).

Figure 2-5 Enabling package on Accelerator: Transfer Update completion confirmation
2. Now that the new IBM Netezza Analytics package is successfully transferred to the Accelerator, you can apply it by using Apply other software version in Data Studio. Figure 2-6 on page 22 shows the component selection window and RPM Package selected.

Figure 2-6 Enabling package on Accelerator: Apply Updates - RPM package selection
3. You can select one of the packages already transferred but not yet applied on the Accelerator. Figure 2-7 shows the new IBM Netezza Analytics package to be applied.

Figure 2-7 Enabling IBM Netezza Analytics package on Accelerator - version selection
To understand more about this software, the version and build numbers are those of the actually used IBM Netezza Analytics packages, also available on distributed platforms on IBM PureData System for Analytics. Software installation and system management is of course completely different because the packages are not directly reachable in the DB2 Analytics Accelerator appliance; they are more encapsulated by z/OS DB2 with DB2 Analytics Accelerator, however the semantics of the available IBM Netezza Analytics stored procedures with capabilities like predictive analytics modeling algorithms are identical.
4. Confirm that you want to activate IBM Netezza Analytics on the accelerator by clicking OK in the confirmation window (Figure 2-8).

Figure 2-8 Enabling package on Accelerator: Transfer - Update completion confirmation
The system starts applying the software (Figure 2-9).
Figure 2-9 Enabling package on Accelerator: Transfer - Apply progress
The IBM Netezza Analytics software library is installed on the Accelerator, available for all subsystems loaded. Now, the About section in Data Studio GUI looks similar to Figure 2-10.

Figure 2-10 Data Studio GUI showing version details about different components of the Accelerator
For every subsystem, IBM Netezza Analytics functionality must be enabled, which works only after the first table is loaded. It has the effect that some internal data structures for model management and other similar items are initialized. Without enabling IBM Netezza Analytics, using the modeling stored procedures will lead to an error message.
Considerations for enabling and disabling IBM Netezza Analytics
After disabling and re-enabling the optional server package IBM Netezza Analytics (INZA) for a given database on the Accelerator, wait approximately 15 minutes so that you do not interfere with the Accelerator’s internal maintenance daemon, which might still be cleaning up on objects in the Accelerator database.
Registering INZA wrapper stored procedures
The wrapper stored procedures are to be registered using DDL SQL as shown in Example 2-4.
Example 2-4 Registering INZA.DECTREE Stored Procedure
CREATE PROCEDURE "INZA"."DECTREE" (
IN ACCELERATOR_NAME VARCHAR(128) CCSID UNICODE FOR MIXED DATA,
IN PARAMETER CLOB(65536) CCSID UNICODE FOR MIXED DATA,
OUT RETVAL INTEGER,
INOUT MESSAGE CLOB(65536) CCSID UNICODE FOR MIXED DATA)
DYNAMIC RESULT SETS 2
EXTERNAL NAME "AQT02ISP"
LANGUAGE C
MODIFIES SQL DATA
PARAMETER STYLE DB2SQL
FENCED
WLM ENVIRONMENT !WLMENV!
ASUTIME NO LIMIT
COLLID SYSACCEL
RUN OPTIONS
'TRAP(ON),HEAP(32K,32K,ANY,KEEP,8K,4K),POSIX(ON),
STACK(128K,128K,ANY,KEEP,512K,128K),BELOW(4K,4K,FREE),
XPLINK(ON),ALL31(ON),ENVAR("_CEE_ENVFILE_S=DD:AQTENV")'
STAY RESIDENT NO
COMMIT ON RETURN NO
PROGRAM TYPE MAIN
SECURITY USER
PARAMETER CCSID UNICODE;
GRANT EXECUTE ON PROCEDURE "INZA"."DECTREE" TO PUBLIC;
This wraps the Accelerator stored procedure nza.dectree() to the DB2 Analytics Accelerator stored procedure INZA.DECTREE. The first parameter is always the z/OS DB2 DB2 Analytics Accelerator name, the second is being mapped to the base stored procedure (after checking security and doing table name transformations). For more details, see 2.1.2, “DB2 Analytics Accelerator wrapper stored procedure” on page 16. The job to register the wrapper-stored procedures used by SPSS Modeler is in “IBM Netezza Analytics stored procedures” on page 190.
2.2.2 Required DB2 privileges for SPSS users
If you use SPSS Modeler with in-database modeling, or more precise, you use wrapped INZA stored procedures, you must have the following privileges defined in DB2:
•EXECUTE on the wrapper SPs
•EXECUTE on the package SYSACCEL
•Privileges to read the accelerated tables that are to be used
•Authorization to create and to drop tables in the AOTDB (see 2.2.6, “AQT_ANALYTICS_DATABASE variable” on page 33)
2.2.3 SPSS Modeler client
First, install SPSS Modeler client on Windows the usual way. Currently, the client is available only on Windows; running the graphical interface of SPSS Modeler without a Windows client is not possible (this client might be virtual or on a server using Microsoft Remote Desktop if running Apple OS X on a Mac, or Linux).
Enable DB2 Analytics Accelerator
Now, enable DB2 Analytics Accelerator support for SPSS Modeler.
Until the switch is removed from the product, you must first find the configuration file and edit it accordingly:
1. Open Windows file explorer and open your user’s home directory in Windows, which is typically under C:Users.
For instance, Figure 2-11 shows one way to navigate to Users home directory.

Figure 2-11 Navigating to Users home directory
2. Select the field containing the path in standard format. The path is similar to Figure 2-12.
Figure 2-12 Path name in standard format for Users home directory
3. Place the cursor beside your userid. The Windows explorer path name area changes to the traditional MS-DOS style version of the file path (Figure 2-13).
Figure 2-13 Path name in traditional format for Users home directory
4. You can now add the “hidden” directory AppData. You can now see the contained directories. Go to the following folder:
C:Usersoliver.benkeAppDataRoamingIBMSPSSModeler17.1Defaults
If you installed the user preferences in SPSS Modeler client, you see a user.prefs file here. If not, create one.
In any case, make sure it contains a line EnableIDAA=true (update the line to true if it says EnableIDAA=false). A sample files is shown in Figure 2-14.

Figure 2-14 SPSS Modeler client user preference file
Client customization
From the Tools pull-down menu of SPSS Modeler client, open the Options section, and then select Helper Applications. The Helper Applications window opens (Figure 2-15).

Figure 2-15 Helper Applications on SPSS Modeler Client
Select the Enable IBM DB2 for z/OS Data Mining Integration check box, which is not enabled, by default.
In the IBM DB2 for z/OS Connection field, you can define a DB2 connection with the associated Accelerator. It is used by SPSS Modeler in case data is processed in the SPSS Modeler but must return to the Accelerator. So SPSS Modeler uses this connection then to push intermediate data down to the Accelerator, using intermediately created accelerator-only tables. For now, you can leave this field blank because it is typically not required and this is to support a scenario that does not perform well due to data transfer between DB2, Accelerator, and SPSS Modeler.
If the stream you created requires pushback from SPSS Modeler to DB2 (which in this case basically means, to the accelerator) but you did leave this field empty, an error message occurs (as indicated by the red circle with the white letter “X” shown in Figure 2-16 on page 28) when you try to run your stream.
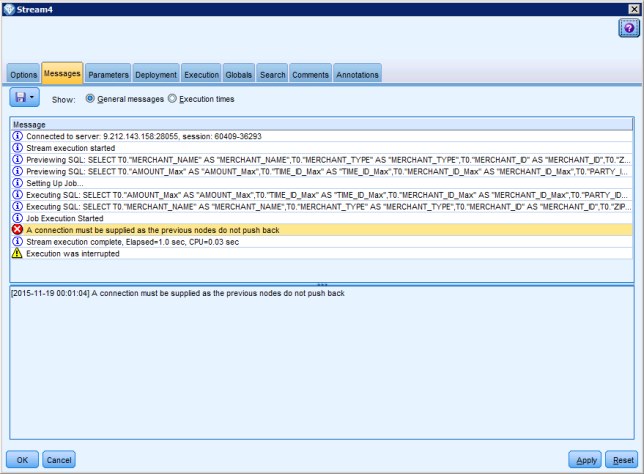
Figure 2-16 Sample error message when DB2 for z/OS connection definition is missing
Although you can add something here so that it always works, be aware that with currently available technology, the pushback might be so resource hungry for your amount of data to process that you might prefer changing the stream slightly rather than paying this resource consumption. Pushback means that all the data produced in SPSS Modeler must be loaded back to DB2 with Accelerator. And in many cases, slight semantical difference exist that force SPSS Modeler to do calculations within the SPSS Modeler server. For example, to trigger this error, we created a stream with a merge node where the merge operation was not a standard join expressible in SQL but Modeler default, “Merge Method: Order”. Probably most people would have preferred an SQL inner join here, if looking at the settings.
After you enable IBM DB2 for z/OS data mining integration, a new Database Modeling tab (palette) becomes available. It shows z/OS DB2 in-database modeling nodes (Figure 2-17).

Figure 2-17 SPSS Modeler client showing “Database Modeling” palette with DB2 for z/OS predictive models
Let SPSS Modeler show you what SQL it generates for z/OS DB2
Seeing what SQL Modeler generates can be interesting, especially regarding in-database processing. By default, generated SQL is not displayed. To change what is displayed, select Tools → Stream Properties → Options → Logging and Status. On this page, enable the SQL display, as shown in Figure 2-18.
After you apply these options, you can view the generated SQL statements, upon execution of your stream, by selecting Tools → Stream Properties → Messages.

Figure 2-18 Options to view generated SQL statements upon stream execution
Optimize SQL for in-database operations
SPSS Modeler can optimize SQL for in-database operations. To enable this function, select Tools → Stream Properties → Options → Optimization and make the selections shown in Figure 2-19.

Figure 2-19 SPSS Client setting to optimize SQL for in-database operations
Client-connected data sources
Using the SPSS Modeler client without a stand-alone SPSS Modeler server is possible. Doing so is sensible if you can ensure that most or all of the triggered processing is running in-database. As in this case, z/OS DB2 and SPSS Modeler server are forwarding the requests scheduled by SPSS Modeler while the accelerator is doing most of the real work.
In this case, first make sure you have SPSS SDAP DataDirect ODBC DSN connections or DB2 ODBC DSN connections to your host. In the SPSS Modeler config directory (the default directory is C:Program FilesIBMSPSSModeler17.1config), edit the odbc-db2-accelerator-names.cfg file.
A sample configuration file is shown in Figure 2-20.

Figure 2-20 Sample configuration file for client-connected data sources
2.2.4 SPSS Modeler server
If significant processing is to be done within SPSS Modeler, use a stand-alone server with large enough memory and file system space, preferably on Linux on z on the same CEC where your OLAP DB2 member is running, connected using HiperSockets.
2.2.5 Data sources in SPSS
Be sure you create two ODBC DSNs per database; you can use one for DB2 base tables and one for accelerated tables. For in-database transformation, it is required that the source nodes are accelerated tables. For the SPSS Scoring Adapter, the source table required to be scored is a DB2 table if used for batch scoring (if used for in-transactional scoring, you do the transaction processing out of the scope of SPSS Modeler client application anyway, and of course there you also run it in DB2).
The odbc-db2-accelerator-names.cfg file must have lines similar to the following lines:
“UB01ACCEL, “MYIDAA”, “UNICODE”
“XB01ACCEL”, “MYIDAA”, “EBCDIC”
In these lines, UB01ACCEL is a DSN with UTF8 Unicode encoding and Accelerator MYIDAA, and XB01ACCEL would be another DSN with Accelerator MYIDAA and EBCDIC encoding.
EBCDIC
EBCDIC data sources are not supported with the IBM SPSS Modeler prior to Version 18.
2.2.6 AQT_ANALYTICS_DATABASE variable
In AQTENV, a new environment variable, AQT_ANALYTICS_DATABASE, denotes a database for creation of accelerator-only output tables in INZA stored procedures and in generic streams for data transformation, driven from SPSS Modeler. The z/OS DB2 should create a new database for that and give all users of SPSS Modeler (or other exploiter of the INZA SPs) the privileges to use DDL statements (CREATE TABLE) in that database.
In addition, a current requirement is to add a file to the config subdirectory of SPSS Modeler server. Assuming you named your database AOTDB, the information shown in Figure 2-21 should be stored in the odbc-db2-custom-properties.cfg file.

Figure 2-21 Specifying Accelerator Database name in the customProperties file of SPSS Modeler server
After making this type of change to the configuration file, you must restart SPSS Modeler.
2.2.7 User management in the SPSS Modeler server
To connect to the SPSS Modeler server, enter the correct user credentials. With a default setup, the credentials might be the root user ID of the Linux on z Systems image, which is probably not what you want. To change this behavior, see the User Authentication section of the IBM SPSS Modeler Server Administration and Performance Guide, or see the IBM Knowledge Center:
2.2.8 Installing SPSS Modeler scoring adapter for DB2 z/OS
The scoring adapter for DB2 z/OS provides score user-defined functions (UDFs) within z/OS. The scoring adapter runs as a UNIX System Services application. A WLM application environment that is specific to the scoring adapter makes sure you can tune it in a way so that all your service level agreements (SLAs) are reached. The scoring adapter runs completely within z/OS, integrated with DB2.
Application programs invoke the score functions in order to get score results. For them, the score UDFs must be installed within DB2, with required access rights given to the users under which the applications are running.
The SPSS Modeler also communicates with the scoring adapter by publishing new models. If publishing a new model, it adds data to specific DB2 tables, and the scoring adapter reads from them in order to get details about the models to be scored.
Prerequisites for the installation are as follows:
•Be sure to have DB2 for z/OS, with all prerequisites, up and running.
•Create a new WLM environment for the scoring adapter.
•Make sure the UNIX System Services is configured as required, and provides a file system that is usable by the scoring adapter with ability to write to a temporary directory. A common error situation is not having enough free space in UNIX System Services TMPDIR, or that the scoring adapter is not able to access it (because the HFS is no longer mounted, or because of missing privileges).
•Install the scoring adapter by using SMP/E.
•Run job control language (JCL), which do the required changes to DB2 z/OS, like creating the tables used to hold the models (as BLOBs), installing the required user-defined functions, set required RACF privileges and bind the scoring adapter package by using DB2 BIND.
Details of the installation are in IBM SPSS Modeler 17.1 Scoring Adapter Installation:
After the installation, you can see the following objects in DB2 for z/OS:
•Tables HUMSPSS.COMPONENTS and HUMSPSS.PUBLISHED_COMPONENTS in HUMSCFDB database.
•HUMSPSS.FLUSH_COMPONENT_CACHE and HUMSPSS.SCORE_COMPONENTS user-defined functions.
2.3 Real-time analytics lifecycle
This section describes the data analytics lifecycle in relation to the business scenario used here. Figure 2-22 on page 35 illustrates data loading, data preparation and transformation, data mining and predictive modeling, and scoring.
The z Systems warehousing and analytics software portfolio is continually evolving and improving. Over the past several years, it has grown to take on new roles. Software products available in the analytics portfolio can exist natively on z Systems, run under Linux for z Systems, and also is available on hybrid platforms.
Data is the new raw material for the 21st century. Data is meant to provide insight into business and offer a competitive edge. Online transaction processing (OLTP) is where this mission-critical data is generated based on business activity. OLTP usually is associated with high volume transaction processing applications like IBM CICS®, IMS™, and WebSphere®, and is a necessity for running a business because that is where the customer interactions and customer transactions are taking place. Data is gathered in the OLTP system and eventually the insights from the operational data is also consumed by the OLTP system, as shown in Figure 2-22.

Figure 2-22 Analytics lifecycle in relation to real-time predictive analytics solution on z Systems
The z Systems environment can support the full lifecycle of a real-time analytics solution on a single, integrated system, combining transactional data, historical data, and predictive analytics.
The following four phases of the in-database analytics lifecycle are depicted at the top of Figure 2-22:
•Data Load or Data Integration phase
•Data Preparation and Transformation phase
•Predictive Modeling phase
•Real-time Scoring phase
Below the four phases, the figure shows the software solutions that can be used to accomplish the corresponding activities involved in the phases. For instance, the DB2 Analytics Accelerator Loader for z/OS can be used to load data into the accelerator (which essentially becomes the “play area” of the data scientist). The DB2 Analytics Accelerator Loader for z/OS can also be used to integrate data from various external sources. Additional information about DB2 Analytics Accelerator Loader for z/OS is in Chapter 3, “Data integration using IBM DB2 Analytics Accelerator Loader for z/OS” on page 41.
IBM DataStage® shown beside the DB2 Analytics Accelerator Loader for z/OS in Figure 2-22 on page 35 can be used to perform in-database transformation, (extract, transform, and load (ETL) or extract, load, and transform (ELT)), from external data sources and so on.
After all the external data is loaded into the accelerator, further data preparation and transformation can be done in-database by using IBM SPSS Modeler. For more information about IBM DataStage and IBM SPSS Data preparation and transformation, see Chapter 4, “Data transformation” on page 83.
The DB2 for z/OS area of Figure 2-22 on page 35 shows a glimpse of what kind of API is involved in the four phases of the in-database analytics lifecycle. This area also reaffirms that the data is always under the control of DB2 for z/OS even when the loading, transforming, and modeling activities are taking place in the accelerator, which is symbolically represented by the diamond shaped proxy tables for each AOT holding the data. The small rectangular boxes with rows and columns represent tables. The tables marked as “Data sources (in DB2 for z/OS)” will be used only by the OLTP transactions whereas the replica tables shown within the accelerator area (bottom section of Figure 2-22 on page 35) will be used by the in-database transformation and in-database modeling processes.
|
Note: The replica tables are not AOTs but they are the accelerated tables pertaining to each of the corresponding DB2 for z/OS source tables. All other tables shown in the Accelerator area are AOTs. Some of the AOTs can be used to hold external data (populated by DB2 Analytics Accelerator Loader for z/OS or IBM DataStage) and the rest of the AOTs might be created by SPSS Modeler to hold transformed and cached node data. The AOT marked as intermediate table for modeling will be the one used by INZA stored procedures to build the predictive analytics model. For more details about modeling, see Chapter 5, “Data modeling using SPSS and DB2 Analytics Accelerator” on page 107.
|
The generated model nugget is shown in the bottom right corner of Figure 2-22 on page 35. When the model is published successfully, a pair of DB2 for z/OS tables will be populated and all the temporary AOTs are deleted automatically. Finally, the model information on the DB2 tables can be used for real-time scoring. More details about real-time scoring are in Chapter 6, “Model scoring” on page 117.
2.3.1 Swim lane diagram of in-database analytics lifecycle
Figure 2-23 shows the key process interactions involved in a typical in-database analytics lifecycle. This swim-lane diagram is an attempt at explaining how SPSS, DB2 for z/OS, and DB2 Analytics Accelerator interact from a data scientist’s perspective.

Figure 2-23 Swim-lane diagram showing in-database analytics process interactions
2.3.2 Interaction between a DB2 DBA and a data scientist
This section summarizes the high level responsibilities and interactions between a database administrator (DBA) and a data scientist with reference to the solution discussed in this book.
Database administrator (DB2 for z/OS)
The DBA makes sure that tables used for analytics are available to the data scientist. As always, the DBA or the security administrator makes sure that exactly the required access privileges are granted to appropriate userids in order to access the data. The tables required for accelerated in-database modeling are loaded by the DBAs through the Data Studio GUI or by other tools capable of invoking the DB2 Analytics Accelerator stored procedures.
Data scientist
The data scientist interactively creates SPSS modeling streams. SPSS Modeler can help to merge tables (using SQL joins), to filter or transform input data. It also provides advanced visualization capabilities and offers various predictive analytics modeling algorithms for use by the data scientist. For real-time analytics, the data scientist makes sure that the generated SQL statement pertaining to the scientist’s selected model can achieve desired performance goals by working with the DBAs.
2.3.3 Key strengths of various components
Table 2-1 lists the key strengths of various components that make up the real-time (in-database) analytics solution discussed in this book.
Table 2-1 Key strengths of components that can be used in your analytics solution on z
|
Your real-time analytics requirement
|
Software Solution (component)
|
|
Highly scalable secured environment for your mission-critical data
|
IBM DB2 for z/OS
|
|
High transaction throughput capability for applications accessing your data
|
|
|
Perform predictive analytics on your mission-critical data
|
IBM SPSS Modeler with SPSS Scoring Adapter for DB2 z/OS
|
|
Frequently build predictive models based on operational data
|
IBM DB2 Analytics Accelerator for z/OS appliance
|
|
Enable machine learning capability on your OLTP applications on z Systems
|
|
|
Combine data from other sources (VSAM, IMS, Oracle, social media, and so on) and perform analytics
|
IBM DB2 Analytics Accelerator Loader for z/OS tool
|
|
Combine business rules with your analytics predictions
|
IBM Collaboration and Deployment Services, and Operational Decision Manager
|
|
Perform data transformation from varied sources
|
IBM DataStage
|
|
Create business analytics visualization reports
|
IBM Cognos® for z/OS
|
|
In-application scoring as part of your real-time analytics solution
|
Zementis
|
Figure 2-24 shows various software packages and tools that can be part of the real-time in-database analytics lifecycle shows in Figure 2-22 on page 35. At the core of this solution is the IBM DB2 Analytics Accelerator for z/OS, as depicted in the center of this lifecycle diagram.
Figure 2-24 also can be correlated with the key strengths of software components and tools that can be used in this solution.
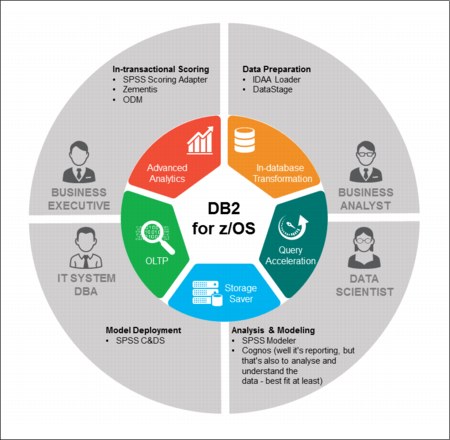
Figure 2-24 Tools and actors of real-time analytics lifecycle with in-database processing at the core
1 For more information, see Optimizing DB2 Queries with IBM DB2 Analytics Accelerator for z/OS, SG24-8005.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.