


Data integration using IBM DB2 Analytics Accelerator Loader for z/OS
Data integration using DB2 Analytics Accelerator Loader for z/OS v2.1 is described in this chapter.
This chapter contains the following topics:
3.1 Functional overview
The IBM DB2 Analytics Accelerator Loader for z/OS v2.1, referred to as just Loader in this publication, is a tool designed to load data directly into the IBM DB2 Analytics Accelerator for z/OS, referred to here as Accelerator. Loader reduces elapsed time while consuming less CPU when compared to traditional methods used to load data into Accelerator. Loader also uses a less complicated process capable of moving data from DB2 and non-DB2 sources, both remote and local, directly into the Accelerator. Although Loader has the ability to load data into both DB2 for z/OS and the Accelerator in parallel, loading data directly into an Accelerator without the need to first load that data into DB2 for z/OS is one of its major strengths.
That simpler process allows data to be moved and transposed in fewer steps involving less administrative time. Loader is a complete end-to-end solution that manages all your Accelerator data movement in a single product.
|
Note: Loader’s strength is its ability to take data and load it directly into the DB2 Analytics Accelerator without the need of first moving that data into DB2.
|
The data source is accessed and converted to the appropriate format and then loaded directly into the Accelerator without the necessity of intermediate files. Extracting the data prior to a load is no longer necessary.
By using Loader, data can be loaded into just the Accelerator or into both the Accelerator and DB2 for z/OS in parallel. Both the LOAD REPLACE or LOAD RESUME options are available when using Loader.
Along with the performance advantage naturally inherent in a process that does not have to “go through” DB2 to get to the Accelerator, Loader makes extensive use of the IBM z Systems Integrated Information Processor (zIIP). By allowing Loader to take advantage of zIIP specialty processors, a percentage of Loader’s CPU costs can be redirected to processors that have no IBM software charges, thus freeing up general computing capacity and lowering overall total cost.
IBM allows customers to purchase additional processing power exclusively for select data serving environments without affecting the total million service units (MSU) rating or machine model designation on zIIP, or z Systems Application Assist Processor (zAAP).
Originally, formatting the input was the client’s responsibility, but now Loader helps with the data mappings.
Loader accepts input from multiple sources and multiple locations. In addition to IMS, Oracle, SMF, z Systems Data Compression (zEDC), Virtual Storage Access Method (VSAM), physical sequential existing locally, these sources could also be located on a different Sysplex or on Linux on z Systems. Figure 3-1 on page 43 shows the relationship of the various data sources to the Loader components. The Accelerator Loader Server, referred to in this document as HLV or HLV started task, performs the mapping and movement from any one of the data sources and prepares the batch JCL for execution on z/OS. Data is passed from HLV to the Accelerator Loader component, referred to as the HLO in this document, using shared memory objects. HLO calls the DB2 utility DSNUTILB, invokes the Loader intercept, and loads the data into the Accelerator.

Figure 3-1 An overview of the entire Loader process
Loader also now provides a high availability load by loading multiple accelerators. Currently, you need to load Accelerator 1, then Accelerator 2, then Accelerator 3, and so on, but after applying the PTF, one statement will allow multiple accelerators to be loaded at once.
DB2 Analytics Accelerator Loader for z/OS v2.1 is documented in the IBM Knowledge Center:
Ultimately, the DB2 Analytics Accelerator Loader provides a simple end-to-end process to consolidate data from multiple sources into an Accelerator.
3.1.1 Loader v2.1 enhancements
DB2 Analytics Accelerator Loader for z/OS, V2.1 provides the following benefits:
•Minimized application impact when loading or refreshing external DB2 for z/OS data by loading in parallel to both DB2 for z/OS and DB2 Analytics Accelerator.
•Increased flexibility when performing business analytics by enabling the load of a consistent set of data with an historical point-in-time into DB2 Analytics Accelerator for query consideration.
•A z Systems solution to quickly load data directly to the Accelerator from many data sources, including IMS, VSAM, sequential files, and Oracle, without the need to land or stage the data in intermediate files. The entire process from data extraction, conversion, and loading is automated in a single batch job step.
•An easy-to-use SQL interface to identify data to be loaded into the Accelerator, including the ability to join and load data from multiple sources to a single Accelerator table.
•Potential further reduction in CPU cost associated with data loading into DB2 Analytics Accelerator as DB2 Analytics Accelerator Loader directs such processing to be executed under an enclave service request block and such processing is authorized to execute on a zIIP specialty engine 1.
•Support for IBM Change Data Capture for z/OS (CDC) replication when loading to both a DB2 table and an Accelerator table.
•The ability to append data to an existing table. This LOAD RESUME capability can help to reduce elapsed time and CPU consumption by avoiding the need to reload the entire table to include the new data to be loaded.
•The ability to automatically create the table on the DB2 Analytics Accelerator if it does not exist and to enable the table for acceleration after the load is successful. This can help to improve user efficiency and may reduce the manual steps required to prepare a table on the appliance for acceleration.
•When performing a load from an external file, you can load SYSREC data that is already in DB2 internal row format. The DB2 UNLOAD utility supports an option to unload the data from a table in FORMAT INTERNAL. This enhancement provides the benefits of reduced CPU consumption and elapsed time in both the UNLOAD and in Accelerator Loader jobs.
For a complete description of DB2 Analytics Accelerator Loader v2.1, see the January 25, 2016 announcement letter:
3.1.2 Loader methods to move data
Loader uses four methods to move data in the Accelerator:
•Dual. Specifies options for loading table data into both the accelerator and DB2 from an external data input file.
•Accelerator Only. Specifies options for loading table data into only the accelerator from an external data input file.
•Consistent. Specifies options for loading data for multiple tables into the accelerator from a cataloged DB2 image copy.
•Image copy. Specifies options for loading data for a single table into the accelerator from a user-defined DB2 image copy.
These methods are discussed in this chapter.
3.1.3 Components and interfaces
This section describes the components and interfaces inherent to Loader.
HLO: Accelerator Loader
The following components are inherent to the HLO Accelerator Loader, which calls the DB2 utility DSNUTILB:
•The batch load utility along with intercept processing.
•The Accelerator Loader communicates with the Accelerator Loader Server with the purpose of loading directly from data sources.
•The DSNUTILB batch job communicates with IDAA and sends data to IDAA.
•Supports loading from a sequential file (without the Accelerator Loader server) when the file is in DB2 Load File format (external load).
•Supports loading the Accelerator from image copies and logs (consistent load).
•The procedure name usually associated with batch component is hloidPROC.
In Example 3-1, a DISPLAY command is issued for the Accelerator Loader started task to verify that the intercept is enabled. Message HLOS0817I identifies that the local DSNUTILB intercept is indeed enabled. The DISPLAY command in the example is preceded with a slash (/) only because the command was issued from SDSF.
Example 3-1 Verifying Loader intercept is active
/F HLO1PROC,DISPLAY INTERCEPT,ALL
HLOS0814I 120 15:44:18.55 Command issued: DISPLAY INTERCEPT,ALL
HLOS0817I 120 15:44:18.55 LOCAL DSNUTILB intercept status is: ENABLED
HLOS0817I 120 15:44:18.55 GLOBAL DSNUTILB intercept status is: ENABLED
HLOS0822I 120 15:44:18.55 DB2 SSID=DBZZ 1110 ID=HLO1 DSNUTILB interception is installed
HLV: Accelerator Loader Server
The Accelerator Loader Server (HLV) performs all access to the data sources for purposes of direct loading. This includes mapping and transforming the data from its source form to a relational record form.
Accelerator Loader Server is accessed through the Data Studio plug-in. It drives the mapping process and builds the appropriate JCL to perform the load process.
The procedure name usually associated with Accelerator Loader Server is hlvidPROC.
Interactive System Productivity Facility (ISPF)
The ISPF interface provides options for building JCL to load or refresh data on the Accelerator. It will generate the JCL, giving the options to save the JCL in a data set of your specifications.
Accelerator Loader studio
The Accelerator Loader studio is a plug-in for the IBM Data Studio. It can be used to quickly transform and load relational and non-relational data to an Accelerator. This plug-in allows for real-time access to the data, which can be read directly from the mapped source and transformed while it is being loaded into the Accelerator tables.
IBM Data Studio enables developers and administrators to create and manage heterogeneous database environments using Eclipse technology. Data Studio is a fully licensed product available at no charge and with no time restrictions that can be downloaded from the IBM Support website:
Accelerator Loader started task
Accelerator Loader runs as a started task on a z/OS. The started task receives input from the interfaces through the supervisor call (SVC) communicating with the DB2 subsystems to run the JCL and load data to the Accelerator. A single started task can process simultaneous requests from multiple users across the system. The started task must be started before you can perform any product functions.
3.2 Getting started
One of the first steps to take before installing Loader is the verification of all the prerequisites. To ensure that you have the most recent prerequisites, preinstallation, and installation notes, see the following locations in the IBM Knowledge Center:
•Preparing to customize
•DB2 Analytics Accelerator Loader V2.1 documentation
3.2.1 Installation
For information about installing the Accelerator Loader studio (required component of the DB2 Loader), see the IBM Knowledge Center:
DB2 Loader can be fully installed with the SMP/E program. The installation instructions for the actual DB2 Loader product, along will all SMP/E requirements, are in the Program Directory for IBM DB2 Analytics Accelerator Loader for z/OS publication:
This document is program number 5639-OLE with FMIDs HHLO210, HALE210, H25F132.
If data is loaded from distributed relational database architecture (DRDA) sources, DB2 Analytics Accelerator Loader for z/OS, V2.1 requires one of the following items:
•IBM InfoSphere® Federation Server, V9.7 (5724-N97)
Analytics Accelerator Loader uses the partitioned data set extended (PDSE) format for the SHLOLOAD, SHLVLOAD, and SHLVRPC target libraries. Some operational differences exist between PDS and PDSE data sets. Make sure you understand the differences between a PDS and PDSE data set before using PDSE. Some of the differences are described at the following web page:
3.2.2 Customization
After Loader is installed, it must be customized for use at your installation. See the Customizing DB2 Analytics Accelerator Loader web page:
Also see the DB2 Analytics Accelerator Loader V2.1 documentation web page:
3.2.3 Workload Management (WLM) performance goals
With z/OS WLM, you can define performance goals and then assign a business importance to each goal. z/OS will decide the resources, such as CPU and storage, that should be allotted so that goal can be met. The system and its resources are constantly monitored and adjusted to meet those defined goals.
The DB2 Analytics Accelerator Loader components should be defined to WLM to ensure that performance is maximized. This includes started tasks, servers, batch workloads, and stored procedure address spaces. Along with Loader, resource management of the load that is running on the Accelerator must also be examined. A typical suggestion is to leave the default settings unless, after observation, you need to change the prioritization. However, the Accelerator resource management is beyond the scope of this book.
Terms used
The following terms are used in this book:
Response time goal
Indicates how quickly you want work to be processed.
Indicates how quickly you want work to be processed.
Velocity goal
Defines how fast work should run when the work is ready.
Defines how fast work should run when the work is ready.
Discretionary goal
Indicates low-priority work with no particular performance goal.
Indicates low-priority work with no particular performance goal.
Enclave
Is the mechanism for managing and monitoring transactions that can span multiple dispatchable units, SRBs, and tasks, in one or more address spaces.
Is the mechanism for managing and monitoring transactions that can span multiple dispatchable units, SRBs, and tasks, in one or more address spaces.
Dispatching priority (DP)
Is a number in the range of 0 - 255 associated with a dispatchable unit of work (TCBs or SRBs). DP is placed in an address space or in an enclave control block to indicate the priority of the dispatchable units for getting CPU service. DP is assigned by WLM and ready work with the highest priority is dispatched first.
Is a number in the range of 0 - 255 associated with a dispatchable unit of work (TCBs or SRBs). DP is placed in an address space or in an enclave control block to indicate the priority of the dispatchable units for getting CPU service. DP is assigned by WLM and ready work with the highest priority is dispatched first.
Service request block (SRB)
Represents a request to execute a system service routine. SRBs are typically created when one address space detects an event that affects a different address space; they provide one mechanism for communication between address spaces.
Represents a request to execute a system service routine. SRBs are typically created when one address space detects an event that affects a different address space; they provide one mechanism for communication between address spaces.
Task control block (TCB)
Represents a task executing within an address space, such as user programs and system programs that support the user programs.
Represents a task executing within an address space, such as user programs and system programs that support the user programs.
TCBs or SRBs may be dispatched on any logical processor of the type required; standard CP or zIIP.
SYSOTHER
Is a “catch all” service class for work with no classification and is assigned to a discretionary goal.
Is a “catch all” service class for work with no classification and is assigned to a discretionary goal.
Accelerator Loader Server
WLM considers the Accelerator Loader Server component to consist of two parts; both parts must be defined to WLM:
•The Data Server started task
The Accelerator Loader Data Server (hlvidPROC started task) provides key support for direct load from source Loader operations. The Accelerator Loader Data Server started task will initiate the HLV threads (enclaves) and is responsible for conducting I/O on behalf of the same.
Accelerator Loader Data Server should be classified to an existing or new service class with the appropriate goals relative to your existing work on the same z/OS image.
•The Loader HLV subsystem that manages the enclaves
The WLM subsystem HLV, a new subsystem defined during the installation of Loader, manages the enclaves running on behalf of Loader jobs and will do the bulk of the work, including data extraction, data conversions, and managing the pipe into DSNUTILB which in turn will pipe into the Accelerator. See Example 3-2.
HLV should be classified to the same service class as hlvidPROC.
Example 3-2 HLV start task proc example
//HLVS PROC SSID=HLVS,OPT=INIT,TRACE=B,MSGPFX=HLV,
// MEM=32G,REG=0000M,HLQ='hlq',HLQ1='hlq1',HLQ2='hlq2'
//*
//IEFPROC EXEC PGM=HLV2IN,REGION=®,TIME=1440,DYNAMNBR=100,MEMLIMIT=&MEM,
// PARM='&OPT,&SSID,&TRACE,&MSGPFX'
//*
//* additional DD statements intentionally excluded
//*
|
Note: Currently there is no means, no qualifiers exist, for granular classification of various work within the HLV subsystem.
|
Do not allow work for the HLV subsystem or the Accelerator Loader Data Server to default to the WLM service class SYSOTHER. If work that uses enclaves is not classified, that work will default to SYSOTHER.
Accelerator Loader started task
The Accelerator Loader started task (hloidPROC) provides the basic services for DSNUTILB plus restart and DB2 catalog access. The Accelerator Loader should be classified to a service class with less than or equally aggressive goals as compared to the Accelerator Loader Server component, the hlvidPROC started task, shown in Example 3-3.
Example 3-3 HLO started task example
//HLOHLO1 PROC OPT=HLO1OPTS,PLCY=HLO1PLCY
//*
//* additional DD statements intentionally excluded
//*
//STCRUN EXEC PGM=HLOSINIT,TIME=1440,REGION=0M
Loader batch job
All Loader tasks are initiated through a JES2 batch job, a sample of which is shown in Example 3-4. These batch jobs call the DB2 utility DSNUTILB with appropriate Loader and DB2 LOAD control cards, invoke the Loader intercept, and load the data into the Accelerator.
Classify existing service classes or new service classes with goals equal to or more aggressive than the HLV WLM subsystem. For critical Loader work, consider using a more aggressive service class (higher importance, velocity, or both) than the rest of the Loader work. This is a way to differentiate resource management of different Loader jobs.
For granular reporting, use unique WLM report classes for all of the Loader components, including the batch jobs just described.
Example 3-4 Loader batch JCL
//ACCLLOAD EXEC PGM=DSNUTILB,REGION=0000M,PARM=('ssid','utility-id')
//*
//* additional DD statements intentionally excluded
//*
//HLODUMMY DD DUMMY
Classification Starting point only
Although not a recommendation, a possible starting point for a workload classification could be the values used on the z/OS system used to gather the metrics in this Redbooks publication. However, do not consider these values to be “the correct” way to set up WLM but rather one example of how a system might be set up. Table 3-1 contains an example of how Loader was set up in WLM in a test environment. This figure also includes samples of other subsystem classifications that Loader might interface with.
Table 3-1  Loader set up in our WLM test environment: goal examples
Loader set up in our WLM test environment: goal examples
Loader set up in our WLM test environment: goal examples|
Note: When implementing resource management for an Accelerator Loader workload, update considerations should not be limited to the z/OS WLM service definitions. Also consider resource management of the load process running on the Accelerator. This portion of the end-to-end load resource management is controlled from the Accelerator configuration console. Although the typical preference is to leave the default settings, you might need to change the prioritization, for example, based on time of the day.
|
A task’s assigned dispatching priority is critical to that task’s performance in a z/OS environment. WLM is responsible for adjusting the dispatching priority based on velocity and importance defined to a service class. For that reason, an important steps is to take time to ensure that the dispatching priority for the Accelerator Loader started tasks are set correctly with respect to other dispatching priorities. The dispatching priority determines the order in which a task uses the processor in a multitasking environment. The Accelerator Loader dispatching priority must be lower than the priority values for the DB2 subsystems that Accelerator Loader will use, but higher than the priority values for any DB2 LOAD utilities for which Accelerator Loader will perform processing. Set the dispatching priorities for these items in the following order, from highest to lowest priority:
1. The address spaces of the DB2 subsystems that Accelerator Loader will use (highest dispatching priority).
2. The Accelerator Loader started tasks.
3. The DB2 LOAD utility that Accelerator Loader intercepts (any dispatching priority under the Accelerator Loader started tasks).
Display WLM Information
Details about the level of WLM being used and the WLM service policy currently active can be displayed by using the IBM z/OS MVS™ DISPLAY WLM command. An example of the output from this command is shown in Example 3-5.
Example 3-5 Results of a z/OS MVS DISPLAY WLM command
D WLM
IWM025I 17.03.00 WLM DISPLAY 121
ACTIVE WORKLOAD MANAGEMENT SERVICE POLICY NAME: IZASBASE
ACTIVATED: 2016/04/14 AT: 12:54:50 BY: USERxx FROM: P52
DESCRIPTION: IZASBASE Changed 01/25/2013 USERxx
RELATED SERVICE DEFINITION NAME: IZASBASE
INSTALLED: 2016/04/14 AT: 12:54:39 BY: USERxx FROM: P52
WLM VERSION LEVEL: LEVEL029
WLM FUNCTIONALITY LEVEL: LEVEL011
WLM CDS FORMAT LEVEL: FORMAT 3
STRUCTURE SYSZWLM_WORKUNIT STATUS: DISCONNECTED
STRUCTURE SYSZWLM_7EB72964 STATUS: DISCONNECTED
STATE OF GUEST PLATFORM MANAGEMENT PROVIDER (GPMP): INACTIVE
WLM managed stored procedure address spaces
Loader takes advantage of two WLM application environments. In the z/OS system that was used to gather the metrics used in this book, the environments were as follows:
•DSNWLM_IDAA. This environment is used by all of the Accelerator stored procedures. These examples of stored procedures use this environment and are also used by Loader:
– SYSPROC.ACCEL_ADD_TABLES
– SYSPROC.ACCEL_REMOVE_TABLES
– SYSPROC.ACCEL_LOAD_TABLES
– SYSPROC.ACCEL_SET_TABLES_ACCELERATION
•DSNWLM_UTILS. This environment is used for processing by the DB2 utility stored procedures DSNUTILU and DSNUTILS (deprecated). This environment is defined to DB2 when DB2 is installed. It is modified by Loader to include the SHLOLOAD load library in the STEPLIB concatenation (see JCL in Example 3-8 on page 52).
To validate the working status of these two stored procedures, the WLM display commands in Example 3-6 can be used. These two display examples use our naming convention for the environment names; your names will differ.
Example 3-6 Display example of WLM managed stored procedure address spaces status
D WLM,APPLENV=DSNWLM_IDAA
IWM029I 10.00.30 WLM DISPLAY 183
APPLICATION ENVIRONMENT NAME STATE STATE DATA
DSNWLM_IDAA AVAILABLE
ATTRIBUTES: PROC=DBZZWLMI SUBSYSTEM TYPE: DB2
D WLM,APPLENV=DSNWLM_UTILS
IWM029I 10.03.10 WLM DISPLAY 185
APPLICATION ENVIRONMENT NAME STATE STATE DATA
DSNWLM_UTILS AVAILABLE
ATTRIBUTES: PROC=DBZZWLMU SUBSYSTEM TYPE: DB2
If the characteristics of these WLM managed stored procedure address spaces change, for example NUMTCB keyword was modified, the environment should be refreshed.
Example 3-7 shows two samples of the WLM modify command to refresh the environments. Again, change the environment names used in the example to match your system.
Example 3-7 A WLM managed stored procedure address space refresh
V WLM,APPLENV=DSNWLM_IDAA,REFRESH
IWM032I VARY REFRESH FOR DSNWLM_IDAA COMPLETED
V WLM,APPLENV=DSNWLM_UTILS,REFRESH
*IWM031I VARY REFRESH FOR DSNWLM_UTILS IN PROGRESS
IWM034I PROCEDURE DBZZWLMU STARTED FOR SUBSYSTEM DBZZ 501
APPLICATION ENVIRONMENT DSNWLM_UTILS
PARAMETERS DB2SSN=DBZZ,APPLENV='DSNWLM_UTILS'
IWM032I VARY REFRESH FOR DSNWLM_UTILS COMPLETED
$HASP100 DBZZWLMU ON STCINRDR
$HASP373 DBZZWLMU STARTED
- --TIMINGS (MINS.)--
----PAGING COUNTS---
-JOBNAME STEPNAME PROCSTEP RC EXCP CPU SRB CLOCK SERV PG
PAGE SWAP VIO SWAPS
-DBZZWLMU DBZZWLMU 00 20 ****** .00 .9 249 0
0 0 0 0
-DBZZWLMU ENDED. NAME- TOTAL CPU TIME= .00 TOTAL
ELAPSED TIME= .9
$HASP395 DBZZWLMU ENDED - RC=0000
Example 3-8 is one sample of the JCL used for the started task procedure for the WLM managed stored procedure address spaces. It represents the DSNWLM_UTILS environment included with DB2 with the modifications to include Loader’s intercept module (SHLOLOAD load library).
Example 3-8 Sample utility WLM managed stored procedure address space procedure
//ssidWLMU PROC APPLENV='DSNWLM_UTILS',
// DB2SSN=ssid,RGN=0K,NUMTCB=1
//IEFPROC EXEC PGM=DSNX9WLM,REGION=&RGN,TIME=NOLIMIT,
// PARM='&DB2SSN,&NUMTCB,&APPLENV'
//STEPLIB DD DISP=SHR,DSN=CEE.SCEERUN
// DD DISP=SHR,DSN=db2hlq.SDSNEXIT
// DD DISP=SHR,DSN=db2hlq.SDSNLOAD
// DD DISP=SHR,DSN=hlq.HLO210.SHLOLOAD
//UTPRINT DD SYSOUT=*
//RNPRIN01 DD SYSOUT=*
//STPRIN01 DD SYSOUT=*
//DSSPRINT DD SYSOUT=*
//SYSIN DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSPRINT DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
Example 3-9 is the JCL sample for the started task used by the Accelerator stored procedures. It includes DD statements that reference the location of the Accelerator stored procedures (in out case, IDAA51.SAQTMOD), the location of the environmental variables used by the Accelerator stored procedures (member AQTENV in library SAQTSAMP), and the PDS hlq.IDAA41.SAQTOSR containing the preprocessed Optimized Schema Representations (OSRs) for the XML System Services parser in member AQTOSR (no longer used in Accelerator 5.1).
The NUMTCB value for the WLM address space that manages the Accelerator stored procedures should be equal to 3 × <value of AQT_MAX_UNLOAD_IN_PARALLEL> + 1. For example, if AQT_MAX_UNLOAD_IN_PARALLEL is set to 4, the NUMTCB value used for this address space should be 13.
Example 3-9 Sample Accelerator WLM managed stored procedure address space proc
//ssidWLMI PROC APPLENV='DSNWLM_IDAA',
// DB2SSN=ssid,RGN=0K,NUMTCB=61
//IEFPROC EXEC PGM=DSNX9WLM,REGION=&RGN,TIME=NOLIMIT,
// PARM='&DB2SSN,&NUMTCB,&APPLENV'
//STEPLIB DD DISP=SHR,DSN=CEE.SCEERUN
// DD DISP=SHR,DSN=db2hlq.SDSNEXIT
// DD DISP=SHR,DSN=db2hlq.SDSNLOAD
// DD DISP=SHR,DSN=db2hlq.SDSNLOD2
// DD DISP=SHR,DSN=hlq.IDAA51.SAQTMOD
// DD DISP=SHR,DSN=XML.HXML1A0.SIXMLOD1
//SYSTSPRT DD SYSOUT=*
//CEEDUMP DD SYSOUT=*
//OUT1 DD SYSOUT=*
//UTPRINT DD SYSOUT=*
//DSSPRINT DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//AQTENV DD DISP=SHR,DSN=hlq.IDAA51.SAQTSAMP(AQTENV)
//* Include the following DD card when using an Accelerator prior to v5.1
//AQTOSR DD DISP=SHR,DSN=hlq.IDAA41.SAQTOSR(AQTOSR)
3.2.4 IBM z Systems Integrated Information Processor (zIIP)
An IBM z Systems Integrated Information Processor (zIIP) is an IBM specialty engine. Specialty engines are the same type of hardware as a general purpose central processor (CP) with the same characteristics and speed as full capacity CP. However, specialty engines can run only specific workloads. Because only specific workloads are run on those processors, IBM can price those workloads efficiently. Thousands of applications can share a general processor, which makes general processors cost-effective for virtualized workloads.
The primary purpose of a zIIP is to help reduce your z Systems software cost. Software charges for many mainframe products are based on CPU consumption. The more CPU used, the greater the increase in your software cost. However, by installing one or more zIIP specialty engines, some of the millions of instructions per second (MIPS), or maybe it should be billions of instructions per second (BIPS) now, that would have been used by a CP, can be redirected to a zIIP. When the software is redirected to run on a zIIP rather than CP, the processors used by that redirected software are not included in the total MSU rating and it does not affect the machine model designation. When the MSU or model does not change, the software charges do not increase.
zIIPs can be used for far more than the HLV and HLO functions of Loader. Between DB2 and z/OS, other functions exist that can also take advantage of a zIIP specialty engine. To help explain why zIIP activity can be reported even when performing non Loader processing, some of the specific workloads that might potentially be redirected to a processor repurposed as a zIIP are listed.
|
Note: On a sub-capacity z13 processor, zIIP specialty engines run at the same speed of a full-capacity processor.
|
The following DB2 for z/OS work is eligible for zIIP:
•The utility BUILD and REBUILD phases for index maintenance
•The UNLOAD phase of REORG
•Most index, COLCARD, FREQVAL, HISTOGRAM statistics collected by RUNSTATS
•Inline statistics for LOAD, REBUILD INDEX, and REORG (about 80%)
•100% of delete processing for LOAD REPLACE with dummy input
•100% of all prefetch (dynamic, list, and sequential)
•100% group buffer pool (GBP) write, castout, p-lock, and notify/exit processing
•100% index pseudo delete cleanup
•Log reads and writes
•Call, commit, and result-set processing for remote stored procedures
•XML parsing
The following non DB2 (or z/OS) activities can use a zIIP and are sometimes overlooked:
•IPSec: Encryption processing, header processing, and crypto validation (93% for bulk data movement).
•HiperSockets for Large messages.
•Simultaneous multithreading (SMT) mode processing is available only for zIIPs, implemented on a z13 and later with z/OS v2.1 and later. With SMT enabled, zIIPs can potentially have 140% or more capacity.
•zAAP on zIIP: Anything that would (or could) run on a zAAP is not eligible to run on a zIIP.
•SDSF in z/OS v2.2 is designed to offload a portion of certain kinds of processing.
•DFSMS SDM of z/OS (processing associated with IBM z/OS Global Mirror (zGM), also known as Extended Remote Copy (XRC).
•IBM SDK for z/OS, Java Technology Edition.
•z/OS XML System Services.
•System Data Mover (SDM).
•DFSORT (Sorting of fixed length rows: 10 -4 0% for utilities).
•DB2 Sort (10 - 20% potentially eligible for redirect).
•Global Mirror for z/OS (formerly Extended Remote Copy): most SDM processing.
•IBM Platform for Apache Spark.
Measurements were performed using 2 - 14 zIIPs, enabled depending on the test being performed. The measurement team does acknowledge that testing with 14 zIIPs might not be realistic and might not translate back to most customer environments. However, with 14 zIIPs, the intention was to minimize or eliminate all zIIP on CP time from becoming part of the measurements and achieve maximum throughput.
While performing measurements using Loader v2.1, the Accelerator Loader Server (referred to as HLV in this document) is responsible for extracting data from any of the allowed data sources where they reside and in memory loading, that address space has a zIIP generosity factor of 100%, attempting to allow all HLV work to execute on a zIIP. Unlike the Accelerator Loader Server (HLV), the zIIP redirect measured for the batch interface responsible for interfacing with DSNUTILB (referred to in this document as HLO) varied and was always lower, sometimes significantly, than Loader’s HLV counterpart.
The Accelerator Loader Server, which performed the data extraction (HLV) and handing the extracted data off to the batch process, experienced more zIIP redirects.
Taking advantage of parallelism (a process also frequently referred to as Map Reduce Client, MRC, or just mapreduce), improves zIIP redirect. However, caution should be taken when choosing the degree of parallelism if attempting to minimize zIIP on CP time (referred to as APPL % IIPCP in the Service Policy Time report, which is part of the IBM RMF™ Workload Activity Report). The concept exists in HLV (not in HLO, classic Loader) where you can specify how many parallel threads you want when loading any data asset, for example VSAM. What that means is that HLV logically partitions by introspecting various VSAM metadata that exist in control blocks.
With HLV, if running a degree of parallelism of 20, there will be 40 enclave SRBs created. This means that for each parallel count value, 2 SRBs running inside the HLV address space exist. No locking occurs between any of these groups of two allowing them to run completely in parallel improving the overall performance of Loader. Within each pair of SRBs, one SRB is responsible for physical I/O while the other SRB performs data transformations and moving data into a shared memory object (shared memory objects are used when moving data between the HLV and HLO components of Loader). Because of this paired SRB per parallel stream concept, attempting to use more zIIPs than available is impossible. If the result of multiplying the parallel value being specified by 2 results in a value greater than the number of zIIPs assigned to the LPAR, RMF is more than likely going to report zIIP on CP time. This is not an issue, but rather a warning to be aware that achieving 100% zIIP on CP redirect might not be possible without considerably overloading an LPAR with zIIPs.
|
Note: To divide the data into logical partitions and process the partitions in parallel when processing a data source using the Data Studio Loader plug-in, click Advanced. Enter a Thread Count value for MapReduce (Server Parallelism Settings). The number of zIIP processors is checked at run time, and one thread is used for each processor that is discovered. The value that you specify overrides the default value (2) and the discovered value.
|
HLO (the batch component of Loader) does not use that pairing architecture. HLO zIIP usage is almost exclusively based on the number of parallel threads delivering data to the Accelerator. However, Loader is still switching back and forth on larger buffers of memory when converting data from the source format received from HLV to the format required by the Accelerator. The majority of HLO zIIP time is used by data conversions. HLO is somewhat limited by how fast it can process data conversions by the rate the data is excepted by Accelerator. Reaching any upper bound of zIIP processing is difficult because HLO is not doing everything on zIIP.
This explains the potential of observing zIIP on CP even with an LPAR overloaded with zIIPs (14 in our example). The 40 SRBs (2 SRBs per each of 20 parallel threads) running nearly much concurrently for HLV can easily exceed the 14 defined zIIPs. Especially Loader required both HLV and HLO together, both consuming zIIPs, even competing with each other for zIIP time, potentially driving more processing to the general purpose processors (CP).
To complete the described scenario with an MRC of 20, across the two Loader address spaces, Loader could potentially use as many as 60 enclave SRBs, all of which could be eligible for zIIP redirect.
This behavior was observed during the measurements performed for this book. Referring to Figure 3-2, the first set of bars on the left represents the CPU cost and elapsed time when running an extract to a sequential file, then using that sequential file as input to the Loader batch interface (HLO). The second set of bars on the right represents using the Accelerator Loader server (HLV). HLV did the extraction and managed moving the data to the batch interface for loading in the Accelerator. An observation was that the HLV process had a 91% decrease in elapsed time over the HLO process. HLV also experienced a 28.6% decrease in total CPU processing cost. In addition to the reduced total CPU cost, there was a 420% increase in the amount of zIIP redirect by the HLV process. These results are dramatic. In addition to reducing elapsed and CPU times by allowing Loader to handle everything from extraction to transformation to Accelerator load, the amount of additional zIIP redirect demonstrates the total overall savings is significant while reducing the complexity of moving a non-DB2 data source into the Accelerator.

Figure 3-2 zIIP redirect comparison
These are expected zIIP redirect generosity factors (theoretical cap) for some of Loader’s data sources:
•VSAM: as high as 100%
•SEQUENTIAL: mid 90%
•SMF Logstreams: as high as 100%
•DRDA: as high as 100%
•ADABAS: as low as 90%
|
Note: A strong suggestion is that the processing option IIPHONORPRIORITY specified in the IEAOPTxx member of PARMLIB never be set to NO. Setting this keyword to NO prevents zIIP processor eligible work from executing on standard general purpose processors (CP) unless resolving resource contention with non-zIIP processor eligible work is necessary. In theory, if one was to specify "IIPHONORPRIORITY = NO", RMF IPPCP time might be loosely equated to wait time. IIPC time would be interpreted as wait time if "HONORPRIORITY = YES" is specified.
|
3.2.5 z Systems advantage
The IBM z Systems platform, including the z13s, z13, and the zEC12, provide function, capacity, and processing power to improve business performance and ensure future growth. Loader fully takes advantage of numerous features made available on the z Systems platform. All of the following features are used by Loader to its advantage. Some are exclusive to the z13 and a few are available on both the z13 and zEC12. Features delivered by the mainframe that could be of benefit to Loader’s performance and operation are as follows:
•z13 family:
– Simultaneous multithreading (SMT) to execute two instruction streams (or threads) on a processor core, which delivers more throughput for Linux on z Systems and zIIPs. See z Systems Simultaneous Multithreading Revolution, REDP-5144.
– Single-instruction, multiple data (SIMD), a vector processing model that provides instruction level parallelism, to speed workloads such as analytics and mathematical modeling. See SIMD Business Analytics Acceleration on z Systems, REDP-5145.
– Higher processor maximums: 141 CPs and 94 zIIPs.
– Availability of up to 10 TB of memory. See z/OS Infrastructure Optimization using Large Memory, REDP-5146.
– 2 GB large pages.
•zEC12 and z13 families:
– 1 MB pageable large pages and large frame exploitation
– IBM z Systems Integrated Information Processor (zIIP)
– Shared Memory Communications over RDMA (SMC-R)
– IBM z Systems Data Compression (zEDC), compression designed for high performance for use with SMF through logger, zlib, Java, BSAM/QSAM, DFSMShsm and DFSMSdss, plus others
– Reduced storage occupancy and increased operations efficiency with IBM zEnterprise® Data Compression
3.2.6 Parallelism
Parallelism is controlled in Loader (HLO) when SYSREC is specified by partition.
Accelerator Loader supports processing multiple partitions of the same table and loading them into the Accelerator in parallel. To enable parallelism and improve performance when loading partitioned objects, you can specify multiple SYSREC data sets. The options module parameter ACCEL_LOAD_TASKS and extended syntax option ACCEL_LOAD_TASKS support this enhancement.
The ACCEL_LOAD_TASKS should be set equal to or less than the Accelerator environmental variable AQT_MAX_UNLOAD_IN_PARALLEL (Example 3-10).
Example 3-10 Parallel parameter from IDAA51B.SAQTSAMP(AQTENV)
AQT_MAX_UNLOAD_IN_PARALLEL=20
# Maximum number of parallel UNLOAD invocations:
# One parallel utility for each partition in a table is theoretically
# possible, but requires significant CPU availability
#
3.3 Scenarios
Loader’s purpose is to copy data into the DB2 Analytics Accelerator. It provides multiple solutions to complete this task and from multiple sources. Regardless of your source, DB2 or non DB2, Loader provides you with the means to accomplish your data load.
Loader has two methods available that this book focuses on in this section:
•Loading directly only to the Accelerator
•Loading data in parallel to both the Accelerator and DB2
The method chosen will be driven by the data and data source. If the data is coming from a non-DB2 source, and there is no need to keep a copy of the data in DB2, why put it there. Loader allows you to load directly or only into the Accelerator. Data sources like SMF, VSAM, Oracle, and others will more than likely not require a copy in DB2. However, data that is used for analytics and for other processes, like online transaction processing (OLTP), might have to be kept in both places: a copy of the data in the Accelerator for analytics and a copy in DB2 for transactions.
Loader does provide other data load options:
•Image copy load (IDAA_LOAD_IC)
•Consistent load (IDAA_CONSISTENT_LOAD).
An image copy load, as one might expect, loads data into a single Accelerator table from a DB2 image copy. The image copy can be from an external DB2 subsystem or the same DB2 subsystem but loading into an alternative table (redirected load). The user must verify the source and target DB2 table structures are the same. JCL examples of image copy load are at the following web page:
Using the IDAA_CONSISTENT_LOAD keyword refreshes the data of multiple tables on the IBM DB2 Analytics Accelerator by working with the Use FlashCopy option. When used with this option, it does these actions:
•Creates a new IBM FlashCopy® image copy for a single table or a list of tables that are transactionally consistent.
•Loads the data from the new image copies into the Accelerator.
•Loads the data from the consistent image copies into the Accelerator.
JCL examples of loading data into the Accelerator using consistent load are at the following web page:
One useful feature of Loader is the simplicity and ease of getting it running for the first time. After the tool is successfully installed, the easiest way to start loading by using Loader is to modify an existing DB2 LOAD job.
To a previously created DB2 LOAD job, add a card and a statement:
•Add either an IDAA_ONLY ON accelerator_name or IDAA_DUAL ON accelerator_name Loader control card.
•Add the //HLODUMMY DD DUMMY statement to the batch JCL to enable the intercept and optionally add the Loader control card ACCEL_ON_SUCCESS_ENABLE YES to enable the newly loaded table in the accelerator.
With a minimum of only two changes, a batch DB2 LOAD job is converted to a Loader job that allows data to be added directly to an accelerator.
3.3.1 ACCEL_LOAD_TASKS
One of the Loader control cards that can affect your load processing performance is ACCEL_LOAD_TASKS. As discussed, this control card affects the amount of parallel processing, and therefore the performance impact that Loader can expect. Increasing the value on ACCEL_LOAD_TASKS can improve your throughput. During testing, the value of ACCEL_LOAD_TASKS was increased from 4 to 20 in increments of 4. For this measurement a single standalone load was performed. No other tasks were competing for resources, other than standard z/OS activity and whole performing measurements.
3.3.2 Sequential Input IDAA_ONLY and IDAA_DUAL
Most measurements were performed using the equivalent of the DB2 LOAD REPLACE function. Loader assumed the table in the Accelerator was either empty or the data in the table could be completely replaced. (Adding new rows to an existing table in the Accelerator using LOAD RESUME YES are described in 3.3.3, “Load RESUME” on page 64.) In this section, loading the Accelerator from an existing table in DB2, loading using Loader’s IDAA_DUAL, and loading using Loader’s IDAA_ONLY are discussed. Some terms used in these JCL samples are explained in “Terms used” on page 47.
The control cards, shown in Figure 3-3 on page 59, are used to produce the results labeled DB2 LOAD followed by Accelerator load or Native Accelerator Load in subsequent figures. A basic LOAD REPLACE with logging disabled was performed in each of the 100 individual partitions. The red arrow in Figure 3-3 on page 59 highlights the ISYSREC template state used in the corresponding INDDN statement. One load input data set existed for each partition. The partition selection was managed using the template variable for the partition number (&PA). One keyword not used is KEEPDICTIONARY. Although compression is more than likely to be used in a real analytics application, disabling it for these measurements was done for simplicity. These control statements only represent one half of the load process.

Figure 3-3 DB2 LOAD REPLACE control cards
The second job stream, Figure 3-4 on page 60, contains the JCL and control cards to invoke the Accelerator stored procedure, SYSPROC.ACCEL_LOAD_TABLES, to load the data just placed into a DB2 table into a table at the Accelerator. This is the second half of the measurement labeled DB2 LOAD followed by Accelerator load or Native Accelerator Load.
Consider the following information about Figure 3-4 on page 60:
•In this batch XML job, label “A” points to the section where the schema and table name to be loaded are specified.
•On the DSN RUN statement, the parameter LOADTABLES (label “C”) causes the program AQTSCALL (label “B”) to call the Accelerator stored procedure SYSPROC.ACCEL_LOAD_TABLES to perform the unload from DB2 and the subsequent load into the Accelerator.
•The AQTP1 statement (line 3) and AQTP2 DD (line 7) have the input control statements that name the Accelerator that will be loaded, and the lock mode that should be used during the load, respectively.
•The lock mode specified on the AQTP2 DD statement can have one of five settings:
– TABLESET (protects all tables being loaded)
– TABLE (protects just the current loading table)
– PARTITIONS (protects the table-space partition)
– NONE (no locking)
– ROW (protects only the row)
•Other keywords can also be specified on the AQTP3 DD statement to control which partitions to load and whether only new partitions should be loaded. These are only examples and there are others. However, they pertain to the Accelerator stored procedure LOAD and do not directly affect how Loader was measured or used during the measurements.

Figure 3-4 Accelerator stored procedure LOADTABLES
The second and third sets of measurements were performed using Loader and the control cards listed in Figure 3-5 on page 61. The second measurement used Loader’s IDAA_DUAL ON load, loading both the DB2 table and Accelerator table in parallel from the same input files. The third measurement performed a load into the Accelerator using only the Loader control card IDAA_ONLY ON.
Consider the following information about Figure 3-5 on page 61:
•Label “A” highlights three Loader control cards used during measurements:
– IDAA_DUAL ON accelerator specifies a parallel load into both DB2 and the Accelerator along with the name of the Accelerator that should be loaded.
– ACCEL_LOAD_TASKS is the number of parallel task that can be used. This value was always set equal to the Accelerator environmental variable, AQT_MAX_UNLOAD_IN_PARALLEL. The ACCEL_LOAD_TASKS can have a maximum value of 20.
– ACCEL_ON_SUCCESS_ENABLE instructs what action to take at the end of a successful load. These measurements not only used this control card but set it to YES so that the table in the accelerator was immediately available at the conclusion of the load.
•Labels “B” and “C” specify the location of the load input file, INDDN, and the REPLACE option. INDDN points to ISYSREC01 at label “C” and ISYSREC02 at label “B”. To improve Loader’s performance and to take advantage of parallelism, each table part must use a separate input file: ISYSREC01, ISYSREC02, up to ISYSRECxx.
•Label “D” shows the IDAA_ONLY loader control card used when loading the Accelerator only.

Figure 3-5 LOAD DATA Control Card Example
The results from this measurement are in the third set of columns labeled Loader to Accelerator Only in Figure 3-6 on page 62 through Figure 3-9 on page 64.
The results from these measurements are displayed four ways:
•Figure 3-6 on page 62 represents the total CPU consumed by the three measurements. This single CPU number includes CP, SRB, and zIIP CPU times.
•Figure 3-7 on page 63 represents the second measurement, which compares total CPU time (CP, SRB, and zIIP again) with the zIIP portion broken out.
•Figure 3-8 on page 63 represents the third way of displaying the data obtained. In this figure, the CP plus SRB time (excluding all zIIP time) is compared to the zIIP time.
•Figure 3-9 on page 64 contrasts the elapsed time of the three measurements.

Figure 3-6 Total CPU with zIIP
In the first scenario (Figure 3-6), the cost to load 2 billion rows into the DB2 using the DB2 LOAD utility and then load that same data in the Accelerator was approximately 1,415 CPU seconds, or about 24 CPU minutes. To load those same 2 billion rows into both DB2 and the Accelerator in parallel was about 51% more expensive at 2,133 CPU seconds. Consider the following two factors when observing this increase.
•The simplicity of running only the single Loader job to load both DB2 and the Accelerator as compared to running the DB2 LOAD followed by an Accelerator load.
•The more important measurement to consider is the 28% decrease in elapsed time demonstrated in Figure 3-9 on page 64.
The numbers from this measurement become more interesting when the zIIP CPU time is examined. Remember that software charges do not apply to work that runs on a zIIP. Any time work can be redirected to a zIIP, the result can be a potential decrease in software cost.
Regarding the measurements, the CPU cost for the combined DB2 LOAD followed by an Accelerator load was again 1,415 CPU seconds. Of that, only approximately 7% was eligible for zIIP redirection. However, examining the second scenario using Loader to perform a parallel load into both DB2 and the Accelerator, a full 50% of the CPU cost was eligible for redirect to a zIIP. That is a significant portion of the total CPU cost for the load. Examining the results of loading only the Accelerator with Loader’s IDAA_ONLY function, up to 78% of the total CPU is eligible for zIIP redirect. Realizing that less work is being accomplished by the last scenario, it is still a significant amount of processing being redirected to zIIP, especially when you consider those times that the data must be loaded into the Accelerator that does not have a DB2 counterpart, Oracle or DB2 LUW for example.

Figure 3-7 Total CPU with zIIP versus breakout time
Figure 3-8 shows the same measurement results except the CPU/SRB time minus zIIP time is being mapped against only the zIIP time.

Figure 3-8 Workload activity results: CPU minus zIIP versus zIIP

Figure 3-9 Elapsed time on initial load
3.3.3 Load RESUME
Loader’s ability to perform the DB2 LOAD utility’s equivalent of a LOAD RESUME YES option requires, at a minimum, DB2 Loader v2 and IBM DB2 Analytics Accelerator for z/OS V4.1.5 (PTF 5). Although DB2 can add data to an existing table that already contains data through LOAD RESUME YES, only Loader has the capability to add data to an existing table in the Accelerator using LOAD RESUME YES. The Accelerator’s native load process, using the stored procedure SYSPROC.ACCEL_LOAD_TABLES, can replace the data in the Accelerator only with a copy of what is in DB2.
LOAD RESUME and LOAD REPLACE have been LOAD utility keywords for almost as long as DB2 has been a product. For clarity, and to help you better understand the differences between LOAD and Loader, the differences between LOAD REUME YES, LOAD RESUME NO, and LOAD REPLACE, as they apply to placing data into the Accelerator, are explained in the following list:
•LOAD REPLACE
Replaces all data in Accelerator with a new copy for IDAA_DUAL and IDAA_ONLY. For an IDAA_ONLY load, the data in the Accelerator replaced and, if any rows exist in the table that resides in DB2, all data in that table is deleted.
•LOAD RESUME
Either YES or NO must be specified on the LOAD RESUME option because no default value exists:
– LOAD RESUME YES
For IDAA_DUAL, data is added in parallel to the existing data in the DB2 table and to the existing data in the Accelerator table. None of the data that existed in either of the tables before the load is affected. For an IDAA_ONLY load, data is added to the existing table in the Accelerator. However, no action is taken against the table in DB2. The data that already exists in the DB2 table is unaffected by the LOAD RESUME YES process.
|
Note: If the Data Studio plug-in is used to create the LOAD RESUME YES Loader job, the drop table and create table functions are disabled and RESUME YES is mutually exclusive with the use of the ACCEL_REMOVE_AND_ADD_TABLES control card.
|
– LOAD RESUME NO
Specifying RESUME NO in Loader has the same effect as specifying LOAD REPLACE. All existing data is replaced.
Load RESUME scenarios
This section describes three DB2 load scenarios.
All numbers shown reflect the sum of the elapsed time from the eight batch LOAD RESUME JOB LOAD RESUME JOBLOGs and the sum of the eight GCP times (CP+SRB) and eight IIP times from the RMF service policy report for each of these scenarios.
Scenario 1: DB2 LOAD followed by Accelerator load
Input data was 200 GB consisting of 2,000,000,000 rows; each row was 100 bytes. The columns in the row consisted of 10 integer columns, 5 decimal (19,2) columns, and 1 decimal (7,5) column. These were the steps:
1. Using the DB2 LOAD utility, a DB2 table was loaded with 200 GB.
2. The Accelerator native load stored procedure was used to load that 200 GB DB2 table from step 1 into the Accelerator.
3. Following the initial table load and simulating a 7-day maintenance week, seven subsequent DB2 LOAD RESUME YES jobs, each with a 10 MB input (add 100,000 rows) were executed.
4. At the completion of the initial LOAD and the seven LOAD RESUME YES jobs, a total of 2,000,700,000 rows or 200070 MB were loaded.
The numbers shown reflect the sum of the elapsed time from the batch LOAD RESUME job, the LOAD RESUME job log, and the RMF service policy CPU time (CP+SRB) and IIP time.
Scenario 2: Loader to Accelerator and DB2 (IDAA_DUAL)
The second scenario had these steps:
1. The 200 GB was loaded in both DB2 and the Accelerator using Loader IDAA_DUAL with REPLACE.
2. Seven more Loader IDAA_DUAL RESUME YES batch LOAD RESUME JOBs were loaded, each using a 10 MB input file.
3. At the conclusion of the 8 loads, a total of 2,000,700,000 rows or 200070 MB were loaded directly into the Accelerator and the DB2 table in parallel.
These numbers reflect the sum of the elapsed time from the batch LOAD RESUME JOB LOAD RESUME JOBLOG and the RMF service policy CPU time (CP+SRB) and IIP time.
Scenario 3: Loader to Accelerator only (IDAA_ONLY)
The third scenario had these steps:
1. Using the Loader IDAA_ONLY feature with REPLACE, the Accelerator was loaded using the same 200 GB file used in the previous scenario.
2. Seven additional Loader IDAA_ONLY RESUME YES batch LOAD RESUME JOBs, each using a 10 MB input file, were run next.
3. At the completion of the initial Loader REPLACE and the seven Loader RESUME YES LOAD RESUME JOBs, a total of 2,000,700,000 rows or 200070 MB were loaded directly into the Accelerator.
Measurements
If the same data exists in a table loaded to the Accelerator and within DB2, Loader becomes a far more efficient and less expensive alternative to an Accelerator native load using the stored procedure. In measurements performed at the IBM Poughkeepsie lab, the determination was that using Loader’s LOAD RESUME YES feature successfully loaded additional data to an existing table. In loading 100,000 new rows to an existing 2 billion row table seven times to represent seven days of updates, Loader’s LOAD RESUME YES used 95% less CPU and completed 81% faster keeping DB2 and the Accelerator data in sync than using the Accelerator’s native load stored procedure. See Figure 3-10 and Figure 3-11 on page 67.

Figure 3-10 LOAD RESUME total CPU (including zIIP)

Figure 3-11 LOAD RESUME elapsed time
3.3.4 IBM DB2 Analytics Accelerator Loader image copy input
Loader’s image copy load will load data for a single table into the Accelerator from the DB2 image copy defined. Example 3-11 demonstrates an image copy load. You use the IDAA_LOAD_IC keyword to load data on the IBM DB2 Analytics Accelerator from an image copy data set.
Example 3-11 Image Copy load using translate OBID feature
IDAA_LOAD_IC
(
GROUP
(
SPACE
(
CREATOR 'USER01'
NAME 'TBHLOA05_T01'
TO_IC 'RSTEST.QA1A.DBHLOTS1.TSHLOSTA.DB2IC1'
OBIDXLAT (
DBID '863,868'
PSID '2,2'
OBID '3,3'
)
)
)
ACCELNAME QA1AACC1
PARALLEL '0,1'
LOG_COPY_PREFERENCE R1R2A1A2
USER_INDICATOR HLO
)
/*
//
An IDAA_CONSISTENT_LOAD is often included in discussions about Loader’s use of image copies. However, using IDAA_CONSISTENT_LOAD specifies the options for loading data for multiple tables into the Accelerator from a cataloged DB2 image copy; image copy specifies options for loading data for a single table into the Accelerator from a user-defined DB2 image copy.
3.3.5 VSAM
This section describes loading data from Virtual Storage Access Method (VSAM) data sets into DB2 and then into the Accelerator.
Table 3-2 provides a description of the environment used for the VSAM measurements.
Table 3-2 Environment used for the VSAM load
|
Processor
|
z13 Model 739: z/OS LPAR with 3 dedicated CPs, 14 dedicated zIIPs
|
|
Memory
|
65 GB
|
|
z/OS
|
V2R2
|
|
DB2
|
V11
|
|
Accelerator DB2 SPs
|
V51 Beta
|
|
Accelerator hardware
|
N3001-010 (Mako full-rack)
|
|
Accelerator software
|
V51 Beta with NPS 7205
|
|
Loader V2.1
|
Pre-general availability (GA): Code Drop 12
|
|
Loader V2.1
key parameters |
ACCEL_LOAD_TASKS = 16; MR threads = ENABLED
|
Measurements were performed for VSAM in three runs:
1. Using a more traditional extract method, data was unloaded form the VSAM KSDS, loaded into DB2, and then loaded into the Accelerator.
2. Again using a traditional extraction process, but this time Loader batch function (HLO) was used to load the data into the Accelerator.
3. Finally, a load was performed using the Accelerator Loader Server (HLV) to map the VSAM KSDS directly to a DB2 table, select the data from the table using SQL, and then pass the data to a batch program that loads the Accelerator.
These runs provided start-to-finish measurements from the start of the COBOL extraction program through DB2 LOAD and then through Accelerator.
As shown in Figure 3-12, a significant decrease in CPU time and elapsed time was measured across the three runs.

Figure 3-12 Value of Loader V21 for Direct Load from VSAM into Accelerator
The VSAM measurements were performed using an HLV server to reference the VSAM data sources. The following paragraphs and figures describe how the process was performed.
1. Using the Accelerator Loader perspective from Data Studio, shown in Figure 3-13 on page 70, expand SQL → Data, and then click the server that will be used to create a virtual table. In this example, the server is HLVS.
2. Right-click Virtual Tables, highlighted in Figure 3-13 on page 70. In the pop-up window, click on Create Virtual Table.

Figure 3-13 Accelerator Loader Data Studio entry panel
3. A list of wizards is displayed. Select a wizard (in this scenario, select VSAM, as highlighted in Figure 3-14) and then click Next.

Figure 3-14 VSAM wizard starting point
4. The dialog window for defining a new VSAM virtual table opens (Figure 3-15). Provide the following information and then click Next:
– In the Name field, provide a name to use for the virtual table.
– The Target field indicates the name of the data set that will contain the metadata for the new created object.
– (Optional) In the Description field, you may add a meaningful description.
– The Current Server field lists the current server being accessed. If you want to change this, click Set Server.

Figure 3-15 Create a VSAM virtual table
Figure 3-16 and Figure 3-17 point to the copybook specifications. The copybook is used by HLV to map the data in the VSAM KSDS to the Accelerator table. Figure 3-16 shows the correct copybook selection. This copybook must match the VSAM file exactly or the mapping process between the VSAM file and the Accelerator table will not work.

Figure 3-16 Selecting a copybook
Figure 3-17 shows the contents of the copybook, the COBOL code that will be used in the data mapping.

Figure 3-17 Contents of the copybook
This final step involves Loader extracting and loading the Accelerator all in a single combined task. To generate the batch job stream to perform this function, complete the following steps if you use the Accelerator Loader studio plug-in for Data Studio:
2. A dialog window opens (labeled “B”). The source subsystem is selected and an SQL query against the virtual table is displayed. Click Validate to verify that the virtual table can be accessed on the specified server. When you are satisfied that all is accurate, click Next.

Figure 3-18 Generating the Load Accelerator JCL
3. The next dialog window opens, which shows the specified target table (Figure 3-19 on page 74). This table will be loaded in the Accelerator. In the panel labeled “C” in the figure, verify that the correct DB2 subsystem and accelerator are specified, enter the authorization ID of the table creator, and the table name. Although you may enter the database and table space information, if you do not supply them, they will be implicitly created.
4. (Optional) Enable parallelism by selecting the Enable check the box in the Parallelism check box and specify a degree of parallelism. If you select Enable, you must also indicate a degree of parallelism in the range of 2 - 20, otherwise, the Next button is not activated. The default value is 1 (no parallelism will be used).
5. Click Next.

Figure 3-19 Generating the Load Accelerator JCL
6. The dialog labeled “D” opens (Figure 3-19). It specifies data sets used by the job stream along with a utility ID. If you click JCL Settings to allow values for job name suffix, job class, message class, regions size, and temporary disk name (like SYSDA, the default). Click Next.
7. The next dialog is for generating the JCL. You can specify the PDS name that will hold the JCL that is about to be generated, the PDS member name for the JCL, and the job name to be used when generating the JCL. You may also specify whether the target table should be created by the Loader by selecting the appropriate check boxes. LOAD REPLACE is the default. Although this value can be changed to LOAD RESUME, if RESUME is used, the ability to drop and create the target table is disabled. Figure 3-20 on page 75 is an example of specifying RESUME rather than the REPLACE option when generating the JCL.
8. After you complete the fields adequately, the Generate button becomes activated so you can click it and the JCL can be created.
If Auto-Run has not been enabled, switch over to the TSO session, locate the appropriate PDS, and submit the job stream just created.
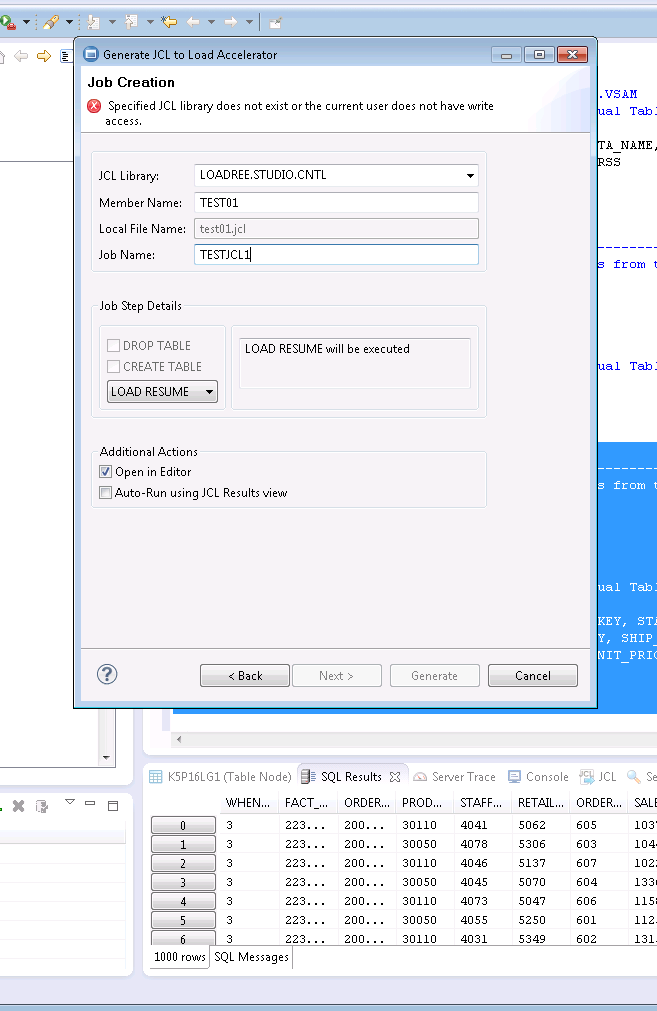
Figure 3-20 Alternate job creation using RESUME
9. After the virtual table is created and associated to the Accelerator table, a job stream can be created to actually complete the load operation. Right-click on the virtual table representing the VSAM file just created.
Measurements
The preceding steps are used for the VSAM measurements in the following sections:
Figure 3-21 on page 76 is referred to in each section.

Figure 3-21 Value of Loader V21 for direct load from VSAM into Accelerator
Traditional extract measurement
The first set of bars in Figure 3-21 represent what was considered a traditional approach without the benefit of Loader. Data was unloaded from the VSAM KSDS to a sequential file using a COBOL application.
After a sequential file was created by the COBOL program, that file was used as input to the DB2 11 LOAD utility to load a DB2 table defined to “match” the VSAM KSDS.
Finally, the DB2 table data was loaded into the Accelerator using the Accelerator stored procedure SYSPROC.ACCEL_LOAD_TABLES. For the 200 GB VSAM KSDS used, this three-step process took over 3 hours to complete, and having to extract the data to a sequential file added a layer of complexity. Also for this measurement, a COBOL program had to be created to unload the VSAM KSDS to a flat file. The assumption was that using a program written specifically to unload the VSAM KSDS would be more representative of a real world scenario.
The three-step process also used a fair amount of CPU time (60 minutes). However, of that 60 minutes of CPU, only 1 minute was redirected to zIIPs. None of the three processes, required to get the data from VSAM to the Accelerator, took advantage of zIIPs.
Extract with batch Loader (HLO) measurement
The second measurement, represented by the second set of bars in Figure 3-21 on page 76, reduced to two steps the processing required to load the VSAM data into the Accelerator by removing the need to run the DB2 11 LOAD utility. The data was again extracted from the VSAM KSDS using a COBOL program to an external file. That extracted file was then loaded into the Accelerator using only the HLO portion of Loader. The combined two steps to extract the data and load it into the Accelerator still took more than 2 hours to complete using 21 minutes of CPU time. However, because Loader is designed to take advantage of zIIPs, the zIIP redirect portion was 15 minutes. That means that of the total CP + zIIP time of 36 minutes, the zIIP redirect accounted for an appreciable 15 minutes or 42% of the total CPU consumed.
The COBOL program used to extract the data from the VSAM file to a sequential file for this measurement was the same COBOL program used in “Traditional extract measurement” on page 76.
Accelerator Loader Server (HLV)
The third measurement took advantage of Loader v2.1 Accelerator Loader Server (HLV) performing a direct load from the VSAM KSDS directly into the Accelerator. No extraction step needed to be performed. HLV was responsible for mapping the data in the VSAM KSDS to the table in the Accelerator. Of the total CPU consumed, 15 CP plus 78 zIIP, approximately 82% percent was redirected to zIIP processors. This significant redirect is a direct result of the zIIP usage of HLV. This also resulted in an elapsed time drop from 189 minutes for the three step process to only 11.5 minutes for the one-step direct load using HLV.
3.4 System Management Facility (SMF)
Loader has the inherent capability to load SMF records from an SMF dump file directly into the Accelerator. A set of virtual tables representing a subset of SMF records is provided in Loader so creating a virtual table is unnecessary. However, associating an SMF file to the Loader process is still necessary.
Figure 3-22 on page 78 shows a sample list of the SMF virtual tables provided with Loader. SMF processing must first be enabled in Loader before any of the virtual SMF tables are available for display. To enable SMF virtual table processing, modify the SEFVTBEVENTS parameter to YES in data set hlq.SHLVEXEC, PDS member hlvidIN00:
MODIFY PARM NAME(SEFVTBEVENTS) VALUE(YES)
The parameter is invoked by the HLS process when the started task begins. The IN00 file is invoked in the procedure by the following DD statement:
//SYSEXEC DD DISP=SHR,DSN=&hlq.EXECFB in the member PROCLIB(HLV1PROC)
The virtual tables provided by Loader are by SMF record type and subtype. There is one table per SMF record type and subtype. Combining the information from multiple SMF virtual tables into a single source using Loader’s virtual views might be necessary in order to complete processing of the SMF data.

Figure 3-22 SMF virtual table example
The Loader SMF mapping data set must also be added to the HLV started task procedure before the SMF virtual tables can be used. If no SMF virtual tables are presented in the Accelerator Loader Studio plug-in, then this data set was not added to the procedure. Add hlq.SMFMAP to the HLVMAPP DD concatenation.
SMF virtual table processing must also be enabled before it can be used. Using the B or E line command, enable the SMF member HLVSMFT2 that is in the Event Facility (SEF) Event Procedure List (Figure 3-23).

Figure 3-23 SMF_Event_Facility_menu.png
The Event Facility (SEF) Event Procedure List is reached by using the following steps:
1. Open the Loader ISPF interface. This might be an option on an ISPF menu panel, or as in this case, invoked directly as a command from ISPF option 6 (Figure 3-24).
.png)
Figure 3-24 ISPF Option 6 Command Shell
2. For the SMF setup, selecting option 1, Server administration (Figure 3-25), will invoke the three server admin functions (Figure 3-26). However, before selecting option 1, complete these two fields on the right side:
– DB2 SSID: Provide the name of the DB2 for z/OS subsystem being used.
– Server ID: Provide the name of Loader’s HLS server.

Figure 3-25 ISPF Loader Admin Main Menu
3. From the Administer Accelerator Loader Server menu (Figure 3-26), server traces can be displayed, the server can be configured, or rules can be managed. To complete the SMF setup, select option 3, Manage rules.

Figure 3-26 Server admin menu
Loader’s ISPF Event Facility (SEF) Control menu opens (Figure 3-27).
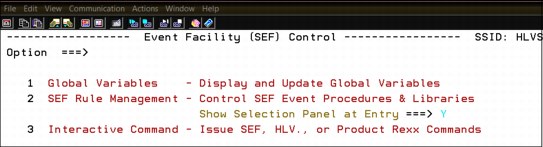
Figure 3-27 Loader Event Facility Control menu
4. Using the configuration list shown Figure 3-28, chose VTB (virtual table rules) to manage the rules for the SMF virtual tables.
.png)
Figure 3-28 SEF Rules Management
Finally, Loader must be made aware of the name of the SMF dump data set. The Loader user guide describes how to modify GLOBAL.SMFTBL2.GDGBASE and GLOBAL.SMFTBL2.DEFAULT to make Loader aware of the location of the SMF data. In our member, the global variable was actually GLOBAL2.SMFTBL2.DEFAULT. From the menu in Figure 3-27, option 1, Global Variables, could be used.
The SMF dump date sets used during our testing were created using IFASMFDP.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.