

Chapter 6
Computationally Secure Information Stealing
Perhaps the two biggest fears that the victim of a computer virus has is that information has been covertly stolen or that data files have been deleted or altered by the virus. This chapter focuses exclusively on the former fear. Such viruses are among the most insidious since they can steal information for an indefinite period of time before ever being noticed.
More specifically, the problem of designing malware to securely and privately steal information is considered. The chapter begins with a straightforward cryptovirological approach that utilizes the public key of the malware author. However, this approach has a significant drawback since the virus code reveals the data that it is trying to steal. This drawback forms the motivation for a stronger model to privately obtain information. This strong model is known as the private information retrieval (PIR) problem. The notion of a PIR scheme is given and various approaches to solving this problem are mentioned.
A computationally secure PIR scheme is then described that has some very desirable properties from an operational standpoint. A few variants of this scheme are presented, thereby developing a heuristic solution that is amenable for use in real-world malware. Such malware is capable of privately stealing information without revealing anything about the information that is sought and without revealing anything about what is taken.
The notion of private information retrieval is closely related to a new notion that will be introduced in this chapter called questionable encryptions. An algorithm that produces questionable encryptions of data may, depending on its inputs, produce valid encryptions or fake encryptions that are actually just random numbers. It is related to private information retrieval since it is intractable to distinguish between the two cases and since a virus that sends questionable encryptions to the author may not be sending encryptions at all.1
Several constructions for a questionable encryption scheme are described as well as an instantiation based on the Phi-Hiding technique. It is shown how to use questionable encryptions to improve the deniable password-snatching attack described in Section 4.2. A further improvement of the deniable password-snatching attack is given based on the notion of malware loaders. Malware loaders are programs that contain enough functionality to load secure malware modules obtained from the network. By themselves they reveal very little regarding the ensuing attack since the modules that are loaded contain the code that is specific to the attacks that are conducted. They form a way of compartmentalizing malware functionality to allow attacks to deploy the truly malicious code from the safety of anonymizing networks.
The chapter concludes with a brief discussion of the cryptocomputing problem. A cryptocomputer is a primitive that has the potential to greatly improve antipiracy technologies as well as malware technologies in the same fell swoop. It is an ambitious new direction for cryptography, since a cryptocomputer is a virtual machine that can perform general computational operations on plaintext data that is hidden within ciphertext without ever exposing the plaintext in the process.
6.1 Using Viruses to Steal Information
Consider the problem of designing a virus to steal information from a host system. A typical scenario involves a tag string that can be used to identify the associated information that is desired by the virus author. For example, if the host contains a salary database indexed by the employee name, the virus can be designed to steal the salary information of a given employee. In the case that the virus writer wants to get the skinny on an employee named Billy Bob, someone that the virus writer feels is overly compensated, the virus writer could design the virus to search for the string “Billy Bob” and steal the associated salary information. The database would contain the entry “Billy Bob, $130,000.” Upon matching the string “Billy Bob” contained in the virus with the entry “Billy Bob” in the database, the virus knows it found the correct database entry. The virus then copies the value 130,000 into an internal viral storage area. Once found, the virus could delete the tag “Billy Bob” within itself in an attempt to hide that which was sought.
The virus certainly accomplishes its stated goal, yet it nonetheless suffers from some obvious drawbacks:
- Stolen Data Revealed: The data is stored within the virus in the clear. This implies that its value will be available to anyone who obtains the virus down the road. In this example the string “130,000” is stored in plaintext form in the virus.
- Tag Information Revealed: Even if the tag is deleted once the data is pilfered, previous snapshots of the virus will reveal the tag that the virus used. Hence, people may still be able to figure out it is Billy Bob's salary that was obtained.
Drawback (1) may be trivially resolved [332]. To fix this problem a randomly generated public key is placed within the virus, thus forming a cryptovirus. When the salary is found, it is asymmetrically encrypted and the resulting ciphertext is stored within the virus. This ciphertext is toted around until the author obtains the virus, extracts the ciphertext, and decrypts it using his or her private key.
As it turns out, drawback (2) can be resolved as well. The solution is non-trivial and forms the bulk of this chapter. What is needed is a private information retrieval algorithm that can privately retrieve Billy Bob's salary without revealing the tag string “Billy Bob.” This information-stealing method is applicable to malware in general, not just viruses. It is equally useful in designing password-snatching Trojans and other Trojans that steal data.
6.2 Private Information Retrieval
In its most basic form, the private information retrieval (PIR) problem is for one party to retrieve the entry in a database that is maintained by one or more other parties without revealing which entry is sought. The formal problem is as follows. A database consists of n entries, each of which stores a single binary digit. The database can be represented by a bit string B = b1b2 · · · bn. The problem is to submit a query i to the database administrator,2 where 1 ≤ i ≤ n in such a way that the i is not revealed to the database administrator, yet bi is returned in response to the query. Hence, bit bi is privately retrieved from the database.
This technology has obvious applicability in practice. For example, consider a high-tech company that wants to obtain a patent but does not want to reveal to the database administrators the exact technology that the company is interested in. If the company could privately retrieve the patent, then this problem would be solved.
The obvious solution to this problem is to simply return the contents of the database in response to the query. However, for large databases this solution is obviously inefficient. The notion of private information retrieval (PIR) was proposed by Chor et al and independently by Cooper et al [61, 71]. The proposed solutions can be broken down into two basic security categories: those that are information theoretically secure,3 and those that are computationally secure.
To date the information theoretically secure solutions involved two or more database administrators that possess copies of the same database and that collectively process the queries of a user. A solution that is information theoretically secure cannot be broken under any circumstances, provided that the entity that supplies the query does not collude with database administrators and provided that the database administrators do not communicate with each other. It is analogous to multiprover proof systems [20].
A solution that is computationally secure is secure only under certain computational intractability assumptions. Schemes that fall under this latter category tend to be more efficient in terms of data storage overhead, since to date the information theoretic solutions assume that the database is replicated two or more times.
Chor and Gilboa demonstrated that it is possible to arrive at a subpolynomial communication complexity with minimal database replication when it is assumed that user inputs are private under a computational intractability assumption [60]. Kushilevitz and Ostrovsky showed that database replication can be avoided entirely [165]. They designed a single-database computational PIR that has subpolynomial communication complexity. It is based on the quadratic residuosity assumption (see Appendix B.3.5). Chachin, Micali, and Stadler presented a two-round computationally secure PIR that assumes the existence of a single database [48]. Their solution is polylogarithmic in n, the size of the database. It is based on two new complexity assumptions (see Appendix B.3.6 and B.3.7). The scheme is remarkably efficient and elegant, partly due to the fact that it is only computationally secure, when compared to other PIR schemes. For this reason it will be described in this chapter.
6.2.1 PIR Based on the Phi-Hiding Problem
The Phi-Hiding PIR scheme consists of three algorithms. These are a query generator, a database algorithm, and a response retriever. The query generator encrypts the query i in such a way that bit bi can be privately retrieved from B. Of course, i is not encrypted in the usual sense, but it is nonetheless concealed from the database administrator. The outputs of this algorithm are a query q that hides i as well as a secret s that can be used to recover bit bi. The database algorithm takes the database B as input as well as q and applies the query to each entry in the database. The end result of this computation is a response r. The value r is returned in response to the query. Finally, the values r and the secret s are supplied to a response-retrieving algorithm. This algorithm outputs bit bi. This PIR is a two-round scheme since q is given to the database administrator in round one and r is returned in round two.
The intuition behind the scheme is as follows. A schema is given that allows a sufficiently large prime number pj to be constructed deterministically for each database entry j. Hence, the database entries 1, 2, ..., n will correspond to primes p1, p2, ..., pn. With overwhelming probability these primes will be distinct. The user wants to obtain the bit in entry i of the database without revealing i. The prime that is used to obtain this bit is pi. A composite m is then constructed that is tailored after this prime. It is crafted in such a way that pi divides ![]() (m) evenly, yet m is difficult to factor even when pi is known. A value x is then chosen uniformly at random from
(m) evenly, yet m is difficult to factor even when pi is known. A value x is then chosen uniformly at random from ![]() . With overwhelming probability x will not have pith roots modulo m. A value in
. With overwhelming probability x will not have pith roots modulo m. A value in ![]() that does not have pith roots modulo m is construed as a binary zero. Hence, with overwhelming probability x will be a binary zero. The database administrator is given the schema to compute the primes as well as x. The administrator uses the schema to compute p1, p2, ..., pn and sets x0 = x. To retrieve the entry, the administrator computes xj =
that does not have pith roots modulo m is construed as a binary zero. Hence, with overwhelming probability x will be a binary zero. The database administrator is given the schema to compute the primes as well as x. The administrator uses the schema to compute p1, p2, ..., pn and sets x0 = x. To retrieve the entry, the administrator computes xj = ![]() mod m and returns xn to the user. With overwhelming probability, xn will not have pith roots modulo m unless bi = 1. Hence, with overwhelming probability the transformations on x will leave xn as a binary zero unless bi = 1 in which case xn with have a pith root, thereby making xn a binary one. So, there is a forced correlation between bit bi and whether or not xn has pith roots or not.
mod m and returns xn to the user. With overwhelming probability, xn will not have pith roots modulo m unless bi = 1. Hence, with overwhelming probability the transformations on x will leave xn as a binary zero unless bi = 1 in which case xn with have a pith root, thereby making xn a binary one. So, there is a forced correlation between bit bi and whether or not xn has pith roots or not.
The scheme utilizes a security parameter k. This value must be chosen such that k > (log n)2. It is not uncommon in a formal cryptographic algorithm to provide 1k as input. Recall that this is the binary string that consists of k binary 1's. The reason for this is to provide a suitable setting for measuring the running time of the algorithm. When 1k is provided as input, it becomes meaningful to say that the algorithm runs in time that is polynomial in the length of its input, no matter how tiny the usual inputs to the algorithm are. So, this custom is utilized in the descriptions of these algorithms.
The algorithm for the query generator is given below. It utilizes the subroutines PrimeGenerator and PhiHide that are subsequently described. Also, the parameter f is covered in Appendix B.3.6.
QueryGenerator(n, i, 1k):
input: integer n (number of bits in the database B)
integer i satisfying 1 ≤ i ≤ n
output: a query q = (m, x, Y) where:
m is a composite that is kf bits in length
x contained in ![]()
Y which consists of k3 k-bit strings
secret s which is the factorization of m
1. generate random k-bit strings y0, y1, ..., yk3−1)
2. set Y = (y0, y1, ..., yk3−1)
3. compute pi = PrimeGenerator (n, i, Y, 1k)
4. compute (Q1, Q2) = PhiHide(f, pi, 1k)
5. compute m = Q1Q2
6. choose x randomly from ![]()
7. output q = (m, x, Y) and s and halt
Algorithm PrimeGenerator generates a prime in a deterministic fashion based on the values a and Y. It utilizes a deterministic primality testing algorithm [5].
PrimeGenerator (n, a, Y, 1k ):
input: integer n (number of bits in the database B)
integer a satisfying 1 ≤ a ≤ n
Y which consists of k3 k-bit strings
output: a k-bit prime pa
1. for j = 0 to 2k−log n do:
2. set A to be the (log n)-bit representation of a
3. set J to be the (k − log n)-bit representation of j
4. set σaj = A||J
5. compute zj = ![]() mod 2k
mod 2k
6. if zj is prime then output pa = zj and halt
7. output pa = zj and halt
A composite integer m is said to ![]() -hide a prime pa if pa divides
-hide a prime pa if pa divides ![]() (m) evenly. It is implicitly assumed that m is difficult to factor completely. Algorithm PhiHide is used to
(m) evenly. It is implicitly assumed that m is difficult to factor completely. Algorithm PhiHide is used to ![]() -hide pa within the composite m.
-hide pa within the composite m.
PhiHide(f, pa, 1k):
input: integer f
k-bit prime pa
output: the factorization s = (Q1, Q2) of a composite m = Q1Q2 where
m is kf bits in length
1. repeatedly choose a random (kf − k)-bit integer q1 until
Q1 = paq1 + 1 is prime
2. choose a random kf-bit prime Q2
3. output s = (Q1, Q2) and halt
The tractability of PhiHide holds under the Phi-Sampling assumption (see Appendix B.3.7). Under the Extended Riemann Hypothesis, algorithm PhiHide runs in expected polynomial time in kf. The database administrator runs DatabaseAlgorithm that takes the database B and query q as input.
DatabaseAlgorithm(B, q, 1k):
input: database B = b1b2 · · · bn consisting of n bits
query q = (m, x, Y)
output: a response r contained in ![]()
1. set n = |B|
2. set x0 = x
3. for j = 1 to n do:
4. compute pj = PrimeGenerator(n, j, Y, 1k)
5. compute ej = pj
7. output r = xn and halt
The value r is then sent back to the entity that submitted the query r. Once obtained, the entity runs algorithm ResponseRetriever on r and the secret s.
ResponseRetriever(n, i, (q, s), r, 1k):
input: integer n (number of bits in the database B)
integer i satisfying 1 ≤ i ≤ n
query q = (m, x, Y)
secret factorization s = (Q1,Q2)
response r ![]()
![]() obtained from database administrator output: a bit b such that b = bi with overwhelming probability
obtained from database administrator output: a bit b such that b = bi with overwhelming probability
1. compute pi = PrimeGenerator(n, i, Y, 1k)
2. compute t = ![]()
3. compute w = rt mod m
4. set b = 0
5. if w =1 then set b =1
6. output b and halt
The probability that a random element in ![]() has a pith root modulo m is exponentially small in k. Observe that ResponseRetriever returns b = 1 if and only if r has pith roots modulo m.
has a pith root modulo m is exponentially small in k. Observe that ResponseRetriever returns b = 1 if and only if r has pith roots modulo m.
6.2.2 Security of the Phi-Hiding PIR
For a retrieval scheme to truly constitute a computationally secure PIR it must satisfy two properties. It must satisfy the correctness property as well as the privacy property. Informally, the correctness property states that with overwhelming probability it should be possible to efficiently construct a query, run the query on the database, and decrypt the query efficiently such that the proper bit is obtained. The privacy property states that there does not exist a circuit that can take the query as input and discern i from it. The formal definition of a computationally secure PIR will now be given.
Definition: Let the three private information retrieval algorithms denoted by QueryGenerator, DatabaseAlgorithm, and ResponseRetriever be efficient algorithms. These algorithms constitute a polylogarithmic computationally secure PIR scheme if there exist constants a, b, c, d > 0 such that,
- Correctness: for all n, for all n-bit strings B, for all i
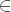 {1, 2, 3,..., n}, and for all k, after the ordered execution of the following steps:
{1, 2, 3,..., n}, and for all k, after the ordered execution of the following steps:
- (a) (q, s) = QueryGenerator(n, i, 1k)
- (b) r = DatabaseAlgorithm(B, q, 1k)
Pr[ResponseRetriever(n, i, (q, s), r, 1k) = bj] > 1 −
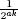 .
.
- Privacy: for all n, for all i, j {1, 2, 3, ..., n}, for all k such that 2k > nb, and for all 2ck-gate circuits A, after the ordered execution of the following steps:
- (a) (q1, s1) = QueryGenerator(n, i, 1k)
- (b) (q2, s2) = QueryGenerator(n, j, 1k)
Pr[A(n,q1, 1k) = 1] − Pr[A(n, q2 1k) = 1] <
 .
.
The correctness assumption says that a computationally secure PIR need only work correctly nearly all of the time, not absolutely all of the time. In short it says that the failure probability must be negligible in k. The privacy property says that there should not exist an adversary circuit A that can distinguish a query containing i from a query containing j with non-negligible probability. It also shows that Q is efficient under the Phi-Sampling assumption (see Appendix B.3.7).
The proof that the aforementioned scheme constitutes a polylogarithmic PIR will not be given here. We refer the reader to the original paper on the scheme [48]. The non-trivial aspect of the proof is in showing that privacy holds. The proof that privacy holds is by contradiction. For the sake of contradiction it is assumed that the privacy condition does not hold for (D, Q, R). From this assumption it follows that an adversary circuit A1 exists that violates the privacy property. It is then shown how to use A1 as an oracle in a guessing circuit C1 that violates the Phi-Hiding assumption (see Appendix B.3.6). This leads to a contradiction since the underlying premise is that the Phi-Hiding assumption holds. Hence, the assumption that the privacy condition does not hold is in error. The guessing circuit C1 performs Lagrange interpolation to find y0, y1, ..., yk3−1 based on the input prime p, i, and randomly chosen k-bit numbers a1, a2, ..., ak3.
6.2.3 Application of the Phi-Hiding Technique
It is instructive to analyze the performance of the Phi-Hiding scheme in a practical scenario. Consider a database that consists of 236 bits and hence n = 236 entries.
![]()
This may therefore be thought of as the problem of privately obtaining a single bit from an eight gigabyte hard drive.
Since k must be greater than (log n)2 it follows that k must be chosen such that k > 362 = 1296. For simplicity suppose that k = 1296. The query contains Y which consists of k3 strings, each of which is k-bits in length. Since 233 bits equals 1 gigabyte this corresponds to,
![]()
It follows that Y is about 328 gigabytes long. A query that is 328 gigabytes would present significant problems in many practical settings.
The Phi-Hiding PIR has a communication complexity that is polylogarithmic in n times a polynomial in the security parameter k. It is this polynomial dependence that may lead to such a large query. Choosing k as such is overkill and this is duly noted in the original paper.
Relaxing the restriction that k be greater than (log n)2 is one way to make this PIR more viable in practice. However, other relaxations may also be considered. Minimizing the size of the query is critical in mobile agent applications, and in viruses in particular since the size of a virus has everything to do with how hard the virus is to find. This provides the motivation for the closely related PIR scheme that is presented in the next section.
6.3 A Variant of the Phi-Hiding Scheme
This variation of the Phi-Hiding PIR utilizes a security parameter k that may be chosen independently of n. In general it is prudent to choose k ≥ 160. The approach is essentially the same, except that a random oracle assumption is used. The random oracle assumption allows the query q to be shrunk considerably. As always care must be taken when instantiating a random oracle. A simple hash function such as SHA-1 will rarely suffice. It should provide an enormous number of output bits (not just 160 as in SHA-1) and correlations should not be possible.
Let RandPrimek be a random function with domain {0, 1}*. This function is implemented using a random oracle H as follows. When RandPrimek(s) is invoked on an input bit string s, RandPrimek in turn invokes H(s). The output of H is a bit string that is countably infinite in length. At the time the oracle was created, each bit in H(s) was chosen with probability 1/2. The random function RandPrimek samples H(s) k-bits at a time and tests for primality using a deterministic primality test [5]. It samples at most k3 strings from H(s) each of which is k-bits in length. The first k-bit sequence that is prime forms the output of R. If no prime is found, then the last k-bit string is output. This is analogous to the original Phi-Hiding scheme that essentially makes k3 attempts at finding a random k-bit prime.
The expected running time of RandPrimek can be ascertained based on the Prime Number Theorem (see Appendix B.2). For a given input string s the probability that no prime is found is at most about (1 − ![]() )k3. It follows that RandPrimek has an efficient expected running time.
)k3. It follows that RandPrimek has an efficient expected running time.
QueryGenerator2(n, i, 1k):
input: integer n (number of bits in the database B)
integer i satisfying 1 ≤ i ≤ n
output: a query q = (m, x, Y) where:
m is a composite that is kf bits in length
x contained in ![]()
y which is a k-bit string
secret s which is the factorization of m
1. generate a random k-bit string y
2. set I to be the (log n)-bit representation of i
3. compute pi = RandPrimek(y||I)
4. compute (Q1, Q2) = PhiHide(f, pi, 1k)
5. compute m = Q1Q2
6. choose x randomly from ![]()
7. output q = (m, x, y) and s and halt
DatabaseAlgorithm2(B, q, 1k):
input: database B = b1b2 · · · bn consisting of n bits
query q = (m, x, y)
output: a response r contained in ![]()
1. set n = |B|
2. set x0 = x
3. for j = 1 to n do:
4. set J to be the (log n)-bit representation of j
5. compute pj = RandPrimek(y||J)
6. compute ej = ![]()
7. compute xj = xejj−1 mod m
8. output r = xn and halt
ResponseRetriever2(n, i, (q, s), r, 1k):
input: integer n (number of bits in the database B)
integer i satisfying 1 ≤ i ≤ n
query q = (m, x, y)
secret factorization s = (Q1, Q2)
response r ![]()
![]() obtained from database administrator
obtained from database administrator
output: a bit b such that b = bi with overwhelming probability
1. set I to be the (log n)-bit representation of i
2. compute pi = RandPrimek(y||I)
3. compute t = ![]()
4. compute w = rt mod m
5. set b = 0
6. if w = 1 then set b = 1
7. output b and halt
This scheme is nearly identical to the original Phi-Hiding PIR scheme. The only significant difference is how the primes p1, p2, ..., pn are chosen. They are still chosen deterministically, yet they are chosen by applying a random oracle to a randomly chosen seed y. The efficiency of this approach is readily apparent since the query is the same as before except that it contains y instead of Y. The value y is k-bits in length whereas Y is k4 bits in length.
The privacy aspect differs in certain respects from the privacy proof of the original Phi-Hiding scheme. Let A1 be the adversary circuit that violates the privacy condition. A guessing circuit C1 may be constructed that (i) uses A1 as an oracle, and that (ii) solves the Phi-Hiding problem. The inputs to A1 must not look suspicious, otherwise A1 can balk and not complete the needed operation. So, whatever inputs C1 concocts, they must conform to the inputs that A1 expects. Hence, C1 must be able to simulate these inputs in such a way that they conform to what A1 expects. Given that this scheme is in the random oracle model, it makes sense to consider simulators for other random oracle cryptosystems.
Bellare and Rogaway gave an elegant formalization of a common cryptographic technique known as the Fiat-Shamir heuristic [18]. They showed how to convert any atomic proof system4 with knowledge error 1/2 in the random oracle devoid model into non-interactive zero knowledge proof system with knowledge error 1/2k(n) where k(n) is a given security parameter. The construction is attractive since it permits the adversary to make 2k(n) oracle queries in an attempt to break the non-interactive zero-knowledge proof system. The salient aspect of this construction that is relevant to this PIR is what is known as the random oracle completion operation. Bellare and Rogaway allow the simulator to prescribe a small (polynomial sized) piece of the oracle, and have the rest magically filled out at random.
The random oracle completion operation, or ROC for short, takes as input (u, v) and returns an oracle R that is random subject to the constraint that R(u) is prefixed by v. The random string completion operation, or RSC for short, is an operation that takes a string v ![]() {0, 1}* as input and appends to it a countably infinite sequence of random bits. So, conceptually, the output of R on input u is v followed by RSC(v).
{0, 1}* as input and appends to it a countably infinite sequence of random bits. So, conceptually, the output of R on input u is v followed by RSC(v).
The operations ROC and RSC can be utilized in the guessing circuit C1(m, p) that takes the composite m and the k-bit prime p as input. The approach is as follows. The value y is chosen to be a random k-bit string and u = y||I is computed. Here I is the (log n)-bit representation of i. A series of k-bit strings are generated randomly until one is found that is prime. This prime is then replaced by p. This sequence of k-bit values forms the bit string v. The ROC operation is performed to compute R = ROC(u, v). The RSC operation then defines the bits that follow v in the output of R. The oracle R is then used as the oracle in the random function RandPrime.
Assuming that the problem instance (m, p) is chosen randomly, this approach produces primes p1, p2, ..., pn that are drawn from the probability distribution that the adversary circuit A1 expects. Of course, one of these primes is in fact p from the problem instance (m, p). In this fashion, A1 is duped by C1 into solving the Phi-Hiding problem.
This computational PIR solves the space problems associated with the PIR query q. However, it does not minimize the running time of the database algorithm. This may prove to be too burdensome in some settings, yet perhaps not in others. It is an interesting research problem to develop a more computationally efficient private information retrieval scheme.
6.4 Tagged Private Information Retrieval
The random oracle based PIR presented in Section 6.3 is a space efficient way to privately obtain a single bit from a database of bits. It is of course possible to define w databases B1, B2, ..., Bw and perform the PIR scheme w times, once for each database. This allows the user to obtain all w bits corresponding to entry i in each database. This effectively forms a single database containing n entries, each of which contains a w-bit string.
However, this scheme is still somewhat abstract and leaves much to be desired in terms of applying it in many practical situations. There may be some situations in which the needed entry may be referenced by an index i, but a more likely scenario is one in which the needed entry is associated with a particular tag string rather than an index i that is contiguous with the other entries. For instance, consider a hacker that wishes to obtain the password of BobbyB142 and no one else. The database consists of the user names as tags and the passwords as database entries. The hacker would like to construct a Trojan horse that privately retrieves the password of BobbyB142 without revealing that his password is sought. The Trojan could be resident and apply the database administrator algorithm to each password that is entered. The Trojan will steal Bobby's password each time he enters it.
The PIR in Section 6.3 can be retrofitted to solve this problem. It can be employed by viewing the database as multiple 1-bit databases. The index sequence i can consist of the binary representations of all current user names. There will of course be huge gaps in this index sequence. It is clearly more desirable to come up with a custom tagged PIR for this problem. This PIR will now be described. The tagged database B is defined as follows,
![]()
Here the ti's are eachs W1 bits in length and the ![]() i's are each W2 bits in length. The value
i's are each W2 bits in length. The value ![]() j = (bj,1, bj,2,..., bj, W2) for 1 ≤ j ≤ n. The problem is to obtain string
j = (bj,1, bj,2,..., bj, W2) for 1 ≤ j ≤ n. The problem is to obtain string ![]() i privately from the database administrator.
i privately from the database administrator.
input: integer n (number of bits in the database B)
integer ti where |ti| = W1
output: a query q = (m, x, Y) where:
m is a composite that is kf bits in length
X consisting of W2 values from ![]()
y which is a k-bit string
secret s which is the factorization of m
1. generate random k-bit string y
2. compute pi = RandPrimek(y||ti)
3. compute (Q1, Q2) = PhiHide(f, pi, 1k)
4. compute m = Q1Q2
5. for j = 1 to W2 do:
6. choose xj randomly from ![]()
7. set X = (x1, x2, ..., xW2)
8. output q = (m, X, y) and s and halt
DatabaseAlgorithm3(B, q, 1k):
input: database B
query q = (m, X, y)
output: a response R consisting of W2 values from ![]()
1. set n equal to the number of entries in B
2. for j = 1 to W2 do:
3. set x0,j = xj
4. for j = 1 to n do:
5. compute pj = RandPrimek(y||tj)
6. for ℓ = 1 to W2 do:
7. compute ej, ℓ = ![]()
8. compute xj,ℓ = ![]() mod m
mod m
9. output R = (xn, 1, xn, 2,..., xn, w2) and halt
ResponseRetriever3(n, ti, (q, s), R, 1k):
input: integer n (number of entries in the database B)
integer ti where |ti| = W1
query q = (m, X, y)
secret factorization s = (Q1, Q2)
response R = (xn,1, xn,2, ..., xn, W2)
output: a bit string ![]() such that
such that ![]() =
= ![]() i with overwhelming probability
i with overwhelming probability
1. compute pi = RandPrimek(y||ti)
2. compute t = ![]()
3. for j = 1 to W2 do:
4. compute w = xtn,j mod m
5. set bi,j = 0
6. if w =1 then set bi,j = 1
7. output ![]() and halt
and halt
The scheme generalizes the random oracle PIR in the obvious way. It uses a series of elements from ![]() to record the desired database entry. Each bit in the retrieved string corresponds to a pith root or non-root. No security argument will be given for this particular scheme. However, it is clear that it is based on the Phi-Hiding problem and gets its security from the intractability of distinguishing higher order residues from non-residues.
to record the desired database entry. Each bit in the retrieved string corresponds to a pith root or non-root. No security argument will be given for this particular scheme. However, it is clear that it is based on the Phi-Hiding problem and gets its security from the intractability of distinguishing higher order residues from non-residues.
The tagged information retrieval algorithm can also be conceptually viewed as a logic circuit. This perspective will be given here; however, it is emphasized that this is for illustrative purposes only and in no way captures the essence of the Phi-Hiding scheme from a cryptographic standpoint. The object is to design a cryptographic pattern matching and storage circuit. If we disregard the cryptographic aspect of this problem, the corresponding circuit can be realized in a straightforward fashion using logic synthesis.5
Suppose that the tag ti is 4-bits long and the associated data bi is also 4 bits long. The circuit contains ti in hardwired form. This is depicted in Figure 6.1. For concreteness suppose that ti = 1110, as in the figure. These bits are encrypted in the tagged information retrieval scheme. Also, the circuit initially contains a 4-bit register x. Each value is initially zero as depicted in the figure. The value x corresponds to X in the tagged information retrieval query.
To operate correctly the circuit must match the input tag with the hardwired tag ti. If they match the corresponding data, bi should be copied into the 4-bit register x. If they don't match, then the register values should remain unchanged. The problem can be broken down into two parts: a pattern-matching circuit and a bit-writing circuit. Consider the pattern-matching circuit. The goal is to produce a binary 0 if the input tag matches the hardwired tag ti and zero otherwise. This can be implemented by first bitwise XORing the tag bits. If they all match then all the resulting bits will be zero. If the bits in a single bit position differ then at least one of the resulting bits will be one. So, by ORing all the resulting bits, the result of the OR will be zero if and only if all bits match. Let the resulting signal bit be denoted by s.
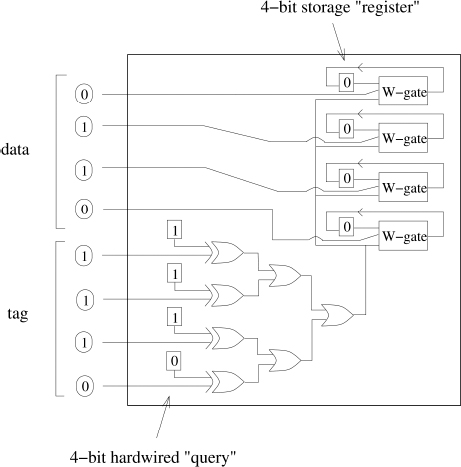
Figure 6.1 Informaton retrieval circuit
The signal s can be used to decide whether or not to copy the associated data bits into the 4-bit register x. This is the job of the W-gates, which stands for writing gates. When s = 0 the W-gates should cause x to assume the value of bj. When s =1 the W-gates should leave x unchanged. This design gives rise to the truth table given in Table 6.1.
In Table 6.1, b denotes one of the bits in bi, xi denotes the corresponding bit in x, and x′ denotes the value that xi will be changed to. Note that whenever s = 0, the output value x′ assumes the value of b. Also, whenever s = 1 the value x′ assumes the value of x.
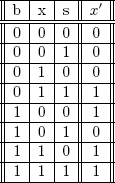
Table 6.1 Truth table for W-gate
It is conventional in boolean algebra to let xs denote the logical AND of x and s where x and s are boolean values. It is also conventional to let x + s denote the logical OR of x and s and ![]() to denote the logical NOT of s.
to denote the logical NOT of s.
The following is how to turn Table 6.1 into a boolean expression using the sum-of-products method. For each output x′ that equals 1, a particular term is created in the boolean expression. Consider a row which contains x′ = 1. The term is the logical AND of the variables with the exception that a variable is negated if its entry contains a zero. For example, the fourth row from the top of Table 6.1 has a zero in the column for b. Hence, the term for this row is ![]() xs. All of the resulting terms are then ORed together. The truth table therefore gives rise to the following boolean equation.
xs. All of the resulting terms are then ORed together. The truth table therefore gives rise to the following boolean equation.
![]()
This boolean expression is implemented in a circuit called W-gate that is given in Figure 6.2.
It is instructive to consider the operation of the circuit in Figure 6.1. Suppose that the circuit is initially given (t1, b1) where t1 is the 4-bit tag and b1 is the 4-bit data value. After this input is processed the circuit is given the input pair (t2, b2) and then (t3, b3). Let (t1, b1) = (1010,1100), (t2, b2) = (1110, 0110), and (t3, b3) = (0101, 1110). Since 1010 ⊕ 1110 = 0100 it follows that s will be 1 for (t1, b1). From the truth table it is evident that the value x does not change whenever s = 1. So by the time (t2, b2) is fed as input to the circuit, x is still 0000. Now consider the input (t2, b2 ). Since 1110 ⊕ 1110 = 0000 it follows that s will be zero for (t2, b2). From the truth table it is clear that the value x is set to be b whenever s = 0. So, by the time (t3, b3) is fed as input to the circuit, x will be 0110. Finally, consider the input (t3, b3). Since 0101 ⊕ 1110 = 1011 it follows that s will be 1 for (t3, b3). From the truth table it is evident that the value x does not change from 0110.

Figure 6.2 W-gate for information-stealing circuit
The amazing thing about the Phi-Hiding scheme is that it effectively implements this circuit without ever revealing the bits that are compared and stored. The tag ti and x are encrypted from the start. Yet, the cryptocircuit nonetheless can both compare bit strings and then store data whenever a match occurs.
6.5 Secure Information Stealing Malware
The computational PIR in Section 6.4 is usable for both honest and malicious purposes. As previously described it can be used to implement a robust PIR based password-snatching Trojan. Of course, it is possible to implement PIR Trojans to take other information as well.
An elegant end-to-end solution is to use a PIR Trojan in conjunction with a mix network. The malware author sends signed queries through the mix net to the PIR Trojan. The PIR Trojan verifies the signature on the queries using the public key of the Trojan author that is contained in the Trojan. If the query is authentic and recent (checking time-stamps, etc.), then it is processed. The Trojan runs the query through the PIR scheme and computes the corresponding result R. This result is then communicated back to the Trojan author. It is already in encrypted form, but can be further encrypted to hide its form. To see this, note that it consists of values drawn from ![]() and this can be statistically detected. So, the Trojan asymmetrically encrypts it and sends it to the author. This can be done via return anonymous remailing, publishing it to a bulletin board through the mix net, and so on. This is an extremely powerful infowar attack since in all aspects of the information theft, the true intentions of the attacker are cryptographically concealed.
and this can be statistically detected. So, the Trojan asymmetrically encrypts it and sends it to the author. This can be done via return anonymous remailing, publishing it to a bulletin board through the mix net, and so on. This is an extremely powerful infowar attack since in all aspects of the information theft, the true intentions of the attacker are cryptographically concealed.
There is no reason why some or all of the tag string ti cannot be dynamic data as well. For example, the last few bits of the tag can be the current date and time. This allows the PIR to privately obtain timely information rather than just static information.
This PIR scheme is very useful in mobile agents to privately retrieve data in untrusted hosts' systems. It can be used by viruses to steal data without revealing that which is sought, provided that the database is defined to contain a large number of entries (some or all of an entire hard drive, for instance).
6.6 Deniable Password Snatching Based on Phi-Hiding
The Phi-Hiding scheme can be used to improve the deniable password-snatching attack (see Section 4.2). A drawback to the deniable password-snatching attack is that it is possible to observe the Trojan properly encrypt login/password pairs at run-time. A transcript of this activity itself forms strong evidence that can be used in a court of law. This possibility can be reduced significantly.
6.6.1 Improved Password-Snatching Algorithm
The improved deniable password-snatching attack is as follows. It is based on the tagged information retrieval scheme that is described in Section 6.4. The Trojan horse contains n prime numbers p1, p2, p3, ..., pn and n composites m1, m2, m3, ..., mn with the property that mi Phi-Hides pi for 1 ≤ i ≤ n. These parameters are chosen according to the Phi-Hiding PIR scheme. Let H(·) be a random function that maps {0, 1}* onto the set {p1, p2, ..., pn}. Hence, a given input string s ![]() {0, 1}* will satisfy H(s) = pi where 1 ≤ i ≤ n with probability 1/n. The random function H is included in the Trojan. Only the Trojan horse author knows the factorization of the n composites. The Trojan horse also contains n circularly linked lists L1, L2, ..., Ln as well as n indexes I1, I2, ..., In that serve as pointers into these lists. Each element of a list is used as a storage location for the ciphertext of a single login/password pair. It is assumed that each login/password pair can be represented using W2 bits. The linked lists are employed in a least recently used fashion. Hence, older ciphertexts are replaced by newer ones.
{0, 1}* will satisfy H(s) = pi where 1 ≤ i ≤ n with probability 1/n. The random function H is included in the Trojan. Only the Trojan horse author knows the factorization of the n composites. The Trojan horse also contains n circularly linked lists L1, L2, ..., Ln as well as n indexes I1, I2, ..., In that serve as pointers into these lists. Each element of a list is used as a storage location for the ciphertext of a single login/password pair. It is assumed that each login/password pair can be represented using W2 bits. The linked lists are employed in a least recently used fashion. Hence, older ciphertexts are replaced by newer ones.
Let s denote the login for a login/password pair that is obtained by the Trojan. Upon obtaining the login/password pair, the Trojan computes pi = H(s). The Trojan concatenates the login with the password and then pads the resulting string with leading zeros to derive a W2-bit string ![]() . This string is effectively the desired database entry in the tagged information retrieval scheme. The Trojan then generates a tuple X = (x1, x2, ..., xW2) randomly, where each element of this tuple is contained in
. This string is effectively the desired database entry in the tagged information retrieval scheme. The Trojan then generates a tuple X = (x1, x2, ..., xW2) randomly, where each element of this tuple is contained in ![]() . The Trojan then applies the tagged information retrieval scheme to this tuple as if it were part of a query for a database entry
. The Trojan then applies the tagged information retrieval scheme to this tuple as if it were part of a query for a database entry ![]() . In other words, for each bit in
. In other words, for each bit in ![]() that is a binary “1,” the corresponding element in the tuple is exponentiated to pi modulo mi. The tuple that results from this process is an encryption of the login/password pair. The Trojan stores this encryption as follows. The Trojan overwrites the entry in Li that is pointed to by Ii with the newly formed encryption. The Trojan advances index Ii and then awaits a new login/password pair. Note that when the index reaches the end of the list, advancing it amounts to setting it back to zero. Also, the Trojan unconditionally copies all n linked lists to the last few unused sectors of every writable floppy that is inserted into the machine.6
that is a binary “1,” the corresponding element in the tuple is exponentiated to pi modulo mi. The tuple that results from this process is an encryption of the login/password pair. The Trojan stores this encryption as follows. The Trojan overwrites the entry in Li that is pointed to by Ii with the newly formed encryption. The Trojan advances index Ii and then awaits a new login/password pair. Note that when the index reaches the end of the list, advancing it amounts to setting it back to zero. Also, the Trojan unconditionally copies all n linked lists to the last few unused sectors of every writable floppy that is inserted into the machine.6
It would be possible to carry out this attack by using only one big circularly linked list, one Phi-Hidden prime, and one composite that hides the prime. To see why this is a bad idea, consider the case in which a given user logs into the machine quite often. When this happens the single list would be saturated with this user's login/password pair. When multiple lists are used only one of the lists would be saturated. The use of hashing with multiple circularly linked lists ensures a good spread of snatched passwords, and the least recently used nature guarantees that the passwords are up-to-date.
6.6.2 Questionable Encryptions
At first sight it may appear that the attack that uses multiple linked lists is needlessly complicated. Also, it might not be clear why this snatching attack is better than the original deniable password-snatching attack that copies asymmetrically encrypted login/password pairs to the disk. The reason that this attack is an improvement is due to the subtle nature of what constitutes theft. For a law enforcement officer to frisk a citizen, there must be probable cause. For the judicial system to convict a citizen, there must be proof that a crime has been committed. The Phi-Hiding password-snatching attack helps cast doubt as to whether or not thievery has occurred.
Consider the ElGamal based deniable password-snatching attack. The Trojan contains the ElGamal public key (y, g, p). For concreteness, let this be the version of ElGamal that is semantically secure against plaintext attacks. Hence, suppose that g has order q where q is prime and p = 2q+1. Let G be the prime order subgroup of ![]() that is generated by g.
that is generated by g.
Observe that it is possible to sample values y ![]() G without knowing the private key x such that y = gx mod p. This implies that the Trojan author could conceivably gift the Trojan with a public key without even knowing the corresponding private key. A defendant that claims that he or she does not know the private key could in fact be telling the truth. It is quite possible that no one knows the private key in this case. However, it is straightforward to verify that the order of y modulo p is q. Hence, it is possible to verify that y is a public key, whether someone knows the private key x for y or not.
G without knowing the private key x such that y = gx mod p. This implies that the Trojan author could conceivably gift the Trojan with a public key without even knowing the corresponding private key. A defendant that claims that he or she does not know the private key could in fact be telling the truth. It is quite possible that no one knows the private key in this case. However, it is straightforward to verify that the order of y modulo p is q. Hence, it is possible to verify that y is a public key, whether someone knows the private key x for y or not.
What this means is that by observation, it is possible to witness the Trojan leak asymmetric ciphertexts in the deniable password-snatching attack, whether they can be decrypted or not. So, it is possible to prove in some sense that sensitive data has been transmitted outside of the machine. This is not the case in the Phi-Hiding password-snatching attack.
In the Phi-Hiding password-snatching attack, either pi divides ![]() (mi) or not. This is not subject to debate. It is either true or it isn't. Hence, if for all i it is the case that pi does not divide
(mi) or not. This is not subject to debate. It is either true or it isn't. Hence, if for all i it is the case that pi does not divide ![]() (mi) then the Trojan is not asymmetrically encrypting anything at all. When this is the case, sensitive information is not being transmitted outside of the host machine. Proving that the Trojan snatches passwords amounts to proving that one of the primes pi divides
(mi) then the Trojan is not asymmetrically encrypting anything at all. When this is the case, sensitive information is not being transmitted outside of the host machine. Proving that the Trojan snatches passwords amounts to proving that one of the primes pi divides ![]() (mi). The presumed intractability of this is closely related to the Phi-Hiding assumption. Under this scheme, it is possible for the Trojan author to deploy a Trojan in which none of the primes are Phi-Hidden. If prosecuted, the Trojan author can prove that none of the primes are Phi-Hidden by revealing the prime power decomposition of the n composites in the Trojan. We argue that the Phi-Hiding password-snatching attack is one of the best ways to snatch passwords from a fielded machine since it places the burden of proof on the prosecution in a very strong way. It is fitting to say that this Trojan satisfies the questionable encryption property, for lack of a better term. The reason that this term seems appropriate is that it is questionable as to whether the Trojan is encrypting anything at all.
(mi). The presumed intractability of this is closely related to the Phi-Hiding assumption. Under this scheme, it is possible for the Trojan author to deploy a Trojan in which none of the primes are Phi-Hidden. If prosecuted, the Trojan author can prove that none of the primes are Phi-Hidden by revealing the prime power decomposition of the n composites in the Trojan. We argue that the Phi-Hiding password-snatching attack is one of the best ways to snatch passwords from a fielded machine since it places the burden of proof on the prosecution in a very strong way. It is fitting to say that this Trojan satisfies the questionable encryption property, for lack of a better term. The reason that this term seems appropriate is that it is questionable as to whether the Trojan is encrypting anything at all.
A natural question to ask is whether or not the deniable password-snatching Trojan satisfies the questionable encryption property when RSA is used. Consider the case that the login/password pairs are encrypted using RSA with a deterministic padding scheme or are encrypted using OAEP. Also, suppose that e is the typical value of 216 + 1 which is prime. The Trojan author can deliberately choose p and q such that gcd(e2, ![]() (pq)) = e. Without loss of generality, let 0 = p − 1 mod e and 0 ≠ q − 1 mod e. Adleman, Manders, and Miller presented a generalization of Tonelli's algorithm to compute rth roots modulo a prime where r is a small prime [4] (see also [174]). Recall that there are r roots in the complete solution set in this case.7 This algorithm is efficient when e is small and can be used to compute eth roots modulo p. When the factorization of n = pq is known it follows that there exists an efficient algorithm to compute eth roots modulo n in this case. In OAEP the correct root will be immediately apparent by verifying the OAEP checksum field that results from hashing. In RSA, the correct root will also likely be apparent by looking for padding bits, an ASCII value that appears to be a login/password pair, and so on. With such a small value for e this approach does not exhibit the questionable encryption property.
(pq)) = e. Without loss of generality, let 0 = p − 1 mod e and 0 ≠ q − 1 mod e. Adleman, Manders, and Miller presented a generalization of Tonelli's algorithm to compute rth roots modulo a prime where r is a small prime [4] (see also [174]). Recall that there are r roots in the complete solution set in this case.7 This algorithm is efficient when e is small and can be used to compute eth roots modulo p. When the factorization of n = pq is known it follows that there exists an efficient algorithm to compute eth roots modulo n in this case. In OAEP the correct root will be immediately apparent by verifying the OAEP checksum field that results from hashing. In RSA, the correct root will also likely be apparent by looking for padding bits, an ASCII value that appears to be a login/password pair, and so on. With such a small value for e this approach does not exhibit the questionable encryption property.
By setting e to be significantly larger than 216 + 1, for example, by making it a 160-bit prime, the RSA cryptosystem exhibits the questionable encryption property. The reason for this is twofold. First, observe that deciding whether or not e divides ![]() (n) evenly is a decision problem that is intimately related to the Phi-Hiding problem. Second, when e does in fact divide
(n) evenly is a decision problem that is intimately related to the Phi-Hiding problem. Second, when e does in fact divide ![]() (n) evenly, it is intractable for the malware author to perform decryption correctly. This follows from the fact that to date, there is no known algorithm for efficiently computing eth roots mod p with such a large prime e. For details the reader is referred to a section in Bach and Shallit entitled, “Computing d-th Roots” [12]. However, the questionable encryption properly need not rely on the inability of the private key holder to compute eth roots. To see this, consider the following alternative. The value e can be set to be the product of numerous small, distinct, and odd primes. As before the value e should be at least 160 bits. In this case it is possible to efficiently compute eth roots modulo p. However, the questionable encryption property still holds due to the fact that there are far too many roots for the private key holder to check. An asymmetric encryption function that exhibits the questionable encryption property is a specialized instance of cryptocomputing since it is possible to observe the function compute a value, but there is no way to tell if the resulting value is an asymmetric ciphertext or not.
(n) evenly, it is intractable for the malware author to perform decryption correctly. This follows from the fact that to date, there is no known algorithm for efficiently computing eth roots mod p with such a large prime e. For details the reader is referred to a section in Bach and Shallit entitled, “Computing d-th Roots” [12]. However, the questionable encryption properly need not rely on the inability of the private key holder to compute eth roots. To see this, consider the following alternative. The value e can be set to be the product of numerous small, distinct, and odd primes. As before the value e should be at least 160 bits. In this case it is possible to efficiently compute eth roots modulo p. However, the questionable encryption property still holds due to the fact that there are far too many roots for the private key holder to check. An asymmetric encryption function that exhibits the questionable encryption property is a specialized instance of cryptocomputing since it is possible to observe the function compute a value, but there is no way to tell if the resulting value is an asymmetric ciphertext or not.
The following are two additional ways to implement questionable encryptions. The first is based on the Goldwasser-Micali cryptosystem (see Appendix C.1.9). Recall that the GM cryptosystem uses a pseudosquare y modulo n where n is the public modulus. The malware designer can choose y to be a quadratic residue modulo n instead of a pseudosquare. It is not hard to see that all of the values in a GM ciphertext will then be randomly chosen quadratic residues. Hence, the malware author will not be able to decipher anything. The author can later prove this by revealing a square root of y and also the factorization of n if the author so desires. This root serves as a witness that there is no trapdoor value for GM that reveals the plaintext. It follows that questionable encryptions can be implemented under the quadratic residuosity assumption. This approach is related to the computationally secure PIR of Kushilevitz and Ostrovsky [165].
The second approach is heuristic in nature. Let (y, g, p) be an ElGamal public key, let g and p be fixed system parameters, and let G be the group generated by G. The value y can be chosen by computing y = H(s). Here s is a large randomly chosen seed and H is a random function with domain {0,1}* (instantiated using a hash function). The range of H is equal to G. The questionable encryption property holds under the presumed intractability of computing a triple (x, y, s) satisfying,
![]()
The pair (y, s) serves as a witness that no one knows the trapdoor value associated with y. This follows from the fact that if x is also known to the malware author then a valid triple must have been found.
A questionable encryption scheme is a form of oblivious transfer and can be regarded as a variant of all-or-nothing disclosure [38, 39]. However, these two notions differ in a couple of ways. A questionable encryption scheme can operate as an asymmetric cipher that is applied repeatedly and independently to many pieces of data, not data defined within the scope of a single protocol as is the case of all-or-nothing disclosure.
Court systems often rely on precedent in dealing with a case. The following is a way to establish a public precedent in regards to questionable encryptions. A virus writer can deploy a virus that computes questionable encryptions of sensitive data and that publishes these encryptions on the Internet. The virus can be designed so that it does not in fact encrypt anything. Once there has been a suitable amount of press coverage, the virus writer can anonymously reveal the factorization of n. This may put many people at ease. There would likely be even more press coverage that mentions that quite surprisingly the virus does not encrypt anything at all. With any luck this occurrence will cast a substantial amount of doubt in subsequent court cases involving questionable encryptions.
A public key cryptosystem that exhibits the questionable encryption property is a general tool for malware. It makes it such that encryptions are questionable in the sense that there is no way of knowing whether or not asymmetric encryptions are really being computed. For example, the SETUP attack on RSA key generation can utilize RSA with a 160-bit prime e. If it is the case that gcd(e, ![]() (n)) = e, then the malware author can later reveal the factorization of n and show that there never was a SETUP attack being performed despite the fact that the basic functionality needed to mount a SETUP attack is present.
(n)) = e, then the malware author can later reveal the factorization of n and show that there never was a SETUP attack being performed despite the fact that the basic functionality needed to mount a SETUP attack is present.
The notion of questionable encryptions has potentially serious implications for copyright law. Consider a provider that illegally transmits copyrighted material to a recipient. For example, a recipient gives the provider a public key and the provider sends the recipient copyrighted material (e.g., MP3 music files) encrypted under the recipient's public key.
Now consider how a questionable encryption scheme can minimize the legal risk for the recipient. Suppose that a questionable encryption scheme is used as the delivery mechanism. If the recipient gives the provider a fake public key that produces a nonce under the asymmetric encryption algorithm, then the recipient receives random numbers instead of copyrighted material and hence the provider and recipient have not violated any copyright laws. In this case the provider is providing a random number generation service. If the public key is real, then the recipient has knowingly elicited copyrighted material that the provider had no right to give.
In this copyright violation scheme, only the recipient can initiate a copyright violation, and only the recipient knows if a violation is even occurring. Strictly speaking, the provider is not knowingly or willingly violating any copyright laws. The use of questionable encryptions for copyright violations therefore adds an extra hurdle to the successful prosecution of rogue recipients of copyrighted material.
It is natural to investigate how law enforcement bodies could try to catch copyright violators. Suppose that an undercover officer registers a real public key with the provider. If the officer later obtains copyrighted material from the provider, then strictly speaking it was the officer that enacted the copyright violation, not the provider. It seems that the officer would have to monitor another user: (1) generate a real public key, (2) register the public key with the provider, and then (3) obtain and decrypt the received ciphertext. This approach would clearly show that the recipient is in violation of the law. However, it is more difficult to show that the provider knowingly duplicated and transferred copyrighted material. In this regard, the notion of questionable encryptions adversely affects the enforceability of copyright laws. Recording industry groups would have a much harder time prosecuting people that use protocols like Gnutella if the underlying data delivery system were designed to use a questionable encryption algorithm.
An issue that was glossed over is the case that the copyrighted material is bulky. For example, a copyrighted file may be 2 to 3 megabytes in size. To deal with bulk data encryptions, a secure number-theoretic pseudorandom number generator can be used. The seed is encrypted with the questionable encryption scheme and the pseudorandom sequence that results from the seed is bitwise XORed with the plaintext. Observe that the seed is lost when the fake public key is used in the questionable encryption. Hence, the resulting ciphertext stream is polynomially indistinguishable from a random bit string with respect to the key holder and everyone else.
6.6.3 Deniable Encryptions
The notion of a deniable encryption was put forth by Canetti, Dwork, Naor, and Ostrovsky [52] and it is related to the notion of questionable encryptions. The utility of computing deniable encryptions is motivated by the following possibility. Consider a situation in which the transmission of encrypted messages is intercepted by an adversary who can later ask the sender to reveal the random choices8 used in generating the ciphertext, thereby exposing the plaintext. An encryption scheme produces deniable encryptions if the sender can produce fake random choices that will make the ciphertext appear to be an encryption of a different plaintext, thereby keeping the true plaintext secret. Similar requirements can be formulated with respect to attacking the receiver and with respect to attacking both parties. A construction was given based on the existence of a trapdoor permutation.
Deniable encryption has several applications. For example, it can be incorporated in current protocols for incoercible and receipt-free voting in a manner that eliminates the need for a physically secure communication channel. It also underlies recent protocols for generalized incoercible multiparty computation that have no physical security assumptions. Also, deniable encryption provides an elegant and simplified construction of a multiparty protocol that is adaptively secure.
One of the differences between deniable encryptions and questionable encryptions is as follows. In a questionable encryption the receiver has a witness that the value is an encryption or a witness that the value is not a witness under a particular PKCS. In a deniable encryption the receiver can effectively present a witness for each possible interpretation of the plaintext. Another difference lies in the setting. A questionable encryption scheme must be such that it produces questionable encryptions while the encryption algorithm is under surveillance. In the deniable encryption setting this is not the case since the sender and receiver share secret information and only the transmitted messages, not the actual computations, are assumed to be observable. In other words, the sender is allowed to compute privately without an adversarial onlooker. These two notions are different and solve different problems yet they are related in the following way: they both permit the recipient to refute the contents of the ciphertext. In questionable encryptions the recipient can claim that nothing is encrypted at all and in the deniable encryption case the recipient can claim that almost any string is encrypted.
6.7 Malware Loaders
The notions of deniable password snatching (that is, subtly broadcasting asymmetric ciphertexts wherein only the attacker can decrypt them), questionable encryptions, and private information retrieval clearly assists an attacker to receive information in such a way that (1) everyone receives the information but only the attacker can decrypt it, and (2) for all anyone knows, the ciphertexts are not ciphertexts but actually nonces, thus implying that information leakage may not have occurred.
Recall that in the original deniable password-snatching attack, the attacker uses a virus to install the cryptotrojan on the host machine. The attacker's only recourse if apprehended in this phase is to claim to be an innocent victim of the virus. This does not bode well for the attacker, since the virus will contain a Trojan that contains functionality for leaking information (although deciding if it really does is still intractable). Any prosecutor would likely try to make the case that the questionable encryptions were in fact encryptions. Since the information retrieval phase can be cryptographically improved, it is natural to ask if the malware deployment phase can be improved as well. In this section this question is answered in the affirmative. The idea utilizes the notions of an operating system, code signing, and signal monitoring. For concreteness it will be described within the context of snatching passwords, although other forms of information stealing are possible.
The attacker randomly generates a symmetric key and a key pair for a digital signature scheme. The symmetric key and digital signature verification public key are placed within a cryptotrojan. The cryptotrojan is designed to operate as follows. When running it constantly listens in on a public broadcast channel. This channel can be a public channel on the Internet, for example. The channel can even be a steganographic channel in graphics files within yet another more visible channel such as Usenet. When it receives a message it decrypts it using the symmetric key. The cryptotrojan then checks the structure of the plaintext data that results. If it is not in the form of a message, followed by a signature on the message, then it is rejected. If it is, then the signature on the message is verified using the public key.9 If the signature is valid then the message is regarded by the cryptotrojan as an authentic message from the attacker.
The Trojan then executes the message as a child process. In UNIX this can be done using fork and exec, for example. The Trojan is thus acting like an operating system that uses code signing to check for authentic code. Since the Trojan loads and runs the process it seems natural to refer to it as a malware loader. The attacker constructs a module that the attacker wants the host system to run. This module is really just a self-contained program. The attacker digitally signs the module using the private signing key, encrypts the module and signature on it with the symmetric key, and then broadcasts the resulting binary string over a subtle public broadcast channel. The Trojan receives the signed and encrypted module from the broadcast channel and runs it only if it is authentic.
One module that the attacker can send is the questionable encryption password snatcher. This module questionably encrypts login/password pairs and broadcasts them on a subtle outgoing public channel. Another module can be a private information retrieval module that accepts queries and then scans information connected to peripherals to construct the response. The response is then broadcast on the subtle outgoing public channel. Like in the original deniable password-snatching attack, the cryptotrojan can be deployed via self-replicating malware.
The attack is a major improvement for the following reason. If the attacker is caught red-handed distributing the self-replicating malware that contains the cryptotrojan then half of the attack code will not be found on the attacker's person. This hampers things greatly from a legal perspective, since the attacker can claim that while yes, self-replicating code was being installed, its payload was only an operating system, which in itself can be quite harmless.
6.8 Cryptographic Computing
In some sense PIR schemes can be considered to be a specialized problem in cryptographic computing. It is the problem of performing secret string matching and string variable assignment while under the scrutiny of untrusted observers. This section covers the more general concept of cryptographic computing.
Cryptographic computing is an area of cryptography that is in its infancy. It is a new, ambitious direction for the field. Originally cryptography sought to provide confidentiality for inert data. Cryptocomputing is concerned with performing useful computations on encrypted data without having to decrypt it, not just the secure transport and storage of encrypted data. This functionality is applicable to software piracy protections schemes as well as secure mobile agents, viruses, worms, and so on.
In fact there is a very close relationship between piracy protection and secure mobile agent theory. They both adhere to the same premise that the underlying machine that is running the software is untrustworthy in some way. The most basic problem is observability: the underlying code can be scrutinized using debugging tools and hence the underlying algorithm can be learned and replicated elsewhere. This presents problems when a company wishes to deploy an unpatented algorithm that they wish to keep as a trade secret. It also poses a problem when a mobile agent is sent off to do work on a public network since the agent and the data it gathers is subject to the scrutiny of untrusted observers. The field of secure mobile agents is gaining in popularity, as evidenced by young workshops such as the IEEE International Conference on Mobile Agents (that had its sixth meeting last year). There has even been enough work in the area of cryptographic mobile agents to warrant general surveys on the subject [231].
However, the notion of performing useful computations in untrusted environments is at least as old as public key cryptography itself. In as early as 1978, around the time that the RSA algorithm was discovered, a sufficient mathematical framework for performing secure computations on an untrusted machine was proposed [100, 244]. Specifically, it was noted that the existence of an additive homomorphism over the ciphertexts of a public key encryption function E defined over an appropriate domain as well as the existence of a multiplicative homomorphism over the ciphertexts would be sufficient to enable general computations over encrypted data akin to that which can be performed by Turing machines. In other words, the primitive would consist of operations (E, ⊕, ⊗) such that for all plaintexts m1 and m2,
![]()
The additive homomorphism is denoted by ⊕, and the multiplicative homomorphism is denoted by ⊗. Interestingly, it is a trivial exercise to identify a multiplicative homomorphism for the RSA function, but the existence of an additive homomorphism for RSA is unknown.
If these primitives were to exist then they could be used to implement a universal logic gate such as a NAND or NOR gate. The gate would not operate on plaintext bits, but instead it would operate on ciphertext bits. For instance, the NAND gate would take as input two ciphertexts that each encrypt a single bit and it would return a ciphertext corresponding to the logical NAND of the two input plaintext bits. This would occur without ever decrypting the input ciphertexts. It is well known that any combinatorial circuit can be synthesized based on a universal gate. It is also well known that any Turing machine can be efficiently simulated by a Boolean circuit [315].
The practical utility of such a primitive may be brought into question, since an encrypted bit would likely occupy 768 or more ciphertext bits in the machine, and each operation is likely to involve multiple modular exponentiations, for instance. However, it would certainly be possible to implement small circuits to perform simple yet useful computations on untrusted hosts.
It is safe to say that researchers have been investigating the existence of these primitives for more than 20 years. However, it is important to bear in mind that this is a quest for a general-purpose cryptographic computing machine, not a machine that needs to solve a particular problem. In the mid-1980s the open research community began investigating dedicated cryptographic computing algorithms.
One such cryptocomputing algorithm appeared in 1986 [2, 99]. The idea was to disguise an instance of a hard problem, such as the discrete-logarithm problem, and have an untrusted machine solve it. The approach allows Alice to hide information from Bob while getting Bob to do some useful work. Alice has y and wants to know the value x such that y = gx mod p. Bob has a magic computer and has a good chance of being able to solve the problem by brute force. Alice would like Bob to solve the problem for her, but does not want Bob to learn x.
Here is how the two of them can accomplish this. Alice chooses r < q randomly and computes yr = ygr mod p. She sends yr to Bob and Bob computes the discrete logarithm of this value using the base g and the modulus p. So, Bob computes v = x + r mod q and sends this value to Alice. Alice recovers x by computing x ≡ v − r ≡ x + r − r mod q. Bob has no way of knowing what the value of x is. Similar results have been shown for the quadratic residuosity problem and the primitive root problem [1, 2].
A problem that is closely related to computing with encrypted data is the problem of performing secure multiparty computation. The first example of this is the famous Millionaire problem: Alice and Bob each have an integer number and they want to know who holds the greater number without having to disclose the numbers to one another. This was first addressed by Andrew Yao [325] in 1982. The more general context is the following. Two or more parties want to determine some property about the pieces of information they hold while keeping them private. The main results in the domain were achieved by Andrew Yao [326] in 1986 for the two-party case.
In 1987 Goldreich et al showed how to securely implement any desired multiparty functionality [116]. The security is guaranteed, provided either a majority of the players are honest or all parties are semi-honest. In other words, all parties send messages according to the protocol, but keep track of and share all intermediate results. Much attention has been paid to the important issue of minimizing the number of rounds of computation in this model. There is a wealth of literature regarding secure multiparty computations [14, 15, 16, 56, 57, 58, 105, 106, 107].
A working group, organized by DARPA, met in October 1996 to discuss security issues regarding the execution of code on machines that are operated by untrusted parties. In 1997 a workshop was held on the subject [80]. It was geared towards developing the semantics, structures, and security assumptions that form the basis for single-party secure computation. It was concluded that numerous approaches lacked formal grounds for security, and that they typically relied on ad hoc or otherwise hidden security assumptions.
In 1997 Sander and Tschudin proposed a method to compute with encrypted functions to overcome the problem of protecting mobile code from its host [250, 251]. Techniques were presented to achieve non-interactive computing with encrypted programs in certain cases and give a complete solution for this problem in certain instances. In particular they gave a protocol that allows non-interactive evaluation of encrypted polynomials over the ring of integers modulo N where N is a smooth (that is, N has no large prime factors). The results are based on the use of homomorphic encryption schemes and function composition techniques. In particular they utilize an additive scheme of Lipton and Sander [176] that is polynomial time indistinguishable under the assumption of the hardness of the Power Residue Hypothesis, which is a generalization of the Quadratic Residue Hypothesis to residues of higher degree.
It is argued that this primitive may be usable in mobile agents that need to remotely sign their output. The agents would thereby be able to create undetachable digital signatures. However, they remark that there are still outstanding technical obstacles that need to be overcome in order to achieve this goal. Research that is related to this was presented in Financial Crypto '02 by Stern et al who gave a method for computing with encrypted rational numbers [103].
The first formal result regarding generalized cryptographic computing was presented in 1999 by Sander et al [252]. It was shown how in one round a protocol for secure evaluation of circuits can be performed in polynomial-time for NC1 circuits (Nick's Class). The protocol involves an input party sending encrypted input to a second party (a cryptocomputer). The second party evaluates the circuit (or a known circuit over its additional private input) non-interactively, securely, and obliviously, and provides the output to the input party without learning it. This directly applies to protection against reverse engineering since under well-established intractability assumptions the reverse engineer provably learns nothing about the program that is being executed. An implementation is presented that is based on the quadratic residuosity problem. This improved on previous results that are specialized to the case of NC1 circuits and that require a constant number of communication rounds. The scenario also coincides with computing with encrypted data when the input is transformed into an output while remaining encrypted throughout the computation. The algorithm utilizes a probabilistic encryption method that is random self-reducible. The paper also gives a new provably secure public key scheme that allows the computation of the logical AND operation using encrypted data. This scheme is homomorphic over a semigroup (instead of a group) and thus also expands the range of algebraic structures that can be encrypted homomorphically.
The work on one-round secure computation has been ongoing [47]. Cachin et al investigate one-round secure computation between two distrusting parties as well: Alice and Bob each have private inputs to a common function, but only Alice, acting as the receiver, is able to learn the output. The protocol is limited to one message from Alice to Bob followed by one message from Bob to Alice. The solution has an advantage over the Sander et al cryptocomputer since it works for polynomial-depth circuits. However, for the purposes of generalized mobile agent computing the solution has a drawback that it cannot iteratively receive inputs and compute values based on previously stored results. All of the inputs must be present at the time the computation commences. The authors propose a remedy to this based on symmetric cryptography but it has various inherent limitations. The solution nonetheless provides stronger evidence regarding the feasibility of executing mobile code in untrusted environments.
1Hence, there is a form of cryptographic obliviousness at work.
2Or administrators, in the case that multiple instances of the database are maintained.
3This is also often referred to as being unconditionally secure.
4For any language L contained in NP.
5Logic synthesis is typically covered in an introductory undergraduate course in electrical engineering.
6Or distributes the lists using some other channel (e.g., steganographic channel, subliminal channel, transmission over a mix network, broadcast channel, etc.).
8As well as the secret key if it exists.
9Timestamps can also be used to guard against replay attacks.