
1
HOW NATURAL LANGUAGE PROCESSING WORKS

In the 19th century, explorers discovered rongorongo, a system of mysterious glyphs on the island of Rapa Nui (commonly known as Easter Island). Researchers have never succeeded in decoding rongorongo inscriptions or even figuring out whether those inscriptions are writing or proto-writing (pictographic symbols that convey information but are language independent). Moreover, although we know that the creators of the glyphs also erected Moai, the large statues of human figures for which the island is most famous, the builders’ motivations remain unclear. We can only speculate.
If you don’t understand people’s writing—or the way in which they describe things—you most likely won’t understand the other aspects of their life, including what they do and why they do it.
Natural language processing (NLP) is a subfield of artificial intelligence that tries to process and analyze natural language data. It includes teaching machines to interact with humans in a natural language (a language that developed naturally through use). By creating machine learning algorithms designed to work with unknown datasets much larger than those two dozen tablets found on Rapa Nui, data scientists can learn how we use language. They can also do more than simply decipher ancient inscriptions.
Today, you can use algorithms to observe languages whose semantics and grammar rules are well known (unlike the rongorongo inscriptions), and then build applications that can programmatically “understand” utterances in that language. Businesses can use these applications to relieve humans from boring, monotonous tasks. For example, an app might take food orders or answer recurring customer questions requesting technical support.
Not surprisingly, generating and understanding natural language are the most promising and yet challenging tasks involved in NLP. In this book, you’ll use the Python programming language to build a natural language processor with spaCy, the leading open source Python library for natural language processing. But before you get started, this chapter outlines what goes on behind the scenes of building a natural language processor.
How Can Computers Understand Language?
If computers are just emotionless machines, how is it possible to train them to understand human language and respond properly? Well, machines can’t understand natural language natively. If you want your computer to perform computational operations on language data, you need a system that can translate natural language words into numbers.
Mapping Words and Numbers with Word Embedding
Word embedding is the technique that assigns words to numbers. In word embedding, you map words to vectors of real numbers that distribute the meaning of each word between the coordinates of the corresponding word vector. Words with similar meanings should be nearby in such a vector space, allowing you to determine the meaning of a word by the company it keeps.
The following is a fragment of such an implementation:
the 0.0897 0.0160 -0.0571 0.0405 -0.0696 ...
and -0.0314 0.0149 -0.0205 0.0557 0.0205 ...
of -0.0063 -0.0253 -0.0338 0.0178 -0.0966 ...
to 0.0495 0.0411 0.0041 0.0309 -0.0044 ...
in -0.0234 -0.0268 -0.0838 0.0386 -0.0321 ...
This fragment maps the words “the,” “and,” “of,” “to,” and “in” to the coordinates that follow it. If you represented these coordinates graphically, the words that are closer in meaning would be closer in the graph as well. (But this doesn’t mean that you can expect the closer-in-meaning words to be grouped together in a textual representation like the one whose fragment is shown here. The textual representation of a word vector space usually starts with the most common words, such as “the,” “and,” and so on. This is the way word vector space generators lay out words.)
NOTE
A graphical representation of a multidimensional vector space can be implemented in the form of a 2D or a 3D projection. To prepare such a projection, you can use the first two or three principal components (or coordinates) of a vector, respectively. We’ll return to this concept in Chapter 5.
Once you have a matrix that maps words to numeric vectors, you can perform arithmetic on those vectors. For example, you can determine the semantic similarity (synonymy) of words, sentences, and even entire documents. You might use this information to programmatically determine what a text is about, for example.
Mathematically, determining the semantic similarity between two words is reduced to calculating the cosine similarity between the corresponding vectors, or to calculating the cosine of the angle between the vectors. Although a complete explanation of calculating semantic similarity is outside the scope of this book, Chapter 5 will cover working with word vectors in more detail.
Using Machine Learning for Natural Language Processing
You can generate the numbers to put in the vectors using a machine learning algorithm. Machine learning, a subfield of artificial intelligence, creates computer systems that can automatically learn from data without being explicitly programmed. Machine learning algorithms can make predictions about new data, learn to recognize images and speech, classify photos and text documents, automate controls, and aid in game development.
Machine learning lets computers accomplish tasks that would be difficult, if not impossible, for them to do otherwise. If you wanted to, say, program a machine to play chess using a traditional programming approach in which you explicitly specify what the algorithm should do in every context, imagine how many if...else conditions you’d need to define. Even if you succeed, users of such an application will quickly discover weak points in your logic that they can take advantage of during the game until you make necessary corrections in the code.
In contrast, applications built on machine learning algorithms don’t rely on predefined logic but use the capability to learn from past experience instead. Thus, a machine learning–based chess application looks for positions it remembers from the previous games and makes the move that leads to the best position. It stores this past experience in a statistical model, which is discussed in “What Is a Statistical Model in NLP?” on page 8.
In spaCy, aside from generating word vectors, machine learning allows you to accomplish three tasks: syntactic dependency parsing (determining the relationships between words in a sentence), part-of-speech tagging (identifying nouns, verbs, and other parts of speech), and named entity recognition (sorting proper nouns into categories like people, organizations, and locations). We’ll discuss all of these at length in the following chapters.
The life cycle of a typical machine learning system has three steps: model training, testing, and making predictions.
Model Training
In the first stage, you train a model by feeding your algorithm a large body of data. For these algorithms to give you reliable results, you must provide a sufficiently large volume of input—significantly more than the rongorongo tablets, for instance. When it comes to NLP, platforms like Wikipedia and Google News contain enough text to feed virtually any machine learning algorithm. But if you wanted to build a model specific to your particular use case, you might make it learn, for example, from customers using your site.
Figure 1-1 provides a high-level depiction of the model training stage.
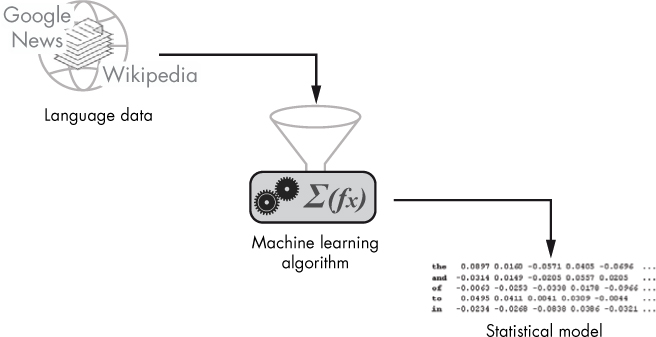
Figure 1-1: Generating a statistical model with a machine learning algorithm using a large volume of text data as input
Your model processes large volumes of text data to understand which words share characteristics; then it creates word vectors for those words that reflect those shared characteristics.
As you’ll learn in “What Is a Statistical Model in NLP?” on page 8, such a word vector space is not the only component of a statistical model built for NLP. The actual structure is typically more complicated, providing a way to extract linguistic features for each word depending on the context in which it appears.
In Chapter 10, you’ll learn how to train an already existing, pretrained model with new examples and a blank one from scratch.
Testing
Once you’ve trained the model, you can optionally test it to find out how well it will perform. To test the model, you feed it text it hasn’t seen before to check whether it can successfully identify the semantic similarities and other features learned during the training.
Making Predictions
If everything works as expected, you can use the model to make predictions in your NLP application. For example, you can use it to predict a dependency tree structure over the text you input, as depicted in Figure 1-2. A dependency tree structure represents the relationships between the words in a sentence.
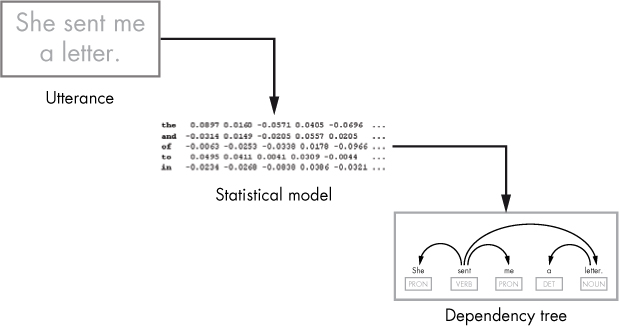
Figure 1-2: Predicting a dependency tree structure for an utterance using a statistical model
Visually, we can represent a dependency tree using arcs of different lengths to connect syntactically related pairs of words. For example, the one shown here tells us that the verb “sent” agrees with the pronoun “she.”
Why Use Machine Learning for Natural Language Processing?
Your algorithm’s predictions aren’t statements of fact; they’re typically calculated with a degree of certainty. To achieve a higher degree of accuracy, you’ll need to implement more complicated algorithms, which are less efficient and less practical to implement. Usually, people strive to achieve a reasonable balance between accuracy and performance.
Because machine learning models can’t predict perfectly, you might wonder whether machine learning is the best approach for building the models used in NLP applications. In other words, is there a more reliable approach based on strictly defined rules, similar to the one used by compilers and interpreters for processing programming languages? The quick answer is no. Here’s why.
To begin with, a programming language contains a relatively small number of words. For example, the Java programming language consists of 61 reserved words, each of which has a predefined meaning in the language.
By contrast, the Oxford English Dictionary, released in 1989, contains 171,476 entries for words in current use. In 2010, a team of researchers at Harvard University and Google counted about 1,022,000 words in a body of digitized texts containing approximately 4 percent of all books ever published. The study estimated that the language would grow by several thousand words a year. Assigning each word to a corresponding number would take too long.
But even if you tried to do it, you’d find it impossible, for several reasons, to determine the number of words used in a natural language. First of all, it’s unclear what really counts as an individual word. For example, should we count the verb “count” as one word, or two, or more? In one scenario, “count” might mean “to have value or importance.” In a different scenario, it might mean, “to say numbers one after another.” Of course, “count” can also be a noun.
Should we count inflections—plural form of nouns, verb tenses, and so on—as separate entities, too? Should we count loanwords (words adopted from foreign languages), scientific terms, slang, and abbreviations? Evidently, the vocabulary of a natural language is defined loosely, because it’s hard to figure out which groups of words to include. In a programming language like Java, an attempt to include an unknown word in your code will force the compiler to interrupt processing with an error.
A similar situation exists for formal rules. Like its vocabulary, many formal rules of a natural language are defined loosely. Some cause controversy, like split infinitives, a grammatical construction in which an adverb is placed between the infinitive verb and its preposition. Here is an example:
spaCy allows you to programmatically extract the meaning of an utterance.
In this example, the adverb “programmatically” separates the preposition and infinitive “to extract.” Those who believe that split infinitives are incorrect could suggest rewriting the sentence as follows:
spaCy allows you to extract the meaning of an utterance programmatically.
But regardless of how you feel about split infinitives, your NLP application should understand both sentences equally well.
In contrast, a computer program that processes code written in a programming language isn’t designed to handle this kind of problem. The reason is that the formal rules for a programming language are strictly defined, leaving no possibility for discrepancy. For example, consider the following statement, written in the SQL programming language, which you might use to insert data into a database table:
INSERT INTO table1 VALUES(1, 'Maya', 'Silver')
The statement is fairly self-explanatory. Even if you don’t know SQL, you can easily guess that the statement is supposed to insert three values into table 1.
Now, imagine that you change it as follows:
INSERT VALUES(1, 'Maya', 'Silver') INTO table1
From the standpoint of an English-speaking reader, the second statement should have the same meaning as the first one. After all, if you read it like an English sentence, it still makes sense. But if you try to execute it in a SQL tool, you’ll end up with the error missing INTO keyword. That’s because a SQL parser—like any other parser used in a programming language—relies on hardcoded rules, which means you must specify exactly what you want it to do in a way it expects. In this case, the SQL parser expects to see the keyword INTO right after the keyword INSERT without any other possible options.
Needless to say, such restrictions are impossible in a natural language. Taking all these differences into account, it’s fairly obvious that it would be inefficient or even impossible to define a set of formal rules that would specify a computational model for a natural language in the way we do for programming languages.
Instead of a rule-based approach, we use an approach that is based on observations. Rather than encoding a language by assigning each word to a predetermined number, machine learning algorithms generate statistical models that detect patterns in large volumes of language data and then make predictions about the syntactic structure in new, previously unseen text data.
Figure 1-3 summarizes how language processing works for natural languages and programming languages, respectively.
A natural language processing system uses an underlying statistical model to make predictions about the meaning of input text and then generates an appropriate response. In contrast, a compiler processing programming code applies a set of strictly defined rules.
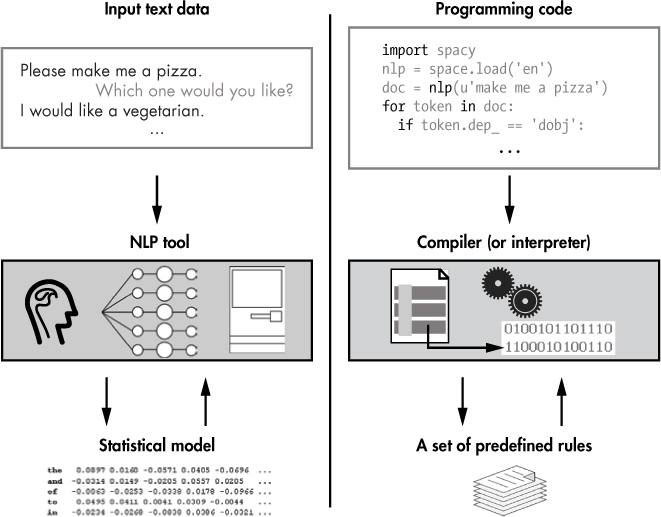
Figure 1-3: On the left, a basic workflow for processing natural language; on the right, a basic workflow for processing a programming language
What Is a Statistical Model in NLP?
In NLP, a statistical model contains estimates for the probability distribution of linguistic units, such as words and phrases, allowing you to assign linguistic features to them. In probability theory and statistics, a probability distribution for a particular variable is a table of values that maps all of the possible outcomes of that variable to their probabilities of occurrence in an experiment. Table 1-1 illustrates what a probability distribution over part-of-speech tags for the word “count” might look like for a given sentence. (Remember that an individual word might act as more than one part of speech, depending on the context in which it appears.)
Table 1-1: An Example of a Probability Distribution for a Linguistic Unit in a Context
VERB |
NOUN |
78% |
22% |
Of course, you’ll get other figures for the word “count” used in another context.
Statistical language modeling is vital to many natural language processing tasks, such as natural language generating and natural language understanding. For this reason, a statistical model lies at the heart of virtually any NLP application.
Figure 1-4 provides a conceptual depiction of how an NLP application uses a statistical model.
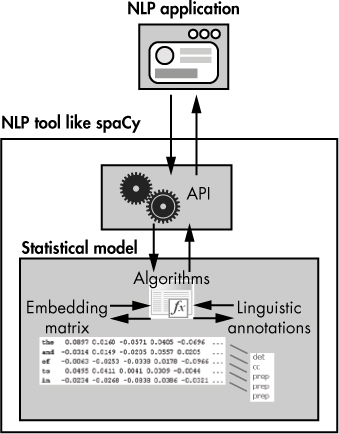
Figure 1-4: A high-level conceptual view of an NLP application’s architecture
The application interacts with spaCy’s API, which abstracts the underlying statistical model. The statistical model contains information like word vectors and linguistic annotations. The linguistic annotations might include features such as part-of-speech tags and syntactic annotations. The statistical model also includes a set of machine learning algorithms that can extract the necessary pieces of information from the stored data.
In real systems, a model’s data is typically stored in a binary format. Binary data doesn’t look friendly to humans, but it’s a machine’s best friend because it’s easy to store and loads quickly.
Neural Network Models
The statistical models used in NLP tools like spaCy for syntactic dependency parsing, part-of-speech tagging, and named entity recognition are neural network models. A neural network is a set of prediction algorithms. It consists of a large number of simple processing elements, like neurons in a brain, that interact by sending and receiving signals to and from neighboring nodes.
Typically, nodes in a neural network are grouped into layers, including an input layer, an output layer, and one or more hidden layers in between. Every node in a layer (except the output layer) connects to every node in the successive layer through a connection. A connection has a weight value associated with it. During the training process, the algorithm adjusts the weights to minimize the error it makes in its predictions. This architecture enables a neural network to recognize patterns, even in complex data inputs.
Conceptually, we can represent a neural network as shown in Figure 1-5.
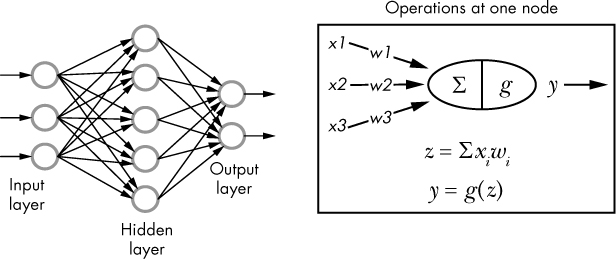
Figure 1-5: A conceptual depiction of the neural network layout and operations at one node
When a signal comes in, it’s multiplied by a weight value, which is a real number. The input and weight values passed on to a neural network generally come from the word vectors generated during the network training.
The neural network adds the results of the multiplications together for each node; then it passes the sum on to an activation function. The activation function generates a result that typically ranges from 0 to 1, thus producing a new signal that is passed on to each node in the successive layer, or, in the case of the output layer, an output parameter. Usually, the output layer has as many nodes as the number of possible distinct outputs for the given algorithm. For example, a neural network implemented for a part-of-speech tagger should have as many nodes in the output layer as the number of part-of-speech tags supported by the system, as illustrated in Figure 1-6.
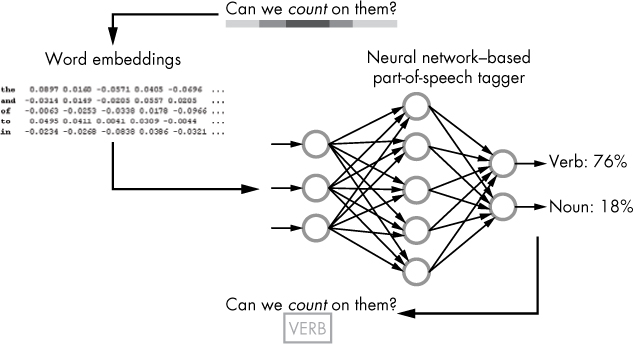
Figure 1-6: A simplified depiction of the part-of-speech tagging process
The part-of-speech tagger then outputs a probability distribution over all possible parts of speech for a given word in a given context.
Convolutional Neural Networks for NLP
The architecture of a real neural network model can be quite complex; it’s formed by a number of different layers. Thus, the neural network model used in spaCy is a convolutional neural network (CNN) that includes a convolutional layer, which is shared between the part-of-speech tagger, dependency parser, and named entity recognizer. The convolutional layer applies a set of detection filters to regions of input data to test for the presence of specific features.
As an example, let’s look at how a CNN might work for the part-of-speech tagging task when performed on the sentence in the previous example:
Can we count on them?
Instead of analyzing each word on its own, the convolutional layer first breaks the sentence into chunks. You can consider a sentence in NLP as a matrix in which each row represents a word in the form of a vector. So if each word vector had 300 dimensions and your sentence was five words long, you’d get a 5 × 300 matrix. The convolutional layer might use a detection filter size of three, applied to three consecutive words, thus having a tiling region size of 3 × 300. This should provide sufficient context for making a decision on what part-of-speech tag each word is.
The operation of a part-of-speech tagging using the convolutional approach is depicted in Figure 1-7.
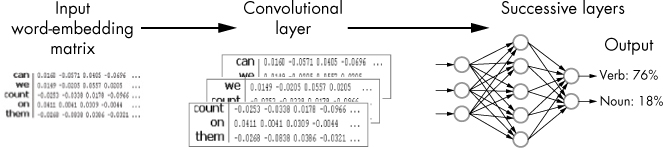
Figure 1-7: A conceptual look at how the convolutional approach works for an NLP task
In the preceding example, the most challenging task for the tagger is to determine what part-of-speech the word “count” is. The problem is that this word can be either a verb or a noun, depending on the context. But this task becomes a breeze when the tagger sees the chunk that includes the “we count on” word combination. In that context, it becomes clear that the word “count” can be only a verb.
A detailed look under the hood of the convolutional architecture is beyond the scope of this book. To learn more about the neural network model architecture behind statistical models used in spaCy, check out the “Neural Network Model Architecture” section in spaCy’s API documentation.
What Is Still on You
As you learned in the preceding section, spaCy uses neural models for syntactic dependency parsing, part-of-speech tagging, and named entity recognition. Because spaCy provides these functions for you, what’s left for you to do as the developer of an NLP application?
One thing spaCy can’t do for you is recognize the user’s intent. For example, suppose you sell clothes and your online application that takes orders has received the following request from a user:
I want to order a pair of jeans.
The application should recognize that the user intends to place an order for a pair of jeans.
If you use spaCy to perform syntactic dependency parsing for the utterance, you’ll get the result shown in Figure 1-8.
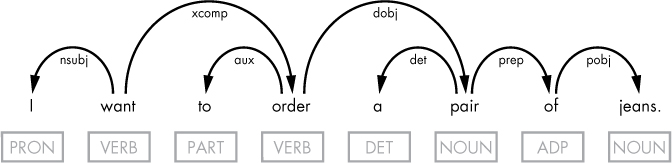
Figure 1-8: The dependency tree for the sample utterance
Notice that spaCy doesn’t mark anything as the user’s intent in the generated tree. In fact, it would be strange if it did so. The reason is that spaCy doesn’t know how you’ve implemented your application’s logic and what kind of intent you expect to see in particular. Which words to consider the key terms for the task of intent recognition is entirely up to you.
To extract the meaning from an utterance or a discourse, you need to understand the following key aspects: keywords, context, and meaning transition.
Keywords
You can use the results of the syntactic dependency parse to choose the most important words for meaning recognition. In the “I want to order a pair of jeans.” example, the keywords are probably “order” and “jeans.”
Normally, the transitive verb plus its direct object work well for composing the intent. But in this particular example, it’s a bit more complicated. You’ll need to navigate the dependency tree and extract “order” (the transitive verb) and “jeans” (the object of the preposition related to the direct object “pair”).
Context
Context can matter when selecting keywords, because the same phrase might have different meanings when interpreted in different applications. Suppose you have the following utterance to treat:
I want the newspaper delivered to my door.
Depending on the context, this statement might be either a request to subscribe to a newspaper or a request to deliver the issue to the door. In the first case, the keywords might be “want” and “newspaper.” In the latter case, the keywords might be “delivered” and “door.”
Meaning Transition
Often, people use more than one sentence to express even a very straightforward intent. As an example, consider the following discourse:
I already have a relaxed pair of jeans. Now I want a skinny pair.
In this discourse, the words reflecting the intent expressed appear in two different sentences, as illustrated in Figure 1-9.
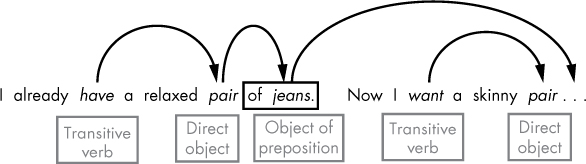
Figure 1-9: Recognizing the intent of the discourse
As you might guess, the words “want” and “jeans” best describe the intent of this discourse. The following are the general steps to finding keywords that best describe the user’s intent in this particular example:
- Within the discourse, find a transitive verb in the present tense.
- Find the direct object of the transitive verb found in step 1.
- If the direct object found in the previous step is a pro-form, find its antecedent in a previous sentence.
With spaCy, you can easily implement these steps programmatically. We’ll describe this process in detail in Chapter 8.
Summary
In this chapter, you learned the basics of natural language processing. You now know that, unlike humans, machines use vector–based representations of words, which allow you to perform math on natural language units, including words, sentences, and documents.
You learned that word vectors are implemented in statistical models based on the neural network architecture. Then you learned about the tasks that are still left up to you as an NLP application developer.