
5
WORKING WITH WORD VECTORS

Word vectors are the series of real numbers that represent the meanings of natural language words. As you learned in Chapter 1, they allow machines to understand human language. In this chapter, you’ll use word vectors to calculate the semantic similarity of different texts, which will allow you to, for example, classify those texts based on the topics they cover.
You’ll start by taking a conceptual look at word vectors so you can get an idea of how to mathematically calculate the semantic similarity between the words represented in the form of vectors. Then you’ll learn how machine learning algorithms generate the word vectors implemented in spaCy models. You’ll use spaCy’s similarity method, which compares the word vectors of container objects to determine the closeness of their meanings. You’ll also learn how to use word vectors in practice and perform preprocessing steps, such as choosing keywords, to make your operations more efficient.
Understanding Word Vectors
When building statistical models, we map words to vectors of real numbers that reflect the words’ semantic similarity. You can imagine a word vector space as a cloud in which the vectors of words with similar meanings are located nearby. For instance, the vector representing the word “potato” should be closer to the vector of the word “carrot” than to that of the word “crying.” To generate these vectors, we must be able to encode the meaning of these words. There are a few approaches to encoding meaning, which we’ll outline in this section.
Defining Meaning with Coordinates
One way to generate meaningful word vectors is by assigning an object or category from the real world to each coordinate of a word vector. For example, suppose you’re generating word vectors for the following words: Rome, Italy, Athens, and Greece. The word vectors should mathematically reflect the fact that Rome is the capital of Italy and is related to Italy in a way that Athens is not. At the same time, they should reflect the fact that Athens and Rome are capital cities, and that Greece and Italy are countries. Table 5-1 illustrates what this vector space might look like in the form of a matrix.
Table 5-1: A Simplified Word Vector Space
Country |
Capital |
Greek |
Italian |
|
Italy |
1 |
0 |
0 |
1 |
Rome |
0 |
1 |
0 |
1 |
Greece |
1 |
0 |
1 |
0 |
Athens |
0 |
1 |
1 |
0 |
We’ve distributed the meaning of each word between its coordinates in a four-dimensional space, representing the categories “Country,” “Capital,” “Greek,” and “Italian.” In this simplified example, a coordinate value can be either 1 or 0, indicating whether or not a corresponding word belongs to the category.
Once you have a vector space in which vectors of numbers capture the meaning of corresponding words, you can use vector arithmetic on this vector space to gain insight into a word’s meaning. To find out which country Athens is the capital of, you could use the following equation, where each token stands for its corresponding vector and X is an unknown vector:
Italy - Rome = X - Athens
This equation expresses an analogy in which X represents the word vector that has the same relationship to Athens as Italy has to Rome. To solve for X, we can rewrite the equation like this:
X = Italy - Rome + Athens
We first subtract the vector Rome from the vector Italy by subtracting the corresponding vector elements. Then we add the sum of the resulting vector and the vector Athens. Table 5-2 summarizes this calculation.
Table 5-2: Performing a Vector Math Operation on a Word Vector Space
Country |
Capital |
Greek |
Italian |
||
― |
Italy |
1 |
0 |
0 |
1 |
+ |
Rome |
0 |
1 |
0 |
1 |
Athens |
0 |
1 |
1 |
0 |
|
Greece |
1 |
0 |
1 |
0 |
By subtracting the word vector for Rome from the word vector for Italy and then adding the word vector for Athens, we get a vector that is equal to the vector Greece.
Using Dimensions to Represent Meaning
Although the vector space we just created had only four categories, a real-world vector space might require tens of thousands. A vector space of this size would be impractical for most applications, because it would require a huge word-embedding matrix. For example, if you had 10,000 categories and 1,000,000 entities to encode, you’d need a 10,000 × 1,000,000 embedding matrix, making operations on it too time-consuming. The obvious approach to reducing the size of the embedding matrix is to reduce the number of categories in the vector space.
Instead of using coordinates to represent all categories, a real-world implementation of a word vector space uses the distance between vectors to quantify and categorize semantic similarities. The individual dimensions typically don’t have inherent meanings. Instead, they represent locations in the vector space, and the distance between vectors indicates the similarity of the corresponding words’ meanings.
The following is a fragment of the 300-dimensional word vector space extracted from the fastText, a word vector library, which you can download at https://fasttext.cc/docs/en/english-vectors.html:
compete -0.0535 -0.0207 0.0574 0.0562 ... -0.0389 -0.0389
equations -0.0337 0.2013 -0.1587 0.1499 ... 0.1504 0.1151
Upper -0.1132 -0.0927 0.1991 -0.0302 ... -0.1209 0.2132
mentor 0.0397 0.1639 0.1005 -0.1420 ... -0.2076 -0.0238
reviewer -0.0424 -0.0304 -0.0031 0.0874 ... 0.1403 -0.0258
Each line contains a word represented as a vector of real numbers in multidimensional space. Graphically, we can represent a 300-dimensional vector space like this one with either a 2D or 3D projection. To prepare such a projection, we can use first two or three principal coordinates of a vector, respectively. Figure 5-1 shows vectors from a 300-dimensional vector space in a 2D projection.
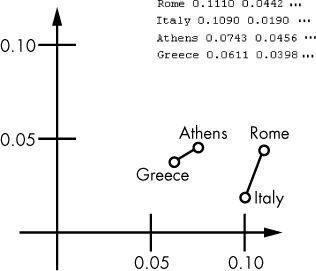
Figure 5-1: A fragment of a 2D projection of a multidimensional vector space
One interesting detail you might notice here is that the lines connecting Greece with Athens and Italy with Rome, respectively, are almost parallel. Their lengths also look comparable. In practice, this means that if you have three out of the above four vectors, you can calculate an approximate location of the missing one, since you know where to shift the vector and how far.
The vectors in the diagram illustrate a country-capital relation, but they could easily have another type of relation, such as male-female, verb tense, and so on.
The Similarity Method
In spaCy, every type of container object has a similarity method that allows you to calculate a semantic similarity estimate between two container objects of any type by comparing their word vectors. To calculate the similarity of spans and documents, which don’t have their own word vectors, spaCy averages the word vectors of the tokens they contain.
NOTE
spaCy’s small models (those whose model size indicator is %sm) don’t include word vectors. You can still use the similarity method with these models to compare tokens, spans, and documents, but the results won’t be as accurate.
You can calculate the semantic similarity of two container objects even if the two objects are different. For example, you can compare a Token object with a Span object, a Span object with a Doc object, and so on.
The following example computes how similar a Span object is to a Doc object:
>>> doc=nlp('I want a green apple.')
>>> doc.similarity(doc[2:5])
0.7305813588233471
This code calculates a semantic similarity estimate between the sentence “I want a green apple.” and the phrase “a green apple” derived from this same sentence. As you can see, the computed degree of similarity is high enough to consider the content of two objects similar (the degree of similarity ranges from 0 to 1).
Not surprisingly, the similarity() method returns 1 when you compare an object with itself:
>>> doc.similarity(doc)
1.0
>>> doc[2:5].similarity(doc[2:5])
1.0
You can also compare a Doc object with a slice from another Doc object:
>>> doc2=nlp('I like red oranges.')
>>> doc2.similarity(doc[2:5])
0.28546574467463354
Here, we compare the sentence “I like red oranges.” stored in doc2 with the span “a green apple” extracted from doc. In this case, the degree of similarity is not so high this time. Yes, oranges and apples are both fruits (the similarity method recognizes this fact), but the verbs “want” and “like” express different states of being.
You can also compare two tokens. In the following example, we compare the Token object “oranges” to a Span object containing a single token “apple.”
>>> token = doc2[3:4][0]
>>> token
oranges
>>> token.similarity(doc[4:5])
0.3707084280155993
First, we explicitly convert the Span object containing a single token “oranges” to a Token object by referring to the first element in the span. Then we calculate how similar it is to the span “apple.”
The similarity() method can recognize words that belong to the same or similar categories and that often appear in related contexts, showing a high level of similarity for such words.
Choosing Keywords for Semantic Similarity Calculations
The similarity method will calculate semantic similarity for you, but for the results of that calculation to be useful, you need to choose the right keywords to compare. To understand why, consider the following text snippet:
Redwoods are the tallest trees in the world. They are most common in the coastal forests of California.
We might classify this text in a variety of ways depending on the set of categories we want to use. If, for example, we’re searching for texts about highest plants on the planet, the phrases “tallest trees” and “in the world” will be the key ones. Comparing these phrases with the search phrases “highest plants” and “on the planet” should show a high level of the semantic similarity. We can do this by extracting noun chunks using a Doc object’s doc.noun_chunk property and then checking the similarity of those noun chunks and the search phrases using the similarity method.
But if we’re looking for texts about places in the world, “California” will be the keyword. Of course, we don’t know in advance which geopolitical name might occur in a text: it could be California or, say, Amazonia. But whatever it is, it should be semantically similar to a word like “geography,” which we can compare with the text’s other nouns (or, even better, with its named entities only). If we’re able to determine that there’s a high level of similarity, we can assume that the named entity in question represents a geopolitical name. (We might also extract the token.ent_type attribute of a Token object to do this, as described in Chapter 2. But we wouldn’t be able to use named entity recognition to check the similarity of words that aren’t named entities, say, fruits.)
Installing Word Vectors
If a spaCy model is installed in your Python environment, you can start using word vectors right away. You can also install a third-party word vector package. Various statistical models use different word vectors, so the results of your operations will differ slightly based on the model you’re using. You can try several models to determine which one works better in your particular application.
Taking Advantage of Word Vectors That Come with spaCy Models
Word vectors come as part of many spaCy models. For example, en_vectors_web_lg includes more than one million unique word vectors defined on a 300-dimensional vector space. Check out https://github.com/explosion/spacy-models/releases/ for details on a particular model.
Typically, small models (those whose names end with sm) don’t contain word vectors. Instead, they come with context-sensitive tensors, which still allow you to work with the similarity methods to compare tokens, spans, and documents—although at the expense of accuracy.
To follow along with the examples given in this chapter, you can use any spaCy model, even small ones. But you’ll get more accurate results if you install a larger model. For details on how to install a spaCy model, refer to “Installing Statistical Models for spaCy” on page 16. Note that you might have more than one model installed in your environment.
Using Third-Party Word Vectors
You can also use third-party packages of word vectors with spaCy. You can check whether a third-party will work better for your application than native word vectors available in a spaCy model. For example, you can use a fastText pretrained model with English word vectors, which you can download at https://fasttext.cc/docs/en/english-vectors.html. The name of a package will identify the size of the package and word vectors, and the kind of data used to train the word vectors. For example, wiki-news-300d-1M.vec.zip indicates that it contains one million 300-dimensional word vectors trained on Wikipedia and the statmt.org news dataset.
After downloading a package, unzip it, and then create a new model from the vectors in the package that you can use with spaCy. To do this, navigate to the folder where you saved the package, and then use the init-model command line utility, like this:
$ python -m spacy init-model en /tmp/en_vectors_wiki_lg --vectors-loc wiki-news-300d-1M.vec
The command converts the vectors taken from the wiki-news-300d-1M.vec file into spaCy’s format and creates the new model directory /tmp/en_vectors_wiki_lg for them. If everything goes well, you’ll see the following messages:
Reading vectors from wiki-news-300d-1M.vec
Open loc
999994it [02:05, 7968.84it/s]
Creating model...
0it [00:00, ?it/s]
Successfully compiled vocab
999731 entries, 999994 vectors
Once you’ve created the model, you can load it like a regular spaCy model:
nlp = spacy.load('/tmp/en_vectors_wiki_lg')
Then you can create a Doc object as you normally would:
doc = nlp(u'Hi there!')
Unlike a regular spaCy model, a third-party model converted for use in spaCy might not support some of spaCy’s operations against text contained in a doc object. For example, if you try to shred a doc into sentences using doc.sents, you’ll get the following error: ValueError: [E030] Sentence boundaries unset...
Comparing spaCy Objects
Let’s use word vectors to calculate the similarity of container objects, the most common task for which we use word vectors. In the rest of this chapter, we’ll explore some scenarios in which you’d want to determine the semantic similarity of linguistic units.
Using Semantic Similarity for Categorization Tasks
Determining two objects’ syntactic similarity can help you sort texts into categories or pick out only the relevant texts. For example, suppose you’re sorting through user comments posted to a website to find all the comments related to the word “fruits.” Let’s say you have the following utterances to evaluate:
I want to buy this beautiful book at the end of the week.
Sales of citrus have increased over the last year.
How much do you know about this type of tree?
You can easily recognize that only the second sentence is directly related to fruits because it contains the word “citrus.” But to pick out this sentence programmatically, you’ll have to compare the word vector for the word “fruits” with word vectors in the sample sentences.
Let’s start with the simplest but least successful way of doing this task: comparing “fruits” to each of the sentences. As stated earlier, spaCy determines the similarity of two container objects by comparing their corresponding word vectors. To compare a single token with an entire sentence, spaCy averages the sentence’s word vectors to generate an entirely new vector. The following script compares each of the preceding sentence samples with the word “fruits”:
import spacy
nlp = spacy.load('en')
➊ token = nlp(u'fruits')[0]
➋ doc = nlp(u'I want to buy this beautiful book at the end of the week. Sales of
citrus have increased over the last year. How much do you know about this type
of tree?')
➌ for sent in doc.sents:
print(sent.text)
➍ print('similarity to', token.text, 'is', token.similarity(sent),'
')
We first create a Token object for the word “fruits” ➊. Then we apply the pipeline to the sentences we’re categorizing, creating a single Doc object to hold all of them ➋. We shred the doc into sentences ➌, and then print each of the sentences and their semantic similarity to the token “fruits,” which we acquire using the token object’s similarity method ➍.
The output should look something like this (although the actual figures will depend on the model you use):
I want to buy this beautiful book at the end of the week.
similarity to fruits is 0.06307832979619851
Sales of citrus have increased over the last year.
similarity to fruits is 0.2712141843864381
How much do you know about this type of tree?
similarity to fruits is 0.24646341651210604
The degree of similarity between the word “fruits” and the first sentence is very small, indicating that the sentence has nothing to do with fruits. The second sentence—the one that includes the word “citrus”—is the most closely related to “fruits,” meaning the script correctly identified the relevant sentence.
But notice that the script also identified the third sentence as being somehow related to fruits, probably because it includes the word “tree,” and fruits grow on trees. It would be naive to think that the similarity measuring algorithm “knows” that orange and citrus are fruits. All it knows is that these words (“orange” and “citrus”) often share the same context with word “fruit” and therefore they’ve been put close to it in the vector space. But the word “tree” can also often be found in the same context as the word “fruit.” For example, the phrase “fruit tree” is not uncommon. For that reason the level of similarity calculated between “fruits” (or “fruit” as its lemma) and “tree” is close to the result we got for “citrus” and “fruits.”
There’s another problem with this approach to categorizing texts. In practice, of course, you might sometimes have to deal with texts that are much larger than the sample texts used in this section. If the text you’re averaging is very large, the most important words might have little to no effect on the syntactic similarity value.
To get more accurate results from the similarity method, we’ll need to perform some preparations on a text. Let’s look at how we can improve the script.
Extracting Nouns as a Preprocessing Step
A better technique for performing categorization would be to extract the most important words and compare only those. Preparing a text for processing in this way is called preprocessing, and it can help make your NLP operations more successful. For example, instead of comparing the word vectors for the entire objects, you could try comparing the word vectors for certain parts of speech. In most cases, you’ll focus on nouns—whether they act as subjects, direct objects, or indirect objects—to recognize the meaning conveyed in the text in which they occur. For example, in the sentence “Nearly all wild lions live in Africa,” you’ll probably focus on lions, Africa, or lions in Africa. Similarly, in the sentence about fruits, we focused on picking out the noun “citrus.” In other cases, you’ll need other words, like verbs, to decide what a text is about. Suppose you run an agricultural produce business and must classify offers from those who produce, process, and sell farm products. You often see sentences like, “We grow vegetables,” or “We take tomatoes for processing.” In this example, the verbs are just as important as nouns in the utterances in the previous examples.
Let’s modify the script on page 70. Instead of comparing “fruits” to entire sentences, we’ll compare it to the sentences’ nouns only:
import spacy
nlp = spacy.load('en')
➊ token = nlp(u'fruits')[0]
doc = nlp(u'I want to buy this beautiful book at the end of the week. Sales of
citrus have increased over the last year. How much do you know about this type
of tree?')
similarity = {}
➋ for i, sent in enumerate(doc.sents):
➌ noun_span_list = [sent[j].text for j in range(len(sent)) if sent[j].pos_
== 'NOUN']
➍ noun_span_str = ' '.join(noun_span_list)
➎ noun_span_doc = nlp(noun_span_str)
➏ similarity.update({i:token.similarity(noun_span_doc)})
print(similarity)
We start by defining the token “fruits,” which is then used for a series of comparisons ➊. Iterating over the tokens in each sentence ➋, we extract the nouns and store them in a Python list ➌. Next, we join the nouns in the list into a plain string ➍, and then convert that string into a Doc object ➎. We then compare this Doc with the token “fruits” to determine their degree of semantic similarity. We store each token’s syntactic similarity value in a Python dictionary ➏, which we finally print out.
The script’s output should look something like this:
{0: 0.17012682516221458, 1: 0.5063824302533686, 2: 0.6277196645922878}
If you compare these figures with the results of the previous script, you’ll notice that this time the level of the similarity with the word “fruits” is higher for each sentence. But the overall results look similar: the similarity of the first sentence is the lowest, whereas the similarity of the other two are much higher.
Try This
In the previous example, comparing “fruits” to nouns only, you improved the results of the similarity calculations by taking into account only the words that matter most (nouns, in this case). You compared the word “fruits” with all the nouns extracted from each sentence, combined. Taking it one step further, you could look at how each of these nouns is semantically related to the word “fruits” to find out which one shows the highest level of similarity. This can be useful in evaluating the overall similarity of the document to the word “fruits.” To accomplish this, you need to modify the previous script so it determines the similarity between the token “fruits” and each of the nouns in a sentence, finding the noun that shows the highest level of similarity.
Extracting and Comparing Named Entities
In some cases, instead of extracting every noun from the texts you’re comparing, you might want to extract a certain kind of noun only, such as named entities. Let’s say you’re comparing the following texts:
“Google Search, often referred to as simply Google, is the most used search engine nowadays. It handles a huge number of searches each day.”
“Microsoft Windows is a family of proprietary operating systems developed and sold by Microsoft. The company also produces a wide range of other software for desktops and servers.”
“Titicaca is a large, deep, mountain lake in the Andes. It is known as the highest navigable lake in the world.”
Ideally, your script should recognize that the first two texts are about large technology companies, but the third text isn’t. But comparing all the nouns in this text wouldn’t be very helpful, because many of them, such as “number” in the first sentence, aren’t relevant to the context. The differences between the sentences involve the following words: “Google,” “Search,” “Microsoft,” “Windows,” “Titicaca,” and “Andes.” spaCy recognizes all of these as named entities, which makes it a breeze to find and extract them from a text, as illustrated in the following script:
import spacy
nlp = spacy.load('en')
#first sample text
doc1 = nlp(u'Google Search, often referred to as simply Google, is the most
used search engine nowadays. It handles a huge number of searches each day.')
#second sample text
doc2 = nlp(u'Microsoft Windows is a family of proprietary operating systems
developed and sold by Microsoft. The company also produces a wide range of
other software for desktops and servers.')
#third sample text
doc3 = nlp(u"Titicaca is a large, deep, mountain lake in the Andes. It is
known as the highest navigable lake in the world.")
➊ docs = [doc1,doc2,doc3]
➋ spans = {}
➌ for j,doc in enumerate(docs):
➍ named_entity_span = [doc[i].text for i in range(len(doc)) if
doc[i].ent_type != 0]
➎ print(named_entity_span)
➏ named_entity_span = ' '.join(named_entity_span)
➐ named_entity_span = nlp(named_entity_span)
➑ spans.update({j:named_entity_span})
We group the Docs with the sample texts into a list to make it possible to iterate over them in a loop ➊. We define a Python dictionary to store the keywords for each text ➋. In a loop iterating over the Docs ➌, we extract these keywords in a separate list for each text, selecting only the words marked as named entities ➍. Then we print out the list to see what it contains ➎. Next, we convert this list into a plain string ➏ to which we then apply the pipeline, converting it to a Doc object ➐. We then append the Doc to the spans dictionary defined earlier ➑.
The script should produce the following output:
['Google', 'Search', 'Google']
['Microsoft', 'Windows', 'Microsoft']
['Titicaca', 'Andes']
Now we can see the words in each text whose vectors we’ll compare.
Next, we call similarity() on these spans and print the results:
print('doc1 is similar to doc2:',spans[0].similarity(spans[1]))
print('doc1 is similar to doc3:',spans[0].similarity(spans[2]))
print('doc2 is similar to doc3:',spans[1].similarity(spans[2]))
This time the output should look as follows:
doc1 is similar to doc2: 0.7864886939527678
doc1 is similar to doc3: 0.6797676349647936
doc2 is similar to doc3: 0.6621659567003596
These figures indicate that the highest level of similarity exists between the first and second texts, which are both about American IT companies. How can word vectors “know” about this fact? They probably know because the words “Google” and “Microsoft” have been found more often in the same texts of the training text corpus rather than in the company of the words “Titicaca” and “Andes.”
Summary
In this chapter, you worked with word vectors, which are vectors of real numbers that represent the meanings of words. These representations let you use math to determine the semantic similarity of linguistic units, a useful task for categorizing texts.
But the math approach might not work as well when you’re trying to determine the similarity of two texts without applying any preliminary steps to those texts. By applying preprocessing, you can reduce the text to the words that are most important in figuring out what the text is about. In particularly large texts, you might pick out the named entities found in it, because they most likely best describe the text’s category.