
Chapter 3: Everyday Objective-C
This chapter covers many everyday best practices for Cocoa development, along with several underused features that more developers should be familiar with. Chapter 4 delves deeper into broad Cocoa patterns; here you focus on language features.
You begin by learning the critical Cocoa naming conventions that will improve your code’s readability. Next you are introduced to memory management using Automatic Reference Counting (ARC). Then you find out how to best use properties and accessors to manage data in your objects. Finally, you learn about categories, extensions, and protocols, which are all commonly used throughout Cocoa.
By the end of this chapter, you should be very comfortable with the most important language features of Objective-C and feel confident that you’re using the best practices of experienced Cocoa developers.
Naming Conventions
Throughout iOS, naming conventions are extremely important. If you understand how to read them correctly, the names of methods and functions throughout the iOS SDK tell you a great deal about how they are supposed to be called and what they do. Once you’re used to the naming conventions, you can often guess what the name of a class or method is, making it much easier to find the documentation for it. This section touches on some of the most important naming convention rules and those that cause problems for developers with experience in other languages.
The best source of information on Cocoa naming conventions is Apple’s Coding Guidelines for Cocoa, which is available at developer.apple.com.
The first thing to know is that, in Cocoa, ease of reading is more important than ease of writing. Code spends much more of its life being read, maintained, and debugged than written. Cocoa naming conventions always favor the reader by striving for clarity over brevity. This is in stark contrast to C, which favors extremely terse naming. Because Objective-C is a dynamic language, the compiler provides far fewer safeguards than a static language such as C++. Good naming is a critical part of writing bug-free code.
The most important attribute of a good name is clarity. The names of methods should make it clear what types they accept and return. For instance, this method is extremely confusing:
- (void)add; // Confusing
It looks like add should take a parameter, but it doesn’t. Does it add some default object?
Names like these are much clearer:
- (void)addEmptyRecord;
- (void)addRecord:(Record *)record;
Now it’s clear that addRecord: accepts a Record. The type of the object should match the name if there is any chance of confusion. For instance, this is a common mistake:
- (void)setURL:(NSString *)URL; // Incorrect
It’s incorrect because something called setURL: should accept an NSURL, not an NSString. If you need a string, then you need to add some kind of indicator to make this clear:
- (void)setURLString:(NSString *)string;
- (void)setURL:(NSURL *)URL;
This rule shouldn’t be overused. It’s better to have a property called name than nameString, as long as there is no Name class in your system that might confuse the reader.
Clear naming also means that you should avoid abbreviations in most cases. Use backgroundColor rather than bgcolor, and stringValue rather than to_str. There are exceptions to the use of abbreviations, particularly for things that are best known by their abbreviation. For example, URL is better than uniformResourceLocator. An easy way to determine whether an abbreviation is appropriate is to say the name out loud. You say “source” not “src.” But most people say “URL” as either “u-ar-el” or “earl.” No one says “uniform resource locator” in speech, so you shouldn’t in code. There are a few abbreviations, such as alloc, init, rect, and pboard, that Cocoa uses for historical reasons that are considered acceptable. Apple has generally been moving away from even these abbreviations as it releases new frameworks.
Several kinds of variables are in a program: instance variables (ivars), static variables, automatic (stack) variables, and so on. It can be very difficult to understand code if you don’t know what kind of variable you’re looking at. Naming conventions should make the intent of a variable clear. After coding in many different styles with different teams, my recommendations are the following:
• Prefix static (package-scoped) variables with s and nonconstant global variables with g. Generally, you should avoid nonconstant globals. The following is a static declaration:
static MYThing *sSharedInstance;
• Constants are named differently in Cocoa than in Core Foundation. In Core Foundation, constants are prefixed with a k. In Cocoa, they are not. File-local (static) constants should generally be prefixed with k in my opinion, but there is no hard-and-fast rule here. The following are examples of a file constant and a public constant:
static const NSUInteger kMaximumNumberOfRows = 3;
NSString * const MYSomethingHappenedNotification = @”SomethingHappened”;
• Method arguments are generally prefixed with an article such as a, an, or the. The last is less common and sometimes suggests a particularly important or unique object. Prefixing your arguments this way helps avoid confusing them with local variables and ivars. It is particularly helpful to avoid modifying them unintentionally.
• Prefix instance variables (ivars) with an underscore. This is the standard that Xcode applies in recent versions and is consistent with automatic synthesis.
• Classes should always begin with a capital letter. Methods and variables should always begin with a lowercase letter. All classes and methods should use camel case—never underscores—to separate words.
Cocoa and Core Foundation use slightly different naming conventions, but their basic approach is the same. For more information on Core Foundation naming, see Chapter 27.
Cocoa naming is tightly coupled with memory management and object ownership. With ARC (discussed in the following section), memory management conventions are no longer as critical, but it is important to understand when working with non-ARC code. The naming convention is quite simple. An object can have one or more owners. When an object has no owners, it’s destroyed (much like in garbage-collected systems). You take ownership whenever you use a method that begins with alloc, new, copy, or mutableCopy. You also take ownership whenever you call retain. When you’re finished with an object, you relinquish ownership by calling release or autorelease. You use autorelease to delay the release of an object until the next time the autorelease pool drains (usually at the end of the event loop). This is mostly used for return values. You should always release objects that you own when you’re done with them, and you should never release objects that you do not own.
The easiest way to implement this ownership system is to exclusively use properties to manage your ivars (except in init and dealloc), and to release all your properties in dealloc.
Even in ARC code, you need to be aware of this naming convention and avoid using alloc, new, copy, mutableCopy, retain, and release to mean anything other than their traditional meanings.
See Advanced Memory Management Programming Guide (developer.apple.com) for more details on manual memory management.
Automatic Reference Counting
Automatic Reference Counting (ARC) greatly reduces the most common programmer error in Cocoa development: mismatching retain and release. ARC does not eliminate retain and release; it just makes them a compiler problem rather than a developer problem most of the time. In the vast majority of cases, this is a major win, but it’s important to understand that retain and release are still going on. ARC is not the same thing as garbage collection. Consider the following code, which assigns a value to an ivar:
@property (nonatomic, readwrite, strong) NSString *title;
...
_title = [NSString stringWithFormat:@”Title”];
Without ARC, _title is underretained in the preceding code. The NSString assigned to it is autoreleased, so it will disappear at the end of the run loop, and the next time someone accesses _title, the program will crash. This kind of error is incredibly common and can be very difficult to debug. Moreover, if _title had a previous value, that old value has been leaked because it wasn’t released.
Using ARC, the compiler automatically inserts extra code to create the equivalent of this:
id oldTitle = _title;
_title = [NSString stringWithFormat:@”Title”];
[_title retain];
[oldTitle release];
The calls to release and retain still happen, so there is a small overhead, and there may be a call to dealloc during the release. But generally this makes the code behave the way the programmer intended it to without creating an extra garbage collection step. Memory is reclaimed faster than with garbage collection, and decisions are made at compile time rather than at runtime, which generally improves overall performance. As with other compiler optimizations, the compiler is free to optimize memory management in various ways that would be impractical for the programmer to do by hand. ARC-generated memory management is often dramatically faster than the equivalent hand-coded memory management.
But this is not garbage collection. In particular, it cannot handle reference (retain) loops the way Snow Leopard garbage collection can. For example, the object graph in Figure 3-1 shows a retain loop between Object A and Object B:
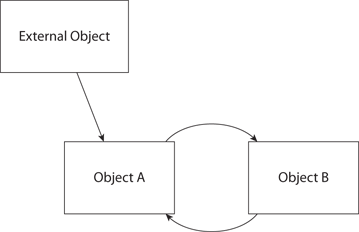
Figure 3-1 A retain loop
If the link from “External Object” to “Object A” is broken, then under Snow Leopard garbage collection, both Object A and Object B will be destroyed because they are orphaned from the program. Under ARC, Object A and Object B will not be destroyed because each still has a retain count greater than zero. So in iOS, you need to keep track of your strong relationships to avoid reference loops.
Property relationships have two main forms: strong and weak, which map to the former retain and assign. As long as there is a strong reference to an object, it will continue to exist. This is nearly identical to shared_ptr in C++, except that the code to manage the reference counts is injected by the compiler rather than determined at runtime with operator overloads.
Objective-C has always had the problem of reference loops, but they really don’t come up that often in practice. Anywhere you would have used an assign property in the past, use a weak property under ARC, and you should be fine. Most reference loops are caused by delegates, and a delegate property should almost always be weak. Weak references have the advantage of automatically being set to nil when the referenced object is destroyed. This is a significant improvement over assign properties, which can point to freed memory.
Prior to ARC, the default storage class for synthesized properties was assign. The default storage class is now strong. This can cause some confusion when converting code. I recommend always providing a storage class for properties.
The other major cause of retain loops is blocks. See Chapter 22 for more information on blocks.
There are two major changes when switching to ARC for most code:
• Don’t use retain, release, or autorelease. You can just delete these. ARC should do the right thing.
• If your dealloc only releases ivars, you don’t need dealloc. This will be done automatically for you, and you can’t call release in any case. If you still need dealloc to do other things (remove KVO observations, for instance), don’t call [super dealloc]. This last change is surprising, but the compiler will give you errors if you forget.
As noted previously, ARC is not garbage collection. It is a compiler feature that injects calls to retain and release at appropriate places in the code. This means that it is fully interoperable with existing, manual memory management code, as long as all the code uses the correct naming conventions. For example, if you call a method named copySomething, ARC will expect the result of that method to have a +1 retain count. If needed, it will insert a balancing release. It doesn’t matter to ARC whether that +1 retain count was created by ARC code inside of copySomething or by manual memory management inside of copySomething.
This breaks if you violate Cocoa’s naming conventions. For instance, if you have a method that returns the copyright notice as an autoreleased string and call the method copyRight, then how ARC behaves depends on whether the calling and called code are both compiled with ARC.
ARC looks at the name copyRight, sees that it begins with copy, and so assumes that it returns a +1 retain count object. If copyRight is compiled with ARC and the calling code is compiled with ARC, everything will still work. ARC will inject an extra retain in copyRight because of its name, and it will inject an extra release in the calling code. It may be a little less efficient, but the code will neither crash nor leak.
If, however, the calling code is compiled with ARC, but copyRight is not, then the calling code will inject an extra release, and the code will crash. If the calling code is not compiled with ARC, but copyRight is, then ARC will inject an extra retain, and the code will leak.
The best solution to this problem is to follow Cocoa’s naming conventions. In this example, you could name this method copyright and avoid the problem entirely. ARC determines the memory management rules based on whole camel case words in the method.
If renaming an incorrect method is impossible, you can add the attribute NS_RETURNS_RETAINED or NS_RETURNS_NOT_RETAINED to your method declaration to tell the compiler which memory management rule to use. These are defined in NSObjCRuntime.h.
ARC introduces four restrictions on your code so that it can properly add retain and release calls for you:
• No calls to retain, release, or autorelease—This is usually the easiest rule. Just delete them. It also means that you cannot override these methods, but you should almost never do that anyway. If you were overriding these methods to implement the Singleton pattern, see Chapter 4 for information about how to properly implement this pattern without overriding these methods.
• No object pointers in C structs—This seldom comes up, but if you have been storing an object in a C struct, you either need to store it in an object or cast it to void* (see the next rule for more information on casting to void*). C structs can be destroyed at any time by calling free, and this interferes with automatically tracking objects that are stored in them.
• No casting between id and void* without a bridging cast—This mostly impacts Core Foundation code. See Chapter 27 for full details on bridging casts and how to use them with ARC.
• No NSAutoreleasePool—Rather than creating your own autorelease pools by hand, just wrap any code you want to have its own pool in a @autoreleasepool{} block. If you had special code to control when you drained your pool, it is almost certainly unnecessary. @autoreleasepool is up to 20 times faster than NSAutoreleasePool.
Most code will have no problem with these rules. There is a new tool in Xcode under the Edit→Refactor menu called Convert to Objective-C ARC…. It will do the majority of the work for you.
ARC is perhaps the greatest advancement in Objective-C since the autorelease pool. If at all possible, you should convert your code to ARC. If you can’t convert everything, convert as much as you can. It is faster, less buggy, and easier to write than manual memory management. Switch to ARC today.
Properties
Objective-C 2.0 introduced several interesting changes. A key improvement was non-fragile ivars. This allows classes to add ivars without recompiling their subclasses. This feature mostly affects framework developers like Apple rather than application developers, but it has some useful side effects. The most popular is synthesized properties.
With the most recent versions of iOS, the compiler will automatically synthesize ivars and the necessary methods for your properties. There is generally no need to use @synthesize anymore.
My recommendation is to switch entirely to properties and automatically synthesized ivars. Put your public properties in the header and your private properties in an extension in the .m file. So a full example might look like this:
MyClass.h
@interface MyClass : NSObject
@property (nonatomic, readwrite, weak) id delegate;
@property (nonatomic, readonly, strong) NSString *readonlyString;
@end
MyClass.m
@interface MyClass () // Private methods
@property (nonatomic, readwrite, strong) NSString *readonlyString;
@property (nonatomic, readwrite, strong) NSString *privateString;
@end
This automatically creates ivars _delegate, _readonlyString, and _privateString. Use these ivars only in init, dealloc (if you have one), and in overridden accessors.
Note how readonlyString is redefined in the class extension to be readwrite. This allows you to create a private setter.
Property Attributes
While I’m discussing properties, I want you to also consider the attributes you apply to your properties. Consider each category in turn.
• Atomicity (atomic, nonatomic; LLVM 4 added the atomic attribute to match nonatomic.)—This is an easy attribute to misunderstand. Its purpose is to make setting and getting the property thread-safe. That does not mean that the underlying object is thread-safe. For instance, if you declare an NSMutableArray property called stuff to be atomic, then self.stuff is thread-safe and self.stuff=otherStuff is thread-safe. But accessing the array with objectAtIndex: is not thread-safe. You will need additional locking to handle that. The atomic attribute is implemented similar to this:
[_propertyLock lock];
id result = [[value retain] autorelease];
[_propertyLock unlock];
return result;
The pattern of retain/autorelease ensures that the object will not be destroyed until the caller’s autorelease pool drains. This protects the caller from other threads releasing the object in the middle of access. Managing the lock and calling retain and autorelease can be expensive (though atomic properties are much cheaper with ARC). If you will never access this property from another thread, or if you need more elaborate locking anyway, then this kind of atomicity is wasteful. It turns out that this is the case most of the time, and you usually want to use nonatomic. In the fairly small number of cases where this kind of atomicity is useful, there unfortunately is no way to call it out because there is no atomic attribute. It’s helpful to add a comment in these cases to make it clear that you’re making the property atomic on purpose.
ARC provides significant performance benefits to atomic properties, and best practices regarding nonatomic may change in the future.
• Writability (readwrite, readonly)—These should be fairly self-explanatory. If a property is readonly, then only a getter will be available. If it is readwrite, then both a setter and getter will be available. There is no writeonly attribute.
• Setter semantics (weak, strong, copy)—These should be fairly obvious, but there are some things to consider. First, you often should use copy for immutable classes such as NSString and NSArray. It’s possible that there is a mutable subclass of your property’s class. For instance, if you have an NSString property, you might be passed an NSMutableString. If that happens and you hold only a reference to the value (strong), your property might change behind your back as the caller mutates it. That often isn’t what you want, and so you will note that most NSString properties use the copy semantic. The same is also usually true for collections such as NSArray. Copying immutable classes is generally very fast because it can almost always be implemented with retain.
Property Best Practices
Properties should represent the state of the object. Getters should have no externally visible side effects (they may have internal side effects such as caching, but those should be invisible to callers). Generally, they should be efficient to call and certainly should not block.
Private Ivars
Although I prefer properties for everything, some people prefer ivars, especially for private variables. You can declare ivars in the @implementation block like this:
@implementation Something {
NSString *_name;
}
This syntax moves the private ivar out of the public header, which is good for encapsulation, and keeps the public header easier to read. ARC automatically retains and releases ivars, just like other variables. The default storage class is strong, but you can create weak ivars as shown here:
@implementation Something {
__weak NSString *name;
}
Accessors
Avoid accessing ivars directly. Use accessors instead. I will discuss a few exceptions in a moment, but first I want to discuss the reasons for using accessors.
Prior to ARC, one of the most common causes of bugs was failure to use accessors. Developers would fail to retain and release their ivars correctly, and the program would leak or crash. Because ARC automatically manages retains and releases, some developers may believe that this rule is no longer important, but there are other reasons to use accessors.
• Key-value observing—Perhaps the most critical reason to use accessors is that properties can be observed. If you don’t use accessors, you need to make calls to willChangeValueForKey: and didChangeValueForKey: every time you modify a property. Using the accessor will automatically call these when they are needed.
• Side effects—You or one of your subclasses may include side effects in the setter. There may be notifications posted or events registered with NSUndoManager. You shouldn’t bypass these unless it’s necessary. Similarly, you or a subclass may add caching to the getter that direct ivar access will bypass.
• Locking—If you introduce locking to a property in order to manage multithreaded code, direct ivar access will violate your locks and likely crash your program.
• Consistency—One could argue that you should just use accessors when you know you need them for one of the preceding reasons, but this makes the code very hard to maintain. It’s better that every direct ivar access be suspicious and explained instead of having to constantly remember which ivars require accessors and which do not. This makes the code much easier to audit, review, and maintain. Accessors, particularly synthesized accessors, are highly optimized in Objective-C, and they are worth the overhead.
That said, you don’t use accessors in a few places:
• Inside of accessors—Obviously, you cannot use an accessor within itself. Generally, you also don’t want to use the getter inside of the setter either (this can create infinite loops in some patterns). An accessor may speak to its own ivar.
• Dealloc—ARC greatly reduces the need for dealloc, but it still comes up sometimes. It’s best not to call external objects inside of dealloc. The object may be in an inconsistent state, and it’s likely confusing to the observer to receive several notifications that properties are changing when what’s really meant is that the entire object is being destroyed.
• Initialization—Similar to dealloc, the object may be in an inconsistent state during initialization, and you generally shouldn’t fire notifications or have other side effects during this time. This is also a common place to initialize read-only variables like an NSMutableArray. This avoids declaring a property readwrite just so you can initialize it.
Accessors are highly optimized in Objective-C and provide important features for maintainability and flexibility. As a general rule, you refer to all properties, even your own, using their accessors.
Categories and Extensions
Categories allow you to add methods to an existing class at runtime. Any class, even Cocoa classes provided by Apple, can be extended with categories, and those new methods will be available to all instances of the class. This approach was inherited from Smalltalk and is somewhat similar to extension methods in C#.
Categories were designed to break up large classes into more manageable pieces, hence the name. If you look at large Foundation classes, you will find that sometimes they’re broken into several pieces. For instance, NSArray includes the NSExtendedArray, NSArrayCreation, and NSDeprecated categories defined in NSArray.h, plus the NSArrayPathExtensions category defined in NSPathUtilities.h. Most of these are split up to make it simpler to implement in multiple files, but some categories, such as the UIStringDrawing category on NSString, exist specifically to allow different code to be loaded at runtime. On Mac, AppKit loads the NSStringDrawing category. On iOS, UIKit loads the UIStringDrawing category. This provides a more elegant way to split up the code than #ifdef does. On each platform, you simply compile the appropriate implementation (.m) files, and the functionality becomes available.
Prior to Objective-C 2.0, @protocol definitions could not include optional methods. Developers used categories as “informal protocols.” The complier knows the methods defined in a category, but it will not generate a warning if the methods aren’t implemented. This state of affairs made all the protocol’s methods optional. I discuss this further in the section “Formal and Informal Protocols,” later in this chapter, but for iOS I do not recommend this use of categories. Formal protocols now support optional methods directly.
Because the compiler will not check that you have implemented methods in the category, using categories solely to break up large classes has tradeoffs. An implementation file that’s getting overly large is often an indication that you need to refactor your class to make it more focused rather than define categories to split it up. But if your class is correctly scoped, you may find splitting up the code with categories is convenient. On the other hand, using categories can scatter the methods into different files, which can be confusing, so use your best judgment.
Declaration of a category is straightforward. It looks like a class interface declaration with the name of the category in parentheses:
@interface NSMutableString (Capitalize)
- (void)capitalize;
@end
Capitalize is the name of the category. Note that no ivars are declared here. Categories cannot declare ivars, nor can they synthesize properties (which is the same thing). You’ll see how to add category data in the section “Category Data Using Associative References.” Categories can declare properties, because this is just another way of declaring methods. They just can’t synthesize properties, because that creates an ivar. The Capitalize category doesn’t require that capitalize actually be implemented anywhere. If capitalize isn’t implemented and a caller attempts to invoke it, the system will raise an exception. The compiler gives you no protection here. If you do implement capitalize, then by convention it looks like this:
@implementation NSMutableString (Capitalize)
- (void)capitalize {
[self setString:[self capitalizedString]];
}
@end
I say “by convention” because there is no requirement that this be defined in a category implementation or that the category implementation must have the same name as the category interface. However, if you provide an @implementation block named Capitalize, then it must implement all the methods from the @interface block named Capitalize. Adding the parentheses and category name after the class name allows you to continue adding methods in another compile unit (.m file). You can implement your category methods in the main implementation block, in a named category implementation block for the class, or not implement them at all.
Technically a category can override methods, but that’s dangerous and not recommended. If two categories implement the same method, then it is undefined which one is used. If a class is later split into categories for maintenance reasons, your override could become undefined behavior, which is a maddening kind of bug to track down. Moreover, using this feature can make the code hard to understand. Category overrides also provide no way to call the original method. I recommend against using categories to override existing methods, except for debugging. Even for debugging, I prefer swizzling, which is covered in Chapter 28.
Because of the possibility of collisions, it’s often a good idea to add a prefix to your category methods if there is any chance that it might collide with Apple or with other categories in your project (such as third-party libraries). For example, you could use the name MY_capitalize, which would be safer. Cocoa generally doesn’t use embedded underscores like this, but in this case, it’s clearer than the alternatives. Whether you do this or not is somewhat a matter of your risk tolerance. I once added a category method pop on NSMutableArray. This collided with a private Apple category that the authors of UINavigationController had added. Since Apple and I implemented our versions of pop differently, the resulting bugs were extremely difficult to track down.
A very good use of categories is to provide utility methods to existing classes. When doing this, I recommend naming the header and implementation files using the name of the original class plus the name of the extension. For example, you might create a simple MyExtensions category on NSDate:
NSDate+MYExtensions.h
@interface NSDate (MYExtensions)
- (NSTimeInterval)timeIntervalUntilNow;
@end
NSDate+MYExtensions.m
@implementation NSDate (MYExtensions)
- (NSTimeInterval)timeIntervalUntilNow {
return [self timeIntervalSinceNow];
}
@end
If you have only a few utility methods, it’s convenient to put them together into a single category with a name such as MYExtensions (or whatever prefix you use for your code). Doing so makes it easy to drop your favorite extensions into each project. Of course, this is also code bloat, so be careful about how much you throw into a “utility” category. Objective-C can’t do dead-code stripping as effectively as C or C++.
If you have a large group of related methods, particularly a collection that might not always be useful, it’s a good idea to break those into their own category. Look at UIStringDrawing.h in UIKit for a good example.
+load
Categories are attached to classes at runtime. It’s possible that the library that defines a category is dynamically loaded, so categories can be added quite late. (Although you can’t write your own dynamic libraries in iOS, the system frameworks are dynamically loaded and include categories.) Objective-C provides a hook called +load that runs when the category is first attached. Like +initialize, you can use this to implement category-specific setup such as initializing static variables. You can’t safely use +initialize in a category because the class may implement this already. If multiple categories implemented +initialize, the one that would run wouldn‘t be defined.
Hopefully, you’re ready to ask the obvious question: “If categories can’t use +initialize because they might collide with other categories, what if multiple categories implement +load?” This turns out to be one of the few really magical parts of the Objective-C runtime. The +load method is special-cased in the runtime so that every category may implement it and all the implementations will run. There are no guarantees on order, and you shouldn’t try to call +load by hand.
+load is called regardless of whether the category is statically or dynamically loaded. It’s called when the category is added to the runtime, which often is at program launch, before main, but could be much later.
Classes can have their own +load method (not defined in a category), and those will be called when the classes are added to the runtime. This is seldom useful unless you’re dynamically adding classes.
You don’t need to protect against +load running multiple times the way you do with +initialize. The +load message is only sent to classes that actually implement it, so you won’t accidentally get calls from your subclasses the way you can in +initialize. Every +load will be called exactly once. You shouldn’t call [super load].
Category Data Using Associative References
Although categories can’t create new ivars, they can do the next best thing: They can create associative references. Associative references allow you to attach key-value data to arbitrary objects.
Consider the case of a Person class. You’d like to use a category to add a new property called emailAddress. Maybe you use Person in other programs, and sometimes it makes sense to have an email address and sometimes it doesn’t, so a category can be a good solution to avoid the overhead when you don’t need it. Or maybe you don’t own the Person class, and the maintainers won’t add the property for you. In any case, how do you attack this problem? First, just for reference, take a look at the Person class:
@interface Person : NSObject
@property (nonatomic, readwrite, copy) NSString *name;
@end
@implementation Person
@end
Now you can add a new property, emailAddress, in a category using an associative reference:
#import <objc/runtime.h>
@interface Person (EmailAddress)
@property (nonatomic, readwrite, copy) NSString *emailAddress;
@end
@implementation Person (EmailAddress)
static char emailAddressKey;
- (NSString *)emailAddress {
return objc_getAssociatedObject(self, &emailAddressKey);
}
- (void)setEmailAddress:(NSString *)emailAddress {
objc_setAssociatedObject(self, &emailAddressKey,
emailAddress,
OBJC_ASSOCIATION_COPY);
}
@end
Note that associative references are based on the key’s memory address, not its value. It does not matter what is stored in emailAddressKey; it only needs to have a unique address. That’s why it’s common to use an unassigned static char as the key.
Associative references have good memory management, correctly handling copy, assign, or retain semantics according to the parameter passed to objc_setAssociatedObject. They are correctly released when the related object is deallocated.
Associative references are a great way of attaching a relevant object to an alert panel or control. For example, you can attach a “represented object” to an alert panel, as shown in the following code. This code is available in the sample code for this chapter.
ViewController.m (AssocRef)
id interestingObject = ...;
UIAlertView *alert = [[UIAlertView alloc]
initWithTitle:@”Alert” message:nil
delegate:self
cancelButtonTitle:@”OK”
otherButtonTitles:nil];
objc_setAssociatedObject(alert, &kRepresentedObject,
interestingObject,
OBJC_ASSOCIATION_RETAIN_NONATOMIC);
[alert show];
Now, when the alert panel is dismissed, you can figure out why you cared:
- (void)alertView:(UIAlertView *)alertView
clickedButtonAtIndex:(NSInteger)buttonIndex {
UIButton *sender = objc_getAssociatedObject(alertView,
&kRepresentedObject);
self.buttonLabel.text = [[sender titleLabel] text];
}
Many programs handle this with an ivar in the caller, such as currentAlertObject, but associative references are much cleaner and simpler. For those familiar with Mac development, this is similar to representedObject, but more flexible.
One limitation of associative references (or any other approach to adding data via a category) is that they don’t integrate with encodeWithCoder:, so they’re difficult to serialize via a category.
Class Extensions
Objective-C 2.0 adds a useful twist on categories, called class extensions. These are declared exactly like categories, except the name of the category is empty:
@interface MYObject ()
- (void)doSomething;
@end
Class extensions are a great way to declare private methods inside of your .m file. The difference between a category and an extension is that methods declared by an extension are exactly the same as methods declared in the main interface. The compiler will make sure you implement them all, and they will be added to the class at compile time rather than at runtime as categories are. You can even declare synthesized properties in extensions.
Formal and Informal Protocols
Protocols are an important part of Objective-C, and in Objective-C 2.0, formal protocols have become common. In Objective-C 1.0, there was no @optional tag for protocol methods, so all methods were mandatory. It’s rare that this kind of protocol is useful. Often, you want some or all of the protocol to be optional. Because this wasn’t possible in Objective-C 1.0, developers commonly used “informal protocols,” and sometimes you’ll still come across these.
An informal protocol is a category on NSObject. Categories tell the compiler that a method exists, but don’t require that the method be implemented. This technique allowed developers to document the interface and prevent compiler warnings, while indicating that any child of NSObject could implement the methods. This isn’t a great approach to defining an interface, but in Objective-C 1.0, it was the best there was.
With Objective-C 2.0, formal protocols can declare optional methods, and many informal protocols on Mac are migrating to formal protocols. Luckily, iOS has always used Objective-C 2.0, so formal protocols are the norm.
Most developers are familiar with how to declare that a class implements a formal protocol. You simply include the protocols in angle brackets after the superclass:
@interface MyAppDelegate : NSObject <UIApplicationDelegate,
UITableViewDatasource>
Declaring a protocol is similarly easy:
@protocol UITableViewDataSource <NSObject>
@required
- (NSInteger)tableView:(UITableView *)tableView
numberOfRowsInSection:(NSInteger)section;
- (UITableViewCell *)tableView:(UITableView *)tableView
cellForRowAtIndexPath:(NSIndexPath *)indexPath;
@optional
- (NSInteger)numberOfSectionsInTableView:(UITableView *)tv;
- (NSString *)tableView:(UITableView *)tableView
titleForHeaderInSection:(NSInteger)section;
...
Note some important points in this example. First, protocols can inherit just like classes. The UITableViewDataSource protocol inherits from the <NSObject> protocol. Your protocols should almost always inherit from <NSObject>, just as your classes inherit from NSObject.
NSObject is split into both a class and a protocol. This is primarily to support NSProxy, which inherits from the protocol, but not the class.
For delegate protocols, the delegating object is always the first parameter. This is important because it allows a single delegate to manage multiple delegating objects. For instance, one controller could be the delegate for multiple UIAlertView instances. Note the slight difference in naming convention when there are parameters other than the delegating object. If no other parameters exist, the class name comes last (numberOfSectionsInTableView:). If there are other parameters, the class name comes first as its own parameter (tableView:numberOfRowsInSection:).
Once you’ve created your protocol, you will often need a property to hold it. The typical type for this property is id<Protocol>:
@property(nonatomic, readwrite, weak) id<MyDelegate> delegate;
This means “any object that conforms to the MyDelegate protocol.” It’s possible to declare both a specific class and a protocol, and it’s possible to declare multiple protocols in the type:
@property(nonatomic, readwrite, weak) MyClass* <MyDelegate,
UITableViewDelegate> delegate;
This indicates that delegate must be a subclass of MyClass and must conform to both the <MyDelegate> and <UITableViewDelegate> protocols.
Protocols are an excellent alternative to subclassing in many cases. A single object can conform to multiple protocols without suffering the problems of multiple inheritance (as found in C++). If you are considering an abstract class, a protocol is often the better choice. Protocols are extremely common in well-designed Cocoa applications.
Summary
Much of good Objective-C is “by convention” rather than enforced by the compiler. This chapter covers several of the important techniques you’ll use every day to get your programs to the next level. Conforming to Cocoa’s naming conventions will greatly improve the reliability and maintainability of your code, and give you key-value coding and observing for free. Correct use of properties will make memory management easy, especially since the addition of ARC. And good use of categories and protocols will keep your code easy to understand and extend.
Further Reading
Apple Documentation
The following documents are available in the iOS Developer Library at developer.apple.com or through the Xcode Documentation and API Reference.
Coding Guidelines for Cocoa
Programming With Objective-C
Other Resources
Cocoa with Love. (Matt Gallagher), “Method names in Objective-C”cocoawithlove.com/2009/06/method-names-in-objective-c.html
CocoaDevCentral. (Scott Stevenson), “Cocoa Style for Objective-C,” cocoadevcentral.com/articles/000082.php