
CHAPTER 7
Business Continuity
In this chapter, you will learn how to
• Identify business continuity objectives
• Determine ideal backup frequency
• Configure backups and validate backup reliability
• Select appropriate backup locations
The ease with which the modern enterprise accesses, transfers, and manipulates data and information has become so transparent that it is often taken for granted. As we stand at the ATM or other cash kiosk and swipe our cards, we fidget impatiently while gigabytes of data speed their way around the world across a complex hybridization of wired and wireless paths to authenticate, check databases, and dispense the requested funds. We would not tolerate the unavailability of such systems. Banking and finance are the obvious industries we think of when we consider business continuity, but of similar importance are those systems that support health, government, utility, transportation operations, and the data in your organization.
The continuity of operations is critical to both government and business settings. The inability to access a system or its data assets can have an adverse and significant effect on a company’s profitability or on the ability of a government to provide even the most basic services. In an era where trillions of dollars in transactions and records move around the world in milliseconds, system outages can be crippling. Natural disasters, human error, cyberterrorism, and system failure are just a few of the catastrophic events that can bring operations to a grinding halt if business continuity planning/implementation have not been performed.
Causes for system outages can be broadly classified in the following manner:
• Human error Unintentional mistakes made by humans
• Intentional Malicious actions with the intent to compromise system functioning and data integrity
• Natural Outages or system malfunctions attributable to natural phenomena such floods, earthquakes, storms, and so on
• System Failures or events attributable to hardware, software, or other system infrastructure; normal “wear and tear” or failure
Business continuity planning (BCP), alternately referred to as business continuity resiliency planning (BCRP), is a detailed plan of contingencies and policies that are used to identify critical systems and data assets, how these systems and assets are backed up, and how they would be recovered. More importantly, BCP provides proactive policies and procedures to ensure the continued availability and reliability of these resources in the event of an incident or disaster. System or network recovery is closely related to BCP. In fact, network recovery plans form the foundation for restoring operations following an incident.
In the past, BCP was done by technical experts in isolation of strategic planning from operations or financial planning. Isolated planning cycles resulted in increased exposure to system failure, an inability to respond rapidly to system and competitive demand, and missed strategic targets. Companies addressed this by aligning system management strategies with strategic planning, resulting in reduced system vulnerability to incidents or catastrophes and better utilization in system investments. The result of this collaboration formed the basis of modern BCP.
International standards such the Open Systems Interconnection Model (OSI) and those promulgated by the International Standards Organization (ISO) inextricably linked our lives, enterprise, and economies. For example, a change in the Mumbai stock exchange ripples quickly through the Nikkei, Hang Seng, and other global stock exchanges. While this has been a boon to interoperability and continues to provide new opportunities for trade, diplomacy, and cooperation, it has also made us aware of many negative unintended challenges and vulnerabilities of such interconnected systems.
Hacking, identity theft, and cyberterrorism have become new weapons in modern warfare. While many point to the physical devastation of September 11, 2001, in the United States or other overt acts of terrorism around the world, the manipulation of data and information technology used to plan and execute these events was equally damaging and continues in ever-increasing frequency. Technology has moved beyond being a tool for planning these acts of terrorism to targeting a country’s information resources, a community’s water or electrical supply, or an individual’s personal assets.
Business Continuity Objectives
The primary objectives of business continuity planning are to provide a proactive strategy to prevent or limit the impact of system failures and to rapidly restore operations when these events occur. Business continuity plans work in conjunction with robust network design and policies and procedures to proactively protect against the loss while minimizing the time needed to bypass the compromised resources or bring the system fully online. Without a solid business continuity strategy, an enterprise exposes itself to lost profitability, time, and credibility among its business partners and customers. The cost of recovery when planning is not performed can far exceed the cost of planning properly and building in safeguards and other mechanisms prior to an outage.
Integrity
Data integrity is the assurance that data remains unchanged after operations on the data, such as copying, modifying, or creating, are completed. Maintaining accurate records of system components, transactions, the location of data, and other critical information is a fundamental requirement of robust business operations and a major goal of BCP. This information allows for the prompt restoration of the most recent and consistent state with minimal loss of data. By maintaining accurate records of resources and any changes made to them, complex computing and mathematical formulas can be used to determine whether data remains unchanged between operations.
Availability
Availability is a key metric of system health and is often a key part of service level agreements. Availability refers to the amount of time the system and data are accessible or online for use. Robust system design coupled with agile BCP provide for problem management. Problem management is a fault-tolerant mechanism that protects the integrity of the network when a failure event occurs. Problem management includes problem detection, isolation, identification, and resolution. The affected part of the network is pinpointed, isolated, and bypassed. Secondary and backup paths, storage, and other resources may be used to reroute data and transactions. Chapter 9 covers how to perform storage replication to another device or site.
One component of availability is the ability for a failed system to automatically restart.
State-of-the-art network intelligence and applications provide a high degree of availability and reliability in providing network resiliency. When a main component of a system becomes defective, the affected system can be isolated and its traffic rerouted to other networked resources.
The next component of availability is hardware fault tolerance. System design and configuration, along with a sound backup and recovery plan, work collectively to minimize loss of service when a hardware fault occurs. As a general rule, a high degree of fault tolerance is possible. Redundant components, paths, and other resources maximize fault tolerance in a given network. Maintaining a high degree of fault tolerance can be an expensive proposition. Chapter 9 covers a variety of areas where redundancy can be used to protect against a single component failure such as multipathing, redundant power supplies, clustering, and cache redundancy. System backups should be scheduled and executed in a nondisruptive manner. Given the sophistication and complexity of modern networks, developing a solid backup and recovery policy may be complicated. Many network resources span multiple time zones, regions, or countries. Hence, the development of this plan should be done collaboratively in order to ensure all of the required resources—people, technology, and so on—are available.
Reliability
While a network or storage may be available, reliability refers to the consistency of performance associated with hardware, software, and infrastructure. Data integrity is also another key metric of reliability. These factors may impact throughput, processing time, updates to databases, and other factors related to a company’s operations.
Data Value and Risk
The transparency of the complex web of applications, technologies, and data that support modern enterprise has led to a sort of “utility” mentality. By this we mean that we’ve become so accustomed to accessing vast amounts of data or processing millions of transactions per second that we expect systems to be available and perform as flawlessly as electricity. It is not until we lose access to these resources or the ability to complete these transactions that we become aware of how dependent we are on them. Unlike other commodities such as oil or grain, data is not tangible. Traditional formulas or means of determining the value of or cost-benefit analyses for tangible assets don’t apply to data.
Capital investment in networks or systems account for a major portion of an enterprise’s operating expenses. Technological obsolescence, innovation, and demand are formidable considerations and contribute to escalating investment costs. Determining the value of the data stored and carried by these systems can be a bit elusive. The aforementioned “utility” mentality has caused many companies to become complacent. Many lack or have inadequate BCPs. It is not until a serious fault or breech occurs that many begin an earnest assessment of the value of their data.
Data valuation and threat assessment are arduous but necessary exercises. Investing the time and resources to do both will inform network design, inform BCP policies, and reduce business impacts when failures occur. For example, it may not be necessary to have redundant paths, servers, storage, and databases at all locations throughout the network. Less critical data or resources will not need to be redundant, allowing those assets deemed critical to be adequately protected. A balanced approach to BCP emerges where system costs and fault tolerance are optimized.

EXAM TIP A potential incident such as data loss or application unavailability can be referred to as a threat. Risk is determined by multiplying the impact of the threat by the likely occurrence of the threat being realized. For example, if the risk of malware infection impacts the business by a loss of one hour of productivity on average and this is expected to happen once a month, then the cost per year is 12 hours of lost productivity. If the organization values this hour of productivity at $200, then the risk per year is estimated to be $2,400.
Data, and the system that supports it, is one of the most valuable assets an enterprise possesses. Data valuation and threat assessment largely depend on the following:
• Data or the application’s value to the organization
• Loss due to the unavailability of the data or application (revenue, time, productivity, brand image, and so on)
• Value the data would have if stolen or accessed without authorization
Accurate data valuation and threat assessment will influence the types and amount of safeguards a company deploys. While elusive, it is not impossible to calculate threat. For example, if the loss of company e-mail for 24 hours would cost the organization $500,000 in lost revenue and the likelihood of this occurring with the current controls in place is 5 percent, the risk this represents is $25,000. The organization can then use this information to determine whether additional controls such as faster restore processes, redundant sites, or other business continuity options would be financially feasible.
Increased awareness of global threat and aggression has led many countries to develop disaster recovery plans and standards specifically designed to prevent and recover from these events. Consequently, international standards for BCP have emerged. For example, in 2004 the United Kingdom began its promulgation of BCP standards as part of the Civil Contingencies Act, which addresses system security, recovery, and protection. As such, the foundations of good BCP include the following:
• Risk assessment The risk assessment analyzes the factors that could impact the integrity, confidentiality, or availability of business systems, along with their likelihood and expected damages, to determine a risk that is typically represented as high, medium, or low or given a cost in dollars.
• Business impact analysis (BIA) The BIA is an estimate of how much it will cost the organization to have systems unavailable because of an incident or disaster. The BIA uses impact scenarios to define likely or possible incidents and the impact or cost it would have on the organization.
• Recovery requirements The recovery time objective (RTO) and recovery point objective (RPO) define how long it will take to restore data and how much data would be lost. These are both described in more detail next.
Whether designed by governments or companies, network management, network disaster recovery, and business operations plans are integrated and used to draft a BCP, which is expressed in optimized system design. Once implemented, this plan must be communicated to all responsible parties in the organization, monitored, and rigorously tested in order to ensure it is capable of responding to the enterprise’s ever-changing landscape.
Recovery Point Objective
The recovery point objective is one of the considerations used to guide business continuity planning. The RPO is basically a measure of the maximum amount of data the organization can tolerate losing. In other words, RPO is the age of the files that must be recovered from backup storage for normal operations to resume in the event that the system, computer, or network fails because of communication, program, or hardware reasons. RPO is a time measurement, specified in seconds, minutes, hours, or days. For example, an RPO of two hours would mean that backups must be able to restore data no older than two hours from the point of failure. The RPO specifies how often backups must be made. RPO often helps administrators decide what optimal disaster recover technology and method to use for specific cases. For instance, when the RPO is one hour, backups can be conducted at least once per hour.
EXAM TIP The defined RPO for a given computer, network, or system dictates the minimum frequency with which backup files must be made for that system.
Recovery Time Objective
Another important aspect in business continuity planning is the recovery time objective. RTO is the maximum tolerable time span that an application, system, computer, or network can be down after some sort of mechanical failure or disaster occurs. RTO is a time measurement, specified in seconds, minutes, hours, or days, and it is used to gauge the extent to which interruption disrupts normal operations as well as the revenue lost per unit of time as a result of data loss. In most cases, these factors depend on the affected application or equipment.
RTO dictates how quickly operations must be restored, so if the RTO is five minutes, backups cannot be stored only on offsite tapes because they could not possibly be restored in five minutes. This would require something like a storage device on the network (nearline storage) with the data on it for recovery.
EXAM TIP Nearline storage is a backup that is located on another storage device on the network.
Mean Time Between Failures
The mean time between failures (MTBF) measures hardware reliability as the average number of hours between expected failures of a component in the system. Storage administrators can use the MTBF as a way to determine what level of support should be purchased or to determine how much effort will be required to repair or return a piece of equipment to service during its expected period of usefulness.
Mean Time to Failure
Mean time to failure (MTTF) is another measurement of hardware reliability as the average number of hours between expected failures. It differs from MTBF in that MTTF is used for equipment that must be replaced rather than repaired. This is important for understanding which parts to have on hand in case they need to be swapped out following a failure. As an example, a hard disk drive (HDD) could have an MTTF of 250,000 hours. Some administrators may want to swap out components preventively before they fail so the MTTF can be used to determine approximately when that will be. This is especially important in situations where a component is not redundant.
Backup Frequency
Data must be backed up on a regular basis. Determining the optimal interval or schedule for system or partial backups should not be calculated by “guesswork” or as a result of haphazard estimation. Once the optimal backup schedule and strategy have been determined, it is important that this be communicated to all appropriate partners and be well documented in associated policies and procedures. Periodic drills and reviews should be conducted to ensure those responsible for maintaining the system are familiar with the actual contingencies, their implementation, and documentation. The resultant schedule should be based on RPO and take into account the potential impact this schedule would have on business operations and other production activities. The amount, distribution, and frequency of use of data will determine the interval and types of backup schemes to employ. Furthermore, the availability of personnel and timing are also critical success factors.
Rotation Schemes
Storage administrators often use various backup rotation schemes to minimize the number of media used for the task. This typically involves the reuse of storage media. These schemes determine how and when removable storage options are utilized and the duration. Industry standards and practices have emerged that seek to balance data restoration and retention needs with the rising cost of storage media and the time required to change tapes and manage tape media such as GFS, first-in first-out, or Tower of Hanoi.
One of the most commonly used rotation schemes is the grandfather-father-son (GFS) backup scheme. GFS uses daily (represented by the “son”), weekly (represented as “father”), and monthly (represented as “grandfather”) sets. Typically, daily backup sets are rotated on a day-to-day basis, weekly backup sets are rotated every week, and monthly backup rotations are done on a monthly basis. Each set may be composed of a single tape or a set of tapes, though this may depend on the amount of data to be stored. Organizations would retain twelve tapes, one for each month; five tapes for each potential week in a month; and five or seven tapes for the daily backups depending on whether the daily backups are performed every day or just on workdays. In total, 22 to 24 tapes are required for this rotation scheme. Variants of GFS also exist, such as GFS with a two-week rolling rotation instead of just five or seven days and the addition of yearly tapes. Some organizations do only three monthly tapes along with four quarterly tapes instead of 12 monthly tapes. These are all variants of GFS.
EXAM TIP GFS and variants of GFS are the most common rotation schemes.
Another possible scheme to perform for backup and recovery operations is the first-in first-out (FIFO) scheme, which saves modified files onto the “oldest” media in a set. By “oldest” here, it refers to the media that contains the data that was archived earliest in the group. For example, if daily backups are performed with 14 tapes, one each day, the resulting backup depth would be equivalent to 14 days. However, with each day, the oldest media would be inserted as backups are performed. The organization can go back to any day within the last 14 days, but any that was removed over 14 days ago would not be recoverable. If tape 1 is used on the first of the month, on the 15th of the month, tape 1 would be overwritten and used again. On the 16th, tape 2 would be overwritten and used again.
A more complex rotation scheme is the Tower of Hanoi, a scheme that is based on the mathematics of the Tower of Hanoi puzzle. A recursive method is often used to optimize the backup cycle. More simply put, with one tape, the tape is reused daily, as shown in Figure 7-1.
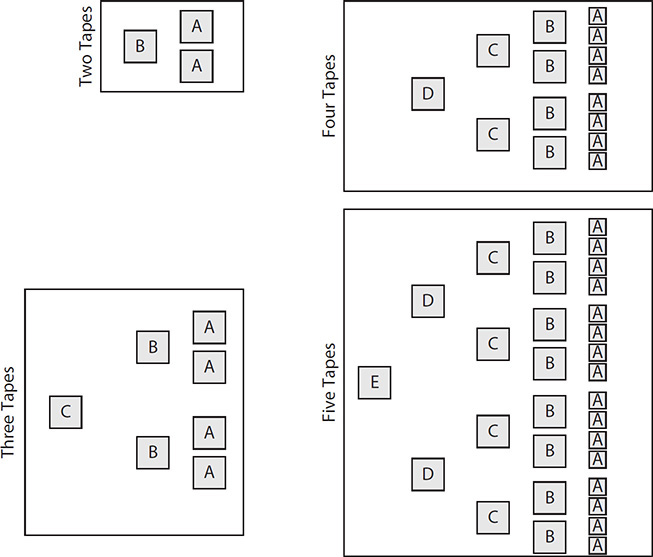
Figure 7-1 Tower of Hanoi tape rotation based on number of tapes
With two tapes, tapes A and B are alternated. With three tapes, the cycle would begin and end with A before going to C and then repeat. Each time a tape is added to the mix, the previous set is replicated with the next tape placed in the middle. The A tape would be used most often, with C being used the least. Figure 7-2 shows what the rotation would look like with five tapes.
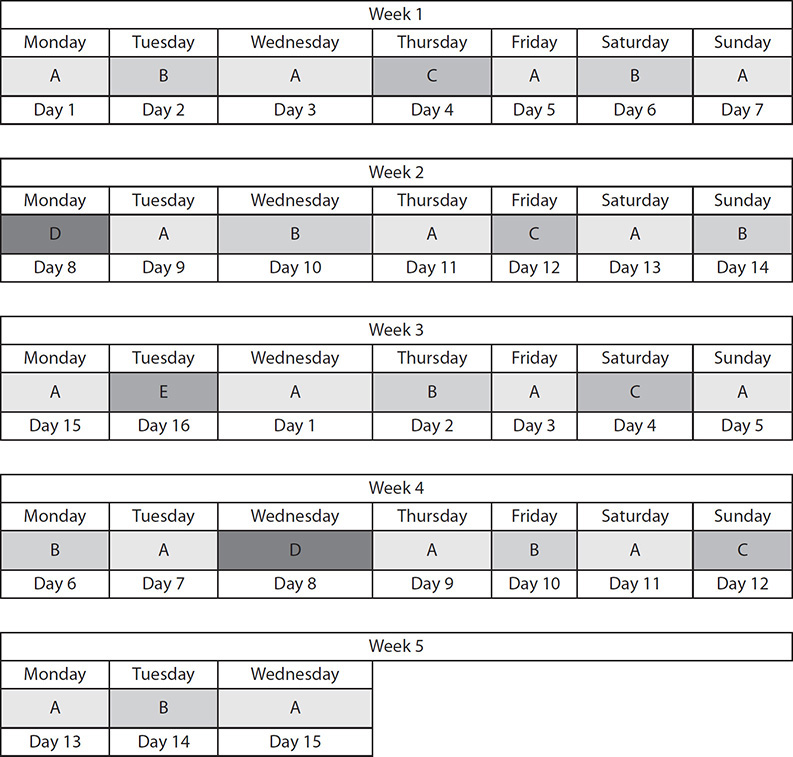
Figure 7-2 Tower of Hanoi tape rotation for five tapes shown over five weeks
Continuous Data Protection
As the required RPO becomes smaller and smaller, backing up information manually may not suffice. In such cases, a more sophisticated and consistent method may be a more logical choice for the organization. Anything less can put the business in a risky position where it may not only miss the RPO and lose data but also suffer a significant profit deficit. In this case, a continuous backup may be the solution to the organization’s data woes. Also called continuous data protection (CDP), this storage system ensures that all the data in an enterprise will be backed up whenever any form of changes is made. Typically, CDP makes an electronic journal containing storage snapshots wherein a storage snapshot is taken for every instance that a modification is done on a backup data. Not only will CDP preserve a record of every transaction made within an enterprise in real time, it can also retrieve the most recent clean copy of an affected file with relative ease.
Contention of Media
Contention happens when more than one device is trying to use the same resource. The device hosting the resource must decide how to allocate it. One scheme provides exclusive access to one user, while another user must wait until that user is finished before using the resource. In another scheme, contention results in both parties using a portion of the available resource. In the first case, one user receives the expected performance, while another user cannot access the file at all until it is available again. In the second scenario, both users have access to the resource, but they both receive less than the expected performance. As you can see, contention results in a series of trade-offs that should be avoided or minimized. So, what resources are typically being vied for in a system? Processor time, memory, storage space, files, and network bandwidth are just a few examples of resources that could be contended for.
Impact on Production
The timing of backup operations can have a negative impact on the performance of a system. Performing backup operations during prime or peak hours of operation can result in increased response time, slower transaction processing, and bottlenecks in terms of storage, transmission paths, and other critical system resources. Backups performed on the same infrastructure as active production or transaction could potentially vie for the same paths, storage, and databases needed by active users. Consequently, capacity planning and performance evaluation of system operations should factor in the elements related to BCP in general and backup schemes specifically. In some instances, it is desirable to create an ad hoc (on demand) or separate network to conduct system backup and recovery tasks. While this is an expensive option, calculations related to the value of transactions or the potential impacts of outages and loss might make it a financially feasible alternative.
Backup Reliability
Once a company has developed a feasible backup and recovery strategy, the next step is to determine which mix of technologies is best suited to the task. The cost, individual characteristics, and availability are used to determine which storage media best matches the scheme’s stated goals, including those of reliability. Reliability is a key factor in storage management. Reliability means that the results of a transaction or process are dependable. Given the fundamental importance of data to an enterprise, storage management should not be treated as a secondary function.
Storage capacity, backup and recovery speed, robustness, and maintenance are also important factors in deciding which technology to adopt for backup reliability. For example, tape backups may be a cost-effective and flexible solution for storing backups; however, the sheer volume of physical tapes that needs to be stored, organized, and managed may not be feasible as the volume of their needs increases.
• Tapes Tapes are an efficient method for writing sequential data to a removable media and are especially well suited for backups and archiving. Tape media is relatively inexpensive compared to nearline and online storage technologies such as hard drives. Figure 7-3 shows a set of LTO3 tapes.

Figure 7-3 LTO3 tapes
Tape drives read and write data sequentially. When reading data in the middle of a tape, the drive will fast-forward the tape to the desired location and then read the data. This is efficient for data that is located in adjacent areas but inefficient for data scattered throughout the tape.
• CD-ROMs Inexpensive and popular, CDs are widely used for data backups. Copying information onto such media is relatively straightforward, but CDs are inefficient when data must be updated or when data sizes exceed the relatively limited size of a CD at 700MB or a DVD at 4.37GB. However, Blu-ray Discs offer storage up to 128GB, and as their price decreases, they prove to be a data backup alternative for more companies.
• External hard drives While this medium is typically cheaper in comparison to tape drive systems, external drives are not redundant. In the event the external drive fails, all of the data could be potentially lost. External hard drives are best suited for small business or those requiring a low-cost backup and recovery platform. External hard drives can be swapped easily using USB or IEEE 1394 FireWire connections.
• SAN array (nearline) Nearline storage is a backup that is located on another storage device on the network. Nearline storage provides a quick recovery time objective, but it requires disks and a server or storage array to be up and running. Nearline storage often uses slower-speed disks such as SATA rather than SAS or FC disks that might be used on production equipment.
• Online backup services For the purposes of convenience, companies can choose to back up their data on the cloud. This option can often make sense for companies when data growth rates are high and the cost and time to set up new equipment would impact business productivity. It can also make sense for small data sets where the cost to procure, operate, and maintain backup equipment is too significant for the relatively small amount of data that needs to be protected. However, there are many additional variables that will need to be considered when using cloud backups, including security concerns, data ownership, and bandwidth limitations.
Backup and Restore Methods
The basic principle in making backups is to create copies of specific data so those copies can be used for restoring information the moment a software/hardware failure occurs. Through such a measure, an individual or organization can have a fail-safe when the inevitable data loss happens, something that may be caused by any of the following: theft, deletion, virus infection, corruption, and so on. Each type of backup and recovery method varies in terms of cost, maintenance of data stored, media selection, and most importantly, the scope and amount of what is captured and retained.
To perform such a vital task, you have the option to do so manually, copying data to a different location/media storage individually, but this is hardly ideal. Most companies utilize some form of backup and recovery software. The type of backup used may actually determine how data is copied to the storage media and often sets the stage for a “data repository model,” which refers to how a backup is saved and organized. Please note that backup software is often licensed based on the number of machines being backed up and their roles, so a database server might consume a license for a server and for a database application, while a file server would utilize only a server license.
Full
The full backup is the starting point for all other backup types, and it often contains all data in the folders and files that have been selected for the purposes of storage. The good thing about full backups is that frequently opting for this method may result in faster albeit simpler restoration processes later. In most cases, restore jobs using other backup types take longer to complete if many different backup jobs must be combined to perform the restore. The next two options, differential and incremental, both take place following a full backup.
Files have a property called the archive bit that notifies software and operating systems of its need to be backed up. The archive bit is set to on when a file changes, and it is reset when certain backup operations are performed. The full backup resets the archive bit on all backed-up files.
Differential
The differential backup contains all files that have been changed since the last full backup. As a consequence, it requires only a full backup and a differential backup to restore data. Nevertheless, the size of this backup can grow larger than a baseline full backup, especially when such a backup procedure is done too many times. The differential backup does not change the archive bit, so each differential backup simply backs up all files that have the archive bit set.
• Pros The time for accomplishing a differential restore is faster than its incremental counterparts.
• Cons Backup times are longer than incremental backups.
Incremental
The incremental backup backs up all the files that have been modified since the last full or incremental backup. Because of such limited scope, this gives incremental backups the advantage of taking the least amount of time to complete, and incremental backups consume the least amount of storage space on backup media. The only thing that makes this option less than ideal is that restore operations often result in lengthy jobs because each incremental backup has to be processed in sequence. Incremental backups back up all files that have the archive bit set and then reset the archive bit. Figure 7-4 shows a weekly full backup followed by incremental or differential backups throughout the week.
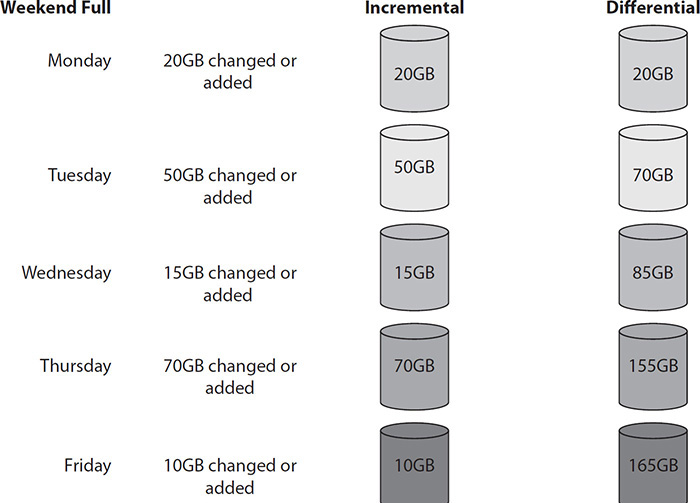
Figure 7-4 Backup schedule using incremental or differential backups
As you can see, the incremental backups are smaller each day because they back up only the data that was changed that day, but the differential backups grow larger each day since they back up all the data that was changed since the last full backup. However, Figure 7-5 shows what backup sets would be required if the server crashes on Thursday. In the incremental solution, the full backup would need to be restored followed by the Monday, Tuesday, and Wednesday incremental backups. In the differential solution, the full backup and then the Wednesday differential would need to be restored.
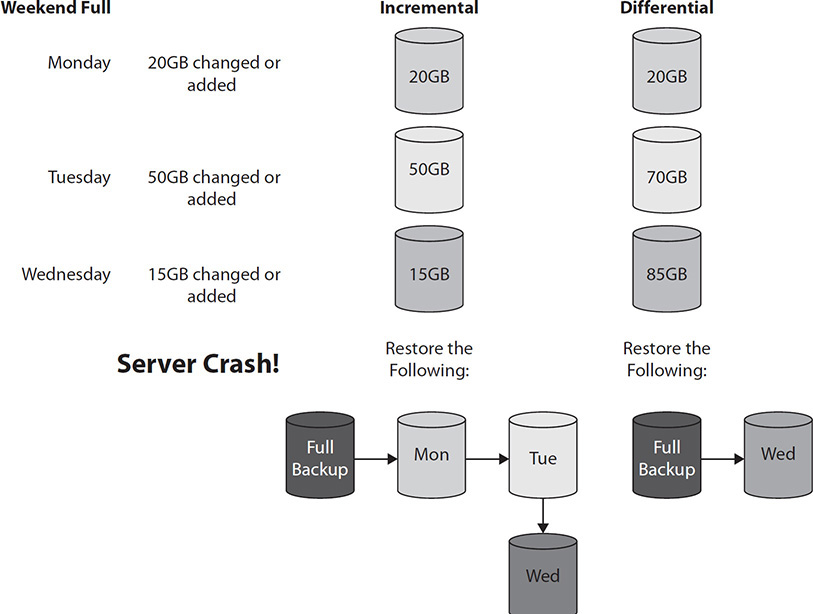
Figure 7-5 Differential vs. incremental restore process
• Pros An incremental backup backs up data faster than the other types and does so while requiring less network drive space, disk, or tape storage space. Plus, you get to keep several versions of one file on various backup sets.
• Cons You need to have all incremental backups in hand when performing a restore. Also, it requires a longer time to restore specific documents since you need to check more than one backup set to find the latest version of the file being retrieved.
EXAM TIP The full backup is performed first, and then incremental or differential backups can be taken.
Progressive
Taking incremental backup one step further is the progressive backup, which backs up only the files that have changed. This results in less data needing to be backed up as long as the original full backup is available since data sets can be restored by referencing the full backup and then any changes to the files. For this type, no additional full backups may be necessary after the initial full backup since the server’s database keeps track of whether certain files need to be backed up.
Backup Implementation Methods
Backup implementation methods can include LAN-free, serverless, and server-based backups. LAN-free backups offer a way to back up data without impacting devices and services on the local area network. Serverless is primarily an extension of LAN-free, but instead of using a device or appliance to move data, it uses a device or storage that is directly connected using a Fibre Channel (FC) or Small Computer System Interface (SCSI). Lastly, server-based backups utilize a server to control the backup operations. In some cases, the backup server may retain the backup data or this data may be archived to other media.
LAN-Free Backup
Local area network (LAN)–free backup is a process of backing up a server’s data to a central storage device without the use of the local area network. Instead, the data is moved over a storage area network (SAN) or using a tape device that is directly attached to the storage subsystem. This is the simplest architecture used with LAN-free, and some of the backup storage used includes tapes or other locally attached storage media. Although there is no backup process that is completely LAN-free because the server still communicates with the backup client, the term is used to illustrate how the bulk of the data is being transferred without the use of the LAN.
The purpose for doing so is to lessen the load on the LAN and reduce the time to complete the backup process. LAN-free is also an alternative to using a simple data copy to storage attached to the network. Apart from reduced backup and recovery times, LAN-free also ensures that there’s less disruption on the systems and other applications being run at the same time. A LAN-free backup can be done either with a backup server or using a storage facility such as a virtual tape library.
Serverless Backup
Usually when a backup is done through a server, time and functions are limited because of the backup window. This makes serverless backup a faster alternative. It is a storage area network solution that leads to lower hardware cost, scalability, improved time effectiveness, and fault tolerance. Because the process doesn’t depend on the resources and bandwidth of a network, the task can be completed faster. It also enables disk-to-tape or disk-to-disk backup.
The process begins with a server specifying what should be backed up, and then the metadata for the files in the backup set is captured. Once this is done, the server’s role is finished, and the device can communicate with the backup device without involving the server unless a change is made to the backup selection list or schedule.
So, what’s the difference between serverless and LAN-free backup? Serverless is primarily an extension of LAN-free, but instead of using a device or appliance to move data, it uses a device or storage that is directly connected using a Fibre Channel or SCSI. It can also be implemented through disk imaging using intelligent agents. These agents will then take a snapshot copy of pointers to the data. Serverless backup in a SAN, on the other hand, uses a data mover, which is embedded into the backup storage itself. What this does is manage the backup process.
EXAM TIP Prior to installing a serverless backup option, make sure that agents or configuration settings specified in the backup solution documentation have been implemented on servers and storage devices.
When it comes to restoring data from a serverless backup, it can be done in two ways: image and session. The former overwrites the drive completely, while the latter restores individual files and directories in file mode. For a successful restoration, a restore job must not be canceled.
Server-Based Backup
Because plenty of information is stored on a server, it must be backed up regularly, typically utilizing backup software or functions built into the operating system such as Windows Backup or file copy scripts.
In a traditional server-based backup, the operation begins when the backup application reads the data from the source to the system memory and then does the formatting needed. The data is then sent to media storage devices where it will be stored. This would require the use of the central processing unit (CPU), various I/O channels, and the system memory. Because the performance of a server is affected while the process is ongoing, server-based backup is not very popular with system administrators. They would have to carry out the task when the application load is less or use other backup methods such as a SAN backup or a high-performance serverless backup.
Backup Reliability Methods
Backup reliability is the level of assurance that backup processes will be able to restore data effectively. The first component of this is ensuring that data integrity is intact, meaning that data has not been altered or corrupted in the process of backing it up or restoring it. One method used to verify integrity is checksums. Next, application verification can be used to provide backup reliability.
Data Integrity
Data integrity refers to how data is maintained accurately and consistently over its entire lifecycle. It plays a vital aspect in the design, implementation, and use of a system used to store, process, or retrieve data. It is the opposite of data corruption, where data is lost during any process. Many aspects can affect data integrity that may differ under a certain context. Generally, though, it can be determined based on the following:
• Human error Errors people made while the data is entered
• Intentional actions Intentional harm to the integrity of data by attackers or malcontent employees
• Transmission error Errors that occur during the movement or transfer of data from one node to another or over the network
• Bugs The presence of software bugs or viruses
• Hardware malfunction The failure of one or more hardware components
• Natural disaster Occurrence events such as fires or floods
Data integrity also ensures that the files saved remain the same from the time the backup is recorded up to the time it’s retrieved. Any intended or unintended changes to the data made during storage, process, and retrieval can also affect integrity.
So, how is data integrity ensured? Physical controls such as controlling access to the area where the servers are kept by allowing only authorized users to get in and out of the area is the first step to ensuring data integrity from human error and intentional actions. This should be combined with specific authorization levels for all users. Other integrity concerns such as transmission errors, bugs, hardware malfunctions, and natural disasters are approached with documented system administration procedures, disaster-recovery plans, and incident response plans. Systems also employ integrity-checking features such as checksums and application verification, discussed next.
Checksums
A checksum, or hash sum, is a small block of digital data that is designed to detect errors that may have occurred during storage and transmission. The checksum function or algorithm is what yields the checksum. When designed properly, it can detect many data errors and verify the overall integrity.
Checksums compute a mathematical number that is unique to the data. This number is created through the use of a standard mathematical formula called an algorithm. Algorithms are designed so that they accurately produce a unique value for a data set. As you can imagine, if two different data sets produced the same value, we could not rely on their integrity because modified or corrupt data could result in the same hash as unmodified data.
This checksum is sent with the data, and the same computation is performed later to verify that the data has not changed. If the checksum generated later does not match the original checksum, something has changed, and the file will be flagged as inconsistent or corrupt.
Among the checksum algorithms, parity byte or parity word is the simplest because it uses the so-called longitudinal parity check. What it does is break the data into words, assigned with a fixed number of bits, and then computes the data. Whatever the result is will then be appended as an extra word. Upon receipt of the message, the XOR of all its words will then be computed to determine whether it yields n zeroes. If not, then an error has occurred during the transmission. Other checksum algorithms include modular sum and position-dependent checksums. Popular algorithms used for this purpose include Message Digest 5 (MD5) and Secure Hash Algorithm (SHA).
Some of the checksum tools available include CHK Checksum Utility, MD5 and SHA Checksum Utility, Advanced Has Calculator, Bitser, MD5 File Hasher for Windows, Jacksum, RHash, j digest, and Parchive. There’s also the straightforward checksum, which is a hashing application used for Windows, and cksum, which is a Unix command.
Application Verification
Backup applications can perform verification on data as part of the backup process. Once a job completes, the backup software will compare the source and destination files to ensure they are the same. This provides more assurance to backup operators and storage administrators that backup jobs are complete and accurate. The verification process does add time to the backup job, though, and it may not be feasible in situations where backup windows are tight.
Backup Locations
Data is the lifeblood of every organization, and it is extremely important that it be available when needed. Once backups have been performed, they must be stored. Careful consideration must be given to protecting these critical copies of a company’s data so that they are not corrupted, lost, or stolen. Storage facilities and locations are just as important as the data itself. Both will have an impact on the integrity of these backups, the time it takes to perform restore functions, and their protection from unintentional and intentional corruption.
The choice of backup solutions when it comes to being in a network is also varied. Data can be backed up on discs, through a local server, or through a remote hosting service. The choice of backup location will ultimately depend on the need because as much as data needs to be backed up, it also needs to be protected. Not every file that a certain employee possesses should be seen by all. Confidentiality—even within one organization—is a concern that should be of utmost importance at all times.
Disk-to-Disk
Disk-to-disk (D2D) backups take data from a disk such as a file share and back it up to another disk such as the storage within or attached to a backup server. D2D involves the copying of data from one disk—in particular, a hard disk—to another hard disk or another storage medium of the disk variety. D2D is often used to quickly take data from production servers to an interim storage location that might be later backed up to tape (see “Disk-to-Disk-to-Tape,” later in this chapter). This reduces the impact on production servers and decreases recovery time.
In a D2D system, the disk where the original files are to be copied from is called the primary disk. The disk where the data will be transferred to is usually referenced as the secondary disk or backup disk.
D2D is almost always confused with virtual tape, which is different. D2D differs from virtual tape in that it allows multiple backup and recovery operations to access the disk at the same time using a true file system.
The primary advantage of a D2D system is that D2D systems do not have to seek the entire tape to find a specific piece of data. They can proceed directly to the data on the disk much faster, saving time and reducing the RTO.
D2D is also closely related to remote backup services. They are similar in a sense that they both store data on disks. But in the case of remote backup services, the data is held at a remote location, and the services are provided by managed backup providers.
Disk-to-Tape
The term disk-to-tape (D2T) is used to refer to a type of data storage backup where information is copied from a disk to a magnetic tape.
In a D2T system, the disk is usually a hard disk, while the tape is a magnetic tape. This kind of system is widely used in enterprises that require vital information to be stored in a safe location in case of disaster recovery so that data recovery can be performed.
Since hard disk storage units are prone to mechanical failure, backups need to be made at regular intervals to prevent catastrophic data loss. This kind of tragic loss of information is the last thing that organizations of any kind and size want to experience. Having data backed up also ensures that a system can be restored to its original state based on the information stored in the backed-up data.
Disk drives have a certain limit when it comes to the amount of data they can store. This is where tape storage units come in to provide the much-needed additional storage capacity.
Magnetic tape units also don’t cost that much, making them a cost-effective solution for backing up data. Another advantage that they have is the capacity to hold large data volumes, making them a suitable backup solution for hard disk units.
A D2T system can work live, meaning as a continuous backup mechanism or an incremental backup solution, where data is added at different intervals regularly.
VTL
A virtual tape library (VTL), discussed in Chapter 5, is an archival backup solution that functions like tape-to-backup software but can be stored in whatever manner is most efficient for the organization such as on disks. This type of technology merging allows for the creation of an optimized backup and recovery solution.
VTL is a disk-based storage unit that appears to back up software as tape. Data is transferred onto disk drives just like it would be on a tape library, but in this case, the transfer is a lot faster. A VTL system is usually composed of a virtual tape appliance or server, as well as software that simulates the traditional tape devices and formats.
The benefits of using a VTL backup solution include storage consolidation and quicker data restore processes. The process of both backup and recovery operations are increased when a VTL solution is used.
Disk-to-Disk-to-Tape
The term disk-to-disk-to-tape (D2D2T) is used to describe a backup solution where data is initially transferred to a disk-based backup system and then copied again to a tape storage when it is most optimal for the organization.
Both disk-based backup systems and tape-based backup systems have advantages and disadvantages. For a lot of computer applications, it is really important to have backed-up data available immediately when the primary source of information becomes inaccessible. When a situation like this happens, it would be unacceptable to transfer data from a tape because it would take a really long time. Using tape in a D2D2T also allows much older data to be moved to an offsite location for disaster recovery protection.
Tape is economical for long-term storage, making it a really cost-effective solution when it comes to backing up data that needs to be kept for a long time. Tape is also portable, which makes it a good candidate for offsite storage. However, a D2D2T system offers long-term storage along with fast disk-to-disk recovery time. A D2D2T system allows a storage administrator to easily automate backups on a daily basis on disks so that it would be easier to implement quick restores. The data can then be moved to tape when the storage administrator has more time to spare.
Vaulting and E-vaulting
Vaulting is the term used to describe the process of sending data to an offsite location. This is done so that the information remains protected from several problems, which include hardware failures, theft, and others. Data is usually transported off the main location using media such as magnetic tape or optical storage.
When backups of data are sent offsite, this ensures that systems and servers can be reloaded with the latest data in case of a disaster, an accidental error, or a system crash. Having a backup sent out of the main location also ensures that a copy of important information exists outside of the main location.
Vaulting is helpful for companies that back up information—be it classified or unclassified—on a regular basis and desire quick access to the data but the option to recover if the site is lost. Some organizations choose an offsite location of their own to store their backed-up information. However, others acquire the services of third parties that specialize in such services.
Commercial vaults where backed-up data is stored is classified into three categories:
• Underground vaults These are often old war bunkers or mines that have been repurposed for data storage.
• Free-standing dedicated vaults These are facilities built as a data storage facility as their primary purpose.
• Insulated chambers These are most often implemented within existing record center buildings or offices for data storage.
There is also another kind of vaulting, but instead of using physical storage, it transfers data electronically, and this is called electronic vaulting or e-vaulting. With this kind of process, data is sent electronically through a remote backup service. It offers the same benefit as vaulting because it is still an effective solution that can be used in a disaster recovery plan.
At its core, e-vaulting refers to the process of creating a backup or replicating important data. The copying process can be done onsite, but the copied data is ultimately transferred offsite. The concept of e-vaulting isn’t entirely new because a lot of companies have been sending backup tapes and duplicating data onto remote disk arrays and virtual tape libraries for a number of years.
Ultimately, the goal of e-vaulting is about protecting data that matters to an organization. The reason for transferring this information out of the main location is to ensure that a copy exists in case of a disaster. Some organizations also do not use e-vaulting for every document they have, only the most vital ones.
Offsite Tape Storage
Offsite tape storage is the storing of backed-up data in a facility that is different from the main location. An organization has two options when it comes to this type of storage solution: It can use its own facilities that are located in a separate place from the main office, or it can acquire the services of a company that specializes in offsite tape storage.
Whether choosing a company-owned storage facility or trusting the backed-up data to a third party, one thing remains constant: Storing data far from the main location is essential for protecting the data. Having data stored offsite is also a good addition to any disaster recovery plan.
There are benefits and disadvantages to choosing an organization-owned storage facility as well as a storage center owned by a third party. With a facility owned by the company, there is always the problem of running out of room. As data increases, so does the need to back it up, especially if it is vital to the organization. Eventually, all of the backed-up information stored in different mediums will take up space, leaving no room for more in the coming years. A benefit of having a company-owned storage center is that the data is maintained within the hands of the company. It is not passed to anyone outside of the organization and is safe in that regard.
When it comes to acquiring services from a third party, the provisioning of a space for company data is the responsibility of the offsite tape storage provider. However, there is an issue when it comes to the safety of the information contained within the storage mediums. The chance of a criminal event happening in a storage facility is not entirely impossible, which makes company data vulnerable in this regard. This is why data encryption plays a huge role when it comes to handing off backed-up information to a third party. The last thing an organization wants is for someone to have free access to confidential information about them or their clients.
Offsite Storage for Disaster Recovery
Disaster recovery (DR) refers to the process, policies, and procedures that a company has in place for the recovery of valuable assets that are very vital to an organization in case of a serious incident that impacts business operations such as a natural disaster.
Disasters are classified into two broad categories. The first is natural disasters, such as earthquakes, floods, hurricanes, or tornadoes. These types of disasters are beyond the control of humans, but having procedures in place that avoid damaging losses to an organization definitely pays off. The second category of disasters are the ones caused by humans, and these include material spills that are hazardous, failure of infrastructure, and bioterrorism—just to name a few. Just like a natural disaster, it helps to have a plan that ensures the survival of a company despite unfortunate events. This is an area where offsite storage helps an organization.
When a disaster makes a facility unavailable, the organization must have a way to continue business. This usually takes the form of an offsite location that can assume the duties of the original facility. Either data from the primary facility is replicated to another facility or processes are put in place to be able to restore data to the other facility quickly.
With offsite storage, crucial data is stored away from the main location of an organization. This way, in case a disaster happens, be it caused by fire, flood, or man, an organization can still ensure its survival and continue business transactions because all the vital information needed to do that was backed up and stored in a different facility.
The benefits of offsite storage include the following:
• Reduced overhead costs While it may seem practical to store backups within the office, the space dedicated to keep rarely accessed data may often be best used for actual business functions. By sending its records to low-priced facilities that are solely dedicated to corporate storage, the enterprise maximizes its workspace and keeps its data secured.
• Rapid response system By storing essential business data offsite, a company can avert the impact of a major crisis as soon as copies of backup data get delivered to the affected office. In the event that some kind of natural calamity would devastate the company’s premises, an offsite backup partner can pull out the necessary data so the organization can get back to doing business as usual.
• Reduced risks of disclosure Having private customer records disclosed to unauthorized individuals can likely shake a consumer’s confidence in a brand, which is a concern that every entrepreneur should look into. Instead of putting such data within the company’s file room where it’s susceptible to malicious intent, it may be best to transport such data to a secure offsite location.
• Increased availability of in-house IT personnel In a day’s work, the office’s IT department has several tasks to take care of, and babysitting data is just one of them. It may be part of their job description to do so, but their effort in collecting critical data and fixing backup systems may be better spent with working on more business-critical tasks.
Offsite Storage for Business Continuity
Offsite storage for business continuity is similar to that for DR, but it can be used for events of a much smaller scale. Offsite backups may be used if the data on the production storage is accidentally deleted. The offsite copy can be used to restore the data. It differs from offsite storage for DR because the primary facility is still available.
Array-Based Backups
Array-based backups are a form of remote replication that replicates an entire storage array or specified portions of the array at once, and this can certainly make the entire replication process more manageable. The downside to this option is that the tools available for this method are usually vendor specific, requiring the same vendor’s products at both locations and sometimes in between to facilitate the replication. This reduces the options businesses have when they decide to invest in such equipment.
Array-based backups utilize technologies such as snapshots, consistency groups, and clones to synchronize data.
Snapshot
Besides the traditional and broad models of replication, organizations can also implement continuous data protection (CDP), and the tools for this method resemble journaling products. They copy each change made to data across the WAN instead of copying individual data, and this often makes it easy to roll back to any single point in time.
For this process, snapshots of data may be pursued. Often, an individual snapshot of a data set is taken at set intervals and then directly sent to a secondary site. But while this method copies the entire data set, it may be quite bandwidth intensive.
At its most basic, a snapshot is like a detailed table of contents but is treated as a complete data backup by a computer. Every snapshot streamlines access to stored data and is certainly one of those backup options that can speed up data recovery procedures.
There are two main types of storage snapshot, and they are split-mirror and copy-on-write. In most cases, there are available tools that can generate either type automatically.
• Split-mirror Split-mirror creates a snapshot of an entire volume when it is executed manually or on a schedule.
• Copy-on-write Copy-on-write creates a snapshot of changes to stored data every time updates on existing data are made or new information is introduced.
Consistency Group
Consistency groups are used for maintaining data integrity and uniformity across multiple volumes or even sites, usually comprising an entire system such as the application, middleware, and back end. The consistency group ensures that a set of writes is performed on each member of the group. Items in a consistency group retain the same data, and writes that occur to one member of the group will not be fully committed until they have been implemented across all members of the consistency group. This ensures that no matter which resource in the consistency group is accessed, the data remains the same.
Clone
A clone is an exact copy of a volume. This kind of backup copy contains all the files in the source volume, and clones have the same content as the original source. A clone is sometimes used as a backup of the startup or boot drive in a computer so that other machines can be created from it, but other uses include creating copies for disaster recovery or testing and development installations, as can be seen in each of the following scenarios:
• Restore earlier OS after failed upgrades Sometimes upgrades made on a computer’s operating system go terribly wrong, rendering the entire system dysfunctional. This may be caused either by a lack of hardware support or by an unexpected software incompatibility. With a system clone, an organization can quickly return to the last functional configuration and make the upgrade failure seem like it never happened at all.
• Restore a “cleaner” system Invisible background applications, malware, registry problems, and junkware—all these can clog up a boot drive to a point when the unit lags significantly. To get back to a faster computing experience, some organizations turn to a cloned boot drive system that has been formatted periodically. This makes cloning a server to environments that operate with multiple computers yet share identical configurations. This makes it easy to reset computers back to a point in time where the system functioned properly and is effective when many computers use the same configuration.
• Restore a unit after a crash When a crash of a startup drive happens, a business can have a clone of a boot drive as its savior since it is an essential data recovery tool for such cases. For systems that don’t have clones, it can take hours, days, or even weeks before the entire hardware is backed up. Similarly, configuring, reloading, and updating systems stored on optical discs can require an equal amount of time.
• Increase drive capacity via upgrades When drive capacity of a computer is becoming a growing concern for a business or user, cloning can help in upgrading the internal drive in a cheap yet fast way. This may often be the case for laptop computer users whose need for bigger hard drives grows as time goes by.
• Create a development or test environment Clones can be used to create a duplicate environment for testing or writing new software or trying system changes without impacting the production environment.
When cloning a data-only drive, information is often copied in chunks instead of being copied as an entire drive. Cloning is typically accomplished with vendor tools that operate on the storage array to create the clone to another logical unit. With such a program, an organization can transfer invisible files or data that users don’t normally have access permission for since the storage array works with the data on a block level rather than a file level.
Chapter Summary
The information in this chapter will assist storage administrators in performing BCP that is best suited for their respective organization. This chapter provided an overview of business continuity, its relationship to network disaster recovery, and the elements of crafting and implementing a sound backup and recovery strategy.
• The recovery point objective is the interval or maximum amount of time the data or system may be lost during an outage.
• The recovery time objective determines the maximum amount of time an enterprise can tolerate an outage.
• Contention may be addressed at the local policy level, which specifies priorities and additional system resources such as infrastructure, servers, and so on.
Various media were discussed in terms of their reliability. Tape is a relatively inexpensive medium for backups in limited amounts of data or small systems. CD-ROM remains a popular, cost-effective choice but offers no redundancy. External hard drives offer more capacity than the two mentioned previously but offer no redundancy. A SAN array requires additional servers and storage on another part of the network. It provides a higher degree of reliability and restoration of system functions.
Next, the various types of backup were explained, each with their relative strengths and weaknesses. Full backs up all data. Differential backs up changes since the last full backup. Incremental backs up all of the files that have changed since the previous full or incremental backup. Progressive incorporates two techniques; it maintains a copy of all files that have changed and then backs up the file or data. Cloud backups can be used on a pay basis for companies where required space is located on storage resources in the “cloud” or at a third-party storage provider.
Several methods for implementing backups were covered. LAN-free is backing up to central storage without using the LAN. Serverless is an extension of LAN-free and provides access to direct connected storage. Server-based is when servers are used for backing up and restoring data.
Data integrity, or the ways in which data accuracy and reliability are maintained, were addressed. It combines both technical and practical aspects in achieving this goal.
• Checksums A checksum or hash sum is a small block of digital data that is designed to detect errors that may have occurred during storage and transmission.
• Application verification This is the ability of backup applications to perform data verification.
• Backup locations These are onsite or offsite alternatives for storing backups.
• Disk-to-disk D2D backups store files to disk rather than other media.
• Disk-to-tape D2T backup files are copied from disk to tape.
• VTL This combines the flexibility of tape and hard drives as a means of storing backups.
• Disk-to-disk-to-tape With D2D2T, data is first copied to disk-based backup storage and then later copied to a tape storage system when optimal for the organization.
• Vaulting and e-vaulting This is a form of offsite storage for backups where specialized vaults—underground, cloud/virtual, protected onsite locations, or freestanding—are used to store backups.
• Offsite tape storage A third-party vendor or storage provider may be used to store backups.
• Disaster recovery Refers to the comprehensive plan that forms the basis of solid BCP. It contains the policies and procedure to be followed in the event of a failure or other data or system-compromising event.
• Business continuity Refers to the ability to restore and maintain total or partial system operations in the event of a failure.
• Array-based storage Using this method, an entire storage array is replicated.
• Snapshot Copies of data are taken at predetermined thresholds or intervals.
• Split-mirror A complete copy is made of the volume.
• Copy-on-write Copies are made each time the data changes.
• Consistency group Consistency groups are used to maintain consistency and reliability of data across multiple volumes.
• Clone This maintains the structure of an exact copy of all data.
Chapter Review Questions
1. Which of the following is not a direct reason why system outages occur?
A. Human error
B. Lack of physical security controls
C. System hardware failure
D. Natural disaster
2. An important metric of determining the goal of returning the systems to an operational state is:
A. Return to service metric
B. Uptime metric
C. Recovery time objective
D. Service level metric
3. Which rotation scheme consists of a daily, weekly, and monthly backup set?
A. Routine backup
B. Tower of Hanoi
C. FIFO
D. GFS
4. What is the difference between vaulting and e-vaulting?
A. E-vaulting archives only electronic data, while vaulting is used for both electronic data and paper documents.
B. Vaulting uses a physically secure location such as a bunker, but e-vaulting is not concerned with where the data is located.
C. E-vaulting sends data offsite electronically, but vaulting sends data offsite through means of physical media.
D. Vaulting is used for paper files, and e-vaulting is used for electronic files.
5. Which backup type results in the smallest size and shortest backup duration?
A. Incremental backup
B. Differential backup
C. Transactional backup
D. Full backup
6. Which backup type requires the fewest number of tapes to restore data to a point in time?
A. Incremental backup
B. Differential backup
C. Transactional backup
D. Progressive backup
7. Which of the following is the primary advantage of LAN-free backups?
A. Lower cost
B. Less impact on the production network
C. More flexibility
D. Higher scalability
Chapter Review Answers
1. B is correct. Lack of physical security controls does not directly result in a system outage.
A, C, and D are incorrect. A, human error, could directly result in an outage if someone unplugs a power or data cable accidentally. A system hardware failure, C, could result in a system outage if redundant components or systems are not in place, and D, natural disasters, could take out an entire facility, directly resulting in system outages.
2. C is correct. The recovery time objective (RTO) specifies how long it should take to recover the data.
A, B, and D are incorrect. A sounds like it would be correct, but it is not an industry term. B is related to how available a site is, and it could express how much downtime occurred over a period, but not what was required per incident. D, the service level metric, is almost the same as the uptime metric, providing an uptime or downtime percentage rather than a time.
3. D is correct. Grandfather, father, son (GFS) uses a daily, weekly, and monthly backup set. The grandfather is the monthly, the father is the weekly, and the son is the daily.
A, B, and C are incorrect. A is incorrect because a routine backup is not specific enough. Routine backups could be quite comprehensive, or they could be simply once a month. B is incorrect because the Tower of Hanoi backup method does not operate on a weekly or monthly basis. It is binary in origin, and the rotation is based on the number of tapes in the set and when the first day in the set begins. C is incorrect because first-in first-out (FIFO) does not specify whether daily, weekly, and monthly tapes will be created, just that the ones that are overwritten will be the oldest tapes in the bunch.
4. C is correct. E-vaulting sends data offsite electronically, but vaulting sends data offsite through means of physical media.
A, B, and D are incorrect. A is incorrect because neither vaulting nor e-vaulting is used with paper documents. B is incorrect because the level of physical security of the data is not a differing criteria between vaulting and e-vaulting. D is incorrect because both vaulting and e-vaulting deal with electronic data.
5. A is correct. An incremental backup contains only the files that have changed since the last incremental backup, so it is the smallest. Since it is backing up less data, it is also the fastest. For the exam, remember that incremental backups take the shortest time to back up but are longer to restore. Differential backups take longer to back up but are faster than incremental backups to restore. B, C, and D are incorrect. B is incorrect because differential backups contain all data that has changed since the last full backup and they are larger than incremental backups. They also take longer to back up but they are faster to restore. C is incorrect because a transactional backup is not covered in this text. D is incorrect because the full backup takes the longest to perform and to restore.
6. B is correct. The differential backup contains the files that have changed since the last full backup. Restoring from a differential always requires only two tapes: the full backup and the differential.
A, C, and D are incorrect. A is incorrect because a restore operation using incremental backups would require the full backup and all incremental backups taken between the full and the current date. C is incorrect because transactional backups are not discussed in this text. D is incorrect because progressive backups would require access to each tape where changes occurred.
7. B is correct. LAN-free backups have less impact on the production network because data is written to locally attached resources rather than network resources. A, C, and D are incorrect. A is incorrect because LAN-free backups cost more due to the increase in equipment. C is incorrect because more flexibility is not as crucial as the lower impact LAN-free backups offer on the production network. D is incorrect because LAN-free backups do not scale any better than other options.