
Procedures for Incident Response
There are a number of key steps necessary to effectively handle an incident. These steps are outlined in the incident response procedures.
FIGURE 12-2 depicts the basic steps of an incident response procedure. Notice the model is built as a continuous improvement model. This means that as lessons are learned from incidents, they are used to improve the incident response program itself. Notice that the controls in place before the incident are improved by people outside the IRT. Implementation of control recommendations is typically not handled by the IRT members. Each of the steps in Figure 12-2 is discussed in this section of the chapter. The important takeaway is that incident response is not a one-time process. It takes significant time and effort to create and support an IRT. The organization’s commitment and appropriate delegation of authority are essential to responding to incidents quickly and effectively.
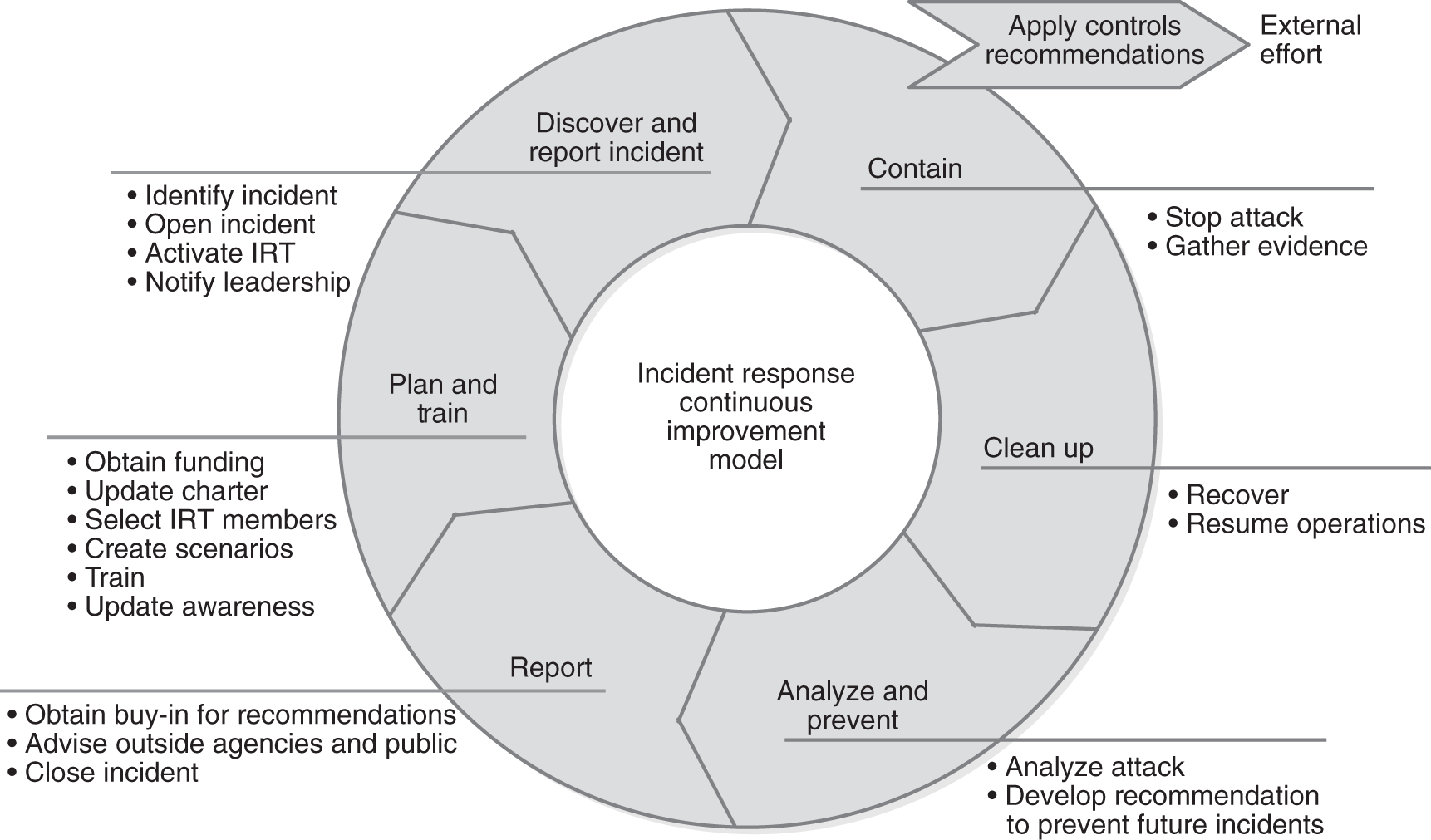
FIGURE 12-2 Incident response continuous improvement model.
Discovering an Incident
Discovering an incident quickly is a complex undertaking. It requires a solid understanding of normal operations. It also requires continuous monitoring for anomalies. It requires that alert employees report unusual events that can be indicators of an incident. An enterprise awareness effort must teach employees how to report suspicious activity.
The signs of an incident can be obvious or subtle. The number of possible signs is enormous. The following is a small sampling:
- Suspicious activity of a coworker is noticed, and accounts within the department’s control do not balance.
- An intrusion detection sensor alerts that a buffer overflow occurred.
- The antivirus software alerts infection across multiple machines.
- Users complain of slow access.
- The system administrator sees a filename with unusual characters.
- The system administrator sees an unknown local account on a server.
- The logs on a server are found to have been deleted.
- Logs indicate multiple failed logon attempts.
These signs do not necessarily mean that an incident has occurred; however, each needs to be investigated to make sure there has been no breach. Some incidents are easy to detect. On the other hand, small, unexplained signs may only hint that an incident has occurred. Such a small sign might be a configuration file that has been changed. A well-trained and capable staff is necessary to evaluate the signs of an incident.
Reporting an Incident
It’s important to establish clear procedures for reporting incidents. This includes methods of collecting, analyzing, and reporting data. When you receive a report of an incident, classify it. This process is often called triage. Triage is an essential part of the incident response process. The triage process creates an immediate snapshot of the current situation. This is used to assess the severity of the threat. When the incident reaches a certain severity, the IRT is activated. This is the official declaration of an incident.
It’s important to note that many security incidents are isolated occurrences, such as computer viruses. These are easily handled with well-established procedures. When an incident is reported, the triage process must be staffed with well-trained individuals who can classify the incident and its severity. A sample severity classification is as follows:
- Severity 4—A small number of system probes or scans are detected, or an isolated instance of a virus is found. The event is handled by automated controls. No unauthorized activity is detected.
- Severity 3—A significant number of system probes or scans are detected, or widespread virus activity is detected. The event requires manual intervention. No unauthorized activity is detected.
- Severity 2—Limited disruptions to business as usual (BAU) operations are detected. Automated controls failed to prevent the event. No unauthorized activity is detected.
- Severity 1—A successful penetration or DoS attack is detected with significant disruption of operations, or unauthorized activity is detected.
There’s no one standard approach to assessing the severity of a reported incident. You may choose to allow the existing procedures to handle severity 3 and 4. The IRT may be activated to handle severity 1 and 2. You want to have a clear definition of terms. Severity 1 uses the phrase “significant interruption of operations.” That definition might vary among organizations. You do not want to interpret definitions so strictly that the definitions lose common sense. For example, consider a breach of the scheduling system for lawn care at a major organization. Yes, it’s a successful penetration. However, it is doubtful it would trigger a severity 1. Although it may seem like a silly example, that’s the problem you have with acting on pure definitions. Definitions cannot cover every situation. The best practice is to use professional judgment in assigning severity classifications. Definitions should provide guidance but not prescriptive rules.
 NOTE
NOTE
During the early stage of an attack, you don’t know what the final impact and damage to the organization will be. During triage, the focus is on understanding the nature of the attack and containment. Severity and incident classifications can help you to quickly come to a decision on how to contain the threat.
A severity classification alone is not used in determining a response. You should also consider the incident classification to understand the nature of the attack. For example, there is a substantial difference between a server being down due to a denial of service and an unauthorized access to your credit database containing millions of customer records. Both incidents may mean access to data is temporarily disrupted, but the latter incident is clearly more serious.
A senior leader in the information security team is typically called to make the formal declaration decision. This person is the chief information security officer or a delegate. His or her responsibility is to ensure the analysis is sound and appropriate to declare an event. Once an incident is formally declared, the IRT response timeline starts. Triage captures all the actions taken to that point. The process activates the IRT plan and notifies upper management. The documentation includes what the basis for the severity was.
Containing and Minimizing the Damage
There are several quick actions you can take to contain the incident. This might include blocking the Internet Protocol (IP) from which the attack is being launched. It also might include disabling the affected user ID or removing the affected server from the network. Regardless of the specific method, the first issue is always to contain the attack. That must always be the priority.
Before a response can be formulated, a decision needs to be made. This involves balancing the needs of the business and the need to pursue the attacker. The BIA can help facilitate that decision. Depending on the impact documented in the BIA and the assets at risk, you can decide to allow the breach to continue to gather information on the hacker or to stop the breach immediately. In simple terms, if low-value assets are being attacked, then you could choose to allow the breach to continue in order to gather information on the attacker. If high-value assets are being attacked, you must stop the breach immediately.
FYI
An organization can use different terms to represent the IRT process and core team. The terms may be different, but the core objectives are the same: Services are to be protected and restored when needed, financial losses are to be minimized, and lessons are to be learned.
You will obviously not know the type of incident in advance. Therefore, you may find that getting preapproval from management to act is difficult to impossible. A decision on what action to take should come from upper management. However, management needs to understand the damage that will occur by allowing the attacker to continue. Having a protocol with management can establish priorities and expedite a decision. The BIA scenario discussion can help expedite leadership understanding of the organization’s priorities and choices. Business leaders should understand in advance the types of decisions they will be asked to make and the range of implications involved.
The IRT will work to classify the attack. It will also work to determine the best means to stop it. You should document each step of the decision-making process. The IRT will also determine if forensics skills are required and if it is appropriate to inform law enforcement.
It’s important to have a set of responses prepared in advance. The initial analysis provides the picture of the threat to prioritize a sequence of prerehearsed steps. This could range from taking the server offline to blocking outside IP addresses. These predetermined responses should be well documented. Documentation should include what level of authority is needed to execute. For example, management may grant the IRT permission to block overseas IP addresses. Blocking domestic IP addresses, however, may need management approval. In that case, management should be alerted early when domestic IP addresses are involved. Such an alert would advise management of the situation and ensure someone is available to make a quick decision.
An important part of containment is evidence-gathering. Parts of the IRT team will be focused on stopping the attack while others take snapshots of logs, configuration, and other evidence. Remember, a successful breach is a crime scene. If there’s a chance you can prosecute the attacker, it’s important to gather as much evidence as possible. You should also disturb the environment as little as possible. This is very difficult when you’re trying to stop an attack. However, it’s important to be aware of the need to collect evidence.
Cleaning Up After the Incident
A core mission of the IRT is to ensure efficient recovery of the operations. Obviously, recovery is focused on getting affected systems back in service, but that is not the only thing that recovery accomplishes. Recovery includes ensuring that the vulnerabilities that permitted the incident have been mitigated. Find out precisely what happened and how it can be prevented or at least mitigated in the future. Mitigation includes both lessening the probability of such an incident reoccurring and lessening the impact.
The recovery phase begins once the threat has been contained. You can implement an effective recovery strategy together with the business continuity plan (BCP) representative. This may require restoring servers and rebuilding operating systems from scratch. The next step would then be to test the affected machines and data. The testing should include looking for any signs of the original incident, such as virus or malware. Once you test the servers and systems, you can certify them to be put back into production.
During the containment phase, you have little time to gather evidence. You have more time in the clean-up phase; however, management may pressure you to resume operations. Forensically image the damaged computer(s), if possible, for further analysis after operations have resumed. That way you know the exact state prior to recovery. There are forensic tools that can perform this function for you.
It should be noted that imaging suspect machines as early as possible is going to be critical if you wish to perform a forensic investigation later. And in the case of law enforcement becoming involved, having forensic images will facilitate their investigation. It is important that you maintain chain of custody from the beginning of the imaging process, in case a criminal case develops. That process is not terribly complicated. You document when the device is imaged, by whom, using what tool. Then you store the image in a secure location and document everyone who has access to that location. That should be as few people as possible. It should be noted that imaging a drive can be a slow process. It often takes several hours to image a machine’s hard drive. It is recommended that even if an organization does not intend to keep full-time forensic specialists on staff, that at least some members of the IRT have some basic forensics training.
If your organization is successfully attacked, it may be attacked again. It’s important that the security controls are hardened to withstand another attack. It is often a good idea to install additional monitoring after systems are brought back online. You can use the additional monitoring to validate that the systems have been hardened. You can also use additional monitoring to change how management approaches future attempts to breach the same systems.
Documenting the Incident and Actions
As a focal point for the enterprise, the IRT can gather information across the organization. The IRT assesses the information gathered during and after the incident to gain insights into the threat. It’s important that all status reports be issued through the IRT manager. Status reports are internal communications between the IRT and management. However, you should assume that others may end up viewing them. They might even end up in a court of law. You should avoid speculation in these reports. The reports should stay with the basic facts. These include what you know and what you are doing about it.
You should start incident analysis immediately upon declaring an incident. Quickly determine the type of threat. Then determine the scope of the incident and the extent of damage. This will allow you to determine the best response. During this analysis you are collecting information to contain the incident. You are also collecting it for future forensic analysis.
Collecting forensic evidence is an important part of the IRT’s responsibility. This means collecting and preserving information that can be used to reconstruct events. Analysis depends on gathering as much information as possible about the following:
- What led up to the event
- What happened during the event
- How effective the response was
There are specific tools and techniques used to collect forensic evidence. It’s important that a trained specialist collects the information. This is because the evidence may end up being used in a court of law. The gathering of information must follow strict rules that the court finds acceptable.
Part of these rules involves a chain of custody. This was mentioned a bit earlier. It’s important not only that the information be gathered a certain way, but also that the information be stored securely after it’s collected. Chain of custody is a legal term referring to how evidence is documented and protected. Evidence must be documented and protected from the time it’s obtained to the time it’s presented at court. In forensics it is difficult to have too much documentation.
 TIP
TIP
You should only use an established forensic tool software package when gathering evidence to be submitted to a court. Examples of such tools are OSForensics by Passmark Software, Forensics Toolkit by Access Data, Blackbag Forensics, or EnCase Forensic by Guidance Software.
There is a basic approach to proving that digital evidence has not been tampered with. It is to take a physical image of machines and calculate a hash value. A physical image is a bit by bit copy of the storage for the machine. The hash value is obtained by running a special algorithm. This algorithm generates a mathematical value based on the exact content of the bit image of the machine. The hash value is essentially a fingerprint of the image. Imaging software will hash the original and the image and compare the two hashes. If one bit of data on the bit image copy is altered in any way, the hash value would change.
The IRT coordinator should maintain an evidence log. All evidence associated with the investigation should be logged in and locked up. If any evidence needs to be examined, it’s logged out and then logged back in. Where possible, once evidence is logged in, only copies should be logged out for further review. It is important to maintain a chain of custody to be sure the material is not altered or tampered with.
Analyzing the Incident and Response
The goal of the analysis is straightforward: It is to identify the weakness in your control. Knowing the weakness allows you to continuously improve your security. It helps prevent the incident from occurring again. As you examine your control, you may find other weaknesses unrelated to the incident. Ideally, you want to be able to identify the following:
- The attacker
- The tool used to attack (if possible)
- The vulnerability that was exploited
- The result of the attack
- The control recommendation that would prevent such an attack from occurring again
Each incident is different and may require a different set of techniques to arrive at these answers. There are some steps you can take to help the analysis:
- Update your network diagram and inventory—Be sure to have a current network diagram and inventory of devices available.
- Profile your network—Map the network traffic by time of day and keep trending information.
- Understand business processes—Understand normal behavior within the network and business.
- Keep all clocks synchronized—Be sure the logs all have a synchronized timestamp.
- Correlate central logs—Be sure logs are centrally captured and easily accessible.
- Create a knowledge base of threats—Create and maintain a library of threat scenarios.
Understanding the environment makes it easier to detect suspicious activity. As you become more familiar with the business processes, you can consider new threat scenarios. These new threat scenarios then need to be fed back into the BIA process. Over time, this builds institutional knowledge on what risks the business faces and how to properly respond.
The key point is to use these incident analyses to be proactive in defending against threats. The reports examine how to close a security weakness as well as why the security weaknesses were not originally considered and closed. Reports improve the risk assessment process as much as they help close a specific vulnerability.
Creating Mitigation to Prevent Future Incidents
Part of the analysis is to trace the origin of the attack. This is important for preventing future incidents. This activity involves finding out how hackers entered the application, systems, or network. The analysis should create a storyboard and timeline of events. The storyboard is a complete picture of the incident. This includes actions taken by the hacker, employees, and IRT.
The IRT may engage outside help in identifying the attacker. This outside help may include consulting firms that specialize in forensic investigations. It may also include various law enforcement agencies. These outside resources have established contacts with Internet service providers (ISPs). They can track down online users. Although the exact identity of the hacker may not always be determined, these firms can often identify the point of origin. In other words, you may never know the hacker’s real name; however, there’s a good chance you will know the country and city of origin. These firms can also provide a profile of the attacker. Such a profile might include the attacker’s level of skill and potential motive. The attacker might be a high school student. It might also be a foreign government. This information could be valuable to know in determining a response.
 WARNING
WARNING
Forensics is a lucrative industry but one that is poorly regulated. In most states, the only requirement is that the examiner have a private investigator’s license or be a member of law enforcement. There is often no requirement for specific training. There are an alarming number of unqualified forensic practitioners. It is important to thoroughly validate any forensic company or individual. It is recommended that you have a forensic company you have checked out and trust on standby.
It is vital that an organization learn from incidents to improve its controls. Sometimes that may mean changing its policies and procedures. Other times it may mean improving security awareness to reduce human error. It can also mean making changes in your security configuration standards.
A final IRT incident report should be published for executive management. This report will bring everyone up to date on the risk that was exploited. It will also show how it was mitigated. The report should answer the following:
- How the incident was started
- Which vulnerabilities were exploited
- How the incident was detected
- How effective the response was
- What long-term solutions are recommended
After a major incident, you should hold a lessons-learned meeting with key stakeholders. This meeting will review key points in the IRT incident report. A lessons-learned meeting should also be held periodically for minor incidents. You can use an annual trending report as an effective measure of progress in reducing risk.
The lessons learned should include how to improve the incident response process. These lessons can be used to help training. They can also help improve IRT skills. Skills can be improved using methods such as additional training. They can also be improved through testing using new scenarios built from the lessons learned.
Handling the Media and Deciding What to Disclose
The PR department will play an important role in communicating the incident to the media and impacted parties. The PR department can correct misinformation that could damage the company’s reputation. The decision to release information to the public is often handled through a press release.
The PR department is also a point of contact for press inquiries. If a reporter contacts the PR department, it’s important that the PR department have the latest information on the incident. How much information to release is a decision for management. It is the role of the IRT management to make sure the PR representative has the core facts. It’s then up to management and the PR department to work out the type of disclosure that’s appropriate for the situation.
Notification may be required that will impact consumers. Many privacy laws require consumers to be notified if their personal information has been breached. Once again, the PR department will work with management and legal to determine what needs to be disclosed to stay in compliance. Note that any attempt to cover up a breach is likely to cause additional harm. In many cases, such a coverup may be illegal. Even if it is not, strictly speaking, illegal, it is likely to damage an organization’s reputation should it come to light.
Business Continuity Planning Policies
A business continuity plan (BCP) policy creates a road map for continuing business operations after a major outage or disruption of services. BCP policies establish the requirement to create and maintain the plan. The BCP policies give guidance for building a plan. These include elements such as key assumptions, accountability, and frequency of testing. BCP policies must clearly define responsibilities for creating and maintaining a BCP. The BCP identifies responsibilities for its execution.
The plan must cover the business’s support structure, which includes things like facilities, personnel, equipment, software, data files, vital records, and relationships with contractors and service providers. When you must have minimum downtimes, BCP planning and documentation must have a high degree of precision.
But suppose a recent risk assessment has identified serious control weaknesses based on poor physical security at the vendor’s facilities. Well-defined BCP policies would require a gap analysis along with the risk assessment. This approach allows you to assess the vendor weaknesses as part of the BCP process. These weaknesses can become scenarios discussed in the BIA. In this example, you may choose to continue this strategic relationship but consider how to mitigate the vendor’s physical security risk.
TIP
Compare the business impact assessment and the business continuity plan. The two should closely align. For example, if the business identifies a critical asset or process in the BIA, then it should be a recovery priority in the BCP. Gaps or discrepancies should be reported to appropriate management.
NOTE
A BCP is about getting essential business operations up and running, which include technology components. A disaster recovery plan, which you’ll learn about later in this chapter, is about full recovery as if the incident never happened. Think of BCP as just enough to keep the organization running.
As previously mentioned, the BIA is the initial step in the business continuity planning process. The purpose of a BIA is to identify the company’s critical processes and assess the impact of a disruptive event. The desired results of the BIA include:
- A list of critical processes and dependencies
- A workflow of processes that include human requirements for recovering key assets
- An analysis of legal and regulatory requirements
- A list of critical vendors and support agreements
- An estimate of the maximum allowable downtime
The BIA is the foundation on which a BCP is developed. The individuals accountable for the BCP should be key stakeholders in the BIA process. These include the auditors who must assess the adequacy of the planning process. Poor-quality results in the BIA will lead to poor-quality BCP planning.
Dealing with Loss of Systems, Applications, or Data Availability
The list of critical systems, applications, and user access requirements comes from the BIA. The BIA also includes maximum downtime. This drives the selection of recovery methods and techniques. As the recovery window is shortened, there must be more reliance on technology. People can react only so fast. Speed of reaction can be a problem if a disaster strikes while individuals are most distracted, such as during a long holiday weekend. Key staff may be away for the holidays and out of communication. In that case, you should rely more heavily on automation and well-documented plans that others can execute in the absence of that staff.
In the case of a long holiday weekend, it may take hours to connect with key personnel who have a reasonable understanding of the event. At worst, it may take days. Coping with the loss of systems and technology requires effective planning. It also requires coordination, often with a greater reliance on manual processes. These manual processes must be well defined.
The BCP policies require the same level of care for the information. Assume a clinic faces a disaster. It chooses to capture information by hand. The information captured needs the same level of care as if the information were entered into a computer. The information may be covered by HIPAA and thus require the same diligence in security and handling. The BCP is not just about recovery; it must detail the access controls needed to protect the information during recovery. These controls might include securely storing and transporting the information.