
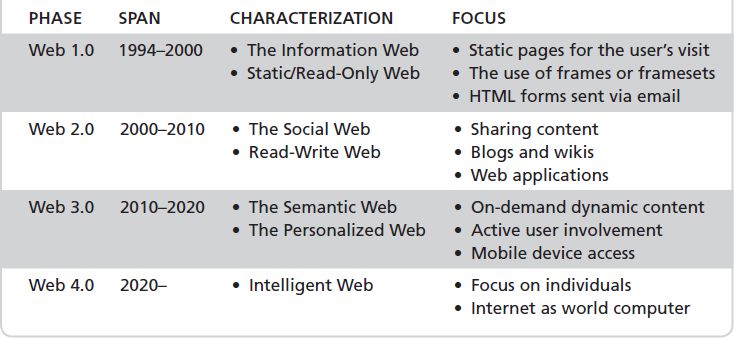
World Wide Web Phases
The World Wide Web is dynamic and in a constant state of change. As the need for new features and functions are requested by users or provided by vendors, the web continues to grow and to become a much broader tool. The impact of these changes on the growth of the web has been separated into four distinct phases, each of which defines the state of the web at a certain time and identifies its use. These time-period phases are Web 1.0, Web 2.0, Web 3.0, and Web 4.0.
The phases that have been identified in the history and future of the World Wide Web are listed in Table 1-3.
Web 1.0
Web 1.0 is often referred to as the “Static Web” or the “Read-Only Web” due to its general lack of user interactions and participation. A user would visit a website, read or capture its information, and then close the site. Web 1.0 was essentially the time when internet connections were made through dial-up modems. Users were inexperienced, and technology was rapidly changing. The following are some characteristics of Web 1.0:
-
Static website content—Websites were noninteractive, displaying information but not much else. Website content was updated infrequently, if ever.
-
Noninteractive sites—Wikis did not exist; user-generated content was minimal. Sites were visited for information gathering and then closed.
-
Limited open-source software—Much of the Web 1.0 software was proprietary and users weren’t able to contribute to its development or enhancements.
Web 1.0 pages often consisted of a single HTML document using frames to organize the presentation of the information. A frame is a portion of the webpage that users accessed. Each frame displayed a different HTML document. The use of frames came from the need to keep information normalized, reusable, and modular, so that when changes were needed, modifications in the code were minimal. For example, if a system of webpages used a menu, it made sense to isolate the menu in a frame. When authors wanted to change only one item in a menu, they could make a single change in the frame where the menu’s HTML code resided rather than making the same change to every webpage.
Web 1.0 Components
Web 1.0 represented the beginnings of the web that exists today. Yes, it would go through a couple of more phases, but Web 1.0 laid the foundation for much of what we have today. A Web 1.0 had essentially four basic design components:
-
Static content
-
Webpage content is retrieved from a server’s file system
-
Webpages constructed around SSI and CGI
-
Frames and tables to position and align the objects on a webpage
Web 2.0
Because the web phases aren’t actually versions, such as Windows 3.0 and Windows 3.1, of the web and its capabilities, there is no hard start and end dates for its phases. Web 2.0 doesn’t mark a point-in-time; rather, it connotes a change in how the web was used and the applications and content it hosted.
Depending on your source, Web 2.0 began (and Web 1.0 ended) somewhere between 2004 and 2006, and some say that it’s still with us; others have begun the next phase (Web 3.0), and still others are discussing a fourth phase. The web phases are more about users interacting through blogs and social media and establishing online friendships and communities. On a business level, it means using blogs and social media to establish grassroots marketing efforts and business awareness. Web 2.0 has served to move the web away from the emphasis on technology and toward being an interactive part of the daily life of its users.
While Web 1.0 primarily provided information on a variety of topics, Web 2.0 shares user-generated content created or managed with tools for formatting, collaboration, and communication. A good example of a Web 2.0 website that offers this range of tools is the WordPress blogging software, which, like other tools of this type, is free and easy to use.
A few topical or purpose-centric websites appear in Web 2.0:
-
Social networking—A big part of Web 2.0, social networking websites enabled users to gather as individuals or as groups to share news, events, and opinions, typically based on common interests. Social networks fit the criteria of Web 2.0 because they enable the connection and interaction among people who share personal or professional interests and other characteristics. Examples of social networking sites are MySpace, Facebook, Twitter, TikTok, SnapChat, and Parler.
-
Blog sites—What began as “web logging” soon became “blogging” in the ever-changing Net language. A blog site allows users to use open-source blogging software to express opinions, share creative writing, or provide commentary of just about anything.
-
User-generated encyclopedias, references, and dictionaries—Perhaps the best know website of this type is Wikipedia, which got its name from the “Wiki Wiki” (meaning “Quick Quick”) taxi cabs in Hawaii. Since its debut in 2001, Wikipedia has spawned many “wiki” or “pedia” sites on a wide range of subject areas and topics. These sites have allowed user-generated reference content to be available to any user of the web. Wikis are referred to as dynamic documents because the content is generally open to anyone who wishes to edit or update the articles.
One thing all Web 2.0 applications have in common is interactivity. Web 2.0 is about sharing, communicating, and revealing. Web 2.0 established that users, acting as developers, are clearly in control of the future of the web and the internet and, as we explore throughout the remainder of this book, security and privacy.
Web 3.0
Web 3.0, which is also known as the “Semantic Web,” represents the transformation of the web into what amounts to one very large online database. Among the technologies emerging within Web 3.0 are blockchaining and decentralization. These developments provide users with an expanded ability to search and categorize content on the web as if it was a local database. Some forecasters see Web 3.0 as enabling online information to be created, manipulated, and stored in what are essentially private online databases from creation to deprecation. However, this vision does have its areas of concern. The primary concern, of course is security. No longer are the internet and web readable by only humans. As the technology advances, computers, using a variety of methods, such as artificial intelligence (AI), can also “read” the content, manipulate it, correlate it, and redefine it with expanded or relaxed context.
Web 3.0 is all about information access, retention, organization, and categorization. On a practical level, Web 3.0 allows you to maintain all information from a calendar to documents and medical records and more online and in a single, easily accessible database. Web 3.0 moves people closer to fully integrating online and offline information, making the browser not only a search engine but a productivity tool.
Blockchain
Blockchain is a peer-to-peer decentralized and distributed ledger technology in which asset records are stored in a scalable format that provides reduced risk. Blockchain operates without any involvement from a third-party authority. For example, let’s say that thrift institutions, which includes banks, saving and loans, and credit unions, no longer exist. You pay a merchant for his goods and services by issuing a personal check against your cryptocurrency account. The transaction is strictly between you and the merchant and is recorded (in the blockchain) as such.
Because blockchain is a decentralized network, it has many benefits over centralized network, including reliability, availability, and privacy. Another key benefit is that a blockchain network has no single point of failure. The benefits of a blockchain network can be categorized into four groups:
-
Availability—Because it is decentralized and peer-to-peer (P2P), a blockchain network remains highly available. Should one of the nodes connected to the network go down, all of the other nodes are still able to access the network. Figure 1-12 illustrates how servers in a single location sets up a single point of failure. If the connection to the servers fails, the network is down. However, in a P2P network, should one node go down, all the rest are able to carry on.
-
Immutability—In a blockchain network, there is no possibility that any stored data can be changed. Any data stored on the blockchain are permanent and cannot be altered or deleted, ever.
-
Security—Blockchain technology is based on cryptography, which means that the records stored on a blockchain network are encrypted for security, availability, and integrity.
-
Transparency—Unlike a centralized system, a blockchain network provides data to be stored in a completely decentralized network that is available and completely transparent to its creating organization.
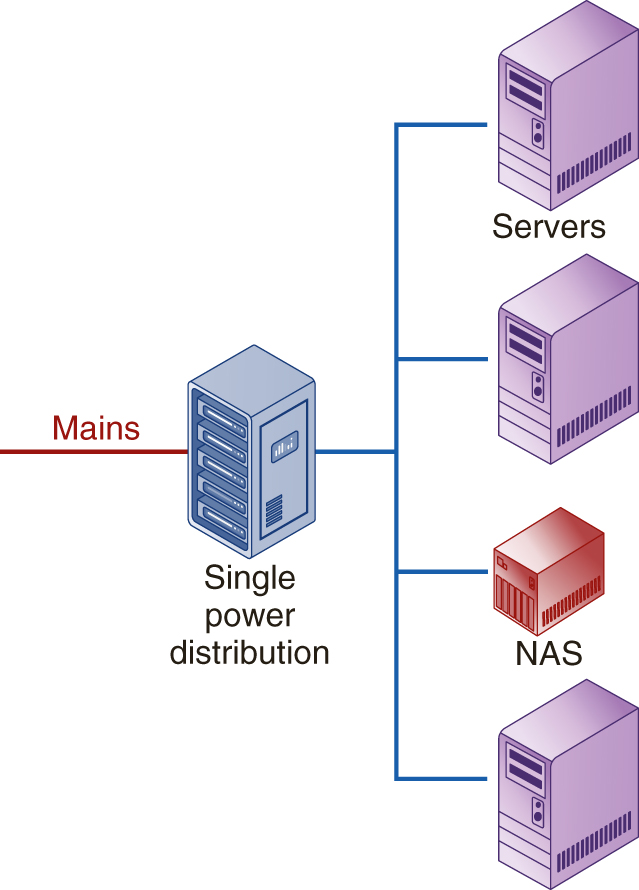
FIGURE 1-12 Servers in a single location can create a single point of failure for a network. A P2P network continues to function should one node fail.
Decentralized Web
As illustrated previously in Figure 1-12, a decentralized peer-to-peer network supports each of the benefits just listed. As important as these benefits are to the future of the web, Web 3.0 introduces new philosophies aimed at making the internet and web more personal to users:
-
No central point of control—The decentralized layout of Web 3.0 may eventually eliminate the need for centralized server farms, content delivery networks (CDNs), and caching services as users retain the ownership and rights to their personal data and documents.
-
Information availability—Because decentralization means that datasets don’t necessarily need to be transferred over great distances, this should allow larger files to be shared, analyzed, and used for reference.
-
Improved web browser capabilities—The use of AI and other software technologies will expand the capabilities of what we now call a web browser, including the capability to sort, calculate, categorize, and filter incoming data to produce answers and to block malware, unreliable data, and data with a bias.
-
Personalization of web experience—This development may be a double-edged sword in that it may help both e-commerce merchants as well as users. AI will be able to improve the function of web advertising toward providing users with ads in which they have demonstrated an interest. In addition, new or improved websites that should be of interest to a user can be presented for viewing.
Web 4.0
Whether we have entered the Web 4.0 phase or not is debatable, but there are signs that if it hasn’t already started, it is not that far off in our future. Perhaps the primary problem with knowing if Web 4.0 has begun is that a clear definition of what it is to include and develop has not as yet been established.
Web 4.0 has been called the “pervasive computing” and the “ubiquitous computing” web most frequently. Less frequent references are the “symbiotic” or “social computing” web. Even with this uncertainty, a number of studies, reports, and articles have reached an informal agreement on what will characterize Web 4.0:
-
Symbiotic interactions between computers and humans may obscure their separation.
-
The internet and web must be “always on” and ubiquitous.
-
The web becomes a large integrated operating system with its resources appearing to be “local.”
-
Machine learning and AI systems learn users’ information needs and anticipate them.
-
The web communicates with users conversationally.
-
Hardware and software advances make the web faster and more reliable.
Keyword Search
Search functions on computers before the web were either index searches, binary searches, or very basic word-in-context searches. These searches primarily looked through indexed document titles, which were slow and not always precise. The browsers introduced during the Web 1.0 phase introduced keyword search, which scanned the content of webpages for keywords (specific words or phrases). Later search engines now use software agents that move through the web scanning website content on servers and following hypertext links it finds in the documents. The information collected is used to index a webpage for key content matching and cataloging.
Search Engines.
First, let’s establish just what a search engine is. A search engine is software running on a central location (typically) that uses other software to locate and categorize searchable content on servers and hosts connected to an internetwork. In other words, when you want to find content on the web that relates to a particular subject, you enter it into the search engine, and the search engine looks through its catalogues for content that matches your search terms and displays a search engine results page (SERP). In general, this is how search software has worked since it was first available on the web.
The general design of a search engine revolves around indexed catalogues or categories that are constantly updated through the use of bots, known as web crawlers or spiders. A web crawler is used by just about all contemporary search engines to virtually scan every piece of content on the internet. It accomplishes this by following the hypertext links in webpage documents, recording each link, and capturing the text content, and page characteristics, such as metadata tags, image descriptions, and any alternative tags (“alt tags”). The crawler then returns to its base, passes the information it has gathered to the search engine, and seeks out the next site to scan.
Search Engine Optimization.
From the site owner’s point of view, SERPs are the most important element of a search engine. Where a site appears on a SERP, and especially the first SERP, has a huge impact on the number of visits a site may have. Numerous studies by a wide range of researchers estimate that less than 6 percent of searchers ever click through to the second page of the search results. The desire to be included in the first page results has led to what is called search engine optimization (SEO). SEO is a process used to increase the chances of a website being included in the first page SERP. Where a site is listed in the search results depends on a variety of factors, which different search engines weight uniquely. SEO services and software attempt to shape the metrics and content of a website to achieve a higher position in the search results. To do this, SEO uses a variety of methods, including the following:
-
Link building—This process searches out websites that include hypertext links to a specific website, typically the site of a client or the user running the process. This helps build the metric that measures the popularity of a site.
-
SEO title tags—Each of the sites listed in a SERP has a hypertext link title for the listed site. It’s important that title tags be as accurate as possible to properly identify the content of a site. Figure 1-13A shows an example of an SEO title tag.
-
Content optimization—The purpose of content optimization is a combination of three objectives: make the content of a webpage more understandable for search engine crawlers, make the webpage content more readable for viewers, and improve the presentation of the on-page content.
-
Meta description—Also called a description meta tag, this is a brief plan-language description of what the webpage contains. This is often the description displayed on the SERP beneath the SEO title tag. Figure 1-13B shows an example of a meta description.
-
Keyword research—This is a process that optimizes a website for words that users are entering into a search engine. If certain words are common to searches for a product, service, or information, it helps the ranking of a website to include the more popular keywords.

FIGURE 1-13 An example of an SEO title tag in search results (A) identifier and (B) plus description.
With the massive growth of information on the web, search engines are faced with the challenge of developing systems that are aware of the relevance of the hits to the user. As the amount of information on the web grows, searching takes more time.
Brief History of Search Engines
The search engines of today illustrate that this technology has come a long way from its early beginnings. Search engines have evolved from searches on specific file types to search capabilities that include graphic searches. The first search tool was Archie, which searched through files available for FTP downloading. Yahoo! searched through a list of popular websites. Alta Vista introduced natural language searches. Lycos introduced categorization and keyword searching. Ask Jeeves used editors to match user searches to content.
Google, with approximately 99 percent of all search inquiries worldwide, is by far the most popular of the search engines. Google’s ranking criteria has evolved into an algorithm that other search engines find hard to match. Google analyzes a variety of factors that include social media, links from other pages, recently updated content, and the trustworthiness of the site. Figure 1-14 shows an image of an early Google homepage in 1998.
FIGURE 1-14 The Google homepage in 1998.
Google and the Google logo are registered trademarks of Google Inc., used with permission.
Directory Portals
Similar to keyword search, directory portals began during Web 1.0 to add purpose or to group the information users retrieved. They are not search engines. They organize groups of links into a structure usually in categories and subcategories. Early instances of directory portals relied on human organization of the structures. In novel examples of directories, the structure emerged out of user tagging. It was common for early directories to charge for the inclusion of a webpage in the portal. They resembled the yellow pages in phone directories where the phone numbers of companies are organized by categories based on the service they provide.
Server-Side Includes and Common Gateway Interface
Two server-based webpage tools used on early webpages were Server-Side Includes (SSI) and the Common Gateway Interface (CGI), not to be confused with Computer-Generated Imagery (CGI). SSI is an interpreted scripting language that was primarily used to merge the content of one or more files into a webpage. Common uses for SSI were the inclusion of standard page elements for an organization, such as page headers, navigation menus, and logos. Web servers knew that a webpage file was SSI-enabled by the use of one of the following file extensions: .shtml, .stm, or .shtm. SSI was developed from components of the NCSA’s HTTP design.
The Common Gateway Interface (CGI) is a function in HTTP with a set of rules and processes that interpret the actions of a webpage to interact with a web server, a database server, and the user’s browser. A common application of CGI for a webpage is the processing of webpage forms. When a webpage sends form data to the web server, CGI intercepts the data and passes it to the appropriate application on the web server. When the application completes its processing, its results are then passed back to the user’s browser by CGI. Figure 1-15 illustrates this flow.
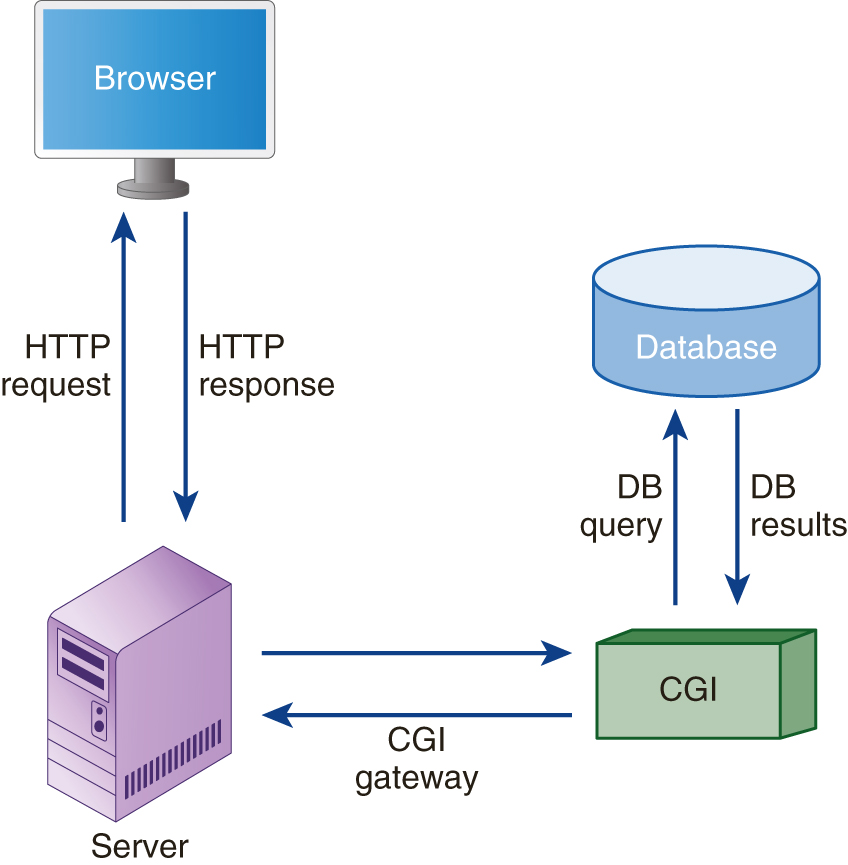
FIGURE 1-15 The flow of CGI elements at the web server.