
Malware, Viruses, Worms, Bugs, and Botnets
Malware, viruses, worms, and bugs have caused headaches for system administrators since the beginning of computer networking. In fact, one of the first known worms was detected as early as 1988 and spread via the Internet. There are different classifications of malware based on size. Whether dealing with large-scale attacks or even simple small attacks, it is important to detect the threat and act accordingly. The action taken will depend on which type of malware has infected the system. However, the way to detect this malware is primarily based on IDSs and data forensics.
Many types of malware are present in today’s cyber space. The large-scale malware consists of worms and botnets (which can be created using worms). Worms have had some of the most devastating effects on computer networking because the code of a worm self-propagates and replicates across systems. Among the most famous examples of this are the Morris worm and the Code Red 1 and 2 worms. The Morris worm was one of the most famous because it was the first worm to be spread via the Internet to affect approximately 6000 machines. At the time (1988), this represented 10% of all computers connected to the Internet. This was achieved by exploiting vulnerabilities in UNIX sendmail, finger, and rsh/rexec, along with weak passwords. The error that transformed this code into an extensive denial-of-service attack was located within the spreading mechanism code. While this was a very large deal at the time, the Code Red 1 and 2 worms were much more intensive. These worms were descendants of the Morris worm and affected more than 500,000 servers. Clearly, this was one of the most catastrophic worms, causing almost $2.6 billion in damages.
Rootkits are also a very large problem within cyber space because they hide the presence of the intruder. Not only does this software hide the attacker’s presence but it also provides a backdoor into the system so the hacker can acquire more information. While there are levels of different sophisticated rootkits, the ones that system administrators worry about the most are rootkits that modify the kernel itself. This is because they are extremely hard to detect once they have been implemented. Once the rootkit has been set up, an attacker can inject spyware into a system to gain further information on the users through the use of keylogging software. In some extreme cases, a hacker may utilize ransomware to “lockdown” a system until a payment has been made that will effectively decrypt the ransomware. The most recent example of this was the CryptoLocker ransomware, which encrypted drives until a Bitcoin payment had been made.
While malware, worms, rootkits, and other bugs will always occur, detecting them is absolutely critical to preserve the integrity of the data within a system. There are intrusion detection systems (IDSs) that consist of software that is specifically designed to monitor networks and system activities for policy violations and abnormalities. Once these abnormalities have been detected, the intrusion detection software will produce a report for the management station. While some IDSs will attempt to stop an intrusion attempt, not all are successful. For this reason, system administrators will employ the use of a honeypot. A honeypot is essentially a quarantined trap within a network. It is disguised as information that would be beneficial to a hacker; however, it is closely monitored for any intruders.
While there are many ways for malware, worms, rootkits, and other bugs to infect a system, properly secured architectures and IDSs are in place to help prevent, and minimize, the effects of this software on computer networking and host-based systems.
Large-scale malware comes in two separate types: worms and botnets. Worms are able to self-propagate, while a botnet is a series of machines that have been compromised and are under the control (command and control [C&C]) of an attacker. This work focuses on the definitions and categorization of common malicious file types and attacks. What’s most interesting about these classifications is that no person is more or less vulnerable from a socioeconomic perspective. High-Profile, well-known, or high-income individuals may be targets of these attacks as often as low-income or other merely basic users of the Internet.
Botnets: Process and Components and History
Botnets are networks of infected processors that represent the aftereffects of infection with multiple forms of malicious applications. Botnets are a networked collection of machines that have been compromised by one of many methods, allowing a single C&C machine or a group of such control machines to send commands out to that network of infected machines, commanding them to perform a selected task in unison. Usually, the owner/operators of these infected machines have no indication that such a process is underway. Thus, a botnet is a distributed cluster of infected computers that unknowingly execute the commands of a malicious control computer. Such distributed botnets are a common approach for implementing distributed denial-of-service (DDoS) attacks. Furthermore, hackers may also rent out the access and control of these botnets to other hacking groups for them to conduct their own malicious intent. The power of these botnets can be measured by a few core variables—the number of machines in the botnet, their total processing power, their connected bandwidth, and the distribution of their geographic locations. All are critical parts in the success of a botnet’s malicious performance. Furthermore, having access to potential machines for infection enhances the botnets’ expansion and reinfection capabilities.
In order to infect machines, multiple mediums or approaches exist to circumvent security measures put in place by end users. These types are not classified by the code itself but rather the approach used to infect. In many cases, multiple approaches are required to infect machines at a high level, so worms and viruses are not mutually exclusive to completing malicious goals. Worms, for example, do not require a host program; they exist on their own, carrying a payload of some basic backdoor components, and they replicate themselves on vulnerable machines as they are discovered. Worms go through four phases:
1. Probe
2. Explore
3. Replicate
4. Deliver payload
As the speed of computers and networks has increased, the rate at which a worm can spread has been enhanced. One of the most rapidly spread early worms was the “Code Red Worm,” but that pales in comparison to the speed with which current state-of-the-art worms spread infection. Chapter 20 will discuss the sophistication and spread of the Stuxnet worm as compared with historical worms. However, the number of new emerging worms has begun to decline.
The reason for the drop in growth is that the United States took action in shifting some top-level network settings on which worms relied. When these were changed, it became more difficult for worms to adapt and continue replicating using the historically effective techniques. The newer Stuxnet worm relies on a technician bringing a worm in by means of a flash drive, rather than fighting through an array of network-defending software, scanners, and defenders. It is personally and manually, but unwittingly, carried around those defenses.
However, there are still worms that will attack the low-hanging fruit of unprotected sites on the Internet, first infecting the obviously unprotected machines before hitting machines with slightly better protection.
Worms typically contain a small amount of code in order to remain nimble as they traverse the Internet and eventually a corporation’s large local area networks (LANs). An example of worm file size and compression is the “Slammer” worm, which infected 75,000 + machines within 10 minutes. It fit inside a single Universal Data Protocol (UDP) packet, which is connectionless in nature, making it the perfect transport protocol medium for worm replication. The UDP base of this worm had significant effects on the worm’s growth abilities.
Worms are an extremely dangerous logical weapon that can directly deliver physical damage, as occurred with the Canadian Logic Bomb or the Stuxnet worm in Iran. But they can also be used for information espionage and for stealing or blocking revenue, as well as for creating their own form of denial of service. Once they are effectively deployed, they may linger within the public Internet for some time with occasional cross-site infection occurring. To fight the global spreading of worms, “white worms” have been designed to infect and clean exploited machines. However, this approach is unpredictable and may cause more harm than the damage they are trying to alleviate. The ethics of releasing disinfecting worms in an uncontrolled fashion across the Internet is highly questionable. Fighting fire with fire is not always the best solution.
A More Detailed Examination of Malware, Viruses, Trojans, and Bots/Botnets
Malware is a contraction of the words “malicious software.” Malware is considered to be any software or file that is harmful to a computer or system. Malware incorporates viruses, worms, bugs, botnets, rootkits, and trapdoors, which can be difficult to discover and sometimes more difficult to eradicate once detected. This section will examine the most common malware, focusing on how various types of malware work and how best to approach blocking, detecting, avoiding, and removing them.
Worms comprise code that replicates by self-propagation and then spreads across systems by arranging to have the code immediately executed. The worm code that is executed can contain both the malware itself as well as the self-propagation and spread technology. It then uses the local computer network to spread itself locally, heavily relying on internal security failures to access target computers. It then seeks access to edge routers as a gateway out to the public Internet and the vast array of global sites that it can then spread to and infect.
Moreover, a worm does not need to attach itself to existing programs in order to perform its infection. The worm can act alone. And when a worm spreads across a network, it does not tend to change the systems on the computers it infects. A worm can stand alone as executable malware or it can infect other software by placing itself at the back-end of existing code and directly affecting that code as it executes or overlaying files that valid code uses as it executes. In the process of spreading from computer to computer, worms may use a significant amount of bandwidth, which helps in their discovery.
Worms typically carry a payload of the malware tasks to be performed, which can also include the delivery of additional trapdoors, Trojan horses, viruses, and so on. The worm is the messenger, digging its way into the system and then delivering the message, the malware payload, to the intended victim(s).
The four phases of a worm’s operation are probing for vulnerabilities, exploiting those vulnerabilities to enter a selected site, performing the replication of copies of itself, and delivering the malicious payload.
Some Examples of Historical Worm Attacks
Released in 1988, this was one of the first computer worms spread by means of an early form of the Internet, and it was certainly the first to gain vast media attention. It was written by graduate student Robert Tappan Morris of Cornell University (son of the famous security expert Robert Morris of the National Security Agency [NSA]). According to Morris, the worm was not written with the intent of doing damage but to gauge the size of the Internet. The result was that the worm infected approximately 6000 machines, which, at the time, represented about 10% of the Internet. It cost around $10 million in downtime and cleanup.
Code Red I and Code Red II Worms
Code Red I was the worm that attacked computers running Microsoft’s IIS web servers on July 15, 2001. It was a direct descendant of Morris’s worm, exploiting buffer overflow in Microsoft’s IIS. It infected more than 500,000 servers, causing $2.6 billion in damage. Fortunately, Kenneth D. Eichmann figured out a way to block that worm. Code Red II, a similar worm to Code Red I, was released two weeks after its predecessor. Unlike Code Red I, Code Red II primarily focused on creating backdoors rather than attacking. While Microsoft had developed a security patch for this exploit, not everyone had installed that patch, allowing Code Red II to still be effective and continue spreading.
This was released on September 18, 2001. It was a worm that used several types of propagation techniques, making it the most widespread worm on the Internet within 22 minutes of initial infection. The name Nimda is the reverse of “admin,” indicating it attempted to use administrator privileges.
The SQL Slammer was a worm that caused denial of service on selected Internet hosts and slowed down Internet traffic. It was spread on January 25, 2003, quickly infecting 75,000 computers within 10 minutes. This worm exploited Microsoft’s Structured Query Language (SQL) server but did not actually use SQL as part of its infected processes.
This worm, also known as Downup, Kido, and Downadup, targeted Microsoft Windows operating systems, as well as performing dictionary attacks on administrator passwords in order to propagate itself and subsequently create botnets. Conficker was first detected in November 2008 and was difficult to defend against due to the combined set of multiple advanced malware techniques that it employed. Conficker eventually infected 9–15 million computers worldwide.
The Conficker worm exploits several vulnerabilities:
1. Protected from Conficker worm: Computers with strong passwords and secured, shared-folder, up-to-date antivirus software and security updates
2. Unprotected from Conficker worm: Network computers with weak passwords and outdated antivirus software and security updates
3. Unprotected from Conficker worm: Out-of-network computers with weak passwords and outdated antivirus software and security updates
4. Unprotected from Conficker worm: Computers with unsecured/open shared folders and outdated antivirus software and security updates
These vulnerabilities to the Conficker worm as submitted by a remote attacker are illustrated in Figure 7.1.
These were passed as attachments to e-mail messages and could be particularly quick in their spread as broadcast e-mails to a large list of associates.
Also known as the ILOVEYOU worm, the Love Bug worm spread through an e-mail message with the subject of the message being “ILOVEYOU,” with an attachment of “LOVE-LETTER-FOR-YOU.txt.vbs.” At the time, the vbs was hidden by default on Windows computers, leading victims to believe it was a normal text file. Opening the attachment activated the attached malicious visual basic script. The worm then damaged the local machine and sent a copy of itself to the addresses in that machine’s Windows address book. The worm was released on May 3, 2000. Overall, the worm managed to cause $5.5–$10 million worth of damage.

Figure 7.1 The array of protection from and vulnerabilities to the Conficker worm.
This worm was released on January 26, 2004, and it became the fastest spreading e-mail worm as of 2004, exceeding the Love Bug worm. There were two versions of MyDoom—Mydoom.A and Mydoom.B. Mydoom.A had two payloads, one to create a backdoor and the other to perform a denial of service. Mydoom.B had the same payloads, but in addition it blocked Microsoft’s website and other popular antivirus websites. The denial-of-service attack was focused on the SCO Group Company.
Identified on January 17, 2007, this worm’s payload included code to create a backdoor Trojan horse that affected Microsoft operating systems. It spread itself using an e-mail with the subject of the e-mail concerning a weather disaster: “230 dead as storm batters Europe.” By January 22, 2007, the Storm worm accounted for 8% of malware infections globally. By June 30, it had infected 1.7 million computers.
A virus is self-replicating code that inserts itself into other computer programs, hard drives, and data files. Viruses utilize attachment approaches to attempt to avoid detection so that they can do their damage, replicate themselves, and spread to infect additional systems. The important aspect common to all viruses is that they are self-replicating program code and install themselves without a user’s consent, either as attachments to existing programs or as stand-alone code. And they do not necessarily have to contain a malicious payload to be considered a virus.
Furthermore, viruses are opportunistic, meaning that their code will continue to seek out ways that will allow them to eventually execute. Typically, the viruses’ execution is triggered by a user action, such as running an infected application or restarting the computer so that as part of the restart process, the infected code is executed. Similar to worms, viruses tend to have a malicious payload and a propagation methodology.
When a virus executes, it also looks for an opportunity to infect additional systems. As an example, a virus might look for a USB-attached flash/thumb drive to infect, so that when the thumb drive is placed in another system, the virus can spread (the Stuxnext worm approach). Another way a virus can spread is when a user sends an e-mail with a virus attached. The virus can alter an intended e-mail attachment and implant itself; this is usually done with a microset of code at the beginning of the original attachment, which, upon execution, branch around the good original code to the virus payload code placed at the end of the original code. To avoid detection, the infected attachment and the original code are compressed down to the original size of the intended attachment code. This virus approach is especially effective in infecting attachment types that are programs (such as Microsoft Word [macros] and PDFs with JavaScript), rather than simple Word documents and simple PDFs. A virus can also send out e-mail on its own with attachments of itself.
So the basic process is that when a virus infects a program or file, it first places a branch routine at the front of the original program and then places the virus payload code at the end of the original program. Upon execution, the entry code branches directly around the original code to the virus code attached at the end for its execution. The combined infected code is then compressed back down to the size of the original code in order to avoid detection. The entry code triggers the decompression of the code as well as the branch to the virus code at the end. Figure 7.2 illustrates this process.

Figure 7.2 Virus wrapped around a program and then shrunk to original size.
Virus code can do anything that is desired. It can pop up messages, delete files, damage hardware, perform keylogging, encrypt your files and hold them for ransom, install potentially logic bombs that can detonate at a later date, and perform any type of deletion or further infiltration.
Viruses do billions of dollars’ worth of damage every year and as a result created the multibillion-dollar antivirus industry (AV). An antivirus runs a signature-based detection. It looks through bytes corresponding to the injected virus code. Once you find a virus, you can protect the computer and other computers by installing a recognizer for the virus. Antivirus companies compete on the basis of the number of signatures they possess.
If you were a virus writer and you realized that companies are finding your viruses and blocking that specific pattern, the ideal thing would be to change the virus or its appearance. Having to write a new virus takes a lot of time, so one solution would be to have the virus alter itself with propagation, making different-looking copies each time it spreads.
Polymorphic code is code that uses a polymorphic engine to mutate while keeping the original algorithm intact. In other words, each time the code runs, the structure changes but the functions do not. Encryption is the most common method used to hide code. It is important to note that encryption alone is not polymorphism. To be considered polymorphic, the encryption and decryption must mutate with each copy of the code, allowing for varied versions while the functions remain the same. When the code runs, the virus decrypts itself to obtain the payload then execute it. Figures 7.3 and 7.4 illustrate an example of a byte that is infected with a virus and what polymorphic code would look like when encrypted and then decrypted.

Figure 7.3 Polymorphic virus infection and decryption process.

Figure 7.4 Polymorphic virus propagation of unrecognizable child viruses.
Polymorphic code was the first technique that became a serious threat to virus scanners. One idea to defend against it is to use narrow signatures that target the decryptor for the polymorphic code. There are a few problems with this countermeasure. For one, there is less code to compare, resulting in more false positives (i.e., code that is fine but is scanned as a threat); also, virus writers can spread the decryptor across the existing code, making it hard to find. A different approach is to analyze code to see if it decrypts. The problem with this strategy is that not all code that has decryption is malicious or unwanted. The other issue is that you have to let the malware decrypt in order to find it, but how long do you allow the malware to run before you stop it? As is the case most of the time, virus writers are two steps ahead of antivirus companies. To combat against these new tactics, virus writers came up with a new solution.
Each time the virus propagates, it generates semantically different versions of itself. In other words, the virus rewrites itself completely each time it infects a new component of the system. When it runs, it produces a logically equivalent version of its own code with various interpretations. This child virus will perform the same task as the parent, but the binary representation will be different. Some ways of doing this include renumbering registers, changing the order of conditional code, reordering operations not dependent on one another, replacing one low-level algorithm with another, or removing some do-nothing padding and replacing it with different do-nothing padding. A metamorphic is extremely large and complex code.
When looking for metamorphic code, the virus scanner looks for its behavior rather than its structure. In other words, what is the outcome of this code? Is it malicious? There are two stages in searching for a virus:
1. Antivirus company analyzes new virus to find behavior signature.
2. Antivirus company software on the end system analyzes suspect code to test for signature match.
As usual, virus writers are two steps ahead. A virus writer can delay the analysis. One major weakness of this type of scan is that it has to find the behavior to find the virus, so if the virus writer can stall the program to not function during a scan, it can avoid being detected. Antivirus companies look for these tactics and skip over them. It is the ever ongoing battle in security.
Getting rid of malware may require restoring or repairing files. If the malware was executed on administrator privileges, it might be best to wipe the slate clean. Once you’re infected, you never really know if you have gotten rid of all the malware on your computer. You will need to be careful about using backups because the virus may have infected your backups as well.
An example would be a forensic analysis showing that a virus introduced a backdoor in/bin/login executable. The cleanup procedure is rebuild/bin/login from source (Figure 7.5).
Once the compiler becomes infected, it is very difficult to correct that compiler. And if a backdoor trap has been created from that compiler infection, it is very difficult to detect it and, even if it is detected, to permanently remove it.
A botnet is a collection of compromised machines under the control of an attacker or botmaster. Botnets are also known as zombie armies, and their name is a contraction of the words “robot” and “network.” Botnets are typically used for denial-of-service attacks. As previously, the method of compromise or propagation is decoupled from the method of control or payload. Typically, a botnet will be spread using a worm, virus, or drive-by infection. The botnet itself is the payload of these tools. Once the target is infected, the bot will get in touch with the botnet C&C. The C&C is what the botmaster will use to send out commands to the various bots. There are a variety of ways to create an architecture with C&C: a star topology, a hierarchical approach, a multiserver approach, and so on. When communicating with C&C, stealthy communication with encryption is used.

Figure 7.5 Introduction of a backdoor trap.
The star topology centralizes the C&C to each bot. Each bot receives instructions directly from the C&C. The advantage is the direct communication with the bots, allowing for quick theft and directions. The disadvantage is that if the C&C is blocked or disabled, the bot is useless (Figure 7.6).
The multiserver approach is a logical extension of a star topology. Instead of having one server, multiple servers are used to give commands. Should a server fail or be removed, the others can take over the commands. Placing the servers geographically near the bots improves speed, and C&Cs hosted in multiple countries can avoid being completely shut down by law. The disadvantage of multiservers is that they take a lot of preparation and effort to build (Figure 7.7).

Figure 7.6 Star topology C&C botmaster to bot topology.

Figure 7.7 A collaborative C&C botmaster.

Figure 7.8 Two-stage C&C of a distributed botnet.
Instead of all the botnets replying to the C&C, some botnets can be put in charge of a cluster of botnets and distribute the commands on the botmaster’s behalf. The problem, however, is that updated commands more often suffer latency issues, making it difficult for the botmaster to use his or her bots for real-time activity. With the hierarchical model, no single bot is aware of the entire botnet, which can make it difficult for security to find and measure its size. Botmasters can sell their individual bots or break them into further subcategories (Figure 7.8).
The first approach, and the most obvious, is to prevent the initial bot infection. However, because the original bot machine infection precedes and is decoupled from the bots’ participation in the botnet attacks, botnets are difficult to stop at both the infection stage and then later in the attack phase.
One approach is to locate and take down the C&C computer, the source of the botnet, and to defuse that C&C along with the botmaster. If you can find the C&C’s IP address, you can have the associated Internet Service Provider (ISP) deny the botmaster’s access. The problem, however, is that the botmaster can keep moving the master server, either by moving to a different domain or by rapidly altering the address associated with that name, a process termed Fast Flux. Botmasters can hide their servers and themselves in a hierarchy of multilayered, multiserver construction. Furthermore, botmasters can also pay their ISP to not shut them down. And there are ISP businesses that guarantee your website will never be shut down. An example of a “no shut down” ISP is GooHost.ru, a located in Russia.
A difficult problem is dealing with those who know how to browse the Internet with anonymity by hiding their IP address using onion routing and anonymity websites, augmented by using other more sophisticated sneaky ways of communicating or computing.

Figure 7.9 Hiding the sender’s address in the delivered message.
There are a variety of options for achieving privacy through technical means, such as removing cookies (including flash cookies) or turning off JavaScript so that Google Analytics cannot track you. In order to hide an IP address, one approach is to trust a third party to perform that obfuscation process.
Hidemyass is one example of a third party that can hide your IP address for you. With Hidemyass, you set up an encrypted virtual private network (VPN) to the Hidemyass site. Then all of your traffic goes to them. An example would be if User A wants to send a message to User B while ensuring that a third party, User C, cannot determine that User A is communicating with User B (Figure 7.9).
Hidemyass will (1) accept messages encrypted for User B submitted by User A, (2) will extract User B’s destination but hide User A’s source address, and (3) will forward the message to User B. The problem with using a third party is that your Internet browsing performance may suffer, and of course it is a fairly pricey service, costing up to $200 a year. A further issue is that your identity can be uncovered by means of “rubber-hose cryptanalysis,” which involves someone “beating” the encryption key Hidemyass employs by means of threat or extortion. In this case, hackers and crackers can attack Hidemyass until they release the desired information (Figure 7.10).
Another option is onion routing. As mentioned in previous chapters, this approach generalizes to an arbitrary number of intermediaries. In other words, servers volunteer to help keep you anonymous and are shuffled as you travel the Internet (Figure 7.11).
As long as any of the volunteering intermediaries are honest and trustworthy, no one can link User A with User B. Onion routing is not without its flaws and risks, however. It affects performance due to the message being bounced around. There is also the threat of rubber-hose cryptanalysis (again, beating the information out of one of your volunteers). The defense against this is to mix the servers in different countries, but this also takes a toll on performance. In the worst case, the attacker may operate all of the mixes or intermediaries. The defense against this is to have a large variety of servers, and today onion routing has around 2000 volunteer servers. The other form of attack involves the attacker watching Alice and Bob and noticing that when Alice sends out an e-mail, Bob gets one around the same time; the attacker is able to put two and two together. The defense against this is to pad messages and/or introduce significant delays. The Tor protocol, for example, pads messages, but that alone is not enough for absolute defense.
One last issue Tor can suffer is leakage. What if all of your HTTP/HTTPS traffic goes through Tor but the rest of your traffic does not (i.e., FTP). The server notices that your anonymous HTTP/HTTPS connection is the same as your FTP connection. This coincidence allows people to put two and two together and deduce that you are the same person. The general problem with anonymity is that it is often put at risk when an adversary can correlate separate sources of information.

Figure 7.10 Transmitting through HMA and an intermediary.

Figure 7.11 Tor anonymizing bidirectional communications.
Sneakiness and Side-Channel Attacks
Steganography is the process of transmitting hidden messages using a known communication channel when used no one knows the message is there. This same principle applies to hiding extra hidden data inside known storage, for instance, hiding a potential worm inside an image file. The overall goal is to sneak communication past a reference monitor (a “warden”). This does not imply confidentiality; if the message is discovered, the malware is revealed, although you could potentially encrypt it. The advantage of steganography over cryptography alone is that the secret message does not attract attention to itself as an object of scrutiny.
Some examples of steganography can be traced back to tattooed heads of slaves. The story is told by Herodotus that in ancient Greece a man’s head was tattooed with a secret message, and then his hair was grown out, hiding the message until he shaved. Some digital examples are least-significant bits of image pixels, or extra tags in HTML documents. All that is necessary for steganography to work is an agreement between the writer of the message and the reader of the message, along with the extra capacity to store the file.
How do you protect yourself from this? If the steganography is well designed and the monitor, or warden, can only watch passing traffic, it can be hard to detect. If, however, we permit the “warden” to modify communication, recode images, canconicalize HTML, or shave the head, then the warden can discover the hidden message.
These are communications between two parties that use a hidden (secret) channel. The goal is to evade reference monitor inspection entirely. In this case, our “warden” is unaware that communication between Users A and B is possible. Just as in steganography, an agreement between sender and receiver must be established in advance for this to work. Here is an example of covert channels. Suppose (unprivileged) process Alice wants to send 128 bits of secret data to (unprivileged) process Bob. Process Alice cannot use pipes, sockets, signals, or shared memory, and she can only read files, not write them. Alice has a few options to get the information to Bob.
■ Method #1: Alice can syslog her data, which B can read via/var/log/.
■ Method #2: Alice can select 128 files in advance. Alice then opens the files for read only purposes that are marked with 1- bits, corresponding to the fact that they are secret. Bob recovers bit values by inspecting access times on files.
■ Method #3: Alice can divide her file’s running time up into 128 slots. The file either executes, or doesn’t execute, in a given time slot depending on a corresponding secret bit being on or off. Bob’s computer monitors Alice’s CPU usage, observing the run-time slots used for her program execution.
■ Method #4: Suppose Alice can run her file 128 times. Each time it either exits after 2 seconds (0 bit) or after 30 seconds (1 bit).
■ Method #5: This list can go on for ever.
The best way to secure against covert channels is, as with steganography, to identify the mechanisms. Some mechanisms can be very hard to remove—the duration of a program execution, for instance. The fundamental issue is the covert channel’s capacity; it takes space to send the messages. Bits (or the bit rate) that the adversary can obtain by using it is one example. It is crucial for security to consider their threat model; the assumption is that the attacker wins, simply because we cannot effectively stop communication, especially if the communication is low rate.
A side-channel attack is any attack based on information gained from the physical implementation of a cryptosystem. For instance, timing information, power consumption, electromagnetic leaks, or sound can provide information and can be exploited to break into a system. Information can also come from higher-layer abstractions. This can be difficult to detect because the leaking elements might be deemed irrelevant information. Unlike steganography or covert channels, we do not assume a cooperating sender/receiver.

Figure 7.12 Code that checks a user’s password.

Figure 7.13 Wild guessing of password.

Figure 7.14 More on the password brute-force guessing process.
An example of code that checks a user’s password is shown in Figures 7.12.
Suppose the attacker’s code can call the “check_password” routine many times, but not millions of times, and the attacker cannot break or inspect the code. How could the attacker infer the master password using only side-channel information? Consider the layout of p in memory (Figure 7.13).
The code (Figure 7.13) checks the password, but what if the attacker wrote a loop to check each iteration? What would happen next is shown in Figure 7.14.
When there is a page fault indicating that the correct letter has not been found, the iterative process moves on to attempt the next guess in the sequence.
How do you stop this? One obvious method is to limit the amount of guesses a user can make. But there is a way around that. Suppose you didn’t end the function each time you guessed? The code goes through each iteration and does not end the function until each iteration is guessed (Figure 7.15).

Figure 7.15 Process of continuous guessing.
Suppose Alice is surfing the web and all of her traffic is encrypted and running through an anonymizer such as Hidemyass. Eve can observe the presence of Alice’s packets and their size but cannot read their contents or determine their ultimate destination. How can Eve deduce that Alice is visiting Fox News? Because Eve knows the size and the amount of packets, she can compare them with Fox News’s page information to see if there is a match.
Can we infer or deduce what terms User A is using to search? Can an attacker using System 1 scan the server of victim User V to see what services User V runs without User V being able to learn User A’s IP address? Generally, he can’t, since after all, how can User A receive the results of probes User A sends to User V unless those probes include User A’s IP address for User V’s replies?
Exploiting Side Channels for Stealth Scanning
Figure 7.16 is an IP header side channel.
The attacker makes requests to a web server and records the IDs used for those transmitted packets. The attacker keeps guessing and tries to time the correct guess with the victim. If the attacker succeeds, he or she will receive the same data that the victim requests (Figure 7.17).

Figure 7.16 16-bit identification code incremented with each transmission.

Figure 7.17 Complete sequence of requests and responses between attacker, patsy, victim.
Suppose Ann, the attacker, works in a building across the street from Victor, the victim. Late one night, Ann can see Victor hard at work in his office but can’t see his LCD display, just the glow off his face. How might Ann snoop on what Victor’s display is showing? Solution: Cables from computer to screen and keyboards act as crude antennas. The cables broadcast weak radio frequency signals corresponding to data streams. They even include faint voltage fluctuations in the power lines (Figure 7.18).
Another way to snoop is based on the fact that keystrokes create sound. The audio components are unique per key. The timing reflects key sequencing, or touch-typing patterns. The attacker can listen in on a convenient microphone, such as a telephone, or can listen from a distance using a laser telescope. Next is an example of a checker routine for Linux servers provided by Coverity.

Figure 7.18 Electric lines leak signals.
A software bug is a flaw, failure, error, or fault in a computer program or system. Bugs are made by developers who make a mistake in the code, such as a syntax error or an error in logic. Bugs can be exploited for malware, and it is important to find bugs in your system. This section will briefly look at different approaches to finding security bugs.
There are numerous bugging programs that check your code for security flaws. One company is Coverity, which is a leading provider of solutions for software quality and security testing. Figure 7.19 shows an example of debugging proprietary software from Coverity, which is “a Synopsys company.” We will use Coverity to focus on how bugs work, how they are found, and how a company’s service can be useful in helping you prevent bugs. Figure 7.19 shows the architecture of the Coverity Security Flaw Analysis platform.
Figure 7.20 is a list of bugs that can be detected by Coverity security software.
Most vulnerabilities and coding patterns are specific to the code base. Coverity offers a variety of “checkers” for your programming needs. The example they provide is for Linux. Issues that apply to the Linux kernel are unlikely to apply in application software. Figure 7.21 shows an example of a checker.
It is important to use checkers with your code to make sure you have no vulnerabilities.

Figure 7.19 Architecture of the Coverity security flaw analysis platform.

Figure 7.20 Bugs detected by the Coverity security package.

Figure 7.21 Coverity Linux checker routine.
Detecting Attacks and Removal Systems
An IDS is a device or software application that monitors network or system activities for malicious activities or policy violations and produces reports to a management station. These IDSs come in a variety of “flavors” and approach the goal of detecting suspicious traffic in different ways. There are network-based (NIDS) and host-based (HIDS) IDSs. Some systems may attempt to stop an intrusion attempt, but this is neither required nor expected of a monitoring system. Intrusion detection and prevention systems (IDPSs) are primarily focused on identifying possible incidents, logging information about them, and reporting attempts. In addition, organizations use IDPSs for other purposes, such as identifying problems with security policies, documenting existing threats, and deterring individuals from violating security policies. IDPSs have become a necessary addition to the security infrastructure of nearly every organization.
IDPSs typically record information related to observed events, notify security administrators of important observed events, and produce reports. Many IDPSs can also respond to a detected threat by attempting to prevent it from succeeding. They use several response techniques, which involve the IDPS stopping the attack itself, changing the security environment (e.g., reconfiguring a firewall), or changing the attack’s content.
Host-Based and Network-Based Intrusion Detection Systems
To recap, there are two main types of IDSs: NIDS and HIDS.
Network-Based Intrusion Detection Systems
An NIDS is placed at a strategic point or points within the network to monitor traffic to and from all devices on the network. It performs an analysis of passing traffic on the entire subnet, works in a promiscuous mode, and matches the traffic that is passed on the subnets to the library of known attacks. New variants of attacks are thus not identifiable. Once an attack is identified or abnormal behavior is sensed, the alert can be sent to the administrator.
An example of using an NIDS would be installing it on the subnet where firewalls are located in order to see if someone is trying to break into the firewall. Ideally, one would scan all inbound and outbound traffic; however, doing so might create a bottleneck, which would impair the overall speed of the network. Two commonly used tools for NIDS are OPNET and NetSim.
Host-Based Intrusion Detection Systems
An HIDS runs on individual hosts or devices on the network. It monitors the inbound and outbound packets from the device only and will alert the user or administrator if suspicious activity is detected. It takes a snapshot of existing system files and matches it to the previous snapshot. If the critical systems files were modified or deleted, an alert is sent to the administrator to investigate. An example of HIDS usage can be seen in mission-critical machines, which are not expected to change their configurations.
Honeypot Traps out in the Network
A honeypot is a trap set to detect, to deflect, or in some manner to counteract attempts at unauthorized use of information systems. Generally, a honeypot consists of a computer, data, or network site that appears to be part of a network but is actually isolated and monitored, and which seems to contain information or a resource of value to attackers. This is similar to the process whereby police bait a criminal and then conduct ongoing undercover surveillance of that criminal and all their activities and contacts. Astar offers an integrated firewall, router, and honeypot service, which is popular among legal authorities and corporations; they deploy the service in their counteractivities against invaders as a way of turning the tables on these criminals and using those same hacking tools to trap and identify the hacking criminals by attracting them to holding and identification sites (Figure 7.22).
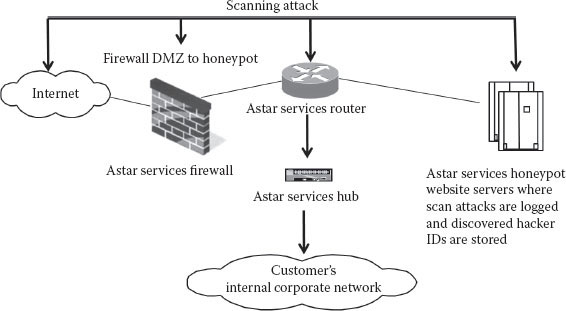
Figure 7.22 Using a honeypot to divert scanning attacks.
In a passive system, the IDS sensor detects a potential security breach, logs the information, and signals an alert on the console or owner. In a reactive system, also known as an intrusion prevention system (IPS), the IPS autoresponds to the suspicious activity by resetting the connection or by reprogramming the firewall to block network traffic from the suspected malicious source. The term IDPS is commonly used where this can happen automatically or at the command of an operator—systems that both “detect” (alert) and “prevent.”
Statistical Anomaly and Signature-Based IDSs
All IDSs use one of two detection techniques:
1. Statistical anomaly–based IDS
a. An IDS that is anomaly based will monitor network traffic and compare it with an established baseline. The baseline will identify what is “normal” for that network—what sort of bandwidth is generally used, what protocols are used, what ports and devices generally connect to each other—and will alert the administrator or user when traffic is detected that is anomalous to, or significantly different from, the baseline. The issue is that it may raise a false positive alarm for legitimate use of bandwidth if the baselines are not intelligently configured.
2. Signature-based IDS
a. A signature-based IDS will monitor packets on the network and compare them with a database of signature or attributes from known malicious threats.
This is similar to the way most antivirus software detects malware. The issue is that there will be a lag between a new threat being discovered in the wild and the signature for detecting that threat being applied to your IDS. During that lag time, your IDS would be unable to detect the new threat.
Though they both relate to network security, an IDS differs from a firewall in that a firewall looks outwardly for intrusions in order to stop them from happening. Firewalls limit access between networks to prevent intrusion rather than signaling an attack from inside the network. An IDS evaluates a suspected intrusion once it has taken place and signals an alarm. An IDS also watches for attacks that originate from within a system. This is traditionally achieved by examining network communications, identifying the heuristics and patterns (often known as signatures) of common computer attacks, and taking action to alert operators. A system that terminates connections is called an IPS and is another form of an application layer firewall.
Attackers use a number of techniques; the following are considered “simple” measures that can be taken to evade IDS:
1. Fragmentation
a. By sending fragmented packets, the attacker will be under the radar and can easily bypass the detection system’s ability to detect the attack signature.
2. Avoiding defaults
a. The Transmission Control Protocol (TCP) port utilized by a protocol does not always provide an indication as to the protocol that is being transported. For example, an IDS may expect to detect a Trojan on port 12345. If an attacker has reconfigured it to use a different port, the IDS may not be able to detect the presence of the Trojan.
3. Coordinated, low-bandwidth attacks
a. Coordinating a scan among numerous attackers (or agents) and allocating different ports or hosts to different attackers makes it difficult for the IDS to correlate the captured packets and deduce that a network scan is in progress.
4. Address spoofing or proxying
a. Attackers can make it more difficult for security administrators to determine the source of the attack by using poorly secured or incorrectly configured proxy servers to bounce an attack. If the source is spoofed and bounced by a server, then it becomes very difficult for an IDS to detect the origin of the attack.
5. Pattern change evasion
a. IDSs generally rely on “pattern matching” to detect an attack. By slightly changing the data used in the attack, it may be possible to evade detection. For example, an Internet Message Access Protocol (IMAP) server may be vulnerable to a buffer overflow, and the IDS is able to detect the attack signature of 10 common attack tools. By modifying the payload sent by the tool so that it does not resemble the data that the IDS expects, it may be possible to evade detection.
Here is a list of basic categories of IDS:
■ Anomaly-based intrusion system
■ Application protocol–based IDS (APIDS)
■ Artificial immune system
■ Autonomous agents for intrusion detection
■ Domain Name System (DNS) analytics
■ Host-based IDS (HIDS)
■ Intrusion prevention system (IPS)
■ Protocol-based IDS (PIDS)
■ Security management
■ Intrusion detection message exchange format (IDMEF)
Here is a list of some free IDSs:
■ ACARM-ng
■ AIDE
■ Bro NIDS
■ Fail2ban
■ OSSEC HIDS
■ Prelude Hybrid IDS
■ Samhain
■ Snort
■ Suricata
A vital complement in detecting attacks is the process of figuring out what happened after a successful attack has occurred. This involves the creation of rich and extensive logs of all activity on a network and of application activity and each database access, read, extraction, and update. A set of tools for analyzing these logs is essential for teams to analyze and understand aberrant activities by the forensic team. This forensic process is one of looking for patterns in activity and comparing those patterns with both known and unusual activity. It also involves understanding the underlying structure of the corporate systems in place in order to detect unusual and possibly aberrant behavior or, data, activity or results.
Detecting Attacks and Attackers with Examples
Symmetric cryptography assumes that all parties already share a secret key. For this type of cryptography to work correctly, the encryption algorithm must be publicly known and the use of a proprietary cipher is discouraged.
Use cases can either be single use or multiuse. Single-use keys are used only once to encrypt a single message. A new key is generated for every e-mail and there is no need for nonce (it is set to zero). Stream ciphers are an example of a single-use key. A multiuse key is used to encrypt many messages and requires either a unique or random nonce.
Block ciphers are the cryptography workhorse. This is a special cipher based on a deterministic algorithm operating on fixed-length groups of bits/blocks with an unvarying transformation that is specified in the symmetric key. These ciphers are important elementary components in the design of many cryptographic protocols and are widely used to implement encryption of bulk data.
The Problem of Detecting Attacks
Given a choice, we’d like our systems to be airtight-secure, but we often do not get that choice. The number one reason is because of cost, resulting in the messy alternative—to detect misuse rather than build a system that can’t be misused. It is important to note that even with airtight security, it is still important to detect for misuse. Misuse might be more about your company’s policy than security. A system has many dimensions to secure, and it’s difficult to decide where to monitor, how to detect problems, how accurate those detections are, and what attackers can do to elude detection.
Suppose you’ve been hired to provide computer security for a company. They offer web-based services via backend programs invoked via this URL: http://company.com/amazeme.exe?profile=info/luser.txt.
Due to the installed base issues, you can’t alter backend components such as amazeme.exe. One form of attack you’re worried about is information leakage via directory traversal. For instance, an attacker could type GET/amazeme.exe?profile=./././../../etc/passwd.
What Is Another Method to Detect This Attack?
Beyond IDS, as mentioned in the previous section, one method you could try to implement is run scripts that analyze log files generated by web servers. One significant advantage of this method is that it is cheap, as web servers generally have logging facilities built into them. It also does not have issues with %-escapes or encrypted HTTPS. The issues come with filename tricks, and the fact that this method cannot actually block attacks and prevent them from occurring. The detection is also delayed, and if the attack is a compromise, then malware might be able to alter the logs before they are analyzed.
Another method is to monitor the system call activity of backend processes—other words, to look for attempts to access to the/etc/passwd. The advantages of this method are that it involves no issues with HTTP complexities, may avoid issues with filename tricks, and only generates an alert if an attack has succeeded. The issues are that you might have to analyze a large amount of data, other processes may make legitimate access causing false positives, or you would prefer detection alert for all attempts.
Up until now, we have suggested simply detecting attacks as they come. But what if you launched attacks on yourself? Vulnerability scanning is a tool that allows you to probe your own systems with a wide range of attacks and to fix any that succeed. The advantages are that it is proactive and prevents future misuse, and it can ignore IDS alarms you know can’t succeed. The downsides are that it can take a lot of work, it is not helpful for systems you cannot modify, and it can be potentially dangerous for disruptive attacks. In practice, this approach is prudent and widely used today.
There are two types of detector errors:
1. False positive: alerting about a problem when in fact there is no problem.
2. False negative: failing to alert about a problem when in fact there is a problem.
Detector accuracy is often assessed in terms of the rates at which these occur. Is it possible to build a detector with perfect detection? The answer is yes, you can have a detector with no false negatives. However, you will pay in false positives. The ideal detector achieves an effective balance between false positives and false negatives. Which is it better to lean toward? It depends on the cost of each type of error. For example, a false positive might lead to paging a duty officer and consuming an hour of their time, while a false negative might lead to a $10K cleaning up and a compromised system because of what was missed. It also critically depends on the rate at which attacks occur on your environment.
Suppose our detector has a false positive rate of 0.1% and a false negative rate of 2% (not bad!). Our servers receive 1000 URLs/day and five of them are attacks.
■ Expected # of false positives each day = 0.1% * 995 = 1
■ Expected # false negatives each day = 2% * 5 = 0.1 (less than a week)
That’s pretty good! But what if our traffic volume increased to 10,000,000 URLs/day and five of them are attacks?
■ Expected # of false positives each day = 10,000
Nothing changed with our detector; just the environment changed. Accuracy grows more difficult when the base rate of activity we want to detect is quite low.
Suppose we’re more worried about a version of the attack that modifies/etc/passwd rather than retrieves it. Say the following code is used:
■ GET/amazeme.exe?profile=/passwd&newcolor=w00t:nIT9q23cjwVs:0:0:/:/bin/bash
How can we detect if this attack was successful? Maybe amazeme.exe generates specific output if a file is modified; if so, look for that. If not, then the NIDS/web-server instrumentation or log monitor all have difficulty in telling if the attack succeeded.
Another approach is a periodic process that looks for changes to sensitive files and creates flags for the operator. This program is not based on file modification time, as a program can simply change that. Instead, compare with a database oh SHA256 hashes. The problem is what if malware compromised the kernel, which can alter the hashes and/or the content returned when reading a given file? One fix for this is not to store hashes on a local system but instead to send over the Internet elsewhere. Another suggestion is to separate all read-only media from the computer booting process and the operating system kernel.
If we can detect attacks, how about blocking them? This is a lot trickier than it sounds. It is not a possibility for retrospective analysis (e.g., a nightly job that looks for logs). It can also be quite hard for a detector that’s not in the data path. For instance, how can a NIDS that passively monitors traffic block attacks? You could change the firewall rules dynamically and forge RST packets. RST is a reset packet used in a TCP reset attack. The TCP header contains a bit known as the “reset” (RST) flag, which when turned on stops the packet flow. RST can be deployed validly or as a step in a hacker’s TCP reset attack. Of course, there is a never-ending race regarding what the attacker does before the block. Another issue is that false positives get expensive. You do not just use up an operator but also begin damaging production activity. Fortunately, today’s technologies pretty much all offer blocking or IPSs.
Suppose we can use the characteristics of malware to find more of it (Figure 7.23).
What’s good about this approach is that its conceptually simple, takes care of known attacks, and makes it easy to share signatures and build up libraries. What is dangerous about it is that you can become blind to novel attacks or miss variants of known attacks. Also, simpler versions tend to look at low-level syntax rather than at the semantics, which can lead to weak power. In other words, it misses variants or generates a lot of false positives.

Figure 7.23 Signature-based detection, a routine example.
The idea here is to focus on known problems rather than known attacks. Figure 7.24 is an example.
Like the signature-based method, this approach is simple, takes care of known attacks, and makes it easy to share and build a library of such problems. In addition, it can detect variants of known attacks and is much more concise than per-attack signatures. The issues are that it cannot detect novel attacks, and signatures can be hard to write or express. In other words, you have to explain to a computer how the attack works; it’s not enough to simply observe that it worked.

Figure 7.24 Match on known problems rather than signatures.
This idea is based on the concept that attacks look peculiar. The high-level approach involves developing a model of normal behavior (based on analyzing historical logs) and flagging activity that deviates from it. For Instance, a processing routine looks at the distribution of characters in URL parameters and learns that some are rare and do not occur repeatedly. The big benefit is the potential detection of a wide range of attacks, including the novel ones. It is not a foolproof method, however. It can still fail to detect known and novel attacks if they do not look peculiar. Also, what happens if your history includes the attacks? Base rate fallacy is particularly acute: If the prevalence of attacks is low, then you are going to see benign outliers more often.
Instead of focusing on behavior, focus on what is allowed. For instance, in FooCorp we decide that all URL parameters sent to foocorp.com servers must have at most one “/” in them. If a URL has more than one “/”, then it should be flagged. What is good about this approach is that it can detect novel attacks and has low false positives. The problem is that this method is expensive. It takes a lot of labor to derive specifications and keep them up to date as things change.
In this approach, we do not look for attacks but for evidence of compromise. In other words, inspect all outgoing web traffic that transmits content for any part of that content that matches names contained in password files. Also look at the sequence of system calls and flag any that, after undergoing prior analysis of a given program, indicates that it does not normally indicate system calls. What’s good about this approach is it can detect a wide range of novel attacks, it has low false positives, and it can be cheap to implement. The problem with this approach is that you can discover you have a problem with no opportunity to prevent it.
For any detection approach, it is important to consider how an adversary might (try to) elude it. It is important to note that, even if an approach is evadable, it is still important to run it, as it can catch most of the unwanted traffic—unless, of course, it is easy to evade. Some evasions reflect an incomplete analysis, for instance, hex escapes or “../////..//../” alias. In principle, we can deal with these if we take extra care in our implementation.
Some evasions exploit deviation from the spec. For instance, double-escapes for SQL injection:
■ %25%32%37 =>%27=>
Some can exploit fundamental ambiguities. The problem grows as the monitoring viewpoint is increasingly removed from ultimate end points. This problem can be particularly acute for network monitoring. For instance, consider detecting occurrences of the string “root” inside a network connection. If we get a copy of each packet, how difficult can it be? (Figure 7.25).

Figure 7.25 Detecting specific text.
How do we fix out-of-order packet delivery for matching purposes searching for problems? We need to reassemble the entire TCP byte stream. We need to match sequence numbers and buffer packets with later data (above a sequence “hole”). The problem is that this potentially requires a lot of storage maintenance of state, plus the attacker can cause us to exhaust state by sending lots of data above a sequence hole. Even TCP reassembly may not be sufficient (Figure 7.26).
How can we address this more complex issue? One idea is to alert the administrator upon seeing a retransmission inconsistency, as it most likely reflects someone with malicious intent. However, this approach does not work. TCP retransmissions broken in this fashion occur in live traffic. Another idea is that if NIDS sees a connection, it should be killed. This idea works in this case, since the benign instance is already fatally broken. But for other evasions, such actions have collateral damage. A third idea is to rewrite traffic to remove all ambiguities.

Figure 7.26 Even TCP reassembly may not be sufficient.
QUESTIONS
1. This method is used to “bait” people who attempt to penetrate other people’s computer systems. What is it?
2. How does a botnet spread?
3. Explain the difference between how worms and viruses are spread and give an example of each.
4. Identify two techniques that protect viruses from virus scanners and explain the purpose of each.
5. These systems are computer network security systems used to protect systems from viruses, malware, and spyware. This system ______ only located on servers and routers. This system ______ located on every host machine.