
Chapter 7
Section Editors: Brian Campanotti
Introduction
Once content has been created, it is critical that it be properly stored, archived, and preserved for future access, protection, distribution, and reuse. This may sound like a fairly straightforward task. However, when you consider the scale of data typically associated with media asset production, the many storage technologies and services available today and launching tomorrow, their associated costs, and the inherent need to protect these valuable digital assets for the long-term, you might start to appreciate the true complexity of the challenge.
Humankind has been dealing with the challenges surrounding storing, maintaining, and preserving information for many millennia. Whether we are talking about primitive paintings on cave walls or hieroglyphics etched into stone, it is clear humanity has strived to ensure longevity of its stories regardless of whether there was any long-term value, real or perceived. Even for the individual, ensuring aging film photographs and digital images will be accessible to our children and future generations can in itself present a very daunting challenge. How should they be stored? In what format? On what technology or cloud service? How should they be organized? How should they be described? These are the very same questions at the heart of the digital archive challenge.
With the exponential growth in data and with specific focus on the creation of content and opportunities for future monetization, distribution, repurposing, and even cultural reference, digital media archive and preservation is now and will continue to be an exciting and challenging topic.
In this chapter, we talk about libraries, storage, repositories, and, more generally, digital archives. Imperative to these digital assets, the associated metadata is paramount in finding, identifying, using, and reusing these assets again in the future. We will touch on considerations, technologies that can be leveraged, best practices, and how to maintain an archive to ensure the speedy and reliable retrieval of assets when needed now and into the future.
Why Digital Archive
There are various stages core to the creation of a media asset regardless of whether it is a simple personal project, short user-generated content targeting online streaming services, or a blockbuster production for a large media production company. Although simplistic, if we trace the lifecycle of a media asset from creation through to distribution/consumption, we can typically break it into several discrete, macro-stages, as shown in Figure 7.1:
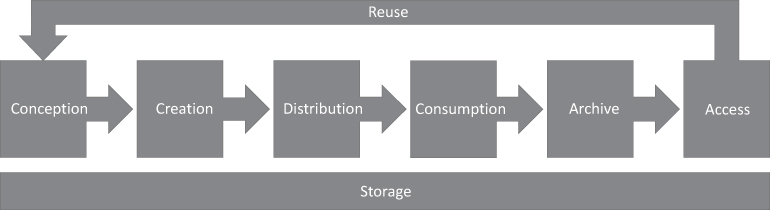
Figure 7.1 Media Asset Lifecycle
Although shown here as a sequence of steps, various pieces of this simplistic asset lifecycle often occur in parallel. In almost every case they all exist in some form or another. Interestingly, each and every one of these individual stages in the asset lifecycle inherently relies on discrete or shared storage but are typically only intended to be transactional in nature (i.e., online disk on an editing platform). The only stage which is not transactional or short-term in nature is the Archive stage which is where we will focus our attention, as it is the gateway to preservation, future access, reuse and repurposing, and monetization.
This asset lifecycle is obviously a large oversimplification of the complexities of the content creation ecosystem, but for argument’s sake we can further classify this into yet higher-level, intrinsically interconnected macro-blocks as shown in Figure 7.2.
Creation
The first obvious stage is creation. This includes conception, acquisition, production, and other steps typical in the media creation process regardless of production scale. This encompasses everything from script and storyline creation through to the generation of a final consumable asset or set of assets. In many modern productions this creation phase could result in targeted products spanning movie theatre release, SVOD (Subscription Video On Demand) release, video and mobile gaming, VAMR (Virtual, Augmented and Mixed Reality), and an ever-increasing set of deliverables to attract, inspire, engage, and maintain viewers in an increasingly competitive and generally fickle consumer landscape.
Consumption
Consumption is the ability to reach end-viewers with the content generated during the creation phase. Again, this could be much more than a single, finished television episode or movie, as emerging platforms are capturing the attention of the viewer and the interest of content creators in a more meaningful and deep way to engage and display their creative art.
Archive
The final intrinsically linked stage is archive. This seemingly simple term has complex ramifications depending on your understanding and the scope and breadth of your implementation. These digital archives can be built to provide storage, protection, and preservation and even enable collaboration during the creative processes. All of these have specific implications which can be part of this stage and enable other stages in the asset lifecycle. Ideally, the objective is to implement a single digital archive system to cover all aspects of storage, protection, and preservation whether we believe we need it or not. It is certainly easier and less costly to architect and build a digital archive platform for the future now than attempt to adapt one later on down the road out of necessity.
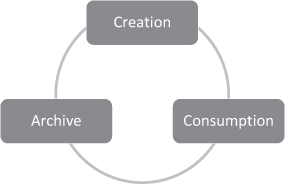
Figure 7.2 Simplified Asset Lifecycle
Libraries, Repositories, and Archives
You may often hear terms such as Digital Library, Digital Repository, and Digital Archive used interchangeably when referring to this final stage of the asset lifecycle, however they are quite different from a philosophical perspective and worth spending some time explaining.
Digital Library
Library: A library is a collection of sources of information and similar resources, made accessible to a defined community for reference or borrowing. It provides physical or digital access to material, and may be a physical building or room, or a virtual space, or both.1
Although conceptually similar to the intent of digital storage and long-term preservation for digital assets, the likelihood of major studios and content producers allowing their content to be freely and openly accessed by the community is minimal. This would obviously conflict with the business models, which allows the creation of these valuable assets in the first place. However, this might very well be the case for historic and cultural archives, as dissemination of the information is the best way to ensure its continuity through the generations.
This topic is too complex to cover in depth here. Although very academic in nature, a large portion of the concepts, strategies, and practices developed inside this area of expertise are leveraged for the more general benefit of the digital archive.
Digital Repository and Digital Archive
These terms for a collection of digital assets stored in some fashion are typically used interchangeably and can be argued are valid in describing the concepts important to the industry. Effectively, the two terms Repository and Archive are defined as:
Repository: A central location in which data is stored and managed.2
Archive: A complete record of the data in part or all of a computer system, stored on an infrequently used medium.3
In fact, examining the definitions above, it is more accurate to describe our scope and objective as a Repository rather than an Archive, as the data we store will often share similar utilization patterns to more active storage devices used in other areas of the asset lifecycle.
To offer an accurate definition and hopefully lay out the scope of this chapter, we provide a somewhat enhanced definition below:
Digital Archive: A central or distributed location where unstructured digital assets are stored on any type of storage technology in various topologies to facilitate long-term access, collaboration, sharing, repurposing, protection and preservation.
For simplicity we will use digital archive from here forward to refer to the concept of a central repository for digital assets.
Preservation
Although clearly our objective is to store, protect, and preserve these digital assets now and into the future, we really must understand the significance of this daunting task. To help with really comprehending the scope and implications of the concept of preservation, we can first examine a definition.
Preservation: the activity or process of keeping something valued alive, intact, or free from damage or decay.4
The interesting point to note is there is no clear timeframe given to this responsibility. The implication is this responsibility is a perpetual one theoretically lasting forever. Obviously, the scope of this statement can be vast as its implications are unbounded, especially when technology is concerned considering its rapid rate of change.
Fortunately, dedicated people embark on careers in preservation sciences to help ensure valuable assets are protected for the long-term, but we can hopefully learn and leverage significant points from this important area of study.
Library and Archive Science
Preservation is something that certainly falls within the scope of library and archive sciences but can and should play a part in all modern digital archive designs and implementations once the true scope is properly understood. To help understand its magnitude, let us examine the definition of Archival Science:
Archival science, or archival studies, is the study and theory of building and curating archives, which are collections of recordings and data storage devices. To build and curate an archive, one must acquire and evaluate recorded materials, and be able to access them later. To this end, archival science seeks to improve methods for appraising, storing, preserving, and cataloging recorded materials. An archival record preserves data that is not intended to change. In order to be of value to society, archives must be trustworthy. Therefore, an archivist has a responsibility to authenticate archival materials, such as historical documents, and to ensure their reliability, integrity, and usability. Archival records must be what they claim to be; accurately represent the activity they were created for; present a coherent picture through an array of content; and be in usable condition in an accessible location. An archive curator is called an archivist; the curation of an archive is called archive administration.5
Therefore, the scope of archive and preservation will outlive those responsible for these activities by definition. Not to imply that everything we create should be stored and protected forever but we can certainly appreciate the historical and monetary value of the original film print of Disney’s Snow White and the Seven Dwarfs released in 1937. Do you think those involved in its creation could have contemplated having to properly maintain this asset when it was placed on a storage shelf close to a century ago? You can hopefully appreciate there is much more to a digital archive than simply storing and arranging files on a specific storage technology.
Further, in this age of deep fakes6 there is ever-increasing importance in the curation and authenticity of these digital archives as trusted repositories and more than just simple archive storage.
In library and archival science, digital preservation is a formal endeavor to ensure that digital information of continuing value remains accessible and usable. It involves planning, resource allocation, and application of preservation methods and technologies, and it combines policies, strategies and actions to ensure access to reformatted and “born-digital” content, regardless of the challenges of media failure and technological change. The goal of digital preservation is the accurate rendering of authenticated content over time.7
The essential guidelines for long-term digital preservation are outlined in the Open Archival Information Systems (OAIS) ISO 14721:2012 standard which has been a point of reference for the archivist community for many years:
The information being maintained has been deemed to need “long term preservation”, even if the OAIS itself is not permanent. “Long term” is long enough to be concerned with the impacts of changing technologies, including support for new media and data formats, or with a changing user community. “Long term” may extend indefinitely. In this reference model there is a particular focus on digital information, both as the primary forms of information held and as supporting information for both digitally and physically archived materials. Therefore, the model accommodates information that is inherently non-digital (e.g., a physical sample), but the modeling and preservation of such information is not addressed in detail. As strictly a conceptual framework, the OAIS model does not require the use of any particular computing platform, system environment, system design paradigm, system development methodology, database management system, database design paradigm, data definition language, command language, system interface, user interface, technology, or media for an archive to be compliant. Its aim is to set the standard for the activities that are involved in preserving a digital archive rather than the method for carrying out those activities.8
Essentially the OAIS reference model defines the scope of long-term preservation and guides one through all of the organization, process, and technical considerations key to achieving preservation goals and objectives. Although not often part of discussions in the entertainment industry, this is often the key reference manual for most memory institutions, libraries, galleries, and historical collection custodians and is certainly equally applicable to our industry.
The good news is there have been technological advances inside our industry where experts have incorporated many of the key tenants of the OAIS Reference Model into systems which store, protect, and preserve digital assets. One example is the Archive eXchange Format (AXF) standard covered in more detail later in this chapter.
There are obviously entire university degree programs designed to prepare people for careers in library and archive sciences, so the full study and its implications are far outside the scope of this chapter. That being said, we will touch on some of the core concepts throughout in helping to build a clear and concise case for the digital archive.
Forever Is a Long Time
In the scope of preservation as it applies to digital archives, we note that we must consider an infinite timeline for our activities to protect and ensure future access to these valuable assets. Of course, it is unrealistic to plan the implementation of a digital archive for eternity, as the cost would likely present an insurmountable barrier, making the initiative impossible to justify from a purely business perspective. That being said, we also cannot effectively plan a digital archive around a finite timeline with the expectation something magical and transformative will happen to alleviate our burden in the future. Unless there is a firm belief the content being produced is simply not worth protecting, which is certainly impossible to judge looking into the future.
We can be pragmatic about this point and ensure we are planning for at least the next decade and make good architectural and sound technical decisions to ensure a higher level of confidence in the sustainability of the digital archive for this more modest long-term time horizon.
What Is an Asset
We have been discussing the storage of assets in our digital archive, but perhaps it is worth taking an intentional step backward to fully comprehend what an asset represents as it applies to our objectives around storage, preservation, and accessibility for the long-term:
As·set: a person or thing that is valuable or useful to someone or something.9
Asset Value
The value or perceived value of an asset can be measured in many different ways, including monetary, historical, cultural, or any combination of these.
The first obvious one is monetary and is normally the motivation for commercial content creators to contemplate any long-term storage and protection strategies. There are others which are arguably much more significant as we are often delving into historical collections to recall or derive references for points in time or tracing back cultural or eco-political data from the past periods. News production is an obvious example where current stories are often enhanced by leveraging historical footage from past events adding context, depth, and even proof of accuracy. Even for major commercial productions, research teams will often scour period footage from various historical archives to capture cultural references and storyline context and even align historical facts from the era.
In addition to the obvious commercial motivations, many important organizations such as the United Nations,10 UNESCO,11 and the Shoah Foundation12 have embarked on digital archive projects to protect and preserve soon-to-be-forgotten cultures, languages, and significant historic events. They are building digital archives containing interviews and first-person testimonials while witnesses to these significant events are still alive. The intent is to ensure these cultures, languages, and significant historic events can never be rewritten, reshaped, or forgotten while providing unmatched archive collections to researchers, scientists, and future generations.
Fundamentally, an expectation of value can be considered a prerequisite in the creation of an asset and certainly the key motivation to store and protect it.
The Asset Construct
An Asset comprises two fundamental components: essence and metadata.
In our case, essence is the video, audio, image, or other data which comprises the actual content of the asset. Metadata is information about the essence such as filename, description, transcripts, context, size, duration, and other critical information. Both of these come together to ultimately define the usefulness and value of an asset and are critical to the true value of a digital archive. Most organizations do a fine job of storing essence but are not always good at storing an asset.
Imagine having only a list of simple files (i.e., AB12.xyz, CD34.xyz, etc.) stored on a storage device. As long as the person who originally created these files or someone who they shared the information with is available, context can be discovered adding meaningfulness to these files. However, we only need to scale this challenge to a few hundred or thousand files to demonstrate the impossible challenge of recalling important relationships, context, and details. We cannot simply rely on an arms-length relationship between these files and the metadata which describes them.
To better understand this asset concept, let’s look at an example we can all easily relate to of a digital photo of a landscape taken on our mobile phone. If someone views this image with nothing to describe it or add context to it, they may still enjoy viewing the photo but have little or no context or understanding of the image or its potential significance. Further, they may even misinterpret or misrepresent it to others. However, if the mobile phone assigned a name to the image with a date and timestamp we already have some additional comprehension of the asset, adding to its value. If the photographer also adds a simple note to the image indicating it was taken at Algonquin Park, Ontario, Canada during a family vacation, the viewer can understand even more about the image and its context, essentially adding to its perceived value and authenticity. If the mobile phone automatically augments the photograph with GPS metadata, the viewer can now locate exactly where the photo was taken on a map, adding even more depth of understanding and perhaps even a greater appreciation of the image. This valuable metadata can then be used to cross reference additional metadata from external services such as finding similar images or examining weather data for exact environmental conditions at the time and location where the photo was taken.
As you can see, the picture, or essence, itself is only a portion of the true value of the asset which is inherently dependent on an immutable connection with its associated metadata. This is a core requirement for digital archives as essence may be valuable only as long as the people who created it are still around to assist with finding and comprehending it. Therefore, the essence is not worth archiving or preserving unless there is associated metadata immutably connected to the essence, forming a valuable asset worthy of storing in a digital archive. If we imagine this same exact digital photo example “at scale” across thousands of digital images in our individual photo collections, you can easily start to realize the relatively insurmountable challenges facing content creators, broadcasters, and custodians when architecting and constructing a digital archive where metadata is not present.
Even a fairly simple and rudimentary folder naming convention (i.e., “Algonquin Park Family Vacation – June 19, 2020”) adds significant value to the essence and helps form an asset. This simple metadata allows us to quickly search, locate, and deduce useful information about the files contained in this named folder. The point here is even the most basic metadata can be extremely valuable in the ability to find, access, and utilize these digital assets now and into the future. We should be careful to ensure metadata is in place as we plan our digital archive but not get blocked looking for metadata panacea since it rarely exists.
The scale of this metadata challenge for broadcasters, content creators, and historical curators with thousands or even millions of assets can be crippling. Without key metadata associated with each essence file, these valuable collections become inaccessible and ultimately are at risk of being lost as they simply cannot be effectively searched.
Recognizing the importance of metadata, many organizations are starting to implement strict metadata collection and curation processes for newly created assets throughout the entire asset lifecycle, right from the conception phase. For legacy asset collections where limited information is available, Artificial Intelligence and Machine Learning (AI/ML) tools are now enabling automated metadata discovery and metadata enrichment for large-scale audio/visual archive collections.13 These AI/ML tools can identify and catalog human faces, animals, locations, objects, landmarks, and more, all while transcribing multi-language audio tracks rendering them searchable. These tools can be used to automatically augment audio/visual essence with searchable metadata automating these historically challenging metadata tagging tasks at scale. These algorithms can learn from the collections themselves and be applied iteratively to continually enhance and deepen our comprehension, and increase the resultant value, of these digital assets.
As AI/ML technology continues to advance, they will likely be the salvation for aging archives and likely bring valuable historical and cultural assets back to the forefront for future generations.
Technical Metadata
On the technical front, knowing what image processor or compression algorithm was used for our photograph, video, or audio recording will give us higher probability of being able to access them (read, view, listen, etc.) in the future. Of course, we can use rudimentary mechanisms such as filename extensions to give us hints, but the deeper and broader this technical metadata is, the more likely we are to benefit from it later.
The good news is most modern systems automatically generate very deep and accurate technical metadata for digital assets including compression details, frame size, frame rate, timecode values, duration, etc. Most also include automated contextual metadata such as GPS data in combination with asset provenance. Provenance is from whence the asset came and can include the username, camera, device, editing platform, or similar device which created the asset along with date, time, etc. This helps future generations to comprehend the birth and life of the asset, an ultimate key to true preservation.
If each time we modify or enhance the digital asset throughout its life, we are careful to include information from where it came and who is currently acting on the asset, we can help future generations better understand an asset they are examining and ensure its authenticity, another important tenant of our digital archive objectives.
Connecting Metadata and Essence
If we remember back to the days of film cameras and printed photographs, we often scribbled a couple of words or the date (its metadata) on the back of the photograph so we could later understand the context when viewing it. When we write metadata on the back of the printed photograph, we have fundamentally and immutably connected the essence and the metadata, and therefore formed an asset which now has inherent long-term value worth preserving.
When designing our digital archive, we need to ensure there is an immutable, pervasive, and sustainable connection between the asset essence and the metadata for the long-term. Historically, the metadata was stored and maintained in systems separate and distinct from the essence storage adding to the complexity and risk regarding future accessibility and preservation. Often times, metadata is stored and maintained in Media Asset Management (MAM) systems or other external database, while the essence is stored on file-based storage devices. There exists a fundamental link or key between these systems which connects the metadata to the essence, but only the combination of both systems can be considered a digital archive storing assets. Obviously, there is an increased risk here when systems are upgraded or replaced where these loose connections between essence and metadata could be lost.
There has been a lot of work in the area of fundamentally connecting essence with metadata to help overcome these potential challenges in the future. On the technology front, many modern object and cloud storage systems allow key/value metadata tagging of assets when created, allowing a fundamental and transportable connection between the two. Standards have also been developed to immutably merge essence and metadata repositories into a scalable asset platform which offers a more sustainable and risk-free digital archive future and will be discussed later in this chapter.
In addition to the access, search and retrieval benefits of fundamentally connected metadata, the capability to dynamically and intelligently orchestrate digital archive storage based on asset metadata is an exciting emerging field. Most legacy digital archive systems rely only on policies built on rudimentary file parameters such as size, age, filename or other static parameter to unintelligently govern storage orchestration. This metadata-driven orchestration approach is further enhanced when considering the metadata enrichment and metadata mining capabilities of modern AI/ML tools. This essentially adds self-evolving intelligence to digital archive orchestration based on formerly unknown or undiscovered information about the assets themselves. More on this exciting concept later in the chapter.
Data Scale
As our industry continues to generate an increasing number of assets, across broader platforms and delivery mechanisms and at increasing resolutions, the scale of data is increasing at an exponential rate.14
The following table gives modest examples of the amount of data one single hour of content represents at common resolutions and framerates in use today. Despite the large numbers, this is only a modest view of the actual data scale, as oftentimes the entire asset lifecycle can result in 10× to 100× more data throughout the process than is represented in the table below.

Figure 7.3 Data Scale in Media and Entertainment
If we consider a major content production company, studio, or even independent producer with thousands or millions of hours of content, the scale of data which needs to be considered when building a long-term storage, protection, and preservation strategy is daunting. Key to this challenge is taking some time to contemplate and understand your ultimate objectives early on in the creation process. If you plan to “keep everything forever” then you need to attempt to calculate the final amount of data, ensure budgets capture this objective, set enough money aside during crunch time to ensure you can meet your objectives, and have a solid understanding of what “forever” actually means. Oftentimes, what begins with noble objectives becomes a burden later on when the production is completed, and someone is tasked with maintaining an unsustainable objective potentially placing these valuable assets at risk of being lost.
As an interesting side note, this is not a new challenge driven by digital production or the data volumes identified above. This has always been a challenge dating back to the days of film and video tape. Placing a recording of your production onto a shelf only solves the “forever” problem for a decade or two even if stored in ideal environmental conditions. Recording media ages and player devices fall out of production and then out of support. You can have all of your assets fully protected and stored, but if you cannot play or recover the data contained on them, then you may as well have destroyed the media earlier on in the process. This leads into the need for periodic maintenance of these media storage technologies to ensure continued access, on sustainable media, a topic we will cover in more depth later in this chapter.
Enterprise and Broadcast Technology Collide
Continuing on our path of setting the stage for the digital archive, it is likely important to differentiate terms often mistakenly used interchangeably and introduce a modern take on the concept of the digital archive.
Backup
These solutions made their way into our industry based on their widespread use in general enterprise Information Technology (IT) environments. Although seemingly in line with our objectives outlined so far, IT backup technologies are fundamentally contrary to the philosophical directives behind the digital archive.
File backups are made to protect critical data but with the underlying intent of never having to access this information if primary systems are healthy. The typical use-case involves data being backed up on a regular basis with the hope it will never have to be accessed. Backup systems can also be used to support disaster recovery by allowing off-site copies of user data to be maintained in the case of a catastrophic event (i.e., fire, flood, ransomware attack). In the case of data loss, these backups can be accessed and affected data safely recovered. This is often a very manually intensive operation but offers protection against data loss.
However, when examining our objectives in building a digital archive, our key motivators in addition to storage were access and reuse which backup systems are fundamentally not designed to handle. Although they often appear the same as digital archives on the surface, they are tuned to be very good at storing but not as great at regular, random data access and reuse. Further, these IT backup systems are always file-based implementations and handle the asset essence only. This necessitates metadata be maintained on the original systems which generated the files further reducing their applicability to our digital archive objectives.
Hierarchical Storage Management (HSM)
Similar to Backups, HSM solutions also made their way to the entertainment industry via enterprise IT. Although seemingly similar in appearance, they also embody concepts fundamentally contrary to the philosophical directives behind the digital archive.
HSM systems assume file-based data which has not been accessed in some time is less important than data recently created or accessed. HSM systems use this fundamental concept to tier (move) this less important, aging data to less expensive storage. This assumes the data will be used less and less as it continues to age and therefore can be stored on less accessible and less expensive storage technology. HSM workflows in our industry may be valid for the tiering of data to less expensive media, but the demands tend to be very unpredictable causing performance bottlenecks in the handling of important retrieval operations from these less accessible storage tiers.
Typical HSM policies may instruct the software to move files not accessed in more than 30 days off primary storage to lesser speed and therefore lower cost storage, with the eventual target typically being data tape. HSM solutions use the clever concept of stub files15 to make user-data appear as if it still resides on primary storage, but allowing it to be moved to cheaper storage tiers leaving just a remnant, or stub, of the original data behind. When users attempt to access data which has been moved by the HSM system, they are simply instructed to wait while their data is retrieved from slower storage tiers. As the usage patterns of data in traditional IT environments tend to support the underlying concept of data aging, HSM systems are frequently deployed to help reduce overall storage costs with minimal user impact.
Additionally, HSM solutions are file-based by their very design and cannot address the complex challenges in these media-centric, big data environments. This simple policy-based file movement between storage tiers does not take into account specific files are often components of more complex assets, and not the assets themselves. As file migration policies are satisfied, the missing context of the object can cause components of a single asset to be scattered between storage layers and amongst several data tapes in the data tape storage tier. This limitation is further exacerbated in unstructured environments where the inability to predict the nature and content of assets make adequate file-handling policy definition impossible limiting agility and adding management challenges to the environment.
Several vendors have worked to adapt the core features of HSM to better fit the digital archive applications in our industry, but they always suffer these same fundamental limitations. Ultimately, HSM solutions are file-based as was the case with backup solutions discussed previously, and their applicability to our digital archive objectives are similarly limited.
Content Storage Management (CSM) and Active Archive
CSM and Active Archives are very similar concept and are designed specifically to serve the needs of digital archive applications in the media industry.
The term Content Storage Management16 was coined in 2006 by Brian Campanotti and Rino Petricola (Front Porch Digital) to describe these differentiated archives specifically targeted toward object-centric, large-scale unstructured data sets and high-demanding usage patterns typical in digital archive applications. These systems offer benefits as they deal with essence files as objects rather than just individual files and handle these complex relationships natively. The term Active Archive was coined in 2010 by members of the Active Archive Alliance17 to describe a similar digital archive system approach.

Figure 7.4 Content Storage Management
Although more attuned to the specific needs of the industry, they both fall short in our pursuit of a modern digital archive. These solutions continue to handle storage orchestration at the essence level, albeit at the object essence level, essentially missing the opportunity to intelligently and adaptively orchestrate assets leveraging dynamic metadata.
Many legacy CSM vendors are struggling to adapt their solutions to better handle the modern demands and challenges of digital archiving. However, layering on modules in an attempt to add modern intelligence to aging CSM platforms is similar to what the HSM vendors did in an attempt adapt their solutions to the media industry in the early days. There is an emerging opportunity to build a modern digital archive solution to better handle not only media assets based on their essence characteristics at the object level, but also to handle these complex, massive-scale storage orchestration challenges leveraging dynamic asset metadata as well.
Software Defined Archive (SDA)
The Software Defined Archive (SDA) concept was first introduced in 2017 by Cloudfirst.io18 as a modern approach to the digital archive. Valuing the past decade or more of digital archive technology evolution, the SDA embraces all of the fundamental capabilities of an Active Archive or CSM solution (i.e. treating essence file collections as objects, etc.), but possesses the ground-up capability to dynamically leverage asset metadata to build a cognitive, metadata orchestrated digital archive system.
Although similar in architecture to CSM solutions, this SDA approach enables the orchestration of media assets on more than just static polices based on its constituent files or objects (i.e. file create date, size, age), handling them as assets (metadata + essence) rather than just the essence files which comprise them. The SDA essentially constructs an intrinsically connected essence and metadata repository which can each be individually enriched, orchestrated, and leveraged to best handle modern digital archive workflows in a fully automated fashion. With the addition of AI/ML metadata enrichment, asset metadata can continuously improve adding significant depth to the capabilities of the digital archive system, enabling it to learn and self-adapt over time.
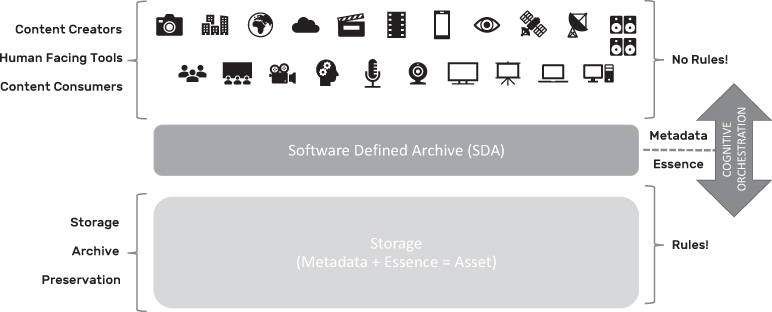
Rather than defining static policies which loosely map to service level agreement (SLA19) targets, these dynamic systems can automatically adapt to different requirements based on rich and deep asset metadata. Imagine having a digital archive that dynamically adapts to trending news stories or sporting event schedules by bringing the most relevant content to more accessible storage automatically, alleviating any requirement for manual intervention. Conversely, the SDA can dynamically route assets to the most cost-effective tier based on current market storage rates while ensuring the most valuable content is maintained in multiple geographic locations and on divergent storage technologies for the highest level of protection possible.
As a simple example, the SLA for a specific production asset may require two copies in the cloud, another may require one copy on the least expensive storage available and another may demand two copies across different cloud providers and one on-premise. The SDA will automatically orchestrate on an asset-by-asset basis to achieve these SLA targets based on individual asset metadata (i.e. production group, inventory number, series, episode, etc.). Further, as SLA targets or asset metadata evolves over time, the SDA always self-reconciles to ensure assets adhere to their specific SLA requirements alleviating much of the administrative burdens typical in legacy archive environments today.
Unfortunately, legacy CSM and Active Archive systems are not able to embrace these modern approaches to true digital asset archiving as they are fundamentally built with a storage-centric focus rather than the necessary asset-centric focus. In many cases where these legacy archive systems are in place, the necessary archive transformation may appear to represent a nearly insurmountable challenge. Archive modernization should be carefully considered, examining factors such as cost, return on investment, workflow benefits, and other key factors, all while ensuring you are simply not delaying an inevitable migration off an aging legacy archive system. Archive transformation will be covered in more detail later in this chapter.
Build versus Buy
This has been a perpetual challenge throughout time. Do software and hardware vendors intimately understand an organization’s operation intimately enough to build a suitable digital archive? Will they meet our specific needs? Is the vendor equally invested in our long-term digital archive objectives?
Arguably, digital archive software development is easier now than ever before with the proliferation of open-source components and standardized interfaces available to most modern storage technologies (i.e. S3). However, experience and countless case-studies clearly demonstrate that open-source is far from free and burdened with the risk of long-term unsustainability.
Digital archive vendors invest significant time and money in architecting and developing solutions to best serve the broader needs of these complex digital archive environments. Although they often cannot be customized to specifically fit any one particular environment, they are best at serving the general objectives, leveraging a broader and rich view of the industry as a whole. This potentially brings additional experience and depth to each new deployment in being able to leverage requirements and features developed across dozens or even hundreds of other forward-thinking organizations.
Custom built applications tend to be the best fit early on but become very difficult to continue to sustain and advance once attention (and budgets) turns to focus on other challenges facing the organization.
Instead of embarking on an in-house digital archive development effort, organizations are better served focusing on assembling a vendor-agnostic commercial engagement and selection of technologies which protect against long-term asset lock-in. As long as the digital archive and/or cloud solutions being considered allow configurable, metadata-centric orchestration policies to be defined and maintained without involving custom development and introduce no proprietary interfaces, asset wrappers or containers, this may be sufficient to ensure long-term asset protection.
There have been several cases over time where a digital archive or storage vendor decided to change their focus or even abandon their products altogether leaving existing users orphaned and desperate to free their assets. Risks need to be considered on both sides of this equation.
The AXF standard covered later in this chapter goes a long way to protecting and preserving your most valuable digital assets and helping avoid vendor lock-in. In fact, through a series of recent events, this hypothesis was proven true as several digital archive vendors were able to natively support the migration of data archives created by other vendors solutions eliminating the necessity to migrate the entire collection prior to decommissioning the legacy vendors solution.
Storage Technology
Fundamental to every backup, HSM, CSM, SDA, or more generally, the digital archive environment is storage. Storage evolves rapidly trying to keep pace with the ever-increasing demands for capacity and speed while optimizing short- and long-term costs. Modern digital assets (like the photos on your mobile phone) will often touch multiple types of storage throughout its lifecycle as is the case with media assets in these digital archive environments. At scale, there are no one-size-fits-all approach, and often these digital archive systems will employ various types of storage, technologies, and generations to achieve their ultimate goals which will also evolve significantly over time. Obviously, the velocity of change and advancement in storage (and compute) technology makes any level of depth here quickly irrelevant but is included for context to the overall discussion surrounding digital archives. Figure 7.6 shows the abbreviated evolution of digital archive storage technologies through the recent millennia.
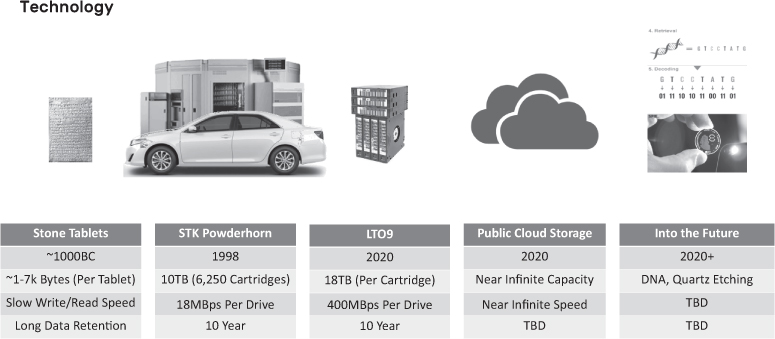
Figure 7.6 The Evolution of Archive Storage Technology
The evolution of digital archive storage over the past two decades has taken us from a robotic device larger than the average family car to a single data tape cartridge with close to twice its capacity, enabling more than 11,000× the storage in the same physical footprint. One can only imagine what the next 20 years will bring!
Despite these impressive advancements, the industry is certainly in need of a storage revolution. Essentially, we are still using the same fundamental technologies we have been for the past 50 years (i.e. transistors, magnetic tape, magnetic spinning disk platters), simply modernized, more dense, more reliable, and lower cost but without any substantive disruption.
Unfortunately, without a significant value proposition to the greater IT/enterprise market, no one can effectively, sustainably, and profitably build technologies specific to the entertainment marketplace to meet its unique demands for cost-effective capacity. Packaging these broader technologies into devices and appliances with unique software which resonate in the entertainment market is normal, but real storage innovation is difficult without the market opportunity to drive it. Ultimately, we will continue to be a slave to storage innovation in other verticals and rely on software and applications to make it relevant to the entertainment market. The good news is, there are current and emerging options which can be effectively combined to meet the specific demands, both technical and commercial, of these digital archive environments.
The following sections highlight storage technologies commonly used in the construction of digital archive systems today.
Solid State
Solid state or flash storage refers broadly to any storage technology which involves silicon-based, persistent memory devices. These contain no moving parts and are typically faster and more reliable than mechanical devices which rely on magnetically aligned particles to store data such as hard drives and data tapes. Solid-state drives (SSDs) are the most common and are usually comprised of various types of solid-state memory. Newer Non-Volatile Memory Express (NVMe) devices demonstrate much higher performance but also carry a higher cost and are therefore more specialized in their applications.
Flash storage is common inside consumer devices such as mobile phones, media players, and smart watches and recently more pervasive in modern laptop computers due to decreasing costs and positive impact on battery performance.
Hard Drives
Hard drives, or more generally, magnetic disks are by far the most pervasive storage devices used today across all industries and applications. High-speed and high-capacity hard drives can be mixed in a single storage device to provide high performance, high capacity, or a balanced combination of both. Many hard drive technologies are in existence with more on the near-term horizon.
Serial Attached SCSI (SAS) and Serial Advanced Technology Attachment (SATA) drives are typically used in higher performance environments. Shingled Magnetic Recording (SMR), Heat-Assisted Magnetic Recording (HAMR), and Microwave-Assisted Magnetic Recording (MAMR) drives are typically larger in capacity and less expensive and therefore targeted at scale-out storage solutions.
Various hard drive technologies offer unique performance and cost profiles and are best suited to specific tiers of storage based on these characteristics. Most often individual hard drives are combined into an array of disks (i.e., RAID). This increases aggregate capacities and improves performance by striping data across multiple drives while offering increased resiliency with the addition of parity data. Individual hard drives and disk array controllers often incorporate solid state cache to improve transactional and read performance over that of the disk alone slightly blurring the boundaries between these discreet storage device types.
Hard drives continue to earn their place in most storage environments, but many ominous technological challenges such as ariel density, superparamagnetism, and others must be overcome to ensure their relevance in the coming years. There is a need to dramatically increase capacity and performance while reducing costs to continue to make them compelling compared to solid-state drive technologies which continue to decline in price due to wide-scale deployment.
Optical Disc
Optical disc has been fighting for relevance in the storage world for many years, held back due to limited adoption, slower performance, and higher costs. The only optical storage technology still commercially available is Blu-ray disc from both Sony and Panasonic. A handful of deployments of optical storage as a digital archive storage tier exist today, primarily as it offers a technologically diverse approach with copies maintained on optical media in addition to traditional data tape or other magnetic media.
Current generation optical discs are significantly less dense and offer much slower performance as compared to competing data tape technologies and have yet to find a critical value proposition to motivate their wide-scale adoption. It is unclear whether the current generation of optical discs will continue to be relevant in these complex and growing digital archive environments without significant near-term advancement.
There have been many companies working on commercializing novel optical technologies such as holographic and others, but none have had a compelling enough case against the continued advancement of mainstream storage technologies such as flash, disk, and data tape.
Data Tape
By far the most pervasive, large-scale storage technology is data tape. When the entertainment market shifted to go tapeless (video tapeless) more than a decade ago, many companies building large-scale digital archives began relying more heavily on data tape for storage. Obviously, data tape does not have any of the legacy issues that video tape had, but it is still based on the very same principles. Of course, it is denser, faster, more reliable, and less expensive than ever before, and these advancements continue generation after generation ensuring its continued near-term relevance for digital archives. Cost-wise it currently remains the least expensive raw storage technology available on the market and is therefore very well suited for on-premise digital archive storage.
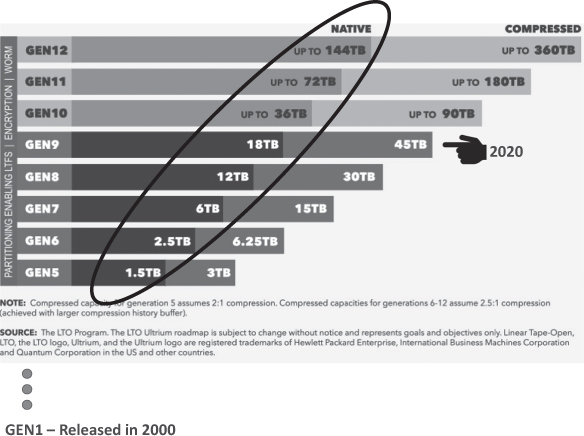
Figure 7.7 Evolution of Data Tape (from the LTO Consortium at lto.org)
Figure 7.7 shows the generational evolution of the most common data tape technology available today, Linear Tape Open (LTO). LTO has continued its generational advancement for more than two decades now since the launch of LTO-1 in 2000 and is by far the most deployed data tape technology in the industry.
These data tape drives and data tapes are almost always deployed in scalable robotic systems with tape slots which can physically store thousands of individual tape cartridges, enabling massive-scale storage footprints. Aggregate tape robotic system capacities are into the exabyte (EB) range with the ability to read and write terabytes (TB) of data per hour leveraging current data tape technology.
Robotic picker arm(s) are used to quickly and reliably move tapes from their home slot (called bins) to a free tape drive where the particular read or write operation can be serviced by the archive software. Once the request has been serviced, the robotic arm(s) moves the tape back to the home bin and then awaits the next request. Tapes can typically be loaded/unloaded in a matter of a few seconds, and tape libraries can contain up to eight robotic arms all working in parallel for massive-scale physical operations with libraries containing hundreds of individual data tape drives. In addition, these tape libraries offer the ability to import/export tapes to support offsite duplicates and limitless storage expansion with external shelving units to house data tapes. While this physical shuffling of data tapes may seem archaic, many businesses are moving back to this type of technology to provide increased protection against cyber and ransomware attacks levering the air-gap protection provided by data tapes sitting on tape shelves physically separated from the data tape drive that can read and write them.
Unfortunately, organizations often have a love–hate relationship with data tape.
The most disliked characteristic of data tape is the need for generational migrations which are very expensive and time consuming at scale. This cycle typically happens every eight to ten years as tape technology ages and new generations are released. Each new generation is faster, denser, and typically more cost-effective per capacity unit. As the digital archive data footprint grows in size, these systems must be periodically upgraded to ensure they are ready for the ever-increasing onslaught of data. Also, the risk of asset loss due to aging and unsupported or even unavailable tape drive technologies is a certain motivator for regular system migrations.
In fact, this migration challenge is not a problem exclusive to data tape as all storage technologies must also be migrated and replaced every so often as they age, fall out of support, or simply begin to fail. This is often referred to as a forklift-upgrade as it requires the physical swapping of infrastructure. When migrating a disk array to another disk array, the process is typically relatively quick due to the performance of disk and the fact these arrays are several orders of magnitude smaller in capacity as compared to large-scale tape archive systems.
With data tape library migrations, each individual tape must be loaded into a tape drive, its data read to a cache location (typically disk drives on an external server), and subsequently written back to a new data tape. Each mount, read, write, and unmount cycle can take several hours, as each data tape can store vast amounts of data. This process then repeats hundreds or even tens of thousands of times to properly migrate all tapes in the digital archive. The mechanical characteristics of tape combined with the scale of these library systems often reaching into the dozens of petabytes (PB) range, migration can be a long process, often taking months or even years. The good news is most digital archive software can handle this as an automated background task alleviating the management burden on the system administrators but still requiring a significant investment of time and money.
These data tape robotic systems also occupy large physical footprints inside customer data centers and require significant maintenance and upkeep as they are large and complex mechanical devices. With a general industry trend toward facility consolidation and away from customers building and maintaining their own data centers, deploying and maintaining these large data tape library footprints is becoming less attractive as organizations look to modernize their infrastructures.
In addition to these technical challenges, several leading data tape technology vendors such as Oracle and HP decided to halt production of their respective technologies over the past decade. This has caused ripples in the industry, with users being forced to engage in costly technology migrations ahead of plan due to these unexpected end-of-life announcements. Additionally, recent challenges emerged regarding the unstable supply of LTO media which has also accentuated long-term sustainability concerns surrounding data tape.
Due to these and many other factors, there exists a general trend away from building and maintaining large on-premise data tape infrastructures across all industries, with many accelerating moves to the cloud.
Public Cloud Services
Although not a storage technology per se, the most exciting area of advancement of digital storage technology is its availability as utility-based cloud storage services.
All major public cloud providers now offer storage services which can be effectively mapped to most or all of those highlighted previously but historically deployed on-premise and managed by the end-customers. The main benefit of these cloud-services is the treatment of storage as a service on the basis of SLAs rather than users having to worry about the specific technologies selected and deployed at any point in time. This means rather than focusing on the storage technology, error rates, storage density, migration timeframes, deployment locations, and other technical specifications, we need only to consider the SLA data published by the cloud-services provider. We no longer need to be concerned with what technologies they use and how they are implemented allowing us to specifically focus on business needs instead.
We recognize that each of these cloud-service providers leverages solid-state, various hard drive types as well as data tape, but you will not find this information published anywhere as they want subscribers to focus only on target SLAs rather than how they are being attained. Based on decades of experience, this is a welcome relief as we can finally focus on our target objectives rather than on the specifics of the technologies implemented, all while not ever worrying about facilities, air conditioning, power, and most importantly data migrations.
Cloud-service providers publish their SLAs in terms of nines (9s) of services such as resiliency – probability of data loss – and availability – probability of data inaccessibility. For example, an availability figure of four nines represents 99.99% time guarantee you will be able to access your data when you want it. Of course, it doesn’t mean that your data will be lost but it might not be immediately available when you request it for less than one hour each year. Of course, this is the worst-case scenario provided by the SLA, so you can normally expect better results. There are much higher SLAs offered in terms of data resiliency, which is good news as this is the main parameter we care about with regard to digital archives. Cloud services typically provide an impressive 11 nines (99.999999999%) of data resiliency.
There are increasing and decreasing SLAs depending on what your objective is and how much you are willing to spend as each tier carries an associated cost. Cloud storage prices are typically metered as a per gigabyte per month fee with no cost to upload or migrate data into the cloud. This means that rather than having to plan for and fund the entire scale of your digital archive footprint at the start, as you have to do with on-premise storage technologies, you simply get started and only ever have to pay for what you consume at that moment in time. In many cases, migration to the cloud may take months or even years so being able to pay for the storage services as you consume it is a significant benefit and could even help to significantly offset associated costs when compared to building out an on-premise infrastructure.
The move to consumption-based storage is referred to as an Operational Expenses (OpEx) rather than the initial Capital Expense (CapEx) required to actually purchase and install on-premise storage hardware. This can be considered a benefit to some organizations depending on their account methods and funding models.
In addition to the two key SLA factors mentioned above, time to first byte of data or data access times vary greatly across different cloud storage tiers and must also be carefully considered. For example, the least expensive tier of Amazon Web Services (AWS) storage today is Glacier Deep Archive (GDA). This tier carries the same SLAs noted above, but it will take 12 hours to access stored data. This is certainly a long time, but accordingly, the cost is quite low and certainly something to consider when looking at long-term archive tiers as compared to on-premise data tape or tape storage shelves. What is more interesting though is that you can retrieve ALL of your data stored in GDA in the same 12-hour period whether it’s a few gigabytes or many petabytes. Of course, more expensive tiers are available with much faster retrieves times, but these must be chosen carefully as consumption costs can quickly add up at scale. Currently, AWS offers more than five storage tiers each with different SLAs and retrieval times. Other major cloud providers such as Google, Microsoft, and others have comparable storage service offerings.
Planning should include detailed analysis of your real-world digital archive utilization patterns rather than be based on any assumptions as mistakes here could become costly. Data modelling and analysis is a very important first step in truly understanding your digital archive and planning your cloud implementation or transformation as it empowers data-driven decisions. The goal is to leverage these data models to accurately forecast and predict total cost of ownership (TCO) of storage technologies and/or services and ensure correct mapping against target storage SLAs before implementation. By understanding how digital archive data is used, the best combination of these many storage technologies and services can be selected to ensure the most cost-effective solution that meets SLA objectives.
In the early days of cloud, users were often concerned with the security of placing these valuable assets in a more public and less controllable environment. The truth of the matter is these cloud providers employ thousands of people focused specifically on security and resiliency, many times more than any one organization could hire themselves. The focus on security also transcends the specific needs of our industry, bringing significant benefits from other industries which are even more concerned with data security and preservation.
Cloud services offer limitless scale which also allows elastic expansion and contraction of services according to the desired objectives. Several niche cloud providers are also more directly targeting the specific needs of the media industry, tuning services and SLAs to better fit those required in digital archive environments.
A significant benefit of moving the digital archive to the cloud is having direct access to the cloud Software-as-a-Service (SaaS) ecosystem. These ecosystems include thousands of applications deployed and available on a subscription basis to build, deploy and advance cloud workflows. Having asset repositories in the cloud can enable the enhancement of asset metadata, distribution of content, asset reformatting and transcoding, launching direct-to-consumer services, and much more. These opportunities are typically too costly and complex to deploy on-premise and can now be used on a pay-as-you-go basis. It is best to fully comprehend the advantages of cloud-based services before embarking on a digital archive cloud transformation initiative, as cloud costs can easily become unwieldy if not fully understood in advance.
By embracing public cloud services, there are also more important opportunities to embrace transformational shifts in traditional content creation, collaboration, and production workflows in addition to those surrounding the digital archive itself. Users also no longer need to concern themselves with generational migrations nor do they need to worry about management, upgrades, replication, etc., as everything is inherently handled by the cloud provider.
This, however, does not change the underlying technologies utilized by these utility cloud providers who are leveraging the same technologies above but allow their subscribers to pay only for the portions they use when they use it and free up critical on-premise resources and budgets for other more core tasks.
The important thing to note here is the move to the cloud does not have to be an all-or-nothing decision. More and more organizations are slowly transforming their digital archives to the cloud, embracing a hybrid model which also spans on-premise archive technologies. These systems continue to support existing on-premise workflows while embracing cloud services and cloud ecosystem benefits where they best suit the tasks at hand at that moment.
Obviously, cost and economics typically play a large part in the decision regarding on-premise, cloud, or hybrid digital archive deployments. In most cases, the cost of deploying a digital archive in the cloud is more expensive than deploying it on-premise levering traditional storage technologies. But this does not always paint an accurate picture if you look at the long-term costs as well as the significant benefits afforded by the SaaS-based cloud ecosystem. Having your digital assets close to an infinitely scalable infrastructure with tens of thousands of apps and tools immediately available without an initial capital investment and spanning a global web of connected facilities can open up significant possibilities which cannot even be fathomed today.
Future Technologies
As mentioned previously, there have not been any truly disruptive advancements in storage technologies over the past several decades. Although significant to the industry, the launch of utility, cloud-based storage services simply leverage already familiar storage technologies.
The fortunate news is there are many research organizations around the globe actively working to disrupt the way we store data, looking at very novel approaches. Many are specifically aiming at the massive-scale, long-term, persistent, preservation grade storage market, which is a perfect fit for our digital archive future. The most interesting and compelling of these is DNA-based storage which leverages the building blocks of life to encode, store, and retrieve data:
The global demand for data storage is currently outpacing the world’s storage capabilities. DNA, the carrier of natural genetic information, offers a stable, resource- and energy-efficient and sustainable data storage solution.20
Several successful commercial demonstrations of DNA-based storage technology are showing promise as a viable storage technology aimed at these long-term preservation applications. They offer the promise of staggering storage densities, unprecedented shelf-life, and high data resiliency, which can allow entire digital archive collections to be maintained in a very small physical footprint without ever having to be migrated.

Figure 7.8 DNA-Based Storage (https://academic.oup.com/nsr/article/7/6/1092/5711038)
As storage technologies are themselves migrated toward cloud-services, it is unlikely any particular organization would choose to independently deploy DNA-based storage as part of their own digital archive. However, public cloud providers could certainly leverage this technology (or others also aiming at this preservation market) at scale to provide a very cost-effective, long-term, preservation grade cloud storage service with decades or even centuries of data resiliency and preservation.
It is obviously unreasonable to base your plans on any one public cloud provider or storage technology vendor to be in business for several centuries, so we need to consider this eventuality if our scope of protection is far reaching enough. It is therefore important we also pay attention to how our data is actually being stored, whether on-premise or in the cloud, to best assure long-term accessibility. We cover this important topic later in this chapter.
Storage Classifications
Arguably, as entertainment and IT/enterprise technologies continue to converge, there are increasing ambiguities surrounding terminology, classifications, and technologies. In an attempt to set a baseline for the tiers of storage and their associated SLAs mentioned previously, we will take an opportunity to define each of the common storage tiers used in IT/enterprise technology and draw a correlation to those typical in entertainment and digital archive workflows.
Although the specific technologies are discussed here for context, it is important to note the corresponding cloud-services offerings are simply provided by matching target SLAs and without specific mention of the technology implemented. This further supports the paradigm shift away from the specifics of technology toward SLA-driven architectures.
Tier 0 Storage
In typical media applications tier 0 storage is usually referred to as performance or render storage and typically assigned to the most demanding and time critical operations. Entertainment workflows involving digital feature film production, ultra-high resolution editing and computer graphics render-farms often require tier 0 storage. Deployments and storage capacities are often limited due to the substantial costs involved, which often push these workflows to lesser cost storage tiers. In more general, IT-centric environments:
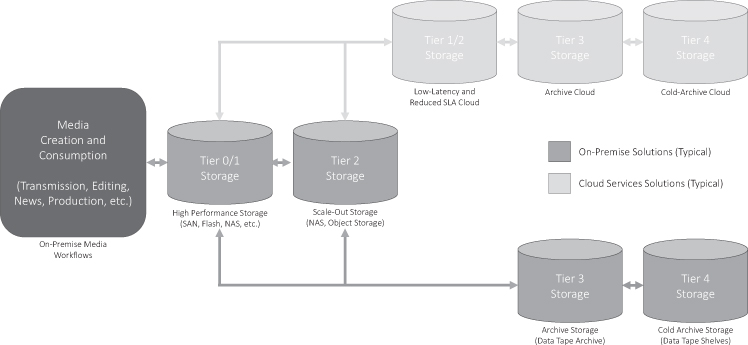
Figure 7.9 On-Premise and Cloud Storage Tier Definitions
Business need: Extremely time sensitive, high value, volatile information needs to be captured, analyzed and presented at the highest possible speed. The primary example is currency trading. Note that this is a special-case situation not found in most business environments.
Storage solution: Only storage with the highest, sub second response speeds is good enough in the currency trading environment, where a single trade can make or lose more than the cost of the entire storage system. The usual solution is solid state storage, although new high speed disk technologies may compete in this space.21
Tier 1 Storage
Tier 1 storage is typically referred to as online storage in media applications and is the most pervasive in terms of on-premise deployments. Tier 1 storage is used during for content acquisition, editing and production processes.
They are often relatively sizeable storage arrays comprised of performance NAS, SAN, and more recently flash/hybrid technologies. They often interconnect many different devices along the asset lifecycle as the usual point of play-to-air, editing and collaboration, sharing and repurposing. In IT-centric terminology, tier 1 storage is defined as:
Business need: Transactional data requires fast, 100% accurate writes and reads either to support customers or meet the requirements of high-speed applications. One common example is online retail. Numerous surveys have shown that even relatively short delays in response to customer actions can result in lost sales, making high performance storage essential.
Storage solution: Generally latest-generation, high-speed disk systems are used. These systems carry a premium price, but this cost is justified because slower performance systems would directly impact the business. However, even as disk becomes faster, solid state storage prices are decreasing, and availability is increasing. As this trend continues solid state “drives” will find their way into the Tier 1 systems of increasing numbers of organizations.22
This part of the lifecycle typically requires less storage than the other stages as it is normally focused on a smaller number of active productions. Because of the demands of production, these are typically performance-centric storage systems.
Tier 2 Storage
Tier 2 storage is the first that usually falls under the scope of the digital archive as it is not an active part of asset acquisition or production workflows. Tier 2 storage is typically the “scale-out” option as contrasted to significantly more expensive tier 0/1 storage. Although tier 2 storage is still relatively fast, it requires an asset copy or move operation back to tier 0/1 storage for continued production, reuse, repurposing, etc. Asset production devices do not typically directly access assets stored on tier 2 storage but rather make requests to the tier 2 storage or archive software to handle archive or restore operations to and from tier 0/1 online storage. In terms of its IT-centric definition:
Business Need: This tier supports many major business applications from email to ERP. It must securely store the majority of active business data, where sub-second response is not a requirement, but reasonably fast response still is needed. Email systems, which generate large amounts of data, are a prime example. While users can tolerate slightly slower response times that is required for transactional systems, they are quickly frustrated by consistently slow response.
Storage solution: Tier 2 technology is always a balance between cost and performance.23
As assets move from the creation and production phases into distribution and dissemination, they are typically moved to much larger, scalable tier 2 storage arrays sometimes referred to as nearline storage (NAS, Object Storage) under control of the digital archive system.
Tier 3 Storage
Tier 3 storage is most specifically in line with our digital archive objectives to ensure the long-term storage, protection, and preservation of valuable media assets. This tier has traditionally been the exclusive domain of on-premise data tape library systems, however with the evolution of equivalent cloud-services, more options exist today than ever before. In this case we will depart slightly from the IT-centric definitions as the use-cases inside our industry differ in the need for another specific, reduced-SLA disk storage tier. Therefore, tier 3 storage typically applies to data tape technologies or its cloud equivalent.
It is important to remember that in our digital archive, assets do not necessarily become less important nor do they become less utilized as they age. The CSM, Active Archive, or SDA-controlled digital archive system does not age content off tier 0, 1, or 2 storage but applies active lifecycle policies to ensure copies are maintained to meet target SLAs and ensure assets remain quickly accessible when needed. This is different in the case of HSM and backup solutions, highlighting their limitations in these digital archive implementations.
The use of near-infinitely scalable data tape archive systems or the equivalent elastic cloud-storage services allows cost-effective expansion of the digital archive system with little operational impact.
Tier 4 Storage
Tier 4 storage is by far the most cost-effective and scalable of all tiers mentioned previously and involves the storage of data tapes outside of the active tape library system on physical shelves. This is typically referred to as offline storage as it requires human intervention to retrieve the assets stored on these tapes. The benefit of this tier 4 storage is it gives the data tape library near infinite capacity at a very low cost, while offline assets and the data tapes that contain them are still actively tracked in the digital archive. When assets are required, a human can simply insert the tapes into the data tape library, and subsequently restored. Obviously, retrieval times vary depending on how quickly a human can find and insert the required tape, but it is typically measured in hours.
Equivalent tier 4 cold archive cloud-services aim to match these SLA retrieval times without the need for user intervention. Retrieval may still take hours for content stored on tier 4 cloud storage, but without the need for any human intervention or technology migrations, the advantages are clear.
Another advantage of this offline storage tier is that copies of data tapes can easily be made by the digital archive and then physically shipped to a different geographical location (i.e., Iron Mountain or other facility) for disaster recovery purposes. In the case of a catastrophic event at the main location, the digital archive can be reconstituted although not immediately as it requires the reconstruction of a physical infrastructure to insert the offline tapes into for retrieval. Although very cumbersome, many digital archive systems allow these individual offline tapes to be read to retrieve important assets to sustain operations through prolonged outage periods. This feature offers an inexpensive way to protect valuable digital archive against massive-scale loss but come at a cost of significant recovery and retrieval times.
Comparatively, cold archive cloud-services offer similar protections but require minimal intervention to bring these assets back online in the case of catastrophic failure of the primary site. Due to the cloud ecosystem and elastic nature of these services, they can also be seen to provide the additional benefit of business continuance as well. Often times, the entire digital archive can be back online and accessible in less than a day and immediately accessible to the cloud ecosystem tools to facilitate continued production, distribution, etc. As these cloud facilities are located geographically separate from the main client facilities, they offer inherent protection against local or regional events as well.
Storage Tier Summary
If we delve into some of the specific characteristics of each of these individual storage tiers, we can quickly see the advantages and disadvantages of each as they apply to specific areas of the asset lifecycle:

Figure 7.10 Storage Tiers Comparison
You can see that cloud services offer similar tiering and distinct advantages as contrasted with each of the on-premise technologies. This is especially relevant if all workloads exist or are migrating to the cloud platform as well.
It is worth repeating that it is not an all-or-nothing decision. This is especially resonant when some existing workflows must remain on-premise while others can benefit from a cloud migration allowing users to leverage the best of both worlds. On-premise storage and cloud storage tiers can be fully integrated to seamlessly provide a hybrid asset lifecycle and digital archive solution, exploiting the distinct benefits each offers.
In the following sections, we will start to connect some of these various concepts to begin to assemble our digital archive.
The Anatomy of a Digital Archive
A digital archive is typically comprised of two complimentary components: software and storage. The digital archive software, or simply archive software, can be considered storage abstraction providing storage orchestration as it aims to intentionally hide the complexities of the underlying storage technologies from higher-level systems while managing automated asset movement, replication, migration, etc. The archive software typically also provides a federated, homogeneous view of all underlying storage for all connected systems and users, again abstracting the storage complexities allowing a focus on SLA target objectives. As discussed previously, there are many generations of archive software in use in the industry ranging from HSM to CSM and on to the emerging and exciting advent of modern SDA platforms.
Digital archive storage is typically comprised of different types of on-premise hardware storage technologies (solid-state storage, hard drives, and data tape archive systems) and more often cloud-based utility storage services. Again, this storage decision does not have to be all-or-nothing, as a mix of on-premise and cloud-services are typical today in hybrid storage systems. This is becoming more and more normal as the significant benefits offered by cloud-based services to next-generation digital archives are realized.
Another important characteristic to note is the digital archive software cannot dictate how the storage is being used by each of the various content production or consumption workflows but rather must support them in an agile fashion as they also morph and evolve. However, the digital archive storage does have to follow a set of very well-defined rules to ensure SLAs are met while mitigating technical factors in handling of data tapes or even moving excessive amounts of data to or from the cloud.
As highlighted, many legacy archive software systems are limited by historical factors effectively limiting the opportunity for fluid modernization to meet the fast-paced change typical in the industry today. Many of these legacy archive vendors, often in the realm of HSM and CSM, are advancing their development efforts in an attempt to support these new workflows and next-generation digital archive concepts but have ultimately moved slower than the industry placing their relevance and sustainability into question.

Another contributing factor to the impending demise of these legacy solutions is the parallel advancement of MAM, media supply chain, and other similar “orchestration” tools which have added the native ability to also control storage services. Once the many complexities of data tape are removed from these digital archive environments, the control of solid-state, disk, and cloud-based services becomes a much simpler task for these other systems as there are only a few standardized interfaces (S3, SMB, NFS) to most modern on-premise and cloud storage services. This makes the task of storage orchestration much easier than in the past, and on the surface, perhaps better suited to these higher-level tools, removing the specific need for digital archive software altogether. For example, MAM systems can orchestrate storage based on user-facing demands and metadata such as upcoming production, news stories and trending topics, and even enhanced and searchable metadata such as facial recognition or audio transcription information. Media supply chain systems can orchestrate storage based on production value, revenue opportunities, or direct-to-consumer demands.
However, there are two significant downsides to this approach. The first is that only the combination of the user facing tool (i.e., MAM) and the storage can be considered a digital archive, intrinsically connecting the two for the long-term. Migration, changes, or replacement of either will have an impact on the other due to this dependency. The second is the inability to effectively service other workflows not governed by these user-facing systems and the risk of having to build multiple digital archive or storage silos as a result. Ultimately, we want a single digital archive solution to traverse all parts of the media organization, servicing each natively and intimately.
Most cloud vendors offer their own simple storage orchestration solutions to manage movement of assets between their own cloud-storage tiers. These are usually quite simplistic policies similar to those found in HSM and CSM solutions based on age, last access time, or object size but could be very cost-effective and simple to manage, best suited to straightforward digital archives in the cloud. The downside of this approach is these tools do not comprehend the demands of media-centric workflows nor do they support hybrid storage or multi-cloud deployments. Essentially you have to place your digital archive and your trust in a single cloud vendor which may or may not be a point of concern.
If you are still considering data tape as a core part of your digital archive or are looking at multi-cloud approaches which are not best managed by your MAM, media supply chain, or other tools, the emerging field of SDA solutions are certainly the best option. SDA software allows assets to be stored across any number of technologies in any deployment fashion (on-prem, cloud, hybrid) and handles all complex storage interactions including replication and migration. These SDA software solutions are inherently vendor-neutral and enable intelligent and agile asset lifecycle control by metadata-driven policies which govern factors such as replication and accessibility at a SLA level.
Storage Abstraction
The storage infrastructure in the previous diagram is intentionally represented as an ambiguous block. Ultimately, we cannot foresee what storage technology fits best in the environment today nor can we attempt to contemplate the future of storage and what options may be available a decade from now. We want to endeavor to ensure our asset lifecycle workflows can continue to evolve and advance over time while maintaining a clear abstraction layer between these workflows and the underlying storage. Obviously, editors working at an edit station should not concern themselves with whether their asset is stored on data tape or in the cloud but rather rest assured their valuable content can be accessed and restored when they need it. Again, this comes down to the shift away from the intimate details of storage to the idea of SLA-driven design and architecture.
There are a few constants in the equations surrounding long-term storage and digital archives in general:
They will employ many different types of storage technology to handle the varying demands of existing and future workflows
They will have to migrate assets to newer storage technologies or different cloud providers over and over again during the life of the digital archive
As mentioned previously in this chapter, these are not new concepts nor requirements and have little to do with the specific technologies selected today or tomorrow. Storage technology choices will likely change more often than the workflows and user-facing tools, devices, and interfaces. It is a core tenant of modern digital archives to handle addition, modifications, removal, and migration of underlying storage technologies transparently with little or no risk to higher-level workflows, and certainly no risk to the digital assets themselves. The digital archive must abstract the complexities of the underlying storage technologies and provide a federated and vendor-neutral view regardless of what storage technology or cloud-service is utilized.
Storage Orchestration
Storage orchestration relates to intelligent and automated asset movement, migration, and replication under the hood of the digital archive software without specific guidance or commands from higher-level systems. Storage orchestration essentially relates to the SLA targets we define and govern how and when content is replicated, moved or migrated, and to which specific target storage devices. For example, an orchestration policy may be defined to ensure a copy of a specific asset class or group is maintained in tier 2 on-premise storage while a parallel copy is made to the least-expensive public cloud tier for disaster recovery. This cloud instance may reside in tier 2 or tier 3 storage for fast access while the production is underway. Once production is complete, it may be automatically deleted off on-premise tier 2 storage and moved to tier 4 cloud storage to minimize storage costs. This same asset could then be intelligently moved back to tier 2 cloud storage based on metadata which defines the production schedule to ensure it is immediately accessible when needed, intelligently overcoming the access latencies for tier 4 cloud storage.
SDA solutions can handle these complex storage orchestration tasks and fundamentally highlight the shortcomings of legacy CSM systems. To empower the paradigm shift towards SLA-driven digital archives, it is imperative these orchestration decisions be based on metadata rather than file or object characteristics typical in these legacy systems.
Archive Maintenance
Historically, film and video tape were used as a storage medium for movie productions, news stories, and episodic content. Most content creators amassed many thousands of these physical assets over many decades of production on several generations of video tape and film technologies. Over time, these legacy video tape and film formats required periodic migration to newer technologies for fear the physical player devices would no longer be available to retrieve the assets. This historical burden was immense as every hour of video tape and film would take at least one hour or more to migrate to a new format. Additionally, this dubbing process typically involved a human to monitor the content during the entire process to ensure the best-possible outcomes, as the original medium would be subsequently disposed of or become inaccessible due to the player machines becoming unavailable. Each time this asset was dubbed, it also went through a generational loss effectively reducing its quality by a small amount each and every time.
When dealing with dozens of hours of content, this migration process was not terribly difficult, costly or time consuming. However, when you scaled an asset collection to thousands or even hundreds of thousands of hours, these migration tasks became almost perpetual and of the scale where few organizations could afford the time or expense. As a result, there are still thousands of important video tape and film collections around the globe at risk of loss due to this insurmountable migration time and expense challenge.
Some innovative content owners recognized the value of these legacy physical archives and embarked on large-scale asset digitization processes. This represented an investment to move asset collections away from their legacy physical storage media and into the realm of assets managed by digital archives.
Periodic asset migration inside the digital archive is typically fully automated as mentioned previously. It often involves no human intervention aside from simply initiating the migration process. As these assets are moving as “bits” of data in the digital archive, automatic integrity checks can be performed on the data to ensure the newly migrated instances are exactly the same as the original one eliminating the costly human quality assurance step. We also benefit from the fact that these are data migrations rather than audio/video migrations, meaning there is no generational loss each time a copy is made as the copy is an exact and authenticated replica of the original instance. As the performance characteristics of modern storage technologies far surpass the “realtime” bounds we encounter when dealing with legacy video tape and film formats, these migrations can occur many times faster than realtime overcoming the challenges of data scale. Lastly, the periodic migration and processing of these digital assets offers a window of opportunity to perform fixes, enhance metadata, validate integrity, increase storage densities and performance, and even embrace new storage technologies and cloud services.
Asset Integrity
When digital assets reside on spinning disk of any sort whether on-premise or in the cloud, it is quite easy for modern digital archive software to automatically validate their integrity. This can be achieved by simply running a checksum calculation when system resources are available or whenever an asset is being restored, moved, or replicated.
This asset integrity-check process assumes a “known good” value for this checksum is stored as metadata along with the asset upon its inception. Asset instances where corruption is discovered can simply be automatically removed and replaced with an instance which has been properly validated residing on another storage system. In cases where a valid instance is not available, human intervention may be needed to leverage digital triage tools to salvage whatever data is still accessible, so it may not represent a total loss. Digital archive best-practices dictate a minimum of two copies of all assets are maintained at all times in geographically separated infrastructures. It is important to note that by making additional copies or instances of assets in the system, their resiliency SLA values combine better ensuring their long-term protection against loss.
Asset integrity checks become much more difficult if your assets are stored on data tape in a tape library system as they are not online and readily accessible at all times. There are competing philosophical camps on whether it is better to periodically load data tape media into tape drives to perform integrity checks on the data or leave them safely sitting inside the tape library peacefully untouched. It is true that loading a data tape is quite a mechanically intensive operation with a fast-moving robotic arm grabbing the tape, transporting it, and loading it into a receptive tape drive. Once inside the drive, the tape needs to be mechanically threaded and wound around a reel inside the tape drive itself, quickly shuttled to the location of the requested data, tape speed and tension stabilized, and the read process started. Despite careful engineering and awe-inspiring design, these mechanically heavy operations could be catastrophic to the sensitive data contained on each tape cartridge. Leaving them peacefully sitting inside the tape robotic system and sparing them the mechanical interruptions may better protect the data contained.
Generally, it is not recommended to sporadically load data tapes into a drive for the sole purpose of validation and integrity checks unless of course the media itself is suspect. The recommendation is to simply leverage the randomized nature of asset access typical in these digital archive environments to statistically verify assets which are contained on cartridges loaded to service other read or write operations. If we consider setting a threshold age of one year (or other somewhat arbitrary figure), there will be “qualifying” assets contained on tapes which are loaded into drives to service actual production requests. By selecting one or more of these qualifying assets contained on tapes which are already loaded, we minimize unnecessary mechanical wear and tear on the tape media and still accomplish our goal of spot-checking validity of assets over time. Spot checking aged assets on media will give a good indication of media and assets at risk and help prevent large-scale asset loss.
Storage migration to newer technologies every decade also enables full asset validation to occur in-path while opening up the additional opportunity for triaging, replacing, and rebuilding failed instances or even making cloud copies.
Connecting the Bits and Pieces
Being able to select and manage any storage type and technology is a wonderful benefit provided by the digital archive. However, as important is the tight integration into the production tools, services, devices, and interfaces used as part of the media asset lifecycle. Our ultimate objective is to have the digital archive fit the creative process and business needs rather than these conforming to fit the digital archive.
Modern SDA solutions expose heterogeneous and globally federated views of the underlying storage via industry standard protocols such as S3, SMB, and NFS. This allows both simple and complex connections to high-level systems such as MAM, media supply chain, and others without them having direct awareness of the underlying storage technologies employed. This allows the digital archive to remain separate and independent from the tools which use it, allowing these tools to be added, removed, upgraded, or decommissioned without affecting the integrity or operations of the digital archive.
Modern SDA platforms are the glue between various human-facing tools, devices and interfaces, and the complex and ever-changing digital archive storage infrastructures.
Archive Transformation and Modernization
With all of these many complex factors taken into consideration, the truth of the matter is that many organizations already have digital archives in place and are faced with specific challenges surrounding their modernization. Depending on whether these digital archives were implemented in an ad-hoc, siloed fashion or as enterprise-class digital archives, there is likely desire or impending need to take a step toward a next-generation digital archive. The ultimate objective is to always focus investment on the future of an organization rather than on its past.
From a digital archive software perspective, the legacy vendor may still exist and continued development of their system to adapt to some of the modern demands of the industry. Careful assessment is required to determine whether the best forward-looking plan is to simply remain status-quo and upgrade existing software to ease the implementation of newer technologies and services or take a more aggressive step to abandon it in favor of more modern solutions or services. If the legacy archive system supports scaling to the cloud, this may be the easiest choice to make as long as vendor lock-in and proprietary interfaces can be avoided, which is often difficult to ensure. Significant investment in time and money could land an organization with a modernized but no more sustainable digital archive solution.
From a storage perspective, these large-scale legacy archive systems almost exclusively rely on aging data tape infrastructures as this has been the defacto standard for close to two decades now. Driven by inertia, the path of least resistance may again be to invest the capital to secure data center space, purchase a new data tape library, data tape drives, and data tape media and perform data migration under legacy archive system control to increase performance, storage density, and asset longevity. Again, this money is likely better spent on a more aggressive cloud transformation plan rather than simply deferring the inevitable migration away from data tape and its complexities.
However, the biggest archive modernization mistake organizations can make is to move from one digital archive software vendor platform managing on-premise data tape to another digital archive software vendor platform also managing on-premise data tape. It is much less risky and less expensive in the long-term to stay with the legacy solution proven in the environment than risk an archive transformation only to end up in much the same place at the end of the migration. Reducing continued investment in these aging legacy archive platforms while planning a more aggressive archive transformation is the best path to the next-generation digital archive. It is much better to simply wait until strategies and budgets support a true archive transformation than to continue to make substantive investments in these legacy systems.
Working toward this end goal, organizations can almost immediately begin to alleviate reliance on legacy archive applications and on-premise data tape infrastructures. In some cases, this could involve a modest upgrade of the legacy archive software to support orchestrating over existing on-premise data tape as well as cloud services. This can help to cloud-enable the digital archive without the necessity to refresh data tape storage infrastructures. This may allow an organization to continue forward with a diminishing reliance on on-premise data tape, begin to realize the benefits of cloud-services, and slowly move away from on-premise storage as it ages out of the environment. Even if this slow migration takes several years to complete, money can be redirected from capital intensive on-premise storage systems to fund increasing cloud adoption. Once the cloud migration is complete, organizations can then determine whether the legacy archive system is still relevant in this new environment, whether it can be replaced or just turned off altogether. Caution is advised as legacy archive vendors are specifically motivated to ensure they maintain control over existing deployments and the digital assets they store, so careful and thorough advanced planning is required to avoid long-term lock-in.
Thankfully, migration solutions exist today which avoid costly and risky upgrades of both legacy archive systems and their underlying storage infrastructures while ensuring no long-term vendor lock-in. These advanced archive migration orchestration solutions can perform fully automated, background asset migrations to the cloud while maintaining uninterrupted legacy archive operations on-premise avoiding costly upgrades altogether. These archive migration solutions effectively borrow some portion of the existing legacy archive system and storage resources to facilitate background archive migration. They also federate and abstract the legacy archive and cloud storage services, effectively making both appear as one virtualized legacy archive to all existing applications already integrated with the legacy archive (i.e. MAM, automation, traffic, etc.). This helps avoid costly and risky upgrades to these business systems and human facing tools, effectively decoupling them from the digital archive now and into the future. During migration, assets are also freed from any proprietary containers or wrappers ensuring all assets arrive in the cloud in an open and accessible format, ready to operate fully independently of the legacy archive system. During and after the migration, migration orchestration solutions ensure on-premise legacy archive systems and cloud storage services remain fully synchronized until the legacy archive system is finally decommissioned. As the legacy archive system continues to operate in parallel during the migration, and for some period afterward, it can be considered a backup or cloud safety-net, allowing a risk-free digital archive transition to the cloud.
Obviously, there is no one-size-fits-all approach to archive transformation. It is recommended that careful planning and consideration be given to the objectives of the organization. It may also be helpful to engage with various subject matter experts (SME) in the field of digital archiving and to leverage the experience of others facing similar journeys.
At a simplistic level, some questions to ponder when planning a next-generation archive transformation:
Are we ready to move off data tape?
Are we facing a fork-lift upgrade of our legacy archive system or storage in the coming years?
What continued value does our legacy archive system bring to the organization?
Can we consider cloud services on a scale larger than just that of our digital archive storage?
In many cases, the largest barrier to archive transformation is the inertia of the status-quo as these legacy archive systems are often tried and true, serving the needs of the organization successfully for many years. It is important to remain focused on the key strategic objectives of the organization and ensure alignment with the plans around digital archive system modernization and transformation. It is also important to remember that these massive-scale migrations can take months or even years to complete, so any planning must take this into account.
Regardless of whether an archive transformation is in the near-term plan, it is recommended that some effort be placed into fully understanding and quantifying sustaining legacy archive costs and risks each year. By regularly assessing factors such as the age of the infrastructure, impending capital intensive upgrades, migration timeframe estimates, sustaining annual hardware and software support costs, tracking legacy archive vendor viability and the expense of skilled employees dedicated to maintaining these infrastructures, organizations can be better prepared to ensure a pragmatic and educated path to their next-generation digital archive.
Standards-Based Digital Asset Protection
Despite all of the considerations necessary in planning and architecting a digital archive system, it is important we also look at the way these valuable assets are stored on the storage systems to best assure long-term accessibility and ensure independence from the archive software itself. This is often referred to as vendor-neutrality and is an important objective in ensuring long-term asset access. There are obvious benefits to storing assets in their native format, but arguably this can limit advantages of other approaches as important metadata and context can be missing.
Important standards development work has been underway over the past decade to embrace the modernization of technologies and approaches to this ongoing preservation challenge. These standards attempt to combine the desire for native access while layering on important metadata-encapsulation and preservation features to better assure long-term viability and access to digital assets. The good news is experts in the field of storage, archive, and preservation have worked with important global standards bodies such as the Society of Motion Picture and Television Engineers (SMPTE) as well as the International Standards Organization (ISO) to solidify this important topic as globally published, international standards.
Archive eXchange Format (AXF) Standard
AXF is an open-standard object-container for digital data and its associated metadata. It allows any type, size, and number of files or data blobs to be stored, transported, and preserved as a collection on any type of storage technology while maintaining full independence of file or operating system and underlying storage. Over a decade in development, AXF addresses the need for a long-term open storage and preservation format while overcoming the limitations of legacy file and container offerings. AXF was first published as an international standard by the SMPTE in 2014 and later by ISO/IEC in 2017.
AXF bundles any type and amount of essence data and associated metadata (structured, unstructured, descriptive, technical, proprietary, etc.) into an immutable, self-describing preservation package while maintaining the ability to dynamically interact with any of the data elements contained inside an object. Its objective is to ensure valuable assets will be protected now and into the future, regardless of the technology you choose today or may choose tomorrow in your digital archive.
AXF is the physical embodiment of the object store concept targeting the transport, storage, and long-term preservation of complex digital asset collections. It is a revolutionary way for digital archive systems to package essence and metadata, extending the encapsulation to the storage devices and technologies they maintain.
AXF is like an advanced ZIP24 package which encapsulates any type and number of data elements (files, folders, data blobs, etc.) in a very well-structured, self-describing data object. An AXF Object carries any type and amount of metadata along with the data payload. It also includes redundant index structures and an embedded file system. This embedded file system ensures independence from any filesystem, operating system, or storage technology on which it is created and stored. This means AXF Objects are universal and can be stored on any type of technology including data tape, spinning disk, flash media, and even the cloud. Because the AXF Object structure is very tightly defined, it is always the same regardless of the technology employed removing the complexity and risk associated with the selection of storage technologies. AXF also adds self-describing characteristics to the media itself, which ensures that it can be accessed and read regardless of whether the digital archive system which originally created it and the AXF Objects it contains is available or not.
AXF is a streaming-centric technology, also being used extensively for the transport of complex file collections across WAN networks as well as to and from the cloud. Because each AXF Object fundamentally connects metadata and the data payload which comprise the asset in an encapsulated container, important context is always maintained. It also includes preservation-centric features and allows the receiving system to track the chain of custody (or provenance) of the asset, validate structures and integrity of data and metadata on-the-fly, and ensure authentication and maintain access control for the asset collections being transported and stored.
Key to the adoption of AXF is its nature as an application-level implementation which does not require the storage vendors do any development to support it. In addition to this, AXF does not rely on any specific or proprietary features of the storage technology used, so it is supported in current as well as older generation technologies. It is currently being used in large-scale digital archive environments across diverse storage and network transport technologies supported by multiple technology vendors.
AXF was specifically developed to address the need for a long-term open storage and preservation format and overcome the limitations in legacy container formats such as Tape ARchive (TAR25). This format was often used by archive systems in the past in order to achieve some level of vendor neutrality and interoperability but lacked key features required for digital archive storage and preservation. AXF technology abstracts the underlying file and operating system technology facilitating long-term portability and accessibility to the files contained in the container while adding several Open Archive Information Systems (OAIS26) preservation characteristics to provide long-term protection for digital assets.
AXF defines the specific method for encapsulation of file or data collections and their associated metadata as well as the mechanism for storage on media storage technology (data tape, magnetic disk, optical media, flash media, cloud, etc.). AXF adds self-describing features to both the AXF Objects and the media on which they are stored, allowing independence from the systems which originally created them. AXF provides a universal and open file-system view of all stored objects, data, files, and metadata allowing exchange with any applications which also comply to the published and maintained international standards.
AXF takes the concept of an object store to the physical level as a fully self-describing, self-contained encapsulation format for complex data collections. AXF provides a standardized way of storing data, files or file collections of any type and size, along with limitless encapsulated metadata of any size and type, on any type of storage technology or device. AXF is independent of the host operating system and file system as well as from the application that originally created the AXF Object ensuring vendor and technology neutrality.
A Closer Look
We have covered much about the architecture and technologies involved in digital archive operations inside the media and entertainment industry. Arguably, more important than where or what is used to store digital assets are the way they are stored on the selected storage technologies or services.
AXF is based on a file and storage medium-agnostic architecture which abstracts the underlying file system, operating system, and storage technology. AXF Objects contain any type, any number, and any size of files as part of its payload, accompanied by any amount and type of structured or unstructured metadata, checksum and provenance information, full indexing structures, and other data within a single self-describing, encapsulated package. The AXF Object includes an embedded file system, which helps abstract complexities and limitations of underlying storage technology, file systems, and operating systems. AXF Object can exist on any data tape, disk, flash, optical media, cloud or other storage technology and can be used for network transport of data.

Figure 7.13 The AXF Construct

Figure 7.14 AXF Objects on Storage Media
As a self-contained and self-describing container, AXF supports large-scale digital archive systems as well as simple standalone applications, facilitating encapsulation or wrapping, long-term protection, and content transport between systems from various vendors which conform to the AXF standard.
AXF is an IT-centric implementation, supporting any type of file or data encapsulation including databases, binary executables, documents, image files, etc. It supports the OAIS model as well as preservationist features such as provenance for both media and objects, unique identifiers (UUID, UMID, ISCI, etc.) support, geo-location tagging, error detection down to the file, and structure level and data-validity spot checking.
AXF Structures
Embedded File System
The AXF standard leverages its own embedded file system. AXF offers a translation between any type of generic file or data set and logical block positions on any type of storage medium being used with or without its own file system. AXF encapsulates a related set of files or data elements with any type and amount of ancillary metadata (structured or unstructured) into a single, well-defined container.
AXF is intended to overcome the limitations of other encapsulation formats, which cannot support complex file structures with millions (or more) of files or handle large assets sizes typical in media and entertainment particularly well. Because of its embedded file system, AXF does not depend on the storage technology. Although optimized for the storage of large assets and collections, the AXF format can be applied to any environment where an open and accessible storage encapsulation format is required for any type of asset collections.
Object Encapsulation
Each AXF Object is a fully self-contained, encapsulated collection of files, data, metadata, and any other ancillary information which adds relevancy or value to its contents. AXF is designed to handle a single file encapsulation or many millions of elements of any type and size.
AXF Objects are equivalent regardless of whether they are created on data tape, disk, flash, cloud or future storage technology with or without file systems. This makes the creation and handling of AXF Objects on differing media deterministic, better ensuring long-term accessibility.
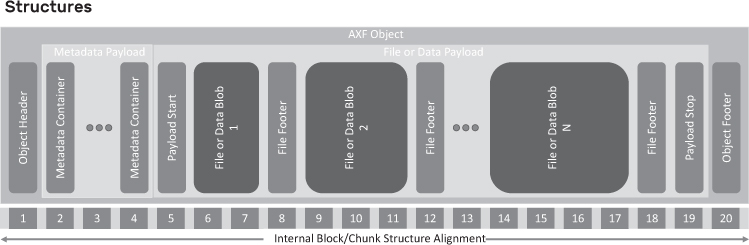
Figure 7.15 AXF Object Internal Structures
Block and Chunk Alignment
To aid in resiliency and performance across any storage device, technology, or medium, each data structure and element contained within an AXF Object is aligned on pre-defined chunk boundaries. These can be independent of the storage technology or medium and can be different for each AXF Object contained on that medium if the medium itself supports this. Chunk size is typically an integer multiple or sub-multiple of blocks on block-based media which also aids in the recoverability of AXF Objects where indices may have been damaged or corrupted.
During each AXF Object creation, copy or movement operation, the application is responsible for ensuring the data is aligned on the block boundary basis defined for the destination storage technology or media. AXF Objects can be specifically tuned to the underlying storage to optimize performance and storage efficiency even down to the level of tuning on an AXF-object-by AXF-object basis, depending on the average, minimum, and maximum sizes of data elements contained within the data payload.
VOL1 Identifier
This VOL1 Identifier structure is included only on data tape media when used to store AXF objects. It is included to identify the tape as AXF Media to other applications and systems which might also try to access these data tapes to ensure they are properly identified. It is not relevant to any other AXF implementations or storage technologies.
Medium Identifier
The AXF Medium Identifier structure contains the AXF volume signature, a UUID, and label for the media as well as information about the storage medium itself. The implementation of the Medium Identifier differs slightly depending on whether the storage medium is linear or nonlinear, and whether it includes a file system or not, but the overall structures are fully compatible.
This structure adds the self-describing media characteristics to AXF so systems that support the format can immediately understand everything necessary about the media to be able to index, read, and recover its contained AXF Objects.
Object Index
The AXF Object Index is an optional structure that assists in the rapid recoverability of AXF-formatted media by foreign systems. Information contained in this structure is sufficient to recover and rapidly reconstruct the entire catalog of AXF Objects on the storage medium – think of it as an advanced File Allocation Table (FAT27).
This Object Index can be periodically written at various points on the storage media or updated periodically on file-based systems to provide enhanced, rapid indexing and recoverability. In a case where the application has not maintained these optional AXF Object Index structures, the contents of each AXF Object can still be reconstructed by rapidly processing each AXF Object Footer structure adding to the multilevel enhanced resiliency of the format.
Inside an AXF Object
Binary Structure Container
The Binary Structure Container is a simple binary envelop which wraps/contains payload information and includes structure identification, index structure checksums, classification information, media/mime types, etc. For AXF structural elements, this payload is simple XML, but in the case of Generic Metadata Containers, it can be anything from binary to text or even source code. The Binary Structure Container allows the application to comprehend its contents allowing it to be stored, validated, tracked, and reliably recovered regardless of its nature or origin. An important characteristic of AXF is that the files or data elements contained in the actual data payload of the AXF Object do not require Binary Structure Containers and are simply bit-for-bit equivalents of the original data, not modified in any way. This is an important feature for preservation in that the asset data is never modified in any way and ensures that even the simplest AXF applications can read and retrieve the data payload from an AXF Object.
Object Header
Each AXF Object begins with an AXF Object Header structure. This structure contains descriptive XML metadata describing the actual contents of the AXF Object such as its unique identifier (UMID/GUID), creation date, descriptive information, file tree information, permissions, etc. This acts as a detailed table of contents or catalog for the data contained inside the AXF Object. By simply parsing this structure, AXF applications can comprehend everything about the asset data, where it came from, what was used to create it, how to retrieve it, etc. This structure contains several mandatory metadata and descriptive elements to ensure long-term accessibility and interoperability between AXF systems.
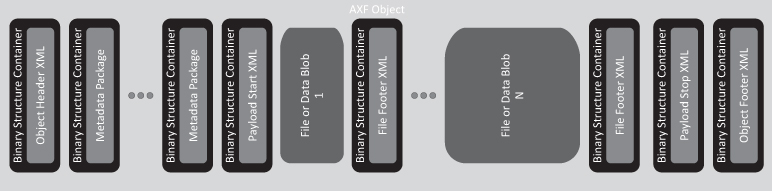
Figure 7.16 AXF Universal Binary Structure Containers
Metadata Container
Following the AXF Object header are any number of optional AXF Generic Metadata packages. These are self-contained, open metadata containers for applications to include AXF Object-specific metadata. This metadata can be structured or unstructured, open or vendor specific, binary or XML, and provides a flexible and dynamic space in which to enrich the depth of the AXF Object and permanently link it to the encapsulated data payload of the object.
There are no constraints or standards governing the type of metadata, the number of packages, or their contents. In the case where there is no metadata to store along with the AXF Object, this structure is simply omitted. Metadata (XML, binary, or other) can be stored in the file payload of the AXF Object as well, but their context may make processing difficult for third-party applications during subsequent restore or replication operations and are often better suited to be carried in the metadata payload section of the AXF Object.
File or Data Payload
Next is a Payload Start structure which marks the start of the essence data payload of the AXF Object. This is a simple, empty structure which can be easily located by even the simplest AXF applications.
The file or data payload of an AXF Object consists of zero or more Data + Data Padding + Data Footer triplets. This is the actual byte data of the files to be stored within the AXF Object container. File Padding is used to ensure the chunk alignment of all AXF Object files and structure elements which is a fundamental requirement of the AXF standard. The File Footer structure contains the exact size of the preceding file along with file-level checksums, original path information, etc. and can be rapidly processed by the application on-the-fly during operations to retrieve files, validate authenticity and ensure data integrity.
Following the last data elements in the payload, a Payload Stop structure marks the end of the data payload of the AXF Object. This is a simple, empty structure which can be easily located by even the simplest AXF applications.
Object Footer
The final portion of an AXF Object is the AXF Object Footer. It is essentially a repeat of the information contained in the Object Header with some additional information captured during the creation of the AXF Object itself such as file checksums, block positions, and file permissions. The Object Footer is fundamental to the resiliency of AXF and allows efficient re-indexing of AXF media by foreign systems when the content of the media is not previously known (i.e., the self-describing nature of AXF Objects).
Following the initial creation of an AXF Objects, any subsequent move or copy operations mandate the information contained in the AXF Object Footer be fully replicated in the AXF Object Header (if this is not already the case), adding to the redundancy of the AXF standard.
History of AXF
The Early Days
In July 2006, the SMPTE V16-ARC AHG initiative was formed by the three leading digital archive vendors at the time (Front Porch Digital, Masstech and SGL) to focus on the invention and development of an open-standard for the storage and preservation of digital assets on any type of storage device or technology. Merrill Weiss was selected as the SMPTE committee chair to lead this initiative.
In October 2008, the V16-ARC AHG received status as an official working committee under SMPTE and was renamed the 10E30WG-AXF or the AXF working committee. By April 2008, Front Porch Digital was the only remaining founding member in active committee participation. In October 2009, the SMPTE AXF committee ceased activities due to limited participation and the AXF initiative was shelved.
In appreciation of the importance of AXF and the objectives it embodied, Brian Campanotti (CTO, Front Porch Digital at the time) brought the initiative inside of Front Porch Digital to continue its advancement. He formed a small working group including users and members of his development team Grégory Pierre and Benoît Goupil. The original technical framework was abandoned and AXF was reinvented from the ground up while maintaining the key industry and end-user objectives as defined by the original SMPTE committee and by the industry.
Release to the Market
At the National Association of Broadcasters (NAB) conference in Las Vegas in April 2011, Front Porch Digital announced the completion of their AXF implementation and its release to market as part of their DIVArchive V7.0 Content Storage Management (CSM) solution. Brian Campanotti further announced their AXF specification and design would be contributed to SMPTE as an unencumbered straw-man proposal for continued advancement and eventual standardization by the AXF committee. At the same time, an AXF community website (www.axf.io) was launched for vendors and end-users interested in AXF technology to gather industry input and feedback on the invention.
The SMPTE 10E30WG-AXF committee (previously under the TC-10E Essence parent technical committee) was placed under the TC-31FS File Formats and Systems parent committee. As a result of this reorganization, the official name of the SMPTE AXF committee was changed to TC-31FS30 AXF WG, and this straw-man specification formed the basis for its revitalized work.
AXF Becomes a Standard
In September 2014, it was announced that AXF was ratified and published as SMPTE standard ST 2034-1:2014 and is available for direct download from the IEEE Digital Library.28
As part of a personal commitment made in 2011, Brian Campanotti spearheaded an effort to bring the new SMPTE AXF standard to ISO/IEC for standardization to help broaden the reach of this important technology. The ISO/IEC PAS submission process was initiated in March 2016.
The SMPTE AXF standard was submitted to ISO/IEC a year later, and following a two-month translation phase, AXF entered balloting on June 7, 2017. After a two-month balloting period, AXF was ratified in August 2017 as ISO/IEC 12034-1 Standard with no objections from any voting nation. This was a very important moment for the entire AXF team and the industry, eleven years after the original conception of AXF. The ISO/IEC 12034-1 AXF Standard is available for download directly from the ISO/IEC website.29
AXF Adoption
AXF has been successfully deployed across various storage technologies (flash, disk, tape, optical, and cloud) and a multitude of file-based asset types in many industries touching various applications and environments. In addition to storage and preservation, AXF is used by several global organizations facilitating authenticated and protected WAN-based transport of valuable assets between globally distributed facilities, as well as to-and-from multiple cloud service providers.
AXF has been successfully deployed on all major storage technologies in industries spanning from national archives, museums, government agencies, film production, and broadcasting to generic IT compliance archiving. It is estimated there are hundreds of petabytes of the world’s most valuable (monetarily, historical, cultural) digital assets stored, protected, and preserved by AXF – a true testament to the dedication and hard work of many companies and individuals over the past decade.
AXF Today
The SMPTE AXF Committee and the axf.io community remain active today. Tracking and assisting development organizations and end-users with their AXF implementations, collecting requirements and suggestions for expansion and improvement. In addition to this, work is underway on AXF Part 2 which extends the reach of AXF earlier in the digital asset creation lifecycle. Essentially, AXF Part 2 is a “de-encapsulated” version of AXF Part 1, allowing for each component to be created, manipulated, edited, versioned, etc. during its lifecycle, while capturing important metadata and provenance information essentially reaching back to the birth of the asset. Obviously, a large part of AXF Part 2 is the ability to map bidirectionally between AXF Part 1 and Part 2.
This work extends the relevance of AXF from the birth of a digital asset through to its eternally preserved life, capturing protecting and preserving as much as possible along the journey.
Conclusion
There are many complex factors to be considered when looking to implement or modernize an existing digital archive system. The shift from purpose-built storage silos deployed and evolved over time to a modern, federated digital archive can represent a monumental shift for an organization having to consider requirements from stakeholders across the organization. The challenge is further exacerbated for organizations which span many facilities or even many countries and likely possess very different views on the digital archive.
Careful analysis backed by real world data is the best first step toward fully comprehending the requirements and associated costs and can help to point organizations in the right direction when planning this important endeavor. Although we often head into these projects with lofty goals and objectives, costs will ultimately be the primary driver of decisions and even many concessions along the way.
Modern cloud-services have enabled us to look at digital archives from a service level agreements (SLA) perspective rather than bother with the specific pros and cons of each specific storage technologies and how they fit into our architecture and our budgets. This fact empowers organizations to take a business driven, asset-centric approach to their digital archives rather than the traditional and much more complex storage-centric approach.
However, for many organizations the shift from CapEx to OpEx will present financial challenges which often times are not fully understood at the onset. Careful TCO planning, modeling and analysis combined with a solid understanding of the objectives can empower accurate and predictable cloud cost control.
Organizations must understand the importance of development, funding and sustaining a solid digital archive strategy and its importance to future value, growth and agility. As viewer and consumption demands change, it is an important enabling technology that empowers organizations to be ready to react and pivot to ensure growth, relevance, and a viable business future.
Today, cloud-services enable a level of agility for organizations never before seen. New direct-to-consumer services can be quickly launched leveraging the assets of an organization in a very cost-effective fashion. By rapidly assessing viewer reach and return on investment, these new services can be quickly adapted, tuned, expanded or even cancelled. Because of cloud pay-as-you-go pricing, financial exposure in these cases is minimal when compared to the capital and time intensive launch of new on-premise services in the past. Key to this agility is having the digital assets readily accessible and close to the tools and services which will leverage them in the cloud, which is simply not possible or practical if on-premise data tape infrastructures continue to warehouse digital assets. Although proven over the past two decades as the most reliable and cost-effective digital archive storage, these aging approaches to digital archives are falling by the wayside in favor of more modern architectures and cloud-centric services due to the significant benefits they provide.
The choice of digital archive software is also a daunting challenge but can be easily assessed once the goals and objectives have been defined. Obviously, there is no need to introduce additional complexities and vendor systems if there is not a clear advantage to the organization. In some cases, organizations will choose to solely rely on tools and services provided by their selected cloud vendor. For some, they may choose to proceed with MAM or media supply chain systems to orchestrate assets across their storage tiers. For others, a modern digital archive approach enabling cognitive metadata-driven asset orchestration leveraging SDA technologies may be the best fit. Regardless of the forward-facing plan, it is clear that money invested in aging legacy archive systems and its related storage infrastructures is not money well spent.
No one would generate, acquire or produce content unless there was some perceived long-term value. It is important that decisions be made carefully and backed by data and analysis to ensure the best chance of long-term availability and accessibility to valuable digital assets. Lessons should be learned from those who have gone before, and no one should assume their objectives differ materially from others grappling with similar challenges and hoping to achieve the same digital archive objectives.
As technology continues to advance, best practices should be leveraged to ensure the most risk-free path is chosen. Leveraging modern storage and cloud-services natively or enabled by advanced SDA digital archive solutions can best assure a trouble-free path to long-term storage, archive, and preservation now and into the future.
Digital archives store and protect the crown jewels of any organization and must be attended to with care.
Notes
6 https://www.popularmechanics.com/technology/security/a28691128/deepfake-technology/
8 https://en.wikipedia.org/wiki/Open_Archival_Information_System
9 https://www.oxfordlearnersdictionaries.com/definition/american_english/asset
11 http://www.unesco.org/new/en/communication-and-information/access-to-knowledge/linguistic-diversity-on-internet/initiative-bbel/stakeholders/unesco-strategy-for-the-safeguarding-of-endangered-languages/
13 https://aws.amazon.com/solutions/implementations/media2cloud/
26 https://en.wikipedia.org/wiki/Open_Archival_Information_System