
![]()
Backup and Recovery in RAC
by Syed Jaffar Hussain
Oracle Real Application Clusters (RAC) minimizes the impact of unplanned instances outages with its high-availability infrastructure. Nevertheless, it remains a crucial and very challenging task for DBAs to safeguard business-critical data from database failures and ensure its continuous availability. Data loss may occur in the form of any hardware, software, or disk failures or unintentional human error. As a result, the DBA must develop and test comprehensive strategies for database backup and recovery operations. More importantly, a key factor to consider is the ability to restore and recover the database within business-agreed time limits (such as a service-level agreement, or SLA) to ensure quick database accessibility to the end users.
It is important to emphasize that there are no substantial differences in the ways in which database backup and recovery operations are performed in clustered and nonclustered environments. This chapter focuses on leveraging Recovery Manager (RMAN) advantages in the RAC environment to develop optimal backup and recovery procedures. This chapter also explains the concepts of instance and crash recovery mechanics in RAC environments and demonstrates various Oracle Cluster Registry (OCR) file recovery scenarios.
RMAN Synopsis
RMAN is an Oracle client tool that was first introduced with Oracle v8 to perform a wide range of database backup and recovery operations. With RMAN, DBAs can develop comprehensive, reliable, and secure database backup and recovery procedures. RMAN ships with Oracle RDBMS software and is automatically installed upon Oracle database software installation for no additional cost. The DBA can later adjust the RMAN configuration according to database needs. RMAN simplifies all Oracle database backup and recovery procedures, and the use of RMAN is highly recommended by Oracle.
RMAN offers the following key benefits:
- A wide range of flexible backups: tablespace, datafile, image copy, incremental, fast increment, encrypted, full database, and so on.
- Support for various levels of recovery scenarios: block-level, complete, incomplete, point-in-time, tablespace, table, and so on.
- Management of cold and hot database backups.
- A command-line interface (CLI) and Oracle Enterprise Manager (OEM) GUI interfaces.
- Fast incremental backups.
- Compressed and encrypted backup support.
- Ability to detect and repair data block corruptions.
- Multisection backups to improve large data file backups.
- Undo backup optimization.
- Support for backups to disk or tape devices.
- Validation of existing backup consistency.
- Cross-platform database transportation.
- Simplified backup and recovery procedures.
- Easy to duplicate a database, construct a standby database, and clone the database.
- Close coordination with the Oracle database engine.
- Recovery operation can be tested without actually being performed.
- Capacity to record 7 days of database backup and recovery operations action in the database control file by default.
- Support for backup and various recovery scenarios of 12c new container and pluggable databases.
- Storage snapshot optimization for third-party technologies.
- With 12c, a table or table partition can be recovered from RMAN backups.
Figure 8-1 represents a typical RMAN connection workflow.

Figure 8-1. RMAN connection workflow
Media Management Layer
To be able to perform database backup and recovery operations to and from tape, a media management library (MML) should be configured and must be integrated with RMAN. Oracle Secure Backup (OSB) provides a media manager layer and supports RMAN backup and recovery operations to tape on the majority of operating systems (OS). Similarly, there are a few third-party vendor media management solutions available for the same purpose, such as Symantec NetBackup, EMC NetWorker Module for Oracle, IBM Tivoli Data Protection for Oracle (TDPO), and HP Data Protector (DP).
Once the media manager software is successfully installed, it needs to be tightly integrated and must interact with RMAN. After the configuration, ensure that an RMAN can interact without any issues, and you need to configure or set the SBT channels in RMAN pointing to appropriate media manager software. The following examples of different MML options illustrate the backup run level configuration settings with RMAN:
OSB:
RMAN> run{
ALLOCATE CHANNEL ch00 DEVICE TYPE sbt
PARMS 'SBT_LIBRARY=/<dir_location>/lib/libobk.so,
ENV=(OB_DEVICE=drive1,OB_MEDIA_FAMILY=datafile_mf)';
.......
Release channel ch00;
}
Symantec NetBackup:
RMAN> run{
allocate channel ch00 type 'SBT_TAPE';
allocate channel ch01 type 'SBT_TAPE';
SEND 'NB_ORA_CLIENT=host_name,NB_ORA_POLICY=RONDB_FULL_LEVEL0,NB_ORA_SERV=netbackup_master_server_name';
..
release channel ch00;
release channel ch01;
}
IBM TDPO:
RMAN> run{
ALLOCATE CHANNEL ch00 type 'sbt tape' parms 'ENV=(TDPO_OPTFILE=/opt/tivoli/tsm/client/tdpo.opt)';
;
..
release channel ch00;
release channel ch01;
}
You must ensure that the MML is configured successfully without any issues; otherwise, you will run into troubles executing backup/recovery operations. Similarly, you can also define static MML tape configuration in the RMAN configuration.
Online Backup and Recovery Prerequisites
As a prerequisite to perform a wide range of online database backup and recovery operations, with or without RMAN, the database in the context must be configured in archivelog mode with a few additional recovery-related database initialization parameters. The following procedure configures a RAC database in archivelog mode and also sets the database recovery–related initialization parameters:
- Define a user-specified, upper-limit size to the recovery destination:
SQL> alter system set db_recovery_file_dest_size=1g SCOPE=BOTH SID='*'; - Specify a shared recovery destination path (in this example, an ASM diskgroup) in which archivelogs from all instances of a RAC database will be stored:
SQL> alter system set db_recovery_file_dest = '+DG_RONDB_ARCH' SCOPE=BOTH SID='*';
![]() Note In a RAC database, the settings must remain consistent across all instances.
Note In a RAC database, the settings must remain consistent across all instances.
To enable archivelog mode:
- Shut down the database first:
# srvctl stop database –d RONDB –o immediate - Mount the first instance either from the SQL*Plus prompt or by using the srvctl command, as follows:
SQL> startup mount;
# srvctl start database –d RONDB –o mount
Unlike pre-11gR2, you don’t need to off/on the cluster_database parameter to switch between the archive/noarchive modes.
- Switch the database mode to archivelog and start the database using the following examples:
SQL> alter database archivelog;
SQL> alter database open; - To start the rest of the instance, use one of the following examples:
# srvctl start database –d RONDB
# srvctl start instance –d RONDB –I RONDB2
Once the preceding settings are made, connect to SQL*Plus and verify the database log mode and recovery parameters using the following commands:
SQL> SELECT log_mode FROM v$database;
SQL> archive log list
The outcome should be similar to the following:
SYS @RONDB1 >archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 10
Next log sequence to archive 12
Current log sequence 12
From the preceding output, you can see that the database log mode is in Archive Mode now, and the archivelog location is set to Flash Recovery Area.
Non-RAC vs. RAC Database
Before we really jump in and get started on backup and recovery concepts in the RAC environment, let’s examine the architectural differences between a clustered and a nonclustered database.
There are no substantial architectural differences between a single instance and RAC database except that multiple instances access a single physical database in the RAC environment. Moreover, every instance has its own undo tablespace, a set of individual redo groups, and thereby generates instance-specific archived logs. No additional or special skills are required to manage database backup and recovery for a RAC database. In contrast, there is a significant difference in the way instance, media, or crash recoveries are performed in a RAC database. When an instance is involved in any sort of recovery operation, and if it requires the redo/archive log generated by the other instance in the context, the instance that is performing the recovery must have access to the other instance redo/archive logs to successfully complete the recovery. Therefore, it is strongly advised to put the redo/archive logs at a shared location so that all instances of the RAC database can have access.
Figure 8-2 depicts the architectural differences between a standalone and a RAC database.

Figure 8-2. RAC vs. non-RAC architecture
Shared Location for Redo and Archive Logs
As stated earlier, each instance in a RAC database typically consists of its own set of redo logs and generates individual archive logs. The redo group and archive logs in a RAC database are solely identified by a distinct thread number to avoid ambiguity. For example, a redo member and archive log of instance 1 will be identified as thread_1.
Despite each instance having absolute control over its own redo and archive logs, it is essential that all instances have the privilege to read each other’s redo and archive logs to successfully perform various RAC database recovery tasks, such as instance recovery, crash recovery, and media recovery. It is a requirement for a RAC database to have the redo logs across all instances on a shared destination, also preferably archive logs, to ensure accessibility between the instances.
Oracle strongly suggests making use of the Fast Recovery Area (FRA), which is a centralized location for all backup-related and recovery-related files. The FRA could be configured on an ASM diskgroup, Cluster Filesystem, or Network File System by configuring the two dynamic database initialization parameters. When there is no FRA specified during database creation process, the FRA will be automatically set under the Oracle base directory.
When no shared spfile is used, the following procedure needs to run across all instances and must contain the same values. If a shared spfile is configured, you need only to run the commands from one instance:
- Set a user upper-limit size to the recovery destination:
SQL> alter system set db_recovery_file_dest_size=10G scope=both; - Specify the recovery path destination:
SQL> alter system set db_recovery_file_dest='+DG_RONDB_ARCH' scope=both;
Figure 8-3 illustrates the concept of a centralized recovery area in a RAC database.

Figure 8-3. FRA settings
Following are a few useful database dynamic views that render a better understanding of FRA usage and other specific details:
SQL> SELECT * FROM V$RECOVER_AREA_USAGE;
SQL> SELECT * FROM V$FLASH_RECOVERY_AREA_USAGE;
SQL> SELECT * FROM V$RECOVERY_FILE_DEST
Snapshot Control File Configuration
Beginning with 11.2.0.2, for any form of database control file backup operations, Oracle no longer acquires the controlfile enqueue lock. This change requires snapshot control file accessibility to all instances in a RAC database, in contrast to a single-instance database, to successfully complete a manual or auto control file backup operation. When the snapshot control file is not accessible or doesn’t exist across instances, the backup of control file operations, including RMAN backups, will fail with an ‘ORA-00245: control file backup operation failed’ error.
To prevent an ORA-00245 error, the snapshot control file must be placed on a shared location or on ASM DISKGROUP, ensuring that each instance of RAC database has the read and write ability on the file.
The following procedure explains the process to configure the snapshot control file on an ASM DISK GROUP:
RMAN> CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+DG_RONDB/snapcf_RONDB.f';
Upon configuration, the following message will be displayed at RMAN prompt:
using target database control file instead of recovery catalog
new RMAN configuration parameters:
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+DG_RONDBsnapcf_RONDB.f;
new RMAN configuration parameters are successfully stored
To display snapshot control file configuration details, connect to an RMAN prompt and execute one of the following commands:
RMAN> show all;
RMAN> show snapshot controlfile name;
Multiple Channels Configuration for RAC
On a RAC database, it is feasible to have multiple channels allocated and scattered over multiple instances to scale up the backup and recovery workload. This section explains how to configure parallelism to enable load balancing for a preallocated (automatic) or runtime RMAN channel.
Parallelism for Load Balancing
Parallelism must be configured in RMAN prior to making use of multichannel configuration for balancing the backup and restore workload over multiple instances. The following example configures the parallelism and enables the load balancing option, also overwriting any pre-existing parallelism configuration settings:
RMAN> configure device type disk parallelism 2;
new RMAN configuration parameters:
CONFIGURE DEVICE TYPE DISK PARALLELISM 2 BACKUP TYPE TO BACKUPSET;
new RMAN configuration parameters are successfully stored
RMAN> show all; -- shows RMAN configuration settings
RMAN configuration parameters for database with db_unique_name RONDB are:
........
CONFIGURE DEVICE TYPE DISK PARALLELISM 2 BACKUP TYPE TO BACKUPSET; <<<<<
Persistent Multichannel Configuration
To scale an RMAN backup workload over multiple instances, you need to allocate multiple channels directing the connection to an individual instance. The allocation of channels can be a preconfigured or just a one-time (dynamic) allocation.
The following example configures a preconfigured (auto) and instance-specific connection. RMAN will utilize the preconfigured (auto) channels to perform the job when no channels have been allocated within the backup and recovery operations.
RMAN> configure channel 1 device type disk connect 'sys/password@RONDB_1';
RMAN> configure channel 2 device type disk connect 'sys/password@RONDB_2';
The RONDB_1 and RONDB_2 TNS configurations used in the preceding example are defined in instances 1 and 2, respectively, and contain pointers to individual instances. Ensure that the TNS configuration does not use a service name that is configured to multiple instances and that the load balancing option is turned off.
All RMAN backups followed after the configurations will automatically allocate two channels over instances 1 and 2, and the workload will be balanced across instances.
Runtime (One-Time) Multichannel Configuration
Similarly, multiple channels also can be defined dynamically just for the duration of backup runtime by specifying them within the RMAN backup script, as follows:
run
{
allocate channel 1 device type disk connect='sys/password@rondb_1';
allocate channel 2 device type disk connect='sys/password@rondb_2';
...
}
run
{
allocate channel 1 device type disk connect='sys/password@RONDB_RMAN';
......
}
When a backup is initiated with multiple channels, you will see a message similar to the following:
Starting backup at 13-NOV-12
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=102 instance=RONDB_2 device type=DISK
allocated channel: ORA_DISK_2
channel ORA_DISK_2: SID=16 instance=RONDB_1 device type=DISK
In the first example, two channels are dynamically allocated on two different instances using a predefined TNS connect string, specific to each instance, and the TNS connection does not have the load balancing option enabled. With this approach, you can control which channel should go to which instance, rather than relying on automatic load balancing algorithms.
Similarly, in the second example, two channels are dynamically allocated using a TNS or service connection with load balancing options turned on. This approach banks on the load balancing algorithm and allocates channels on instances according to a predefined formula.
Moreover, the life of the dynamic channel is strictly limited to the runtime. Once the backup operations get completed, the channels are no longer valid.
During a database backup, if the instance on which the backup was initiated terminates unexpectedly, the backup job won’t fail; instead, the other channel from an active instance would take over the job and complete the backup. Assuming that, a backup operation with two channels has been initiated from instance 1 and the instance has terminated while the backup is in progress. In this context, the other active channel, from instance 2, would take over the job and complete the backup with the following RMAN message:
channel ORA_DISK_1: starting piece 1 at 13-NOV-12
RMAN-03009: failure of backup command on ORA_DISK_2 channel at 11/13/2012 17:17:11
RMAN-10038: database session for channel ORA_DISK_2 terminated unexpectedly
channel ORA_DISK_2 disabled, job failed on it will be run on another channel
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03009: failure of backup command on NIL channel at 11/13/2012 17:17:11
RMAN-10038: database session for channel NIL terminated unexpectedly
channel ORA_DISK_2: starting piece 1 at 13-NOV-12
RMAN-03009: failure of backup command on ORA_DISK_2 channel at 11/13/2012 17:29:20
RMAN-10038: database session for channel ORA_DISK_2 terminated unexpectedly
channel ORA_DISK_2 disabled, job failed on it will be run on another channel
![]() Note The database status (OPEN or MOUNT) must remain constant across all nodes during a backup or the backup will fail.
Note The database status (OPEN or MOUNT) must remain constant across all nodes during a backup or the backup will fail.
Additionally, the backup destination must be accessible to all the instances involved in the backup operation. If the backup location is inaccessible or doesn’t exist to any particular instance involved in the backup operation, the backup will fail with ‘unable to create file’ errors. This is particularly significant when the backups are taken to a disk location. Similarly, when backing up the database to tape, ensure that the tape and media manager driver are configured properly on all the nodes involved in the backup.
Figure 8-4 depicts the architecture for multichannel disk or tape RMAN configuration.

Figure 8-4. RMAN TAPE connection workflow
Parallelism in RAC
Enforcing parallelism can sometimes produce fruitful results, including enhancing the performance of SQL queries, scaling up typical database manageability activities, and accelerating RMAN backup and recovery operations. In this section, we discuss the significance of parallelism and exactly how it helps RMAN backup, restore, and recovery operations in a RAC database.
When a database backup or restore operation is pioneered with multiple channels, Oracle determines and sets the degree of parallelism based on the number of allocated channels for that job; thus, any restore or recovery command (applying incremental backups) will span a corresponding number of slave processes to get the job done quickly. Moreover, for media recovery tasks, such as applying archive logs, Oracle sets the parallelism automatically based on the number of CPU resources on the node. In contrast, the PARALLEL hint with RECOVER statement will limit and overwrite the default degree of parallelism. Last but not least, when there are a huge number of archive logs to be applied as part of the recovery, parallelism indeed helps speed up the recovery time.
There have been some bugs reported of late with regards to parallel media recovery due to a few OS-related and storage-related issues. These can be avoided by disabling parallelism by specifying NOPARALLEL in conjunction with the RECOVER command.
Instance/Crash Recovery in RAC
A recovery operation on an Oracle database can be classified into two phases: media and instance/crash recovery. A database instance or crash recovery is needed when an instance starts up after an abnormal stop. Typically, when an instance fails or ends abruptly, it leaves the data files in an inconsistent state and also sets the current online redo group flag in an open state. In a RAC database, when one or more instances fail, the surviving instance does the instance recovery on behalf of the failed instances. When all instances of a RAC database fail, the instance that comes up first does the crash recovery on behalf of other instances. An instance recovery is automatically done by the Oracle System Monitor (SMON) background process without intervention from the DBA.
The prime objective of an instance/crash recovery is to ensure database consistency right after an instance failure. The SMON process in that context reads the online redo logs and applies the redo changes to the appropriate data blocks into their respective data files. An instance/crash recovery is done in two phases: rolling forward and rolling back. During the rolling-forward phase, all committed transactions (data blocks) that are not written yet to the concerned data files will be applied to the proper data files. In the rolling-back phase, all uncommitted transactions occurring before the instance crash will be rolled back, reading the undo segments to guarantee database consistency.
Instance Recovery
Though instance recovery mechanisms remain identical in nonclustered and clustered environments, the way that instance/crash recovery steps are carried out in a RAC database is slightly dissimilar from single-instance database instance recovery mechanics.
Contrary to a stand-alone database, when a dead (failed) instance is detected by a surviving instance in a RAC database, the SMON of the surviving instance initiates and does the instance recovery for the failed instance. Likewise, when multiple instances of a RAC database fail, even if the failure is of all instances except one, the surviving instance is responsible to perform recovery steps for all the failed instances. Figure 8-5 illustrates an instance recovery mechanism in RAC by a surviving node.

Figure 8-5. RAC database FRA settings
Crash Recovery
In the event of a RAC database having an all-instances failure, the instance that comes up first will perform the crash recovery on behalf of the database. As already explained in the section ‘Shared Location for Redo and Archive Logs,’ ensure that all instances are able to access each others’ redo logs in order to perform the recovery operations.
Parallel Recovery
In this section, we will explain and provide some guidelines to enhance the recovery duration, key parameters, and other settings that reflect improving the recovery time significantly to ensure quick database or instance accessibility.
The duration required for an instance or crash recovery plays a pretty important role in instance and database accessibility to the end user for general usage. It is indeed essential to consider appropriate actions and steps to enhance the recovery time.
On a multiple CPU resource-based node, Oracle automatically sets the optimal degree of parallelism and does the instance recovery in parallel to run the recovery operations. You can also make use of the RECOVERY_PARALLISM and PARALLEL_MIN_SERVERS initialization parameters to enable parallelism. When the RECOVERY_PARALLISM parameter value is set to 2 or higher but can’t be higher than the PARALLEL_MAX_SERVER value, Oracle automatically sets the degree of parallelism for instance/crash recovery operations. Set the parameter RECOVERY_PARALLELISM value either to 0 or 1 on a multi-CPU-based server to disable parallel recovery option.
Ensure that your platform supports async I/O and is enabled. It can also be enabled by setting the DISK_ASYNCH_IO init parameter value to TRUE. The async I/O plays a key role in improving instance recovery during the first phase (first-pass log read) of recovery.
Another way of improving the instance recovery time is to have an adequate DEFAULT CACHE size of the DB BUFFER CACHE SIZE, as instance recovery utilizes about 50% of the DEFAULT CACHE size from the actual default buffer cache size. You can verify whether the DEFAULT CACHE size is adequate or not. If the DEFAULT CACHE size is too low, you can see the related error message in the alert.log.
Monitor and View Instance Recovery Details
Instance recovery operation details are logged in the alert logs as well as in the SMON trace file. Refer to the alert.log file to find out the details, such as when the recovery began and when it was completed. For additional details on recovery, you can also refer to the SMON trace file.
Furthermore, the ESTD_CLUSTER_AVAILABILE_TIME column in the GV$INSTANCE_RECOVERY dynamic view shows the amount of time (in seconds) that the instance will be frozen. Therefore, the longer the time, the longer will be the estimated instance recovery.
Instance/Crash Recovery Internals in RAC
To provide a better understanding of the way that an instance recovery is performed in a RAC database, we constructed a small test scenario. As part of the test case, the following tasks were carried out on instance 1:
- A new table created
- A few records inserted and committed
- All records deleted with 'delete * from table_name'
- A couple of records inserted
- Instance 1 was aborted from the other SQL window
The following recovery action is performed by a surviving instance SMON background process for the dead instance:
- Surviving instance acquires the instance recovery enqueue.
- After Global Cache Services (GCS) are remastered, the SMON then reads the redo logs of the failed instance to recognize the resources (data blocks) that are needed for the recovery.
- Global Resource Directory will be frozen after acquiring all necessary resources.
- At this stage, all data blocks, except that needed for recovery, become accessible.
- SMON starts recovering the data blocks identified earlier.
- Immediately after the recovery, the individual data blocks become accessible.
- All uncommitted transactions are also rolled back to maintain the consistency.
- Once all the data blocks are recovered, the instance is fully available for end users.
Here is a walkthrough of the alert.log of the surviving instance that does the recovery for the failed instance. Most of the action is recorded in the context of instance recovery; you can refer to the log file to understand how things have been performed by the instance. All of the previously explained steps can be seen in the alert.log:
Reconfiguration started (old inc 12, new inc 14) <<<<<
List of instances:
2 (myinst: 2)
Global Resource Directory frozen <<<<<
* dead instance detected - domain 0 invalid = TRUE <<<<<
Communication channels reestablished
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Sun Nov 18 11:39:19 2012
LMS 0: 0 GCS shadows cancelled, 0 closed, 0 Xw survived
Set master node info
Submitted all remote-enqueue requests
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Post SMON to start 1st pass IR <<<<<
Sun Nov 18 11:39:22 2012
minact-scn: Inst 2 is now the master inc#:14 mmon proc-id:24545 status:0x7
minact-scn status: grec-scn:0x0000.00000000 gmin-scn:0x0000.00384a18 gcalc-scn:0x0000.00384a24
minact-scn: master found reconf/inst-rec before recscn scan old-inc#:14 new-inc#:14
Sun Nov 18 11:39:22 2012
Instance recovery: looking for dead threads
Beginning instance recovery of 1 threads
Submitted all GCS remote-cache requests <<<<<
Post SMON to start 1st pass IR
Fix write in gcs resources
Reconfiguration complete
parallel recovery started with 2 processes <<<<<
Started redo scan
Completed redo scan
read 53 KB redo, 68 data blocks need recovery
Sun Nov 18 11:39:27 2012
Warning: recovery process P000 cannot use async I/O
Sun Nov 18 11:39:27 2012
Warning: recovery process P001 cannot use async I/O
Started redo application at
Thread 1: logseq 20, block 42789 <<<<<
Recovery of Online Redo Log: Thread 1 Group 2 Seq 20 Reading mem 0 <<<<
Mem# 0: +DG_LINQ/rondb/onlinelog/group_2.286.795350031
Completed redo application of 0.03MB
Sun Nov 18 11:39:27 2012
Completed instance recovery at
Thread 1: logseq 20, block 42842, scn 3709030
67 data blocks read, 68 data blocks written, 53 redo k-bytes read
Thread 1 advanced to log sequence 21 (thread recovery)
Redo thread 1 internally disabled at seq 21 (SMON)
Also, refer to the SMON trace file for an in-depth understanding of instance recovery.
How to Back Up and Restore Archive Logs
When an instance maintains a local destination in which to put its archive logs separately, then a separate channel must be allocated for each instance to back up the archive logs from the destination. However, when archive logs are placed at a shared location, and multiple channels are allocated, all allocated channels will then back up the archived logs. The same rule applies when deleting archive logs.
To restore one or more archive logs manually from a particular instance, the instance THREAD number must be specified in conjunction with the RESTORE ARCHIVE LOG command, as demonstrated in the following:
RMAN> restore archivelog logseq =200 thread 1;
RMAN> restore archivelog ass 'from' word logseq =100 until
logseq=110 thread 2;
The first example shows how to restore a specific archive log, and the second example shows how to restore a range of archived logs from a particular instance. When a THREAD clause is not specified, the following RMAN error will be encountered:
RMAN-20242: specification does not match any archived log in the repository
The following example demonstrates how to restore a set of archived logs from different instances at one time:
RMAN> run
{
configure channel 1 device type disk connect='sys/password@rondb_1';
configure channel 2 device type disk connect='sys/password@rondb_2';
restore archivelog from logseq 14 until logseq 16 thread 1;
restore archivelog from logseq 65 until logseq 70 thread 2;
}
Real-World Examples
The objective of this section is to provide working examples for some of the frequently used RMAN RAC scenarios. We don’t aim to demonstrate a step-by-step procedure; we’ll focus only on those core details that are suitable for RMAN in RAC environment.
Best Database Backup Strategies
In the following sections, we discuss some of the industry standard backup strategies.
Configure fast incremental backups: You need to connect to the database and enable the Block Change Tracking (BCT) option for optimized fast incremental backups on the database. Ensure that the BCT file is stored on a shared location so that all instances have the read and write ability on the file. The command provided enables the fast incremental backup option on the database:
SQL> ALTER DATABASE ENABLE BLOCK CHANGE TRACKING;
After enabling the BCT feature, let’s verify it by querying the v$block_change_tracking dynamic view:
SQL> SELECT * FROM v$block_change_tracking;
![]() Note When BCT is configured, ensure that either the BCT file is available or the feature is disabled before opening the database after completing the database restore and recover procedure on the same host or on a new host.
Note When BCT is configured, ensure that either the BCT file is available or the feature is disabled before opening the database after completing the database restore and recover procedure on the same host or on a new host.
Now it is time to develop a script for full database level 0 backup to initiate a base backup for subsequent incremental backups. The following script will have two channels allocated to TAPE, will back up the database along with the archive logs, and will also remove the archive logs after the backup:
--- rondb_full_db_bkp.sh
--- RONDB RMAN ONLINE FULL DATABASE BACKUP, LEVEL 0
rman{
ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE' CONNECT sys/password@rondb_1;
ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE' CONNECT sys/password@rondb_2;
SEND 'NB_ORA_CLIENT=host_name,NB_ORA_POLICY=RONDB_FULL_LEVEL0,NB_ORA_SERV=netbackup_master_server_name';
BACKUP DATABASE INCREMENTAL LEVEL=0FORMAT 'u%ROMDB_FULL_LEVEL_0.bkp' plus
ARCHIVELOG DELETE INPUT;
RELEASE CHANNEL ch00;
RELEASE CHANNEL ch01;
}
Now we will have an incremental cumulative database level 1 backup script. The following script performs an incremental cumulative backup to back up a database and archive logs together. Of course, the logs will be removed after the backup:
--- rondb_incr_db_bkp.sh
--- RONDB RMAN ONLINE INCREMENTAL DATABASE BACKUP, LEVEL 1
rman{
ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE' CONNECT sys/password@rondb_1;
ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE' CONNECT sys/password@rondb_2;
SEND 'NB_ORA_CLIENT=host_name,NB_ORA_POLICY=RONDB_FULL_LEVEL0,NB_ORA_SERV=netbackup_master_server_name';
BACKUP DATABASE INCREMENTAL LEVEL=1 CUMULATIVEFORMAT
'u%RONDB_FULL_LEVEL_0.bkp' plus ARCHIVELOG DELETE INPUT;
RELEASE CHANNEL ch00;
RELEASE CHANNEL ch01;
}
Having developed a full and incremental database backup, we typically schedule full database level 0 backup once a week followed by the incremental backup for the rest of the week. You can schedule the jobs through netbackup, in the crontab on a Unix platform, and so on.
If the application is highly OLTP and the database is tending to generate a huge number of archived logs, you may also develop a separate script scheduled at regular intervals to back up the archived logs and remove them after backup to avoid a database hang situation due to a lack of space left for archiving.
You should alter the preceding scripts to suit your environment and schedule the backup policy as per your organizational standards.
Restore a RAC Database to a Single-Instance Database
Notwithstanding clustered or nonclustered, the database restore procedure remains the same. However, the following additional post–database restore steps need to be carried out on the single-instance database after opening the database:
Proceed with disabling additional instances thread and remove redo groups.
SQL> SELECT instance,thread#,status,enabled FROM v$thread;
SQL> SELECT instance,group# FROM v$log WHERE thread=<thread_number>;
SQL> SELECT tablespace_name,contents FROM dba_tablespaces WHERE contents = 'UNDO';
Upon determining the thread number, redo groups, and undo tablescapes for the additional instances, now it is time to remove them from the database. The following set of SQL statements will achieve this:
SQL> ALTER DATABASE disable THREAD <thread_number>;
SQL> ALTER DATABASE drop logfile group <group_number>;
SQL> DROP TABLESPACE <undo_instance_specific> including contents and datafiles;
Assuming that a RAC database with three instances restored to a single-instance database, you need to follow the preceding procedure for instances 2 and 3 in order to have a clean single-instance database.
Configure RAC Standby Database
In the following example, we demonstrate how to configure a standby RAC database with two instances to a RAC primary database with two instances. The primary RAC database name used in the context is RONDB, and the standby RAC database is named RONDBS. Prior to getting into the real action, we will assume that the same version, platform, Clusterware, and Oracle RBDMS binaries are configured and operational at the standby location. The objective is to explain the procedure to set up a standby RAC database; the data guard configuration and the switchover/failover mechanism, however, is not part of our objective.
Once the standby environment is ready, run through the following tasks on the standby site:
- Create and mount necessary ASM DISKGROUPS across the nodes on which RAC standby instances are going to be placed.
- Configure a listener for the standby instances and a TNS connection pointing to the primary database instance on the standby nodes.
- After preparing SPFILE and the password file, and creating all necessary directory structures, start up the standby instance in NOMOUNT state: SQL> STARTUP NOMOUNT.
- Initiate the active standby database configuration procedure from the standby instance RMAN:
# rman connect target sys/password@prim auxiliary /
RMAN> duplicate target database for standby from active database
spfile
parameter_value_convert 'RONDB','RONDBS'
set db_unique_name='RONDBS'
set fal_client='PRIM'
set fal_server='STDBY'
set standby_file_management='AUTO'
set log_archive_config='dg_config=(RONDBS,RONDB)'
set log_archive_dest_1='service=RONDBS ASYNC
valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=RONDBS';
- Once the standby database is successfully configured, create standby redo logs on the standby instance of the same number (plus one additional group) and the same size as the primary database redo logs. It is highly recommended to have an additional standby redo group for each instance, in contrast to the primary database instance redo groups count. Presume that a primary instance has three redo groups and each redo member is sized 100M; therefore, we will have four standby redo groups for each standby instance with the same redo log member size.
Run the following SQL statements on the standby instance:
SQL> ALTER DATABASE ADD STANDBY LOGFILE THREAD 1
GROUP 11 SIZE 100M,
GROUP 12 SIZE 100M,
GROUP 13 SIZE 100M,
GROUP 14 SIZE 100M;
SQL> ALTER DATABASE ADD STANDBY LOGFILE THREAD 2
GROUP 15 SIZE 100M,
GROUP 16 SIZE 100M,
GROUP 17 SIZE 100M,
GROUP 18 SIZE 100M;
- Now it is time to turn on auto-managed recovery and start applying logs in real time. Run the following command on the standby instance:
SQL> alter database recover managed standby database using current logfile
disconnect from session; - Finally, add the second standby instance and configure standby database details in the OCR. Run through the following set of statements from the command prompt:
# srvctl add database –d RONDBS –o /u00/app/oracle/product/12.1.0/db_1 –r PHYSICAL_STANDBY
# srvctl add instance –d RONDBS_1 –n rac1
# srvctl add instance –d RONDBS_2 –n rac2 - Configure a TNS connection pointing to the first standby instance and then run through the following steps on the primary database, from the first instance:
SQL> ALTER SYSTEM SET LOG_ARCHIVE_CONFIG='DG_CONFIG=(RONDB,RONDBS)' SCOPE=BOTH;
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_1='LOCATION=<ARCHVIE_LOCATION> VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=RONDB'
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2=SERVICE=<RONDBS_TNS> VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=RONDBS'
Manage RMAN with OEM Cloud Control 12c
As mentioned earlier, RMAN can be managed and invoked through a command-line prompt interface or through an OEM (also referred to as OEM Cloud Control 12c). We will run through some of the OEM screenshots here to manage and schedule a database backup and recovery operation through OEM.
- Log in to OEM Cloud Control 12c using the predefined login credentials (Figure 8-6).

Figure 8-6. OEM Cloud Control 12c availability screen
- From the Targets drop-down list, select the Databases option.
- Click the desired database name from the list displayed under the Databases list.
- Go to the Backup & Recovery setting from the Availability drop-down list, which will display the following options: Schedule Backup, Manage Current Backups, Backup Reports, Restore Points, Perform Recovery, Transactions, Backup Settings, Backup/Recovery/Catalog settings.
To configure Device and Tape settings, such as parallelism, backup location, backup type: default, compression or image copy, and to set tape settings, go to the Device tab under Backup Settings, as shown in Figure 8-7.

Figure 8-7. OEM Cloud Control 12c Backup_setting_device screen
The Backup Set tab provides options to adjust the backup piece size that is useful while backing up a large database and wanting to control the backup piece size. Additionally, the compression algorithm gives choices to set different levels of algorithm; that is, BASIC, LOW, MEDIUM, and HIGH, subject to separate licensing. When the Optimizer for Load choice turned on, it controls compression processing by optimizing CPU usage, as shown in Figure 8-8.

Figure 8-8. OEM Cloud Control 12c Backup_setting_backup_set screen
The Policy tab (Figure 8-9) offers the following settings:
- Controlfile, SPFILE auto backup option on any structural changes and with every database physical backup. In addition, you can specify the default destination for these auto backups.
- Flexibility to skip the read only and offline datafiles that were backed up once.
- Can turn on BCT feature to take faster incremental backups.
- Tablespaces can be excluded as part of the complete database backups.
- You can also set the retention policy for backups and archive logs according to your requirements.

Figure 8-9. OEM Cloud Control 12c Backup_setting_policy screen
Click the OK button at the bottom right to save all backup settings done in the preceding steps.
The Recovery Settings comes with options to adjust the Mean Time To Recovery (MTTR) values to enable the fast-start checkpoint feature, which helps during instance/crash recovery. In addition, FRA settings can be managed and adjusted. Click the Apply initialization parameter option to save changes in SPFILE only. To apply the change with immediate effect, click the Apply button displayed at the bottom right. For all details, see Figure 8-10.

Figure 8-10. OEM Cloud Control 12c recovery settings screen
Schedule Backup (Figure 8-11) offers automated and customized backup strategy settings. The customized backup lets you schedule the backup for full database, tablespaces, datafiles, archived logs, and so on, whereas the automated option provides auto backup management.
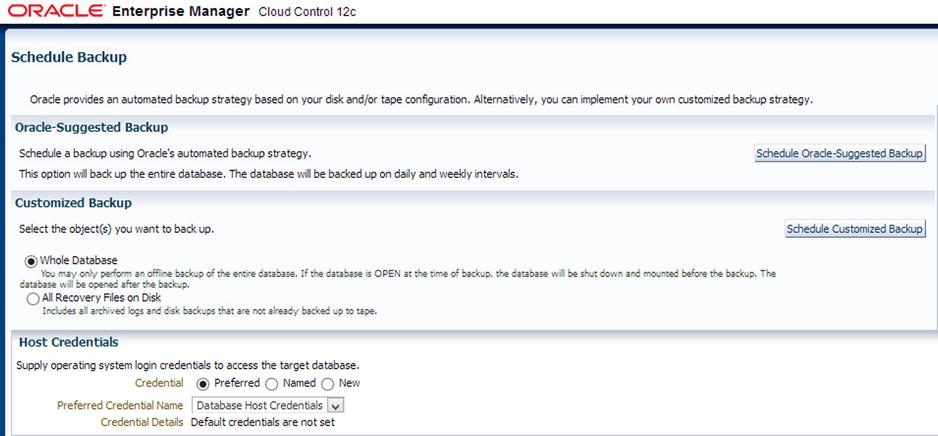
Figure 8-11. OEM Cloud Control 12c schedule backup screen
The Backup Sets option under the Manage Current Backups section provides detailed reports to existing backups that include backup piece completion time, where the backup piece is placed, and the status. Simultaneously, there are options to run through crosscheck, delete, and validate the obsolete, expired, and valid backup pieces. Have a look at Figure 8-12.

Figure 8-12. OEM Cloud Control 12c manage current backups screen
The Perform Recovery section provides various recovery scenarios: complete database, datafiles, tablespaces, tables, archived logs, etc. Recovery operation types include complete recovery and point-in-time recovery. Look at Figures 8-13 and 8-14.

Figure 8-13. OEM Cloud Control 12c manage recovery_fulldb_settings screen

Figure 8-14. OEM Cloud Control 12c manage recovery_table_settings screen
OCR is beyond a doubt one of the most critical components of Oracle Clusterware, and its uninterrupted availability is necessary to the cluster resources function. Keeping in mind this criticality, Oracle offers several options to protect the OCR file from physical or logical corruptions, unintentional human errors, and single points of failure. The OCR file is automatically backed up every 4 hours by Oracle Clusterware and can also be backed up manually on demand. To avoid a single point of failure, consider multiplexing the file up to a maximum of five copies.
You really need to understand and be aware of all possible methods to protect and recover OCR from different failures. In this section, we shall highlight various OCR recovery scenarios.
Let’s verify the existing OCR details. For that, you need to log in as root and execute the following to view OCR details:
# ocrcheck
Logical corruption verification will be skipped if the preceding command is executed as a nonprivileged user.
To view the OCR file name and path, use the following command:
# ocrcheck -config
Automatic/manual backup details are listed using the following command:
# ocrconfig -showbackup
The following are a few OCR restore procedures that can be used in the event of all OCR files being either corrupted or lost.
Scenario 1: The following demonstrates a procedure to restore OCR from autogenerated OCR backups:
As the root user, get the auto backup availability details using the following command:
# ocrconfig –showbackup
Stop Clusterware on all nodes using the following command as root user:
# crsctl stop crs [-f]
-- Use the –f option to stop the CRS forcefully in the event that the crs stack couldn't be stopped normally due to various errors.
As root user, restore the most recently valid backup copy identified in the preceding step. Use the following restore example:
# ocrconfig –restore backup02.ocr
Upon restore completion, as root user, bring up the cluster stack and verify the OCR details subsequently on all nodes using the following commands:
# crsctl start crs
# cluvfy comp ocr –n all -verbose
Scenario 2: The following demonstrates a procedure to recover OCR in an ASM diskgroup, assuming that the ASM diskgroup got corrupted or couldn’t be mounted:
After locating the most recent valid automatic or manual OCR backup, stop the cluster on all nodes. To stop the cluster, use the command mentioned in the previous procedure.
Start the clusterware in exclusive mode using the following command as root user:
# crsctl start crs –excl -nocrs
Connect to the local ASM instance on the node and recreate the ASM diskgroup. Use the following SQL examples to drop and re-create the diskgroup with the same name:
SQL> drop diskgroup DG_OCR force including contents;
SQL> create diskgroup DG_OCR external redundancy disk 'diskname' attribute
'COMPATIBLE.asm'='12.1.0';
Upon ASM disk re-creation, restore the most recent valid OCR backup. Use the example explained in the previous scenario.
If the voting disk exists in the same disk group, you also need to re-create the voting disk. Use the following example:
# crsctl replace votedisk +DG_OCR
After successfully completing the preceding steps, shut down the cluster on the local node and start the clusterware on all nodes subsequently.
Scenario 3: In the following example, we demonstrate the procedure to rebuild an OCR file in the event of all files becoming corrupted and when there is no valid backup available.
To be able to rebuild the OCR, you need to first unconfigure and then reconfigure the cluster. However, noncluster resource information, such as database, listener, services, instance, etc. needs to be manually added to the OCR. Therefore, it is important to collect the resource information using the crsctl, srvctl, oifcfg, etc., utilities.
To unconfigure the cluster, run the following example as root user across all nodes in sequence:
#$GI_HOME/crs/install/rootcrs.pl –deconfig –force –verbose
Upon successfully executing the preceding on all nodes, the following needs to be run on the first node of the cluster:
#$GI_HOME/crs/install/roortcrs.pl –deconfig –force –verbose –lastnode
After unconfiguring the cluster, you will now have to configure the cluster as root user with the following example:
#$GI_HOME/crs/config/config.sh
The config.sh invokes Grid Infrastructure configuration framework in Graphical User Interface (GUI) mode, and you need to provide the appropriate input through pages that displayed. Finally, you will have to run the root.sh to complete the configuration.
After recovering the OCR file from various failure scenarios, run through the following set of postrecovery steps to verify the OCR file integrity and cluster availability on all nodes:
# ocrcheck
# cluvfy comp ocr-n all –verbose
# crsctl check cluster -all
Summary
In a nutshell, this chapter summarized and offered the most useful tools, tips, and techniques to design and deploy optimal database backup and recovery procedures in a RAC environment using the RMAN tool. In addition, the internal mechanics behind instance and crash recovery operations in a RAC environment were explained in great detail. The chapter concluded by discussing and demonstrating various OCR recovery scenarios.